
Development and Evaluation of Speech Synthesis System Based on Deep Learning Models


Abstract
:1. Introduction
2. Related Work
3. Lexicon of the Azerbaijani Language
- Two identical vowels, one following the other in a word, are pronounced as one long vowel (e.g., “saat” [sa:t] (“clock”)).
- The sound [y] is included between two different consecutive vowels (e.g., “radio” [radiyo] (“radio”)).
- Once the so-called vowels “əa”, “üə”, “üa” converge, the first one falls and the second one stretches (e.g., “müavin” [ma:vin] (”deputy”)).
- In the case that o or ö are followed by the sound [v], the v drops and the vowels are stretched (e.g., “dovşan” [do:şan] (“rabbit”)).
- When certain suffixes with conjunctive y at the beginning are added to polysyllabic words ending in “a” or “ə”, these vowels become one of the closed vowel sounds ([ı], [i], [u], [ü]) during pronunciation (e.g “babaya” [babıya] (“to grandfather”)).
- If the consonants “qq”, “pp”, “tt”, “kk” merge in the middle of a word, one of them changes during pronunciation (e.g., “tappıltı” [tapbıltı] (“thud”)).
- If the sounds b, d, g, c, q, k, z come at the end of a word, they change during pronunciation to p, t, k, ç, x, x’, s, respectively (e.g., “almaz” [almas] (“diamond”)).
- If a consonant comes after the k sound in the middle of a word, its pronunciation is k = x ‘ (e.g., məktəbli [məx’təbli] (“student”)).
4. Methodology
4.1. Tacotron
- 1-D convolutional filters bank, where the convolved inputs are used to generate local and contextual information. Afterward, the outputs are added together and combined over time to build increased local invariances. This sequence is then passed to the several fixed-width 1-D convolutions and added with the input sequence.
- Bidirectional gated recurrent unit (GRU) [19] recurrent neural network (RNN) [20] used to derive sequential features from the forward context and backward context.
- Encoder module is necessary for extracting solid, consistent text representations. The procedure starts with the embedding of the one-hot representation of each character into a continuous vector. Subsequently, the vector passes through the non-linear transformations of the bottleneck layer, also known as pre-net, which helps to improve generalization, and the transformations of the CBHG module to reduce overfitting and mispronunciations. This gives the final representation of the outputs of the encoder used as the attention module.
- Decoder is a content-based tanh attention decoder, where the input is a concatenated context vector with the attention RNN output. During each time step, it creates the attention query. In addition, the decoder is implemented with a GRU stack containing vertical residual connections as it helps to speed up convergence. Moreover, due to the highly redundant representation of the raw spectrogram, and as the seq2seq target can be highly compressed while it provides prosody information for an inversion process, the 80-band mel-scale spectrogram is used as the target of the seq2seq, that will be further converted to waveform in post-processing network.
- The decoder output layer represents a fully connected output layer. It serves to anticipate the decoder targets. As the prediction process uses prediction of r frames at once, it reduces training time together with inference time as well as increases the convergence rate.
- Post-processing net is necessary to convert the seq2seq target to target, which will be further converted into a waveform. This network learns to predict the spectral value displayed on a linear frequency scale. Information contained in the post-processing net that includes both forward and backward information is used to correct the prediction error. As a post-processing net, Tacotron uses the CBHG module.
4.2. Deep Convolutional Text-to-Speech
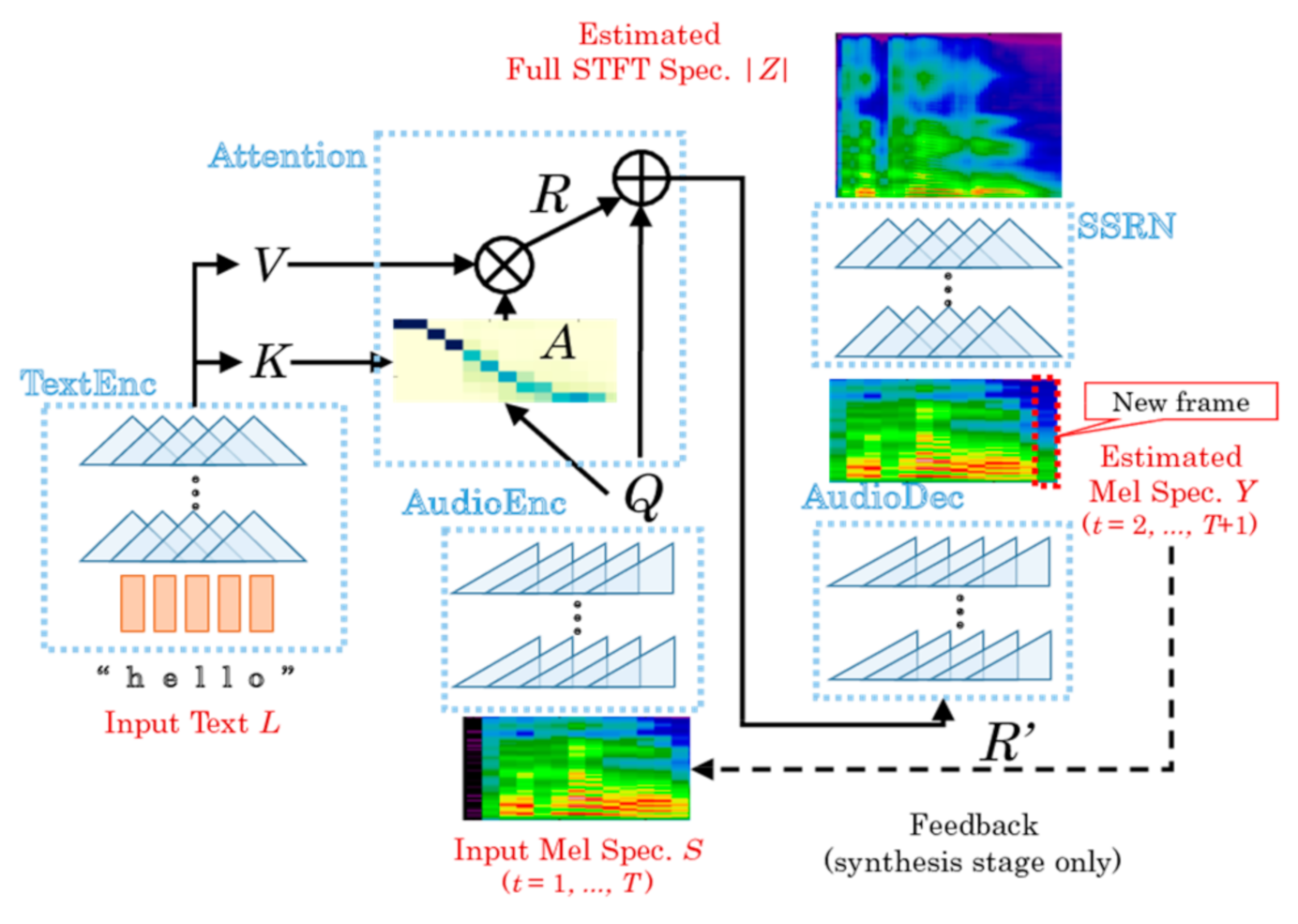
- Text to mel spectrogram network, which forms a mel spectrogram from an input text and is composed of four submodules:
- The text encoder encodes an input sentence L of N characters into the matrices of keys and values K, V of dimension 256 × N.(K, V) = TextEnc(L)
- The audio encoder encodes the coarse mel spectrogram S1:F,1:T, considering that S is a normalized mel spectrogram with applied mel filter bank, where F is the number of frequency bins and T is the length of the previously spoken speech, into a matrix Q with dimension 256 × T.Q = AudioEnc (S1: F,1: T)
- Attention matrix A evaluates how closely the n-th character in the sentence is related with t-th time frame of the mel spectrogram.where softmax function determines whether it is the searched character or not. In case if Ant 1 with n-th character, it starts to look at ln + 1 or characters near it or near ln at the subsequent time t + 1. Assuming that these characters are encoded column V, then a seed R ∈ R256xT that is decoded to subsequent frames S1: F,2: T + 1R = Attention (Q, K, V): = V A
- Audio Decoder decodes the concatenated matrix R’ = [R, Q] to synthesize a coarse mel spectrogram.Y1: F,2: T + 1 = AudioDec (R’)Afterward, this result is compared with temporally shifted ground truth S1: F, 2: T + 1 by a loss function, which is the sum of L1 loss [24] function and binary convergence, that is calculated by:where Ýft = logit (Ýft). The error is back propagated to the network parameters.Dbin(Y|S) := Eft[−SftÝft + log(1 + expÝf)] + const
- Spectrogram Super-resolution network. The network synthesizes a full spectrogram from the obtained coarse mel spectrogram.
5. Data Collection and Processing
6. Evaluation Methods
- Subjective tests. These are the listening tests where each listener judges speech quality and naturalness.
- Objective tests. Tests where measurement of voice performance estimated by applying appropriate speech signal processing algorithms.
- Intelligibility-index of the correctness in the interpretation of the words. This metric can be evaluated using the following tests:
- Diagnostic Rhyme Test (DRT)-subjective test, based on pairs of words with confusable rhyming and differs only in a single phonetic feature. In this test, listeners have to identify the index of the given word [26]. The percentage of the right answers is used as an intelligibility metric.
- Modified Rhyme Test (MRT)-subjective test, similar to the previous test, except the fact that it is based on different sets of six words [27].
- Semantically Unpredictable Sentence (SUS)-subjective test, based on sentences of randomly selected words [28]. Using this method, the intelligibility can be evaluated using the formula below:where C is the number of the correct predicted sentences, S is the total number of the tested sentences and L is the number of listeners.
- Quality-index of the naturalness, fluency, clarity. This metric can be evaluated using the following methods:
- ABX test-subjective test, where listeners make comparison between the synthesized sentence by system A and synthesized sentence by system B in terms of the closeness to the originally voiced sentence X [29].
- Mel Cepstral Distortion (MCD)-objective test, that measures the difference between synthesized and natural mel cepstral sequences consisting of extracted mel-frequency cepstral coefficients [30]. This difference shows how the reproduced speech is closer to the natural one. MCD can be calculated by the formula:where , are mel frequency cepstral coefficients of the t-th frame from the reference and predicted audio, d is dimension index from 0 to 24, t is time (frame index) and T’ is the number of non-silence frames.
- Segmental Signal-to-noise ratio (SNRseg) objective test, which measures noise ratio between two signals [29]. This ratio can be calculated using the formula below:where is the original signal, is the synthesized signal, N is the frame length, M is the number of frames in the speech signal.
- Perceptual evaluation of speech quality (PESQ)-objective test, which allows to predict the results of MOS evaluation [29]. This helps to automate the MOS evaluation and make this process faster. PESQ is calculated by the following formula:where a0 = 4.5, + a1 = −0.1, a2 = −0.0309, dsym is the average disturbance and dasym is the average asymmetrical disturbance value.PESQ = a0 + a1·dsym + a2·dasym
7. Experiments
8. Discussion and Results
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Taylor, P. Communication and Language. In Text-to-Speech Synthesis; Cambridge University Press: Cambridge, UK, 2009; pp. 13–15. [Google Scholar]
- Tabet, Y.; Boughazi, M. Speech Synthesis Techniques. A Survey. In Proceedings of the International Workshop on Systems, Signal Processing and Their Applications (WOSSPA), Tipaza, Algeria, 9–11 May 2011. [Google Scholar]
- Kaur, G.; Singh, P. Formant Text to Speech Synthesis Using Artificial Neural Networks. In Proceedings of the 2019 Second International Conference on Advanced Computational and Communication Paradigms (ICACCP), Gangtok, India, 25–28 February 2019. [Google Scholar]
- Tsukanova, A.; Elie, B.; Laprie, Y. Articulatory Speech Synthesis from Static Context-Aware Articulatory Targets. In International Seminar on Speech Production; Springer: Berlin/Heidelberg, Germany, 2018; pp. 37–47. Available online: https://hal.archives-ouvertes.fr/hal-01937950/document (accessed on 30 September 2020).
- Jurafsky, D.; Martin, J.H. Speech and Language Processing, 2nd ed.; Prentice Hall: Hoboken, NJ, USA, 2008; pp. 249–284. [Google Scholar]
- Jeon, K.M.; Kim, H.K. HMM-Based Distributed Text-to-Speech Synthesis Incorporating Speaker-Adaptive Training. 2012. Available online: https://www.researchgate.net/publication/303917802_HMM-Based_Distributed_Text-to-Speech_Synthesis_Incorporating_Speaker-Adaptive_Training (accessed on 30 September 2020).
- Qian, Y.; Fan, Y.; Hu, W.; Soong, F.K. On the Training Aspects of Deep Neural Network (DNN) for Parametric TTS Synthesis. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; Available online: https://ieeexplore.ieee.org/document/6854318 (accessed on 30 September 2020).
- Arık, S.Ö.; Chrzanowski, M.; Coates, A.; Diamos, G.; Gibiansky, A.; Kang, Y.; Li, X.; Miller, J.; Raiman, J.; Sengupta, S.; et al. Deep Voice: Real-time Neural Text-to-Speech. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Latif, S.; Cuayahuitl, H.; Pervez, F.; Shamshad, F.; Ali, H.S.; Cambria, E. A survey on deep reinforcement learning for audio-based applications. arXiv 2021, arXiv:2101.00240. [Google Scholar]
- He, Q.; Xiu, Z.; Koehler, T.; Wu, J. Multi-rate attention architecture for fast streamable Text-to-speech spectrum modeling. arXiv 2021, arXiv:2104.00705. [Google Scholar]
- Liu, R.; Sisman, B.; Li, H. Graphspeech: Syntax-aware graph attention network for neural speech synthesis. arXiv 2020, arXiv:2104.00705. [Google Scholar]
- Rustamov, S.; Saadova, A. On an Approach to Computer Synthesis of Azerbaijan speech. In Proceedings of the Conference: Problems of Cybernetics and İnformatics, Baku, Azerbaijan, 12–14 September 2014. [Google Scholar]
- Aida–Zade, K.R.; Ardil, C.; Sharifova, A.M. The Main Principles of Text-to-Speech Synthesis System. Int. J. Signal Process. 2013, 6, 13–19. [Google Scholar]
- Valizada, A.; Akhundova, N.; Rustamov, S. Development of Speech Recognition Systems in Emergency Call Centers. Symmetry 2021, 13, 634. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Quoc, V.L. Sequence to Sequence Learning with Neural Networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Wang, Y.; Skerry-Ryan, R.; Stanton, D.; Wu, Y.; Weiss, J.R.; Jaitly, N.; Yang, Z.; Xiao, Y.; Chen, Z.; Bengio, S.; et al. Tacotron: Towards End-to-End Speech Synthesis. arXiv 2017, arXiv:1703.10135. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway networks. arXiv 2015, arXiv:1505.00387. [Google Scholar]
- Jin, Y.; Xie, J.; Guo, W. LSTM-CRF Neural Network with Gated Self Attention for Chinese NER. IEEE Access 2019, 7, 136694–136703. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Sherstinsky, A. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) Network. arXiv 2018, arXiv:1409.3215. [Google Scholar]
- Griffin, D.; Lim, J. Signal estimation from modified short-time Fourier transform. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 236–243. [Google Scholar] [CrossRef]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Tachibana, H.; Uenoyama, K.; Aihara, S. Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention. arXiv 2017, arXiv:1710.08969. [Google Scholar]
- Janocha, K.; Czarnecki, W.M. On Loss Functions for Deep Neural Networks in Classification. arXiv 2017, arXiv:1702.05659. [Google Scholar]
- ReadBeyond. Aeneas. 2020. Available online: https://github.com/readbeyond/aeneas (accessed on 13 May 2020).
- Voiers, W.; Sharpley, A.; Hehmsoth, C. Diagnostic Evaluation of Intelligibility in Present-Day Digital. In Research on Diagnostic Evaluation of Speech Intelligibility; National Technical Information Service: Springfield, VA, USA, 1975; pp. 87–92. Available online: https://apps.dtic.mil/dtic/tr/fulltext/u2/755918.pdf (accessed on 12 June 2020).
- House, A.; Williams, C.; Heker, M.; Kryter, K. Articulation testing methods: Consonantal differentiation with a closed response set. J. Acoust. Soc. Am. 1965, 37, 158–166. [Google Scholar] [CrossRef] [PubMed]
- Benoît, C.; Griceb, M.; Hazanc, V. The SUS test: A method for the assessment of text-to-speech synthesis intelligibility using Semantically Unpredictable Sentences. Speech Commun. 1988, 18, 381–392. [Google Scholar] [CrossRef]
- Loizou, P.C. Speech Quality Assessment. In Multimedia Analysis, Processing and Communications; Springer: Berlin/Heidelberg, Germany, 2011; pp. 623–654. Available online: https://ecs.utdallas.edu/loizou/cimplants/quality_assessment_chapter.pdf (accessed on 15 August 2020).
- Kominek, J.; Schultz, T.; Black, A.W. Synthesizer Voice Quality of New Languages Calibrated with Mean Mel Cepstral Distortion. In Proceedings of the SLTU-2008—First International Workshop on Spoken Languages Technologies for Under-Resourced Languages, Hanoi, Vietnam, 5–7 May 2008; Available online: https://www.cs.cmu.edu/~awb/papers/sltu2008/kominek_black.sltu_2008.pdf (accessed on 18 April 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rating | Quality of Synthesized Audios by Systems A and B |
|---|---|
| 3 | A very good |
| 2 | A better |
| 1 | A good |
| 0 | About the same |
| 1 | B good |
| 2 | B better |
| 3 | B very good |
| Rating | Speech Quality | Level of Distortion |
|---|---|---|
| 5 | Excellent | Imperceptible |
| 4 | Good | Just perceptible, but not annoying |
| 3 | Fair | Perceptible and slightly annoying |
| 2 | Poor | Annoying, but not objectionable |
| 1 | Bad | Very annoying and objectionable |
| Test Type | No of Test Sentences | No of Sent. without OOV Words | No of Sent. with 1 OOV Word | No of Sent. with 2 OOV Words | No of Sent. with 3 OOV Words | No of Sent. with 4 OOV Words |
|---|---|---|---|---|---|---|
| AB | 5 | 5 | ||||
| MOS for system A | 14 | 3 | 6 | 4 | 1 | |
| MOS for system B | 14 | 3 | 6 | 4 | 1 | |
| SUS for system A | 10 | 3 | 4 | 3 | ||
| SUS for system B | 10 | 3 | 4 | 3 |
| System | MOS (95% CI) |
|---|---|
| Tacotron | 3.49 ± 0.193 |
| DC TTS | 3.36 ± 0.187 |
| System | SUS Score F% |
|---|---|
| Tacotron | 49% |
| DC TTS | 45% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Valizada, A.; Jafarova, S.; Sultanov, E.; Rustamov, S. Development and Evaluation of Speech Synthesis System Based on Deep Learning Models. Symmetry 2021, 13, 819. https://doi.org/10.3390/sym13050819
Valizada A, Jafarova S, Sultanov E, Rustamov S. Development and Evaluation of Speech Synthesis System Based on Deep Learning Models. Symmetry. 2021; 13(5):819. https://doi.org/10.3390/sym13050819
Chicago/Turabian StyleValizada, Alakbar, Sevil Jafarova, Emin Sultanov, and Samir Rustamov. 2021. "Development and Evaluation of Speech Synthesis System Based on Deep Learning Models" Symmetry 13, no. 5: 819. https://doi.org/10.3390/sym13050819
APA StyleValizada, A., Jafarova, S., Sultanov, E., & Rustamov, S. (2021). Development and Evaluation of Speech Synthesis System Based on Deep Learning Models. Symmetry, 13(5), 819. https://doi.org/10.3390/sym13050819