Abstract
Target detection at the hive gate of a beehive can be used to effectively monitor invasive beehive species. However, in the natural environment, there is often a multi-target and multi-scale problem at the hive gate, making it difficult for beekeepers to accurately detect the internal state of the hive. (1) To solve the above problems, this paper proposes an improved RetinaNet target detection network, DY-RetinaNet, for the identification of common species at the hive doors of beehives in natural environments, i.e., Chinese bees, wasps, and cockroaches. (2) First, to solve the multi-target multi-scale problem presented in this paper, we propose replacing the FPN layer in the initial model RetinaNet with a symmetric structure BiFPN layer consisting of a feature pyramid, which allows the model to better balance the feature information of different scales. Then, for the loss function, using CIOU loss instead of smooth L1 loss makes the network more accurate for small target localization at multiple scales. Finally, the dynamic head framework is added after the model backbone network, due to the benefits of its multi-attention mechanism, which makes the model more concerned with multi-scale recognition in a multi-target scenario. (3) The experimental results of the homemade dataset show that DY-RetinaNet has the best network performance, compared to the initial model RetinaNet, when the backbone network is ResNet-101-BiFPN, and the mAP value of DY-RetinaNet is 97.38%. Compared with the initial model, the accuracy is improved by 6.77%. The experimental results from the public dataset MSCOCO 2017 show that DY-RetinaNet is better than the existing commonly used target-detection algorithms, such as SSD, YOLOV3, Faster R-CNN, Mask R-CNN, FCOS, and ExtremeNet. These results verify that the model has strong recognition accuracy and generalization ability for multi-target multi-scale detection.
1. Introduction
Honey bees are one of the most important insects for improving the human environment and an important partner for human survival, playing an important role in agriculture, medicine, and daily life. In China, honey bee farming is still artificial, and honey bee colonies in the natural environment are often invaded and harmed by foreign species; pure wild bee species are still a minority, and most honey bee colonies are farmed and cared for by humans. In Fujian Province, due to the natural environment, outdoor beehives have been affected by invasive species which have caused great damage to the honey bee population inside the hives, resulting in a decrease in honey production and a thinning of the population. The most common invasive species in beehives are cockroaches and wasps. Cockroaches enter the hive to build nests and eat honey, while wasps attack and eat bees outside the hive or at the hive door. Therefore, beekeepers need to pay close attention to the survival status of the bee colony inside the hive. In addition, there is often a multi-objective and multi-scale problem at the hive entrance, making it difficult for beekeepers to accurately predict the internal state of the hive [1]. Accurately detecting the category of beehive import and export species, and taking timely prevention and control measures, are important to reduce honey production, increase beekeepers’ income, and ensure the safety of beehive interiors.
Early models for target detection that address multiple targets at multiple scales include the directional gradient histogram HOG method, and the multi-scale deformation model DPM method. Of these models, the DPM model is the most widely used and is an extension of the HOG model; it uses a simple method, starting with the target multi-view and deformation problem, to achieve fast computational speed and adaptation to target deformation [2]. The algorithmic procedure begins by performing feature extraction using the HOG method, but keeping only the extracted cells, then feature fusion using the DPM method, and finally classification using SVM. However, when facing multi-scale targets, feature extraction for different targets requires different, artificially designed excitation modules with a large workload. Traditional target detection models have two main problems: first, the sliding window is not targeted in the test, which can generate redundancy in the sliding window; second, the designed model is not sufficiently robust and reliable for multi-scale detection [3].
With the improvement of internet performance and the rise of the deep learning field in recent years, convolutional neural networks have gradually replaced traditional recognition methods and become the main algorithm for target recognition tasks. In 2016, Liu et al. proposed the SSD network [4], which itself uses multiple layers of convolutional features to predict targets separately, allowing the range of scales that need to be predicted in each layer to be reduced, greatly reducing the model building time, while subliminally establishing the foundation for later multi-scale target recognition. Meanwhile, Redmon et al. proposed the YOLO algorithm [5], which uses only the last layer of features in the model for classification and regression. With such an impressive speed, what is sacrificed is its detection accuracy, especially for small-scale targets, which are essentially unrecognizable. Subsequently, Redmon et al. proposed an improved version of this algorithm: the YOLO-V2 [6] algorithm, which introduced the candidate frame mechanism in the RPN layer of the Faster R-CNN method based on the initial YOLO, and used the multi-layer features for target recognition and detection. Thus, YOLO-V2 shows a significant improvement in accuracy. In order to solve the recognition problem of multi-scale targets, more and more researchers have focused on the field of feature fusion. In 2017, Lin et al. proposed the FPN network [7], which effectively solves the feature fusion problem between multiple layers in the convolutional layer, and presents a key theoretical basis for the subsequent development of feature fusion technology. The algorithm makes direct predictions of features after the fusion of multi-layer features, and the deep-level feature information is fused with the shallow-level feature information by up-sampling, thus solving the problem of inaccuracy in processing category information in shallow-level feature maps. For multi-scale target detection tasks, it has become a common architectural approach to use the fusion technique of different convolutional features for the detection of targets at different scales [8].
The above methods in deep learning have low recognition accuracy in multi-target multi-scale domains. In this study, an improved RetinaNet target detection network DY-RetinaNet is proposed for common species recognition, i.e., Chinese bees, wasps, and cockroaches, at beehive nest gates in natural environments. DY-RetinaNet uses a weighted feature pyramid network (BiFPN), enhances the multi-scale feature fusion of the network, and replaces the smooth L1 loss in the initial model RetinaNet with CIOU loss, making the network more accurate for small target localization at multiple scales. In addition, by adding a dynamic head frame after the model backbone network, the detection and recognition performance of the model is enhanced.
The main contributions of this paper are summarized as follows:
- In this paper, we studied the outdoor hive breeding of Chinese bees in the Ning de region of Fujian Province, China, in response to the research requirements, and constructed a dataset containing images of three species of Chinese bees, wasps, and cockroaches. In addition, a data enhancement method is used to prevent the model from the overfitting phenomenon, and to improve the adaptability of the model in practical applications.
- Replacing the FPN network in RetinaNet with a symmetric structure BiFPN, which is composed of feature pyramids, enables the model to perform simple and fast multi-scale feature fusion and to better balance feature information at different scales, accelerating the convergence of the network.
- There is a multi-target multi-scale problem in the dataset, and in order to accurately predict the position information of small targets, CIOU loss is used to make the model more accurate in identifying small targets.
- In this paper, we propose adding a dynamic head framework after the model backbone network, to enhance its scale perception of the feature map extracted from the backbone network at the feature level, enhance spatial perception at the spatial location, enhance task perception at the output channel, better integrate the semantic and detailed information of multi-scale multi-targets, and enhance the characterization ability of the target detection head to make the model more effective in multi-target multi-scale recognition, and significantly improve its recognition accuracy.
2. Materials and Methods
2.1. Building the Dataset
The image data for this experiment were captured by camera at the hive door of Chinese bee hives in the Ning de area, Fujian Province, China, focusing on Chinese bees, cockroaches, and wasp species for subsequent target identification in the model. The image acquisition method used in this paper involves installing the camera directly above the hive door and saving the images on the computer, in real time, through a WiFi connection. Since the shooting process requires no bees to block the lens, the camera is assembled on the outside of the hive several hours before it is officially used, to enable the bees to adapt to the presence of the camera. The camera model selected for this paper is the Hikvision ds-2dc3a40iw-d, which supports proportional zoom and data zoom and can observe the whole hive door area. The technical parameters of this camera are shown in Table 1.

Table 1.
The technical parameters of the camera.
After the initial acquisition of the image, in order to avoid the repetition or blur of the image in the dataset, the experimenter needs to select the image for the experiment and preprocess it with the image [9]. Finally, the basic dataset of 10,000 images is obtained, including 6000 for Chinese bees, 2000 for wasps, and 2000 for cockroaches. The size of each image is 640 × 640 pixels.
2.2. Data Augmentation
In order to prevent the overfitting problem in the case of small datasets, this paper uses data enhancement technology for the training samples to enhance the images, such as flipping, rotation, saturation and stretching. Through the above image enhancement method, the basic dataset is expanded from 10,000 images to 16,000 images, in which the image ratio of Chinese bees, cockroaches, and wasps is 2:1:1. In the process of establishing the dataset, the training set and the test set are randomly divided into 7:3. The details of the dataset are shown in Table 2.
Table 2.
Dataset sum.
3. RetinaNet Model Structure
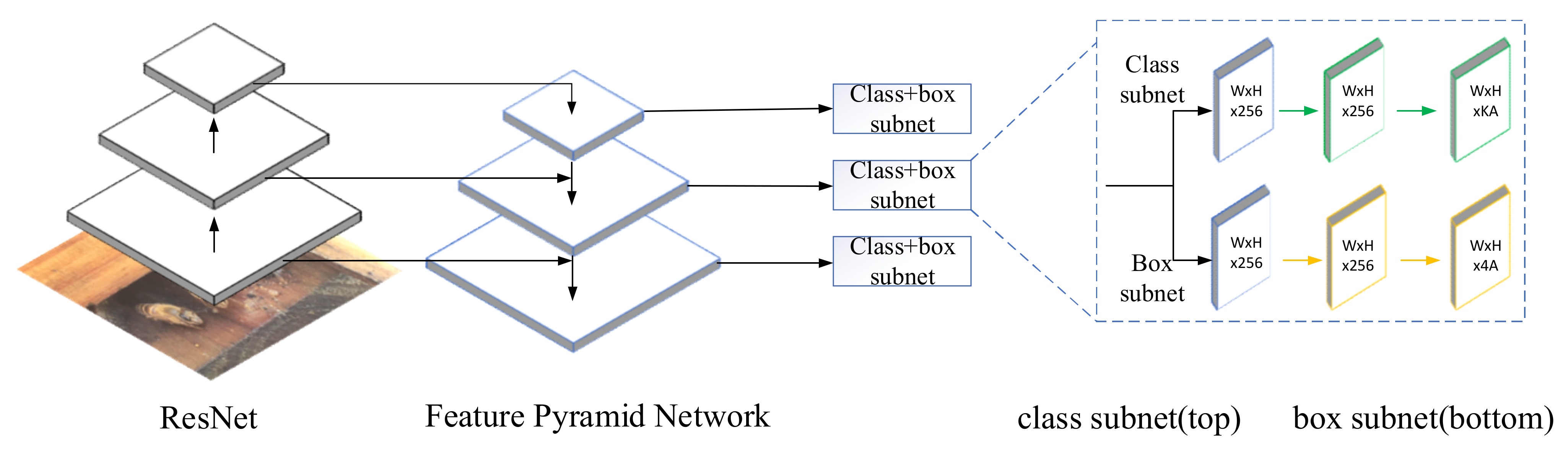
The RetinaNet model is a single-stage model, commonly used in computer vision today, which has a simple structure and fast recognition [10]. As shown in Figure 1, the model consists of two parts, i.e., a backbone network and two prediction branch networks. It works as follows: after receiving the input image, RetinaNet divides the image into a grid of different sizes, and first extracts features from this image through the backbone network ResNet, and then builds the FPN layer on top of the ResNet network structure, i.e., the three depth feature layers extracted in ResNet are fused with the FPN layer, after which each fused feature layer is predicted individually. The last two prediction branch networks are divided into two parts, classification and box regression, with the class sub-network performing target classification on the output of the backbone network, and the box regression sub-network performing target bounding box regression, with the parameters shared between the different layers of the whole structure, but not between the classification and regression branches.
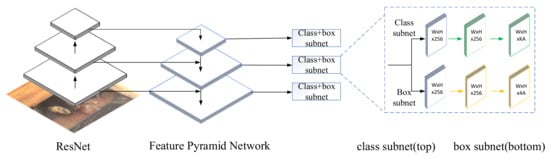
Figure 1.
RetinaNet model.
3.1. Backbone Feature Extraction Network
Compared to the manual feature extraction methods used in machine learning, convolutional neural networks (CNNs) are used as a tool for feature extraction in deep learning because of their ability to automatically extract image features, eliminating the complex feature engineering phase in machine learning, and reducing the training parameters of the model. Nowadays, some extensive convolutional neural network models have been proposed. However, the increasing number of layers of neural networks leads to the phenomenon of network degradation when the network is deep. To solve this problem, He et al. proposed a 101-layer residual network in 2015, which effectively solved the gradient degradation problem and won the 2015 ImageNet Large-scale Visual Recognition Challenge [11]. Therefore, this paper studies the selection of a residual network as the backbone network of the model in order to effectively solve the constant mapping problem, and to optimize the overfitting phenomenon brought about by the complex network, so that both the network performance and the classification effect are better.
3.2. Feature Pyramid Network (FPN)
FPN is able to fuse the information from different feature layers by gradually propagating the deep layer information to the shallow layer, so that each layer produces a feature map of a different size, and is able to make predictions independently on different feature layers, effectively improving the performance of multi-scale target detection [12].
In Figure 1, the RetinaNet model builds the FPN on the ResNet structure of the backbone network, and the feature layers extracted by the backbone network are connected in a bottom-up and top-down horizontal manner [13]. When the image is input into the backbone network ResNet structure, the five feature layers obtained by the backbone network extraction, named C1, C2, C3, C4, and C5, each contain different degrees of semantic information, and the three feature layers C3, C4, and C5, which contain higher levels of semantic information, are convolved, upsampled, and fused, to obtain the five new effective feature layers P3, P4, P5, P6, and P7.
4. Improved Model: DY-RetinaNet
4.1. DY-RetinaNet Model Structure
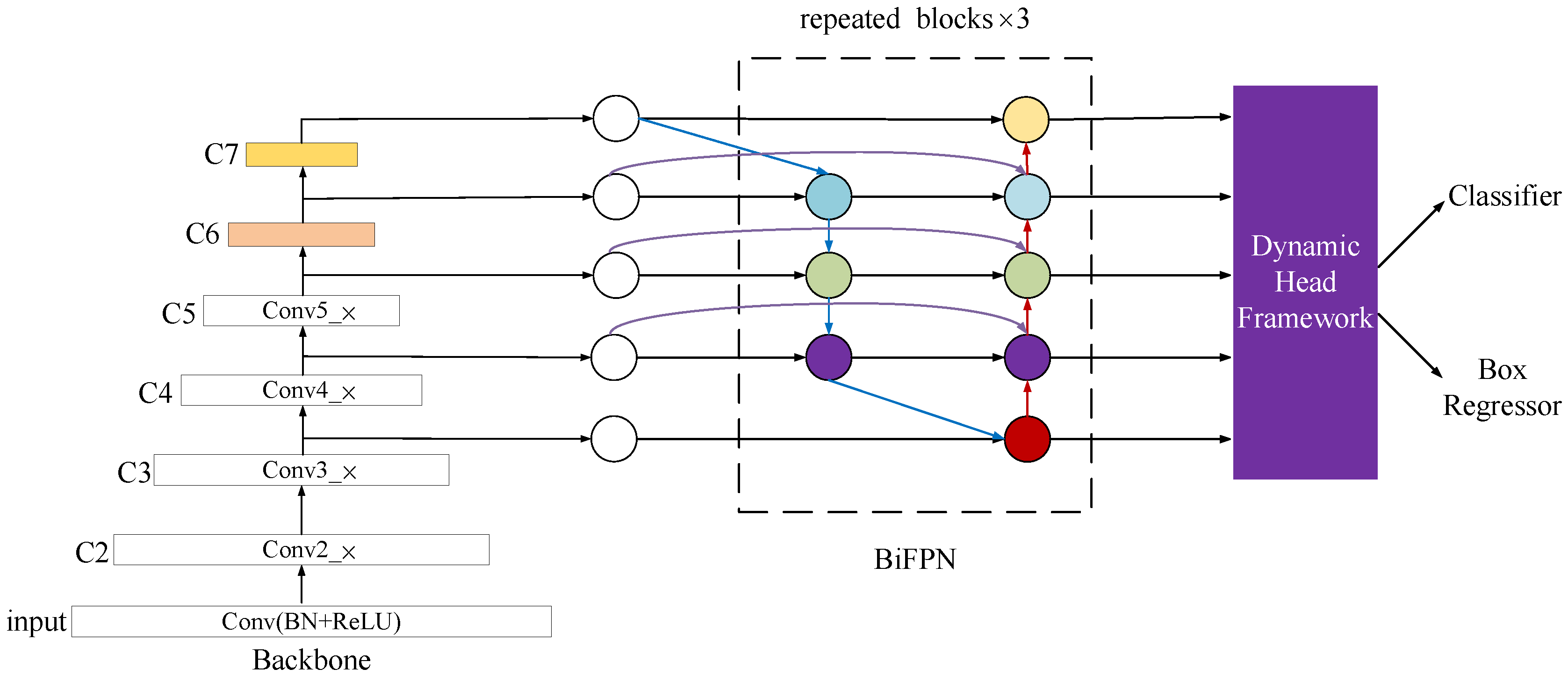
DY-RetinaNet is improved with RetinNet as the baseline network, and the network workflow is as follows: first, the image is input to the ResNet network structure to extract the target feature information from the image. Secondly, the BiFPN network fuses the features of layers C3, C4, and C5 extracted by the backbone network in a multi-scale manner, through cross-scale connectivity and weighted feature fusion, to obtain the multi-scale feature information of the target. Finally, the dynamic head framework is added to the backbone network, based on the multi-attention mechanism of the dynamic head framework, which can be used to process multiple tasks, simplifying the model architecture while improving efficiency. After the superposition of three different dimensional attention mechanisms within the dynamic head framework, the performance of the target detection head is effectively improved, making the model more focused on multi-scale multi-target recognition. The structure of the DY-RetinaNet model proposed in this paper is shown in Figure 2.
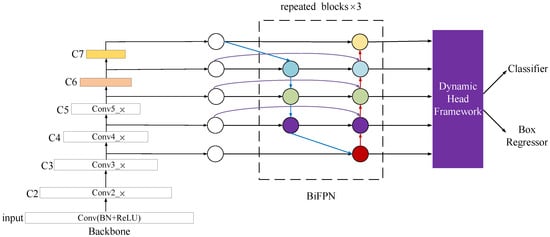
Figure 2.
DY-RetinaNet model structure.
4.2. Bidirectional Feature Pyramid Network (BiFPN)
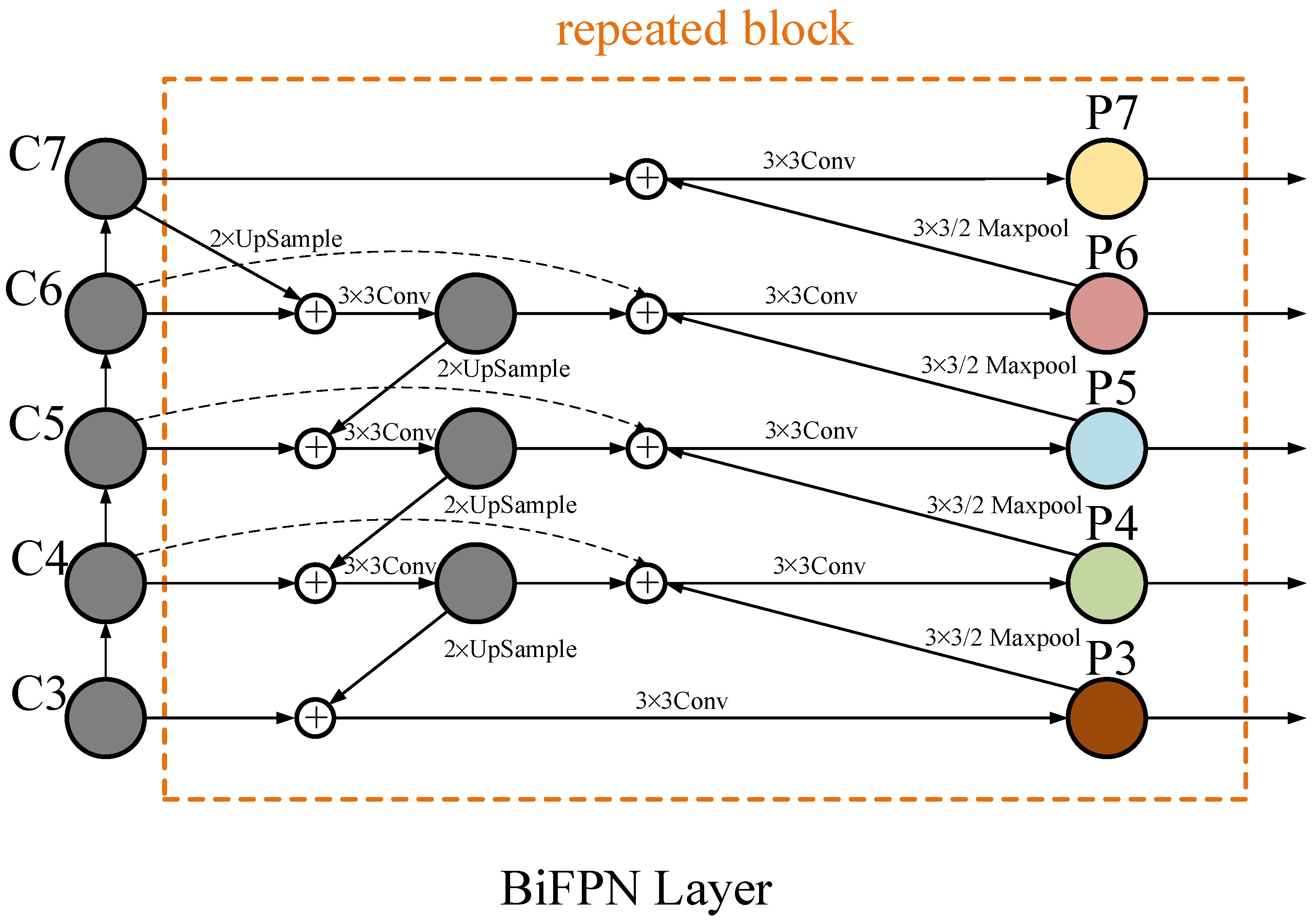
In this study, DY-RetinaNet enables the model to perform multi-scale fusion simply and efficiently by introducing BiFPN as a replacement for the FPN layer in the initial model RetinaNet. Since the model affects the final fusion layer of output features differently when the input features are fused at different resolutions, feature fusion can be performed adaptively at this time by introducing learnable weights, such that an efficient feature fusion structure is constructed, i.e., a weighted bi-directional feature pyramid network (BiFPN) [14]. The structure of BiFPN is shown in Figure 3. It applies the idea of bi-directional fusion by repeatedly applying top-down and bottom-up bi-directional channels, and adds double lateral connections between features at the same level to enable the network to perform efficient multi-scale feature fusion. At the same time, corresponding weights are assigned to the importance of different input features, and the feature information at different scales is balanced by the weights. After the superposition of multiple BiFPN structures, the final output features fuse the semantic features at high and low levels.
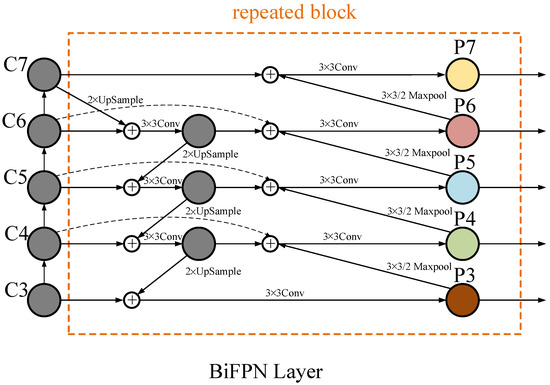
Figure 3.
BiFPN structure.
4.3. Dynamic Head Framework
Previous works have improved the performance of target detection from different perspectives, and it is difficult to analyze the metrics from a unified perspective. However, a paper on target detection published by Microsoft in 2021 mentions the dynamic head framework [15]. In that paper, it was noted that the dynamic head framework unifies the representation of many different target detection methods using attention mechanisms for scale perception through attention mechanisms between feature levels for scale perception, between spatial locations for spatial perception, and within output channels for task perception, which can significantly improve the representation of the model detection head without increasing computational effort.
The network structure of the dynamic head framework, which is shown in Figure 4 above, uses the attention mechanism from three different dimensions unified in one framework to change the feature map extracted from the feature pyramid network into a 3-dimensional tensor of the same scale, where: L (level) represents the number of levels, S (space) is the width–height product of the feature map (H*W), and C (channel) represents the number of channels. The * in the figure indicates that the framework pays attention to each independent dimension in the fusion feature map of different levels through the decentralized attention mechanism. and the three attention modules are described as follows:

Figure 4.
Dynamic head framework.
- Scale-aware attention: this module is used in the dimensional level to recognize objects of different scales. Different levels of feature map correspond to different target scales; increasing attention at a given level can reveal a variety of semantic information of relative importance to enhance the scale-awareness of feature learning and target detection.
- Spatial-aware attention: spatial perception attention. This module is used in dimension space (height × width) and executed in the spatial dimension. The difference in spatial position corresponds to the geometric transformation of the target; adding attention in the spatial dimension enhances the spatial position perception of the target detector.
- Task-aware attention: this module is used in the dimension channel, according to the different convolutional kernel responses returned by the target. Different channels respond to different tasks; adding attention to the channel dimension can enhance the perception of target detection for different tasks.
For a given feature tensor , the self-attentive mechanism equation is shown in Equation (1) below:
However, the general implementation of this attention mechanism is to use the fully connected layer directly, which adds a high amount of computation to the model; this approach is less appropriate. The dynamic head framework transforms this self-attentive mechanism into a three-dimensional attention module with the following expression, as shown in Equation (2):
In Equation (2), , and represent different attention functions that act on three different dimensions, L, S, and C, respectively.
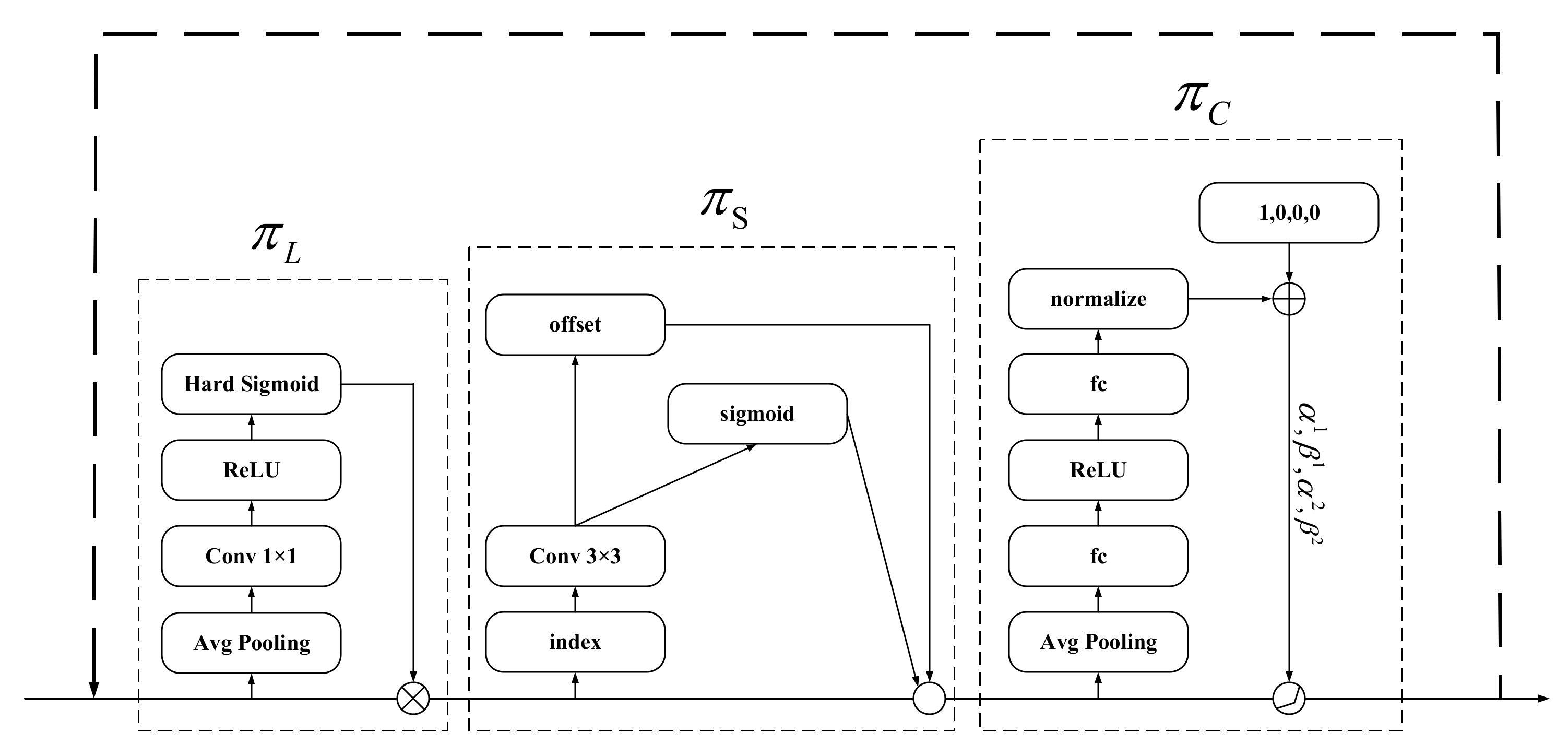
The three attention modules used by the dynamic head framework are shown in Figure 5 below:
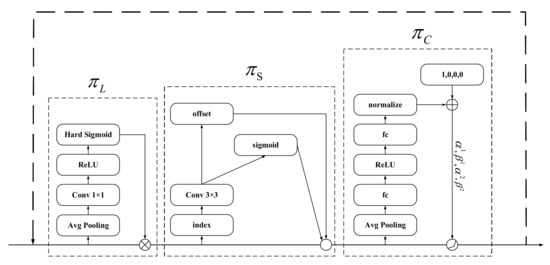
Figure 5.
Dynamic head attention module.
4.3.1. Scale-Aware Attention ()
The scale awareness capability of target detection is enhanced by introducing scale-aware attention to dynamic fusion at different scales, based on the semantic importance of different scales in the L dimension of the input space.
The scale-aware attention function is shown in Equation (3) above, where is a linear function of 1 × 1 convolutional layers and is a hard sigmoid function.
4.3.2. Spatial-Aware Attention ()
The spatial perception capability of target detection is enhanced by introducing spatially perceptive attention, based on the effect of the high dimensionality of S. The process is decomposed into two steps, where the first step uses deformable convolutions [16] to make attention learning sparse, and the second step aggregates features at different levels at the same spatial location.
The spatial-aware attention function is shown in Equation (4) above, and K is the number of sparsely sampled positions, whereby is the spatial offset by self-learning, can be learned from deformable convolution, and represents the importance of self-learning at position .
4.3.3. Task-Aware Attention ()
The ability of target detection to sense different tasks is enhanced by introducing task-aware attention, and a switch, which controls whether the hyperparameter learns the threshold of activation, automatically turns the channel on or off to suit different tasks.
The task-aware attention function is shown in Equation (5) above, and the max() is a hyperparametric function learning the threshold value of the activated channel. is the feature cut at the channel. The module first reduces the dimensionality by pooling, then goes through two fully connected layers and a BN layer, and finally normalizes the output using the shifted sigmoid function.
In summary, the dynamic head framework employs an attention mechanism for each of the three independent dimensions in the feature map, where the scale perception module makes the model more sensitive to scale differences of foreground targets; the space perception module makes the model focus on foreground targets to distinguish their spatial locations; and the task perception module dynamically turns the channels of the feature map on or off to adapt to different tasks. Based on the flexibility and efficiency of this framework, DY-RetinaNet adds a dynamic head framework after the model backbone network to effectively improve the performance of the model without increasing the amount of redundant computation, and enhances the model’s ability to recognize multiple targets at multiple scales.
4.4. Loss Function
CIOU loss makes the model’s prediction frame regression converge faster and more accurately, as it takes into account three important factors between the prediction frame and the target frame: overlap area, centroid distance, and aspect ratio. Therefore, DY-RetinaNet uses CIOU loss as a replacement for the smooth L1 loss in the initial RetinaNet model; this allows the model to identify small targets at multiple scales more accurately. The loss function of DY-RetinaNet consists of box regression loss and classification loss, i.e., CIOU loss and focal loss. The commonly used box regression loss function is IOU (intersection over union) loss. The calculation formula is shown in Equation (1) below:
A in the above Equation (6) is the real box and B is the prediction box.
However, IOU loss has two drawbacks: firstly, it cannot accurately reflect the overlap of two frames; secondly, when two frames do not intersect, the distance between these two frames cannot be accounted for. Therefore, Zheng et al. proposed DIOU Loss to directly regress the distance between the centroids of the two boxes on the basis of IOU to solve the above-mentioned drawbacks [17]. In contrast, CIOU loss adds the penalty term of the aspect ratio between the two boxes on the basis of DIOU loss [17], which speeds up the box regression convergence and makes the predicted box more consistent with the real box. The expression of CIOU loss is shown in the following equation:
In the above equation, is the Euclidean distance between the centers of the two frames, represents the predicted frame, represents the real frame, is the diagonal distance between the outer rectangles of the two frames, is the weight coefficient, and is a measure of the similarity between the aspect ratio of the predicted frame and the target frame.
In Equation (9), and are the width and height of the real frame, and are the width and height of the predicted frame, represens the width-to-height ratio of the real frame, represents the width-to-height ratio of the predicted frame.
The classification loss is focal loss [18]. This function allows the model to quickly focus on difficult samples by reducing the weights of easy-to-classify samples. The definition is shown in the following Equation (10):
In the above equation, is called the modulation coefficient, where is called the adjustment factor, which is able to adjust the rate of weight decay. is the weighting factor, which is able to balance the importance of positive and negative samples, is the probability that the predicted outcome is correct, and denotes the true value label.
5. Experimental Results and Analysis
5.1. Experimental Environment
The operating environment of this experiment is shown in the Table 3.
Table 3.
Experimental environment.
5.2. Experimental Parameters
In order to reduce the model computation time and cost, this experiment uses the model parameters of pre-trained MSC-COCO to initialize the network weights of DY-RetinaNet. In order to make the network converge faster and consider the memory size of GPU, the adjustment factor was set to 2, and the weighting factor was set to 0.25. To prevent the interference of different IOU thresholds in the experiment, the IOU threshold was set to 0.5, and the other experimental parameters of this study were set as shown in Table 4.
Table 4.
Experimental parameter settings.
5.3. Evaluation Indicators
In this paper, we use the mean average precision (mAP), a common evaluation metric in deep learning, to evaluate the results of all the experiments conducted in this study. Using precision as the vertical coordinate and recall as the horizontal coordinate, the P–R curve is drawn; the area enclosed by the X-axis below the curve is called AP. Then, AP is calculated for each class, and all of the calculated APs are summed up and then averaged. At this time, the mAP is obtained. This is the calculation method of mAP, and the calculation formula is shown in the following equation:
where TP denotes the number of positive samples considered positive, FP denotes the number of negative samples considered positive, FN denotes the number of negative samples considered negative, and C denotes the total number of categories.
Precision = TP/(TP + FP)
Recall = TP/(TP + FN)
The public dataset MSCOCO 2017 has target detection evaluation criteria [19], as shown in Table 5.
Table 5.
MSCOCO evaluation indicators.
5.4. Analysis of Experimental Results
5.4.1. Model Comparison of Different Backbone Networks
This experiment uses the initial models RetinaNet and DY-RetinaNet with different backbone networks for model training on a homemade dataset. The experimental results are shown in Table 6, where AP1 represents the recognition accuracy for Chinese bees, AP2 represents the recognition accuracy for wasps, AP3 represents the recognition accuracy for cockroaches, and mAP represents the average recognition accuracy of the first three categories.
Table 6.
Comparison of different backbone networks.
As can be seen from Table 6, when the backbone network is ResNet-50-BiFPN, the mAP of both models shows an improvement as compared to the mAP when the backbone network is VGG-19. The mAP of RetinaNet and DY-RetinaNet increases by 3.09% and 5.61%, respectively. As the level of the backbone network deepens when the backbone network is ResNet-101-BiFPN, the best performance of both models is achieved when the backbone network is ResNet-101-BiFPN. The mAP of DY-RetinaNet is 97.38%, which is 3.74% higher than the mAP when the backbone network is ResNet-50-BiFPN, and 5.92% higher than the mAP when the backbone network is ResNet-152-BiFPN. The decrease in mAP when the backbone network is ResNet-152-BiFPN is partly due to the overfitting produced by the model, and the performance of the deep network detection is not as stable as that of the shallow network. This shows that DY-RetinaNet has the best model performance when the backbone network is ResNet-101-BiFPN.
5.4.2. Ablation Experiments
In order to demonstrate the effect of each module on the model performance, this study conducted ablation experiments on the homemade dataset. The modules included in this experimental model are backbone, BiFPN, CIOU loss, and dynamic head framework (DYH). To ensure consistency, these experiments were conducted under the same experimental conditions and parameters, and the backbone used throughout was ResNet-101.
The experimental results are shown in Table 7. The mAP is 89.15% when only the backbone network is available, and it becomes 94.65% when the backbone network is combined with BiFPN, which is 5.5% higher than the former result. It can be seen from the results that BiFPN can enhance the multi-scale fusion of the model, which is beneficial for multi-target multi-scale detection. The addition of CIOU loss after the two modules of backbone and BiFPN improves the mAP by 0.7%; the detection accuracy is also improved, but not significantly. However, CIOU loss can help the model to locate small targets more accurately at multiple scales. The detection accuracy of the model after combining the backbone network with BiFPN, CIOU loss, and DYH, is 97.38%, which is significantly improved compared with the recognition accuracies of the modules before the combination of modules. The experimental results show that DYH can significantly improve the model’s performance by combining the three dimensions to build a unified head with multiple attentions, which makes the model more focused on multi-scale recognition under multiple targets. In summary, the model DY-RetinaNet proposed in this paper has strong recognition accuracy in the multi-target multi-scale domain.
Table 7.
Ablation experiment.
5.4.3. Model Performance Comparison on Public Datasets
To verify the generalization capability of DY-RetinaNet within the domain of multi-target multi-scale recognition, the model is compared with current common target detection algorithms on the MSCOCO 2017 public dataset. Under the same experimental conditions, this experiment uses the target detection evaluation metrics of the MSCOCO 2017 dataset for evaluation, and the experimental results are shown in Table 8. Compared with the other models in the table, DY-RetinaNet shows better detection results with its AP of 42.6, which shows an improvement of 9.6% compared to the one-stage model YOLOV3, 7.7% compared to the two-stage model Faster R-CNN, and 1.1% compared to the center-based anchor-free model FCOS. The experimental results demonstrate that DY-RetinaNet shows high recognition accuracy in the face of target detection on different scales.
Table 8.
Comparison of detection accuracy.
6. Discussion
In this study, we propose an improved RetinaNet target detection network, DY-RetinaNet, for identifying common species, i.e., Chinese bees, wasps, and cockroaches, at beehive nest gates in natural environments. The experimental results show that the average recognition accuracy of this model, DY-RetinaNet, reaches 97.38%, which is 6.77% better than the accuracy of the initial model RetinaNet; this includes 98.15% recognition accuracy for Chinese bees, 96.93% for wasps, and 97.06% for cockroaches. This proves that the model can help beekeepers effectively monitor invasive beehive species, and therefore meets the experimental requirements of this study.
Comparing the results of this study with the research results produced by other authors, as shown in Table 9, it can be seen that the results of Zhao et al. [20], Zhang et al. [21], and Duan et al. [22] are less accurate than the model proposed in this paper on the same public dataset. However, despite the fact that the accuracy of the model of Cai et al. [23] is higher than the results of this paper, the accuracy of their model is much lower than ours when identifying small-scale targets. In summary, the model proposed in this paper has strong recognition accuracy and good generalization performance for multi-target and multi-scale recognition.
Table 9.
Comparison with the results of other authors.
7. Conclusions
In order to solve the multi-target multi-scale problem that occurs at beehive nest gates in natural environments, and to enable beekeepers to effectively monitor beehive species invasion, this paper proposes an improved RetinaNet target detection network, DY-RetinaNet, for common species identification (i.e., Chinese bees, wasps, and cockroaches) at beehive nest gates in natural environments,. The model uses a BiFPN network as a replacement for the FPN network in the initial model RetinaNet, allowing the model to perform multi-scale feature fusion easily and efficiently. In addition, a dynamic head frame is added after the model backbone network to enhance the model performance without increasing computation, so that the model focuses more on multi-scale recognition under multiple targets.
DY-RetinaNet obtained the mAP value of 97.38% by model comparison on the homemade dataset, which is 6.77% higher than the initial model accuracy. Additionally, to verify the generalization and effectiveness of the model, it has been compared with existing common target detection algorithms on public datasets, and it is concluded that the model has high recognition accuracy when facing multi-target multi-scale recognition. This study effectively improves the detection of multiple targets at multiple scales; however, the model has the problem of oversized parameters, and future research should be directed towards improving the scalability of the model by "pruning" and lightweighting it for deployment on embedded and mobile devices, to prepare the algorithm for use in the detection of and warning systems for species invasion in smart beehives.
Author Contributions
Conceptualization, X.H. and C.L.; methodology, X.H. and S.L.; software, X.H. and C.L.; validation, X.H. and C.L.; writing—original draft preparation, X.H.; writing—review and editing, S.L.; visualization, X.H. and C.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Berkaya, S.K.; Gunal, E.S.; Gunal, S. Deep learning-based classification models for beehive monitoring. Ecol. Inform. 2021, 64, 101353. [Google Scholar] [CrossRef]
- Wang, J.; Song, L.; Li, Z.; Sun, H.; Sun, J.; Zheng, N. End-to-end object detection with fully convolutional network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15849–15858. [Google Scholar]
- Huang, S.; Liu, Q. Addressing scale imbalance for small object detection with dense detector. Neurocomputing 2022, 473, 68–78. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Boudjit, K.; Ramzan, N. Human detection based on deep learning YOLO-v2 for real-time UAV applications. J. Exp. Theor. Artif. Intell. 2022, 34, 527–544. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhan, J.; Hu, Y.; Cai, W.; Zhou, G.; Li, L. PDAM–STPNNet: A Small Target Detection Approach for Wildland Fire Smoke through Remote Sensing Images. Symmetry 2021, 13, 2260. [Google Scholar] [CrossRef]
- Zhao, S.; Peng, Y.; Liu, J.; Wu, S. Tomato leaf disease diagnosis based on improved convolution neural network by attention module. Agriculture 2021, 11, 651. [Google Scholar] [CrossRef]
- Liang, Y.; Wang, G.; Li, W.; He, Y.; Liang, X. A new object detection method for object deviating from center or multi object crowding. Displays 2021, 69, 102042. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, F.; Wang, R.; Xie, C.; Yang, P.; Liu, L. Fusing multi-scale context-aware information representation for automatic in-field pest detection and recognition. Comput. Electron. Agric. 2020, 169, 105222. [Google Scholar] [CrossRef]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7036–7045. [Google Scholar]
- Chen, J.; Mai, H.; Luo, L.; Chen, X.; Wu, K. Effective feature fusion network in BIFPN for small object detection. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 699–703. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Havard, W.; Besacier, L.; Rosec, O. Speech-coco: 600k visually grounded spoken captions aligned to mscoco data set. arXiv 2017, arXiv:1707.08435. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).