
SI-GCN: Modeling Specific-Aspect and Inter-Aspect Graph Convolutional Networks for Aspect-Level Sentiment Analysis

Abstract
1. Introduction
- We propose the SI-GCN, a novel model for aspect-level sentiment analysis that integrates syntactic dependencies, contextual information, and commonsense knowledge within a unified GCN framework. This integrated approach enables the SI-GCN to effectively capture sentiments associated with aspects that lack explicit emotional expressions, addressing the limitations of previous methods.
- We introduce a dual affine attention mechanism in the SI-GCN that combines specific-aspect and inter-aspect emotional features. This mechanism allows the model to capture both the direct sentiment linked to a particular aspect and the influence of other aspects within the same context, resulting in a more nuanced sentiment analysis compared to prior models that treat aspects in isolation.
- Extensive experiments on four standard datasets demonstrate that the SI-GCN significantly outperforms existing baseline models in terms of accuracy and F1 score. Its superior performance, particularly in handling multi-word aspects without explicit emotional cues, validates the effectiveness and generalizability of our model in aspect-level sentiment analysis.
2. Related Work
2.1. Aspect-Level Sentiment Analysis
2.2. Graph Convolutional Network
- Zhao et al. [49] proposed a GCN framework that incorporates a bidirectional attentional mechanism. By leveraging positional information, their model effectively captures aspect-specific sentiment signals, demonstrating improved performance in sentiment analysis tasks.
- Global and Local Dependency Guided GCNs (GL-GCN): Zhu et al. [50] introduced the GL-GCN, a novel architecture that integrates both global and local dependency information. This approach effectively captures structural characteristics, emphasizing the importance of combining different dependency types for a more comprehensive understanding of sentiment.
3. Problem Definition
- represents a sentence consisting of m words.
- defines an aspect consisting of n words which form a sub-sequence within sentence S. The “start” index specifies the initial position of the aspect within the sentence, highlighting its contextual boundaries.
- (0) for neutral;
- (1) for positive;
- (2) for negative.
- (1)
- Aspect 1: camera quality
- Aspect Sub-sequence: .
- .
- Contextual Analysis: The sentiment toward this aspect is influenced by the phrase “is excellent”, which positively describes the camera quality.
- Sentiment Polarity: (Positive).
- (2)
- Aspect 2: battery life
- Aspect Sub-sequence: .
- .
- Contextual Analysis: The sentiment toward this aspect is influenced by the phrase “is disappointing”, which negatively describes the battery life.
- Sentiment Polarity: (Negative).
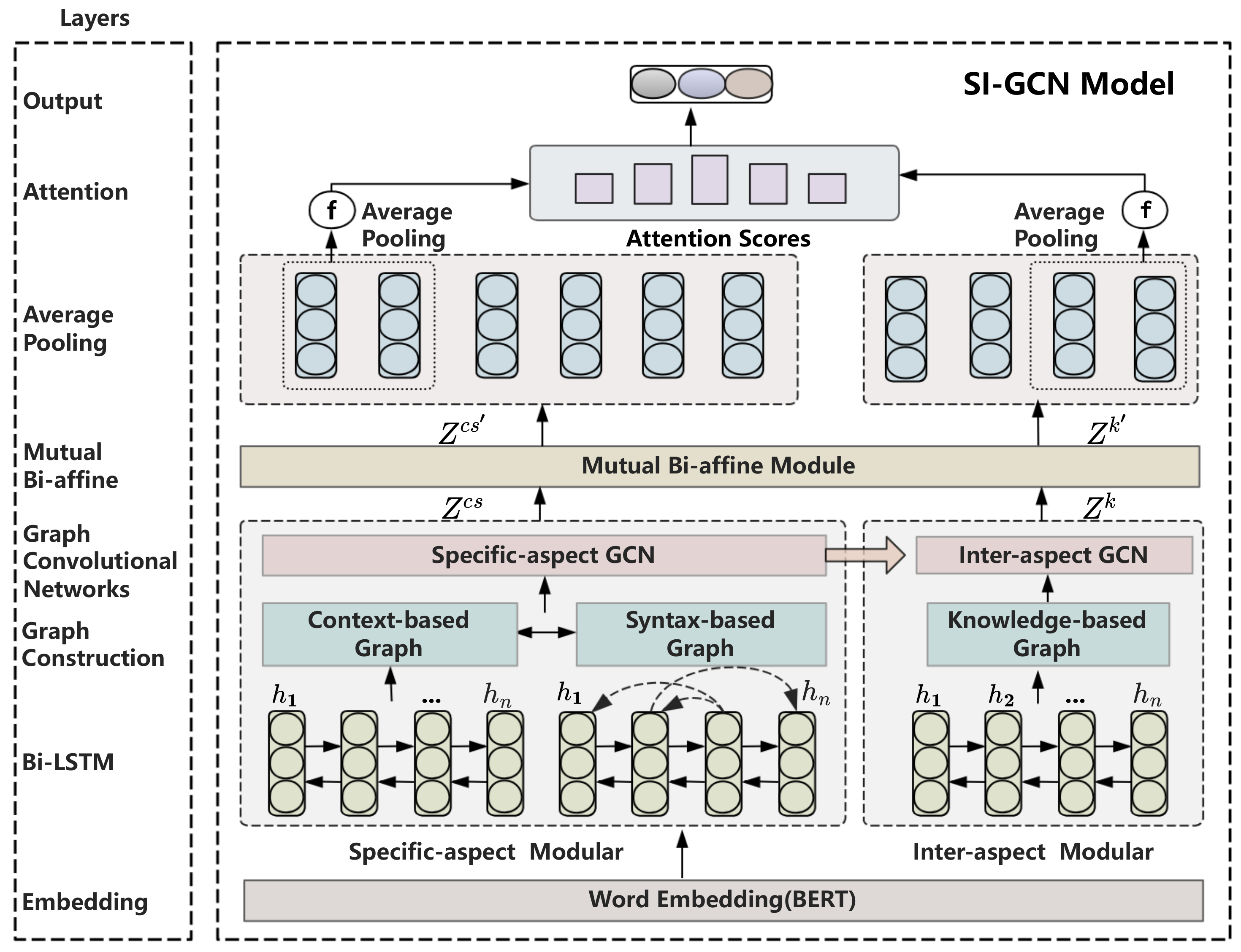
4. Methodology
- Research Goals: The primary objectives of this research encompass two aspects. First, we aim to develop an innovative method for ALSA that integrates various data sources, including syntactic dependencies, contextual information, and commonsense knowledge. Second, we seek to evaluate the performance of the SI-GCN model against existing state-of-the-art models within specific sentiment analysis tasks, thereby establishing its efficacy and robustness.
- Theoretical Framework: This study is grounded in the foundational principles of Graph Convolutional Networks (GCNs), while also extending and innovating upon this framework to address the complex challenges of aspect-level sentiment analysis. We introduce two novel variants of GCNs: the Specific-aspect GCN and the Inter-aspect GCN. These models are specifically designed to capture the intricacies of sentiment expression with remarkable precision. The Specific-aspect GCN focuses on isolating and analyzing sentiment related to individual aspects, ensuring that the model’s attention is not diluted by irrelevant information. This specialized GCN employs an advanced graph construction technique that explicitly represents the relationships between aspect-specific features and their corresponding sentiments, thereby enhancing the model’s ability to detect subtle variations in sentiment. Complementing the Specific-aspect GCN is the Inter-aspect GCN, which is designed to capture the interdependencies and interactions among different aspects. This component enables a comprehensive understanding of the sentiment landscape by modeling how the sentiment of one aspect may influence another, effectively addressing a critical limitation of existing GCN-based approaches.
- (1)
- Initial Feature Extraction (Section 4.1): The process begins with advanced embedding techniques, utilizing pre-trained models like BERT to generate high-dimensional semantic representations of input text. These embeddings encode rich contextual information, serving as the foundational input for subsequent modules.
- (2)
- Graph Construction (Section 4.2): The SI-GCN model constructs interconnected graphs that represent diverse linguistic and semantic relationships essential for ALSA tasks. Four graph types are developed:
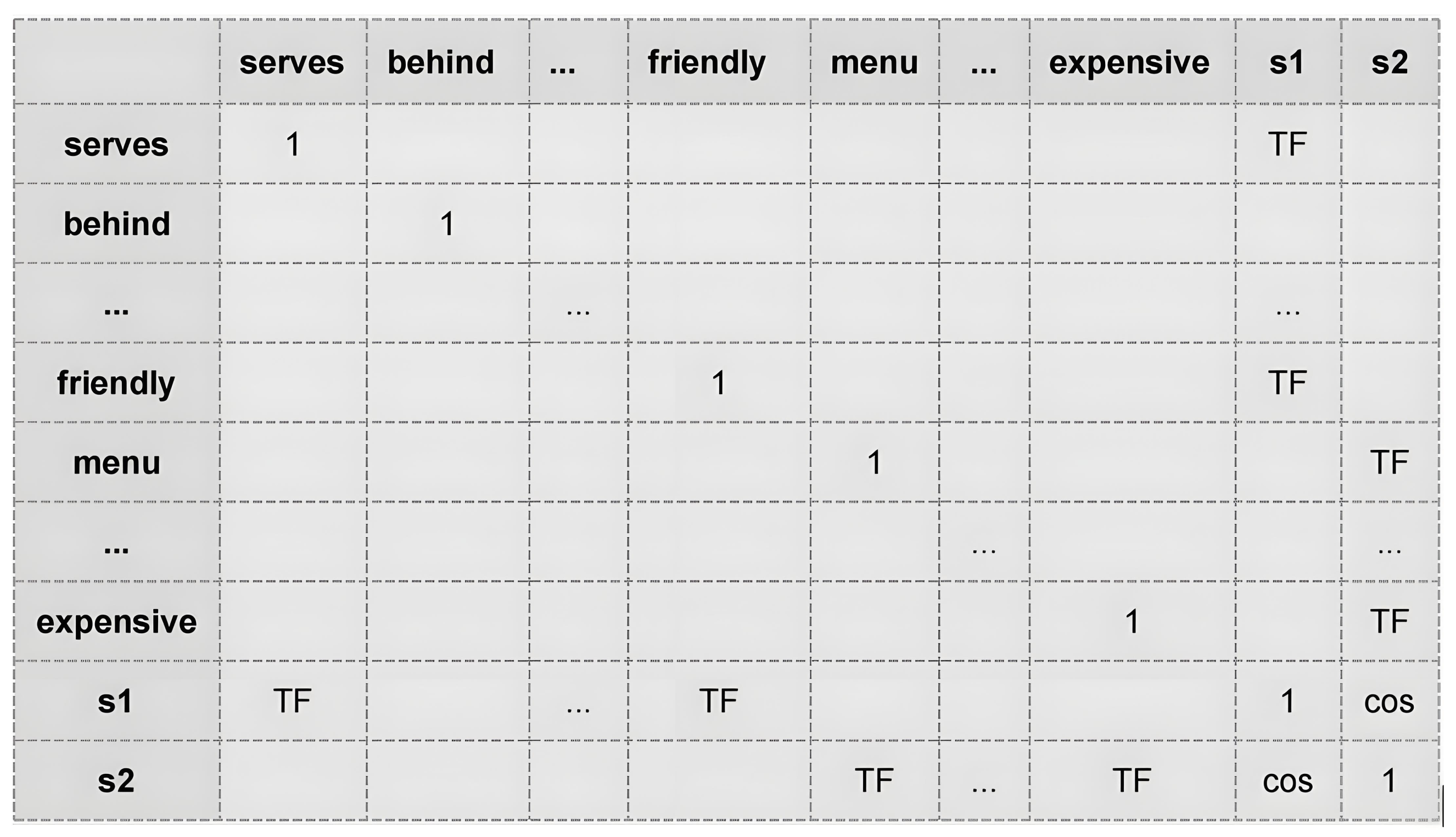
- Context-Based Graph (Section 4.2.1): This graph highlights interactions between aspect terms and their surrounding context, with connections determined using semantic measures such as cosine similarity and term frequency-inverse document frequency (TF-IDF).
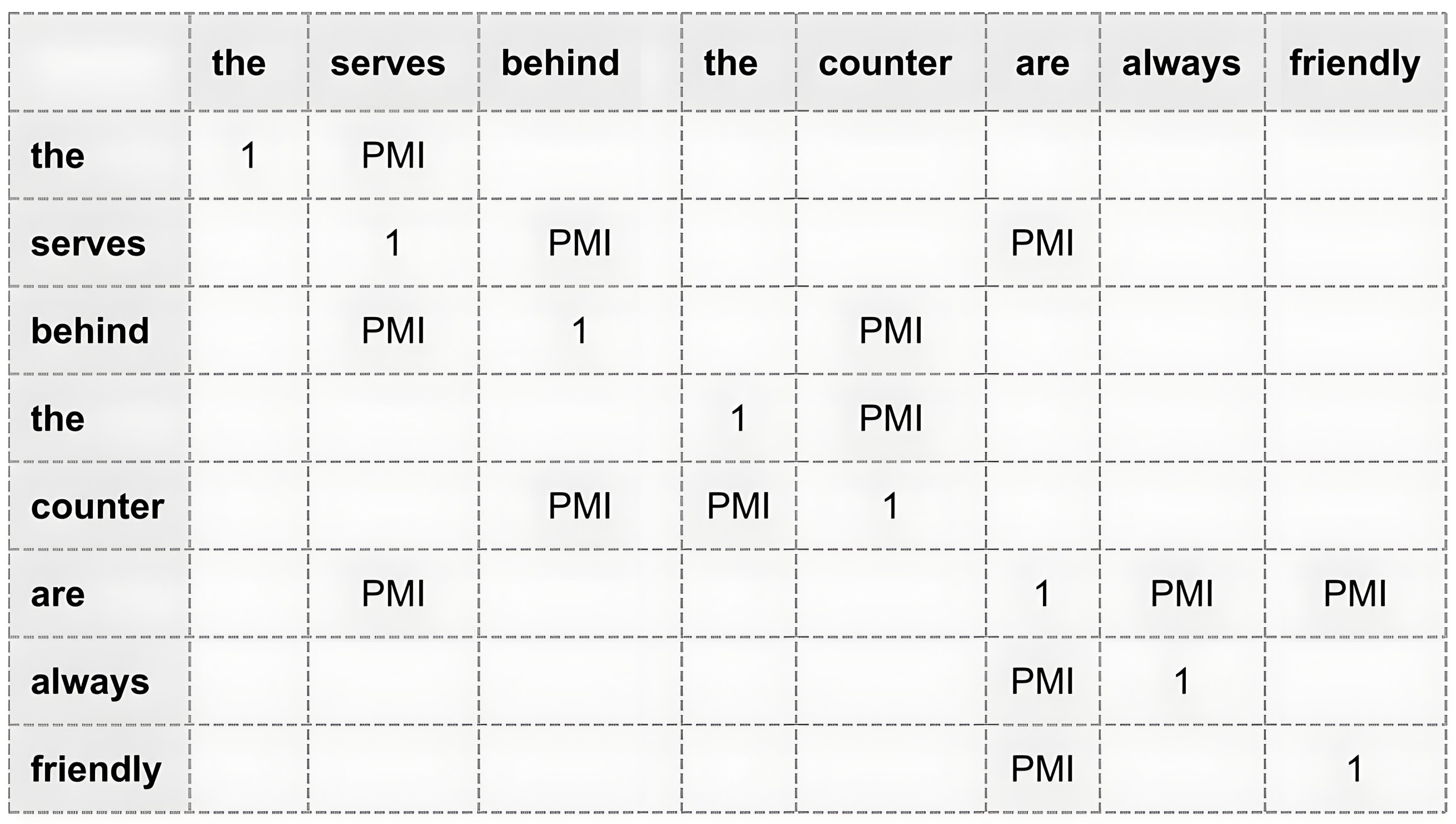
- Syntax-Based Graph (Section 4.2.1): Derived from syntactic dependency parsing, this graph models structural relationships, including subjects, objects, and predicates, quantified using Pointwise Mutual Information (PMI).
- Context–Syntax Graph (Section 4.2.1): By merging the context and syntax graphs, this unified graph captures both semantic and syntactic dependencies, providing a holistic view of textual relationships.
- Knowledge-Based Graph (Section 4.2.2): Integrating external commonsense knowledge from SenticNet6 [51], this graph links textual words to conceptual nodes (e.g., emotions and polarity) to enrich semantic understanding.
- (3)
- Specific-Aspect Module (Section 4.2.1): The Specific-aspect GCN processes the context–syntax graph to analyze the target aspect in relation to its contextual and syntactic surroundings. Iterative graph convolutions produce node-level representations that encapsulate aspect-specific sentiment information.
- (4)
- Inter-Aspect Module (Section 4.2.2): Leveraging the knowledge graph , the Inter-aspect GCN models interactions among multiple aspects within a sentence. By incorporating commonsense relationships and implicit connections, this module captures relational sentiment dynamics across aspects.
- (5)
- Mutual Bi-Affine Module (Section 4.3): The outputs from the Specific-aspect GCN and Inter-aspect GCN are refined through the Bi-affine module, which employs dual transformations to enhance feature interactions. Average pooling aggregates the aspect node representations, enabling efficient feature fusion.
- (6)
- Attention Scores and Prediction (Section 4.4): A retrieval-based attention mechanism dynamically assigns weights to context terms, highlighting the most relevant features associated with aspect terms. The aggregated features are used to refine the aspect-specific input. The final layer applies a softmax function to classify the sentiment polarity (positive, negative, or neutral) for each aspect. This layer leverages the fused representations and attention-enhanced features for precise predictions.
- (7)
- Comprehensive Execution Steps of the SI-GCN Model (Section 4.5): This section provides a detailed explanation of the SI-GCN algorithm, outlining its comprehensive workflow.
4.1. Initial Feature Extraction
4.1.1. Word Embedding: Foundation of Semantic Analysis
4.1.2. Bi-LSTM: Contextual Embeddings from Sequential Data
- (1)
- Input to Bi-LSTM: The output from the BERT embeddings (Section 4.1.1) serves as the input to our Bi-LSTM network. Each word’s BERT embedding, which encapsulates both the lexical semantics and the contextual nuances thanks to the BERT attention mechanisms, is processed by the Bi-LSTMs to extract even more refined features that consider bidirectional contextual dependencies.
- (2)
- Operation of Bi-LSTM: The Bi-LSTM processes these embeddings to produce two sets of hidden states: forward hidden states () and backward hidden states (). These hidden states of a word are generated as follows:where represents the embedded representation of the i-th word from the BERT model, denotes the parameters of the LSTM, and represents the vector concatenate operation. To distinguish the different focuses of feature extraction by Bi-LSTM in our SI-GCN model, we denote the hidden contextual representations derived from Bi-LSTM as for context sequences and for aspect sequences.
4.2. Core Analytical Framework: Graph Convolutional Networks
- Vertices: Represent words in the sentences.
- Edges: Depict relationships between words. These could be syntactic, as derived from dependency parsing, or semantic, sourced from domain knowledge or commonsense relationships.
- Adjacency Matrix A: The matrix effectively represents these connections, where if there is a relationship between the i-th and j-th word and 0 otherwise.
- (1)
- Specific-aspect GCN (Specific-GCN): This GCN employs a context–syntax graph to model the intricate relationships within sentence structures, emphasizing syntactical and contextual interdependencies pertinent to the identified aspects. This enables the Specific-GCN to effectively focus on and identify sentiment polarities associated with particular aspects.
- (2)
- Inter-aspect GCN (Inter-GCN): This GCN leverages a knowledge graph to integrate extensive semantic relationships and commonsense knowledge, enhancing the contextual understanding required for accurate sentiment interpretation across multiple aspects. This approach enables sentiment analysis to go beyond the surface-level text, incorporating inferred meanings and relational knowledge for a deeper understanding.
4.2.1. Specific-Aspect Module
- (1)
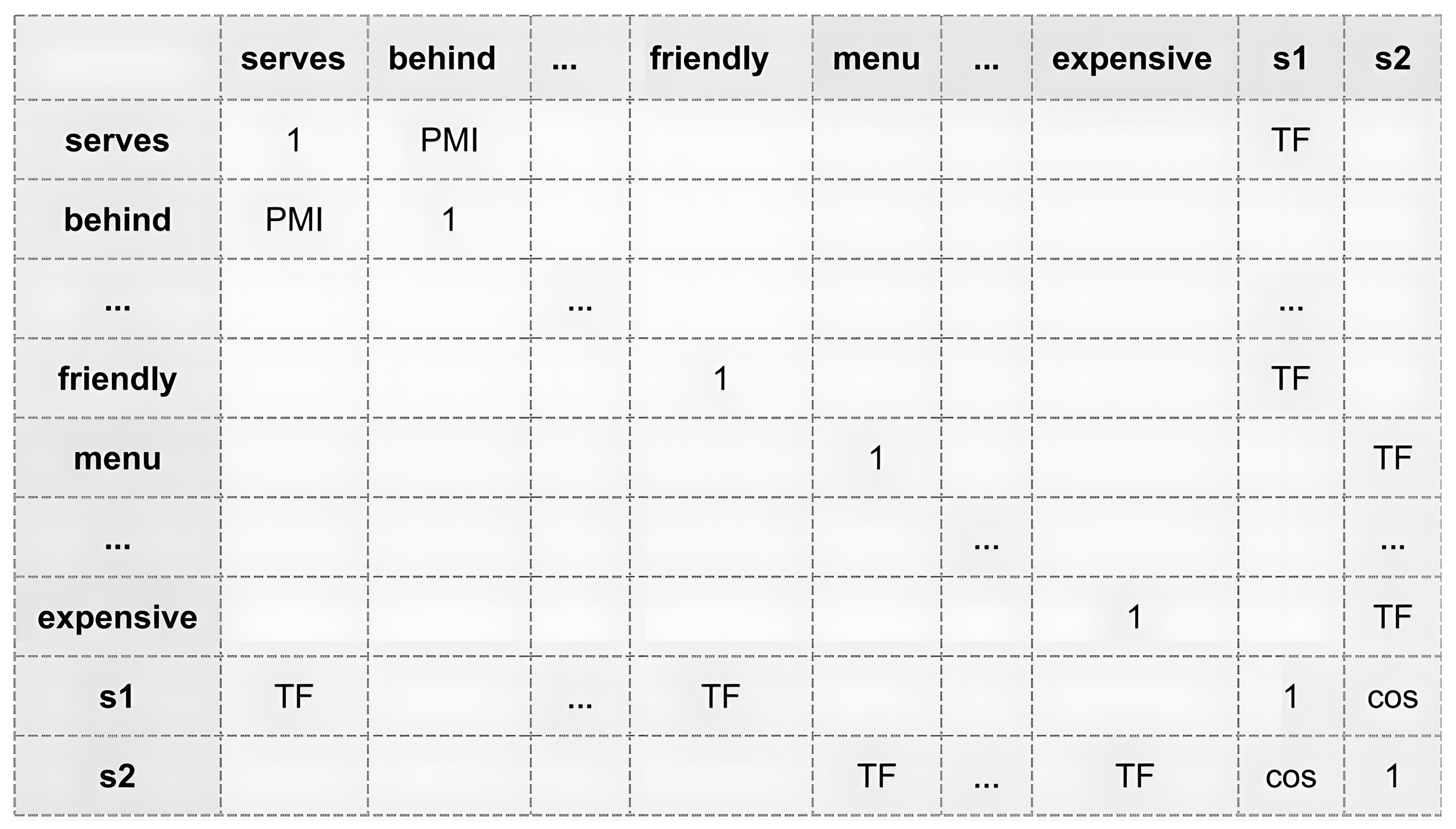
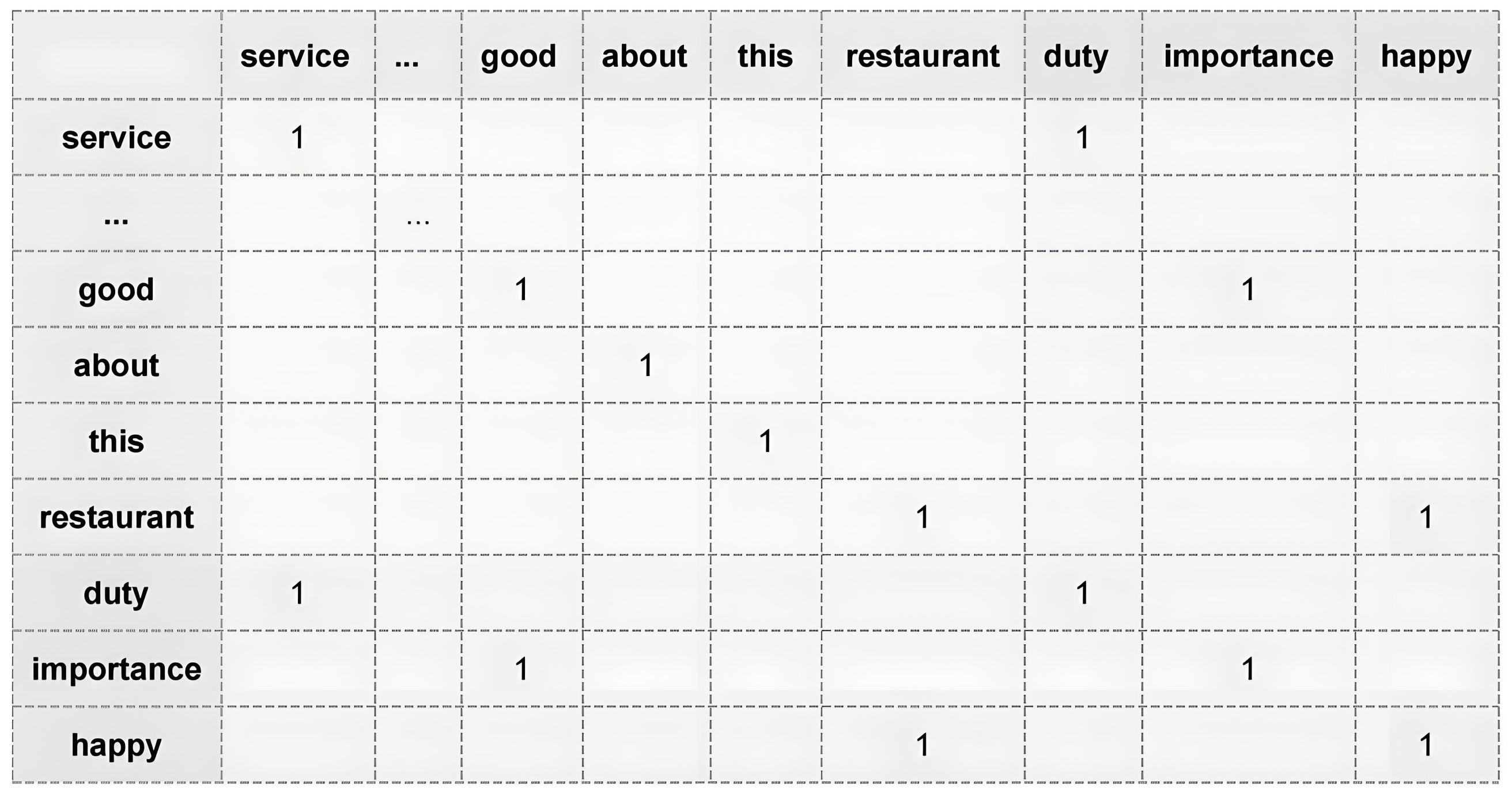
- Construction of context-based graph: .
- Vertices: : These represent not only individual words within a sentence but also the sentence as a whole, thereby enhancing contextual understanding.
- Edges: : These connections span all vertices to capture the diverse relationships that may influence sentiment.
- Adjacency Matrix: : This matrix is essential for representing the intricate connections within the graph, constructed based on varying degrees of contextual association among nodes.
- (2)
- Construction of Syntax-based Graph: .
- Vertices: : Represent all words in the sentence, encapsulating each word as a discrete node within the graph.
- Edges: : These are formed based on syntactic dependencies identified between words, such as nominal subjects (nsubj), objects (pobj), and determiners (det).
- Adjacency Matrix: : This matrix captures the presence and strength of syntactic connections between word pairs within the sentence.
- (3)
- Synthesize: and to construct context and syntax graph: .
- Vertices: : The vertices consist of the union of the nodes from both the context-based and syntax-based graphs , incorporating all words and sentence-level entities. This allows to leverage both contextual and syntactic properties of the text.
- Edges: : The edge set combines relationships defined in both and , i.e., , facilitating a comprehensive representation that incorporates both types of linguistic connections—contextual and syntactic.
- Adjacency Matrix: : The adjacency matrix for is a fusion of the matrices from and , where the interactions between nodes are based on multiple dimensions of textual relationships:
- (4)
- Implementation of Specific-aspect GCN.
| Algorithm 1 Running process of Specific-aspect GCN via context–syntax graph. |
| Require: A sentence–aspect pair Ensure: The output of Specific-aspect GCN 1: for ; do 2: ▹ Construct a Contextual adjacency matrix 3: if then 4: 5: else if then 6: 7: else if then 8: 9: else 10: 11: end if 12: ▹ Construct a Syntax adjacency matrix 13: if then 14: 15: else if then 16: 17: else 18: 19: end if 20: ▹ Construct a context–syntax adjacency matrix 21: Similar to the above, we obtain by Equation (7) 22: Finally, is obtained from via Equation (8) 23:end for |
4.2.2. Inter-Aspect Module
- (1)
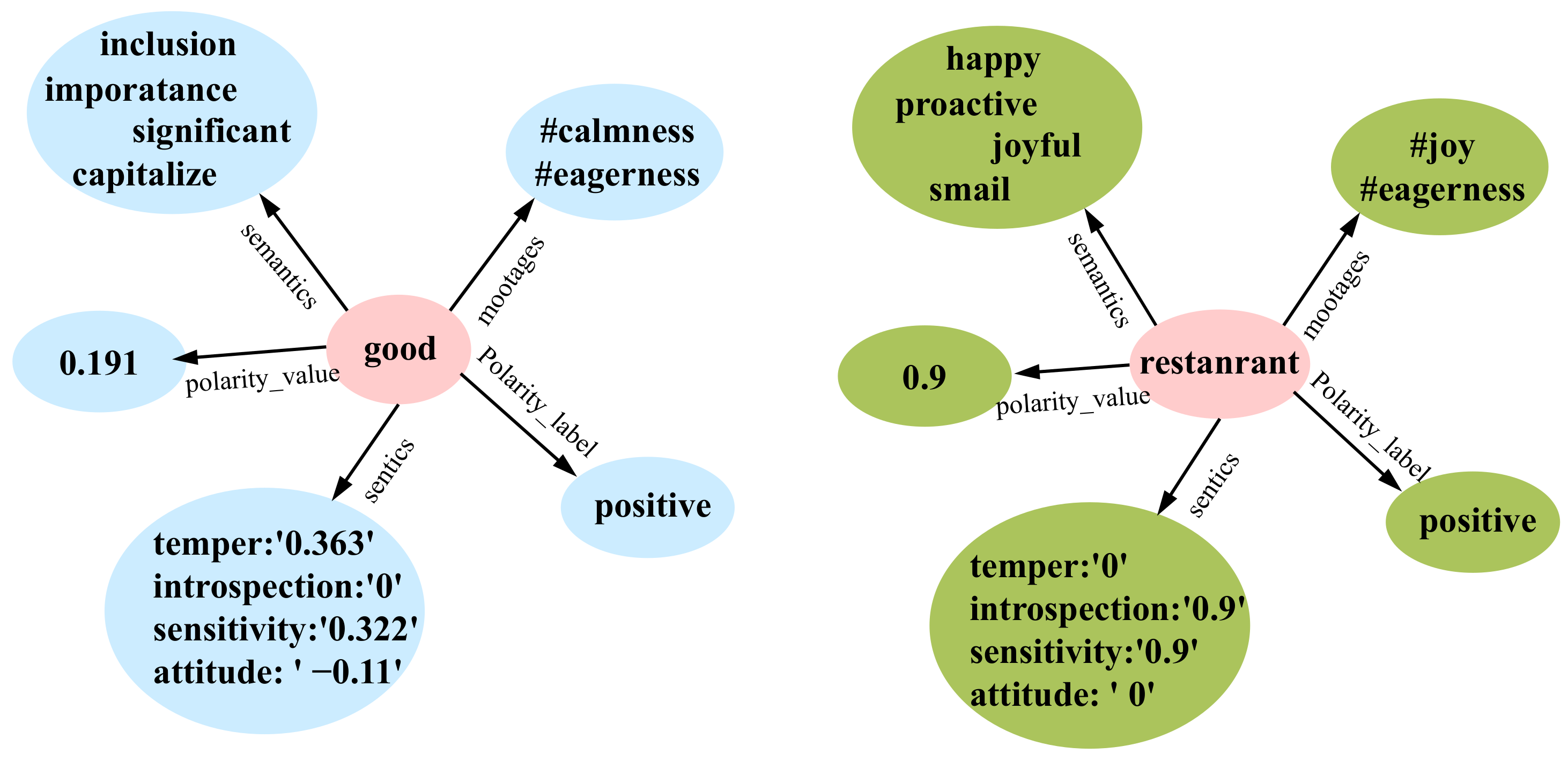
- Construction of Knowledge-based Graph: .
- Polarity_label: This parameter indicates the sentiment classification of a word as positive, negative, or neutral, with several subcategories for each label.
- Polarity_value: This parameter quantifies the emotional intensity or polarity of a word, typically represented as a specific value. Higher values correspond to greater emotional strength.
- Sentics: This parameter offers fine-grained sentiment analysis, encompassing dimensions such as introspection, sensitivity, attitude, and temper.
- Semantics: This parameter identifies words with semantic relationships to the specified term. For example, the word “good” is semantically related to “significant”, among others.
- Vertices: : The graph’s vertices include two primary types of nodes: word nodes and knowledge nodes. Word nodes represent the actual words or terms within the analyzed text. Knowledge nodes represent conceptual or categorical information related to the words, derived from extensive knowledge bases though SenticNet. They encapsulate broader semantic and relational data that enrich the contextual understanding of words.
- Edges: : The edge set includes connections between all pairs of nodes, regardless of their type. These edges play a vital role in capturing both explicit and implicit relationships.
- Adjacency Matrix: : This matrix forms the core of the graph’s structural definition and is detailed by the following rules:
- (2)
- Implementation of Inter-aspect GCN.
| Algorithm 2 Running process of Inter-aspect GCN via knowledge-based graph. |
| Require: A sentence–aspect pair Ensure: The output of Inter-aspect GCN 1: for ; do 2: ▹ Construct the adjacency matrix of a knowledge graph 3: if then 4: 5: else if then 6: 7: else if then 8: 9: else 10: 12: Finally, is obtained from via Equation (10) 13: end for |
4.3. Mutual Bi-Affine Module: Enhancing Feature Interactions
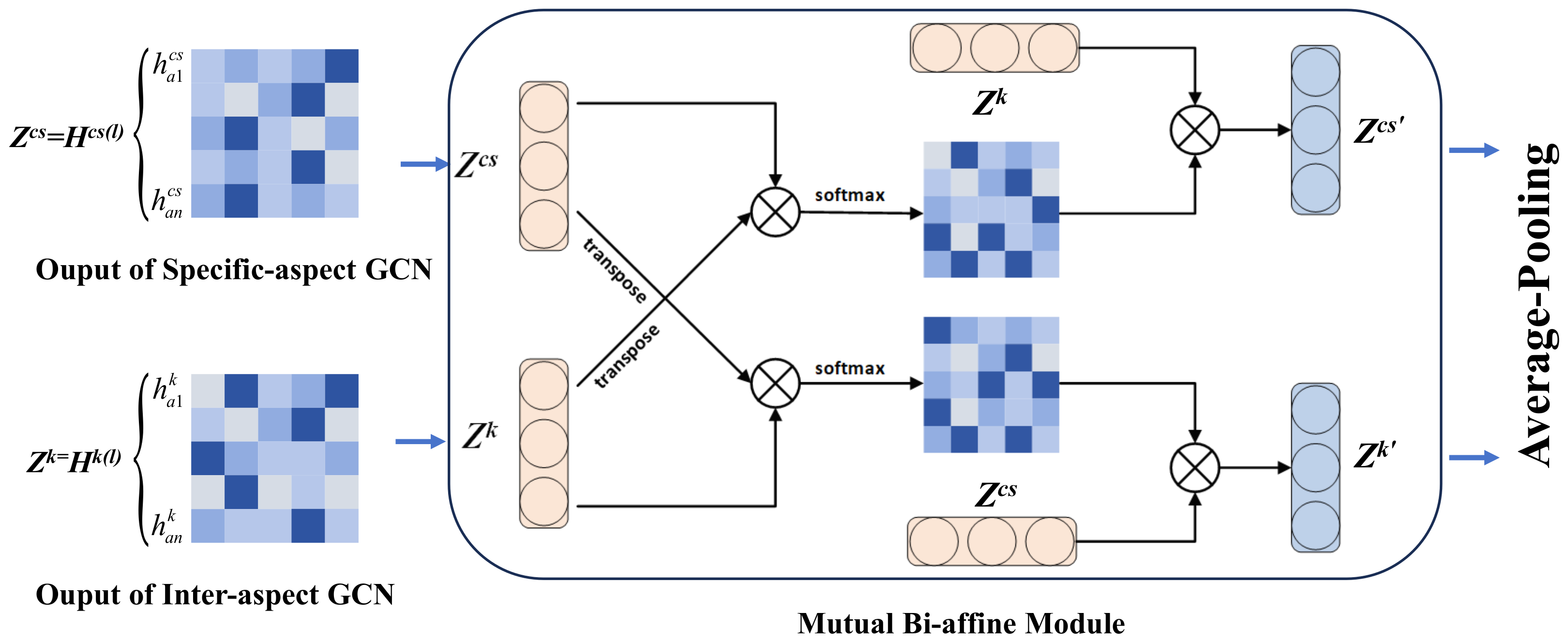
4.4. Attention Scores: Prioritizing Relevant Features
4.5. Comprehensive Execution Steps of the SI-GCN Model
| Algorithm 3 Workflow of the SI-GCN model. |
| Input: Sentence–aspect couple , where represents the sentence with m words, denotes the aspect with n-words Output: Aspect sentiment polarity y 1: Obtain output through Specific-aspect module 2: Obtain output through Inter-aspect module 3: Using the Bi-affine module to obtain the output and of both modules by Equations (11) and (12) 4: Using average-pooling to fuse the node representations of the two modules r by Equations (13)–(15) 5: Leveraging a retrieval-based attention strategy to extract key features linked to aspect words as defined by Equations (16) and (17) 6: Using softmax to obtain the final classification result y by Equation (18) 7: return |
5. Experiments
5.1. Datasets and Experiment Setting
5.2. Evaluation Metrics
5.3. Baseline Methods
- (1)
- Syntax-based Methods:
- R-GAT [57]: This method introduces an innovative aspect-centric dependency tree structure to effectively encapsulate syntactic details. By refactoring and pruning the standard dependency parse tree to focus on the target aspect, R-GAT enhances the model’s ability to capture crucial syntactic information relevant to the aspect.
- DGEDT [58]: The DGEDT model employs a dual-transformer architecture that combines planar representations derived from the transformer with graph-based representations from the dependency graph through iterative interactions. This approach effectively leverages the strengths of both representations, resulting in improved performance in modeling dependency relationships for aspect-level sentiment analysis tasks.
- LSTM+synATT+TarREP [30]: This model fuses syntactic details with an attention mechanism to bolster the representation of target terms.
- (2)
- Context-based Methods:
- TD-LSTM [59]: This model captures the context surrounding an aspect word using two LSTM networks. One LSTM processes the context from the left of the aspect word, while the other processes it from the right. The aspect word serves as the dividing marker for these directional models.
- ATAE-LSTM [28]: This model excels at identifying the relevance of context words to a given aspect by integrating an attention mechanism with LSTM. This combination enables effective semantic modeling of sentence structure with a focus on aspect-specific context.
- MemNet [29]: This model integrates the content and position of a specified aspect into a memory network by constructing memory representations based on contextual information. Through an attention mechanism, it captures the most relevant information to determine the emotional tendencies of different aspects.
- IAN [6]: To strengthen the attention mechanism on both aspect and context, IAN employs interactive learning between them. This approach generates representations for both targets and contexts, enabling the acquisition of context-dependent aspect representations.
- MGAN [60]: This model combines dependency trees with neural networks to extract sentence feature representations using Bi-LSTM. The architecture incorporates a broad-category aspect classification task to complement the detailed aspect item classification task and introduces an innovative attention mechanism to align features between the tasks effectively.
- (3)
- Knowledge-based Methods:
- Sentic-LSTM [60]: This model extends the traditional LSTM by integrating commonsense knowledge to guide information flow, enhancing its ability to process sentiment-related information effectively.
- SK-GCN1 and SK-GCN2 [37]: These models combine a syntactic dependency tree with a commonsense knowledge graph using GCN, forming a hybrid syntactic and knowledge-driven architecture. This integration significantly improves aspect-level sentiment analysis by leveraging both structural and conceptual relationships.
- (4)
- Other Neural Network Methods:
- ASGCN-DT and ASGCN-DG [20]: These models leverage GCN-based dependency trees to extract syntactic information and word dependencies. By utilizing directed and undirected graphs, they identify and capture sentiment specific to particular aspects.
- AGCN-MEAN and AGCN-MAX [61]: These models enhance the capability of graph convolutional networks to model emotions by incorporating two distinct aggregator functions. These functions gather information from adjacent nodes using different aggregation methods.
- AFGCN and InterGCN [33]: These approaches construct heterogeneous graphs for each instance by capturing specific-aspect focus and inter-aspect contextual dependencies. The interaction is facilitated by extracting emotional features from both aspect-focused and inter-aspect perspectives.
5.4. Main Results and Analysis
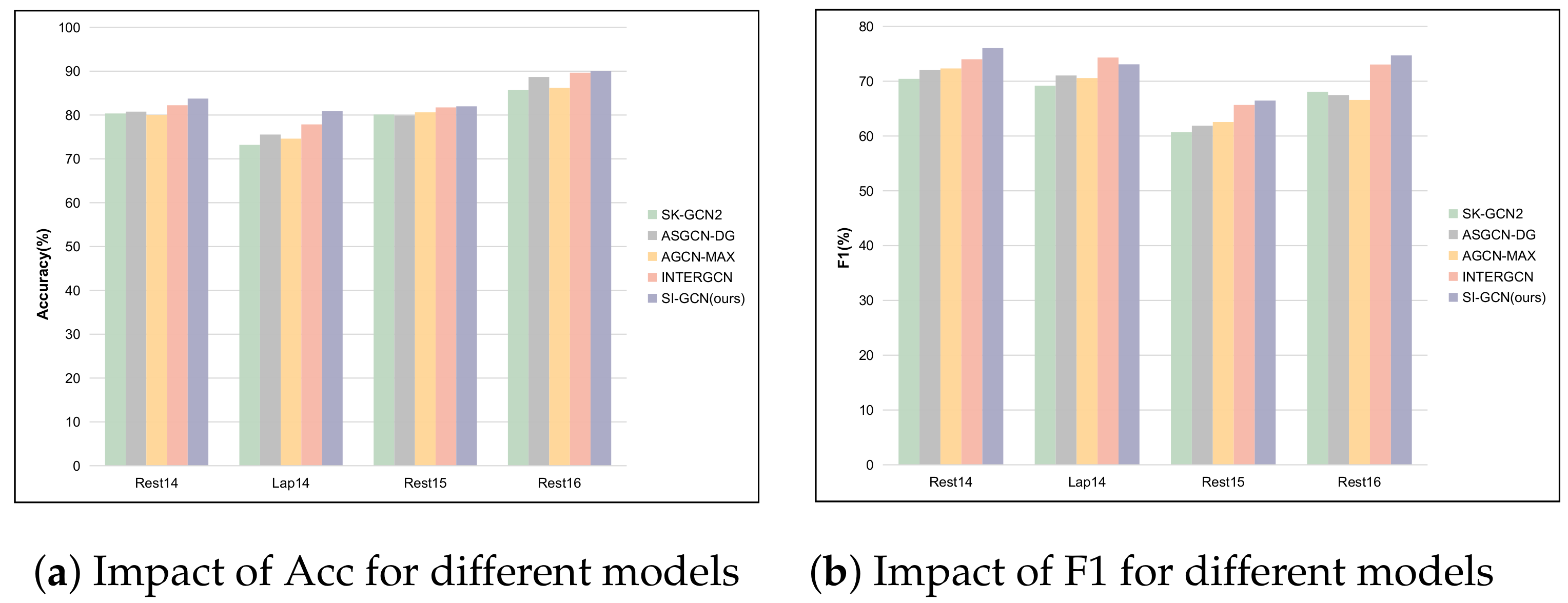
- Within the Laptop14 dataset, although the F1 score of the proposed SI-GCN model is slightly lower than that of the InterGCN model by 0.23%, the Acc is significantly higher, showing an improvement of 3.07%. Moreover, the SI-GCN model consistently outperforms other models that utilize syntactic, contextual, and knowledge-based information across the remaining three datasets. These experimental results confirm the effectiveness of SI-GCN for aspect-level sentiment analysis. The findings demonstrate that integrating multiple sources of information—context, syntax, and knowledge—from various perspectives significantly enhances sentiment analysis performance.
- Furthermore, the SI-GCN model achieves superior performance compared to ASGCN-DT and AGDCN-DG, which rely solely on heterogeneous graphs over syntactic dependencies. This underscores the importance of incorporating commonsense knowledge and contextual information alongside syntactic dependency trees for more effective aspect-level sentiment analysis.
- An intriguing observation from the experimental results is that models incorporating commonsense knowledge generally achieve higher average performance compared to those relying solely on syntactic or contextual information. This underscores the greater potential of commonsense knowledge in aspect-level sentiment analysis. Incorporating commonsense knowledge into the Specific-aspect module enables better identification of sentiment polarity in complex sentences and provides significant advantages in handling sentences with implicit sentiment polarity.
- In the Restaurant14 dataset, 36.58% of sentences contain multifaceted words. Compared to the best baseline model, InterGCN, the Acc and F1 values of SI-GCN are increased by 1.52% and 2.03%, respectively. These results demonstrate that our model excels in processing sentences with multiple aspect terms, highlighting the importance of the interactive extraction capabilities of both the Specific-GCN and Inter-GCN modules. The effectiveness of SI-GCN in handling multifaceted sentences emphasizes the critical role of incorporating both specific-aspect and inter-aspect contextual dependencies in aspect-level sentiment analysis tasks.
- Additionally, the SI-GCN model exhibits substantial improvements over the pre-trained BERT model. This indicates that our method can effectively augment the capabilities of pre-trained language models, thereby enhancing the performance of sentiment analysis tasks.
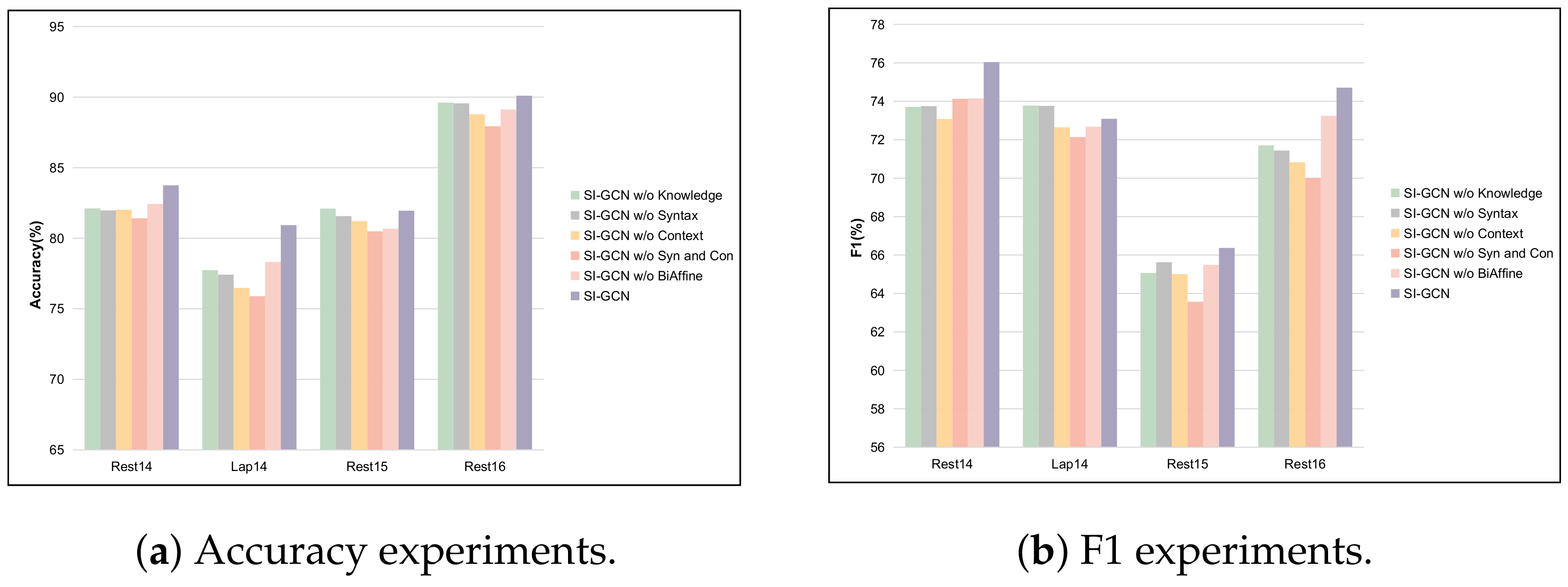
5.5. Ablation Study
- w/o Knowledge: This condition eliminates the SI-GCN knowledge branch (Inter-aspect module) and retains solely the Specific-aspect module.
- w/o Syn and Con: This condition eliminates the SI-GCN knowledge branch (Inter-aspect module) and retains solely the Specific-aspect module.
- w/o Syntax: This condition excludes syntactic information from the Specific-aspect module, maintaining both contextual information and the Inter-aspect module.
- w/o Context: This condition removes contextual information from the Specific-aspect module while preserving syntactic information and the Inter-aspect module.
- w/o Bi-affine: This condition eliminates the dual affine module, preventing interaction between the Specific-aspect module and the Inter-aspect module.
5.6. Discussion
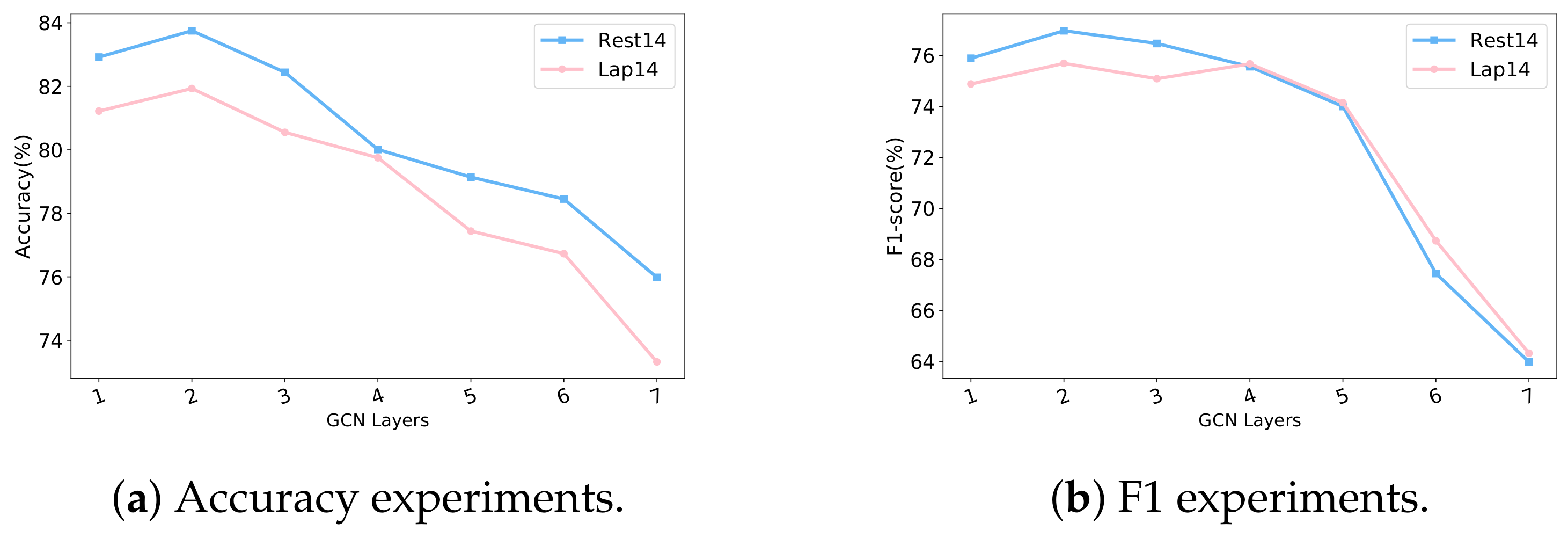
5.6.1. Influence of GCN Layer Configuration on Model Performance
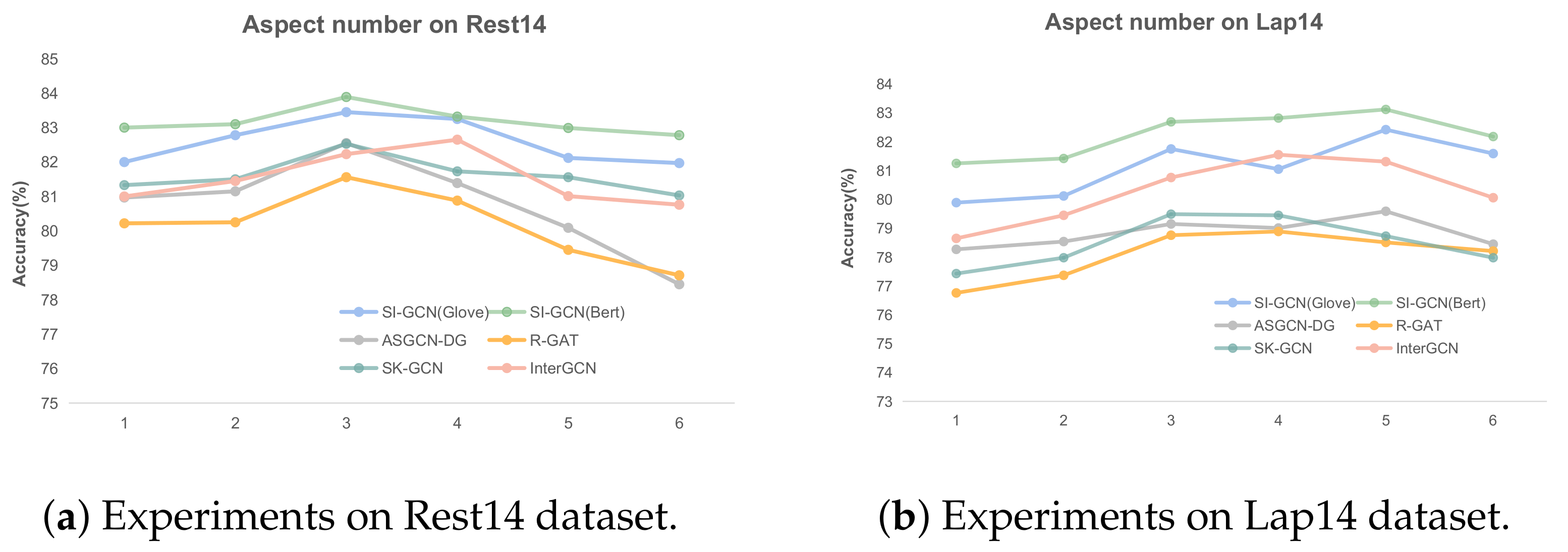
5.6.2. Model Accuracy for Multi-Aspect Discrimination
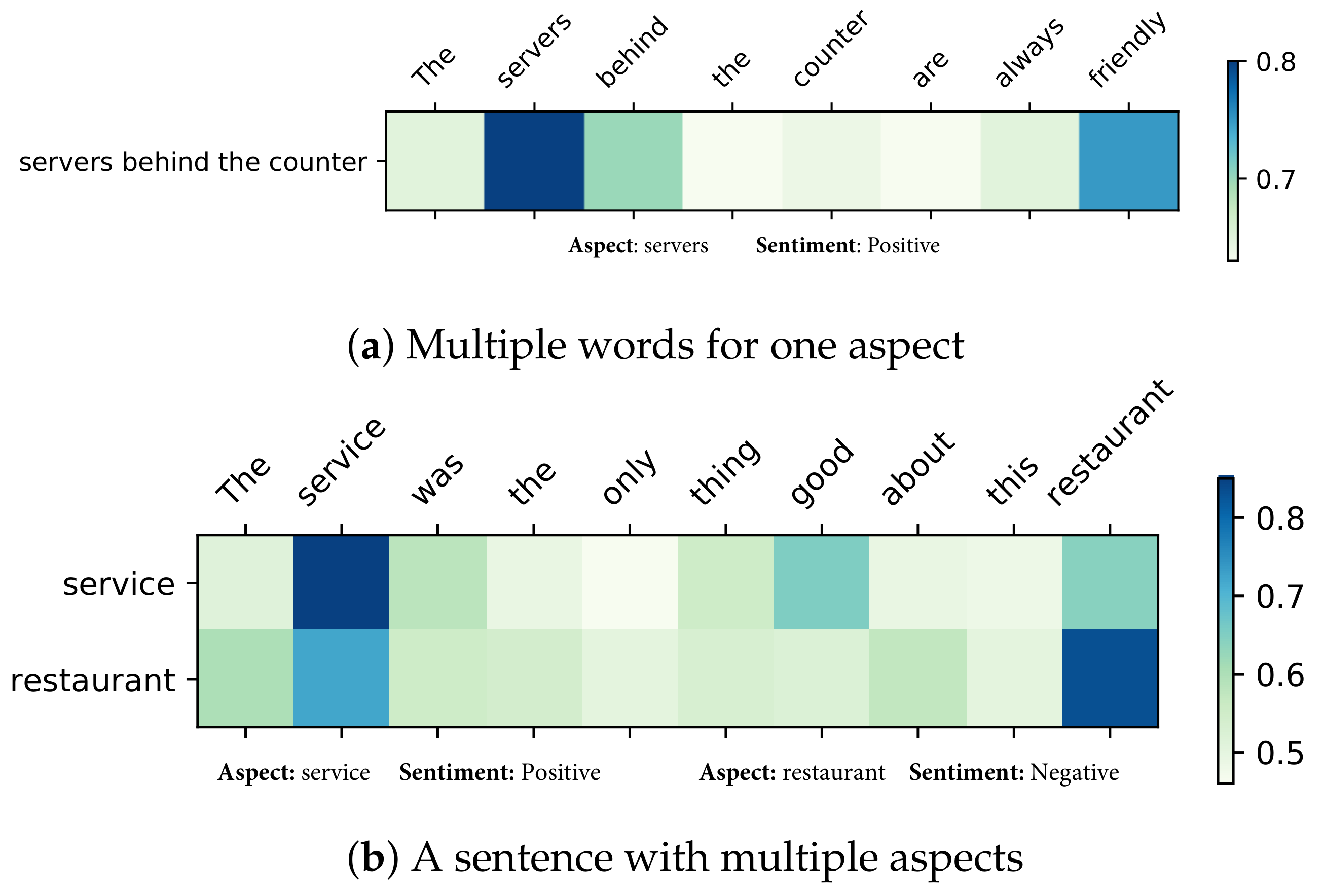
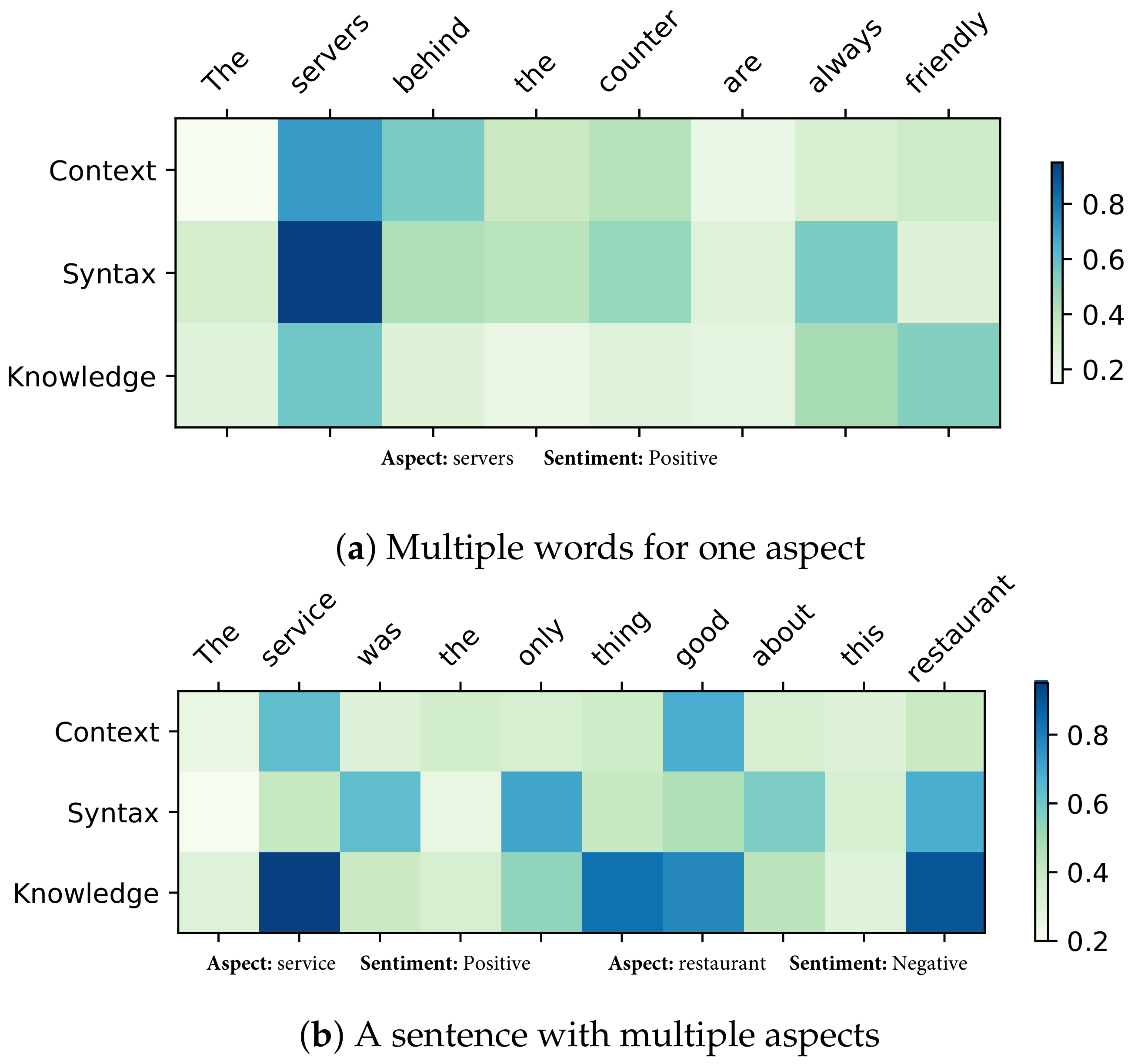
5.6.3. Visualization
- (1)
- Special Sentences
- The servers behind the counter are always friendly.
- The service was the only thing good about this restaurant.
- (2)
- Effect of Different Modules:
5.7. Case Study
- (1)
- In the first example, the sentence “food is good, but service is dreadful” demonstrates that all models successfully identify the relevant opinion word “great” associated with the aspect term “food”, resulting in an accurate prediction. This success is attributed to the close association between the aspect word “food” and its corresponding opinion word “great”. However, for the aspect term “service”, both the AT-LSTM and Specific-GCN models fail to accurately predict the corresponding opinion word “dreadful”.
- (2)
- In the analysis of the second example, the aspect word “place” lacks an explicit sentiment, and relying solely on its inherent meaning may lead other models to misclassify it as neutral. However, our SI-GCN model effectively determines the sentiment orientation of the aspect by integrating multi-view representations.
- (3)
- The third example involves a sentence with an aspect composed of multiple words, making it challenging for the model to accurately identify the focal point, specifically the word “size”. In such cases, models are more likely to focus on the modifying word “smaller”, resulting in incorrect predictions of negative sentiment. Nevertheless, our experimental results demonstrate that only the Specific-GCN and SI-GCN models accurately predict the sentiment polarity, underscoring the effectiveness of our model in capturing critical aspect words.
- (4)
- The fourth case involves a long, complex sentence. Our experiments showed that most models tend to focus on the words “replacing” and “problem” in the subordinate clause, leading to biased predictions for the aspect words.
- (5)
- Further analysis reveals that the context-based model ATAT-LATM and the syntax-based model Inter-GCN perform worse than combined models, such as Specific-GCN, which integrate both context and syntax. This observation suggests that a synergistic integration of these approaches can enhance the encoding of syntactic and contextual information, thereby establishing deeper relationships between aspects and their corresponding opinion terms.
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cheng, J.; Zhao, S.; Zhang, J.; King, I.; Zhang, X.; Wang, H. Aspect-level Sentiment Classification with HEAT (HiErarchical ATtention) Network. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 97–106. [Google Scholar] [CrossRef]
- Schouten, K.; Frasincar, F. Survey on Aspect-Level Sentiment Analysis. IEEE Trans. Knowl. Data Eng. 2016, 28, 813–830. [Google Scholar] [CrossRef]
- Zhou, J.; Huang, J.X.; Chen, Q.; Hu, Q.V.; Wang, T.; He, L. Deep Learning for Aspect-Level Sentiment Classification: Survey, Vision, and Challenges. IEEE Access 2019, 7, 78454–78483. [Google Scholar] [CrossRef]
- Fu, Y.; Chen, X.; Miao, D.; Qin, X.; Lu, P.; Li, X. Label-semantics enhanced multi-layer heterogeneous graph convolutional network for Aspect Sentiment Quadruplet Extraction. Expert Syst. Appl. 2024, 255, 124523. [Google Scholar] [CrossRef]
- Jiang, L.; Li, Y.; Liao, J.; Zou, Z.; Jiang, C. Research on non-dependent aspect-level sentiment analysis. Knowl.-Based Syst. 2023, 266, 110419. [Google Scholar] [CrossRef]
- Ma, D.; Li, S.; Zhang, X.; Wang, H. Interactive Attention Networks for Aspect-Level Sentiment Classification. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, VIC, Australia, 19–25 August 2017; pp. 4068–4074. [Google Scholar] [CrossRef]
- Liu, B.; Zhang, L. A Survey of Opinion Mining and Sentiment Analysis. In Mining Text Data; Springer: Boston, MA, USA, 2012; pp. 415–463. [Google Scholar] [CrossRef]
- Qiu, J.; Liu, C.; Li, Y.; Lin, Z. Leveraging sentiment analysis at the aspects level to predict ratings of reviews. Inf. Sci. 2018, 451, 295–309. [Google Scholar] [CrossRef]
- Zhang, F.; Zhou, Y.; Sun, P.; Xu, Y.; Han, W.; Huang, H.; Chen, J. CRAS: Cross-domain recommendation via aspect-level sentiment extraction. Knowl. Inf. Syst. 2024, 66, 5459–5477. [Google Scholar] [CrossRef]
- Li, Y.; Caragea, C. Multi-Task Stance Detection with Sentiment and Stance Lexicons. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 6298–6304. [Google Scholar] [CrossRef]
- Bhavan, A.; Mishra, R.; Sinha, P.P.; Sawhney, R.; Shah, R.R. Investigating Political Herd Mentality: A Community Sentiment Based Approach. In Proceedings of the 57th Conference of the Association for Computational Linguistics, Florence, Italy, 28 July– 2 August 2019; pp. 281–287. [Google Scholar] [CrossRef]
- Li, Q.; Weng, L.; Ding, X. A Novel Neural Network-Based Method for Medical Text Classification. Future Internet 2019, 11, 255. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, L.; Zeng, C.; Lu, W.; Chen, Y.; Fan, T. Construction of an aspect-level sentiment analysis model for online medical reviews. Inf. Process. Manag. 2023, 60, 103513. [Google Scholar] [CrossRef]
- Shadadi, E.; Kouser, S.; Alamer, L.; Whig, P. Novel approach of Predicting Human Sentiment using Deep Learning. J. Comput. Sci. Eng. 2022, 3, 107–119. [Google Scholar] [CrossRef]
- Fan, F.; Feng, Y.; Zhao, D. Multi-grained Attention Network for Aspect-Level Sentiment Classification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3433–3442. [Google Scholar] [CrossRef]
- Zheng, Y.; Li, X.; Su, G.; Ma, J.; Ning, C. Position-aware Hybrid Attention Network for Aspect-Level Sentiment Analysis. In Proceedings of the Information Retrieval—26th China Conference, Xi’an, China, 14–16 August 2020; Proceedings; pp. 83–95. [Google Scholar] [CrossRef]
- Xue, W.; Li, T. Aspect Based Sentiment Analysis with Gated Convolutional Networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 2514–2523. [Google Scholar] [CrossRef]
- Ren, F.; Feng, L.; Xiao, D.; Cai, M.; Cheng, S. DNet: A lightweight and efficient model for aspect based sentiment analysis. Expert Syst. Appl. 2020, 151, 113393. [Google Scholar] [CrossRef]
- Gao, R.; Jiang, L.; Zou, Z.; Li, Y.; Hu, Y. A Graph Convolutional Network Based on Sentiment Support for Aspect-Level Sentiment Analysis. Appl. Sci. 2024, 14, 2738. [Google Scholar] [CrossRef]
- Zhang, C.; Li, Q.; Song, D. Aspect-based Sentiment Classification with Aspect-specific Graph Convolutional Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 4567–4577. [Google Scholar] [CrossRef]
- Huang, B.; Carley, K.M. Syntax-Aware Aspect Level Sentiment Classification with Graph Attention Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 5468–5476. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–11. [Google Scholar] [CrossRef]
- Kiritchenko, S.; Zhu, X.; Cherry, C.; Mohammad, S.M. NRC-Canada-2014: Detecting Aspects and Sentiment in Customer Reviews. In Proceedings of the 8th International Workshop on Semantic Evaluation, Dublin, Ireland, 23–24 August 2014; pp. 437–442. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, Y.; Liu, T.; Duan, J. Deep Learning for Event-Driven Stock Prediction. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 2327–2333. [Google Scholar]
- Vo, D.; Zhang, Y. Target-Dependent Twitter Sentiment Classification with Rich Automatic Features. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 1347–1353. [Google Scholar]
- Yu, J.; Zha, Z.; Wang, M.; Chua, T. Aspect Ranking: Identifying Important Product Aspects from Online Consumer Reviews. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 1496–1505. [Google Scholar]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment Classification using Machine Learning Techniques. In Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing, Philadelphia, PA, USA, 6–7 July 2002; pp. 79–86. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based LSTM for Aspect-level Sentiment Classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016; pp. 606–615. [Google Scholar] [CrossRef]
- Tang, D.; Qin, B.; Liu, T. Aspect Level Sentiment Classification with Deep Memory Network. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016; pp. 214–224. [Google Scholar] [CrossRef]
- He, R.; Lee, W.S.; Ng, H.T.; Dahlmeier, D. Effective Attention Modeling for Aspect-Level Sentiment Classification. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1121–1131. [Google Scholar]
- Phan, M.; Ogunbona, P.O. Modelling Context and Syntactical Features for Aspect-based Sentiment Analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3211–3220. [Google Scholar] [CrossRef]
- Pang, S.; Xue, Y.; Yan, Z.; Huang, W.; Feng, J. Dynamic and Multi-Channel Graph Convolutional Networks for Aspect-Based Sentiment Analysis. In Proceedings of the Findings of the Association for Computational Linguistics, Online Event, 1–6 August 2021; pp. 2627–2636. [Google Scholar] [CrossRef]
- Liang, B.; Yin, R.; Gui, L.; Du, J.; Xu, R. Jointly Learning Aspect-Focused and Inter-Aspect Relations with Graph Convolutional Networks for Aspect Sentiment Analysis. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain (Online), 8–13 December 2020; pp. 150–161. [Google Scholar] [CrossRef]
- Liu, J.; Zhong, Q.; Ding, L.; Jin, H.; Du, B.; Tao, D. Unified Instance and Knowledge Alignment Pretraining for Aspect-Based Sentiment Analysis. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 2629–2642. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Q.; Ahmed, M.H.M.; Li, Z.; Pan, W.; Liu, H. Joint Inference for Aspect-Level Sentiment Analysis by Deep Neural Networks and Linguistic Hints. IEEE Trans. Knowl. Data Eng. 2021, 33, 2002–2014. [Google Scholar] [CrossRef]
- Ma, Y.; Peng, H.; Cambria, E. Targeted Aspect-Based Sentiment Analysisvia Embedding Commonsense Knowledge into an Attentive LSTM. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Zhou, J.; Huang, J.X.; Hu, Q.V.; He, L. SK-GCN: Modeling Syntax and Knowledge via Graph Convolutional Network for aspect-level sentiment classification. Knowl.-Based Syst. 2020, 205, 106292. [Google Scholar] [CrossRef]
- Zhong, Q.; Ding, L.; Liu, J.; Du, B.; Jin, H.; Tao, D. Knowledge Graph Augmented Network Towards Multiview Representation Learning for Aspect-based Sentiment Analysis. IEEE Trans. Knowl. Data Eng. 2022, 35, 10098–10111. [Google Scholar] [CrossRef]
- Durga, P.; Godavarthi, D.; Kant, S.; Basa, S.S. Aspect-based drug review classification through a hybrid model with ant colony optimization using deep learning. Discov. Comput. 2024, 27, 19. [Google Scholar] [CrossRef]
- Xu, B.; Li, S.; Xue, X.; Han, Y. SE-GCN: A Syntactic Information Enhanced Model for Aspect-Based Sentiment Analysis. In Proceedings of the Web and Big Data, Jinhua, China, 30 August–1 September 2024; pp. 154–168. [Google Scholar] [CrossRef]
- Yuan, Z.; Xu, S.; Yang, A.; Xu, F. Aspect-based Sentiment Analysis Model Based on Multi-hop Information. In Proceedings of the 2023 5th International Conference on Frontiers Technology of Information and Computer (ICFTIC), Qiangdao, China, 17–19 November 2023; pp. 566–569. [Google Scholar] [CrossRef]
- Zhao, Q.; Yang, F.; An, D.; Lian, J. Modeling Structured Dependency Tree with Graph Convolutional Networks for Aspect-Level Sentiment Classification. Sensors 2024, 24, 418. [Google Scholar] [CrossRef] [PubMed]
- Sun, X.; Liu, Z.; Li, H.; Ying, F.; Tao, Y. Chinese text dual attention network for aspect-level sentiment classification. PLoS ONE 2024, 19, e0295331. [Google Scholar] [CrossRef]
- Marcheggiani, D.; Titov, I. Encoding Sentences with Graph Convolutional Networks for Semantic Role Labeling. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 1506–1515. [Google Scholar] [CrossRef]
- Bijari, K.; Zare, H.; Kebriaei, E.; Veisi, H. Leveraging deep graph-based text representation for sentiment polarity applications. Expert Syst. Appl. 2020, 144, 113090. [Google Scholar] [CrossRef]
- Marcheggiani, D.; Bastings, J.; Titov, I. Exploiting Semantics in Neural Machine Translation with Graph Convolutional Networks. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 486–492. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. Graph Convolutional Networks for Text Classification. In Proceedings of the AAAI conference on artificial intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 7370–7377. [Google Scholar] [CrossRef]
- Sun, K.; Zhang, R.; Mensah, S.; Mao, Y.; Liu, X. Aspect-Level Sentiment Analysis Via Convolution over Dependency Tree. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 5678–5687. [Google Scholar] [CrossRef]
- Zhao, P.; Hou, L.; Wu, O. Modeling sentiment dependencies with graph convolutional networks for aspect-level sentiment classification. Knowl.-Based Syst. 2020, 193, 105443. [Google Scholar] [CrossRef]
- Zhu, X.; Zhu, L.; Guo, J.; Liang, S.; Dietze, S. GL-GCN: Global and Local Dependency Guided Graph Convolutional Networks for aspect-based sentiment classification. Expert Syst. Appl. 2021, 186, 115712. [Google Scholar] [CrossRef]
- Cambria, E.; Li, Y.; Xing, F.Z.; Poria, S.; Kwok, K. SenticNet 6: Ensemble Application of Symbolic and Subsymbolic AI for Sentiment Analysis. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 105–114. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Phan, H.T.; Nguyen, N.T.; Hwang, D. Convolutional attention neural network over graph structures for improving the performance of aspect-level sentiment analysis. Inf. Sci. 2022, 589, 416–439. [Google Scholar] [CrossRef]
- Dozat, T.; Manning, C.D. Deep Biaffine Attention for Neural Dependency Parsing. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar] [CrossRef]
- Wang, K.; Shen, W.; Yang, Y.; Quan, X.; Wang, R. Relational Graph Attention Network for Aspect-based Sentiment Analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3229–3238. [Google Scholar] [CrossRef]
- Tang, H.; Ji, D.; Li, C.; Zhou, Q. Dependency Graph Enhanced Dual-transformer Structure for Aspect-based Sentiment Classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6578–6588. [Google Scholar] [CrossRef]
- Tang, D.; Qin, B.; Feng, X.; Liu, T. Effective LSTMs for Target-Dependent Sentiment Classification. In Proceedings of the COLING 2016, 26th International Conference on Computational Linguistics, Proceedings of the Conference: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 3298–3307. [CrossRef]
- Ma, Y.; Peng, H.; Khan, T.; Cambria, E.; Hussain, A. Sentic LSTM: A Hybrid Network for Targeted Aspect-Based Sentiment Analysis. Cogn. Comput. 2018, 10, 639–650. [Google Scholar] [CrossRef]
- Zhao, M.; Yang, J.; Zhang, J.; Wang, S. Aggregated graph convolutional networks for aspect-based sentiment classification. Inf. Sci. 2022, 600, 73–93. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Positive | Neural | Negative | |||
|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | |
| Rest14 | 2164 | 728 | 637 | 196 | 807 | 196 |
| Lap14 | 994 | 341 | 464 | 169 | 870 | 128 |
| Rest15 | 1178 | 439 | 50 | 35 | 382 | 328 |
| Rest16 | 1620 | 597 | 88 | 38 | 709 | 190 |
| Parameter | Value | Explanation |
|---|---|---|
| dim_w | 300 | Dimensionality of word embeddings, initialized using pre-trained models. |
| dim_h | 300 | Dimensionality of the hidden layer representation. |
| dim_k | 200 | Dimensionality of knowledge graph embeddings, representing conceptual relationships. |
| dropout_rate | 0.1 | Dropout rate applied to mitigate overfitting during training. |
| learning_rate | Learning rate for the optimizer to control model updates. | |
| n_epoch | 50 | Number of epochs for model training. |
| num_layers | 2 | Number of GCN layers to define the model’s depth. |
| bs | 64 | Batch size for processing the dataset during training. |
| seed | 29 | Seed value for random number generation to ensure reproducibility. |
| Category | Model | Rest14 | Lap14 | Rest15 | Rest16 | ||||
|---|---|---|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | Acc | F1 | ||
| Syntax | R-GAT [57] | 83.30 | 76.08 | 77.42 | 73.76 | - | - | - | |
| DGEDT [58] | 83.30 | 76.08 | 77.42 | 73.76 | 76.39 | 58.70 | 82.16 | 54.21 | |
| LSTM+SynATT [30] | 79.43 | 69.25 | 70.87 | 66.53 | 78.03 | 58.30 | 83.27 | 65.76 | |
| Context | TD-LSTM [59] | 78.00 | 66.73 | 71.83 | 68.43 | 76.39 | 58.70 | 82.16 | 54.21 |
| ATAE-LSTM [28] | 78.60 | 67.02 | 68.88 | 63.93 | 78.48 | 60.53 | 83.77 | 61.71 | |
| MemNet [29] | 78.16 | 65.83 | 70.33 | 64.09 | 77.89 | 59.52 | 83.04 | 56.91 | |
| IAN [6] | 77.86 | 66.31 | 71.79 | 65.92 | 78.58 | 54.94 | 82.42 | 57.12 | |
| MGAN [60] | 81.25 | 71.94 | 75.39 | 72.47 | 79.36 | 57.26 | 87.06 | 62.29 | |
| Knowledge | SENTIC LSTM [60] | 79.43 | 70.32 | 70.88 | 67.19 | 79.55 | 60.56 | 83.01 | 68.22 |
| SK-GCN [37] | 80.54 | 70.14 | 73.04 | 68.41 | 79.76 | 61.37 | 83.82 | 64.84 | |
| SK-GCN [37] | 80.36 | 70.43 | 73.20 | 69.18 | 80.12 | 60.70 | 85.17 | 68.08 | |
| others | ASGCN-DT [20] | 80.86 | 72.19 | 74.14 | 69.24 | 79.34 | 60.78 | 88.69 | 66.64 |
| ASGCN-DG [20] | 80.77 | 72.02 | 75.55 | 71.05 | 79.89 | 61.89 | 88.99 | 67.48 | |
| AGCN-MEAN [61] | 80.02 | 71.02 | 75.07 | 70.96 | 80.07 | 62.70 | 87.98 | 65.78 | |
| AGCN-MAX [61] | 80.52 | 72.33 | 74.61 | 70.58 | 80.62 | 62.55 | 86.20 | 66.58 | |
| AFGCN [33] | 81.79 | 73.42 | 76.96 | 73.29 | 81.55 | 65.08 | 89.12 | 70.60 | |
| InterGCN [33] | 82.23 | 74.01 | 77.86 | 74.32 | 81.76 | 65.67 | 89.77 | 73.05 | |
| SI-GCN (ours) | 83.75 | 76.04 | 80.93 | 73.09 | 81.95 | 66.37 | 90.10 | 74.71 | |
| SK-GCN1+BERT [37] | 81.87 | 73.42 | 79.31 | 75.11 | 82.72 | 63.34 | 86.03 | 69.69 | |
| SK-GCN2+BERT [37] | 83.48 | 75.19 | 79.00 | 75.57 | 83.20 | 66.78 | 87.19 | 72.02 | |
| AFGCN+BERT [33] | 86.57 | 80.36 | 82.53 | 79.10 | 85.02 | 70.89 | 90.76 | 76.88 | |
| InterGCN+BERT [33] | 87.12 | 81.02 | 82.87 | 79.32 | 85.42 | 71.05 | 91.27 | 78.32 | |
| SI-GCN+BERT (ours) | 88.96 | 83.67 | 84.02 | 78.54 | 87.45 | 71.83 | 93.23 | 78.21 | |
| Model | Rest14 | Lap14 | Rest15 | Rest16 | ||||
|---|---|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | Acc | F1 | |
| SI-GCN w/o Knowledge(Specific-GCN) | 82.11 | 73.71 | 77.74 | 73.78 | 82.10 | 65.70 | 89.61 | 71.71 |
| SI-GCN w/o Syntax | 81.97 | 73.75 | 77.42 | 73.76 | 81.57 | 65.63 | 89.56 | 71.44 |
| SI-GCN w/o Context | 82.02 | 73.08 | 76.48 | 72.65 | 81.22 | 65.01 | 88.79 | 70.83 |
| SI-GCN w/o Syn and Con(Inter-GCN) | 81.41 | 74.13 | 75.89 | 72.14 | 80.49 | 63.57 | 87.94 | 70.01 |
| SI-GCN w/o Bi-affine | 82.43 | 74.15 | 78.32 | 72.68 | 80.67 | 65.49 | 89.12 | 73.25 |
| SI-GCN | 83.75 | 76.04 | 80.93 | 73.09 | 81.95 | 66.37 | 90.10 | 74.71 |
| Model | Aspect | Attention Visualization | Prediction | TrueLabel |
|---|---|---|---|---|
| ATAE-LSTM [28] | food, service | food but the service was ! | (1✓,0✗) | (1,−1) |
| place | i recommend this to everyone | 0✗ | 1 | |
| size | the size was a bonus because of | −1✗ | 1 | |
| logic board | more likely it will require the logic board once they they have a problem and come up with a | 1✗ | −1 | |
| ASGCN-DG [20] | food, service | Great the service was ! | (−1✗,−1✓) | (1,−1) |
| place | I recommend place to | 0✗ | 1 | |
| size | the size was a bonus because of space | −1✗ | 1 | |
| logic board | it will require the logic board once they admit they have a problem and come up with a solution | 1✗ | −1 | |
| Inter-GCN [33] | food, service | Great food the service was ! | (0✗,−1✓) | (1,−1) |
| place | I to everyone | 1✓ | 1 | |
| size | the smaller size was a bonus because of space | −1✗ | 1 | |
| logic board | More likely it will the logic board they they have a and come up with a solution | 1 ✗ | −1 | |
| Specific-GCN | food, service | food but the service dreadful! | (1✓,0✗) | (1,−1) |
| place | I recommend this to | 0✗ | 1 | |
| size | the smaller was a bonus because of space restrictions | 1✓ | 1 | |
| logic board | More likely it will replacing the logic board once they admit they have a and colorboxb onecome up with a solution | −1✓ | −1 | |
| SI-GCN | food, service | food but the service was ! | (1✓,−1✓) | (1,−1) |
| place | I this place to | 1✓ | 1 | |
| size | the was a bonus because of space | 1✓ | 1 | |
| logic board | More likely it will require replacing the once they admit they have a and come up with a solution | −1✓ | −1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Zhu, Y.; Hu, J.; Chen, X. SI-GCN: Modeling Specific-Aspect and Inter-Aspect Graph Convolutional Networks for Aspect-Level Sentiment Analysis. Symmetry 2024, 16, 1687. https://doi.org/10.3390/sym16121687
Huang Z, Zhu Y, Hu J, Chen X. SI-GCN: Modeling Specific-Aspect and Inter-Aspect Graph Convolutional Networks for Aspect-Level Sentiment Analysis. Symmetry. 2024; 16(12):1687. https://doi.org/10.3390/sym16121687
Chicago/Turabian StyleHuang, Zexia, Yihong Zhu, Jinsong Hu, and Xiaoliang Chen. 2024. "SI-GCN: Modeling Specific-Aspect and Inter-Aspect Graph Convolutional Networks for Aspect-Level Sentiment Analysis" Symmetry 16, no. 12: 1687. https://doi.org/10.3390/sym16121687
APA StyleHuang, Z., Zhu, Y., Hu, J., & Chen, X. (2024). SI-GCN: Modeling Specific-Aspect and Inter-Aspect Graph Convolutional Networks for Aspect-Level Sentiment Analysis. Symmetry, 16(12), 1687. https://doi.org/10.3390/sym16121687