1. Introduction
Artificial Intelligence (AI) models and methods are parts of our lives. However, most of the AI techniques are blackboxes in the sense, that they do not explain how and why they arrived at a specific conclusion. Explainable AI try to overcome this situation, developing models with interpretable semantics and transparency [
1,
2]. Fuzzy Cognitive Maps (FCMs) are one of the earliest EAI models, introduced by B. Kosko [
3]. FCMs are recurrent neural networks employing weighted causal relation between the model’s concepts. Due to their modelling ability and interpretability, these models have a wide range of application [
4,
5].
Although FCMs have an enormous number of applications, only a few studies are devoted to the analytical and not empirical discussion of their behaviour. Boutalis et al. [
6] examined the existence and uniqueness of fixed points of FCMs. Lee and Kwon studied the stability of FCMs using Lyapunov method [
7]. Knight et al. [
8] analyzed FCMs with linear and sigmoid transfer functions. In [
9], the authors generalized the findings of [
6] to FCMs with arbitrary sigmoid function. All of these studies arrived to the conclusion (although in a different form) that when the parameter of the sigmoid threshold function is small enough, then the FCM converges to a unique fixed point, regardless of the initial activation values.
The hybridisation of rough set theory and fuzzy set theory [
10,
11] provide a not only promising, but fruitful combination of different methods of handling and modelling uncertainty [
12,
13].
The application areas encompass a wide variety of sciences, so only a few of them are mentioned here, without the need for completeness. Fuzzy rough sets and fuzzy rough neural networks have been applied in feature selection problems [
14], evolutionary fuzzy rough neural networks have been developed for stock prediction [
15]. Fuzzy rough set models are used in multi-criteria decision-making in [
16]. Classification tasks have been solved by fuzzy rough granular neural networks in [
17]. The combination of unsupervised convolutional neural networks and fuzzy-rough C-mean was used effectively for clustering of large-scale image dataset in [
18]. The environmental impact of a renewable energy system was estimated using fuzzy rough sets in [
19]. The interval-valued fuzzy-rough based Delphi method was applied for evaluating the siting criteria of offshore wind farms in [
20]. Another current direction is the fusion of neutrosophic theory and rough set theory [
21]. An example of its application is the emission-based prioritization of bridge maintenance projects [
22]. Nevertheless, in the aspect of this paper, fuzzy rough granular networks [
23] are the most exciting applications of the synergy of fuzzy and rough theories.
Granular Computing [
24] uses information granules, such as classes, clusters, subsets etc., just like humans do. Granular Neural Networks (GNNs) [
25] make a synergy between the celebrated neural networks and granular computing [
26]. Rough Cognitive Networks (RCN) are GNNs, introduced by Nápoles et al. [
27], combining the abstract semantic of the three-way decision model with the neural reasoning mechanism of Fuzzy Cognitive Maps for addressing numerical decision-making problems. The information space is discretized (granulated) by using Rough Set Theory [
28,
29], which has many other interesting applications [
30,
31,
32,
33]. According to simulation results, RNN was capable to outperform standard classifiers. On the other hand, learning the similarity threshold parameter had significant computational cost.
Rough Cognitive Ensembles (RCEs) was proposed to overcome this computational burden [
34]. It employs a collection of Rough Cognitive Networks as base classifiers, each operating at a different granularity level. This allows suppressing the requirement of learning a similarity threshold. Nevertheless, this model is still very sensitive to the similarity threshold upon which the rough information granules are built.
Fuzzy-Rough Cognitive Maps (FRCNs) has been introduced by Nápoles et al. [
35]. The main feature of FRCNs is that the crisp information granules are replaced with fuzzy-rough granules. Based on simulation results, FRCNs show performance comparable to the best blackbox classifiers.
Vanloffelt et al. [
36] studied the contributions of building blocks to the FRCNs’ performance via empirical simulations with several different network topologies. They concluded that the connections between positive neurons might not necessary to maintain the performance of FRCNs. The theoretical study by Concepción et al. [
37] discussed the contribution of negative and boundary neurons. Moreover, they arrived at the conclusion that negative neurons have no impact on the decision, and the ranking between positive neuron remains invariant during the whole reasoning process.
Besides the results presented in [
37], this paper was motivated by the fact that only a few studies are discussing the behaviour of cognitive networks from the strict mathematical point of view. Nevertheless, such studies may provide us with information about what we can or cannot achieve with these models. Analyzing the behaviour and contribution of the building blocks unveils the exact role of components of the complex structure: which part is crucial and which one is unnecessary etc. In this paper, we do not develop, neither implement another new fuzzy-rough model. Instead, we analyze the behaviour of FRCNs, which are comparable in performance to the best black-box classifiers. Because of their proven competitiveness [
35], there is no need for further model verification and validation.
In the current paper, the dynamical behaviour of fuzzy-rough cognitive networks is examined. The main contributions are the following: first, we show that stable positive neurons have at most two different activation values for any initial activation vectors. Then we show that a certain point with equal coordinates (called
trivial fixed point) is always a fixed point, nevertheless, not always a fixed point attractor. Furthermore, a condition for the existence of a unique, globally attractive fixed point is also stated. Complete analysis of the dynamics of positive neurons for two and three decision classes is provided. Finally, we show that for a higher number of classes, the occurrence of limit cycles is a necessity and the vast majority of initial activation values lead to oscillation. The rest of the paper is organized as follows. In
Section 2, we recall the construction of fuzzy-rough cognitive maps and overview the existing results about their behaviour. In
Section 3, a summary of the mathematical background necessary for further investigation of the dynamics of FRCNs is provided, including contraction mapping and elements of bifurcation theory.
Section 4 presents general result about the dynamics of positive neurons, condition for unique fixed point attractor and refinement of some findings of [
37].
Section 5 introduces size-specific results for FRCNs, providing a complete description for the case of two and three decision classes and pointing out that over a specific size, oscillation behaviour will be naturally present.
Section 6 discusses the relation of the behaviour of positive neurons to the final decision class of FRCNs. The paper ends with a short conclusion in
Section 7.
4. General Results on the Dynamics of Positive Neurons
In this section, we introduce some general results about the dynamics of positive neurons. Size specific results are presented in
Section 5.
With start with the refinement of a result from [
37]. Further investigation of the function
(see Equation (
14)) provides more information about the possible fixed points of positive neurons (see
Figure 2). It has been shown that there are at most one positive neuron with activation value higher than
. If
, then a specific value may be produced by at most three different values of
x. But two of these values are higher than
, thus only one of them get a role in the activation vector. It means that one coordinate of the activation vector is greater than
and the remaining ones are less than
and they have equal values.
Consider now the case, when . Observe that the graph of is symmetrical about the point (it can be easily verified analytically). Let us choose a specific value , such that the horizontal line has three intersection points with the graph. Denote the first coordinates of theses point by (). Using the symmetry of the function, we can conclude that . Consequently, . Since the sum of the activation values is less than 1 (), it follows that there can be at most two different values ( and ) in the activation vector for any given .
Summarizing this short argument, if the activation vector of positive neurons converges to a fixed point, then it may have at most two different coordinate values.
The iteration rule for the updating of the neurons’ activation values has the form
where the sigmoid is applied coordinate-wise and
W is the connection matrix of the network. Based on the construction of the network (see Algorithm 1), it has the following block form:
where
O,
I denote zero matrix and identity matrix, respectively.
describes the connections from boundary to decision neurons (it contains 0 s and 0.5 s, their positions depend on non-empty boundary regions),
describes the connections between positive neurons (if
, then
, else
),
contains the connections from positive neurons to decision neurons.
Because of the upper-diagonal block structure, instead of dealing with the whole matrix, we can use the blocks. It has been proved in [
37] that activation values of the negative and boundary neurons converge to the same unique value, which depends on
, but independent of the initial activation values. Positive neurons influence themselves, each other and decision neurons, but do not receive input from other set of neurons. Their activation values are propagated to the decision neurons. In a long run, when neurons reach a stable state (or the iteration is stopped by achieving the maximal number of iterations), the propagated value is their stable (or final) state. In the following, we examine the long-term behaviour of positive neurons.
Lemma 1. For every and every number of decision classes N, there always exists a fixed point of the positive neurons, whose coordinates are the same. Nevertheless, this fixed point is not always a fixed point attractor.
Proof. Consider the fixed point equation for every
:
If
for every
, then it simplifies to the following equation:
We show that there always exists a unique solution to this equation. Let us introduce the function
Function
is continuous and differentiable, moreover
and
, thus it has at least one zero in
. According to Rolle’s theorem, between two zeros of a differentiable function its derivative has a zero. The derivative is
which is always positive. It means that there is exactly one zero of
in
. Consequently, we have shown that for any given
and
N, there is exactly one fixed point of the positive neurons with equal coordinates. There may be other fixed points, but their coordinates are not all the same. □
The following lemma plays a crucial role in the proof of Theorem 2 and in the examination of the Jacobian of the iteration mapping.
Lemma 2. Let be an matrix with the following entries: Then the eigenvalues of are (with multiplicity one) and 2 (with multiplicity ).
Proof. Basic linear algebra. □
Theorem 2. Consider a fuzzy cognitive map (recurrent neural network) with sigmoid transfer function () and with weight matrix whose entries are Ifthen it has exactly one fixed point. Moreover, this fixed point is a global attractor, i.e., the iteration starting from any initial activation vector ends at this point. Proof. We are going to show that if the condition in theorem is fulfilled, then the mapping
is contraction, thus according to Banach’s theorem, it has exactly one fixed point and this fixed point is globally asymptotically stable, i.e., iterations starting from any initial vectors arrive to this fixed point. Let us choose two different initial vectors,
P and
. Then
Here the first inequality comes from the fact that the derivative of the sigmoid function
is less than or equals
and
is Lipschitzian, while the second inequality comes from the definition of the induced matrix norm. Since
is a real, symmetric matrix its spectral norm (
) equals the maximal absolute values of its eigenvalues. By Lemma 2,
. According to the definition of contraction (Equation (
15)), if the coefficient of
is less than one, then the mapping is a contraction and by Theorem 1 it has exactly one fixed point and this fixed point is globally asymptotically stable. The inequality in the Theorem comes by a simple rearranging:
□
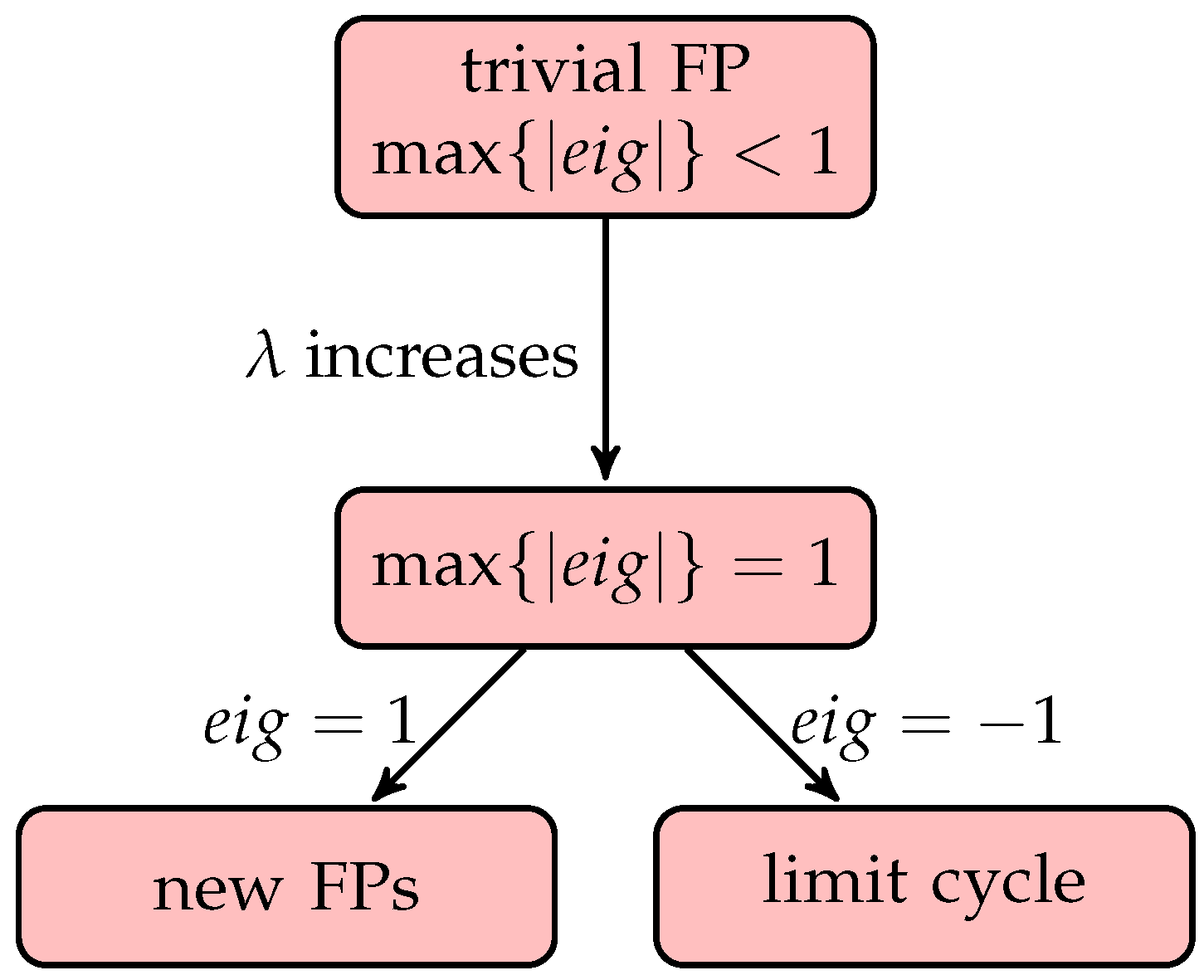
The immediate corollary of Theorem 2 and Lemma 1 is if there is a unique globally attracting fixed point, then its coordinates are equal. We will refer to fixed point with equal coordinates as
trivial fixed point. The whole complex behaviour of positive neurons (and in such a way, fuzzy-rough cognitive networks) evolves from this trivial fixed point via bifurcations (see the flowchart
Figure 3 for the way to the first bifurcation). In
Section 5, we show that different size of FRCNs (different number of decision classes
N) may show significantly different qualitative behaviour.
5. Dynamics of Positive Neurons
First we provide the Jacobian at the trivial fixed point. In general (except the case
), this fixed point is a function of
and
N. Let us denote the coordinates of the trivial fixed point by
. Then the
entry of the Jacobian of the mapping
at this point, using the fact that
and for the sigmoid function
:
The whoole Jacobian matrix evaluated at the trivial fixed point is the following:
Its eigenvalues are times the eigenvalues of : and . As the value of increases, at a certain point the absolute value of the eigenvalue with the highest modulus reaches one, the trivial fixed point loses its global stability and a bifurcation occurs. The type of this bifurcation has great effect on the further evolution and dynamics of the system. Based on the eigenvalues of , we see that Neimark-Sacker bifurcation does not occur here, but saddle-node and perido-doubling bifurcations do play an important role.
5.1.
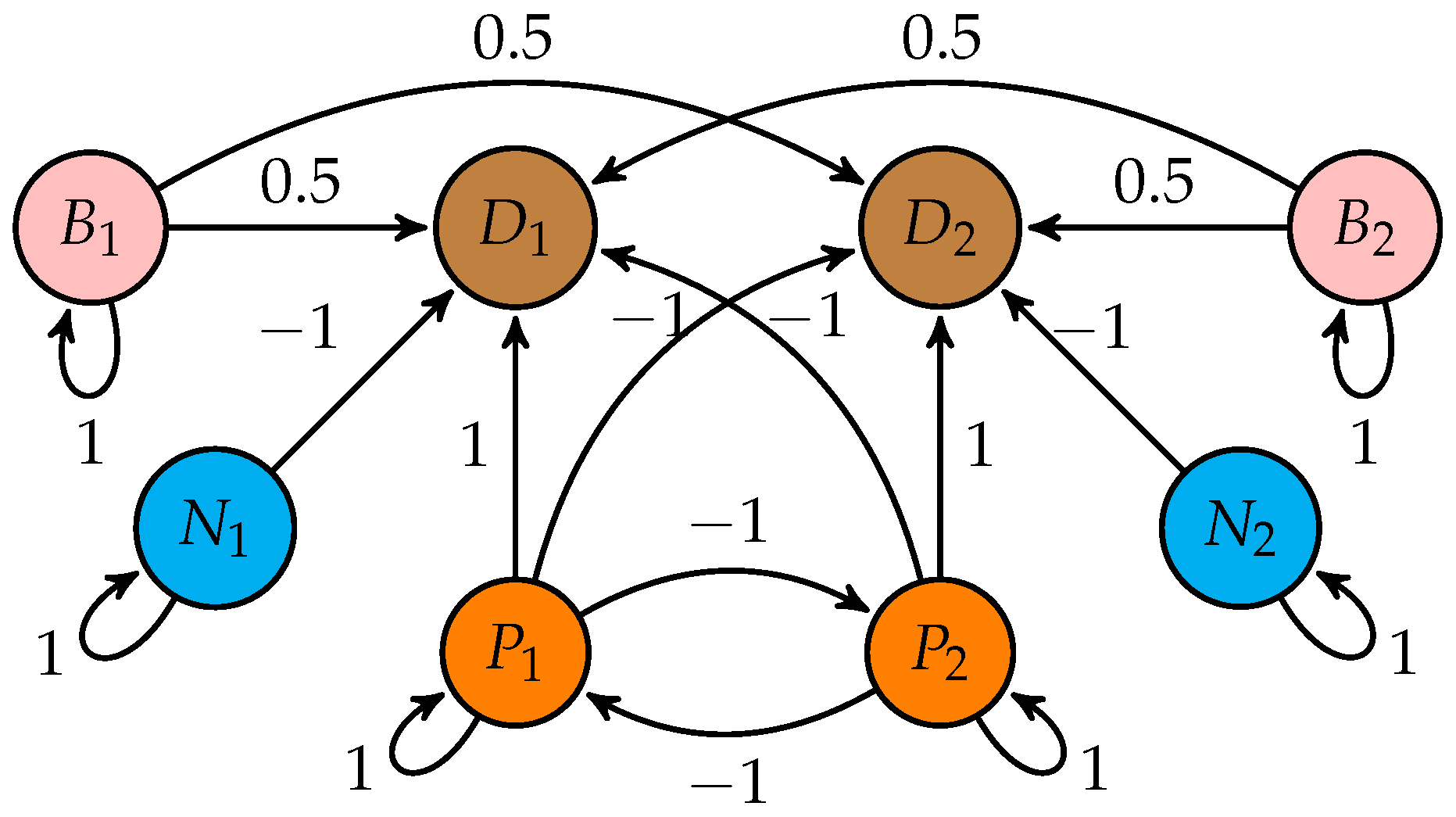
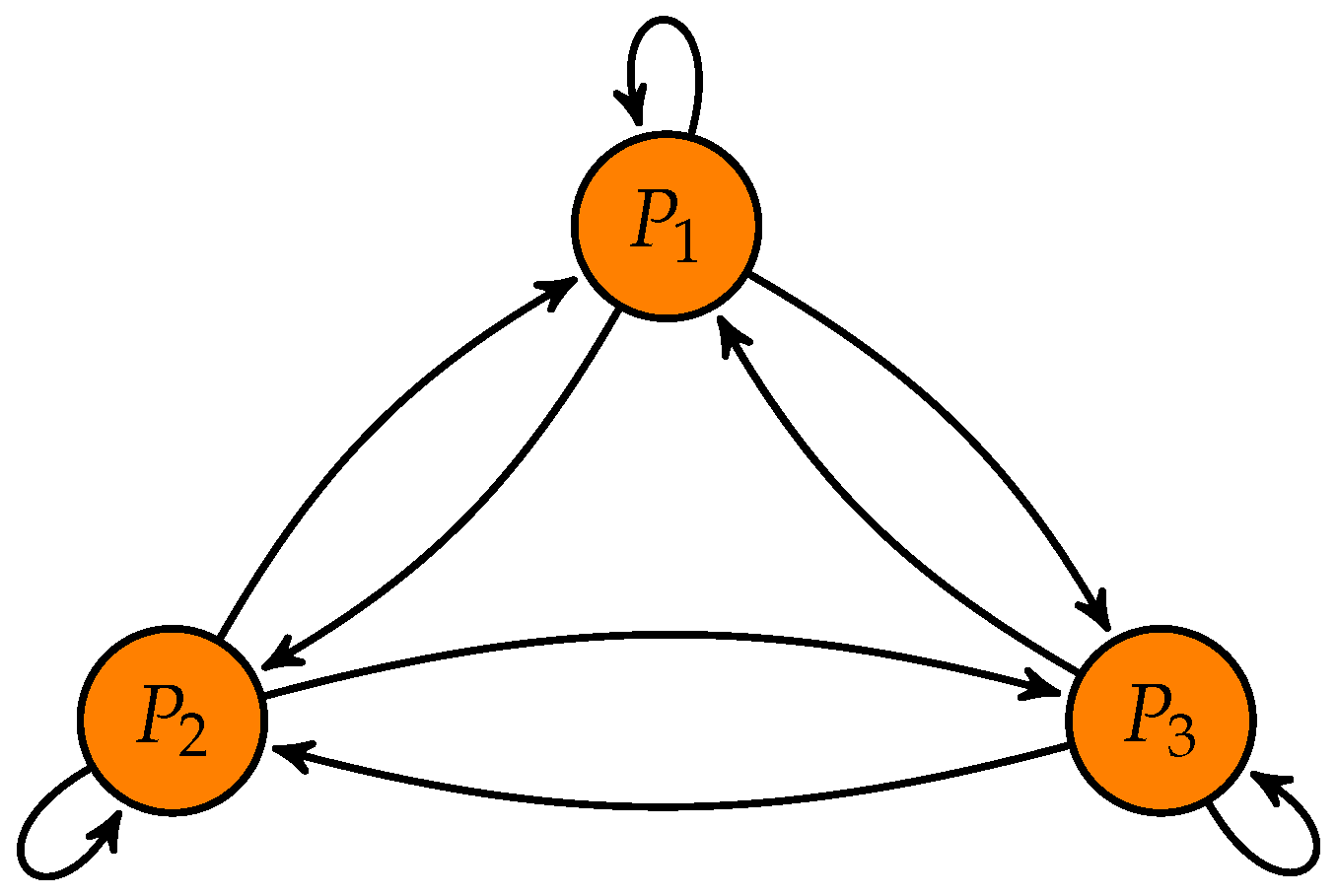
Consider first the case when we have only two decision classes. The relations between the positive neurons can be seen in
Figure 1. The weight matrix describing the connections is the following (subscript
P refers to positive):
Easy to check the the point
is always a fixed point of the mapping
, since
and
. According to Theorem 2, if
, then it is the only fixed point, moreover it is globally asymptotically stable, i.e., strating from any initial activation vector, the iteration will converge to this fixed point. The Jacobian of the mapping at this fixed point is
and its eigenvalues are 0 and
. When the eigenvalue
(
), a bifurcation occurs, giving birth to two new fixed points. In the following, we are going to show that for every
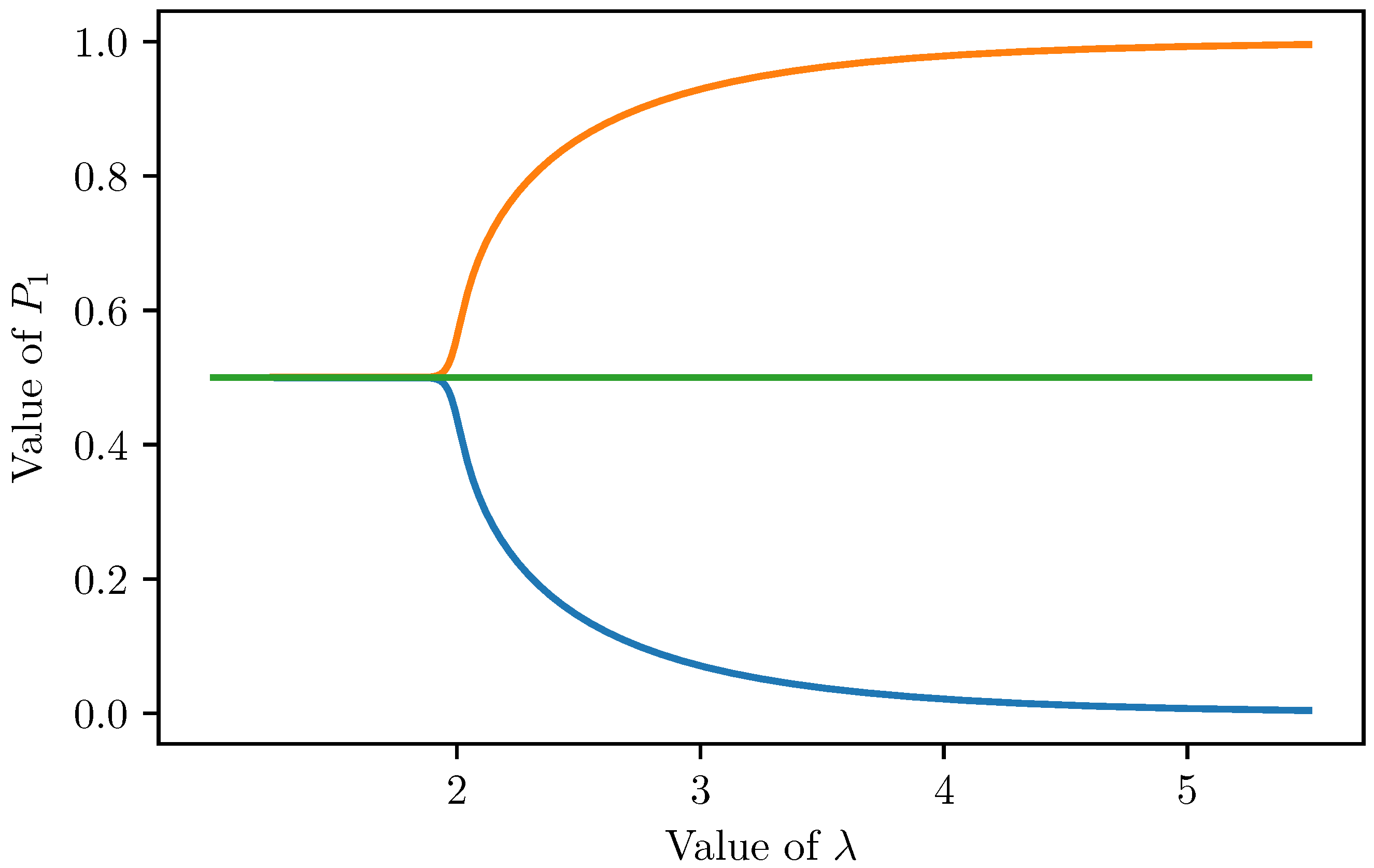
, there are exactly three fixed points, moreover these fixed points have the following coordinates:
,
and
, where
is a fixed point of a one dimensional mapping described below.
Let us assume that
is a fixed point of the mapping, then
Since
f is the sigmoid function, we have that
, consequently
So for a fixed point the coordinates are
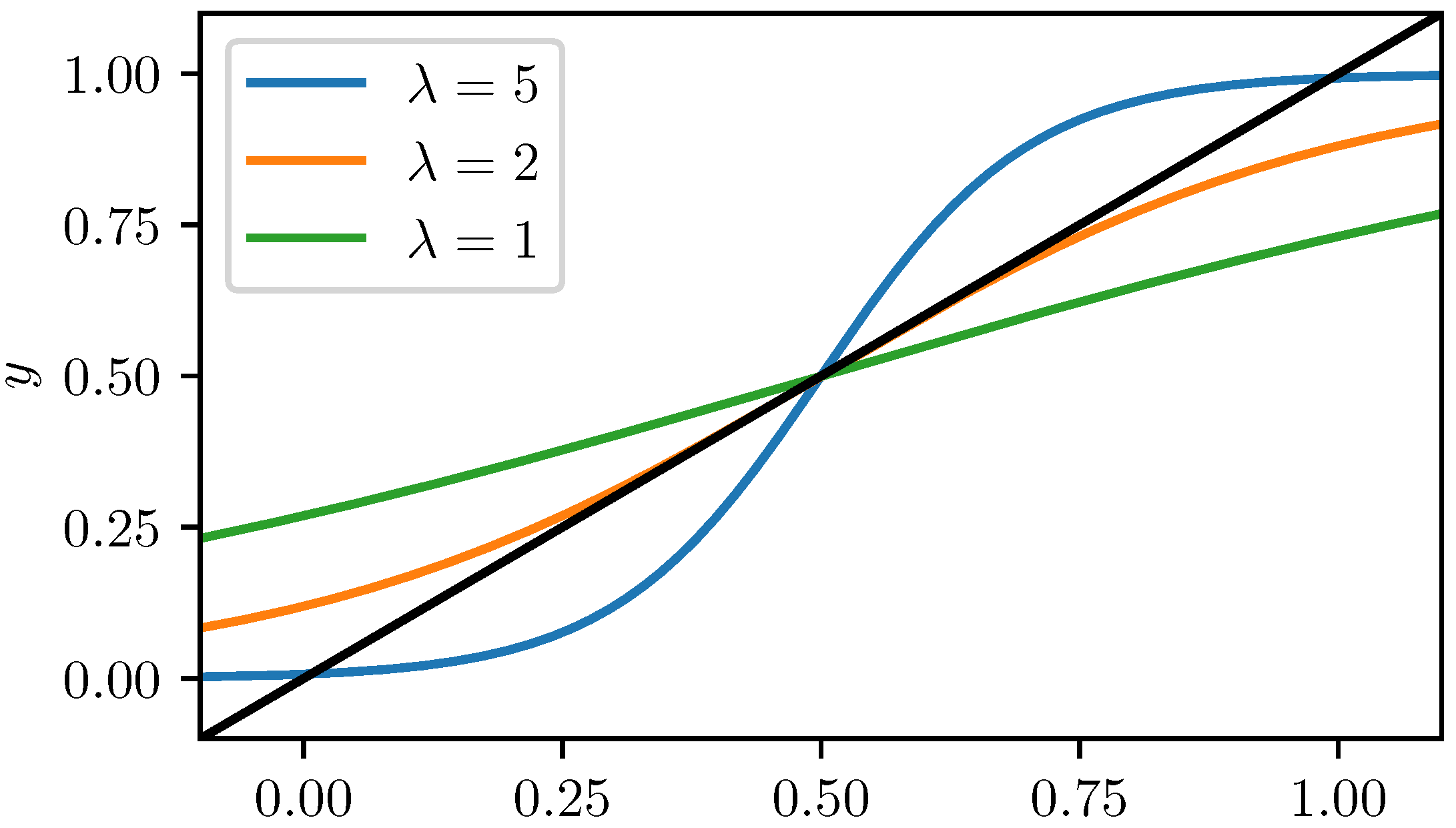
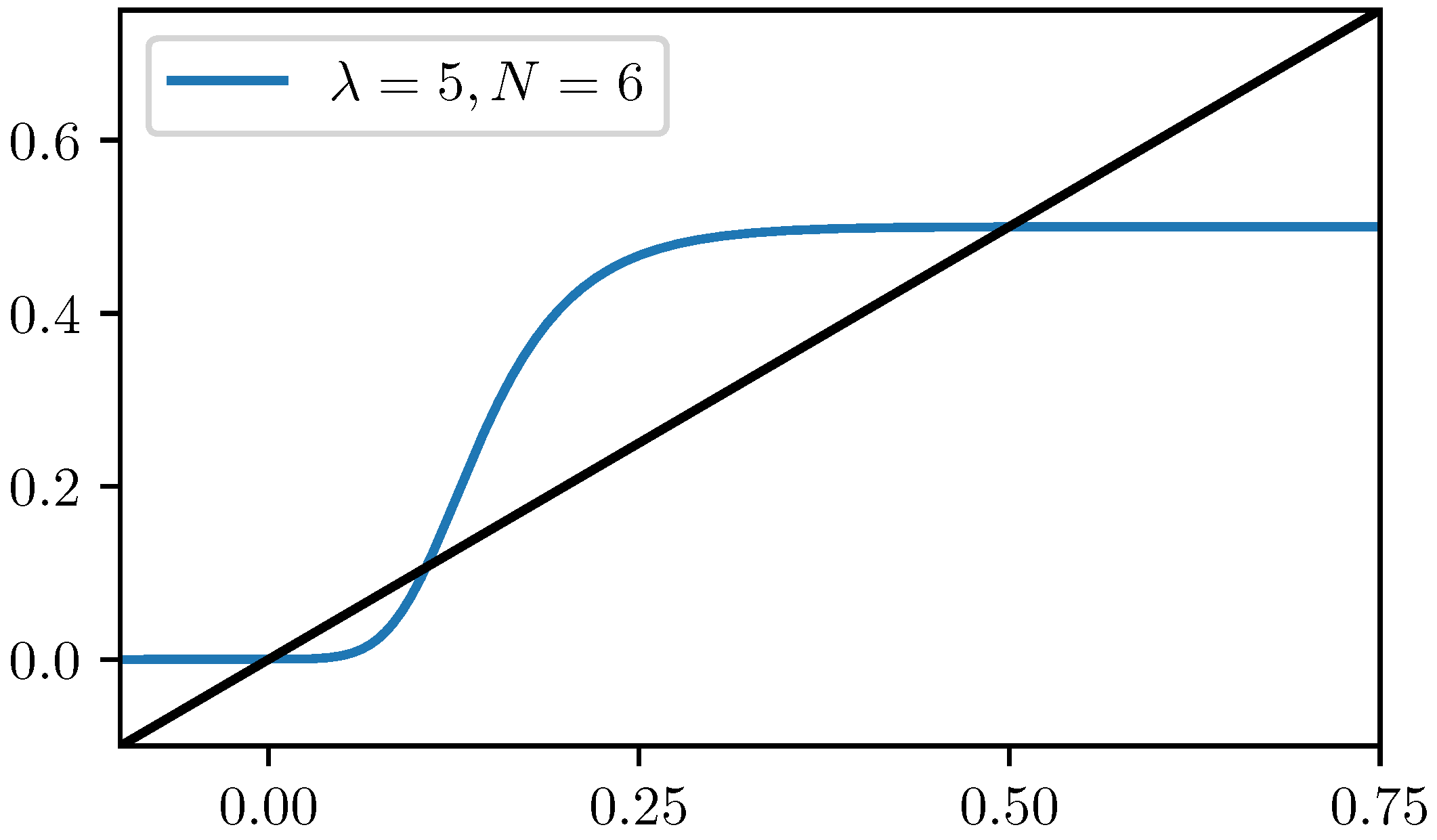
. The first equation leads to the following fixed point equation:
It means that the FPs of the positive neurons can be determined by solving Equation (
39). From the graphical point of view, easy to see that if
, then it has exactly one solution (
), but if
, then there are three different solutions:
,
and
(see
Figure 4).
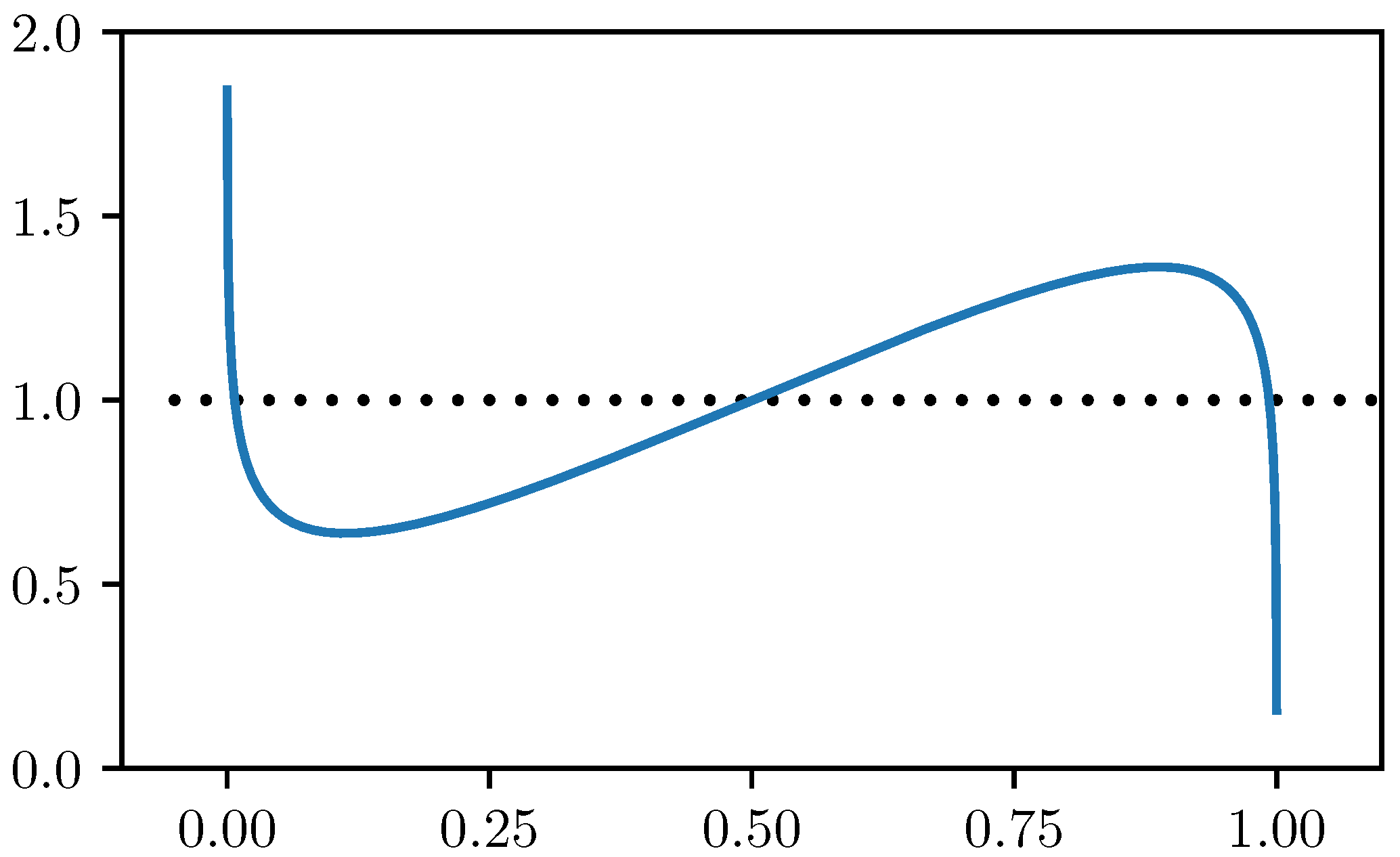
From the analytical viewpoint, we have to solve the equation
Applying the inverse of
and rearranginig the terms:
As it was pointed out in [
37], if
, then the left hand side has local minimum at
less than one, and local maximum at
greater than one. If
, then the function is strictly monotone decreasing. Using continuity of the function, we conclude that there are exactly three solutions for every
and there is a unique solution if
(see
Figure 5).
For , the fixed points are , and .
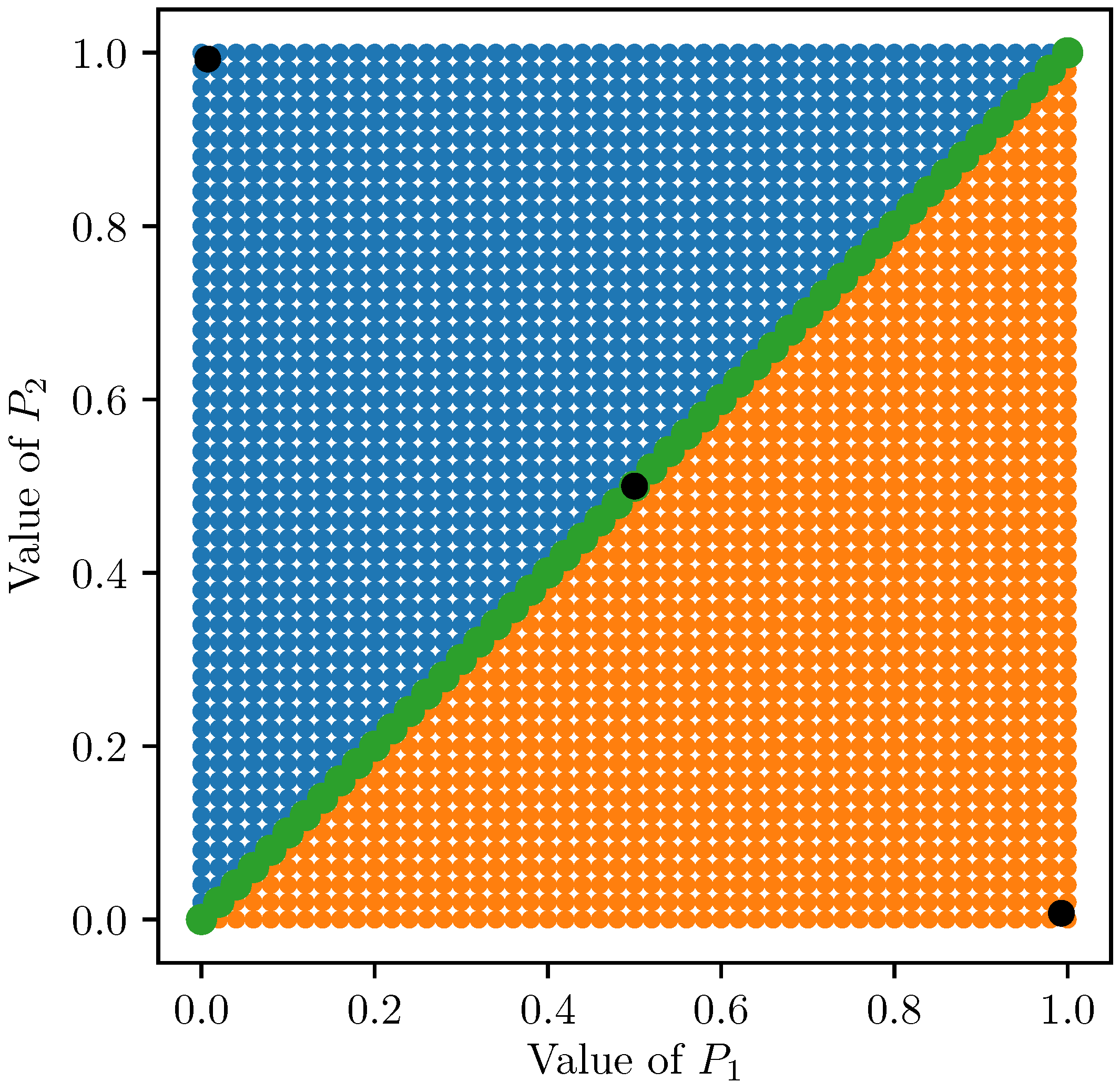
Let us examine the basins of attraction for the three different fixed points, i.e.,
and the fixed points are
,
and
, with
. Consider a point
as initial activation vector (see
Figure 6).
If
, then the iteration leads to the fixed point
, since
If , then , so this ordering remains invariant during the iteration process. Moreover, after the first iteration step it reduces to a one dimensional iteration with initial value and updating equation . If , then fixed point attracts this one-dimensional iteration. Consequently, the original two-dimensional itertaion converges to .
Similarly, if , then the iteration ends in .
The size of the basin of attraction can be considered as the number of its points. In the strict mathematical sense it is infinity, of course. On the other hand, the basin of fixed point is a one dimensional object (line segment), while the basins of and are two-dimensional sets (triangles), so they are ‘much more bigger’ sets.
In applications, we always work with sometimes large, but finite numbers of points, based on the required and available precision. Let us define the level of granularity as the length of subintervals, when we divide the unit interval into
n equal parts. Then the division points are
, so we have
points. The basin of fixed point
contains
points, while the basins of the two other fixed points have
,
points. By increasing the number of division points, the proportion of the basins tend to zero and
, as it was expected.
In a certain sense, it means that fixed points and are more important than fixed point , since much more initial activation values lead to these points.
5.2.
The structure of the connections between positive neurons can be seen in
Figure 7. In this case, the eigenvalues of
are
(with multiplicity one) and 2 (with multiplicity two). The fixed point with equal coordinates loses its global asymptotic stability when the absolute value of its larger eigenvalue equals one. Since the positive eigenvalue has the higher absolute value, this bifurcation results in new fixed points. Nevertheless, this eigenvalue has multiplicity two, so it is not a simple bifurcation, i.e., not only a pair of new fixed points arise, but a couple of new FPs. The trivial fixed point becomes a saddle point, i.e., it attracts points in a certain direction, but repells them in other directions. If we further increase the value of the parameter
, then the absolute value of the negative eigenvalue reaches one and the trivial fixed point suffers a bifurcation again. Since the eigenvalue is
, this is a period-doubling bifurcation, giving birth to a two-period limit cycle.
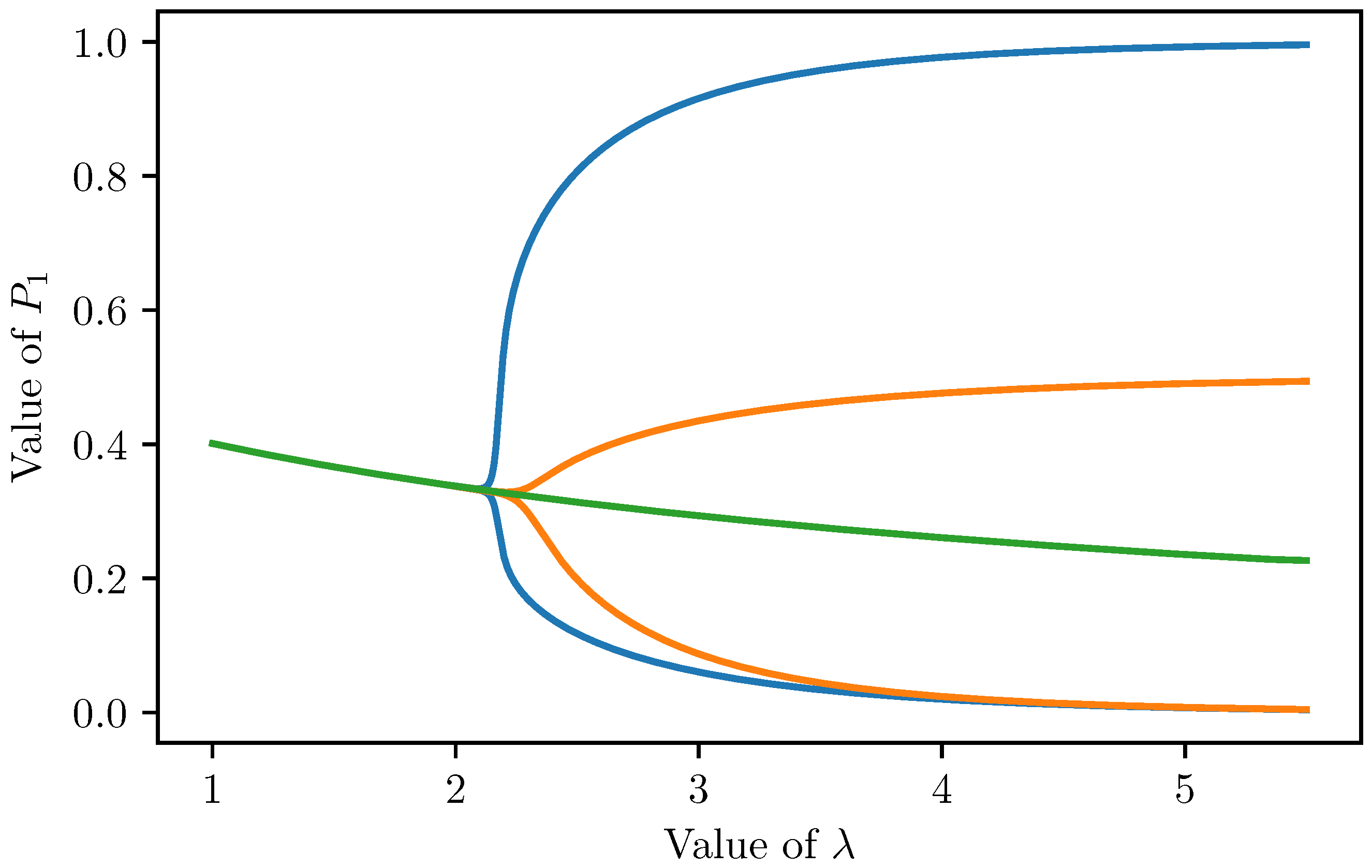
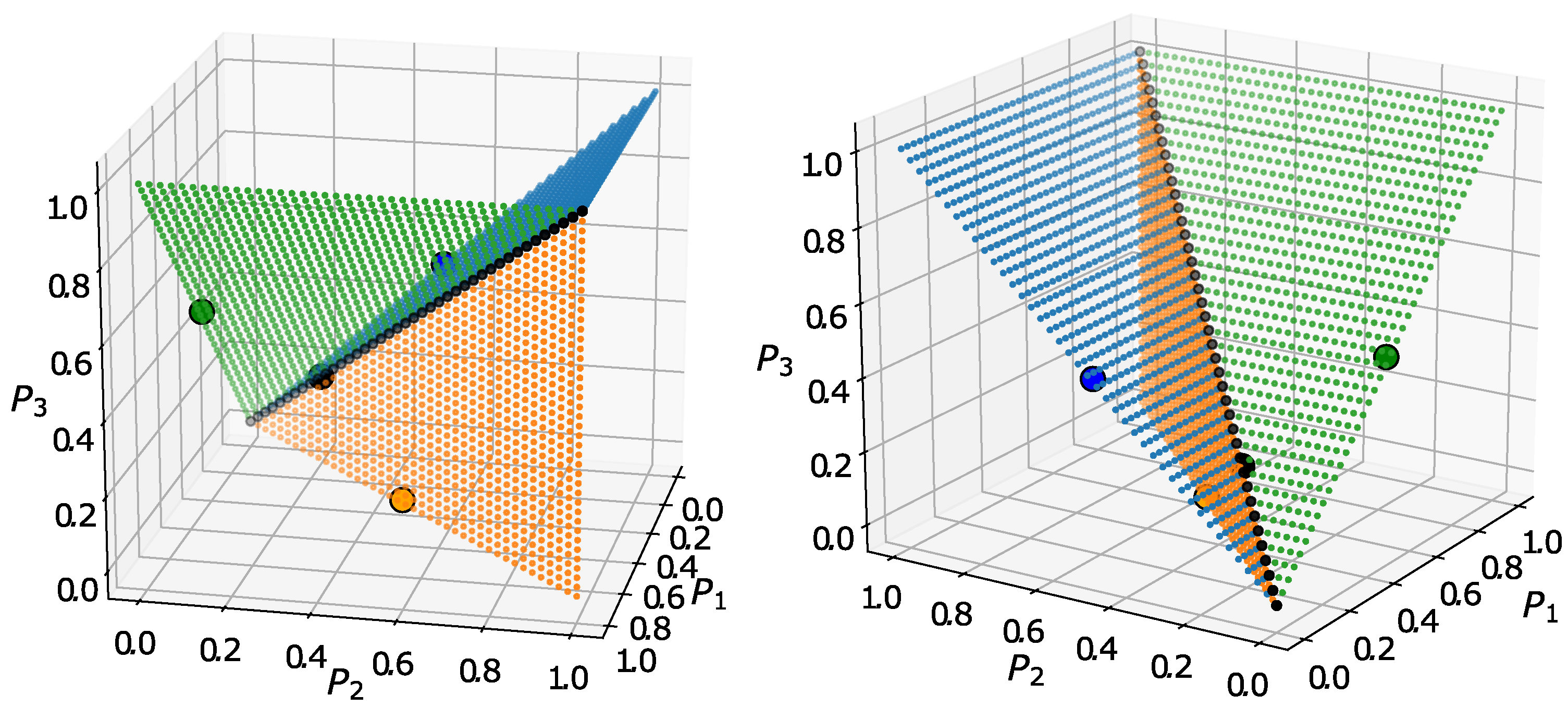
We show that there are three type of fixed points:
The trivial fixed point with equal coordinates ();
Fixed points with one high and two low values ();
Fixed points with one low and two medium coordinates ().
The existence of
is clear, as it was shown by Lemma 1. As it was pointed out in
Section 4, the non-trivial fixed points have two different coordinate values. Let us denote these values by
x,
x and
y. Then the fixed point equation is
which simplifies to the following system of equations:
By substituting
x, we have
It is again a fixed point equation, whose number of solutions depends on the value of parameter
(see
Figure 8):
if (rounded), then there is exactly one solution, it refers to the trivial fixed point ();
if , then there are three different solutions, one refers to , one to s and one to .
Using the values of y, we can determine the values of x. Furthermore, if y is high, then based on the equation , we may conclude that x is low. Similarly, if y is low, then x is medium. Finally, there are seven fixed points:
the fixed point with equal coordinates ();
three fixed points with one high and two low values ();
three fixed points with one low and two medium values (s).
For , these fixed points are (rounded to four decimals)
(),
and its permutations (),
and its permutations ().
Initial activation values lead to these fixed points according to the following:
if , then the iteration converges to ;
if , then the iteration converges to ;
if , then the iteration converges to .
Ranking is preserved between positive neurons, in the sense that if , then . Since the number of possible outcomes is very limited (only three cases without permutations), it means that some differences in the initial activation values will magnified, for example if the initial activation vector is , then the iteration converges to . On the other hand, some large differences will be hidden: initial activation vector leads again to .
Limit cycle occurs, when the negative eigenvalue of the Jacobian computed at the trivial fixed point reaches
(at about
). Similarly to the trivial fixed point, the elements of the limity cycle have equal coordinates. Let us denote these points by
and
. The members of a two-period limit cycle are fixed points of the double iterated function.
In coordinate-wise form this provides the following system of equations:
If , then it has a unique solution. It refers to the trivial fixed point, since this point is a fixed point of the double-iterated function, too. If , then there are two other solutions, low and medium, these are the coordinates of the two-period limit cycle. For example, for , these points are and .
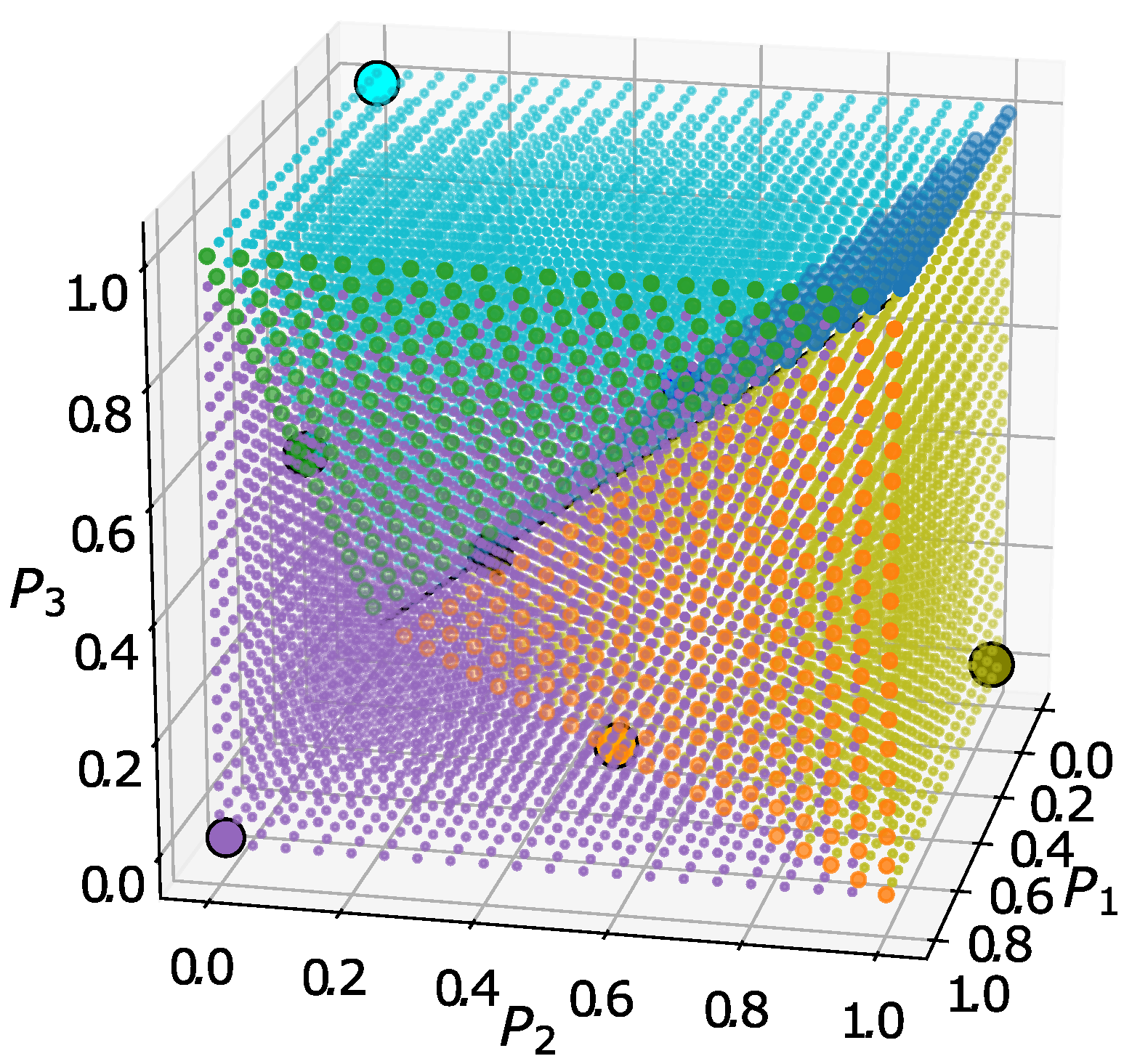
For a general case, basins of attraction of a dynamical systems are difficult to determine and sometimes it is analytically not feasible task [
41,
42], enough to mention the famous graph of Newton’s method’s basin ofattractions [
43]. We examined the basin of attraction of the fixed points by putting an equally spaced grid on the set of possible initial values of positive neurons
,
and
, and applied the grid points as initial activation values.
Table 1 shows the sizes of the basins of attraction for different granurality. Results are visualized in
Figure 9 and
Figure 10.
5.3.
If the FRCN has
decision classes, then the eigenvalues of the Jacobian at the trivial fixed point have the same magnitude, but with different sign. So positive and negative eigenvalues reaches one (in absolute value) at the same value of parameter
(see
Figure 11), causing the appearance of new fixed points and limit cycle simultaneuosly. The trivial fixed point is no longer an attractor, but fixed points with pattern one high, three low and two medium, two low values do exists.
If , then the absolute value of the negative eigenvalue of the Jacobian evaluated at the trivial fixed point is higher then the positive value, consequently first a period-doubling bifurcation occurs and the trivial fixed point loses its attractiveness. We should note that occurence of fixed points of type and is not linked to the other (positive) eigenvalue, since they occur earlier, for a smaller value of .
For the general case (
N decision classes), there exist two types of fixed points with the following patterns: one high,
low values and two medium,
low values. The fixed point equations for the one high (
),
low (
) pattern
which leads to the following one-dimensional fixed point problem:
The pattern two medium (
),
low (
) values leads to the following equations:
from which we get the a one-dimensional fixed point problem:
Nevertheless, these fixed points are less important for multiple decision classes.
Finally, we provide a geometrical reasoning of the structure of fixed points. Consider two fixed points of type , i.e., they have one high and low coordinates. Their basins of attractions are separated by a set, whose points do belong to none of them, but lie on an dimensional hyperplane ‘between’ them. Without loss of generality, we may assume that one fixed point is and the other one is . Because of symmetry, the hyperplane is perpendicular the line connecting and , i.e., its normal vector is paralel to . Additionally, the hyperplane crosses the line at the middle point of and , which has coordinates . Consequently, the equation of the separating hyperplane is . The separating set is a subset of this plane with the additional constrain , for every . Consequently, a fixed point of type has two medium coordinates with equal values (), and equal, but low coordinates. Since there are N fixed points of type , there are fixed points of type .
Simulation results show, that for
, limit cycles tend to steal the show. Limit cycle oscillates between two activation vectors with equal coordinates (the equality of the coordinates is an immediate consequence of symmetry). Let us denote these points by
and
. The members of a two-period limit cycle are fixed points of the double iterated function.
In coordinate-wise form this gives the following system of equations:
For
values generally applied in fuzzy cognitive maps and for
used in FRCNs, this fixed point equation has three solutions: one refers to the trivial fixed point, which is no longer a fixed point attractor, the other two (
low and
medium) are coordinates of the elements of the limit cycle (see
Figure 12).
Simulation results show that by increasing the number of decision classes, more and more initial values arrive to a limit cycle. We put equally spaced
N dimensional grid on the set
with stepsize
,
,
and
, then applied the gridpoints as initial activation values of the positive neurons. Since any particular real-life dataset finally turns into initial activation values for the FRCN model, it means that these gridpoints can be viewed as representations of possible datasets, up to the predefined precision (i.e., step size). Iteration stopped when convergence or limit cycle was detected or the predefined maximum numbers of steps reached. As we can observe in
Table 2, most of the initial values finally arrive to a limit cycle.
6. Relation to Decision
It has been proved previously, that values of negative and boundary neurons converge to the same value (it is ≈ 0.9930 for ) and the dynamical behaviour of positive neurons was analyzed in the preceding sections. Now we examine their effect on the decision neurons and such a way, on the final decision.
Decision neurons have only input values, they do not influence each other, neither other types of neurons. As a consequence, the sigmoid transfer function
only transform their values into the
interval, but does not change the order of the values (with respect to the ordering relation ‘≤’), since
is strictly monotone increasing. Before analyzing the effects of the results of the previous sections, we briefly summarize the conclusion of [
37]:
assuming that the activation values of positive neurons reach a stable state, they concluded that negative neurons have no influence on FRCNs’ performance, but the ranking of positive neurons’ activation values and the number of boundary neurons connected to each decision neuron have high impact. Based on the previous sections, below we ad some more insights to this result.
If positive neurons reach a stable state (fixed point), then this stable state have either the pattern one high and low values () or two medium and low values (), the trivial fixed point with equal coordinates () plays a rule only for 2 and 3 decision classes. These values are unique and completely determined by the parameter and the number of decision classes N. It means that the number of possible final states is very limited. This fact was mentioned in the case of decision classes, but valid for every cases. Namely, small differences between the initial activation vales could be magnified by the exploitation phase. Almost equal initial activation values with proper maximum lead to the pattern of one high and low values, resulting in something like a winner-takes-all rule. Although the runner-up has only a little smaller initial value, after reaching the stable state, it needs the same number of boundary connections to overcome the winner, as the one with very low initial value needs.
If the maximal number of iterations is reached without convergence (i.e., the activation value vector oscillates in a limit cycle), then the iteration is stopped and the last activation vector is taken. It has either or pattern with equal coordinates. In this case, the positive neurons have absolutely no effect on the final decision. The classification goes to the neuron with the highest number of boundary connections, regardless of the small or large differences between the initial activation values of the positive neurons.
7. Conclusions and Future Work
The behaviour of fuzzy-rough cognitive networks was studied applying the theory of discrete dynamical systems and their bifurcations. The dynamics of negative and positive neurons was fully discussed in lthe iterature, so we focused on the behaviour of positive neurons. It was pointed out, that the number of fixed points is very limited and their coordinate values follow a specific pattern (, , ). Additionally, it was proved that when the number of decision classes is greater than three, the limit cycles unavoidably occur, causing the recurrent reasoning inconclusive. Simulations show that proportion of initial activation values leading to limit cycles increases with the number of decision classes, and the waste number of scenarios lead to oscillation. In this case, the decision relies totally on the number of boundary neuron connected to each decision neurons, regardless of the initial activation value of positive neurons.
The method applied in the paper may be followed in the analysis of other FCM-like models. As we have seen, if the parameter of the sigmoid threshold function is small enough, then an FCM has one and only one fixed point, which is globally asymptotically stable. If we increase the value of the parameter, then a fixed-point bifurcation occurs, causing an entirely different dynamical behaviour. If the weight matrix has a nice structure, for example in the case of positive neurons, then there is a chance to find the unique fixed point in a simple form or as a limit of a lower-dimensional iteration and determine the parameter value at the bifurcation point. Similarly, based on the eigenvalues of the Jacobian evaluated at this fixed point we can determine the type of bifurcation. Nevertheless, general FCMs have no well-structured weight matrices, since weights are usually determined by human experts or learning methods. It means some limitations on the generalization of the method applied. Theoretically, we can find unique fixed points and the bifurcation point, but this task is much more difficult for a general weight matrix.
Another exciting and important research direction is the possible generalization of the results to the extensions of fuzzy cognitive maps. Some well-known extensions are fuzzy grey cognitive maps (FGCMs) [
44], interval-valued fuzzy cognitive maps (IVFCMs) [
45], intuitionistic fuzzy cognitive maps (IFCMs) [
46,
47], temporal IFCMs [
48], the combination of fuzzy grey and intuitionistic FCMs [
49], interval-valued intuitionistic fuzzy cognitive maps (IVIFCMs) [
50]. This future work probable requires deep mathematical inspection on interval-valued dynamical systems and may lead to several new theoretical and practical results on interval-valued cognitive networks, as well.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
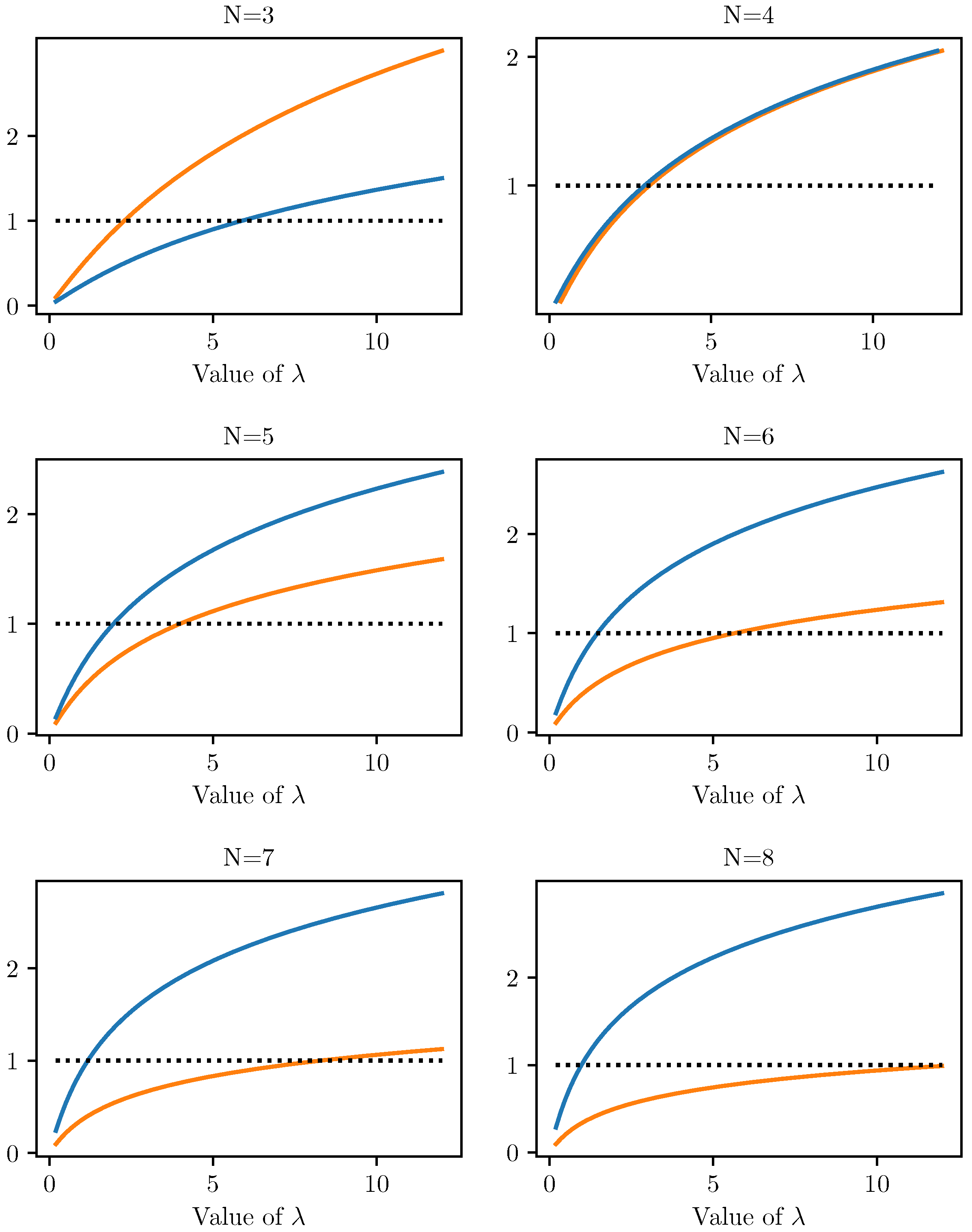{kind=link}
{kind=link}