Abstract
In recent years, computer vision technology has been extensively applied in the field of defect detection for transportation infrastructure, particularly in the detection of road surface cracks. Given the variations in performance and parameters across different models, this paper proposes an improved Faster R-CNN crack recognition model that incorporates attention mechanisms. The main content of this study includes the use of the residual network ResNet50 as the basic backbone network for feature extraction in Faster R-CNN, integrated with the Squeeze-and-Excitation Network (SENet) to enhance the model’s attention mechanisms. We thoroughly explored the effects of integrating SENet at different layers within each bottleneck of the Faster R-CNN and its specific impact on model performance. Particularly, SENet was added to the third convolutional layer, and its performance enhancement was investigated through 20 iterations. Experimental results demonstrate that the inclusion of SENet in the third convolutional layer significantly improves the model’s accuracy in detecting road surface cracks and optimizes resource utilization after 20 iterations, thereby proving that the addition of SENet substantially enhances the model’s performance.
1. Introduction
Highways, as critical infrastructure within the transportation system, always prioritize ensuring their safe and stable operation. Road surface cracks are a common pathology that poses a serious threat to road safety and longevity. Regular damage inspection is essential to ensure efficient service and extend the lifespan of highways. During the operational phase of a highway, regularly employing effective methods to detect and repair surface cracks is crucial for maintaining normal road operations and ensuring traffic safety [1]. Currently, traditional detection methods rely heavily on manual segmented patrols, requiring maintenance personnel to regularly inspect and repair specific sections. This approach is subjective, inefficient, and can lead to safety hazards.
The rapid development of computer vision technology alongside deep learning has paved new paths for automatic crack detection. Deep learning demonstrates high efficiency in image recognition and processing, enabling it to effectively identify and detect road surface cracks, which significantly aids in speeding up and enhancing the accuracy of crack detection. Deep learning models based on convolutional neural networks (CNNs), such as VGG and ResNet, have shown excellent performance in road surface crack detection. This paper focuses on research based on Faster-RCNN from convolutional neural networks, effectively integrating region proposal generation with CNN feature extraction [2].
This study concentrates on the basic structure and early optimization of R-CNN and its derivative algorithms. Ren et al. [3] demonstrated through experiments that classifiers based on convolutional layers are more effective for object detection tasks than those based on fully connected layers. They also found that using a deeper ConvNet as the feature classifier could achieve better detection performance, laying the groundwork for subsequent algorithm improvements.
As the R-CNN algorithm continues to evolve, researchers have begun to focus on its improvements in specific application scenarios. Liao et al. [4] designed a Semantic Enhancement Module (SEM) on the basis of Mask R-CNN and conducted feature fusion to prevent information loss during the feature extraction process. Li’s [5] research delved into the performance of Mask R-CNN under different iteration counts and depths of residual networks. Additionally, Huang et al. [6] introduced multi-scale detection techniques to Faster R-CNN, specifically optimizing for small object detection.
In terms of network structure and performance enhancement, Xin et al. [7] significantly improved detection efficiency by replacing VGG16 with HDC in Faster R-CNN. Similarly, Wang et al. [8] replaced VGG16 with ResNet101 and adopted a multi-scale training strategy, enhancing the model’s robustness. Zhao et al. [9] improved Faster R-CNN by introducing a feature pyramid network, increasing the accuracy of target localization in complex backgrounds. Dai et al. [10] enhanced crack detection accuracy through a design that incorporates multi-level ROI pooling layers, effectively eliminating biases introduced by integer quantization in ROI pooling.
Although Faster-RCNN has already achieved significant results in the field of image recognition, by introducing SENet, we further explore how to optimize the model’s ability to recognize cracks through attention mechanisms, overcoming limitations within the model and enhancing its performance. The attention mechanism was initially proposed in 2014 as part of the encoder–decoder framework in RNNs to enhance the encoding capabilities for long input sentences. Subsequently, this concept was widely applied to RNNs [11] to improve their ability to handle complex sequential data.
In the field of target detection algorithms for road crack detection, significant advancements have been achieved. Firstly, He et al. [12] combined unmanned aerial vehicles (UAVs) with the MUENet algorithm, effectively extracting morphological features of cracks through a dual-path module (MADPM), thus accelerating the detection of road cracks. Furthermore, Nguyen et al. [13] introduced an innovative two-stage convolutional neural network (CNN) that isolates noise and artifacts in the first stage and specifically learns the context of cracks in the second stage, achieving precise detection and segmentation of road cracks at the pixel level. Feng et al. [14] demonstrated how to leverage multi-scale feature maps in CNNs by weighting pixel values in corresponding areas of different layers and using the sum of these values as the output, thereby enhancing the performance of road crack detection.
Additionally, Xu et al. [15] developed the Cross-Attention-guided Feature Alignment Network (CAFANet), which uses a dual-branch visual encoder model to integrate multi-scale features of road damage. The application of a Feature Alignment Block (FAB) significantly improves the perception of damaged areas, reduces background interference, and achieves more precise damage detection and segmentation. Li et al. [16] developed CrackTinyNet (CrTNet), specifically designed for detecting tiny surface cracks on roads, using a novel BiFormer general visual transformer and optimizing the loss function to a normalized Wasserstein distance, effectively preventing excessive loss of information about small objects in the network structure.
Moreover, Hacıefendioğlu et al. [17] demonstrated the capability of deep learning to quickly and cost-effectively identify existing cracks using a pre-trained Faster R-CNN to detect cracks under various shooting, weather conditions, and lighting levels on concrete road surfaces. Lastly, Guo et al. [18] proposed the MN-YOLOv5 model, which utilizes MobileNetV3 as a new backbone feature extraction network instead of the basic network of YOLOv5, significantly reducing the number of model parameters and GFLOPs. This model also incorporates a coordinate attention lightweight attention module to enhance the network’s accuracy in locating and detecting targets.
These studies not only improve the efficiency and precision of road crack detection but also provide a solid technological foundation for the future development of intelligent traffic systems.
In the field of deep learning, attention mechanisms have become a key technology for enhancing the performance of computer vision tasks. Inspired by the human cognitive system, attention mechanisms mimic human awareness of specific information, emphasizing crucial details to focus more on the essential aspects of the data. For instance, in vision tasks such as crack detection, the adoption of various complementary attention mechanisms effectively enhances the model’s ability to recognize crack details, particularly in complex backgrounds or low-quality images. Moreover, the application of attention techniques is not limited to a single model; they can be seamlessly integrated into large networks to handle different data modalities, see Ref. [19]. This broad application of attention mechanisms across various domains sets the stage for more specialized innovations in the architecture of convolutional neural networks. In 2018, the introduction of SE-Net and its successful application in ImageNet2017 marked a revolutionary application of attention mechanisms in CNNs. SE-Net optimizes the representation of feature maps by learning feature weights [20]. In the same year, the CBAM [21] paper further innovated by introducing a Spatial Attention Module (SAM) and a Channel Attention Module (CAM), providing more comprehensive attention information. Following this, in 2019, SK-Net [22] and DA-Net, along with the Pyramid Feature Attention Network [23], enhanced the efficiency of attention networks from the perspectives of convolutional kernel importance and parallel attention information acquisition [24]. In 2020, ECA-Net refined the attention mechanism by proposing a dimensionality-preserving local cross-channel interaction strategy and an adaptive method for selecting one-dimensional convolutional kernel sizes, building upon the SE-Net block. That same year, the introduction of ResNeSt was a significant milestone; it integrated ideas from ResNet [25], SE-Net, and SK-Net, optimizing the network structure through a Split-Attention block and demonstrating the potential of residual networks in handling complex tasks [26]. Although the structure of SENet is relatively simple, its effectiveness in practical applications and its inspirational impact on subsequent research underscore its core value. Therefore, this paper will focus on research based on the SENet attention mechanism.
The aforementioned network structures and attention mechanisms provide new ideas for image recognition tasks like crack detection. Particularly, the introduction of attention mechanisms, by improving the representation of feature maps, enables dynamic selection of relevant information during the decoding process, significantly enhancing the performance of traditional models. These innovations not only increase the accuracy of detection but also enhance the model’s adaptability to complex scenes and its robustness.
Following the discussion of the critical role of network structures and attention mechanisms in enhancing the performance of deep learning models, the number of iterations also plays a significant role in tuning and optimizing neural network parameters within deep learning algorithms. Stochastic Gradient Descent (SGD), as the core algorithm for parameter optimization in neural networks, lays the foundation for training deep learning models with its simplicity and effectiveness [27]. However, SGD is prone to becoming stuck at saddle points and local minima. To address this, the momentum gradient descent method was introduced, which uses the momentum of previous gradients to overcome these issues, speeding up convergence and improving algorithm stability [28].
As neural networks become more complex, adaptive learning rate algorithms have emerged as an important direction. The AdaGrad [29] algorithm was the first to use the sum of squared historical gradients to adjust each step’s update step, achieving an adaptive learning rate. Although AdaGrad performs well in the early stages, as the number of iterations increases, the accumulated gradient sum causes the learning rate to decrease too quickly. To mitigate this issue, the RMSProp algorithm was introduced, which uses a sliding exponential average of squared gradients to adjust the learning rate, effectively addressing AdaGrad’s limitations.
It is evident that the number of iterations not only affects the convergence speed of the model but also plays a decisive role in the adaptive adjustment of the learning rate. Properly setting the number of iterations ensures that the algorithm does not converge prematurely to a local optimum or stall due to too small a learning rate, making full use of each update step to optimize model performance.
Crack detection fundamentally involves identifying patterns and anomalies in images, where symmetry plays a pivotal role. In roads or other infrastructures, cracks may disrupt the original symmetry patterns, leading the detection models to implicitly learn to recognize these disruptions as indications of cracks. Furthermore, the use of ResNet50 and the symmetric operations involved in its layers—where convolutional filters are uniformly applied across the entire image—helps maintain the structural integrity of image features. This uniform application is crucial for accurately identifying symmetry and its disruptions. Additionally, integrating the SENet attention module can be seen as a strategy to maintain a balance (or symmetry) of feature importance across network layers. By recalibrating feature responses to emphasize global information, it promotes a balanced representation that is vital for distinguishing subtle crack features against complex backgrounds. This balanced representation significantly enhances the accuracy and reliability of crack detection.
Although current methods have made progress in road crack detection, they still face challenges in accurately recognizing crack features against complex backgrounds and low resource utilization. To address these issues, this study proposes an improved Faster R-CNN model integrated with SENet, aimed at exploring solutions through the following aspects:
(1) The paper optimizes the structure of the Faster-RCNN model by selecting ResNet50 as the basic backbone network for feature extraction, simplifying the learning objectives of the network layers, which makes the optimization process more efficient;
(2) The paper integrates SENet during the feature extraction stage of Faster-RCNN, optimizing the learning objectives of the network layers. By focusing attention, it enhances the model’s perception accuracy of crack features, making the entire optimization process more efficient and goal-oriented;
(3) Based on experiments, the paper concludes that after integrating the SENet attention mechanism, the network structure reaches optimal performance with 20 iterations, efficiently utilizing resources.
2. Methods
2.1. R-CNN and SENet Related
2.1.1. Overview of Faster R-CNN
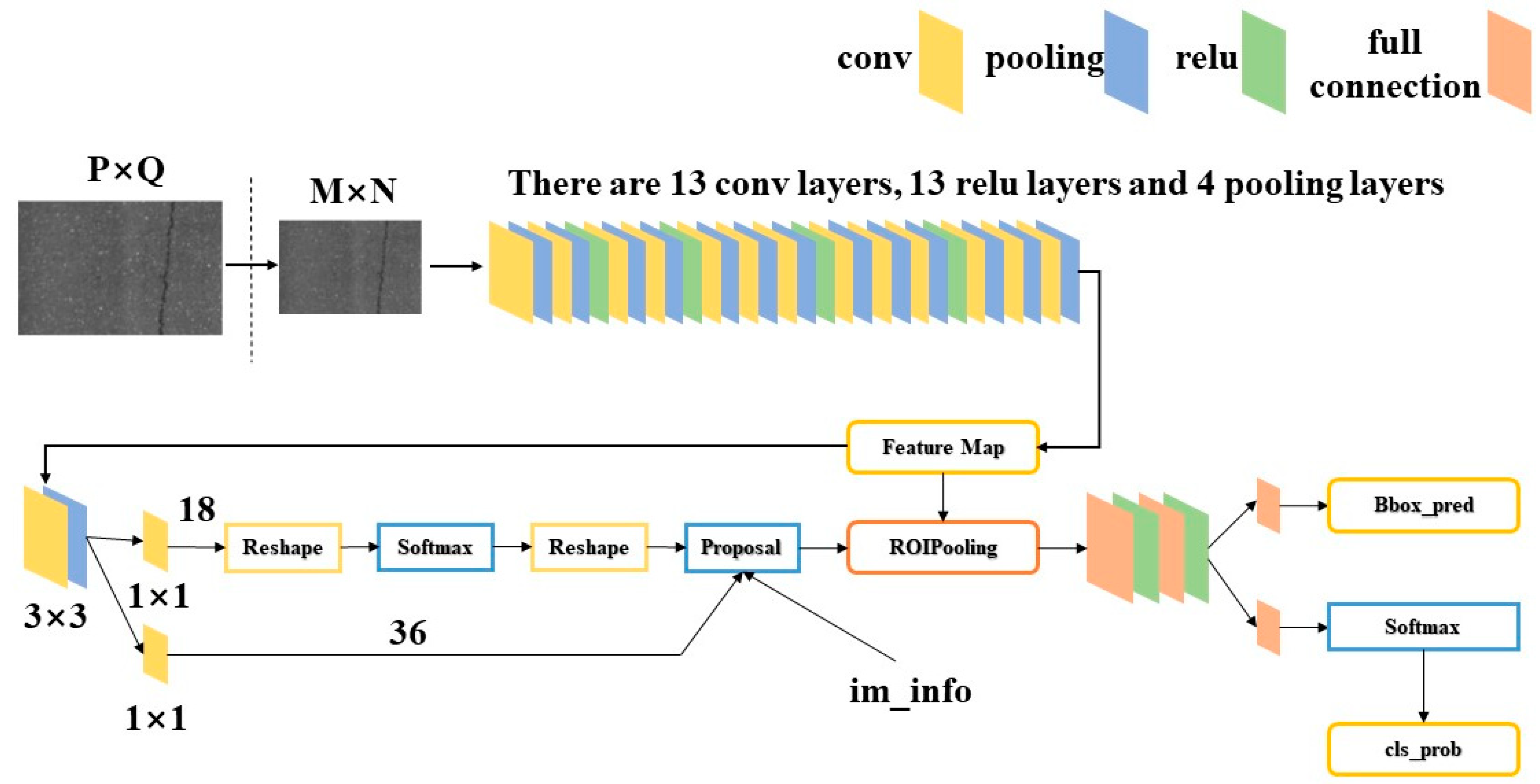
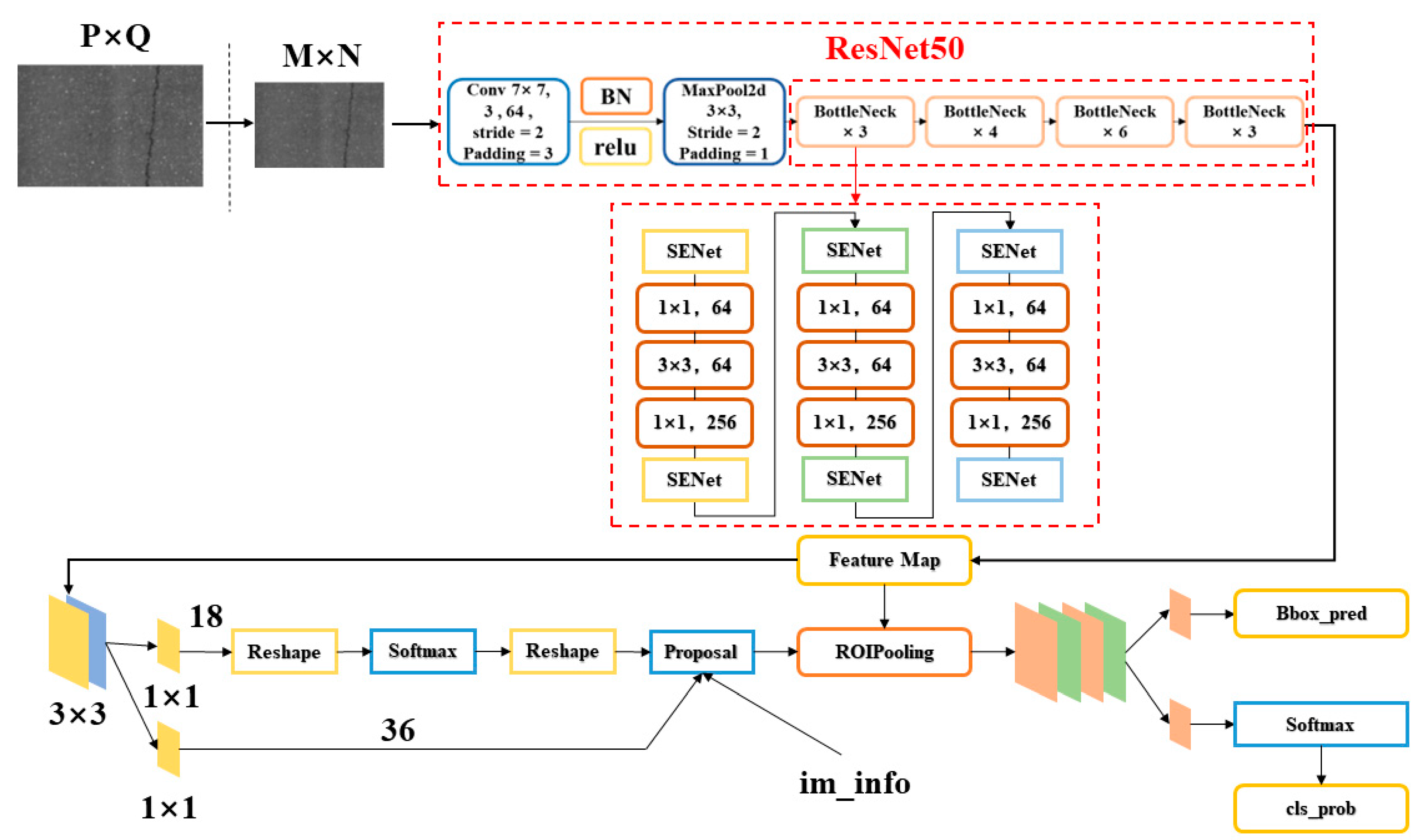
Building on the foundation of Fast R-CNN, the Faster R-CNN [30,31] algorithm was introduced. Compared to Fast R-CNN, Faster R-CNN incorporates a Region Proposal Network (RPN), which replaces the original Selective Search method. RPN maps each sliding window position to a low-dimensional feature vector, which is then fed into two fully connected layers: one for classification prediction and the other for bounding box regression. For each window, typically k different sizes or ratios of default bounding boxes are set, meaning each position can predict k candidate regions, known as anchors. RPN is essentially a Fully Convolutional Network (FCN) that generates several candidate anchors on the scale of the original image, and then identifies targets in the foreground and background using CNN. Figure 1 illustrates the network structure of Faster R-CNN.
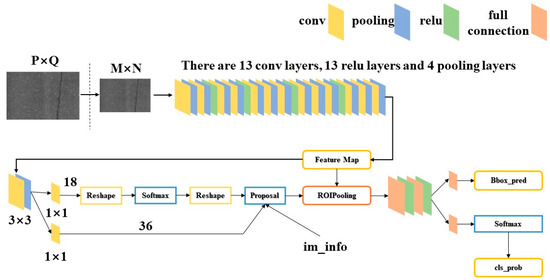
Figure 1.
Network Structure of Faster R-CNN.
Faster R-CNN can be viewed as a combination of RPN and Fast R-CNN. In this architecture, the RPN is responsible for generating candidate regions for targets, while Fast R-CNN extracts features from each candidate region to perform classification and bounding box regression tasks. Since the features are shared between the two processes, this can increase inference speed. The introduction of RPN [32] replaces the traditional selective search, and due to its higher efficiency, Faster R-CNN is able to accelerate the training and prediction speed of the entire model.
Having understood these basic components of Faster R-CNN, we will explore the principles of ResNet in the next Section. ResNet is another key technology commonly used in Faster R-CNN, whose deep network structure provides strong support for feature extraction.
2.1.2. Principles of ResNet
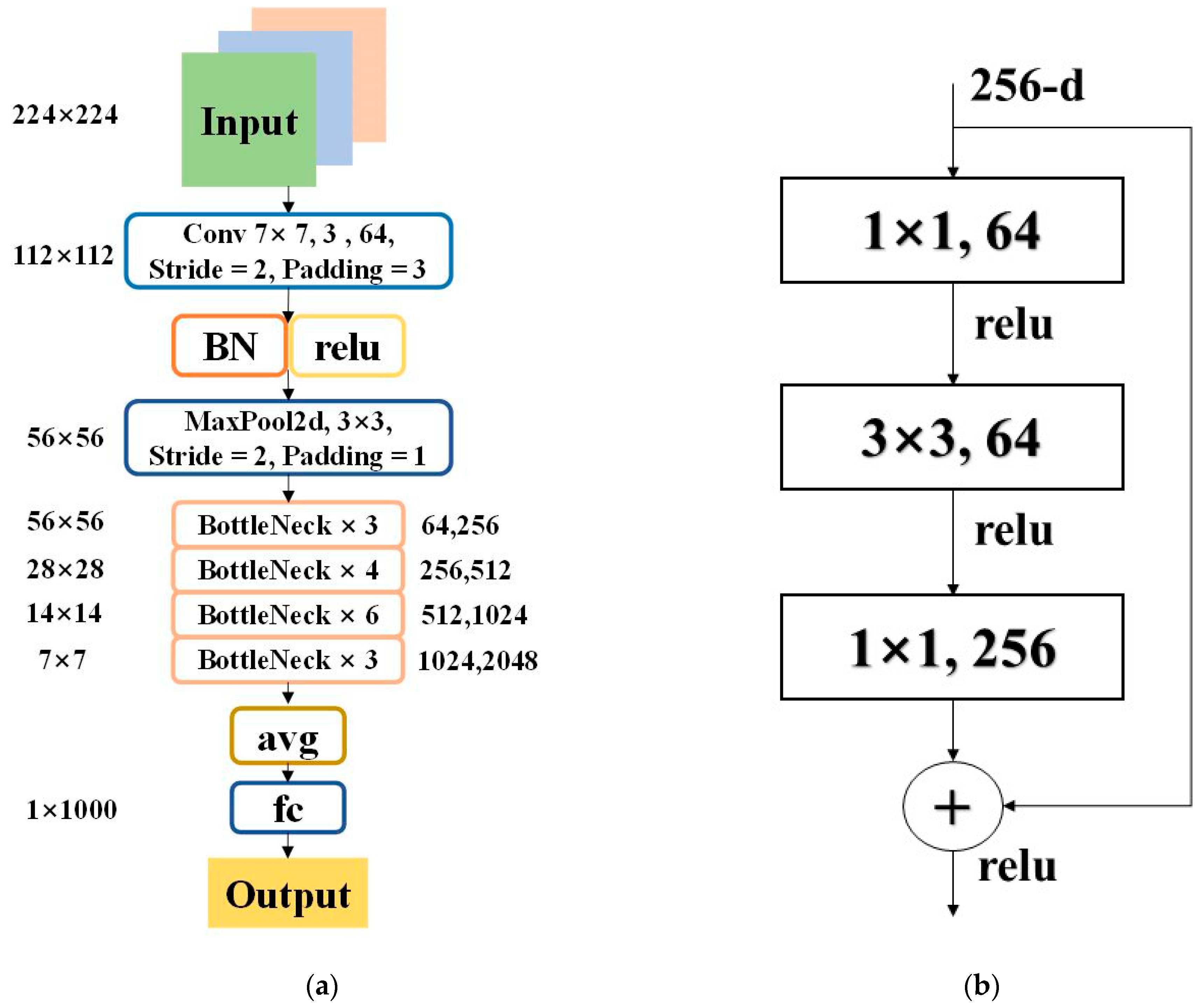
ResNet [33], proposed by Kaiming He and his team, marks a significant innovation in the field of deep learning. ResNet addresses the degradation problem encountered during the training of deep learning networks by introducing a residual learning framework, which enables the training of deeper networks to achieve better-performing models. Figure 2a shows the specific network configuration of ResNet50, and part (b) provides a detailed depiction of a typical residual structure.
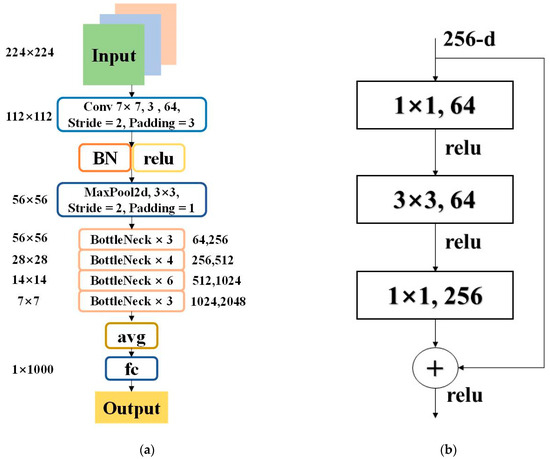
Figure 2.
ResNet50 Network Configuration and Residual Structure Diagram: (a) The specific network configuration of ResNet50. (b) A detailed depiction of a typical residual structure.
The core innovation of ResNet lies in the introduction of the residual structure, as shown in Figure 2b. Unlike traditional approaches that directly learn the original mapping relationships, ResNet trains network layers to learn a residual function F(x) = H(x) − x. The output of this function is then added back to the input x, forming F(x) + x. This design simplifies the learning objectives of the network layers, making the optimization process more efficient.
The primary purpose of introducing the residual structure in ResNet is to address the problems of vanishing and exploding gradients that occur as the network depth increases. While the overall trend in network layers is to increase depth, simply stacking more layers—i.e., traditional stacked structures—can lead to gradient issues that hinder network convergence. Issues are somewhat mitigated by standardized initialization and intermediate normalization layers, but ResNet’s residual learning approach provides a more fundamental solution. ResNet resolves the degradation issue of deep neural networks with the idea of residual learning: by adding several identity mapping layers to a shallow network whose accuracy has plateaued, it achieves the objective of increasing network depth without increasing error.
Several variants of ResNet have been developed to suit different computational and performance needs. ResNet-18 and ResNet-34 are lighter models, using a basic residual block structure with two convolutional layers each, suitable for applications where computational efficiency is crucial. On the other hand, ResNet-50, ResNet-101, and ResNet-152 employ a more complex “bottleneck” design, using three layers of convolution in each block to deepen the network and provide higher levels of abstraction, suitable for tasks requiring more complex image processing.
In this study, ResNet-50 was chosen because it offers the best balance between depth and computational efficiency. The ResNet-50 structure is powerful enough to capture complex features in the data while remaining manageable in terms of computational resources and training time. This model has demonstrated its ability to optimize model accuracy in our experimental setup without additional computational burden.
Although ResNet significantly improves the training of deep networks through its residual structure, further performance enhancement can be achieved by introducing SENet (Squeeze-and-Excitation Networks). This network enhances the model’s accuracy and efficiency by recalibrating the interrelationships between channels within the network and optimizing feature representation.
2.1.3. SENet
SENet (Squeeze-and-Excitation Networks) [34] is an innovative network architecture introduced by Hu and colleagues, which won the ImageNet2017 competition in the Image Classification task. While most convolutional neural network models enhance network performance by increasing depth in the spatial dimensions, such as the VGG architecture and the Inception model, SENet focuses on the relationships between feature channels. It optimizes network functionality by explicitly modeling the interdependencies among these channels. Specifically, SENet recalibrates feature channels by evaluating each channel’s contribution to the overall features during the network’s feature learning process, then enhances features that are beneficial for the current task and suppresses less important features based on these contribution values.
Figure 3 shows the network structure of SENet. The diagram illustrates that it primarily involves two operations: first, “Squeeze” (Fsq), which compresses the feature maps through global average pooling, aggregating the spatial information of each channel into a single value; followed by “Excitation” (Fex), which uses fully connected layers to learn the dependencies between channels and outputs the importance weights for each channel. These weights are then used to recalibrate the channels in the original feature maps, amplifying important features and suppressing lesser ones, thereby enhancing the network’s ability to capture critical information.

Figure 3.
SENet Network Structure.
2.2. Improved Model Architecture Combination Scheme
In this study, we focus on exploring the effects of integrating the SENet attention module at different positions within the ResNet50-enhanced Faster-RCNN architecture. Specifically, to gain a deeper understanding of how the attention mechanism affects model performance, the SENet module is integrated into the first, second, and third convolutional layers of each bottleneck of ResNet50. In deep learning networks, bottleneck layers play a crucial role in image recognition tasks. They not only reduce the number of parameters and computational burden but also help in extracting and conveying key feature information. However, as network depth increases, the efficient bottleneck layers can also lead to information loss, especially during the transformation of important features. Therefore, this study proposes integrating the SENet attention module at the bottleneck layer to enhance the network’s ability to extract and utilize useful features. This approach could potentially enhance the model’s focus on features during the extraction phase and further analyze and compare the specific impacts of these three different integration points on model parameters and performance.
2.2.1. Model Architecture Design
This study utilizes a model based on the widely used Faster RCNN architecture for image recognition tasks, which includes a feature extraction network, a Region Proposal Network (RPN), and a head network responsible for classification and regression. To enhance the capability to handle complex image tasks, we replace the traditional convolutional network with the efficient ResNet50. Renowned for its deep structure and innovative residual links, ResNet50 effectively mitigates the degradation issues in training deep networks. Our goal is to fully utilize the depth and capabilities of ResNet50 in feature extraction, especially for detail-sensitive crack detection tasks. In this setup, ResNet50 serves as the feature extraction network, responsible for extracting rich feature information from input images. RPN then uses these features to determine potential target areas, and finally, the classification and regression head further analyzes and locates these areas.
2.2.2. SENet Module Integration Design
To further enhance the performance of Faster R-CNN in crack detection, this study integrates the SENet module into ResNet50. The SENet module is designed to preprocess at the input of each convolutional layer and is applied again to the output feature maps after the convolution operation. This strategy introduces a channel-level attention mechanism, dynamically adjusting the importance of input feature channels, and optimizing the entire model’s feature processing flow. This study will deeply analyze the specific impact of the SENet module at these three different integration points on model performance, with a focus on improving model accuracy. Through this comparison, we aim to identify the most effective integration point to maximize the model’s ability to recognize crack features.
In practice, the SENet module first extracts global information from the feature maps of each channel through a global average pooling operation. Then, two fully connected layers perform feature compression and expansion, respectively, and generate the weights for each channel through the ReLU activation function. These weights are used to weight each channel of the original feature maps, achieving feature recalibration and optimization, and enhancing the network’s efficiency in capturing critical information.
Figure 4 illustrates the improved Faster R-CNN model architecture used in this study, integrating both ResNet50 and the SENet module. As shown, the SENet module is strategically integrated into the first three bottleneck convolutional layers of ResNet50, with the aim of introducing channel-level attention mechanisms at critical stages to optimize the model’s processing and recognition capabilities for complex image features.
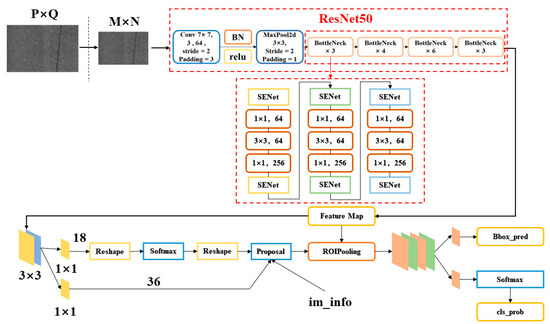
Figure 4.
Enhanced Network Structure of the Improved Model.
3. Experimental Design and Setup
The experimental environment setup for this paper is primarily configured as follows: The computer host is equipped with an AMD Ryzen5 3600 processor, NVIDIA GeForce 2060 6 G graphics card, and 16 GB of RAM. The host system runs on Ubuntu 20.04. All experiments described herein are based on the MMDetection image recognition development environment and have been appropriately configured. The experiments are conducted in a Python 3.7 environment with CUDA 10.2.
3.1. Training Process and Parameter Settings
The model’s training parameters are set as follows (see Table 1 below for details):

Table 1.
Table of relevant parameters during model training.
3.2. Dataset Description and Preprocessing
The dataset used in this experiment contains 1000 images of road surface cracks, with 800 for training and 200 for testing, this allocation (80% for training, 20% for testing) is designed to prevent overfitting problems during training to ensure the model’s ability to generalize on unknown data. All images have a resolution of 1500 × 1000 pixels and are stored in JPG format. Although the dataset includes several types of cracks, such as transverse cracks, longitudinal cracks, and alligator cracks, they are grouped into one category in this study. This decision was made to focus on improving the overall crack detection capability of our model, specifically aiming to improve the detection accuracy of different types of cracks without targeting specific types. This approach allows us to verify the validity of the model in a wider range of scenarios and lays a solid foundation for future studies that may involve the differentiation of crack types.
All crack images have been annotated using the LabelMe tool, as shown in Figure 5. In LabelMe, the annotation information for each crack is saved in JSON format, which contains the polygon coordinates and category information of the crack. After annotation, the crack images are fed into the neural network model to support network training. Before being input into the network, all images undergo preprocessing steps including simple data augmentation and resizing to 640 × 640 pixels. The annotation information extracted from JSON format is converted to a format suitable for training, such as a mask image or directly converted to the annotation frame coordinates required for network training. These operations help the model achieve better robustness and accuracy in practical applications.

Figure 5.
Crack image dataset annotation.
3.3. Experimental Settings: Number of Iterations and Integration Points of the Attention Mechanism
This study’s experimental setup aims to explore the impact of integrating the SENet attention module at different positions within the ResNet50-based Faster R-CNN architecture, as well as the impact of varying the number of iterations on model accuracy. The experiment first identifies the optimal number of iterations to ensure the model achieves the best performance balance during training. Subsequently, based on this optimal number, further exploration into the specific effects of the attention module integration points is conducted.
3.3.1. Selection of Iteration Count
The experiment uses the Faster R-CNN model improved with ResNet50, integrating the SENet attention module at each bottleneck convolutional layer to enhance performance in crack detection tasks. To accurately determine the optimal number of iterations, we start with a smaller number of iterations, such as 10, and gradually increase to 15, 20, and 30, until model performance no longer significantly improves or overfitting occurs. At each iteration point, the model’s performance on the validation set (such as accuracy and loss values) will be recorded and analyzed to monitor overfitting and confirm performance stability.
After determining the optimal number of iterations, this count will be used for all subsequent experiments to assess the specific effects of different SENet integration points.
3.3.2. Selection of Integration Points for the Attention Mechanism
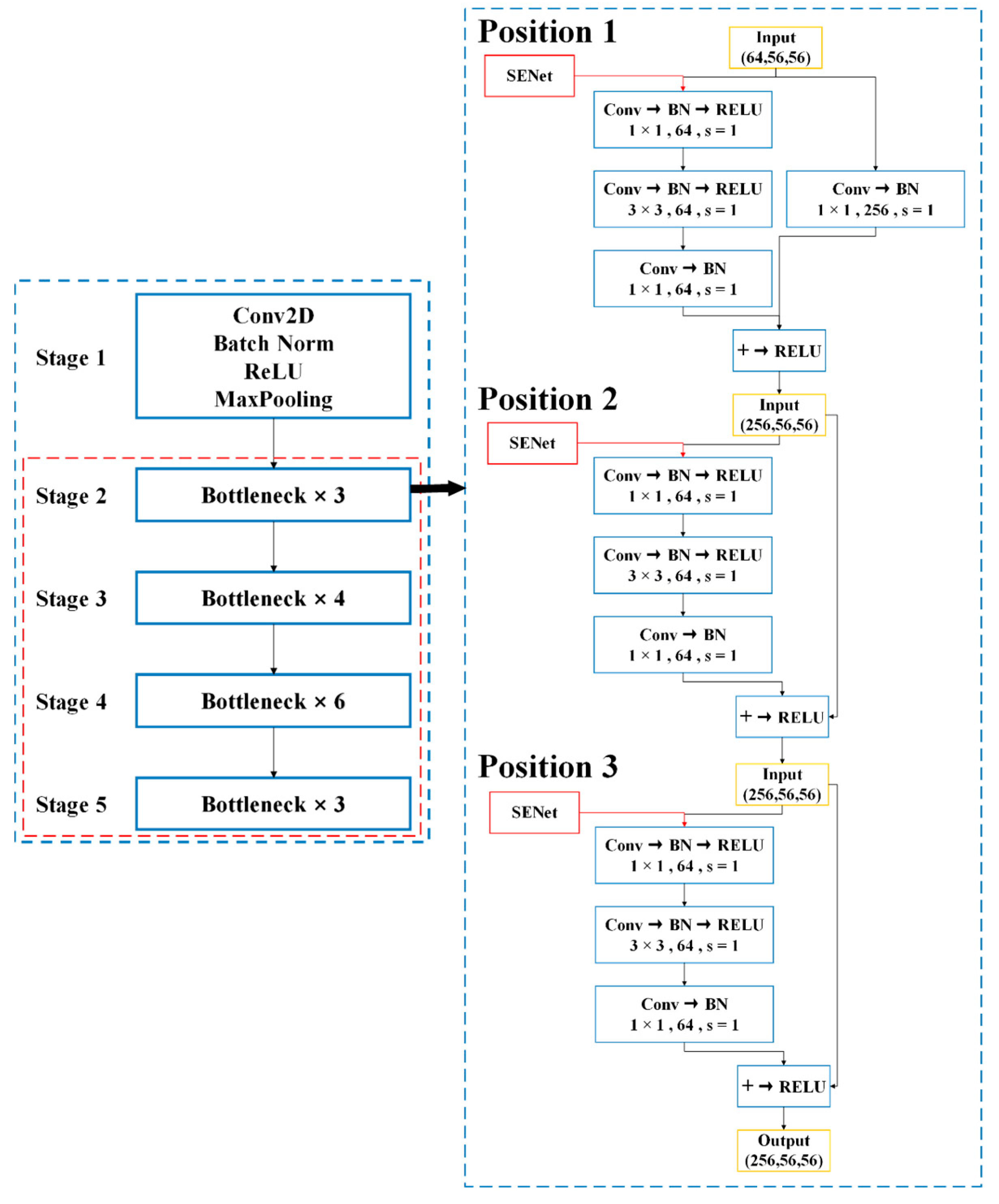
Integrating attention mechanisms in deep learning models, especially for detail-sensitive tasks like crack detection, has been proven to significantly enhance model performance. By integrating the SENet module, our model utilizes the ‘Squeeze-and-Excitation’ (SE) process to dynamically enhance feature representations. During the squeezing phase, features within each channel are aggregated to form a global understanding, which is then recalibrated in the excitation phase through learnable transformations. This recalibration adjusts feature activations by explicitly modeling the interdependencies among channels, thereby enhancing the model’s ability to prioritize useful features over irrelevant ones. This study aims to explore the effects of integrating the SENet attention module at different layers within the ResNet50-based improved Faster RCNN model. As shown in Figure 6.
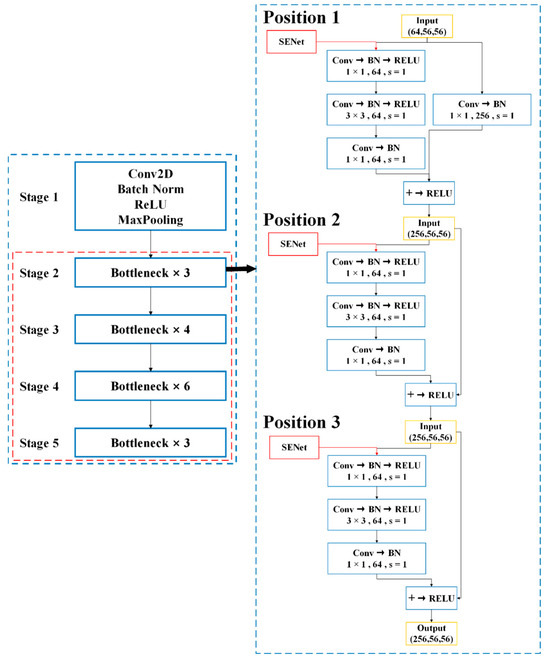
Figure 6.
Integration Points of the Attention Mechanism in the Network.
For this purpose, based on the improved Faster RCNN model, ResNet50 is chosen as the backbone network, and the convolutional layers in ResNet50′s bottleneck layers are selected as integration points: the first layer (near the input), middle layer (central position), and last layer (near the output). These positions are chosen based on their representational and functional differences within the network. The integration of attention mechanisms at the bottleneck layers of ResNet50 is based on the unique representational and functional roles of each layer. The first bottleneck layer captures low-level features, such as edges and textures, providing a foundation for the model to focus on information-rich features in the early stages. The middle layer processes more complex intermediate features, acting as a bridge between low-level textural features and high-level semantic features, while the final bottleneck layer is responsible for high-level semantic abstraction, directly linked to the execution of the final tasks. Integrating attention mechanisms optimizes the feature specificity of each layer, enhances the model’s focus on key semantic features, and improves accuracy and reliability, especially in object classification within complex scenes. This strategic enhancement not only reduces redundancy in feature maps but also significantly improves the model’s computational efficiency and effectiveness in handling diverse visual tasks. SENet modules are integrated before and after each selected layer to recalibrate the feature channels. This includes adjusting the feature channels’ weights using the SENet module before each layer’s input and applying SENet again after the convolution operation to further optimize the output features. Models at each integration point will be trained under the determined optimal iteration count, ensuring other factors like optimizer, learning rate, and batch size are standardized to ensure consistency and comparability of results.
The performance of models at different integration points on the validation set is compared using performance metrics such as mean average precision (mAP) and F1 score and so on. Through these experiments, we aim to identify the most effective integration points for the SENet module within the improved network architecture.
3.4. Experimental Evaluation Metrics
To comprehensively assess the performance of the Faster R-CNN model improved with ResNet50 after integrating the SENet attention module, this study employs Mean Average Precision (mAP) as the key evaluation metric.
Mean Average Precision (mAP): The area under the curve calculated at different threshold settings for model precision and recall; mAP is a common metric in evaluating object detection models, reflecting the model’s overall performance in detection tasks.
For a given IoU threshold θ, the AP for each category can be expressed as:
- –
- : The highest precision at recall rate r under IoU threshold θ.
mAP can be expressed as the average of APs across all categories:
- –
- N is the number of categories, is the AP of the ith category under IoU threshold θ.
Precision: Precision refers to the proportion of true positive samples among all samples identified as positive by the model, used to measure the accuracy of the model in identifying positive classes. It is calculated as follows:
where TP represents true positives, i.e., the correctly identified positive samples, and FP represents false positives, i.e., the negative samples incorrectly identified as positive.
Recall: Recall is the proportion of positive samples correctly identified by the model out of all actual positive samples, used to measure the model’s capability in identifying all positive samples. It is calculated as follows:
where FN represents false negatives, i.e., the positive samples incorrectly not identified as positive.
F1 Score: The F1 Score is the harmonic mean of Precision and Recall, reflecting a balance between these two metrics. It is especially applicable in scenarios where both precision and recall are equally valued. The formula is as follows:
In this study, we employed Mean Average Precision (mAP50), Precision, Recall, and F1 Score as the primary evaluation metrics to comprehensively assess the performance of the model. mAP50, by setting an IoU threshold of 0.5, not only ensures the accuracy of the detection boxes but also allows for some positional deviations, making it particularly suitable for crack detection tasks that are sensitive to location. Precision, Recall, and F1 Score collectively measure the model’s efficiency in correctly identifying and locating targets, ensuring a comprehensive and practical evaluation of the model.
4. Experimental Results and Analysis
4.1. Model Comparative Analysis Experiment
This study introduces the latest object detection algorithms, including YOLOv8, YOLOv9, and YOLOv10, and comprehensively evaluates the performance comparison of these models with the Faster R-CNN architecture based on ResNet50 in road crack detection. This comparison aims to demonstrate the advantages of choosing Faster R-CNN for specific application scenarios.
To ensure the fairness and effectiveness of the comparison, all models were tested under the same hardware and dataset conditions, with identical parameter configurations. We specially designed iterative tests ranging from short-term to long-term to assess the performance of each model at different training stages:
Twenty iterations: To quickly assess the initial performance of each model and establish a baseline comparison with Faster R-CNN.
Fifty iterations: To further analyze and compare the efficiency and effectiveness of the models during early to mid-stage training.
One hundred iterations: To explore the performance of the models after extended training, particularly assessing the stability and reliability of the YOLO series.
Two hundred and three hundred iterations: To evaluate the performance stability and learning saturation of the models after very long training periods.
Through this structured iterative testing, we not only assess the performance of the models at different training stages but also gain a more comprehensive understanding of each model’s effectiveness and reliability in practical applications. The relevant experimental results are shown in Table 2.
Table 2.
YOLO series-related experimental results.
In this study, after just 5 iterations, Faster R-CNN achieved an mAP50 of 0.268, significantly higher than YOLOv8 (0.07319), YOLOv9 (0.15048), and YOLOv10 (0.04859) after 20 iterations, demonstrating superior initial performance. As the iteration number increased to 15 and 20, Faster R-CNN’s mAP50 further improved to 0.512 and 0.538, respectively, showing a slight advantage over the YOLO series at 100 iterations (YOLOv8 at 0.5307, YOLOv9 at 0.52225, and YOLOv10 at 0.40682). Even compared to the YOLO series at 200 and 300 iterations (YOLOv8 at 0.57694, YOLOv9 at 0.52688, and YOLOv10 at 0.49361), Faster R-CNN reached an mAP50 of 0.571 at 30 iterations. While YOLOv8 and YOLOv9 show slight advantages in mAP50 after 200 and 300 iterations, they require a higher number of iterations to achieve this level, highlighting the differentiated capabilities of the network models, but also demonstrating that Faster R-CNN can achieve comparable performance in a shorter training cycle.
Furthermore, after 15 iterations, Faster R-CNN’s F1 score significantly increased to 0.5333. In contrast, YOLOv8 and YOLOv9 reached F1 scores of 0.60810 and 0.59292 after 200 iterations. Although these values are higher than Faster R-CNN’s F1 score of 0.3 at 20 iterations, Faster R-CNN exhibits quicker learning efficiency. Despite YOLOv9’s slightly superior performance in some metrics, Faster R-CNN demonstrates better time efficiency, which is crucial for practical applications requiring quick deployment and updates. Moreover, due to the use of a Region Proposal Network (RPN), Faster R-CNN exhibits more precise object detection accuracy and localization, which becomes particularly evident in subsequent test images.
The comparative analysis indicates that in dealing with this road crack dataset, even at lower iteration counts, Faster R-CNN can achieve performance levels similar to those of the YOLO series at higher iterations. The relevant experimental results are shown in Table 3. Although not the most time-efficient from a training perspective, its high accuracy and robustness in object detection tasks make it a more suitable choice for many practical applications.
Table 3.
Data from Faster R-CNN experiments without attentional mechanisms.
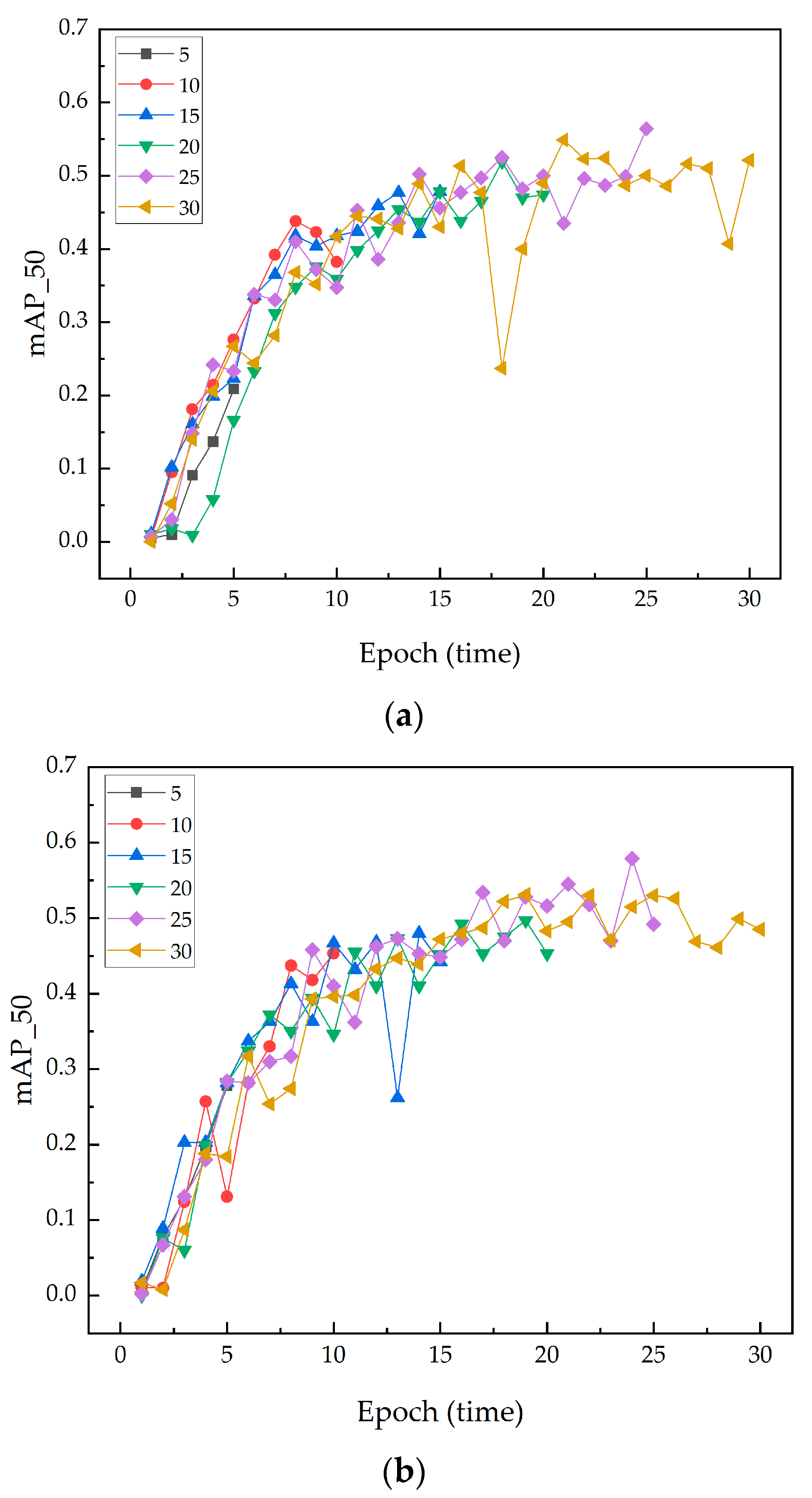
4.2. Performance Comparison at Different Iteration Counts
This study investigated the impact of different iteration counts on the performance of a Faster R-CNN model enhanced with ResNet50 and integrated with the SENet attention module at various bottleneck convolutional layers. Model performance was assessed at 5, 10, 15, 20, 25, and 30 iterations. The relevant experimental results are shown in Table 4.
Table 4.
Performance Comparison at Different Iteration Counts.
The experimental results demonstrated that at the first and third integration points, the model achieved a balanced performance between mAP_50 and F1 scores at 20 iterations. Although iterations at 25 and 30 occasionally showed higher mAP_50 and F1 scores, the highest values consistently occurred within the range of 20 ± 2 iterations. This consistency underscores the robustness of the model at these integration points, indicating optimal performance in terms of both accuracy and precision-recall balance. At the second integration point, the model performed optimally at 30 iterations, reaching a peak mAP_50 of 0.663. However, at this iteration count, the performance at the first and third integration points did not reach their peak. Although the performance at the second position at 30 iterations was notable, considering overall efficiency and stability, 20 iterations were identified as the optimal iteration count. This iteration count demonstrated efficient and stable performance at two of the positions. Compared to fewer or greater numbers of iterations, 20 iterations maintained high detection accuracy while effectively preventing overfitting or underfitting.
Moreover, the analysis of F1 scores supports the superiority of 20 iterations. At this iteration count, the model not only exhibited excellent performance in terms of mAP_50 but also achieved the highest F1 scores, particularly evident at the first and third integration points with scores of 0.4000 and 0.2000, respectively. These scores are significantly higher than those at other iteration counts, further indicating that the model achieved an optimal balance between precision and recall, resulting in the best overall performance.
Determining the optimal iteration count is critically important in the training process of deep learning models, as it affects both model performance and computational efficiency. In selecting the best iteration count, it is also essential to consider the importance of overall performance. By analyzing and comparing performance across different iteration counts and F1 scores, this study was able to identify the most effective iteration count for integrating the SENet module into the Faster R-CNN for crack detection.
The test result image of the third integrated location test set was selected for display, as shown in Figure 7.

Figure 7.
Display of test set results with different iterations.
4.3. Impact of Attention Mechanism Integration Points on Performance
After establishing 20 iterations as the optimal count for training the model, this study next explores how different integration points of the SENet attention module within the bottleneck layers of the model affect crack detection performance. Selecting the best integration point can further optimize model performance, especially in the extraction and processing of key features. The analysis in this part will be based on the previously determined optimal iteration count to ensure the accuracy and reliability of the evaluation results. The relevant experimental results are shown in Table 5.
Table 5.
Performance Comparison of SENet at Different Integration Points.
In this study, the impact of the SENet attention module integrated at different positions on the mAP_50 values was analyzed in detail, complemented by m_AP and mAP_75 metrics for a comprehensive performance evaluation. The experimental results indicate that integrating the SENet attention module at the third convolutional layer position yields an average mAP50 of 0.6748, which shows a significant performance improvement compared to the first integration position at 0.6460 and the second at 0.6334. Additionally, the third position also excels in the mAP_75 metric, achieving an average value of 0.3550.
Compared to the baseline model without integrated SENet, the third integration position shows a notable increase in mAP_50 after adding the SENet attention module, with a maximum increase from 0.6710 to 0.7090, approximately a 3% growth. This position demonstrates that integrating attention mechanisms at deeper network layers can effectively enhance the model’s ability to capture complex features. However, the mAP_50 performance at the first integration position is similar to or slightly lower than when SENet is not integrated, suggesting that adding SENet at an earlier stage in the network might have a limited impact on the overall model performance.
Through these experiments, this study demonstrates that adding the SENet attention mechanism in the third convolutional layer of the bottleneck layer in the improved model can effectively enhance the accuracy of crack detection. The test result image of the third integrated location test set was selected for display, as shown in Figure 8.

Figure 8.
(a) Third integration location Add SENet test set results display. (b) Comparison with the YOLO series.
4.4. Model Performance Analysis
4.4.1. Discussion on the Choice of Iteration Count
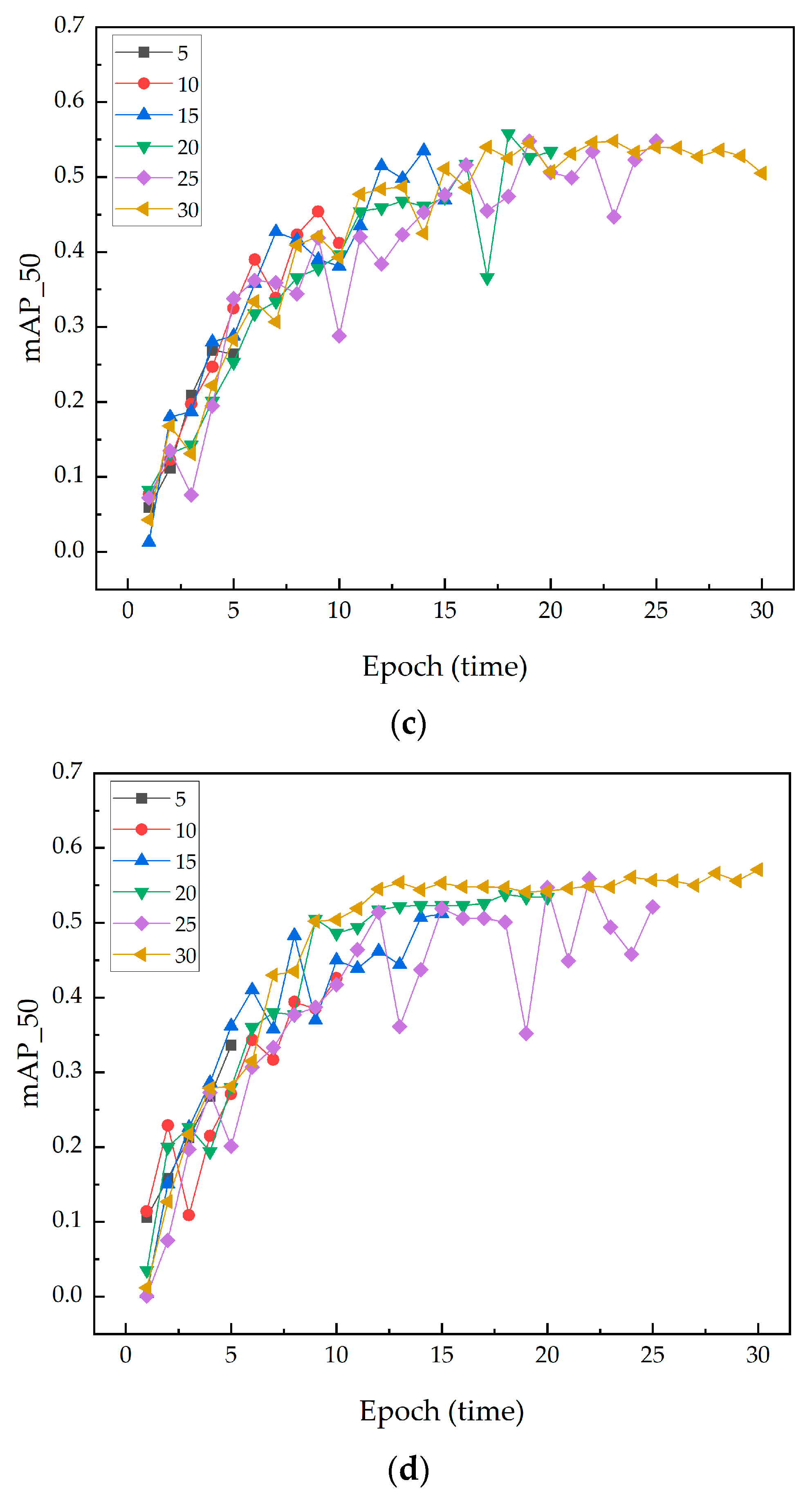
This study primarily investigated the importance of selecting an appropriate iteration count when integrating the SENet attention module at different convolutional layer positions within the model. While higher iteration counts showed potential performance gains at the second integration position, 20 iterations significantly improved performance at the first and third integration positions, demonstrating their global superiority. The decision to choose 20 iterations as the optimal count is based on its balanced performance across key indicators, particularly the high mAP50 values, which highlight the model’s excellent detection capability at higher confidence levels. This is crucial for crack detection tasks that require high precision and reliability. Moreover, compared to lower or higher iteration counts, 20 iterations achieved more stable performance, reducing fluctuations and uncertainties during training. These findings are significant for optimizing training strategies in deep learning models, especially when integrating complex structures like SENet. Figure 9 illustrates the changes in mAP_50 with SENet integrated at different positions.
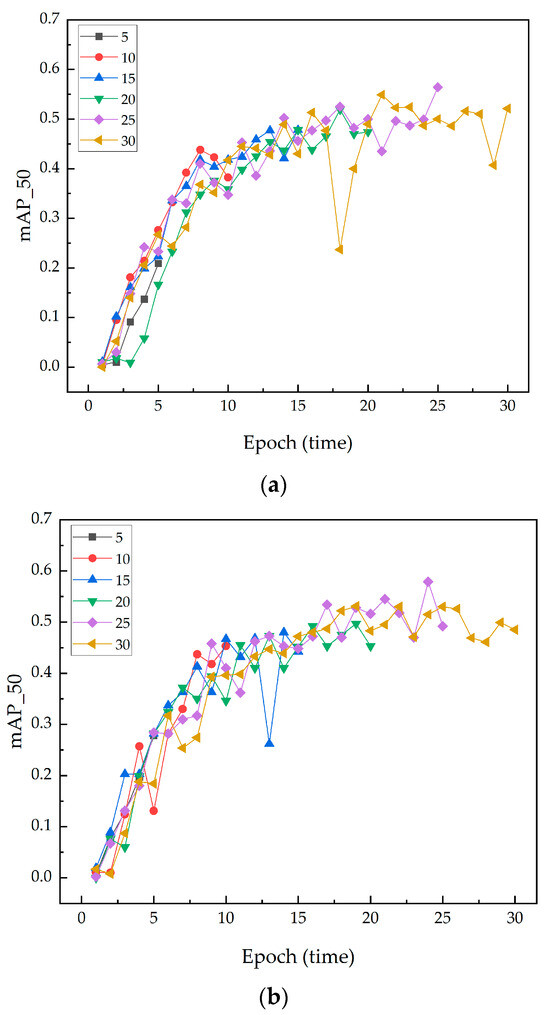
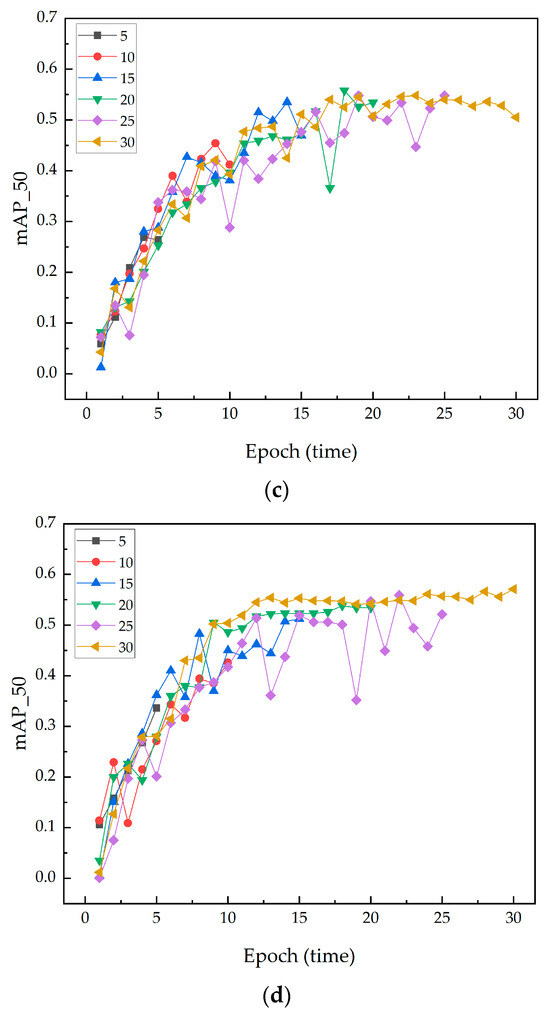
Figure 9.
The changes in mAP50 with SENet integrated at different positions: (a) First integration position. (b) Second integration position. (c) Third integration location. (d) No SENet is inserted.
4.4.2. Discussion on the Choice of Integration Points for the Attention Mechanism
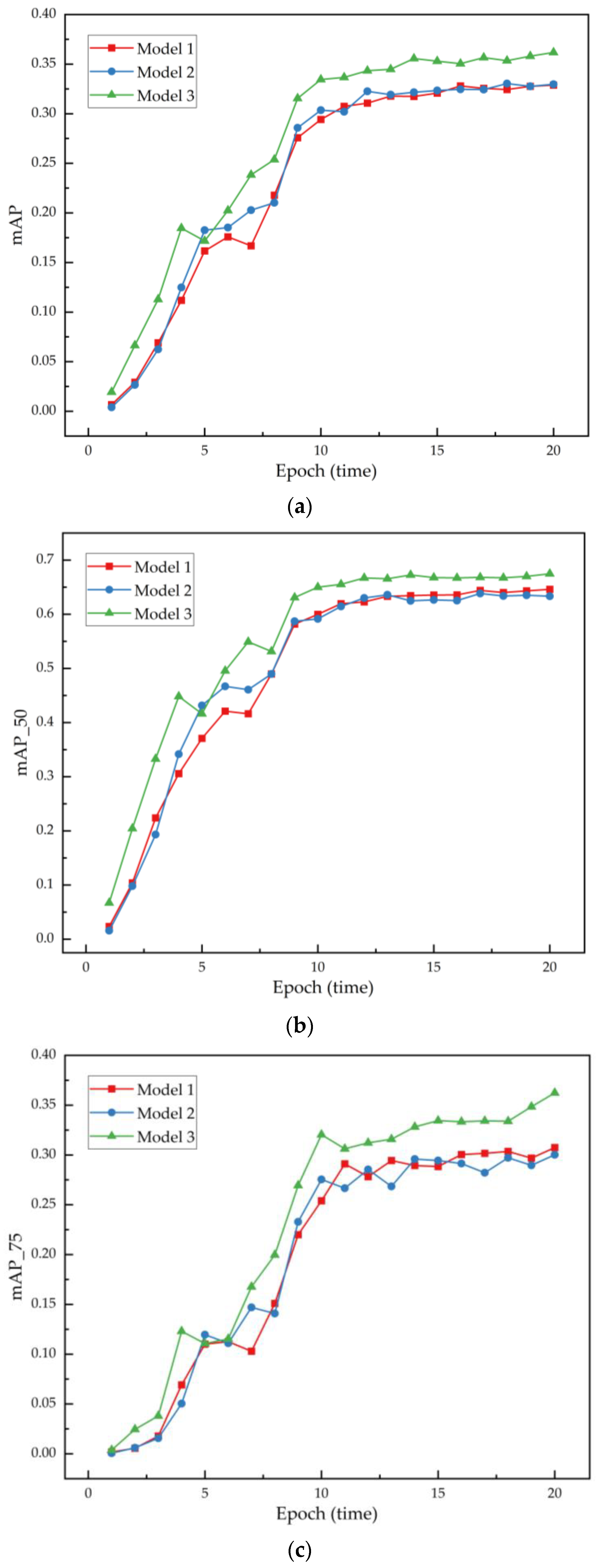
Further experimental analysis primarily focused on the critical role of integration points for the attention mechanism in optimizing model performance. Integrating the SENet module at the third convolutional layer not only excelled in Mean Average Precision (mAP_50) detection at an IoU threshold of 0.5 but also demonstrated superior performance in more challenging target detections (mAP_75). This performance likely stems from the third convolutional layer’s more effective use of advanced features adjusted by SENet, allowing the model to more accurately capture complex crack features at deeper levels. Compared to the first and second integration positions, the configuration at the third position significantly reduced fluctuations and uncertainties during training, providing more stable and reliable performance for detail-sensitive tasks such as crack detection. These results provide important practical guidance for integrating attention mechanisms sensibly in deep learning models, especially suitable for applications that demand high accuracy and reliability. Figure 10 shows the mAP, mAP_50, and mAP_75 for models with SENet integrated at different positions at 20 iterations.
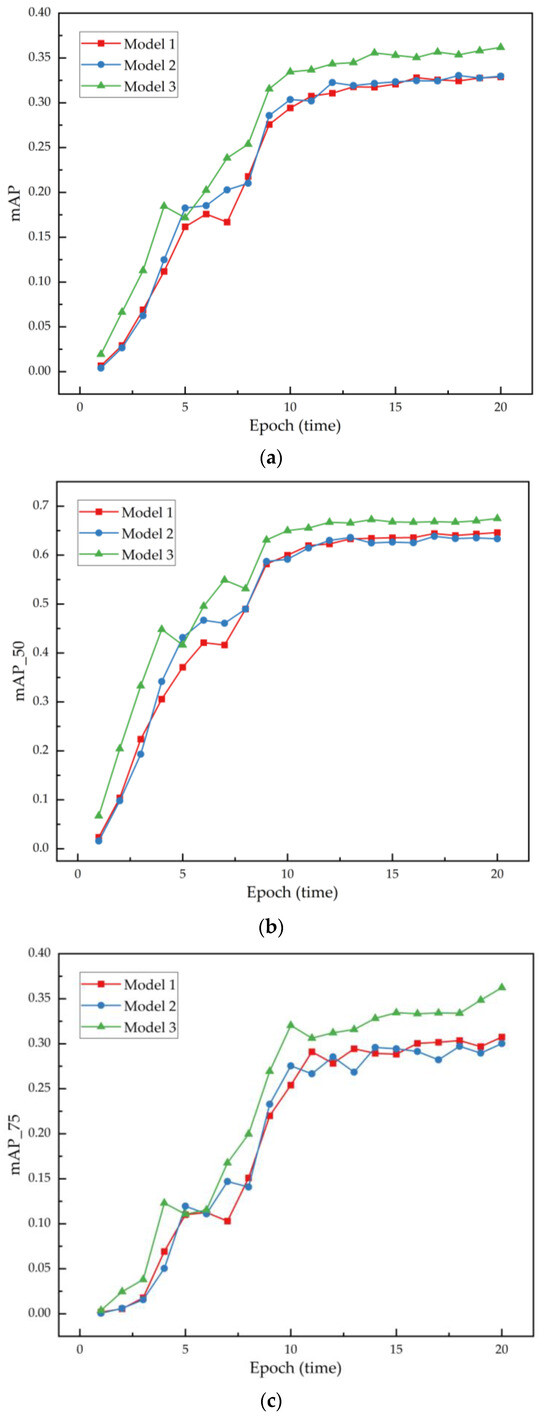
Figure 10.
The mAP, mAP_50, and mAP_75 for models with SENet integrated at different positions at 20 iterations: (a) The average of mAP of the model at different locations. (b) The average of mAP_50 of the model at different locations. (c) The average of mAP_75 of the model at different locations.
4.5. Selection of Attention Mechanisms and Ablation Experiments
In previous experiments, the optimal integration points and iteration counts for the SENet attention module within the improved model were determined, and a performance improvement was observed. To illustrate the impact of different attention mechanisms on model performance and as a basis for choosing the SENet attention module, this Section will compare SENet with three other attention mechanisms, including ECANet, the Global Context Block (GC) and BAM, and conduct detailed ablation experiments. The relevant experimental results are shown in Table 6.
Table 6.
Performance Comparison of Different Attention Mechanisms.
As shown in the table, all attention mechanisms were evaluated under the same training conditions: a learning rate of 0.02, 20 iterations, and training and test set sizes of 950 and 50, respectively. Each attention mechanism was integrated at the third integration point of the improved model to assess its effects.
The table shows that SENet achieved the highest mAP_50 value of 0.7090, demonstrating superior performance compared to models without any attention mechanism (mAP_50 of 0.6710) and other attention mechanisms like ECANet (mAP_50 of 0.4540) and GC (mAP_50 of 0.6320). In terms of mAP_75, while SENet’s performance was better than the others, the improvement was not as pronounced, suggesting that different attention mechanisms may perform differently under more stringent IoU thresholds.
The findings from the experiments in this paper provide practical references for training strategies and the integration of attention mechanisms in deep learning models. Especially in detail-sensitive and high-precision tasks such as crack detection, determining the appropriate number of iterations and the integration points for attention mechanisms is crucial for optimizing model performance. Our results offer an effective strategy to enhance model detection accuracy while maintaining computational efficiency. However, the limitations of this study lie in the specificity of the experimental environment and dataset, which may affect the generalizability of the results. Different tasks or datasets might require different iteration counts and strategies for integrating attention mechanisms. Additionally, the integration of the SENet module may increase computational complexity, which needs to be balanced in practical applications.
5. Conclusions
This study experimentally validated the effectiveness of integrating the SENet attention mechanism within the improved Faster R-CNN model, particularly for detail-oriented tasks such as crack detection. We identified the optimal number of iterations and the integration points for the attention mechanism. However, the study’s limitations lie in its dependence on specific experimental environments and datasets, which may affect the generalizability of the results.
In summary, this study provides valuable insights into the selection of iteration counts and the determination of integration points for attention mechanisms in deep learning models. Our experimental results underscore the importance of considering these factors in model design and training, particularly when performing detail-sensitive tasks.
Future research could explore the optimal iteration counts and attention mechanism positions for different application scenarios including various types of datasets and application areas such as urban traffic monitoring, natural disaster damage assessment, etc., to further enhance model applicability and efficiency.
Author Contributions
Methodology, Q.L., J.G., X.X. and H.Y.; investigation, Q.L., J.G., H.Y. and X.X.; resources, H.Y. and X.X.; data curation, H.Y. and X.X.; writing—original draft preparation, Q.L., J.G. and X.X.; writing—review and editing, Q.L., J.G., X.X. and H.Y.; project administration, H.Y. and X.X.; funding acquisition, H.Y. and X.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (No: 52308323), Natural Science Foundation of Jiangsu Province, China (BK20220502), and Suzhou Innovation and Entrepreneurship Leading Talent Plan (No. ZXL2022488).
Data Availability Statement
The data provided in this work are available from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Xu, H.; Su, X.; Wang, Y.; Cai, H.; Cui, K.; Chen, X. Automatic Bridge Crack Detection Using a Convolutional Neural Network. Appl. Sci. 2019, 9, 2867. [Google Scholar] [CrossRef]
- Li, H.; Li, M.; Li, K.; Zhao, X. The application of Mask RCNN model in pavement defect detection. Sci. Technol. Innov. 2020, 29, 131–132. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, C.; Xiao, S. Object Detection Based on Fast/Faster RCNN Employing Fully Convolutional Architectures. Math. Probl. Eng. 2018, 2018, 1–7. [Google Scholar] [CrossRef]
- Liao, Y.; Dou, D. Design and research of bridge crack detection method based on Mask RCNN. J. Appl. Opt. 2022, 43, 100–105, 118. [Google Scholar] [CrossRef]
- Li, H. Research on Pavement Defect Detection Method Based on Deep Learning. Master Thesis, Changchun University, Changchun, China, 2021. [Google Scholar]
- Huang, J.; Shi, Y.; Gao, Y. Multi-scale Faster-RCNN detection algorithm for small targets. J. Comput. Res. Dev. 2019, 56, 319–327. [Google Scholar]
- Xin, F.; Zhang, H.; Pan, H. Hybrid dilated multilayer faster RCNN for object detection. Vis. Comput. 2024, 40, 393–406. [Google Scholar] [CrossRef]
- Wang, H.; Xiao, N. Underwater Object Detection Method Based on Improved Faster RCNN. Appl. Sci. 2023, 13, 2746. [Google Scholar] [CrossRef]
- Zhao, W.; Xu, M.; Cheng, X.; Zhao, Z. An Insulator in Transmission Lines Recognition and Fault Detection Model Based on Improved Faster RCNN. IEEE Trans. Instrum. Meas. 2021, 70, 5016408. [Google Scholar] [CrossRef]
- Dai, X.; Chen, H.; Zhu, C. Research on Surface defect detection and implementation of metal workpiece based on improved Faster RCNN. Surf. Technol. 2020, 49, 362–371. [Google Scholar]
- Liang, B.; Liu, Q.; Xu, J.; Zhou, Q.; Zhang, P. Target-specific sentiment analysis based on multi-attention convolutional neural networks. J. Comput. Res. Dev. 2017, 54, 1724–1735. [Google Scholar]
- He, X.; Tang, Z.; Deng, Y.; Zhou, G.; Wang, Y.; Li, L. UAV-based road crack object-detection algorithm. Autom. Constr. 2023, 154, 105014. [Google Scholar] [CrossRef]
- Nguyen, N.H.T.; Perry, S.; Bone, D.; Le, H.T.; Nguyen, T.T. Two-stage convolutional neural network for road crack detection and segmentation. Expert. Syst. Appl. 2021, 186, 115718. [Google Scholar] [CrossRef]
- Feng, H.; Xu, G.S.; Guo, Y. Multi-scale classification network for road crack detection. IET Intell. Transp. Syst. 2019, 13, 398–405. [Google Scholar] [CrossRef]
- Xu, C.; Zhang, Q.; Mei, L.; Chang, X.; Ye, Z.; Wang, J.; Ye, L.; Yang, W. Cross-Attention-Guided Feature Alignment Network for Road Crack Detection. ISPRS Int. J. Geo-Inf. 2023, 12, 382. [Google Scholar] [CrossRef]
- Li, H.; Peng, T.; Qiao, N.; Guan, Z.; Feng, X.; Guo, P.; Duan, T.; Gong, J. CrackTinyNet: A novel deep learning model specifically designed for superior performance in tiny road surface crack detection. IET Intell. Transp. Syst. 2024. [Google Scholar] [CrossRef]
- Hacıefendioğlu, K.; Başağa, H.B. Concrete Road Crack Detection Using Deep Learning-Based Faster R-CNN Method. Iranian Journal of Science and Technology. Trans. Civ. Eng. 2022, 46, 1621–1633. [Google Scholar] [CrossRef]
- Guo, G.; Zhang, Z. Road damage detection algorithm for improved YOLOv5. Sci. Rep. 2022, 12, 15523. [Google Scholar] [CrossRef]
- Hassanin, M.; Anwar, S.; Radwan, I.; Khan, F.S.; Mian, A. Visual attention methods in deep learning: An in-depth survey. Inf. Fusion. 2024, 108, 102417. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. CBAM: Convolutional Block Attention Module; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Liu, Y.; Zhu, Q.; Cao, F.; Chen, J.; Lu, G. High-Resolution Remote Sensing Image Segmentation Framework Based on Attention Mechanism and Adaptive Weighting. ISPRS Int. J. Geo-Inf. 2021, 10, 241. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, M.; Feng, H.; Xu, Z.; Li, Q. Split-Attention Multiframe Alignment Network for Image Restoration. IEEE Access 2020, 8, 39254–39272. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Zhang, Z.; Lin, H.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R. ResNeSt: Split-Attention Networks. arXiv 2020, arXiv:2004.08955. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar] [CrossRef]
- Kandula, A.R.; Narayan, S.; Sathya, R. Performing Uni-variate Analysis on Cancer Gene Mutation Data Using SGD Optimized Logistic Regression. Int. J. Eng. Trends Technol. 2021, 69, 59–67. [Google Scholar] [CrossRef]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. J. Mach. Learn. Res. 2011, 12, 257–269. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Zhao, X.; Li, W.; Zhang, Y.; Gulliver, T.A.; Feng, Z. A Faster RCNN-Based Pedestrian Detection System. In Proceedings of the 2016 IEEE 84th Vehicular Technology Conference (VTC-Fall), Montreal, QC, Canada, 18–21 September 2016. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. 2015, 39, 640–651. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions; Cornell University Library: Ithaca, NY, USA, 2014. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G.; Albanie, S. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).