
Offline Computation of the Explicit Robust Model Predictive Control Law Based on Deep Neural Networks

Abstract
:1. Introduction
2. Problem Description
3. Robust Design of a Probability-Based DNN Controller
3.1. Guaranteeing the Stability of the DNN Controller
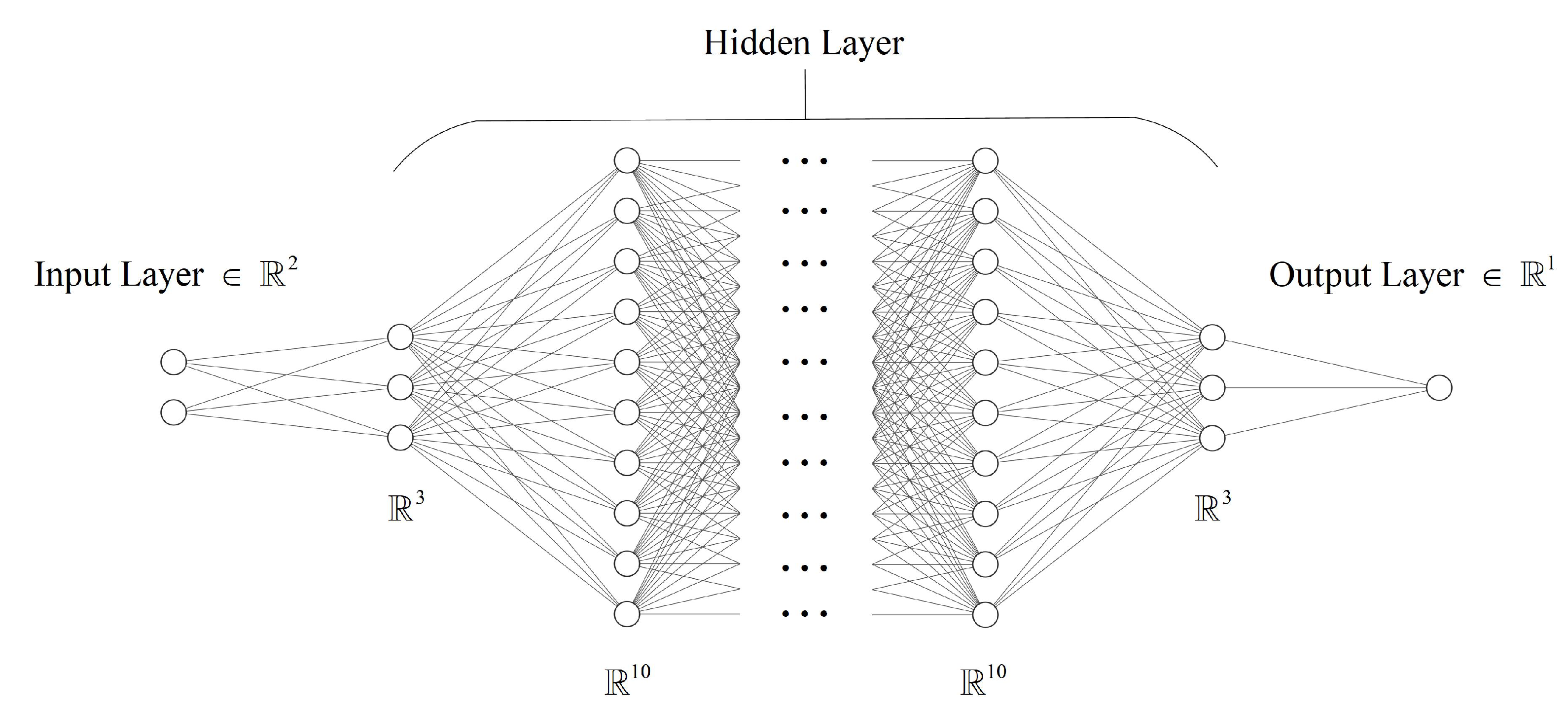
3.2. Network Model and Parameter Updating
3.3. Training Strategy for the DNN Controller
| Algorithm 1 Learn the robust MPC control law using DNN. |
|
3.4. Computational Complexity
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kothare, M.V.; Balakrishnan, V.; Morari, M. Robust constrained model predictive control using linear matrix inequalities. Automatica 1996, 32, 1361–1379. [Google Scholar] [CrossRef] [Green Version]
- Kouvaritakis, B.; Rossiter, J.A.; Schuurmans, J. Efficient robust predictive control. IEEE Trans. Autom. Control 2000, 45, 1545–1549. [Google Scholar] [CrossRef]
- Angeli, D.; Casavola, A.; Mosca, E. Ellipsoidal low-demanding MPC schemes for uncertain polytopic discrete-time systems. In Proceedings of the 41st IEEE Conference on Decision and Control, Vols 1–4, Las Vegas, NV, USA, 10–13 December 2002; pp. 2935–2940. [Google Scholar]
- Wan, Z.Y.; Kothare, M.V. Efficient robust constrained model predictive control with a time varying terminal constraint set. Syst. Control. Lett. 2003, 48, 375–383. [Google Scholar] [CrossRef]
- Wan, Z.Y.; Kothare, M.V. An efficient off-line formulation of robust model predictive control using linear matrix inequalities. Automatica 2003, 39, 837–846. [Google Scholar] [CrossRef]
- Sui, D.; Feng, L.; Ong, C.J.; Hovd, M. Robust explicit model predictive control for linear systems via interpolation techniques. Int. J. Robust Nonlinear Control 2010, 20, 1166–1175. [Google Scholar] [CrossRef]
- Tian, X.; Peng, H.; Zhou, F.; Peng, X. A synthesis approach of fast robust MPC with RBF-ARX model to nonlinear system with uncertain steady status information. Appl. Intell. 2021, 51, 19–36. [Google Scholar] [CrossRef]
- Hu, Z.; Shi, P.; Wu, L. Polytopic Event-Triggered Robust Model Predictive Control for Constrained Linear Systems. IEEE Trans. Circuits Syst. Regul. Pap. 2021, 68, 2594–2603. [Google Scholar] [CrossRef]
- Zamani, A.; Bolandi, H. Continuous-time Nonlinear Robust MPC for Offset-free Tracking of Piece-wise Constant Setpoints with Unknown Disturbance. Int. J. Control Autom. Syst. 2022, 20, 1063–1075. [Google Scholar] [CrossRef]
- Ding, B.C.; Xi, Y.G.; Cychowski, M.T.; O’Mahony, T. Improving off-line approach to robust MPC based-on nominal performance cost. Automatica 2007, 43, 158–163. [Google Scholar] [CrossRef]
- Dai, L.; Yu, Y.; Zhai, D.H.; Huang, T.; Xia, Y. Robust model predictive tracking control for robot manipulators with disturbances. IEEE Trans. Ind. Electron. 2020, 68, 4288–4297. [Google Scholar] [CrossRef]
- Preitl, Z.; Precup, R.E.; Tar, J.K.; Takács, M. Use of multi-parametric quadratic programming in fuzzy control systems. Acta Polytech. Hung. 2006, 3, 29–43. [Google Scholar]
- Precup, R.E.; David, R.C.; Roman, R.C.; Petriu, E.M.; Szedlak-Stinean, A.I. Slime mould algorithm-based tuning of cost-effective fuzzy controllers for servo systems. Int. J. Comput. Intell. Syst. 2021, 14, 1042–1052. [Google Scholar] [CrossRef]
- Ucgun, H.; Okten, I.; Yuzgec, U.; Kesler, M. Test Platform and Graphical User Interface Design for Vertical Take-Off and Landing Drones. Sci. Technol. (ROMJIST) 2022, 25, 350–367. [Google Scholar]
- Bumroongsri, P.; Kheawhom, S. An off-line robust MPC algorithm for uncertain polytopic discrete-time systems using polyhedral invariant sets. J. Process Control 2012, 22, 975–983. [Google Scholar] [CrossRef]
- Tang, X.; Qu, H.; Wang, P.; Zhao, M. Constrained off-line synthesis approach of model predictive control for networked control systems with network-induced delays. ISA Trans. 2015, 55, 135–144. [Google Scholar] [CrossRef]
- Zhang, K.; Shi, Y. Adaptive model predictive control for a class of constrained linear systems with parametric uncertainties. Automatica 2020, 117, 108974. [Google Scholar] [CrossRef] [Green Version]
- Kayacan, E.; Kayacan, E.; Ahmadieh Khanesar, M. Identification of Nonlinear Dynamic Systems Using Type-2 Fuzzy Neural Networks—A Novel Learning Algorithm and a Comparative Study. IEEE Trans. Ind. Electron. 2015, 62, 1716–1724. [Google Scholar] [CrossRef]
- O’Shea, T.; Hoydis, J. An Introduction to Deep Learning for the Physical Layer. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 563–575. [Google Scholar] [CrossRef] [Green Version]
- Pan, S.T.; Liu, M.X.; Forero-Romero, J.; Sabiu, C.; Li, Z.G.; Miao, H.T.; Li, X.D. Cosmological parameter estimation from large-scale structure deep learning. Sci. China (Phys. Mech. Astron.) 2020, 63, 40–54. [Google Scholar] [CrossRef]
- Rigatos, G.; Siano, P.; Selisteanu, D.; Precup, R. Nonlinear optimal control of oxygen and carbon dioxide levels in blood. Intell. Ind. Syst. 2017, 3, 61–75. [Google Scholar] [CrossRef]
- Dumitrache, I.; Caramihai, S.I.; Moisescu, M.A.; Sacala, I.S. Neuro-inspired Framework for cognitive manufacturing control. IFAC-PapersOnLine 2019, 52, 910–915. [Google Scholar] [CrossRef]
- Zamfirache, I.A.; Precup, R.E.; Roman, R.C.; Petriu, E.M. Policy iteration reinforcement learning-based control using a grey wolf optimizer algorithm. Inf. Sci. 2022, 585, 162–175. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer Feedforward Networks Are Universal Approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Chen, S.; Saulnier, K.; Atanasov, N.; Lee, D.D.; Kumar, V.; Pappas, G.J.; Mora, M. Approximating Explicit Model Predictive Control Using Constrained Neural Networks. In Proceedings of the 2018 Annual American Control Conference (ACC), Milwaukee, WI, USA, 27–29 June 2018; pp. 1520–1527. [Google Scholar]
- Lucia, S.; Karg, B. A deep learning-based approach to robust nonlinear model predictive control. IFAC-PapersOnLine 2018, 51, 511–516. [Google Scholar] [CrossRef]
- Karg, B.; Alamo, T.; Lucia, S. Probabilistic performance validation of deep learning-based robust NMPC controllers. Int. J. Robust Nonlinear Control 2021, 31, 8855–8876. [Google Scholar] [CrossRef]
- Hertneck, M.; Kohler, J.; Trimpe, S.; Allgower, F. Learning an Approximate Model Predictive Controller With Guarantees. IEEE Control Syst. Lett. 2018, 2, 543–548. [Google Scholar] [CrossRef] [Green Version]
- Pin, G.; Filippo, M.; Pellegrino, F.A.; Fenu, G.; Parisini, T. Approximate model predictive control laws for constrained nonlinear discrete-time systems: Analysis and offline design. Int. J. Control. 2013, 86, 804–820. [Google Scholar] [CrossRef]
- Wang, D.; Wei, W.; Yao, Y.; Li, Y.; Gao, Y. A Robust Model Predictive Control Strategy for Trajectory Tracking of Omni-directional Mobile Robots. J. Intell. Robot. Syst. 2020, 98, 439–453. [Google Scholar] [CrossRef]
- Gosztolya, G.; Grosz, T.; Toth, L. Social Signal Detection by Probabilistic Sampling DNN Training. IEEE Trans. Affect. Comput. 2018, 11, 164–177. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Jiao, L.C. Fast Sparse Deep Neural Networks: Theory and Performance Analysis. IEEE Access 2019, 7, 74040–74055. [Google Scholar] [CrossRef]
- Lee, T.; Kang, Y. Performance Analysis of Deep Neural Network Controller for Autonomous Driving Learning from a Nonlinear Model Predictive Control Method. Electronics 2021, 10, 767. [Google Scholar] [CrossRef]
- Abbas, H.A. A new adaptive deep neural network controller based on sparse auto-encoder for the antilock bracking system systems subject to high constraints. Asian J. Control 2021, 23, 2145–2156. [Google Scholar] [CrossRef]
- Oravec, J.; Bakosova, M. Soft Constraints in the Robust MPC Design via LMIs. In Proceedings of the 2016 American Control Conference (ACC), Boston, MA, USA, 6–8 July 2016; pp. 3588–3593. [Google Scholar]
- Serra, T.; Tjandraatmadja, C.; Ramalingam, S. Bounding and Counting Linear Regions of Deep Neural Networks. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80. [Google Scholar]
- Han, H.; Kim, H.; Kim, Y. An Efficient Hyperparameter Control Method for a Network Intrusion Detection System Based on Proximal Policy Optimization. Symmetry 2022, 14, 161. [Google Scholar] [CrossRef]
- Abdellah, A.R.; Alshahrani, A.; Muthanna, A.; Koucheryavy, A. Performance Estimation in V2X Networks Using Deep Learning-Based M-Estimator Loss Functions in the Presence of Outliers. Symmetry 2021, 13, 2207. [Google Scholar] [CrossRef]
- Costa, M.A.; Braga, A.; Menezes, B. Improving generalization of MLPs with sliding mode control and the Levenberg–Marquardt algorithm. Neurocomputing 2007, 70, 1342–1347. [Google Scholar] [CrossRef]
- Pascanu, R.; Montúfar, G.; Bengio, Y. On the number of response regions of deep feed forward networks with piece-wise linear activations. arXiv 2013, arXiv:1312.6098. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Error | Control Strategy | |||||
|---|---|---|---|---|---|---|
| (−60,−40] | (−40,−20] | (−20,0] | [0,20] | (20,40] | (40,60) | |
| Max () | 6.5 | 6.7 | 6.8 | 6.9 | 6.6 | 6.5 |
| Mean () | 5.2 | 5.3 | 5.5 | 5.5 | 5.4 | 5.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, C.; Jiang, X.; Li, P.; Liu, J. Offline Computation of the Explicit Robust Model Predictive Control Law Based on Deep Neural Networks. Symmetry 2023, 15, 676. https://doi.org/10.3390/sym15030676
Ma C, Jiang X, Li P, Liu J. Offline Computation of the Explicit Robust Model Predictive Control Law Based on Deep Neural Networks. Symmetry. 2023; 15(3):676. https://doi.org/10.3390/sym15030676
Chicago/Turabian StyleMa, Chaoqun, Xiaoyu Jiang, Pei Li, and Jing Liu. 2023. "Offline Computation of the Explicit Robust Model Predictive Control Law Based on Deep Neural Networks" Symmetry 15, no. 3: 676. https://doi.org/10.3390/sym15030676