
MRE: A Military Relation Extraction Model Based on BiGRU and Multi-Head Attention

Abstract
:1. Introduction
- (1)
- We encode the input military text using the pre-trained language model. The word features and position features of military text are combined to generate the vector feature of military text, and then the semantic features of military text can be expressed more effectively.
- (2)
- We apply a multi-head attention mechanism combined with BERT into military relation extraction. As a variant of self-attention, the core idea of this approach is to calculate self-attention from multiple dimensional spaces, so that, based on effective expression of semantic features in military texts from BERT, the model can learn more semantic features in military texts from different subspaces, and thus capture more contextual information.
- (3)
- We establish the types and tagging methods of military relations, and construct a certain scale corpus of military relations via analyzing the semantic features of military texts.
2. Related Works
3. Military Relation Extraction Model
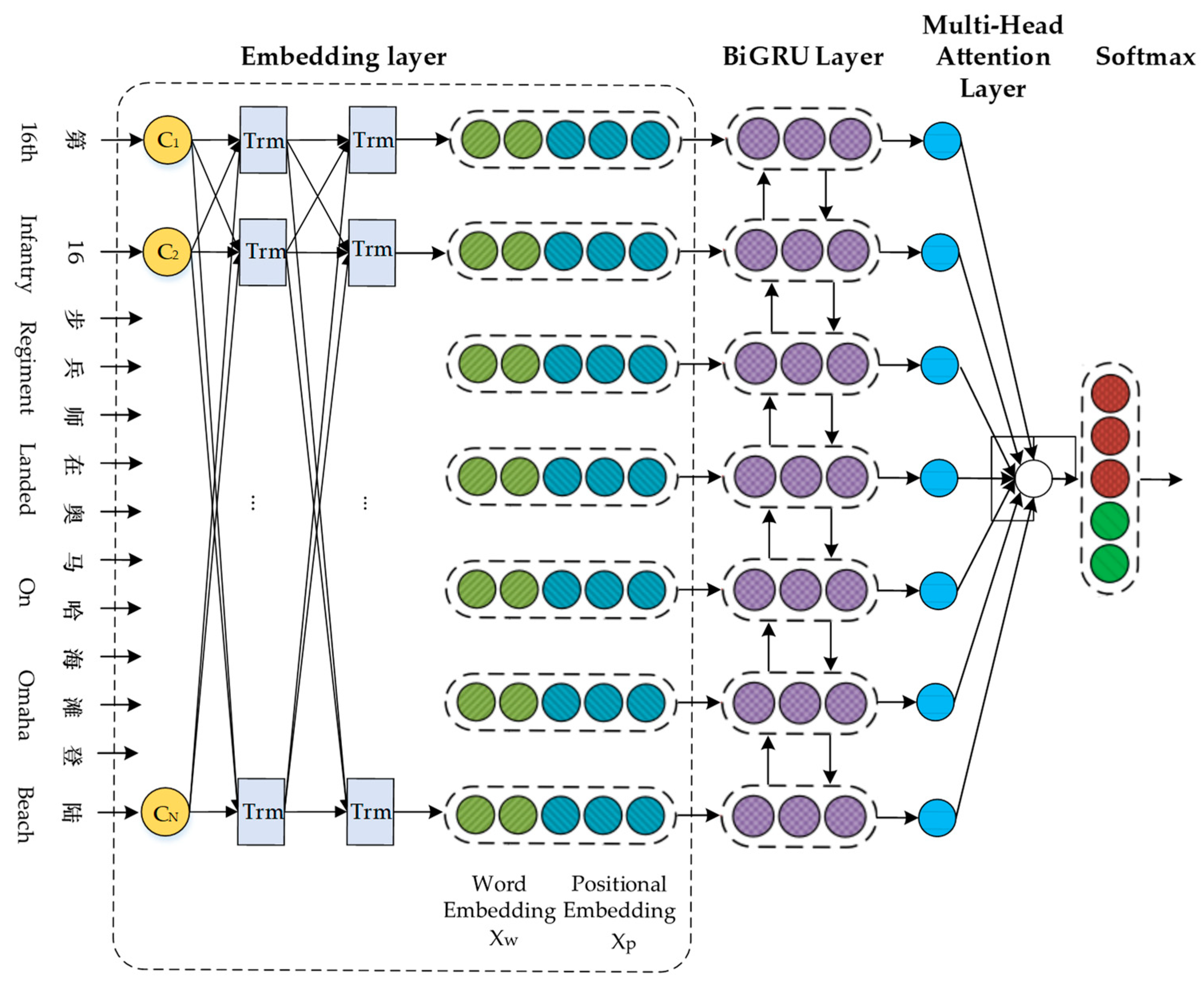
3.1. Embedding Layer
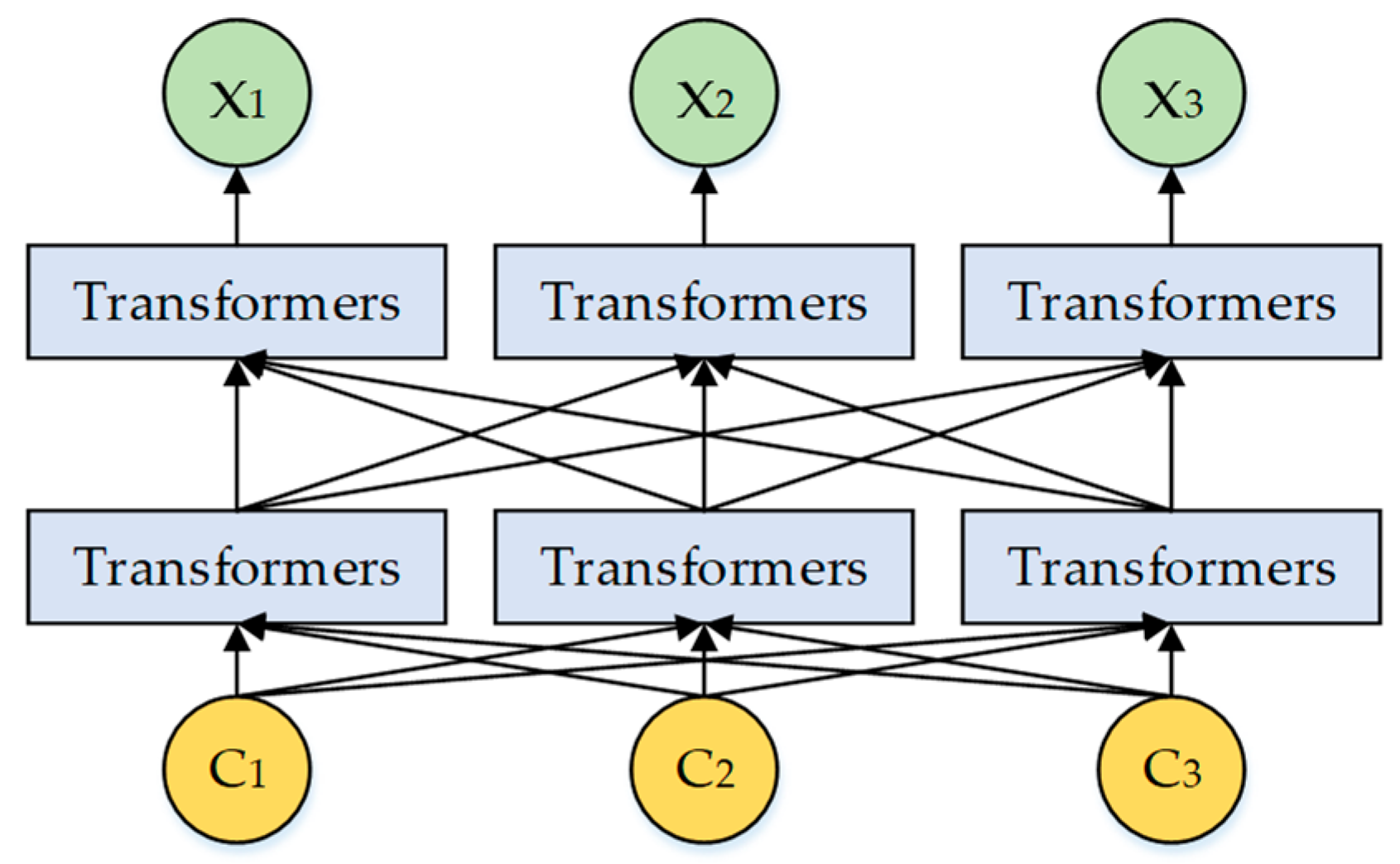
3.1.1. Word Embedding
3.1.2. Position Embedding
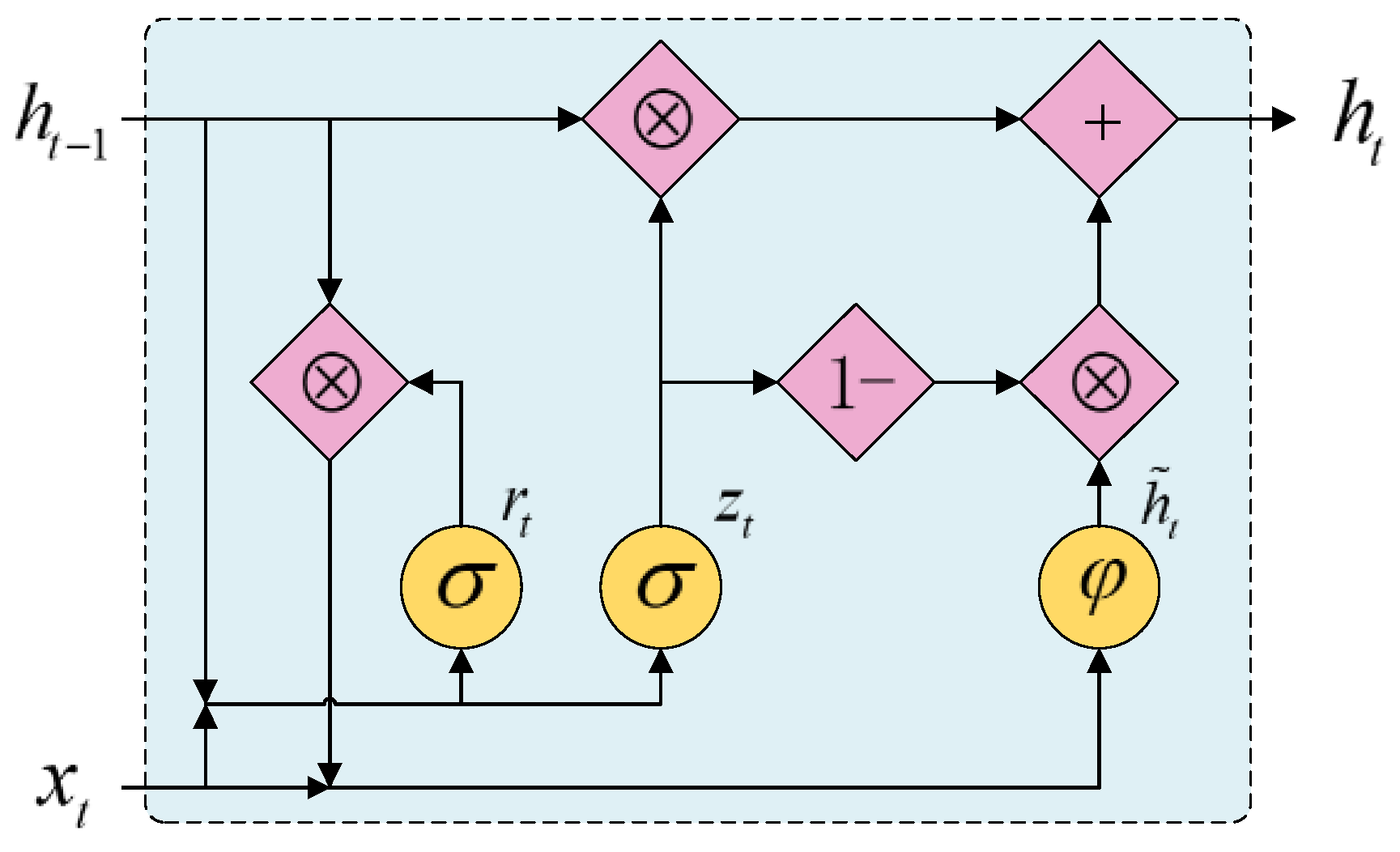
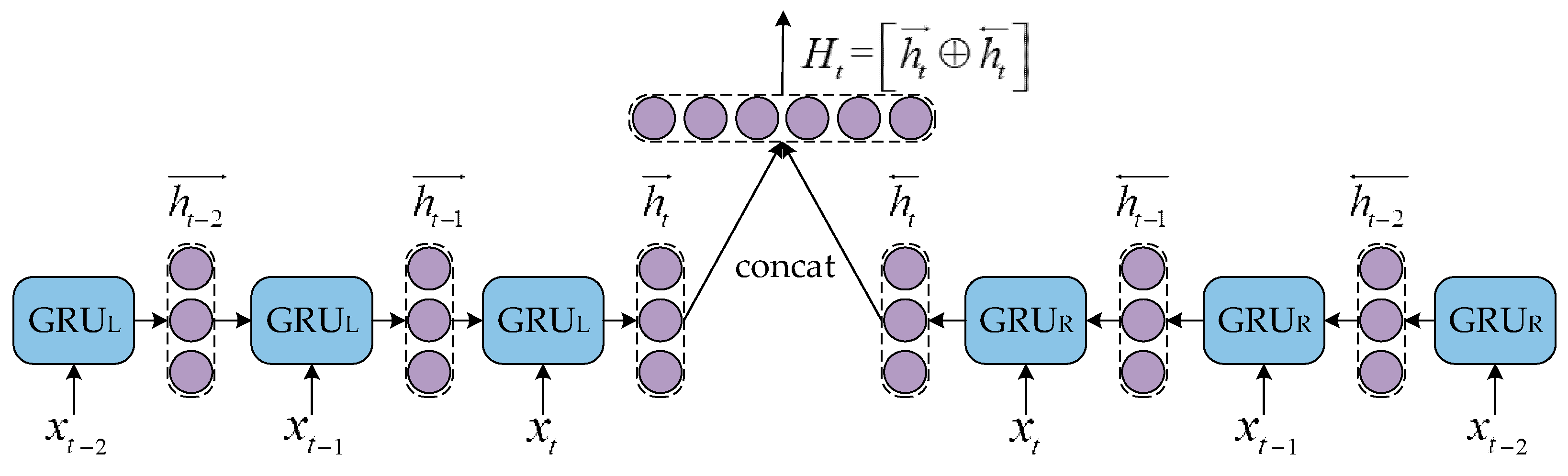
3.2. BiGRU Layer
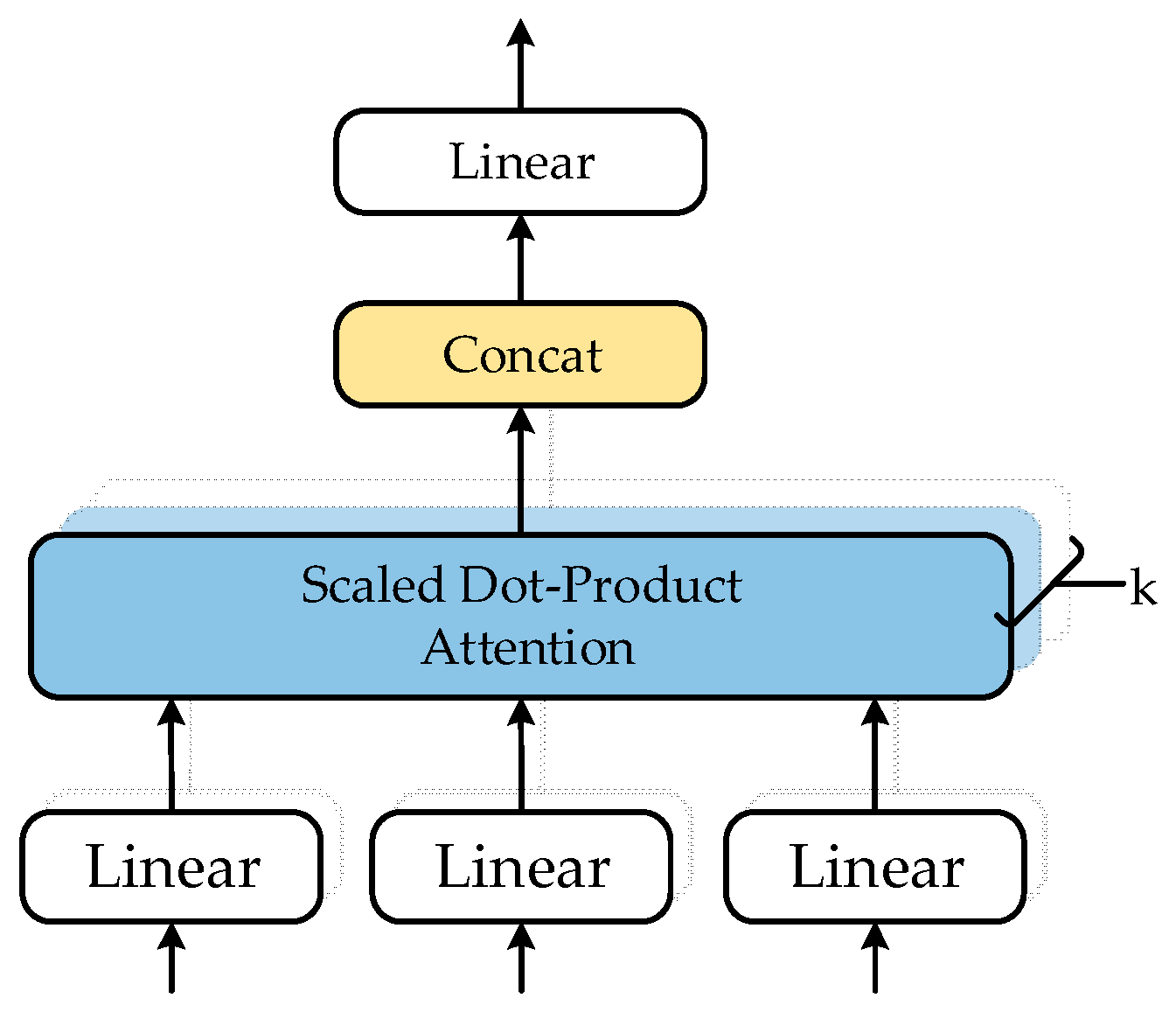
3.3. Multi-Head Attention Layer
3.4. Ouput Layer
4. Experiments and Results
4.1. Dataset
4.2. Evaluation Criterion
4.3. Parameters Setting
4.4. Results and Analysis
4.4.1. Comparison of Result on Different Embedding Methods
- Feature representation of Word2Vec + word;
- Feature representation of Word2Vec + word + position;
- Feature vector representation of BERT + word;
- Feature vector representation of BERT + word + position.
4.4.2. Comparison of Result on Different Feature Extraction Models
- Traditional non-attention models: BiLSTM, BiGRU;
- Based on the traditional attention models: BiLSTM-ATT model, BiGRU-ATT;
- Based on the improved attention models: BiLSTM-2ATT, BiGRU-2ATT.
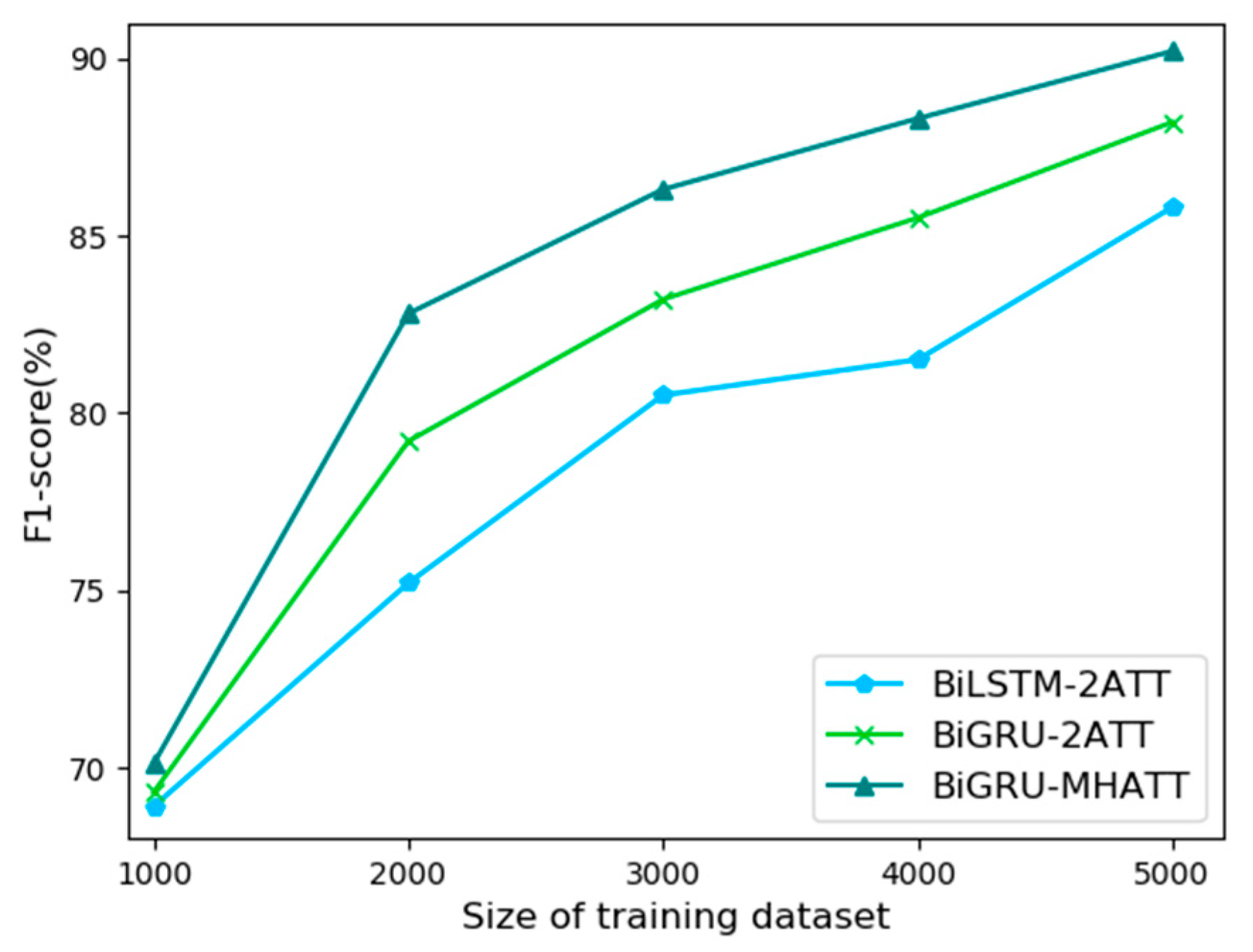
4.4.3. Comparison of Result on Different Training Data Sizes
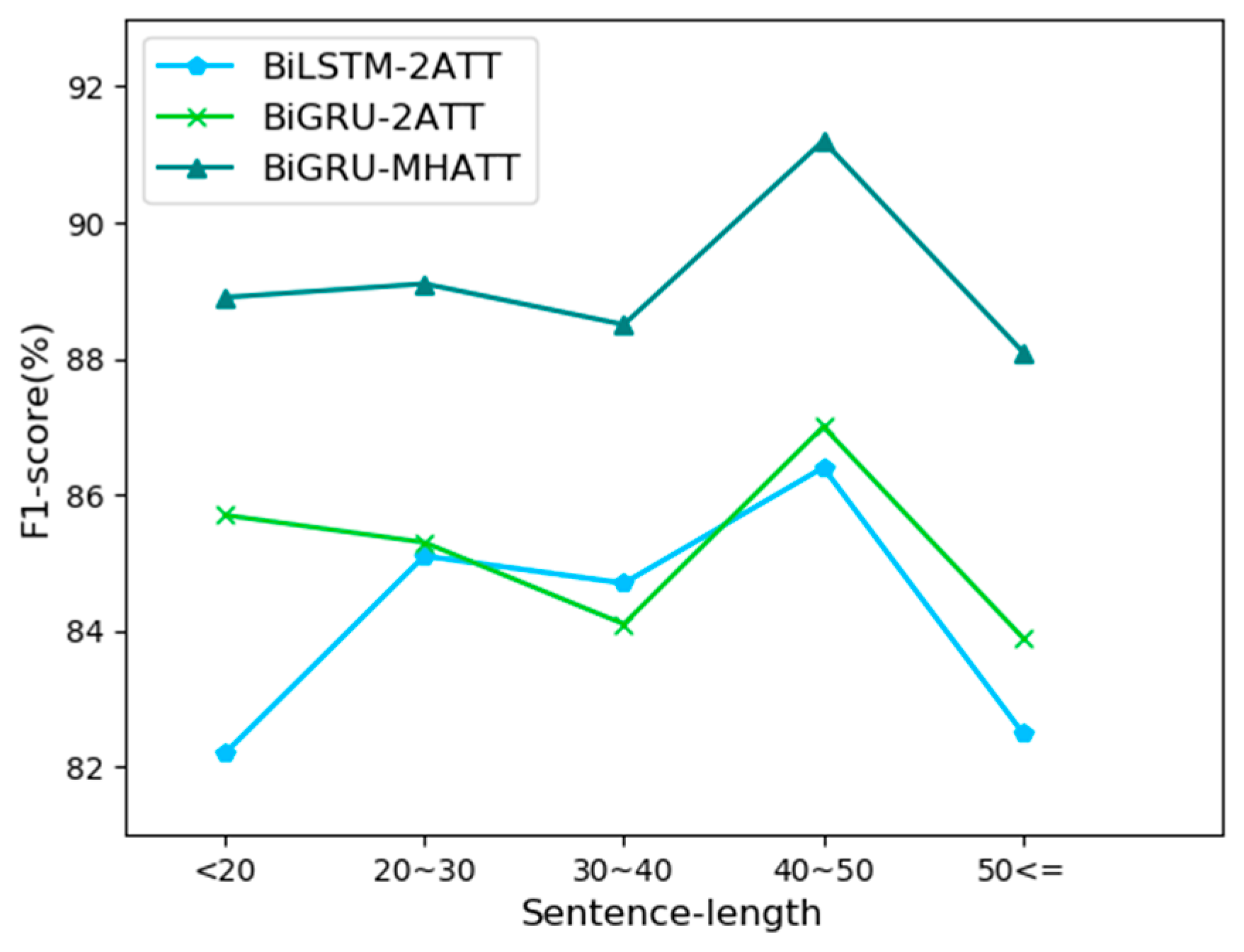
4.4.4. Comparison of Result on Different Sentence Length
4.4.5. Comparison of Result on Dataset SemEval-2010 Task 8
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ding, K.; Liu, S.; Zhang, Y.; Zhang, H.; Zhou, X. A knowledge-enriched and span-based network for joint entity and relation extraction. Comput. Mater. Contin. 2021, 680, 377–389. [Google Scholar] [CrossRef]
- Zhao, K.; Xu, H.; Cheng, Y.; Li, X.; Gao, K. Representation iterative fusion based on heterogeneous graph neural network for joint entity and relation extraction. Knowl.-Based Syst. 2021, 219, 106888. [Google Scholar] [CrossRef]
- Li, Y.; Huang, W. Weak supervision recognition of military relations. Electron. Des. Eng. 2018, 1, 77–78. [Google Scholar]
- Kambhatla, N. Combining lexical, syntactic, and semantic features with maximum entropy models for extracting relations. In Proceedings of the ACL 2014 on Interactive Poster Demonstration Sessions, Barcelona, Spain, 21–26 July 2004. [Google Scholar]
- Suchanek, F.M.; Ifrim, G.; Weikum, G. Combining linguistic and statistical analysis to extract relations from Web documents. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 712–717. [Google Scholar]
- Bunescu, R.C.; Mooney, R.J. A shortest path dependency kernel for relation extraction. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing (HLT/EMNLP 2005), Vancouver, BC, Canada, 6–8 October 2005; pp. 724–731. [Google Scholar]
- Wang, M. A re-examination of dependency path kernels for relation extraction. In Proceedings of the IJCNLP, Hyderabad, India, 7–12 January 2008; pp. 841–846. Available online: https://aclanthology.org/I08-2119.pdf (accessed on 8 September 2021).
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation classification via convolutional deep neural network. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- Zhang, S.; Zheng, D.; Hu, X.; Yang, M. Bidirectional long short-term memory networks for relation classification. In Proceedings of the PACLIC; 2015; pp. 73–78. Available online: https://aclanthology.org/Y15-1009.pdf (accessed on 8 September 2021).
- Dos Santos, C.; Xiang, B.; Zhou, B. Classifying relations by ranking with convolutional neural networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 626–634. [Google Scholar]
- Xu, Y.; Mou, L.; Li, G.; Chen, Y.; Peng, H.; Jin, Z. Classifying relations via long short-term memory networks along shortest dependency paths. arXiv 2015, arXiv:1508.03720. [Google Scholar]
- Che, W.X.; Liu, T.; Li, S. Automatic Entity Relation Extraction. J. Chin. Inf. Process. 2005, 19, 1–6. [Google Scholar]
- Zelenko, D.; Aone, C.; Richardella, A. Kernel methods for relation extraction. J. Mach. Learn. Res. 2003, 3, 1083–1106. [Google Scholar]
- Plank, B.; Moschitti, A. Embedding semantic similarity in tree kernels for domain adaptation of relation extraction. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (ACL 2013), Sofia, Bulgaria, 4–9 August 2013; Volume 1, pp. 1498–1507. [Google Scholar]
- Liu, C.Y.; Sun, W.B.; Chao, W.H.; Che, W.X. Convolution neural network for relation extraction. In Proceedings of the 9th International Conference on Advanced Data Mining and Applications, Hangzhou, China, 14–16 December 2013; pp. 231–242. [Google Scholar]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Zhang, D.; Wang, D. Relation classification via recurrent neural network. arXiv 2015, arXiv:1508.01006. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.-W.; Xu, B. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin, Germany, 7–12 August 2016; pp. 207–212. [Google Scholar]
- Cho, K.; Van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 14–16 October 2014; pp. 1724–1734. [Google Scholar]
- Luo, X.; Zhou, W.; Wang, W.; Zhu, Y.; Deng, J. Attention-based relation extraction with bidirectional gated recurrent unit and highway network in the analysis of geological data. IEEE Access 2018, 6, 5705–5715. [Google Scholar] [CrossRef]
- Zhang, L.X.; Hu, X.W. Research on character relation extraction from Chinese text based on Bidirectional GRU neural network and two-level attention mechanism. Comput. Appl. Softw. 2018, 35, 136–141. [Google Scholar]
- Zhou, H.; Yang, Y.; Ning, S.; Liu, Z.; Lang, C.; Lin, Y. Combining Context and Knowledge Representations for Chemical-Disease Relation Extraction. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019, 16, 1879–1889. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Z.; Sun, Y.; Zhu, J.; Tang, S.; Ma, H. Improve relation extraction with dual attention-guided graph convolutional networks. Neural Comput. Appl. 2021, 33, 1773–1784. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. An Ambient Intelligence-Based Human Behavior Monitoring Framework for Ubiquitous Environments. Information 2021, 12, 81. [Google Scholar] [CrossRef]
- Liu, C.; Yu, Y.; Li, X.; Wang, P. Application of Entity Relation Extraction Method under CRF and Syntax Analysis Tree in the Construction of Military Equipment Knowledge Graph. IEEE Access 2020, 8, 200581–200588. [Google Scholar] [CrossRef]
- Wang, C.; He, X.; Zhou, A. Open Relation Extraction for Chinese Noun Phrases. IEEE Trans. Knowl. Data Eng. 2021, 33, 2693–2708. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-trained of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Kwon, H. Friend-Guard Textfooler Attack on Text Classification System. IEEE Access 2021, 99. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Thakur, N.; Han, C.Y. Multimodal Approaches for Indoor Localization for Ambient Assisted Living in Smart Homes. Information 2021, 12, 114. [Google Scholar] [CrossRef]
- Doddington, G.; Mitchell, A.; Przybocki, M.; Ramshaw, L.; Strassel, S.; Weischedel, R. The automatic content extraction (ACE)program-tasks, data, and evaluation. In Proceedings of the COLING, Stroudsburg, PA, USA, 23–27 August 2004; pp. 2014–2329. Available online: http://www.lrec-conf.org/proceedings/lrec2004/pdf/5.pdf (accessed on 8 September 2021).
- Girju, R.; Nakov, P.; Nastase, V.; Szpakowicz, S.; Turney, P.; Yuret, D. Classification of semantic relations between nominals. In Proceedings of the SemEval, Prague, Czech Republic, 23–24 June 2007; pp. 13–18. Available online: https://aclanthology.org/S07-1.pdf (accessed on 8 September 2021).
- Han, X.; Zhu, H.; Yu, P.; Wang, Z.; Yao, Y.; Liu, Z.; Sun, M. FewRel: A large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation. arXiv 2018, arXiv:1810.10147. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Coarse-Grained | Fine-Grained | Type Description |
|---|---|---|
| Command Relation | Command (Com) | Superior commands subordinate. |
| Affiliation (Aff) | A subordinate is subordinate to a superior. | |
| Equivalent (Eq) | No superior-subordinate relation. | |
| Coreference (CoF) | Two entities represent the same organization. | |
| Remove (Rem) | Remove superior-subordinate command relation. | |
| Position Relation | Enemy (En) | The two organizations are hostile. |
| Alliance (Alli) | The two organizations are alliance. | |
| Location Relation | Deploy (Dep) | Entity is in a specific location. |
| Route | Entity is in a position. | |
| Equipment Relation | Own | Organization configures some equipment. |
| Link | Organization links some equipment. Equipment links some equipment. | |
| Target Relation | Target | Organization attacks some organization. Organization attacks some location. |
| Entity 1 | Entity 2 | Relation | Military Sentence |
|---|---|---|---|
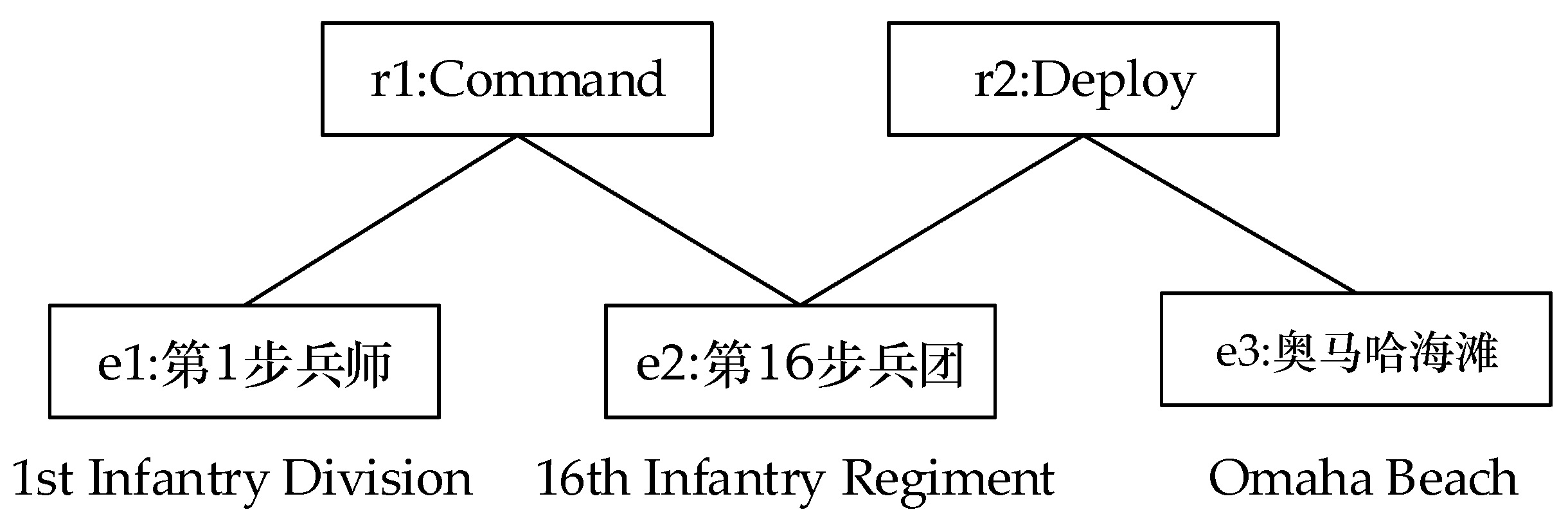
| 第1步兵师 1st Inf Div. | 第16步兵团 16th Inf Regiment | Command | 第1步兵师命令第16步兵团进攻 1st Inf Div. ordered 16th Inf Regiment to attack |
| 第1步兵师 1st Inf Div. | 第4骑兵团 4th Cavalry Regiment | Remove | 第1步兵师 (欠第4骑兵团) 1st Inf Div. (Remove 4th Cavalry Regiment) |
| 第16步兵团 16th Inf Regiment | 奥马哈海滩 Omaha Beach | Deploy | 第16步兵团登陆奥马哈海滩 16th Inf Regiment landed on Omaha Beach |
| 第16步兵团 16th Inf Regiment | 德军352师 German 352nd Inf Div. | Enemy | 第16步兵团当面之敌为德军352师 The enemy of 16th Inf Regiment was the German 352nd Inf Div. |
| 第16步兵团 16th Inf Regiment | 燧发枪营 Fusiliers Battalion | Target | 第16步兵团向燧发枪营发起攻击 16th Inf Regiment attacked Fusiliers Battalion |
| Coarse-Grained | Fine-Grained | Number of Samples |
|---|---|---|
| Command Relation | Command (Com) | 1354 |
| Affiliation (Aff) | 1110 | |
| Equivalent (Eq) | 320 | |
| Coreference (CoF) | 120 | |
| Remove (Rem) | 106 | |
| Position Relation | Enemy (En) | 876 |
| Alliance (Alli) | 332 | |
| Location Relation | Deploy (Dep) | 102 |
| Route | 1380 | |
| Equipment Relation | Own | 149 |
| Link | 158 | |
| Target Relation | Target | 98 |
| Hyperparameters | Property Value |
|---|---|
| Hidden Layers | 12 |
| Hidden Size | 768 |
| Hidden Dropout Prob | 0.1 |
| Attention Heads | 12 |
| Position Embeddings | 512 |
| Hyperparameters | Property Value |
|---|---|
| Word Embedding | 200 |
| Position Embedding | 50 |
| Hidden Layer Node Number | 240 |
| Batch Size | 64 |
| Learning Rate | 0.002 |
| Epoch | 30 |
| Hyperparameters | Property Value |
|---|---|
| Word Embedding | 200 |
| Learning Rate | 0.002 |
| k | F1-Score (%) |
|---|---|
| 1 | 88.2 |
| 2 | 88.7 |
| 4 | 89.5 |
| 6 | 90.2 |
| 10 | 89.3 |
| 15 | 89.2 |
| 30 | 88.1 |
| Model | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|
| Word2Vec + word | 77.9 | 78.6 | 78.2 |
| Word2Vec + word + position | 81.9 | 82.7 | 82.3 |
| BERT + word | 85.6 | 86.1 | 85.8 |
| BERT + word + position | 90.8 | 89.6 | 90.2 |
| Model | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|
| BiLSTM | 74.6 | 78.1 | 76.3 |
| BiGRU | 75.3 | 81.1 | 78.1 |
| BiLSTM-ATT | 79.1 | 82.4 | 80.7 |
| BiGRU-ATT | 81.2 | 85.3 | 83.2 |
| BiLSTM-2ATT | 82.5 | 85.9 | 84.2 |
| BiGRU-2ATT | 87.2 | 85.1 | 86.1 |
| BiGRU-MHATT (ours) | 90.8 | 89.6 | 90.2 |
| Model | SemEval-2010 Task 8 | Military Corpus |
|---|---|---|
| BiLSTM-ATT | 84.0 | 80.7 |
| BiGRU-ATT | 85.2 | 83.2 |
| BERT-BiGRU-MHATT | 84.2 | 90.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Y.; Yang, R.; Jiang, X.; Zhou, D.; Yin, C.; Li, Z. MRE: A Military Relation Extraction Model Based on BiGRU and Multi-Head Attention. Symmetry 2021, 13, 1742. https://doi.org/10.3390/sym13091742
Lu Y, Yang R, Jiang X, Zhou D, Yin C, Li Z. MRE: A Military Relation Extraction Model Based on BiGRU and Multi-Head Attention. Symmetry. 2021; 13(9):1742. https://doi.org/10.3390/sym13091742
Chicago/Turabian StyleLu, Yiwei, Ruopeng Yang, Xuping Jiang, Dan Zhou, Changsheng Yin, and Zizhuo Li. 2021. "MRE: A Military Relation Extraction Model Based on BiGRU and Multi-Head Attention" Symmetry 13, no. 9: 1742. https://doi.org/10.3390/sym13091742
APA StyleLu, Y., Yang, R., Jiang, X., Zhou, D., Yin, C., & Li, Z. (2021). MRE: A Military Relation Extraction Model Based on BiGRU and Multi-Head Attention. Symmetry, 13(9), 1742. https://doi.org/10.3390/sym13091742