
Statistical Modeling for Some Real Applications in Reliability Analysis Using Non-Parametric Hypothesis Testing

Abstract
:1. Introduction
- i.
- increasing failure rate (IFR), ifor
- ii.
- New better than used (NBU), if
- iii.
- iv.
- Used better than aged in expectation (UBAE), if
2. Testing Exponentiality
2.1. Complete Data
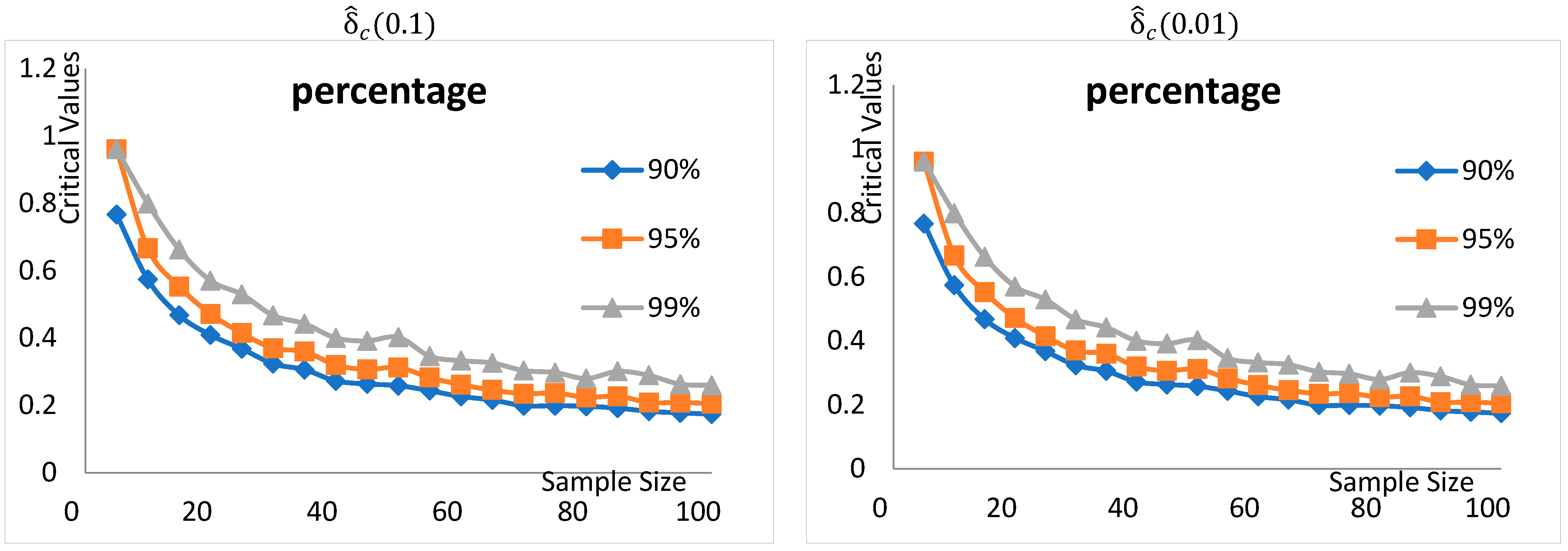
2.2. Critical Values
2.3. Relative Efficiency
- i.
- LFR:
- ii.
- Makeham distribution (MD):
- iii.
- Weibull distribution (WD):
2.4. Empirical Power for Different Alternatives
2.5. Applications for Complete Data
- Data # 1: The test statistic from Table 5 was applied to the leukemia dataset and compared with the critical value from Table 1. A total of 40 patients with blood cancer (leukemia) from one of the Saudi Arabian Ministry of Health hospitals are represented by this statistic, which shows their ages (in years). The exponentiality of the null hypothesis is not rejected by our test for any value of s.
3. Censored Data
3.1. Right-Censored Data Testing
3.2. Power Estimates
3.3. Applications
4. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| IFR | Increasing failure rate. |
| IFRA | Increasing failure rate average. |
| NBU | New better than used. |
| NBUE | New better than used in expectation. |
| NBRUL | New better than renewal used in Laplace transform ordering. |
| NBUCL | New better (worse) than used in a convex Laplace ordering. |
| DMRL | Decreasing mean residual life. |
| UBA | Used better than age. |
| UBAC | Used better than age in convex order. |
| UBAC (2) | Used better than age in concave order. |
| UBAL | Used better than age in Laplace transform. |
| UBAmgf | Used better than age in moment generating function. |
| mgf | moment generating function. |
References
- Deshpande, J.V.; Kochar, S.C.; Singh, H. Aspects of positive aging. J. Appl. Probab. 1986, 23, 748–758. [Google Scholar] [CrossRef]
- Klefsjo, B. The HNBUE and HNWUE classes of life distribution. Nav. Res. Logist. Q. 1982, 29, 331–344. [Google Scholar] [CrossRef]
- Ahmad, I.A. Moments inequalities of aging families with hypotheses testing applications. J. Stat. Plan. Inference 2001, 92, 121–132. [Google Scholar] [CrossRef]
- Ahmad, I.A. Some properties of classes of life distributions with unknown age. Stat. Probab. Lett. 2004, 9, 333–342. [Google Scholar] [CrossRef]
- Bakr, M.E.; Al-Babtain, A.A.; Khosa, S.K. Statistical Modeling of Some Cancerous Diseases Using the Laplace Transform Approach of Basic Life Testing Issues. Comput. Math. Methods Med. 2022, 2022, 8964869. [Google Scholar] [CrossRef]
- Barlow, R.E.; Proschan, F. Statistical Theory of Reliability and Life Testing. Probability Models; To Begin With: Silver Spring, MD, USA, 1981. [Google Scholar]
- Rolski, T. Mean residual life. Bull. Int. Stat. Inst. 1975, 4, 266–270. [Google Scholar]
- Abu-Youssef, S.E.; Ali, N.S.A.; Bakr, M.E. Used Better than Aged in mgf Ordering Class of Life Distribution with Application of Hypothesis Testing. J. Stat. Appl. Probab. Lett. 2020, 7, 27–32. [Google Scholar]
- Etman, W.B.H.; EL-Sagheer, R.M.; Abu-Youssef, S.E.; Sadek, A. On some characterizations to NBRULC class with hypotheses testing application. Appl. Math. Inf. Sci. 2022, 16, 139–148. [Google Scholar]
- EL-Sagheer, R.M.; Eliwa, M.S.; Alqahtani, K.M.; EL-Morshedy, M. Asymmetric randomly censored mortality distribution: Bayesian framework and parametric bootstrap with application to COVID-19 data. J. Math. 2022, 2022, 8300753. [Google Scholar] [CrossRef]
- Abu-Youssef, S.E.; Ali, N.S.A.; Bakr, M.E. Non-parametric testing for unknown age (UBAL) class of life distribution. J. Test. Eval. 2019, 48, 1–13. [Google Scholar]
- Bakr, M.E.; Nagy, M.; Al-Babtain, A.A. Non-parametric hypothesis testing to model some cancers based on goodness of fit. AIMS Math. 2022, 7, 13733–13745. [Google Scholar] [CrossRef]
- EL-Sagheer, R.M.; Mahmoud, M.A.W.; Etman, W.B.H. Characterizations and testing hypotheses for NBRUL-to class of life distributions. J. Stat. Theory Pract. 2022, 16, 31–44. [Google Scholar] [CrossRef]
- Mahmoud, M.A.W.; EL-Sagheer, R.M.; Etman, W.B.H. Moments inequalities for NBRUL distributions with hypotheses testing applications. Austrian J. Stat. 2018, 47, 95–104. [Google Scholar]
- Bakr, M.E.; Al-Babtain, A. Non-Parametric Hypothesis Testing for Unknown Aged Class of Life Distribution Using Real Medical Data. Axioms 2023, 12, 369. [Google Scholar] [CrossRef]
- Kaur, A.; Prakasarao, B.L.S.; Singh, H. Testing for second order stochastic dominance of two distributions. Econ. Theory 1994, 10, 849–866. [Google Scholar] [CrossRef]
- Klar, B.; MÄuller, A. Characterizations of classes of lifetime distributions generalizing the NBUE class. J. Appl. Prob. 2003, 40, 20–32. [Google Scholar] [CrossRef]
- Bryson, M.C.; Siddiqui, M.M. Some criteria for aging. J. Am. Statist. Assoc. 1969, 64, 1472–1483. [Google Scholar] [CrossRef]
- Marshall, A.W.; Proschan, F. Classes of life distributions applicable in replacement with renewal theory implications. Sixth Berkeley Symp. Math. Stat. Probab. 1972, 1, 395–415. [Google Scholar]
- Shaked, M.; Shanthikumar, J.G. Stochastic Orders and Their Applications; Academic Press: New York, NY, USA, 1994. [Google Scholar]
- Mahmoud, M.A.W.; Diab, L.S. On testing exponentiality against HNRBUE based on a goodness of fit. Int. J. Rel. Appl. 2007, 8, 27–93. [Google Scholar]
- Ghosh, S.; Mitra, M. A new test for exponentiality against HNBUE alternatives. Commun. Stat. Theor. Meth. 2020, 49, 27–43. [Google Scholar] [CrossRef]
- Mahmoud, M.A.W.; Hassan, E.M.A.; Gadallah, A.M. On NRBUL Class of Life Distributions. J. Egypt. Math. Soc. 2018, 26, 483–490. [Google Scholar] [CrossRef]
- Navarro, J.; Pellerey, F. Preservation of ILR and IFR aging classes in sums of dependent random variables. Appl. Stoch. Models Bus. Ind. 2022, 38, 240–261. [Google Scholar] [CrossRef]
- El-Morshedy, M.; Al-Bossly, A.; El-Sagheer, R.M.; Almohaimeed, B.; Etman, W.B.H.; Eliwa, M.S. A Moment Inequality for the NBRULC Class: Statistical Properties with Applications to Model Asymmetric Data. Symmetry 2022, 14, 2353. [Google Scholar] [CrossRef]
- Navarro, J. Preservation of DMRL and IMRL aging classes under the formation of order statistics and coherent systems. Stat. Probab. Lett. 2018, 137, 264–268. [Google Scholar] [CrossRef]
- Mahmoud, M.A.W.; Abdul Alim, A.N. A Goodness of Fit Approach to for Testing NBUFR (NWUFR) and NBAFR (NWAFR) Properties. Int. J. Reliab. Appl. 2008, 9, 125–140. [Google Scholar]
- Abu-Youssef, S.E.; Gerges, S.T. Based on the goodness of fit approach, a new test statistic for testing NBUCmgf class of life distributions. Pak. J. Statist. 2022, 38, 129–144. [Google Scholar]
- Abu-Youssef, S.E.; El-Toony, A.A. A New Class of Life Distribution based on Laplace Transform and It’s Applications. Inf. Sci. Lett. 2022, 11, 355–362. [Google Scholar]
- Lee, A.J. U-Statistics Theory and Practice; Marcel Dekker, Inc.: New York, NY, USA, 1990. [Google Scholar]
- Ahmad, I.A.; Alwasel, I.A.; Mugdadi, A.R. A goodness of fit approach to major life testing problems. Int. J. Reliab. Appl. 2001, 2, 81–97. [Google Scholar]
- Jamal, F.; Reyad, H.; Chesneau, C.; Nasir, M.A.; Othman, S. The Marshall-Olkin odd Lindley-G family of distributions: Theory and applications. Punjab Univ. J. Math. 2020, 51, 111–125. [Google Scholar]
- Almetwally, E.M.; Alharbi, R.; Alnagar, D.; Hafez, E.H. A new inverted toppleone distribution: Applications to the COVID-19 mortality rate in two different countries. Axioms 2021, 10, 25. [Google Scholar] [CrossRef]
- Abbas, K.; Hussain, Z.; Rashid, N.; Ali, A.; Taj, M.; Khan, S.A.; Manzoor, S.; Khalil, U.; Khan, D.M. Bayesian Estimation of Gumbel Type-II Distribution under Type-II Censoring with Medical Applications. J. Comput. Math. Methods Med. 2020, 7, 1876073. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| n | 90% | 95% | 99% | 90% | 95% | 99% |
|---|---|---|---|---|---|---|
| 5 | 0.0269568 | 0.0376037 | 0.0583109 | 0.00229131 | 0.003089 | 0.0044668 |
| 10 | 0.022075 | 0.0300524 | 0.0462416 | 0.00180829 | 0.00239556 | 0.0034263 |
| 15 | 0.0201512 | 0.0264841 | 0.0405875 | 0.00158865 | 0.00209656 | 0.00300109 |
| 20 | 0.0175885 | 0.0233625 | 0.0344135 | 0.00139708 | 0.00181139 | 0.0026182 |
| 25 | 0.0157562 | 0.0216115 | 0.0319283 | 0.0012824 | 0.00168031 | 00239751 |
| 30 | 0.0145093 | 0.0195368 | 0.0293987 | 0.00120351 | 0.00154123 | 0.00212703 |
| 35 | 0.0136182 | 0.0180498 | 0.0266419 | 0.00111429 | 0.00146195 | 0.00205294 |
| 40 | 0.0131065 | 0.017101 | 0.0248728 | 0.00103891 | 0.00135436 | 0.00188826 |
| 45 | 0.0127 | 0.0168735 | 0.0244385 | 0.00100398 | 0.00129905 | 0.00185749 |
| 50 | 0.0118313 | 0.0156481 | 0.0232832 | 0.000979758 | 0.00128491 | 0.00178655 |
| 55 | 0.0114589 | 0.0152271 | 0.021865 | 0.00092096 | 0.00116987 | 0.00166315 |
| 60 | 0.0111349 | 0.0145445 | 0.0210173 | 0.000897631 | 0.00114625 | 0.00160462 |
| 65 | 0.0104427 | 0.0139471 | 0.0202393 | 0.00086986 | 0.00111567 | 0.00154781 |
| 70 | 0.0105306 | 0.0137865 | 0.0195862 | 0.000829601 | 0.00108286 | 0.00153534 |
| 75 | 0.00972476 | 0.012878 | 0.0192712 | 0.000797139 | 0.00104552 | 0.00148272 |
| 80 | 0.00949736 | 0.0124992 | 0.0182769 | 0.000773635 | 0.000989083 | 0.0014461 |
| 85 | 0.00939424 | 0.012363 | 0.0179713 | 0.000759779 | 0.000981124 | 0.00137304 |
| 90 | 0.00909839 | 0.0120664 | 0.0174325 | 0.000724814 | 0.000938991 | 0.00134655 |
| 95 | 0.00893048 | 0.0117764 | 0.0170683 | 0.000723773 | 0.00092358 | 0.00129325 |
| 100 | 0.00878876 | 0.0113728 | 0.0167065 | 0.000701153 | 0.000916134 | 0.00129516 |
| Distribution | ||||
|---|---|---|---|---|
| S = 0.01 | S = 0.1 | |||
| LFR | 1.1456 | 1.3 | 1.35 | 1.30 |
| Makeham | 0.5455 | 0.58 | 0.803 | 0.86 |
| Weibull | _____ | 0.791 | 0.99 | 0.97 |
| Distribution | n | |||
|---|---|---|---|---|
| LFR | 10 | 0.9958 | 1 | 1 |
| 20 | 1 | 1 | 1 | |
| 30 | 1 | 1 | 1 | |
| Gamma | 10 | 1 | 1 | 1 |
| 20 | 1 | 1 | 1 | |
| 30 | 1 | 1 | 1 | |
| Weibull | 10 | 0.567 | 0.993 | 1 |
| 20 | 0.568 | 1 | 1 | |
| 30 | 0.573 | 1 | 1 |
| Dataset No. | Observations | Source |
|---|---|---|
| 1 | 0.019, 0.129, 0.159, 0.203, 0.485, 0.636, 0.748, 0.781, 0.869, 1.175, 1.206, 1.219, 1.219, 1.282, 1.356, 1.362, 1.458, 1.564, 1.586, 1.592, 1.781, 1.923, 1.959, 2.134, 2.413, 2.466, 2.548, 2.652, 2.951, 3.038, 3.6, 3.655, 3.745, 4.203, 4.690, 4.888, 5.143, 5.167, 5.603, 5.633, 6.192, 6.655, 6.874 | Bakr et al. [5] |
| 2 | 1.1, 1.4, 1.3, 1.7, 1.9, 1.8, 1.6, 2.2, 1.7, 2.7, 4.1, 1.8, 1.5, 1.2, 1.4, 3.0, 1.7, 2.3, 1.6, 2.0 | Jamal et al. [32] |
| 3 | 3.1091, 3.3825, 3.1444, 3.2135, 2.4946, 3.5146, 4.9274, 3.3769, 6.8686, 3.0914, 4.9378, 3.1091, 3.2823, 3.8594, 4.0480, 4.1685, 3.6426, 3.2110, 2.8636, 3.2218, 2.9078, 3.6346, 2.7957, 4.2781, 4.2202, 1.5157, 2.6029, 3.3592, 2.8349, 3.1348, 2.5261, 1.5806, 2.7704, 2.1901, 2.4141, 1.9048 | Almetwally et al. [33] |
| 4 | Censored observations: 0.57, 1.86, 3.00, 3.00, 0.14, 0.14, 0.29, 0.43, 0.57, 3.29, 3.29, 6.00 6.00, 6.14, 8.71, 10.57, 11.86, 15.57, 16.57, 27.57, 32.14, 33.14, 47.29, 17.29, 18.71, 21.29, 23.86, 26.00 | Kamran Abbas et al. [34] |
| Uncensored: 0.43, 2.86, 3.14, 3.14, 3.43, 3.43, 3.71, 3.86, 6.14, 6.86, 9.00, 9.43 10.71, 10.86, 11.14, 13.00, 14.43, 15.71, 18.43, 18.57, 20.71, 29.14, 29.71, 40.57, 48.57, 49.43, 53.86, 61.86, 66.57, 68.71, 68.96, 72.86, 72.86. |
| Data # 1 | ||
| Data # 2 | ||
| Data # 3 |
| n | 90% | 95% | 99% | 90% | 95% | 99% |
|---|---|---|---|---|---|---|
| 5 | 0.498088 | 0.636364 | 0.636364 | 0.766628 | 0.960396 | 0.960396 |
| 10 | 0.336134 | 0.382473 | 0.517396 | 0.573876 | 0.666684 | 0.799073 |
| 15 | 0.265439 | 0.323231 | 0.430404 | 0.467642 | 0.55297 | 0.662725 |
| 20 | 0.208552 | 0.275179 | 0.356835 | 0.408777 | 0.471459 | 0.570148 |
| 25 | 0.165984 | 0.206825 | 0.290894 | 0.367748 | 0.414611 | 0.529359 |
| 30 | 0.152646 | 0.196752 | 0.277819 | 0.323765 | 0.369765 | 0.467179 |
| 35 | 0.124209 | 0.163155 | 0.240493 | 0.305978 | 0.35976 | 0.442183 |
| 40 | 0.101562 | 0.143398 | 0.214079 | 0.272452 | 0.319695 | 0.400209 |
| 45 | 0.0849952 | 0.123347 | 0.197554 | 0.263558 | 0.306832 | 0.391493 |
| 50 | 0.0887608 | 0.140263 | 0.202561 | 0.258478 | 0.312231 | 0.402083 |
| 55 | 0.0719956 | 0.109207 | 0.199241 | 0.243516 | 0.282715 | 0.345942 |
| 60 | 0.0642098 | 0.100345 | 0.168729 | 0.226144 | 0.261391 | 0.332767 |
| 65 | 0.0539372 | 0.0898383 | 0.162777 | 0.216027 | 0.245622 | 0.325733 |
| 70 | 0.0412581 | 0.0808866 | 0.149023 | 0.198931 | 0.234524 | 0.303373 |
| 75 | 0.0359189 | 0.0682674 | 0.127837 | 0.198921 | 0.236463 | 0.297495 |
| 80 | 0.0330002 | 0.0635518 | 0.119355 | 0.197349 | 0.223904 | 0.279493 |
| 85 | 0.0310688 | 0.0656815 | 0.120076 | 0.191855 | 0.227 | 0.300977 |
| 90 | 0.0243409 | 0.0542047 | 0.107965 | 0.182472 | 0.208744 | 0.288981 |
| 95 | 0.0182163 | 0.0497125 | 0.111521 | 0.17774 | 0.208666 | 0.262691 |
| 100 | 0.00599188 | 0.0371824 | 0.0824509 | 0.173808 | 0.205047 | 0.259568 |
| Distribution | n | |||
|---|---|---|---|---|
| LFR | 10 | 0.956 | 0.96 | 0.971 |
| 20 | 0.983 | 0.991 | 0.999 | |
| 30 | 0.991 | 0.992 | 1 | |
| Weibull | 10 | 1 | 1 | 1 |
| 20 | 1 | 1 | 1 | |
| 30 | 1 | 1 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bakr, M.E. Statistical Modeling for Some Real Applications in Reliability Analysis Using Non-Parametric Hypothesis Testing. Symmetry 2023, 15, 1735. https://doi.org/10.3390/sym15091735
Bakr ME. Statistical Modeling for Some Real Applications in Reliability Analysis Using Non-Parametric Hypothesis Testing. Symmetry. 2023; 15(9):1735. https://doi.org/10.3390/sym15091735
Chicago/Turabian StyleBakr, Mahmoud E. 2023. "Statistical Modeling for Some Real Applications in Reliability Analysis Using Non-Parametric Hypothesis Testing" Symmetry 15, no. 9: 1735. https://doi.org/10.3390/sym15091735