1. Introduction
The growing need for clean energy around the world may be partially met by photovoltaic (PV) power, a renewable, safe, and adaptable distributed energy supply [
1]. Over the past few decades, PV power has drawn more attention [
2]; its integration has had substantial positive effects on the economy and the environment. Due to its erratic and intermittent nature, significant PV penetration, however, also poses a number of new difficulties for the operation of current grid systems [
3]. These difficulties include intermittent power generation, high installation costs, and the PV power supply’s vulnerability to weather conditions [
4]. Forecasting PV electricity is an effective way to deal with these difficulties. For large-scale PV penetration in the primary power grid, precise forecasting of PV energy generation is acknowledged as a requirement [
5]. The approaches of forecasting PV power can be categorized into three groups depending on the forecasting time horizon: long-term PV power forecasting (LTPVF), middle-term PV power forecasting (MTPVF), and short-term PV power forecasting (STPVF). Short-term forecasting is the process of predicting the amount of PV power that will be produced over the next hour, several hours, day, or even seven days. Forecasting for medium-term PV electricity is performed over periods of time longer than a week to a month. The long-term forecasts of PV power generation range from one month to one year.
Many studies have been conducted recently that go in-depth on the subject of short-term photovoltaic power forecasting (STPVF). The traditional statistical method, e.g., the Autoregressive Integrated Moving Average (ARIMA) was previously employed as the initial STPVF attempt. Support vector machine (SVM), Gaussian process regression (GPR) and extreme learning machine (ELM) are three conventional machine learning (ML) models that are used frequently in STPVF. However, in the STPVF challenge with complex and lengthy data, these techniques perform poorly. The dependable forecasting performance needed for the construction of reliable PV energy systems cannot be attained by standard methodologies for PV energy prediction. Deep learning (DL) techniques based on neural networks are significantly more favored than typical statistical approaches and machine learning techniques for understanding the long-term patterns of PV power data. Recently, both STPVF situations have used a variety of deep learning neural networks, including recurrent neural network (RNN), gated recurrent units (GRU), long short-term memory (LSTM), convolutional neural network (CNN) and transformer-based models. Deep learning approaches have been used to make some progress, although these techniques still have major drawbacks. As an illustration, consider single-step forecasting, sophisticated computing, and significant memory costs.
Furthermore, it was commonly acknowledged in earlier studies to use a decomposition technique or stationarization to pre-process time series for nonstationary and nonlinear signals. This can make the raw time series less complex and non-stationary, which will increase prediction accuracy and provide deep models a more stable data distribution. Decomposition and stationarization are typically used to pre-process historical data before projecting future series for forecasting activities. However, this pre-processing is constrained by the simple decomposition impact of historical series and ignores the series’ long-term hierarchical interaction with its underlying patterns. Wu et al. suggested Autoformer as an alternative to transformers for long-term time series prediction based on the concept of decomposition [
6]. The Autoformer model is enabled to split the information about long-term trends of anticipated hidden series gradually by embedding deconstruction blocks as the internal operators. The inherent non-stationarity of real-world time series, however, also serves as useful guidance for identifying temporal connections for forecasting. For predicting real-world burst events, the stationarized series that lacks inherent non-stationarity may be less useful.
In response to the above-mentioned drawbacks, we propose a novel Autoformer model with de-stationary attention and multi-scale framework (ADAMS) for the research of STPVF. The forecast modeling of PV power data is performed for capturing and understanding the symmetry inherent and non-stationarity in data patterns by the ADAMS model and employing it in order to predict future PV power data. On the Yulara datasets, where the PV power data is taken from DKASC, which is located at the Desert Knowledge Precinct in Central Australia, the performance of the proposed model is validated. Large random variations and non-stationary data patterns are present in this data. Therefore, it is essential to be able to recover the fluctuation curves while assessing the performance of models. ADAMS performs satisfactorily in the experiment while forecasting fluctuation curves. Additionally, the suggested ADAMS has reduced compute complexity and memory cost to 0(L logL), and it can perform several steps of predicting. The primary innovations and novelties in this paper are as follows:
An improved ADAMS model is proposed for STPVF. The extra multi-scale framework and de-stationary attention is added to the Autoformer model. According to the results, the ADAMS is contributing to extract features more deeply and handle complicated, non-stationary data, which lowers forecasting error.
Some additional methods are used as the baselines to test the efficacy of the ADAMS that is proposed. Autoformer, Informer, Transformer, LSTM, GRU, and RNN are all used in this paper. They are utilized for short-term PV power forecast with prediction lengths of 4 to 24. The MSE, MAE, RMSE, and adjusted R-squared were employed as evaluation measures for accuracy.
More tests with a temporal resolution of one hour were conducted to further demonstrate the usefulness of the proposed ADAMS. According to expectations, the suggested ADAMS model achieves the best performance across all experimental forecasting models when compared to earlier projects, giving strong evidence that the suggested model works.
The remainder of this research is organized as follows: the second section gives a detailed summary of previous work relevant to STPVF. The third section introduces thoroughly the suggested ADAMS neural network. Next, the fourth section illustrates the experimental preparation and framework. The fifth section contains the STPVF experiment using ADAMS and the analysis of the result. Finally, the sixth section sums up this study.
2. Related Work
Time series statistical analysis known as ARIMA is commonly employed in forecasting. Numerous academics have assessed the model in various forecasting applications. While the forecasting accuracy increased as the forecasting horizon was expanded, ARIMA has performed poorly in long-term time series. Because the long-term data has a lot of high-dimension hidden features, there are not enough parameters in ARIMA, which prevents it from fitting these long-term data.
Machine learning techniques have recently been suggested for forecasting PV power. Traditional techniques of machine learning, such as SVM, are frequently suggested for predicting PV power. In a study they released in 2020, Pan et al. shown that using SVM for the very short-term prediction is feasible and using ant colony optimization to determine the best parameters of this model [
7]. For the purpose of anticipating hourly PV power generation, Zhou et al. used the ELM to model the input features, a genetic algorithm to optimize the relevant parameters of their forecasting model [
8]. They also adopted a customized similar day analysis based on five meteorological components.
Despite the widespread use of ML techniques, there are still a number of significant drawbacks, including the following: (1) they heavily depend on the quality of the feature engineering used; (2) they are unable to deal with complex feature scenarios with high irregularity; and (3) they exhibit unstable predictive power, making them inappropriate as a component for the reliable decision making required for any power system. They are unsuitable as a part of the trustworthy decision-making required for any power system since they have unstable forecasting ability, strongly depend on the level of the feature engineering employed, and are unable to handle complicated feature situations with high irregularity. Consequently, to provide more accurate predictions, ML algorithms are frequently integrated with other methods.
Recurrent networks are effective in simulating dependencies in sequential data, as shown in recent DL literature. Because of its ability to extract hidden information during graph processing using the convolution principle, CNN has received a lot of attention in the field of computer vision (CV). A growing number of studies have been published on hybrid CNN models for PV power forecasting in order to adapt to time-series forecasting applications. A CNN-BiGRU hybrid technique was suggested in one study by Zhang et al. to anticipate PV power for a PV power facility in Korea range [
9]. Zang et al. used a hybrid method based on CNN to precisely predict how much energy a short-term photovoltaic system would produce [
10]. The training time series must be brief due to the convolution calculation’s high computing complexity, and a lack of data could result in a major overfitting issue. In natural language processing, RNN and its unique variant, LSTM, which is built with a memory cell architecture to record essential information, have been frequently proposed. The LSTM and RNN techniques have been suggested in prior studies for STPVF. For instance, Gao et al. proposed a day-ahead power output time-series forecasting methods based on LSTM, in which ideal weather type and non-ideal weather types have been separately discussed [
11].
Thanks to its capability to manage long-term interdependence without disappearing gradient, LSTM has been widely used. However, location information and long-term correlations are frequently present in energy time series, therefore the LSTM is unable to acquire a major amount of input properties that can have a considerable impact on prediction performance. Additionally, because of the restricted computer memory, both LSTM and RNN approaches can only predict one timestep forward, which takes more time if the aim is to provide the prediction of multiple timesteps ahead. This difficulty is caused by the enormous memory occupation. However, error accumulation, the fatal flaw in single-step forecasting, significantly enhanced the unreliability of forecasting multiple timesteps in advance.
In 2017, the Transformer model, which is well-known for its self-attention mechanism, was suggested and is currently being employed in the field of NLP [
12]. The self-attention mechanisms and the enhanced later version, which have replaced the conventional memory block in LSTM and the initial attention mechanism, have produced more accuracy in longer language comprehension. Some academics think it might increase the capacity for prediction. However, it cannot be directly implemented to time series forecasting because of the high computation time, large memory utilization, and abrupt decline in forecasting rate. Many academics have worked hard and provided numerous solutions to these problems. The sparse decomposition of the attention matrix is considered in Ref. [
13]. The logsparse Transformer is proposed in Ref. [
14], which adds a convolutional self-attention mechanism. Longformer, a linear expansion of the attention mechanism with series length, is introduced in Ref. [
15]. The complication of the entire self-attention in time and space is reduced by a novel self-attention mechanism in Ref. [
16]. An improved version of Transformer called Informer, which has been tried on four sizable data sets, is established in Ref. [
17]. It offers an alternative answer to the time series prediction issue. However, rather than concentrating on a section of the time series, all of these approaches with better self-attention only do so for an individual historical period. Due to the exceedingly small attention horizon, the single self-attention worked quite badly when the training data had significant variations.
Wu et al. used an enhanced self-attention method called auto-correlation in a work they released in 2021 in which they took advantage of a decomposition architecture [
6]. The NBEATS model and high accuracy on the power price dataset were achieved by Oreshkin and his colleagues, who also introduced the canonical decomposition architecture [
18]. The input dimension does, however, have a limit on the original NBEATS. With the use of an auto-correlation mechanism and a decomposition block, Autoformer built on the concept of temporal decomposition [
19]. Additionally, Autoformer forecasts very long future data in a single computing step, which takes much less time. In light of the fact that the Autoformer model obtains high accuracy on numerous datasets but has not been used for the STPVF job, this research suggests an ADAMS model that will eventually produce a favorable forecasting accuracy for the STPVF.
3. ADAMS Network Architecture
The goal of PV power forecasting is to estimate future length Lpred from historical length Lseq. For multi-step forecasting, a new ADAMS is suggested in this paper. The complexity and non-stationarity of data and the calculation efficiency are the two key difficulties in PV power forecasting, as mentioned previously. To solve these problems:
In addition to replacing the conventional self-attention mechanism, the auto-correlation mechanism serves to identify temporally dependent trends in large historical data sets.
The de-stationary module is incorporated to the auto-correlation mechanism to acquire hidden characteristics from the non-stationary time series data. In this way, the model can not only retain the important information of the original sequence, but also eliminate the non-stationarity of the original data.
A projected time series is refined iteratively at many scales with shared weights using the multi-scale framework, introducing changes to the architecture and a normalization method that was especially created to produce considerable speed increases with little additional computational effort.
3.1. Decomposition Architecture
To break down complex time patterns into more predictable parts, a deep decomposition architecture [
6] with embedded sequence decomposition is introduced.
3.1.1. Series Decomposition Block
One of the most crucial techniques for time series forecasting is decomposition, which can divide the series into trend-cyclical and seasonal components, to learn about complicated temporal information in the context of long-term forecasting. These two sections each depict the series’ long-term development and seasonality. However, since the future is simply uncertain, direct decomposition is not feasible for next series. We introduce a series decomposing block as an internal operation of model to address this conundrum. This block can gradually recover the long-term stable trend from projected intermediary hidden factors. To put it more specifically, we modify the moving average to eliminate cyclical variations and emphasize long-term trends. The procedure is as follows for length
input series
:
where, respectively,
indicate the seasonal and trend-cyclical components that were extracted. To maintain the same series length, we use the
moving average with the padding procedure. To summarize the aforementioned equations, which is a model inner block, we utilize:
3.1.2. Model Inputs
The past
time steps
serve as the encoder part’s inputs. The seasonal part is denoted as
.
stand for the trend-cyclical part. In order to be refined,
and
are both present in the input of the ADAMS model decoder. Each initialization has two components: a placeholder with length
filled with scalars, and a component deconstructed from the second half
, with length
to supply late information.
is the input of the encoder. It is expressed as follows:
where
, respectively, represent the cyclical and seasonal elements of
, and
, respectively, stand for the blank spaces filled with
and the average of
.
3.1.3. Encoder
The encoder concentrates on the seasonal component modeling. Past seasonal data from the encoder’s output will be used as cross information to help the decoder improve forecast outcomes. Let us say there are
encoder layers. The summary equations for the
-th encoder layer are
. Details are shown as follows:
where “_” denotes the portion of the trend that was deleted. The output of the
-th encoder layer is indicated by
.
is the embedded
. The seasonal component is represented as
after the
-th series decomposition block in the
-th layer, respectively.
3.1.4. Decoder
The accumulating architecture for trend-cyclical elements and the layered auto-correlation technique for seasonal elements are both included in the decoder. The internal auto-correlation and encoder-decoder auto-correlation found in each decoder layer allow for the improvement of prediction and use of historical seasonal data, respectively. It should be noted that the architecture collects the prospective trend from the intermediary hidden variables throughout the decoder, enabling the model to gradually improve the trend forecasting and remove disturbance information for the discovery of addictions based on the period in the auto-correlation. Assume there are
layers in the decoder. The equations of the
-th decoder layer can be condensed as
using the potential variable
from the encoder. It is possible to formalize the decoder as follows:
where the output of the
-th decoder layer is indicated by
. The
-th sequence decomposition in the
-th layer is represented by
, which stand for seasonal factors and periodic factors, respectively. The projector for the
-th extracted trend
is represented by
.
3.2. Auto-Correlation Mechanism
For the purpose of realizing series-wise connections and making better use of the information in the sequence, the auto-correlation technique [
6] is added to substitute the attention method of point-to-point connections. In this module, based on the theory of random process, the self-attention mechanism of point-wise connection is discarded, and the auto-correlation technique of series-wise connection is realized, which has complexity and breaks the bottleneck of information utilization.
3.2.1. Period-Based Dependencies
The similar phasing points across eras is seen to actually produce identical sub-processes. For a real separate-time series
, we can use the following equations to derive the autocorrelation, which can be expressed as:
The resemblance between and lag series is reflected by . We utilize the autocorrelation as the unnormalized confidence of the anticipated period length. After the calculation process, the largest feasible range of period lengths are selected. The aforementioned estimated periods are used to construct the period-based dependencies, which can then be weighted using the relevant autocorrelation.
3.2.2. Time Delay Aggregation
The sub-series are connected between estimated periods by the period-based dependencies. In order to roll the series based on a chosen time lag of , we therefore provide the time delay aggregation block. In contrast to the point-wise dot-product aggregation in the self-attention mechanism, this process can line up same sub-series that are in the similar phasing point of predicted periods. The sub-series is then combined using softmax normalized confidences.
We receive query
, key
, and value
for the alone head scenario and series
with length-
after the projection process. It can thus easily take the role of self-attention. The process of auto-correlation is presented as below:
where,
is a hyper-parameter. Let
, and
is to obtain the arguments of the
autocorrelations. The series
and
have an autocorrelation called
. The process to
with time lag is represented by
. It causes components that have been moved past the first position to be reintroduced at the last position.
,
are from the encoder
and will be scaled to length-
, and
is from the previous block of the decoder for the encoder-decoder auto-correlation.
For the multi-head version adopted in this paper, with
channels,
heads, and the
-th head’s query, key, and value denoted as
individually. The multi-head auto-correlation are calculated as:
3.2.3. Efficient Computation
Period-based dependencies are intrinsically sparse and point to sub-processes that are in the similia phasing place as the parent period. In this case, we choose the longest delays in order to avoid choosing the opposite phases. Equations (7) and (8) have an
complexity due to the fact that we aggregate series with length
. Based on the Wiener-Khinchin theorem, when the time series
are given,
can be determined using Fast Fourier-Transforms for the autocorrelation computation (Equation (6)).
where
is the FFT’s inverse and
,
stands for the FFT.
is in the frequency domain, and “∗” denotes the conjugate operation. It should be noted that the FFT may calculate the series autocorrelation of all lags in
at once. Auto-correlation achieves
complexity as a result.
3.3. Multi-Scale Framework
For accurate time series prediction, it is necessary to introduce structural prior considering multi-scale information. Autoformer introduced some emphasis on scale-awareness by mandating separate computational routes for the trend and seasonal components of the input time series. However, this structural prior only concentrated on two scales: low-frequency and high-frequency components. A multi-scale framework [
20] with a cross-scale normalizing mechanism was created in order to detect the timing dependent patterns in long history data and to substitute for the conventional self-attention method in light of their significance to forecasting. We present an original iterative scale-refinement paradigm that is easily adaptable to various transformer-based time series forecasting architectures. At the same time, we apply cross-scale normalization to the transformer’s outputs to reduce distribution shifts between scales and windows.
We repeatedly apply the same neural module at various temporal scales given an input time-series
. The initial look-back window
is fed into the encoder at
-th step
after being scaled down by a factor of
using an average pooling operation. On the other hand, a linear interpolation is used to upsample the input to the decoder
by a factor of
. The array of
is used to initialize the variable
. The model carries out the following tasks:
where
and
are the look-back and horizon windows at the
-th step at time
, respectively. We may define
and
as the inputs to the normalization if we assume that
is the output of the forecasting module at step
and time
:
Finally, we calculate the error between and as the loss function to train the model.
We normalize each input series based on the temporal average of
and
for a set of input series
with dimensions
and
, respectively, for the encoder and the decoder of the transformer in step
-th.
where
is the average over the temporal dimension of the concatenation of both look-back window and the horizon.
In keeping with earlier research, we embed our input so that it has the same quantity of features as the hidden dimension of model. There are three components to the embedding: (1) value embedding, which employs a linear layer to translate each step’s input observations
to the model’s dimensionality. To further indicate whether an observation is originating from the look-back window, zero initialization, or the prediction of the prior stages, we concatenate a further value of
, respectively. (2) Temporal embedding, which once more embeds the time stamp associated with each observation into the model’s hidden dimension via a linear layer. Before transferring the network to the linear layer, we concatenate an additional value of 1/
as the current scale for the network. (3) In addition, we employ a fixed positional embedding that is customized for each scale
as follows:
3.4. De-Stationary Attention
Simply weakening non-stationarity may lead to excessive stationarity, and this paper examines photovoltaic power generation power prediction from the perspective of stationarity. We introduce an attention module [
21] with de-stationarity to smooth out the time series and update internal mechanisms to re-incorporate non-stationary information. In this way, the model can not only learn on the normalized sequence, but also allow the model to find specific time dependencies based on the complete sequence information before the stationary. The module consists of two parts: time series non-stationarity is reduced through series stationarization, and non-stationary data from raw series is reincorporated with de-stationary attention. These designs enable forecasting model to concurrently enhance data predictability and maintain model capacity.
In order to reduce the non-stationarity of each input sequence, a simple and effective stabilization method is adopted for the original input sequence. For each input sequence, the mean and variance of the input sequence are used to transform it into a Gaussian distribution with
and
, so as to eliminate the difference of time series statistics in different time windows:
where the element-wise division is denoted by
, and the element-wise product is denoted by
. The distribution of the model’s input becomes more stable as a result of the normalization module’s reduction of the distributional difference among each input time series.
After using the basic model to predict the future value, the output results of the model are reversely processed by adopting the mean and variance to obtain the final prediction result
. The denormalization module can be expressed as follows:
where
denotes the base mode predicting the future value with length-
and
is its output.
Through the transformation of the above two stages, the input of stabilized data can be obtained from the basic model, which follows a stable distribution and is easier to generalize. This approach also renders the model equivariant to time series translational and scaling perturbations, which is advantageous for predicting the photovoltaic power sequence.
The non-stationarity of the original series cannot be fully recovered merely by de-normalization, even while the statistics of each time series are expressly returned to the appropriate prediction. The model is more likely to provide outputs that are overly stationary and erratic, which is inconsistent with the original series’ inherent non-stationarity. We present a unique de-stationary attention technique that may approximate the attention that is received without stationarization and identify the specific temporal correlations from original non-stationary data in order to address the over-stationarization issue produced by series stationarization.
In order to learn de-stationary factors from the statistics of each unstationarized
independently, we use a multi-layer perceptron as the projector. The following formula is used to calculate de-stationary attention:
where
denote de-stationary factors, the input of MLP is the time series before the original smoothing. Therefore, the de-stationary attention technique learns time dependence from stationary and non-stationary sequences. While retaining the innate temporal dependency of the original sequences, it can profit from the predictability of stationary sequences.
3.5. Adaptive Loss Function
Time-series forecasting models become more susceptible to outliers when they are trained using the typical MSE aim. Using targets that are more resistant to outliers, e.g., the Huber loss [
22], is one potential option. However, such targets typically perform poorly when there are no significant outliers. Because the data are diverse, we instead use the adaptive loss [
23]:
4. Experimental Preparation and Framework
In this section, we describe how we set up our evaluation framework: the data used, the choices of baseline model to be compared and their parameter settings, data preprocessing, and the error metrics applied.
4.1. Experimental Input Data
The Desert Knowledge Australia Solar Center (DKASC) in Alice Springs, Australia, provided the historic PV energy data used in this study. This information can be freely accessed at [
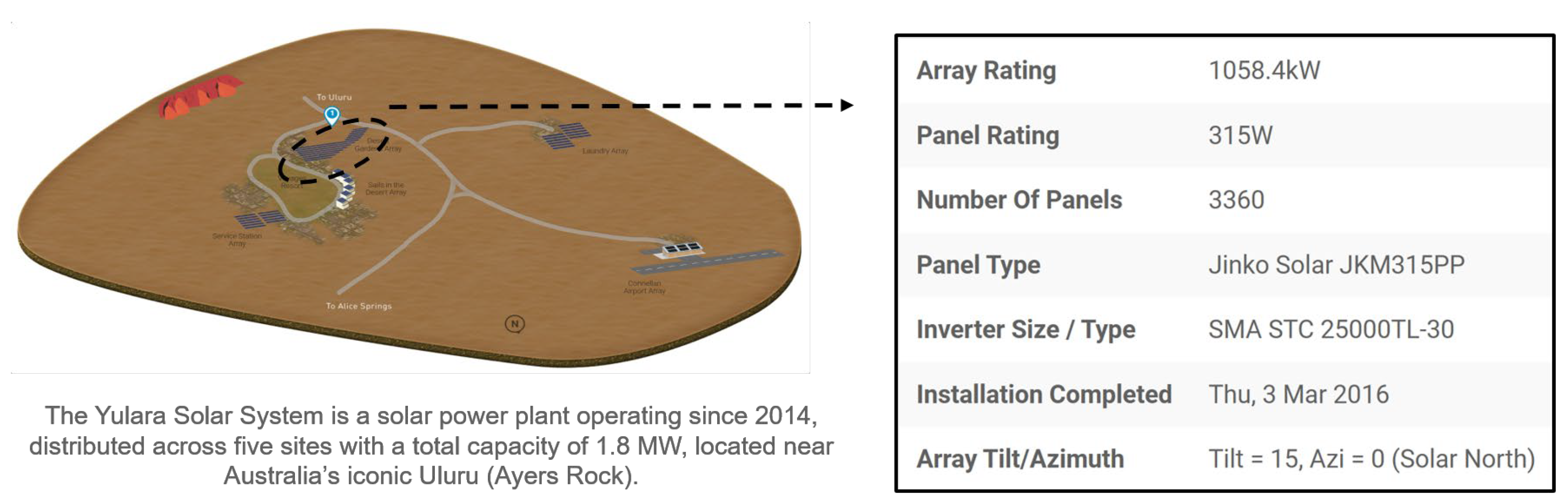
24] and is part of a public dataset. The Alice Springs, Yulara, and NT solar power plants are part of the DKASC center. A solar power facility made up of five sites plus a weather station is called the Yulara Solar System. Therefore, the data is selected from No.1 (1058.4 kW, poly-Si, Fixed, 2016, Desert Gardens) at Yulara Solar System in this study. Its location is shown in
Figure 1.
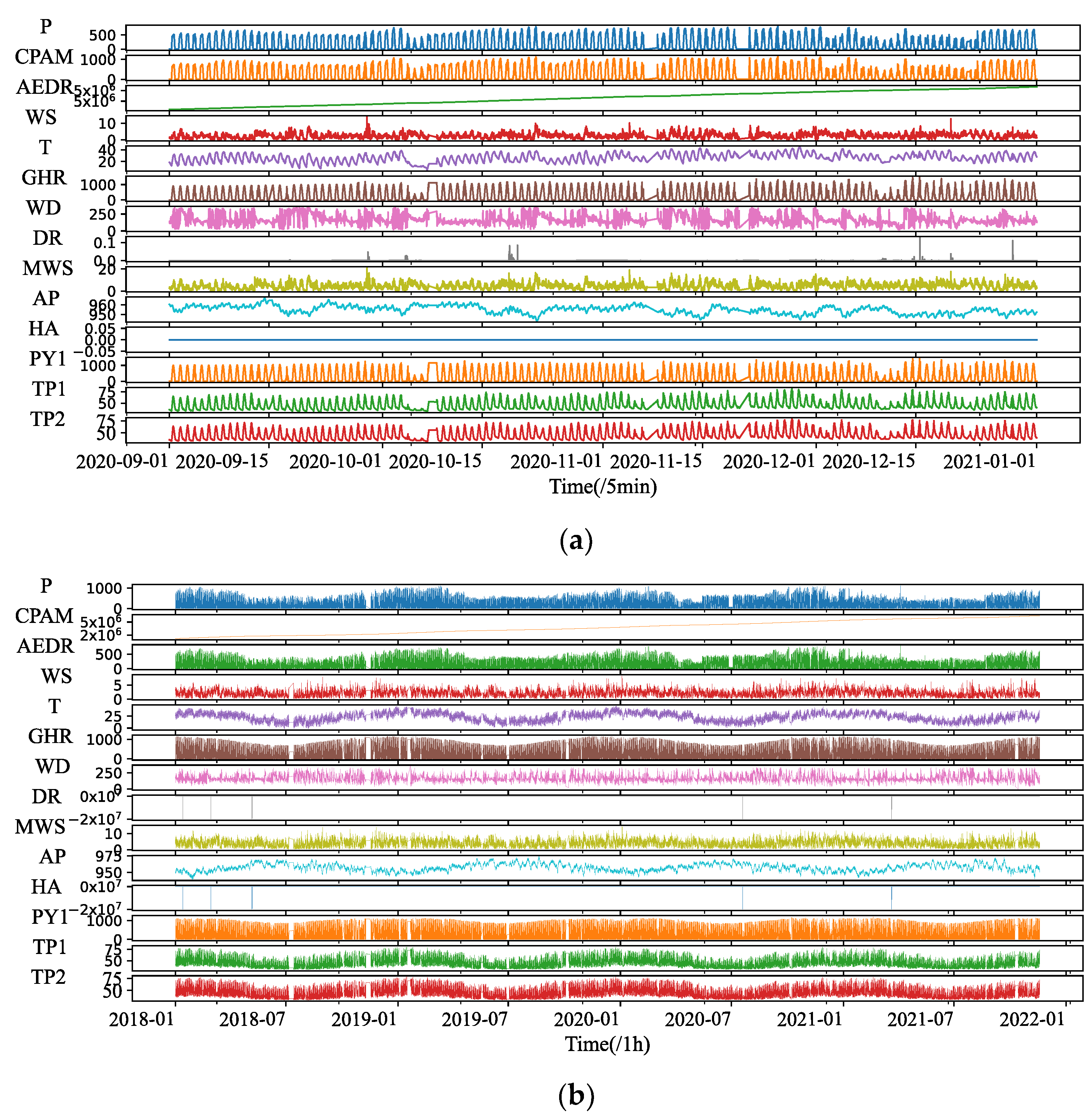
The total installed capacity of the PV system is 1058.4 kW, and both the historical power data and the weather data have a 5 min time precision. The historical data set includes Active Power (P), Wind Speed (WS), Wind Direction (WD), Weather Temperature Celsius (T), Weather Daily Rainfall (DR), Global Horizontal Radiation (GHR), Max Wind Speed (MWS), Air Pressure (AP), Hail Accumulation (HA), Pyranometer 1(PY1), Temperature Probe 1 and 2 (TP1&TP2).
We use two datasets for the proposed models to learn, including the 4 months power data with a resolution of 5 min, from 1 September 2020 to 31 December 2020, a total of 34,080 samples, and the 4 years PV power data with a resolution of 1 h, from 2017 to 2020, a total of 33,740 samples.
Figure 2 displays the historic PV time series of two datasets, where the label of the vertical axis is the abbreviation of all variable names in the data set, and the horizontal axis represents the length of the time step of the data set.
4.2. Experimental Framework
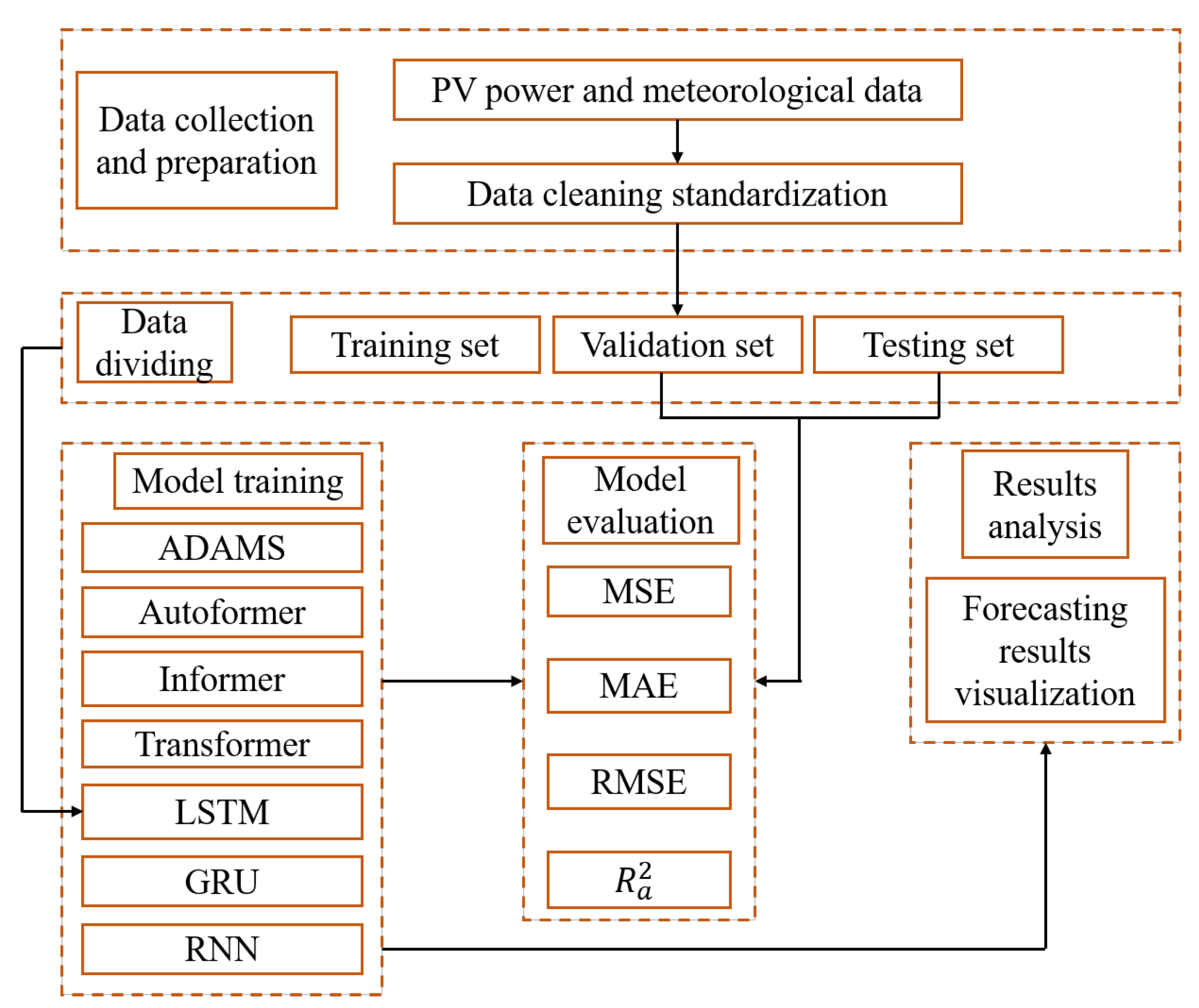
ADAMS and six other experimental competitive models are suggested in this work. Autoformer, Informer, Transformer, LSTM, GRU, and RNN are the baseline models. Data collection, data preparation, data dividing, model training, model evaluation, and results analysis are all included in the fundamental building blocks of STPVF.
Figure 3 depicts the entire experimental flow diagram, and
Table 1 includes a list of the parameter settings for models like the ADAMS.
4.3. Data Pre-Processing
The initial step of study involves the collection and pre-processing of data. The data needs to be preprocessed to ensure the performance of our model. Due to maintenance issues or device failure, there are occasional cases where data is missing. The chosen datasets are then processed by deleting any negative numbers for electricity generation and interpolating any existing missing values. For a variety of reasons, the dataset was divided into three sections. The training set, validation set, and test set each make up 70%, 20%, and 10% of the datasets, respectively.
4.4. Evaluation Metrics
Four different evaluation indices, including Mean Square Error (MSE), Mean Absolute Error (MAE), Root Mean Square Error (RMSE), and adjusted R-squared (
), were utilized to assess the performance of the models in this study. These are their expressions:
where
is the amount of PV energy sample points utilized to calculate the prediction error,
is the actual PV power values,
is the mean of the prediction period taken into consideration, and
is the predicted values. MSE is a frequently employed metric to assess the efficacy of time series forecasting. In this paper, all baseline models used the MSE as a loss function. The real circumstance of the error between the forecasting value and the actual value can be better reflected by MAE because it is less sensitive to outliers. RMSE is prone to high values and accentuates the distance between significant mistakes. Better performance is indicated by these indicators’ lower levels.
denotes R-squared and it represents the percentage of variance that the model accounts for and displays the correlation between forecasted and actual values. By considering the effects of additional independent factors that have a propensity to distort the outcomes of
measurements,
, a modified form of
, increases accuracy and reliability. Its value ranges from 0 to 1. The lager value of this indicator means better performance.
5. Experiment and Analysis
The PV power forecasting results of the suggested model and six baseline models are summarized and analyzed in this section. In this study, forecasting is conducted in four different prediction lengths (4, 8, 12 and 24) using data with a 5 min precision as well as data with an hourly resolution. Since the epoch periods of the seven models used in the experiments of this work differ significantly, additional convergence parameters, for instance the speed of loss converge of the seven models trained under the datasets, are not compared. In this research, each forecasting approach is implemented using Python 3.8, which runs on a computer with 12th Intel(R) Xeon(R) Platinum 8255C CPU 2.5 GHz 43 GB and NVIDIA GeForce RTX 3080 GPU 12 GB.
5.1. Experiment I: 5-min PV Power Forecasting Experiment
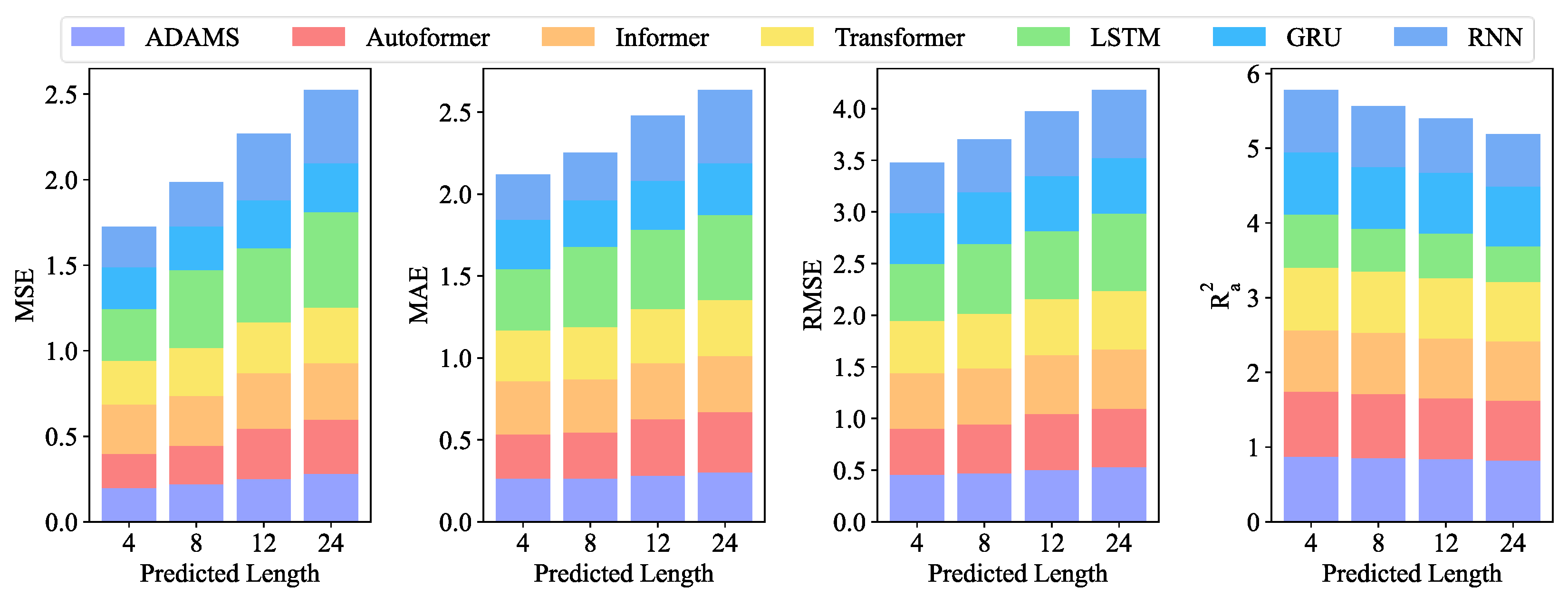
On the 5 min resolution dataset, we contrast and examine the suggested model with the other six models. In the experiment, obviously, the suggested model has performed uniformly the best of all the models.
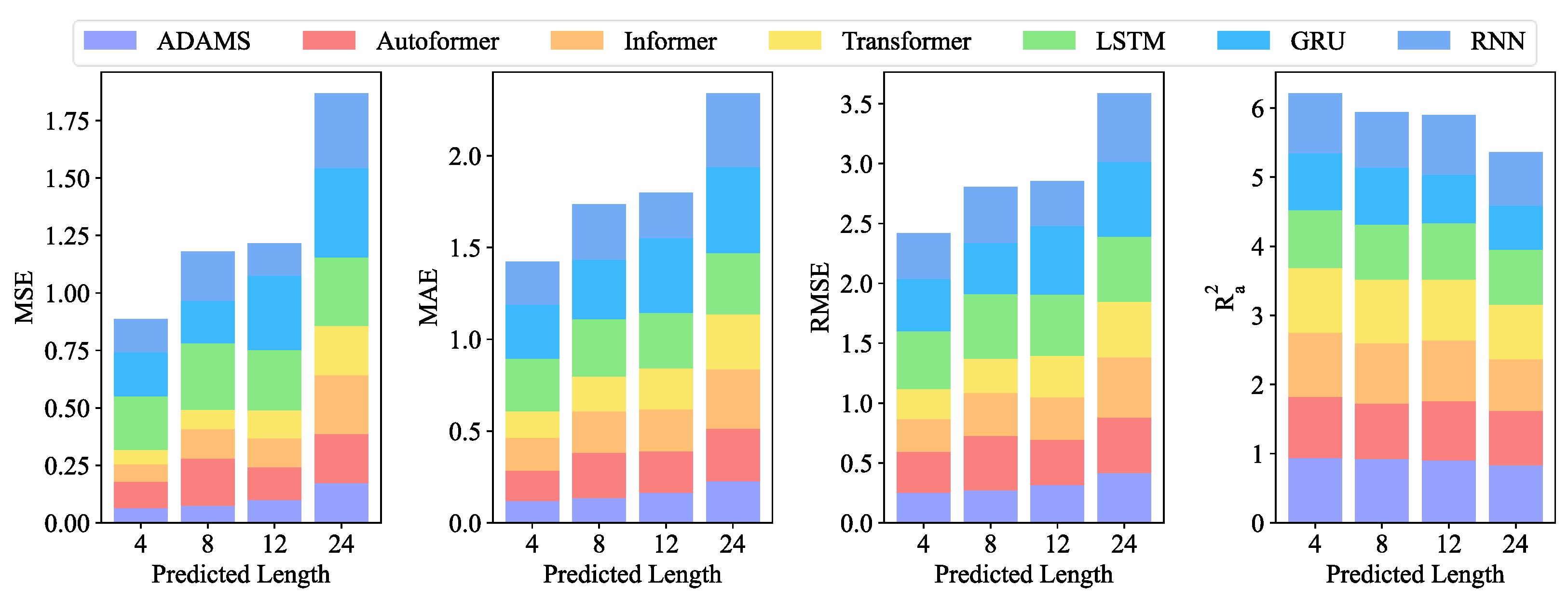
Table 2 lists the thorough analyses of the predicted outcomes.
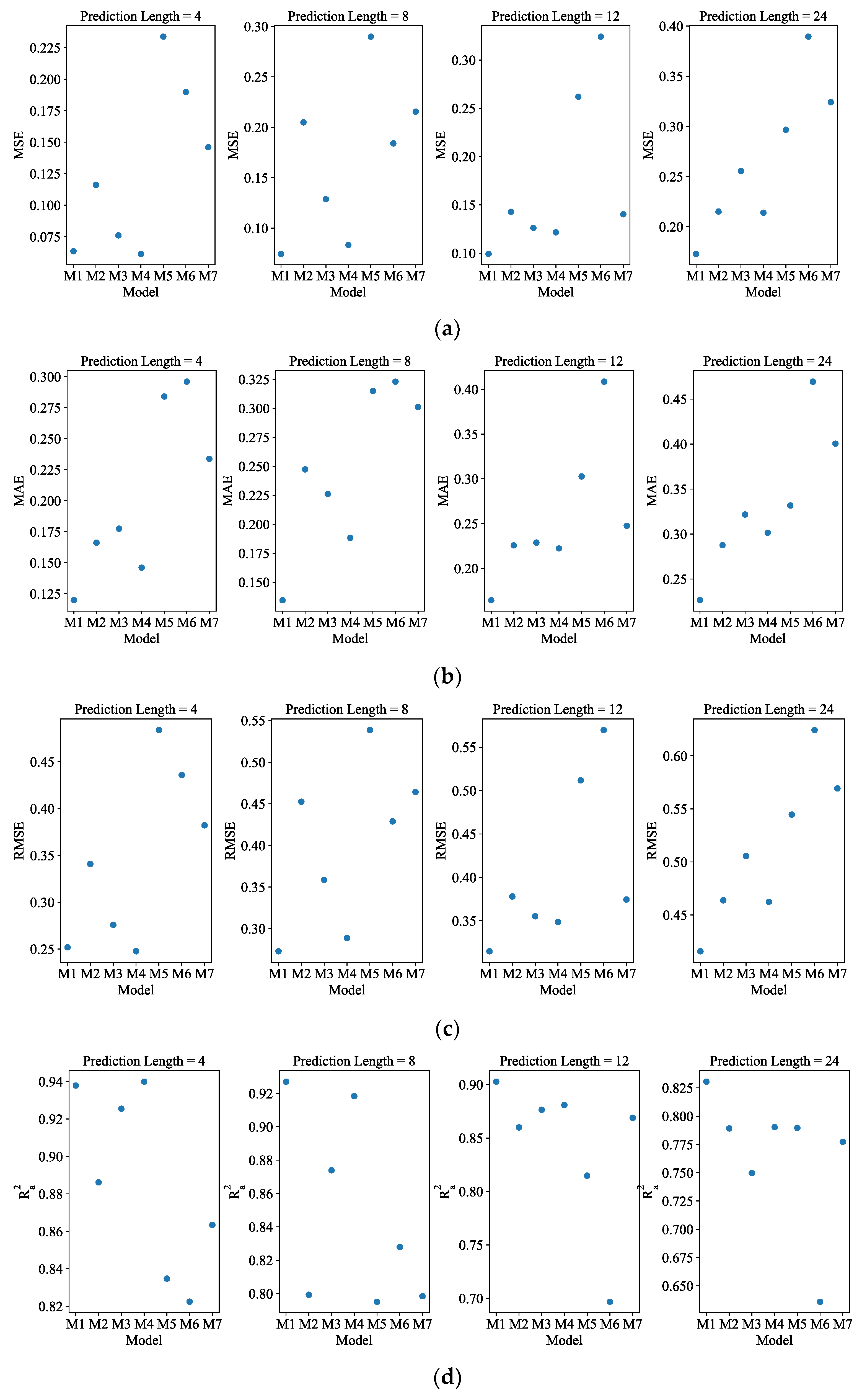
Figure 4 displays the visual bar chart.
Figure A1 shows the visual scatter plot. According to
Table 2, ADAMS achieved the best MSE of 0.061 in the forecasting of length-4, whereas Autoformer, Informer, Transformer, LSTM, GRU, and RNN achieved MSEs of 0.116, 0.076, 0.063, 0.304, 0.190, and 0.146, respectively. As can be observed from
Figure 4, when the forecasting interval is extended to length-24, the prediction errors for most competing approaches worsen. The suggested model exhibits better predicting performance for all four forecasting lengths within 120 min for data with a 5 min resolution. The prediction precision of all models exhibits a general tendency of declining with increasing length.
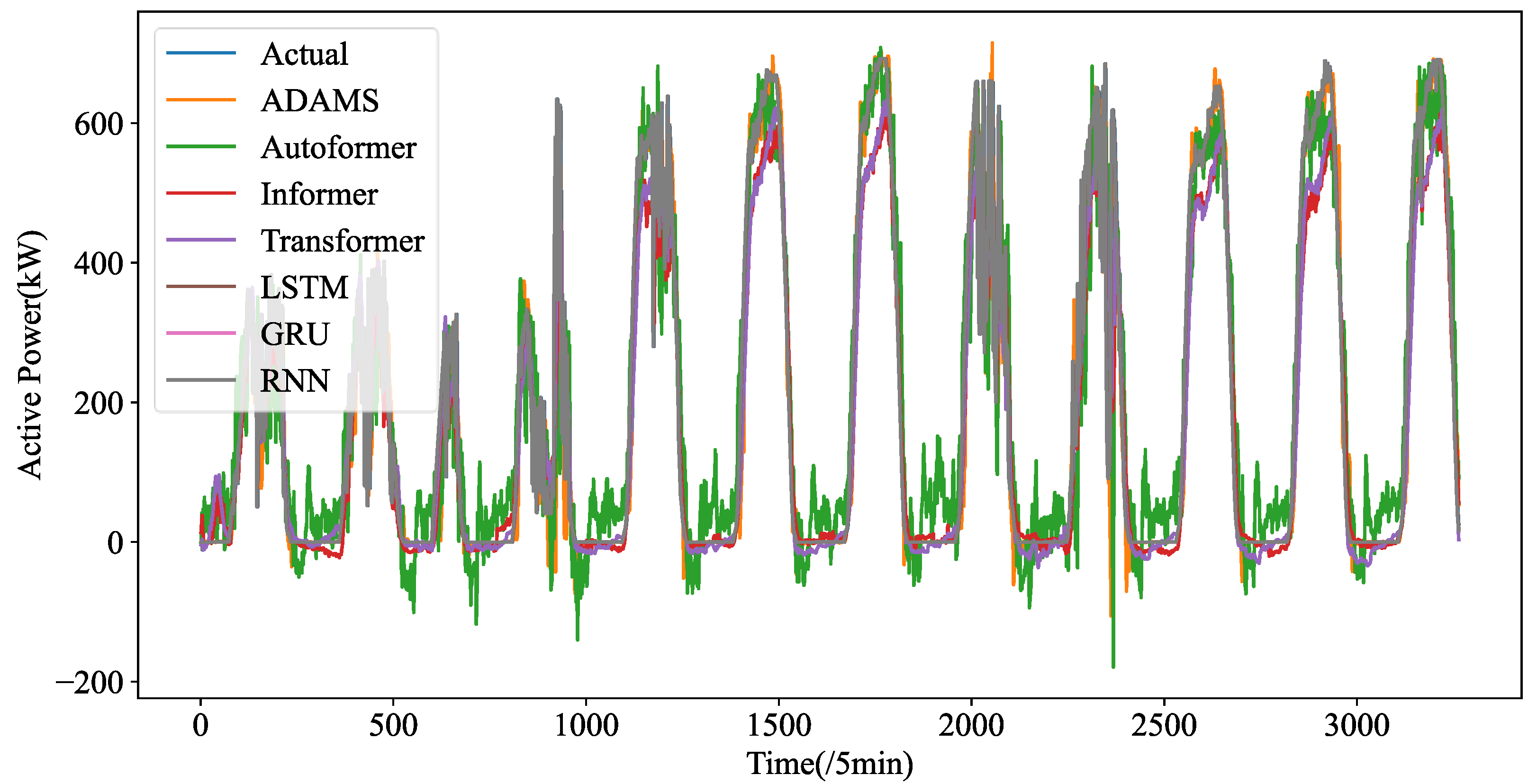
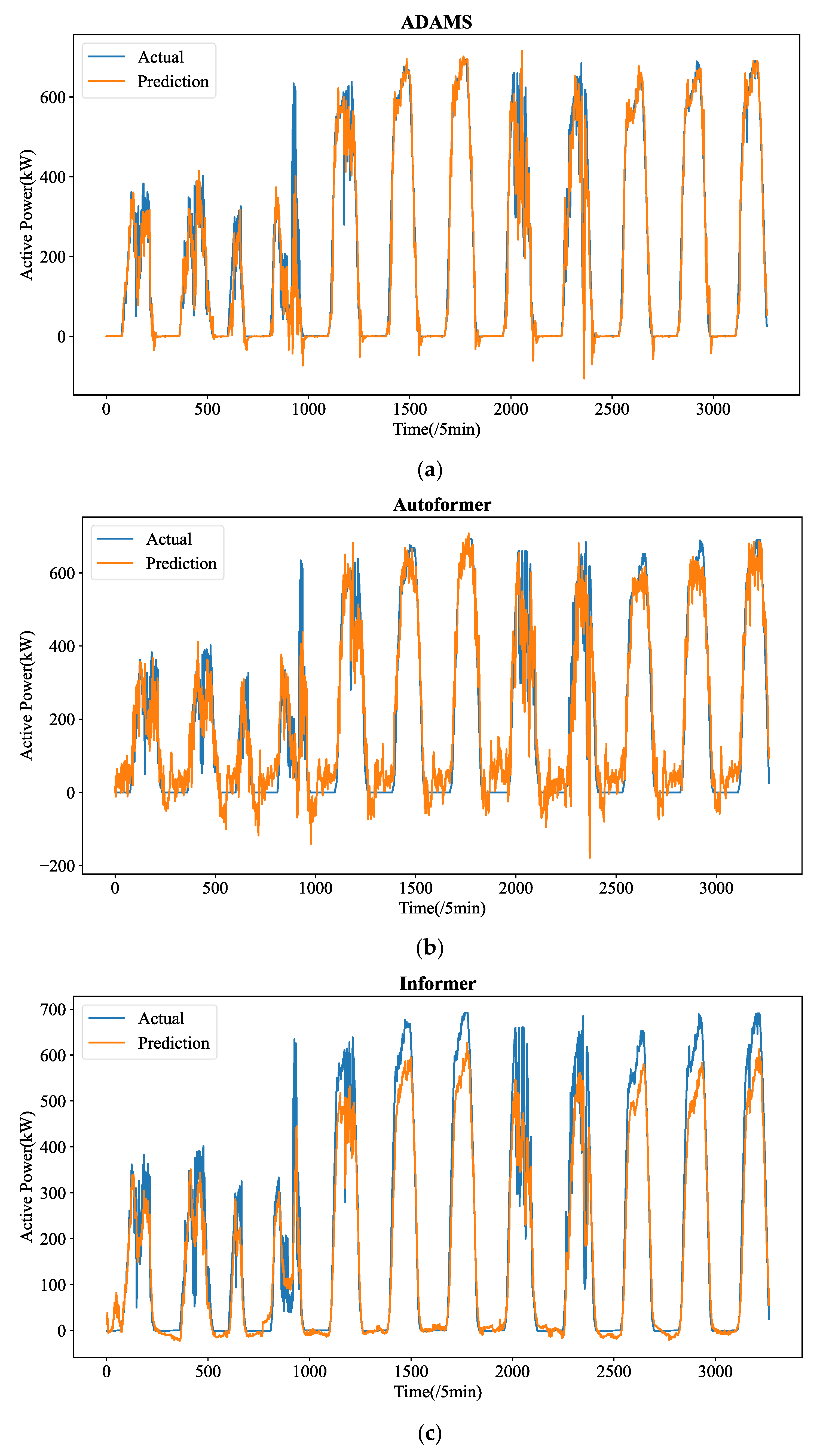
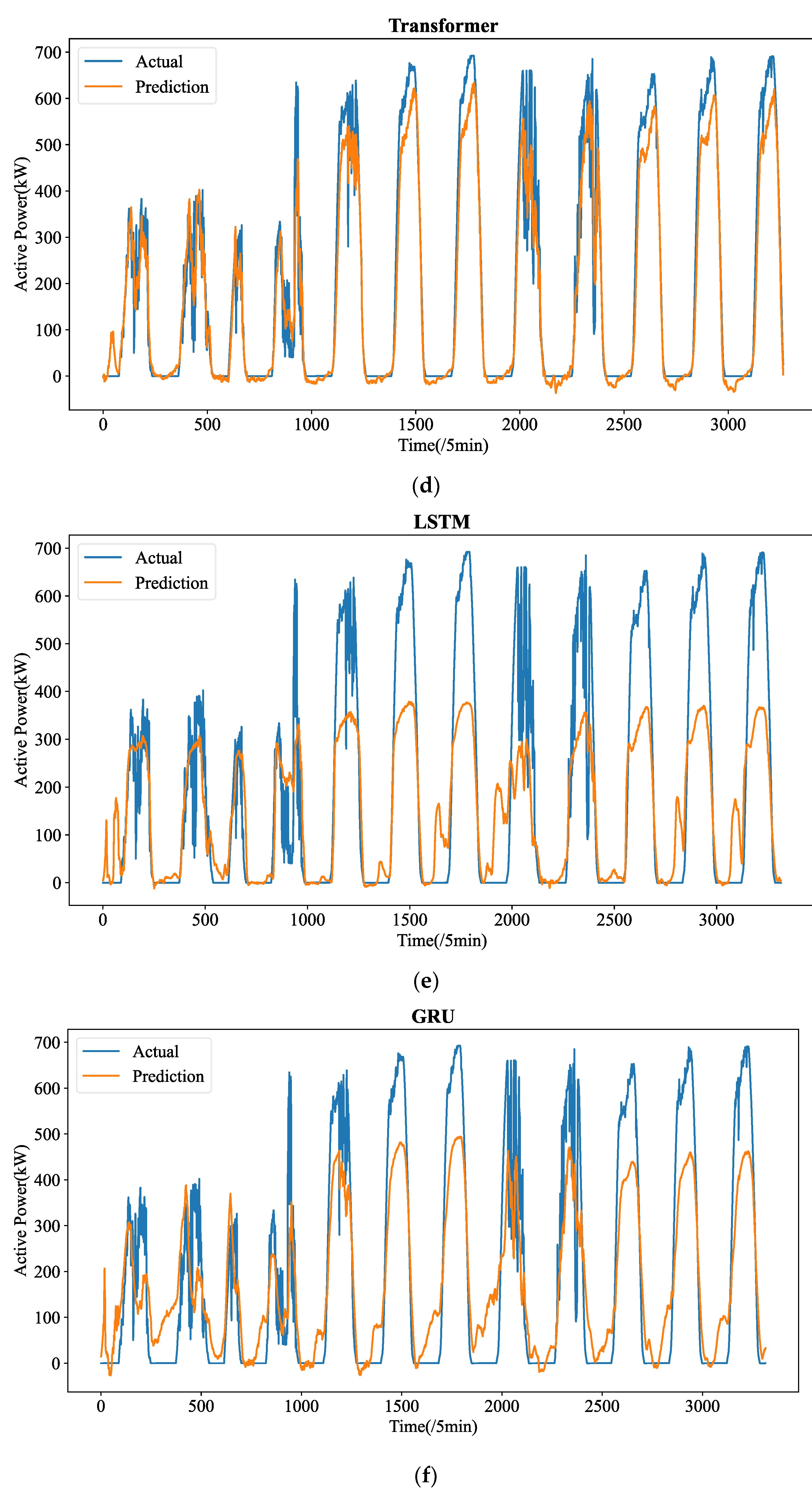
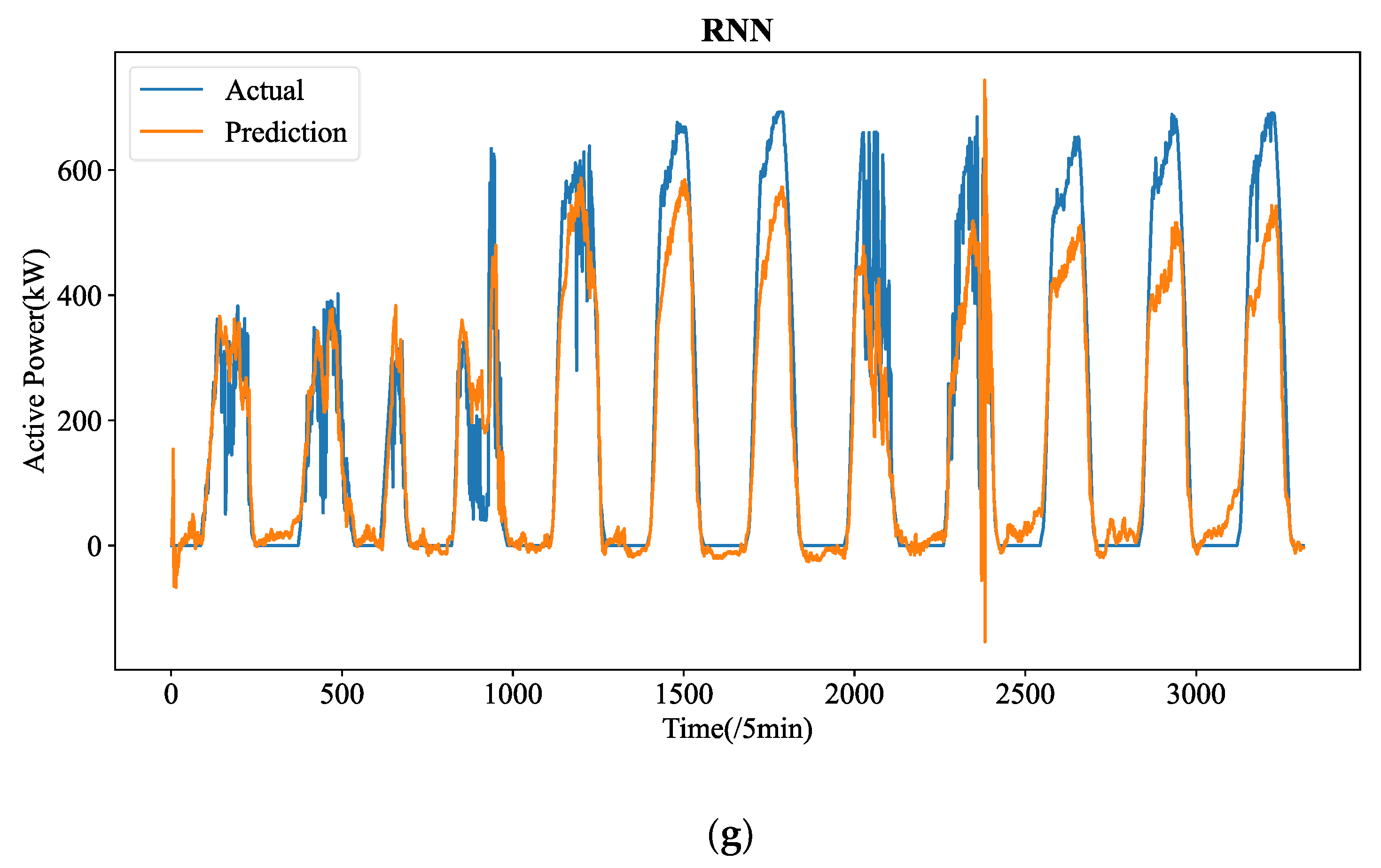
Figure 5 shows the forecasting curves of all models for the length-24 forecasting results. The forecasting curves of each model are shown in
Figure A3. We can observe that ADAMS is also proved to be the most successful model in reconstructing the fluctuation details. One-step prediction models, e.g., LSTM, GRU, and RNN are frequently used; multi-step prediction procedures will cause significant error accumulation issues. In particular, the prediction mistake from the earlier forecasting would accrue in the upcoming forecast, adding significant forecasting bias and leading to much higher MSE. Additionally, the PV power data patterns are very intricate. Their ability to learn historical details will be severely hampered by the limited computer memory. They cannot effectively learn global patterns in their memory cell without a heuristic selection process. Instead, they are only able to recall patterns in extremely small ranges, which could interfere with forecasting. The four transformer-based prediction models perform well in terms of accuracy. Too many variations have been predicted by models such as LSTM and RNN, which is referred to as the overfitting phenomena. The approximate fluctuation curves have been effectively reconstructed by Autoformer, Informer, and Transformer, however certain crucial elements have not been precisely predicted. In contrast, ADAMS accurately restores a number of significant information, including minor variations and turning points, which constitute the better understanding of the time series.
Therefore, even if the datasets exhibit extremely fluctuating patterns, the suggested ADAMS is adept at projecting PV power time series over the very short-term (5 min resolution) and recovering the precise fluctuation tendencies. Additionally, the suggested ADAMS has generated an excellent result that can serve as a fresh baseline in future research on STPVF. Although ADAMS outperforms competing approaches in our comparative trials, we did not compare ADAMS to competing approaches because, according to earlier research, ADAMS outperforms rival approaches in forecasting.
5.2. Experiment II: Hourly PV Power Forecasting Experiment
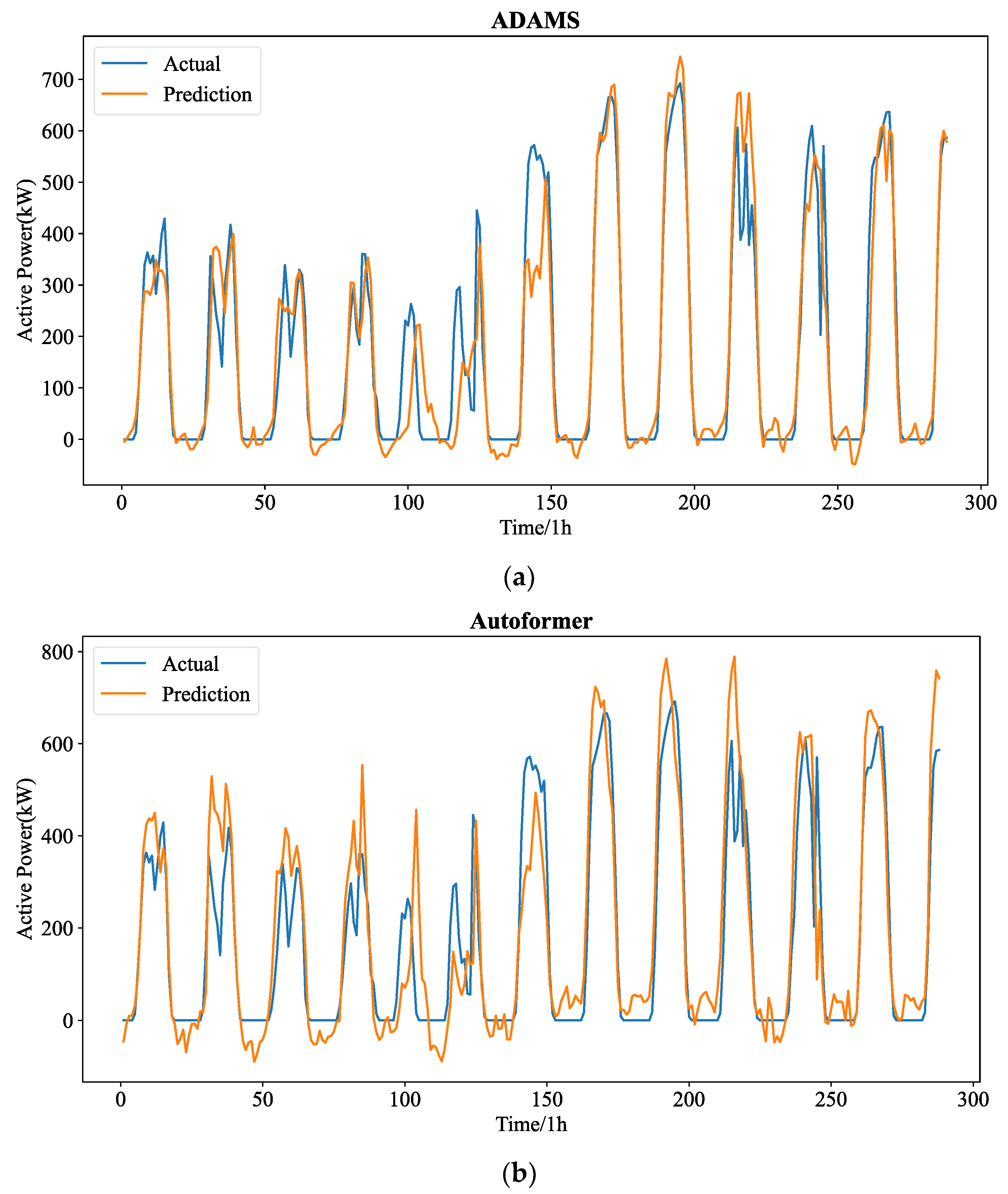
The forecasting precision of each experimental model is examined using hourly PV power data to supply more conclusive evidence of the efficacy of our suggested ADAMS. In
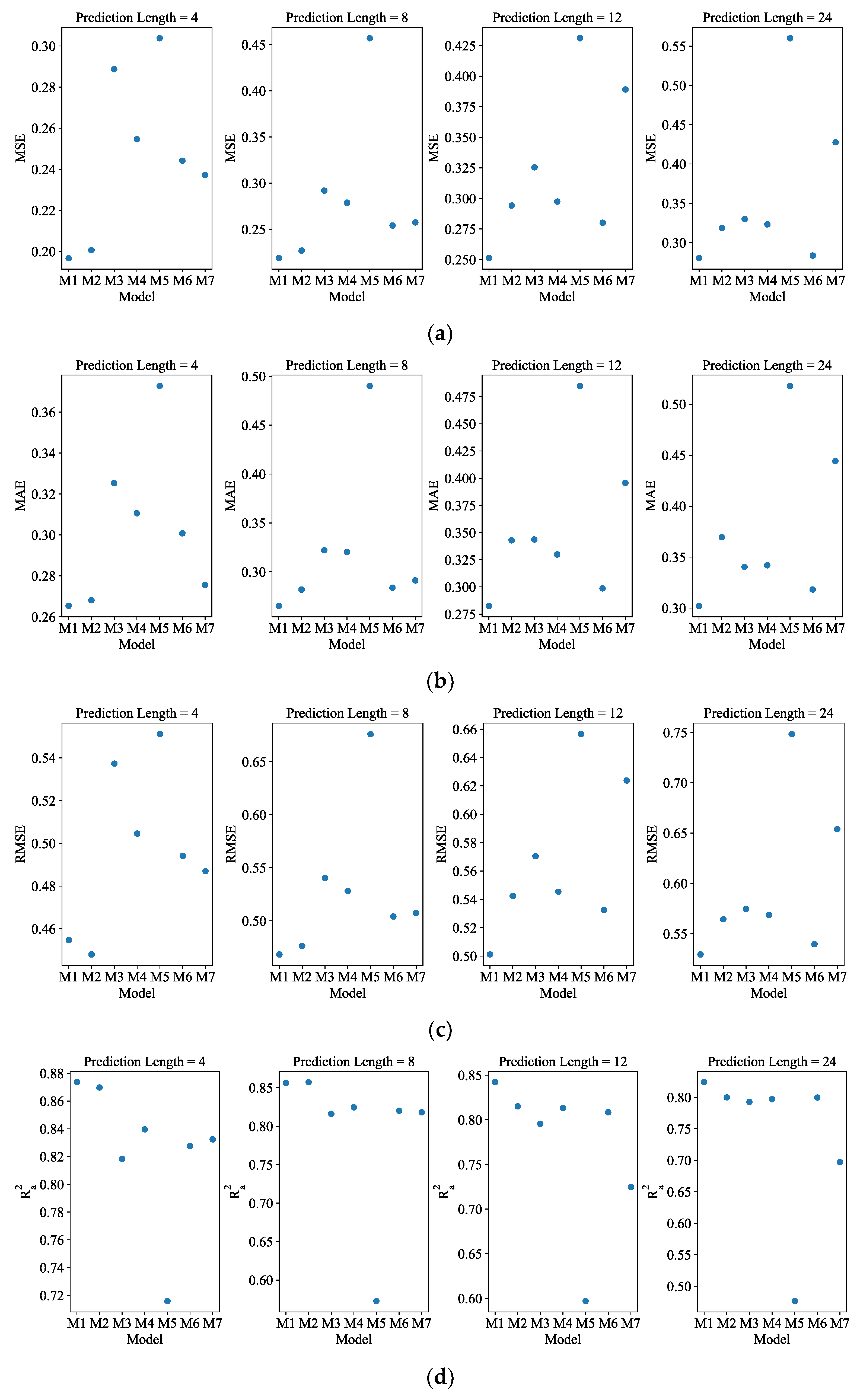
Table 3,
Figure 6 and
Figure A2, an error evaluation, a visual bar chart and a visual scatter plot are shown, respectively. Among all the models available, the ADAMS is still the model that performs the best, according to
Table 3. For all of the lengths in advance, ADAMS has the maximum number of the four evaluation indexes best values, as shown in
Table 3, while Autoformer and GRU each account for one. Additionally, ADAMS displays the best values across all evaluation indexes for all future lengths. It is important to note that LSTM predicts the curve poorly, with MSE values of 0.304, 0.457, 0.431, and 0.560 being the highest. For hourly resolution of data, the ADAMS model exhibits better predicting performance for all four pre-lengths throughout a day, as shown in
Figure 6 which displays the forecasting outcomes of all models. The prediction accuracy of all models has a general declining trend with increasing length, similarly to the Exp. I.
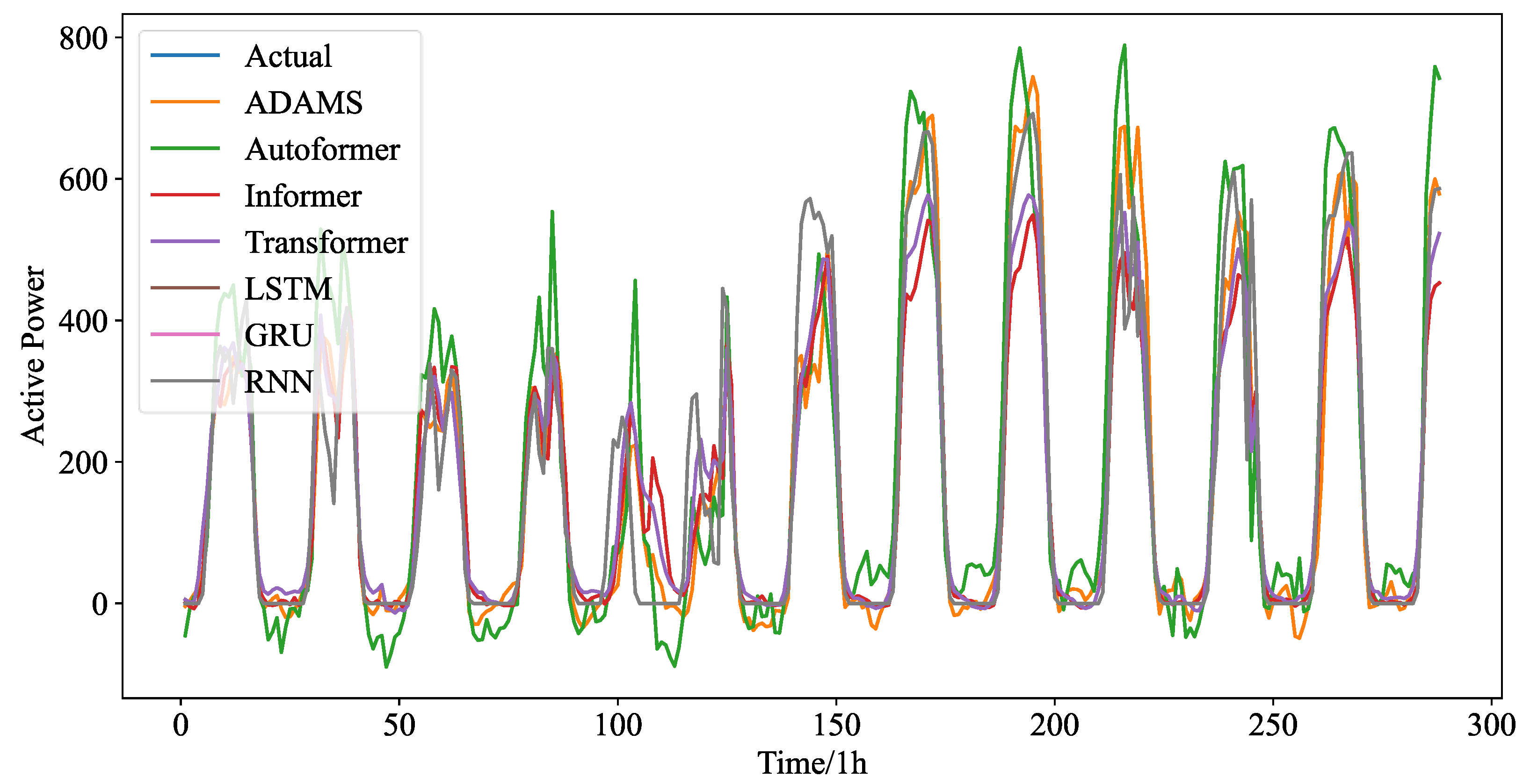
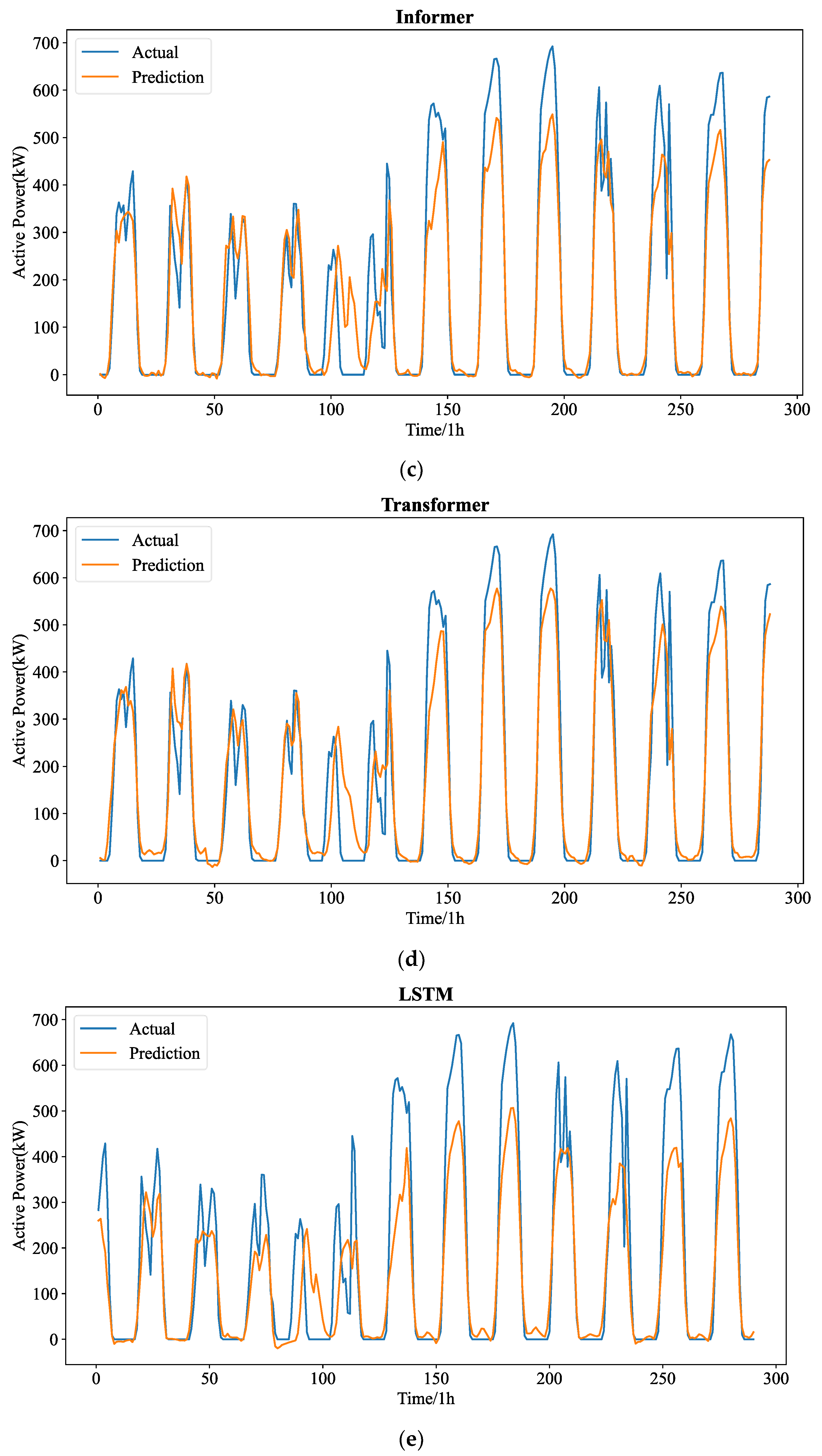
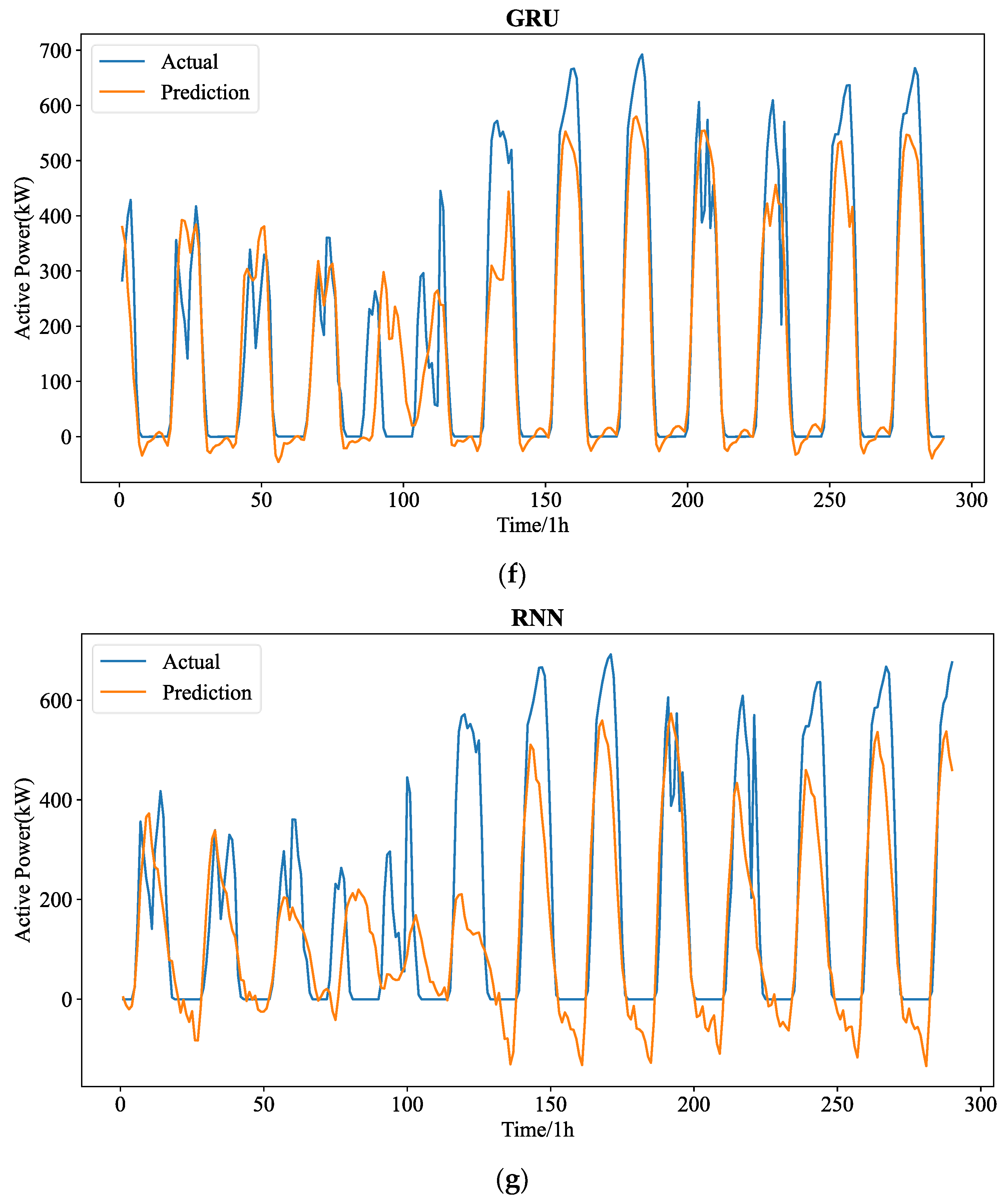
Figure 7 shows the forecasting curves of all models for the length-24 forecasting results. The forecasting curves of each model are shown in
Figure A4. It can be seen that the hourly PV statistics are more consistent and less randomly erratic than the 5 min PV data. However, the predicting curves of all models reveal that 5 min resolution data are more favorable to good forecasting performance. This depends on the temporal properties of the PV power time series themselves, and as resolution rises, so does the number of historical values that can be used for forecasting.
When comparing Exp. I and Exp. II, we can find that the ranges of for the hourly resolution data and the 5 min resolution data for all lengths of seven models are 0.476 to 0.873 and 0.636 to 0.940, respectively. The forecasting of length-4 shows the highest for both resolutions, while the length-12 and length-24 show the lowest . As observed from the aforementioned, the quality of fit of the model decreases with increasing pre-length on the two resolution datasets. The quality of fit of the model is better in the higher resolution (5 min resolution) data set. The complete range of the predicted PV power can be explained by the suggested model in 0.824 to 0.938. As seen from the aforementioned, on both resolution data sets, the quality of fit of the model increases with increasing resolution, with the 5 min resolution data set having the best fit. On both resolution data sets, the goodness of fit of the model decreases with increasing predicted length.
5.3. Diebold-Mariano Test
In order to evaluate the null hypothesis on the difference in accuracy between two forecasting models, Diebold and Mariano proposed explicit tests [
25,
26]. Model prediction errors can be non-Gaussian, non-zero-mean, serially correlated, and contemporaneously correlated, and the loss function is not required to be quadratic or symmetric [
25]. The strength of ADAMS is not overwhelming to Autoformer and Transformer, as shown in
Table 2 and
Table 3. The Diebold-Mariano test are run as a result to perform more research.
Let be the null hypothesis, which states that there is no difference in prediction accuracy between the two models. be the alternative hypothesis, which states that the prediction accuracy between the two models is obviously different. MSE is the loss function used in this hypothesis test. If the p-value is higher than 0.05, there is no difference. will be allowed if p-value is less than 0.05.
Table A1 and
Table A2 display the outcomes of the Diebold-Mariano test. As a result, it can be shown that
p-value is never greater than 0.05, proving that the PV power calculated by the ADAMS is substantially more accurate than that of the other models under comparison.
5.4. Ablation Study
We used Exp.1 (length-24) to conduct ablation research to confirm the effects of various improvement measures in the ADAMS model. The multi-scale framework, the de-stationary attention module, and the adaptive loss function (replaced by MSE), respectively, are removed from ADAMS via the , , and functions.
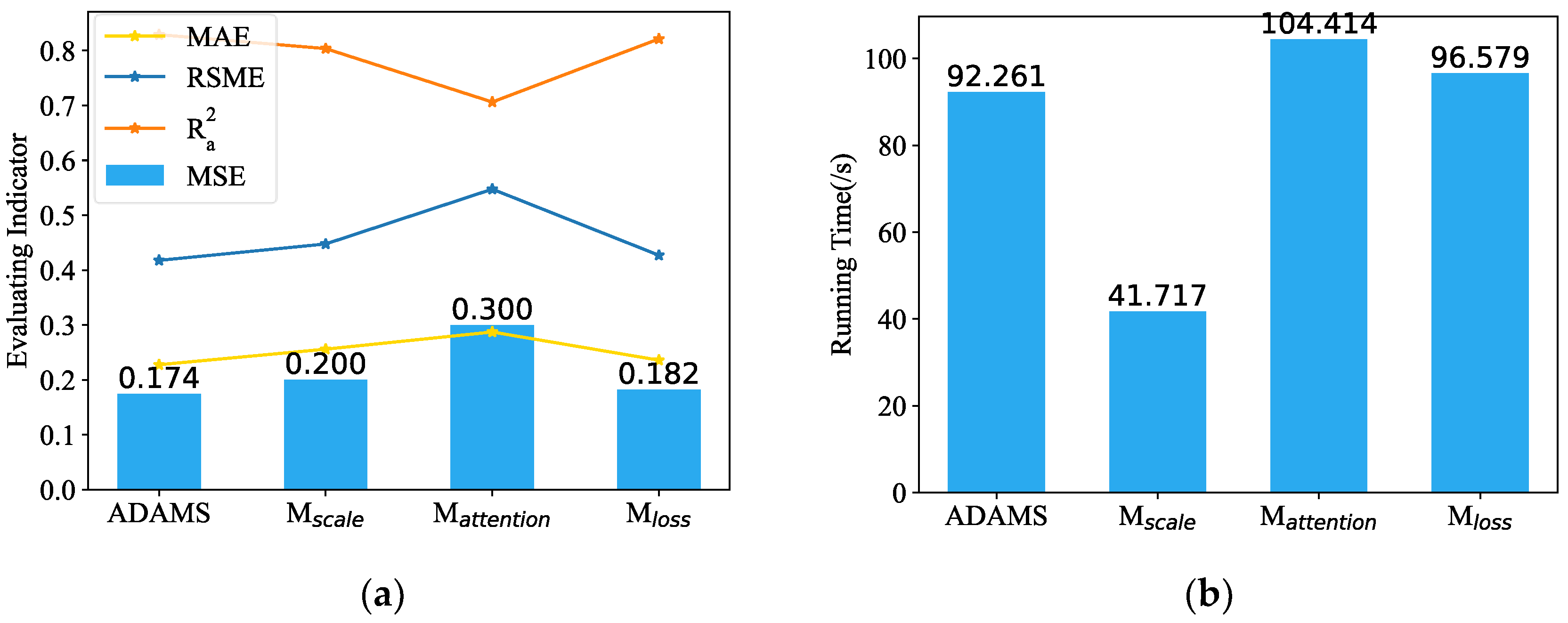
According to
Figure 8, the MSE increases to 1.72 times when the
is utilized, showing that the de-stationary attention significantly improves the objectivity and dependability of the outcome prediction. The removal of the multi-scale module shortens training time but increases MSE by 4.598%. When the adaptive loss function was applied in place of the MSE, the MSE increased by 14.943% while the training time increased a little. Three other evaluation indicators also show a similar situation. The statistical results demonstrate that the proposed ADAMS model, which incorporates all performance enhancement techniques, performs best, and that the most effective performance enhancement technique for ADAMS accuracy is de-stationary attention, followed by multi-scale framework and adaptive loss function.
5.5. Further Study
It makes sense that the longer the training time series, the more knowledge the models can pick up, resulting in a better forecasting outcome. The longer training datasets, it turns out, may not necessarily result in a forecast that is more correct. On the other hand, longer series datasets underperformed, with greater MSE, MAE, RMSE, and lower
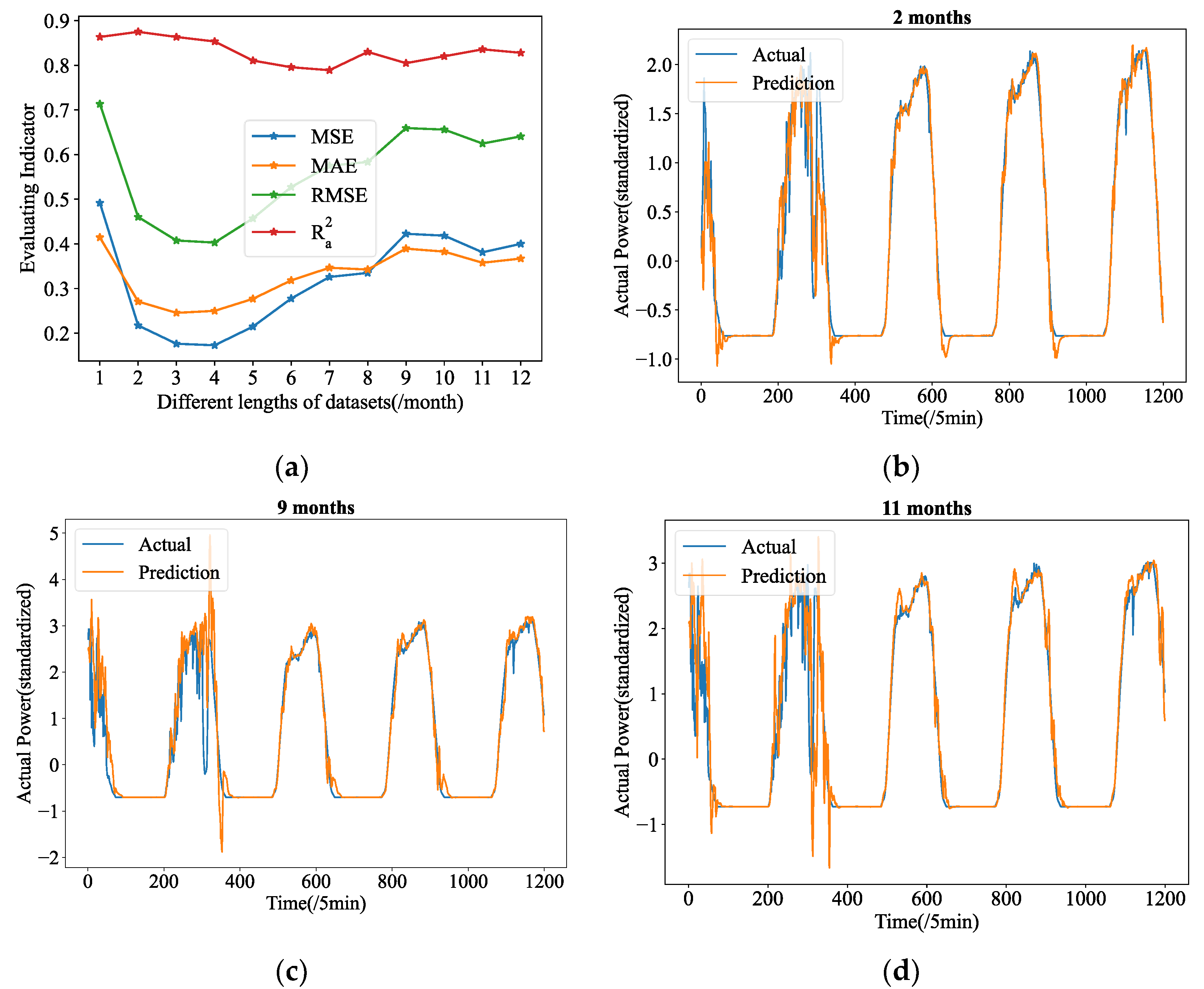
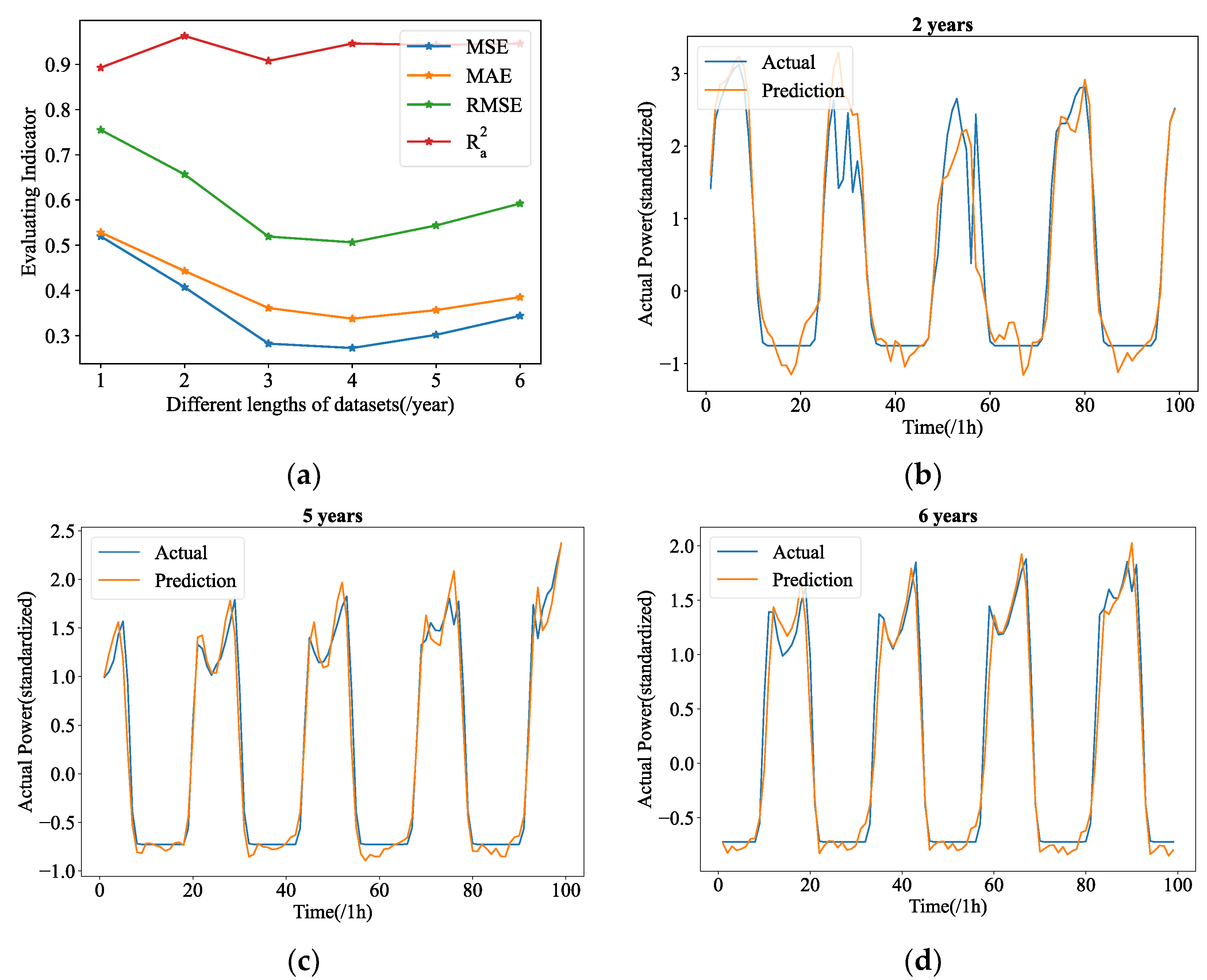
. Further studies are conducted as a result, in which we built up 12 experimental groups with PV power data of the 5 min resolution data provided by Yulara Solar System, ranging in duration from 1 month to 12 months. Additionally, six experimental groups are set up collecting data with hourly resolution ranging from one year to six years. In these experiments, their forecasting tasks are fixed at length-24 in advance.
Figure 9a and
Figure 10a display the four evaluation indicators from various experimental groups of 5 min and hourly resolution data, respectively. As seen in
Figure 9a, the total MSE has witnessed a rising trend as dataset lengths have increased to a given value, with the lowest points occurring at lengths of 4 months. As shown in
Figure 10a, the lowest point of MSE appears at the length of 4 years. Therefore, the 4 months datasets (5 min resolution) and 4 years datasets (hourly resolution) are those we used for this study.
It is interesting to note that some experimental groups with longer datasets even exhibit overfitting during testing, defying the conventional wisdom that more data will help to reduce overfitting in deep learning. In
Figure 9b–d, the forecasting outcomes of the 2 months, 9 months, and 11 months datasets are depicted. Evidently, for the two-month datasets, the insufficient PV power data makes it quite natural for models to overfit the training data. When there is insufficient data, as shown in
Figure 9, the predicted curve shows obvious error compared with the real curve. The predicting curves of 9 months and 11 months, when the time series data are considerably longer than 2 months, however, shows greater fluctuation, and even has several serious errors. This makes them much more inconsistent with the ground truth patterns. As for the hourly resolution data, additional data is required to fully understand this phenomenon, however the Yulara Solar system currently only has six years’ worth of data.
It is quite difficult to provide sufficient proof in a very short amount of time due to the inadequate data. This work presented two ideas for our future research in STPVF based on this peculiar phenomenon:
Due to the global use of self-attention and auto-correlation while training, if the time series is too lengthy, they will likely be dispersed to some historical data from the distant past that is unrelated to the current trends. The current PV power in STPVF only roughly correlates to the prior trend over a narrow range. Therefore, the historical PV power from a long time ago could seriously impair auto-correlation or self-attention.
Because the long-ago historical data disturbs the auto-correlation if the previous historic patterns resemble strikingly the current ones, the parallel historic patterns may lead the model to incorrectly predict the current trend based on the parallel historic patterns. That is to say, the forecasting errors have increased because the model has overfitted the past time series.
6. Conclusions
A novel neural network model is suggested in this paper to address the STPVF. This research suggested the ADAMS, in which the additional de-stationary attention is introduced in both the encoder and decoder modules, to find specific time dependencies based on the complete sequence information before the stationary, to resolve the extreme fluctuations and irregular trends of STPVF data. In order to find the time dependent patterns in long history data, Autoformer also utilized a multi-scale framework with a cross-scale normalization method. ADAMS and other competitive models are used to perform STPVF, using the Yulara Solar System in Central Australia as the case study. The experiment exhibits the suggested ADAMS’s capacity to foresee frequent variations as well as to extract deeper information from extremely erratic data patterns. It is important to note that, in contrast to earlier studies, the suggested ADAMS produced an excellent result in STPVF. This work also performed an experiment of the STPVF based on the hourly resolution PV power dataset to further demonstrate the superiority of the proposed ADAMS. The additional case study also offers compelling proof that ADAMS excels at deep knowledge learning and restores crucial information even from slicker data. Additionally, the proposed ADAMS was versatile, and besides the exogenous variables used in this paper for PV energy prediction, other exogenous variables can be used. Moreover, it is able to adapt to time series with different characteristics, and it can be used for forecasting tasks in other fields in future research.
Although most studies have shown that adding more data helps to solve the overfitting issue, in the area of STPVF, a larger time series dataset for learning may not be able to better predict future PV power. Two possibilities are put out in response to this counterintuitive phenomenon. On the one hand, larger datasets could disperse the auto-correlation to ancient historical time series from a long time ago. On the other hand, the model may be led astray to overfit the historical data by the dispersed auto-correlation. Future research will focus on providing a strict demonstration of the proposed assumptions and determining the ideal duration of the training datasets for STPVF.
Author Contributions
Conceptualization, Y.H. and Y.W.; methodology, Y.H.; software, Y.H.; validation, Y.H.; formal analysis, Y.H.; investigation, Y.H.; resources, Y.H.; data curation, Y.H.; writing—original draft preparation, Y.H.; writing—review and editing, Y.H.; visualization, Y.H.; supervision, Y.W.; project administration, Y.H. funding acquisition, Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partially supported by the Natural Science Foundation of Hubei Province (No. 2020CFB546), National Natural Science Foundation of China under Grants 12001411, 12201479, and the Fundamental Research Funds for the Central Universities (WUT: 2021IVB024, 2020-IB-003).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Figure A1.
The visual scatter plot of four error evaluations (5 min resolution data): (a) MSE; (b) MAE; (c) RMSE; (d) . The abscissa M1 to M7 represent ADAMS, Autoformer, Informer, Transformer, LSTM, GRU, and RNN, respectively.
Figure A1.
The visual scatter plot of four error evaluations (5 min resolution data): (a) MSE; (b) MAE; (c) RMSE; (d) . The abscissa M1 to M7 represent ADAMS, Autoformer, Informer, Transformer, LSTM, GRU, and RNN, respectively.
Figure A2.
The visual scatter plot of four error evaluations (hourly resolution data): (a) MSE; (b) MAE; (c) RMSE; (d) . The abscissa M1 to M7 represent ADAMS, Autoformer, Informer, Transformer, LSTM, GRU, and RNN, respectively.
Figure A2.
The visual scatter plot of four error evaluations (hourly resolution data): (a) MSE; (b) MAE; (c) RMSE; (d) . The abscissa M1 to M7 represent ADAMS, Autoformer, Informer, Transformer, LSTM, GRU, and RNN, respectively.
Appendix B
Figure A3.
The forecasting curves of each model for the length-24 forecasting results (5 min resolution data): (a) ADAMS; (b) Autoformer; (c) Informer; (d) Transformer; (e) LSTM; (f) GRU; (g) RNN.
Figure A3.
The forecasting curves of each model for the length-24 forecasting results (5 min resolution data): (a) ADAMS; (b) Autoformer; (c) Informer; (d) Transformer; (e) LSTM; (f) GRU; (g) RNN.
Figure A4.
The forecasting curves of each model for the length-24 forecasting results (hourly resolution data): (a) ADAMS; (b) Autoformer; (c) Informer; (d) Transformer; (e) LSTM; (f) GRU; (g) RNN.
Figure A4.
The forecasting curves of each model for the length-24 forecasting results (hourly resolution data): (a) ADAMS; (b) Autoformer; (c) Informer; (d) Transformer; (e) LSTM; (f) GRU; (g) RNN.
Appendix C
Table A1.
The outcomes of the Diebold-Mariano test (5 min resolution data).
Table A1.
The outcomes of the Diebold-Mariano test (5 min resolution data).
| | Models | ADAMS | Autoformer | Informer | Transformer | LSTM | GRU | RNN |
|---|
| 4 | ADAMS | 0.00 × 10+00 | 4.89 × 10−02 | 1.37 × 10−02 | 1.30 × 10−12 | 1.39 × 10−133 | 1.13 × 10−235 | 1.00 × 10−292 |
| Autoformer | 4.89 × 10−02 | 0.00 × 10+00 | 9.01 × 10−07 | 8.26 × 10−24 | 5.84 × 10−135 | 1.74 × 10−232 | 1.07 × 10−280 |
| Informer | 1.37 × 10−02 | 9.01 × 10−07 | 0.00 × 10+00 | 3.38 × 10−28 | 3.61 × 10−156 | 2.08 × 10−289 | 0.00 × 10+00 |
| Transformer | 1.30 × 10−12 | 8.26 × 10−24 | 3.38 × 10−28 | 0.00 × 10+00 | 6.14 × 10−156 | 3.70 × 10−289 | 0.00 × 10+00 |
| LSTM | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 4.98 × 10−93 | 1.01 × 10−171 |
| GRU | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 4.98 × 10−93 | 0.00 × 10+00 | 1.70 × 10−61 |
| RNN | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 1.01 × 10−171 | 1.70 × 10−61 | 0.00 × 10+00 |
| 8 | ADAMS | 0.00 × 10+00 | 9.78 × 10−75 | 3.27 × 10−58 | 6.80 × 10−03 | 2.61 × 10−42 | 0.00 × 10+00 | 0.00 × 10+00 |
| Autoformer | 9.78 × 10−75 | 0.00 × 10+00 | 5.81 × 10−25 | 1.12 × 10−74 | 6.05 × 10−01 | 0.00 × 10+00 | 0.00 × 10+00 |
| Informer | 3.27 × 10−58 | 5.81 × 10−25 | 0.00 × 10+00 | 0.00 × 10+00 | 1.37 × 10−45 | 0.00 × 10+00 | 0.00 × 10+00 |
| Transformer | 6.80 × 10−03 | 1.12 × 10−74 | 0.00 × 10+00 | 0.00 × 10+00 | 3.46 × 10−48 | 0.00 × 10+00 | 0.00 × 10+00 |
| LSTM | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| GRU | 0.00 × 10+00 | 2.91 × 10−123 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 3.21 × 10−35 |
| RNN | 0.00 × 10+00 | 1.58 × 10−274 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 3.21 × 10−35 | 0.00 × 10+00 |
| 12 | ADAMS | 0.00 × 10+00 | 3.00 × 10−109 | 5.20 × 10−02 | 7.14 × 10−01 | 1.32 × 10−191 | 1.48 × 10−10 | 3.42 × 10−253 |
| Autoformer | 3.00 × 10−109 | 0.00 × 10+00 | 6.72 × 10−131 | 2.07 × 10−114 | 2.60 × 10−139 | 5.26 × 10−21 | 2.84 × 10−248 |
| Informer | 5.20 × 10−02 | 6.72 × 10−131 | 0.00 × 10+00 | 3.50 × 10−07 | 0.00 × 10+00 | 6.73 × 10−09 | 1.35 × 10−223 |
| Transformer | 7.14 × 10−01 | 2.07 × 10−114 | 3.50 × 10−07 | 0.00 × 10+00 | 0.00 × 10+00 | 4.59 × 10−04 | 0.00 × 10+00 |
| LSTM | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| GRU | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| RNN | 0.00 × 10+00 | 2.92 × 10−193 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| 24 | ADAMS | 0.00 × 10+00 | 1.67 × 10−03 | 7.54 × 10−185 | 1.26 × 10−07 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| Autoformer | 1.67 × 10−03 | 0.00 × 10+00 | 2.19 × 10−163 | 2.25 × 10−02 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| Informer | 7.54 × 10−185 | 2.19 × 10−163 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 4.88 × 10−293 |
| Transformer | 1.26 × 10−07 | 2.25 × 10−02 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| LSTM | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 2.50 × 10−02 | 0.00 × 10+00 |
| GRU | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 2.50 × 10−02 | 0.00 × 10+00 | 0.00 × 10+00 |
| RNN | 0.00 × 10+00 | 0.00 × 10+00 | 4.88 × 10−293 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
Table A2.
The outcomes of the Diebold-Mariano test (hourly resolution data).
Table A2.
The outcomes of the Diebold-Mariano test (hourly resolution data).
| | Models | ADAMS | Autoformer | Informer | Transformer | LSTM | GRU | RNN |
|---|
| 4 | ADAMS | 0.00 × 10+00 | 6.89 × 10−03 | 1.41 × 10−109 | 1.48 × 10−56 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| Autoformer | 6.89 × 10−03 | 0.00 × 10+00 | 2.55 × 10−135 | 1.44 × 10−80 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| Informer | 1.41 × 10−109 | 2.55 × 10−135 | 0.00 × 10+00 | 9.37 × 10−81 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| Transformer | 1.48 × 10−56 | 1.44 × 10−80 | 9.37 × 10−81 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| LSTM | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 9.18 × 10−01 | 5.54 × 10−02 |
| GRU | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 9.18 × 10−01 | 0.00 × 10+00 | 1.19 × 10−01 |
| RNN | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 5.54 × 10−02 | 1.19 × 10−01 | 0.00 × 10+00 |
| 8 | ADAMS | 0.00 × 10+00 | 2.02 × 10−12 | 2.60 × 10−222 | 1.38 × 10−214 | 3.19 × 10−141 | 8.17 × 10−62 | 5.39 × 10−133 |
| Autoformer | 2.02 × 10−12 | 0.00 × 10+00 | 1.18 × 10−290 | 7.43 × 10−288 | 1.19 × 10−194 | 6.69 × 10−123 | 1.98 × 10−179 |
| Informer | 2.60 × 10−222 | 1.18 × 10−290 | 0.00 × 10+00 | 3.87 × 10−06 | 1.94 × 10−21 | 2.07 × 10−97 | 9.84 × 10−02 |
| Transformer | 1.38 × 10−214 | 7.43 × 10−288 | 3.87 × 10−06 | 0.00 × 10+00 | 2.99 × 10−13 | 1.11 × 10−77 | 8.22 × 10−01 |
| LSTM | 3.19 × 10−141 | 1.19 × 10−194 | 1.94 × 10−21 | 2.99 × 10−13 | 0.00 × 10+00 | 7.97 × 10−44 | 4.68 × 10−07 |
| GRU | 8.17 × 10−62 | 6.69 × 10−123 | 2.07 × 10−97 | 1.11 × 10−77 | 7.97 × 10−44 | 0.00 × 10+00 | 5.75 × 10−34 |
| RNN | 5.39 × 10−133 | 1.98 × 10−179 | 9.84 × 10−02 | 8.22 × 10−01 | 4.68 × 10−07 | 5.75 × 10−34 | 0.00 × 10+00 |
| 12 | ADAMS | 0.00 × 10+00 | 2.20 × 10−221 | 0.00 × 10+00 | 1.46 × 10−121 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| Autoformer | 2.20 × 10−221 | 0.00 × 10+00 | 8.02 × 10−96 | 6.72 × 10−09 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| Informer | 0.00 × 10+00 | 8.02 × 10−96 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| Transformer | 1.46 × 10−121 | 6.72 × 10−09 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| LSTM | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 1.14 × 10−150 | 4.54 × 10−185 |
| GRU | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 1.14 × 10−150 | 0.00 × 10+00 | 0.00 × 10+00 |
| RNN | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 4.54 × 10−185 | 0.00 × 10+00 | 0.00 × 10+00 |
| 24 | ADAMS | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 2.18 × 10−172 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| Autoformer | 0.00 × 10+00 | 0.00 × 10+00 | 9.87 × 10−08 | 3.20 × 10−95 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| Informer | 0.00 × 10+00 | 9.87 × 10−08 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| Transformer | 2.18 × 10−172 | 3.20 × 10−95 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
| LSTM | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 6.16 × 10−03 | 0.00 × 10+00 |
| GRU | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 6.16 × 10−03 | 0.00 × 10+00 | 0.00 × 10+00 |
| RNN | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 | 0.00 × 10+00 |
References
- Kabir, E.; Kumar, P.; Kumar, S.; Adelodun, A.A.; Kim, K.-H. Solar energy: Potential and future prospects. Renew. Sustain. Energy Rev. 2018, 82, 894–900. [Google Scholar] [CrossRef]
- Creutzig, F.; Agoston, P.; Goldschmidt, J.C.; Luderer, G.; Nemet, G.; Pietzcker, R.C. The underestimated potential of solar energy to mitigate climate change. Nat. Energy 2017, 2, 1–9. [Google Scholar] [CrossRef]
- Stein, G.; Letcher, T.M. 15—Integration of PV Generated Electricity into National Grids. In A Comprehensive Guide to Solar Energy Systems; Letcher, T.M., Fthenakis, V.M., Eds.; Academic Press: Cambridge, MA, USA, 2018; pp. 321–332. [Google Scholar]
- Cervone, G.; Clemente-Harding, L.; Alessandrini, S.; Delle Monache, L. Short-term photovoltaic power forecasting using Artificial Neural Networks and an Analog Ensemble. Renew. Energy 2017, 108, 274–286. [Google Scholar] [CrossRef]
- Agoua, X.G.; Girard, R.; Kariniotakis, G. Short-Term Spatio-Temporal Forecasting of Photovoltaic Power Production. IEEE Trans. Sustain. Energy 2018, 9, 538–546. [Google Scholar] [CrossRef]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting. Adv. Neural Inf. Process. Syst. 2021, 34, 22419–22430. [Google Scholar]
- Pan, M.; Li, C.; Gao, R.; Huang, Y.; You, H.; Gu, T.; Qin, F. Photovoltaic power forecasting based on a support vector machine with improved ant colony optimization. J. Clean. Prod. 2020, 277, 123948. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhou, N.; Gong, L.; Jiang, M. Prediction of photovoltaic power output based on similar day analysis, genetic algorithm and extreme learning machine. Energy 2020, 204, 117894. [Google Scholar] [CrossRef]
- Zhang, C.; Peng, T.; Nazir, M.S. A novel integrated photovoltaic power forecasting model based on variational mode decomposition and CNN-BiGRU considering meteorological variables. Electr. Power Syst. Res. 2022, 213, 108796. [Google Scholar] [CrossRef]
- He, Y.; Gao, Q.; Jin, Y.; Liu, F. Short-term photovoltaic power forecasting method based on convolutional neural network. Energy Rep. 2022, 8, 54–62. [Google Scholar] [CrossRef]
- Ghannay, S.; Favre, B.; Estève, Y.; Camelin, N. Word Embedding Evaluation and Combination. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC′16), Portorož, Slovenia, 23–28 May 2016; European Language Resources Association (ELRA): Portorož, Slovenia, 2016; pp. 300–305. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. 2017. [Google Scholar] [CrossRef]
- Child, R.; Gray, S.; Radford, A.; Sutskever, I. Generating Long Sequences with Sparse Transformers. arXiv 2019, arXiv:1904.10509. [Google Scholar]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.-X.; Yan, X. Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Wang, S.; Li, B.Z.; Khabsa, M.; Fang, H.; Ma, H. Linformer: Self-Attention with Linear Complexity. arXiv 2020, arXiv:2006.04768. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021. [Google Scholar]
- Oreshkin, B.N.; Carpov, D.; Chapados, N.; Bengio, Y. N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. arXiv 2020, arXiv:1905.10437. [Google Scholar]
- West, M. Time series decomposition. Biometrika 1997, 84, 489–494. [Google Scholar] [CrossRef]
- Shabani, A.; Abdi, A.; Meng, L.; Sylvain, T. Scaleformer: Iterative Multi-scale Refining Transformers for Time Series Forecasting. arXiv 2022, arXiv:2206.04038. [Google Scholar]
- Liu, Y.; Wu, H.; Wang, J.; Long, M. Non-stationary Transformers: Exploring the Stationarity in Time Series Forecasting. Adv. Neural Inf. Process. Syst. 2022. [Google Scholar] [CrossRef]
- Huber, P.J. Robust Estimation of a Location Parameter. Ann. Math. Stat. 1964, 35, 73–101. [Google Scholar] [CrossRef]
- Barron, J.T. A General and Adaptive Robust Loss Function. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4326–4334. [Google Scholar]
- DKASC, DKA Solar Centre; Alice Springs, Australia. Available online: https://dkasolarcentre.com.au/locations/alice-springs (accessed on 25 March 2022).
- Diebold, F.X.; Mariano, R.S. Comparing Predictive Accuracy. J. Bus. Econ. Stat. 1995, 13, 253–263. [Google Scholar]
- Harvey, D.; Leybourne, S.; Newbold, P. Testing the equality of prediction mean squared errors. Int. J. Forecast. 1997, 13, 281–291. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









