Abstract
With the rise of mobile social networks, an increasing number of consumers are shopping through Internet platforms. The information asymmetry between consumers and producers has caused producers to misjudge the positioning of agricultural products in the market and damaged the interests of consumers. This imbalance between supply and demand is detrimental to the development of the agricultural market. Sentiment tendency analysis of after-sale reviews of agricultural products on the Internet could effectively help consumers evaluate the quality of agricultural products and help enterprises optimize and upgrade their products. Targeting problems such as non-standard expressions and sparse features in agricultural product reviews, this paper proposes a sentiment analysis algorithm based on an improved Bidirectional Encoder Representations from Transformers (BERT) model with symmetrical structure to obtain sentence-level feature vectors of agricultural product evaluations containing complete semantic information. Specifically, we propose a recognition method based on speech rules to identify the emotional tendencies of consumers when evaluating agricultural products and extract consumer demand for agricultural product attributes from online reviews. Our results showed that the F1 value of the trained model reached 89.86% on the test set, which is an increase of 7.05 compared with that of the original BERT model. The agricultural evaluation classification algorithm proposed in this paper could efficiently determine the emotion expressed by the text, which helps to further analyze network evaluation data, extract effective information, and realize the visualization of emotion.
1. Introduction
With the development of the economy and Internet platforms, users are increasingly commenting on agricultural products, and the accumulation of agricultural product comments will inevitably cause issues of information overload. Agricultural producers need to efficiently obtain relevant information from the huge number of reviews. Compared with reviews in common text, online user reviews of agricultural products have the following characteristics: (1) domain-specificity with many specialized terms; (2) short sentences and little information; (3) obvious colloquialization of consumer expressions, common use of Internet terms and buzzwords, and a free writing style. Comments on agricultural products also show potential correlations with the user’s views on the different dimensions or attributes of the evaluation object. Therefore, it is necessary to use automated methods to extract the objects and user sentiment tendencies from the huge amount of user comments on agricultural products, and forming meaningful sentiment labels.
Sentiment Analysis (SA) is the process of classifying opinions and mining subjective texts with emotional overtones using natural language processing and text mining techniques [1]. Typically, the tasks studied in sentiment analysis can be divided into sentiment feature extraction, sentiment polarity classification, sentiment retrieval, generalization, etc. [2]. Zhang et al. [3] proposed a method based on fine-grained sentiment analysis and the Kano model to extract consumer demand for air purifier product attributes from online reviews. Shen et al. [4] used independent memory networks to learn user profiles and product information for review classification, resulting in a dual user and product memory network (DUPMN) model for sentiment analysis. Fu et al. [5] proposed a multifaceted sentiment analysis of Chinese online social commentaries (MSA-COSRs) to automatically discover the aspects discussed in Chinese social commentaries and the sentiments expressed by different aspects. Although Traditional Machine Learning and deep learning-based sentence classification methods show good performance in short text classification tasks, the static word vectors used in these models cannot represent multiple meanings of words in different contexts and cannot fully represent the fine-grained relationships between phrases and clauses.
In recent years, BERT [6] has become a state-of-the-art (SOTA) Natural Language Processing (NLP) model. It uses a pretraining task to obtain a priori semantic knowledge from a large unlabeled corpus and transfers this knowledge to the model to improve semantic feature extraction. With the classification function of BERT, Bedi et al. [7] developed a model to propose sentiment and complaint classifications based on energy-related tweets. Lin et al. [8] combined ensemble learning methods with text sentiment analysis to obtain a model based on BERT to identify harmful news, providing readers with a method to identify harmful news content. There are many asymmetric entity relationships in long sentences, so it is a challenge to construct comprehensive and reasonable entity features. In addition, sentiment analysis of Chinese is still a challenging task due to the lack of physical separation between Chinese words.
To this end, our study extracts sentiment tags from the comment corpus of agricultural products, focusing on the correlation between evaluation words and rating objects. We propose a sentiment analysis algorithm for product reviews based on an improved BERT model. This algorithm uses the BERT model to obtain context-dependent dynamic word vectors to solve multi-sense representation of words. Meanwhile, it extracts the feature vectors of phrases and inter-sentences in complex long sentences through word-level and sentence-level LSTM networks to explore the deep semantic information of sentences. We introduce the Focal Loss loss function to reduce the weight of easily classified samples, and the model is guided to focus on the samples with ambiguous emotion expressions and agricultural characteristic emotions, thus improving the model’s emotion classification accuracy.
2. Related Work
2.1. Semantic Sentiment Analysis (SSA)
Sentiment analysis is generally defined as finding out the author’s opinion about an entity by analyzing people’s sentiments, opinions, attitudes, and emotions about specific elements (topics, products, individuals, organizations, and, etc.) [9]. Daniel et al. [10] proposed an unsupervised learning sentiment calculator based on a sentiment lexicon to analyze the sentiment polarity of events posted on the financial community of Twitter for financial transactions events. Popescu et al. [11] selected nouns and noun phrases that frequently appear in comments as candidate features and evaluated these features by calculating the mutual information value with a search engine. Penalver-Martinez et al. [12] adopted a semantic ontology approach to improve the efficiency of feature extraction and employed a vector analysis-based approach for the sentiment analysis of movie reviews. Zhao et al. [13] proposed an unsupervised model of “clustering first, extraction later” and then applied this approach to extract sentiment information.
The majority of research on sentiment analysis based on machine learning focuses on the optimization of feature extraction algorithms. Yu et al. [14] used the Naive Bayes algorithm (NB) to explore the relative importance and interrelatedness of social media and traditional media on the short-term stock performance of companies. Manek et al. [15] performed feature extraction based on the Gini index. Akhtar et al. [16] proposed a cascade framework for the pruning and compression of feature selection. Meanwhile, they used a particle swarm optimization approach that integrates maximum entropy, conditional random field, and a support vector classifier for sentiment analysis. The effectiveness of this method was validated by feature extraction and sentiment analysis tasks in two different domains. Colace et al. [17] achieved satisfactory results with the Latent Dirichlet Allocation (LDA) based approach as an extraction tool for sentiment views in social networks and collaborative learning environments. In recent years, the development of artificial intelligence has led to the gradual application of deep learning-based methods for textual sentiment analysis. Giatsoglou et al. [18] proposed to put text documents in lexical, word embedding, and hybrid vector representation, and then used this to make a machine learning model for document sentiment polarity classification. This method can detect people’s opinions in different languages quickly and flexibly. Although all of the aforementioned methods are used for semantic sentiment analysis, they all have limitations.
2.2. BERT
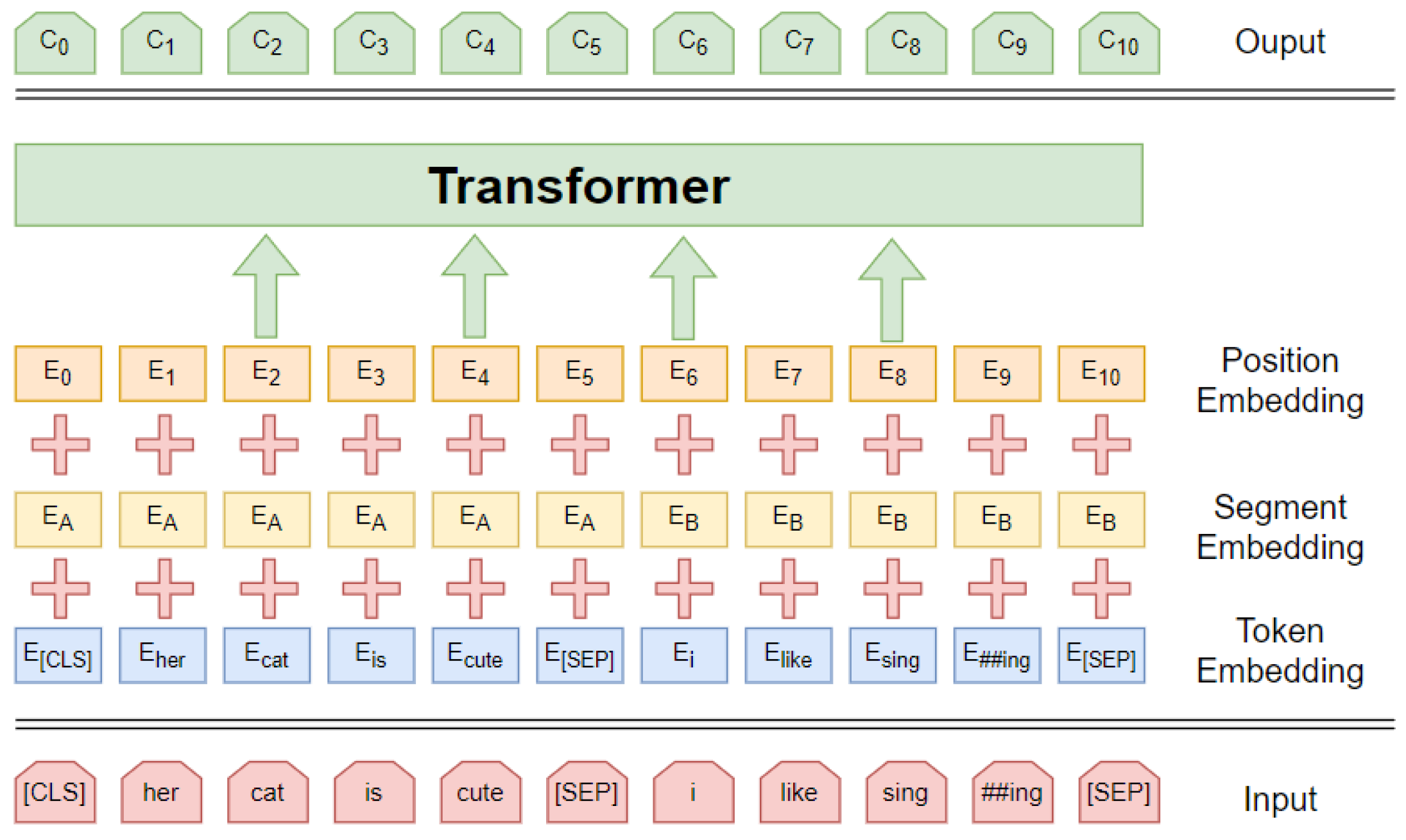
BERT is a SOTA language representation model for a wide range of tasks [6]. It has been proven that the bidirectional training language representation model performs better in corpus feature extraction and context interpretation than the unidirectional language model, as shown in Figure 1. To achieve better vector representation, the Bert model uses a transformer structure to learn the contextual information of the input words, which integrates a multi-headed self-attentive mechanism to comprehensively mine the information in different locations under different subspaces and encode the information representation to each location. The main innovation of BERT is the use of a masked language model and next sentence prediction to capture word and sentence representations, respectively. Many researchers have applied a pre-trained BERT to improve the performance of semantic analysis tasks. For example, Lee et al. [19] used BERT as a word embedding method to integrate a BiLSTM network with an attention mechanism for medical text inference to extract deep semantic information from medical texts. Ohsugi et al. [20] proposed a conversational machine understanding model using BERT to encode each question and answer independently in a multi-round environment. Zhang et al. [21] proposed a BERT-JAM model for machine translation tasks and achieved good results. He et al. [22] proposed a multimodal fusion BERT model to explore time-dependent interactions between different modalities. The experimental results on a public dataset showed that this model achieves good performance.
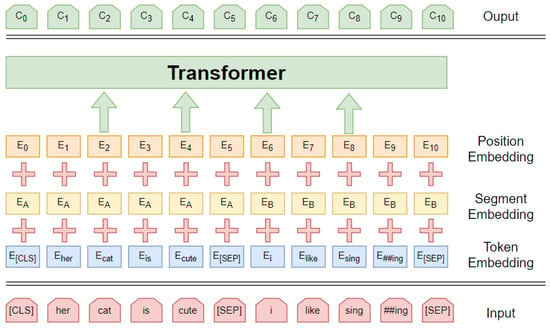
Figure 1.
Structure of the BERT model.
Moreover, BERT can also be used to analyze other languages, such as Chinese [23], Arabic [24], French [25], etc. However, BERT can only obtain character-level representations before training [26]. For example, in Figure 2, the two sentences input into BERT have the same meaning. The token of the English sentence is a word, whereas the token of the Chinese sentence is a character.

Figure 2.
Representation difference between Chinese and English sentences input into the bidirectional encoder in the BERT model.
Li et al. [27] proposed a BERT-based sentiment analysis model for Chinese stock reviews. They used a BERT pre-trained language model to represent stock reviews at the sentence level and then fed the obtained feature vectors to a layer for classification. He et al. [28] proposed a new and accurate method that can automatically identify implicit relations in Chinese discourse using BERT and the proposed tree structure. Wan et al. [29] proposed a relation classification method (EC_BERT) based on the BERT model augmented with entity and entity context information. EC_BERT uses BERT to obtain a vector of sentence feature representations and combines the context utterance information of two target entities and feeds it into a simple neural network for relation classification. The method achieves better performance on the relation classification task than previous methods. These findings suggest that BERT can be used for sentiment analysis of agricultural products.
3. Method
3.1. LSTM
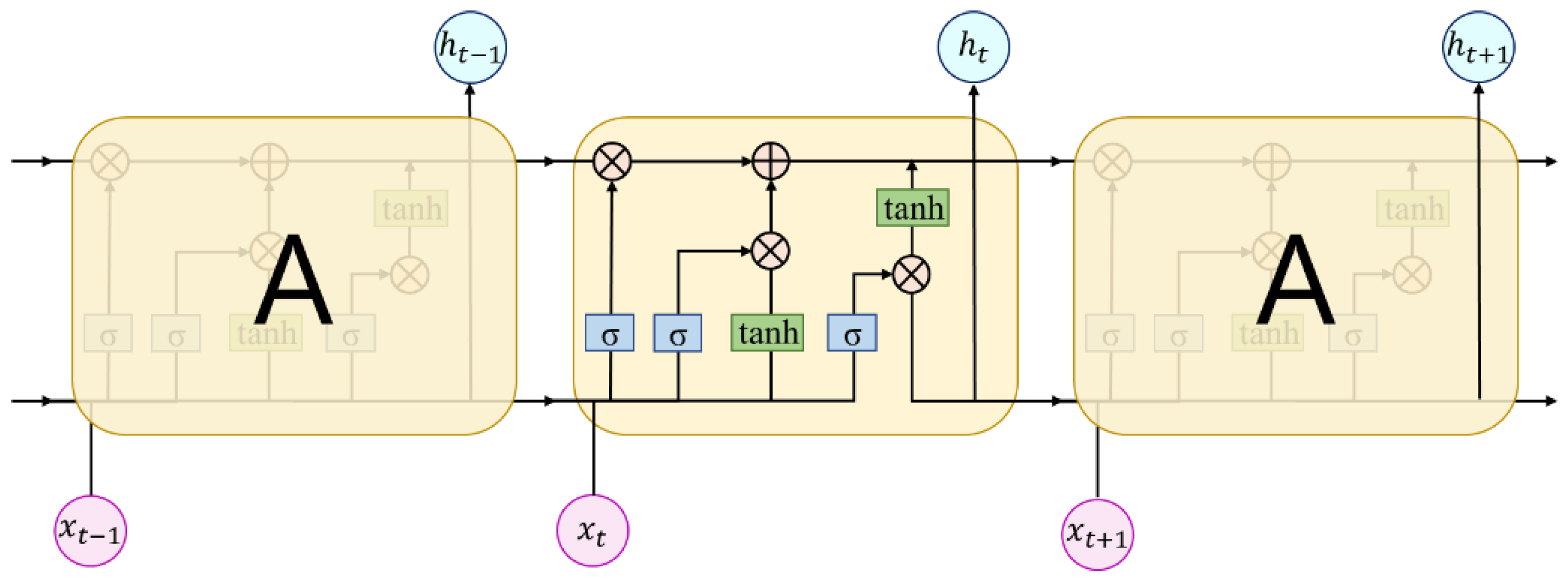
For intent classification tasks of long complex sentences, the LSTM network can filter information from the input units, and each input unit may have a different degree of influence on the final classification result. The network adds input gates, output gates, and forgetting gates for selecting information, and adds memory units for storing and updating information through different gates to the RNN. The updating process of the LSTM network is as follows: in time step , the forgetting gate, , first determines the information that can be forgotten based on the input, , at the current moment and the output, , from the previous moment, and the input gate, , determines the information that needs to be updated. For example, the network will create a new memory unit candidate, , through the tanh function for words that have a high impact on intention, such as “好(good)” and “便宜(cheap)”. The updated memory units, , are filtered by combining the forgetting gate, , with the memory units, , of the previous moment to obtain the updated memory units to store the latest information. Meanwhile, the information flow is updated by the control gate and forgetting gate to generate the new output, .
As shown in Figure 3, the original LSTM is limited by the fact that the model only works on sequence-related data and cannot perform parallel operations. As for the information used in both directional streams in Bi-LSTM, the gradient still disappears after the sequence length exceeds a certain limit, which affects model learning accuracy. The sentence-level LSTM takes the sentence-level state as input, and performs parallel operations to improve feature extraction of text for complex emotional information in agricultural product evaluations.
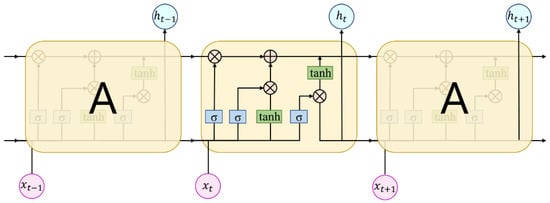
Figure 3.
The LSTM operation flow chart.
3.2. S-LSTM
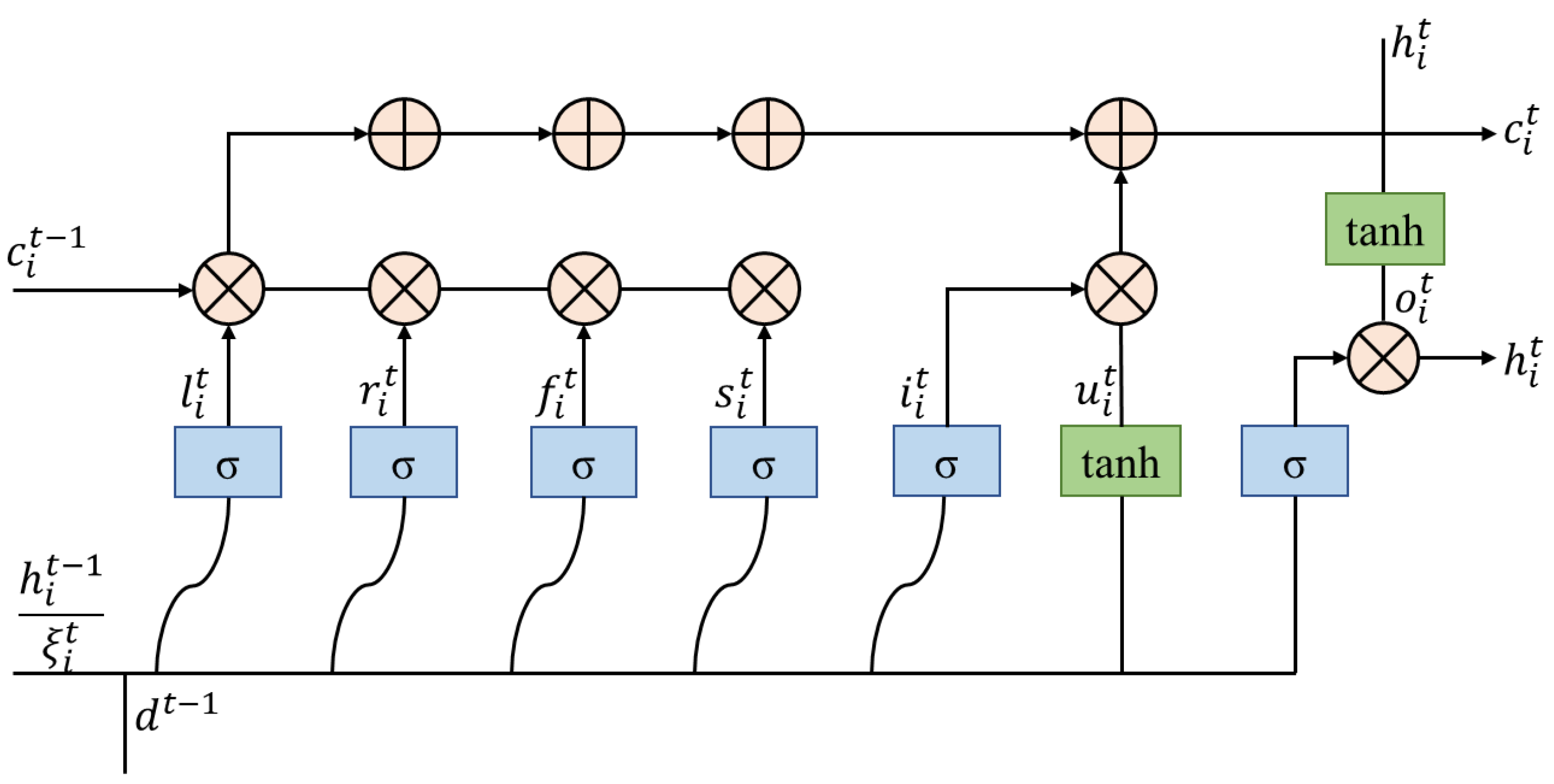
Unlike BiLSTM, which encodes only one word at time, (time step), sentence-level LSTM encoding semantically encodes all words of the input text and the whole text at time, . For a given agricultural product evaluation statement, , represents the i-th Chinese character and represents the length of the evaluation statement. The hidden vector of each word, , and the hidden vector of the whole sentence, , is combined. The LSTM state at moment, , is formalized as, , which consists of each word, , the word-level sub-state of, , and the sentence-level state of the whole evaluation, .
As for the initial state, . The cyclic time step, , is used to model the information exchange from the previous moment state, , to the current moment state, . The transition consists of a word-level state transition and a sentence-level state transition.
Figure 4 presents the LSTM operation flow of the hidden state, , whose update rules are shown in Equations (1)–(11):
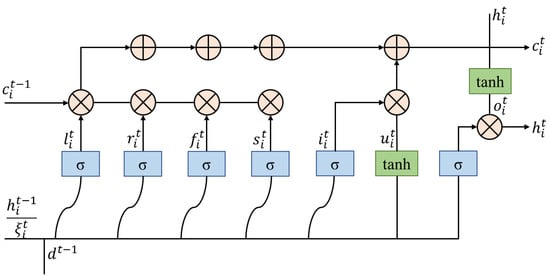
Figure 4.
The LSTM operation flow of the hidden state, .
.
The connection, , of forward-backward hidden vectors is used to construct the context window information, and the window size can control the degree of information exchange with neighboring words. The control gates, , , , , and control the input, ; the cell state of the content of the left text segment, ; the cell state, , of the i-th text content; the cell state, , of the right text segment; and the cell state, , of the sentence-level cell, and normalizes this information. The transformation from the cell state, , to the hidden state, , of the output gate is indicated by . The model parameters are , and is the sigmoid function.
At moment, , the update of the sentence-level state of the whole text, , is shown in Equations (12)–(18).
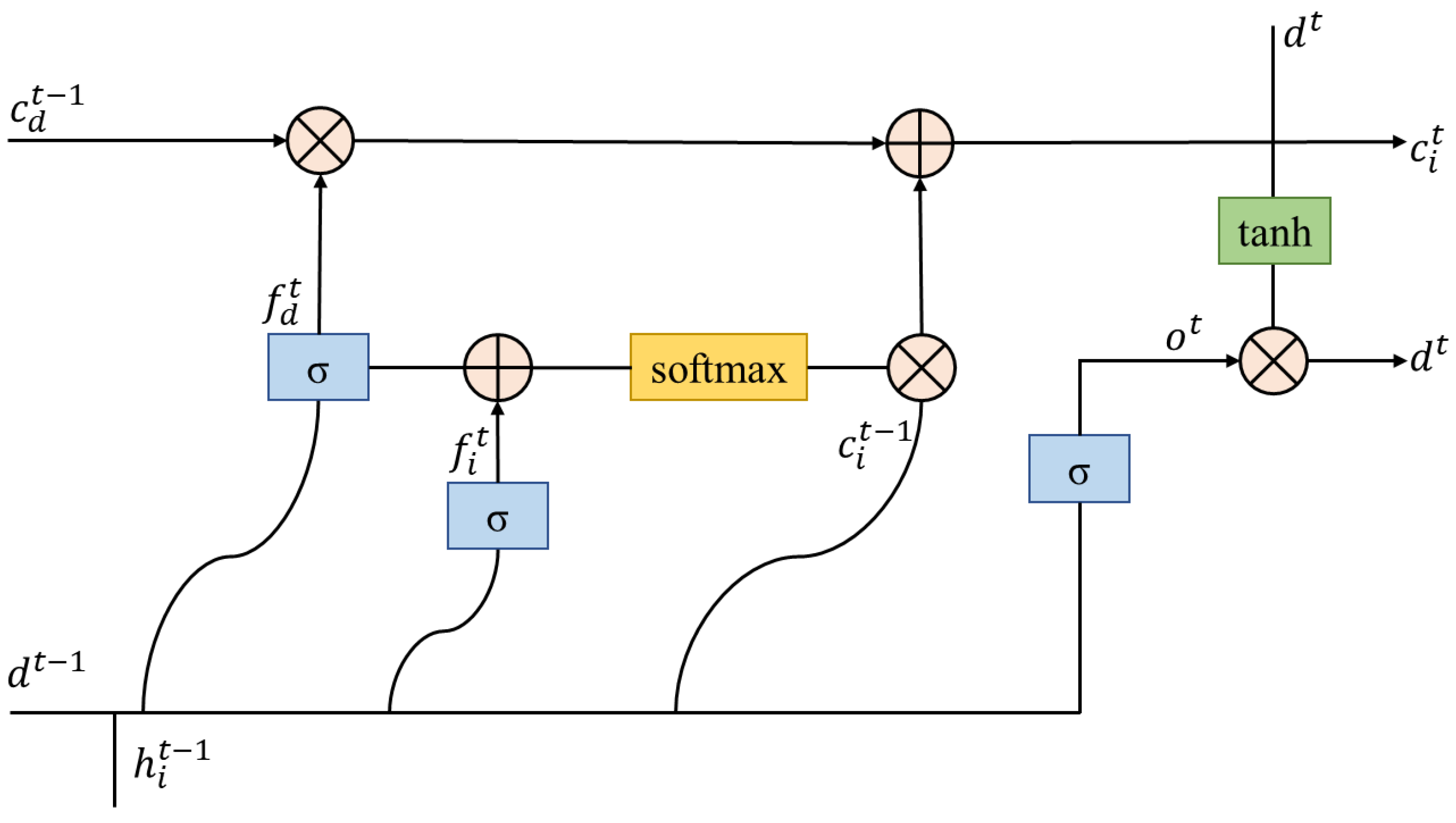
The training model adds multiple forgetting gates to the existing output, input, and loop gates of the original LSTM model, as shown in Figure 5. This way the model can receive more feature information and adjust the state of the time step for deep feature learning; thus, improving the model’s feature learning ability.
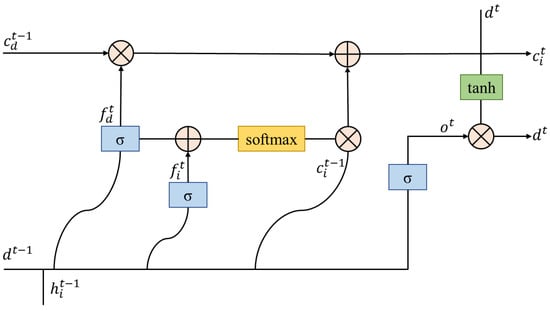
Figure 5.
The LSTM operation flow of the sentence-level state, dt.
3.3. Improved BERT
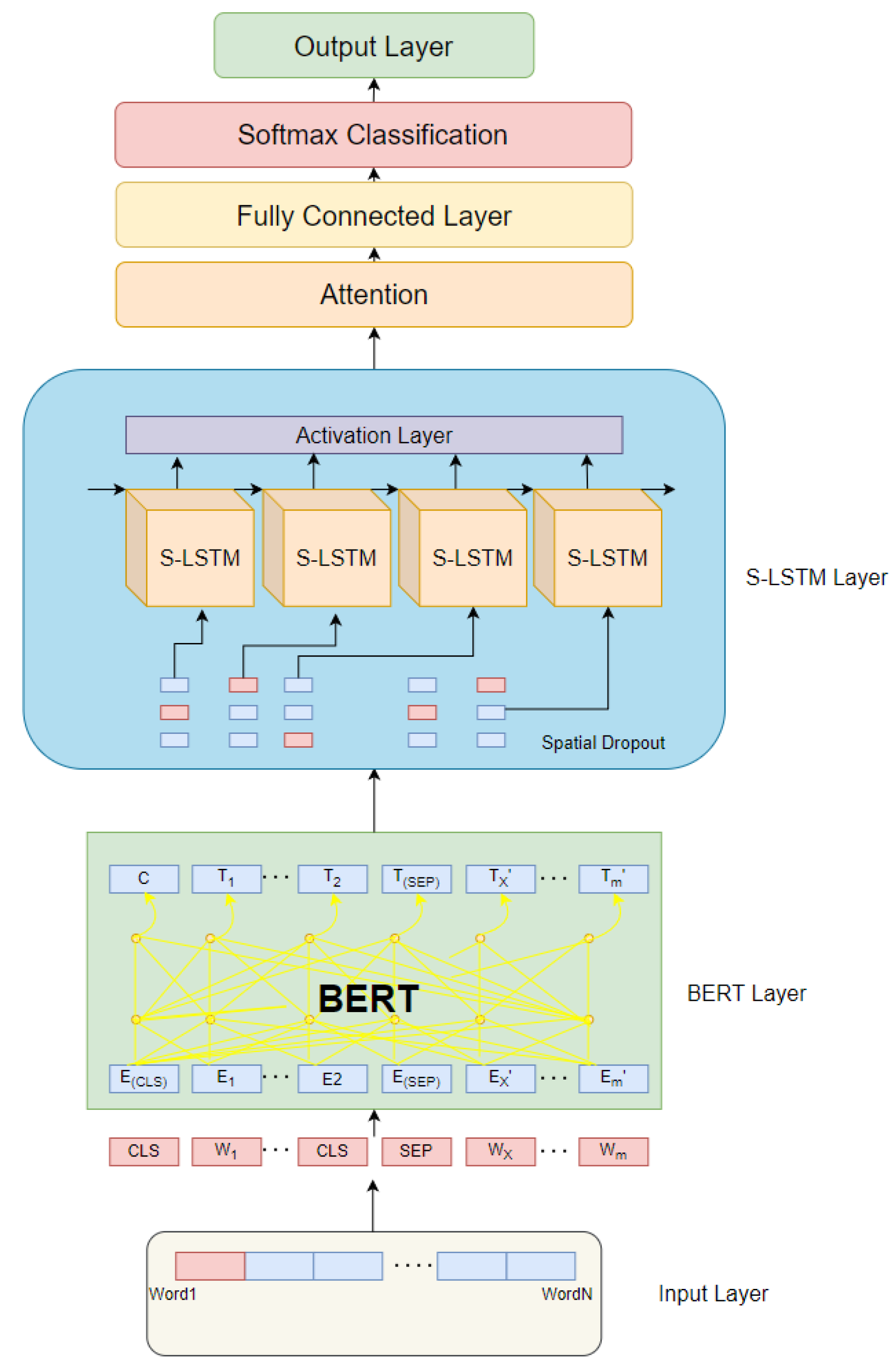
The main function of the input layer is to convert the agricultural comment text into a format that can be recognized by the model. In the input layer, the input of position vectors, word vectors, and segment vectors are stitched together: (1) Word vector: the model does not perform word separation for Chinese text and directly uses a single word as the base unit of the text. The word vector contains the main feature information. (2) Position vector: compared with recurrent neural networks and short- and long-term memory networks, BERT cannot determine the position of input words by its model structure alone. For example, “I can’t like Gochujang rice” and “I may not like Gochujang rice” express different emotional tendencies. So, this paper adds location vectors to remember word position. (3) Segment vector: used to distinguish two input texts to meet the needs of different tasks.
The BERT model outputs both sentence-level and character-level feature vectors. As shown in Figure 6, the leftmost output of the model (CLS) represents the sentence vector that contains the semantics of the whole sentence, and the remaining parts represent the vector output of each character. The BERT model consists of a twelve-layer Transformer network, which mainly uses the Encoder part of the Transformer network. In the Encoder part, the attention mechanism is used to calculate the Input-Output relationship and to learn features that cannot be learned by the shallow network through a deeper network level.
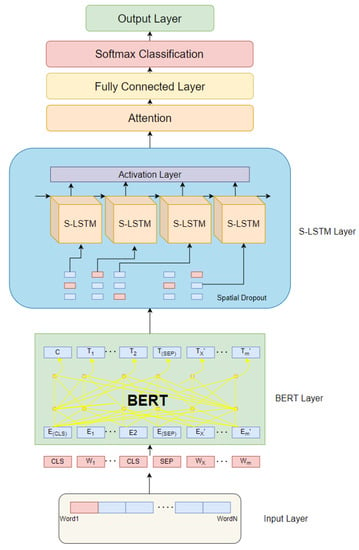
Figure 6.
The structure of the improved BERT model.
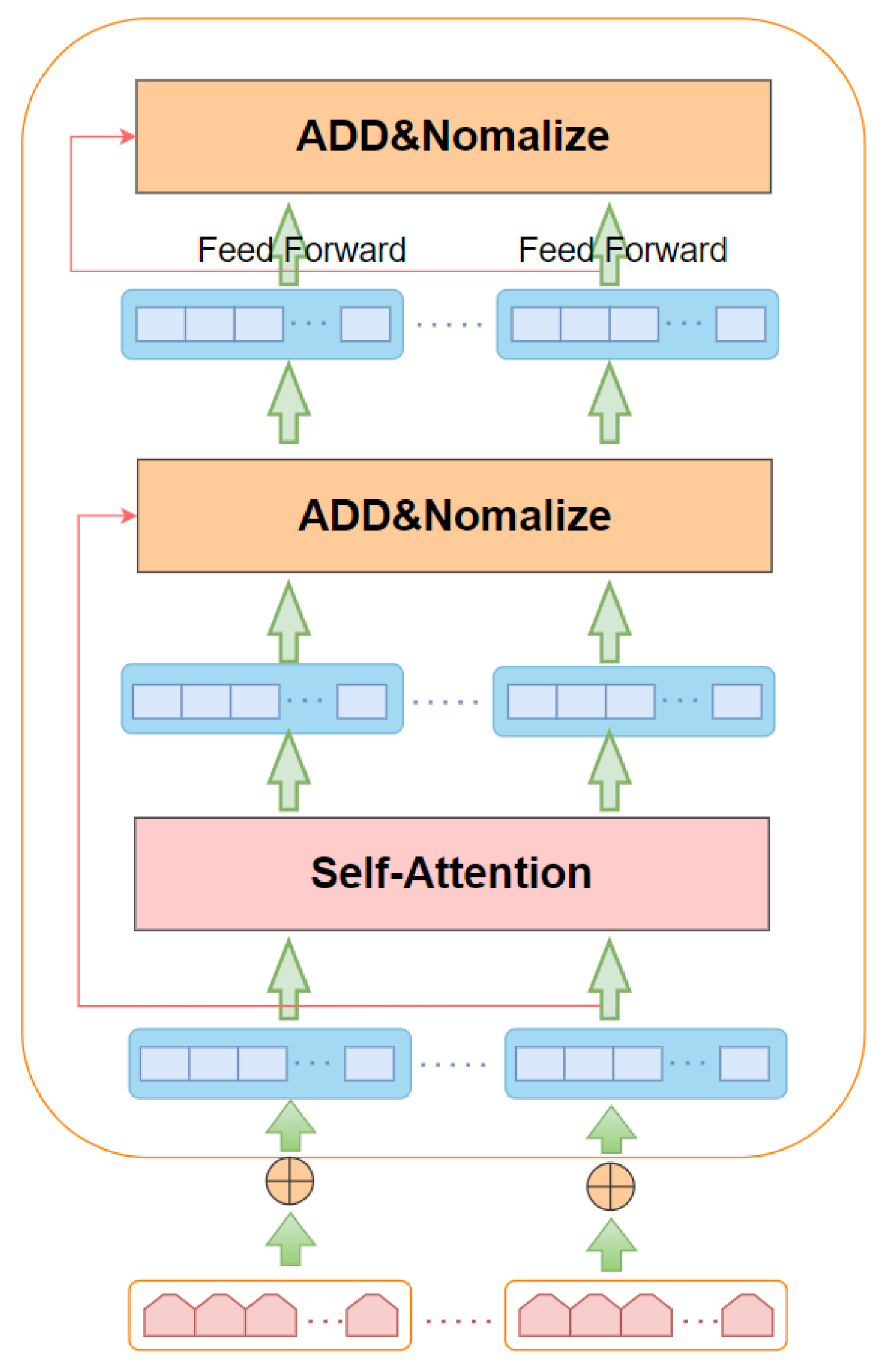
The structure of each Transformer in the BERT model is shown in Figure 7. The Transformer consists of several overlapping units, and each of them is composed of two parts: a self-attentive mechanism and a feedforward neural network. The Self-Attention mechanism helps the current node to focus on the current word and obtain the semantics of the context. Each of these sub-layers incorporates a residual network and a normalization operation.
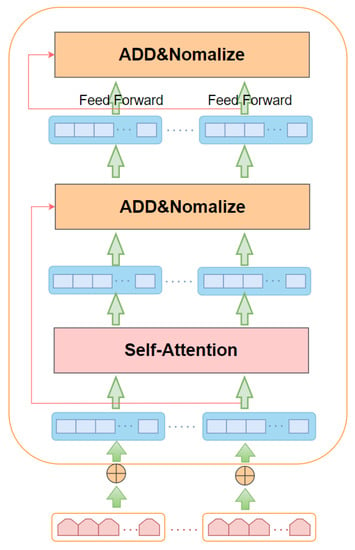
Figure 7.
Transformer coding unit structure.
The output of each sub-layer is represented as follows:
The sub-layers within the unit are designed with residual connections to achieve information transfer between layers. The input to the Encoder is an embedded representation of a word in a sentence. The Self-attention layer allows the Encoder to view the information before and after each word as it encodes. The output of the Encoder is passed through another layer, where Add means the input and output of the Self-attention layer are added, and Norm means the output of the Self-attention layer is normalized. In this way, the output of the Self-attention layer has a fixed mean of 0 and a standard deviation of 1. The normalized list of vectors is then passed into a fully connected feed-forward neural network. The main module in the Encoder section is Self-attention, and its core idea is to calculate the interrelationship between each word in a sentence and all the words in that sentence, and then use these interrelationships to adjust the weight of each word. The new expression of each word contains not only the semantics of the word, but also its relationship with other words, so the vector obtained by this method has a more global expression than the traditional word vector. Multiple Self-Attention mechanisms are used for parallel computation, and the outputs are multiplied by a random initialized matrix. The final result is outputted by a linear transformation.
3.4. Loss Function
This paper conducts sentiment analysis research on agricultural product review data, and there are sentiment feature word differences in agricultural product review data. The review data containing common sentiment feature words and with positive and negative sentiment tendency categories occupy most of the data set. Their sentiment features are more prominent and easier to be correctly classified, making the model biased toward easily classified samples that dominate in number during training. To address this issue, this paper introduces the Focal Loss function to reduce the weight of easily classified samples and focus the model more on fuzzy sentiment expression and sample data containing sentiment feature words in the agricultural domain. The cross-entropy formula for bi-classification is shown in Equation (20):
In the above formula, CE refers to cross-entropy, denotes the prediction probability, and denotes the label value.
The Focal Loss function is obtained by improving the cross-entropy loss function for data imbalance, as shown in Equations (21) and (22).
This paper validates γ = 2 in the experiment. When γ = 0, Focal Loss becomes the cross-entropy loss function. When a large value is assigned to and a small weight is assigned to the easily classified samples, the Focal Loss function reduces the loss value of the easy classification, making its contribution to the overall loss reduced. In this paper, multiclassification sentiment analysis is performed for sentiment, and the modified cross-entropy loss function is shown in Equation (23), which meets the requirements of the multiclassification task.
In the above formula, denotes the true sample label, denotes the predicted category of the model output, and n is the number of categories.
4. Experiments
4.1. Data Acquisition and Preprocessing
The review data obtained from different sources had some differences. To ensure the comprehensiveness and representativeness of information sources, the agricultural product reviews were obtained from four channels: social media, news websites, e-commerce websites, and offline surveys. The data were processed with comment de-duplication, mechanical compression, de-word processing, and semantic comment deletion to construct a clean, original corpus.
In this paper, the product review data is annotated with manual sentiment categories, and sentiment is categorized into positive, negative, and neutral sentiment reviews. The introduction of the categories is presented in Table 1:

Table 1.
Classification labeling.
To ensure the objectivity and accuracy of the labeled data, the same batch of data is labeled twice, and the labeling results of the two groups of data are verified against one another. In this way, 6152 positive sentiment data items, 1873 neutral sentiment data items, and 7925 negative sentiment data items were obtained.
The data were randomly sorted; 70% were taken as the training set, 15% as the validation set, and 15% as the test set. The model parameters were continuously adjusted and optimized according to the classification effect on the validation set. Finally, the model was tested on the test set.
In this paper, the original dataset, balanced dataset, and data-enhanced dataset were constructed to investigate the performance of the BERT model on different types of datasets (The data set parameters as shown in Table 2):
Table 2.
Data set parameters.
- (1)
- As imbalance in a dataset affects the optimal performance of the model, a balanced dataset needs to be approximated by balancing the corpus. To reduce the influence of the imbalanced dataset on the BERT model and achieve optimal results, a balanced dataset was built based on the minimum amount of sentiment data among the three categories, and 2000 data items were randomly selected from each of the three sentiment categories to build the balanced dataset.
- (2)
- The sentiment labeling results indicated that the proportion of sentiment categories in the agricultural product review data set was unbalanced. To conduct our experiment and observe our model perform in a real environment, we assumed that the proportion of data categories in the data set was consistent with practice and constructed the original data set based on this proportion.
- (3)
- To investigate the effect of the improved BERT model to handle the problem of sentiment feature word discrepancy and to investigate whether this problem was affected by the balance of the dataset, we constructed a data-enhanced balanced dataset by adding a few class samples based on the balanced dataset using the back-translation method.
4.2. Experimental Environment
The computing hardware used in the experiment was RTX 2080Ti (NVIDIA, 11GB), and the deep learning framework was TensorFlow. The specific configuration of the experimental environment is shown in Table 3.
Table 3.
Experimental environment.
4.3. Model Parameter Setting
The relevant parameters of the model are shown in Table 4.
Table 4.
Model parameter settings.
4.4. Experimental Results
In this experiment, Precision (P), Recall (R), and F1 values were used as evaluation indexes. Precision (P) refers to the proportion of the number of correctly classified sentences to the number of all sentences predicted, and Recall (R) refers to the proportion of the number of correctly classified sentences to the number of true sentences for a particular classification. In practice, Precision (P) and Recall (P) are contradictory measures, where a high recall rate may result in a low accuracy rate, and vice versa. The F1 value is a combination of precision and recall, and the higher the F1 value, the better the model performance. As this paper focused on a multi-category classification task, the classification performance of the model was evaluated by the average value of each metric for each category.
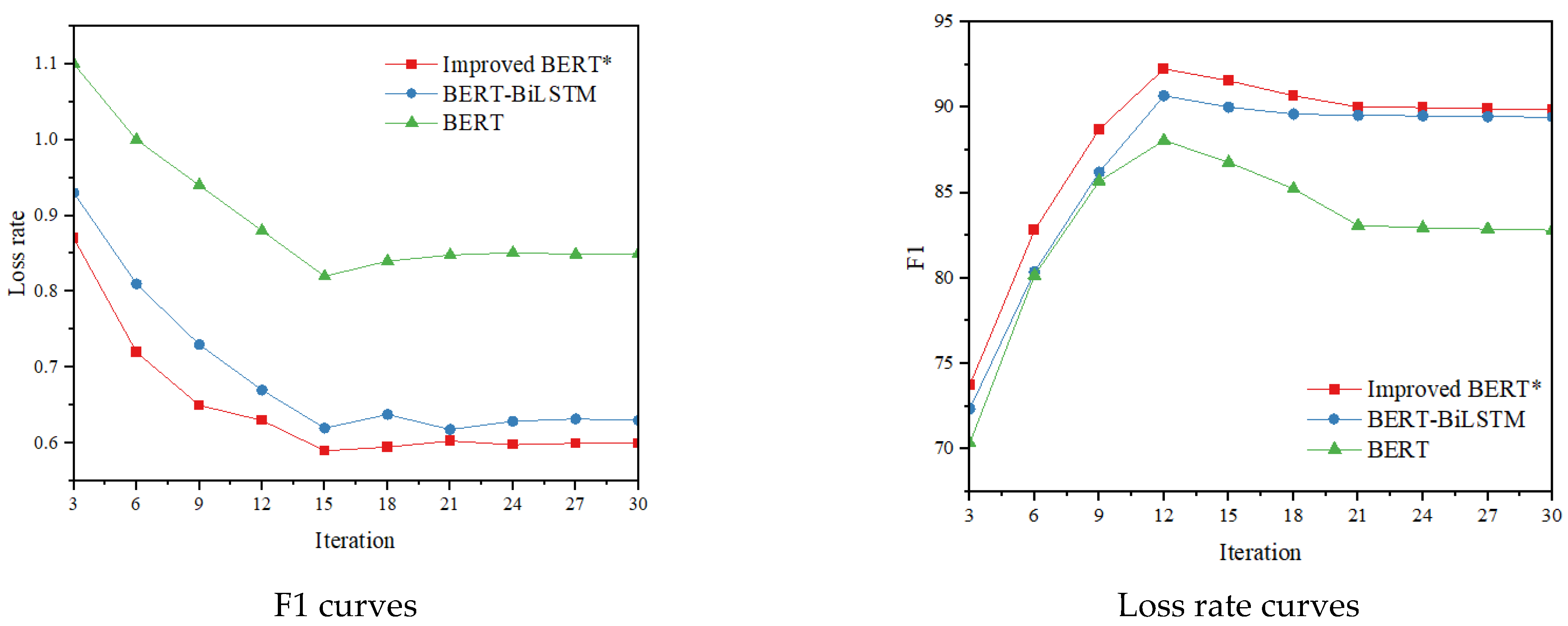
The F1 and loss rate changes of BERT, BERT-BiLSTM, and our method on both the original dataset and the data-enhanced balanced dataset in 30 iterations are shown in Figure 8.
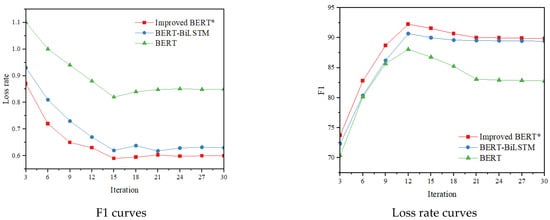
Figure 8.
F1 curves and loss rate curves of the three models. ‘*’ indicates that FL is used as the loss function.
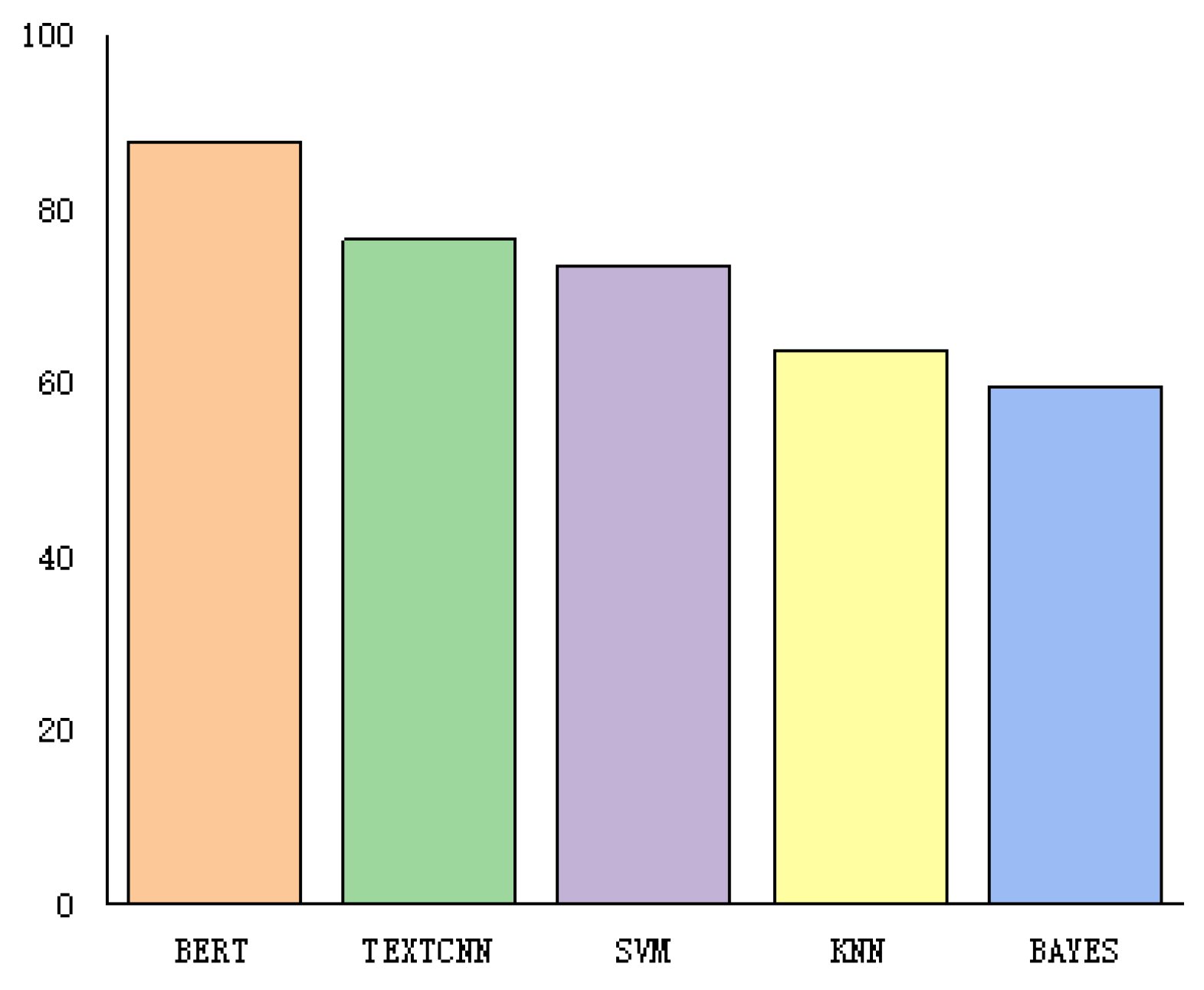
Experiments were conducted on the balanced dataset, and the BERT model proposed in this paper was compared with the Convolutional Neural Network for Text Classification (TextCNN) and traditional machine learning models, including support vector machine (SVM), k nearest neighbors (KNN), and BAYES. The experimental results are shown in Table 5 and Figure 9.
Table 5.
Comparison between the BERT model and machine learning models on the balanced dataset.
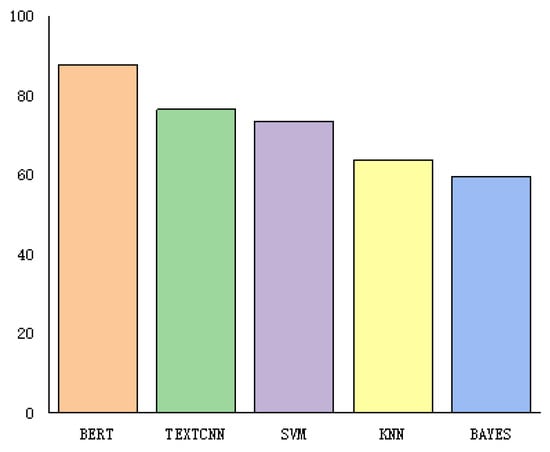
Figure 9.
Comparison of experimental results of BERT and machine learning methods.
Experiments were conducted on both the original dataset and the data-enhanced balanced dataset to compare the improved BERT and BERT-BiLSTM models. Whether this method is effective in classifying the sentiment of agricultural products remains to be verified. The experimental results are shown in Table 6 and Figure 10.
Table 6.
Comparison of experimental results of the improved BERT* on both the original dataset and the data-enhanced balanced dataset.
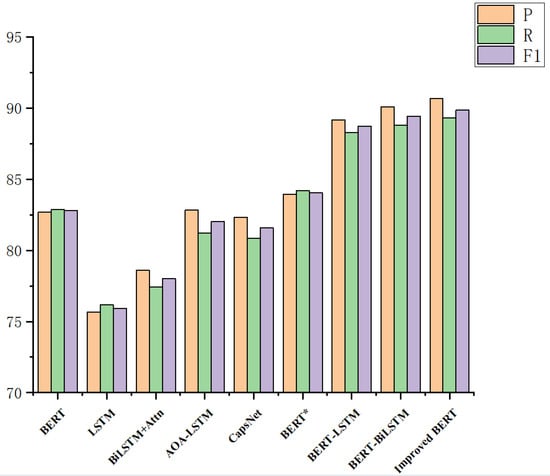
Figure 10.
Comparison of experimental results of the improved BERT model.
In this study, the proposed improved BERT model segmented texts according to Chinese language characteristics, which was different from the traditional method of using sentiment dictionaries, relying on the text vectors derived from the context to solve the problem of sentiment analysis for agricultural product evaluation. Model performance was evaluated using the F1 value metric, and BERT achieved good performance in comparison with traditional machine learning methods (the F1 value improved by more than 11). In the comparison experiment on deep learning methods, the F1 value of the BERT model with modified loss function was improved by 1.25 compared with that of the original model, whereas the F1 value of the BERT-LSTM model reached 88.72. The F1 value of the SOTA BERT-BiLSTM model reached 89.42, whereas the F1 value of the improved BERT model using sentence-level LSTM was improved by 7.05 compared with that of the original BERT model. The F1 value of the improved BERT model using sentence-level LSTM was improved by 7.05 compared with that of the original BERT model, and the F1 value was improved by 0.44 compared with that of the BERT-BiLSTM model. Sentence-level LSTM was used to divide the text vector obtained from the pre-trained model, and text features were extracted to solve the problem of LSTM and Bi-LSTM that causes the semantic association between contexts to gradually weaken with the passing of states [36]. Sentence-level LSTM method was used to encode agricultural product evaluation sentences to construct sentence-level states of the entire text with global information. The experimental results indicate that the model has good prospects for applications in the sentiment analysis field for agricultural product evaluation.
5. Discussion
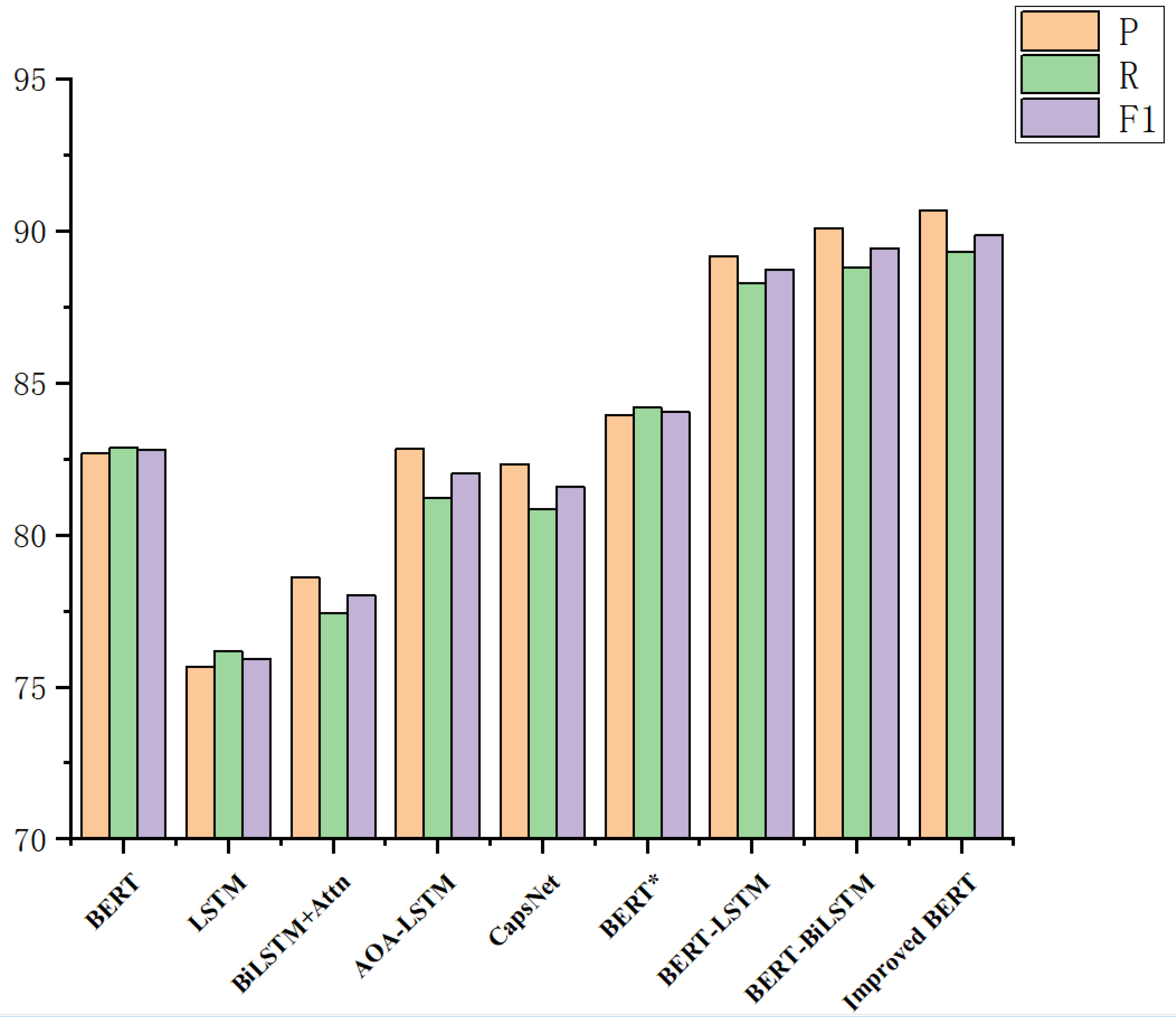
From the above experiments, we found that the improved BERT model outperformed other similar natural language processing models in performance evaluation indicators such as accuracy, recall, and F1-score, and had advantages in sentiment analysis for agricultural product evaluation. At present, there are many studies on sentiment analysis of Chinese reviews [21,35,36]. We selected methods with source code to test the performance of their proposed method using our dataset. The results are shown in Table 7.
Table 7.
Comparison between the improved BERT model and previously proposed models using the balanced dataset.
The experimental results show that the performance of our model in sentiment analysis of agricultural product evaluation is state-of-the-art, and can better complete the task of sentiment classification.
As reviewers and consumers have common buyer interests, consumers are more inclined to believe the information provided by reviewers than product information provided by merchants. Online reviews reflect emotional tendencies, satisfaction, and product information. Such reviews can help consumers eliminate some doubts, reduce their risk perception, and enhance their willingness to buy. Therefore, for enterprises, starting from the emotional tendencies of users, more accurately excavating the advantages and disadvantages of products and sales plays an important role in improving consumers’ willingness to buy and increasing online sales of agricultural products.
6. Conclusions and Future Work
In this study, we proposed a sentiment analysis algorithm based on the improved BERT model to obtain sentence-level feature vectors of agricultural product evaluations containing complete semantic information. The obtained feature vectors were fed into a classifier for sentiment classification. The output layer of BERT was connected to the sentence-level LSTM (S-LSTM) network, and the features were hierarchically extracted by the LSTM. Additionally, this paper introduces the Focal Loss function that reduces the weight of easy-to-classify samples in model training and guides the model to focus on feature word samples with more ambiguous sentiment expression and agricultural characteristic sentiment. Compared with other task-specific and general task-independent pre-training models, the improved BERT model performs better for Chinese emotion analysis tasks.
In future research, we aim to apply this novel method to different key domains to validate generalizability and test the model on multilingual datasets to observe its performance in other languages. In the current study, we used a clean original corpus for sentiment analysis of agricultural product evaluation. However, in the actual online detection process, some merchants publish false positive reviews that do not accurately reflect real purchase experiences, by brushing orders and establishing a service [39], creating a high-quality store image to attract consumers, in order to increase sales, and even going to competitors’ stores to deliberately fabricate malicious and slanderous bad reviews. These fake reviews seriously interfere with consumers’ purchasing decisions. Therefore, finding a method to detect and delete fake online reviews and improve the quality of data has become an urgent problem that needs to be solved. At the same time, agricultural product reviews often include information in the forms of text, images, and videos. The next step of research should focus on the multimodal data fusion of online review text, images, and videos, and establishing a multimodal data mining model. We also plan to test this model further using data sets in different languages (e.g., Arabic, English, French, etc.) and observing how the model performs in other languages.
Author Contributions
Y.C. and L.L. conceived the idea of this paper; Z.S. designed and W.M. completed the experiments; W.M. made modifications to the experiments; Y.C. and Z.S. wrote and revised the paper. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Hunan Province Key R&D Program: Research and the development of tea oil rapid identification technology and equipment (Grant No. 2022NK2048); General project of Natural Science Foundation of Hunan Province (Grant No. 2020JJ4142).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data required to reproduce these findings cannot be shared at this time as the data is also part of an ongoing study.
Acknowledgments
The authors would like to thank all the reviewers who participated in the review.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Deng, L. Deep Learning: Methods and Applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef] [Green Version]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- Zhang, J.; Zhang, A.; Liu, D.; Bian, Y. Customer preferences extraction for air purifiers based on fine-grained sentiment analysis of online reviews. Knowl.-Based Syst. 2021, 228, 107259. [Google Scholar] [CrossRef]
- Shen, J.; Ma, M.D.; Xiang, R.; Lu, Q.; Vallejos, E.P.; Xu, G.; Huang, C.-R.; Long, Y. Dual memory network model for sentiment analysis of review text. Knowl.-Based Syst. 2020, 188, 105004. [Google Scholar] [CrossRef]
- Xianghua, F.; Guo, L.; Yanyan, G.; Zhiqiang, W. Multi-aspect sentiment analysis for Chinese online social reviews based on topic modeling and HowNet lexicon. Knowl.-Based Syst. 2013, 37, 186–195. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Bedi, J.; Toshniwal, D. CitEnergy: A BERT based model to analyse Citizens’ Energy-Tweets. Sustain. Cities Soc. 2022, 80, 103706. [Google Scholar] [CrossRef]
- Lin, S.-Y.; Kung, Y.-C.; Leu, F.-Y. Predictive intelligence in harmful news identification by BERT-based ensemble learning model with text sentiment analysis. Inf. Process. Manag. 2022, 59, 102872. [Google Scholar] [CrossRef]
- Serrano-Guerrero, J.; Olivas, J.A.; Romero, F.P.; Herrera-Viedma, E. Sentiment analysis: A review and comparative analysis of web services. Inf. Sci. 2015, 311, 18–38. [Google Scholar] [CrossRef]
- Daniel, M.; Neves, R.F.; Horta, N. Company event popularity for financial markets using Twitter and sentiment analysis. Expert Syst. Appl. 2017, 71, 111–124. [Google Scholar] [CrossRef]
- Popescu, A.-M.; Etzioni, O. Extracting product features and opinions from reviews. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005. [Google Scholar]
- Peñalver-Martinez, I.; Garcia-Sanchez, F.; Valencia-Garcia, R.; Rodríguez-García, M.Á.; Moreno, V.; Fraga, A.; Sánchez-Cervantes, J.L. Feature-based opinion mining through ontologies. Expert Syst. Appl. 2014, 41, 5995–6008. [Google Scholar] [CrossRef]
- Zhao, L.; Huang, M.; Sun, J.; Luo, H.; Yang, X.; Zhu, X. Sentiment Extraction by Leveraging Aspect-Opinion Association Structure. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015. [Google Scholar]
- Yu, Y.; Duan, W.; Cao, Q. The impact of social and conventional media on firm equity value: A sentiment analysis approach. Decis. Support Syst. 2013, 55, 919–926. [Google Scholar] [CrossRef]
- Manek, A.S.; Shenoy, P.D.; Mohan, M.C. Aspect term extraction for sentiment analysis in large movie reviews using Gini Index feature selection method and SVM classifier. World Wide Web 2016, 20, 135–154. [Google Scholar] [CrossRef] [Green Version]
- Akhtar, M.S.; Gupta, D.; Ekbal, A.; Bhattacharyya, P. Feature selection and ensemble construction: A two-step method for aspect based sentiment analysis. Knowl.-Based Syst. 2017, 125, 116–135. [Google Scholar] [CrossRef]
- Colace, F.; Casaburi, L.; De Santo, M.; Greco, L. Sentiment detection in social networks and in collaborative learning environments. Comput. Hum. Behav. 2015, 51, 1061–1067. [Google Scholar] [CrossRef]
- Giatsoglou, M.; Vozalis, M.G.; Diamantaras, K.; Vakali, A.; Sarigiannidis, G.; Chatzisavvas, K.C. Sentiment analysis leveraging emotions and word embeddings. Expert Syst. Appl. 2017, 69, 214–224. [Google Scholar] [CrossRef]
- Lee, L.-H.; Lu, Y.; Chen, P.-H.; Lee, P.-L.; Shyu, K.-K. NCUEE at MEDIQA 2019: Medical Text Inference Using Ensemble BERT-BiLSTM-Attention Model. In Proceedings of the 18th BioNLP Workshop and Shared Task, Florence, Italy, 1 August 2019. [Google Scholar]
- Ohsugi, Y.; Saito, I.; Nishida, K.; Asano, H.; Tomita, J. A Simple but Effective Method to Incorporate Multi-turn Context with BERT for Conversational Machine Comprehension. arXiv 2019, arXiv:1905.12848. [Google Scholar]
- Zhang, Z.; Wu, S.; Jiang, D.; Chen, G. BERT-JAM: Maximizing the utilization of BERT for neural machine translation. Neurocomputing 2021, 460, 84–94. [Google Scholar] [CrossRef]
- He, J.; Hu, H. MF-BERT: Multimodal Fusion in Pre-Trained BERT for Sentiment Analysis. IEEE Signal Process. Lett. 2022, 29, 454–458. [Google Scholar] [CrossRef]
- Yao, L.; Jin, Z.; Mao, C.; Zhang, Y.; Luo, Y. Traditional Chinese medicine clinical records classification with BERT and domain specific corpora. J. Am. Med. Inform. Assoc. 2019, 26, 1632–1636. [Google Scholar] [CrossRef]
- Zhang, C.; Abdul-Mageed, M. No Army, No Navy: BERT Semi-Supervised Learning of Arabic Dialects. In Proceedings of the Fourth Arabic Natural Language Processing Workshop, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Kondratyuk, D. Cross-Lingual Lemmatization and Morphology Tagging with Two-Stage Multilingual BERT Fine-Tuning. In Proceedings of the 16th Workshop on Computational Research in Phonetics, Phonology, and Morphology, Florence, Italy, 2 August 2019. [Google Scholar]
- Wang, Y.; Sun, Y.; Ma, Z.; Gao, L.; Xu, Y. An ERNIE-Based Joint Model for Chinese Named Entity Recognition. Appl. Sci. 2020, 10, 5711. [Google Scholar] [CrossRef]
- Li, M.; Chen, L.; Zhao, J.; Li, Q. Sentiment analysis of Chinese stock reviews based on BERT model. Appl. Intell. 2021, 51, 5016–5024. [Google Scholar] [CrossRef]
- Jiang, D.; He, J. Tree Framework with BERT Word Embedding for the Recognition of Chinese Implicit Discourse Relations. IEEE Access 2020, 8, 162004–162011. [Google Scholar] [CrossRef]
- Wan, Y.; Sun, L.Y.; Zhao, P.; Wang, J.F.; Tu, S. Relation Classification Based on Information Enhanced BERT. J. Chin. Inf. Process. 2021, 35, 69–77. [Google Scholar]
- Chen, T.; Chen, Y.; Lv, M.; He, G.; Zhu, T.; Wang, T.; Weng, Z. A Payload Based Malicious HTTP Traffic Detection Method Using Transfer Semi-Supervised Learning. Appl. Sci. 2021, 11, 7188. [Google Scholar] [CrossRef]
- Rizwan, A.; Iqbal, N.; Ahmad, R.; Kim, D.-H. WR-SVM Model Based on the Margin Radius Approach for Solving the Minimum Enclosing Ball Problem in Support Vector Machine Classification. Appl. Sci. 2021, 11, 4657. [Google Scholar] [CrossRef]
- Choi, S. Combined kNN Classification and Hierarchical Similarity Hash for Fast Malware Detection. Appl. Sci. 2020, 10, 5173. [Google Scholar] [CrossRef]
- Oh, H.-J.; Syifa, M.; Lee, C.-W.; Lee, S. Land Subsidence Susceptibility Mapping Using Bayesian, Functional, and Meta-Ensemble Machine Learning Models. Appl. Sci. 2019, 9, 1248. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Tian, K. A Novel Financial Text Sentiment Analysis-Based Approach for Stock Index Prediction. Quant. Tech. Econ. 2021, 38, 124–145. [Google Scholar]
- Leng, J.; Wang, D.; Ma, X.; Yu, P.; Wei, L.; Chen, W. Bi-level artificial intelligence model for risk classification of acute respiratory diseases based on Chinese clinical data. Appl. Intell. 2022, 1–18. [Google Scholar] [CrossRef]
- Hsieh, Y.; Zeng, X. Sentiment Analysis: An ERNIE-BiLSTM Approach to Bullet Screen Comments. Sensors 2022, 22, 5223. [Google Scholar] [CrossRef]
- Zhou, L.; Bian, X. Improved text sentiment classification method based on BiGRU-attention. J. Phys. Conf. Ser. 2019, 1345, 032097. [Google Scholar] [CrossRef]
- Miao, Y.L.; Cheng, W.F.; Ji, Y.C.; Zhang, S.; Kong, Y.L. Aspect-based sentiment analysis in Chinese based on mobile reviews for BiLSTM-CRF. J. Intell. Fuzzy Syst. 2021, 40, 8697–8707. [Google Scholar] [CrossRef]
- Feng, J.Y.; Wu, D.D.; Wang, B.; Wang, Z.; Mu, W.S. Online Comments Analysis and Its Application Research Progress in E-commerce of Fresh Agricultural Products. Trans. Chin. Soc. Agric. Mach. 2021, 52, 504–512. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).