
An Approach for Chart Description Generation in Cyber–Physical–Social System

Abstract
:1. Introduction
2. Related Work
2.1. Manufacturing Chart Data Extraction
2.2. Chart Description Generation
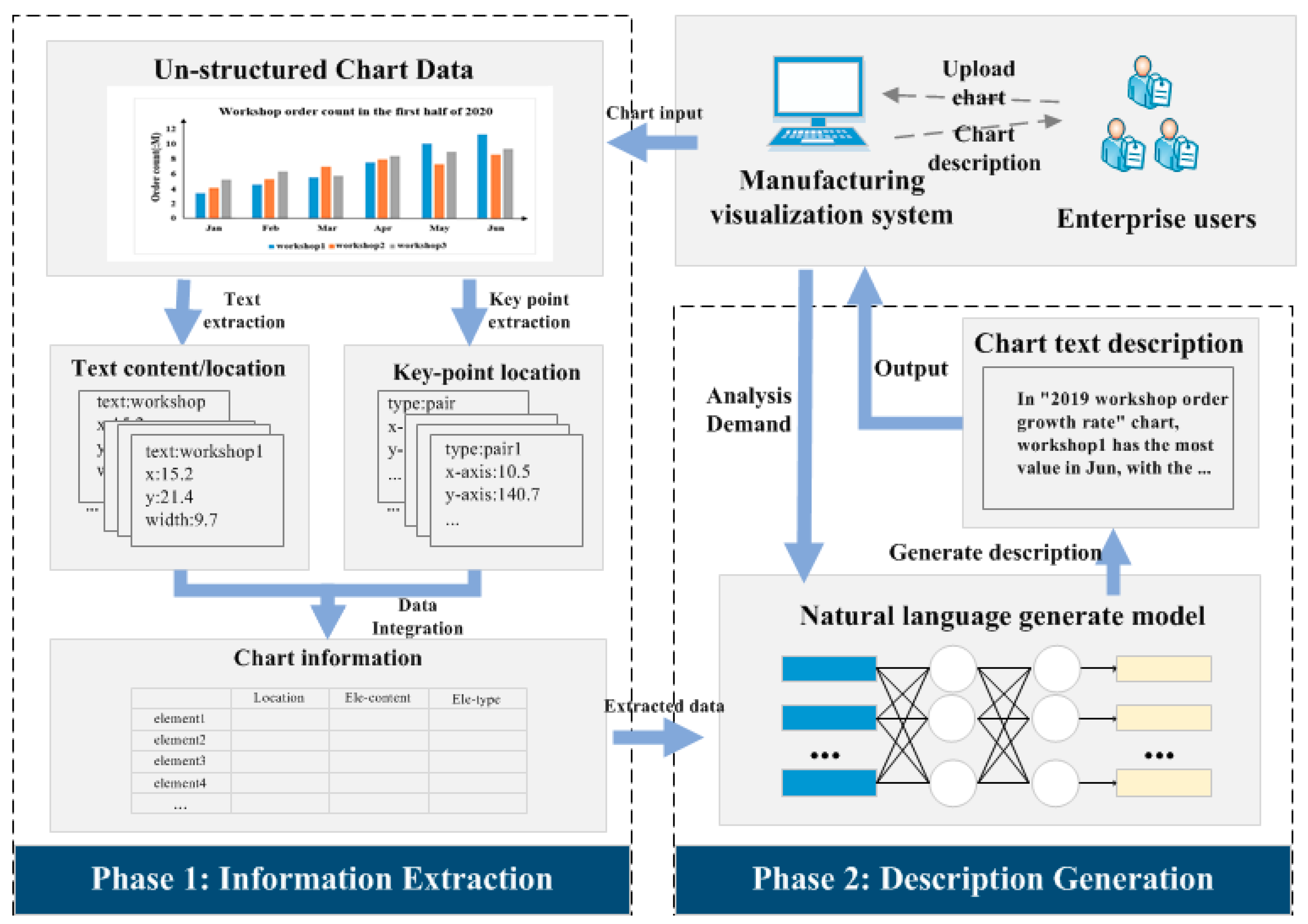
3. Data Information Extraction from Chart
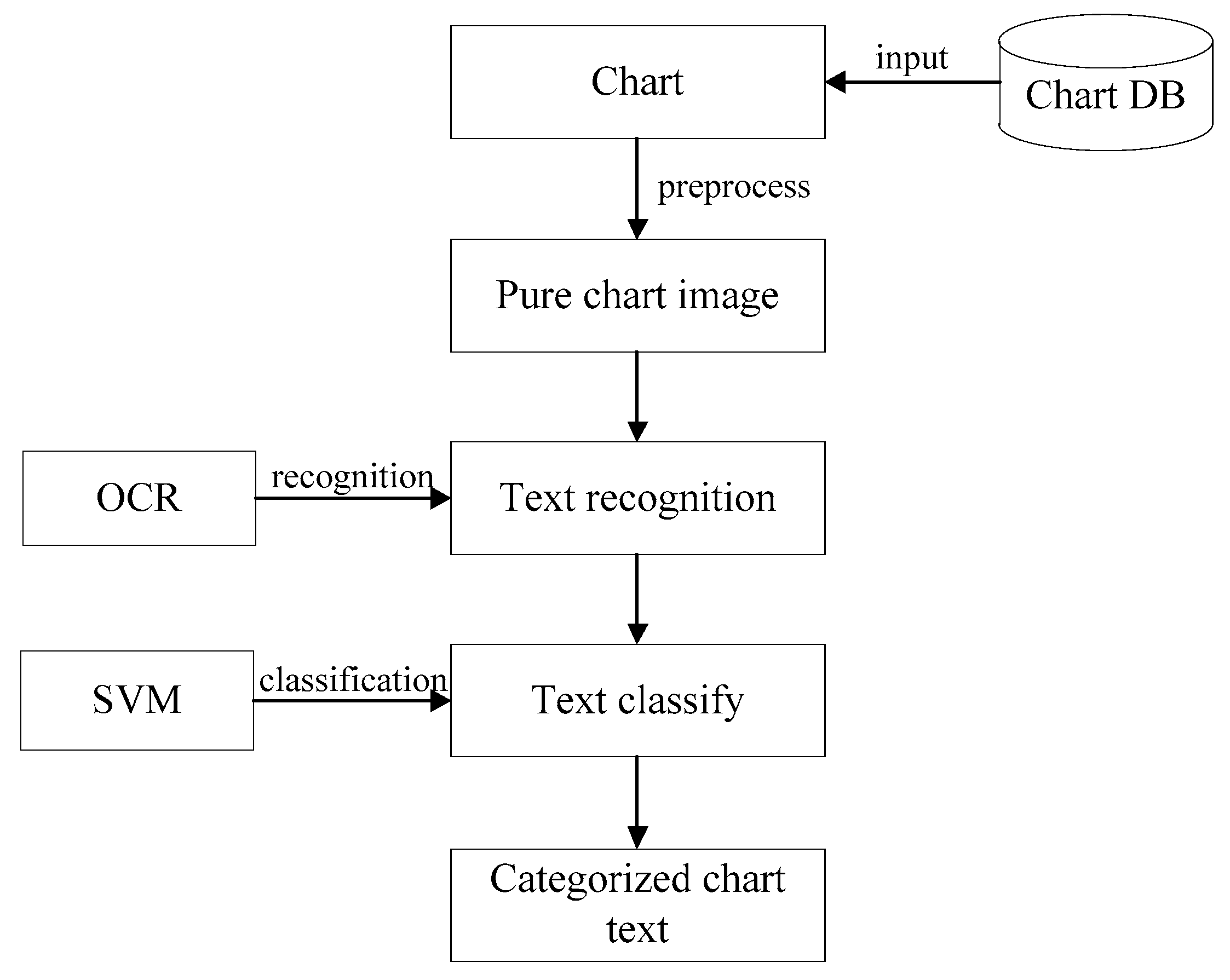
3.1. Chart Text Extraction
3.2. Key Point Detection
4. Deep Learning Methodology for Chart Description Generation
4.1. Problem Description and Assumption
4.2. The Model of Natural Language Generation for Chart Description
5. Application Cases and Experiments
5.1. Dataset and Settings
5.2. Comparative Experiments and Discussions
5.2.1. Chart Data Extraction Evaluation
5.2.2. Chart Description Generation Evaluation
5.3. Application Case in Manufacturing Enterprise
5.4. Evaluation and Discussion
5.4.1. Evaluating the Practicality of MECDG Model
5.4.2. Evaluating the Effectiveness of MECDG Model
5.4.3. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Leng, J.; Jiang, P.; Liu, C.; Wang, C. Contextual self-organizing of manufacturing process for mass individualization: A cyber-physical-social system approach. Enterp. Inf. Syst. 2020, 14, 1124–1149. [Google Scholar] [CrossRef]
- Zhou, Y.; Yu, F.R.; Chen, J.; Kuo, Y. Cyber-physical-social systems: A state-of-the-art survey, challenges and opportunities. IEEE Commun. Surv. Tutor. 2020, 22, 389–425. [Google Scholar] [CrossRef]
- Yilma, B.A.; Panetto, H.; Naudet, Y. Systemic formalisation of cyber-physical-social system (CPSS): A systematic literature review. Comput. Ind. 2021, 129, 103458. [Google Scholar] [CrossRef]
- Leng, J.; Jiang, P. A deep learning approach for relationship extraction from interaction context in social manufacturing par-adigm. Knowl. Based Syst. 2016, 100, 188–199. [Google Scholar] [CrossRef]
- Leng, J.; Zhang, H.; Yan, D.; Liu, Q.; Chen, X.; Zhang, D. Digital twin-driven manufacturing cyber-physical system for parallel controlling of smart workshop. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 1155–1166. [Google Scholar] [CrossRef]
- Jha, A.V.; Appasani, B.; Ghazali, A.N.; Pattanayak, P.; Gurjar, D.S.; Kabalci, E.; Mohanta, D.K. Smart grid cyber-physical systems: Communication technologies, standards and challenges. Wirel. Netw. 2021, 27, 2595–2613. [Google Scholar] [CrossRef]
- Feng, J.; Yang, L.T.; Gati, N.J.; Xie, X.; Gavuna, B.S. Privacy-preserving computation in cyber-physical-social systems: A survey of the state-of-the-art and perspectives. Inf. Sci. 2020, 527, 341–355. [Google Scholar] [CrossRef]
- Leng, J.; Jiang, P. Evaluation across and within collaborative manufacturing networks: A comparison of manufacturers’ in-teractions and attributes. Int. J. Prod. Res. 2018, 56, 5131–5146. [Google Scholar] [CrossRef]
- Luo, X.; Yuan, Y.; Zhang, K.; Xia, J.; Zhou, Z.; Chang, L.; Gu, T. Enhancing statistical charts: Toward better data visualization and analysis. J. Vis. 2019, 22, 819–832. [Google Scholar] [CrossRef]
- Ren, D.; Lee, B.; Brehmer, M. Charticulator: Interactive construction of bespoke chart layouts. IEEE Trans. Vis. Comput. Graph. 2019, 25, 789–799. [Google Scholar] [CrossRef] [PubMed]
- Zeng, W.; Dong, A.; Chen, X.; Cheng, Z.-L. VIStory: Interactive storyboard for exploring visual information in scientific publications. J. Vis. 2021, 24, 69–84. [Google Scholar] [CrossRef]
- Davila, K.; Setlur, S.; Doermann, D.; Bhargava, U.K.; Govindaraju, V. Chart mining: A survey of methods for automated chart analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1. [Google Scholar] [CrossRef]
- Burns, R.; Carberry, S.; Schwartz, S.E. An automated approach for the recognition of intended messages in grouped bar charts. Comput. Intell. 2019, 35, 955–1002. [Google Scholar] [CrossRef]
- Xu, Z.; Huang, D.; Min, T.; Ou, Y. A fault diagnosis method of rolling bearing integrated with cooperative energy feature extraction and improved least-squares support vector machine. Math. Probl. Eng. 2020, 2020, 6643167. [Google Scholar]
- De Oliveira, C.L.T.; Silva, A.T.D.A.; Campos, E.M.; Araujo, T.D.O.; Mota, M.P.; Meiguins, B.S.; De Morais, J.M. Proposal and evaluation of textual description templates for bar charts vocalization. In Proceedings of the 2019 23rd International Conference Information Visualisation (IV); Institute of Electrical and Electronics Engineers (IEEE), Paris, France, 2–5 July 2019; pp. 163–169. [Google Scholar]
- Sohn, C.; Choi, H.; Kim, K.; Park, J.; Noh, J. Line Chart Understanding with Convolutional Neural Network. Electronics 2021, 10, 749. [Google Scholar] [CrossRef]
- Cliche, M.; Rosenberg, D.; Madeka, D.; Yee, C. Scatteract: Automated extraction of data from scatter plots. In Transactions on Petri Nets and Other Models of Concurrency XV; Springer Science and Business Media LLC: Berlin, Germany, 2017; pp. 135–150. [Google Scholar]
- Savva, M.; Kong, N.; Chhajta, A.; Fei-Fei, L.; Agrawala, M.; Heer, J. ReVision: Automated classification, analysis and redesign of chart images. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011; pp. 393–402. [Google Scholar]
- Choudhury, S.R.; Wang, S.; Giles, C.L. Curve separation for line graphs in scholarly documents. In Proceedings of the 16th ACM/IEEE-CS on Joint Conference on Digital Libraries; Association for Computing Machinery (ACM), Newark, NJ, USA, 19–23 June 2016; pp. 277–278. [Google Scholar]
- Siegel, N.; Horvitz, Z.; Levin, R.; Divvala, S.; Farhadi, A. FigureSeer: Parsing result-figures in research papers. In Transactions on Petri Nets and Other Models of Concurrency XV; Springer: Amsterdam, The Netherlands, 2016; pp. 664–680. [Google Scholar] [CrossRef]
- Choi, J.; Jung, S.; Park, D.G.; Choo, J.; Elmqvist, N. Visualizing for the non-visual: Enabling the visually impaired to use visualization. Comput. Graph. Forum 2019, 38, 249–260. [Google Scholar] [CrossRef]
- Jung, D.; Kim, W.; Song, H.; Hwang, J.I.; Lee, B.; Kim, B.; Seo, J. Chartsense: Interactive data extraction from chart images. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 6706–6717. [Google Scholar]
- Poco, J.; Heer, J. Reverse-engineering visualizations: Recovering visual encodings from chart images. Comput. Graph. Forum 2017, 36, 353–363. [Google Scholar] [CrossRef]
- Luo, J.; Li, Z.; Wang, J.; Lin, C.-Y. ChartOCR: Data extraction from charts images via a deep hybrid framework. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Virtual. 5 January 2021; pp. 1916–1924. [Google Scholar]
- Al-Zaidy, R.A.; Giles, C.L. Automatic extraction of data from bar charts. In Proceedings of the 8th International Conference on Knowledge Capture, ACM, Palisades, NY, USA, 7–10 October 2015; p. 30. [Google Scholar]
- Zadeh, L. A prototype-centered approach to adding deduction capability to search engines-the concept of protoform. In Proceedings of the IEEE Intelligent Systems, New Orleans, LA, USA, 7 August 2002; pp. 523–525. [Google Scholar]
- Bryan, C.; Ma, K.; Woodring, J. Temporal summary images: An approach to narrative visualization via interactive annotation generation and placement. IEEE Trans. Vis. Comput. Graph. 2017, 23, 511–520. [Google Scholar] [CrossRef]
- Hullman, J.; Diakopoulos, N.; Adar, E. Contextifier: Automatic generation of annotated stock visualizations. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 2707–2716. [Google Scholar]
- Mahmood, A.; Bajwa, I.; Qazi, K. An automated approach for interpretation of statistical graphics. In Proceedings of the International Conference on Intelligent Human-Machine Systems and Cybernetics, Hangzhou, China, 26–27 August 2014; pp. 376–379. [Google Scholar]
- Kallimani, J.S.; Srinivasa, K.G.; Eswara, R.B. Extraction and interpretation of charts in technical documents. In Proceedings of the 2013 International Conference on Advances in Computing, Communications and Informatics (ICACCI), IEEE, Mysore, India, 22–25 August 2013; pp. 382–387. [Google Scholar]
- Liu, C.; Xie, L.; Han, Y.; Wei, D.; Yuan, X. AutoCaption: An approach to generate natural language description from visualization automati-cally. In Proceedings of the IEEE Pacific Visualization Symposium (PacificVis), Tianjin, China, 14–17 April 2020; pp. 191–195. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. arXiv 2018, arXiv:1808.01244. [Google Scholar]
- Smith, R. An overview of the Tesseract OCR engine. In Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), Curitiba, Parana, 23–26 September 2007; Volume 2, pp. 629–633. [Google Scholar]
- Geler, Z.; Kurbalija, V.; Ivanović, M.; Radovanović, M. Weighted kNN and constrained elastic distances for time-series classification. Expert Syst. Appl. 2020, 162, 113829. [Google Scholar] [CrossRef]
- Newell, A.; Yang, K.; Jia, D. Stacked Hourglass Networks for Human Pose Estimation. In European Conference on Computer Vision; Springer International Publishing: New York, NY, USA, 2016; pp. 483–499. [Google Scholar]
- Cambria, E.; White, B. Jumping NLP Curves: A review of natural language processing research. IEEE Comput. Intell. Mag. 2014, 9, 48–57. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Bai, X. Text classification based on LSTM and attention. In Proceedings of the 2018 Thirteenth International Conference on Digital Information Management (ICDIM), Porto, Portugal, 19–21 September 2018; pp. 29–32. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Park, J.; Yi, D.; Ji, S. Analysis of Recurrent Neural Network and Predictions. Symmetry 2020, 12, 615. [Google Scholar] [CrossRef]
- Satyanarayan, A.; Russell, R.; Heer, J.; Hoffswell, J.; Heer, J. Reactive vega: A streaming dataflow architecture for declarative interactive visual-ization. IEEE Trans. Vis. Comput. Graph. 2016, 22, 659–668. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Chen, L.; Wu, M. Intelligent Workshop Quality Data Integration and Visual Analysis Platform Design. Comput. Integr. Manuf. Syst. 2021, 27, 1641–1649. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vega Charts | Manufacture Charts | |
|---|---|---|
| Bar charts | 5358 | 2123 |
| Line charts | 3360 | 1254 |
| Scatter charts | 2123 | 674 |
| MECDG | ReVision | ChartSense | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Prec | Rec | F1 | Prec | Rec | F1 | Prec | Rec | F1 | |
| Bar | 91.2% | 94.6% | 92.9% | 78.3% | 84.6% | 81.3% | 90.7% | 92.1% | 91.3% |
| Scatter | 90.5% | 95.1% | 92.7% | 79.1% | 87.1% | 82.9% | 86.9% | 90.4% | 88.6% |
| Line | 88.7% | 92.4% | 90.5% | 73.8% | 79.8% | 76.6% | 78.2% | 85.3% | 81.5% |
| Average | 90.1% | 94.0% | 92.1% | 77.1% | 83.8% | 80.3% | 85.3% | 89.3% | 87.2% |
| Prec | Rec | F1 | |
|---|---|---|---|
| Chart text extraction | 88.2% | 96.3% | 92.1% |
| Key point extraction | 91.8% | 95.2% | 93.5% |
| BLEU | |
|---|---|
| RNN | 63.2% |
| LSTM | 73.5% |
| MECDG | 92.7% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Zhao, K. An Approach for Chart Description Generation in Cyber–Physical–Social System. Symmetry 2021, 13, 1552. https://doi.org/10.3390/sym13091552
Chen L, Zhao K. An Approach for Chart Description Generation in Cyber–Physical–Social System. Symmetry. 2021; 13(9):1552. https://doi.org/10.3390/sym13091552
Chicago/Turabian StyleChen, Liang, and Kangting Zhao. 2021. "An Approach for Chart Description Generation in Cyber–Physical–Social System" Symmetry 13, no. 9: 1552. https://doi.org/10.3390/sym13091552
APA StyleChen, L., & Zhao, K. (2021). An Approach for Chart Description Generation in Cyber–Physical–Social System. Symmetry, 13(9), 1552. https://doi.org/10.3390/sym13091552