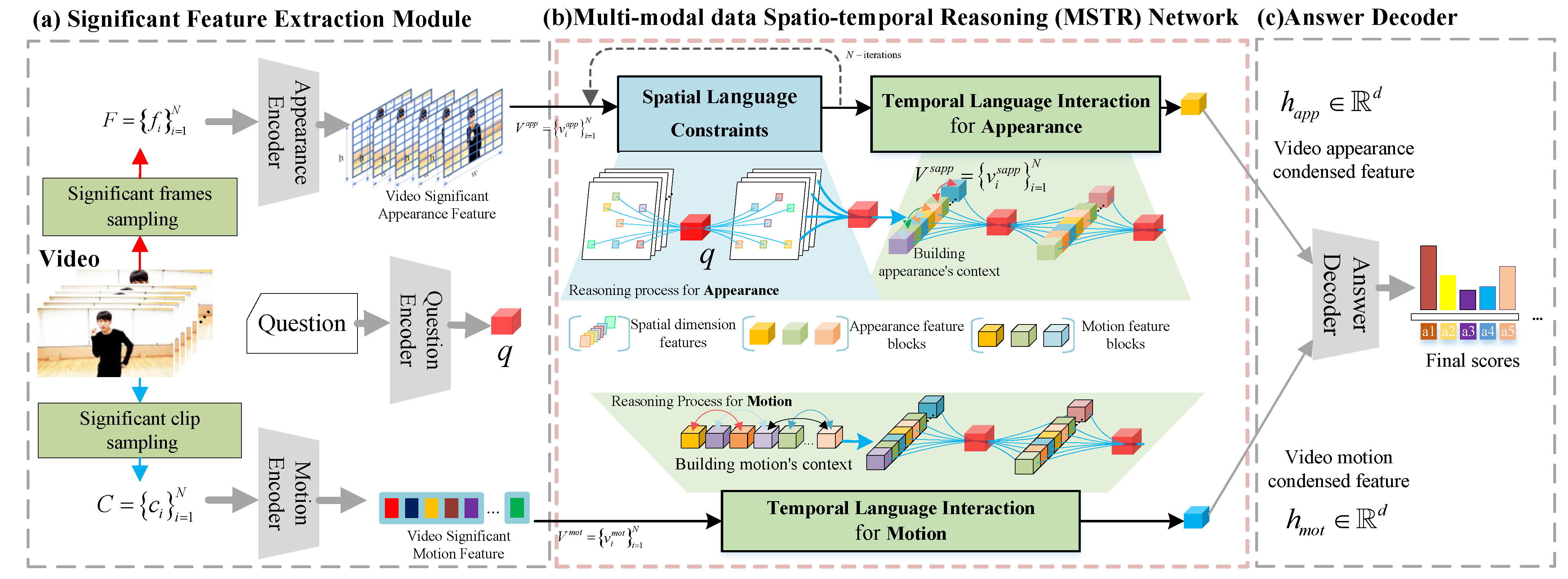
3.2. Significant Feature Extraction Module
Multi-modal information (motion and appearance as the description of the video) is not evenly distributed in the video frame sequence. Different from multi-modal video information by uniform sampling, in this paper, we propose a significant feature extraction module to accurately sample the significant frame/clips of the video by the characteristic that the spatial difference of pixels between video frames can reflect the development and change of temporal information. Moreover, a series of deep networks are used to capture significant features in the above frames and clips.
Formally, we consider a video
of length
L, which contains a set of frames. At first, we use the frame difference method to obtain the sequence
of the pixel spatial difference between adjacent frames. Moreover, the following formula is used to weaken the difference between frames and obtain the sequence
of spatial differences of pixels with context information:
where
is the weight parameter, and
s is the sliding window length. If the sliding window is outside of the video sequence, we fill it with the
or
. Then, according to the above distribution, more sampling points are arranged in the region with large spatial pixel variation and
N sampling points are used to obtain the
significant frames.
Finally, we use the res5c layer (i.e.,
) of ResNet [
14], and apply an average pooling with a linear projection matrices
to extract the appearance feature
provided by the frame corresponding to each sampling point, where
w,
h, and
d are the height, width, and feature dimension of
feature map.
Moreover, for each sampling point
, we take adjacent frames
to
to capture the context information near the sampling point, where
is the position of the sampling point in the video, and we can obtain the
significant clips . Finally, the ResNeXt-101 [
19,
20] with linear projection matrices
is used to extract the motion feature
.
For
linguistic representation, we first embed all words in the question and all words in candidate answers in the case of multi-choice questions into vectors of 300 dimensions with pre-trained GloVe Word Embeddings [
46]. Then, we use biLSTM to obtain the context information. Finally, we concatenate the output hidden states of the forward and backward LSTM passes as a linguistic representation. Through the above process, we can obtain the semantic information
of the question and the semantic information
of the candidate answers, where
represents the number of candidate answers for multi-choice tasks.
3.3. Multi-Modal Data Spatio-Temporal Reasoning Network
A video QA solution needs to understand the above multi-modal information. It also needs the ability of visual language interaction to provide effective visual semantic clues for the final question reasoning. In order to satisfy the above requirements, we propose a multi-modal data spatio-temporal reasoning network composed of a spatial language constraint (SLC) module and a temporal language interaction (TLI) module. With the above module, the visual language interaction between vision and question can be established, along with the story of the video, and provide the most accurate and reasonable visual semantic information for video QA tasks. Specifically, we use multi-modal visual features and as the visual information input of the MSTR network. Under the guidance of question q, we use TLI and SLC modules to deduce and integrate effective semantic cues existing in video appearance and motion features.
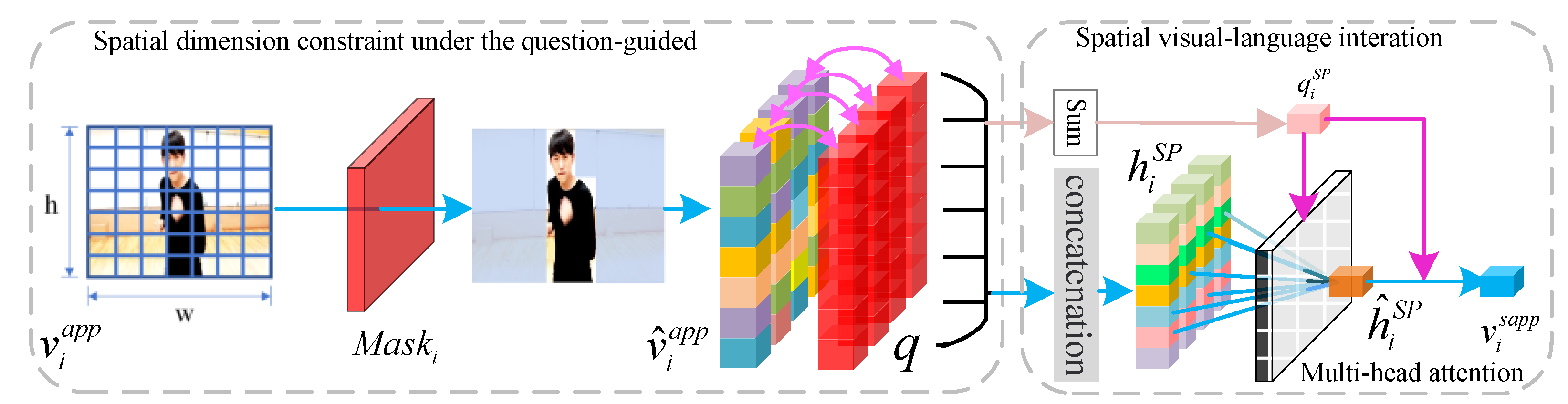
The
spatial language constraint module (SLC) aims to obtain the spatial visual clues related to the question.
Figure 2 shows the module structure in detail. The question
q is used to perceive the spatial dimensions related to the question in the appearance feature
of a significant frame and obtain the question label
, which marks the correlation between each spatial dimension and the question. This process can be defined as follows:
where
and
are different linear projection matrices (in this paper,
W always is a linear projection matrix), ELU is the Exponential Linear Unit [
47],
represents the tensor concatenation, and ⊙ represents the element-wise multiplication. Through the above formula, we can preliminarily obtain spatial features
related to the question.
Then, the following formula
is used further to obtain the semantic interaction feature
between the spatial appearance feature
and the question
q, which is the spatial semantic clue hidden state of the significant frame.
where
. At the same time, we notice that the question can perceive the video content related to the question, and video content can also complete the supplementary understanding of the question. Therefore, we sum the spatial semantic information
to obtain the video question
after the spatial semantic supplement.
Then, in order to further use question
with the spatial semantic supplement to analyze and summarize the hidden states of spatial semantic clues, we use a multi-head attention model [
38] to explore the semantic relationship between visual semantics
and question
. This model is shown in the following formula:
where
and
are different linear projection matrices,
. Through this formula, we can realize the question’s analysis of spatial information and obtain the condensed spatial semantic expression
that the question
pays attention to
from different linear spaces.
Finally, we fuse the spatial semantic supplement question
with the condensed spatial semantic expression
as the spatial semantic clue
of the frame
. The formula is as follows:
where
. With the above process, we can complete the spatial semantic interaction between appearance features
of significant frames and question
q, and obtain a higher level of appearance condensed representation
.
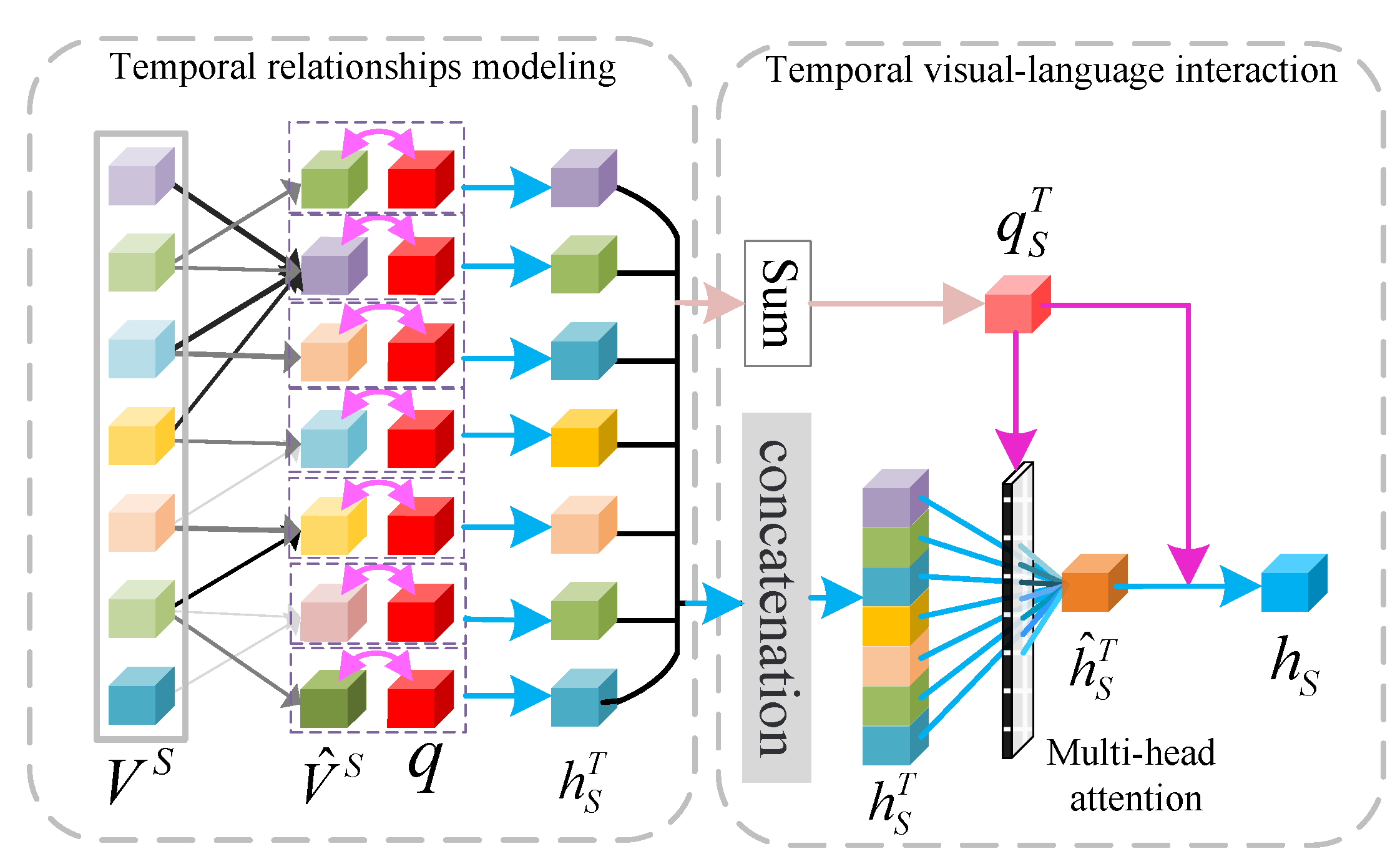
In the
temporal language interaction module (TLI), we symmetrically conduct temporal language interaction modeling for the higher level of appearance features
and motion features
, respectively, and obtain condensed visual clues related to the question.
Figure 3 shows this module’s details. It takes the question
q and the video feature
as input, and outputs the higher-level visual semantic feature
. When
is defined as
and
, respectively, the condensed visual clues are
and
.
Firstly, we take
as the input of a multi-head attention model to explore the temporal correlation of
itself. Ignoring the multi-head process of Equation (
7), the final output is given by:
Then, in order to analyze the hidden temporal semantic clues
existing in the context, the following formula is used to obtain the semantic interaction feature of
and question feature
q:
where
are different linear projection matrices. Identical to the SLC module, we sum the temporal semantic information
to obtain the video question
supplemented by the temporal semantic information.
Moreover, the question
and hidden temporal semantic information
are taken as the input of multi-head attention, which serves to realize the question analysis of the temporal information and obtain the condensed temporal semantic expression
related to the question
. Ignoring the multi-head process of Equation (
7), the process is given by:
Finally, we fuse the temporal semantic supplement question
with the condensed temporal semantic expression
as the semantic clue
of the video. The formula is as follows:
where
. With the above process, we can symmetrically realize the temporal visual language reasoning for the appearance feature and motion features and obtain higher-level visual semantic clues
and
.
3.4. Answer Decoder
To deal with video questions that need to understand both appearance and motion information, the video QA model needs to have the ability to integrate this multi-modal information. In this paper, different answer decoders with loss functions are adopted for the final QA reasoning to fulfil the answer prediction of different question types.
Open-ended questions. We treat the open-ended questions as multi-label classification problems. Firstly, we take the features
and the question
q as input, and use the following formula to decode the open-ended questions:
where
,
,
are linear projection matrices, and
represents the length of the answer space
. Then, we obtain the final score
of each candidate answer:
Finally, the highest score is selected as the prediction answer:
The cross-entropy loss function is used for the open-ended questions.
Repetition count task. We obtain the number
of repetitions of the action by the following formula:
where
,
are linear projection matrices. Moreover, we use a rounding function for integer count results. Finally, mean squared error (MSE) is used as the loss function.
Multi-choice question. The multi-choice question is treated as a multi-label classification problem. Firstly, we take the features
,
q and
as input, and the following formula is used to decode the multi-choice question:
where
,
, and
are linear projection matrices. Finally, the candidate with the largest
value is selected as the answer such that:
In this type of video QA, the cross-entropy loss function is used for training.
In order to ensure that the multi-modal information of our video QA solution is not lost, we use multi-task loss to train our network:
where
and
represent the loss value of predicted results in the appearance and motion branches of the MSTR network, respectively. In addition,
represents the loss value of the last predicted results of our video QA solution.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}