
Reasoning Method Based on Intervals with Symmetric Truncated Normal Density



Abstract
:1. Introduction
- We propose a novel reasoning method, which can make a conclusion about whether the system is likely to have potential risks caused by non-error factors when the system state is still inside the set. However, the previous method can give the assessment only when the system state is not inside the set. The method is more effective than other methods [20,21,22] for safety-critical systems if the time complexity of the specific problem is acceptable.
- Some lemmas (Lemmas 1, 2 and Theorem 1) and their proofs are provided, which partially simplify the calculations. These lemmas and theorem are beneficial to the methods, which are also based on symmetric truncated normal intervals in other fields.
- We provide an engineering example and the Maple codes to make our reasoning method easier to apply to the industrial field.
2. Preliminaries
2.1. Interval Random Errors
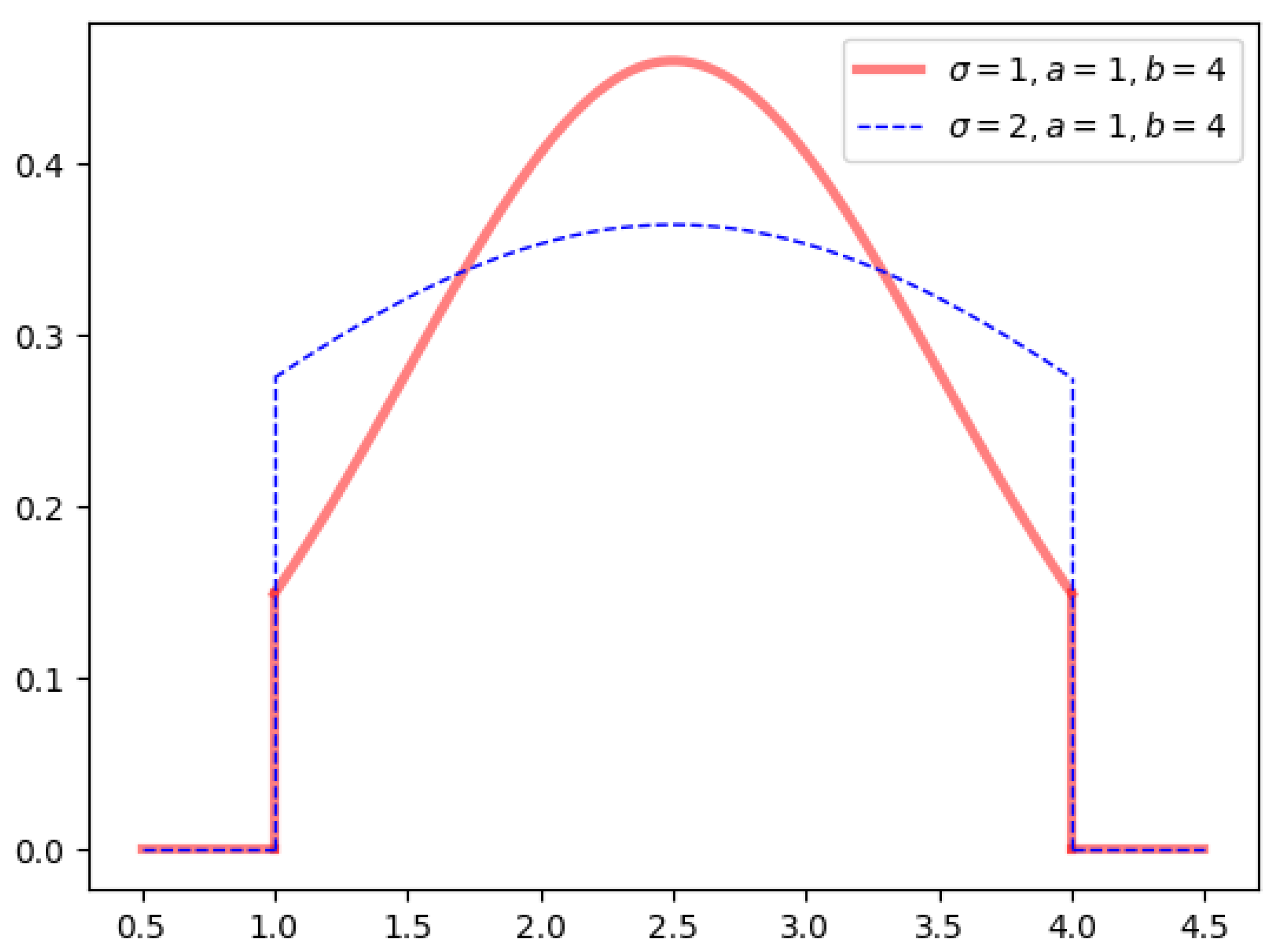
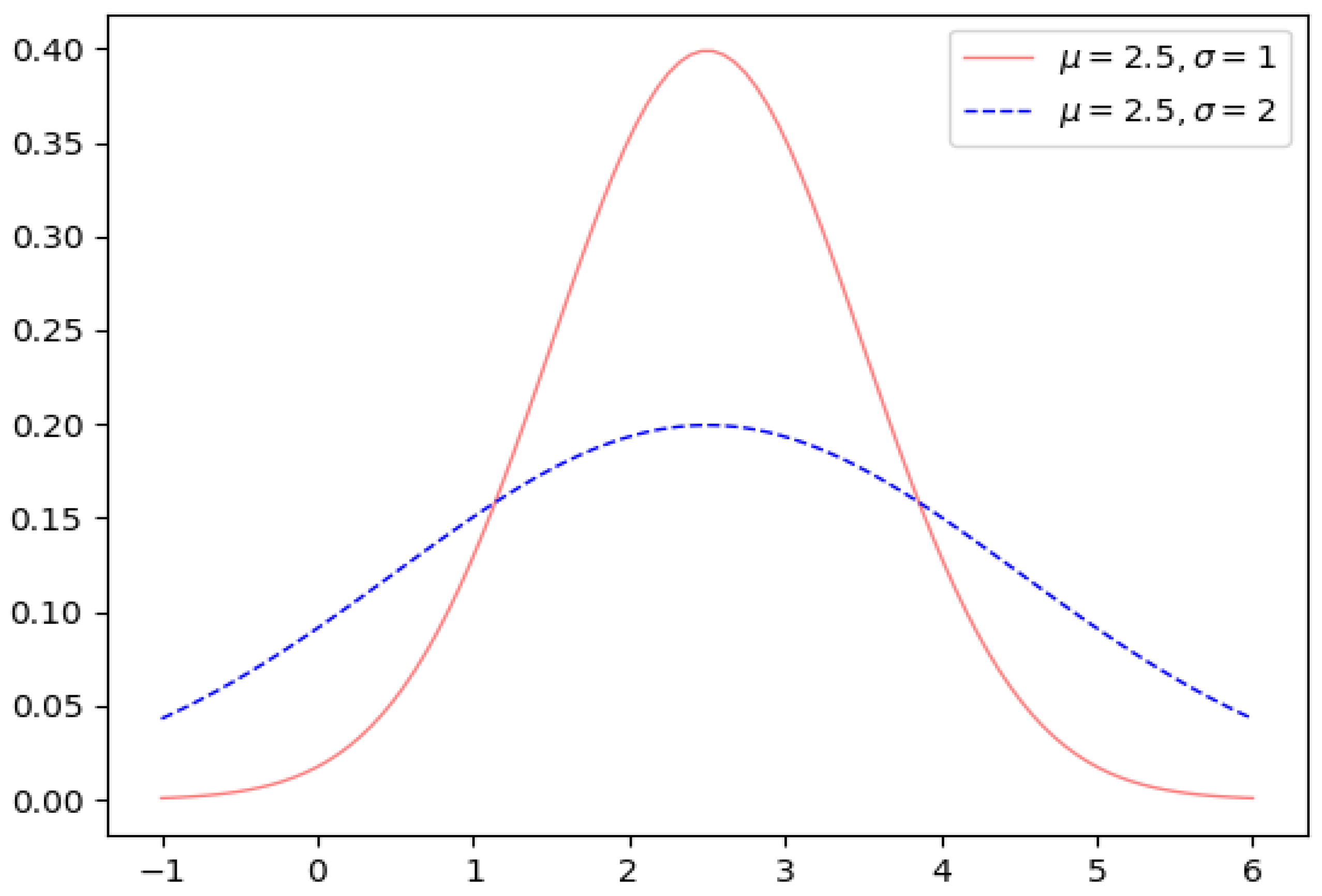
2.2. Intervals with Symmetric Truncated Normal Density Function
3. Truncated Normal Interval-Based Reasoning Method
3.1. Reasoning Method between Polynomial Errors Assertions
3.1.1. Implication Relationship
3.1.2. Problems of Previous Reasoning Methods
3.2. Reasoning Method Based on Truncated Normal Interval
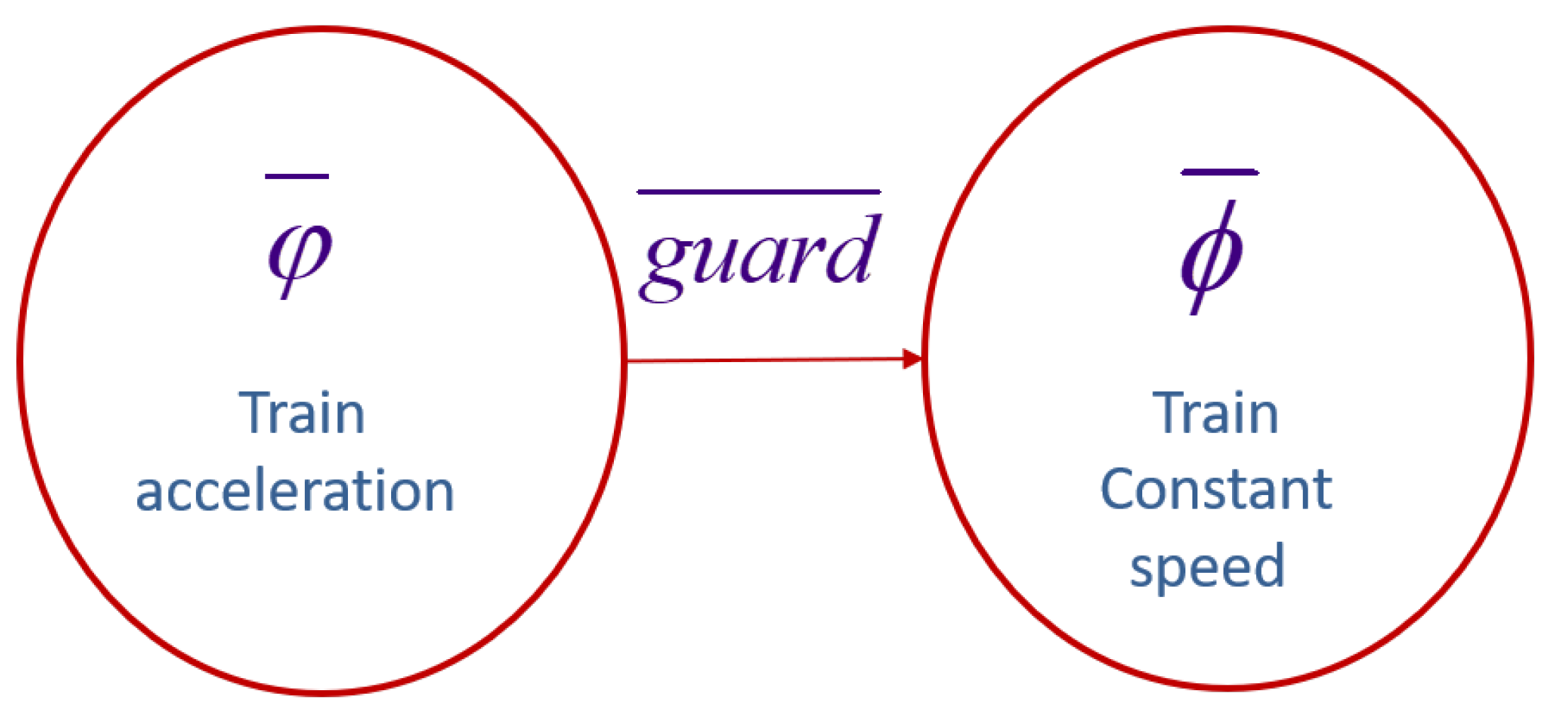
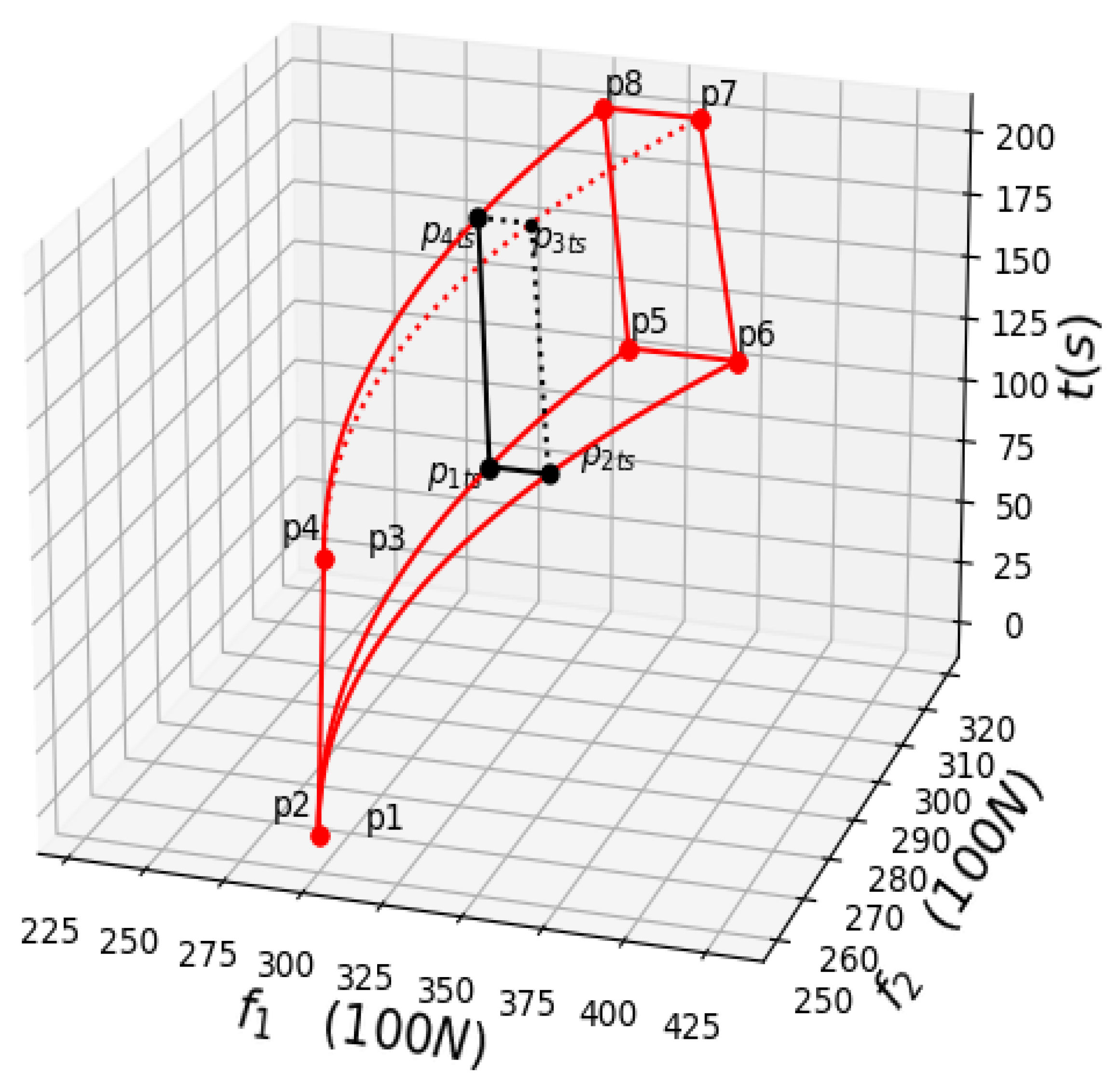
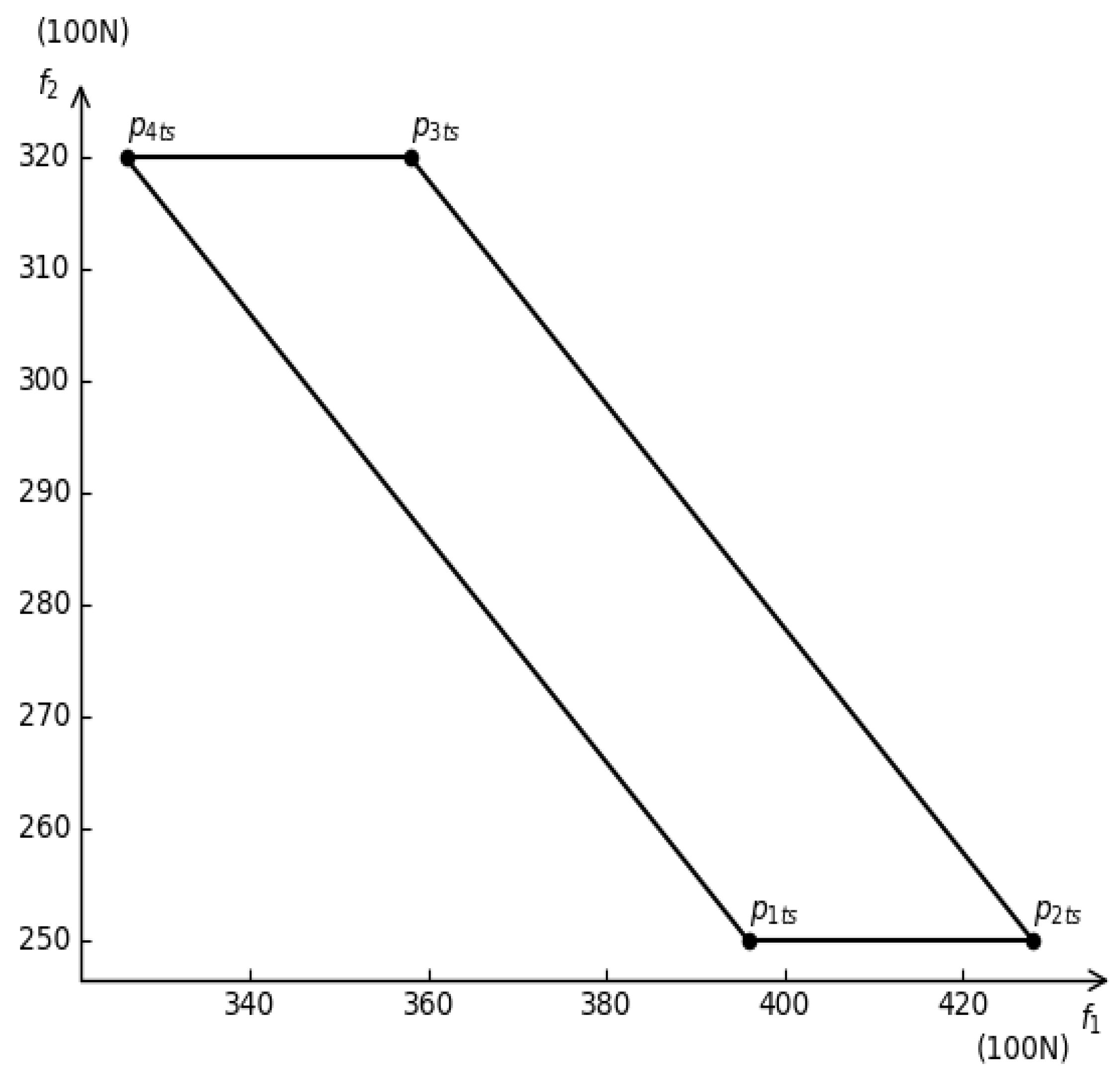
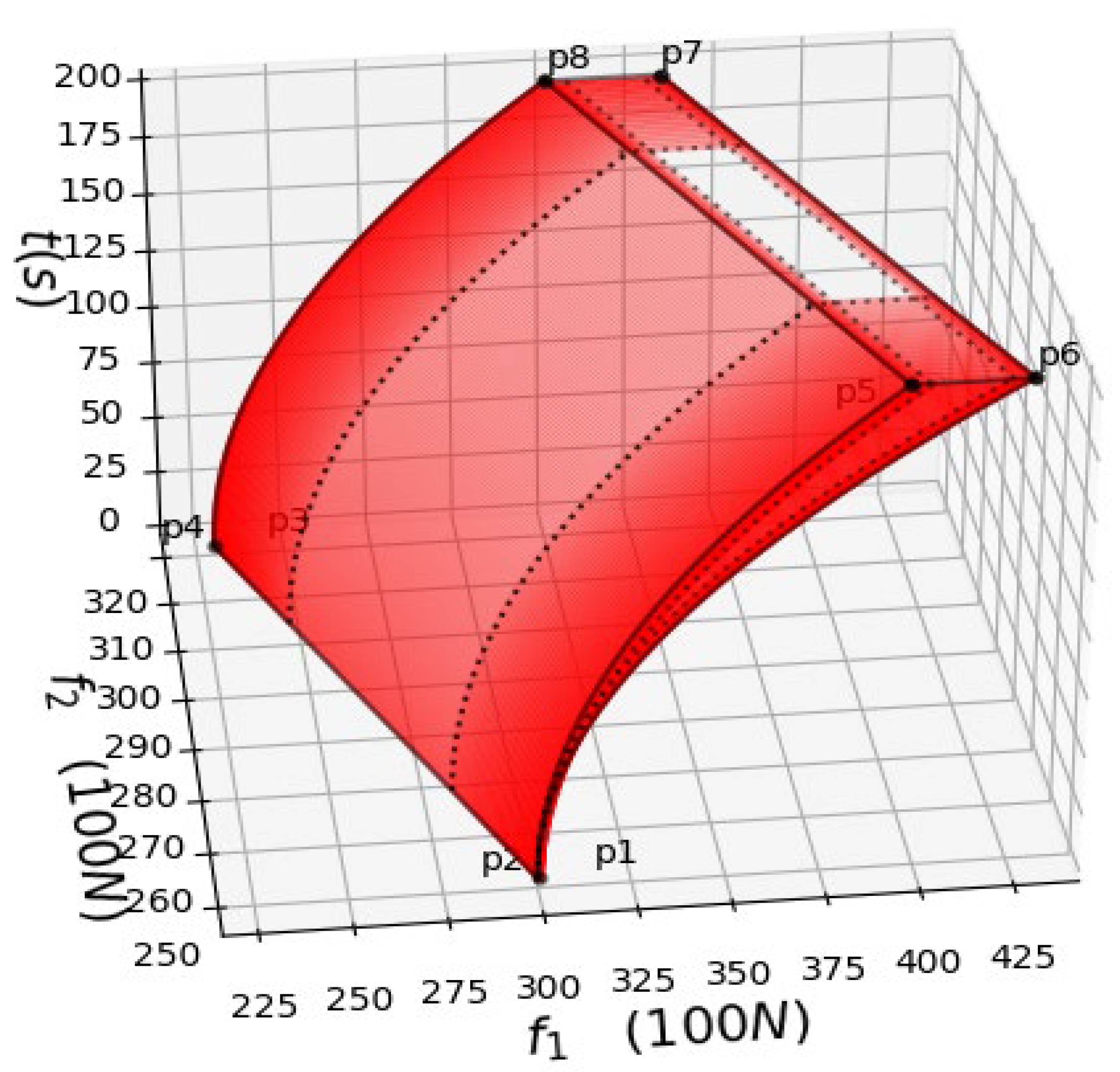
4. Verification of Two-Body Decentralized Power System during Train Acceleration
4.1. Two-Body Problem of Train Acceleration
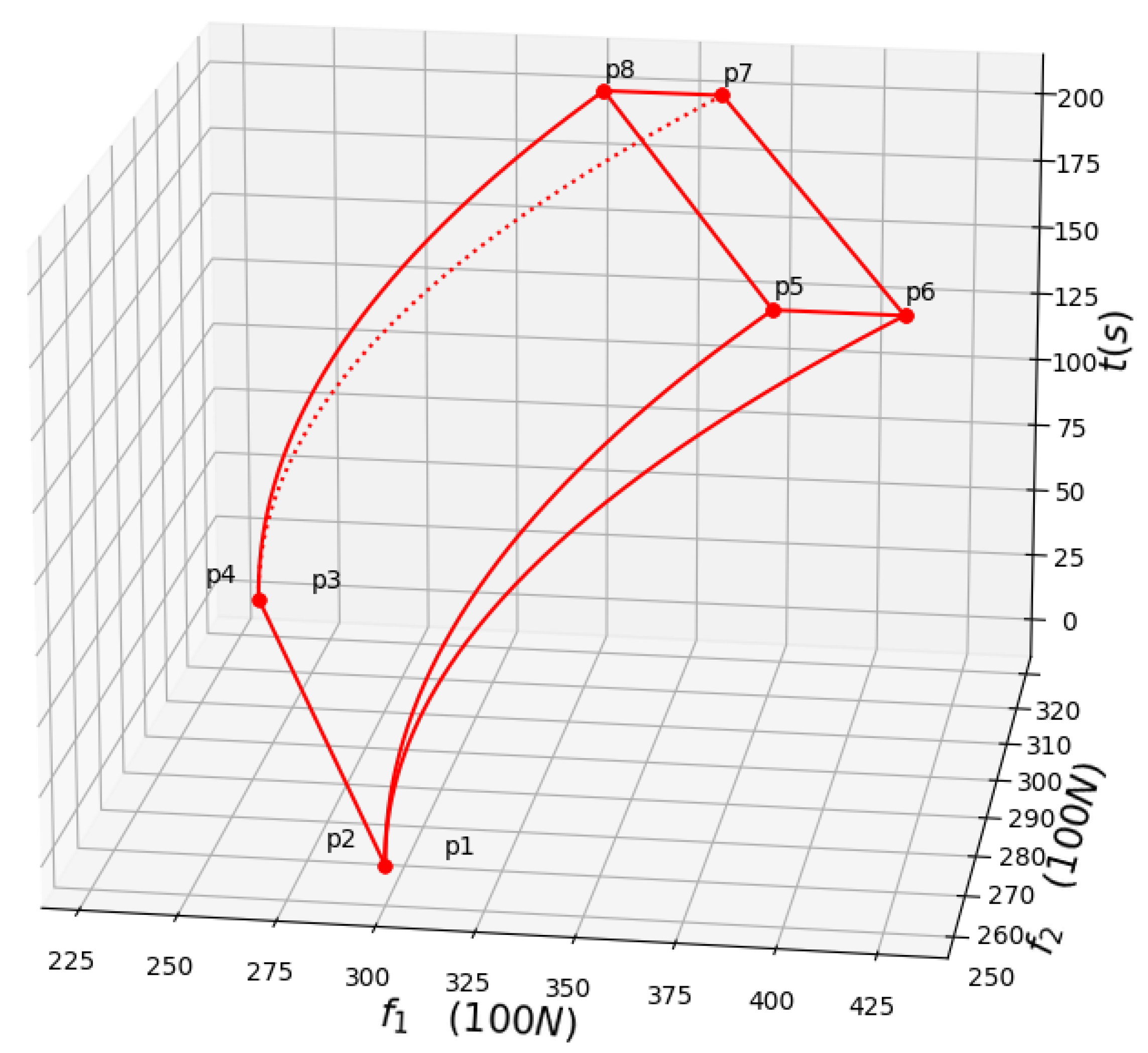
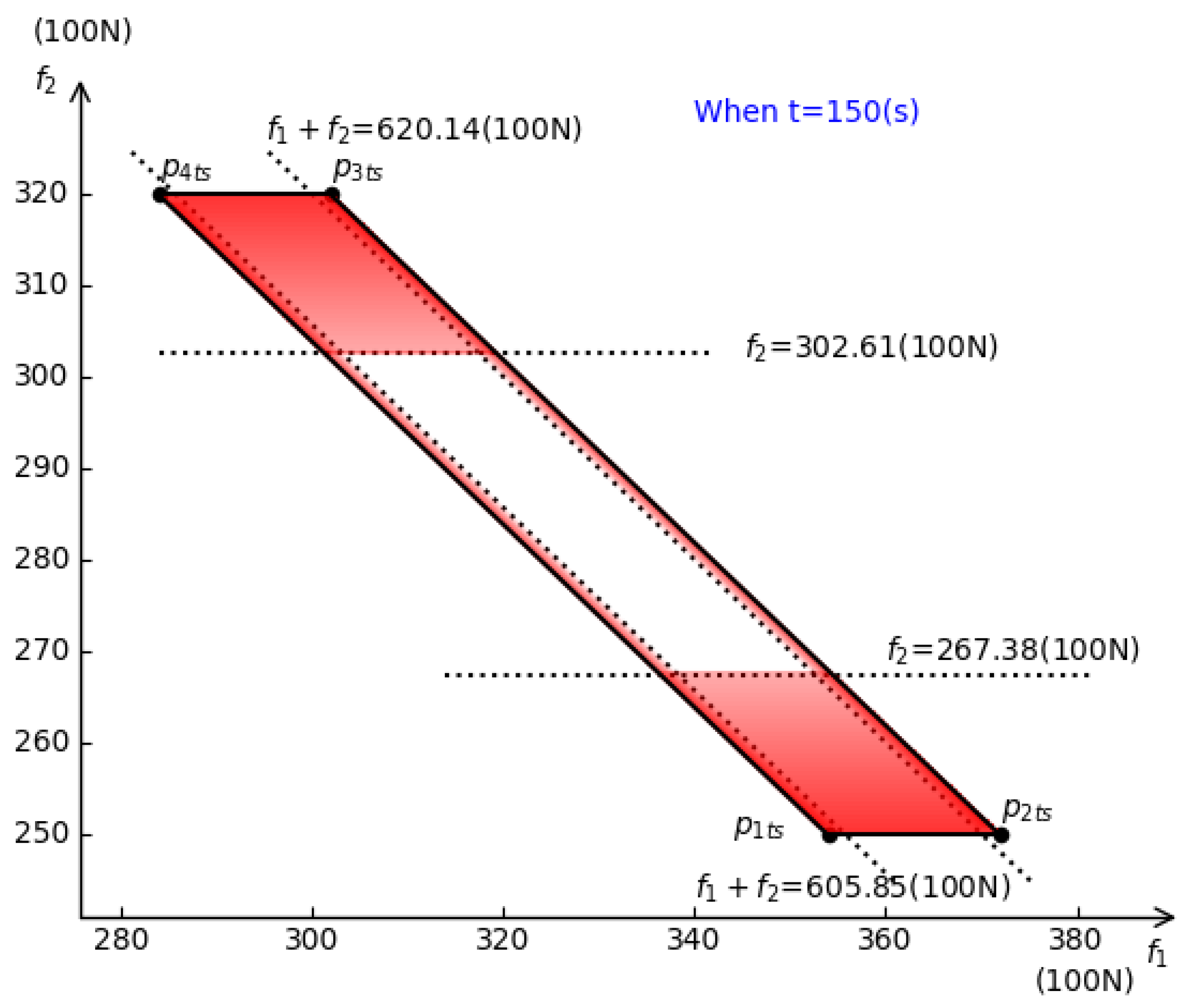
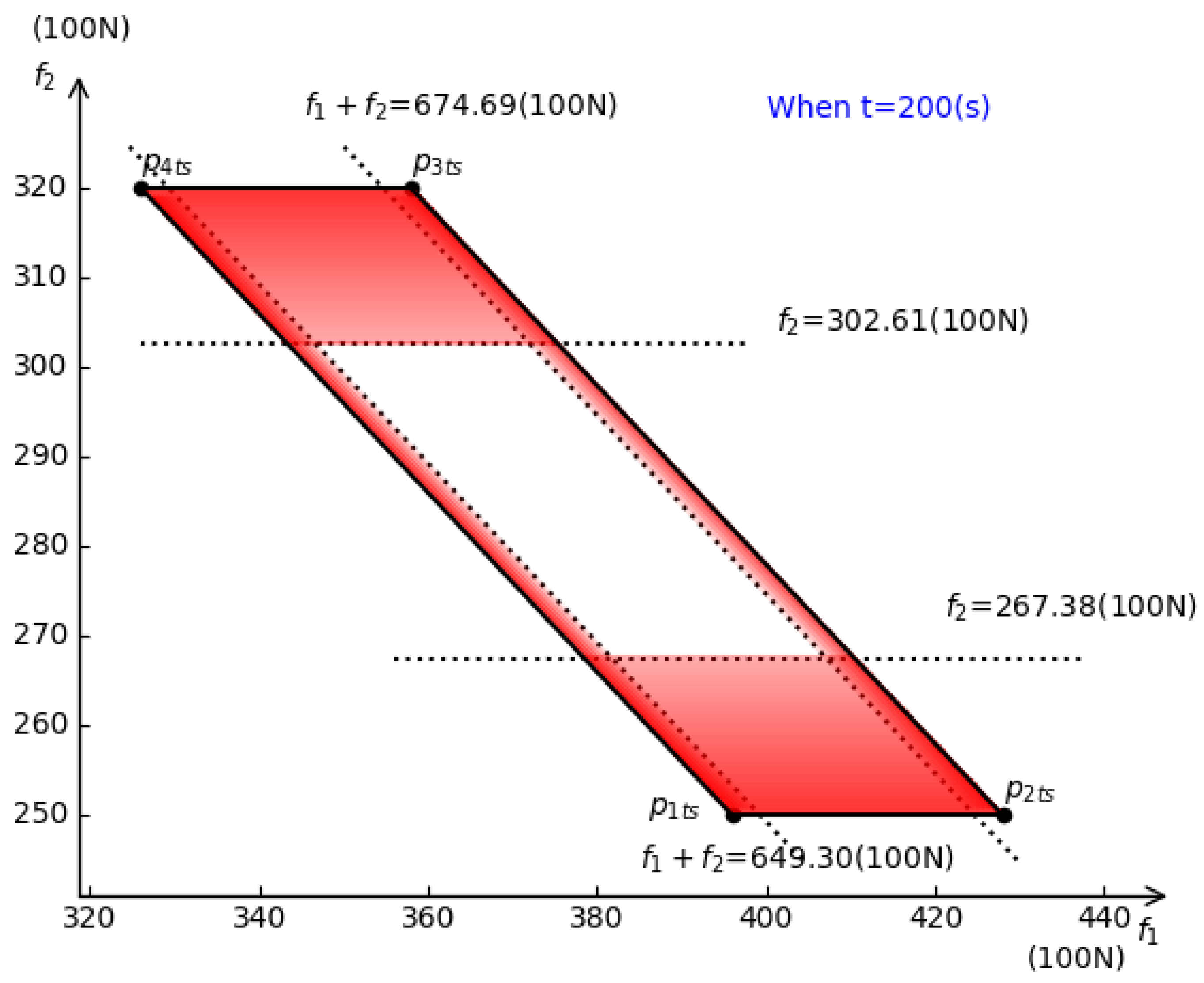
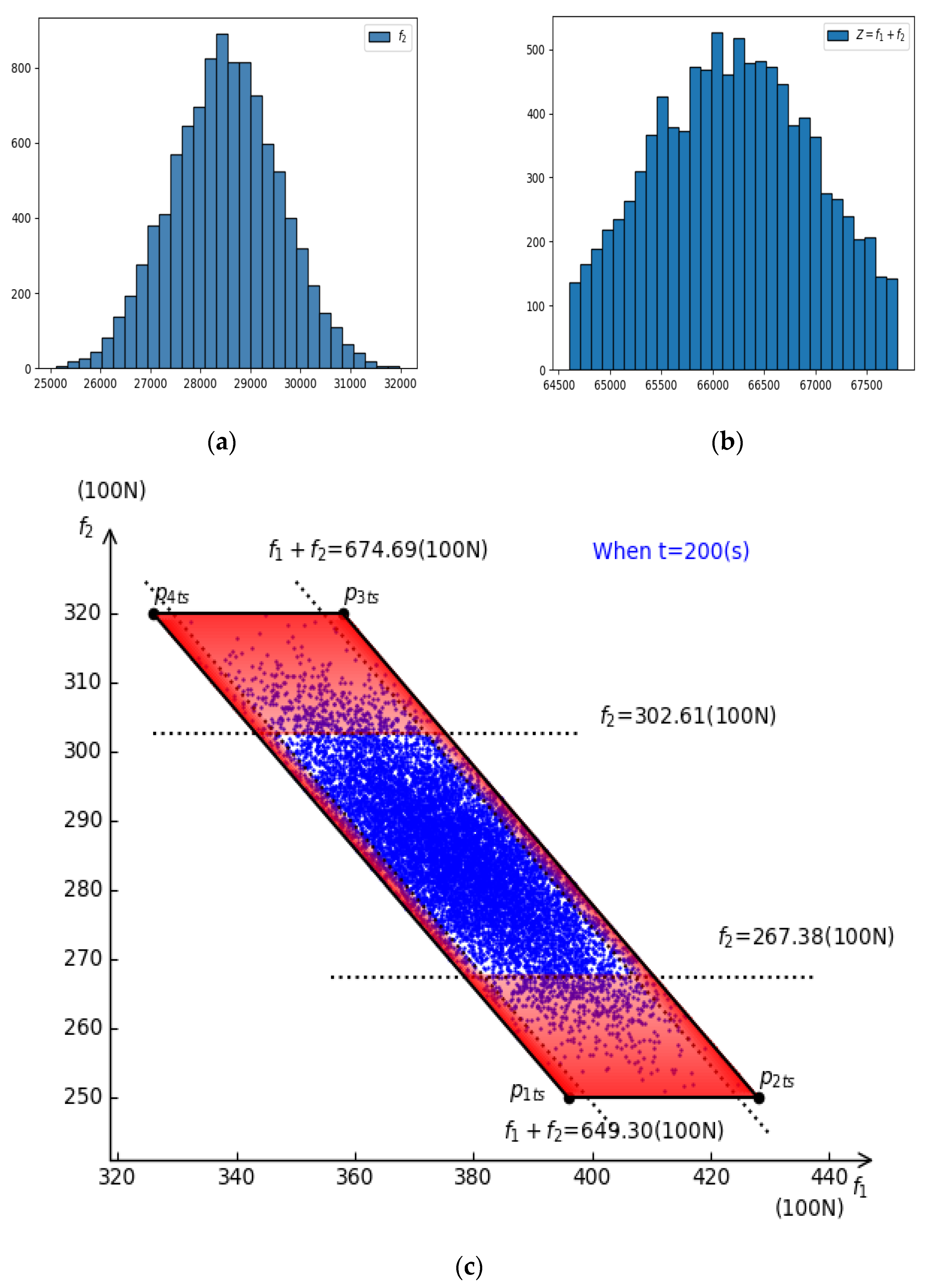
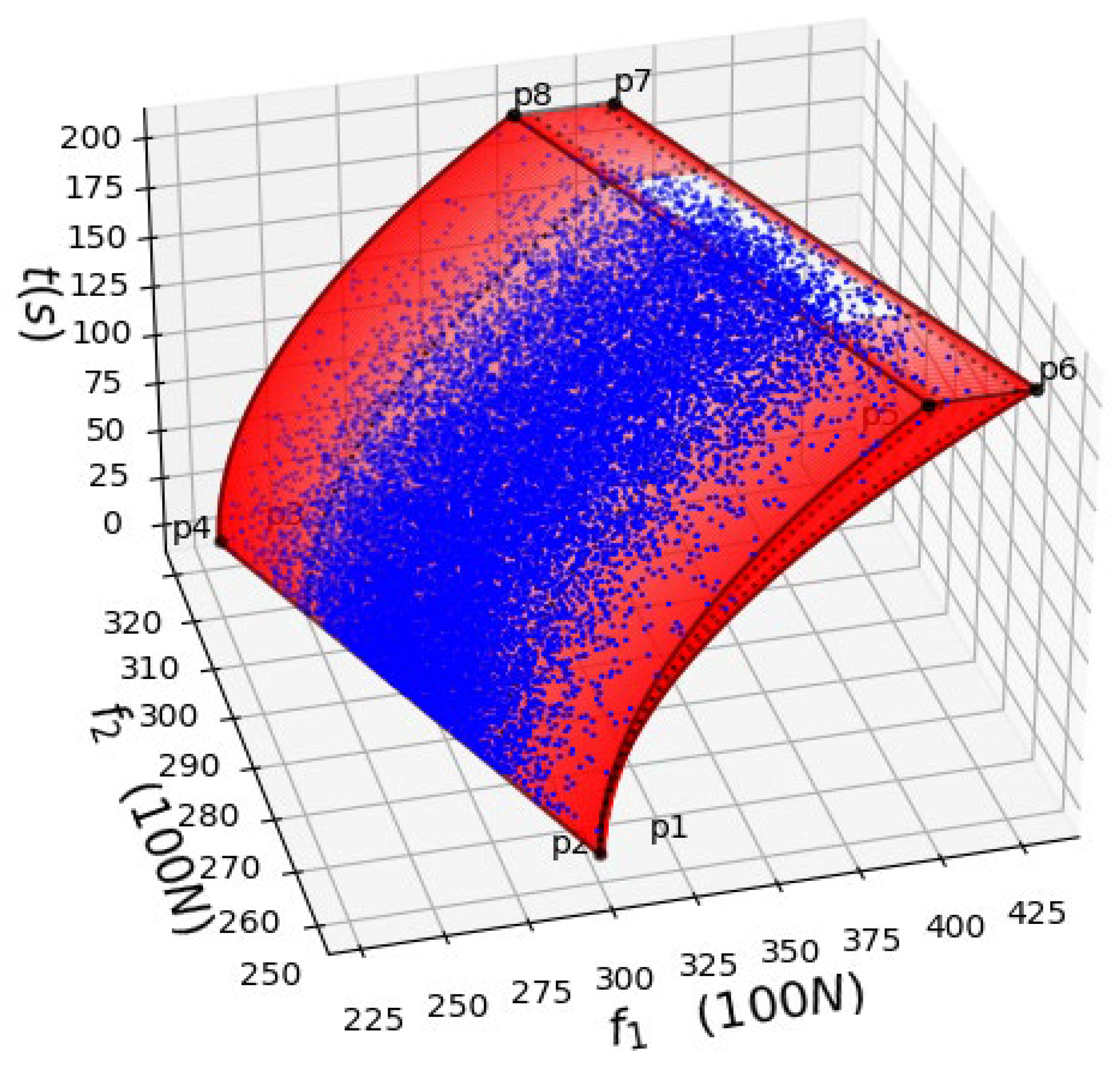
4.2. Simulation and Test
| Algorithm 1 used to generate simulation cases |
| 1: begin |
| 2: t = 1, ; 3: while (t <= 200) begin while |
| 4: Generate n cases ), according to acceptance –rejection sampling; 5: Take into formula (20), then calculate them and obtain ; |
| 6: ; end while |
| 7: end |
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fisher, M.; Cardoso, R.C.; Collins, E.C.; Dadswell, C.; Dennis, L.A.; Dixon, C.; Farrell, M.; Ferrando, A.; Huang, X.; Jump, M.; et al. An Overview of Verification and Validation Challenges for Inspection Robots. Robotics 2021, 10, 67. [Google Scholar] [CrossRef]
- Sun, M.; Lu, Y.; Feng, Y.; Zhang, Q.; Liu, S. Modeling and Verifying the CKB Blockchain Consensus Protocol. Mathematics 2021, 9, 2954. [Google Scholar] [CrossRef]
- Wang, J.; Zhan, N.J.; Feng, X.Y.; Liu, Z.M. Overview of formal methods. J. Softw. 2019, 30, 33–61. [Google Scholar]
- Clarke, E.M.; Henzinger, T.A.; Veith, H.; Bloem, R. Handbook of Model Checking; Springer: Cham, Switzerland, 2018; Chapter 12; ISBN 9783030132330. [Google Scholar]
- Desai, A.; Dreossi, T.; Seshia, S.A. Combining Model Checking and Runtime Verification for Safe Robotics. In Runtime Verification, Proceedings of the International Conference on Runtime Verification, Seattle, WA, USA, 13–16 September 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 172–189. [Google Scholar] [CrossRef]
- Uribe, T.E. Combinations of model checking and theorem proving. In Proceedings of the International Workshop on Frontiers of Combining Systems, Nancy, France, 22–24 March 2000; pp. 151–170. [Google Scholar]
- Shankar, N. Combining theorem proving and model checking through symbolic analysis. Int. Conf. Concurr. Theory 2000, 1877, 1–16. [Google Scholar]
- Wu, J. Algebraic methods for mechanical theorem proving in many-valued logics. Chin. J. Comput. 1996, 10, 773–779. [Google Scholar]
- Fu, J.; Wu, J.; Tan, H. A deductive approach towards reasoning about algebraic transition systems. Math. Probl. Eng. 2015, 607013. [Google Scholar] [CrossRef]
- Platzer, A. Logical Analysis of Hybrid Systems: Proving Theorems for Complex Dynamics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010; ISBN 9783642145087. [Google Scholar]
- Liu, J.; Zhan, N.; Zhao, H. Computing semi-algebraic invariants for polynomial dynamical systems. In Proceedings of the Ninth ACM International Conference on Embedded Software, Taipei, Taiwan, 9–14 October 2011; pp. 97–106. [Google Scholar]
- Elias, J. Automated Geometric Theorem Proving: Wu’s Method. Master’s Thesis, University of Montana, Missoula, MT, USA, 2006. [Google Scholar] [CrossRef]
- Buchberger, B. Gröbner bases: An algorithmic method in polynomial ideal theory. Multidimens. Syst. Theory 1995, 89–127. [Google Scholar] [CrossRef]
- Arnon, D.S.; Collins, G.E.; McCallum, S. Cylindrical algebraic decomposition. I. The basic algorithm. SIAM J. Comput. 1984, 13, 865–877. [Google Scholar] [CrossRef] [Green Version]
- Wang, D. Elimination Methods. Springer: Wien, Austria, 2001; ISBN 9783709162026. [Google Scholar]
- Fulton, N.; Mitsch, S.; Quesel, J.D.; Völp, M.; Platzer, A. KeYmaera X: An axiomatic tactical theorem prover for hybrid systems. In Proceedings of the Conference on Automated Deduction, Berlin, Germany, 1–7 August 2015; pp. 527–538. [Google Scholar] [CrossRef]
- Hunt, W.A.; Kaufmann, M.; Strother, M.J.; Slobodova, A. Industrial hardware and software verification with acl2. Philos. Trans. R. Soc. A 2017, 375, 20150399. [Google Scholar] [CrossRef] [PubMed]
- Chatterjee, K.; Zavadskas, E.K.; Tamošaitienė, J.; Adhikary, K.; Kar, S. A Hybrid MCDM Technique for Risk Management in Construction Projects. Symmetry 2018, 10, 46. [Google Scholar] [CrossRef] [Green Version]
- Kondratyev, A.; Stetter, H.J.; Winkler, S. Numerical computation of Gröbner bases. In Proceedings of the CASC2004 (Computer Algebra in Scientific Computing), Chişinău, Moldova, 11–15 September 2004; pp. 295–306. [Google Scholar]
- Wu, P.; Xiong, N.; Liu, J.; Huang, L.; Ju, Z.; Ji, Y.; Wu, J. Interval number-based safety reasoning method for verification of decentralized power systems in high-speed trains. Math. Probl. Eng. 2021, 6624528. [Google Scholar] [CrossRef]
- Wu, P.; Wu, J. Reasoning method based on linear error assertion. J. Comput. Appl. 2021, 41, 2199–2204. [Google Scholar] [CrossRef]
- Wu, P.; Xiong, N.; Xiong, J.; Wu, J. Reasoning method between polynomial error assertions. Information 2021, 12, 309. [Google Scholar] [CrossRef]
- Burkardt, J. The Truncated Normal Distribution. Available online: https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf. (accessed on 16 November 2021).
- Robert, C.P. Simulation of truncated normal variables. Stat. Comput. 1995, 5, 121–125. [Google Scholar] [CrossRef] [Green Version]
- Castillo, N.O.; Gallardo, D.I.; Bolfarine, H.; Gómez, H.W. Truncated Power-Normal Distribution with Application to Non-Negative Measurements. Entropy 2018, 20, 433. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barr, D.; Sherrill, E. Mean and variance of truncated normal distributions. Am. Stat. 1999, 53, 357–361. [Google Scholar]
- Shoenfield, J.R. Mathematical Logic; AK Peters/CRC Press: Natick, MA, USA, 2001; ISBN 1568811357. [Google Scholar]
- Csörgő, M. Quantile Processes with Statistical Applications; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1983; ISBN 0898711851. [Google Scholar]
- Volgushev, S.; Chao, S.-K.; Cheng, G. Distributed inference for quantile regression processes. Ann. Stat. 2019, 47, 1634–1662. [Google Scholar] [CrossRef] [Green Version]
- Belohlavek, R.; Dauben, J.W.; Klir, G.J. Fuzzy Logic and Mathematics: A Historical Perspective; Oxford University Press: Oxford, UK, 2017; ISBN 9780190200015. [Google Scholar]
- Nazari, S.; Fallah, M.; Kazemipoor, H.; Salehipour, A. A fuzzy inference-fuzzy analytic hierarchy process-based clinical decision support system for diagnosis of heart diseases. Expert Syst. Appl. 2018, 95, 261–271. [Google Scholar] [CrossRef]
- Mehrabi, M.; Pradhan, B.; Moayedi, H.; Alamri, A. Optimizing an Adaptive Neuro-Fuzzy Inference System for Spatial Prediction of Landslide Susceptibility Using Four State-of-the-art Metaheuristic Techniques. Sensors 2020, 20, 1723. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, H.; Liu, X.; Wang, X.; Liu, Y. A fuzzy inference and big data analysis algorithm for the prediction of forest fire based on rechargeable wireless sensor networks. Sustain. Comput. Infor. Syst. 2018, 18, 101–111. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Advantage | Disadvantage |
|---|---|---|
| Methods [20,21] (linear error assertions) | Better time complexity compared to other methods in the table. | May be invalid for non-convex zero set; Lack of error probability information. |
| Method [22] (error polynomial assertions) | Valid for non-convex zero set. | Very high time complexity; Lack of error probability information. |
| Method [30] (fuzzy reasoning) | Based on fuzzy logic; it has well-established theoretical support. | Weak statistical significance. |
| The method in this article | Strong statistical significance. Identifies potential faults earlier than methods [20,21]. | Higher time complexity than that of the methods [20,21]. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, P.; Hou, Z.; Liu, J.; Wu, J. Reasoning Method Based on Intervals with Symmetric Truncated Normal Density. Symmetry 2022, 14, 25. https://doi.org/10.3390/sym14010025
Wu P, Hou Z, Liu J, Wu J. Reasoning Method Based on Intervals with Symmetric Truncated Normal Density. Symmetry. 2022; 14(1):25. https://doi.org/10.3390/sym14010025
Chicago/Turabian StyleWu, Peng, Zhenjie Hou, Jiqiang Liu, and Jinzhao Wu. 2022. "Reasoning Method Based on Intervals with Symmetric Truncated Normal Density" Symmetry 14, no. 1: 25. https://doi.org/10.3390/sym14010025