
Predicting the Intention to Donate Blood among Blood Donors Using a Decision Tree Algorithm


Abstract
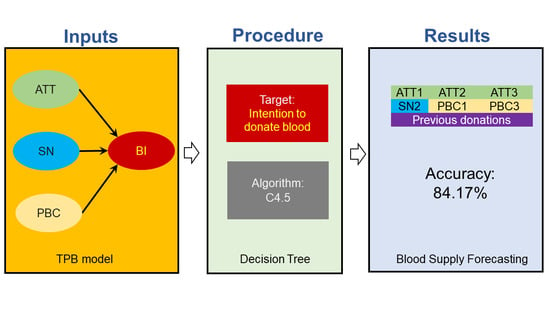
:
1. Introduction
2. Methods
2.1. Data
2.2. Decision Tree Algorithm
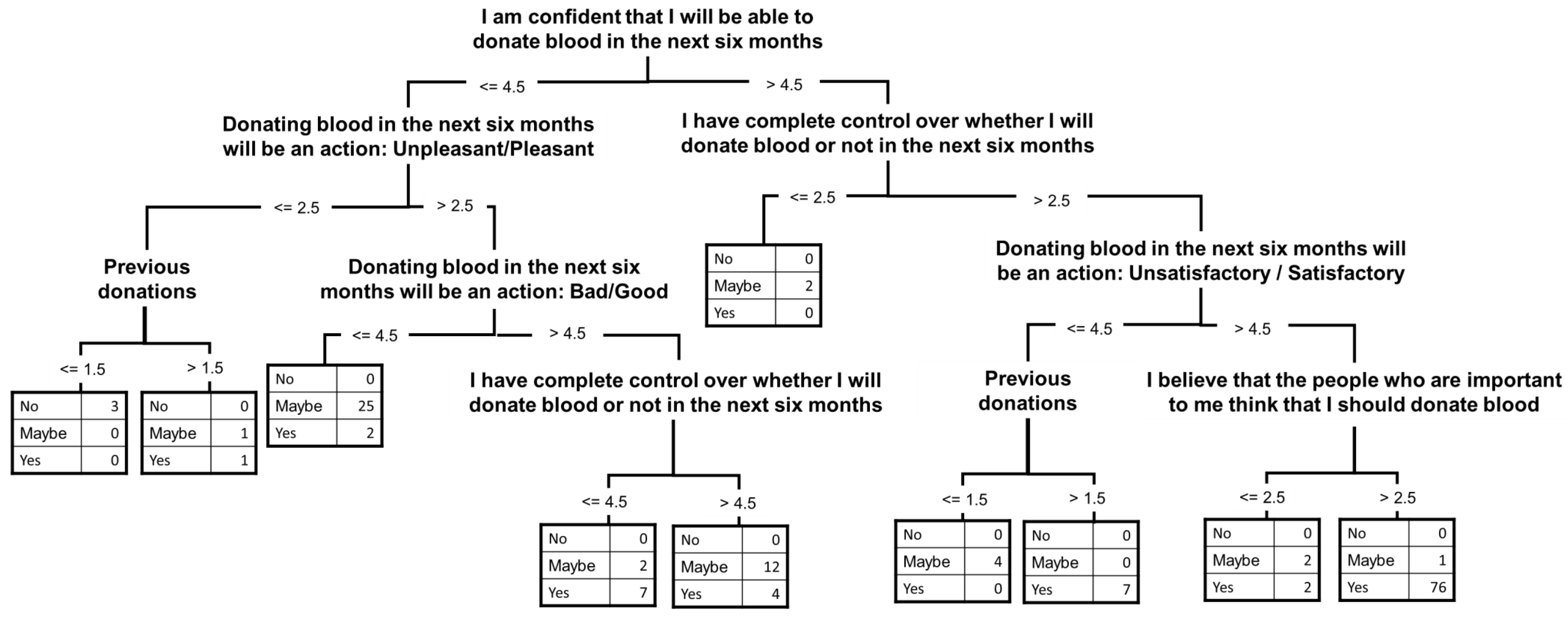
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Latif, S.; Usman, M.; Manzoor, S.; Iqbal, W.; Qadir, J.; Tyson, G.; Castro, I.; Razi, A.; Kamel Boulos, M.N.; Weller, A.; et al. Leveraging Data Science to Combat COVID-19: A Comprehensive Review. IEEE Trans. Artif. Intell. 2020, 1, 85–103. [Google Scholar] [CrossRef]
- Van der Aalst, W. Process mining: Data science in action. In Process Mining: Data Science in Action; Springer: Berlin/Heidelberg, Germany, 2016; pp. 1–467. ISBN 9783662498514. [Google Scholar]
- Adar, E.; Adamic, L.A. Tracking information epidemics in blogspace. In Proceedings of the IEEE Proceedings—2005 IEEE/WIC/ACM International Conference on Web Intelligence, WI 2005, Compiegne, France, 19–22 September 2005; Volume 2005, pp. 207–214. [Google Scholar]
- Shahid, O.; Nasajpour, M.; Pouriyeh, S.; Parizi, R.M.; Han, M.; Valero, M.; Li, F.; Aledhari, M.; Sheng, Q.Z. Machine learning research towards combating COVID-19: Virus detection, spread prevention, and medical assistance. J. Biomed. Inform. 2021, 117, 103751. [Google Scholar] [CrossRef]
- Schatteman, O.; Woodhouse, D.; Terino, J. Supply Chain Lessons from Covid-19: Time to Refocus on Resilience. Bain Co. 2020, 1–8. Available online: https://supplychainasia.org/wp-content/uploads/2016/03/bain-brief-supply-chain-lessons-from-covid-19.pdf?__cf_chl_jschl_tk__=pmd_431801601e87c861e8107856a41518f84524b4ad-1628560194-0-gqNtZGzNAjijcnBszQX6 (accessed on 7 July 2021).
- Shih, H.; Rajendran, S. Comparison of Time Series Methods and Machine Learning Algorithms for Forecasting Taiwan Blood Services Foundation’s Blood Supply. J. Healthc. Eng. 2019, 2019, 6123745. [Google Scholar] [CrossRef]
- Rajendran, S.; Ravindran, A.R. Platelet ordering policies at hospitals using stochastic integer programming model and heuristic approaches to reduce wastage. Comput. Ind. Eng. 2017, 110, 151–164. [Google Scholar] [CrossRef]
- Rajendran, S.; Ravi Ravindran, A. Inventory management of platelets along blood supply chain to minimize wastage and shortage. Comput. Ind. Eng. 2019, 130, 714–730. [Google Scholar] [CrossRef]
- Li, N.; Chiang, F.; Down, D.G.; Heddle, N.M. A decision integration strategy for short-term demand forecasting and ordering for red blood cell components. Oper. Res. Health Care 2021, 29, 100290. [Google Scholar] [CrossRef]
- Sandaruwan, P.A.J.; Dolapihilla, U.D.L.; Karunathilaka, D.W.N.R.; Wijayaweera, W.A.D.T.L.; Rankothge, W.H.; Gamage, N.D.U. Towards an Efficient and Secure Blood Bank Management System. In Proceedings of the 2020 IEEE 8th R10 Humanitarian Technology Conference (R10-HTC), Kuching, Malaysia, 1–3 December 2020; pp. 1–6. [Google Scholar]
- Shih, H.; Rajendran, S. Stochastic Inventory Model for Minimizing Blood Shortage and Outdating in a Blood Supply Chain under Supply and Demand Uncertainty. J. Healthc. Eng. 2020, 2020, 8881751. [Google Scholar] [CrossRef]
- Haw, J.; Holloway, K.; Masser, B.M.; Merz, E.-M.; Thorpe, R. Blood donation and the global COVID-19 pandemic: Areas for social science research. Vox Sang. 2021, 116, 363–365. [Google Scholar] [CrossRef] [PubMed]
- Gupta, A.M.; Ojha, S.; Nagaraju, P.; Poojary, M.; SH, S.; Sathyan, V.; Ansari, A. Impact of the novel coronavirus disease and lockdown on the packed red blood cells inventory management: An experience from a tertiary care oncology center in Western India. Hematol. Transfus. Cell Ther. 2021, 43, 126–132. [Google Scholar] [CrossRef] [PubMed]
- Rafiee, M.H.; Kafiabad, S.A.; Maghsudlu, M. Analysis of blood donors’ characteristics and deferrals related to COVID-19 in Iran. Transfus. Apher. Sci. 2021, 60, 103049. [Google Scholar] [CrossRef]
- Stanworth, S.J.; New, H.V.; Apelseth, T.O.; Brunskill, S.; Cardigan, R.; Doree, C.; Germain, M.; Goldman, M.; Massey, E.; Prati, D.; et al. Effects of the COVID-19 pandemic on supply and use of blood for transfusion. Lancet Haematol. 2020, 7, e756–e764. [Google Scholar] [CrossRef]
- Franchini, M.; Farrugia, A.; Velati, C.; Zanetti, A.; Romanò, L.; Grazzini, G.; Lopez, N.; Pati, I.; Marano, G.; Pupella, S.; et al. The impact of the SARS-CoV-2 outbreak on the safety and availability of blood transfusions in Italy. Vox Sang. 2020, 115, 603–605. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Leung, J.N.S.; Lee, C.-K. Impact of the COVID-19—A regional blood centre’s perspective. ISBT Sci. Ser. 2020, 15, 362–364. [Google Scholar] [CrossRef]
- Khalilinezhad, M.; Minaei, B.; Vernazza, G.; Dellepiane, S. Prediction of healthy blood with data mining classification by using Decision Tree, Naive Baysian and SVM approaches. In Proceedings of the Sixth International Conference on Graphic and Image Processing, Beijing, China, 24–26 October 2015; Volume 9443, pp. 1–10. [Google Scholar]
- Boonyanusith, W.; Jittamai, P. Blood Donor Classification Using Neural Network and Decision Tree Techniques. In Proceedings of the World Congress on Engineering and Computer Science, San Francisco, CA, USA, 24–26 October 2012; pp. 1–5. [Google Scholar]
- Khalid, N.S.C.; Burhanuddin, M.A.; Asmala, A.; Ghani, M. Classification Techniques in Blood Donors Sector—A Survey. In Proceedings of the e-Proceeding of Software Engineering Postgraduates Workshop (SEPoW) 2013, Melaka, Malaysia, 19 November 2013; pp. 114–118. [Google Scholar]
- Alajrami, E.; Abu-Nasser, B.S.; Khalil, A.; Musleh, M.M.; Barhoom, A.M.; Naser, S.A. Blood Donation Prediction using Artificial Neural Network. Int. J. Acad. Eng. Res. 2019, 3, 1–7. [Google Scholar]
- Wahono, H.; Riana, D. Prediksi Calon Pendonor Darah Potensial Dengan Algoritma Naïve Bayes, K-Nearest Neighbors dan Decision Tree C4.5. J. Ris. Komput. 2020, 7, 7–14. [Google Scholar] [CrossRef]
- Singer, G.; Ratnovsky, A.; Naftali, S. Classification of severity of trachea stenosis from EEG signals using ordinal decision-tree based algorithms and ensemble-based ordinal and non-ordinal algorithms. Expert Syst. Appl. 2021, 173, 114707. [Google Scholar] [CrossRef]
- Wu, X.; Kumar, V.; Ross, Q.J.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Tanyu, B.F.; Abbaspour, A.; Alimohammadlou, Y.; Tecuci, G. Landslide susceptibility analyses using Random Forest, C4.5, and C5.0 with balanced and unbalanced datasets. CATENA 2021, 203, 105355. [Google Scholar] [CrossRef]
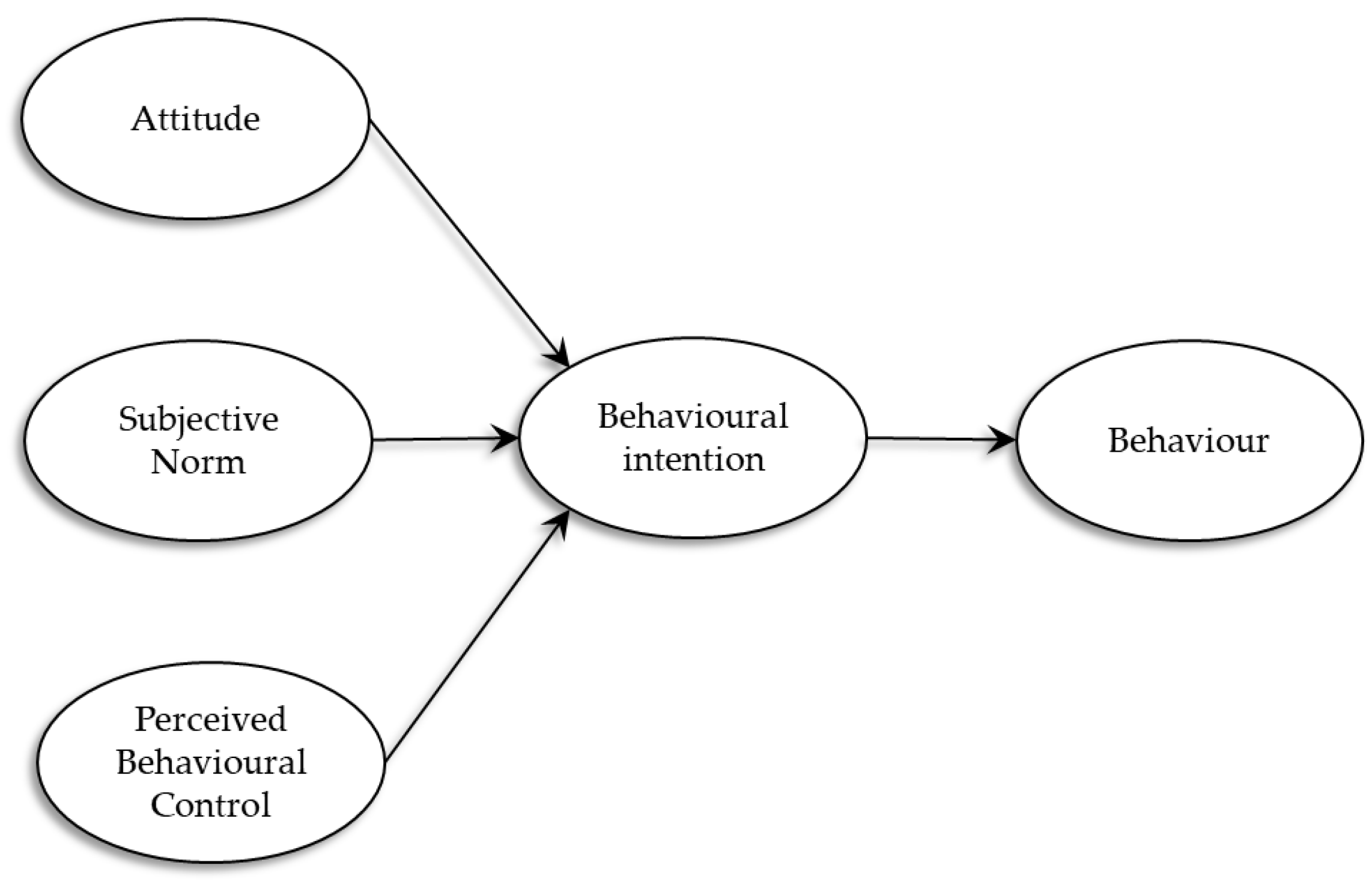
- Ajzen, I. The theory of planned behavior. Organ. Behav. Hum. Decis. Process. 1991, 50, 179–211. [Google Scholar] [CrossRef]
- Fishbein, M. A theory of reasoned action: Some applications and implications. Neb. Symp. Motiv. 1980, 27, 65–116. [Google Scholar]
- Grandón, E.; Ramirez-Correa, P.E. Managers/Owners’ Innovativeness and Electronic Commerce Acceptance in Chilean SMEs: A Multi-Group Analysis Based on a Structural Equation Model. J. Theor. Appl. Electron. Commer. Res. 2018, 13, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Ramírez-Correa, P.; Rondán-Cataluña, F.J.; Moulaz, M.T.; Arenas-Gaitán, J. Purchase intention of specialty coffee. Sustainability 2020, 12, 1329. [Google Scholar] [CrossRef] [Green Version]
- Ramírez-Correa, P.; Ramírez-Santana, M. Predicting condom use among undergraduate students based on the theory of planned behaviour, Coquimbo, Chile, 2016. Int. J. Environ. Res. Public Health 2018, 15, 1689. [Google Scholar] [CrossRef] [Green Version]
- Ramírez-Rivas, C.; Alfaro-Pérez, J.; Ramírez-Correa, P.; Mariano-Melo, A. Predicting Telemedicine Adoption: An Empirical Study on the Moderating Effect of Plasticity in Brazilian Patients. J. Inf. Syst. Eng. Manag. 2021, 6, em0135. [Google Scholar]
- Ramírez-Correa, P.; Ramírez-Rivas, C.; Alfaro-Pérez, J.; Melo-Mariano, A. Telemedicine acceptance during the COVID-19 pandemic: An empirical example of robust consistent partial least squares path modeling. Symmetry 2020, 12, 1593. [Google Scholar] [CrossRef]
- France, J.L.; Kowalsky, J.M.; France, C.R.; McGlone, S.T.; Himawan, L.K.; Kessler, D.A.; Shaz, B.H. Development of common metrics for donation attitude, subjective norm, perceived behavioral control, and intention for the blood donation context. Transfusion 2014, 54, 839–847. [Google Scholar] [CrossRef]
- Wevers, A.; Wigboldus, D.H.J.; van Baaren, R.; Veldhuizen, I.J.T. Return behavior of occasional and multigallon blood donors: The role of theory of planned behavior, self-identity, and organizational variables. Transfusion 2014, 54, 805–813. [Google Scholar] [CrossRef] [PubMed]
- M’Sallem, W. Role of motivation in the return of blood donors: Mediating roles of the socio-cognitive variables of the theory of planned behavior. Int. Rev. Public Nonprofit Mark. 2021. [Google Scholar] [CrossRef]
- Saha, S.; Chandra, B. Understanding the underlying motives and intention among Indian blood donors towards voluntary blood donation: A cross-sectional study. Transfus. Clin. Biol. 2018, 25, 109–117. [Google Scholar] [CrossRef]
- Torrent-Sellens, J.; Salazar-Concha, C.; Ficapal-Cusí, P.; Saigí-Rubió, F. Using digital platforms to promote blood donation: Motivational and preliminary evidence from Latin America and Spain. Int. J. Environ. Res. Public Health 2021, 18, 4270. [Google Scholar] [CrossRef]
- Jouybari, T.A.; Jalilian, F.; Mirzaei-Alavijeh, M.; Karami-Matin, B.; Mahboubi, M.; Aghaei, A. Prevalence, Socio-Cognitive and Demographic Determinants of Blood Donation. Int. J. Adv. Biotechnol. Res. 2016, 7, 1534–1539. [Google Scholar]
- Aschale, A.; Fufa, D.; Kekeba, T.; Birhanu, Z. Intention to voluntary blood donation among private higher education students, Jimma town, Oromia, Ethiopia: Application of the theory of planned behaviour. PLoS ONE 2021, 16, e0247040. [Google Scholar] [CrossRef]
- Lim, B.C.; Chew, K.Y.; Tay, S.L. Understanding healthcare worker’s intention to donate blood: An application of the theory of planned behaviour. Psychol. Health Med. 2021. [Google Scholar] [CrossRef]
- Giles, M.; Cairns, E. Blood donation and Ajzen’s theory of planned behaviour: An examination of perceived behavioural control. Br. J. Soc. Psychol. 1995, 34, 173–188. [Google Scholar] [CrossRef]
- Armitage, C.J.; Conner, M. Social cognitive determinants of blood donation. J. Appl. Soc. Psychol. 2001, 31, 1431–1457. [Google Scholar] [CrossRef]
- Giles, M.; McClenahan, C.; Cairns, E.; Mallet, J. An application of the Theory of Planned Behaviour to blood donation: The importance of self-efficacy. Health Educ. Res. 2004, 19, 380–391. [Google Scholar] [CrossRef] [Green Version]
- Lemmens, K.P.H.; Abraham, C.; Hoekstra, T.; Ruiter, R.A.C.; De Kort, W.L.A.M.; Brug, J.; Schaalma, H.P. Why don’t young people volunteer to give blood? An investigation of the correlates of donation intentions among young nondonors. Transfusion 2005, 45, 945–955. [Google Scholar] [CrossRef] [PubMed]
- Charseatd, P. Role of religious beliefs in blood donation behavior among the youngster in Iran: A theory of planned behavior perspective. J. Islam. Mark. 2016, 7, 250–263. [Google Scholar] [CrossRef]
- Robinson, N.G.; Masser, B.M.; White, K.M.; Hyde, M.K.; Terry, D.J. Predicting intentions to donate blood among nondonors in Australia: An extended theory of planned behavior. Transfusion 2008, 48, 2559–2567. [Google Scholar] [CrossRef] [Green Version]
- Gilchrist, P.T.; Masser, B.M.; Horsley, K.; Ditto, B. Predicting blood donation intention: The importance of fear. Transfusion 2019, 59, 3666–3673. [Google Scholar] [CrossRef]
- Masser, B.M.; White, K.M.; Hyde, M.K.; Terry, D.J.; Robinson, N.G. Predicting blood donation intentions and behavior among Australian blood donors: Testing an extended theory of planned behavior model. Transfusion 2009, 49, 320–329. [Google Scholar] [CrossRef] [Green Version]
- Masser, B.M.; White, K.M.; Hamilton, K.; McKimmie, B.M. An examination of the predictors of blood donors’ intentions to donate during two phases of an avian influenza outbreak. Transfusion 2011, 51, 548–557. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Masser, B.M.; Hyde, M.K.; Ferguson, E. Exploring predictors of Australian community members’ blood donation intentions and blood donation–related behavior during the COVID-19 pandemic. Transfusion 2020, 60, 2907–2917. [Google Scholar] [CrossRef] [PubMed]
- Eysenbach, G. Improving the quality of web surveys: The Checklist for Reporting Results of Internet E-Surveys (CHERRIES). J. Med. Internet Res. 2004, 6, e132. [Google Scholar] [CrossRef] [PubMed]
- Tan, P.N.; Steinbach, M.; Kumar, M. Introduction to Data Mining; Pearson Education: London, UK, 2016. [Google Scholar]
- Rojas-Córdova, C.; Heredia-Rojas, B.; Ramírez-Correa, P. Predicting Business Innovation Intention Based on Perceived Barriers: A Machine Learning Approach. Symmetry 2020, 12, 1381. [Google Scholar] [CrossRef]
- Lee, V.E.; Liu, L.; Jin, R. Decision trees: Theory and algorithms. In Data Classification; Chapman and Hall/CRC: Boca Raton, FL, USA, 2014; pp. 115–148. ISBN 0429102631. [Google Scholar]
- Salzberg, S.L. C4.5: Programs for Machine Learning by J. Ross Quinlan. Morgan Kaufmann Publishers, Inc., 1993. Mach. Learn. 1994, 16, 235–240. [Google Scholar] [CrossRef] [Green Version]
- Pabreja, K.; Bhasin, A. A Predictive Analytics Framework for Blood Donor Classification. Int. J. Big Data Anal. Healthc. 2021, 6, 1–14. [Google Scholar] [CrossRef]
- Guglielmetti Mugion, R.; Pasca, M.G.; Di Di Pietro, L.; Renzi, M.F. Promoting the propensity for blood donation through the understanding of its determinants. BMC Health Serv. Res. 2021, 21, 1–20. [Google Scholar] [CrossRef]
- Bednall, T.C.; Bove, L.L.; Cheetham, A.; Murray, A.L. A systematic review and meta-analysis of antecedents of blood donation behavior and intentions. Soc. Sci. Med. 2013, 96, 86–94. [Google Scholar] [CrossRef]
- Davahli, M.R.; Karwowski, W.; Fiok, K.; Wan, T.; Parsaei, H.R. Controlling safety of artificial intelligence-based systems in healthcare. Symmetry 2021, 13, 102. [Google Scholar] [CrossRef]
- Felder, R.; Silverman, L. Learning and teaching styles in engineering education. Eng. Educ. 1988, 78, 674–681. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Latent Variable | Item | Description | Average | SD | Asymmetry | Kurtosis |
|---|---|---|---|---|---|---|
| Subjective Norms | SN1 | People who are important to me would recommend that I donate blood | 4.61 | 0.719 | −2.059 | 4.598 |
| SN2 | I believe that the people who are important to me think that I should donate blood | 4.26 | 0.953 | −1.015 | 0.012 | |
| SN3 | If I donated blood, the people who are important to me would approve | 4.57 | 0.730 | −1.627 | 1.822 | |
| Perceived Behavioural Control | PBC1 | I have complete control over whether I will donate blood or not in the next six months | 4.55 | 0.875 | −2.181 | 4.557 |
| PBC2 | How much control do you have over whether you donate blood or not in the next six months? (No control/complete control) | 4.48 | 0.834 | −1.798 | 3.275 | |
| PBC3 | I am confident that I will be able to donate blood in the next six months | 4.32 | 1.060 | −1.670 | 2.134 | |
| Attitude | ATT1 | Donating blood in the next six months will be an action: Unpleasant/Pleasant | 4.48 | 0.873 | −2.088 | 4.722 |
| ATT2 | Donating blood in the next six months will be an action: Bad/Good | 4.66 | 0.648 | −2.178 | 5.913 | |
| ATT3 | Donating blood in the next six months will be an action: Unsatisfactory/Satisfactory | 4.54 | 0.810 | −1.933 | 3.812 | |
| ATT4 | Donating blood in the next six months will be an action: Pointless/Worthwhile | 4.64 | 0.685 | −2.197 | 5.507 | |
| Behavioural Intention | BI1 | I would like to donate blood in the next six months | 4.55 | 0.854 | −2.361 | 5.946 |
| BI2 | I intend to donate blood in the next six months | 4.31 | 1.054 | −1.669 | 2.322 | |
| BI3 | I will donate blood in the next six months | 4.19 | 1.014 | −1.243 | 1.119 |
| Variable | N | % | |
|---|---|---|---|
| Education | |||
| Primary | 22 | 11 | |
| Secondary | 74 | 38 | |
| Tertiary | 101 | 51 | |
| Previous donations | |||
| Never | 73 | 37 | |
| 1 to 3 | 77 | 39 | |
| 4 or more | 47 | 24 | |
| Donation reason | |||
| Knowing someone | 72 | 37 | |
| Another reason | 125 | 63 | |
| Gender | |||
| Male | 95 | 48 | |
| Female | 102 | 52 | |
| Total | 197 | 100 | |
| Age | Mean 32.1 ± 11.00 | ||
| Range 18–60 years | |||
| Parameter | Value | Description |
|---|---|---|
| Algorithm | C4.5 | C4.5 sets up decision tree models based on a training dataset using the concept of information entropy. |
| Split criteria | Gain Ratio | Gain Ratio normalises the information gain of an attribute against the amount of entropy that attribute has. First, the information gain of all features is determined, and then the average information gain is calculated. Second, the gain ratio is calculated for all attributes whose calculated information gain is greater than or equal to the average information gain. Finally, the feature with the highest gain ratio is chosen to divide the data. |
| Maximum depth | 4 | Maximum depth refers to the maximum distance between the root of the tree and any leaf. |
| Optimisation strategy | Grid | This strategy runs the process for all combinations of selected parameter values and then determines the optimal values. |
| Validation | 10-fold cross-validation | Of the ten sub-samples, only one subsample is preserved as validation data for model testing, and the remaining nine subsamples are used as training data. Thus, the process is repeated repeatedly, with each of the ten subsamples used exactly once as validation data. Finally, the results ten are averaged to generate one estimate. |
| Accuracy: 84.17% | No (True) | Maybe (True) | Yes (True) | Class Precision |
|---|---|---|---|---|
| No (pred.) | 2 | 2 | 1 | 40.00% |
| Maybe (pred.) | 1 | 38 | 11 | 76.00% |
| Yes (pred.) | 0 | 9 | 87 | 90.62% |
| Class recall | 66.67% | 77.55% | 87.88% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salazar-Concha, C.; Ramírez-Correa, P. Predicting the Intention to Donate Blood among Blood Donors Using a Decision Tree Algorithm. Symmetry 2021, 13, 1460. https://doi.org/10.3390/sym13081460
Salazar-Concha C, Ramírez-Correa P. Predicting the Intention to Donate Blood among Blood Donors Using a Decision Tree Algorithm. Symmetry. 2021; 13(8):1460. https://doi.org/10.3390/sym13081460
Chicago/Turabian StyleSalazar-Concha, Cristian, and Patricio Ramírez-Correa. 2021. "Predicting the Intention to Donate Blood among Blood Donors Using a Decision Tree Algorithm" Symmetry 13, no. 8: 1460. https://doi.org/10.3390/sym13081460
APA StyleSalazar-Concha, C., & Ramírez-Correa, P. (2021). Predicting the Intention to Donate Blood among Blood Donors Using a Decision Tree Algorithm. Symmetry, 13(8), 1460. https://doi.org/10.3390/sym13081460