Abstract
This work presents a new distribution that allows modeling data from a random variable with non-negative values. The new family is defined by a stochastic representation of a scaled mixture of a random variable with a Gompertz distribution (G) and a random variable with a uniform distribution on the interval (0,1). The result of this gives rise to a new random variable with a Slash Gompertz () distribution that is more flexible than the Gompertz distribution, that is, it better models atypical data, presenting tails heavier than the Gompertz distribution. The density and some general properties of the resulting family are studied, including its moments and kurtosis coefficient. The inference of the parameters is carried out using the method of moments and maximum likelihood. Finally, illustrations of particular cases of this family are shown, adjusting in this case two sets of real data and estimating the parameters by maximum likelihood, where it is verified that this new family of distributions fits the reliability function better than the distributions of Gompertz (G), Slash Birnbaum Saunders (), Slash Weibull (), and Gompertz-Verhults ().
1. Introduction
The Gompertz curve or Gompertz function is a type of mathematical model designed to describe a time series and is named after Benjamin Gompertz (1779–1865) (see [1]). The function was originally designed to describe human mortality, but has since been modified for application in biological sciences. The model is defined by
where “a” is an asymptote, since
“b”, “c” are positive numbers, where “b” sets the offset along the x axis y “c” sets the growth rate.
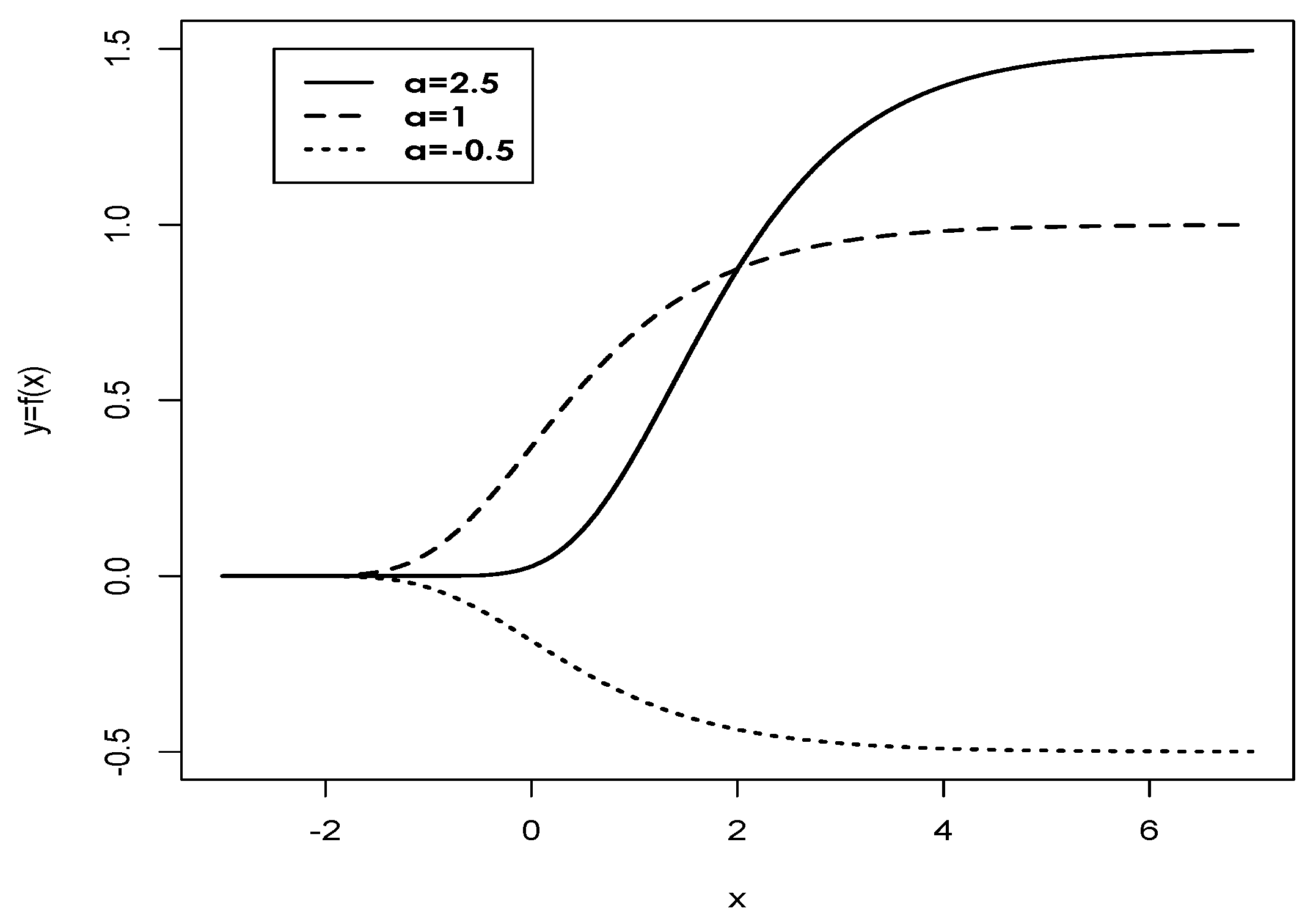
Figure 1 shows the behavior of the Gompertz function for different values of “a”.
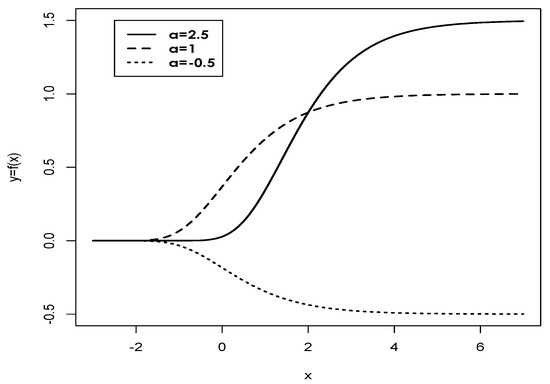
Figure 1.
Plot of Gompertz function for (solid line), (dotted line), (dashed line) and .
1.1. The Gompertz Distribution
The Gompertz distribution is important in describing the pattern of adult deaths (Wetterstrand [2]; Gavrilov and Gavrilova [3]). For low levels of infant (and young adult) mortality, the Gompertz mortality rate extends to lifetime (Vaupel [4]) of populations with no observed mortality slowdown.
The Gompertz distribution has received considerable attention from demographers and actuaries. Pollard and Valkovics [5] were the first to study the Gompertz distribution minutely. However, their results are valid only in the case where the initial level of mortality is very close to 0. Kunimura [6] reached similar conclusions. both defined the moment-generating function of the Gompertz distribution in terms of the complete or incomplete gamma function and its results are approximated or left in the function of an integral. Willemse and Koppelaar [7] reformulated the Gompertz death rate and derived properties for this reformulation. Later, Marshall and Olkin [8] described the negative Gompertz distribution; a Gompertz distribution with a negative aging rate. Willekens [9] provided connections between Gompertz, Weibull and other distributions of extreme values of Type I.
An important function used in computing the moments of the Gompertz distribution is the generalized integro-exponential function, which is defined by the following integral representation:
where , and is the gamma function. For further details, the reader is referred to Milgram [10] and Chiccoli et al. [11].
The Gompertz distribution has a continuous probability density function with scale parameter and shape parameter ,
with support on . In actuarial or demographic applications, X usually indicates the age which cannot be negative, leading to a bounded support at . The Truncated Distribution produces a suitable density function by scaling the parameter to correspond to (Mohan et al. [12]). The cumulative distribution function is
Moments of the Gompertz distribution can be given explicitly by the generalized integro-exponential function (Milgram [10]), which offers an exact power series representation of them. The j-th moment of a random variable X with Gompertz distribution is
where , is the generalized integro-exponential function (Milgram [10]).
1.2. The Slash Standard Distribution
The Slash distribution is the distribution of the ratio of two independent random variables, one with a standard normal distribution (X) and the other with a uniform distribution (U) in . whose stochastic representation is,
where and independent and q is the parameter related to the kurtosis of the distribution. It will be denoted as and its density function has the following expression
where is the gamma function and is the gamma incomplete function. This distribution has heavier tails than the normal distribution. The properties of this family are discussed in Rogers and Tukey [13] and Mosteller and Tukey [14].
The maximum likelihood estimators for the location and scale parameters are discussed in Kafadar [15]. Gómez, Quintana and Torres [16], and Gómez and Venegas [16] extend the Slash distribution to the elliptical Slash family. Genc [17] presented a symmetric generalization of the Slash distribution. More recently, Gómez, Olivares-Pacheco and Bolfarine [18] use the elliptic Slash family to extend the Birnbaum Saunders distribution. Reyes, Gómez and Bolfarine [19] introduce the modified Slash distribution replacing the uniform distribution with the exponential distribution of parameter 2, transforming it into a more flexible distribution that better captures outliers.
The paper is organized as follows: In Section 2, a closed expression for the pdf of a model is obtained along with its most relevant indicators: moments, kurtosis coefficient, etc. Section 3 presents some important properties. Section 4 is dedicated to presenting some estimation methods such as the method of moments and maximum likelihood. A simulation study has been included to evaluate the performance of the proposals. Two applications to a real data set is given in Section 5, in which the new distribution fits better than other models of similar distribution. Finally, a discussion is presented in Section 6.
2. Slash Gompertz Distribution
The Slash Gompertz distribution is introduced by replacing in (5) the standard normal distribution by a Gompertz distribution with parameters and , transforming this into a distribution with higher kurtosis. We will start by deriving its density function.
2.1. Density Function
The Slash Gompertz distribution has the following stochastic representation
where ≡ means equivalence in distribution, and X, U are independent random variables, such that and , where is the scale parameter, is the shape parameter and is the kurtosis parameter, so we say follows a Slash Gompertz distribution and will be denoted by .
Proposition 1.
Let W be a random variable such that , then its probability density function (pdf) is given by
where is the Incomplete Generalized Integro-Exponential function (Milgram [10]).
Proof.
Using the stochastic representation given in (7) and the random variable transformation method, we obtain
making the change of variable and developing the integral, the result is obtained. □
Corollary 1.
If in (8), then the probability density function (pdf) of W is given by
and we will say that follows a canonic Gompertz Slash distribution, and is denoted by .
Proof.
Making in (8) the result is obtained. □
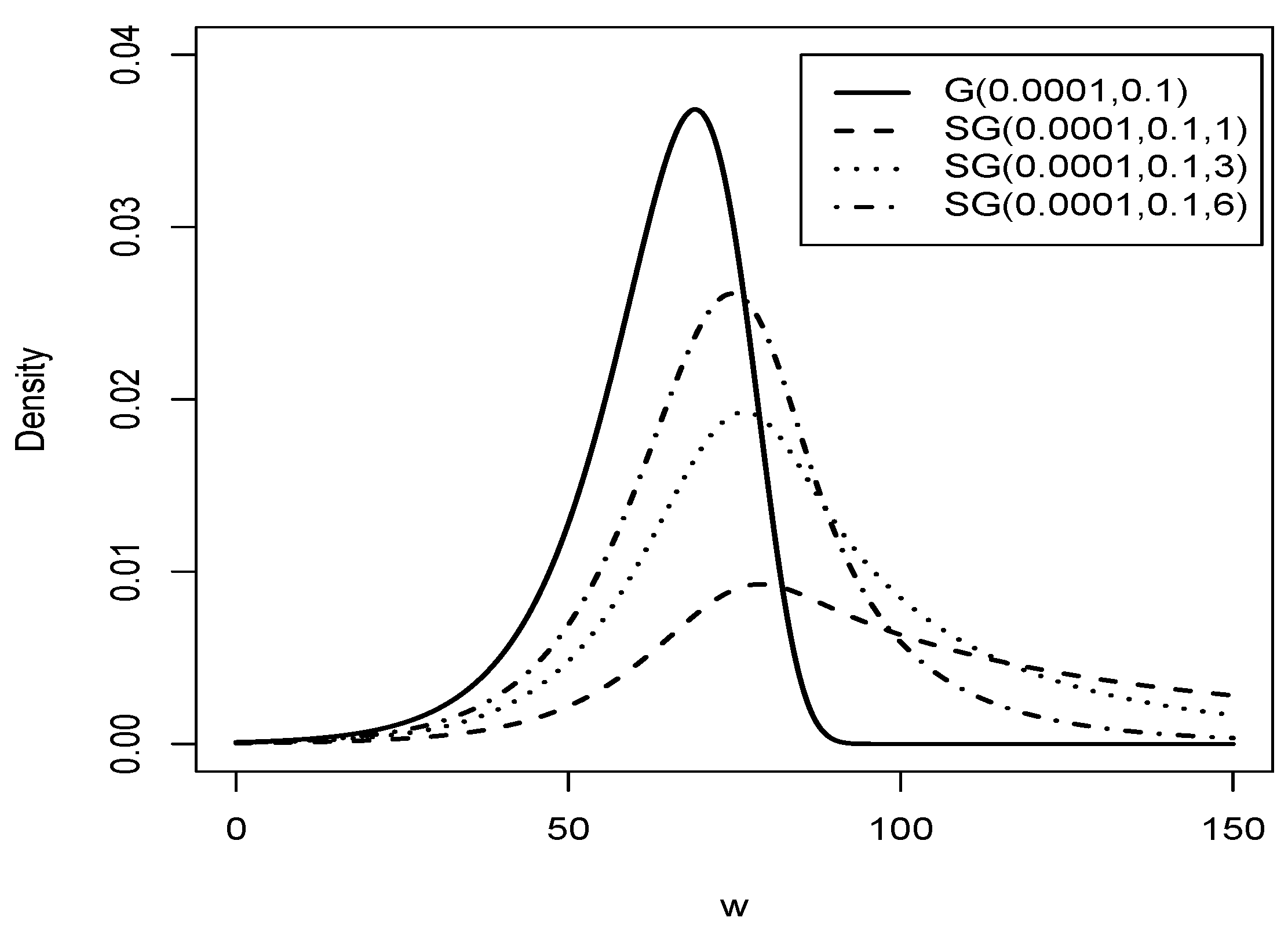
Figure 2 shows the plot of the Slash Gompertz distribution with = 0.0001 and = 0.1 and different values of q, compared to the Gompertz distribution with = 0.0001 and = 0.1.
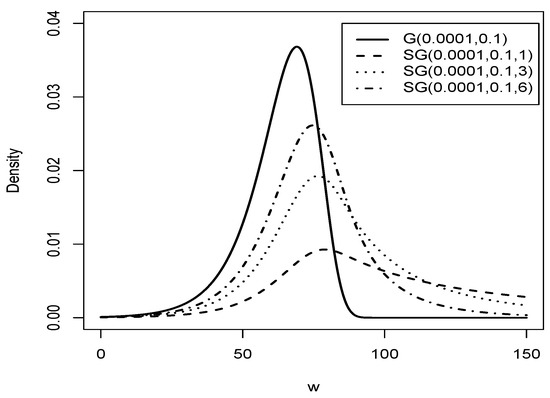
Figure 2.
Graphic of comparison of the G distribution (solid line) with distribution for = 0.0001, = 0.01 and (dashed line), (dotted line), (dashed dotted line).
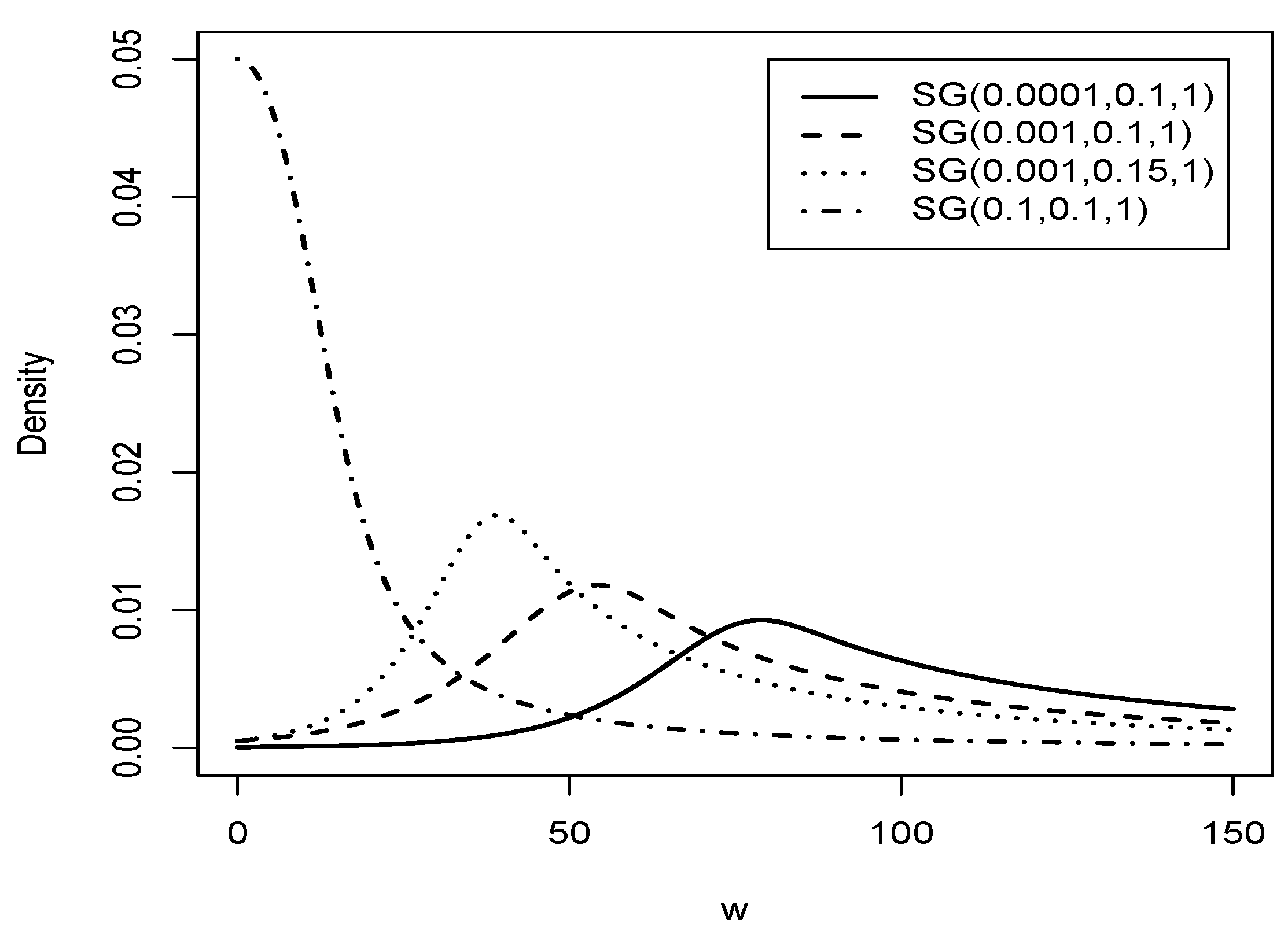
Figure 3 shows the graph of the Slash Gompertz distribution for different values of and with .
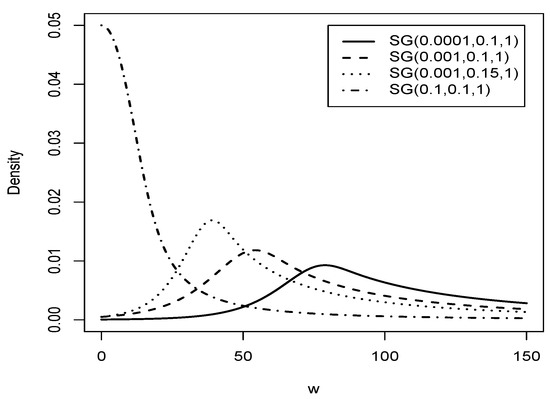
Figure 3.
Graphic comparison of the distribution for and different values of and .
Proposition 2.
Let . Then, the cdf of W is given by
Proof.
Expanding the integral gives the result. □
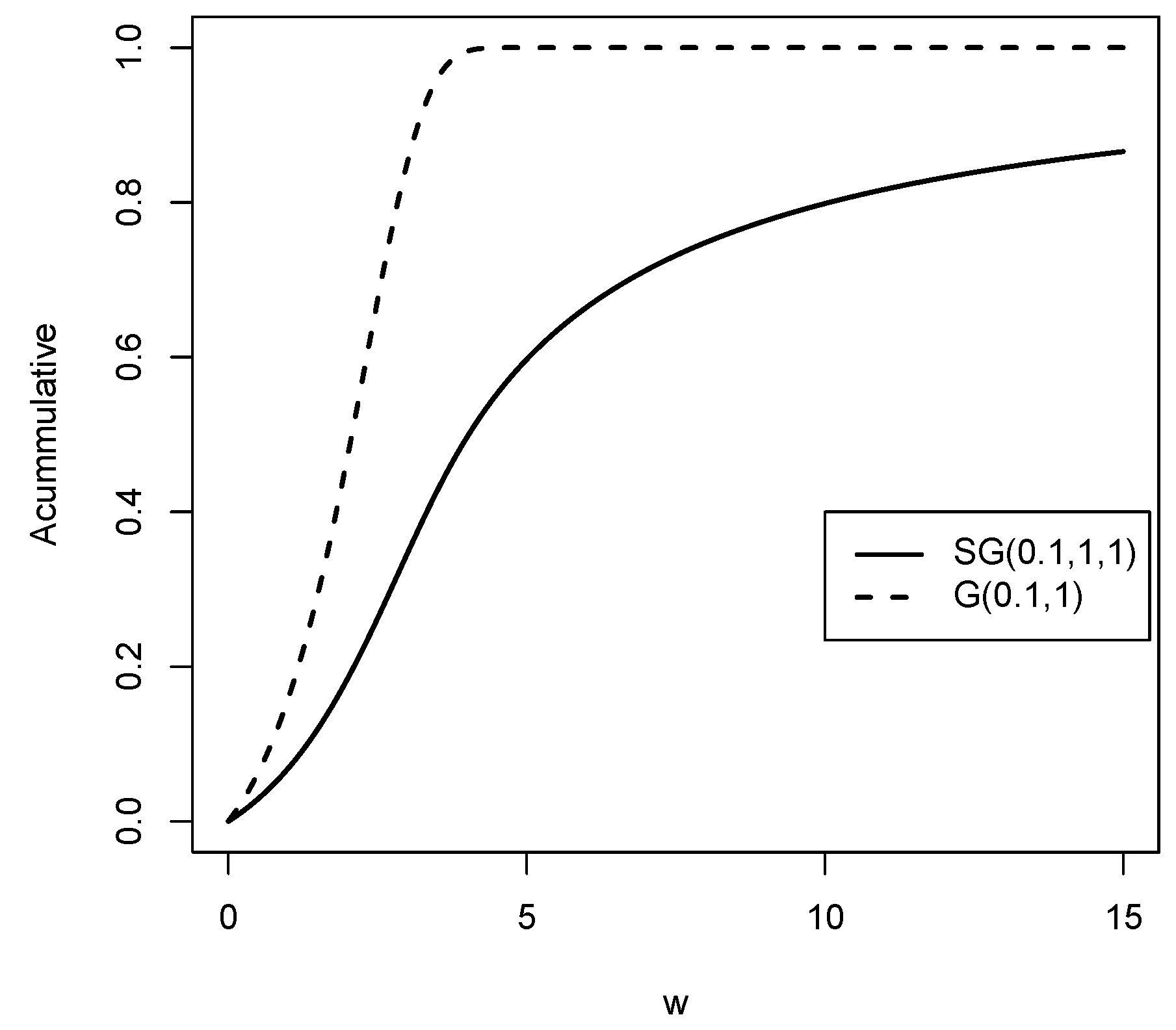
In Figure 4, we graphically illustrate the behavior of the cumulative distribution function of the Slash Gompertz distribution and the Gompertz distribution.
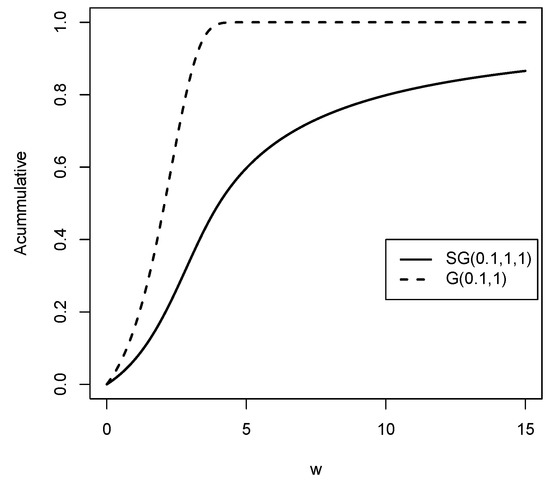
Figure 4.
Cumulative distribution functions for the distributions compared to the G distribution for values of , and q.
2.2. The Reliability and Hazard Rate Functions
Two important measures of reliability are the reliability function and the hazard (failure) rate function. The reliability function of a random variable Y is defined by , where denotes the cdf of Y. The hazard rate function is defined by . For the distribution, as a direct consequence of Proposition 1 and Proposition 2, both measures of reliability can be expressed in closed form. The corresponding expressions are easily obtained.
Proposition 3.
Let . Then, the Hazard function of W is given by
Proof.
Replacing and you get the result. □
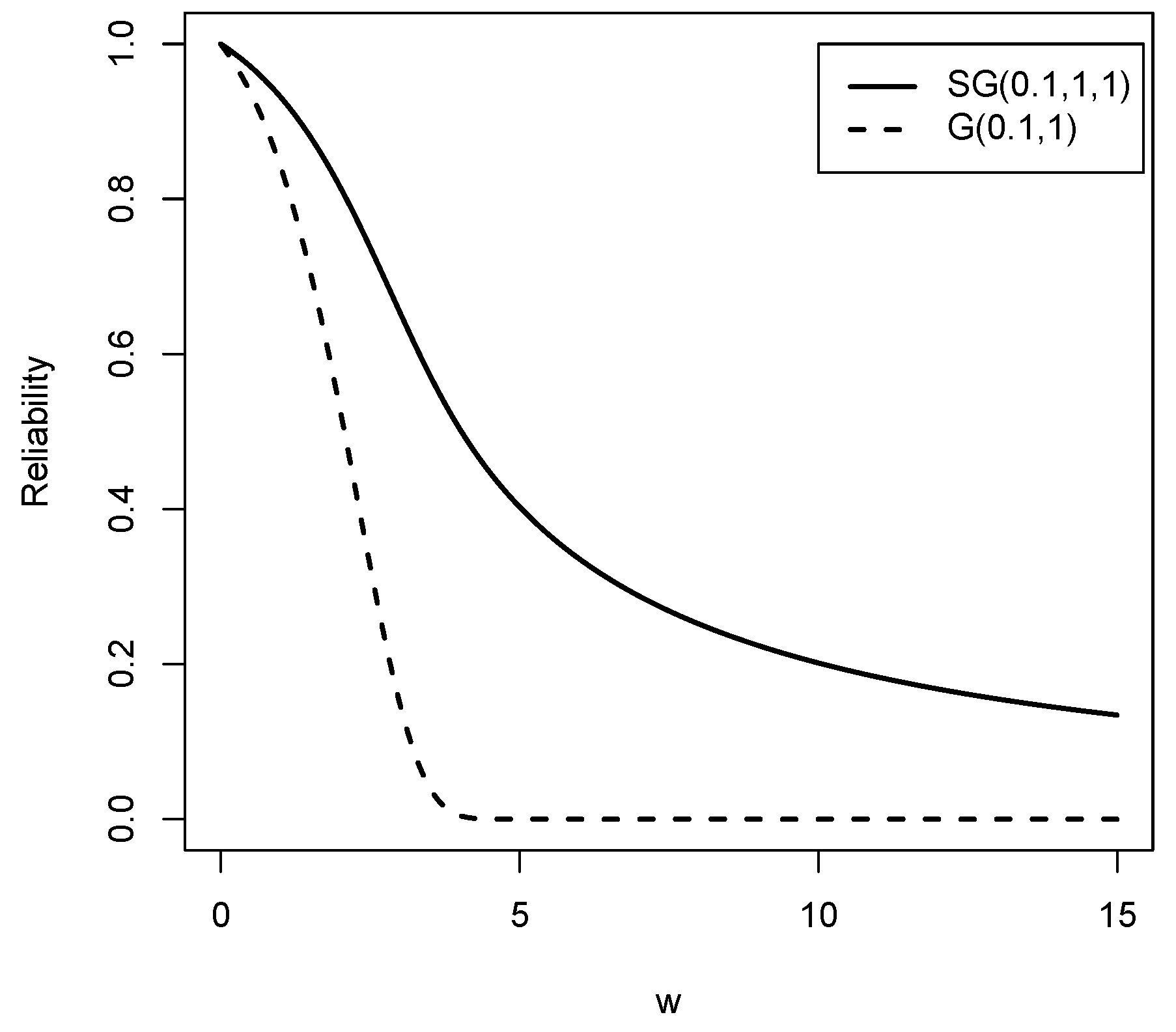
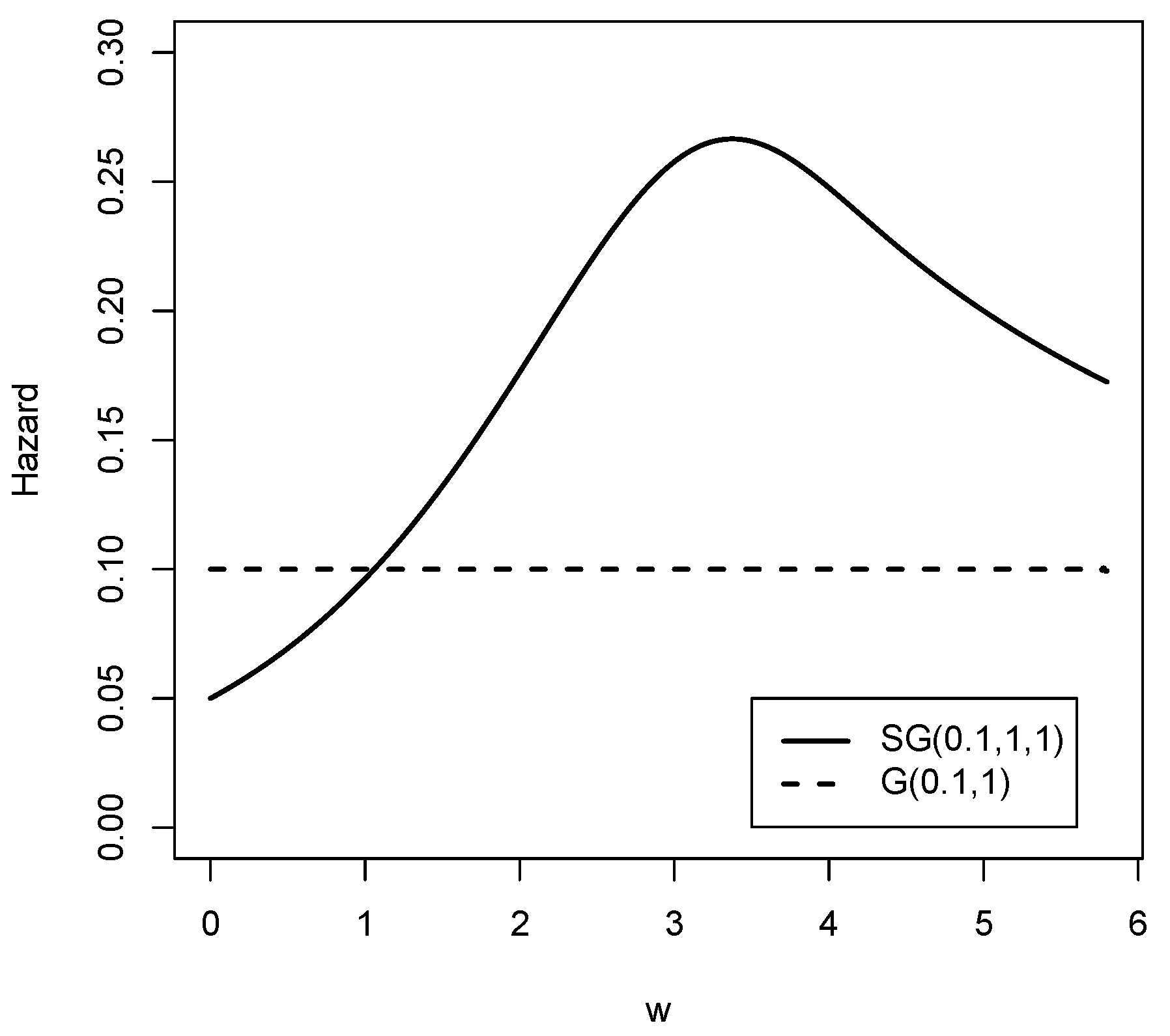
Figure 5 and Figure 6 show the reliability function and the hazard rate function respectively of the Slash Gompertz law for different values of the parameters compared to the Gompertz distribution. It is clear that both functions exhibit a wide variety of forms. Therefore, the new family of distributions is flexible enough to model real data sets with high kurtosis.
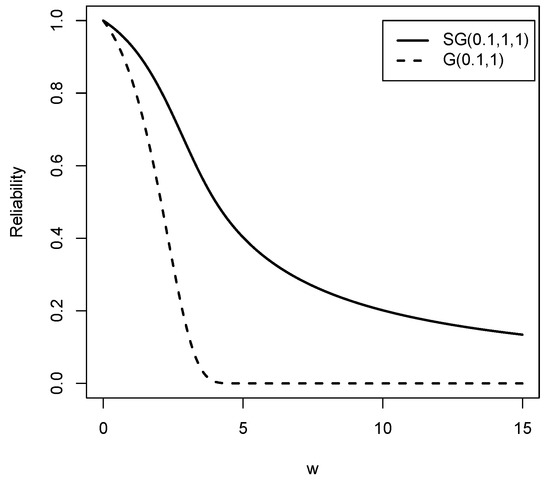
Figure 5.
Reliability functions for the distributions compared to the G distribution for values of , and .
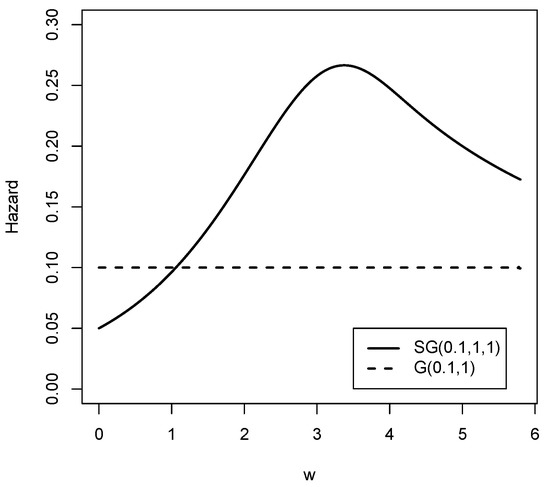
Figure 6.
The hazard rate functions for the and G distribution.
2.3. Reliability Function Comparison of Gompertz, Slash Birnbaum Saunders and Slash Gompertz Distributions
In this section, we make a brief comparison which illustrates that the tails of the Slash Gompertz distribution are heavier than the Gompertz distribution and the Slash Birnbaum Saunders distribution. For this we consider the Gompertz, Slash Birnbaum Saunders and Slash Gompertz distributions with , and . Table 1 shows for different values of y in the mentioned distributions. It is evident that the Slash Gompertz distribution has much heavier tails than the Gompertz and Slash Birnbaum Saunders distributions.

Table 1.
Reliability function comparison for distributions of G, and .
Table 1 illustrates the fact that the Slash Gompertz distributions have heavier tails than the tails of the Gompertz and Slash Birnbaum Saunders distribution.
2.4. The rth Moment of a Gompertz Slash Distributed Random Variable W
The following proposition presents us with a formula that, through the use of numerical techniques, allows us to calculate the rth moment of a Slash Gompertz distribution.
Proposition 4.
Let then for and the rth moment of random variable W is
where
Proof.
Let X and U be independent random variables such that:
where , expanding we have that , .
Also as we have that . Finally, substituting these results in (14) the result is obtained. □
2.5. Expected Value, Variance, Skewness and Kurtosis of a Gompertz Slash Distributed Random Variable W
Corollary 2.
The expected value of random variable , is
Proof.
□
Corollary 3.
The variance of random variable , is
Proof.
The variance of a random variable W
Concentrating on , if W is Slash Gompertz distributed, from (13):
Proposition 5.
The coefficient skewness of random variable , is
for all .
Proof.
Proposition 6.
The coefficient kurtosis of random variable , is
for all .
Proof.
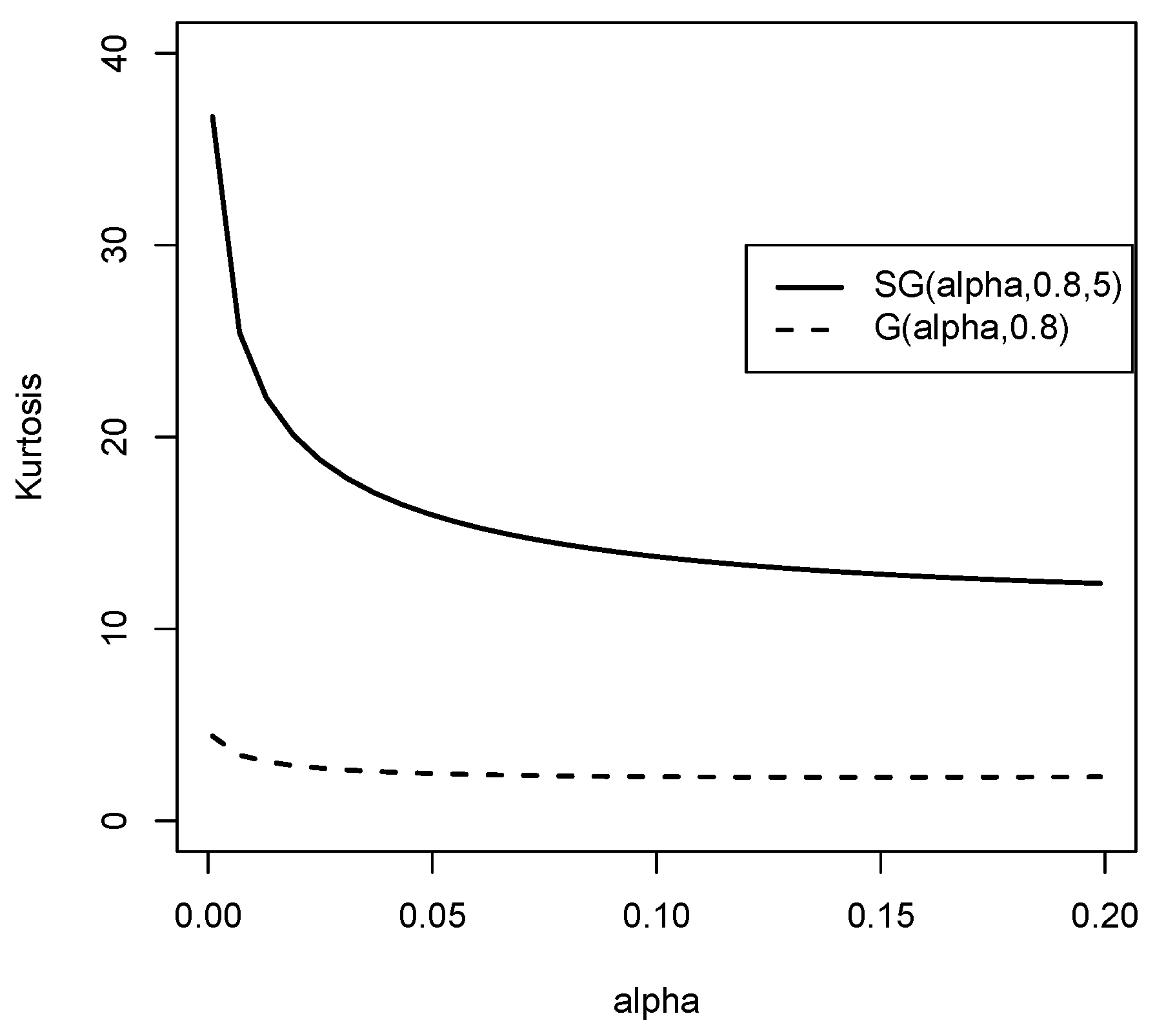
Figure 7 graphically shows that for small values of alpha, the kurtosis coefficient is higher in the SG distribution than in the G distribution.
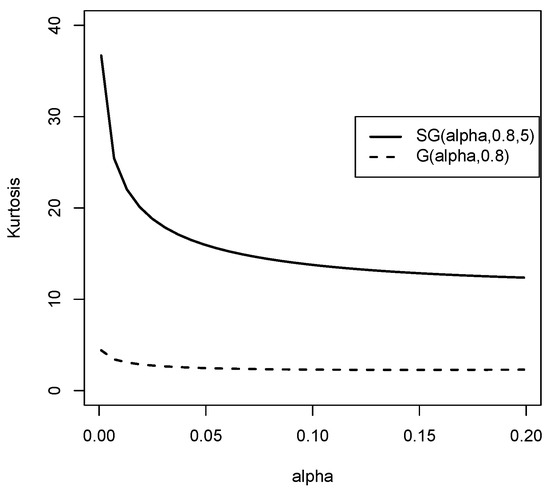
Figure 7.
Kurtosis coefficient graphic for the and the Gompertz distribution.
3. Some Statistical Properties
3.1. Failure Rate Function
The failure (or hazard) rate function of the distribution is given by
where .
Proposition 7.
For any , and , the random variable X has increasing failure rate (IFR).
Proof.
The first derivative of h can be written as follows
It is clear that since , , and which implies the result. □
3.2. Mean Residual Life
An important reliability quantity for positive random variables is the mean residual life, which is defined as , . It is well-known that if a random variable has IFR, then its mean residual life is decreasing. Therefore, the mean residual life of X is a decreasing function in t. Furthermore, an analytical expression for the mean residual life is given in the following result.
Proposition 8.
The mean residual life function of X is given by
, where
Proof.
Let . Then, by standard integration,
which implies the result. □
3.3. Incomplete Moments
The first incomplete moment of X is defined as
Proposition 9.
Let X be a random variable with distribution. Then,
Proof.
An interesting application of the first incomplete moment is that the mean deviation about the mean of X can be directly obtained, specifically by means of the relation
where .
3.4. The Lorenz Curve and the Gini Index
The Lorenz curve, , can also be obtained from the first incomplete moment and the expected value of X, specifically the following closed-form expression is obtained
The Gini index is the measure of inequality associated with the Lorenz curve. For the random variable X, the Gini index is defined by
The next result, an analytical expression is provided for .
Proposition 10.
Let X be a random variable with distribution. The Gini index is given by
where .
4. Inference
4.1. Moment Estimators
The following proposition shows us the set of equations, which through the use of numerical techniques, allow us to calculate the moment estimators of the parameters of a Slash Gompertz distribution.
Proposition 11.
Let be a random sample from the distribution of the random variable , so that the moment estimators from for can be obtained numerically by solving the following system of nonlinear equations.
where , y are the first three sample moments not centered respectively.
Proof.
Replacing the population moments by the sample moments and using (13) gives that
and solving (30) for q gives the numerical equation for given in (27). Furthermore, replacing q by in (31) and (32), we obtain the numerical equations given in (28) and (29) for the moment estimators and , respectively. □
4.2. Maximum Likelihood Estimate
Given a random sample of a distribution , the corresponding log-likelihood function can be written as
with hence the likelihood equations are given by
where
where .
The solutions of the Equations (34)–(36) can be obtained using numerical procedures such as Newton-Raphson.
An approach to obtain the MLE for the model is through the optim function developed in the R software, the specific method is the L-BFGS-B developed by Byrd et al. [20] where each variable can be obtained by lower and/or upper bounds. This method uses a limited memory modification of the quasi-Newton method. For large samples, the estimated variance can be calculated by inverting the Hessian matrix, which can be calculated numerically using R software.
4.3. Simulation Study
Using the representation given in (7), it is possible to generate random numbers for the distribution , which leads to the following algorithm.
- Simulate
- Compute
- Simulate
- Compute
It then follows that then . Table 2 shows the results of the simulation studies, illustrating the behavior of the MLEs for 2000 generated samples of sizes , 100, 200 and 500 of the distributed population as . For each sample generated, the MLEs were calculated numerically using the Newton-Raphson procedure. The means, standard deviation (sd), average length of interval (ali) is the average length of the condence interval and the empirical coverage (c) of the respective EMV of the parameters, based on a 95% confidence interval.
Table 2.
Simulation of 2000 iterations of the model .
Table 2 shows that as the sample size increases, the parameter estimates converge. asymptotically to the true value of the parameters. Also, the standard deviations and the average length of the confidence intervals decrease as n increases, showing the consistency of the estimates. On the other hand, the empirical coverage is adequate, since it is close to 95%.
5. Applications with Real Data
The numerical illustrations below are intended to show that the model can be an alternative to modeling unimodal data from different areas.
5.1. Application 1
We consider data from a study of warp breakage during weaving of fabrics (see Quesenberry, C.P., & Kent, J. [21]), 100 yarn samples were tested. The number of stress cycles was determined until rupture for each yarn sample, for which their statistical measurements were obtained and the maximum likelihood estimators of the parameters of the Slash Gompertz distribution are obtained and compared with those of the Gompertz distribution and the Slash Birnbaum Saunders distribution with their corresponding standard errors.
Table 3 shows a summary of statistical measures for the data set where the number of stress cycles until rupture was determined for each thread sample, it can be seen that the data has a high level of kurtosis.
Table 3.
Summary statistics for the rupture data set.
In Table 4 is shown the best fit of the new model compared to the Gompertz and Slash Birnbaum Saunders distribution, since the Akaike Information Criterion (AIC) and Bayesian information criterion (BIC) values are much lower than their competitors.
Table 4.
Maximum likelihood estimators for rupture data with their corresponding standard errors in parentheses and AIC, BIC criteria.
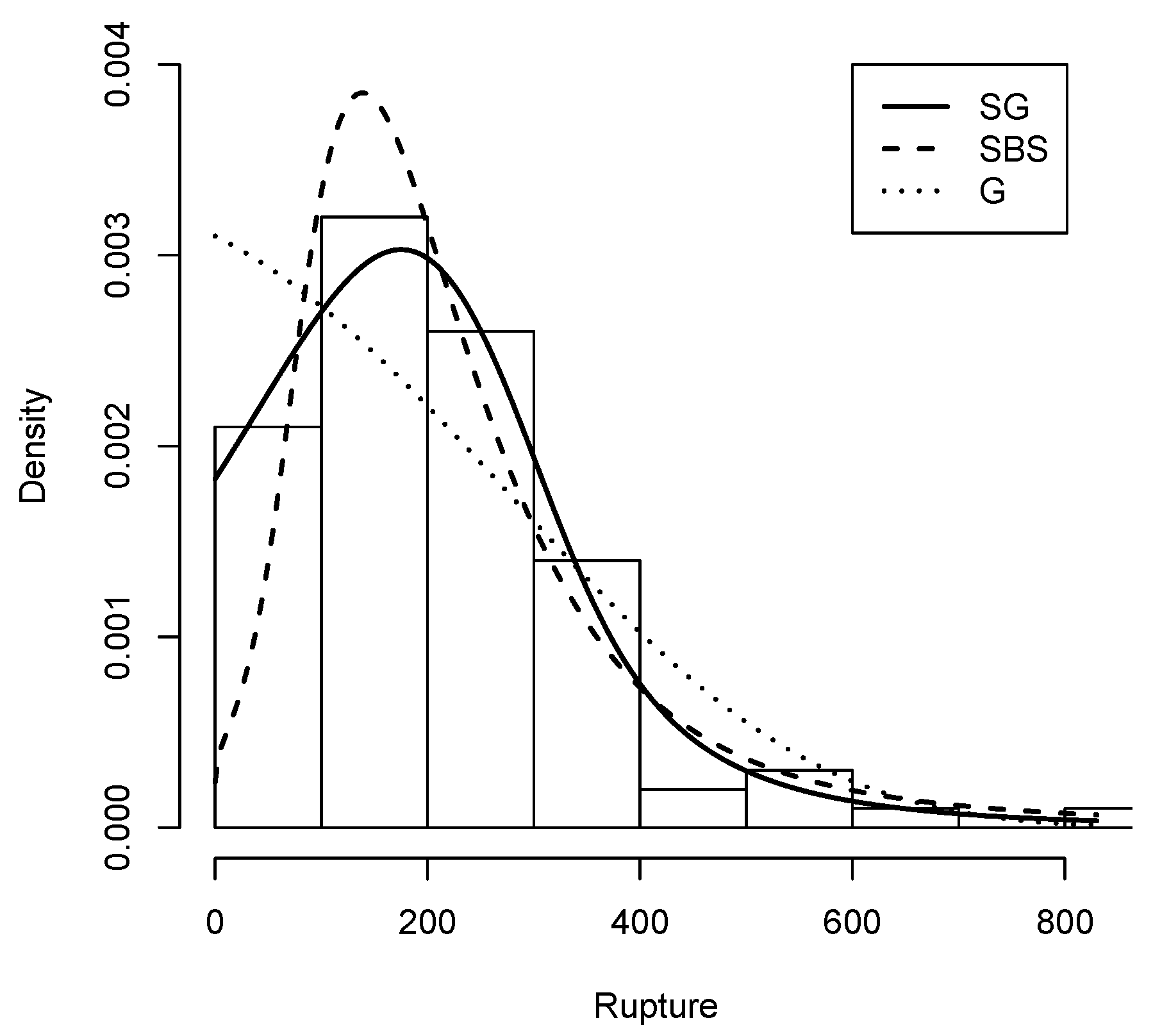
The histogram plot of the rupture data with the Slash Gompertz distribution fitted with the maximum likelihood estimators of its parameters is shown in Figure 8 compared with the Gompertz distribution and the Slash Birnbaum Saunders distribution.
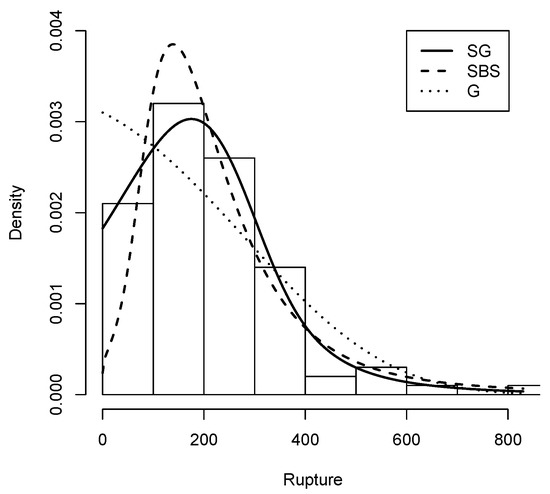
Figure 8.
Rupture data histogram with Density (solid line), G density (dashed line) and density (dotted line).
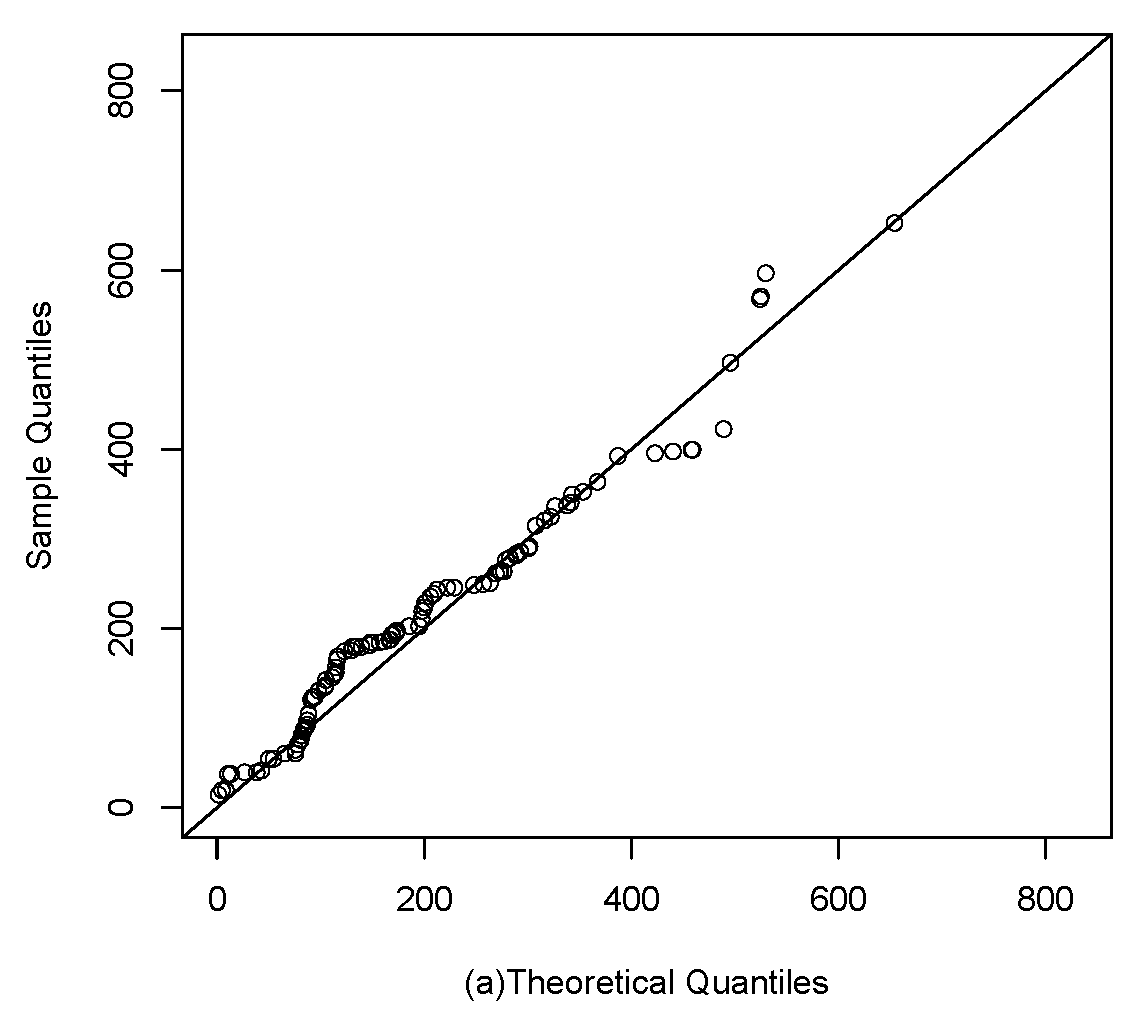
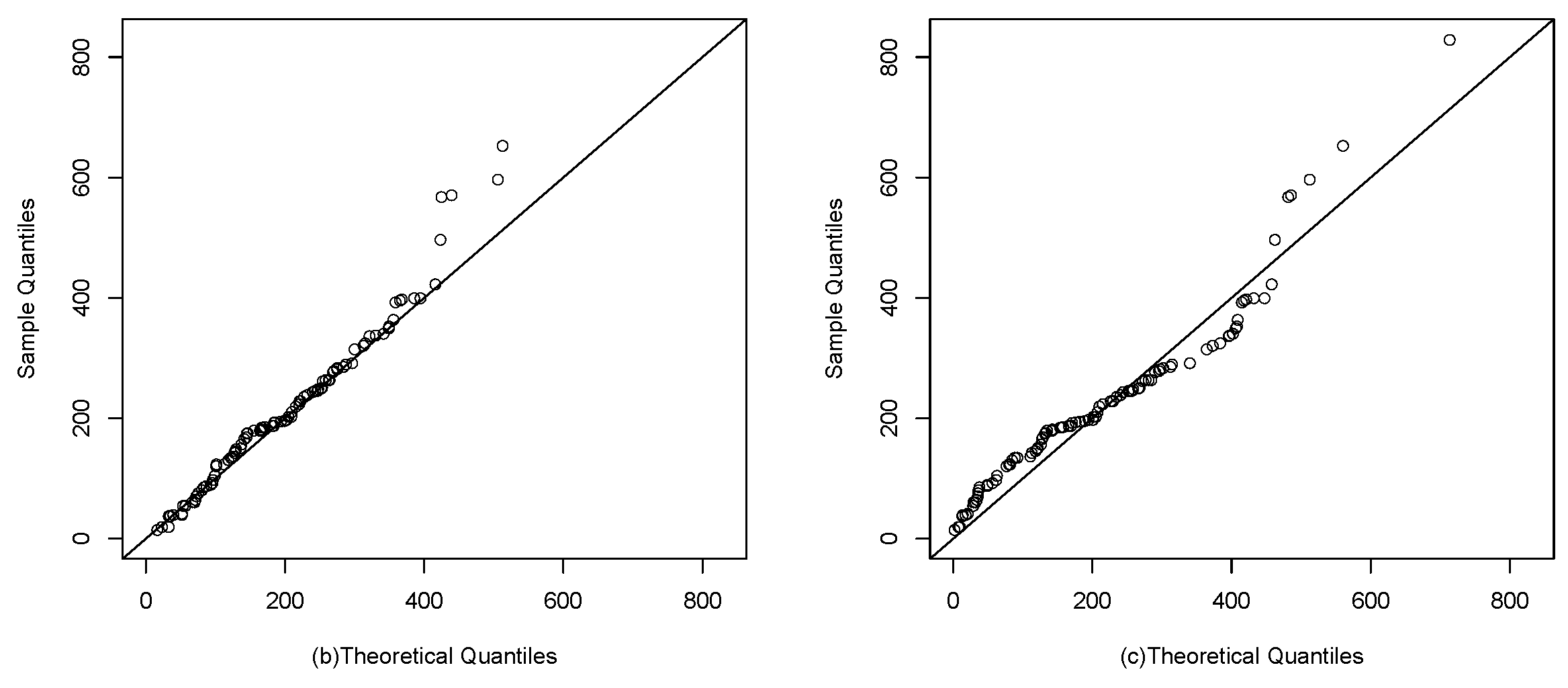
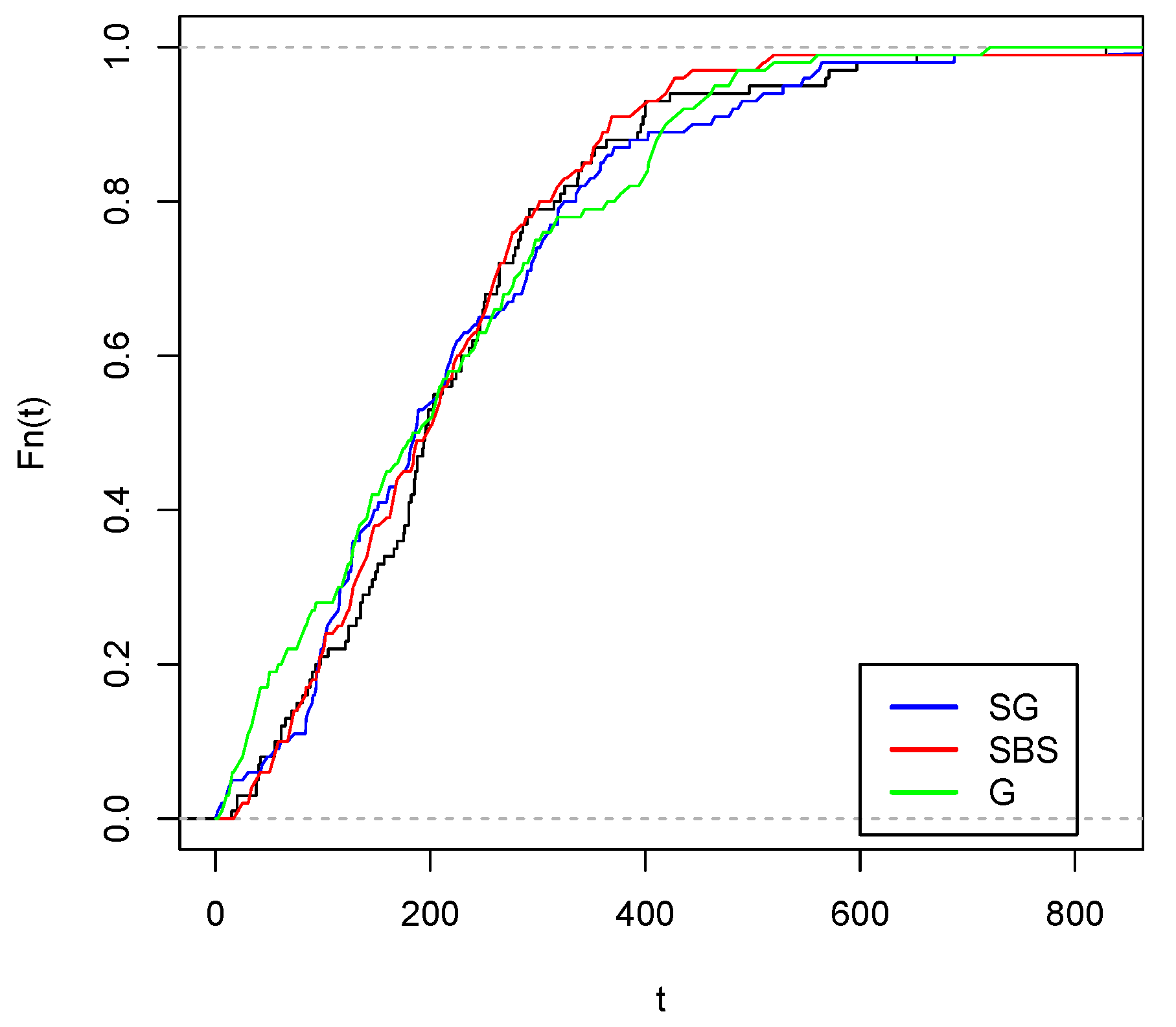
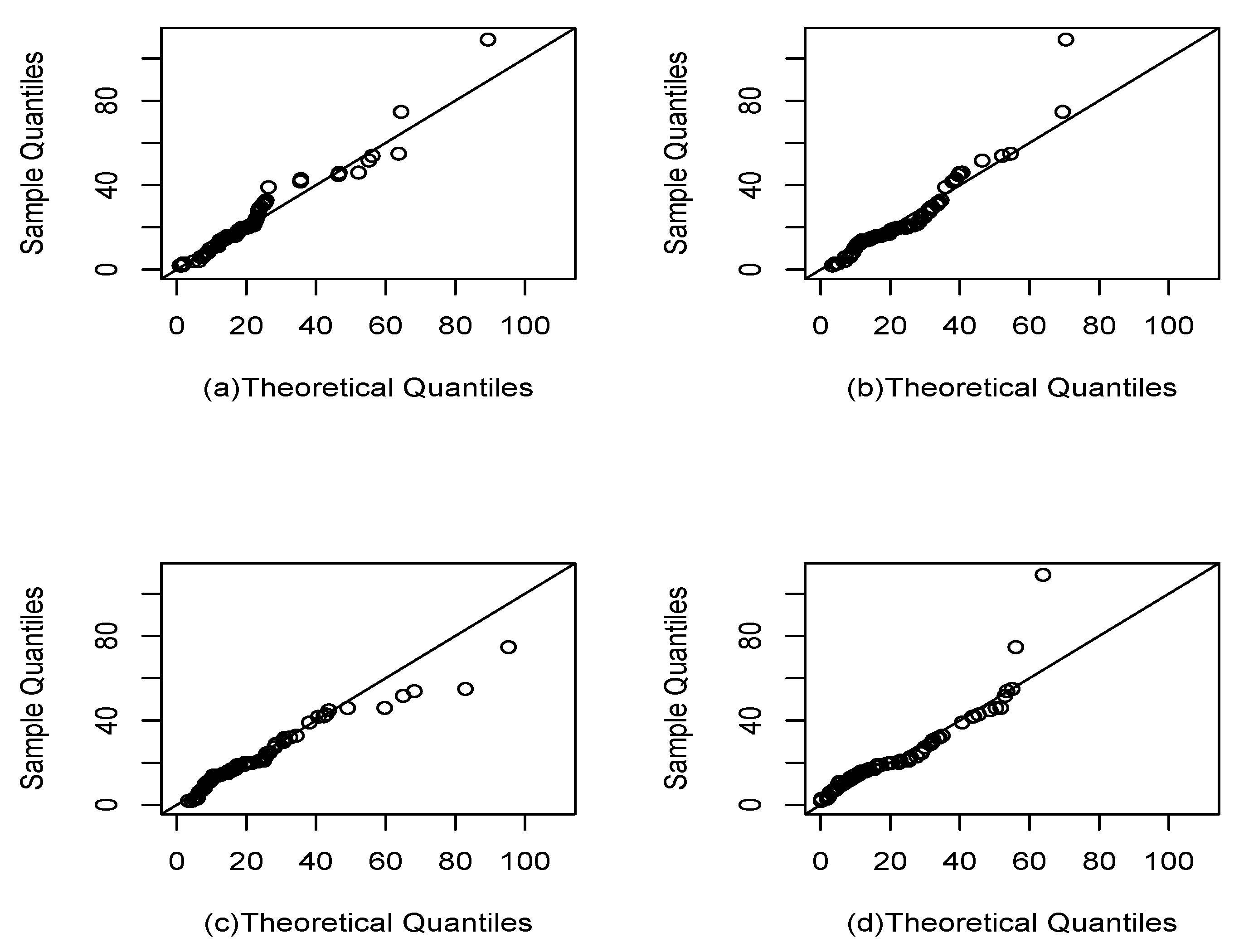
Figure 9 and Figure 10 visually show the best fit of the studied model compared to the Gompertz and Slash birnbaum Saunders distributions. In the first, the theoretical quantiles approximate the line much better than the competing distributions. While in the second, the approximation of the empirical CDF of the model of interest is closer to the empirical CDF of the data.

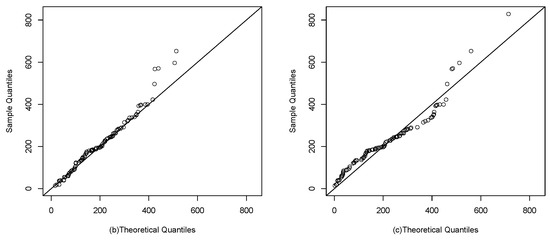
Figure 9.
Q-q plots: (a), (b) and G (c).
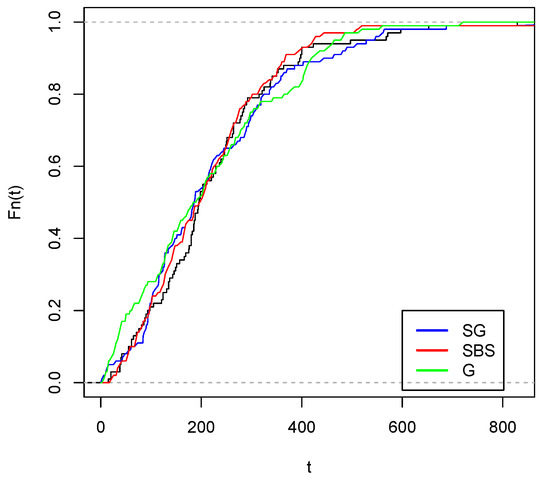
Figure 10.
Empirical cdf with estimated c.d.f. (red color), estimated G c.d.f. (green color) and estimated cdf (blue color).
5.2. Application 2
In this application we consider the Gompertz-Verhulst () distribution M. Ahsanullah et al. [22], whose density function is given by
and the Slash Weibull distribution, Olivares-Pacheco, J.O., Cornide-Reyes H.C., Monasterio, M. [23], whose density function is given by:
with .
Following illustration is related to the nickel content in soil samples analyzed at the Mining Department (Department of Mines) of University of Atacama, Chile. The parameters of the Slash Gompertz distribution are estimated and compared with the Gompertz, Slash Weibull and Gompertz-Verhulst distributions with their corresponding standard errors.
Table 5 shows a summary of statistical measures for the data set on nickel content, it can be seen that the data has a high level of kurtosis.
Table 5.
Summary statistics for the nickel content data set.
Table 6 shows the best fit of the Slash Gompertz compared to the Gompertz, Slash Weibull and Gompertz-Verhulst distribution, because the AIC and BIC values are lower than those of its competitors.
Table 6.
Maximum likelihood estimators for nickel data with their corresponding standard errors in parentheses and AIC, BIC criteria.
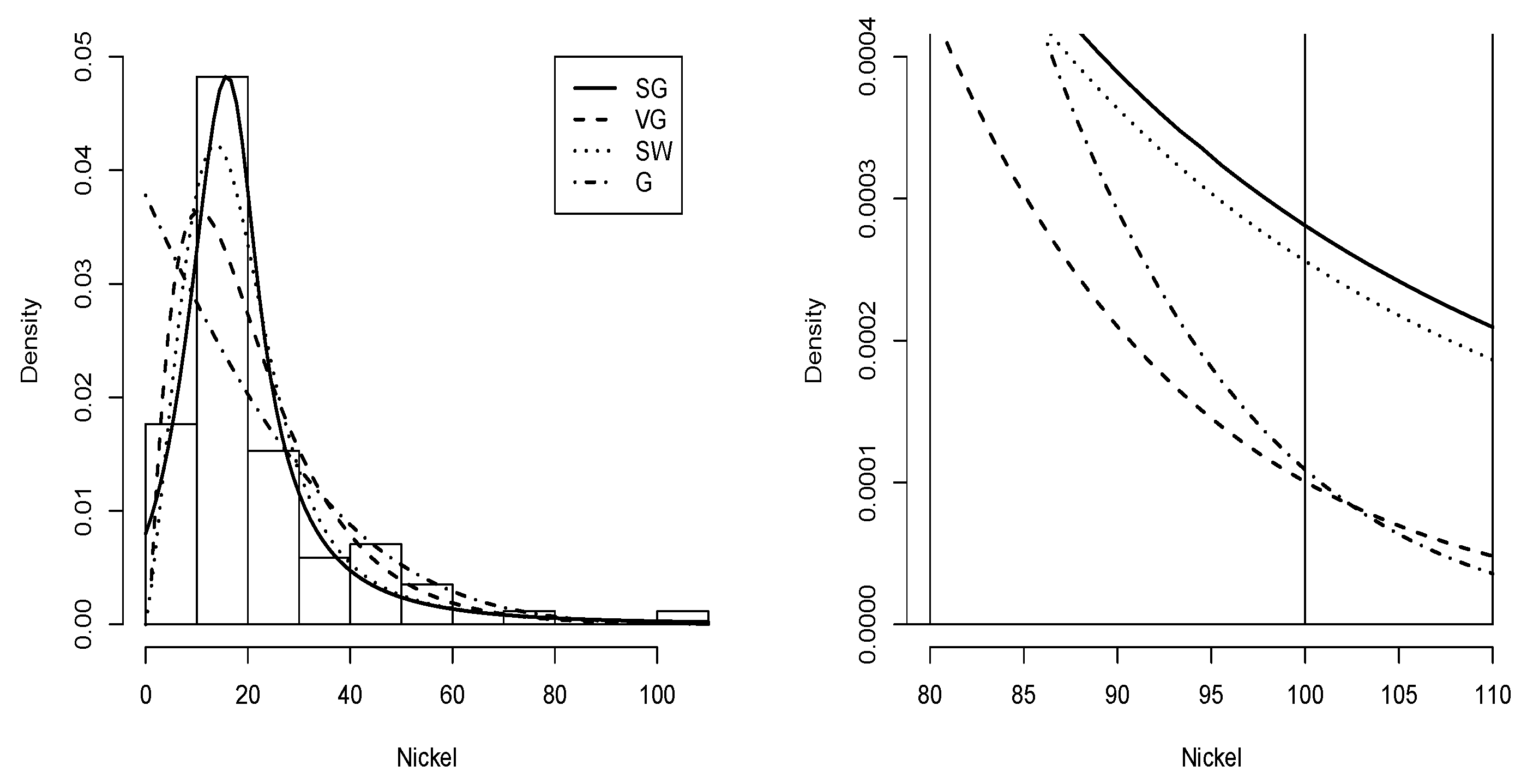
The histogram plot of the nickel data with the Slash Gompertz distribution fitted with the maximum likelihood estimators of its parameters is shown in Figure 11 compared with the Gompertz-Verhulst, Slash Weibull and Gompertz distributions. It also better captures outlier data.
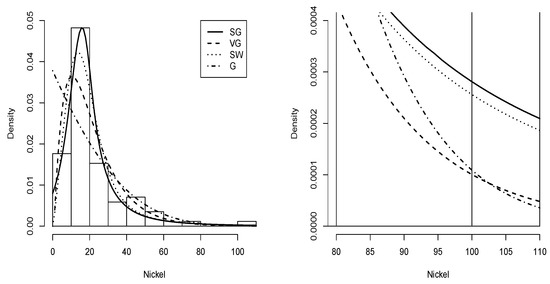
Figure 11.
Data nickel histogram with density (solid line), density (dashed line), density (dotted line) and G density (dashed-dotted line).
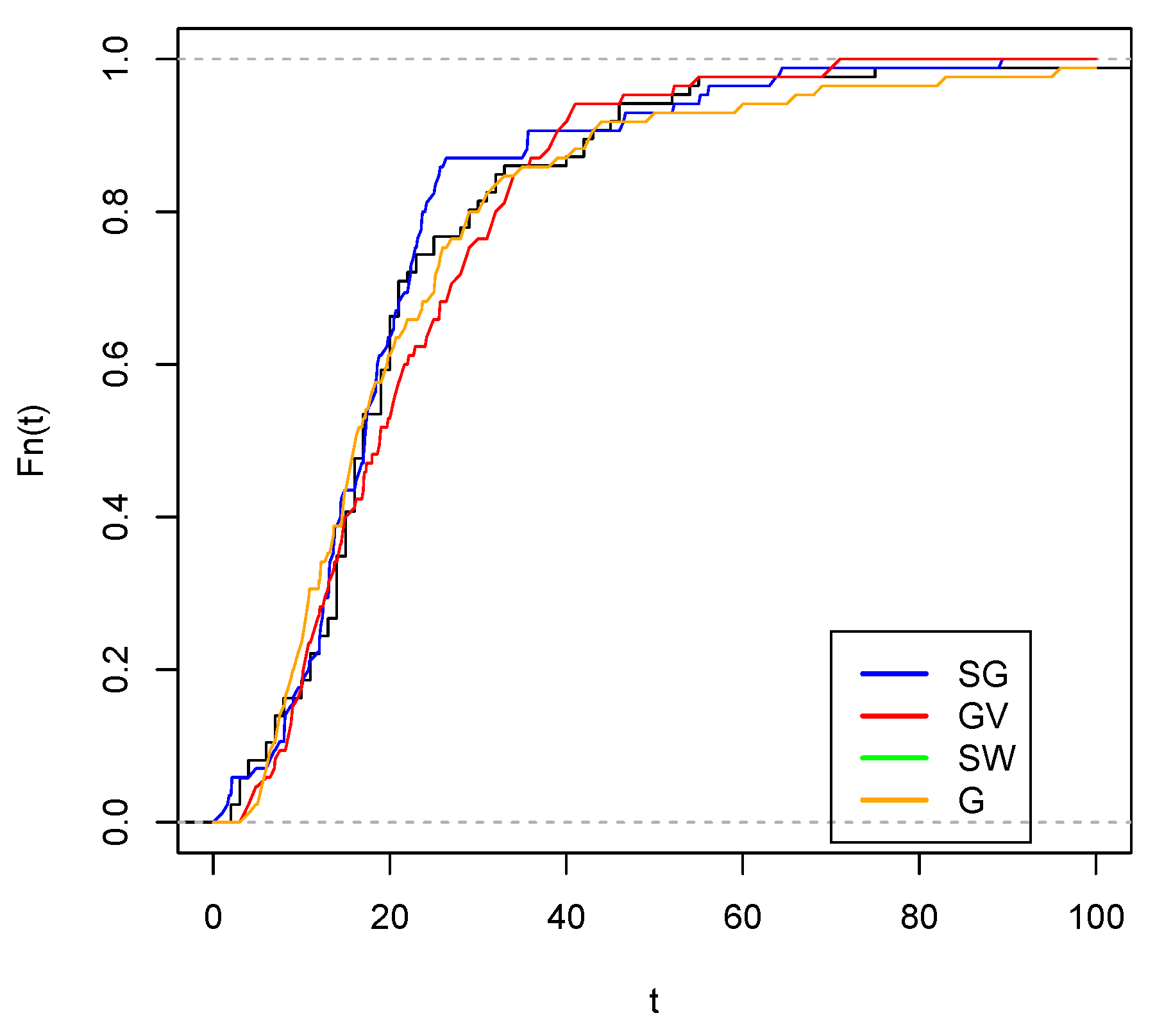
Figure 12 and Figure 13 show the best fit of the Slash Gompertz model compared to the Slash Weibull and Gompertz-Verhulst distributions. In the first, it can be seen that the theoretical quantiles are quite close to the line with respect to the Slash Gompertz, Gompertz-Verhulst and Slash Weibull distributions. In the second figure, the approximation of the empirical CDF of the studied model is closer to the empirical CDF than the other distributions.
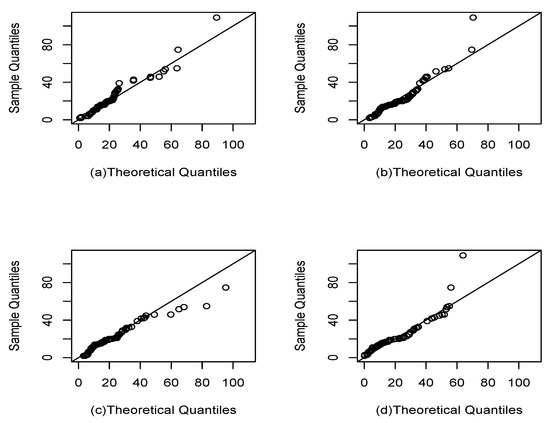
Figure 12.
Q-q plots: (a), (b) (c) and G (d).
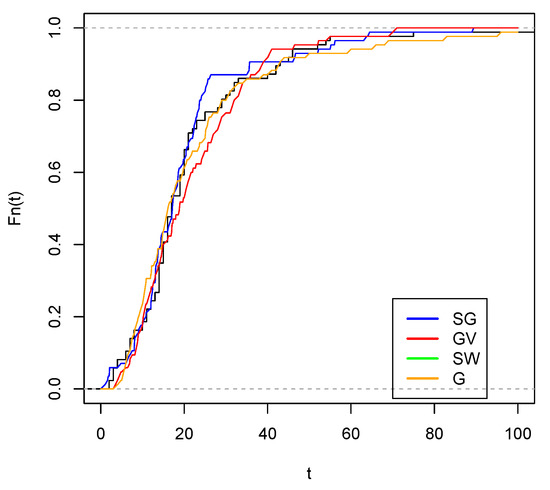
Figure 13.
Empirical cdf with estimated G c.d.f. (orange color), c.d.f. (green color), estimated c.d.f. (red color) and estimated cdf (blue color).
5.3. Comparison of Estimated Reliability
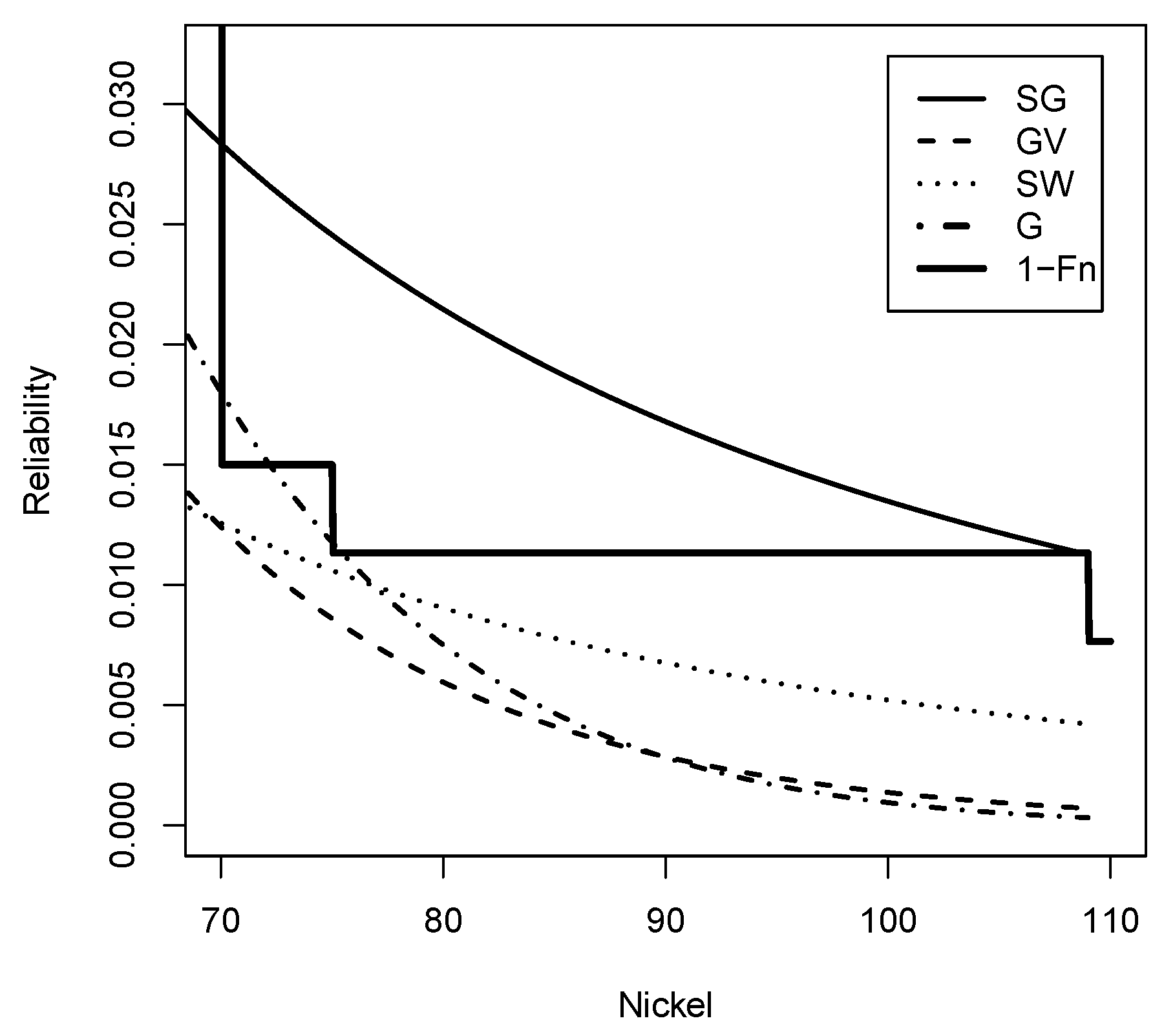
Figure 14 visually confirms that the Slash Gompertz distribution captures a greater amount of extreme data compared to its competitors.
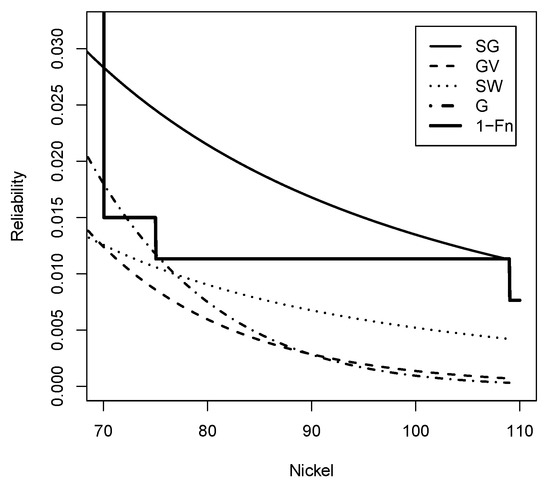
Figure 14.
Reliability function (Solid line), (dashed line), (dotted line), G (dashed-dotted line) and Empirical reliability (Solid Line) for nickel data set.
Table 7 theoretically demonstrates that the studied model has a higher kurtosis compared to the competing distributions.
Table 7.
Estimation of reliability for , , and G models for the rupture dataset.
6. Discussion
We introduce a new distribution with positive support based on the Gompertz distribution. The objective is to obtain a more flexible model that models asymmetric data with high kurtosis. We consider a study of the univariate version. We perform parametric estimation using the method of moments and maximum likelihood. We carry out a simulation study to see the behavior of the estimators of the parameters of the new distribution. We present two illustrations with data sets, where we show that the Slash Gompertz distribution fits real data better than the Gompertz, Birnbaum Saunders Slash, Slash Weibull, and Gompertz-Verhulst distributions, to model the reliability function of the data distribution.
Author Contributions
Data curation, J.R.; formal analysis, J.R., M.A.R., P.L.C. and J.A.; investigation, J.R., M.A.R. and P.L.C.; methodology, J.R., M.A.R., P.L.C. and J.A.; writing—original draft, J.R., M.A.R., P.L.C. and J.A.; writing—review and editing, M.A.R., P.L.C. and J.A.; Funding Acquisition, J.R., M.A.R. and J.A. All authors have read and agreed to the published version of the manuscript.
Funding
Research of J.R., M.A.R. and J.A. was supported by Universidad de Antofagasta through project SEMILLERO UA 2022.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The research of Jimmy Reyes, Mario A. Rojas and Jaime Arrué was supported by internal project Semillero 2022 of the University of Antofagasta. The authors would like to thank the referee for his/her constructive suggestions that improved the final version of this paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gompertz, B. On the nature of the expressive function of the law of human mortality and on a new way of determining the value of vital contingencies. Philos. Trans. R. Soc. Lond. 1825, 115, 513–583. [Google Scholar] [CrossRef]
- Wetterstrand, W. Parametric models for life insurance mortality data: Gompertz’s law over time. Trans. Soc. Actuar. 1981, 33, 159–175. [Google Scholar]
- Gavrilov, L.; Gavrilova, N. The Biology of Life Span: A Quantitative Approach; Harwood Academic Publishers: Chur, Switzerland, 1991. [Google Scholar]
- Vaupel, J.W. How the change in age-specific mortality affects life expectancy (PDF). Estud. Población 1986, 40, 147–157. [Google Scholar] [CrossRef] [Green Version]
- Pollard, J.; Valkovics, E. The Gompertz distribution and its applications. Genus 1992, 48, 15–29. [Google Scholar] [PubMed]
- Kunimura, D. The Gompertz distribution estimation of parameters. Actuar. Res. Clear. House 1998, 2, 65–76. [Google Scholar]
- Willemse, W.; Koppelaar, H. Knowledge elicitation of Gompertz‘ law of mortality. Scand. Actuar. J. 2000, 29, 168–179. [Google Scholar] [CrossRef]
- Marshall, A.; Olkin, I. Life Distributions; Springer: New York, NY, USA, 2007. [Google Scholar]
- Willekens, F. Gompertz in context: The Gompertz and related distributions. In Forecasting Mortality in Developed Countries-Insights from a Statistical, Demographic and Epidemiological Perspective, European Studies of Population; Tabeau, E., Jeths, A.V.B., Heathcote, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; Volume 9, pp. 105–126. [Google Scholar]
- Milgram, M.S. The Generalized Integro-Exponential Function. Math. Comput. 1985, 44, 443–445. [Google Scholar] [CrossRef]
- Chiccoli, C.; Lorenzutta, S.; Maino, G. Concerning some integrals of the generalized exponential-integral function. Comput. Math. Appl. 1992, 23, 13–21. [Google Scholar] [CrossRef] [Green Version]
- Mohan, L.; Garg, B.; Rao, R.; Redmond, C.K. Maximum-Likelihood Estimation of the Parameters of the Gompertz Survival Function. J. R. Stat. Soc. 1970, 19, 152–159. [Google Scholar]
- Rogers, W.H.; Tukey, J.W. Understanding Some Long-Tailed Symmetrical Distributions. Stat. Neerl. 1972, 26, 211–226. [Google Scholar] [CrossRef]
- Mosteller, F.; Tukey, J.W. Data Analysis and Regression; Addison-Wesley: Boston, MA, USA, 1977. [Google Scholar]
- Kafadar, K. A Biweight Approach to the One-Sample Problem. J. Am. Stat. Assoc. 1982, 77, 416–424. [Google Scholar] [CrossRef]
- Gómez, H.W.; Quintana, F.A.; Torres, F.J. A New Family of Slash-Distributions with Elliptical Contours. Stat. Probab. Lett. 2007, 77, 717–725, Erratum in Stat. Probab. Lett. 2008, 78, 2273–2274. [Google Scholar] [CrossRef]
- Genc, A.I. A Generalization of the Univariate Slash by a Scale-Mixture Exponential Power Distribution. Commun. Stat. Simul. Comput. 2007, 36, 937–947. [Google Scholar] [CrossRef]
- Gómez, H.W.; Olivares-Pacheco, J.F.; Bolfarine, H. An Extension of the Generalized Birnbaum-Saunders Distribution. Stat. Probab. Lett. 2009, 79, 331–338. [Google Scholar] [CrossRef]
- Reyes, J.; Gómez, H.W.; Bolfarine, H. Modified slash distribution. Statistics 2012, 47. [Google Scholar] [CrossRef]
- Byrd, R.H.; Lu, P.; Nocedal, J.; Zhu, C. A Limited Memory Algorithm for Bound Constrained Optimization. SIAM J. Sci. Comput. 1995, 16, 1190–1208. [Google Scholar] [CrossRef]
- Quesenberry, C.P.; Kent, J. Selecting among probability distributions used in reliability. Technometrics 1982, 24, 59–65. [Google Scholar] [CrossRef]
- Ahsanullah, M.; Shakil, M.; Golam Kibria, B.M. A Note on a Characterization of Gompertz-Verhulst Distribution. J. Stat. Theory Appl. 2014, 13, 17–26. [Google Scholar] [CrossRef] [Green Version]
- Olivares-Pacheco, J.O.; Cornide-Reyes, H.C.; Monasterio, M. An Extension of the Two-Parameter Weibull Distribution. Rev. Colomb. Estad. 2010, 33, 2. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).