
Utilizing Language Models to Expand Vision-Based Commonsense Knowledge Graphs



Abstract
:1. Introduction
1.1. Commonsense Definition
1.2. Contributions
- A multi-modal methodology for constructing commonsense knowledge graphs;
- A process of generating question/answer-based prompts for language models based on triples extracted from an existing commonsense knowledge graph, or based on the input from users;
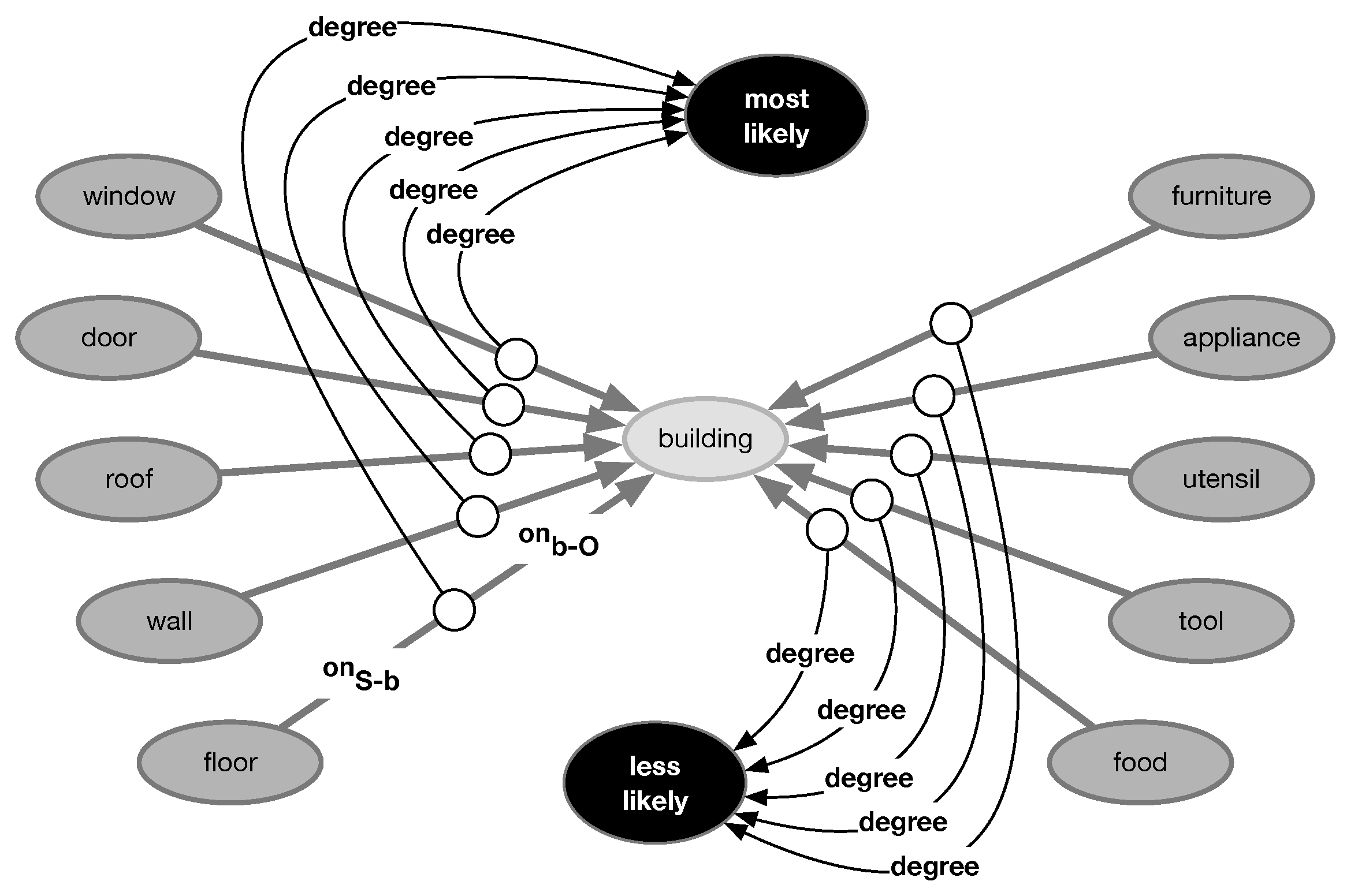
- An expansion of the standard structure of knowledge graphs by introducing an approach to add degrees of likeliness as indicators of the ‘strength’ of triples that are added to commonsense knowledge graphs; the degrees are expressed with linguistic terms, such as more likely, less likely;
- An evaluation process based on Amazon Mechanical Turk.
2. Related Work
2.1. Expansion of Knowledge Bases
2.2. Construction and Expansion of Commonsense Knowledge
3. Image-Based Construction of Commonsense Knowledge Graph
3.1. Extraction of Scene Graphs
3.2. Fusion of Scene Graphs
4. Expanding Knowledge Graph Using Language Model
4.1. Methodology
4.2. Language Models
4.3. Language Model Prompts
| prompt: | Q: What can be found on table in bar? Name five. |
| A: bottle, class, cup, napkin, fork. | |
| Q: What can be found on table in conference room? Name five. | |
| GPT-3 response: | paper, glass, laptop, phone, box. |
5. Expansion of Commonsense Graph
- Asking for subjects and objects for given relations using a basic prompt template;
- Asking for the most and least likely subjects and objects for given relations to construct fuzzy triples;
- Asking for the most and least likely objects with novel relations given by a user.
5.1. Simple Triples
- Extract five triples with the relation from the WpKG.
- Select randomly one triple from the set of five, say, triple k; it is used in the process of customization of a prompt template for the relation.
- –
- Extract a set of five most popular objects Obj fitting 〈subject, relation, -〉 from the WpKG.
- –
- Extract a set of five most popular subjects Sub fitting 〈 -, relation, object〉 from the WpKG.
- –
- Audit the instantiated prompt and make changes if necessary.
- For each extracted triple 〈subject, relation, object〉:
- –
- Put subject and relation into the question template and append to the prompt.
- –
- Put the prompt to the language model to initiate the text generation.
- –
- Extract the five new objects Obj from the generated text.
- –
- Add five new triples 〈subject, relation, -〉 with objects from Obj to WpKG.
- –
- Put relation and object into the question template and append to the prompt.
- –
- Put the prompt to the language model to initiate the text generation.
- –
- Extract the five new subjects Sub from the generated text.
- –
- Add five new triples 〈-, relation, object〉 with subjects from Sub to WpKG.
5.2. Fuzzy Triples with Linguistic Terms
5.3. Fuzzy Triples with Novel User-Provided Relations
6. Discussion
6.1. Vision-Based Commonsense Graph
6.2. Preliminary Experiments with Language Models
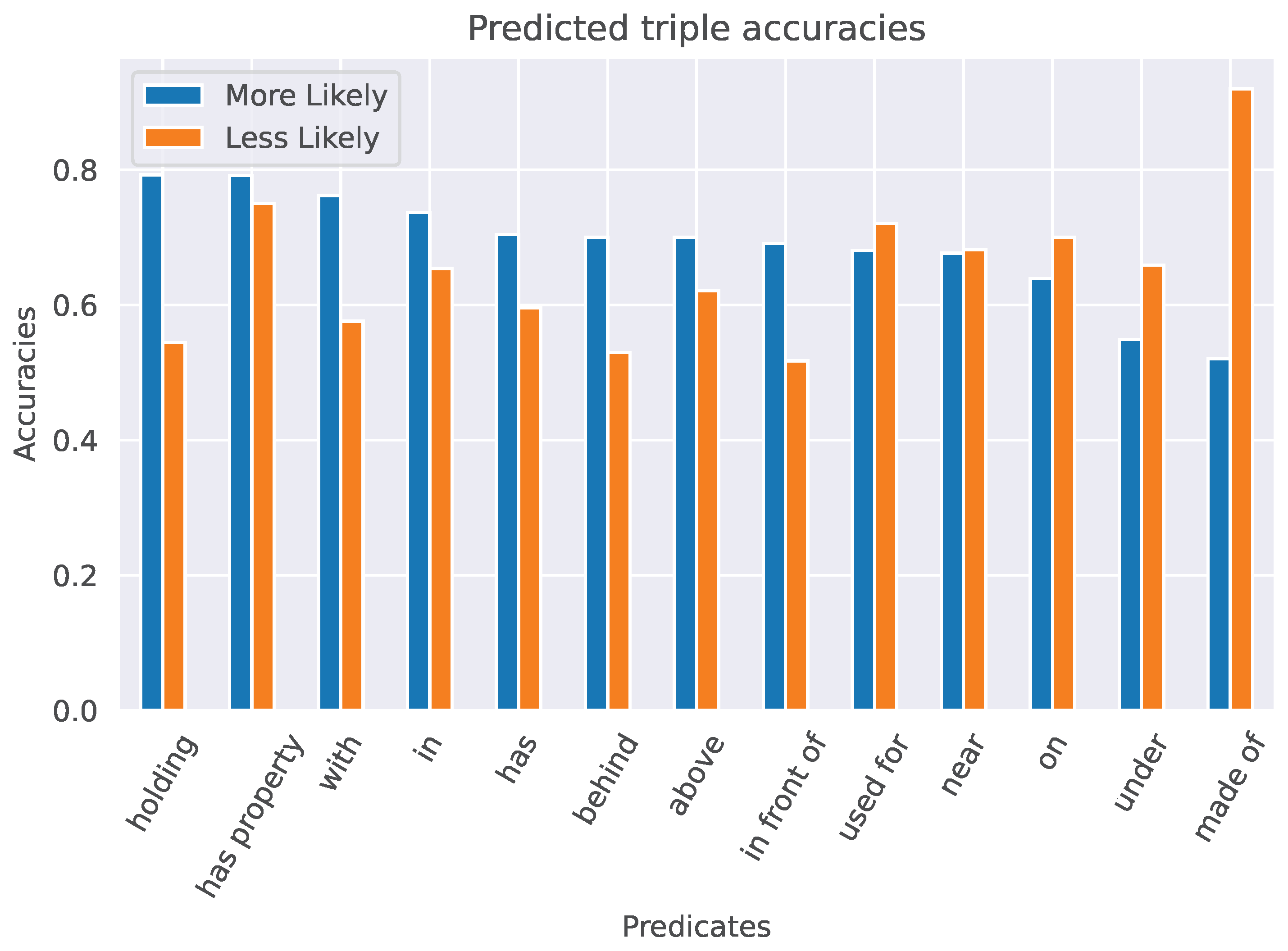
6.3. Evaluation of Commonsense Knowledge Graph
- Shoe is used for running. –> Correct with 0.95 confidence.
- Shoe is not likely to be alive. –> Incorrect with 0.95 confidence.
- Shoe is not usually made of stone. –> Correct with 0.65 confidence.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| WpKG | World-Perceiving Knowledge Graph |
| C-WpKG | Contextual World-Perceiving Knowledge Graph |
| GPT | Generative Pre-Trained Transformer |
| BERT | Bidirectional Encoder Representations from Transformers |
| AI | Artificial Intelligence |
| DPbM | Detection Probability-Based Method |
| ROM | Relative Occurrence Method |
| WOM | Weighted Occurrence Method |
| VG | Visual Genome |
References
- Hwang, J.D.; Bhagavatula, C.; Bras, R.L.; Da, J.; Sakaguchi, K.; Bosselut, A.; Choi, Y. COMET-ATOMIC 2020: On Symbolic and Neural Commonsense Knowledge Graphs. In Proceedings of the AAAI, Virtual Conference, 2–9 February 2021. [Google Scholar]
- West, P.; Bhagavatula, C.; Hessel, J.; Hwang, J.D.; Jiang, L.; Bras, R.L.; Lu, X.; Welleck, S.; Choi, Y. Symbolic knowledge distillation: From general language models to commonsense models. arXiv 2021, arXiv:2110.07178. [Google Scholar]
- LeCun, Y. A Path Towards Autonomous Machine Intelligence Version 0.9.2. Available online: https://openreview.net/pdf?id=BZ5a1r-kVsf (accessed on 27 June 2022).
- Choi, Y. The Curious Case of Commonsense Intelligence. J. Am. Acad. Arts Sci. 2022, 151, 139–155. [Google Scholar] [CrossRef]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the opportunities and risks of foundation models. arXiv 2021, arXiv:2108.07258. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the EMNLP, Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Rezaei, N.; Reformat, M.Z.; Yager, R.R. Image-Based World-perceiving Knowledge Graph (WpKG) with Imprecision. Inf. Process. Manag. Uncertain Knowl. Based Syst. 2020, 1237, 415–428. [Google Scholar]
- Rezaei, N.; Reformat, M.Z.; Yager, R.R. Generating Contextual Weighted Commonsense Knowledge Graphs. In Proceedings of the International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems, Milan, Italy, 11–15 July 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 593–606. [Google Scholar]
- Tang, K.; Niu, Y.; Huang, J.; Shi, J.; Zhang, H. Unbiased Scene Graph Generation From Biased Training. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3713–3722. [Google Scholar]
- McCarthy, J. Formalizing Common Sense; Intellect Books: Bristol, UK, 1990; Volume 5. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-relational Data. In Proceedings of the Advances in Neural Information Processing Systems; Burges, C.J., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2013; Volume 26. [Google Scholar]
- Yang, B.; Yih, W.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; Conference Track Proceedings. Bengio, Y., LeCun, Y., Eds.; 2015. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Wang, C.; Liu, X.; Song, D.X. Language Models are Open Knowledge Graphs. arXiv 2020, arXiv:2010.11967. [Google Scholar]
- Petroni, F.; Rocktäschel, T.; Riedel, S.; Lewis, P.; Bakhtin, A.; Wu, Y.; Miller, A. Language Models as Knowledge Bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 2463–2473. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (Long and Short Papers). Association for Computational Linguistics: Minneapolis, SP, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Zhang, S.; Roller, S.; Goyal, N.; Artetxe, M.; Chen, M.; Chen, S.; Dewan, C.; Diab, M.; Li, X.; Lin, X.V.; et al. Opt: Open pre-trained transformer language models. arXiv 2022, arXiv:2205.01068. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. Palm: Scaling language modeling with pathways. arXiv 2022, arXiv:2204.02311. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Chi, E.; Le, Q.; Zhou, D. Chain of thought prompting elicits reasoning in large language models. arXiv 2022, arXiv:2201.11903. [Google Scholar]
- Rezaei, N.; Reformat, M.Z. Super-Prompting: Utilizing Model-Independent Contextual Data to Reduce Data Annotation Required in Visual Commonsense Tasks. arXiv 2022, arXiv:2204.11922. [Google Scholar]
- Khot, T.; Sabharwal, A.; Clark, P. What’s Missing: A Knowledge Gap Guided Approach for Multi-hop Question Answering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 2814–2828. [Google Scholar]
- Fabbri, A.R.; Ng, P.; Wang, Z.; Nallapati, R.; Xiang, B. Template-Based Question Generation from Retrieved Sentences for Improved Unsupervised Question Answering. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4508–4513. [Google Scholar]
- Jastrzębski, S.; Bahdanau, D.; Hosseini, S.; Noukhovitch, M.; Bengio, Y.; Cheung, J. Commonsense mining as knowledge base completion? A study on the impact of novelty. In Proceedings of the Workshop on Generalization in the Age of Deep Learning, Munich, Germany, 8–14 September 2018; Association for Computational Linguistics: New Orleans, LO, USA, 2018; pp. 8–16. [Google Scholar] [CrossRef]
- Davison, J.; Feldman, J.; Rush, A.M. Commonsense knowledge mining from pretrained models. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 1173–1178. [Google Scholar]
- Chen, X.; Shrivastava, A.; Gupta, A. NEIL: Extracting Visual Knowledge from Web Data. In Proceedings of the IEEE International Conference on Computer Vision 2013, Sydney, Australia, 1–8 December 2013; pp. 1409–1416. [Google Scholar]
- Speer, R.; Chin, J.; Havasi, C. Conceptnet 5.5: An open multilingual graph of general knowledge. In Proceedings of the Thirty-first AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4444–4451. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Zellers, R.; Yatskar, M.; Thomson, S.; Choi, Y. Neural Motifs: Scene Graph Parsing with Global Context. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5831–5840. [Google Scholar]
- Holtzman, A.; Buys, J.; Du, L.; Forbes, M.; Choi, Y. The Curious Case of Neural Text Degeneration. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Hayes, A.F.; Krippendorff, K. Answering the Call for a Standard Reliability Measure for Coding Data. Commun. Methods Meas. 2007, 1, 77–89. [Google Scholar] [CrossRef]
- Li, X.; Taheri, A.; Tu, L.; Gimpel, K. Commonsense Knowledge Base Completion. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; (Volume 1: Long Papers). Association for Computational Linguistics: Berlin, Germany, 2016; pp. 1445–1455. [Google Scholar] [CrossRef]
- Zhang, H.; Khashabi, D.; Song, Y.; Roth, D. TransOMCS: From linguistic graphs to commonsense knowledge. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 4004–4010. [Google Scholar]
- Wang, X.; Wei, J.; Schuurmans, D.; Le, Q.; Chi, E.; Zhou, D. Self-consistency improves chain of thought reasoning in language models. arXiv 2022, arXiv:2203.11171. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SIMPLE_TEMPLATE_A for 〈subject〉 | |
| prompt: | Answer with five items separated with comma. |
| Q: What is 〈relation〉 〈object〉? Name five. | |
| A: elements of Sub | |
| Q: What is 〈relation〉 〈object〉? Name five. | |
| SIMPLE_TEMPLATE_B for 〈object〉 | |
| prompt: | Answer with five items separated with comma. |
| Q: What 〈subject〉 can be 〈relation〉? Name five. | |
| A: elements of Obj | |
| Q: What 〈subject〉 can be 〈relation〉? Name five. |
| user: | Answer with five items separated with comma. |
| Q: What is on building? Name five. | |
| A: letter, door, sign, leaf, light. | |
| Q: What is 〈relation〉 〈object〉? Name five. | |
| where: | relation = on |
| object = { building, sign, man, plate, head } | |
| GPT-3 responses for | |
| building: | subject {letter, door, sign, leaf, light} |
| sign: | subject {words, letters, numbers, shapes, colors} |
| man: | subject {shirt, pants, belt, shoes, socks} |
| plate: | subject {food, drink, utensils, napkin, tablecloth} |
| head: | subject {hair, hat, ear, eyebrow, eyelash } |
| user: | Answer with five items separated with comma. |
| Q: What window can be on? Name five. | |
| A: pole, car, bus, house, tree. | |
| Q: What 〈subject〉 can be 〈relation〉? Name five. | |
| where: | subject = { window, letter, hat, food, hair } |
| relation = on | |
| GPT-3 responses for | |
| window: | object {pole, car, bus, house, tree} |
| letter: | object {A, B, C, D, E } |
| hat: | object {baseball, cowboy, graduation, party, winter} |
| food: | object {apple, banana, orange, pear, grape} |
| hair: | object {head, beard, eyebrows, eyelashes, pubic} |
| FUZZY_TEMPLATE_X for the linguistic term most likely | |
| prompt: | Answer with five items separated with comma. |
| Q: Whatmost likelyhas window? Name five. | |
| A: Window is usually used to see through. Therefore, train, building, house, car, bus. | |
| Q: What number canmost likelybe on? Name five. | |
| A: Number is made of digits and can be written on different things for information. | |
| Therefore, train, sidewalk, track, street, building. | |
| Q: What ismost likely 〈relation〉 〈object〉? Name five. | |
| Q: What does/is 〈subject〉 most likely be/- 〈relation〉? Name five. | |
| FUZZY_TEMPLATE_Y for the linguistic term less likely | |
| prompt: | Answer with five items separated with comma. |
| Q: Whatless likelyhas window? Name five. | |
| A: Window is usually used to see through. Therefore, hat, drawer, vase, basket, box. | |
| Q: What number canless likelybe on? Name five. | |
| A: Number is made of digits and can be written on different things for information. | |
| Therefore, window, people, rock, tree, jacket. | |
| Q: What isless likely 〈relation〉 〈object〉? Name five. | |
| Q: What does/is 〈subject〉 less likely be/- 〈relation〉? Name five. | |
| user: | Answer with five items separated with comma. |
| Q: Whatmost likelyhas window? Name five. | |
| A: Window is usually used to see through. | |
| Therefore, train, building, house, car, bus. | |
| Q: What number canmost likelybe on? Name five. | |
| A: Number is made of digits and can be written on | |
| different things for information. | |
| Therefore, train, sidewalk, track, street, building. | |
| Q: What 〈subject〉 canmost likelybe 〈relation〉? Name five. | |
| where: | subject = { window, letter, hat, food, hair } |
| relation = on | |
| GPT-3 responses for | |
| window: | object {train, building, house, car, bus} |
| letter: | object {train, sidewalk, track, street, building} |
| hat: | object {baseball cap, fedora, beanie, cowboy hat, sun hat} |
| food: | object {apple, banana, orange, grape, strawberry} |
| hair: | object{person, animal, doll, toy, statue} |
| user: | Answer with five items separated with comma. |
| Q: Whatless likelyhas window? Name five. | |
| A: Window is usually used to see through. | |
| Therefore, train, building, house, car, bus. | |
| Q: What number canless likelybe on? Name five. | |
| A: Number is made of digits and can be written on | |
| different things for information. | |
| Therefore, train, sidewalk, track, street, building. | |
| Q: What 〈subject〉 canless likelybe 〈relation〉? Name five. | |
| where: | subject = { window, letter, hat, food, hair } |
| relation = on | |
| GPT-3 responses | |
| window: | object {number, people, rock, tree, jacket} |
| letter: | object {number, people, rock, tree, jacket} |
| hat: | object {window, book, cat, person, wall} |
| food: | object {sink, counter, stove, refrigerator, table} |
| hair: | object {shoulder, leg, foot, arm, hand} |
| user: | Answer with five items separated with comma. |
| Q: Whatmost likelyhas window? Name five. | |
| A: Window is usually used to see through. | |
| Therefore, train, building, house, car, bus. | |
| Q: What number canmost likelybe on? Name five. | |
| A: Number is made of digits and can be written on | |
| different things for information. | |
| Therefore, train, sidewalk, track, street, building. | |
| Q: What is 〈subject〉 most likely 〈relation〉? Name five. | |
| where: | subject = arm |
| relation{used for, made of, has property} | |
| GPT-3 responses for | |
| used for: | object {lifting, carrying, pushing, pulling, holding} |
| made of: | object {human, animal, plastic, metal, wood} |
| has property: | object {to move, to bend, to be strong, to be flexible, to grip} |
| user: | Answer with five items separated with comma. |
| Q: Whatless likelyhas window? Name five. | |
| A: Window is usually used to see through. | |
| Therefore, train, building, house, car, bus. | |
| Q: What number canless likelybe on? Name five. | |
| A: Number is made of digits and can be written on | |
| different things for information. | |
| Therefore, train, sidewalk, track, street, building. | |
| Q: What is 〈subject〉 less likely 〈relation〉? Name five. | |
| where: | subject = arm |
| relation{used for, made of, has property} | |
| GPT-3 responses for | |
| used for: | object {hat, drawer, vase, basket, box} |
| made of: | object {metal, plastic, glass, wood, fabric} |
| has property: | object {number, window, glass, bottle, box} |
| Weighing Schema | Accept | Reject | N/A | Accuracy (%) | Alpha |
|---|---|---|---|---|---|
| DPbM | 560 | 22 | 18 | 93.0 | 0.78 |
| ROM | 526 | 60 | 14 | 87.6 | 0.63 |
| WOM | 538 | 51 | 11 | 89.7 | 0.72 |
| Triple Type | N | Overall Accuracy | Likely Accuracy | Unlikely Accuracy |
|---|---|---|---|---|
| Simple | 122 | 72.95% | N/A | N/A |
| with Linguistic Terms | 287 | 67.94% | 68.09% | 67.81% |
| with New Relations | 148 | 72.97% | 66.22% | 79.73% |
| Simple | with Linguistic Terms | with New Relations |
|---|---|---|
| Q: What is in room? Name five. | Q: What is most likely to be in bowl? Name five. | Q: What is shoe most likely used for? Name five. |
| A: bed, table, chair, lamp, computer. | A: Bowl is a container and can hold different things. Therefore, rice, cereal, milk, soup, fruit. | A: Shoe is used to protect feet. Therefore, running, walking, hiking, climbing, dancing. |
| Q: What does face have? Name five. | Q: Where is flower less likely in? Name five. | Q: What property does sidewalk most likely have? Name five. |
| A: eyes, nose, mouth, ears, chin. | A: Flower is a natural thing and needs soil, water and sunlight to grow. Therefore, sink, oven, book, pencil, phone. | A: Sidewalk is a path for pedestrians. Therefore, it is usually level, made of concrete, has a curb, is smooth, and is wide. |
| Q: What food can be on? Name five. | Q: What hat can most likely be on? Name five. | Q: What property does arm less likely have? Name five. |
| A: apple, banana, orange, pear, grape. | A: Hat is worn on the head and can be made of different materials. Therefore, baseball cap, fedora, beanie, cowboy hat, sun hat. | A: Arm is a body part and usually has skin, muscle, bone, and hair. Therefore, number, window, glass, bottle, box. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rezaei, N.; Reformat, M.Z. Utilizing Language Models to Expand Vision-Based Commonsense Knowledge Graphs. Symmetry 2022, 14, 1715. https://doi.org/10.3390/sym14081715
Rezaei N, Reformat MZ. Utilizing Language Models to Expand Vision-Based Commonsense Knowledge Graphs. Symmetry. 2022; 14(8):1715. https://doi.org/10.3390/sym14081715
Chicago/Turabian StyleRezaei, Navid, and Marek Z. Reformat. 2022. "Utilizing Language Models to Expand Vision-Based Commonsense Knowledge Graphs" Symmetry 14, no. 8: 1715. https://doi.org/10.3390/sym14081715
APA StyleRezaei, N., & Reformat, M. Z. (2022). Utilizing Language Models to Expand Vision-Based Commonsense Knowledge Graphs. Symmetry, 14(8), 1715. https://doi.org/10.3390/sym14081715