
Modeling and Optimization for Multi-Objective Nonidentical Parallel Machining Line Scheduling with a Jumping Process Operation Constraint


Abstract
:1. Introduction
2. Literature Review
3. Problem Description and Mathematical Modeling
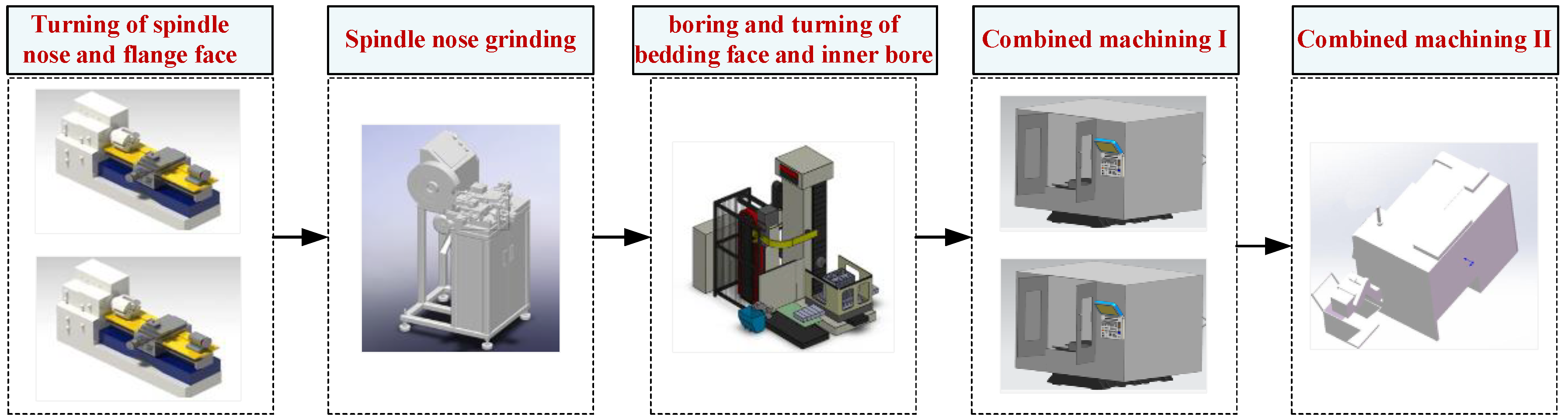
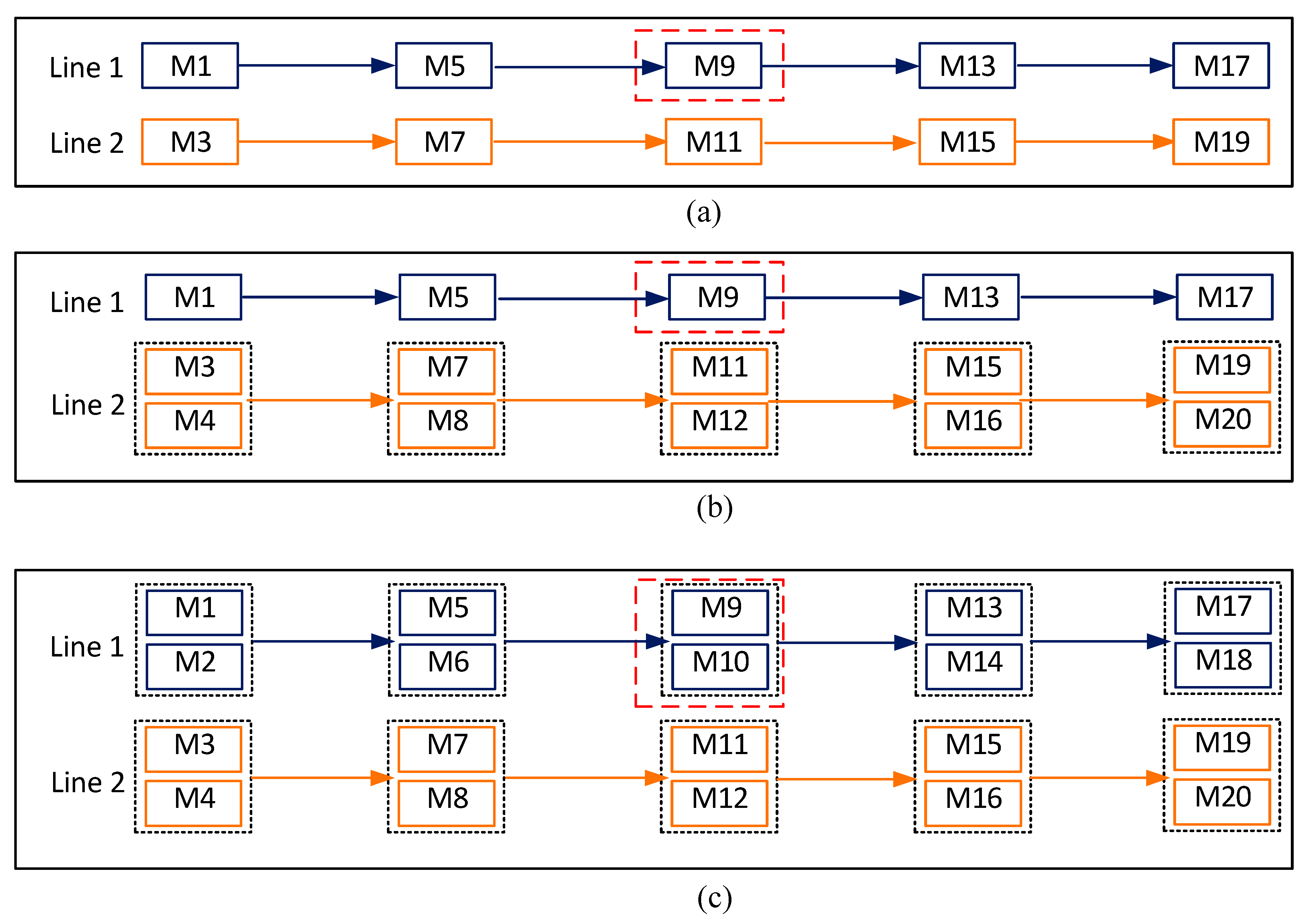
3.1. Problem Definition and Assumption
- (1)
- The type, quantity, and due date of each order are known.
- (2)
- The jobs in each order are of the same type.
- (3)
- All the machines in the production system are available at the beginning.
- (4)
- The processing times and setup times of the jobs on each machine do not overlap.
- (5)
- Each job can be processed on only one machine at any time, each machine can process only one job at any time, and operations cannot be interrupted.
- (6)
- For each job, the jumping operation can only occur once.
- (7)
- The jumping process operation point is singular, fixed, and unidirectional.
- (8)
- The setup time and machine breakdown time are ignored.
3.2. Mathematical Modeling
4. Proposed MOGWO/D Algorithm
4.1. Original GWO
4.2. MOGWO/D Algorithm Framework
| Algorithm 1 MOGWO/D |
| Input: |
| A multiobjective problem; |
| A stopping criterion; |
| A set of uniformly spread weight vectors |
| population size (equal to the number of the weight vectors or subproblems); |
| neighborhood size; |
| : the number of position vectors in the neighborhood to be updated of a subproblem (where ). |
| Output: |
| External population, EP for short. |
| Step 1) Initialization: |
| Step 1.1) Set EP = ∅; |
| Step 1.2) Generate a set of uniformly distributed weight vectors , calculate the Euclidean distances of any pair of weight vectors, for are T closest weight vectors of the weight vecto λi. |
| Step 1.3) Randomly generate an initial population or use a problem-specific approach. The objective of each position vector is calculated and labeled as |
| Step 1.4) Initialize |
| Step 1.5) Calculate for each , and the three best position vectors are labeled as and , respectively corresponding to weight vector . |
| Step 2) Update: |
| for i = 1, 2, ⋯,N, do |
| Step 2.1) Randomly select T′ indexes , then yield a set of new position vectors according to the Equations (20)–(23) by the guidance of |
| Step 2.2) Update of . Comparing the value of with and , then update with the three best position vectors of all. |
| Step 2.3) Update of z. For each j = 1, 2, ⋯, m, if |
| Step 2.4) Update of neighborhood. For each |
| Step 2.5) Update of EP. Add to EP if no vectors in EP dominate ; if the number of vectors exceeds the EP capacity, the kth nearest neighbor method is used as a truncation strategy. If the vectors in EP are dominated by , remove from EP. |
| Step 3) Stopping criterion: |
| If the stopping criteria is satisfied, stop running and output EP. Otherwise, return to Step 2. |
4.3. Generate a Set of Uniform Weight Vectors
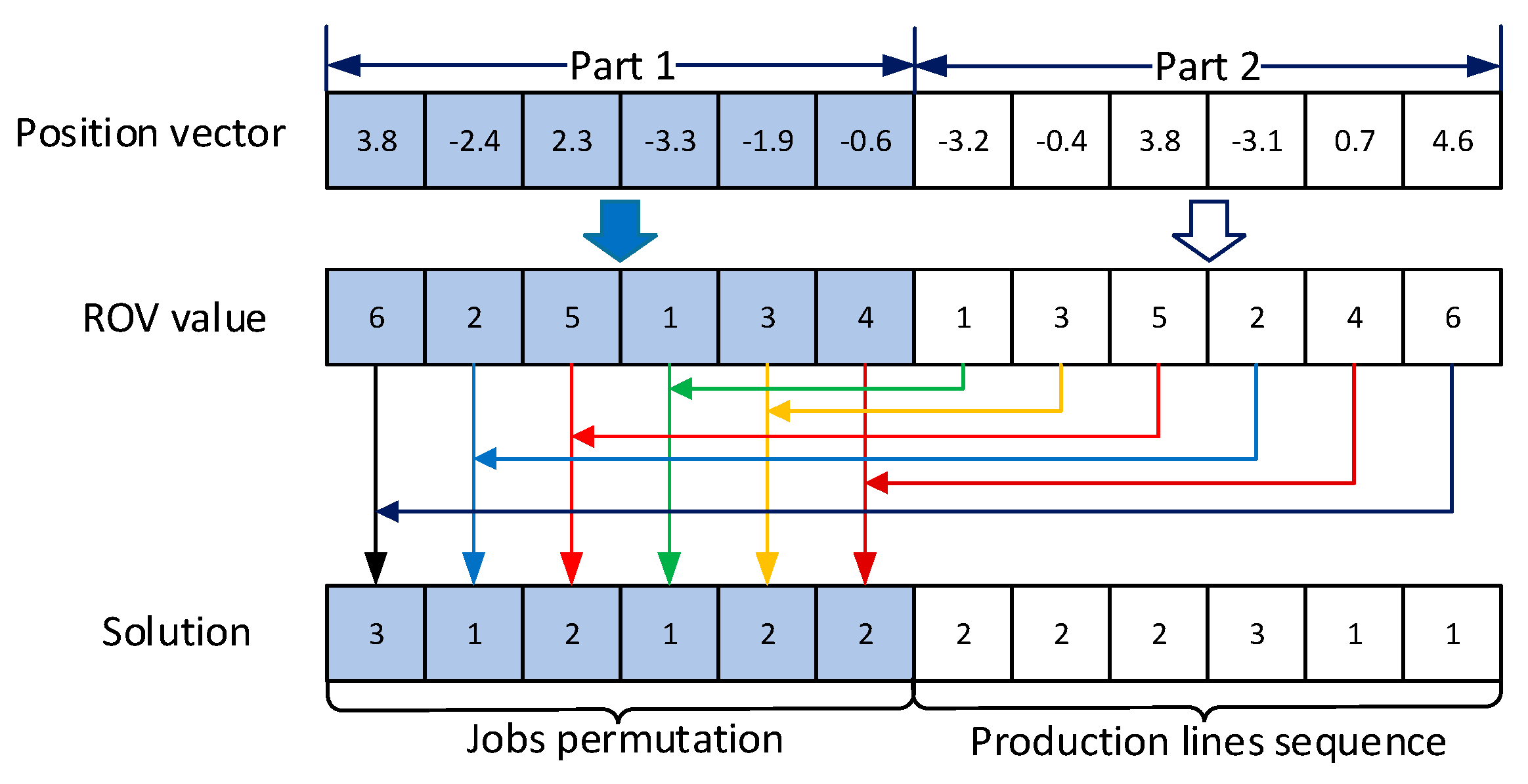
4.4. Encoding and Decoding
4.5. Updating the Position Vectors
| Algorithm 2 The update process of one iteration |
| While(stopping condition is not satisfied){ |
| //Main loop |
| for(i = 1; i ≤ N; i++) |
| {//optimize N subproblems simultaneously |
| idxes = getRandoms(T′, B(i)); |
| selectedPop = getIndividuals(neighborhood, idxes); |
| sortedPop = sort(PS(i)); |
| //update the reference point; |
| } |
| } |
4.6. Updating the External Population (EP)
5. Computational Experiments and Results Analysis
5.1. Evaluation Metrics
- (1)
- Generational distance (GD) [57]. The GD is the most common multi-objective indicator for convergence. It is used to calculate the mean Euclidean distance between the obtained Pareto front and the Pareto optimal front. The calculation formula for the GD is as follows.where is the Euclidean distance from point of the obtained Pareto front to the closest point in the Pareto optimal front, and is the number of nondominated solutions in the obtained Pareto front; therefore, GD denotes the mean value of the closest distance from each point in the obtained Pareto front to the Pareto optimal front. A smaller GD value indicates that the obtained Pareto front is closer to the Pareto optimal front; namely, the obtained Pareto front has good convergence. When GD equals zero, the obtained Pareto front is located at the Pareto optimal front.
- (2)
- Inversed generational distance (IGD) [58]. This metric is a variant of the GD and is a comprehensive performance indicator. This metric represents the mean Euclidean distance from the points in the Pareto optimal front to the obtained Pareto front. The formulation of the IGD is as follows.where denotes the number of points in the Pareto optimal front and is the Euclidean distance from point in the Pareto optimal front to the closest point in the obtained Pareto front. A smaller IGD value indicates better convergence and diversity for the obtained Pareto front. In our experiments, the nondominated solutions obtained from all independent runs of the four algorithms on each instance are regarded as the Pareto optimal front of that instance.
- (3)
- Spread () [37]. is the diversity metric of the multi-objective optimization that can measure the distribution and spread of solutions. is calculated as follows.where is the number of objectives and is the number of solutions in the obtained Pareto front. is the minimum Euclidean distance from the nondominated solutions in the obtained Pareto front to the extreme point of the Pareto optimal front, and is the Euclidean distance of the closest pairwise points in the obtained Pareto front, and is the average value of . A smaller value of represents a better distribution and increased diversity. The calculation of ∆ is simple and does not require knowledge of the whole Pareto optimal front, it uses only the extreme objectives of the Pareto optimal front.
5.2. Instance Generation
5.3. Parameter Settings
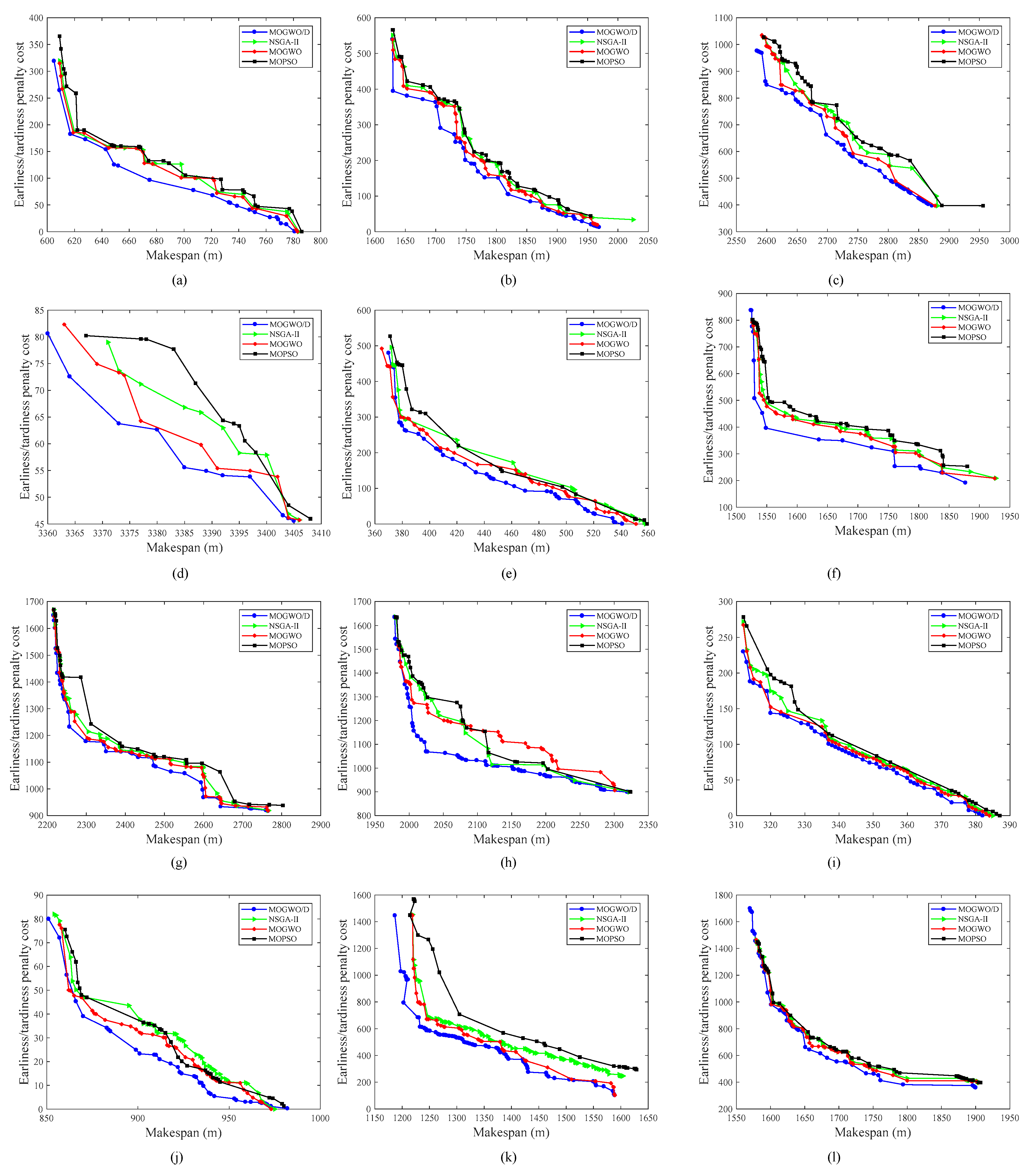
5.4. Experimental Results Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| the index of orders, | |
| the number of orders | |
| the number of jobs in order | |
| the total number of jobs, | |
| a set of jobs, | |
| the index of jobs, | |
| the total number of production lines | |
| a set of production lines, | |
| the index of production lines, | |
| the number of operations, which is equals to the number of stages | |
| a set of operations, | |
| the index of operations, which is also the index of stages, | |
| the jumping process point of production line , | |
| the index of job types | |
| the number of job types | |
| the index of machines | |
| the number of machines at stage s of production line | |
| the processing time of operation for a job of type on machine | |
| the earliness penalty cost coefficient of order | |
| the tardiness penalty cost coefficient of order | |
| a sufficiently large positive number | |
| takes a value of 1 if stage of type can be processed on production line and 0 otherwise | |
| takes a value of 1 if job is included in order and 0 otherwise | |
| takes a value of 1 if the type of jobs in order is and 0 otherwise | |
| the trapezoidal fuzzy number for trapezoidal fuzzy due date of order , where | |
| Decision variables | |
| binary variable, taking a value of 1 if operation of job is processed on production line and 0 otherwise | |
| binary variable, taking a value of 1 if operation and of job are both processed on production line and 0 otherwise | |
| binary variable, taking a value of 1 if operation of job is processed before job on machine of production line and 0 otherwise | |
| binary variable, taking a value of 1 if operation of job is processed before job on machine of production line and 0 otherwise | |
| the completion time of operation of job on machine of production line | |
| the completion time for order | |
| the fuzzy due date earliness/tardiness penalty cost of order o | |
References
- Mohammadi, M.; Ghomi, S.; Jafari, N. A genetic algorithm for simultaneous lotsizing and sequencing of the permutation flow shops with sequence-dependent setups. Int. J. Comput. Integr. Manuf. 2011, 24, 87–93. [Google Scholar] [CrossRef]
- Varmazyar, M.; Salmasi, N. Sequence-dependent flow shop scheduling problem minimising the number of tardy jobs. Int. J. Prod. Res. 2012, 50, 5843–5858. [Google Scholar] [CrossRef]
- Yue, L.; Guan, Z.; Zhang, L.; Ullah, S.; Cui, Y. Multi objective lotsizing and scheduling with material constraints in flexible parallel lines using a Pareto based guided artificial bee colony algorithm. Comput. Ind. Eng. 2019, 128, 659–680. [Google Scholar] [CrossRef]
- Jungwattanakit, J.; Reo De Cha, M.; Chaovalitwongse, P.; Werner, F. A comparison of scheduling algorithms for flexible flow shop problems with unrelated parallel machines, setup times, and dual criteria. Comput. Oper. Res. 2009, 36, 358–378. [Google Scholar] [CrossRef]
- Low, C. Simulated annealing heuristic for flow shop scheduling problems with unrelated parallel machines. Comput. Oper. Res. 2005, 32, 2013–2025. [Google Scholar] [CrossRef]
- Soltani, S.A.; Karimi, B. Cyclic hybrid flow shop scheduling problem with limited buffers and machine eligibility constraints. Int. J. Adv. Manuf. Technol. 2014, 76, 1739–1755. [Google Scholar] [CrossRef]
- Tadayon, B.; Salmasi, N. A two-criteria objective function flexible flowshop scheduling problem with machine eligibility constraint. Int. J. Adv. Manuf. Technol. 2013, 64, 1001–1015. [Google Scholar] [CrossRef]
- Ruiz, R.; Maroto, C. A genetic algorithm for hybrid flowshops with sequence dependent setup times and machine eligibility. Eur. J. Oper. Res. 2007, 169, 781–800. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Chen, L. A re-entrant hybrid flow shop scheduling problem with machine eligibility constraints. Int. J. Prod. Res. 2018, 56, 5293–5305. [Google Scholar] [CrossRef]
- Oddi, A.; Rasconi, R.; Cortellessa, G.; Magazzeni, D.; Maratea, M.; Serina, I. Leveraging constraint-based approaches formulti-objective flexible flow-shop scheduling with energy costs. Intell. Artif. 2016, 10, 147–160. [Google Scholar]
- Méndez, C.A.; Henning, G.P.; Cerdá, J. An MILP continuous-time approach to short-term scheduling of resource-constrained multistage flowshop batch facilities. Comput. Chem. Eng. 2001, 25, 701–711. [Google Scholar] [CrossRef]
- Malik, A.I.; Kim, B.S. A multi-constrained supply chain model with optimal production rate in relation to quality of products under stochastic fuzzy demand. Comput. Ind. Eng. 2020, 149, 106814. [Google Scholar] [CrossRef]
- Malik, A.I.; Sarkar, B. Coordinating supply-chain management under stochastic fuzzy environment and lead-time reduction. Mathematics 2019, 7, 480. [Google Scholar] [CrossRef] [Green Version]
- Wu, H.C. Solving the fuzzy earliness and tardiness in scheduling problems by using genetic algorithms. Expert Syst. Appl. 2010, 37, 4860–4866. [Google Scholar] [CrossRef]
- Bukchin, J.; Dar-El, E.M.; Rubinovitz, J. Mixed model assembly line design in a make-to-order environment. Comput. Ind. Eng. 2002, 41, 405–421. [Google Scholar] [CrossRef]
- Caridi, M.; Sianesi, A. Multi-Agent Systems in production planning and control: An application to the scheduling of mixed-model assembly lines. Int. J. Prod. Econ. 2000, 68, 29–42. [Google Scholar] [CrossRef]
- Askin, R.G.; Zhou, M. A parallel station heuristic for the mixed-model production line balancing problem. Int. J. Prod. Res. 1997, 35, 3095–3106. [Google Scholar] [CrossRef]
- Emde, S.; Boysen, N. Optimally locating in-house logistics areas to facilitate JIT-supply of mixed-model assembly lines. Int. J. Prod. Econ. 2010, 135, 393–402. [Google Scholar] [CrossRef]
- Lopes, T.C.; Michels, A.S.; Sikora, C.; Magatão, L. Balancing and cyclical scheduling of asynchronous mixed-model assembly lines with parallel stations. J. Manuf. Syst. 2019, 50, 193–200. [Google Scholar] [CrossRef]
- Zhao, X.; Liu, J.; Ohno, K.; Kotani, S. Modeling and analysis of a mixed-model assembly line with stochastic operation times. Nav. Res. Logist. 2010, 54, 681–691. [Google Scholar] [CrossRef]
- Khalid, Q.S.; Arshad, M.; Maqsood, S.; Kim, S. Hybrid particle swarm algorithm for products’ scheduling problem in cellular manufacturing system. Symmetry 2019, 11, 729. [Google Scholar] [CrossRef] [Green Version]
- Mcmullen, P.R.; Tarasewich, P. A beam search heuristic method for mixed-model scheduling with setups. Int. J. Prod. Econ. 2005, 96, 273–283. [Google Scholar] [CrossRef]
- Leu, S.S.; Hwang, S.T. GA-based resource-constrained flow-shop scheduling model for mixed precast production. Autom. Constr. 2002, 11, 439–452. [Google Scholar] [CrossRef]
- Wang, B.; Guan, Z.; Ullah, S.; Xu, X.; He, Z. Simultaneous order scheduling and mixed-model sequencing in assemble-to-order production environment: A multi-objective hybrid artificial bee colony algorithm. J. Intell. Manuf. 2017, 28, 419–436. [Google Scholar] [CrossRef]
- Bahman, N.; Ahmed, A.; Katayoun, B. A realistic multi-manned five-sided mixed-model assembly line balancing and scheduling problem with moving workers and limited workspace. Int. J. Prod. Res. 2019, 57, 643–661. [Google Scholar]
- Alghazi, A.; Kurz, M.E. Mixed model line balancing with parallel stations, zoning constraints, and ergonomics. Constraints 2018, 23, 123–153. [Google Scholar] [CrossRef]
- Rajeswari, N.; Shahabudeen, P. Bicriteria parallel flow line scheduling using hybrid population-based heuristics. Int. J. Adv. Manuf. Technol. 2009, 43, 799–804. [Google Scholar] [CrossRef]
- Haq, A.N.; Balasubramanian, K.; Sashidharan, B.; Karthick, R.B. Parallel line job shop scheduling using genetic algorithm. Int. J. Adv. Manuf. Technol. 2008, 35, 1047–1052. [Google Scholar]
- Meyr, H.; Mann, M. A decomposition approach for the general lotsizing and scheduling problem for parallel production lines. Eur. J. Oper. Res. 2013, 229, 718–731. [Google Scholar] [CrossRef]
- Mumtaz, J.; Guan, Z.; Yue, L.; Zhang, L.; He, C. Hybrid spider monkey optimisation algorithm for multi-level planning and scheduling problems of assembly lines. Int. J. Prod. Res. 2020, 58, 6252–6267. [Google Scholar] [CrossRef]
- Ebrahimipour, V.; Najjarbashi, A.; Sheikhalishahi, M. Multi-objective modeling for preventive maintenance scheduling in a multiple production line. J. Intell. Manuf. 2013, 26, 1–12. [Google Scholar] [CrossRef]
- Mumtaz, J.; Guan, Z.; Yue, L.; Wang, Z.; Rauf, M. Multi-level planning and scheduling for parallel pcb assembly lines using hybrid spider monkey optimization approach. IEEE Access 2019, 7, 2169–3536. [Google Scholar] [CrossRef]
- Liu, Z.Z.; Wang, Y.; Huang, P.Q. A many-objective evolutionary algorithm with angle-based selection and shift-based density estimation. Inf. Sci. 2017, 509, 400–419. [Google Scholar] [CrossRef] [Green Version]
- Goldberg, D.E.; Korb, B.; Deb, K. Messy genetic algorithms: Motivation, analysis, and first results. Complex Syst. 1989, 3, 493–530. [Google Scholar]
- Zitzler, E.; Thiele, L. Multiobjective evolutionary algorithms: A comparative case study and the strength Pareto approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef] [Green Version]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the Performance of the Strength Areto Evolutionary Algorithm; Evolutionary Methods for Design, Optimization and Control with Applications to Industrial Problems (EUROGEN 2001), Athens, Greece, September; Giannakoglou, K.C., Tsahalis, D.T., Périaux, J., Papailiou, K.D., Fogarty, T., Eds.; International Center for Numerical Methods in Engineering (CIMNE): Barcelona, Spain, 2002; pp. 95–100. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Beume, N.; Naujoks, B.; Emmerich, M. Sms-emoa: Multiobjective selection based on dominated hypervolume. Eur. J. Oper. Res. 2007, 181, 1653–1669. [Google Scholar] [CrossRef]
- Bader, J.; Zitzler, E. Hype: An algorithm for fast hypervolume-based many-objective optimization. Evol. Comput. 2011, 19, 45–76. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Hui, L. MOEA/D: A multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Li, H.; Landa-Silva, D. An adaptive evolutionary multi-objective approach based on simulated annealing. Evol. Comput. 2014, 19, 561–595. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tan, Y.Y.; Jiao, Y.C.; Hong, L.; Wang, X.K. MOEA/D-SQA: A multi-objective memetic algorithm based on decomposition. Eng. Optim. 2012, 44, 1–21. [Google Scholar] [CrossRef]
- Cai, D.; Yuping, W.; Miao, Y. A new multi-objective particle swarm optimization algorithm based on decomposition. Inf. Sci. 2015, 325, 541–557. [Google Scholar]
- Ke, L.; Zhang, Q.; Battiti, R. MOEA/D-ACO: A Multiobjective Evolutionary Algorithm Using Decomposition and Antcolony. IEEE Trans. Cybern. 2013, 43, 1845–1859. [Google Scholar] [CrossRef] [PubMed]
- Alhindi, A.; Alhindi, A.; Alhejali, A.; Alsheddy, A.; Tairan, N.; Alhakami, H. MOEA/D-GLS: A multiobjective memetic algorithm using decomposition and guided local search. Soft Comput. 2019, 23, 9605–9615. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, W.; Tsang, E.; Virginas, B. Expensive multiobjective optimization by MOEA/D with gaussian process model. IEEE Trans. Evol. Comput. 2010, 14, 456–474. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, Q.; Zhou, A.; Gong, M.; Jiao, L. Adaptive replacement strategies for MOEA/D. IEEE Trans. Cybern. 2017, 46, 474–486. [Google Scholar] [CrossRef]
- Ho, Y.C.; Pepyne, D.L. Simple explanation of the no-free-lunch theorem and its implications. J. Optim. Theory Appl. 2002, 115, 549–570. [Google Scholar] [CrossRef]
- Murata, T.; Gen, M.; Ishibuchi, H. Multi-objective scheduling with fuzzy due-date. Comput. Ind. Eng. 1998, 35, 439–442. [Google Scholar] [CrossRef]
- Vela, C.R.; Afsar, S.; Palacios, J.J.; González-Rodríguez, I.; Puente, J. Evolutionary tabu search for flexible due-date satisfaction in fuzzy job shop scheduling. Comput. Oper. Res. 2020, 119, 104931. [Google Scholar] [CrossRef]
- Wen, X.; Li, X.; Gao, L.; Wang, K.; Li, H. Modified honey bees mating optimization algorithm for multi-objective uncertain integrated process planning and scheduling problem. Int. J. Adv. Robot. Syst. 2020, 17, 172988142092523. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Scheffé, H. Experiments with Mixtures. J. Roy. Statist. Soc. 1958, 20, 344–360. [Google Scholar] [CrossRef]
- Li, B.B.; Wang, L.; Liu, B. An effective PSO-based hybrid algorithm for multiobjective permutation flow shop scheduling. IEEE Trans. Syst. Man Cybern. Paart A Syst. Hum. 2008, 38, 818–831. [Google Scholar] [CrossRef]
- Mirjalili, S.; Saremi, S.; Mirjalili, S.M.; Coelho, L. Multi-objective grey wolf optimizer: A novel algorithm for multi-criterion optimization. Expert Syst. Appl. 2015, 47, 106–119. [Google Scholar] [CrossRef]
- Coello, C.A.C.; Pulido, G.T.; Lechuga, M.S. Handling multiple objectives with particle swarm optimization. IEEE Trans. Evol. Comput. 2004, 8, 256–279. [Google Scholar] [CrossRef]
- Zitzler, E.; Thiele, L.; Laumanns, M.; Fonseca, C.M.; Fonseca, V. Performance assessment of multiobjective optimizers: An analysis and review. IEEE Trans. Evol. Comput. 2003, 7, 117–132. [Google Scholar] [CrossRef] [Green Version]
- Jiang, S.; Ong, Y.; Zhang, J.; Feng, L. Consistencies and contradictions of performance metrics in multiobjective optimization. IEEE Trans. Cybern. 2014, 44, 2391–2404. [Google Scholar] [CrossRef] [PubMed]
- Oguz, C.; Ercan, M.F. A genetic algorithm for hybrid flow-shop scheduling with multiprocessor tasks. Complex Syst. 2005, 8, 323–351. [Google Scholar]






{kind=link}
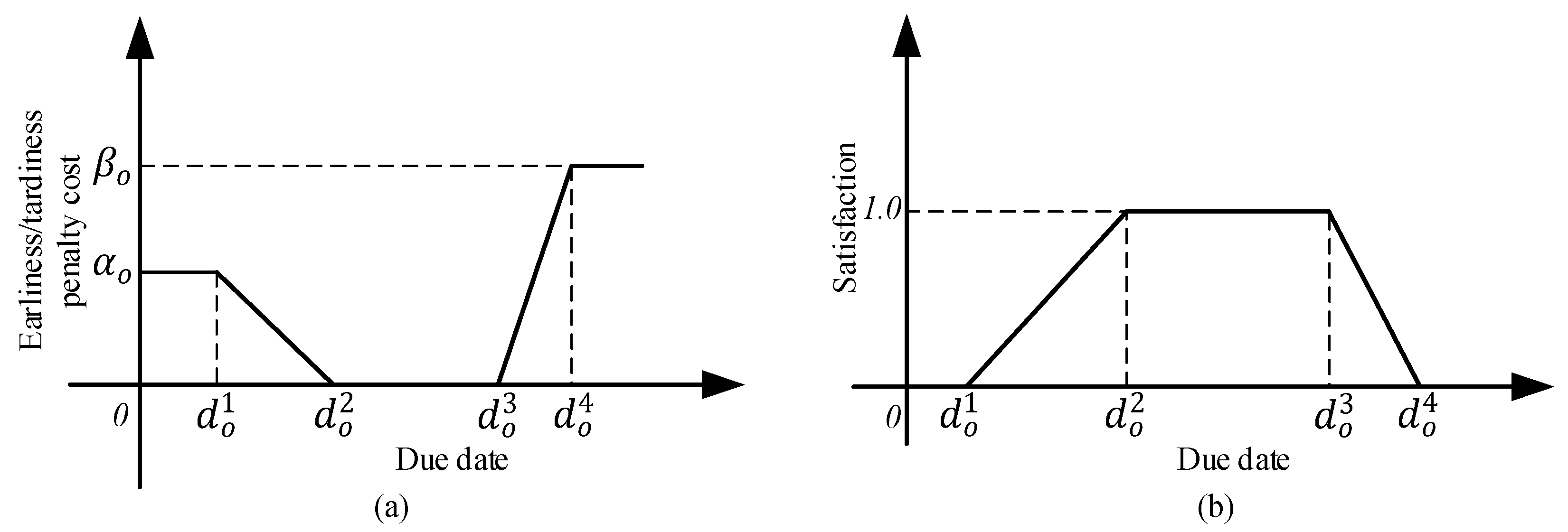{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Order No. | Number of Jobs | Job Type |
|---|---|---|
| 1 | 2 | 3 |
| 2 | 3 | 1 |
| 3 | 1 | 2 |
| Job Types | Available Quantity | Optional Lines | ||
|---|---|---|---|---|
| 0 | 1 | 2 | ||
| 1 | 2 | 1 | 2 | |
| 2 | 3 | 1 | 2 | 3 |
| 3 | 3 | 1 | 2 | 3 |
| Job Types | Stage 1 | Stage 2 | Stage 3 | Stage 4 | Stage 5 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 41 | 41 | 30 | 30 | 39 | 39 | 34 | 34 | 42 | 42 | 31 | 31 | 26 | 26 | 49 | 49 | 23 | 23 | ||
| 2 | 40 | 40 | 31 | 31 | 42 | 42 | 34 | 34 | 40 | 40 | 32 | 32 | 23 | 23 | 50 | 50 | 23 | 23 | ||
| 3 | 40 | 40 | 32 | 32 | 38 | 38 | 32 | 32 | 41 | 41 | 32 | 32 | 47 | 47 | 26 | 26 | 52 | 52 | 24 | 24 |
| 4 | 39 | 39 | 32 | 32 | 41 | 41 | 32 | 32 | 39 | 39 | 29 | 29 | 48 | 48 | 26 | 26 | 52 | 52 | 24 | 24 |
| 5 | 42 | 42 | 34 | 34 | 40 | 40 | 34 | 34 | 39 | 39 | 30 | 30 | 24 | 24 | 51 | 51 | 24 | 24 | ||
| 6 | 40 | 40 | 35 | 35 | 39 | 39 | 31 | 31 | 42 | 42 | 31 | 31 | 23 | 23 | 46 | 46 | 22 | 22 | ||
| 7 | 39 | 39 | 32 | 32 | 40 | 40 | 32 | 32 | 40 | 40 | 33 | 33 | 54 | 54 | 24 | 24 | 54 | 54 | 24 | 24 |
| 8 | 43 | 43 | 31 | 31 | 42 | 42 | 31 | 31 | 43 | 43 | 34 | 34 | 57 | 57 | 26 | 26 | 56 | 56 | 26 | 26 |
| Type | Available Quantity | Optional Lines | ||
|---|---|---|---|---|
| 0 | 1 | 2 | ||
| 1 | 2 | 2 | 3 | - |
| 2 | 2 | 2 | 3 | - |
| 3 | 3 | 1 | 2 | 3 |
| 4 | 3 | 1 | 2 | 3 |
| 5 | 3 | 2 | 3 | - |
| 6 | 3 | 2 | 3 | - |
| 7 | 3 | 1 | 2 | 3 |
| 8 | 3 | 1 | 2 | 3 |
| MOGWO/D | NSGA-II | MOGWO | MOPSO |
|---|---|---|---|
| Population size (N): 60 and iterations: 300 (20 and 40 jobs) | Population size (N): 60 and iterations: 300 (20 and 40 jobs) | Population size (): 60 and iterations: 300 (20 and 40 jobs) | Population size (): 60 and iterations: 300 (20 and 40 jobs) |
| Population size (): 100 and iterations: 500 (60 and 80 jobs) | Population size (N): 100 and iterations: 500 (60 and 80 jobs) | Population size (): 100 and iterations: 500 (60 and 80 jobs) | Population size (): 100 and iterations: 500 (60 and 80 jobs) |
| Population size (): 240 and iterations: 800 (120 and 160 jobs) | Population size (): 240 and iterations: 800 (120 and 160 jobs) | Population size (): 240 and iterations: 800 (120 and 160 jobs) | Population size (): 240 and iterations: 800 (120 and 160 jobs) |
| Population size (): 300 and iterations: 1000 (180 and 240 jobs) | Population size (): 300 and iterations: 1000 (180 and 240 jobs) | Population size(): 300 and iterations: 1000 (180 and 240 jobs) | Population size (): 300 and iterations: 1000 (180 and 240 jobs) |
| The external population size: | Crossover rate: 0.9 | The external population size: | The external archive size: |
| The neighborhood size: 20 (for all instances) | Mutation rate: 0.1 | The inertia weight wo = 0.4 | |
| = 6 (for all instances) | The acceleration coefficients = 2.0 | ||
| Problems | MOGWO/D | NSGA-II | MOGWO | MOPSO | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GD | IGD | GD | IGD | GD | IGD | GD | IGD | |||||
| 1_2_10 | 3.11E-2 | 3.93E-3 | 2.62E-1 | 7.52E-2 | 1.20E-2 | 7.96E-1 | 6.52E-2 | 1.02E-2 | 7.56E-1 | 8.50E-2 | 1.33E-2 | 7.70E-1 |
| 6.73E-3 | 8.93E-4 | 4.68E-2 | 8.07E-3 | 1.62E-3 | 8.51E-2 | 7.80E-3 | 2.01E-3 | /6.50E- | 1.06E-2 | 1.67E-3 | 7.80E-2 | |
| 1_4_10 | 1.38E-2 | 4.36E-3 | 3.57E-1 | 3.32E-2 | 1.47E-2 | 8.15E-1 | 2.86E-2 | 1.18E-2 | 8.62E-1 | 3.82E-2 | 1.69E-2 | 7.71E-1 |
| 5.11E-3 | 1.03E-3 | 6.08E-2 | 1.05E-2 | 3.66E-3 | 1.00E-1 | 9.12E-3 | 3.19E-3 | 9.77E-2 | 1.32E-2 | 3.93E-3 | 7.77E-2 | |
| 1_6_10 | 7.45E-3 | 2.09E-3 | 6.24E-1 | 5.82E-2 | 8.47E-3 | 7.61E-1 | 2.96E-2 | 4.17E-3 | 7.50E-1 | 8.15E-2 | 1.08E-2 | 6.43E-1 |
| 9.70E-3 | 6.04E-4 | 6.19E-2 | 6.83E-2 | 1.19E-2 | 5.64E-1 | 3.16E-2 | 3.61E-3 | 5.55E-1 | 1.29E-1 | 1.68E-2 | 5.35E-1 | |
| 1_8_10 | 1.70E-3 | 1.05E-3 | 3.90E-1 | 8.44E-3 | 4.70E-3 | 8.74E-1 | 4.62E-3 | 2.88E-3 | 8.31E-1 | 1.27E-2 | 6.14E-3 | 6.97E-1 |
| 8.40E-4 | 4.09E-4 | 2.95E-2 | 3.99E-3 | 3.14E-3 | 2.23E-1 | 1.72E-3 | 1.26E-3 | 5.83E-2 | 1.06E-2 | 5.77E-3 | 4.15E-1 | |
| 1_2_20 | 2.36E-2 | 1.74E-2 | 3.81E-1 | 3.46E-2 | 4.84E-2 | 1.01E + 00 | 3.94E-2 | 4.60E-2 | 1.02E + 00 | 2.54E-2 | 5.02E-2 | 9.70E-1 |
| 3.96E-2 | 8.09E-3 | 1.95E-1 | 4.16E-2 | 5.90E-3 | 7.97E-2 | 4.96E-2 | 9.25E-3 | 1.44E-1 | 2.30E-2 | 3.68E-3 | 4.40E-2 | |
| 1_4_20 | 1.12E-2 | 4.20E-3 | 3.64E-1 | 2.20E-2 | 1.02E-2 | 7.68E-1 | 2.00E-2 | 9.37E-3 | 7.80E-1 | 2.48E-2 | 1.11E-2 | 7.60E-1 |
| 5.60E-3 | 2.48E-3 | 4.85E-2 | 8.89E-3 | 4.67E-3 | 4.50E-2 | 8.78E-3 | 4.78E-3 | 5.88E-2 | 1.04E-2 | 4.81E-3 | 8.10E-2 | |
| 1_6_20 | 3.49E-2 | 1.94E-2 | 4.68E-1 | 3.59E + 01 | 4.37E-2 | 9.65E-1 | 3.83E + 01 | 4.08E-2 | 9.36E-1 | 3.74E + 01 | 4.69E-2 | 9.96E-1 |
| 1.56E-2 | 4.78E-3 | 7.30E-2 | 1.32E + 02 | 1.05E-2 | 1.97E-1 | 1.43E + 02 | 1.04E-2 | 2.23E-1 | 1.27E + 02 | 1.32E-2 | 2.16E-1 | |
| 1_8_20 | 3.02E + 01 | 3.22E-3 | 5.40E-1 | 8.49E + 01 | 7.62E-3 | 8.48E-1 | 7.42E + 01 | 7.19E-3 | 9.86E-1 | 9.41E + 01 | 9.05E-3 | 7.21E-1 |
| 6.97E + 01 | 2.23E-3 | 9.90E-2 | 1.69E + 02 | 6.33E-3 | 5.76E-1 | 1.67E + 02 | 5.32E-3 | 4.56E-1 | 1.69E + 02 | 7.71E-3 | 6.13E-1 | |
| 1_2_30 | 4.34E-2 | 5.87E-3 | 1.93E-1 | 1.51E-1 | 1.69E-2 | 7.50E-1 | 1.16E-1 | 1.45E-2 | 7.12E-1 | 1.77E-1 | 1.89E-2 | 7.55E-1 |
| 2.94E-2 | 1.03E-3 | 7.06E-2 | 3.79E-2 | 3.32E-3 | 1.02E-1 | 3.69E-2 | 2.81E-3 | 9.66E-2 | 3.80E-2 | 3.85E-3 | 1.00E-1 | |
| 1_4_30 | 3.26E-2 | 1.08E-2 | 3.92E-1 | 5.55E-2 | 2.68E-2 | 8.50E-1 | 5.43E-2 | 2.41E-2 | 8.14E-1 | 5.57E-2 | 2.82E-2 | 8.27E-1 |
| 1.98E-2 | 7.54E-3 | 5.74E-2 | 2.93E-2 | 1.55E-2 | 6.21E-2 | 3.06E-2 | 1.54E-2 | 7.18E-2 | 2.82E-2 | 1.54E-2 | 6.66E-2 | |
| 1_6_30 | 4.64E + 01 | 1.60E-1 | 4.35E-1 | 6.90E + 01 | 3.61E-1 | 8.93E-1 | 5.37E + 01 | 3.44E-1 | 8.81E-1 | 1.23E + 02 | 3.75E-1 | 9.42E-1 |
| 2.02E + 02 | 9.72E-2 | 6.76E-2 | 3.00E + 02 | 2.10E-1 | 1.23E-1 | 2.33E + 02 | 2.10E-1 | 1.44E-1 | 4.29E + 02 | 2.12E-1 | 1.51E-1 | |
| 1_8_30 | 1.76E + 02 | 3.22E + 00 | 6.02E-1 | 3.62E + 02 | 1.07E + 01 | 1.28E + 00 | 2.77E + 02 | 8.59E + 00 | 1.29E + 00 | 3.94E + 02 | 1.50E + 01 | 1.27E + 00 |
| 1.35E + 02 | 4.78E + 00 | 7.64E-2 | 1.71E + 02 | 1.10E + 01 | 6.85E-2 | 1.74E + 02 | 1.05E + 01 | 1.12E-1 | 1.84E + 02 | 1.06E + 01 | 5.52E-2 | |
| 2_2_10 | 1.69E-3 | 1.05E-3 | 3.76E-1 | 6.66E-3 | 5.14E-3 | 1.02E + 00 | 4.83E-3 | 3.34E-3 | 8.82E-1 | 9.05E-3 | 7.88E-3 | 1.14E + 00 |
| 3.88E-4 | 1.91E-4 | 3.07E-2 | 9.63E-4 | 8.87E-4 | 8.09E-2 | 8.66E-4 | 4.83E-4 | 7.77E-2 | 1.57E-3 | 2.14E-3 | 6.75E-2 | |
| 2_4_10 | 7.71E-3 | 9.17E-4 | 4.50E-1 | 3.38E-2 | 5.39E-3 | 8.93E-1 | 2.75E-2 | 3.31E-3 | 9.12E-1 | 4.15E-2 | 7.50E-3 | 9.21E-1 |
| 5.79E-3 | 4.21E-4 | 5.34E-2 | 2.28E-2 | 2.90E-3 | 9.24E-2 | 1.53E-2 | 6.50E-4 | 9.76E-2 | 3.02E-2 | 5.06E-3 | 8.74E-2 | |
| 2_6_10 | 1.60E-1 | 3.14E-2 | 5.50E-1 | 2.21E-1 | 6.49E-2 | 8.99E-1 | 2.05E-1 | 5.64E-2 | 8.87E-1 | 2.37E-1 | 7.13E-2 | 9.23E-1 |
| 1.30E-1 | 5.50E-3 | 1.04E-1 | 1.05E-1 | 9.55E-3 | 1.09E-1 | 1.18E-1 | 8.56E-3 | 9.91E-2 | 1.04E-1 | 9.18E-3 | 1.13E-1 | |
| 2_8_10 | 1.04E-3 | 3.60E-3 | 6.16E-1 | 1.03E-3 | 1.04E-3 | 5.81E-2 | 1.37E-4 | 3.20E-4 | 5.46E-2 | 7.52E-4 | 2.21E-3 | 4.89E-2 |
| 2.20E-4 | 1.69E-3 | 5.64E-2 | 4.49E-3 | 4.53E-3 | 2.53E-1 | 5.96E-4 | 1.40E-3 | 2.38E-1 | 3.28E-3 | 9.64E-3 | 2.13E-1 | |
| 2_2_20 | 1.26E-3 | 7.85E-4 | 3.51E-1 | 2.74E-2 | 1.50E-2 | 1.11E + 00 | 9.37E-3 | 3.80E-3 | 9.47E-1 | 3.72E-2 | 2.48E-2 | 1.28E + 00 |
| 4.72E-4 | 1.52E-4 | 2.68E-2 | 2.04E-2 | 7.67E-3 | 1.18E-1 | 4.89E-3 | 5.08E-4 | 9.58E-2 | 2.59E-2 | 8.00E-3 | 2.26E-1 | |
| 2_4_20 | 6.34E-3 | 2.90E-3 | 4.98E-1 | 2.15E-2 | 9.74E-3 | 1.05E + 00 | 1.55E-2 | 6.88E-3 | 1.03E + 00 | 2.68E-2 | 9.90E-3 | 9.77E-1 |
| 4.19E-3 | 1.71E-3 | 5.70E-2 | 1.48E-2 | 6.84E-3 | 1.52E-1 | 7.67E-3 | 2.89E-3 | 1.40E-1 | 1.37E-2 | 6.18E-3 | 2.52E-1 | |
| 2_6_20 | 1.67E-2 | 8.88E-3 | 5.86E-1 | 2.19E-2 | 1.60E-2 | 9.59E-1 | 1.86E-2 | 1.45E-2 | 9.07E-1 | 2.81E-2 | 1.85E-2 | 9.74E-1 |
| 6.75E-3 | 3.72E-3 | 4.58E-2 | 7.23E-3 | 5.75E-3 | 5.46E-2 | 5.82E-3 | 5.77E-3 | 6.54E-2 | 9.63E-3 | 6.00E-3 | 7.60E-2 | |
| 2_8_20 | 1.89E-2 | 1.88E-2 | 6.05E-1 | 2.26E-2 | 3.12E-2 | 9.34E-1 | 2.16E-2 | 2.95E-2 | 9.08E-1 | 2.56E-2 | 3.28E-2 | 9.84E-1 |
| 9.36E-3 | 9.15E-3 | 6.20E-2 | 9.38E-3 | 1.41E-2 | 8.92E-2 | 8.77E-3 | 1.38E-2 | 9.37E-2 | 1.17E-2 | 1.43E-2 | 1.13E-1 | |
| 2_2_30 | 1.07E-3 | 9.50E-4 | 4.10E-1 | 8.16E-3 | 9.67E-3 | 1.12E + 00 | 5.01E-3 | 5.72E-3 | 9.80E-1 | 1.22E-2 | 1.46E-2 | 1.24E + 00 |
| 5.40E-4 | 4.77E-4 | 4.66E-2 | 4.11E-3 | 8.56E-3 | 2.01E-1 | 3.22E-3 | 5.86E-3 | 1.80E-1 | 4.87E-3 | 8.92E-3 | 1.63E-1 | |
| 2_4_30 | 1.75E-2 | 1.65E-2 | 4.80E-1 | 2.22E-2 | 2.91E-2 | 8.30E-1 | 2.08E-2 | 2.78E-2 | 8.44E-1 | 2.35E-2 | 3.04E-2 | 8.43E-1 |
| 1.63E-2 | 9.82E-3 | 6.57E-2 | 1.55E-2 | 2.00E-2 | 2.98E-1 | 1.47E-2 | 1.97E-2 | 3.17E-1 | 1.63E-2 | 2.03E-2 | 3.02E-1 | |
| 2_6_30 | 9.06E-3 | 5.89E-3 | 6.22E-1 | 1.24E-2 | 9.63E-3 | 9.98E-1 | 1.10E-2 | 9.27E-3 | 9.70E-1 | 1.39E-2 | 9.81E-3 | 1.01E + 00 |
| 6.63E-3 | 3.02E-3 | 7.22E-2 | 7.18E-3 | 4.56E-3 | 8.25E-2 | 7.36E-3 | 4.69E-3 | 8.23E-2 | 7.24E-3 | 4.29E-3 | 8.61E-2 | |
| 2_8_30 | 1.40E-2 | 2.55E-2 | 6.39E-1 | 1.54E-2 | 4.10E-2 | 1.00E + 00 | 1.55E-2 | 4.00E-2 | 1.03E + 00 | 1.62E-2 | 4.18E-2 | 1.02E + 00 |
| 5.97E-3 | 9.17E-3 | 4.74E-2 | 5.50E-3 | 1.45E-2 | 7.58E-2 | 5.57E-3 | 1.45E-2 | 7.57E-2 | 5.85E-3 | 1.47E-2 | 6.46E-2 | |
| 3_2_10 | 3.81E-3 | 2.44E-3 | 2.93E-1 | 7.36E-3 | 7.38E-3 | 6.54E-1 | 6.53E-3 | 6.16E-3 | 6.26E-1 | 8.96E-3 | 8.81E-3 | 6.70E-1 |
| 5.73E-4 | 1.96E-4 | 3.01E-2 | 6.19E-4 | 7.85E-4 | 6.62E-2 | 6.45E-4 | 4.02E-4 | 4.89E-2 | 9.92E-4 | 1.10E-3 | 4.24E-2 | |
| 3_4_10 | 1.75E-3 | 4.21E-3 | 6.30E-1 | 1.80E-2 | 3.63E-2 | 1.03E + 00 | 1.48E-2 | 2.00E-2 | 1.13E + 00 | 1.68E-2 | 4.94E-2 | 1.01E + 00 |
| 1.65E-3 | 9.72E-4 | 5.37E-2 | 1.96E-2 | 1.55E-2 | 1.44E-1 | 1.58E-2 | 1.23E-2 | 1.05E-1 | 1.66E-2 | 4.51E-3 | 6.04E-2 | |
| 3_6_10 | 3.05E-3 | 2.02E-3 | 5.03E-1 | 3.45E-2 | 1.69E-2 | 9.37E-1 | 1.35E-2 | 8.79E-3 | 1.01E + 00 | 4.13E-2 | 1.33E-2 | 6.96E-1 |
| 2.82E-3 | 1.20E-3 | 7.36E-2 | 2.52E-2 | 1.63E-2 | 3.19E-1 | 8.74E-3 | 5.07E-3 | 2.55E-1 | 4.68E-2 | 1.35E-2 | 4.67E-1 | |
| 3_8_10 | 8.48E-4 | 8.06E-4 | 4.09E-1 | 2.30E-2 | 1.55E-2 | 1.09E + 00 | 4.49E-3 | 3.82E-3 | 1.01E + 00 | 3.23E-2 | 1.80E-2 | 8.86E-1 |
| 4.96E-4 | 4.08E-4 | 3.25E-2 | 1.70E-2 | 1.20E-2 | 2.93E-1 | 2.69E-3 | 2.88E-3 | 1.40E-1 | 3.31E-2 | 1.52E-2 | 5.31E-1 | |
| 3_2_20 | 3.22E-3 | 9.19E-4 | 3.59E-1 | 2.72E-2 | 1.32E-2 | 1.14E + 00 | 1.40E-2 | 4.41E-3 | 9.26E-1 | 3.86E-2 | 2.67E-2 | 1.29E + 00 |
| 1.27E-3 | 1.41E-4 | 3.27E-2 | 8.04E-3 | 4.61E-3 | 9.75E-2 | 4.02E-3 | 1.22E-3 | 9.68E-2 | 1.02E-2 | 4.68E-3 | 1.31E-1 | |
| 3_4_20 | 4.37E-3 | 9.39E-4 | 3.66E-1 | 1.32E-2 | 3.46E-3 | 8.24E-1 | 9.38E-3 | 2.58E-3 | 8.42E-1 | 1.89E-2 | 4.74E-3 | 8.89E-1 |
| 2.73E-3 | 1.84E-4 | 7.22E-2 | 6.55E-3 | 6.67E-4 | 1.14E-1 | 5.05E-3 | 4.39E-4 | 1.11E-1 | 9.37E-3 | 8.16E-4 | 1.16E-1 | |
| 3_6_20 | 6.68E-3 | 3.27E-3 | 5.18E-1 | 1.88E-2 | 9.60E-3 | 1.07E + 00 | 1.47E-2 | 8.03E-3 | 1.05E + 00 | 2.63E-2 | 1.29E-2 | 1.08E + 00 |
| 4.66E-3 | 1.89E-3 | 4.42E-2 | 9.13E-3 | 4.32E-3 | 1.18E-1 | 7.62E-3 | 3.77E-3 | 7.74E-2 | 1.91E-2 | 5.64E-3 | 1.27E-1 | |
| 3_8_20 | 2.79E-3 | 1.74E-3 | 4.18E-1 | 9.66E-3 | 6.78E-3 | 9.36E-1 | 8.24E-3 | 5.52E-3 | 9.39E-1 | 1.63E-2 | 1.28E-2 | 1.01E + 00 |
| 2.21E-3 | 1.28E-3 | 4.86E-2 | 4.76E-3 | 4.90E-3 | 2.91E-1 | 5.74E-3 | 6.58E-3 | 1.19E-1 | 1.59E-2 | 1.33E-2 | 2.97E-1 | |
| 3_2_30 | 3.92E-3 | 3.23E-3 | 2.34E-1 | 1.19E-2 | 1.08E-2 | 5.27E-1 | 1.00E-2 | 8.67E-3 | 5.25E-1 | 1.39E-2 | 1.34E-2 | 5.42E-1 |
| 1.48E-3 | 3.54E-4 | 4.10E-2 | 5.13E-3 | 7.11E-4 | 1.04E-1 | 6.26E-3 | 6.82E-4 | 1.67E-1 | 3.99E-3 | 8.41E-4 | 1.09E-1 | |
| 3_4_30 | 3.24E-2 | 1.14E-2 | 1.30E-1 | 3.05E-3 | 2.14E-3 | 1.31E-1 | 4.24E-3 | 4.28E-3 | 1.79E-1 | 2.39E-3 | 3.05E-3 | 1.49E-1 |
| 8.88E-3 | 2.88E-3 | 6.68E-2 | 9.15E-3 | 6.46E-3 | 3.94E-1 | 9.13E-3 | 9.65E-3 | 4.35E-1 | 9.50E-3 | 9.34E-3 | 4.47E-1 | |
| 3_6_30 | 8.38E-3 | 1.36E-2 | 5.02E-1 | 1.76E-2 | 1.76E-2 | 4.33E-1 | 3.87E-2 | 3.30E-2 | 7.28E-1 | 2.12E-2 | 2.43E-2 | 4.22E-1 |
| 3.06E-3 | 5.69E-3 | 5.45E-2 | 3.95E-2 | 3.05E-2 | 5.44E-1 | 6.29E-2 | 3.14E-2 | 4.95E-1 | 4.61E-2 | 3.89E-2 | 5.25E-1 | |
| 3_8_30 | 1.76E-2 | 1.20E-2 | 4.68E-1 | 3.21E-2 | 2.64E-2 | 1.02E + 00 | 2.79E-2 | 2.50E-2 | 1.04E + 00 | 4.39E-2 | 2.84E-2 | 1.02E + 00 |
| 9.12E-3 | 4.95E-3 | 5.92E-2 | 1.45E-2 | 1.03E-2 | 1.18E-1 | 1.23E-2 | 9.90E-3 | 1.10E-1 | 3.48E-2 | 1.08E-2 | 1.38E-1 | |
| Statistics | 33/30 | 34/34 | 35/33 | 0/1 | 1/0 | 0/1 | 2/3 | 1/1 | 1/0 | 1/2 | 0/1 | 0/2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, G.; Guan, Z.; Yue, L.; Mumtaz, J.; Liang, J. Modeling and Optimization for Multi-Objective Nonidentical Parallel Machining Line Scheduling with a Jumping Process Operation Constraint. Symmetry 2021, 13, 1521. https://doi.org/10.3390/sym13081521
Xu G, Guan Z, Yue L, Mumtaz J, Liang J. Modeling and Optimization for Multi-Objective Nonidentical Parallel Machining Line Scheduling with a Jumping Process Operation Constraint. Symmetry. 2021; 13(8):1521. https://doi.org/10.3390/sym13081521
Chicago/Turabian StyleXu, Guangyan, Zailin Guan, Lei Yue, Jabir Mumtaz, and Jun Liang. 2021. "Modeling and Optimization for Multi-Objective Nonidentical Parallel Machining Line Scheduling with a Jumping Process Operation Constraint" Symmetry 13, no. 8: 1521. https://doi.org/10.3390/sym13081521
APA StyleXu, G., Guan, Z., Yue, L., Mumtaz, J., & Liang, J. (2021). Modeling and Optimization for Multi-Objective Nonidentical Parallel Machining Line Scheduling with a Jumping Process Operation Constraint. Symmetry, 13(8), 1521. https://doi.org/10.3390/sym13081521