1. Introduction
News content that is easier to consume is due to the introduction of social media [
1]. The development of social media is a double-edged sword as it also has negative effects, such as bringing us unspeakable pain. Social media is different from traditional media (newspapers, television and radio), and the new news trend of “fake news” is also welcomed by social media, which quickly spreads some news with intentionally misleading information. The malicious activities of attackers, spammers and fraudsters are also due to the typical characteristics of the openness and sharing of online social networks. One of the highest security threats in online social networks is social robots, which are more vulnerable to attackers. The interaction between social robots and humans on social media is the imitation of computer software that automatically generates content, and this imitation will also change their behaviour. Creating an illusion is the main goal of these social robots, so the positive influence of social networks on public opinion can be explained in this way [
2]; political penetration [
3] is triggered and malicious content is also widely spread. These malicious social robots will also have a negative impact on popular social networks, mainly on human users.
At present, social robots on Twitter are facing three main challenges, mainly in the following respects: it is difficult to fully extract features, which is the first challenge of social robots on Twitter because they are characterized by complexity. In order for a social robot to avoid being discovered, it is necessary for it to pretend to be an ordinary user. To describe social robots more accurately, it is necessary to consider their characteristics and various contents. Only extracting the features of social robots from a single angle [
4,
5] cannot fully describe them, which is the result of many existing types of research. Building a detection model only uses a small number of features, considering the features of social robots [
6,
7] and studying them from several perspectives, which is the research content of other works. It is difficult to obtain large-scale tags for research datasets from Twitter, which is the second challenge. On Twitter, the lack of large-scale reliable datasets is caused by the relative rarity of social robot detection research; it needs rich, experienced support and takes a lot of time to mark manual proofing. Small-scale datasets [
4,
7,
8] are the basis of most existing studies. Another great challenge of current research is to accurately and effectively scale datasets, which is needed for the detection of social robots on Twitter. When classical detection methods are used to detect social robots on Twitter, their performance is not very good. This is the third challenge. The performance of detection methods has been improved because machine learning detection methods have been used in previous work [
4,
9], but there is still much work to be done. Therefore, the detection method needs to be further developed for the detection of high-performance social robots based on deep neural networks.
BERT can learn the semantic information of the text in advance on large-scale text, and then fine-tune it on the Twitter dataset to learn the distribution characteristics of the Twitter data, so as to overcome the pain point of missing the large-scale dataset. However, GCN has a good ability to capture and learn the propagation and co-occurrence relationships of Twitter and can learn the complex features of Twitter robots in multiple dimensions.
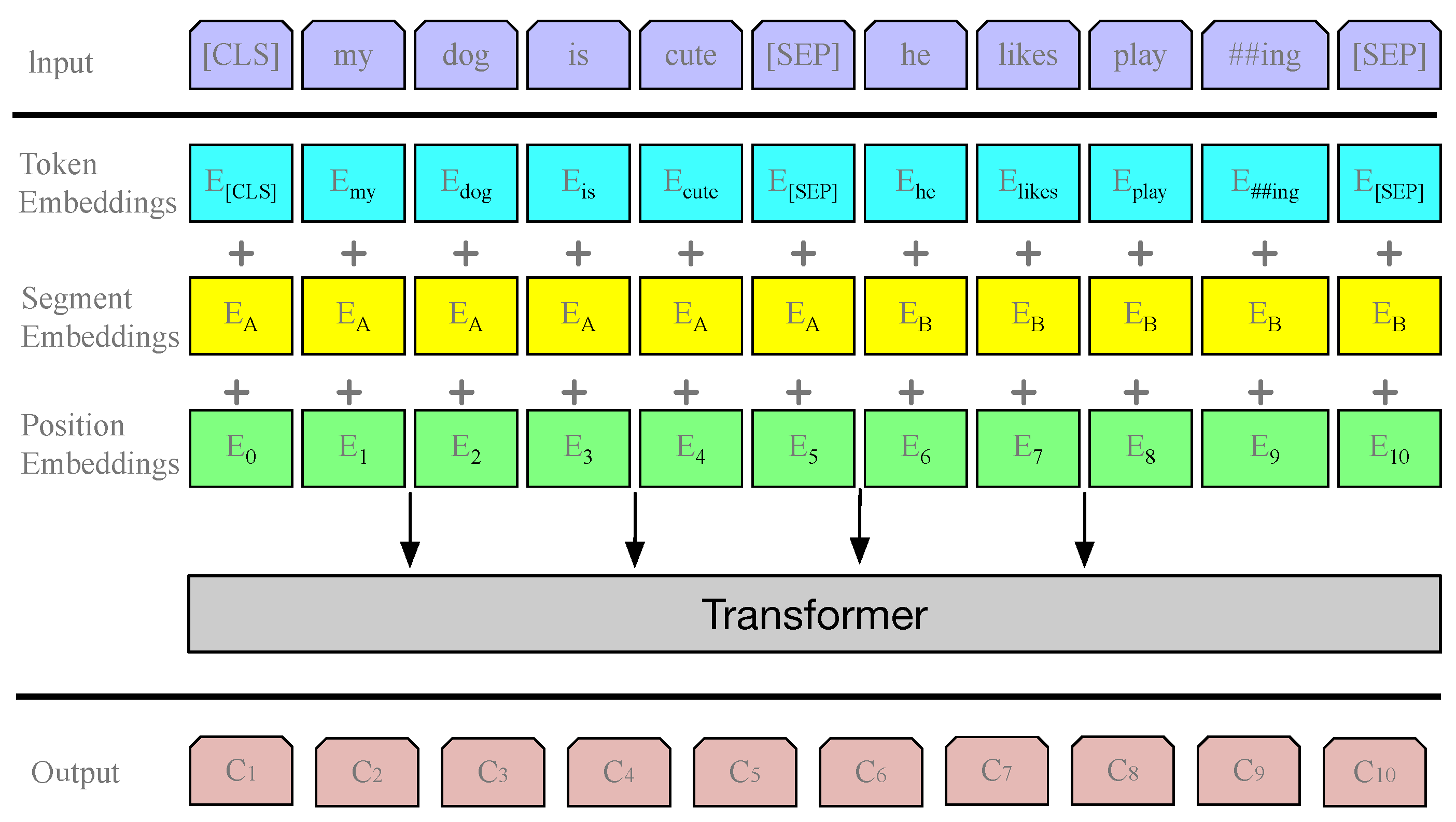
As shown in
Figure 1, a new model—BGSRD—is proposed in this work, and the detection of social robots is, through its symmetry, a combination of BERT and GCN. Large-scale pre-training and transduction learning of social robot detection is carried out by this model, combining the following advantages. BGSRD constructs a heterogeneous graph of the corpus, which uses pre-trained BERT embedded nodes as word or document nodes to classify, initialize and use the GCN of robot classification. The model that can take advantage of the two worlds is obtained by jointly training BERT and GCN modules: (1) massive raw data can be pre-trained on a large scale; (2) The label’s influence through the edge of the graph can be carried out through the transduction learning of the representation of learning training data and unlabeled test data. The above three challenges can be overcome by combining the pre-training model and a graph neural network. The successful combination of large-scale pre-training and the power of the graph network is the BGSRD model. At the same time, a better performance is obtained, especially on a wide range of social robot detection datasets.
This major contribution includes:
We combine pre-trained language model BERT and Graph Convolutional Networks to detect social bots;
We can fuse semantic information by applying BERT multi-head attention, and a better-integrated representation can be generated by each text;
We adopt a novel graph neural network method to detect social robots. This is research on embedding a heterogeneous graph and graph neural network to learn words and documents through the whole corpus modelling.
2. Related Works
With the spread of robot accounts on social networks, there are more and more studies on social robot account detection. With the development of related research, related methods can be divided into the following categories [
10]: crowdsourced social machine account detection platform, detection technology via traditional machine learning, detection technology over deep learning, detection technology using social network graphs, and so forth.
2.1. Crowdsourcing Social Machine Account Detection Platform
Reference [
11] proposes a crowdsourcing social machine account detection platform. It is considered that machine account detection is a relatively simple technology for human beings, so an online Turing detection platform is created. By employing a large number of workers and experts to test the account data in Facebook and Renren, the same account data are provided to multiple workers, and the opinions of the majority are taken as the final judgment.
However, its disadvantages are also very obvious. It would be better to do this in the early days of social networking, but the cost is almost unrealistic for established social networking platforms. The number of users of various mainstream social platforms has experienced explosive growth in the past few years. For example, the number of monthly active users of Twitter reached 336 million in 2019, which was an increase of 2.5 times compared with 2012 [
12]. Compared with this high cost and inefficient service, it is not applicable. Due to the massive number of users and data every day, such a scheme can only stay in the process of theory and experiment, but cannot really be put into practical application.
2.2. Detection Technology Based on Machine Learning
The most common technology for the detection of machine accounts is based on machine learning, and is the mainstream detection technology at present. Taking this problem as a binary classification problem is the essence of machine account detection technology based on machine learning. After the required features are extracted from the account, the classification algorithm is used to analyze the data, and the detection model is trained. Then, the model is used to analyze the data of the account that needs to be classified and classify it.
2.3. Detection Technology Based on Deep Learning
With the development of deep learning, more and more studies have been applying it to machine account detection. Deep learning is a branch of machine learning. Deep learning takes artificial neural networks as the basic framework within which to conduct data representation learning [
13]. Recently, with the rapid development of deep learning, more and more studies have also been applied to machine account detection. One branch of machine learning is deep learning. Deep learning learns data representation based on artificial neural networks [
13]. Unlike with traditional machine learning, an in-depth study of the data needs more data and time to train the model; deep learning, at the same time, can use unsupervised, or characteristics of, semi-supervised learning and use a hierarchical feature extraction algorithm to replace the artificial nerual network [
14] and obtain the characteristics, which can save time and discover some hidden features.
LSTM (Long Short-term Memory) is a kind of temporal cyclic neural network, first published in 1997 [
15]. It is especially designed to solve the general cyclic neural network RNN (recurrent neural network, RNN). Suitable for processing and predicting events with long intervals and delays in time series, they are now often constructed as part of large deep neural networks. Researchers of machine account detection also use LSTM in correlation experiments and projects [
16,
17]. CNN (convolutional neural network) and LSTM networks have been used in machine account detection [
16]. The CNN network is used to extract the characteristics and relations of the Twitter text content. The second layer regards the Twitter metadata as time information and uses the time information as the input to LSTM to extract the time characteristics of users’ social activities. Finally, in the fusion feature layer, the previous content features and metadata features are fused to detect the machine account, and the final detection results are obtained.
Reference [
17], using Twitter content and metadata, detected machine accounts at the level of tweets, extracted contextual features from user metadata, and provided them as auxiliary input to the LSTM network that processed the tweet’s text. The model only needs one tweet to determine whether it is a machine account. Reference [
18] used the BiLSTM (Bi-directional Long Short-Term Memory) algorithm to detect machine accounts. BiLSTM is an algorithm using bidirectional LSTM, and the two LSTMs are in opposite directions. Together they form the BiLSTM network. The model uses the context of tweets as input, and enters the BiLSTM network after word embedding. Finally, the outputs of forward LSTM and backward LSTM are stitched together, and then the normalized function is used for classification so as to obtain the required detection results. This model only uses the content of tweets as input, and does not use other features. The advantage of this method is that it saves a lot of working time of feature extraction, does not need manual features and prior knowledge, can improve work efficiency, and is more convenient to deploy in the scene of batch detection. Reference [
19] proposed a two-stage, graph-based machine account detection system. The system utilizes supervised learning and unsupervised learning. Reference [
20] uses incremental learning to process data in real-time. Although the convergence time of the model is longer, the final model produces a superior classification performance and is suitable for stream-based detection systems.
Similarly, the detection technology based on deep learning also has its disadvantages. When the dataset is not large enough, the effect of the neural network is often poor and the phenomenon of over-fitting easily occurs.
2.4. Detection Technology Based on Social Graph
The detection technology based on a social graph is mainly based on the social network graph formed between users in the social network. The social network graph can be used to understand and analyze the relationships between users on the social network platform. Therefore, the detection technology based on a social graph focuses on the relationships between users. After all, in a social network, no accounts exist in isolation, and they are all connected to each other. The social graph of normal users and machine accounts is often very different. For example, a large part of normal users’ good friends come from real friends, who follow each other and interact often. Machine accounts, on the other hand, do not have such features. They will have fewer mutual friends, which is obvious in the social graph. They will also have fewer comments and likes, and most of them will tweet or retweet to expand their influence. There will also be a difference in the percentage of friends between normal users and computer accounts. Therefore, the structure of the social graph of normal users is significantly different from that of machine accounts, and the detection scheme based on the social graph uses this difference, together with the network characteristics of users, to identify and detect machine accounts.
SybilRank [
21] represents an example of this framework: an opposing party can control multiple social machine accounts (often referred to as Sybils in this case) to impersonate different identities and launch attacks or infiltrations. Proposed strategies for detecting Sybil accounts often rely on examining the structure of the social graph. For example, SybilRank assumes that Sybil accounts only show a small number of links to legitimate users, rather than primarily to other Sybil accounts because they require a large number of social connections to show a trustworthy status. This feature can be used to identify dense, interconnected social machine accounts. In addition, research such as Sybilwalk [
22], Gang [
23], SybilScar [
24], and Sybilfuse [
25] are all machine account detection methods based on social interaction correlation diagrams.
4. Experiments
4.1. Datasets
We ran experiments on five widely-used social bot detection benchmarks: cresci-rtbust [
30], botometer-feedback [
31], gilani [
32], cresci-stock-2018 [
33,
34], midterm [
35]. These datasets are in the same format, including crawling time, user profile, description, followers, location, URL, and so forth. We have put these datasets with our code on GitHub (
https://github.com/shanmon110/BGSRD (accessed on 22 November 2021)). The existing common datasets are summarized in
Table 1. The difference between the number of accounts and the original number is caused by removing invalid accounts from the dataset. Stefano Crescis’ research team and Reference [
35] have collected many datasets, which are of great help to the study of machine accounts on social networks.
4.2. Baselines
Cresci-rtbust [
30]: A new technology that only needs the time stamp of retweets for each analyzed account is used to detect the retweeting social robot, so there is no need to provide a complete user timeline or social graph.
Botometer [
31]: A popular robot detection tool was developed by Indiana University. Botometer is based on Random Forest classifiers; given a Twitter account, Botometer extracts over 1000 features relative to the account from data easily provided by the Twitter API, and produces a classification score called a bot score: the higher the score, the greater the likelihood that the account is controlled completely or in part by software.
gilani: Reference [
36] mentions three methods with which to conduct experiments on gilani; we will compare these three methods as a baseline. gilani has two main parts: bot and analyser. The bot fetches a trending topic or a popular tweet, disassembles the information in the topic or tweet, and the analyser is used for analysis.
cresci-stock: References [
33,
34] proposed a method for detecting social robots in the financial field. cresci-stock studies tweets related to the stocks of the five main financial markets in the US and bot detection techniques.
midterm [
35,
37]: Realization of efficient analysis and scalability to process all Twitter’s public tweet streams in real time through a framework that uses minimal account metadata.
4.3. Experimental Setup
Document embedding is the output feature of using a [CLS] token. Compared with BERT and RoBERTa, it is the feedforward layer that obtains the final prediction. BGSRD is realized by using BERTbase and two layers of GCN. Learning rate initialization 1 × 10
is used for the GCN module, and 1 × 10
is used for fine-tuning the BERT module. Our model is realized mainly by using RoBERTa and GAT (Graphic Attention Network) [
38]. Learning edge weights is not based on a predefined weight matrix but on the attention mechanism, especially when GAT variants are trained on the same graph as GCN variants. The input length for setting BERT is 18, 128 is the batch size, and 200 is the dimension of the GCN hidden layer. The number of attention heads of GAT is set as 8 and 0.5 is the default value of dropout. The parameter is updated by using the Adam optimizer.
4.4. Results and Analysis
The detection results of the robot can be seen in
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6. BGSRD technology achieves the best detection performance because BERT with GNN is used for feature extraction. In most evaluation indicators, in fact, BGSRD technology has defeated many other competitors. Extracting information features from our referral time series is one of the expected advantages of supporting GNN. The second-best overall result is obtained through each model. Most of the worst results are obtained by the evaluated technology in terms of accuracy index, which is interesting because there are many legal accounts that are wrongly classified as a robot. From a result comparison, this is different from the previous robot detection results.
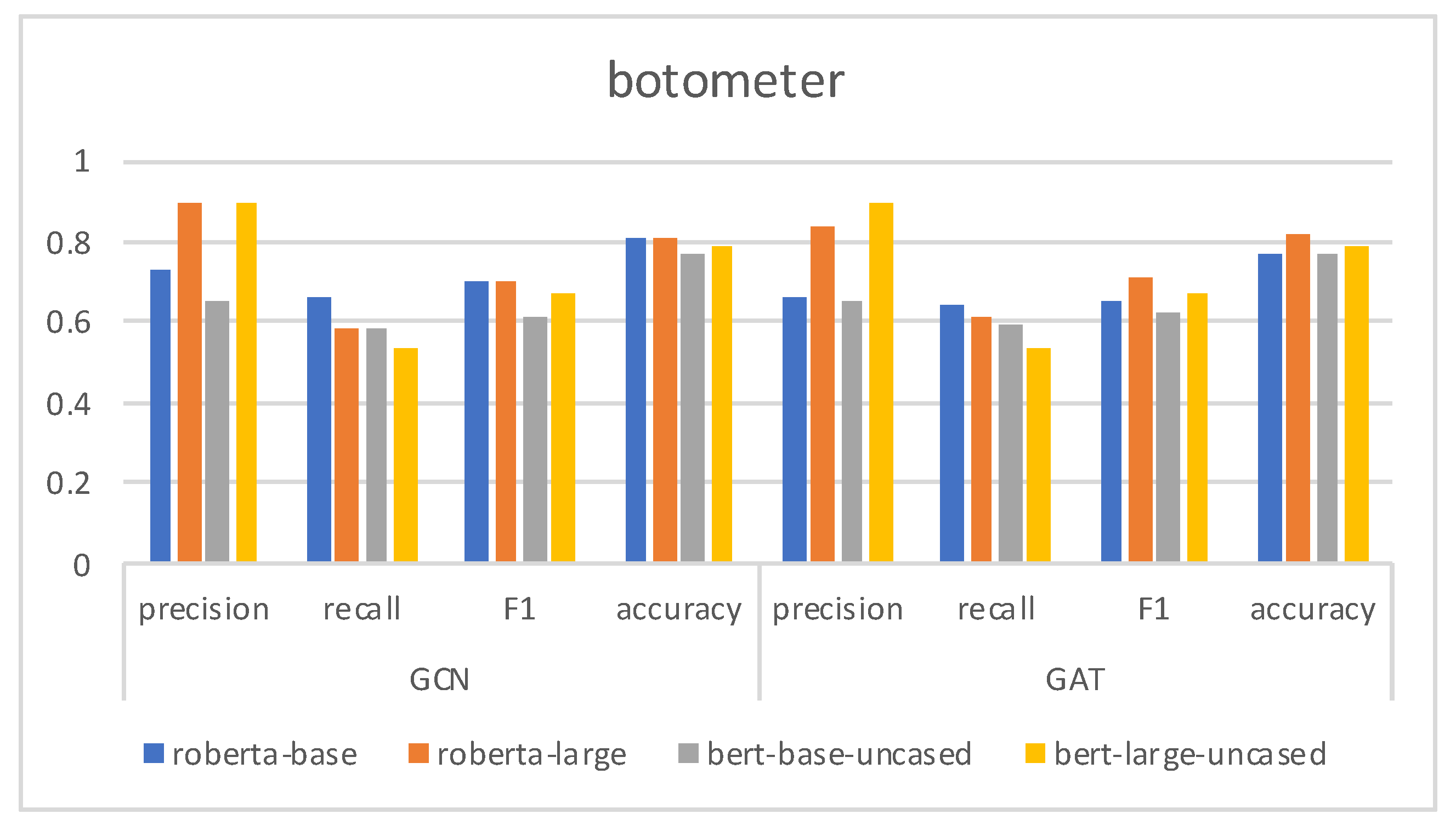
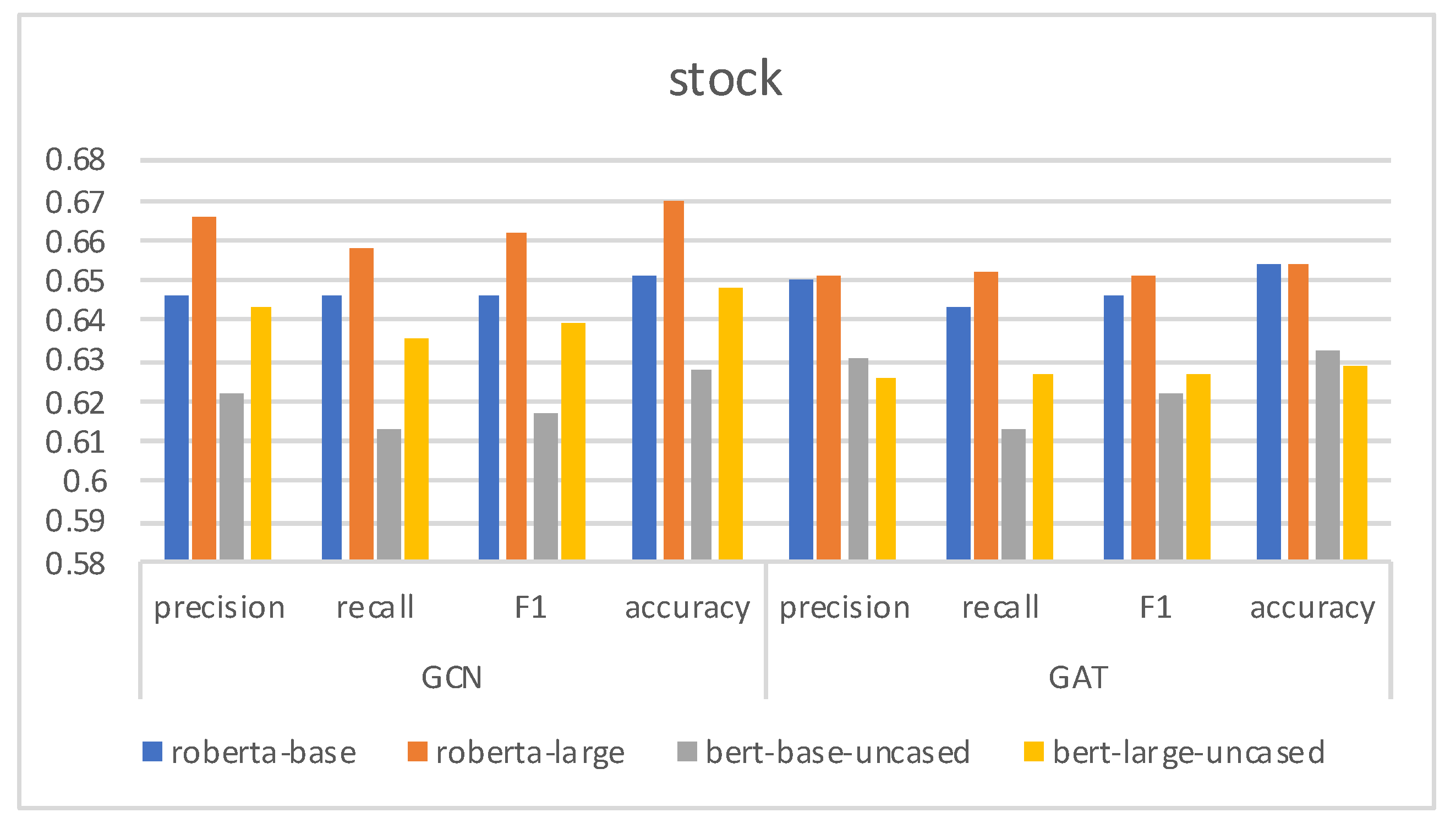
We also observe that the model with the BGSRD set of features performs consistently well overall, outperforming or obtaining similar results to the other models. The excellent performance of the model containing D in the stock dataset is also worth mentioning, where it performs the best. This provides evidence that the compression statistics extracted from the Digital DNA can detect bots that behave coordinately, as happens with stock. Moreover, by combining D with data selection it is possible to build a classifier that can generalise properly in different domains. Alternatively, the model with BGSRD, except for the stock dataset, produces results that outperform those of the other models on some occasions. Besides, it shows the best specificity in all cases and is scalable. BGSRD seems to be more robust against the bots in five datasets, probably because its features cover more aspects other than the user metadata, and BERT is used to study more semantic information. Results also confirm that is possible to obtain a competitive performance using just a small set of features, rather than a bigger one such as Botometer.
4.5. Ablation Study
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
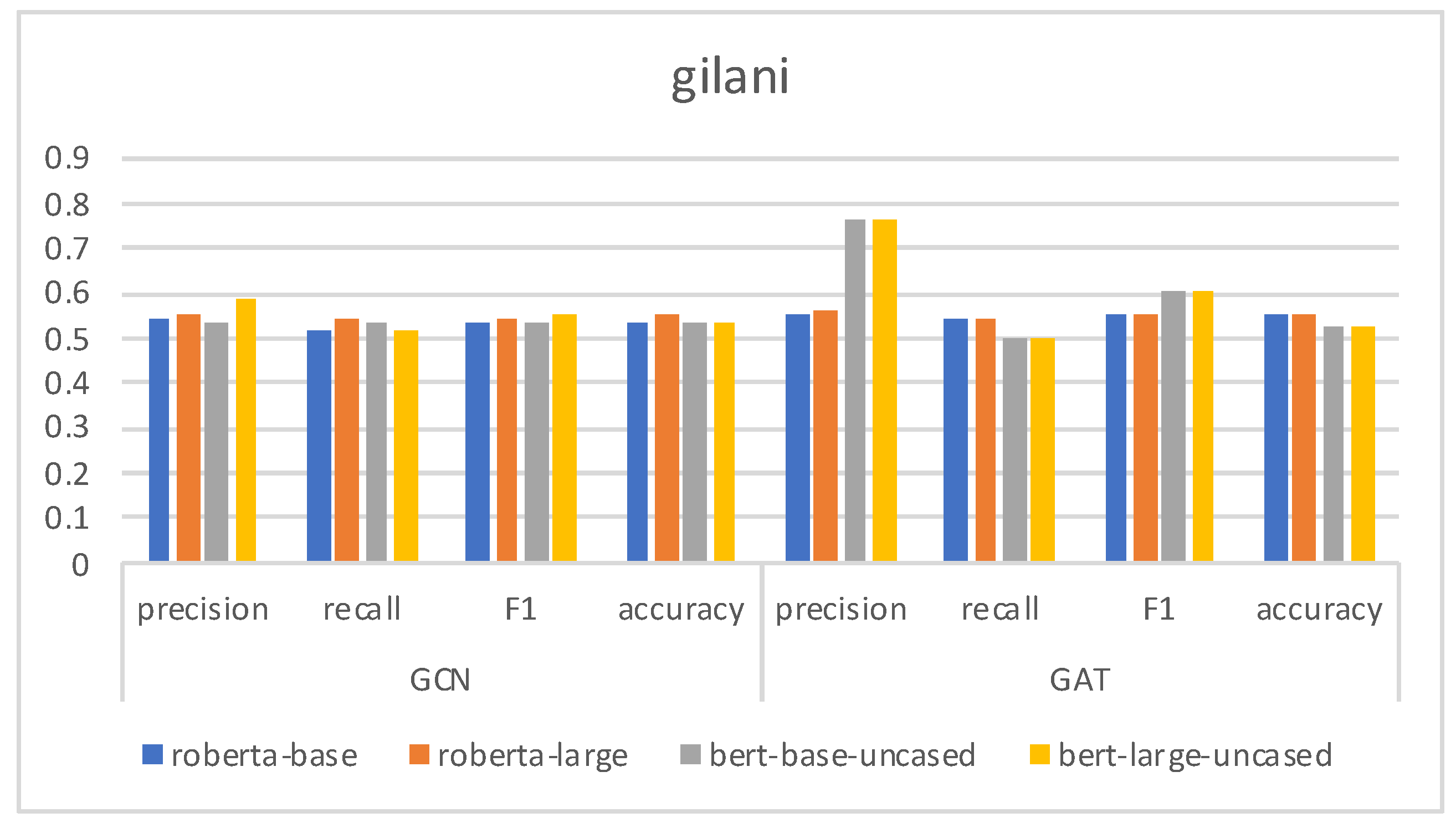
Figure 8 presents the various evaluation indicators of each model. We can see that BGSRD and RoBERTaGCN perform the best across all datasets. Using BERT or RoBERT with GCN generally performs better than using them with GAT, except for Gilani, which is due to content posted by social bots having the characteristics of propagation, while GCN can learn the propagation characteristics of fake content. Roberta-base and roberta-large improve the performance on datasets more significantly than bert-base-uncased and bert-large-uncased. The main reason for this is that the average length in the dataset is relatively long: long text may produce more document connections transmitted through intermediate word nodes because of the graph constructed by word document statistics and, at the same time, the messages transmitted by the graph will be more favorable to passing, and the performance will be better when combined with GCN. On cresci, botometer, stock and midterm datasets, the reason the GCN model performs better than the GAT model can be explained; compared with other datasets, datasets with shorter documents (such as Gilani) have less performance improvement because the ability of the graph structure is limited. BERTGAT and RoBERTaGAT also benefit from the graph structure. Their performance is not as good as that of the GCN variant because of the lack of edge weight information.
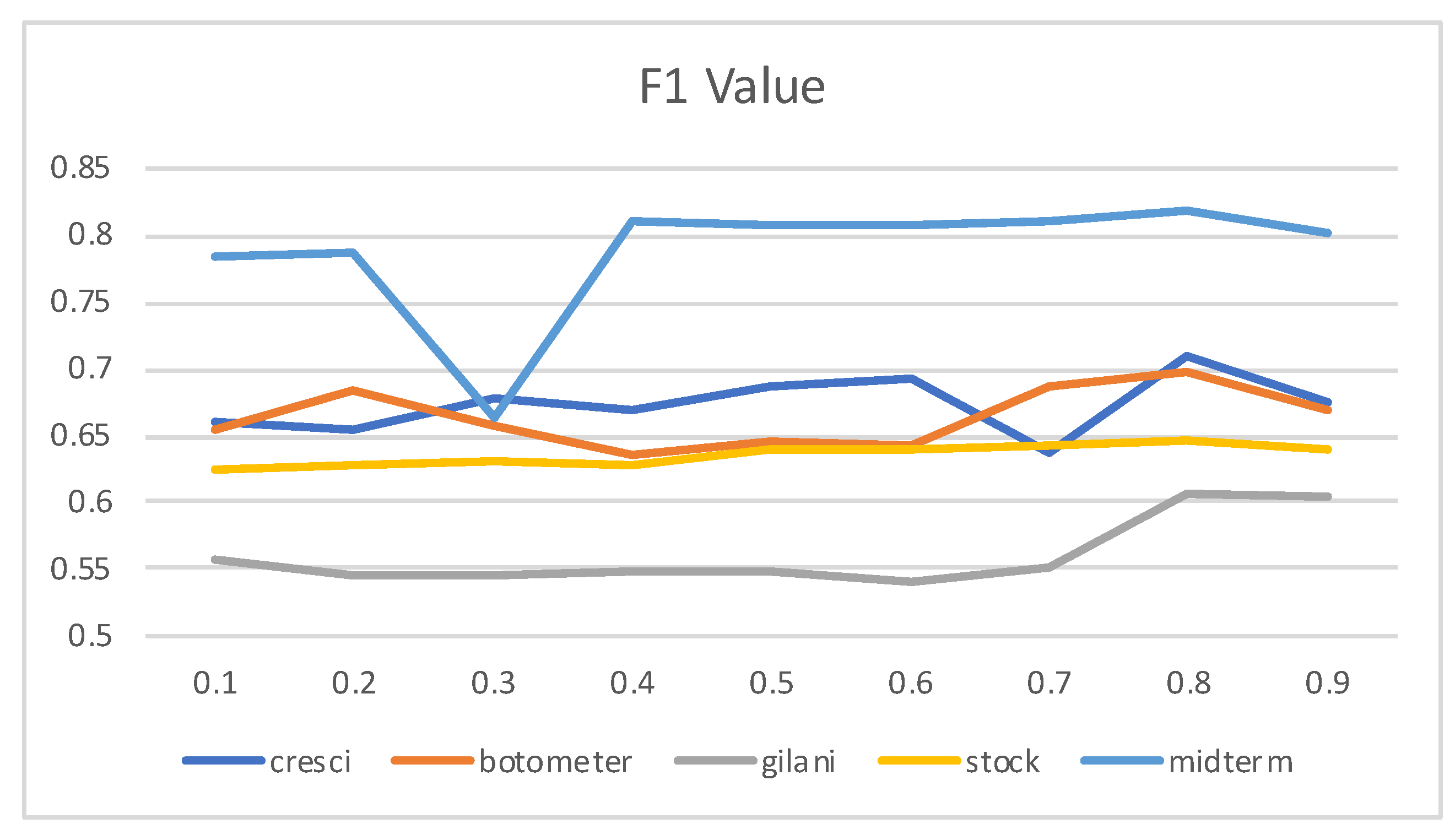
4.6. The Effect of
The tradeoff between BGSRD and BERT is trained by
control. The optimal value of
will be different according to different tasks. The accuracy of RoBERTaGCN with different
is mainly shown in
Figure 9. The value of F1 is always higher on cresci, and the value of
is larger at this time. The explanation for this is the high performance of the graph-based method. When
, the model achieves the best performance, which is slightly better than that of using the GCN prediction alone (
).
4.7. Discussion
Powerful robots for detecting results and learning to predict documents and word embedding are mainly realized by BGSRD, which we can see from the experimental results. Among them, the GCN model is essentially transduction, which is a major limitation of this study because, in GCN training, document nodes are tested (without labels). Therefore, it is impossible for Text GCN to quickly generate embedding and predict invisible test documents. The best performance can be achieved only when a small learning rate is set by the RoBERTa module and when fine-tuned RoBERTa is used.
5. Conclusions and Future Work
BGSRD makes full use of the scale pre-training model and transduction learning for the classification of large social robots. The training of BGSRD is carried out by using a repository that stores all embedded documents. This is effective training, and some can be updated according to the small batch of samples. The detection of the classification problem of incoming text nodes is mainly carried out by constructing a heterogeneous whole corpus of generous word document maps and translating social robot texts. Limited tag documents are mainly realized through the framework of capturing global co-occurring words by BGSRD. It can be built on any document encoder and any graphic model. This method performs excellently on multiple benchmark datasets through a simple two-layer BERT combined with GCN.
We currently only detect social robots from semantic information and textual relationships and social robot detection requires more complex features to better recognize them. Future works may focus on digging for more account features under the surface, such as the sentiment analysis of tweets. The detection scheme also needs to be more comprehensive. For example, machine learning can be combined with social graphs to jointly analyze account characteristics and social network graphs, and human judgment mechanisms can be introduced into some joints. After all, humans can better identify the differences between machine accounts and human users. In order to further improve the robustness and detection capability of the detection technology, it is even necessary to further analyze the next possible update direction of the machine account and obtain the feature dimensions that can be used to detect the new machine account from the analysis results. Confrontational thinking leads to more powerful, generalized, and even preventative testing techniques.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}