
Research on Prediction Method of Gear Pump Remaining Useful Life Based on DCAE and Bi-LSTM

Abstract
:1. Introduction
2. Theoretical Background
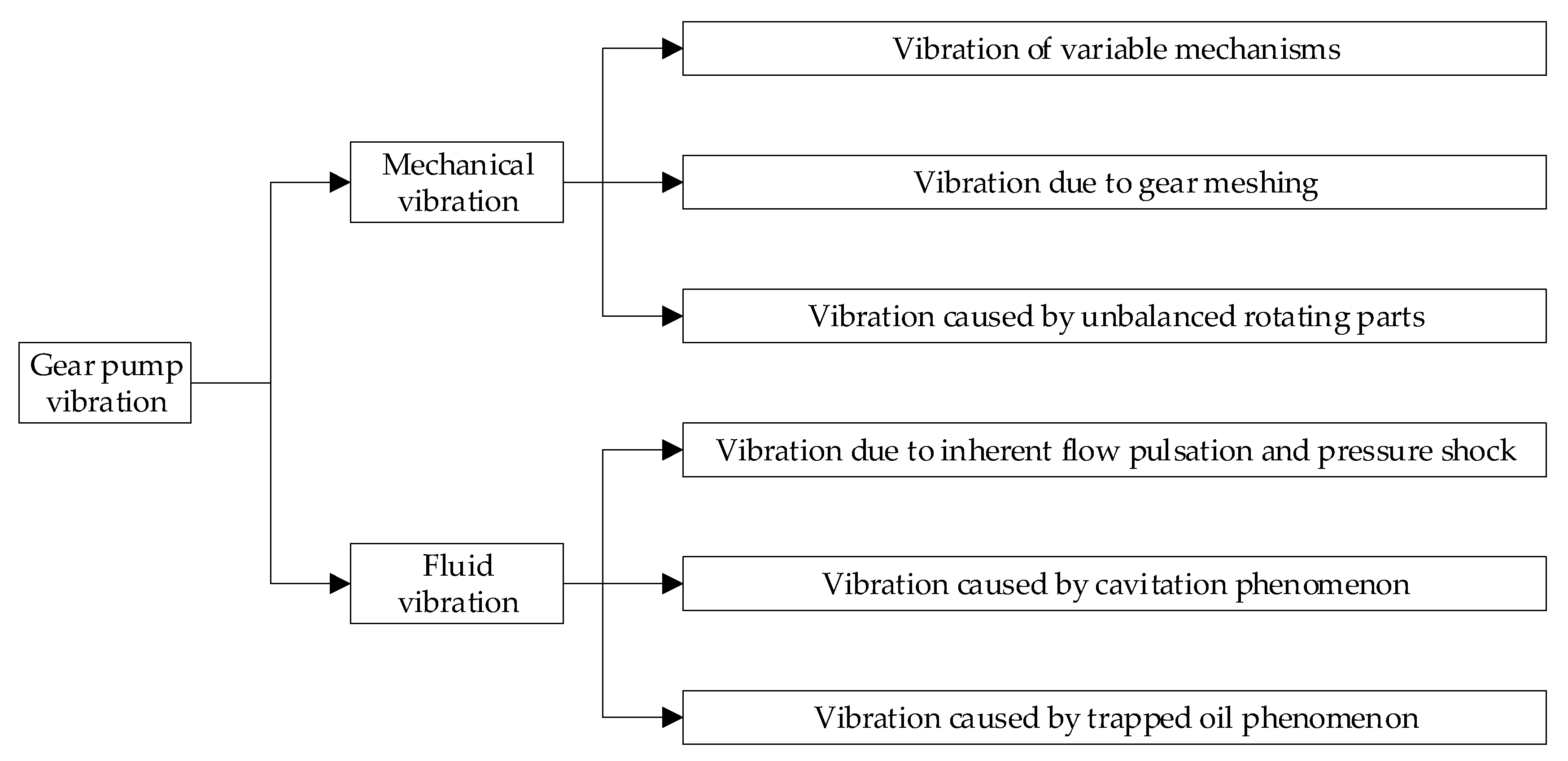
2.1. Degradation Analysis of Gear Pump
2.2. Autoencoder (AE)
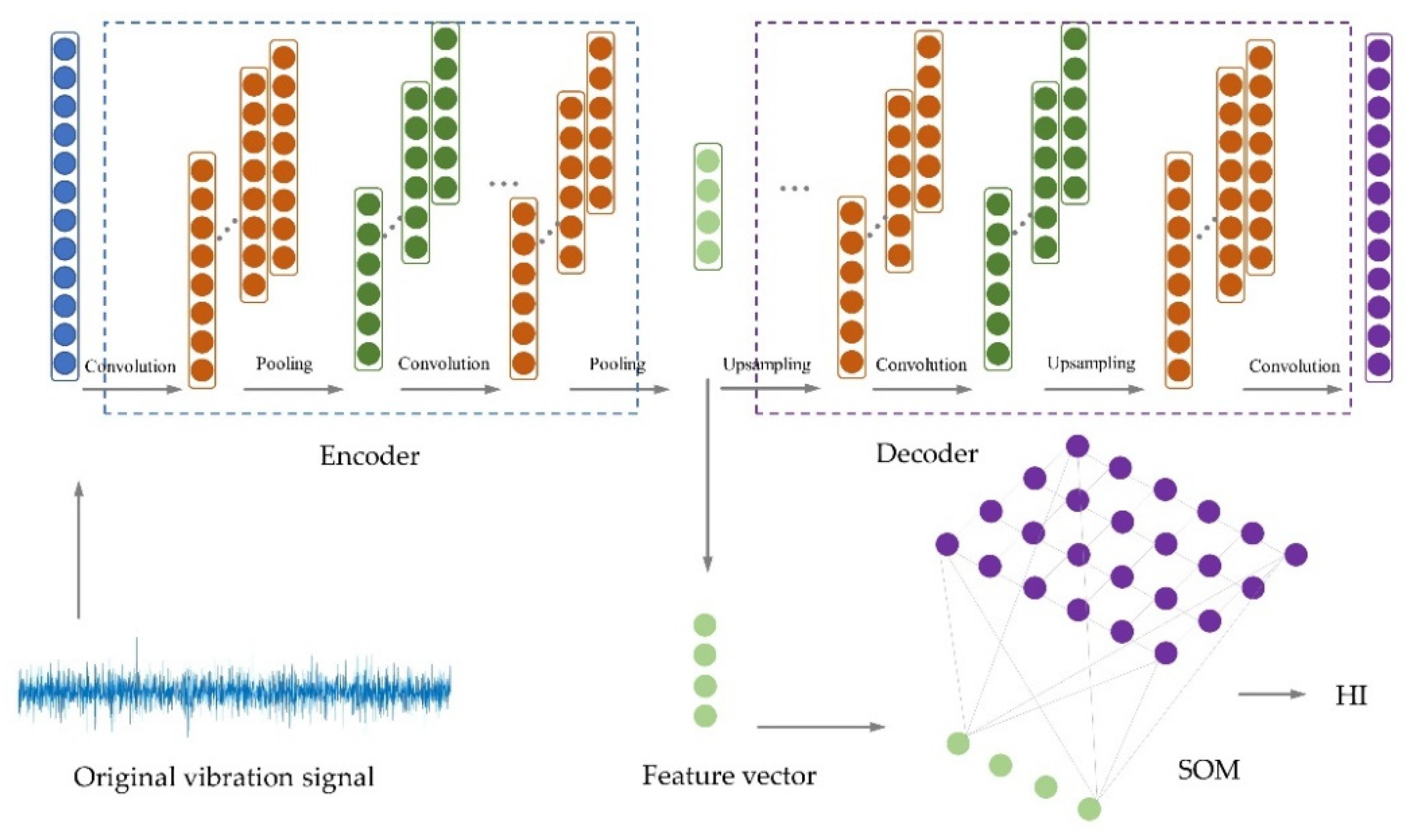
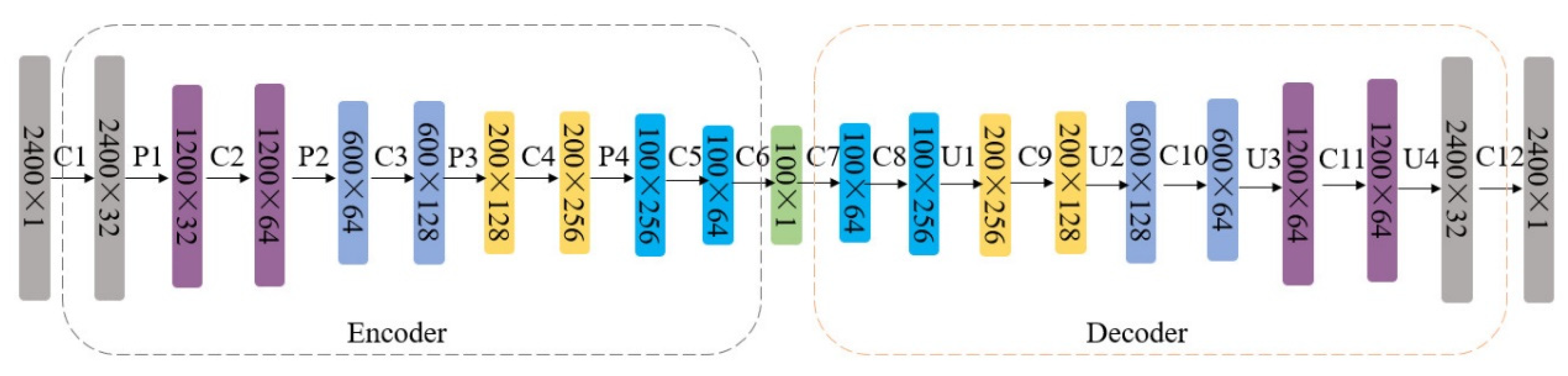
Convolutional Autoencoder (CAE)
2.3. Convolutional Neural Network (CNN)
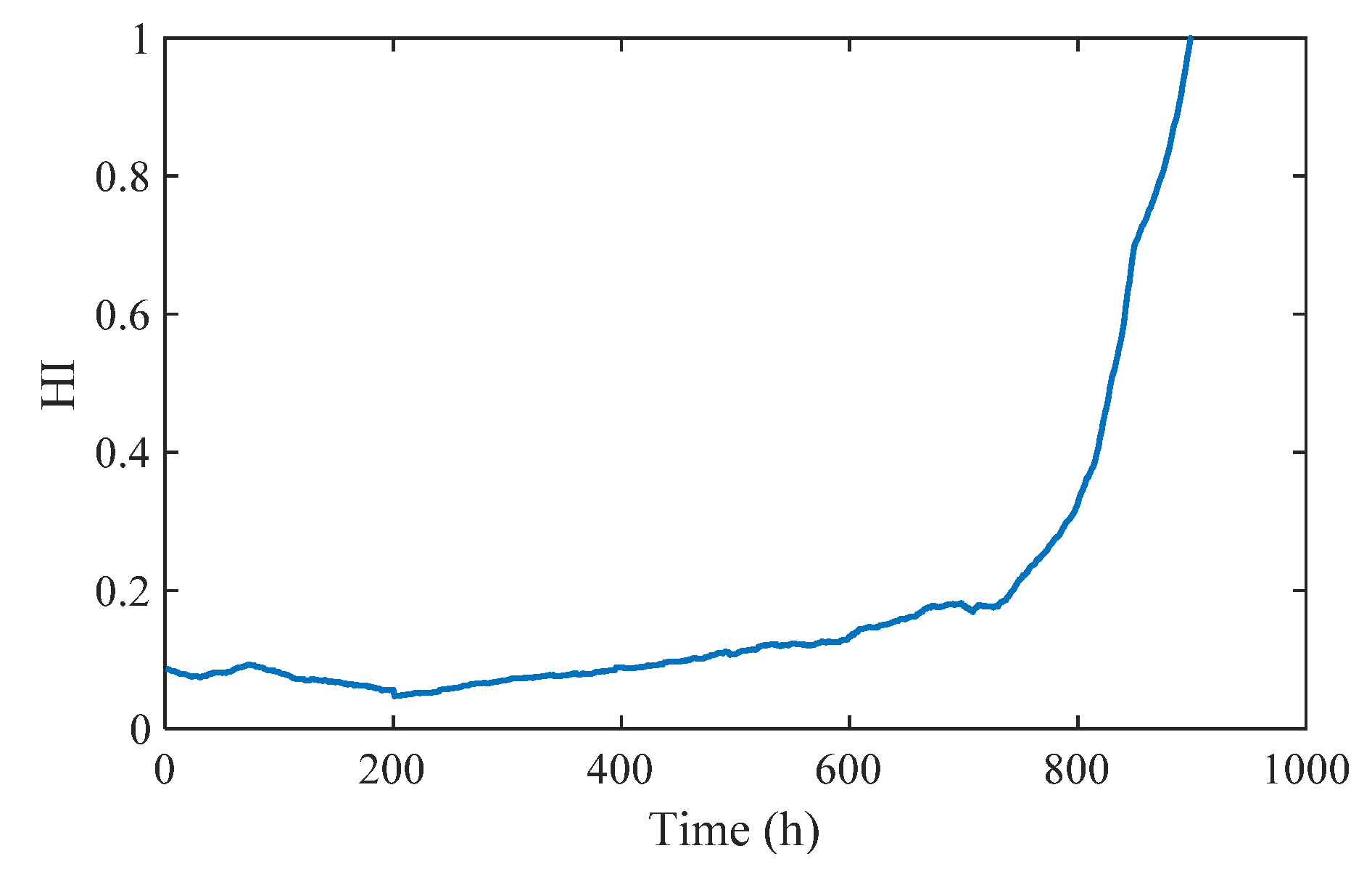
2.4. Self-Organizing Map (SOM) Network
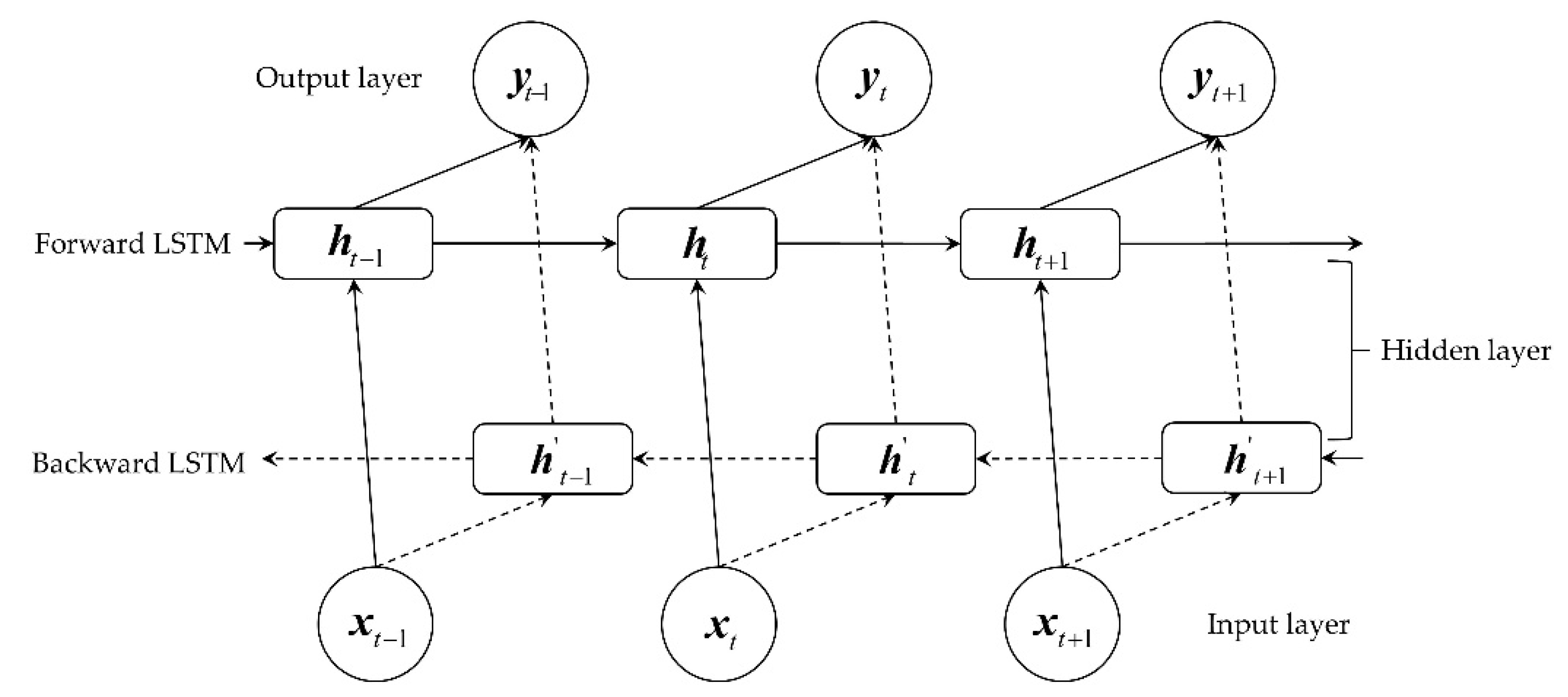
2.5. Long Short-Term Memory (LSTM)
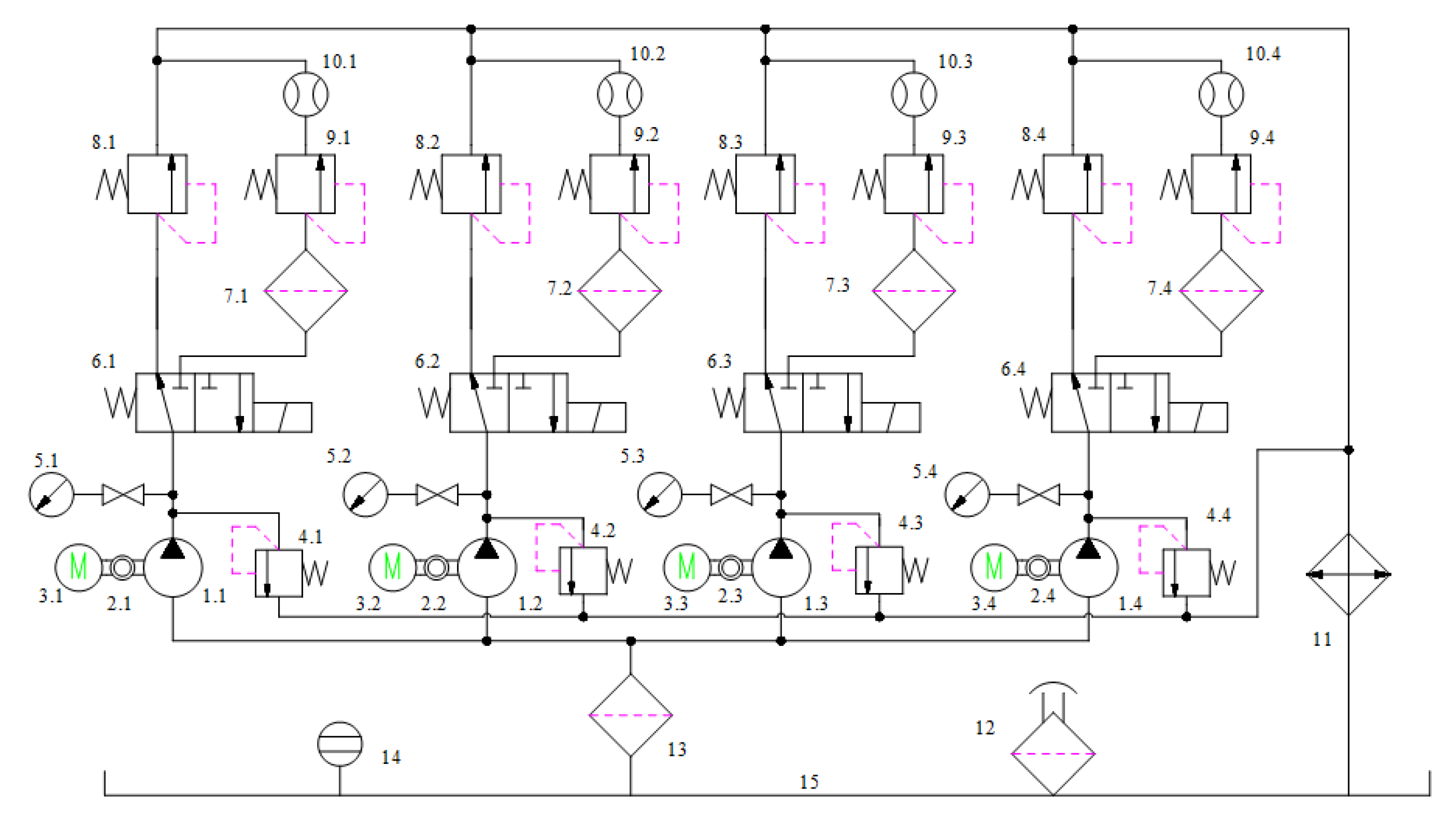
3. Experimental Settings
- (1)
- The pressure of the collection branch is adjusted to 20 MPa, and the test pressure is adjusted to the first stage pressure of 23 MPa;
- (2)
- The system is switched to the collection branch, and the preliminary flow of the gear pump is recorded;
- (3)
- During the test, at first, the system works under the accelerated pressure for 10 min, and then the system is switched to the collection branch for data acquisition;
- (4)
- The test method uses a non-substitute time tac-tail life test. The whole experiment is divided into three stages, and the time length of each stage is 300 h. The pressure of the first stage is 23 MPa, the pressure of the second stage is 25 MPa, and the pressure of the third stage is 27 MPa until the end of the operation.
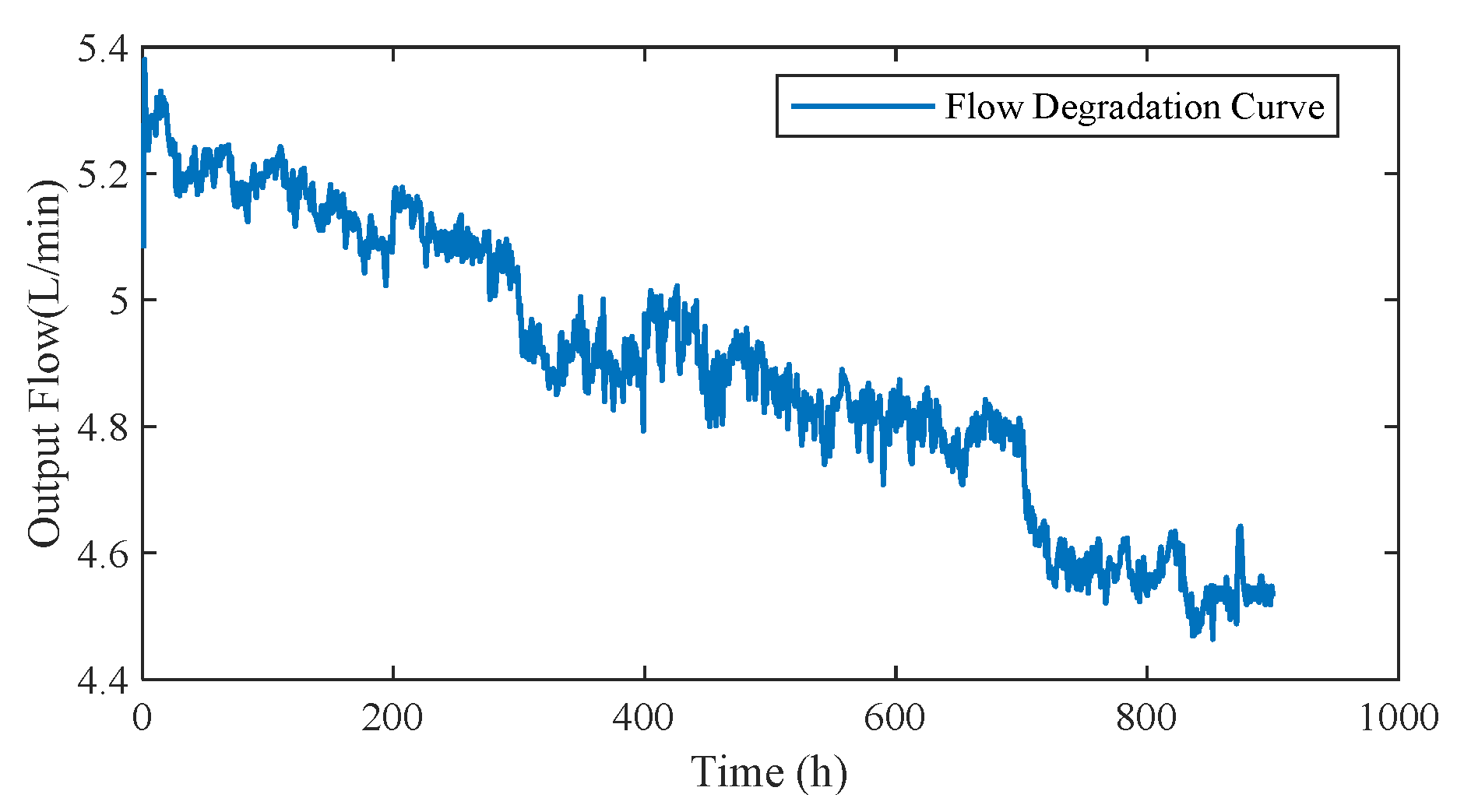
Determination of Test Data
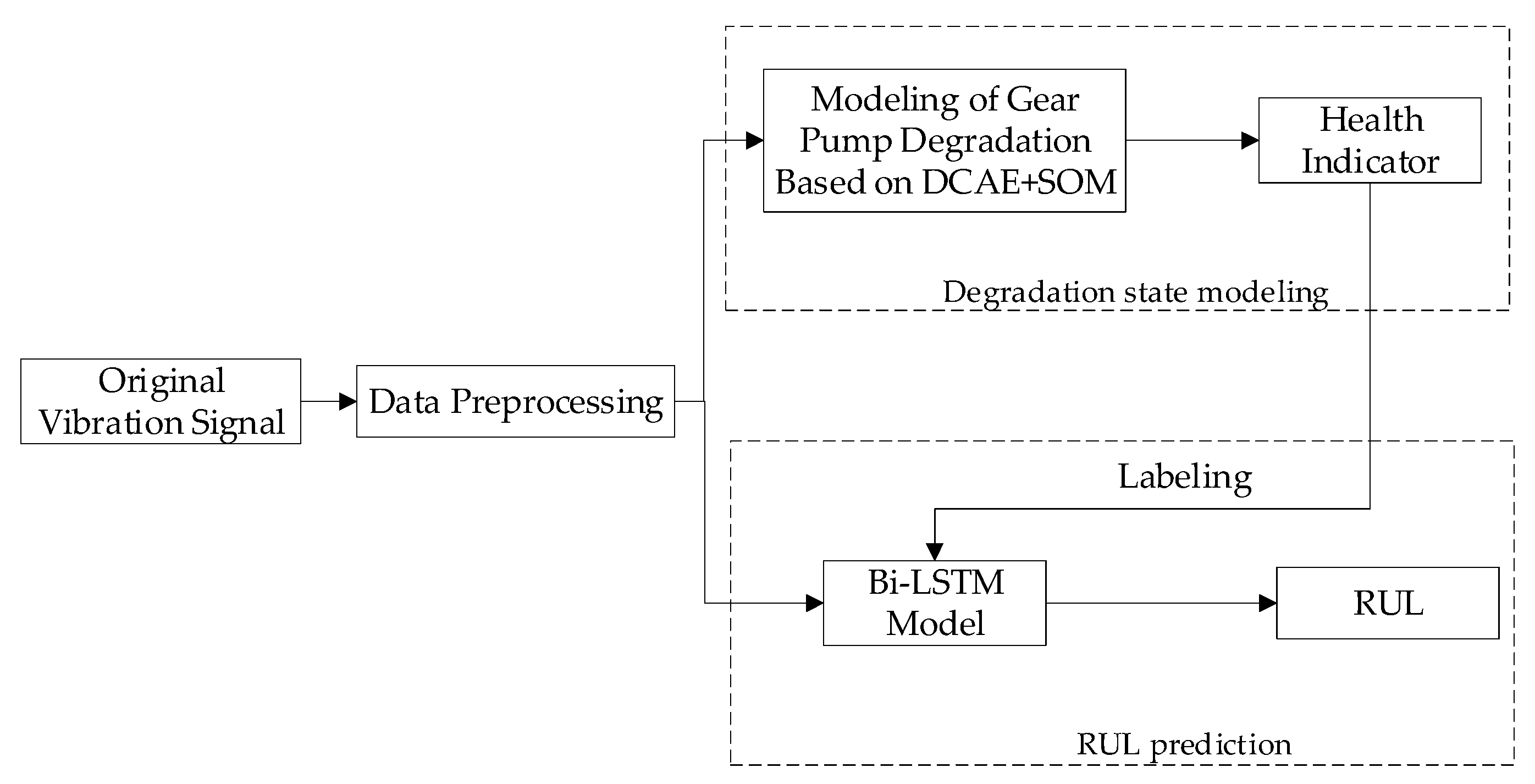
4. Modeling of Gear Pump Degradation State
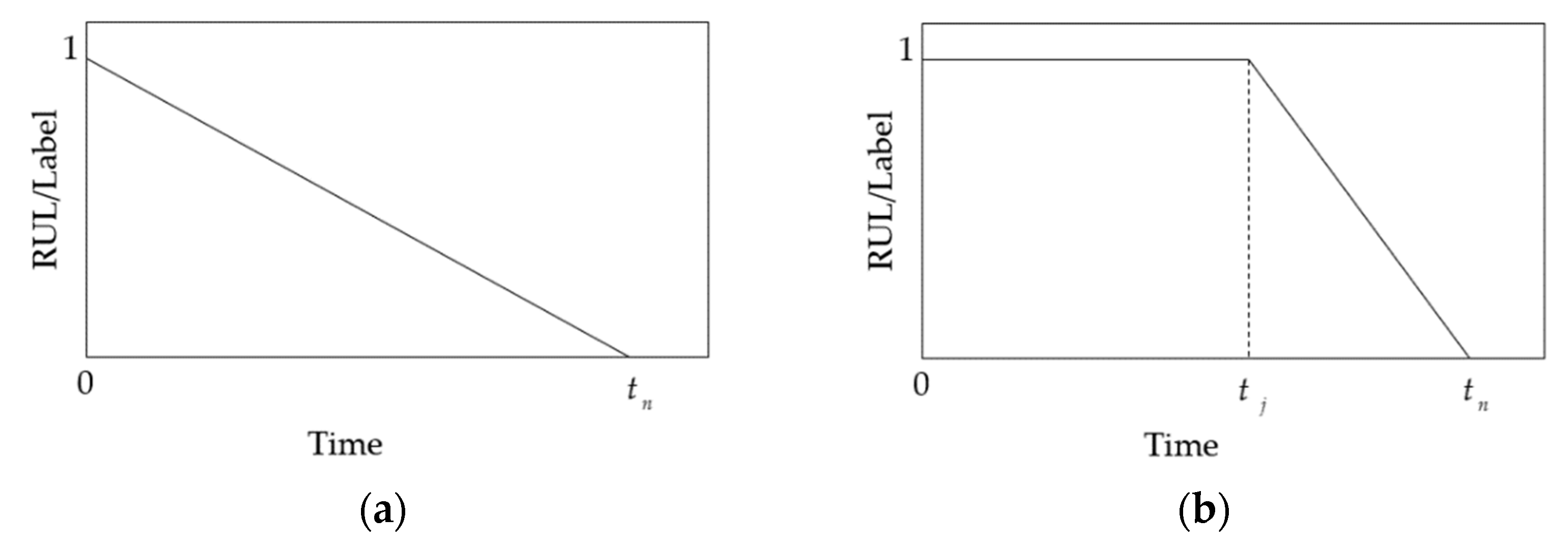
Parameter Selection
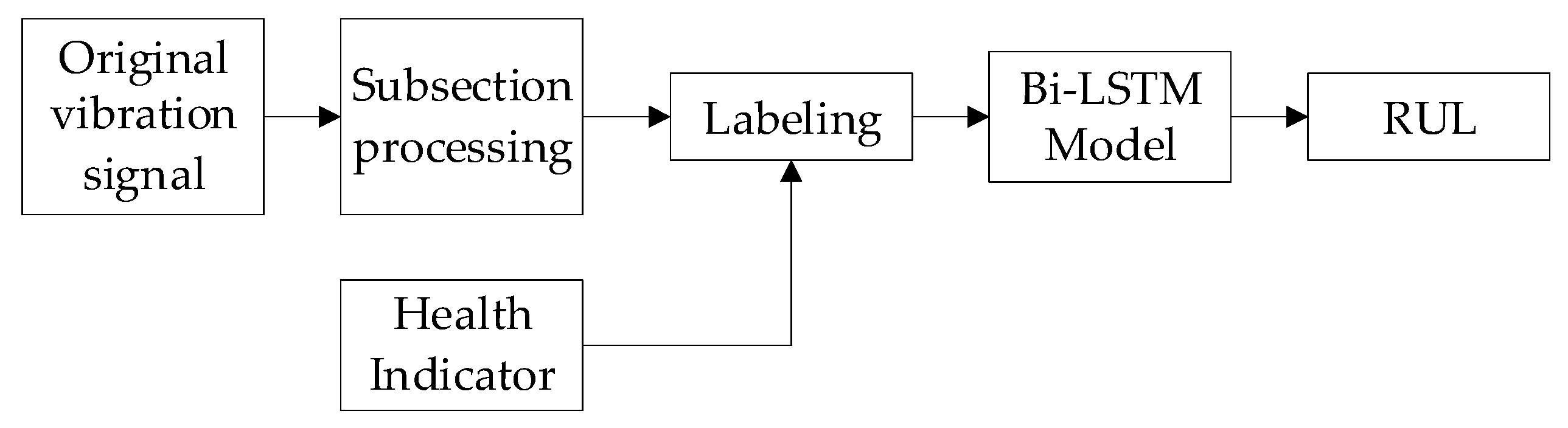
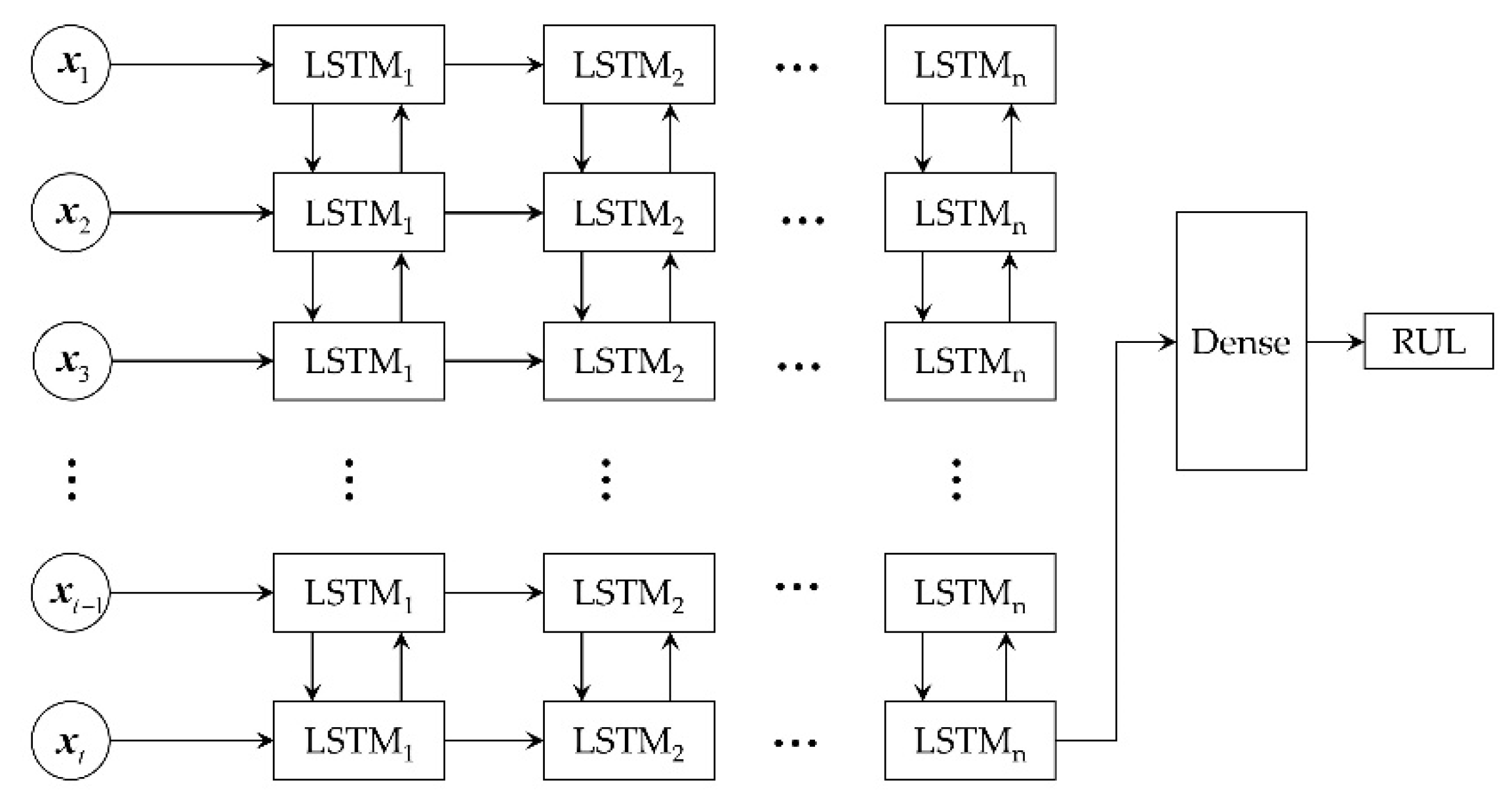
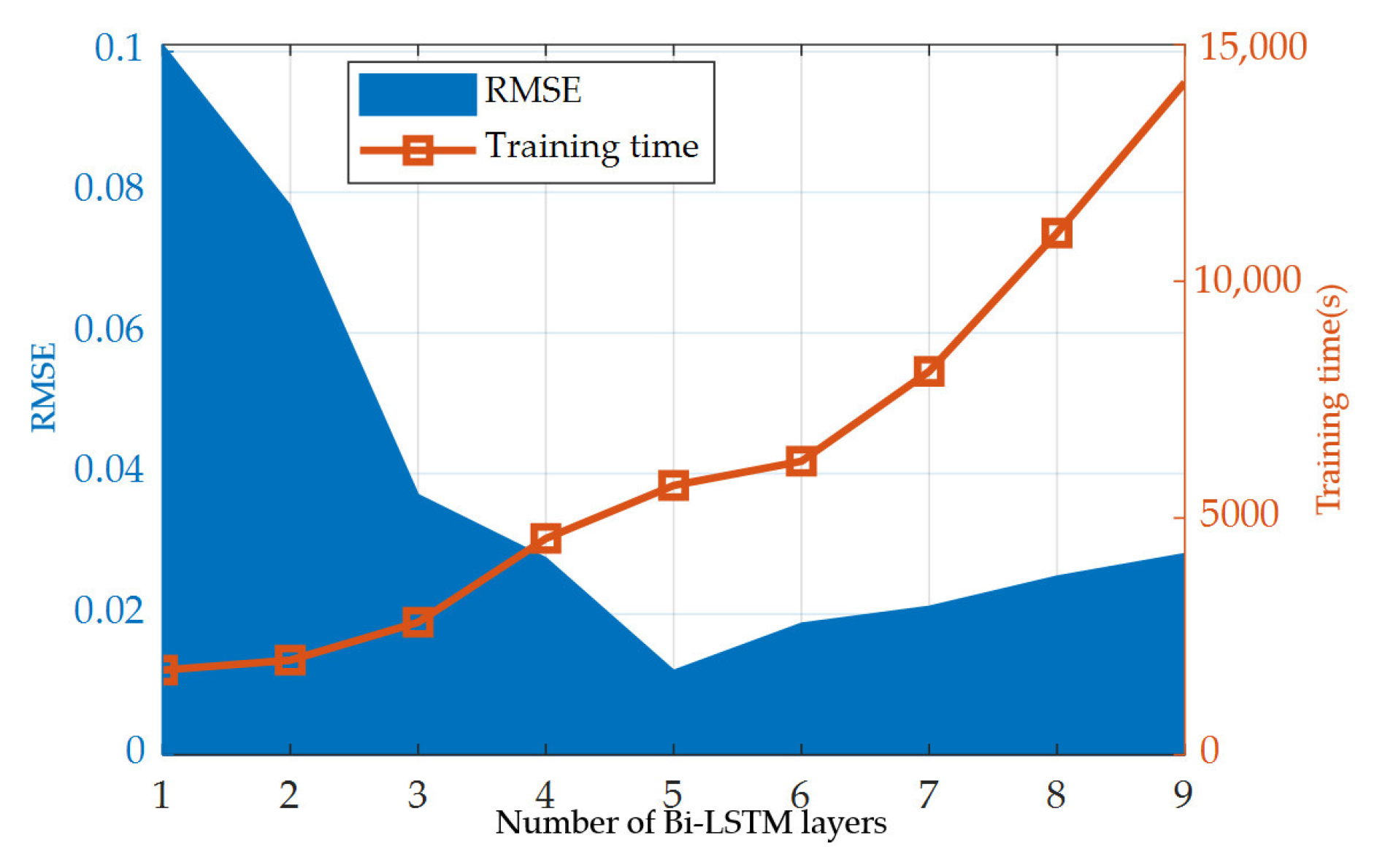
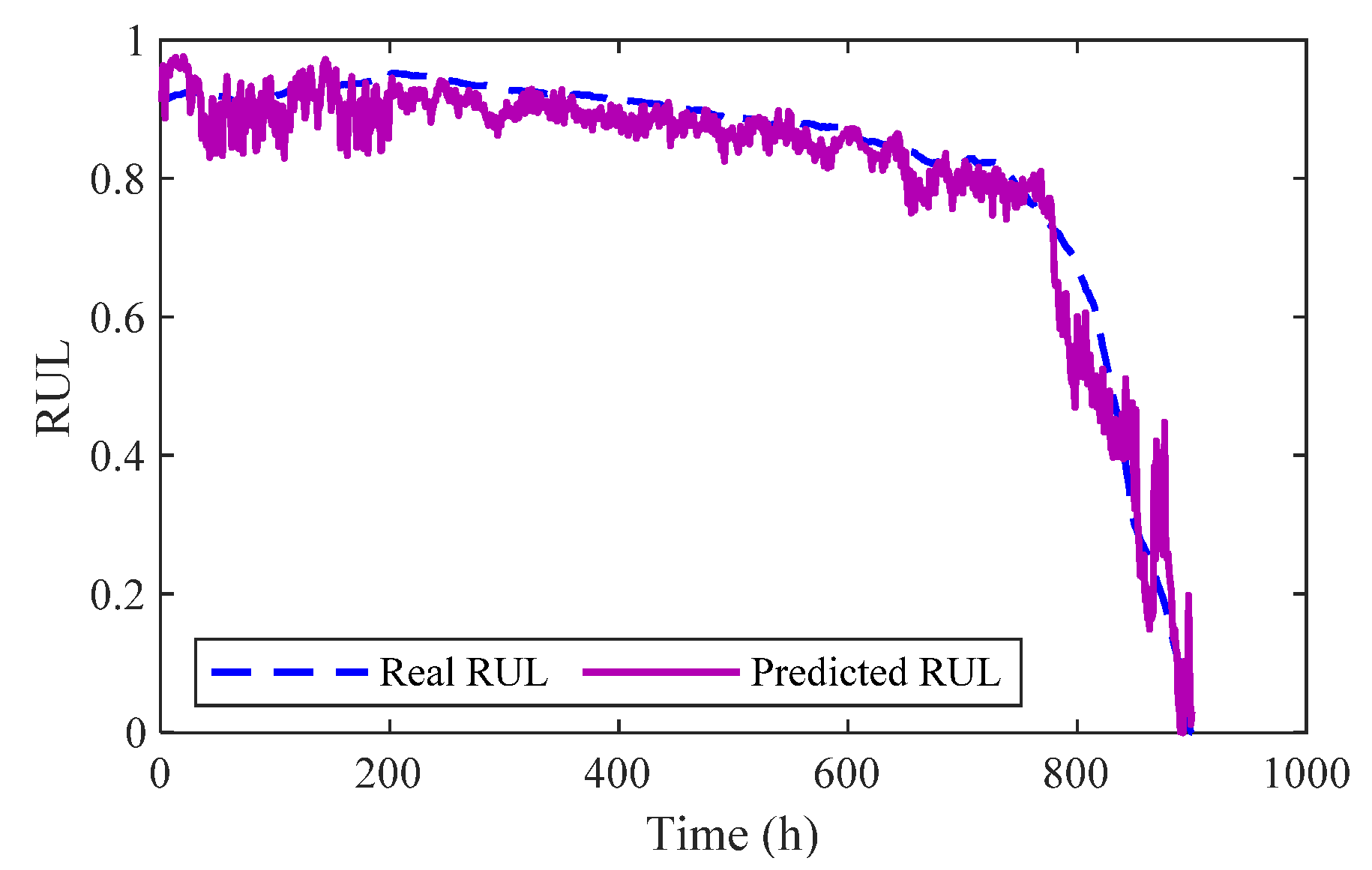
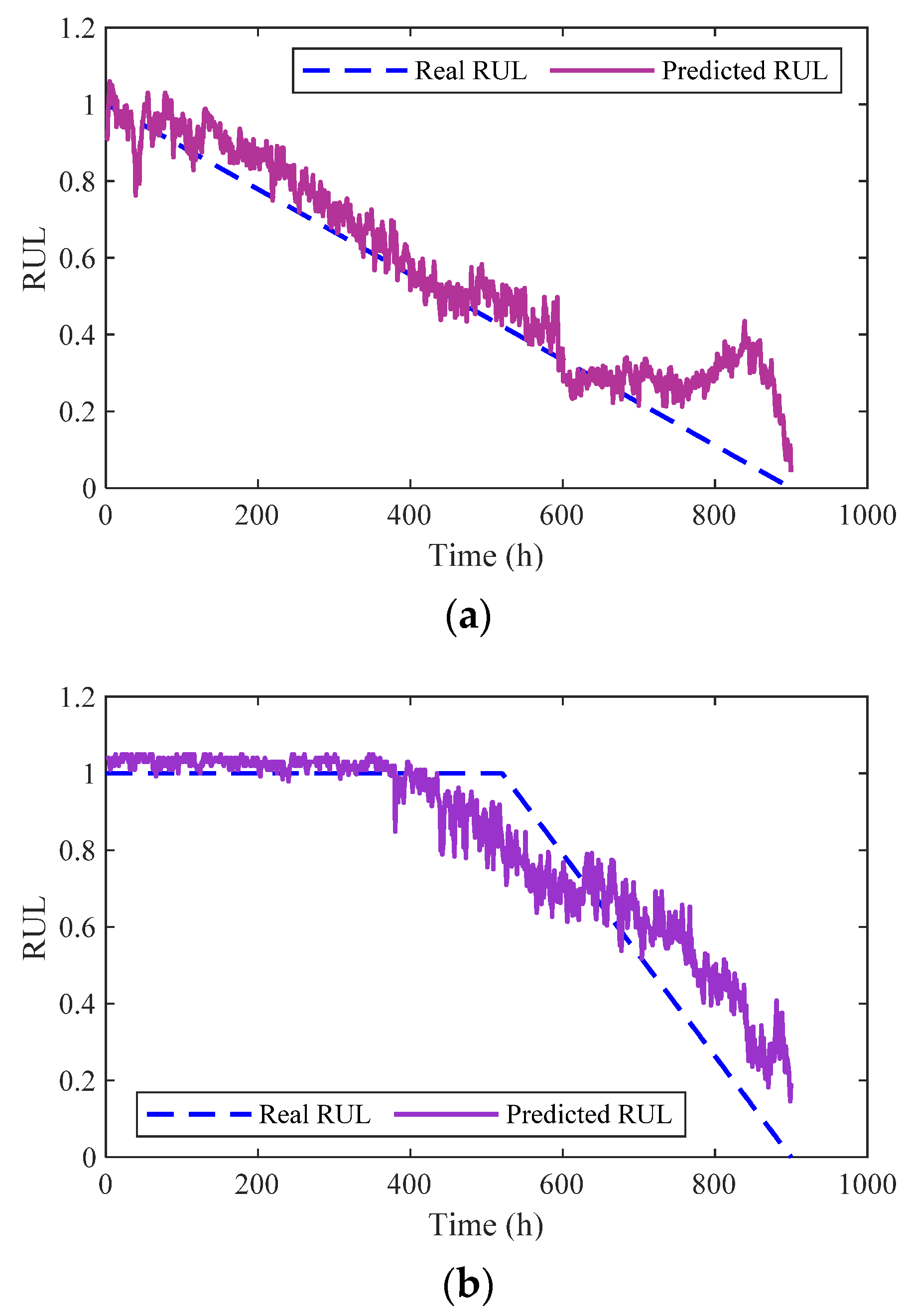
5. Prediction of RUL Based on Bi-LSTM
6. Conclusions
- A modeling method of gear pump degradation state combining a DCAE and SOM is proposed. The one-dimensional convolution kernel is used in the DCAE to improve the feature extraction capability of the model for one-dimensional vibration signals. The SOM network performs high-dimensional feature dimensionality reduction and obtains the HI of the gear pump. The entire modeling process is carried out in an unsupervised manner, reducing the dependence on manual labor.
- A Bi-LSTM-based gear pump life prediction model is proposed. The model’s analysis of the associations between data is enhanced by the Bi-LSTM unit. The model is trained directly through the original data, and the output is the predicted value of RUL, realizing the end-to-end prediction. Especially in the process of data labeling, the HI value of the gear pump is used as the data label, instead of relying on manual labeling, which reduces the labeling error rate and dramatically enhances the quality of the training data. The evaluation indicators show that the presented method has superior prediction precision.
- The three central ideas of the proposed RUL scheme are one-dimensional convolution, the Bi-LSTM unit and the self-labeling of data. Thus, the scheme is very suitable for dealing with one-dimensional time-series data with strong correlation. The solution reduces the dependency on both manual and sophisticated signal processing algorithms and offers great flexibility and adaptability.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lei, Y.; Li, N.; Guo, L.; Li, N.; Yan, T.; Lin, J. Machinery health prognostics: A systematic review from data acquisition to RUL prediction. Mech. Syst. Signal Process. 2018, 104, 799–834. [Google Scholar] [CrossRef]
- Guo, S.; Chen, J.; Lu, Y.; Wang, Y.; Dong, H. Hydraulic piston pump in civil aircraft: Current status, future directions and critical technologies. Chin. J. Aeronaut. 2020, 33, 16–30. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, Z. A new hybrid model of sparsity empirical wavelet transform and adaptive dynamic least squares support vector machine for fault diagnosis of gear pump. Adv. Mech. Eng. 2020, 12, 1061–1068. [Google Scholar] [CrossRef]
- Fausing Olesen, J.; Shaker, H.R. Predictive Maintenance for Pump Systems and Thermal Power Plants: State-of-the-Art Re-view, Trends and Challenges. Sensors 2020, 20, 2425. [Google Scholar] [CrossRef]
- Cherniha, R.; Davydovych, V. A Mathematical Model for the COVID-19 Outbreak and Its Applications. Symmetry 2020, 12, 990. [Google Scholar] [CrossRef]
- Al-Ayyoub, M.; Nuseir, A.; Alsmearat, K.; Jararweh, Y.; Gupta, B. Deep learning for Arabic NLP: A survey. J. Comput. Sci. 2018, 26, 522–531. [Google Scholar] [CrossRef]
- Bhatt, D.; Patel, C.; Talsania, H.; Patel, J.; Vaghela, R.; Pandya, S.; Modi, K.; Ghayvat, H. CNN Variants for Computer Vision: History, Architecture, Application, Challenges and Future Scope. Electronics 2021, 10, 2470. [Google Scholar] [CrossRef]
- Ma, X.; Hu, Y.; Wang, M.; Li, F.; Wang, Y. Degradation State Partition and Compound Fault Diagnosis of Rolling Bearing Based on Personalized Multilabel Learning. IEEE Trans. Instrum. Meas. 2021, 70, 3520711. [Google Scholar] [CrossRef]
- Hamadache, M.; Jung, J.H.; Park, J.; Youn, B.D. A comprehensive review of artificial intelligence-based approaches for rolling element bearing PHM: Shallow and deep learning. JMST Adv. 2019, 1, 125–151. [Google Scholar] [CrossRef] [Green Version]
- Ma, M.; Mao, Z. Deep-Convolution-Based LSTM Network for Remaining Useful Life Prediction. IEEE Trans. Ind. Inform. 2021, 17, 1658–1667. [Google Scholar] [CrossRef]
- Zhao, Q.; Cheng, G.; Han, X.; Liang, D.; Wang, X. Fault Diagnosis of Main Pump in Converter Station Based on Deep Neural Network. Symmetry 2021, 13, 1284. [Google Scholar] [CrossRef]
- Tang, S.; Yuan, S.; Zhu, Y. Deep Learning-Based Intelligent Fault Diagnosis Methods Toward Rotating Machinery. IEEE Access 2020, 8, 9335–9346. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. Deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- Rezaeianjouybari, B.; Shang, Y. Deep learning for prognostics and health management: State of the art, challenges, and opportunities. Measurement 2020, 163, 107929. [Google Scholar] [CrossRef]
- Guo, R.; Li, Y.; Zhao, L.; Zhao, J.; Gao, D. Remaining Useful Life Prediction Based on the Bayesian Regularized Radial Basis Function Neural Network for an External Gear Pump. IEEE Access 2020, 8, 107498–107509. [Google Scholar] [CrossRef]
- Liang, X.; Duan, F.; Bennett, I.; Mba, D. A Sparse Autoencoder-Based Unsupervised Scheme for Pump Fault Detection and Isolation. Appl. Sci. 2020, 10, 6789. [Google Scholar] [CrossRef]
- Li, Z.; Jiang, W.; Zhang, S.; Xue, D.; Zhang, S. Research on Prediction Method of Hydraulic Pump Remaining Useful Life Based on KPCA and JITL. Appl. Sci. 2021, 11, 9389. [Google Scholar] [CrossRef]
- Tang, S.; Yuan, S.; Zhu, Y.; Li, G. An Integrated Deep Learning Method towards Fault Diagnosis of Hydraulic Axial Piston Pump. Sensors 2020, 20, 6576. [Google Scholar] [CrossRef]
- Chen, H.; Xiong, Y.; Li, S.; Song, Z.; Hu, Z.; Liu, F. Multi-Sensor Data Driven with PARAFAC-IPSO-PNN for Identification of Mechanical Nonstationary Multi-Fault Mode. Machines 2022, 10, 155. [Google Scholar] [CrossRef]
- Tang, H.; Fu, Z.; Huang, Y. A fault diagnosis method for loose slipper failure of piston pump in construction machinery under changing load. Appl. Acoust. 2021, 172, 107634. [Google Scholar] [CrossRef]
- Lan, Y.; Hu, J.; Huang, J.; Niu, L.; Zeng, X.; Xiong, X.; Wu, B. Fault diagnosis on slipper abrasion of axial piston pump based on Extreme Learning Machine. Measurement 2018, 124, 378–385. [Google Scholar] [CrossRef]
- Babikir, H.A.; Elaziz, M.A.; Elsheikh, A.H.; Showaib, E.A.; Elhadary, M.; Wu, D.; Liu, Y. Noise prediction of axial piston pump based on different valve materials using a modified artificial neural network model. Alex. Eng. J. 2019, 58, 1077–1087. [Google Scholar] [CrossRef]
- Jiang, W.; Li, Z.; Li, J.; Zhu, Y.; Zhang, P. Study on a Fault Identification Method of the Hydraulic Pump Based on a Combi-nation of Voiceprint Characteristics and Extreme Learning Machine. Processes 2019, 7, 894. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Li, G.; Wang, R.; Tang, S.; Su, H.; Cao, K. Intelligent Fault Diagnosis of Hydraulic Piston Pump Based on Wavelet Analysis and Improved AlexNet. Sensors 2021, 21, 549. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Ding, Q.; Sun, J.-Q. Intelligent rotating machinery fault diagnosis based on deep learning using data aug-mentation. J. Intell. Manuf. 2018, 31, 433–452. [Google Scholar] [CrossRef]
- Ma, J.; Li, S.; Wang, X. Condition Monitoring of Rolling Bearing Based on Multi-Order FRFT and SSA-DBN. Symmetry 2022, 14, 320. [Google Scholar] [CrossRef]
- Bhavsar, K.; Vakharia, V.; Chaudhari, R.; Vora, J.; Pimenov, D.Y.; Giasin, K. A Comparative Study to Predict Bearing Deg-radation Using Discrete Wavelet Transform (DWT), Tabular Generative Adversarial Networks (TGAN) and Machine Learning Models. Machines 2022, 10, 176. [Google Scholar] [CrossRef]
- Zhan, Y.; Sun, S.; Li, X.; Wang, F. Combined Remaining Life Prediction of Multiple Bearings Based on EEMD-BILSTM. Symmetry 2022, 14, 251. [Google Scholar] [CrossRef]
- Cao, Y.; Jia, M.; Ding, P.; Ding, Y. Transfer learning for remaining useful life prediction of multi-conditions bearings based on bidirectional-GRU network. Measurement 2021, 178, 109287. [Google Scholar] [CrossRef]
- Pang, Y.; Jia, L.; Liu, Z. Discrete Cosine Transformation and Temporal Adjacent Convolutional Neural Network-Based Re-maining Useful Life Estimation of Bearings. Shock. Vib. 2020, 2020, 8240168. [Google Scholar]
- Wang, R.; Shi, R.; Hu, X.; Shen, C.; Shi, H. Remaining Useful Life Prediction of Rolling Bearings Based on Multiscale Con-volutional Neural Network with Integrated Dilated Convolution Blocks. Shock. Vib. 2021, 2021, 8880041. [Google Scholar]
- Fiebig, W.; Korzyb, M. Vibration and dynamic loads in external gear pumps. Arch. Civ. Mech. Eng. 2015, 15, 680–688. [Google Scholar] [CrossRef]
- Al-Obaidi, A.R. Investigation of effect of pump rotational speed on performance and detection of cavitation within a cen-trifugal pump using vibration analysis. Heliyon 2019, 5, e01910. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liou, C.-Y.; Cheng, W.-C.; Liou, J.-W.; Liou, D.-R. Autoencoder for words. Neurocomputing 2014, 139, 84–96. [Google Scholar] [CrossRef]
- Azarang, A.; Manoochehri, H.E.; Kehtarnavaz, N. Convolutional Autoencoder-Based Multispectral Image Fusion. IEEE Access 2019, 7, 35673–35683. [Google Scholar] [CrossRef]
- Akhtar, N.; Ragavendran, U. Interpretation of intelligence in CNN-pooling processes: A methodological survey. Neural Comput. Appl. 2019, 32, 879–898. [Google Scholar] [CrossRef]
- Wang, X.; Mao, D.; Li, X. Bearing fault diagnosis based on vibro-acoustic data fusion and 1D-CNN network. Measurement 2021, 173, 108518. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Xu, F.; Huang, Z.; Yang, F.; Wang, D.; Tsui, K.L. Constructing a health indicator for roller bearings by using a stacked au-to-encoder with an exponential function to eliminate concussion. Appl. Soft Comput. 2020, 89, 106119. [Google Scholar] [CrossRef]
- Cui, J.; Ren, L.; Wang, X.; Zhang, L. Pairwise comparison learning based bearing health quantitative modeling and its ap-plication in service life prediction. Future Gener. Comput. Syst. 2019, 97, 578–586. [Google Scholar] [CrossRef]
- Deutsch, J.; He, D. Using Deep Learning-Based Approach to Predict Remaining Useful Life of Rotating Components. IEEE Trans. Syst. Man Cybern. Syst. 2018, 48, 11–20. [Google Scholar] [CrossRef]
- Rai, A.; Kim, J.-M. A novel health indicator based on the Lyapunov exponent, a probabilistic self-organizing map, and the Gini-Simpson index for calculating the RUL of bearings. Measurement 2020, 164, 108002. [Google Scholar] [CrossRef]
- Wang, H.; Peng, M.-J.; Miao, Z.; Liu, Y.-K.; Ayodeji, A.; Hao, C. Remaining useful life prediction techniques for electric valves based on convolution auto encoder and long short term memory. ISA Trans. 2021, 108, 333–342. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Hu, K.; Cheng, Y.; Zhu, H.; Shao, X.; Wang, Y. Data-driven remaining useful life prediction via multiple sensor sig-nals and deep long short-term memory neural network. ISA Trans. 2020, 97, 241–250. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component Name | Component Model | Component Performance Parameter |
|---|---|---|
| Gear pump | CBWF-304 | Rated pressure: 20 MPa; rated speed: 2500 r/min; theoretical displacement: 4 mL/r |
| Acceleration sensor | YD-36D | Sensitivity: 0.002 V/ms−2; frequency range: 1–12,000 Hz |
| Flowmeter | MG015 | Measuring range: 1–40 L/min |
| Pressure sensor | PU5400 | Measuring range: 0–400 bar |
| Data acquisition card | NI PXIe-6363 | 16 bits; 2 MS/s |
| Method | Pump1 | Pump2 | Pump3 | Pump4 | |
|---|---|---|---|---|---|
| DCAE + SOM | Mon | 0.21 | 0.22 | 0.17 | 0.15 |
| Corr | 0.94 | 0.96 | 0.91 | 0.89 | |
| PCA | Mon | 0.20 | 0.12 | 0.15 | 0.13 |
| Corr | 0.75 | 0.76 | 0.79 | 0.73 | |
| SAE | Mon | 0.17 | 0.11 | 0.12 | 0.09 |
| Corr | 0.87 | 0.78 | 0.81 | 0.77 | |
| PASCAL | Mon | 0.21 | 0.14 | 0.15 | 0.12 |
| Corr | 0.90 | 0.84 | 0.87 | 0.85 |
| Number | Number of Convolution Kernels | Number of Convolution Layers | Convolution Kernel Size |
|---|---|---|---|
| Structure 1 | 32-64-128-256-64-1-64-256-128-64-32-1 | 12 | 3 × 1 |
| Structure 2 | 32-64-128-256-64-1-64-256-128-64-32-1 | 12 | 7 × 1 |
| Structure 3 | 128-256-512-1024-512-1-512-1024-512-256-128-1 | 12 | 3 × 1 |
| Structure 4 | 32-64-128-256-512-1024-512-256-1-256-512-1024-512-256-128-64-32-1 | 18 | 3 × 1 |
| Structure 5 | 16-32-64-1-64-32-16-1 | 8 | 3 × 1 |
| Number | Gear Pump1 | Gear Pump2 | Gear Pump3 | Gear Pump4 | ||||
|---|---|---|---|---|---|---|---|---|
| Mon | Corr | Mon | Corr | Mon | Corr | Mon | Corr | |
| Structure 1 | 0.21 | 0.94 | 0.22 | 0.96 | 0.17 | 0.91 | 0.15 | 0.89 |
| Structure 2 | 0.14 | 0.85 | 0.17 | 0.85 | 0.13 | 0.87 | 0.12 | 0.75 |
| Structure 3 | 0.19 | 0.91 | 0.17 | 0.92 | 0.15 | 0.89 | 0.15 | 0.89 |
| Structure 4 | 0.05 | 0.35 | 0.01 | 0.33 | 0.03 | 0.34 | 0.02 | 0.35 |
| Structure 5 | 0.08 | 0.45 | 0.09 | 0.55 | 0.10 | 0.59 | 0.11 | 0.60 |
| Structure 6 | 0.19 | 0.90 | 0.18 | 0.92 | 0.14 | 0.89 | 0.11 | 0.85 |
| Method | Evaluation Index | Gear Pump1 | Gear Pump2 | Gear Pump3 | Gear Pump4 |
|---|---|---|---|---|---|
| HI–Method | MAE | 0.025 | 0.026 | 0.019 | 0.033 |
| RMSE | 0.012 | 0.028 | 0.037 | 0.027 | |
| Score | 0.601 | 0.624 | 0.599 | 0.581 | |
| Method 2 | MAE | 0.094 | 0.184 | 0.051 | 0.074 |
| RMSE | 0.101 | 0.189 | 0.153 | 0.159 | |
| Score | 0.457 | 0.319 | 0.356 | 0.349 | |
| Method 3 | MAE | 0.074 | 0.052 | 0.049 | 0.089 |
| RMSE | 0.103 | 0.098 | 0.089 | 0.074 | |
| Score | 0.462 | 0.474 | 0.431 | 0.399 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Jiang, W.; Yue, Y.; Zhang, S. Research on Prediction Method of Gear Pump Remaining Useful Life Based on DCAE and Bi-LSTM. Symmetry 2022, 14, 1111. https://doi.org/10.3390/sym14061111
Wang C, Jiang W, Yue Y, Zhang S. Research on Prediction Method of Gear Pump Remaining Useful Life Based on DCAE and Bi-LSTM. Symmetry. 2022; 14(6):1111. https://doi.org/10.3390/sym14061111
Chicago/Turabian StyleWang, Chenyang, Wanlu Jiang, Yi Yue, and Shuqing Zhang. 2022. "Research on Prediction Method of Gear Pump Remaining Useful Life Based on DCAE and Bi-LSTM" Symmetry 14, no. 6: 1111. https://doi.org/10.3390/sym14061111
APA StyleWang, C., Jiang, W., Yue, Y., & Zhang, S. (2022). Research on Prediction Method of Gear Pump Remaining Useful Life Based on DCAE and Bi-LSTM. Symmetry, 14(6), 1111. https://doi.org/10.3390/sym14061111