
Improved Path Planning for Indoor Patrol Robot Based on Deep Reinforcement Learning




Abstract
:1. Introduction
2. Background
3. Improved Algorithm
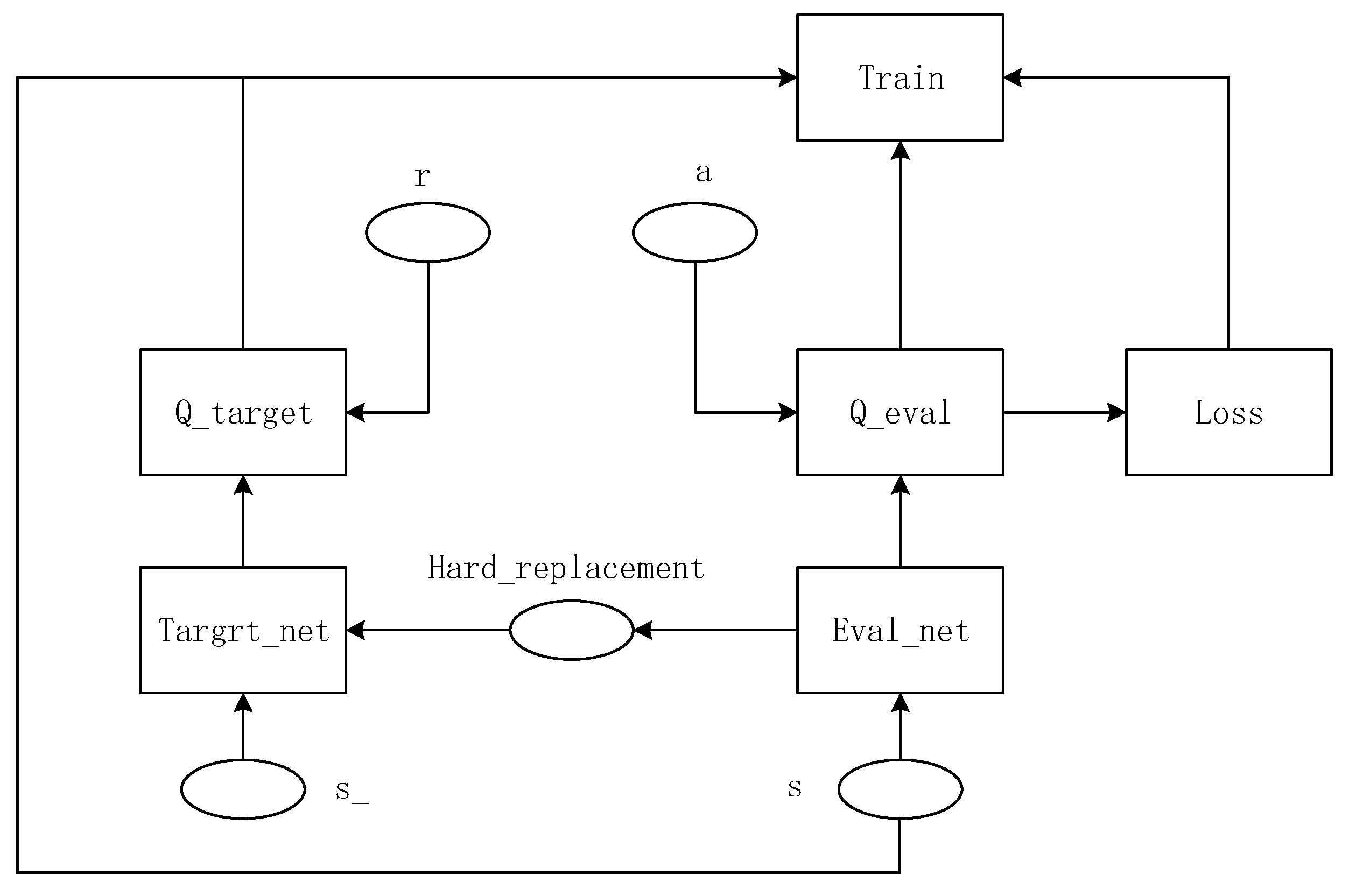
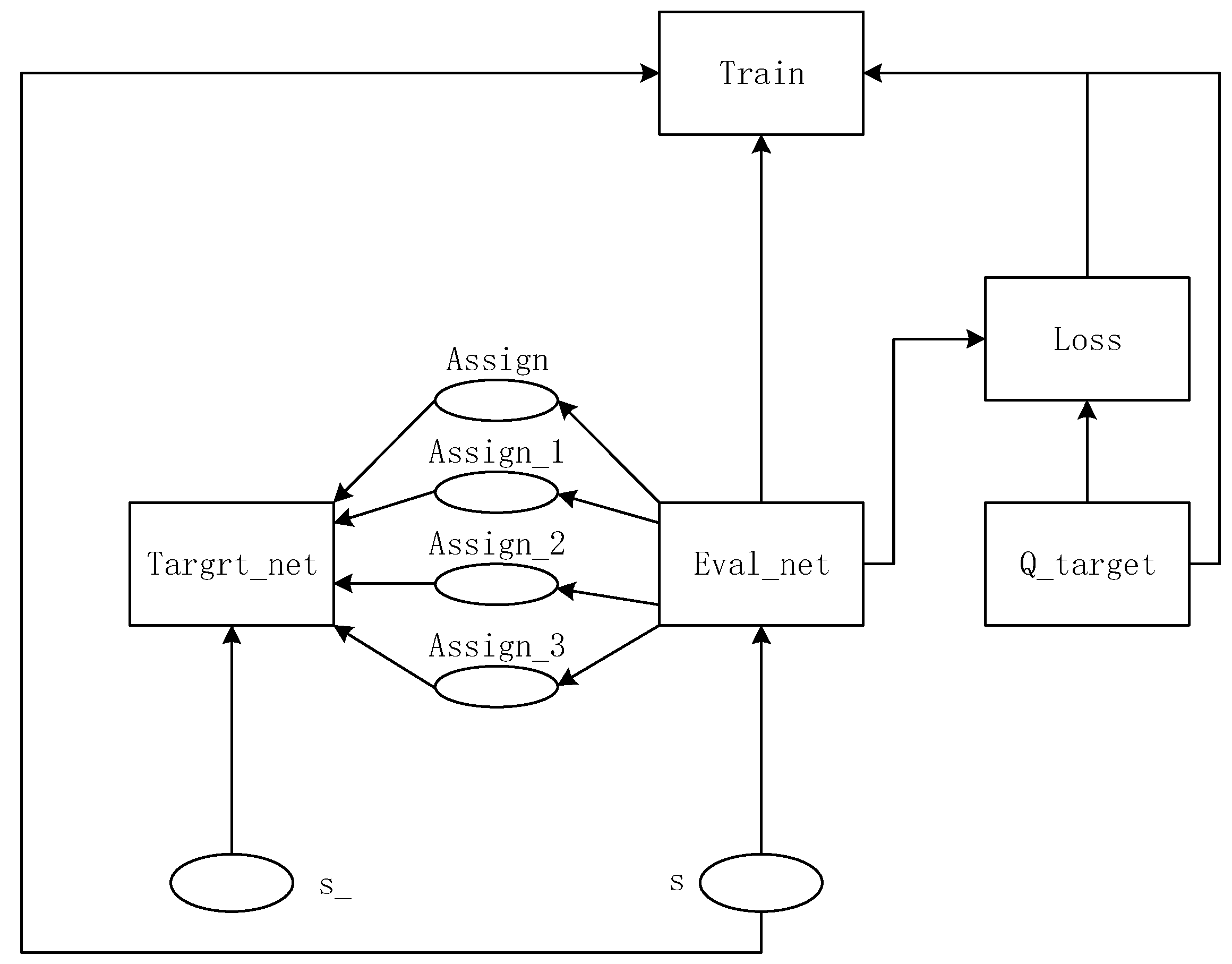
3.1. Overview of Improved DQN Algorithm
| Algorithm 1. Improved Deep Q-learning Network Based on Patrol Robot. |
| Initialize replay memory D to capacity N |
| Initialize action-value function Q with random weights |
| for episode = 1, M do |
| Initialize sequence from replay memory D and preprocess sequenced θ, |
| for t = 1, T do |
| With probability ε select a random action |
| Otherwise select optimal action |
| Execute action in emulator, observe new reward function and next image |
| Set transition and store it in D |
| Preprocess |
| Sample random mini-batch of transitions from D |
| Set |
| Perform a gradient descent step on |
| Update policy gradient |
| end for |
| end for |
3.2. Improved Target Point Function
3.3. Improved Reward and Punishment Function
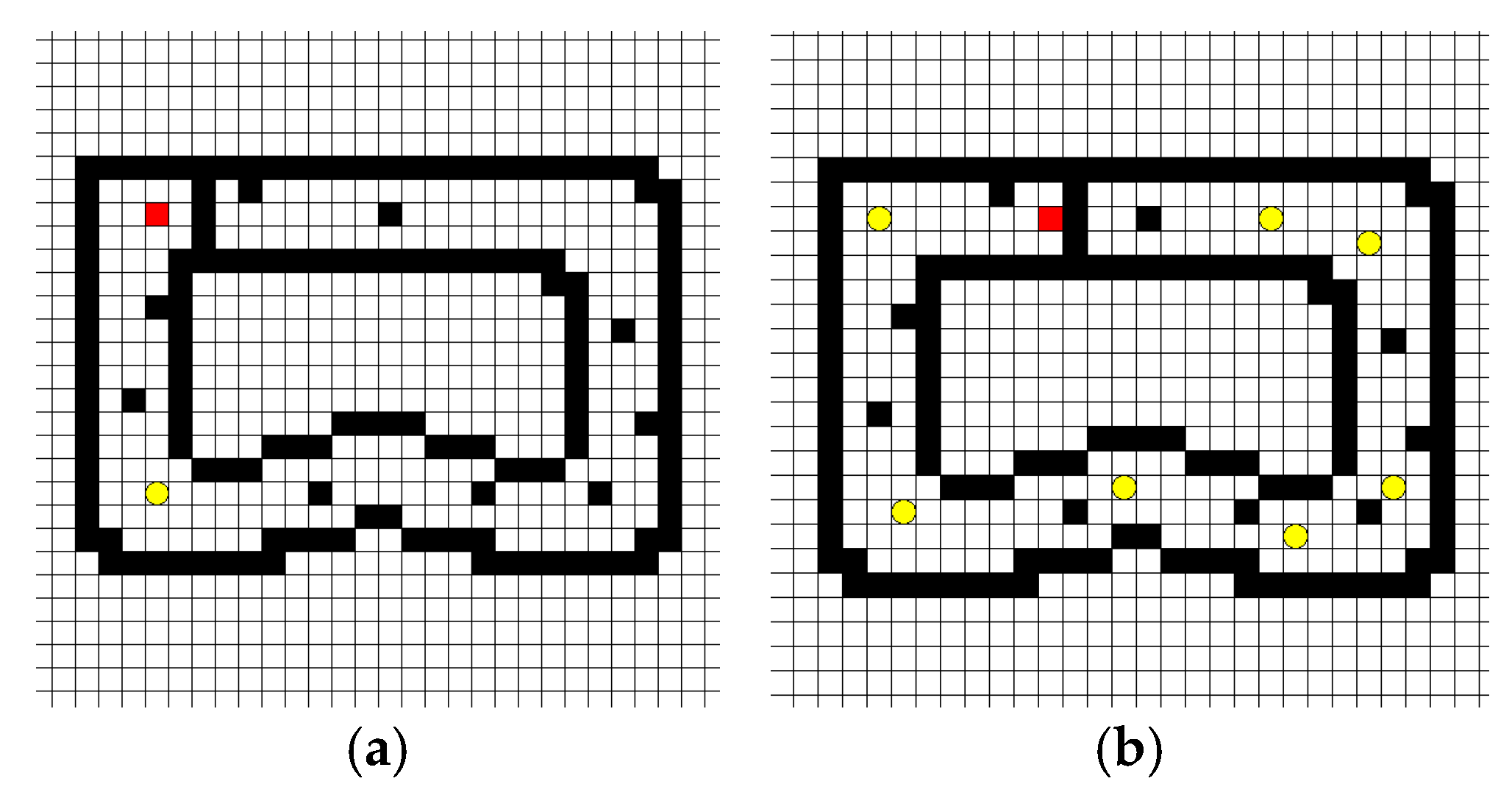
4. Experimental Analysis and Results
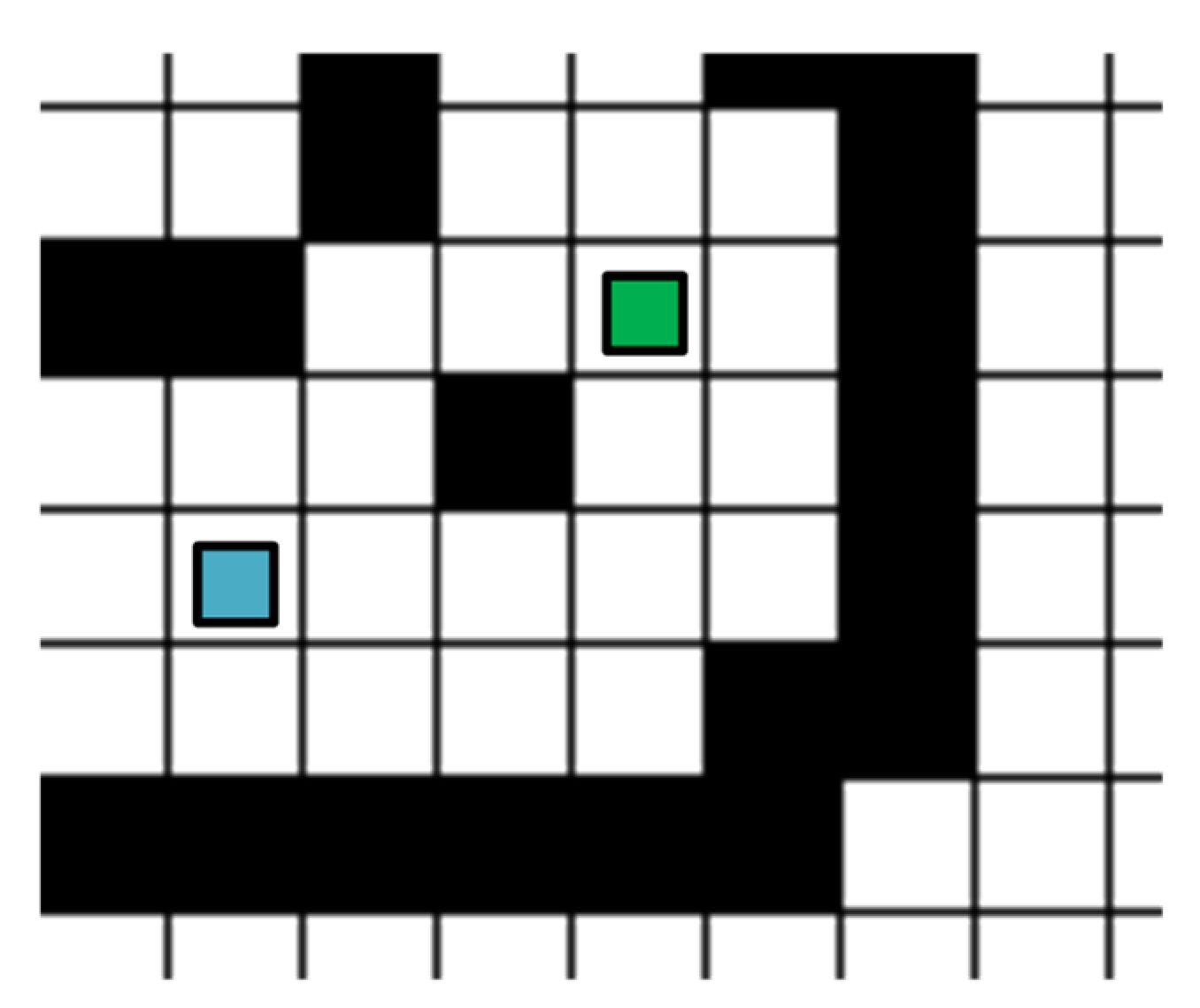
4.1. Experimental Environment and Parameter Configuration
4.2. Experimental Modeling Procedure
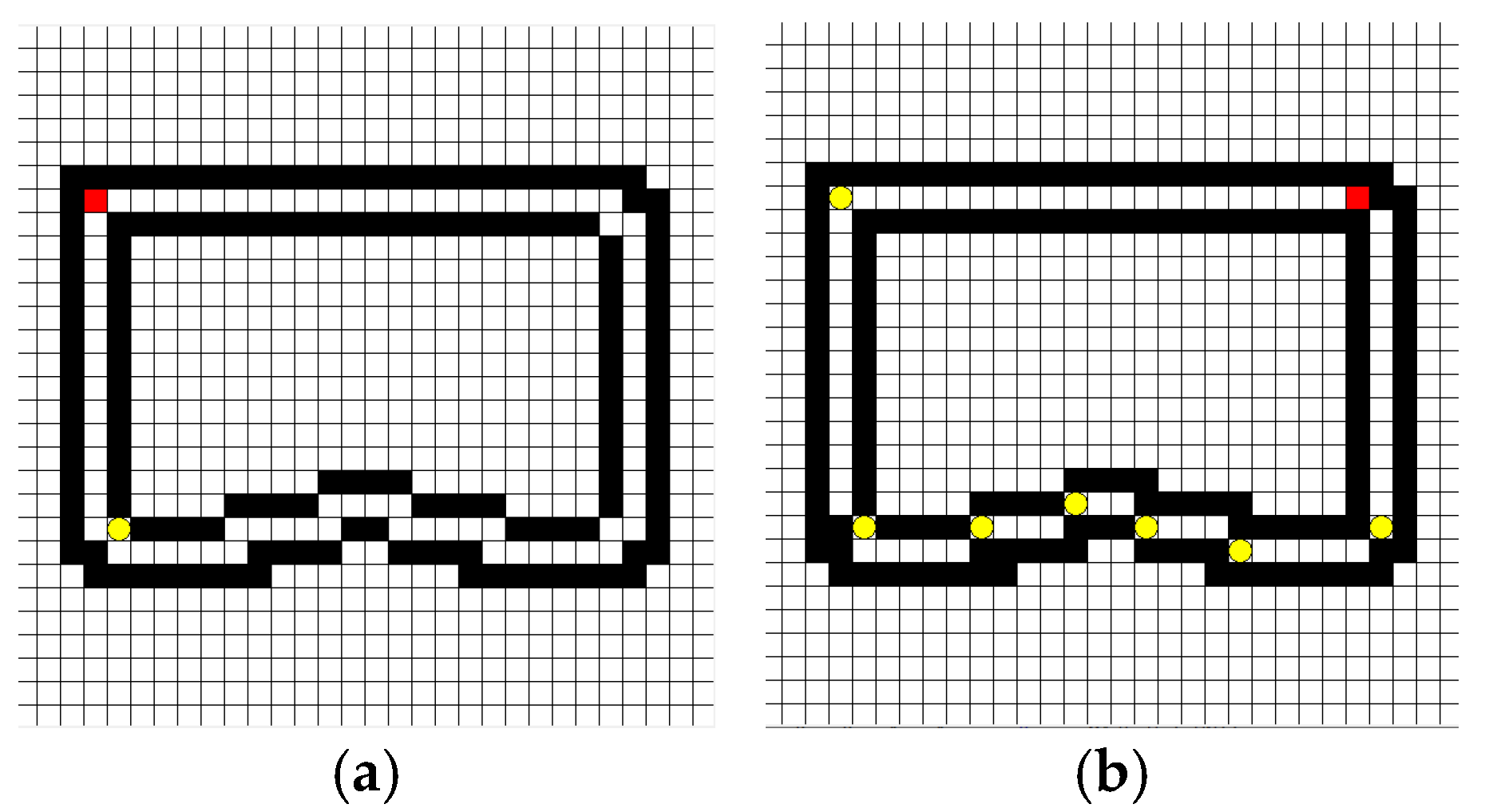
4.3. Analysis of Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, Y.; Wang, J.; Duan, X. Research on Path Planning Algorithm of Indoor Mobile Robot. In Proceedings of the 2013 International Conference on Mechatronic Sciences, Electric Engineering and Computer (MEC), Shenyang, China, 20–22 December 2013. [Google Scholar]
- Wang, C.; Zhu, D.; Li, T.; Meng, M.Q.H.; Silva, C.D. SRM: An Efficient Framework for Autonomous Robotic Exploration in Indoor Environments. arXiv 2018, arXiv:1812.09852. [Google Scholar]
- Candra, A.; Budiman, M.A.; Pohan, R.I. Application of A-Star Algorithm on Pathfinding Game. J. Phys. Conf. Ser. 2021, 1898, 012047. [Google Scholar] [CrossRef]
- Rostami, S.M.H.; Sangaiah, A.K.; Wang, J.; Liu, X. Obstacle avoidance of mobile robots using modified artificial potential field algorithm. EURASIP J. Wirel. Commun. Netw. 2019, 2019, 70. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Qiao, B.; Zhao, W.; Chen, X. A Predictive Path Planning Algorithm for Mobile Robot in Dynamic Environments Based on Rapidly Exploring Random Tree. Arab. J. Sci. Eng. 2021, 46, 8223–8232. [Google Scholar] [CrossRef]
- Lynnerup, N.A.; Nolling, L.; Hasle, R.; Hallam, J. A Survey on Reproducibility by Evaluating Deep Reinforcement Learning Algorithms on Real-World Robots. In Proceedings of the Conference on Robot Learning: CoRL 2019, Osaka, Japan, 30 October–1 November 2019; Volume 100, pp. 466–489. [Google Scholar]
- Zhang, C.; Ma, L.; Schmitz, A. A sample efficient model-based deep reinforcement learning algorithm with experience replay for robot manipulation. Int. J. Intell. Robot. Appl. 2020, 4, 217–228. [Google Scholar] [CrossRef]
- Chen, Y.; Leixin, X. Deep Reinforcement Learning Algorithms for Multiple Arc-Welding Robots. Front. Control Eng. 2021, 2, 1. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Tai, L.; Li, S.; Liu, M. A Deep-Network Solution towards Model-Less Obstacle Avoidance. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016. [Google Scholar]
- Yu, X.; Wang, P.; Zhang, Z. Learning-Based End-to-End Path Planning for Lunar Rovers with Safety Constraints. Sensors 2021, 21, 796. [Google Scholar] [CrossRef]
- Miao, K.; Ma, J.; Li, Z.; Zhao, Y.; Zhu, W. Research on multi feature fusion perception technology of mine fire based on inspection robot. J. Phys. Conf. Ser. 2021, 1955, 012064. [Google Scholar] [CrossRef]
- Shi, X.; Lu, J.; Liu, F.; Zhou, J. Patrol Robot Navigation Control Based on Memory Algorithm. In Proceedings of the 2014 4th IEEE International Conference on Information Science and Technology, Shenzhen, China, 26–28 April 2014; pp. 189–192. [Google Scholar]
- Xu, H.; Chen, T.; Zhang, Q.; Lu, J.; Yang, Z. A Deep Learning and Depth Image based Obstacle Detection and Distance Measurement Method for Substation Patrol Robot. IOP Conf. Ser. Earth Environ. Sci. 2020, 582, 012002. [Google Scholar]
- Dong, L.; Lv, J. Research on Indoor Patrol Robot Location based on BP Neural Network. IOP Conf. Ser. Earth Environ. Sci. 2020, 546, 052035. [Google Scholar] [CrossRef]
- Van Nguyen, T.T.; Phung, M.D.; Pham, D.T.; Tran, Q.V. Development of a Fuzzy-based Patrol Robot Using in Building Automation System. arXiv 2020, arXiv:2006.02216. [Google Scholar]
- Ji, J.; Xing, F.; Li, Y. Research on Navigation System of Patrol Robot Based on Multi-Sensor Fusion. In Proceedings of the 2019 8th International Conference on Advanced Materials and Computer Science(ICAMCS 2019), Chongqing, China, 6–7 December 2019; pp. 224–227. [Google Scholar] [CrossRef]
- Xia, L.; Meng, Q.; Chi, D.; Meng, B.; Yang, H. An Optimized Tightly-Coupled VIO Design on the Basis of the Fused Point and Line Features for Patrol Robot Navigation. Sensors 2019, 19, 2004. [Google Scholar] [CrossRef] [Green Version]
- Zhao, F.; Yang, Z.; Li, X.; Guo, D.; Li, H. Extract Executable Action Sequences from Natural Language Instructions Based on DQN for Medical Service Robots. Int. J. Comput. Commun. Control 2021, 16, 1–12. [Google Scholar] [CrossRef]
- Seok, P.K.; Man, P.J.; Kyu, Y.W.; Jo, Y.S. DQN Reinforcement Learning: The Robot’s Optimum Path Navigation in Dynamic Environments for Smart Factory. J. Korean Inst. Commun. Inf. Sci. 2019, 44, 2269–2279. [Google Scholar]
- Sasaki, H.; Horiuchi, T.; Kato, S. Experimental Study on Behavior Acquisition of Mobile Robot by Deep Q-Network. J. Adv. Comput. Intell. Intell. Inform. 2017, 21, 840–848. [Google Scholar] [CrossRef] [Green Version]
- Han, B.; Zhao, Y.; Luo, Q. Walking Stability Control Method for Biped Robot on Uneven Ground Based on Deep Q-Network. J. Beijing Inst. Technol. 2019, 28, 220–227. [Google Scholar]
- Rahman, M.M.; Rashid, S.; Hossain, M.M. Implementation of Q learning and deep Q network for controlling a self balancing robot model. Robot. Biomim. 2018, 5, 8. [Google Scholar] [CrossRef] [Green Version]
- da Silva, I.J.; Perico, D.H.; Homem TP, D.; da Costa Bianchi, R.A. Deep Reinforcement Learning for a Humanoid Robot Soccer Player. J. Intell. Robot. Syst. 2021, 102, 69. [Google Scholar] [CrossRef]
- Peng, X.; Chen, R.; Zhang, J.; Chen, B.; Tseng, H.W.; Wu, T.L.; Meen, T.H. Enhanced Autonomous Navigation of Robots by Deep Reinforcement Learning Algorithm with Multistep Method. Sens. Mater. 2021, 33, 825. [Google Scholar] [CrossRef]
- Tallamraju, R.; Saini, N.; Bonetto, E.; Pabst, M.; Liu, Y.T.; Black, M.J.; Ahmad, A. AirCapRL: Autonomous Aerial Human Motion Capture using Deep Reinforcement Learning. IEEE Robot. Autom. Lett. 2020, 5, 6678–6685. [Google Scholar] [CrossRef]
- Abanay, A.; Masmoudi, L.; Elharif, A.; Gharbi, M.; Bououlid, B. Design and Development of a Mobile Platform for an Agricultural Robot Prototype. In Proceedings of the 2nd International Conference on Computing and Wireless Communication Systems, Larache, Morocco, 14–16 November 2017; pp. 1–5. [Google Scholar]
- Budiharto, W.; Santoso, A.; Purwanto, D.; Jazidie, A. A method for path planning strategy and navigation of service robot. Paladyn 2011, 2, 100–108. [Google Scholar] [CrossRef]
- Arvin, F.; Samsudin, K.; Nasseri, M.A. Design of a Differential-Drive Wheeled Robot Controller with Pulse-Width Modulation. In Proceedings of the 2009 Innovative Technologies in Intelligent Systems and Industrial Applications, Kuala Lumpur, Malaysia, 25–26 July 2009; pp. 143–147. [Google Scholar]
- Bethencourt, J.V.M.; Ling, Q.; Fernández, A.V. Controller Design and Implementation for a Differential Drive Wheeled Mobile Robot. In Proceedings of the 2011 Chinese Control and Decision Conference (CCDC), Mianyang, China, 23–25 May 2011; pp. 4038–4043. [Google Scholar]
- Zeng, D.; Xu, G.; Zhong, J.; Li, L. Development of a Mobile Platform for Security Robot. In Proceedings of the 2007 IEEE International Conference on Automation and Logistics, Jinan, China, 18–21 August 2007; pp. 1262–1267. [Google Scholar]
- Sharma, M.; Sharma, R.; Ahuja, K.; Jha, S. Design of an Intelligent Security Robot for Collision Free Navigation Applications. In Proceedings of the 2014 International Conference on Reliability Optimization and Information Technology (ICROIT), Faridabad, India, 6–8 February 2014; pp. 255–257. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Batch | 32 |
| Episode | 10,000 |
| Learning rate α | 0.01 |
| Reward decay γ | 0.9 |
| 0.9 |
| Operation time | 300 s | 80 s | 63 s | 35 s |
| Convergence steps | 2000 | 1500 | 750 | 600 |
| Total training steps | 2600 | 1800 | 5500 | 3100 |
| Loss function | 0.030 | 0.040 | 0.010 | 0.015 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, J.; Mao, S.; Wu, Z.; Kong, P.; Qiang, H. Improved Path Planning for Indoor Patrol Robot Based on Deep Reinforcement Learning. Symmetry 2022, 14, 132. https://doi.org/10.3390/sym14010132
Zheng J, Mao S, Wu Z, Kong P, Qiang H. Improved Path Planning for Indoor Patrol Robot Based on Deep Reinforcement Learning. Symmetry. 2022; 14(1):132. https://doi.org/10.3390/sym14010132
Chicago/Turabian StyleZheng, Jianfeng, Shuren Mao, Zhenyu Wu, Pengcheng Kong, and Hao Qiang. 2022. "Improved Path Planning for Indoor Patrol Robot Based on Deep Reinforcement Learning" Symmetry 14, no. 1: 132. https://doi.org/10.3390/sym14010132
APA StyleZheng, J., Mao, S., Wu, Z., Kong, P., & Qiang, H. (2022). Improved Path Planning for Indoor Patrol Robot Based on Deep Reinforcement Learning. Symmetry, 14(1), 132. https://doi.org/10.3390/sym14010132