
Symmetrical and Asymmetrical Sampling Audit Evidence Using a Naive Bayes Classifier


Abstract
:1. Introduction
- It demonstrates that machine learning algorithms can simplify auditors’ work. Enterprises can thus reduce the number of auditors and save human expenses. Few auditors are needed to obtain representative samples.
- It exploits a machine-learning-based tool to support the sampling of audit evidence. Auditors had similar tools.
- It shows that an ordinary Naive Bayes classifier can be a perfect ’Black Box’ to support the selection of audit evidence.
2. Literature Review
3. Naive Bayes Classifier
- i.
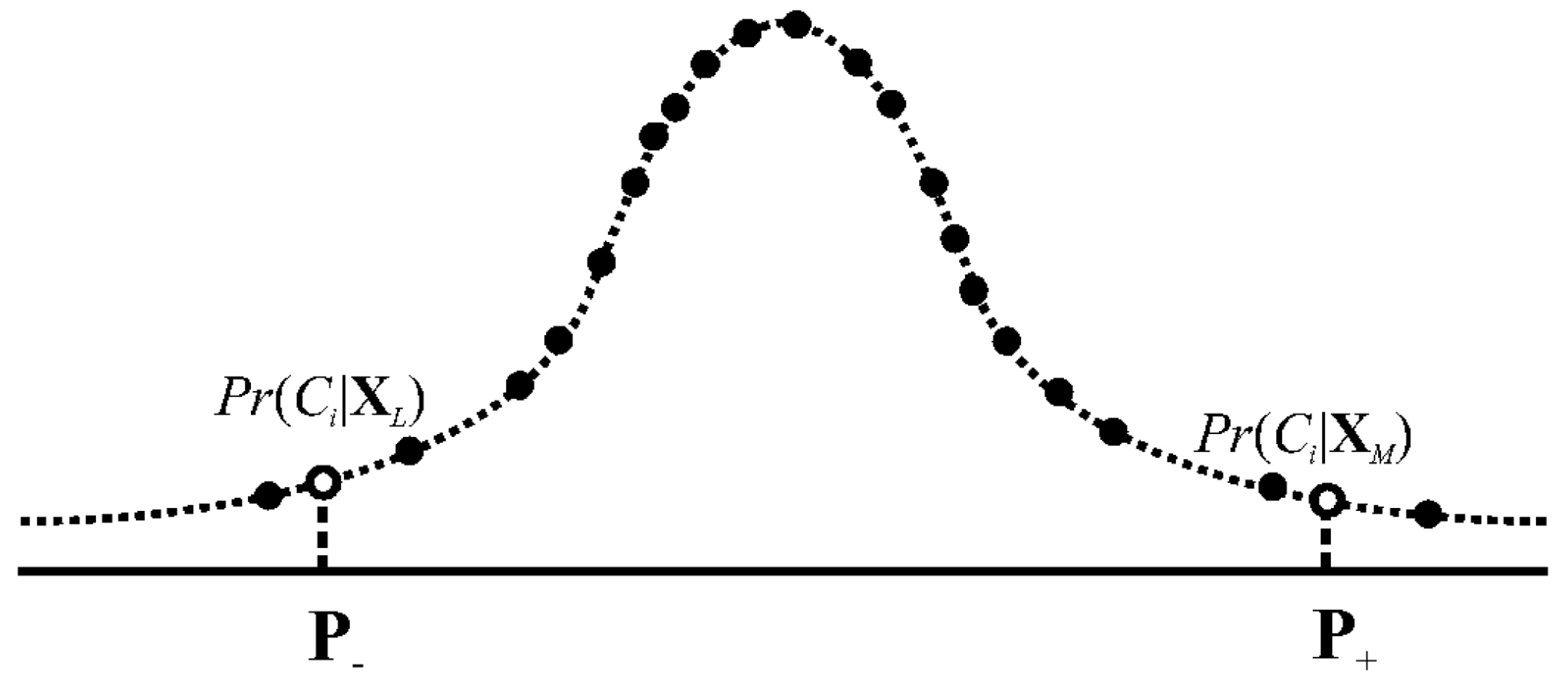
- User-based approach: In an attempt to generate unbiased representations of data, classify and compute two percentile symmetric around the median of each class according to an auditor’s professional preferences. Draw the bounded by the resulting percentiles as audit evidence;
- ii.
- Item-based approach: Suppose the represent risky samples. Asymmetrically sample them based on the values as audit evidence after classifying .
3.1. User-Based Approach
3.2. Item-Based Approach
3.3. Hybrid Approach
4. Results
4.1. Experiment 1
4.2. Experiment 2
4.3. Experiment 3
5. Discussion
- Conventional sampling methods [7] may not profile the full diversity of data; thus, they may provide biased samples. Since this study samples data after classifying them using a Naive Bayes classifier, it substitutes for a sampling method to profile the full diversity of data. The experimental results of Section 4 indicate that the Naive Bayes classifier classifies three open data sets accurately, even if they are excessive. Those accurate classification results indicate that we capture the full diversity of the experimental data.
- Developing conventional sampling methods may not consider complex patterns or correlations in data [7]. In this study, we handle complex correlations or patterns in data (for example, a graph structure in Section 4.3) using a Naive Bayes classifier. This design mitigates the sampling bias caused by complex patterns or correlations if it provides accurate classification results.
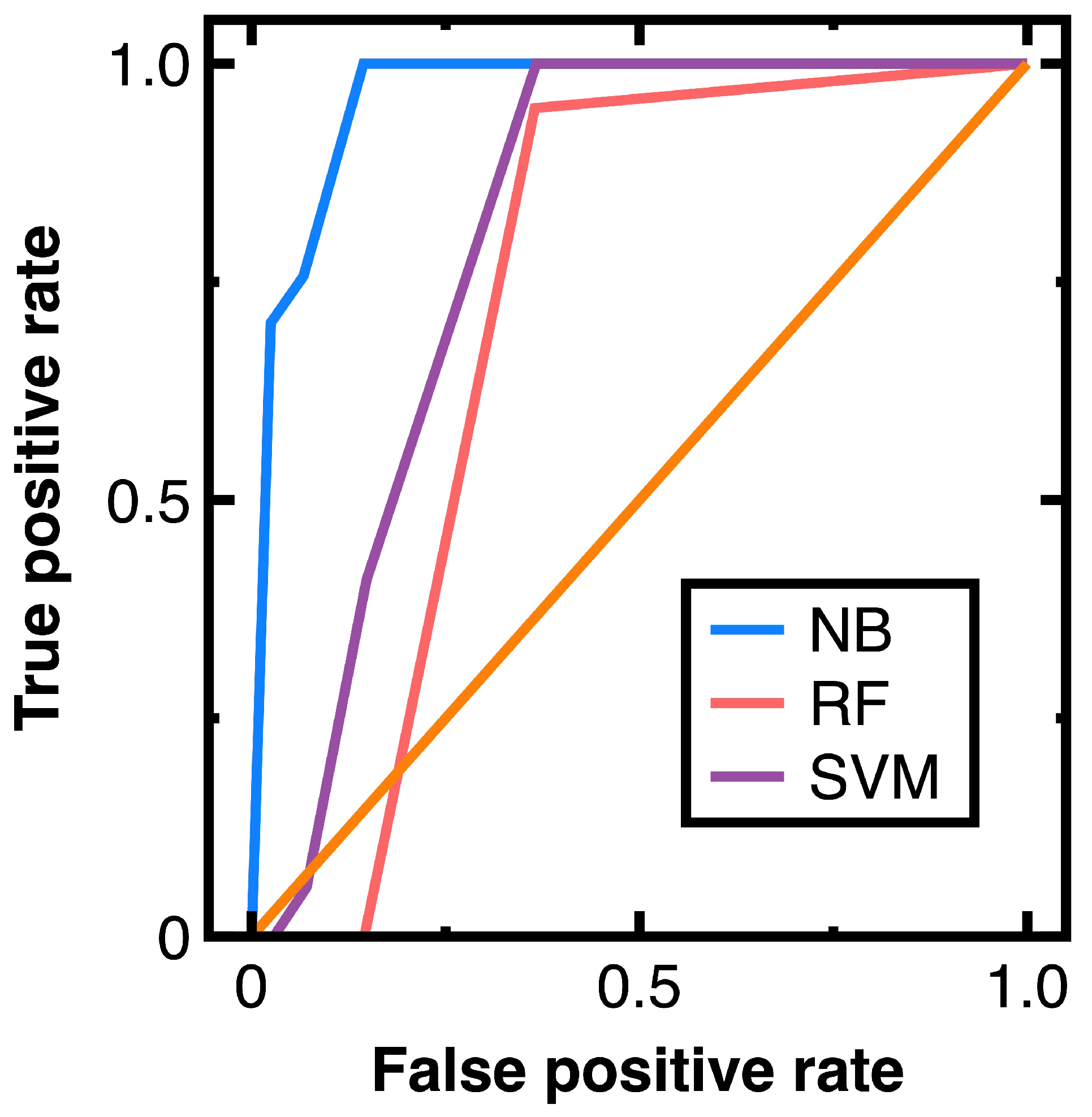
- Section 4.3 indicates that a Naive Bayes classifier works well for big data in a money laundering problem. It outperforms the random forest classifier and support vector machines model with a radial basis function kernel in classifying massive vertices. Thus, we illustrate that the efficiency of sampling big data can be improved. One can sample risker nodes modeling fraudulent financial accounts without profiling specific groups of nodes.
- The development of conventional sampling methods considers structured data; however, they struggled to handle unstructured data such as spam messages in Section 4.2. We resolve this difficulty by employing a Naive Bayes classifier before sampling.
- Since this study samples data from each class classified by a Naive Bayes classifier, accurate classification results eliminate sample frame errors and improper sampling sizes.
- Although the source of this study is Taiwan’s auditors’ unsatisfactory workplace environment, our resulting works are applicable to auditors in other nations.
- It is still possible that a Naive Bayes classifier provides inaccurate classification results. One should test the classification accuracy before sampling with machine learning integration.
- In implementing Section 3.2, thresholds are needed. However, we should inspect variations of the prior probabilities for determining proper values. They denote the second limitation of our machine-learning-based sampling.
6. Conclusions
- A Naive Bayes classifier is a more suitable classification algorithm for implementing the sampling with machine learning integration. It calculates posterior probabilities for the classification. These posterior probabilities are perfectly suitable as attributes in sampling.
- Sampling with machine learning integration has the benefits of providing unbiased samples, handling complex patterns or correlations in data, processing unstructured or big data, and avoiding sampling frame errors or improper sampling sizes.
- An ordinary Naive Bayes classifier is sufficient as a ’Black Box’ for sampling data. Implementing a Naive Bayes classifier to sample excessive data can be completed by a few auditors.
- The first step of sampling unstructured data can be classifying these unstructured data. Sampling classification results is the next step.
- Machine learning can help reduce human expenses. It mitigates the need for more young auditors. With the introduction of machine learning algorithms, enterprises require few auditors.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Deng, H.; Sun, Y.; Chang, Y.; Han, J. Probabilistic Models for Classification. In Data Classification: Algorithms and Applications; Aggarwal, C.C., Ed.; Chapman and Hall/CRC: New York, NY, USA, 2014; pp. 65–86. [Google Scholar]
- Schreyer, M.; Gierbl, A.; Ruud, T.F.; Borth, D. Artificial intelligence enabled audit sampling— Learning to draw representative and interpretable audit samples from large-scale journal entry data. Expert Focus 2022, 4, 106–112. [Google Scholar]
- Zhang, Y.; Trubey, P. Machine learning and sampling scheme: An empirical study of money laundering detection. Comput. Econ. 2019, 54, 1043–1063. [Google Scholar] [CrossRef]
- Aitkazinov, A. The role of artificial intelligence in auditing: Opportunities and challenges. Int. J. Res. Eng. Sci. Manag. 2023, 6, 117–119. [Google Scholar]
- Chen, Y.; Wu, Z.; Yan, H. A full population auditing method based on machine learning. Sustainability 2022, 14, 17008. [Google Scholar] [CrossRef]
- Bertino, S. A measure of representativeness of a sample for inferential purposes. Int. Stat. Rev. 2006, 74, 149–159. [Google Scholar] [CrossRef]
- Guy, D.M.; Carmichael, D.R.; Whittington, O.R. Audit Sampling: An Introduction to Statistical Sampling in Auditing, 5th ed.; John Wiley & Sons: New York, NY, USA, 2001. [Google Scholar]
- Schreyer, M.; Sattarov, T.; Borth, D. Multi-view contrastive self-supervised learning of accounting data representations for downstream audit tasks. In Proceedings of the Second ACM International Conference on AI in Finance Virtual Event, New York, NY, USA, 3–5 November 2021. [Google Scholar] [CrossRef]
- Schreyer, M.; Sattarov, T.; Reimer, G.B.; Borth, D. Learning sampling in financial statement audits using vector quantised autoencoder. arXiv 2020, arXiv:2008.02528. [Google Scholar]
- Lee, C. Deep learning-based detection of tax frauds: An application to property acquisition tax. Data Technol. Appl. 2022, 56, 329–341. [Google Scholar] [CrossRef]
- Chen, Z.; Li, C.; Sun, W. Bitcoin price prediction using machine learning: An approach to sample dimensional engineering. J. Comput. Appl. Math. 2020, 365, 112395. [Google Scholar] [CrossRef]
- Liberty, E.; Lang, K.; Shmakov, K. Stratified sampling meets machine learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Hollingsworth, J.; Ratz, P.; Tanedo, P.; Whiteson, D. Efficient sampling of constrained high-dimensional theoretical spaces with machine learning. Eur. Phys. J. C 2021, 81, 1138. [Google Scholar] [CrossRef]
- Artrith, N.; Urban, A.; Ceder, G. Constructing first-principles diagrams of amorphous LixSi using machine-learning-assisted sampling with an evolutionary algorithm. J. Chem. Phys. 2018, 148, 241711. [Google Scholar] [CrossRef] [PubMed]
- Huang, F.; No, W.G.; Vasarhelyi, M.A.; Yan, Z. Audit data analytics, machine learning, and full population testing. J. Financ. Data Sci. 2022, 8, 138–144. [Google Scholar] [CrossRef]
- Kolmogorov, A. Sulla determination empirica di una legge di distribuzione. G. Inst. Ital. Attuari. 1933, 4, 83–91. [Google Scholar]
- Wasserman, S.; Faust, K. Social Network Analysis: Methods and Applications, 1st ed.; Cambridge University Press: Cambridge, NY, USA, 1994. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original Data | Audit Evidence | |
|---|---|---|
| Range | [104.78, 225.24] | [104.78, 225.24] |
| Standard deviation | 24.55 | 24.53 |
| Interquartile range | 34.58 | 34.58 |
| Skewness | 0.674 | 0.673 |
| Coefficient of variation | 0.1731 | 0.173 |
| Metric | Value |
|---|---|
| Accuracy | 0.983 |
| Precision | 0.992 |
| Recall | 0.989 |
| Specificity | 0.992 |
| F1 score | 0.99 |
| Class Variable | Degree Centrality | Clustering Coefficient | Total Number of Members |
|---|---|---|---|
| 1 | [0, 2) | [0, 1] | 338,800 |
| 2 | [2, 4) | [0, 1] | 117,323 |
| 3 | [4, 6) | [0, 0.417] | 41,720 |
| 4 | [6, 10) | [0, 0.367] | 22,743 |
| 5 | [10, ∞) | [0, 0.28] | 15,304 |
| Metric | Averaged Value |
|---|---|
| Accuracy | 0.995 |
| Precision | 0.992 |
| Recall | 0.989 |
| Specificity | 0.992 |
| F1 score | 0.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sheu, G.-Y.; Liu, N.-R. Symmetrical and Asymmetrical Sampling Audit Evidence Using a Naive Bayes Classifier. Symmetry 2024, 16, 500. https://doi.org/10.3390/sym16040500
Sheu G-Y, Liu N-R. Symmetrical and Asymmetrical Sampling Audit Evidence Using a Naive Bayes Classifier. Symmetry. 2024; 16(4):500. https://doi.org/10.3390/sym16040500
Chicago/Turabian StyleSheu, Guang-Yih, and Nai-Ru Liu. 2024. "Symmetrical and Asymmetrical Sampling Audit Evidence Using a Naive Bayes Classifier" Symmetry 16, no. 4: 500. https://doi.org/10.3390/sym16040500
APA StyleSheu, G. -Y., & Liu, N. -R. (2024). Symmetrical and Asymmetrical Sampling Audit Evidence Using a Naive Bayes Classifier. Symmetry, 16(4), 500. https://doi.org/10.3390/sym16040500