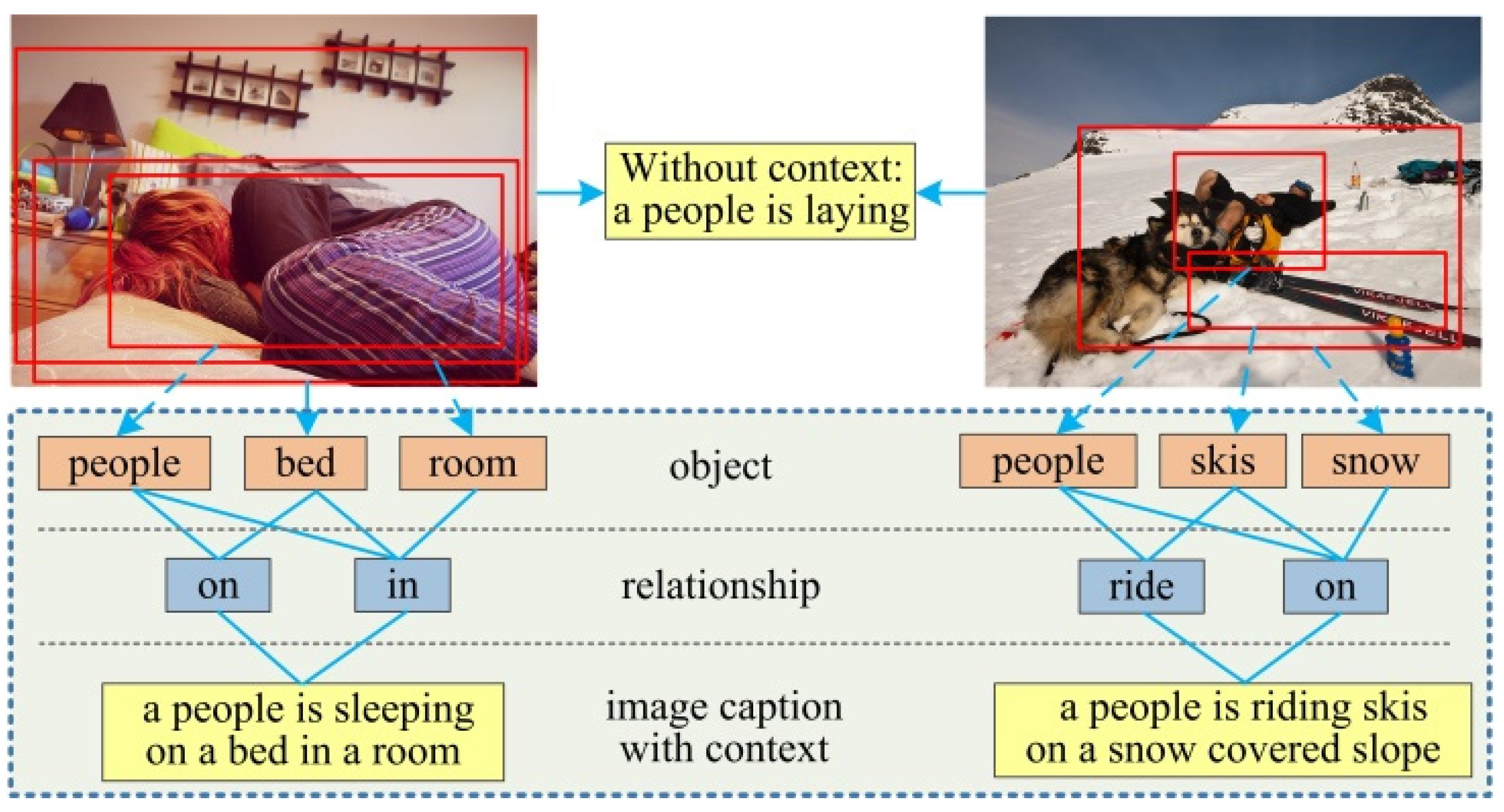
3.1. Model Overview
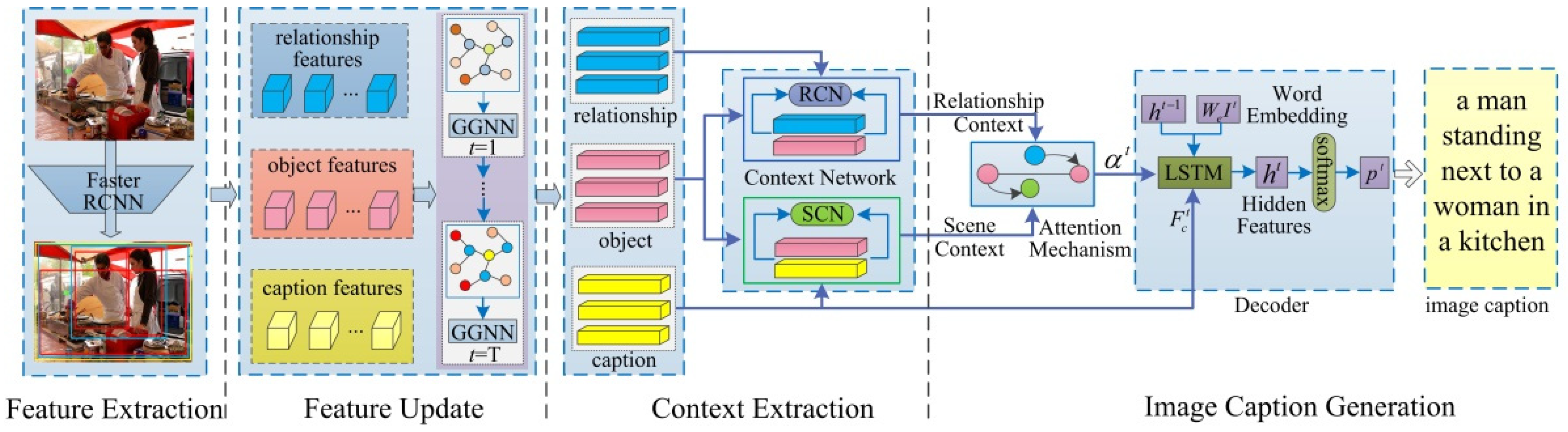
We propose a Multi-level Semantic Context Information (MSCI) model, which through a feature update structure jointly refines the features of the object, relationship, and caption semantic layers, and leverages the context information between the different semantic layers to improve the accuracy and comprehensiveness of the generated caption. The MSCI model mainly consists of four parts: feature extraction, feature update, context information extraction, and caption generation. The whole framework of our model (MSCI) is shown in
Figure 2, and it is a symmetric structure.
The entire process of the model is summarized as follows: (1) Region proposal and feature extraction. To generate region proposals of objects, relationship phrases and image captions, and extract the features of each region for different semantic tasks. (2) Feature updating. To mutual connect the features of object, relationship, and caption semantic layers based on their spatial relationships, and then jointly iteratively update these features by the GGNN [
16]. (3) Context information extraction. A context information extraction network is used to extract relationship context information and scene context information from the updated semantic features, and then take the context information as the input of the attention mechanism. (4) Image caption generation. The output of the attention mechanism and the caption features are merged into the decoding structure to generate description sentences. The core of our work is to use the GGNN for simultaneously passing and updating the features of different semantic layers, and introduce a context extraction network to extract the context information between the different semantic layers to simultaneously improve the accuracy of object detection and relationship detection, and the accuracy and comprehensiveness of the generated image caption.
3.3. Feature Updating
We use the model I to represent the scene image, where represents the region proposal set, represents the node set, represents the scene of the image. denote the object regions, relationship regions and caption regions, and denote the nodes of object, relationship, and caption, respectively.
The core of each node
in the model is the ability to encode features from other neighboring nodes and propagate its messages to neighbor nodes to achieve feature update. Therefore, we use a memory and propagate a structure that can memorize the node messages and simultaneously integrate the information from other nodes. Gated Graph Neural Network (GGNN) [
16] is an end-to-end trainable network architecture that can not only memorize the node features, but also integrate the received information from other neighboring nodes, and update the node representation in a recurrent fashion. Some works have successfully used the GGNN for visual tasks including semantic segmentation and image recognition [
44,
45]. We will view the proposal regions in the image as nodes and connect them based on their spatial relationships, and then leverage the GGNN to propagate and update the features of object, relationship, and caption nodes to explore the interaction and context information between objects, and object and image scene. For each node corresponding to the region that is detected in the image, we use the features extracted from the corresponding region to initialize the input feature of the node, and otherwise, it is initialized by a
d-dimension zero vector. Supposing
denotes the feature vector of object, relationship, and caption region, respectively. The message passing and updating procedure of object regions, relationship regions and caption regions can be written as follows.
At each time step
, each node first aggregates messages from its neighbor nodes, which can be expressed as:
where
represent the feature messages of object node and relationship node respectively.
stands for the neighbors of node
. Each relationship node will be connected to two object nodes, and each caption node will be connected to multiple object nodes and relationship nodes. Then, the model incorporates information
from the other neighbor nodes and its previous hidden state as input to update its hidden state at the current moment by a gated mechanism similar to the gated recurrent unit [
16].
We first compute the reset gate
where
represents the sigmoid activation function,
and
respectively represent the weight matrix,
represents the information received by node
at time step
, and
represents the hidden state of node
at the previous moment. Similarly, the update gate
is computed by
The activation function of the unit
can be expressed as:
where:
where
denotes the element-wise multiplication, tanh is the tangent active function,
and
are the learned weight matrixes, respectively. In this way, each node can aggregate messages from its neighboring nodes, and propagate its message to other neighboring nodes. After iterations
times, we can obtain the final hidden state
for each node. We adopt a fully connected network layer
to compute the output feature for each node, and the network takes the initial hidden state
and final hidden state
of the node as input. For each proposed region, we aggregate all correlated output features of the node and express it as the feature
of the region.
For the obtained features of each object region, we send it into an object classification fully connected network layer to predict the class label of the object. For the obtained features of each relationship region, we use a relationship classification fully connected network layer that takes it and the extracted relationship context in the subsequent network as input to predict the class label of the relationship. The updated features of caption region and the extracted context information in subsequent network are fed into the captioning model to generate the description sentence. With this structure of feature passing and updating, each node can aggregate messages from its neighboring nodes and propagate its messages to the neighboring nodes to achieve feature update. The updated features will be used to extract context information and generate captions.
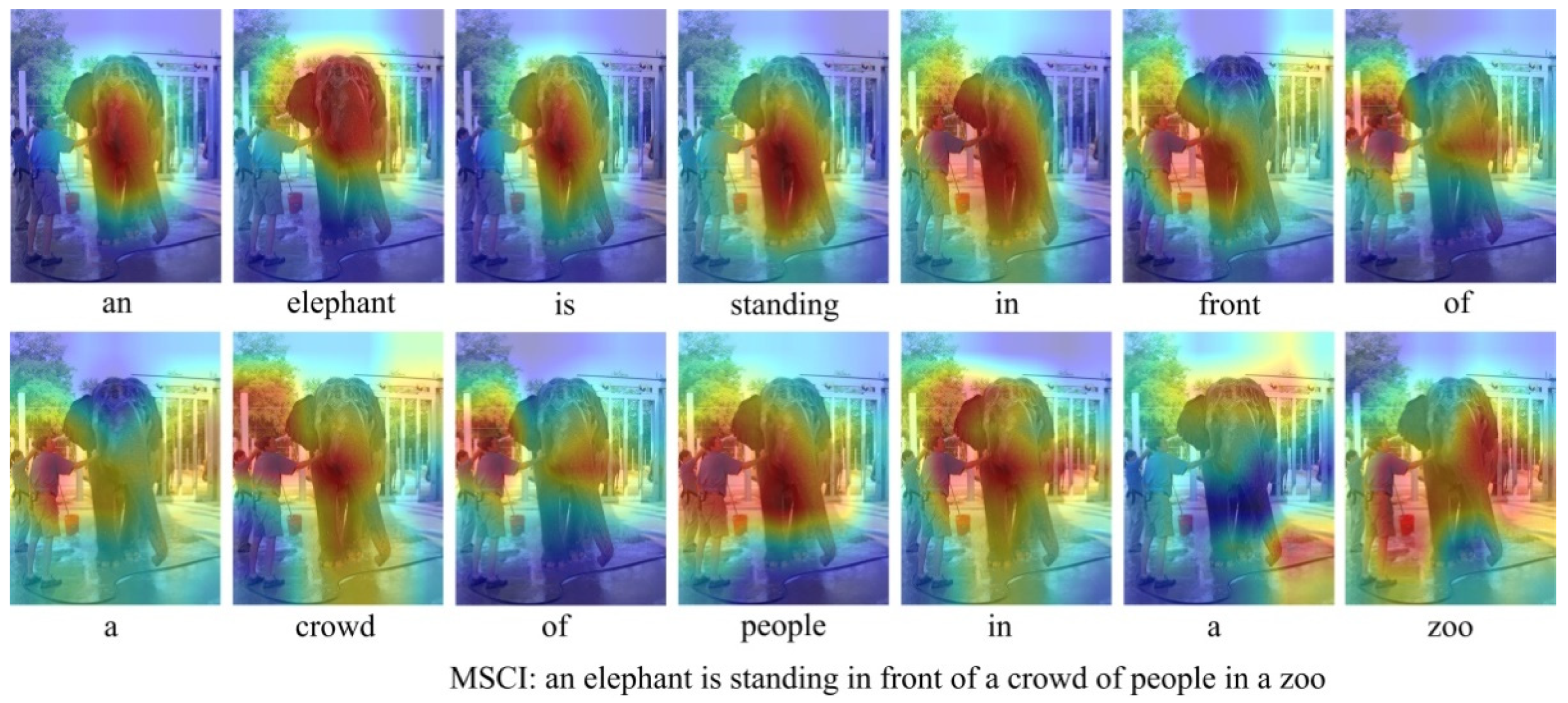
3.5. Image Captioning
Image captioning uses natural language to generate description sentences corresponding to the semantic content of the image. We use a spatial attention mechanism that takes the relationship context information and scene context information as input, and then the attention mechanism dynamically selects image features related to word generation at the current moment from the feature vector of caption region according to the hidden state of the LSTM network to guide word generation. The model selects the relationship context information
, scene context information
, and the previous hidden state
of the LSTM network in the decoder to determine the weight
of the relationship context information and scene context information corresponding to the target object at the current moment.
where
is an attention mechanism model, and its output results are normalized to obtain the weight distribution of context information at time step
, these weight denotes the captioning model pay attention to the context information.
The input information
of the captioning model at the current time includes the caption feature
, the relationship context information
, the scene context information
, and their corresponding attention weight information
.
The model uses the output
and hidden state
at the previous moment and the input information
at the current moment to calculate the hidden state
of the LSTM at the current moment, then according to the hidden state
, the output
at the previous moment and the input information
at the current moment, the probability distribution of the output word at the current moment is obtained by Softmax:
We first use the cross-entropy loss to train the proposed model. Given the ground-truth captions
, and
represents the parameter in the model, the cross-entropy loss function
can be written as:
where
represents the output probability of the word
. Subsequently, we introduce the reinforcement learning (RL) method [
13,
33] to optimize the model to maximize the expected reward:
where
is the CIDEr reward function,
represents the word sequence sampled by the model, and
represents the probability distribution of the words. Finally, the gradient of each training sample can be approximated:
The token <S> indicates the model start to generate the description sentence, and selects the word with the highest probability distribution as the output word at the current moment. The words are generated in a recurrent fashion until the stop token <E> or the maximum length of the word sequence is reached.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}