Abstract
H.266/VVC introduces the QTMT partitioning structure, building upon the foundation laid by H.265/HEVC, which makes the partitioning more diverse and flexible but also brings huge coding complexity. To better address the problem, we propose a fast CU decision algorithm based on FSVMs and DAG-SVMs to reduce encoding time. The algorithm divides the CU-partitioning process into two stages and symmetrically extracts some of the same CU features. Firstly, CU is input into the trained FSVM model, extracting the standard deviation, directional complexity, and content difference complexity of the CUs, and it uses these features to make a judgment on whether to terminate the partitioning early. Then, the determination of the partition type of CU is regarded as a multi-classification problem, and a DAG-SVM classifier is used to classify it. The extracted features serve as input to the classifier, which predicts the partition type of the CU and thereby prevents unnecessary partitioning. The results of the experiment indicate that compared with the reference software VTM10.0 anchoring algorithm, the algorithm can save 49.38~58.04% of coding time, and BDBR only increases by 0.76~1.37%. The video quality and encoding performance are guaranteed while the encoding complexity is effectively reduced.
1. Introduction
With the advent of UHD video in recent years, video frame rates have been increasing and video quality has also been improving, while the amount of data generated has exploded at the same time, resulting in a huge burden on memory and bandwidth for both transmission and storage. As shown by the Ericsson 2022 Mobile Report, video traffic is growing at a rate of around 50% per year, accounting for nearly 75% of all mobile data traffic, and is expected to increase to 79% by 2027 [1]. To better adapt to the development of the video market, the Joint Video Experts Team released a novel video coding standard—the Versatile Video Coding—in July 2020 [2]. Relative to the prior video coding standard, HEVC, the performance of VVC is improved by about 40%. While maintaining the same resolution, the data compression rate is greatly improved, the data volume is reduced by 50%, and 4K to 16K resolution and 360° video are supported, but the complexity has multiplied. For example, in the All-Intra configuration, the complexity of the VVC encoder is 31 times greater than HEVC, whereas the VVC decoder is 1.8 times more complex than that [3]. Specifically, its performance is superior to H.265/HEVC because VVC carries out technical optimization on each module of the prediction module, transformation module, quantization module, entropy encoding module and loop filter module. For example, in the prediction module, intra-frame prediction modes are refined, increasing from the original 35 modes to the present 67 modes [4], which greatly improves the accuracy of prediction. There are also new technologies such as the cross-component linear model, matrix weight intra-prediction and affine motion-compensated prediction [5]. In addition, the maximum size of CUs in H.266/VVC is 128 × 128, and the smallest size of CUs is 4 × 4. Better compression efficiency can be obtained by using the QTMT partition structure in CU partitioning; QTMT partition structure includes: quadtree (QT), vertical binary tree (BTV), horizontal binary tree (BTH), vertical ternary tree (TTV), and horizontal ternary tree (TTH) [6]. As shown in Figure 1, only QT-partitioned leaf nodes can be split by the MTT structure, but MTT-partitioned leaf nodes cannot be split by QT; that is, if a QT leaf node is split by TT, then the middle part of the CU after being split cannot be split by BT or QT. If a QT leaf node is partitioned by BT, the partitioned part cannot be partitioned by QT. Such a flexible partition structure allows VVC to make more types of partitions for different textures of coding units, supporting more CU partition shapes than just squares, such as rectangles, while reducing prediction residuals.
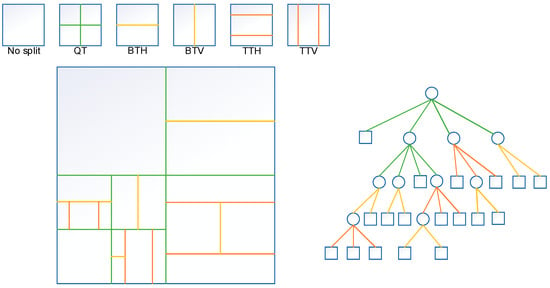
Figure 1.
CU splitting pattern in QTMT structure.
To attain optimal partition results, the rate-distortion cost of all splitting modes is calculated at each partition depth layer in VVC, and the best partition result is obtained based on the partition type of the minimum RD cost. According to the research, the process of QTMT-based CU partitioning in intra-encoding accounts for 93.84% of the total coding time, while the sum of the other processes accounts for only 6.16% of the time [7], which shows that flexible CU partitioning makes a significant contribution to improving the encoding performance of VVC but also increases the total coding time and greatly increases the coding complexity. This limits the application of VVC in the mobile terminal and other application scenarios with high requirements for real-time video coding [8]. As a result, it is imperative to develop a fast coding-unit partition algorithm that enhances encoding efficiency, diminishes encoding complexity, and upholds video quality.
Different from existing algorithms, we propose a fast CU-partitioning algorithm based on FSVMs and DAG-SVMs. Firstly, a CU early termination model based on FSVMs is proposed, which can judge whether the CU input to the FSVM classifier is the optimal size; secondly, an early partition model for CU based on DAG-SVMs is proposed, in which the CU to be split is input to the proposed DAG-SVM classifier and the type of partition of this CU is predicted by reasonably extracting the required features. The algorithm is bifurcated into two stages, resulting in a reduction in computational complexity and coding time. This, in turn, enhances coding efficiency while ensuring optimal coding quality.
The remaining sections of this paper are structured as follows: In Section 2, a review of previous research aimed at reducing the complexity of VVC is presented. Section 3 describes the application of FSVMs and DAG-SVMs to fast CU partitioning in VVC. Section 4 provides an account of the experimental results and analyzes them. The paper is summarized in Section 5.
2. Related Works
VVC utilization of the QTMT partition structure for CU partitioning is a crucial factor contributing to its high coding complexity. Therefore, reducing complexity has become an urgent problem. Most of the existing fast CU-partitioning algorithms achieve complexity reduction via skipping or stopping superfluous RDO pre-emptively. The algorithms can be broadly divided into two categories, and the combination of related methods has gradually become a research hotspot.
2.1. Based on Traditional Algorithms
In the research into traditional algorithms of fast CU-partitioning decisions, the aim of improving coding efficiency and reducing complexity is achieved by using image features based on texture, depth, and gradient to skip or terminate unnecessary splitting patterns early. In accordance with reference [9], a rapid algorithm for intra-CU partitioning on the basis of variance and the Sobel operator is presented, judging whether the CU needs to be split according to the gradient feature to avoid unnecessary partition. Reference [10] proposed an improved intra-sub-partition algorithm, which split the CU into sub-CUs according to different directions and then selected the optimal partitioning mode. Liu et al. [11] proposed a fast intra-CU-partitioning algorithm on the basis of cross-block difference, which obtained the difference mainly through the gradient of CU and sub-CU, thus skipping unnecessary horizontal and vertical partitioning. Li et al. [12] proposed a fast partitioning algorithm based on the tunable decision model, which used the difference between the raw luminance pixel and the predicted luminance pixel to establish an early skip model of MTT partitioning for each CU, saving a lot of time. In reference [13], the computational complexity of VVC is markedly decreased via calculating the texture complexity of the coding unit in the intra-prediction to determine whether it is split or not, avoiding unnecessary splitting patterns based on the relevance between texture direction and CU-partitioning patterns. Chen et al. [14] introduced a fast algorithm for intra-partitioning that employs variance and gradient, terminating the further partitioning of simple-texture CUs, calculating the gradient based on the Sobel operator to determine whether the QT partition is selected, and finally selecting the partition mode by the variance of the sub-CUs. The traditional algorithm improves the video encoding efficiency of VVC to a certain extent, but it is difficult to further improve the encoding efficiency.
2.2. Machine Learning Based
Machine learning has grown by leaps and bounds and has been widely used in various disciplines in recent years; examples include image classification and co-saliency detection [15], which have good applications in coding-unit fast-partition algorithms. Zhang et al. proposed a DenseNet-based prediction model in [16], which first uses CNN to forecast the probability of 4 × 4 size CUs in each 64 × 64 size CU as the partition boundary, and then skips unnecessary RDO, thus speeding up the encoding performance to reduce the complexity. Reference [17] proposed a fast CU-partition decision method that relies on the Random Forest model, which first splits the CU into different regions on the basis of the texture complexity, calculates the values of different directions of the CU in the complex region, uses the Canny operator to calculate the gradient, and finally uses the RFC model to select the optimal splitting pattern. Wu et al. [18] proposed a fast SVM-based CU-classification algorithm, which trains CU classifiers of different sizes and uses texture features to predict CU-classification patterns and terminate redundant classifications early. He et al. [19] proposed an algorithm based on Random Forest designed to simplify the CU classification, which first classifies CUs using an RF classifier to forecast the best splitting pattern for simple and complex CUs and uses an RF model to predict whether to end the partition early for fuzzy regions of CUs. Park et al. [20] proposed a fast decision algorithm for lightweight neural networks, which first designed two feature types based on TT-related statistical features, and then fed these features into the proposed LNN model, which judged whether to skip TT split. Shu et al. [21] proposed an adaptive and low-loss fast algorithm that extracts the gradient, entropy and depth of neighboring blocks to train SVM classifiers, and introduced a pre-scene-cut detection algorithm that reduces the size and computational complexity of the training set. Reference [22] proposed an efficient partition algorithm combining visual perception and machine learning, which uses the Random Forest model as the MTT partition model, and the feature set—consisting of the horizontal projection, vertical projection and QP of visually distinguishable pixel points—is taken as input, which in turn predicts the CU-partition type and omits unnecessary splitting. Bdallah et al. [23] proposed an early termination hierarchical convolutional neural network-based model for 64 × 64 CUs for partition prediction, skipping unnecessary partitions.
So as to effectively decrease the complexity of CU classification, this paper treats CU partition as a multi-category problem; we divide it into two stages, design a FSVM classifier and a DAG-SVM classifier, and find that CU classification is closely related to image features through statistical analysis and the algorithm making most of these features, to speed up CU partitioning.
3. Proposed Algorithm
In this content, the percentage of the QTMT partitioning structure in VVC is first statistically analyzed, and then we elaborate on the FSVM-based CU early termination algorithm and DAG-SVM-based CU early decision algorithm; determine whether the CU needs to be split and the direction of partition; extract image correlation features from the CU and select valid features using the F-score method; train the DAG-SVM model offline and learn the FSVM model online; and finally summarize the overall algorithm.
3.1. Statistical Analysis of QTMT Division Structure
In VVC, CUs adopt the QTMT partitioning structure. To optimize the efficiency of CU partitioning, we first carry out statistical analysis on the CU-partitioning mode. The current study employs video sequences featuring distinct resolutions and content types [24], which are all executed on VTM10.0 and encoded with the All-Intra configuration at the value of the QP of {22,27,32,37}. Figure 2 shows the distribution of some CU-partition types, encompassing dimensions ranging from 64 × 64 to 8 × 8. As we can see from the figure, the smaller the CU size, the greater the proportion of NS, with a greater proportion of MTT partition in the 32 × 16 to 8 × 32 CUs. We can note that the 32 × 8 CUs will no longer be TTH-divided and the 8 × 32 CUs will no longer be TTV-divided. Overall, the proportion of QT splitting is minimal. In summary, if QT partitioning is only predicted early, the reduction in coding complexity is limited [25]. Therefore, in this paper, the FSVM classifier and DAG-SVM classifier are used to determine whether CUs will continue to be divided, as well as the direction of division, which can effectively reduce coding complexity.
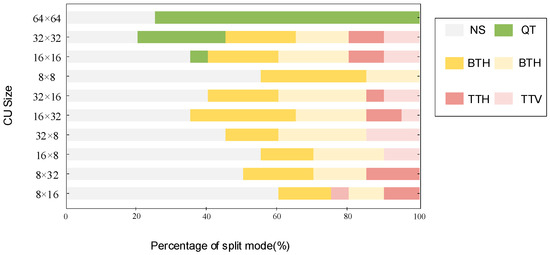
Figure 2.
Distribution of CU splitting patterns for 64 × 64–8 × 8 sizes.
3.2. Early Termination Algorithm Based on FSVMs
The classification of SVMs is a kind of traditional machine learning method. It is mainly used for data classification of the second class, as shown in Figure 3. Its main idea is to create a hyperplane, making the distance between the data on both sides of the plane the largest, as the hyperplane can accurately provide generalization ability for classification problems. In the traditional SVM model, we assume the training set , as the input feature vector of the CU, and is the category label of the CU. Using RBF as the kernel function, the optimal hyperplane in the sample space is described by the linear equation as:
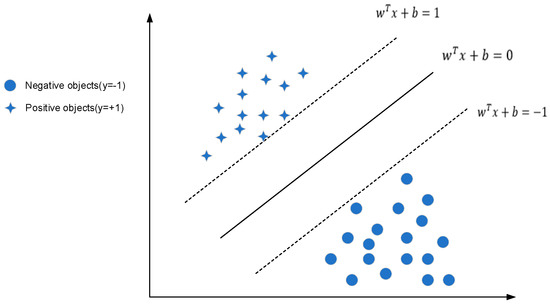
Figure 3.
Support Vector Machines.
The training set should consist of samples that meet the following criteria:
In order to sort the optimal hyperplane into a convex quadratic programming problem:
where is the mapping from input vector to feature space, we introduce penalty parameter and slack variable for each sample point, and the Formula (3) is optimized and transformed into:
The penalty parameter is used to adjust the tolerance of classification errors, and the tolerance of classification errors is inversely proportional to the value of . Finally, by constructing the Lagrangian function, the following is obtained:
where is the kernel function and denotes the Lagrange multiplier vector.
In the traditional Support Vector Machine, although it is a powerful tool to solve classification problems, in many practical classification tasks there may be noise or outliers, which will cause a certain impact on the classification hyperplane. Additionally, the noise tolerance of the SVM is poor. Fuzzy Support Vector Machine [26] can properly improve these problems and assign different fuzzy membership degrees to each sample, so as to determine the classification hyperplane more accurately.
As shown in Figure 4, sample A is a positive sample, while sample B has the distribution properties of negative samples, and the two types of samples have good classification characteristics. Given a training set , eigenvector for CU samples, including , for two categories; is the fuzzy membership function, indicating that belongs to the reliability of , where . Mapping the samples to a high-dimensional feature space using the mapping function ,the transformed training sample is obtained accordingly, and is the classification hyperplane. The kernel function is the same as in the SVM model, which is .
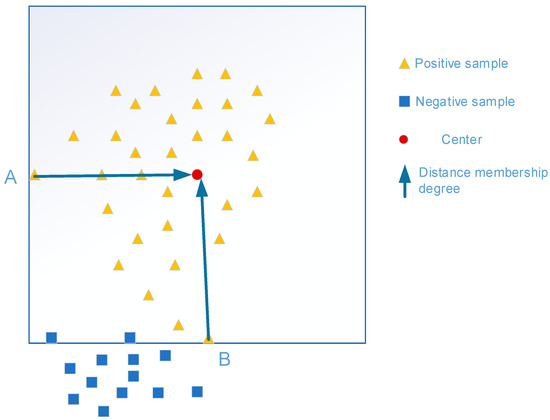
Figure 4.
Relationship between sample distribution and membership degree (A: a positive sample; B: a positive sample with the properties of a negative sample distribution).
The general expression for the Fuzzy Support Vector Machine (FSVM) is as follows:
where and are penalty parameters for positive and negative samples, respectively, and the slack variable . The centers of the two types of samples are:
where is the number of positive sample data and is the number of negative sample data. In order to make more accurate classification results, this is combined with distance and information entropy construct membership functions , where is the control factor and or less.
According to the analysis in Section 3.1, the partition of CUs is closely associated with the texture complexity. The more complex the CU texture is, the greater the probability of being divided. The smoother the texture is, the smaller the partition probability is [27]. Therefore, the problem of the early termination of coding-unit partition is transformed into a binary classification problem. The following features are selected here:
: The standard deviation between the luminance value of the current CU and the average luminance value can express the texture complexity of the current CU. Let and denote its width and height, and represent the luminance value at the coordinate , and is represented as
: Direction texture complexity. Obtain the gradient of the current CU horizontally, vertically, at 45° and 135°, respectively, using the Sobel operator, and then the expression is:
: The difference complexity of the current CU texture content and the depth of the CU also have a certain relationship with the complexity of the content. The basic unit is a 64 × 64 CU, and the content texture difference of the sub-CU with different depths is extracted. is expressed as:
where n is the number of smallest-size CUs.
Therefore, the feature set of the FSVM classifier consists of three feature vectors: , and , to judge whether the current CU is the optimal size.
FSVMs and DAG-SVMs adopt the same training set and adopt the online training mode of feature sets , and . The advantages are easy to execute and can provide an effective solution for large-scale classification problems [28]. Finally, the FSVM classifier and DAG-SVM classifier are integrated into the encoder VTM-10.0.
3.3. Fast CU Partitioning Based on DAG-SVMs
However, due to the introduction of the QTMT partitioning structure in H.266/VVC, CU partitioning is no longer a simple binary classification problem. Currently, among the problems for the SVM when realizing multi-class classification, there are mainly the 1-vs-1 method and DAG-SVM [29]. The DAG-SVM consists of leaf nodes and n leaves. For n-class classification problems, the process of generating DAG requires the construction of an SVM.
The DAG-SVM consists of leaf nodes and n leaves. For n-class classification problems, the process of generating DAGs requires the construction of an SVM. The DAG-SVM classifier model just needs decision functions in the classification process to obtain results, which is simpler and has a high running speed. For CU sizes ranging from 64 × 64 to 8 × 8, there are also five partition modes to choose, apart from no partition. The anchoring algorithm selects the partition mode with the minimum RDO, which is complicated and greatly increases the computational complexity. This part of the algorithm addresses the problem of choosing the type of CU partition [30] by constructing a DAG-SVM classifier that makes judgments about how to split CUs of different sizes. More specifically, transforming the problem into a five-category problem, as shown in Figure 5, where nodes 1-vs-5 are obtained by training the training samples with class labels 1 and 5, respectively. Assuming that the classification path of a sample with class label 1 in the sample set is determined by the classification result of each node, the sample will pass through four nodes and eventually be classified into class 1. Similarly, the other samples in the sample set will also pass through four nodes and eventually be classified into the corresponding classes.
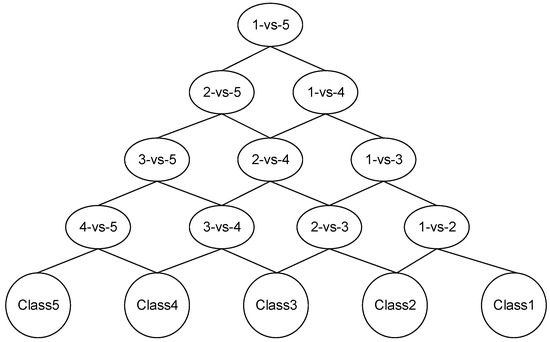
Figure 5.
Five classes of DAG-SVM classifier.
To make the results more accurate, class distances in cluster analysis are added here. The center of gravity of each class and the inter-class distance of each class are first calculated. Assume the class has samples, then the center of gravity of the class is:
where denotes the -th sample of class , and similarly, denotes the center of gravity of class . The interclass distance is expressed as
where and denote the -th component of the center of gravity and , denotes the number of features of the sample, and are the parameters of the difference between and , denoting the direct distance between the two classes, and and denote the distance between a class and itself, which in turn yields the symmetric matrix . At this point, the arithmetic mean of the data in each row of the matrix , i.e., the average distance of class from the other classes in a sample set containing classes, is expressed as
Then, the obtained are ranked according to their size. When there are two or more categories with equal , they are ranked according to the number in ascending order, and all categories are ranked as for the class label, and according to in descending order. The one with the largest average distance is , then , and alternately , and finally the DAG-SVM classifier is generated.
Image features are inextricably linked to CU partition. Through the statistics of the CU-partition results, we found that CUs with a horizontal texture orientation tend to be split horizontally, while CUs with vertical texture orientation will be split vertically. Additionally, if there is a large textural difference between two neighboring CUs, the CUs tend to choose to split, otherwise they are not; as the QP value decreases, the likelihood of a smaller CU partition increases. This means that selecting features with a high correlation can effectively improve performance, but an excessive number of features can also take more time, so we will select features:
: Quantization parameter of the current CU. When the QP increases, the number of CUs with larger sizes increases and the number of CUs with smaller sizes decreases.
: The directional complexity of the current CU. Using the Sobel operator to calculate the gradients in the different directions of the CU, and can be expressed as:
In which is the width of the current CU and represents its height, and is the pixel matrix, which can be expressed as
where denotes the luminance value at position , and the luminance values around position , then the direction complexity can be represented as
: The standard deviation among the luminance values of the current coding unit and its average luminance value serves as an indicator of the CU’s texture complexity, and is expressed as
The variables W and H denote the width and height of the current CU, indicates the luminance value in the CU at coordinates , and indicates the average luminance value of the CU, which is expressed as
Here, we used the F-score method [31] to evaluate the correlation between features, and the DAG-SVM was trained using the features with higher correlations based on the results. The feature set consisted of three features: , , and .
To enable the DAG-SVM model to be trained and applied to the new dataset to make accurate predictions, an offline training mode [32] is used here, with video sequences of different resolutions selected from the UHD video training set. These sequences have good diversity and cover various aspects. The encoding of all training sequences was performed in VTM-10.0, utilizing the All-Intra configuration and four QP values: {22, 27, 32, 37}; these data were normalized prior to training to remove dimensionality effects between features.
3.4. Overall Algorithm
This paper proposes a fast CU-partition algorithm based on FSVMs and DAG-SVMs, which includes an early termination algorithm and an early decision algorithm, where the early termination algorithm used for judging whether the current CU size is the optimal size based on the , and feature sets is based on the FSVM model, and the early decision algorithm used for predicting the current coding-unit partition method according to the , , and feature sets is based on the DAG-SVM model. According to the above analysis process, the flow chart for the proposed fast partition algorithm for CUs in this paper is illustrated in Figure 6. The detailed process is presented below based on the analysis discussed earlier.
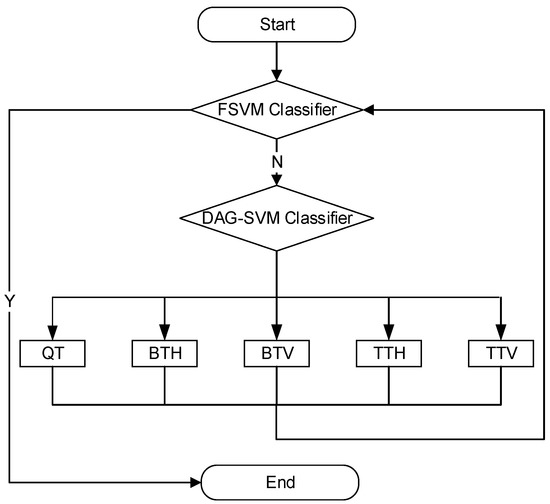
Figure 6.
Overall flow chart of the proposed algorithm.
Step 1: Extract relevant features of the video sequence during the encoding of the video sequence and obtain a subset of features via the F-score method to be used as input to the FSVM classifier and the DAG-SVM classifier for training;
Step 2: Calculate the distance between the five partitions according to Equation (12), then calculate the mean of the inter-class distance according to Equation (13), and then place the classifier with the larger mean in the upper layer node of the DAG-SVM according to its mean;
Step 3: Input the , and features extracted from the CU into the early termination model FSVM classifier to determine whether the current CU size is the optimal size. If the classifier outputs “Yes”, end the CU classification directly; if it outputs “No”, continue with the subsequent encoding, and go to Step 4;
Step 4: Extract features such as , , and from the CU that needs to be divided and input them into the DAG-SVM classifier to calculate the center of gravity of the current CU, predict the division method, and complete the partition. Then, input the divided CU into the FSVM classifier again, and go to step 3;
Step 5: The FSVM judges that the CU is the optimal size, and the split ends.
4. Experimental Results
In this content, so as to validate the effectiveness of the proposed algorithm, the algorithm was applied to selected CTC standard test sequences of 6 classes, with a total of 21 different video contents and different texture complexities [33]. These video sequences are: A1 (4K), A2 (4K), B (1080p), C (WVGA), D (QWVGA) and E (720p); the above test sequences constitute the test set of the algorithm. Table 1 shows the configuration in which the experiments were performed with this algorithm, following the JVET general test conditions.

Table 1.
Experimental setup.
We select and as the standards to measure performance, and the encoding time-saving rate is denoted by TS, which measures the reduced complexity’s performance. The evaluation of RD performance is measured using BDBR [34]. is defined as:
expresses the coding time of the algorithm proposed, and expresses the encoding time of the reference test model VTM10.0.
4.1. Analysis of Experimental Results
To more effectively assess the encoding efficiency of the algorithm, we combined the algorithm proposed in this paper with three different types of state-of-the-art algorithms, representing machine learning methods [35], deep learning methods [36] and traditional methods [37]. The configurations in Table 1 were used on VTM10.0 software, and the experimental results are shown in Table 2.
Table 2.
Comparison of the encoding performance of the proposed algorithm with three other algorithms in VTM10.0.
It can be observed from the experimental results presented in Table 2 that the proposed algorithm achieves an average reduction of 54.04% compared to the original VTM10.0 and increases the BDBR by 1.07% (negligible). For different classes of video sequences, the most reduction in coding time is achieved in class A1, with an average reduction of 56.68%, while class B video sequences have the next-highest reduction in complexity, indicating that the algorithm performs better for high-resolution video sequences. The proposed algorithm achieves a 57.47% reduction in coding time in the “Kimono” sequence, which is the optimal time-saving amount, and 45.41% minimum coding time-saving in the “KristenAndSara” sequence. All the sequences participating in the experiment perform well in our algorithm.
To further analyze the RD performance of the proposed algorithm, we selected two different kinds of video sequences—Kimono and Johnny—from the experimental sequences and compared the RD performance using the reference software VTM10.0 and the proposed algorithm in this paper. As can be seen in Figure 7, the RD curves of the proposed algorithm and VTM10.0 basically overlap, but the encoding time is greatly reduced. This indicates that the algorithm in this paper can basically achieve the same coding quality as the anchoring algorithm while significantly reducing the coding time, ensuring both a reduction in coding time and a guarantee of coding performance.
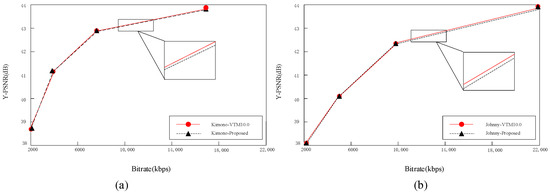
Figure 7.
RD performance of the proposed model in this paper. (a) RD of the Kimono; (b) RD of the Johnny.
4.2. Comparison with Other Algorithms
We compared the present algorithm with Zhao [35], Huang [36] and NI [37], and the results are shown in Table 2 and Figure 8, where the reduction in coding complexity is the main improvement of our algorithm. Compared with the SVM-based fast CU-partitioning algorithm proposed by Zhao et al. [35], the coding time was reduced by 0.56% on average and the BDBR was reduced by 0.43% on average, especially for the sequence FoodMarket4, saving 7.53% of the coding time. Compared with the Random Forest and ResNet-based fast CU-partitioning algorithm proposed by Huang et al. [36], the coding time was significantly reduced by an average of 19.52% and the BDBR increased by only 0.47%, especially in Class D videos where the coding time was reduced the most by an average of 31.08%. Compared with the gradient-based fast CU-delineation algorithm proposed by NI et al. [37], this algorithm reduced the coding time by an average of 5.11%, while the BDBR increased by only 0.51%; the class B sequences performed the best, with an average reduction in coding time of 6.36%.
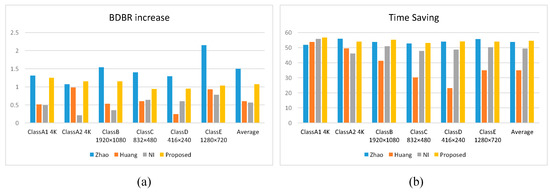
Figure 8.
The average coding performance of this algorithm and other algorithms in different categories (a) BDBR increase; (b) Time-saving.
In addition, the three algorithms [35,36,37] are compared with our algorithm in terms of their contribution to reducing complexity. Table 3 shows an analytical table of the contribution of our algorithm to the reduction in coding complexity compared with algorithms from [35,36,37], from which the superiority of the model proposed in this paper can be more clearly demonstrated.
Table 3.
Comparison of the contribution of the proposed with others.
4.3. Supplementary Analysis
The method of selecting the optimal division pattern in VVC uses the brute force RDO search method, recursively checks the RD cost of all possible CUs from top to bottom, and selects the combination with the lowest RD cost as the final division result. However, due to the QTMT division structure introduced in H.266/VVC, a CTU encoding process requires the calculation of 5781 CUs, whereas the proposed algorithm can make early decisions on whether to split CUs and how to split them, greatly reducing the time and space overheads associated with RDO searching. The running time and space consumption of the proposed model and the VTM anchoring algorithm were therefore analyzed, and the results are shown in Figure 9. From the figure, it can be found that the time overhead of the proposed model is less than 8% for all video sequences compared to VTM, with an average time overhead of 6.25%, which is only a small fraction of the total coding time. This is due to the FSVM early termination model and the DAG-SVM early decision model in the proposed algorithm, which can omit most of the redundant checking process in unnecessary CU partition.
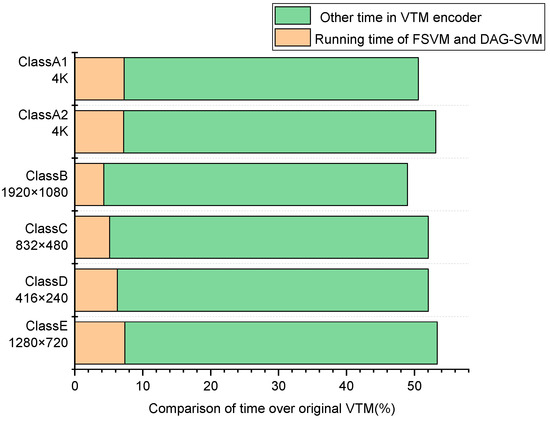
Figure 9.
Running time of the proposed FSVM model, DAG-SVM model and VTM encoder.
In addition, we also compare the number of blocks divided by the CU. Figure 10 shows the number of blocks processed by the proposed algorithm compared to the original VTM, and our algorithm can complete CU partition by processing only 21.13% of the blocks, which greatly reduces the complexity of CU partition.
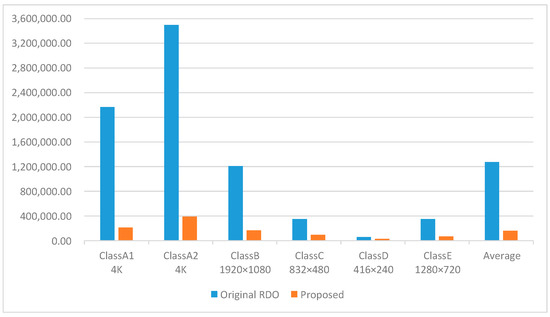
Figure 10.
Comparison of the number of CU blocks handled by the proposed and VTM.
In conclusion, the fast intra-coding-unit partitioning decision algorithm based on FSVMs and DAG-SVMs proposed in this paper performs better in reducing coding complexity, whether compared with the VTM10.0 anchoring algorithm or other advanced algorithms. Moreover, the proposed algorithm achieves a negligible loss in coding quality while significantly reducing encoding complexity and maintaining encoding efficiency, thus achieving a better balance between the two.
5. Conclusions
This paper proposes a fast CU-partition decision algorithm based on FSVMs and DAG-SVMs to achieve the purpose of reducing the encoding complexity in VVC. The QTMT partitioning structure makes CU partition more flexible. Therefore, we divided the partition of CUs into two stages, respectively designing the FSVM model and DAG-SVM model to predict whether the CU needs to terminate the partitioning prematurely and to determine the type of partitioning. Two perfect cooperation models are employed: the first is used to determine whether CU split needed to be terminated early, as a binary classification problem, using the standard deviation, the direction of complexity and the contents of the complexity of CU differences. Secondly, the judgment of the partition type of the CU is seen as a multi-classification problem, and the DAG-SVM classifier is used to classify it; the extracted features serve as input for the classifier, and then the partition type of the CU is predicted to avoid unnecessary division. The experimental results indicate that the proposed algorithm obviously achieves a reduction of 54.49% in encoding time compared to the standard reference software VTM10.0 while incurring a negligible increase of 1.07% in BDBR. Furthermore, it outperforms the RD performance of other existing fast CU-partition decision algorithms. Thus, the algorithm effectively balances encoding performance and complexity.
Author Contributions
Conceptualization, F.W. and Z.W.; methodology, F.W.; software, Z.W.; validation, F.W., Q.Z. and Z.W.; formal analysis, Z.W.; investigation, Z.W.; resources, Q.Z.; data curation, Z.W.; writing—original draft, Z.W.; writing—review and editing, F.W.; visualization, F.W.; supervision, Q.Z.; project administration, Q.Z.; funding acquisition, Q.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China No.61771432, 61302118, and 61702464, the Basic Research Projects of Education Department of Henan No. 21zx003, and No.20A880004, the Key Research and Development Program of Henan No. 222102210156, and the Postgraduate Education Reform and Quality Improvement Project of Henan Province YJS2021KC12 and YJS2022AL034.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
| VVC | Versatile Video Coding |
| HEVC | High-Efficiency Video Coding |
| CU | Coding Unit |
| FSVM | Fuzzy Support Vector Machine |
| DAG-SVM | Directed Acyclic Graph Support Vector Machine |
| CTU | Coding Tree Unit |
| MTT | Multi-Type Tree |
| QTMT | Quad-tree with Nested Multi-type Tree |
| RDO | Rate Distortion Optimization |
| QT | Quad Tree |
| BTH | Horizontal Binary Tree |
| BTV | Vertical Binary Tree |
| TTH | Horizontal Trinomial Tree |
| TTV | Vertical Trinomial Tree |
| QP | Quantization Parameter |
| TS | Time-Saving |
| BDBR | Bjøntegaard Delta Bit Rate |
| VTM | VVC Test Model |
References
- Sullivan, G.J.; Ohm, J.R.; Han, W.J.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Saldanha, M.; Sanchez, G.; Marcon, C.; Agostini, L. Complexity Analysis of VVC Intra Coding. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 3119–3123. [Google Scholar]
- Werda, I.; Maraoui, A.; Sayadi, F.E.; Masmoudi, N. Fast CU Partition and Intra Mode Prediction Method for HEVC. In Proceedings of the 2022 IEEE 9th International Conference on Sciences of Electronics, Technologies of Information and Telecommunications (SETIT), Hammamet, Tunisia, 28–30 May 2022; pp. 562–566. [Google Scholar]
- Huang, Y.; Xu, J.; Zhang, L.; Zhao, Y.; Song, L. Intra Encoding Complexity Control with a Time-Cost Model for Versatile Video Coding. In Proceedings of the 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin, TX, USA, 27 May–1 June 2022; pp. 2027–2031. [Google Scholar]
- Liu, X.; Li, Y.; Liu, D.; Wang, P.; Yang, L.T. An Adaptive CU Size Decision Algorithm for HEVC Intra Prediction Based on Complexity Classification Using Machine Learning. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 144–155. [Google Scholar] [CrossRef]
- Huang, Y.W.; Hsu, C.W.; Chen, C.Y.; Chuang, T.D.; Hsiang, S.T.; Chen, C.C.; Chiang, M.S.; Lai, C.Y.; Tsai, C.M.; Su, Y.C.; et al. A VVC Proposal with Quaternary Tree Plus Binary-Ternary Tree Coding Block Structure and Advanced Coding Techniques. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1311–1325. [Google Scholar] [CrossRef]
- Islam, M.Z.; Ahmed, B. A Machine Learning Approach for Fast CU Partitioning and Time Complexity Reduction in Video Coding. In Proceedings of the 2021 5th International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 17–19 December 2021; pp. 1–5. [Google Scholar]
- Zhu, L.; Zhang, Y.; Kwong, S.; Wang, X.; Zhao, T. Fuzzy SVM-Based Coding Unit Decision in HEVC. IEEE Trans. Broadcast 2018, 64, 681–694. [Google Scholar] [CrossRef]
- Fan, Y.; Sun, H.; Katto, J.; Ming’E, J. A Fast QTMT Partition Decision Strategy for VVC Intra Prediction. IEEE Access 2020, 8, 107900–107911. [Google Scholar] [CrossRef]
- Akbulut, O.; Konyar, M.Z. Improved Intra-Subpartition Coding Mode for Versatile Video Coding. Signal Image Video Process. 2022, 16, 1363–1368. [Google Scholar] [CrossRef]
- Liu, H.; Zhu, S.; Xiong, R.; Liu, G.; Zeng, B. Cross-Block Difference Guided Fast CU Partition for VVC Intra Coding. In Proceedings of the 2021 International Conference on Visual Communications and Image Processing (VCIP), Munich, Germany, 5–8 December 2021; pp. 1–5. [Google Scholar]
- Li, Y.; Yang, G.; Song, Y.; Zhang, H.; Ding, X.; Zhang, D. Early Intra CU Size Decision for Versatile Video Coding Based on a Tunable Decision Model. IEEE Trans. Broadcast 2021, 67, 710–720. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhao, Y.; Jiang, B.; Huang, L.; Wei, T. Fast CU Partition Decision Method Based on Texture Characteristics for H.266/VVC. IEEE Access 2020, 8, 203516–203524. [Google Scholar] [CrossRef]
- Chen, J.; Sun, H.; Katto, J.; Zeng, X.; Fan, Y. Fast QTMT Partition Decision Algorithm in VVC Intra Coding Based on Variance and Gradient. In Proceedings of the 2019 IEEE Visual Communications and Image Processing (VCIP), Sydney, Australia, 1–4 December 2019; pp. 1–4. [Google Scholar]
- Qian, X.; Zeng, Y.; Wang, W.; Zhang, Q. Co-Saliency Detection Guided by Group Weakly Supervised Learning. IEEE Trans. Multimed. 2022, 1. [Google Scholar] [CrossRef]
- Zhang, Q.; Guo, R.; Jiang, B.; Su, R. Fast CU Decision-Making Algorithm Based on DenseNet Network for VVC. IEEE Access 2021, 9, 119289–119297. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, Y.; Huang, L.; Jiang, B. Fast CU Partition and Intra Mode Decision Method for H.266/VVC. IEEE Access 2020, 8, 117539–117550. [Google Scholar] [CrossRef]
- Wu, G.; Huang, Y.; Zhu, C.; Song, L.; Zhang, W. SVM Based Fast CU Partitioning Algorithm for VVC Intra Coding. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Korea, 22–28 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Quan, H.; Wu, W.; Luo, L.; Zhu, C.; Guo, H. Random Forest Based Fast CU Partition for VVC Intra Coding. In Proceedings of the 2021 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Chengdu, China, 22–28 May 2021; pp. 1–5. [Google Scholar]
- Park, S.H.; Kang, J.W. Fast Multi-Type Tree Partitioning for Versatile Video Coding Using a Lightweight Neural Network. IEEE Trans. Multimed. 2021, 23, 4388–4399. [Google Scholar] [CrossRef]
- Shu, C.; Yang, C.; An, P. An Online SVM Based VVC Intra Fast Partition Algorithm With Pre-Scene-Cut Detection. In Proceedings of the 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin, TX, USA, 27 May 2022–1 June 2022; pp. 3033–3037. [Google Scholar]
- Chen, M.J.; Lee, C.A.; Tsai, Y.H.; Yang, C.M.; Yeh, C.H.; Kau, L.J.; Chang, C.Y. Efficient Partition Decision Based on Visual Perception and Machine Learning for H.266/Versatile Video Coding. IEEE Access 2022, 10, 42141–42150. [Google Scholar] [CrossRef]
- Abdallah, B.; Belghith, F.; Ben Ayed, M.A.; Masmoudi, N. Low-Complexity QTMT Partition Based on Deep Neural Network for Versatile Video Coding. Signal Image Video Process. 2021, 15, 1153–1160. [Google Scholar] [CrossRef]
- Lin, T.L.; Jiang, H.Y.; Huang, J.Y.; Chang, P.C. Fast Intra Coding Unit Partition Decision in H.266/FVC Based on Spatial Features. J. Real-Time Image Process. 2020, 17, 493–510. [Google Scholar] [CrossRef]
- Bouaafia, S.; Khemiri, R.; Messaoud, S.; Ben Ahmed, O.; Sayadi, F.E. Deep Learning-Based Video Quality Enhancement for the New Versatile Video Coding. Neural Comput. Appl. 2022, 34, 14135–14149. [Google Scholar] [CrossRef]
- He, S.; Deng, Z.; Shi, C. Fast Decision Algorithm of CU Size for HEVC Intra-Prediction Based on a Kernel Fuzzy SVM Classifier. Electronics 2022, 11, 2791. [Google Scholar] [CrossRef]
- HoangVan, X.; NguyenQuang, S.; DinhBao, M.; DoNgoc, M.; Duong, D.T. Fast QTMT for H.266/VVC Intra Prediction Using Early-Terminated Hierarchical CNN Model. In Proceedings of the 2021 International Conference on Advanced Technologies for Communications (ATC), Ho Chi Minh City, Vietnam, 14–16 October 2021; pp. 195–200. [Google Scholar]
- Li, T.; Xu, M.; Tang, R.; Chen, Y.; Xing, Q. DeepQTMT: A Deep Learning Approach for Fast QTMT-Based CU Partition of Intra-Mode VVC. IEEE Trans. Image Process. 2021, 30, 5377–5390. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, Y.; Huang, L.; Jiang, B.; Wang, X. Fast CU Partition Decision for H.266/VVC Based on the Improved DAG-SVM Classifier Model. Multimed. Syst. 2021, 27, 1–14. [Google Scholar] [CrossRef]
- Menon, V.V.; Amirpour, H.; Timmerer, C.; Ghanbari, M. INCEPT: Intra CU Depth Prediction for HEVC. In Proceedings of the 2021 IEEE 23rd International Workshop on Multimedia Signal Processing (MMSP), Tampere, Finland, 6–8 October 2021; pp. 1–6. [Google Scholar]
- Tang, G.; Jing, M.; Zeng, X.; Fan, Y. Adaptive CU Split Decision with Pooling-Variable CNN for VVC Intra Encoding. In Proceedings of the 2019 IEEE Visual Communications and Image Processing (VCIP), Sydney, Australia, 1–4 December 2019; pp. 1–4. [Google Scholar]
- Zhao, J.; Li, P.; Zhang, Q. A Fast Decision Algorithm for VVC Intra-Coding Based on Texture Feature and Machine Learning. Comput. Intel. Neurosc. 2022, 2022, 7675749. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, S.; Zhang, J.; Wang, S.; Ma, S. Probabilistic Decision Based Block Partitioning for Future Video Coding. IEEE Trans. Image Process. 2018, 27, 1475–1486. [Google Scholar] [CrossRef] [PubMed]
- Yao, Y.; Wang, J.; Du, C.; Zhu, J.; Xu, X. A Support Vector Machine Based Fast Planar Prediction Mode Decision Algorithm for Versatile Video Coding. Multimed. Tools Appl. 2022, 81, 17205–17222. [Google Scholar] [CrossRef]
- Zhao, J.; Wu, A.; Zhang, Q. SVM-Based Fast CU Partition Decision Algorithm for VVC Intra Coding. Electronics 2022, 11, 2147. [Google Scholar] [CrossRef]
- Huang, Y.H.; Chen, J.J.; Tsai, Y.H. Speed up H.266/QTMT Intra-Coding Based on Predictions of ResNet and Random Forest Classifier. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 10–12 January 2021; pp. 1–6. [Google Scholar]
- Ni, C.T.; Lin, S.H.; Chen, P.Y.; Chu, Y.T. High Efficiency Intra CU Partition and Mode Decision Method for VVC. IEEE Access 2022, 10, 77759–77771. [Google Scholar] [CrossRef]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).