
Quality Evaluation Method of Automatic Software Repair Using Syntax Distance Metrics

Abstract
:1. Introduction
2. Related Work
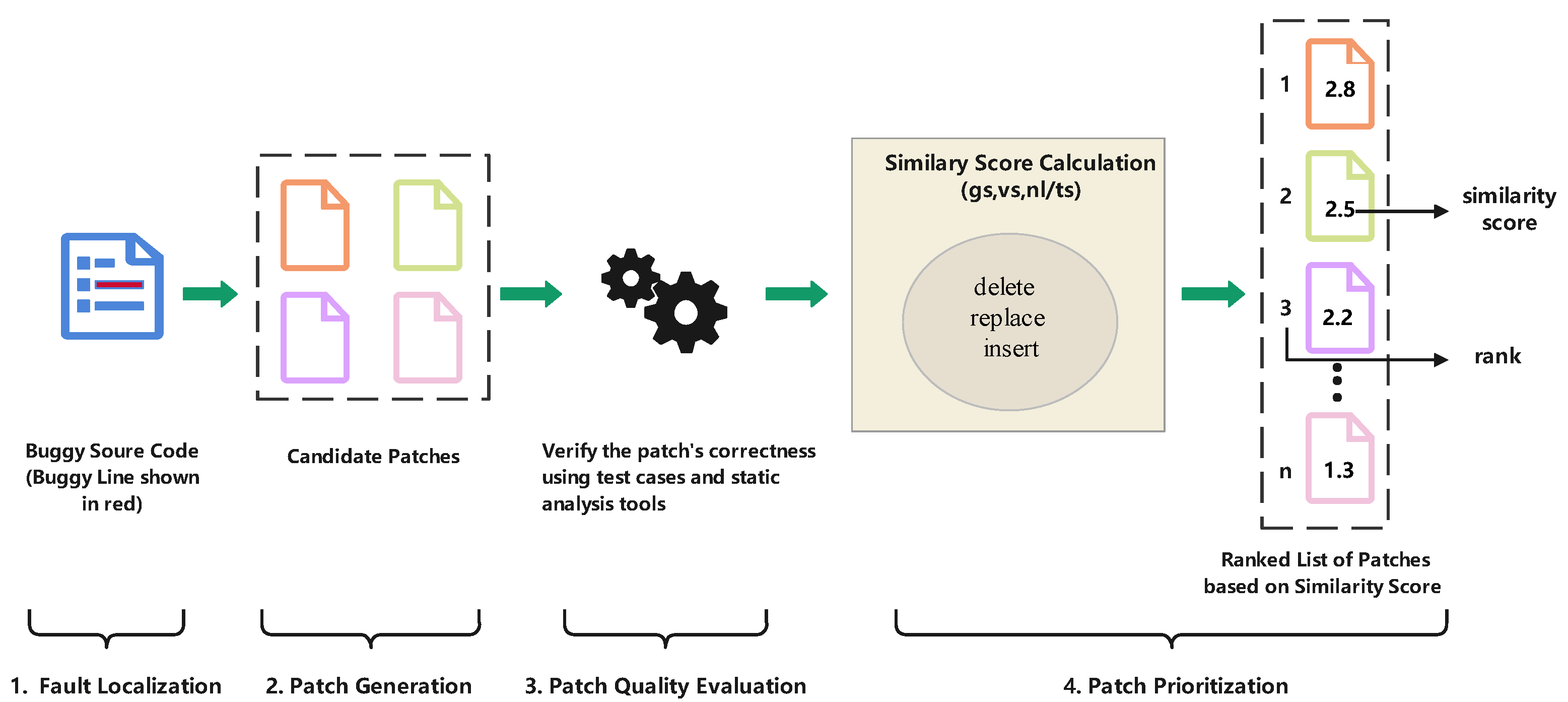
3. Patch Recommendation Based on Syntax Distance
3.1. Variable Similarity
3.2. Expression Similarity
3.3. Structure Similarity
3.4. Repair Location
3.5. The Recommendation Value of the Joint Feature
4. Results
4.1. Ability to Evaluate Real Patches
4.2. Ability to Evaluate Patch Quality by Different Features
4.3. Comparison with Existing Methods
5. Threats to Validity
6. Discussion and Limitations
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nilizadeh, A. Automated Program Repair and Test Overfitting: Measurements and Approaches using Formal Methods. In Proceedings of the 2022 IEEE Conference on Software Testing, Verification and Validation, Valencia, Spain, 4–14 April 2022. [Google Scholar]
- Gao, X.; Wang, B.; Duck, G.J.; Ji, R.; Xiong, Y.; Roychoudhury, A. Beyond tests: Program Vulnerability Repair via Crash Constraint Extraction. In ACM Transactions on Software Engineering and Methodology; Association for Computing Machinery: New York, NY, USA, 2021. [Google Scholar]
- Yi, J.; Ismayilzada, E. Speeding up constraint-based program repair using a search-based technique. Inf. Softw. Technol. 2022, 146, 106865. [Google Scholar] [CrossRef]
- Xiong, Y.; Liu, X.; Zeng, M.; Lu, Z.; Gang, H. Identifying patch correctness in test-based program repair. In Proceedings of the 40th International Conference on Software Engineering, Gothenburg, Sweden, 27 May–3 June 2018. [Google Scholar]
- Xu, T.; Chen, L.; Pei, Y.; Zhang, T.; Pan, M.; Furia, C.A. Restore: Retrospective Fault Localization Enhancing Automated Program Repair. IEEE Trans. Softw. Eng. 2022, 48, 309–326. [Google Scholar] [CrossRef]
- Cao, H.; Liu, F.; Shi, J.; Chu, Y.; Deng, M. Automated Repair of Java Programs with Random Search via Code Similarity. In Proceedings of the IEEE 21st International Conference on Software Quality, Reliability and Security Companion, Haikou, China, 6–10 December 2021. [Google Scholar]
- Kechagia, M.; Mechtaev, S.; Sarro, F.; Harman, M. Evaluating Automatic Program Repair Capabilities to Repair API Misuses. IEEE Trans. Softw. Eng. 2022, 48, 7. [Google Scholar] [CrossRef]
- Goues, C.L.; Pradel, M.; Roychoudhury, A. Automated program repair. Commun. ACM 2019, 62, 56–65. [Google Scholar] [CrossRef]
- Yi, W. Anti-patterns for Java automated program repair tools. In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering, New York, NY, USA, 21–25 December 2020. [Google Scholar]
- Dong, Y.; Zhang, L.; Pang, S.; Yin, W.; Li, H. Automatic repair of semantic defects using restraint mechanisms. Symmetry 2020, 12, 1563. [Google Scholar] [CrossRef]
- Dong, Y.; Wu, M.; Zhang, L.; Yin, W.; Wu, M.; Li, H. Priority Measurement of Patches for Program Repair Based on Semantic Distance. Symmetry 2020, 12, 2102. [Google Scholar] [CrossRef]
- Wen, M.; Chen, J.; Wu, R.; Hao, D.; Cheung, S.C. Context-Aware Patch Generation for Better Automated Program Repair. In Proceedings of the 2018 IEEE/ACM 40th International Conference on Software Engineering, Gothenburg, Sweden, 27 May–3 June 2018. [Google Scholar]
- Al-Bataineh, O.I.; Grishina, A.; Moonen, L. Towards More Reliable Automated Program Repair by Integrating Static Analysis Techniques. In Proceedings of the 2021 IEEE 21st International Conference on Software Quality Reliability and Security, Haikou, China, 6–10 December 2021. [Google Scholar]
- Dong, Y.; Sun, Y.; Wang, X. Automatic Repair Method for Null Pointer Dereferences Guided by Program Dependency Graph. Symmetry 2022, 14, 1555. [Google Scholar] [CrossRef]
- Xuan, J.; Martinez, M.; DeMarco, F.; Clément, M.; Marcote, S.L.; Durieux, T.; Le Berre, D.; Monperrus, M. Nopol: Automatic Repair of Conditional Statement Bugs in Java Programs. IEEE Trans. Softw. Eng. 2017, 43, 34–55. [Google Scholar] [CrossRef]
- Li, D.; Wong, W.E.; Jian, M.; Geng, Y.; Chau, M. Improving Search-Based Automatic Program Repair with Neural Machine Translation. IEEE Access 2022, 10, 51167–51175. [Google Scholar] [CrossRef]
- Nilizadeh, A.; Leavens, G.T.; Le, X.-B.D.; Păsăreanu, C.S.; Cok, D.R. Exploring True Test Overfitting in Dynamic Automated Program Repair using Formal Methods. In Proceedings of the 2021 14th IEEE Conference on Software Testing, Verification and Validation, Porto de Galinhas, Brazil, 12–16 April 2021. [Google Scholar]
- Jiang, J.; Xiong, Y.; Zhang, H.; Gao, Q.; Chen, X. Shaping Program Repair Space with Existing Patches and Similar Code. In Proceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis, Amsterdam, The Netherlands, 16–21 July 2018. [Google Scholar]
- Yuan, Y.; Banzhaf, W. Arja: Automated repair of java programs via multi-objective genetic programming. IEEE Trans. Softw. Eng. 2018, 46, 10. [Google Scholar] [CrossRef]
- Yu, Z.; Martinez, M.; Danglot, B.; Durieux, T.; Monperrus, M. Alleviating patch overfitting with automatic test generation: A study of feasibility and effectiveness for the Nopol repair system. Empir. Softw. Eng. 2019, 24, 33–67. [Google Scholar] [CrossRef]
- Yang, D.; Liu, K.; Kim, D.; Koyuncu, A.; Kim, K.; Tian, H.; Lei, Y.; Mao, X.; Klein, J.; Bissyandé, T. Where were the repair ingredients for Defects4j bugs? Empir. Softw. Eng. 2021, 26, 122. [Google Scholar] [CrossRef]
- Wang, Y.; Gao, F.; Wang, L.; Yu, T.; Zhao, J.; Li, X. Automatic Detection, Validation, and Repair of Race Conditions in Interrupt-Driven Embedded Software. Empir. Softw. Eng. 2022, 48, 346–363. [Google Scholar] [CrossRef]
- Liu, K.; Koyuncu, A.; Kim, D.; Bissyandé, T. TBar: Revisiting template-based automated program repair. In Proceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis, Beijing, China, 15–19 July 2019. [Google Scholar]
- Koyuncu, A.; Liu, K.; Bissyandé, T.; Kim, D.; Klein, J.; Monperrus, M.; Le, T.Y. Fixminer: Mining relevant fix patterns for automated program repair. Empir. Softw. Eng. 2020, 25, 1980–2024. [Google Scholar] [CrossRef]
- Liu, K.; Koyuncu, A.; Kim, D.; Bissyandé, T. Avatar: Fixing semantic bugs with fix patterns of static analysis violations. In Proceedings of the 2019 IEEE 26th International Conference on Software Analysis, Evolution and Reengineering, Hangzhou, China, 24–27 February 2019. [Google Scholar]
- Liu, K.; Koyuncu, A.; Bissyandé, T.; Kim, D.; Klein, J.; Le, T.Y. You cannot fix what you cannot find! an investigation of fault localization bias in benchmarking automated program rep systems. In Proceedings of the 2019 12th IEEE Conference on Software Testing, Validation and Verification (ICST), Xi’an, China, 22–27 April 2019. [Google Scholar]
- Martinez, M.; Monperrus, M. Ultra-large repair search space with automatically mined templates: The Cardumen mode of Astor. In Proceedings of the International Symposium on Search Based Software Engineering, Montpellier, France, 8–10 September 2018. [Google Scholar]
- Yang, G.; Jeong, Y.; Min, K.; Lee, J.-W.; Lee, B. Applying Genetic Programming with Similar Bug Fix Information to Automatic Fault Repair. Symmetry 2018, 10, 92. [Google Scholar] [CrossRef]
- Li, Y.; Wang, S.; Nguyen, T.N. DEAR: A Novel Deep Learning-based Approach for Automated Program Repair. In Proceedings of the 2022 IEEE/ACM 44th International Conference on Software Engineering, Pittsburgh, PA, USA, 25–27 May 2022. [Google Scholar]
- Malyshev, N.; Dudina, I.; Kutz, D.; Novikov, A.; Vartanov, S. SMT Solvers in Application to Static and Dynamic Symbolic Execution. In Proceedings of the 2019 Ivannikov Ispras Open Conference, Moscow, Russia, 5–6 December 2019. [Google Scholar]
- Zhang, J.; Liu, K.; Kim, D.; Li, L.; Liu, Z.; Klein, J.; Bissyandé, T.F. Revisiting Test Cases to Boost Generate-and-Validate Program Repair. In Proceedings of the 2021 IEEE International Conference on Software Maintenance and Evolution, Luxembourg, 27 September–1 October 2021. [Google Scholar]
- Tan, S.H.; Yoshida, H.; Prasad, M.R.; Roychoudhury, A. Anti-patterns in Search-Based Program Repair. In Proceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering, Seattle, WA, USA, 13–18 November 2016. [Google Scholar]
- Asad, M.; Ganguly, K.; Sakib, K. Impact of Combining Syntactic and Semantic Similarities on Patch Prioritization. In Proceedings of the 2019 IEEE International Conference on Software Maintenance and Evolution, Cleveland, OH, USA, 29 September–4 October 2019. [Google Scholar]
- Etemadi, K.; Tarighat, N.; Yadav, S.; Martinez, M.; Monperrus, M. Estimating the potential of program repair search spaces with commit analysis. J. Syst. Softw. 2022, 188, 111263. [Google Scholar] [CrossRef]
- Lin, B.; Wang, S.; Wen, M.; Mao, X. Context-Aware Code Change Embedding for Better Patch Correctness Assessment. ACM Trans. Softw. Eng. Methodol. 2022, 31, 3. [Google Scholar] [CrossRef]
- Durieux, T.; Monperrus, M. IntroClassJava: A Benchmark of 297 Small and Buggy Java Programs. Ph.D. Thesis, Universite Lille 1, Villeneuve-d’Ascq, France, 2016. [Google Scholar]
- Saidani, I.; Ouni, A.; Mkaouer, M.W.; Palomba, F. On the impact of continuous integration on refactoring practice: An exploratory study on travistorrent. Inform. Softw. Tech. 2021, 138, 106618. [Google Scholar] [CrossRef]
- Górski, T. Continuous delivery of blockchain distributed applications. Sensors 2022, 22, 128. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Available Information | Generation and Verification | Semantically-Driven |
|---|---|---|
| No Information | jKali, jGenProg, jMutRepair, ARJA | Nopol, DynaMoth |
| Syntax Information | CapGen, GPSBFI | - |
| Semantic Information | CapGen, SimFix, DTSFix, DEAR | ACS |
| Historical Information | CapGen, SimFix | - |
| Template Information | Tbar, FixMiner, AVATAR, kPar, Cardumen | - |
| Repair Tools | Version Number | Creator | Location |
|---|---|---|---|
| jKali | 2016 | Martinez et al. | Orlando, FL, USA |
| jGenProg | 2016 | Martinez et al. | Orlando, FL, USA |
| jMutRepair | 2016 | Martinez et al. | Orlando, FL, USA |
| ARJA | 2018 | Yuan et al. | East Lansing, MI, USA |
| Nopol | 2017 | Xuan et al. | Wuhan, China |
| DynaMoth | 2016 | Durieux et al. | INRIA, France |
| CapGen | 2018 | Wen et al. | Hong Kong, China |
| SimFix | 2018 | Xiong et al. | Beijing China |
| DTSFix | 2022 | Deng et al. | Qingdao, China |
| ACS | 2017 | Xiong et al. | Beijing, China |
| Tbar | 2019 | Liu et al. | Luxembourg |
| FixMiner | 2020 | Koyuncu et al. | Luxembourg |
| AVATAR | 2019 | Liu et al. | Luxembourg |
| kPar | 2019 | Liu et al. | Luxembourg |
| Cardumen | 2016 | Martinez et al. | Orlando, FL, USA |
| DEAR | 2022 | Li et al. | New Jersey, USA |
| Project | NO | DY | SI | JK | CA | JG | TB | KP | AC | AR | AV | FI | CR | JM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Chart | 1/6 | 1/6 | 4/9 | 0/6 | 5/66 | 0/5 | 7/17 | 3/13 | 2/2 | 1/10 | 5/12 | 5/12 | 2/4 | 1/4 |
| Lang | 3/7 | 1/6 | 5/16 | 0/0 | 9/29 | 0/2 | 6/21 | 1/18 | 3/3 | 0/2 | 4/13 | 0/2 | 0/0 | 0/2 |
| Math | 1/21 | 1/28 | 12/28 | 1/10 | 14/152 | 3/11 | 8/22 | 4/21 | 12/17 | 3/13 | 3/17 | 7/14 | 1/6 | 2/11 |
| Time | 0/1 | 0/5 | 1/2 | 0/2 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/1 | 0/0 | 0/0 |
| Total | 5/35 | 2/50 | 22/55 | 1/18 | 28/247 | 3/18 | 21/60 | 8/52 | 17/22 | 4/25 | 12/42 | 12/29 | 3/10 | 3/17 |
| Precision | 14% | 4% | 40% | 5% | 11% | 17% | 35% | 15% | 77% | 16% | 29% | 41% | 30% | 18% |
| BugID | Rank | Rv | AC | AR | AV | KP | TB | DY | JK | NO | SI | JG | CA | FI | CR | JM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Chart1 | 1 | 0.38 | - | 0/1 | 1/1 | 1/1 | 1/1 | 0/1 | 0/1 | - | 1/1 | - | 1/1 | 1/1 | - | 1/1 |
| Chart4 | 1 | 1.0 | - | - | 1/1 | 1/1 | 1/1 | - | - | - | - | - | - | 1/1 | - | - |
| Chart7 | 2 | 0.33 | - | 0/1 | 0/1 | 0/1 | 0/1 | - | - | - | 1/1 | 0/1 | - | 0/1 | - | 0/1 |
| Chart8 | 1 | 0.75 | - | - | - | - | - | - | - | - | - | - | 1/62 | - | - | - |
| Chart9 | 1 | 0.67 | - | - | - | - | 1/1 | - | - | 0/1 | - | - | - | - | - | - |
| Chart11 | 1 | 0.67 | - | - | 1/1 | - | 1/1 | - | - | - | - | - | 1/1 | 1/1 | 1/1 | - |
| Chart12 | 1 | 1.0 | - | 1/1 | - | 0/1 | 0/1 | - | - | - | 0/1 | - | - | 0/1 | - | - |
| Chart14 | 1 | 1.0 | 1/1 | 0/1 | 0/1 | 0/1 | 0/1 | 0/1 | - | - | - | - | - | 0/1 | - | - |
| Chart19 | 1 | 1.0 | 1/1 | 0/1 | 1/1 | - | 1/1 | - | - | - | - | - | - | 1/1 | - | - |
| Chart20 | 1 | 0.42 | - | - | - | - | 1/1 | - | - | - | 1/1 | - | - | - | - | - |
| Chart24 | 1 | 0.71 | - | - | 1/1 | - | 1/1 | - | - | - | - | - | 1/1 | 1/1 | 1/1 | - |
| Math4 | 1 | 1.0 | 1/1 | - | 1/1 | - | - | - | - | 0/1 | - | - | - | - | - | - |
| Math5 | 1 | 0.5 | 1/1 | - | - | - | 1/1 | - | - | - | - | - | 1/4 | - | - | - |
| Math30 | 1 | 0.33 | - | - | - | - | - | - | - | - | - | - | 1/1 | 1/1 | - | - |
| Math33 | 1 | 0.8 | - | - | - | - | - | - | - | 0/1 | - | - | 1/1 | - | - | - |
| Math35 | 1 | 1.0 | 1/1 | 1/1 | - | - | - | - | - | - | - | - | - | - | - | - |
| Math41 | 1 | 1.0 | - | - | - | - | - | - | 0/1 | 0/1 | 1/1 | - | - | - | - | - |
| Math50 | 2 | 0.5 | - | 0/1 | 0/1 | 0/1 | 0/1 | 1/1 | 1/1 | - | - | 0/1 | - | 0/1 | - | 0/1 |
| Math53 | 1 | 1.0 | - | - | - | - | - | - | - | - | 1/1 | 1/1 | 2/2 | - | - | - |
| Math57 | 1 | 1.0 | - | - | 0/1 | - | 1/1 | - | - | - | 1/1 | - | 1/1 | 1/1 | - | 0/1 |
| Math58 | 1 | 1.0 | - | 1/1 | - | 1/1 | - | 0/1 | - | - | - | - | 1/1 | 1/1 | 1/1 | - |
| Math59 | 1 | 1.0 | - | - | 1/1 | - | - | - | - | - | 1/1 | - | 1/1 | - | - | - |
| Math63 | 1 | 0.67 | - | - | - | 0/1 | 0/1 | - | - | - | 0/1 | - | 1/9 | 0/1 | 0/1 | - |
| Math65 | 1 | 1.0 | - | - | - | - | 1/1 | - | - | - | - | - | 1/1 | - | - | - |
| Math70 | 1 | 0.67 | - | - | - | 1/1 | 1/1 | - | - | - | 1/1 | 1/1 | 1/1 | - | - | - |
| Math71 | 1 | 0.67 | - | - | - | - | - | 0/1 | - | - | 1/1 | - | - | - | - | - |
| Math75 | 1 | 1.0 | - | - | - | 1/1 | 1/1 | - | - | 1/1 | 1/1 | 1/1 | 1/1 | 1/1 | - | |
| Math79 | 1 | 1.0 | - | - | 1/1 | - | 1/1 | - | - | - | - | - | 1/1 | 1/1 | 1/1 | - |
| Math80 | 1 | 1.0 | - | 0/1 | 0/1 | 0/1 | 0/1 | 0/1 | - | 0/1 | 0/1 | 0/1 | 1/125 | 0/1 | - | 1/1 |
| Math85 | 1 | 0.41 | 1/1 | 0/1 | - | - | 0/1 | 0/1 | - | - | 0/1 | 0/1 | 1/4 | 0/1 | 0/1 | 1/1 |
| Math89 | 1 | 0.15 | 1/1 | - | 1/1 | 1/1 | 1/1 | - | - | - | - | - | - | - | - | - |
| Lang6 | 1 | 0.38 | - | - | 1/1 | - | - | - | - | - | - | - | 1/1 | - | - | - |
| Lang7 | 1 | 1.0 | - | - | 1/1 | - | 1/1 | - | - | - | - | - | 1/1 | 1/1 | 1/1 | - |
| Lang10 | 1 | 0.5 | - | - | 0/1 | 0/1 | 1/1 | - | 1/1 | - | 0/1 | - | - | - | - | - |
| Lang24 | 1 | 1.0 | 1/1 | - | - | 0/1 | 0/1 | - | - | - | - | - | - | - | - | - |
| Lang33 | 1 | 1.0 | - | - | - | - | 1/1 | - | - | - | 1/1 | - | - | - | - | - |
| Lang39 | 1 | 1.0 | - | - | 0/1 | - | 0/1 | - | - | - | 1/1 | - | - | - | - | - |
| Lang43 | 1 | 1.0 | - | - | - | 0/1 | 0/1 | - | - | - | - | 1/1 | - | - | - | - |
| Lang57 | 1 | 0.33 | - | - | 1/1 | 0/1 | 1/1 | - | - | - | - | - | 3/3 | - | - | 1/1 |
| Lang58 | 1 | 0.5 | - | - | 0/1 | 0/1 | 0/1 | - | - | - | - | - | 0/1 | 1/1 | - | - |
| Lang59 | 1 | 0.8 | - | - | 0/1 | 0/1 | 1/1 | - | - | - | - | - | 1/20 | - | - | 1/1 |
| Lang60 | 1 | 0.75 | - | - | - | - | 0/1 | - | - | - | 1/1 | - | - | - | 1/1 | - |
| Bug ID | Plausible | CapGen Rank | PPSD Rank | SSDM Rank |
|---|---|---|---|---|
| Chart1 | 10 | 1 | 1 | 2 |
| Chart7 | 8 | 2 | 2 | 2 |
| Chart14 | 7 | 4 | 1 | 7 |
| Chart19 | 5 | 2 | 1 | 2 |
| Math50 | 9 | 2 | 2 | 3 |
| Math63 | 14 | 1 | 1 | 3 |
| Math73 | 3 | 3 | 1 | 2 |
| Math80 | 135 | 3 | 1 | 1 |
| Math82 | 4 | 2 | 1 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, Y.; Tang, D.; Cheng, X.; Yang, Y. Quality Evaluation Method of Automatic Software Repair Using Syntax Distance Metrics. Symmetry 2022, 14, 1751. https://doi.org/10.3390/sym14081751
Dong Y, Tang D, Cheng X, Yang Y. Quality Evaluation Method of Automatic Software Repair Using Syntax Distance Metrics. Symmetry. 2022; 14(8):1751. https://doi.org/10.3390/sym14081751
Chicago/Turabian StyleDong, Yukun, Daolong Tang, Xiaotong Cheng, and Yufei Yang. 2022. "Quality Evaluation Method of Automatic Software Repair Using Syntax Distance Metrics" Symmetry 14, no. 8: 1751. https://doi.org/10.3390/sym14081751
APA StyleDong, Y., Tang, D., Cheng, X., & Yang, Y. (2022). Quality Evaluation Method of Automatic Software Repair Using Syntax Distance Metrics. Symmetry, 14(8), 1751. https://doi.org/10.3390/sym14081751