1. Introduction
The Hybrid Flow Shop (HFS) is composed of serial production stages, where each stage contains a set of identical and parallel machines. At least one of the stages contains more than one machine to be considered an HFS. The machines are intended to process a set of jobs consecutively from the first stage to the last one in that order. This is the flow side of the HFS. Each machine in each stage is able to process at most one job at the same time, and a given job is processed by only one machine in each stage. The HFS is a generalization of other interesting shops, including the single machine, the parallel machine and the flow shop. The scheduling problem in an HFS environment is a very interesting scheduling problem encountered in several real-life situations, especially in manufacturing processes such as the electronic ships industry [
1], the cable industry [
2], and the textile industry [
3]. On the other hand, the HFS scheduling problem and several of its variants are shown to be NP-Hard in the strong sense, which constitutes a theoretical challenge. The HFS scheduling problem is extensively studied, and abundant literature is provided [
4,
5,
6,
7]. Solving the HFS scheduling problems optimally or approximately is the topic of extensive studies where several algorithms are proposed. These algorithms are the heuristics, metaheuristics and exact procedures. In this context, the reader is referred to [
4,
5] for more details on the HFS scheduling problems.
Modeling real-life situations accurately over the HFS scheduling problem requires taking into consideration the parameters (restrictions) with high impact as much as possible, including the job release times, setup times, machine unavailability, etc. Taking into consideration these restrictions (release date, setup times, etc.) according to the real situation allows for narrowing the gap between the theory and the practical aspects. In this context, authors in [
8] studied an HFS scheduling problem with setup times and proposed a genetic algorithm to solve it efficiently and approximately. The setup time parameter is encountered in an industrial area, where machines require a time duration for their preparation to process jobs. In this case, the setup time is not neglected compared to the processing times. An HFS scheduling problem with lag times and sequence-dependent setup times was addressed in [
9]. In order to solve the latter problem approximately, an immune algorithm was proposed and evaluated over an intensive experimental study. In [
10], an HFS scheduling problem with multiprocessor tasks was addressed. In this kind of real-life scheduling problem, a job requires more than a machine to be processed. For the latter problem, an efficient genetic algorithm was proposed. An HFS scheduling problem with transportation times was examined in [
11]. The transportation time parameter is required in several real-life applications. Indeed, this situation is encountered where the transportation time between the stages is comparable to the processing times and, therefore, cannot be neglected. The latter problem was solved using a Simulated Annealing metaheuristic.
The removal time for a job is the required time to remove a finished processed job from a machine. Removal time is among the encountered real-life parameters (restrictions) in the manufacturing and industrial areas. In these cases, the removal time is comparable to the processing time and cannot be neglected. Thus the removal time is taken into consideration separately from the processing time. This situation occurs, for example, in the steel industry where a produced part is extracted from a mold during a removal time that is more important than the processing time itself. In addition, the removal time restriction is encountered in the bio-process industry, where fermentation techniques are utilized [
12]. In some HFS scheduling problems, the transportation time between stages is neglected compared to the processing time. This occurs when the stages are close to each other [
13]. In other real-world situations, the transportation time of a job is an important factor and cannot be neglected.
In this study, the two-stage HFS scheduling problem with removal and transportation times between the stages is examined. In this problem, two serial stages with identical parallel machines for each one are used to process a set of jobs. Each job is processed in a machine from the first stage, removed, and transported to the second stage. A machine in the latter stage processes the job, and the processed job is then removed. The makespan (maximum completion time) is the objective function to be minimized.
After exploring much of the presented literature for the HFS problem, to the best of our knowledge, there is no study taking into consideration the removal times and the transportation time simultaneously for an HFS scheduling problem to date. Consequently, the related work literature review will be restricted to HFS scheduling problems with transportation times or removal times.
In this context, the authors of [
14] studied the HFS problem with transportation time, sequence setup time and rework. An efficient Enhanced Harmony Search Algorithm was proposed to solve the studied problem. The HFS problem with dynamic transportation waiting time is examined in [
15], where a memetic algorithm is proposed to provide a near-optimal solution. An HFS problem with transportation time and setup time is addressed in [
16]. In order to solve the latter problem, an effective electromagnetism metaheuristic is presented. In [
11], an HFS problem with transportation and setup times is examined with respective objective functions of the total tardiness and total completion time. A simulated annealing metaheuristic is proposed to tackle this problem. The HFS problem with robotic transportation time and release dates is studied in [
17]. The makespan is minimized, and an ant colony optimization algorithm, as well as a genetic algorithms, are proposed. The two-stage HFS problem with transportation restrictions is treated in [
18]. In the latter problem, the second stage is composed of two identical and parallel machines, while the first stage contains only one machine. The transportation between stages is ensured by a transporter with a capacity of one, and an efficient heuristic algorithm is proposed to determine a near-optimal solution. In [
19], an HFS problem with transportation time and batching restrictions is considered, and a polynomial time heuristic is proposed for a particular case. For the general case, a pseudo-polynomial algorithm is presented. In [
20], an HFS problem with robots’ transportation and blocking restrictions is considered. An efficient simulated annealing metaheuristic is proposed for the makespan minimization. An extensive experimental study provides strong evidence of the effectiveness and efficiency of the proposed procedure. The two-stage HFS problem with robots’ transportation between stages is addressed in [
21]. Two dedicated machines are contained in the first stage, while the second stage has only one machine. A complexity study of the considered problem, as well as some of its particular cases, is performed. For the NP-hard ones, two efficient heuristics are developed.
In [
22], an HFS problem with setup and removal times is addressed. Four heuristic algorithms are proposed and assessed over an intensive experimental study, which shows their efficiency. An HFS problem with removal time and precedence constraints is addressed in [
23]. In the latter research work, the authors proposed six heuristic algorithms, which are shown to be efficient in a computational study. The authors of [
24] examined an HFS problem with setup and removal times. The parallel machines in each stage are unrelated. In order to approximately solve the latter studied problem, a heuristic algorithm is proposed to provide an initial solution. This initial solution is then improved over the application of a simulated annealing metaheuristic. An intensive experimental study shows the efficiency of the proposed algorithm. A real-world HFS scheduling problem with removal time and other restrictions is considered in [
12]. An exact algorithm based on a mixed-integer formulation is proposed. This formulation is enriched by new inequalities, and the computational results provide strong evidence that the proposed algorithm is efficient for industrial instances (small size test problems).
According to the existing literature, the HFS scheduling problem with transportation and removal times has not been addressed; thus, the open gap lies in studying this kind of problem and trying to provide efficient procedures to solve it.
In this work, firstly, the studied problem is formally defined, and a set of its interesting properties is established. These properties concern the complexity and the symmetry of the studied problem. Secondly, a new family of lower bounds is proposed. These lower bounds are of two categories. The first category is based on the optimal solution to the parallel machine scheduling problem with release dates and delivery times. The second category is based on the idle machine times. Thirdly, a new two-phase heuristic is proposed. The first phase builds an initial solution and the second phase improves it. The optimal solution to the parallel machine scheduling problem with release dates and delivery times is used in the latter heuristic. Finally, an exact Branch and Bound algorithm is developed. This procedure includes efficient lower bounds and dominance rules, allowing to reduce the size of the search tree. An extensive experimental study is carried out to evaluate the performance and the efficiency of the proposed procedures.
The parallel machine scheduling problem with release dates and delivery times plays a key role in the development of the proposed procedures. For further insight into the latter problem, the readers are referred to [
25,
26,
27,
28,
29].
The contributions of this study are scientific and practical. These contributions are:
To the best of our knowledge, this is the first time the hybrid flowshop scheduling problem with transportation and removal times is addressed.
Proposal of new interesting and useful proprieties for the studied problem, allowing the improvement of the solution.
Development of a new set of efficient lower bounds.
Proposal of a heuristic algorithm that is able to provide the optimal solution or near-optimal solution within an acceptable computational time.
Presentation of Branch and Bound exact procedure able to optimally solve hard test problems within an acceptable computational time.
Allowing to model real-world manufacturing systems, where the removal and transportation times are not neglected as in the steel industry.
The rest of this paper is organized as follows. The studied scheduling problem is formally defined in
Section 2, in addition to the presentation of some of its interesting properties. A family of tight and new lower bounds is the topic of
Section 3. In
Section 4, a heuristic algorithm, which is composed of two phases, is proposed. The details of an exact Branch and Bound algorithm are presented in
Section 5. In order to evaluate the performance of the proposed algorithms, an intensive experimental study is carried out in
Section 6. Finally, a conclusion summarizing the main findings and presenting the possible extensions of this work is presented.
2. Problem Statement and Proprieties
This section is intended to define the studied problem and the presentation of some of its relevant proprieties.
2.1. Problem Statement
The two-stage hybrid flow shop scheduling problem with removal and transportation times is stated as follows. A set of n jobs has to be processed in a production shop composed of two serial stages and . Each stage contains a set of identical parallel machines such that . Each job is first processed in an available machine from during . After that, the job is removed from this machine during . Once removed, the job is transported to a buffer belonging to the second stage during . In stage , an available machine treats the job j during . The removal of job j from this machine takes units of time. The completed processed job remains in the machine until it is removed and released. The buffer’s capacity is too large to store all the jobs. All the machines and jobs are available for processing from time zero. The processing times , the removal times , and the transportation times are assumed to be positive integers and deterministic . Each machine processes at most one job at the same time, and the preemption is not allowed. Each job is processed by only one machine in each stage. The main purpose is to determine a feasible schedule that minimizes the maximum completion time (makespan). More precisely, for a feasible schedule if is the starting time of job j in stage then is its completion time. It is worth mentioning that is the completion processing time of job j in stage , and at the same time, it is the earliest date to start the removal operation. Since, the machine will not be available until the job j is removed, the removal operation should start as soon as possible (at ). Therefore, the makespan, which is denoted , is given by the expression: . In this case, the optimal makespan and the requested optimal schedule satisfy: with as the set of feasible schedules.
Using the three-field notation
[
30], the studied scheduling problem is denoted
. In the latter notation,
refers to a flow shop with two stages and
are indicating that each stage contains parallel machines. The jobs characteristics’
and
are the removal and the transportation times. The last and third field is reserved for the objective function to be minimized, which is the maximum completion time (makespan) in this study. In the following is a summary of the latter notations.
number of jobs.
number of machines in the first stage .
number of machines in the second stage .
processing time of job j in stage , .
removal time of job j in stage , .
transportation time of job j .
starting time of job j in stage , relatively to schedule .
completion time of job j in stage , relatively to schedule .
makespan of schedule .
optimal makespan.
To illustrate the studied problem, the following example is presented.
Example 1. Consider the instance with , and . The processing times and the transportation times ( and ) are presented in Table 1. Figure 1 presents a feasible schedule for the addressed scheduling problem, relative to the data provided in
Table 1.
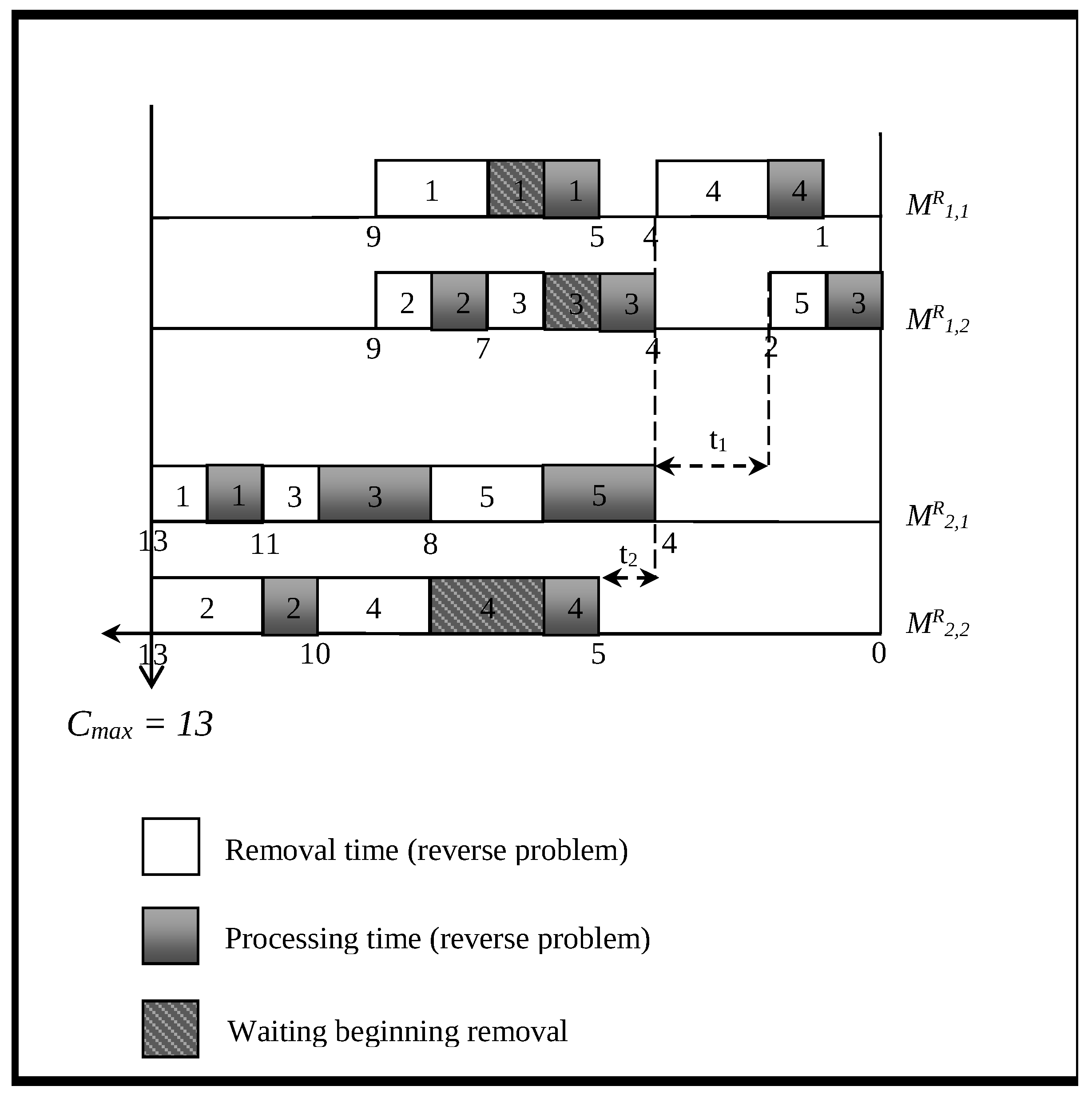
In
Figure 1, job 4 is not removed from machine
immediately after finishing processing (at time 5). Instead of that, the beginning of the removal operation is postponed until time 7. Therefore, the release of job 4 from machine
is performed at time 8. Then the removal time is not a part of the processing time for job 4. In addition, within time interval
, job 4 remains in machine
and blocks it, i.e., no other job is processed within this time interval. The period
is a waiting period for removing job 4.
2.2. Proprieties
In this section, two relevant results are presented, where the first one is about the complexity of the current problem. The second result concerns the introduction of another problem called the “symmetric” or “reverse” or “backward” problem relative to the studied problem. These two problems have the same optimal solution, which suggests the systematic investigation of both of them in order to improve the obtained results.
2.2.1. Complexity
In addition to its practical interest, the two-stage hybrid flow shop scheduling problem is a challenging one from a theoretical point of view. This is due to the following lemma (Lemma 1).
Lemma 1. The problem is strongly NP-Hard.
Proof. The two-stage hybrid flow shop problem
is strongly NP-Hard [
31]. Since,
is a particular case of
, then
is strongly NP-Hard. □
2.2.2. Symmetry
Definition 1. Naturally, has a reverse problem, which is obtained by inverting the flow of the jobs from stage toward stage . Formally, the reverse problem is obtained by setting up: First stage , second stage , the processing, removal, and transportation times , , , , , , and . The studied problem ( to ) is the forward problem and the reverse problem ( to ) is the backward problem. The reverse problem is denoted and defined as the symmetric of .
In
Figure 2, the reverse feasible schedule for the reverse (backward) problem is presented for Example 1.
The studied scheduling problem and its corresponding problem present the following interesting propriety.
Proposition 1. and are equivalent, i.e., any feasible schedule for one of these two problems is also a feasible schedule for the other problem with equal makespan.
Proof. Consider as a feasible schedule for with a maximum completion time . All the allocations of jobs to the machines and their sequences are kept as in . The jobs are right-shifted until the last scheduled ones in the machines of reach . Therefore, a feasible schedule for the backward problem is obtained. The timeline scale t is transformed to a new one: . According to the construction of , the critical paths for and are the same. Thus, and have the same makespan. The same reasoning holds for the backward problem, and the equivalency of the two problems is proven. □
The latter proposition yields the following result.
Corollary 1. Optimal solutions for and are the same.
Proof. Let be an optimal schedule for with optimal makespan . According to the latter proposition (Proposition 1), the reverse schedule for the backward problem has the same makespan . Assume that there is another schedule () for the backward problem with better solution C (). Based on the latter proposition (Proposition 1), the corresponding schedule of the forward problem has the same makespan C. This means that there is a schedule for with makespan . This contradicts the fact that is the optimal makespan for the forward problem. Conversely, following the same reasoning for the backward problem, an optimal schedule for the backward problem induces an optimal schedule for the forward problem. □
Remark 1. Consequently, the reverse scheduling problem is automatically explored in order to provide a better solution.
4. Heuristic Algorithm
A heuristic algorithm is proposed in this section. This heuristic is mainly based on the optimal solution to the parallel machine scheduling problem with release dates and delivery times (). Two consecutive phases comprise this heuristic. The first phase is a constructive one allowing to obtain an initial solution. The second phase is an improvement phase that might enhance the initial solution. This section starts by presenting a useful result relating two parallel machines scheduling problems, where the respective objective functions are the maximum completion time () and the maximum lateness ().
Proposition 3. The two scheduling problems , are equivalents. In other words, these two problems have the same optimal solution.
Proof. The
problem is transformed into the
problem by setting for each job
j a due date
, where
C is an upper bound for
(optimal solution). Conversely, starting from the
problem and setting
, then, naturally, a delivery time for each job
is given by
. If
denotes the starting time of the job
j in a feasible schedule, then the maximum lateness satisfies
. Therefore,
□
In the sequel, the first phase of the proposed heuristic is presented over the following pseudo-code.
PHASE I: Initial solution
- I.1
Initialization: , , and .
- I.2
Solve the obtained problem .
- I.3
Collect the completion time for each , of the solution to (I.2).
- I.4
Set , , , and 0
- I.5
Solve the obtained problem .
- I.6
For each , Set as the starting processing time of the solution in (I.5).
- I.7
Set .
The inputs of phase one are , , , , , , and . The output is an initial feasible solution. The first phase consists in consecutively solving two parallel machine scheduling problems such that the flow constraint is satisfied. In other terms, a job cannot start processing in the second stage before completing processing and removing in the first stage and before being transported to stage . The inputs for the first problem are presented in (I.1). These inputs state that the delivery time takes into account the transportation time as well as the processing and the removal times in stage ( ). This is the minimum elapsed time after leaving stage . The solution to (I.2, I.3) provides a feasible schedule in which the completion times are denoted . The inputs for the second parallel machine problem are displayed in (I.4). The flow constraint is satisfied by setting the release dates for as . This is the minimum duration to reach after exiting . The resolution of the second parallel machine problem is performed in (I.5). These two feasible schedules allow obtaining a feasible one for the problem by concatenating them. There are no contradictions since . The value of the upper bound (upper bound for the forward problem) is trivially obtained in steps (I.6, I.7).
Once an initial feasible solution is obtained, the improvement phase starts. A pseudo-code of this phase is presented as follows.
PHASE II: Improvement phase
- II.1
Set , , and .
- II.2
Solve the problem .
- II.3
Set () as the completion time of the solution in (II.2).
- II.4
If then go to (II.10), Else .
- II.5
Set , , and 0
- II.6
Solve the problem .
- II.7
For each set as the starting time for the solution in (II.6).
- II.8
If then Set
- II.9
Go to (II.1).
- II.10
STOP.
It is worth mentioning that the input of phase two is the already obtained initial solution in phase one, and the output is an improved solution. The current phase is intended to enhance the initial solution. This is performed by iteratively visiting each time stage and keeping the other one as it is. The schedule in the visited stage is modified without contradiction with the fixed schedule in the other stage. This guarantees a feasible schedule for the studied problem at the end of each iteration. At the beginning of this phase, the schedule in the second stage is maintained, and in the first stage the due date of each job is set to where are the starting time in the schedule of . Thus, any new schedule in does not contradict the one in (II.1). A parallel machine scheduling problem with lateness as the objective function is then solved (II.2). Consequently, the optimal lateness satisfies , and two cases have to be considered. The first case is obtained when , where no enhancement is detected and the improvement phase is halted. The second encountered case is for , where an improvement is obtained and the new upper bound’s value is readjusted as: (II.3). In the latter case, the procedure is to be continued, and the second stage is visited by fixing the already obtained schedule in . A new parallel machine problem is obtained in (II.6), with inputs as cited in (II.5). The release dates in are set where are the completion times in . This allows to avoid any contradiction with the new obtained schedule in after solving the problem (II.6). If the obtained optimal makespan satisfies , then an improvement is detected and the upper bound is readjusted as (II.8). The procedure is then restarted from the first stage (II.9). The whole procedure is halted when .
Because of the symmetry of the studied problem, the current heuristic is applied to the reverse (backward) problem, and the obtained upper bound is denoted
. Therefore, the resulting final upper bound after exploring the studied problem and its reverse is:
Remark 3. The main component of the latter heuristic is the resolution of the two NP-Hard problems and . This is obtained by running the proposed exact algorithm in [25]. In the case where an optimal solution is not reached within a prefixed limit time, the best upper bound (best lateness) and the corresponding feasible schedule are considered. 5. Exact Procedure
In the previous sections, a set of lower bounds and a heuristic algorithm are proposed. Obviously, if the values of the heuristic and the lower bounds are equal, then the optimal solution is reached. In the other case, an exact procedure is proposed to find an optimal solution. Clearly, the heuristic and the lower bounds are helpful in narrowing the search interval for the exact procedure. In this study, the Branch and Bound (B&B) algorithm is the exact procedure adopted. The different components of the proposed B&B algorithm are detailed in the sequel.
5.1. Solutions Representation
The solution representation is the first step in the B&B algorithm, and the B&B efficiency is strongly related to this step. In this context, if is a feasible schedule in the first stage then a parallel machine scheduling problem is systematically induced in the second stage. The parameters of this problem are the release dates, given by where is the completion time of job j relative to the feasible schedule in the first stage. In addition, for the same problem, the processing times are expressed as for each job . Clearly, the optimal solution of the problem allows obtaining a feasible solution for the studied problem . This is performed by concatenating the two feasible solutions and . Therefore, solving the problem is equivalent to determining, in the first stage, a feasible schedule satisfying where is the set of all feasible schedules in the first stage, and the optimal makespan of the problem quoted above. In addition, a feasible schedule is represented throughout a permutation of n jobs, where the respective starting times and of the jobs and respectively, satisfy ≤ for Thus, a feasible solution to the studied problem is represented by a permutation of the n jobs.
5.2. Branching Strategy
In the search tree associated with the B&B algorithm, any node at level k is denoted . In this node, let be a partial schedule of k jobs in the first stage. It is worth mentioning that the partial schedule is explicitly represented throughout a partial permutation of the k scheduled jobs in node . The remaining unscheduled jobs at node are considered the descendants. Therefore, from node , the branching consists of selecting a job from the set of unscheduled jobs and creating a new node represented over the partial permutation . Clearly, the branching process from node results in nodes at level . Consequently, at level , a feasible schedule is obtained in the first stage . Naturally, a parallel machine scheduling problem with release dates is obtained in the second stage. For the latter problem, where is the completion time of job j relatively to the feasible schedule . The exploration of the B&B search tree is performed using the first strategy.
5.3. Bounding Strategy
In this section, two lower bounds and a polynomial heuristic algorithm are proposed for each node. Useful notations and definitions are given as follows. A node in the search tree is denoted N with , where is the root node. The set of the scheduled and removed jobs at node N is denoted as , and the set of unscheduled job(s) is . Let be the completion time of job and also let be the availability of machine contained in the first stage after scheduling all . Without loss of generality, assume that the machines’ availabilities in the first stage are sorted in increasing order : .
5.3.1. First Stage Relaxed Capacity-Based Lower Bound
If the number of machines in the first stage is assumed to be infinite (capacity relaxation), then an unscheduled job finishes processing at time
. This is the time for job
j to start processing in the second stage. Clearly, a scheduled job
j is ready to be processed in the second stage at time
. Consequently, in the second stage, a parallel machine scheduling problem
with release dates is obtained. The processing times
and the release dates
for the latter problem are expressed as follows.
Clearly, any lower bound for the latter problem is a lower bound at node N. The first lower bound is based on the following result.
Proposition 4. If A is a subset of jobs such that , and denotes the release date in the increasing sorted order set thenis valid lower bound for the obtained sub-problem at node N. Proof. Let
be the optimal makespan for the problem
. For a machine
, let
be the starting time of the first processed job. The time in each machine
is subdivided into total processing and removing
, and idle time
. Clearly,
Thus,
Since
,
and based on (
8), the following inequality holds:
. This ends the proof. □
If all the subsets , such that are explored, then might be improved and is a valid lower bound. In this case, an exponential number of subsets has to be explored, which is out of reach. However, only a polynomial number of subsets has to be explored according to the following proposition.
Proposition 5. A valid lower bound at node N is given by . This lower bound has a complexity of .
Proof. Trivially,
with
the
member of the increasing sorted list
. If
denotes a subset of
J satisfying
then clearly
. Let
be a function on the job subsets defined by
with
and
. Thus,
, and
. Based on the latter result,
needs
time to be computed. Knowing
, the main effort for the computation of
lies on the determination of the job
. The determination of
requires at most
time. Based on the two previous observations, the computation of
for
is performed in
time. □
5.3.2. Lower Bound Based on the Machines’ Availabilities
At node
N of the search tree, some jobs are already scheduled, and then at the first stage, a parallel machine problem is induced. This parallel machine problem
is defined on the set of unscheduled jobs
. In addition, the machines are subject to availabilities constraints and the jobs are characterized by their delivery times. The availability
of machine
is the completion time of the last scheduled job on it (if not,
). For a job
, the delivery time is
and the processing time is
. Without loss of generality, the availabilities are assumed to satisfy
. Clearly, any lower bound for the problem
is a lower bound at node
N. It is worth mentioning that, in some cases, less than
machines are required in an optimal schedule to process the jobs. This is basically because of the the availability constraints. In order to bound the number of the utilized machines in an optimal schedule, the following result is recalled [
33].
Proposition 6 ([
33]).
Let be an upper bound on the optimal makespan of the problem. Then, the number of utilized machines m in an optimal schedule is bounded as follows.with: where .
is the smallest k satisfying . Otherwise, .
At this stage, the second lower bound is presented in the following proposition.
Proposition 7. Let be a subset of jobs and assume that m machines are used in an optimal schedule, then a valid lower bound is expressed as follows.where is the member of the set sorted in increasing order. Proof. For an optimal schedule with optimal makespan that uses m machines, the first processed jobs in each machine starts at . The last scheduled jobs in each machine has a delivery time . If is the total load in , then and . Since , and , then , which ends the proof. □
Clearly, is a valid lower bound at node N. To compute , a polynomial number of subsets A has to be explored. This is the content of the following result.
Proposition 8. is a polynomial valid lower bound with a complexity
Proof. The proof is conducted as in Proposition 5, where:
replaces
replaces
is a constant.
□
An immediate consequence is the following result.
Corollary 4. is a valid lower bound at node N with complexity Clearly,
is a lower bound at node
N.
5.3.3. Upper Bounding Strategy
A greedy polynomial heuristic algorithm HL is computed at node . This heuristic algorithm is based on a priority list. In this HL heuristic, the available unscheduled job with the largest is scheduled in the most available machine in the first stage. The scheduling in the second stage is performed after all the jobs are scheduled in the first stage. In the second stage, among the unscheduled and available jobs, the one with the largest is scheduled in the first available machine in the second stage.
The following pseudo-code presents the main steps of HL.
HL Heuristic
Phase 1—Scheduling in the first stage
1.1. Set.
1.2.Schedule in the first stage the jobwith the largestin the most available machine.
1.3. Set.
1.4. If
then
go to
Step
1.2.
Phase 2—Scheduling in the second stage
2.1. Set
a release date
for each job
( completion time ofin the first stage
).
2.2.Set.
2.3.Schedule an available jobwith the largest in the most available machine in the second stage.
2.4. Set.
2.5. IfThengo to Step2.6, Elsego to Step2.3.
2.6. STOP.
The main computational effort in HL is sorting the jobs according to their non-increasing order of , which requires time.
5.4. Additional Improvements
Additional improvements are proposed for the B&B algorithm in order to reduce the search tree size and, therefore, shorten the computational time. Among these improvements is a set of dominance rules. In addition, based on the symmetric propriety of the studied problem, the backward problem is systematically explored. In this context, the B&B algorithm is extended to the backward problem. These two main improvements are the respective topics of the two next subsections.
5.4.1. Dominance Rules
In order to eliminate additional nodes from the B&B search tree, dominance rules are proposed. Indeed, some nodes are shown to be dominated by others, and in this case, there is no need to explore them. In this work, the dominance rules presented in [
34] are extended to the studied problem
. More precisely, the unscheduled jobs
at node
N are the candidates to be branched in the next step of exploration. In addition, if
is the partial schedule at node
N then,
If there are two jobs and that have the same characteristics: , , , , and , then the two nodes represented, respectively, by partial schedules and are the same and one of them should be eliminated.
If , then the two nodes represented, respectively, by partial schedules and are the same, and one of them should be eliminated. This dominance rule is based on the symmetric availability of the two first machines (
5.4.2. Systematical Forward-Backward Procedure
Due to the symmetry of the studied problem (as mentioned in Proposition 1, the forward and the backward problems are investigated systematically. This is performed in order to obtain better results. In this context, the B&B algorithm is applied for the forward and the backward problems consecutively and iteratively. The obtained result for one of problems is the input for the other one. A time limit is set up for the B&B algorithm to find an optimal solution. If the B&B fails, then it moves to the other problem. This iterative procedure is cyclic, and it is halted if there is no improvement for the lower bounds and upper bounds or the optimal solution is not reached.
6. Computational Results
In order to evaluate the performance and the efficiency of the proposed procedures, an extensive experimental study on benchmark test problems was carried out. All the procedures were coded in C and implemented in a Pentium IV 2.8GHz Personal Computer with 1GBRAM.
6.1. Test Problems
In this study, the test problems are selected from an existing one for the hybrid flow shop environment [
35]. These data are extended to include the transportation and removal times. Therefore, the number of jobs
n and the number of machines in both stages
are given as follows.
The number of jobs n.
The number of machines in both stages ∈.
Recall that in this study the transportation and removal times are not neglected compared to the processing times. Two cases are considered: either the transportation and removal times are similar to the processing times or they are more important (double) than the processing times. To generate test problems satisfying the two previous cases, the processing times are set as:
Three positive integers a, b, c are assigned, respectively, to removal time in the first stage , transportation time , and removal time in the second stage . In addition, . Following the latter notations, the removal time in the first stage , transportation time , and removal time in the second stage are generated as follows.
The removal times in the first stage are randomly and uniformly generated in .
The transportation times are randomly and uniformly generated in .
The removal times in the second stage are randomly and uniformly generated in .
If, for example, then the removal time in the first stage is compared to the processing times, and if , then the removal time in the first stage is more important than the processing times. This remark holds for and . For each combination, , a, b, and c, 10 test problems are generated, and a set of 2560 test problems is obtained.
6.2. Performance of the Proposed Procedures
At this stage, it is worth recalling that three kinds of procedures are proposed in this work. These procedures are the lower bounds, the heuristic algorithm, and the B&B procedure. The roles of these procedures are complementary. Indeed, for each test problem, the lower bound
is computed first. After that, and in a second phase, the heuristic algorithm is executed, and a feasible solution with upper bound value’s
is obtained. If
, then an optimal solution is reached. In the other case where
, the B&B is executed with input
. This means that the B&B algorithm takes advantage of the heuristic algorithm and does not start from scratch. Since the studied problem is NP-Hard, a time limit is set for the B&B algorithm. If an optimal solution is not reached within this time limit, then the lower bound is utilized to calculate the relative gap for a test problem. The expression of the relative gap is presented as follows.
Consequently, the presented experimental results concern the three procedures simultaneously.
The utilized parameters to assess the performance of the proposed algorithms are:
The rate parameters, which means that , , and .
Number of test problems solved at the root node (
: (
4), (
5)).
Number of test problems solved by the B&B algorithm and not solved at the root node.
Number of unsolved test problems by the heuristic algorithm and B&B procedure.
Percent of solved test problems.
Mean computational time (in seconds) for solving the test problems.
The average relative gap of unsolved instances.
The maximum relative gap of the unsolved instances.
It is worth mentioning that the performance measure assesses the performance of both the heuristic algorithm and the lower bound. Indeed, a test problem is optimally solved using the heuristic algorithm if . If a test problem is not optimally solved using the heuristic algorithm, then the B&B algorithm is activated, and the performance measure assesses the efficiency of the B&B algorithm. The parameter measures the performance of the combined three procedures (lower bound, heuristic algorithm, and the B&B). The computational time solving the test problems is an important parameter that should be taken into account while evaluating the performance of an algorithm; this parameter is . For the unsolved test problems, the mean relative gap is an interesting parameter showing the efficiency of the proposed procedures. Indeed, if is relatively small, then the proposed procedure is not providing the optimal solution but a near-optimal solution, which is very close to the optimal solution.
The experimental results are reported in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7. More precisely,
Table 2 is presenting the overall results. In
Table 3, the impact of the number of jobs
n on the performance of the proposed procedures is displayed. The effect of the machines’ distribution
on the efficiency and performance of the developed algorithms is presented.
Table 5 presents the results considering the simultaneous impact of
n,
, and
on the performance of the presented procedures. The effect of the rates
on the behavior of the proposed procedures is presented in
Table 6.
A summary of the general experimental results is displayed in
Table 2.
Based on
Table 2, one can observe that the percentage of solved test problems at the root node is
(1960 out of 2560). This is evidence of the efficiency of the proposed lower bounds and the heuristic algorithm. Furthermore, the B&B procedure is able to solve
(605 out of 2560) of the test problems and
of the unsolved test problems (605 out of 870 unsolved test problems at the root node). Solving a test problem requires on average only
s, which is a moderate computational time. In addition, the unsolved test problems present an average relative gap of
. All the presented results provide evidence of the efficiency and the effectiveness of the proposed procedure in solving even large size instances (up to 200 jobs) in a moderate CPU time.
The effect of the number of jobs on different results is presented in
Table 3.
Based on
Table 3 and as expected, for
, all the test problems were solved even if approximately
(159 out of 320) were considered using the B&B algorithm. In addition, for
, the average time for solving the test problems reached its minimum with
s. The minimum solved percentage (
) is reached, respectively, for
and
, with respective values
and
. In addition, for
and
, the maximum
(maximum gap) are reached with
and
, respectively. For
, the maximum
is reached with
s. The percentage of solved test problems is increasing as the number of jobs is increasing from
onward. Furthermore, the average relative gap is decreasing as the number of jobs increases from
onward. Except for
, the highest percentage of solved test problems
is reached for
. This means that the developed procedures perform well for the large size test problems.
The effect of the distribution of the machines in the two stages is reported in
Table 4.
According to
Table 4, the unbalanced
distributions of the machines (
;
) present the easiest test problems to be solved. Indeed, for these latter distributions, almost all the test problems are solved, and the respective percentages of the solved problems are
and
. In addition, for the unbalanced distributions, the maximum gap
as well as the average time
are reaching their minimum. The balanced
distributions (
;
) are the hardest ones to be solved and the respective
are
and
. For the balanced distributions, one can observe that
is decreasing as the number of machines increases. Therefore, the proposed procedures are favorable for the unbalanced distribution of machines.
Detailed results considering the number of jobs
n and machines in the stages
and
are presented in
Table 5.
Based on
Table 5, the easiest test problems to be solved are the ones with unbalanced machine distribution and a large number of jobs (
,
), where the percentage of solved problems reaches
. In addition, the hardest test problems are those with
and
), where the
reaches its minimum, which is
.
The effect of the rates [a: b: c] on the performance of the proposed procedures results is presented in
Table 6.
Based on
Table 6, the rates
, where the removal time in the first stage is more important compared to the other parameters (processing times, transportation times, and removal time in the first stage), presents the highest percentage of solved test problems, which is
. Since the studied problem is symmetric, a comparable behavior is expected for the rates
. For these rates
, the percentage of solved test problems is
. The least
is reached for the rates
with a value of
, which corresponds to the case where the transportation times are the most important parameter. In addition, the removal times are dominating the transportation times in terms of importance. Indeed, in the cases where
or
, the value of the rate
b is not affecting the results.
In order to identify the reasons behind the lowest percentage (
) of solved test problems for the rates
, the detailed results are presented for these rates in
Table 7.
Based on
Table 7, the lowest value of
is reached for
,
,
,
,
, and
, where the percentage of solved test problems is only
. Even for
,
, and
, the percentage of solved test problems is
. Clearly for the rates
and
, the hardest test problems to be solved are those with the highest balanced load:
,
, and the transportation times (
).






{kind=link}
{kind=link}