
A Systematic Multichimera Transform for Color Image Representation



Abstract
:1. Introduction
- A simple image transform is proposed based on recursively finding the similarity between a precomputed codebook and image blocks.
- A simple set of 2D functions are derived to build a codebook independently of image contents and dimensions. The size of the codebook is relatively proportional to the image block size.
- This transform supports different image block sizes, which eventually leads to obtaining different compression ratios.
- The matching process between image and codebook is directly conducted without any complex transformations or huge mathematical calculations.
2. Theoretical Background
2.1. Advantages of Mathematical Representation Instead of Data
- Simplified processing: Image processing fields such as filtering, edge detection, resizing, and color conversion require working on each pixel (point in the image). As a result, a huge number of mathematical operations are required. If data are converted into some mathematical representations, this reduces the required number of operations.
- Image analysis and classification: Image analysis and classification depend on similarity between image details. This similarity is sensitive to many factors, such as resizing, rotation, noise contamination, and color changes, while the similarity between mathematical functions could be simpler, faster, and more stable in comparison with the similarity between images. For example, to remove image background, a full analytical process is required to first capture the background and then scan all points to remove the background. If the image is represented as a set of functions, the detection and removal of the background could be simpler because the modification of some coefficients in the function is expected to remove the image background. Our previous work in [25] applied the multichimera transform to image analysis and reconstruction.
- Image security: converting an image block into a mathematical representation provides autocoding for the image because an intruder cannot restore the image without having a particular function library.
2.2. Properties of the Proposed Mathematical Representation
- Efficiency of 2D image representation: the first condition to satisfy a successful transformation; output values of the mathematical expression should be able to give a three-dimensional surface similar in topology to the original image points with small error.
- Simple form functions: Mathematical expressions or functions should be as simple and commonly used as possible; but this requirement might conflict with the first condition. To solve this conflict, an optimization process could be implemented with some skill and experience to determine the type of function depending on the basis of the transformation process, and taking into account the rest of the conditions.
- Suitability for fractals: An important goal of fractal geometry is to describe images in terms of transformations that in some way keep images unaltered. One of the most common properties of fractal geometry is the complex form that results from a simple process.
- Approval for digital: Logical operations and functions are the simplest mathematical form with the fastest implementation, and are more consistent with the computer language. The set of the 2D binary functions that are employed to represent the image in the proposed transform satisfies this condition (see Section 3.1). These functions would make the conversion process more flexible.
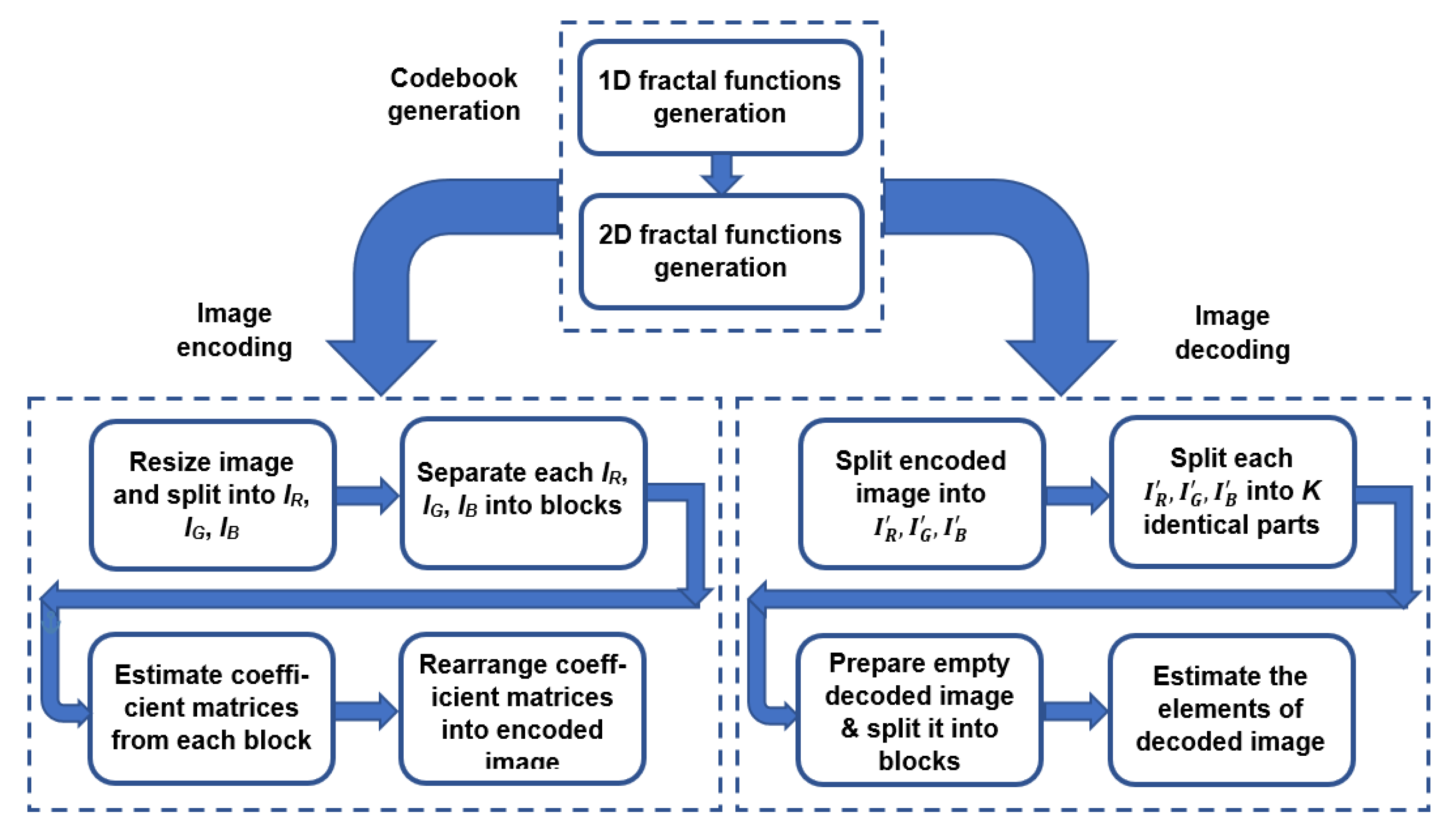
3. Systematic Multichimera Transform (SMCT)
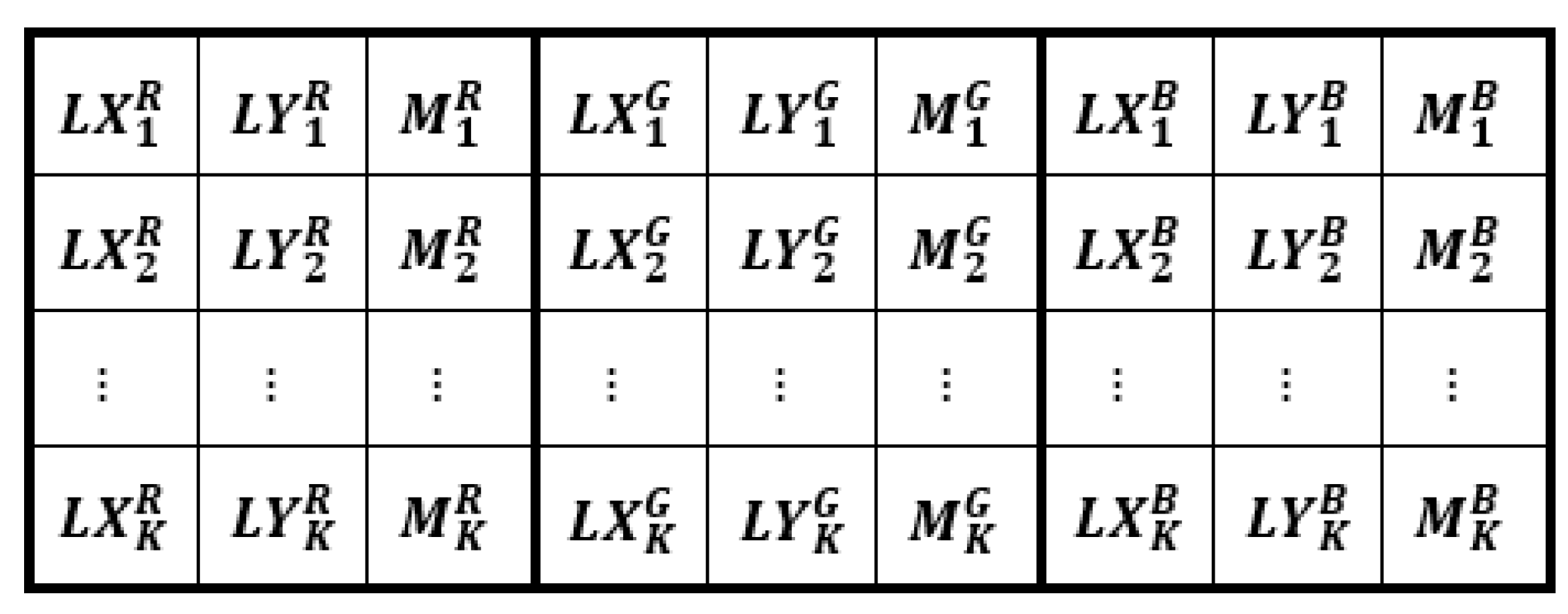
3.1. Codebook Establishment
3.2. Image Encoding
3.3. Image Decoding
4. Experiments and Results
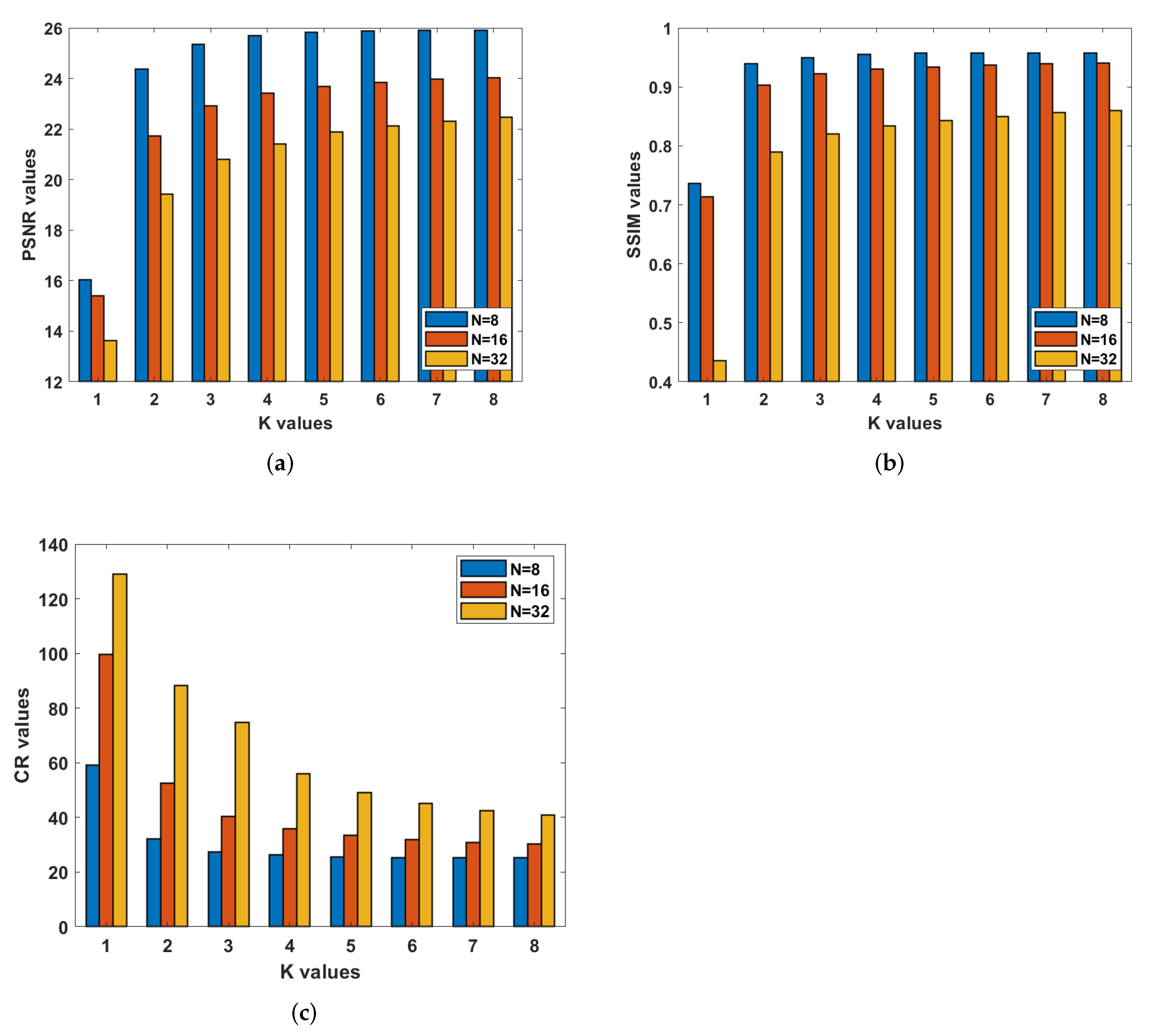
4.1. Length of Coefficient Vector (K) versus Quality and
4.2. Influence of Parameter T versus Quality
4.3. Parameter K versus Parameter N
4.4. Comparison with Standard Transforms
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SMCT | Systematic multichimera transform |
| SSIM | Structural similarity index |
| PSNR | Peak signal-to-noise ratio |
| DWT | Discrete wavelet transform |
| DCT | Discrete cosine transform |
| WHT | Walsh–Hadamard transform |
| KLT | Karhunen–Loeve transform |
| JPEG | Joint Photographic Experts Group |
| PCA | Principal component analysis |
| MAE | Mean absolute error |
| CR | Compression ratio |
| CB | Codebook |
| MSE | Mean square error |
References
- Svynchuk, O.; Barabash, O.; Nikodem, J.; Kochan, R.; Laptiev, O. Image Compression Using Fractal Functions. Fractal Fract. 2021, 5, 31. [Google Scholar] [CrossRef]
- Fares, K.; Amine, K.; Salah, E. A robust blind color image watermarking based on Fourier transform domain. Optik 2020, 208, 164562. [Google Scholar] [CrossRef]
- Abdulsattar, F.S. Towards a high capacity coverless information hiding approach. Multimed. Tools Appl. 2021, 80, 18821–18837. [Google Scholar] [CrossRef]
- UmaMaheswari, S.; SrinivasaRaghavan, V. Lossless medical image compression algorithm using tetrolet transformation. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 4127–4135. [Google Scholar] [CrossRef]
- Zhao, R.; An, L.; Song, D.; Li, M.; Qiao, L.; Liu, N.; Sun, H. Detection of chlorophyll fluorescence parameters of potato leaves based on continuous wavelet transform and spectral analysis. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 259, 119768. [Google Scholar] [CrossRef]
- Khalid, M.J.; Irfan, M.; Ali, T.; Gull, M.; Draz, U.; Glowacz, A.; Sulowicz, M.; Dziechciarz, A.; AlKahtani, F.S.; Hussain, S. Integration of discrete wavelet transform, DBSCAN, and classifiers for efficient content based image retrieval. Electronics 2020, 9, 1886. [Google Scholar] [CrossRef]
- Wang, Z.; Li, X.; Duan, H.; Zhang, X.; Wang, H. Multifocus image fusion using convolutional neural networks in the discrete wavelet transform domain. Multimed. Tools Appl. 2019, 78, 34483–34512. [Google Scholar] [CrossRef]
- Bhuyan, M.K. Computer Vision and Image Processing: Fundamentals and Applications; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Surówka, G.; Ogorzalek, M. Wavelet-based logistic discriminator of dermoscopy images. Expert Syst. Appl. 2021, 167, 113760. [Google Scholar] [CrossRef]
- Begum, M.; Ferdush, J.; Uddin, M.S. A Hybrid robust watermarking system based on discrete cosine transform, discrete wavelet transform, and singular value decomposition. J. King Saud-Univ.-Comput. Inf. Sci. 2021, in press. [Google Scholar] [CrossRef]
- Balsa, J. Comparison of Image Compressions: Analog Transformations. Proceedings 2020, 54, 37. [Google Scholar] [CrossRef]
- Acharya, D.; Billimoria, A.; Srivastava, N.; Goel, S.; Bhardwaj, A. Emotion recognition using fourier transform and genetic programming. Appl. Acoust. 2020, 164, 107260. [Google Scholar] [CrossRef]
- Almurib, H.A.; Kumar, T.N.; Lombardi, F. Approximate DCT image compression using inexact computing. IEEE Trans. Comput. 2017, 67, 149–159. [Google Scholar] [CrossRef]
- Brahimi, N.; Bouden, T.; Brahimi, T.; Boubchir, L. A novel and efficient 8-point DCT approximation for image compression. Multimed. Tools Appl. 2020, 79, 7615–7631. [Google Scholar] [CrossRef]
- Brahimi, N.; Bouden, T.; Brahimi, T.; Boubchir, L. Efficient multiplier-less parametric integer approximate transform based on 16-points DCT for image compression. Multimed. Tools Appl. 2021, 1–24. [Google Scholar] [CrossRef]
- Geetha, V.; Anbumani, V.; Murugesan, G.; Gomathi, S. Hybrid optimal algorithm-based 2D discrete wavelet transform for image compression using fractional KCA. Multimed. Syst. 2020, 26, 687–702. [Google Scholar] [CrossRef]
- Abdulsattar, F.S. On the Effectiveness of Using Wavelet-based LBP Features for Melanoma Recognition in Dermoscopic Images. In Proceedings of the 2021 International Conference on Information Technology (ICIT), Amman, Jordan, 14–15 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 406–411. [Google Scholar]
- Zheng, P.; Huang, J. Efficient encrypted images filtering and transform coding with walsh-hadamard transform and parallelization. IEEE Trans. Image Process. 2018, 27, 2541–2556. [Google Scholar] [CrossRef]
- Dziech, A. New Orthogonal Transforms for Signal and Image Processing. Appl. Sci. 2021, 11, 7433. [Google Scholar] [CrossRef]
- Yang, C.; Zhang, X.; An, P.; Shen, L.; Kuo, C.C.J. Blind Image Quality Assessment Based on Multi-Scale KLT. IEEE Trans. Multimed. 2020, 23, 1557–1566. [Google Scholar] [CrossRef]
- Radünz, A.P.; Bayer, F.M.; Cintra, R.J. Low-complexity rounded KLT approximation for image compression. J. -Real-Time Image Process. 2022, 19, 173–183. [Google Scholar] [CrossRef]
- Khalaf, W.; Zaghar, D.; Hashim, N. Enhancement of curve-fitting image compression using hyperbolic function. Symmetry 2019, 11, 291. [Google Scholar] [CrossRef] [Green Version]
- Khalaf, W.; Al Gburi, A.; Zaghar, D. Pre and Postprocessing for JPEG to Handle Large Monochrome Images. Algorithms 2019, 12, 255. [Google Scholar] [CrossRef] [Green Version]
- Khalaf, W.; Mohammad, A.S.; Zaghar, D. Chimera: A New Efficient Transform for High Quality Lossy Image Compression. Symmetry 2020, 12, 378. [Google Scholar] [CrossRef] [Green Version]
- Mohammad, A.S.; Zaghar, D.; Khalaf, W. Maximizing Image Information Using Multi-Chimera Transform Applied on Face Biometric Modality. Information 2021, 12, 115. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DWT | DCT | SMCT |
|---|---|---|
| Elements of its (Haar) basis functions consist of −1 and +1 only. | Elements of its basis functions are between −1 and +1. | Elements of its basis functions consist of 0 and 1. |
| The energy of its elements is fixed. | The energy of its elements is fixed. | The energy of its elements is decreasing. |
| Orthogonal | Orthogonal | Nonorthogonal |
| Symmetrical | Symmetrical | Symmetrical |
| Image | Quality Metric | K Parameter | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ||
| PSNR | 14.81 | 25.48 | 26.99 | 27.57 | 27.86 | 28 | 28.07 | 28.1 | |
| Lenna | SSIM | 0.535 | 0.946 | 0.959 | 0.964 | 0.966 | 0.967 | 0.968 | 0.968 |
| CR | 75.42 | 34.1 | 28.57 | 27.21 | 26.55 | 26.24 | 26.04 | 25.94 | |
| PSNR | 14.53 | 19.46 | 20.28 | 20.71 | 20.97 | 21.1 | 21.16 | 21.18 | |
| Baboon | SSIM | 0.375 | 0.644 | 0.69 | 0.72 | 0.735 | 0.743 | 0.747 | 0.748 |
| CR | 77.16 | 21.29 | 17.45 | 16.1 | 15.45 | 15.13 | 14.98 | 14.92 | |
| PSNR | 16.03 | 24.38 | 25.36 | 25.7 | 25.83 | 25.89 | 25.91 | 25.92 | |
| Peppers | SSIM | 0.736 | 0.939 | 0.95 | 0.955 | 0.957 | 0.957 | 0.958 | 0.958 |
| CR | 59.15 | 32.07 | 27.41 | 26.23 | 25.67 | 25.39 | 25.28 | 25.20 | |
| PSNR | 14.72 | 27.34 | 29.32 | 29.84 | 30.02 | 30.11 | 30.14 | 30.15 | |
| House | SSIM | 0.508 | 0.928 | 0.952 | 0.96 | 0.963 | 0.964 | 0.965 | 0.966 |
| CR | 105.41 | 40.85 | 34.63 | 32.94 | 31.97 | 31.53 | 31.14 | 30.96 | |
| PSNR | 11.38 | 23.37 | 24.68 | 25.1 | 25.27 | 25.35 | 25.38 | 25.39 | |
| Airplane | SSIM | 0.585 | 0.793 | 0.842 | 0.86 | 0.869 | 0.873 | 0.876 | 0.877 |
| CR | 105.26 | 40.37 | 30.32 | 28.88 | 28.02 | 27.59 | 27.41 | 27.27 | |
| PSNR | 14.12 | 21.93 | 23.09 | 23.59 | 23.81 | 23.92 | 23.96 | 23.97 | |
| Lake | SSIM | 0.523 | 0.83 | 0.864 | 0.878 | 0.884 | 0.887 | 0.888 | 0.888 |
| CR | 66.62 | 25.99 | 21.74 | 20.63 | 20.09 | 19.88 | 19.78 | 19.76 | |
| T | Quality Metric | K Parameter | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ||
| 0.15 | PSNR | 14.79 | 25.37 | 26.86 | 27.46 | 27.79 | 27.95 | 28.04 | 28.08 |
| SSIM | 0.534 | 0.945 | 0.958 | 0.963 | 0.965 | 0.967 | 0.968 | 0.968 | |
| 0.25 | PSNR | 14.81 | 25.48 | 26.99 | 27.57 | 27.86 | 28.00 | 28.07 | 28.10 |
| SSIM | 0.535 | 0.946 | 0.959 | 0.964 | 0.966 | 0.967 | 0.968 | 0.968 | |
| 0.35 | PSNR | 14.82 | 25.50 | 27.00 | 27.55 | 27.82 | 27.95 | 28.00 | 28.02 |
| SSIM | 0.535 | 0.947 | 0.959 | 0.964 | 0.966 | 0.967 | 0.967 | 0.967 | |
| 0.45 | PSNR | 14.82 | 25.42 | 26.92 | 27.48 | 27.74 | 27.86 | 27.91 | 27.92 |
| SSIM | 0.535 | 0.947 | 0.959 | 0.964 | 0.965 | 0.966 | 0.967 | 0.967 | |
| 0.55 | PSNR | 14.79 | 25.14 | 26.69 | 27.30 | 27.58 | 27.70 | 27.75 | 27.77 |
| SSIM | 0.532 | 0.945 | 0.958 | 0.963 | 0.965 | 0.965 | 0.966 | 0.966 | |
| 0.65 | PSNR | 14.72 | 24.54 | 26.21 | 26.99 | 27.33 | 27.48 | 27.55 | 27.57 |
| SSIM | 0.528 | 0.941 | 0.956 | 0.961 | 0.963 | 0.964 | 0.964 | 0.965 | |
| 0.75 | PSNR | 14.53 | 23.55 | 25.38 | 26.32 | 26.82 | 27.06 | 27.18 | 27.24 |
| SSIM | 0.518 | 0.932 | 0.950 | 0.957 | 0.961 | 0.962 | 0.963 | 0.963 | |
| 0.85 | PSNR | 14.23 | 22.21 | 24.09 | 25.27 | 25.95 | 26.35 | 26.56 | 26.67 |
| SSIM | 0.502 | 0.917 | 0.940 | 0.951 | 0.956 | 0.958 | 0.960 | 0.960 | |
| 0.95 | PSNR | 13.73 | 20.48 | 22.35 | 23.64 | 24.52 | 25.09 | 25.45 | 25.65 |
| SSIM | 0.476 | 0.891 | 0.922 | 0.937 | 0.946 | 0.951 | 0.954 | 0.955 | |
| Image | Quality Metric | Transform | ||
|---|---|---|---|---|
| DWT | DCT | SMTC | ||
| Lenna | PSNR | 26.77 | 27.2 | 27.57 |
| SSIM | 0.954 | 0.955 | 0.964 | |
| Baboon | PSNR | 20.28 | 20.41 | 20.71 |
| SSIM | 0.655 | 0.657 | 0.720 | |
| Peppers | PSNR | 25.39 | 26.18 | 25.7 |
| SSIM | 0.946 | 0.953 | 0.955 | |
| House | PSNR | 28.41 | 29.07 | 29.84 |
| SSIM | 0.937 | 0.937 | 0.960 | |
| Airplane | PSNR | 24.78 | 25.31 | 25.10 |
| SSIM | 0.836 | 0.773 | 0.860 | |
| Lake | PSNR | 23.00 | 23.61 | 23.59 |
| SSIM | 0.849 | 0.852 | 0.878 | |
| Average | PSNR | 24.77 | 25.29 | 25.41 |
| SSIM | 0.862 | 0.854 | 0.889 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdulsattar, F.S.; Zaghar, D.; Khalaf, W. A Systematic Multichimera Transform for Color Image Representation. Symmetry 2022, 14, 516. https://doi.org/10.3390/sym14030516
Abdulsattar FS, Zaghar D, Khalaf W. A Systematic Multichimera Transform for Color Image Representation. Symmetry. 2022; 14(3):516. https://doi.org/10.3390/sym14030516
Chicago/Turabian StyleAbdulsattar, Fatimah Shamsulddin, Dhafer Zaghar, and Walaa Khalaf. 2022. "A Systematic Multichimera Transform for Color Image Representation" Symmetry 14, no. 3: 516. https://doi.org/10.3390/sym14030516
APA StyleAbdulsattar, F. S., Zaghar, D., & Khalaf, W. (2022). A Systematic Multichimera Transform for Color Image Representation. Symmetry, 14(3), 516. https://doi.org/10.3390/sym14030516