3.1. Simulation Study
A simulation is performed to study the behavior of the MLEs of the parameters
,
and
of the MAPE distribution in terms of their averages, absolute biases (ABs) and mean square errors (MSEs) of the estimates obtained from 1000 samples under different scenarios for sample sizes
. The results are in
Table 2.
We compare the MAPE distribution with some other extensions of the exponential distribution, specifically the Beta exponential (Beta-E), Kumaraswamy exponential (Kw-E) and Marshall–Olkin exponential (MOE), using a random sample of size 100 generated from the MAPE distribution with , and . The sample values are:
1.885041737, 4.986048585, 3.066673918, 0.959772040, 2.825368368, 0.824435649, 1.294124159, 1.012800439, 5.167502802, 1.068702611, 9.623282708, 2.156111659, 5.752932638, 3.670298312, 1.832103403, 8.127591949, 3.185589749, 0.068173249, 3.384436805, 1.746315020, 2.993498932, 12.453617304, 4.934371758, 7.789793514, 2.734155022, 2.642853318, 3.251226831, 7.176859866, 0.203007024, 5.584507972, 1.169154800, 0.437596269, 2.547156770, 1.606106547, 4.204954374, 4.496538512, 1.295321912, 3.177033049, 1.044723861, 1.646249159, 0.645593200, 2.402715247, 6.392833545, 7.284959565, 0.001960174, 4.312072308, 2.283924227, 0.462808553, 6.438231855, 4.652210157, 0.370191192, 3.436350472, 2.670331310, 3.058598962, 0.850709308, 6.201166734, 4.893258106, 3.137402020, 5.488975387, 6.466631233, 4.510068949, 2.098932480, 1.210160010, 0.350602649, 6.132940426, 1.215480205, 3.524247143, 1.599821076, 2.080543331, 1.868623797, 7.776530949, 1.203310307, 6.869488403, 5.233742062, 0.889446491, 4.337990211, 8.693465053, 1.555651987, 0.927514150, 4.653270469, 2.223475490, 2.077584863, 5.174423467, 10.262362345, 3.124613475, 3.487773970, 3.801199648, 2.102226125, 3.247546812, 2.429156739, 4.481736907, 1.595783483, 0.693145920, 6.019549617, 5.427266512, 2.496379854, 1.445541279, 2.085743446, 1.159817418 and 6.736977612.
The measures adopted to compare the models are the Akaike information criterion (AIC), Bayesian information criterion (BIC) and Hannan–Quinn information criterion (HQIC), along with the Kolmogorov–Smirnov (KS) goodness of fit and its
p-value. The Kw-E, MOE and Beta-E distributions are fitted with the
R script Newdistns [
26].
Table 3 reports the MLEs of the model parameters and the statistics mentioned before. It is clear that the MAPE model fitted the sample with the largest
p-value among all models and smaller KS statistics, as well as minimum values of the maximized log-likelihood, AIC, BIC and HQIC.
We compare the MAPN distribution with the (i) normal distribution and (ii) sinh-arcsinh distribution (SAS) with parameters
and
(defined in [
27]) using a random sample of size 100 generated from the standard MAPN
model. The sample values are:
−0.08363545, −0.18607357, 1.86273702, 2.25638263, 0.73660602, 0.43807657, 0.70991234, 1.49379206, 1.22935919, 1.04610514, 0.06031000, 1.95055682, 2.36414619, 1.35644650, 2.18061418, 1.02696357, 1.14251296, 0.33830318, 1.43612497, 0.99086614, 1.05799729, 3.68323963, 1.56528289, 1.75877235, 1.01704320, 1.26556227, 1.35099527, −0.63300406, 2.20036565, 1.55478240, 0.80134930, 0.88848599, 1.45800153, 0.80765750, 0.10462775, 1.52265250, 1.09206144, 0.98159601, 2.16970680, 1.37697204, 1.53911634, 1.14643762, 1.46446260, 2.21276767, 1.73042459, 1.21417199, 1.20884293, 1.40146066, 0.92637279, 0.73564445, 0.22756120, 2.35066872, 2.67684033, 0.94056519, 1.04040666, 1.19934400, 1.00711623, 1.88954724, 3.57866792, 1.81844198, 0.90083021, 2.00987153, 1.77569782, 1.32619050, 1.42991050, 1.93232500, 0.76668545, 1.30735528, 0.97714293, 0.47458649, 0.85462981, 2.24507741, 3.08341050, 2.30797564, 0.69125516, 1.09488414, 2.19492667, 1.10441197, 1.32840119, 1.99843395, 2.51819041, 1.42571479, 2.98604819, 1.72972425, 1.18167532, 1.47923676, 0.75889338, 2.05254023, 1.27701296, 1.98314559, 0.07153798, 2.10196116, 2.10919545, 1.23909188, 1.06198103, 0.22265900, 1.03588769, 1.16160506, −1.52414087 and 0.70722877.
Table 4 provides the MLEs of the model parameters and the statistics mentioned before. It is clear that the MAPN model fitted to the generated sample has the smallest KS, minus log-likelihood, AIC, BIC and HQIC values and largest
p-value.
3.2. Real Datasets
The performance of the MAPE distribution is verified by comparing it with the baseline distribution (exponential with rate
) and five other competitive models: (i) the Weibull distribution with shape parameter
and scale parameter
, (ii) the Marshall–Olkin exponential (MOE) distribution with parameters
and
as given by [
5], (iii) the APE distribution with parameters
and
as defined in [
8], (iv) the Beta-E distribution with parameters
,
and
as defined in [
28] and (v) the Kumaraswamy exponential (Kw-E) distribution with parameters
,
and
as defined in [
29].
Three datasets were analyzed to demonstrate the performance of the proposed model. The measures used to compare the models are the Akaike information criterion (AIC), Bayesian information criterion (BIC) and Hannan–Quinn information criterion (HQIC), along with the Kolmogorov–Smirnov (KS) goodness of fit and its
p-value. The exponential and Weibull distributions are fitted with the
R script fitdistrplus [
30], whereas the MOE, Kw-E and Beta-E distributions are fitted with the
R script Newdistns [
26].
3.2.1. Diagnostic Wisconsin Breast Cancer Data
The two datasets are part of the Diagnostic Wisconsin Breast Cancer Data, which describe some characteristics of the cell nuclei presented in a digitized image of a fine needle aspirate of a breast mass. The dataset was collected and made open by Wolberg et al. at the University of Wisconsin. These data were first used in [
31], and they are available at the UC Irvine Machine Learning Repository [
32].
The Diagnostic Wisconsin Breast Cancer Data contain 30 features (V3, V4,..., V32) for each cell nucleus. The MAPE model is applied to V8 and V14.
Table 5 and
Table 6 provide, for V8 and V14, respectively, the MLEs of the parameters of all models and the statistics: minus maximized log-likelihood function, AIC, BIC, HQIC, KS and
p-values. It is clear that whereas the exponential distribution failed to fit the data, the MAPE distribution succeeded. It fitted the two datasets with the lowest values of the minus maximized log-likelihood, AIC, BIC, HQIC and KS statistics, as well as the largest
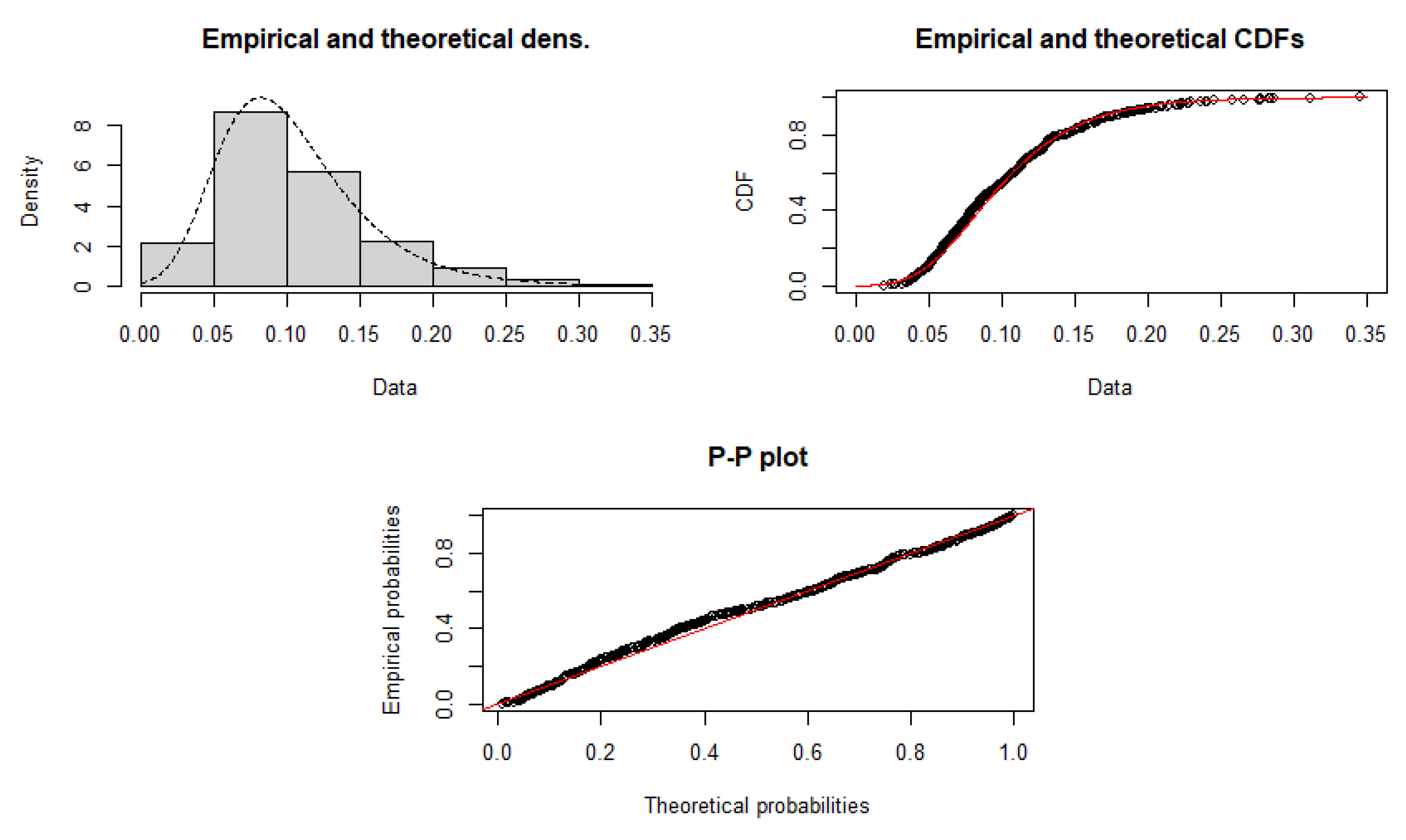
p-values among all models. Thus, it is revealed to be the best model for these data. To compare the empirical distribution of the data with the MAPE distribution,
Figure 4 and
Figure 5 display: (a) a relative histogram and fitted MAPE distribution, (b) plots of the fitted MAPE survival function and the empirical survival and (c) a probability vs. probability (P-P) plot, respectively. These plots support the results reported in
Table 5 and
Table 6.
3.2.2. Failure Stress of Carbon Fibers
The dataset refers to the failure stresses (in GPa) of 64 bundles of carbon fibres [
33] which were also analyzed in [
34] using LET-F family. We transform the recorded failure stresses (
x) using the transformation
. The observations are:
0.000, 0.231, 0.302, 0.327, 0.356, 0.449, 0.460, 0.495, 0.496, 0.544, 0.553, 0.553, 0.573, 0.617, 0.621, 0.624, 0.631, 0.674, 0.713, 0.715, 0.717, 0.723, 0.758, 0.774, 0.837, 0.839, 0.955, 1.016, 1.027, 1.036, 1.036, 1.076, 1.095, 1.129, 1.224, 1.238, 1.244, 1.319, 1.322, 1.334, 1.342, 1.363, 1.371, 1.393, 1.431, 1.445, 1.476, 1.507, 1.534, 1.592, 1.600, 1.636, 1.653, 1.661, 1.727, 1.951, 1.970, 1.985, 2.070, 2.123, 2.126, 2.324, 2.494 and 3.119.
Table 7 provides the MLEs of the parameters of the models and the above statistics. Clearly, the MAPE model fitted the data with the largest
p-value among all fitted models and smaller KS Statistics, as well as minimum values of the maximized log-likelihood, AIC, BIC and HQIC.
Figure 6 supports the results reported in
Table 7.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}