1. Introduction
Recently, several generalized families (also known as generators) of univariate distribution have been constructed based on classical distributions. These generators provide greater flexibility by adding one or more parameters to a baseline model. For example, Marshall-Olkin-G [
1], transmuted-G [
2], odd Lomax-G [
3], Marshall-Olkin alpha-power-G [
4], and odd Dagum-G [
5], amongst others. The flexibility of these generalized models can be expressed in terms of their ability to model various real-life data encountered in different applied fields, in particular, reliability engineering, medicine, survival analysis, agriculture, actuarial sciences, demography, and others. The flexibility of generalized models is important to model several shapes of aging and failure criteria.
Shaw and Buckley [
2] introduced a useful technique of adding a new parameter to an existing distribution called the transmuted-G (T-G) family, which is adopted to propose generalized forms of classical distributions. The T-G family has received widespread recognition in the literature and more than 70 generalized models have been proposed based on the T-G class. For example, the transmuted log-logistic [
6], transmuted Marshall-Olkin Fréchet [
7], and transmuted Burr XII [
8], amongst others. Tahir and Cordeiro [
9] listed more than 50 generalized models that were extended using the T-G family.
Several authors have constructed extended forms of the T-G class. Some notable examples are: transmuted exponentiated generalized-G [
10], transmuted geometric-G [
11], Kumaraswamy transmuted-G [
12], generalized transmuted-G [
13], and transmuted transmuted-G [
14], and complementary generalized transmuted Poisson-G families [
15].
The cumulative distribution function (CDF) of the T-G class has the form
Its probability density function (PDF) reduces to
where
is a shape parameter;
and
are the baseline CDF and PDF, respectively; with parameter vector
. The T-G density is a mixture of a baseline density and an exponentiated-G (Exp-G) density with power parameter 2. For
, the T-G class reduces to the baseline distribution.
We were motivated to adopt the T-G family to extend another class of distributions called the Burr X-G (BX-G) class [
16] and provide a wider family that can be used to effectively model various real-life data. Hence, the aim of this study was two-fold: First, we wanted to propose a new extended form of the BX-G class based on the T-G class, called the transmuted Burr X-G (TBX-G) family. Various general properties of the TBX-G class are derived. Secondly, we discussed eight estimation methods of the TBX-exponential parameters: maximum likelihood (MLE), Anderson–Darling (ADE), right-tail Anderson–Darling (RADE), Cramér–von Mises minimum distance (CVME), ordinary least squares (OLSE), weighted least-squares (WLSE), maximum product of spacings (MPSE), and percentile (PCE) estimators, and compared them, in terms of their absolute value of biases (
), mean squared error (MSE), and mean relative error (MRE), using extensive simulations to develop a guideline for choosing the best estimation approach that produces more accurate estimates for the model parameters. The estimation methods were compared based on partial and overall ranks to choose the best estimation method, which will be of important interest to applied statisticians, practitioners, and engineers.
Yousof et al. [
16] proposed a new generator for the construction of new extended and flexible versions from classical models, which is known as BX-G. Consider the PDF and CDF of a baseline distribution with a parameter vector
,
, and
; then, the CDF of the BX-G class, with a positive-shape parameter
, takes the form
The PDF of the BX-G family reduces to
To this end, we define the CDF and PDF of the proposed TBX-G family. By inserting Equation (
3) into Equation (
1), the TBX-G family can be specified by the following CDF (for
)
The PDF of the TBX-G class has the form
Hereafter, a random variable () with PDF (6) is denoted by X∽TBX-G. The TBX-G class reduces to the BX-G family with . The TBX-G is a wider family of continuous distributions. It includes the BX-G family and provides greater flexibility in modeling real life data.
Finally, we summarize the findings of the proposed TBX-G class as follows: (1) Its sub-models provide unimodal, symmetrical, left-skewed, right-skewed, and reversed-J densities. They have decreasing, increasing, bathtub, upside-down bathtub, J-shaped, and reversed-J shaped hazard rates, which are frequently encountered in real-life applied areas. (2) Its special sub-models perform very well compared with other competing models, which are generated by well-known families under the same baseline model. (3) The sub-models generated by the TBX-G class are capable of modeling different shapes of ageing and failure criteria. Hence, the TBX-G can be a useful alternative to several classes for modeling skewed data in application(s).
The reminder of the paper is organized as follows: Two sub-models called the TBX-exponential (TBXE) and TBX-log-logistic (TBXLL) distributions are presented in
Section 2. Various general properties of the TBX-G family are explored in
Section 3. Properties of the TBXE model are discussed in
Section 4. The maximum likelihood estimation for the TBX-G parameters are derived in
Section 5. In
Section 6, we estimate the TBXE parameters using eight estimation approaches.
Section 7 is devoted to studying the behavior of these estimators via simulation results. In
Section 8, we illustrate the flexibility of the new class using two real-life applications, showing that the TBXE model can provide a better fit than other competing models. Some concluding remarks are provided in
Section 9.
7. Simulations
Here, we compare the eight estimation methods: WLSE, OLSE, MLE, MPSE, CVME, ADE, RADE, and PCE, using numerical simulations in terms of the average of absolute value of biases (
),
, the average of mean squared errors (MSEs),
, and the average of mean relative errors (MREs),
. The simulation results can be used to develop a guideline for choosing the best estimation approach that provides more accurate estimates for the TBXE parameters. The R software (version 4.0.3) [
17] was used to generate 5000 random samples from the TBXE distribution for sample sizes
50, 150, 300, and 400, along with different parameter values.
The simulation results, including absolute value of bias, MSE, and MRE, for different estimators and eight parameters combinations are reported in
Table A1,
Table A2,
Table A3,
Table A4,
Table A5,
Table A6,
Table A7 and
Table A8 in
Appendix A. These tables show the rank of each of the estimators among all the estimators in each row, the superscripts are the indicators, and the
is the partial sum of the ranks for each column in a certain sample size.
Table 1 lists the partial and overall ranks of the estimators.
We observed that the behavior of the estimates of the TBXE parameters obtained using the eight methods of estimation are quite reliable. The bias decreased as n increased, showing that these estimates are asymptotically unbiased estimators. The MSE and MRE decreased as n increased, showing that these estimators are consistent.
All estimator methods showed consistency, except the MLE estimator method, which showed consistency for all parameter combinations except for combinations and .
Form
Table 1 and for the parameter combinations, we conclude that the ADE method outperformed all the other estimator methods (overall score of 71.5). Therefore, based on our study, we can consider the ADE method as the best.
8. Modeling Two Real Data
This section provides a discussion on the flexibility of TBXE distribution in fitting two real-world data sets from engineering science and comparing it with other competing distributions. The discrimination criteria, including minus maximized log-likelihood (), Akaike information criterion (AIC), the corrected Akaike information criterion (CAIC), Bayesian information criterion (BIC), Hannan information criterion (HQIC), Cramér–Von Mises (W), Anderson–Darling (A), and Kolmogorov–Smirnov (K-S) statistics, with their corresponding p-values, are used to compare the fitted competitive distributions.
Data set I represents the data of the breaking stress of carbon fibers, which consist of 100 observations, and was introduced by Nichols and Padgett [
18]. This data set was analyzed by [
19,
20].
Data set II refers to time-to-failure (
h) of the turbocharger of one type of engine, as reported in [
21]. The data consist of 40 observations and are used to show the flexibility of TBXE model compared with the same distributions for the first data set.
The two analyzed data sets are used to show the flexibility of the TBXE model compared with some well-known distributions such as Marshall–Olkin logistic exponential (MOLE) [
22], gamma (Ga), beta exponential (BE) [
23], generalized transmuted Poisson exponential (GTPE) [
24], alpha power exponential (APE) [
25], transmuted generalized exponential (TGE) [
26], exponential (TEGE) [
10], exponentiated exponential (EE) [
27], transmuted exponentiated generalized Fréchet–Weibull mixture exponential (FWME) [
28], and exponential (E) distributions.
Some descriptive statistics of data sets I and II are reported in
Table 2 and
Table 3, respectively.
Table 4 and
Table 5 report parameters estimates with their corresponding standard errors,
, AIC, CAIC, BIC, HQIC,
W,
A, and (K-S) statistics (K-S (stat)) with their corresponding
p-value (K-S (
p-value)), for the given data sets using ADE (as recommended in the Simulations section). The figures in these tables reveal that the new TBXE model provides a close fit to the modeled data sets compared with other competing distributions.
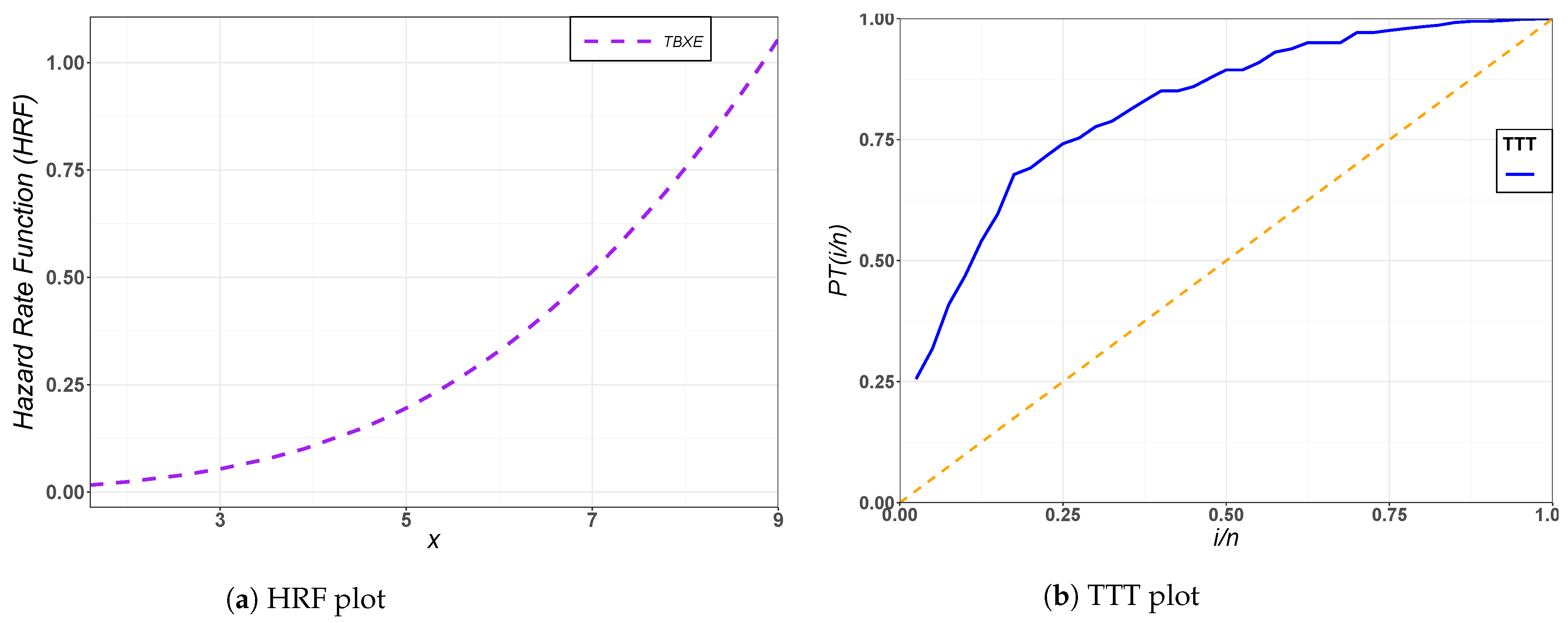
The fitted PDF and CDF plots for the TBXE model and other fitted models for the first and second data sets are depicted in
Figure 3 and
Figure 4, respectively. The HRF plot of the TBXE and total time on test (TTT) plot for the first and second data sets are depicted in
Figure 5 and
Figure 6, respectively. The TTT plot can be use for identifying the behavior of the HRF of the data.
Figure 7 and
Figure 8 provide the plots of the probability–probability (PP) of the TBXE model and other fitted models for the two data sets, respectively.




 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







