
K-Means Clustering Algorithm Based on Memristive Chaotic System and Sparrow Search Algorithm

Abstract
:1. Introduction
- (1)
- Chaotic mapping is used to establish the population of SSA to disperse the initial sparrows as evenly as feasible. Chaos sequences are produced by a memristive chaotic system, which has properties of conditional symmetry. Introducing such sequences aims to increase the variety of the sparrow population.
- (2)
- The improved SSA is used to optimize the location of the clustering centroids in the K-means algorithm. It has the potential to reduce the impact of random initial clustering centroids and the possibility of falling into an optimal local solution. Comparative experiments show that the proposed method can further improve the performance of K-means.
- (3)
- The improved K-means clustering algorithm is applied to analyze Chinese college students’ performance, which verifies the effectiveness and practicability of the method proposed in this paper.
2. Methods
2.1. Sparrow Search Algorithm
2.1.1. Principle of a Sparrow Search Algorithm
2.1.2. Steps of the Sparrow Algorithm
2.2. Memristive Chaotic Sparrow Search Algorithm
2.2.1. Introduction of a Memristive Chaotic System
2.2.2. Initializing SSA Population with Memristive Chaotic Sequence
- (1)
- Three chaotic sequences (x, y, and z) are generated by Equation (6). The parameters are set according to Section 2.2.1.
- (2)
- One of the chaotic sequences is chosen from step one, such as y, and mapped to the problem’s solution space in step three.
- (3)
- The initial value of the sparrow population is taken from the constructed chaotic sequence S, which is given bywhere ub and lb represent the problem’s maximum and minimum values, respectively.S = lb + (ub − lb) × y
2.3. K-Means Clustering Algorithm
2.3.1. Cluster Analysis Technology
2.3.2. Principle of K-Means Algorithm
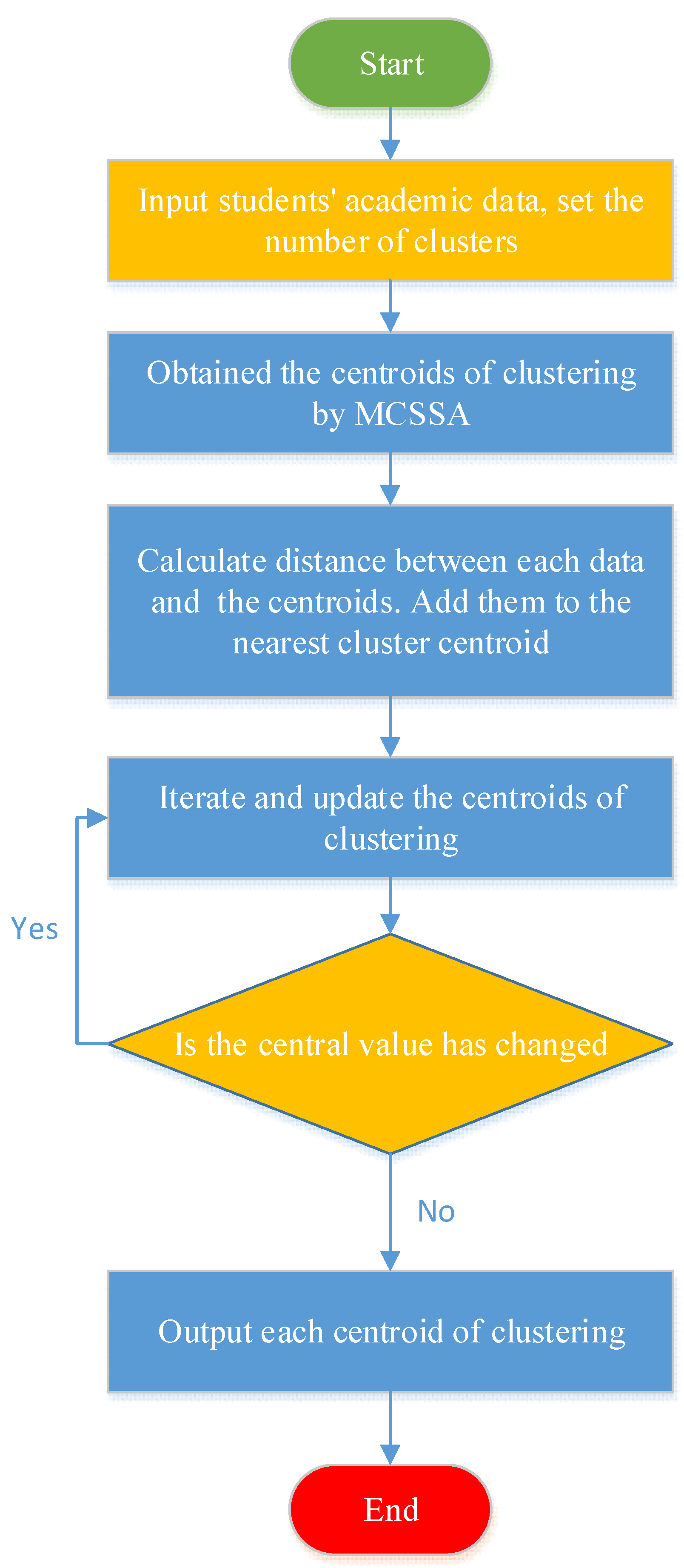
2.3.3. Flow of K-Means Algorithm
2.3.4. K-Means Clustering Algorithm Based on MCSSA
3. Experiments Results
3.1. Experiments on Standard Data Sets
3.2. Experiments on Students’ Academic Data
3.2.1. Source of Students’ Academic Data
3.2.2. Students’ Academic Data Preprocessing
3.2.3. Selection of K Value
3.2.4. Comparative Experimental Results
3.2.5. Analysis of the Overall Effect of Clustering
3.2.6. Clustering Centroids Effect Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rawat, S. Challenges and opportunities with big data. In Shifting Global Powers and International Law: Challenges and Opportunities; Routledge: New York, NY, USA, 2014. [Google Scholar]
- Ulbricht, L.; von Grafenstein, M. Big data: Big power shifts? Internet Policy Rev. 2016, 5, 1–8. [Google Scholar] [CrossRef]
- Johnston, L.; Jeffryes, J. Data Management Skills Needed by Structural Engineering Students: Case Study at the University of Minnesota. J. Prof. Issues Eng. Educ. Pract. 2013, 140, 05013002. [Google Scholar] [CrossRef]
- Foroughi, A.; Yan, G.; Shi, H.; Chong, D. A Web 3.0 ontology based on similarity: A step toward facilitating learning in the Big Data age. J. Manag. Anal. 2015, 2, 216–232. [Google Scholar] [CrossRef]
- Gupta, B.; Goul, M.; Dinter, B. Business Intelligence and Big Data in Higher Education: Status of a Multi-Year Model Curriculum Development Effort for Business School Undergraduates, MS Graduates, and MBAs. Commun. Assoc. Inf. Syst. 2015, 36, 449–476. [Google Scholar] [CrossRef]
- Singh, S.; Misra, R.; Srivastava, S. An empirical investigation of student’s motivation towards learning quantitative courses. Int. J. Manag. Educ. 2017, 15, 47–59. [Google Scholar] [CrossRef]
- Hoffman, S.; Podgurski, A. The use and misuse of biomedical data: Is bigger really better? Am. J. Law Med. 2013, 39, 497. [Google Scholar] [CrossRef]
- Duan, L.; Xiong, Y. Big data analytics and business analytics. J. Manag. Anal. 2015, 2, 1–21. [Google Scholar] [CrossRef]
- Amalina, F.; Hashem IA, T.; Azizul, Z.H.; Fong, A.T.; Firdaus, A.; Imran, M.; Anuar, N.B. Blending Big Data Analytics: Review on Challenges and a Recent Study. IEEE Access 2019, 8, 3629–3645. [Google Scholar] [CrossRef]
- Ang, L.M.; Ge, F.L.; Seng, K.P. Big Educational Data & Analytics: Survey, Architecture and Challenges. IEEE Access 2020, 8, 116392–116414. [Google Scholar]
- Edwards, R.; Fenwick, T. Digital analytics in professional work and learning, Studies in Continuing Education. Stud. Contin. Educ. 2016, 38, 213–227. [Google Scholar] [CrossRef]
- Waheed, H.; Hassan, S.U.; Aljohani, N.R.; Wasif, M. A bibliometric perspective of learning analytics research landscape. Behav. Inf. Technol. 2018, 37, 941–957. [Google Scholar] [CrossRef]
- Salihoun, M. State of Art of Data Mining and Learning Analytics Tools in Higher Education. Int. J. Emerg. Technol. Learn. (IJET) 2020, 15, 58. [Google Scholar] [CrossRef]
- Quadir, B.; Chen, N.S.; Isaias, P. Analyzing the educational goals, problems and techniques used in educational big data research from 2010 to 2018. Interact. Learn. Environ. 2020, 1–17. [Google Scholar] [CrossRef]
- Zhang, X. Evaluating the quality of internet-based education in colleges using the regression algorithm. Mob. Inf. Syst. 2021, 2021, 7055114. [Google Scholar] [CrossRef]
- Jiang, X. Online English teaching course score analysis based on decision tree mining algorithm. Complexity 2021, 2021, 5577167. [Google Scholar] [CrossRef]
- Yang, F.; Li, F.W.B. Study on student performance estimation, student progress analysis, and student potential prediction based on data mining. Comput. Educ. 2018, 123, 97–108. [Google Scholar] [CrossRef]
- Hu, C.; Ma, Y.; Chen, T. Application on Online Process Learning Evaluation Based on Optimal Discrete Hopfield Neural Network and Entropy Weight TOPSIS Method. Complexity 2021, 2021, 2857244. [Google Scholar] [CrossRef]
- Lei, D.; Zhu, Q.; Chen, J.; Lin, H.; Yang, P. Automatic k-means clustering algorithm for outlier detection. In Information Engineering and Applications; Springer: London, UK, 2012; pp. 363–372. [Google Scholar]
- Yu, H.; Chen, L.; Yao, J.; Wang, X. A three-way clustering method based on an improved DBSCAN algorithm. Phys. A Stat. Mech. Appl. 2019, 535, 122289. [Google Scholar] [CrossRef]
- Yogatama, D.; Tanaka-Ishii, K. Multilingual spectral clustering using document similarity propagation. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–7 August 2009; pp. 871–879. [Google Scholar]
- Zhao, L.; Wang, Z.; Zuo, Y.; Hu, D. Comprehensive Evaluation Method of Ethnic Costume Color Based on K-Means Clustering Method. Symmetry 2021, 13, 1822. [Google Scholar] [CrossRef]
- Chen, G.; Liu, Y.; Ge, Z. K-means Bayes algorithm for imbalanced fault classification and big data application. J. Process Control 2019, 81, 54–64. [Google Scholar] [CrossRef]
- Fang, C.; Liu, H. Research and Application of Improved Clustering Algorithm in Retail Customer Classification. Symmetry 2021, 13, 1789. [Google Scholar] [CrossRef]
- Zhang, H.; Peng, Q. PSO and K-means-based semantic segmentation toward agricultural products. Future Gener. Comput. Syst. 2022, 126, 82–87. [Google Scholar] [CrossRef]
- Agarwal, M.; Jaiswal, R.; Pal, A. k-means++ under Approximation Stability. Theor. Comput. Sci. 2015, 588, 37–51. [Google Scholar] [CrossRef]
- Park, H.S.; Jun, C.H. A simple and fast algorithm for K-medoids clustering. Expert Syst. Appl. 2009, 36, 3336–3341. [Google Scholar] [CrossRef]
- Kuo, R.J.; Mei, C.H.; Zulvia, F.E.; Tsai, C.Y. An application of a metaheuristic algorithm-based clustering ensemble method to APP customer segmentation. Neurocomputing 2016, 205, 116–129. [Google Scholar] [CrossRef]
- Paul, S.; De, S.; Dey, S. A Novel Approach of Data Clustering Using An Improved Particle Swarm Optimization Based K–Means Clustering Algorithm. In Proceedings of the 2020 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 2–4 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Kaur, A.; Pal, S.K.; Singh, A.P. Hybridization of Chaos and Flower Pollination Algorithm over K-Means for data clustering. Appl. Soft Comput. 2020, 97, 105523. [Google Scholar] [CrossRef]
- Ouyang, A.; Pan, G.; Yue, G.; Du, J. Chaotic Cuckoo Search Algorithm for High-dimensional Functions. J. Comput. 2014, 9, 1282–1290. [Google Scholar] [CrossRef]
- Liu, H.; Abraham, A.; Clerc, M. Chaotic dynamic characteristics in swarm intelligence. Appl. Soft Comput. 2007, 7, 1019–1026. [Google Scholar] [CrossRef]
- Boushaki, S.I.; Kamel, N.; Bendjeghaba, O. A new quantum chaotic cuckoo search algorithm for data clustering. Expert Syst. Appl. 2018, 96, 358–372. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, W. An efficient parameter adaptive support vector regression using K-means clustering and chaotic slime mould algorithm. IEEE Access 2020, 8, 156851–156862. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Muthuswamy, B. Implementing memristor based chaotic circuits. Int. J. Bifurc. Chaos 2010, 20, 1335–1350. [Google Scholar] [CrossRef]
- Xiong, Q.; Shen, J.; Tong, B.; Xiong, Y. Parameter Identification for Memristive Chaotic System Using Modified Sparrow Search Algorithm. Front. Phys. 2022, 10, 533. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Cluster Integrity | K-Means | PSOK-Means | SSAK-Means | MCSSAK-Means |
|---|---|---|---|---|---|
| Iris k = 3 | Best value | 97.52 | 97.33 | 97.33 | 97.33 |
| Worst value | 152.50 | 123.85 | 123.85 | 123.85 | |
| Average value | 111.43 | 108.35 | 107.41 | 102.15 | |
| Execution Time(s) | 0.0008 | 0.1641 | 0.2384 | 0.2435 | |
| Wine k = 3 | Best value | 16,556 | 16,556 | 16,556 | 16,556 |
| Worst value | 22,456 | 18,437 | 18,437 | 18,437 | |
| Average value | 19,774 | 17,069 | 17,196 | 17,069 | |
| Execution Time(s) | 0.0027 | 0.2097 | 0.4924 | 0.5126 | |
| Absenteeism_at_work k = 20 | Best value | 1.32 × 107 | 7.32 × 105 | 7.20 × 105 | 7.18 × 105 |
| Worst value | 1.50 × 107 | 2.08 × 106 | 1.44 × 106 | 1.45 × 106 | |
| Average value | 1.35 × 107 | 1.35 × 106 | 1.02 × 106 | 1.00 × 106 | |
| Execution Time(s) | 0.0027 | 4.23 | 11.5431 | 11.7789 |
| Class 1 | Class 2 | Class 3 | Class 4 | Class 5 | Class 6 | Class 7 | Class 8 | Class 9 | Class 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 89.47 | 92.25 | 95.50 | 92.67 | 86.00 | 89.67 | 89.50 | 85.67 | 90.00 | 89.00 |
| 2 | 90.29 | 90.00 | 96.00 | 91.33 | 87.00 | 90.00 | 89.17 | 88.67 | 90.00 | 85.00 |
| 3 | 88.12 | 88.25 | 95.50 | 91.33 | 90.00 | 87.00 | 92.67 | 83.00 | 90.00 | 87.00 |
| 4 | 88.35 | 85.00 | 92.50 | 85.67 | 87.00 | 88.33 | 86.00 | 86.33 | 90.00 | 85.00 |
| … | … | … | … | … | … | … | … | … | … | … |
| 106 | 67.76 | 49.25 | 60.50 | 73.00 | 84.00 | 58.67 | 51.50 | 66.33 | 60.00 | 85.00 |
| K Value | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| MCSSA | 3897.56 | 2623.78 | 2191.67 | 971.92 | 1570.90 | 3065.85 | 2094.65 |
| SSA | 5452.07 | 5049.31 | 3260.4202 | 2294.43 | 2728.45 | 4304.64 | 2350.59 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, Y.; Xiong, Q.; Qiu, Z.; Xie, Y. K-Means Clustering Algorithm Based on Memristive Chaotic System and Sparrow Search Algorithm. Symmetry 2022, 14, 2029. https://doi.org/10.3390/sym14102029
Wan Y, Xiong Q, Qiu Z, Xie Y. K-Means Clustering Algorithm Based on Memristive Chaotic System and Sparrow Search Algorithm. Symmetry. 2022; 14(10):2029. https://doi.org/10.3390/sym14102029
Chicago/Turabian StyleWan, Yilin, Qi Xiong, Zhiwei Qiu, and Yaohan Xie. 2022. "K-Means Clustering Algorithm Based on Memristive Chaotic System and Sparrow Search Algorithm" Symmetry 14, no. 10: 2029. https://doi.org/10.3390/sym14102029