
RAHC_GAN: A Data Augmentation Method for Tomato Leaf Disease Recognition




Abstract
:1. Introduction
- Adding a set of continuous hidden variables to the input of the generative adversarial network to improve the diversity of the generated images. Due to the intra-class differences of the same tomato disease being small, the traditional generative adversarial network has difficulty learning the intra-class differences, and then it will generate similar images, resulting in the phenomenon of mode collapse [37]. In order to avoid this phenomenon, we use the hidden variable and class label to generate tomato leaves with different diseases. The class label is used to generate specific disease classes, and the hidden variable is used to improve the potential changes in the same class. For each class of disease, we capture the potential differences within the class by changing the value of the hidden variable, such as the area size and severity of the disease, so as to supplement the information within the class and enrich the diversity of the generated images.
- The fusion of residual attention block and multi-scale discriminator to enrich disease information of generated pictures. We add residual attention blocks to the generator. The residual network deepens the network depth and avoids network degradation. The attention mechanism makes the generator pay more attention to the disease information in the leaves from the perspectives of channel and space and guides the generation of tomato diseased leaves with obvious disease features. In addition, we introduce a multi-scale discriminator, which can capture different levels of information in the image, enrich the texture and edges of the generated leaves, and make the generated leaves more complete, richer in detail, and clearer in texture.
- Using RAHC_GAN to expand the training set to meet the large amount of data needed for neural network training. We use the expanded data set as the training set, train four kinds of recognition networks (AlexNet, VGGNet, GoogLeNet, and ResNet) through transfer learning, and use the test set for performance evaluation. The experimental results show that in multiple recognition networks, the performance of the expanded data set is better than that of the original training set.
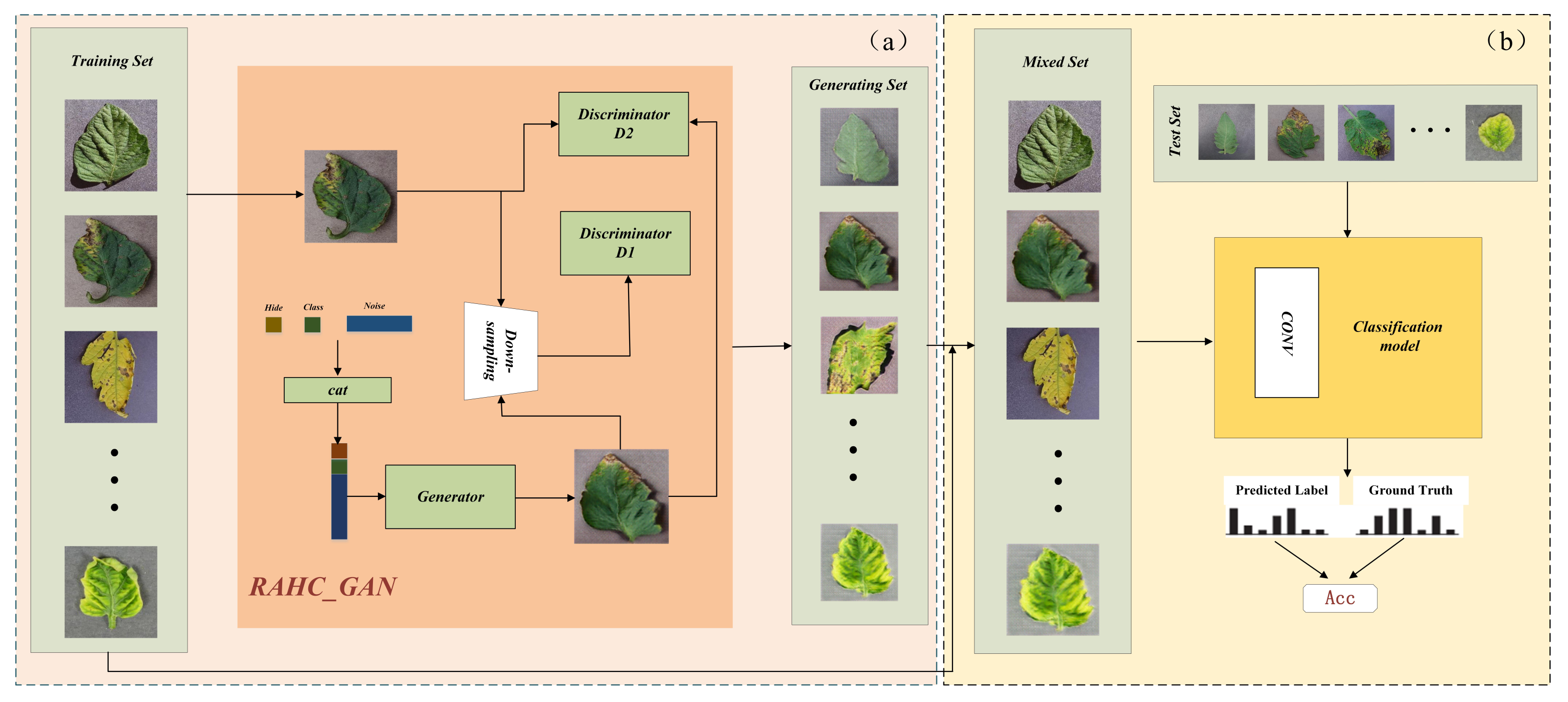
2. Materials and Methods
2.1. Related Works
2.1.1. ACGAN
2.1.2. CBAM
2.2. Building RAHC_GAN for Tomato Leaf Disease Recognition
2.2.1. The Overview of RAHC_GAN
2.2.2. The Generative Network G
2.2.3. The Discriminative Network D
2.2.4. Loss Function
2.2.5. Recognition Model for Tomato Leaf Disease Identification
3. Results
3.1. Data Set
3.2. Experimental Setup
3.3. RAHC_GAN Model Exploration
3.3.1. Number of Residual Blocks for Plant Image Generation
3.3.2. Different Scale of Discriminators for Plant Image Generation
3.3.3. The Recognition Performance on Different Expansion Numbers of Training Set
3.3.4. The Effect of Hidden Variables
3.4. The Comparative Experiment
3.5. The Ablation Experiment
3.6. The Recognition Performance on Other Plants
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Giovannucci, E. Tomatoes, Tomato-Based Products, Lycopene, and Cancer: Review of the Epidemiologic Literature. J. Natl. Cancer Inst. 1999, 91, 317–331. [Google Scholar] [CrossRef]
- Li, N.; Wu, X.; Zhuang, W.; Xia, L.; Zhou, Y. Tomato and lycopene and multiple health outcomes: Umbrella review. Food Chem. 2020, 343, 128396. [Google Scholar] [CrossRef]
- Mazidi, M.; Ferns, G.A.; Banach, M. A high consumption of tomato and lycopene is associated with a lower risk of cancer mortality: Results from a multi-ethnic cohort. Public Health Nutr. 2020, 23, 1–7. [Google Scholar] [CrossRef]
- Shijie, J.; Peiyi, J.; Siping, H.; Haibo, S. Automatic detection of tomato diseases and pests based on leaf images. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–27 October 2017; pp. 2510–2537. [Google Scholar] [CrossRef]
- Liu, J.; Wang, X. Correction to: Early recognition of tomato gray leaf spot disease based on MobileNetv2-YOLOv3 model. Plant Methods 2021, 17, 19. [Google Scholar] [CrossRef]
- Mohanty, S.P.; Hughes, D.P.; Salathe, M. Using Deep Learning for Image-Based Plant Disease Detection. Front. Plant Sci. 2016, 7, 1419. [Google Scholar] [CrossRef] [Green Version]
- Khandelwal, I.; Raman, S. Analysis of Transfer and Residual Learning for Detecting Plant Diseases Using Images of Leaves. In Computational Intelligence: Theories, Applications and Future Directions; Springer: Singapore, 2019; Volume II, pp. 295–306. [Google Scholar] [CrossRef]
- Ma, A.; As, B.; Sa, C.; As, D.; Sg, A. ToLeD: Tomato Leaf Disease Detection using Convolution Neural Network. Procedia Comput. Sci. 2020, 167, 293–301. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. Proc. AAAI Conf. Artif. Intell. 2017, 34, 13001–13008. [Google Scholar] [CrossRef]
- Takahashi, R.; Matsubara, T.; Uehara, K. Data Augmentation Using Random Image Cropping and Patching for Deep CNNs. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 2917–2931. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Cisse, M.; Dauphin, Y.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Chou, H.P.; Chang, S.C.; Pan, J.Y.; Wei, W.; Juan, D.C. Remix: Rebalanced Mixup. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar] [CrossRef]
- Bin, L.; Zhang, Y.; He, D.; Li, Y. Identification of Apple Leaf Diseases Based on Deep Convolutional Neural Networks. Symmetry 2017, 10, 11. [Google Scholar] [CrossRef] [Green Version]
- Mohamad, A.H.A.; Ismail, N.; Ahmad, I.M.Y.; Nasir Taib, M. VGG16 for Plant Image Classification with Transfer Learning and Data Augmentation. Int. J. Eng. Technol. 2018, 7, 90–94. [Google Scholar] [CrossRef]
- Shi, Y.; Qin, T.; Liu, Y.; Lu, J.; Shen, D. Automatic Data Augmentation by Learning the Deterministic Policy. arXiv 2019, arXiv:1910.08343. [Google Scholar]
- DeVries, T.; Taylor, G.W. Dataset Augmentation in Feature Space. arXiv 2017, arXiv:1702.05538. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Strategies From Data. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 113–123. [Google Scholar] [CrossRef]
- Ho, D.; Liang, E.; Stoica, I.; Abbeel, P.; Chen, X. Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules. In Proceedings of the 36th International Conference on Machine Learning(ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 4843–4856. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2014, 63, 139–144. [Google Scholar] [CrossRef]
- Bowles, C.; Chen, L.; Guerrero, R.; Bentley, P.; Gunn, R.; Hammers, A.; Dickie, D.A.; Hernández, M.; Wardlaw, J.; Rueckert, D. GAN Augmentation: Augmenting Training Data using Generative Adversarial Networks. arXiv 2018, arXiv:1810.10863. [Google Scholar]
- Shrivastava, A.; Pfister, T.; Tuzel, O.; Susskind, J.; Webb, R. Learning from Simulated and Unsupervised Images through Adversarial Training. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2242–2251. [Google Scholar] [CrossRef] [Green Version]
- Tran, N.T.; Tran, V.H.; Nguyen, N.B.; Nguyen, T.K.; Cheung, N.M. On Data Augmentation for GAN Training. IEEE Trans. Image Process. 2021, 30, 1882–1897. [Google Scholar] [CrossRef]
- Niu, S.; Li, B.; Wang, X.; Lin, H. Defect Image Sample Generation With GAN for Improving Defect Recognition. IEEE Trans. Autom. Sci. Eng. 2020, 17, 1611–1622. [Google Scholar] [CrossRef]
- Douarre, C.; Crispim-Junior, C.F.; Gelibert, A.; Tougne, L.; Rousseau, D. Novel data augmentation strategies to boost supervised segmentation of plant disease. Comput. Electron. Agric. 2019, 165, 104967. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Purbaya, M.E.; Setiawan, N.A.; Adji, T.B. Leaves image synthesis using generative adversarial networks with regularization improvement. In Proceedings of the International Conference on Information and Communications Technology, Yogyakarta, Indonesia, 6–7 March 2018; pp. 360–365. [Google Scholar] [CrossRef]
- Odena, A.; Olah, C.; Shlens, J.B. Conditional image synthesis with auxiliary classifier GANs. In Proceedings of the 2017 International Conference on Machine Learning(ICML), International Convention Centre, Sydney, Australia, 11–15 August 2017; pp. 4043–4055. [Google Scholar]
- Tang, X.L.; Du, Y.M.; Liu, Y.W.; Li, J.X.; Ma, Y.W. Image Recognition With Conditional Deep Convolutional Generative Adversarial Networks. Zidonghua Xuebao/Acta Autom. Sin. 2018, 44, 855–864. [Google Scholar] [CrossRef]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Zhao, Y.; Chen, Z.; Gao, X.; Song, W.; Zhang, Z. Plant Disease Detection using Generated Leaves Based on DoubleGAN. IEEE/ACM Trans. Comput. Biol. Bioinform. 2021. [Google Scholar] [CrossRef]
- Arsenovic, M.; Karanovic, M.; Sladojevic, S.; Anderla, A.; Stefanovic, D. Solving Current Limitations of Deep Learning Based Approaches for Plant Disease Detection. Symmetry 2019, 11, 939. [Google Scholar] [CrossRef] [Green Version]
- Qin, X.H.; Wang, Z.; Jiepeng, Y.; Zhou, Q.; Zhao, P.; Wang, Z.y.; Huang, L. Using a one-dimensional convolutional neural network with a conditional generative adversarial network to classify plant electrical signals. Comput. Electron. Agric. 2020, 174, 105464. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Li, E.; Liang, Z. Detection of Apple Lesions in Orchards Based on Deep Learning Methods of CycleGAN and YOLOV3-Dense. J. Sens. 2019, 2019, 1–13. [Google Scholar] [CrossRef]
- Szegedy, C.; Wei, L.; Jia, Y.; Sermanet, P.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Zhu, F.; He, M.; Zheng, Z. Data augmentation using improved cDCGAN for plant vigor rating. Comput. Electron. Agric. 2020, 175, 105603. [Google Scholar] [CrossRef]
- Liu, B.; Tan, C.; Li, S.; He, J.; Wang, H. A Data Augmentation Method Based on Generative Adversarial Networks for Grape Leaf Disease Identification. IEEE Access 2020, 8, 102188–102198. [Google Scholar] [CrossRef]
- Arjovsky, M.; Bottou, L. Towards Principled Methods for Training Generative Adversarial Networks. arXiv 2017, arXiv:1701.04862. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–198. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable representation learning by information maximizing generative adversarial nets. In Proceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, Barcelona, Spain, 5 December 2016; Volume 29, pp. 2180–2188. [Google Scholar]
- Guo, Y.; Li, H.; Zhuang, P. Underwater Image Enhancement Using a Multiscale Dense Generative Adversarial Network. IEEE J. Ocean. Eng. 2020, 45, 862–870. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. Comput. Sci. 2014. [Google Scholar]
- Brahimi, M.; Arsenovic, M.; Laraba, S.; Sladojevic, S.; Boukhalfa, K.; Moussaoui, A. Deep Learning for Plant Diseases: Detection and Saliency Map Visualisation. In Human and Machine Learning; Zhou, J., Chen, F., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 93–117. ISBN 978-3-319-90402-3. [Google Scholar] [CrossRef]
- Jha, G.; Cecotti, H. Data augmentation for handwritten digit recognition using generative adversarial networks. Multimed. Tools Appl. 2020, 79, 35055–35068. [Google Scholar] [CrossRef]
- Rao, S.; Danish, S.; Keflemariam, S.; Tesfagergish, H.; Tesfamariam, R.; Habtemariam, T. Pathological Survey on Disease Incidence and Severity of Major Diseases on Tomato and Chilli Crops Grown in Sub Zoba Hamelmalo, Eritrea. Int. J. Res. Stud. Agric. Sci. 2016, 2, 20–31. [Google Scholar]
- Jin, Y.; Zhang, J.; Li, M.; Tian, Y.; Zhu, H.; Fang, Z. Towards the Automatic Anime Characters Creation with Generative Adversarial Networks. arXiv 2017, arXiv:1708.05509. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-Attention Generative Adversarial Networks. PMLR 2018, 97, 7354–7363. [Google Scholar]
- Mao, Q.; Lee, H.Y.; Tseng, H.Y.; Ma, S.; Yang, M.H. Mode Seeking Generative Adversarial Networks for Diverse Image Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 12744–12753. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Xu, K.; Zhu, J.; Zhang, B. Triple Generative Adversarial Nets. arXiv 2017, arXiv:1703.02291. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm 1 |
|---|
| INPUT: Training set X,Test set ,the epoch of RAHC_GAN ,the epoch of recog- nition network ,the batch size of RAHC_GAN ,the batch size of recognition network |
|
| Class | Train (Origin) | Train (Origin + Augment) | Test |
|---|---|---|---|
| Healthy | 1000 | 2000 | 250 |
| Spot disease | 1000 | 2000 | 250 |
| Septoria leaf spot | 1000 | 2000 | 250 |
| Bacterial spot | 1000 | 2000 | 250 |
| Late blight | 1000 | 2000 | 250 |
| Yellow leaf curl virus disease | 1000 | 2000 | 250 |
| Total | 6000 | 12000 | 1500 |
| AlexNet | VGGNet | GoogLeNet | ResNet | |
|---|---|---|---|---|
| ACGAN | 94.7 | 92.4 | 94.9 | 96.8 |
| Res4 | 95.3 | 94.6 | 95.0 | 97.1 |
| Res8 | 95.0 | 93.9 | 95.1 | 96.9 |
| Res16 | 95.3 | 94.9 | 95.3 | 97.6 |
| Res32 | 94.5 | 94.2 | 94.1 | 98.0 |
| AlexNet | VGGNet | GoogLeNet | ResNet | |
|---|---|---|---|---|
| 2D(64|128) | 94.8 | 95.1 | 95.5 | 97.6 |
| 2D(128|256) | 94.7 | 94.4 | 93.9 | 96.9 |
| 3D(32|64|128) | 93.7 | 94.8 | 95.4 | 97.3 |
| 3D(64|128|256) | 94.3 | 93.9 | 95.0 | 97.2 |
| AlexNet | VGGNet | GoogLeNet | ResNet | |
|---|---|---|---|---|
| Baseline | 94.1 | 93.1 | 93.8 | 97.7 |
| Conventional | 94.5 | 93.0 | 95.7 | 97.7 |
| Random erasing | 94.6 | 93.0 | 94.8 | 97.6 |
| ACGAN | 94.7 | 92.4 | 94.9 | 96.8 |
| DCGAN | 94.9 | 95.1 | 94.7 | 96.6 |
| SAGAN | 93.6 | 92.1 | 95.2 | 97.3 |
| MSGAN | 95.0 | 93.5 | 95.8 | 97.5 |
| RAHC_GAN | 95.9 | 95.3 | 96.5 | 98.1 |
| AlexNet | VGGNet | GoogLeNet | ResNet | |
|---|---|---|---|---|
| ACGAN | 94.7 | 92.4 | 94.9 | 96.8 |
| +R+A | 94.9 | 93.6 | 95.5 | 97.5 |
| +R+H+A | 95.7 | 94.7 | 96.1 | 97.7 |
| RAHC_GAN | 95.9 | 95.3 | 96.5 | 98.1 |
| Apple | Grape | Corn | ||||||
|---|---|---|---|---|---|---|---|---|
| Class | Train | Test | Class | Train | Test | Class | Train | Test |
| Scab | 500 | 125 | Black_rot | 500 | 125 | Gray_leaf_spot | 200 | 50 |
| Black_rot | 500 | 125 | Black_Measles | 1000 | 250 | Common_rust | 500 | 125 |
| Cedar_apple_rust | 200 | 50 | Healthy | 200 | 50 | Healthy | 500 | 125 |
| Healthy | 1000 | 250 | Leaf blight | 500 | 125 | Northern_leaf_blight | 500 | 125 |
| Apple | Grape | Corn | |||||||
|---|---|---|---|---|---|---|---|---|---|
| a | b | c | a | b | c | a | b | c | |
| baseline | 97.5 | 97.5 | 99.5 | 98.7 | 98.4 | 99.5 | 96.7 | 96.9 | 98.4 |
| ACGAN | 97.8 | 97.8 | 99.6 | 97.1 | 98.7 | 99.3 | 97.7 | 97.4 | 98.6 |
| RAHC_GAN | 98.0 | 99.1 | 99.8 | 99.1 | 98.7 | 99.8 | 98.1 | 98.1 | 98.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, H.; Luo, D.; Chang, Z.; Li, H.; Yang, X. RAHC_GAN: A Data Augmentation Method for Tomato Leaf Disease Recognition. Symmetry 2021, 13, 1597. https://doi.org/10.3390/sym13091597
Deng H, Luo D, Chang Z, Li H, Yang X. RAHC_GAN: A Data Augmentation Method for Tomato Leaf Disease Recognition. Symmetry. 2021; 13(9):1597. https://doi.org/10.3390/sym13091597
Chicago/Turabian StyleDeng, Hongxia, Dongsheng Luo, Zhangwei Chang, Haifang Li, and Xiaofeng Yang. 2021. "RAHC_GAN: A Data Augmentation Method for Tomato Leaf Disease Recognition" Symmetry 13, no. 9: 1597. https://doi.org/10.3390/sym13091597
APA StyleDeng, H., Luo, D., Chang, Z., Li, H., & Yang, X. (2021). RAHC_GAN: A Data Augmentation Method for Tomato Leaf Disease Recognition. Symmetry, 13(9), 1597. https://doi.org/10.3390/sym13091597