
Research on Aspect-Level Sentiment Analysis Based on Text Comments

Abstract
:1. Introduction
- The SemEval 14 Restaurant Review dataset is divided into two versions, ATSA and ACSA. For ATSA, we extract aspect terms from sentences and map them with the corresponding sentiment polarity, and then remove sentences with the same opinion in one aspect or multiple aspects. For ACSA, each sentence is mapped to an aspect category and corresponds to the sentiment of that aspect category.
- A baseline model, CapsNet-BERT, is proposed. By optimizing the dynamic routing algorithm and sharing global parameters, the relationship between the local features of text sentences and the overall sentiment polarity is obtained, avoiding the degradation of aspect-level sentiment analysis to single sentence-level sentiment analysis.
- The baseline model CapsNet-BERT connects the aspect embedding with each word of the sentence embedding and feeds it back to the bidirectional GRU through the residual connections to obtain a contextual representation, which more accurately predicts the sentiment polarity of related sentences.
2. Related Works
2.1. Augmenting ABSA with Capsule Networks
2.2. Using BERT Model to Study ABSA
- It breaks the limitation that RNN models cannot perform parallel operations on a large data corpus of textual contexts.
- In contrast to CNN, the number of operations required to compute the association between two locations does not increase with distance.
- In the attention mechanism, examine the content of the textual context word attention distribution. Each focus can learn to perform different tasks.
3. Experimental Design
3.1. Datasets
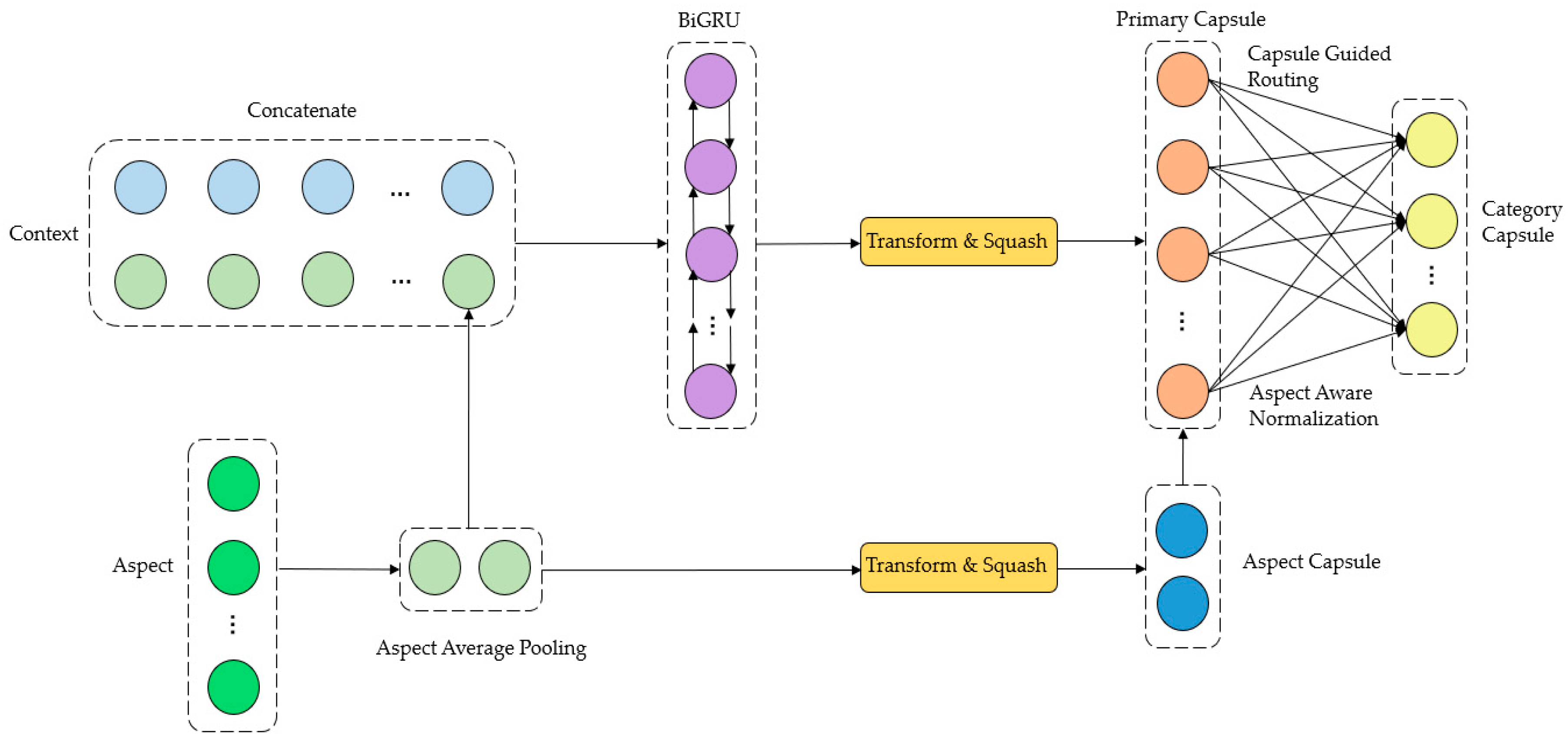
3.2. Model Design
3.3. Methodology
3.3.1. Embedding Layer
3.3.2. Encoding Layer
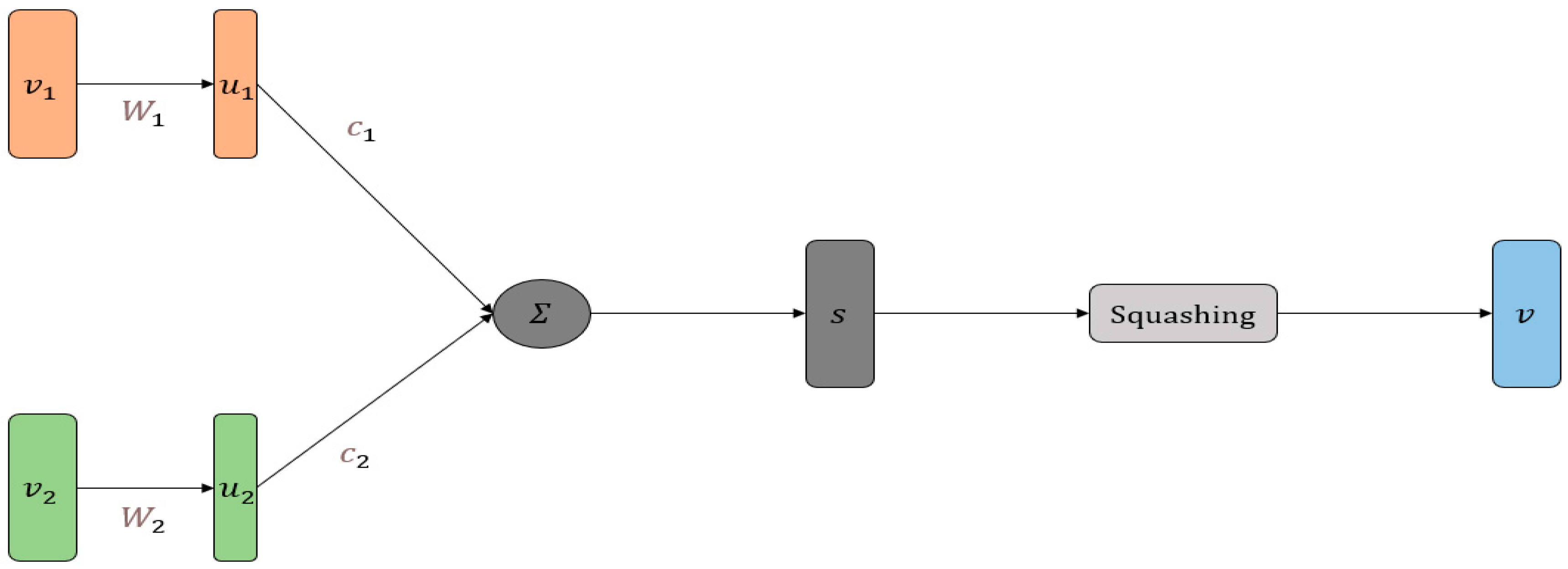
3.3.3. Primary Capsule Layer
- Aspect aware normalization, in order to overcome the problem of training instability due to variation in sentence length, we use aspect capsule to normalize the primary capsule weights [33]. When applied to text, the uncertainty of text length can lead to instability in the training process, which is a problem that needs to be addressed by the capsule network. Specifically, when the text is long, the number of primary capsules is large, which will cause the mold of the upper-layer capsule to become larger, resulting in a higher probability of each upper-layer superstructure capsule unit cell. Therefore, the standardization mechanism (scaling the values of a column of numerical features in the training set to a mean of 0 and a variance of 1) is used in the paper, and standardization in deep learning better maintains sample spacing. When there are outliers in the samples, normalization may “crowd” the normal samples together. For example, if there are three samples, and the value of a feature is 1, 2, 10,000, suppose 10,000 is an outlier, after using normalization, the normal 1 and 2 will be “squeezed” together. If the classification labels of 1 and 2 are opposite, then when we use gradient descent to train the classification model, it will take longer for the model to converge because it requires more effort to separate the samples, whereas standardization does a good job in this regard, at least it does not “squeeze” the samples together. Standardization is more in line with the statistical assumption that for a numerical feature, it is very likely to follow a normal distribution. Standardization is actually based on the implicit assumption that the normal distribution is adjusted to a standard normal distribution with mean 0 and variance 1. where is the learning parameter, as shown in Formula (8):
- Capsule guided routing exploits the prior knowledge between sentiment contextual text attribute categories to improve the routing process [18,34]. In the training process, the sentiment matrix is calculated by averaging the manually collected word embeddings of similar sentiment words, and then the number of sentiment categories is obtained. is the dimensionality of the sentiment embedding. The input squeeze activation function to obtain the sentiment capsules = [, …, ], and then the routing weight is calculated by measuring the similarity between the primary capsule layer and the sentiment capsule.
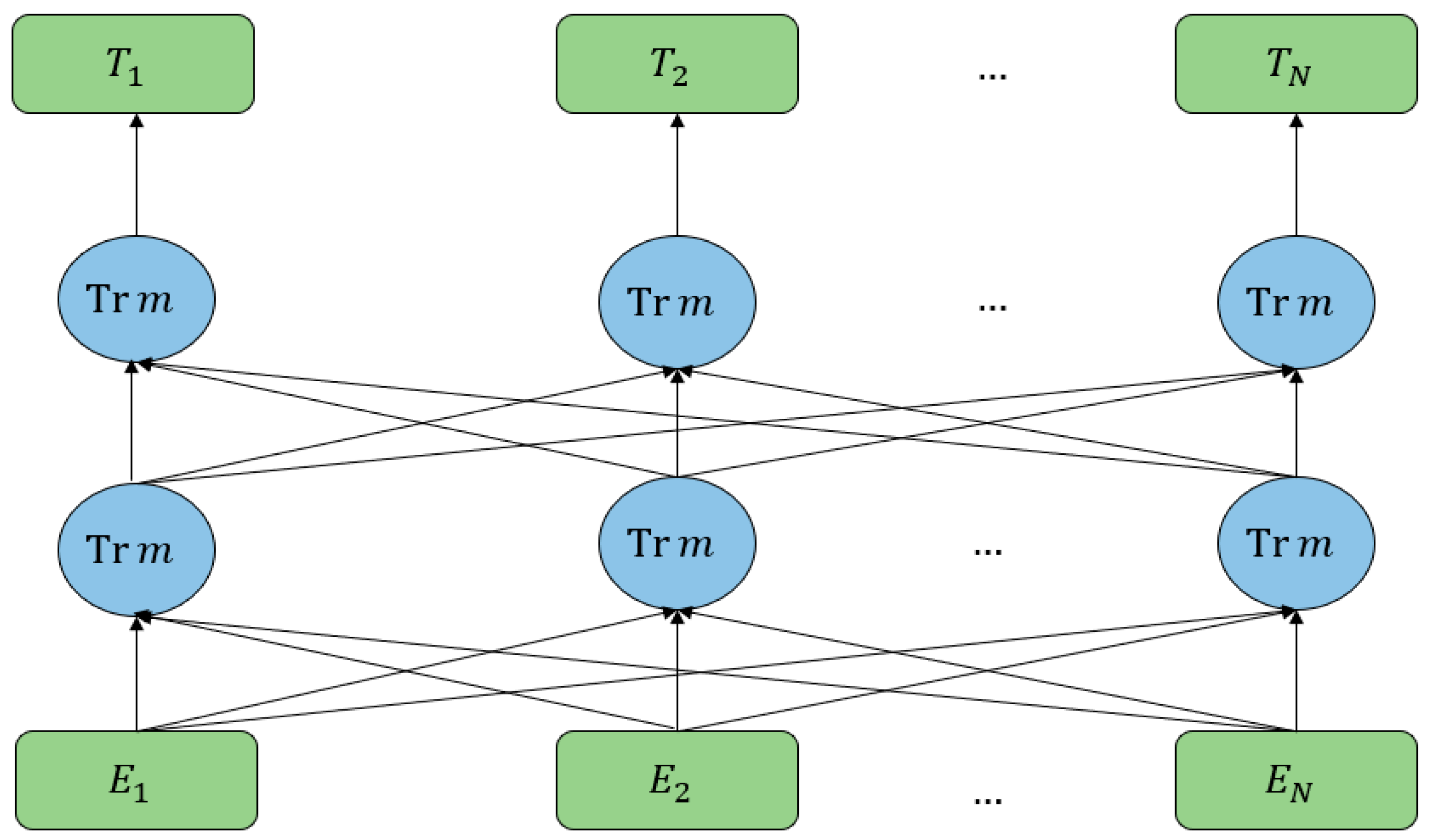
3.3.4. Category Capsule Layer
4. Experimental Details
4.1. Experimental Parameters
4.2. Experimental Evaluation Metrics
4.2.1. Accuracy
4.2.2. Precision
4.2.3. Recall
4.2.4. F1-Measure
4.3. Model Performance Experimental Comparison Analysis
- As described in Table 8, the Laptop Review dataset outperformed ATSA and ACSA in the sentence sentiment classifiers TextCNN and LSTM, suggesting that ATSA and ACSA can avoid degrading the dataset into sentence-level sentiment analysis.
- The SOTA ABSA method on the Laptop Review dataset performs poorly on ATSA and ACSA, indicating that the ATSA and ACSA datasets are challenging to train the corpus for textual contextual affective lexicality.
- Attention-based models without proper modeling of textual word sequences do not perform well because the sequential information of sentences is lost, resulting in inadequate processing of the ATSA and ACSA datasets, and therefore fail to link context to aspects.
- On the datasets Laptop Review, ATSA, and ACSA, the combined CapsNet-BERT performs better than its text feature word extraction model.
4.4. Ablation Study
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Madhoushi, Z.; Hamdan, A.R.; Zainudin, S. Aspect-based sentiment analysis methods in recent years. Asia-Pac. J. Inf. Technol. Multimed. 2019, 7, 79–96. [Google Scholar]
- Moreno-Ortiz, A.; Salles-Bernal, S.; Orrequia-Barea, A. Design and validation of annotation schemas for aspect-based sentiment analysis in the tourism sector. Inf. Technol. Tour. 2019, 21, 535–557. [Google Scholar] [CrossRef]
- Al-Smadi, M.; Al-Ayyoub, M.; Jararweh, Y.; Qawasmeh, O. Enhancing aspect-based sentiment analysis of Arabic hotels’ reviews using morphological, syntactic and semantic features. Inf. Process. Manag. 2019, 56, 308–319. [Google Scholar] [CrossRef]
- Tran, T.U.; Hoang, H.T.T.; Dang, P.H.; Riveill, M. Multitask Aspect_Based Sentiment Analysis with Integrated Bidirectional LSTM & CNN Model. IAES Int. J. Artif. Intell. 2020, 9, 1–7. [Google Scholar]
- Lyu, C.; Chen, B.; Ren, Y.; Ji, D. Long short-term memory RNN for biomedical named entity recognition. BMC Bioinform. 2017, 18, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Yadav, A.; Vishwakarma, D.K. Sentiment analysis using deep learning architectures: A review. Artif. Intell. Rev. 2020, 53, 4335–4385. [Google Scholar] [CrossRef]
- Hemmatian, F.; Sohrabi, M.K. A survey on classification techniques for opinion mining and sentiment analysis. Artif. Intell. Rev. 2019, 52, 1495–1545. [Google Scholar] [CrossRef]
- Yan, W.; Zhou, L.; Qian, Z.; Xiao, L.; Zhu, H. Sentiment Analysis of Student Texts Using the CNN-BiGRU-AT Model. Sci. Program. 2021, 2021, 8405623. [Google Scholar] [CrossRef]
- Lv, Y.; Wei, F.; Cao, L.; Peng, S.; Niu, J.; Yu, S.; Wang, C. Aspect-level sentiment analysis using context and aspect memory network. Neurocomputing 2021, 428, 195–205. [Google Scholar] [CrossRef]
- Pang, G.; Lu, K.; Zhu, X.; He, J.; Mo, Z.; Peng, Z.; Pu, B. Aspect-Level Sentiment Analysis Approach via BERT and Aspect Feature Location Model. Wirel. Commun. Mob. Comput. 2021, 2021, 5534615. [Google Scholar] [CrossRef]
- Sun, C.; Lv, L.; Tian, G.; Liu, T. Deep Interactive Memory Network for Aspect-Level Sentiment Analysis. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2020, 20, 1–12. [Google Scholar] [CrossRef]
- Zhu, T.; Li, L.; Yang, J.; Zhao, S.; Liu, H.; Qian, J. Multimodal sentiment analysis with image-text interaction network. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Pathik, N.; Shukla, P. Aspect Based Sentiment Analysis of Unlabeled Reviews Using Linguistic Rule Based LDA. J. Cases Inf. Technol. 2022, 24, 1–9. [Google Scholar] [CrossRef]
- Naseem, U.; Razzak, I.; Musial, K.; Imran, M. Transformer based deep intelligent contextual embedding for twitter sentiment analysis. Future Gener. Comput. Syst. 2020, 113, 58–69. [Google Scholar] [CrossRef]
- Shuang, K.; Yang, Q.; Loo, J.; Li, R.; Gu, M. Feature distillation network for aspect-based sentiment analysis. Inf. Fusion 2020, 61, 13–23. [Google Scholar] [CrossRef]
- Li, W.; Qi, F.; Tang, M.; Yu, Z. Bidirectional LSTM with self-attention mechanism and multi-channel features for sentiment classification. Neurocomputing 2020, 387, 63–77. [Google Scholar] [CrossRef]
- Zou, H.; Xiang, K. Sentiment classification method based on blending of emoticons and short texts. Entropy 2022, 24, 398. [Google Scholar] [CrossRef]
- Camacho, D.M.; Collins, K.M.; Powers, R.K.; Costello, J.C.; Collins, J.J. Next-generation machine learning for biological networks. Cell 2018, 73, 1581–1592. [Google Scholar] [CrossRef] [Green Version]
- Jagannath, J.; Polosky, N.; Jagannath, A.; Restuccia, F.; Melodia, T. Machine learning for wireless communications in the Internet of Things: A comprehensive survey. Ad Hoc Netw. 2019, 93, 101913. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Tang, P.; Zhao, L. Remote sensing image scene classification using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef] [Green Version]
- Lian, Z.; Liu, B.; Tao, J. SMIN: Semi-supervised Multi-modal Interaction Network for Conversational Emotion Recognition. IEEE Trans. Affect. Comput. 2022. [Google Scholar] [CrossRef]
- Acheampong, F.A.; Nunoo-Mensah, H.; Chen, W. Transformer models for text-based emotion detection: A review of BERT-based approaches. Artif. Intell. Rev. 2021, 54, 5789–5829. [Google Scholar] [CrossRef]
- Orkphol, K.; Yang, W. Word sense disambiguation using cosine similarity collaborates with Word2vec and WordNet. Future Internet 2019, 11, 114. [Google Scholar] [CrossRef] [Green Version]
- Ji, C.; Wu, H. Cascade architecture with rhetoric long short-term memory for complex sentence sentiment analysis. Neurocomputing 2020, 405, 161–172. [Google Scholar] [CrossRef]
- He, Z.; Wang, Z.; Wei, W.; Feng, S.; Mao, X.; Jiang, S. A Survey on Recent Advances in Sequence Labeling from Deep Learning Models. arXiv 2020, arXiv:2011.06727. [Google Scholar]
- Si, Y.; Wang, J.; Xu, H.; Roberts, K. Enhancing clinical concept extraction with contextual embeddings. J. Am. Med. Inform. Assoc. 2019, 26, 1297–1304. [Google Scholar] [CrossRef] [Green Version]
- Vo, A.D.; Nguyen, Q.P.; Ock, C.Y. Semantic and syntactic analysis in learning representation based on a sentiment analysis model. Appl. Intell. 2020, 50, 663–680. [Google Scholar] [CrossRef]
- Yue, L.; Chen, W.; Li, X.; Zuo, W.; Yin, M. A survey of sentiment analysis in social media. Knowl. Inf. Syst. 2019, 60, 617–663. [Google Scholar] [CrossRef]
- Tembhurne, J.V.; Diwan, T. Sentiment analysis in textual, visual and multimodal inputs using recurrent neural networks. Multimed. Tools Appl. 2021, 80, 6871–6910. [Google Scholar] [CrossRef]
- Kumar, A.; Narapareddy, V.T.; Srikanth, V.A.; Neti, L.B.M.; Malapati, A. Aspect-based sentiment classification using interactive gated convolutional network. IEEE Access 2020, 8, 22445–22453. [Google Scholar] [CrossRef]
- He, R.; Lee, W.S.; Ng, H.T.; Dahlmeier, D. Exploiting Document Knowledge for Aspect-level Sentiment Classification. Proc. 56th Annu. Meet. Assoc. Comput. Linguist. 2018, 2, 579–585. [Google Scholar]
- Deng, Y.; Lei, H.; Li, X.; Lin, Y.; Cheng, W.; Yang, S. Attention Capsule Network for Aspect-Level Sentiment Classification. KSII Trans. Internet Inf. Syst. 2021, 15, 1275–1292. [Google Scholar]
- Wadawadagi, R.; Pagi, V. Sentiment analysis with deep neural networks: Comparative study and performance assessment. Artif. Intell. Rev. 2020, 53, 6155–6195. [Google Scholar] [CrossRef]
- Sharma, T.; Kaur, K. Benchmarking Deep Learning Methods for Aspect Level Sentiment Classification. Appl. Sci. 2021, 11, 10542. [Google Scholar] [CrossRef]
- Xu, H.; Liu, B.; Shu, L.; Yu, P.S. BERT Post-Training for Review Reading Comprehension and Aspect-based Sentiment Analysis. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 2324–2335. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Attribute Word (Number) | Each Sentence Contains Attributes (Number) | Each Sentence Contains Aspects (Number) | |
|---|---|---|---|
| Training set | 3805 | 2475 | 2.61 |
| Test set | 955 | 619 | 2.62 |
| Validation set | 1898 | 1241 | 2.60 |
| Attribute Word (Number) | Each Sentence Contains Attributes (Number) | Each Sentence Contains Aspects (Number) | |
|---|---|---|---|
| Training set | 2459 | 1607 | 2.25 |
| Test set | 630 | 411 | 2.25 |
| Validation set | 1280 | 853 | 2.22 |
| Attribute Word (Number) | Each Sentence Contains Attributes (Number) | Each Sentence Contains Aspects (Number) | |
|---|---|---|---|
| Training set | 3351 | 2134 | 2.52 |
| Test set | 1032 | 402 | 2.53 |
| Validation set | 1280 | 853 | 2.51 |
| Recurrent_Capsnet | Values |
|---|---|
| embed_size | 300 |
| dropout | 0.5 |
| num_layers | 2 |
| capsule_size | 300 |
| bidirectional | True |
| optimizer | Adam |
| batch_size | 64 |
| learning_rate | 0.0003 |
| weight_decay | 0 |
| num_epoches | 20 |
| Bert_Capsnet | Values |
|---|---|
| bert_size | 768 |
| dropout | 0.1 |
| capsule_size | 300 |
| optimizer | Adam |
| batch_size | 32 |
| learning_rate | 0.00002 |
| weight_decay | 0 |
| num_epoches | 5 |
| Recurrent_Capsnet | Values |
|---|---|
| embed_size | 300 |
| dropout | 0.5 |
| num_layers | 2 |
| capsule_size | 300 |
| bidirectional | True |
| optimizer | Adam |
| batch_size | 64 |
| learning_rate | 0.0003 |
| weight_decay | 0 |
| num_epoches | 20 |
| Bert_Capsnet | Values |
|---|---|
| bert_size | 768 |
| dropout | 0.1 |
| capsule_size | 300 |
| optimizer | Adam |
| batch_size | 32 |
| learning_rate | 0.00003 |
| weight_decay | 0 |
| num_epoches | 5 |
| Models | ATSA | ACSA | Laptop Review | |||
|---|---|---|---|---|---|---|
| Accuracy | F1 | Accuracy | F1 | Accuracy | F1 | |
| TextCNN | 51.62 | 51.53 | 48.79 | 48.61 | 75.85 | 75.23 |
| LSTM | 50.46 | 50.13 | 48.74 | 48.65 | 75.83 | 75.01 |
| TD_LSTM | 75.49 | 73.38 | - | - | 75.92 | 75.20 |
| AT_LSTM | 77.43 | 73.58 | 66.42 | 65.31 | 73.85 | 72.13 |
| ATAE_LSTM | 77.18 | 71.62 | 70.13 | 66.78 | 77.68 | 76.19 |
| BiLSTM+Attn | 76.18 | 70.62 | 66.25 | 66.16 | 77.47 | 77.12 |
| AOA_LSTM | 76.35 | 71.14 | - | - | 81.25 | 81.06 |
| CapsNet | 79.80 | 73.47 | 73.54 | 67.25 | 80.58 | 80.12 |
| BERT | 82.25 | 79.41 | 84.68 | 75.52 | 79.68 | 78.29 |
| CapsNet-BERT | 83.49 | 80.96 | 85.69 | 76.32 | 80.62 | 79.62 |
| CapsNet-DR | 79.89 | 71.36 | 69.18 | 65.32 | 76.78 | 76.12 |
| CapsNet-BERT-DR | 82.95 | 80.07 | 79.73 | 75.42 | 79.53 | 78.23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, J.; Slamu, W.; Xu, M.; Xu, C.; Wang, X. Research on Aspect-Level Sentiment Analysis Based on Text Comments. Symmetry 2022, 14, 1072. https://doi.org/10.3390/sym14051072
Tian J, Slamu W, Xu M, Xu C, Wang X. Research on Aspect-Level Sentiment Analysis Based on Text Comments. Symmetry. 2022; 14(5):1072. https://doi.org/10.3390/sym14051072
Chicago/Turabian StyleTian, Jing, Wushour Slamu, Miaomiao Xu, Chunbo Xu, and Xue Wang. 2022. "Research on Aspect-Level Sentiment Analysis Based on Text Comments" Symmetry 14, no. 5: 1072. https://doi.org/10.3390/sym14051072
APA StyleTian, J., Slamu, W., Xu, M., Xu, C., & Wang, X. (2022). Research on Aspect-Level Sentiment Analysis Based on Text Comments. Symmetry, 14(5), 1072. https://doi.org/10.3390/sym14051072