
Unified Spatial-Frequency Modeling and Alignment for Multi-Scale Small Object Detection

Abstract
:1. Introduction
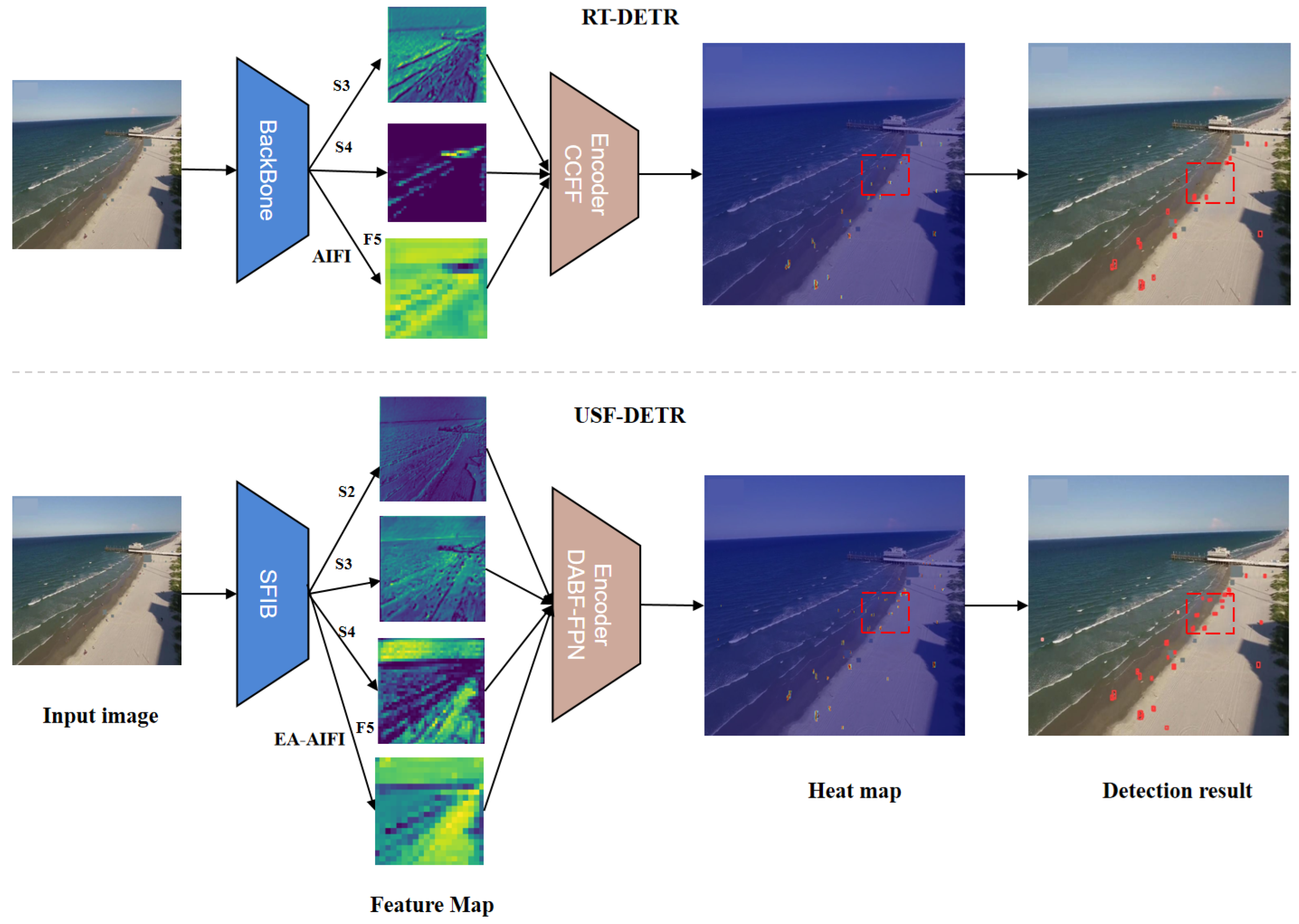
- A novel backbone, SFIB, is proposed that combines spatial and frequency domain features. In the spatial domain, the Scharr operator is utilized to extract details and edge information, enhancing local spatial structure features. In the frequency domain, FFT and IFFT are employed to capture both low-frequency and high-frequency patterns, balancing global and local information. The dynamic weighting integration of spatial and frequency domain features enables the model to comprehensively consider both spatial details and frequency distributions, significantly improving feature extraction capability and multi-scale adaptability in complex scenarios.
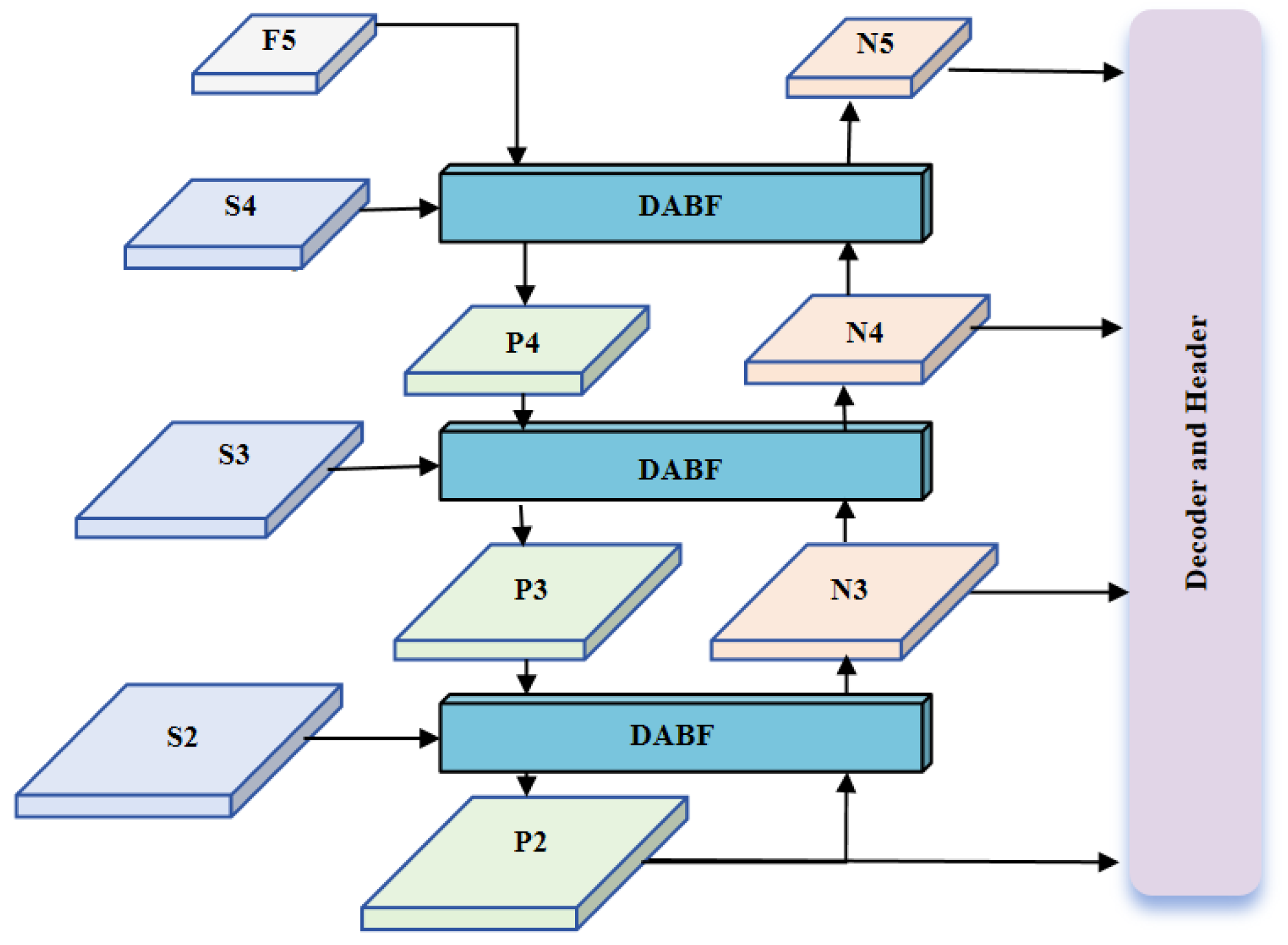
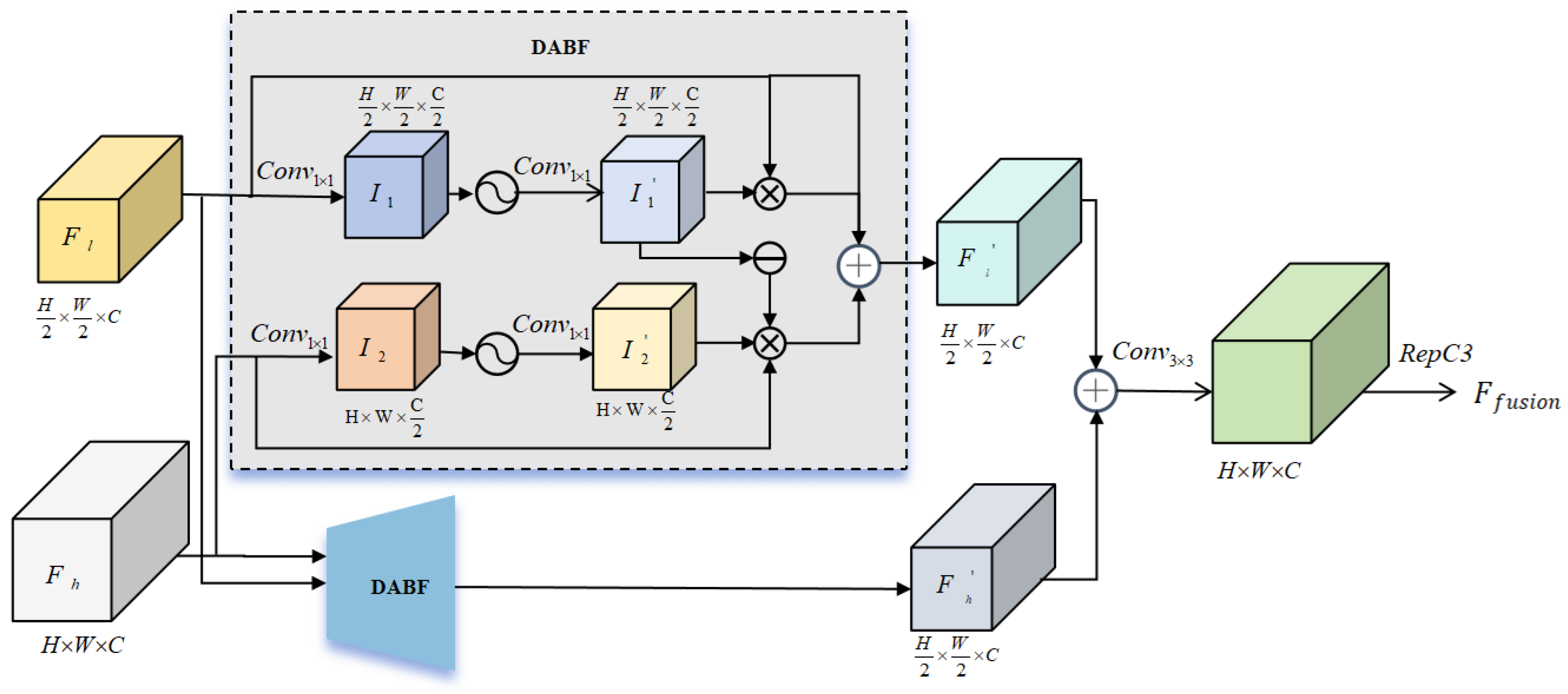
- The proposed DABF-FPN achieves geometric alignment and saliency balance between high- and low-resolution features through a bidirectional fusion mechanism. The DABF module utilizes an adaptive attention mechanism to selectively aggregate boundary details and semantic information based on the resolution and content of feature maps. This enhances the saliency representation of target regions while suppressing background noise, leading to more effective feature fusion and further improving the performance of multi-scale feature integration.
- EA-AIFI introduces Efficient Additive Attention, eliminating key-value interactions and relying solely on linear projections to efficiently encode the query-key relationship. This approach alleviates the computational bottleneck of matrix operations. In combination with positional encoding and a feed-forward network (FFN), EA-AIFI enhances inference speed and robust contextual representation, optimizing both global context modeling and small object detection in terms of efficiency and performance.
2. Related Work
2.1. Transformer-Based Detection Methods
2.2. Small Object Detection Methods in Aerial Images
3. Methodologies
3.1. Overview
3.2. Spatial-Frequency Interaction Backbone (SFIB)
3.2.1. Module Structure
3.2.2. SFI Block
3.3. Dual Alignment and Balance Fusion FPN (DABF-FPN)
3.3.1. Overall Structure
3.3.2. Dual Alignment and Balance Fusion (DABF)
3.4. Efficient Attention-AIFI (EA-AIFI)
4. Experiment
4.1. DataSet
4.2. Evaluation Metrics and Environment
4.2.1. Evaluation Metrics
4.2.2. Experimental Environment
4.3. Ablation Study
4.4. Comparative Experiment
4.4.1. VisDrone
4.4.2. TinyPerson
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cheng, G.; Yuan, X.; Yao, X.; Yan, K.; Zeng, Q.; Xie, X.; Han, J. Towards large-scale small object detection: Survey and benchmarks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13467–13488. [Google Scholar] [CrossRef] [PubMed]
- Mittal, P.; Singh, R.; Sharma, A. Deep learning-based object detection in low-altitude UAV datasets: A survey. Image Vis. Comput. 2020, 104, 104046. [Google Scholar] [CrossRef]
- Jiang, X.; Tang, H.; Li, Z. Global Meets Local: Dual Activation Hashing Network for Large-Scale Fine-Grained Image Retrieval. IEEE Trans. Knowl. Data Eng. 2024, 36, 6266–6279. [Google Scholar] [CrossRef]
- Vaswani, A. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Farhadi, A.; Redmon, J. YOLOv3: An Incremental Improvement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 1–6. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Wang, S.; Wan, C.; Yan, J.; Li, S.; Sun, T.; Chi, J.; Yang, G.; Chen, C.; Yu, T. Hierarchical Scale Awareness for object detection in Unmanned Aerial Vehicle Scenes. Appl. Soft Comput. 2024, 168, 112487. [Google Scholar] [CrossRef]
- Tong, K.; Wu, Y. Deep learning-based detection from the perspective of small or tiny objects: A survey. Image Vis. Comput. 2022, 123, 104471. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings; Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Katharopoulos, A.; Vyas, A.; Pappas, N.; Fleuret, F. Transformers are rnns: Fast autoregressive transformers with linear attention. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 5156–5165. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7036–7045. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Wang, Z.; Guo, J.; Zhang, C.; Wang, B. Multiscale feature enhancement network for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5634819. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Ma, T.; Mao, M.; Zheng, H.; Gao, P.; Wang, X.; Han, S.; Ding, E.; Zhang, B.; Doermann, D. Oriented object detection with transformer. arXiv 2021, arXiv:2106.03146. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, BC, Canada, 11–17 October 2021; pp. 14454–14463. [Google Scholar]
- Sun, Z.; Cao, S.; Yang, Y.; Kitani, K.M. Rethinking transformer-based set prediction for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3611–3620. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Xiao, Y.; Xu, T.; Yu, X.; Fang, Y.; Li, J. A Lightweight Fusion Strategy with Enhanced Inter-layer Feature Correlation for Small Object Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4708011. [Google Scholar] [CrossRef]
- Liu, H.I.; Tseng, Y.W.; Chang, K.C.; Wang, P.J.; Shuai, H.H.; Cheng, W.H. A DeNoising FPN with Transformer R-CNN for Tiny Object Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4704415. [Google Scholar] [CrossRef]
- Du, Z.; Hu, Z.; Zhao, G.; Jin, Y.; Ma, H. Cross-Layer Feature Pyramid Transformer for Small Object Detection in Aerial Images. arXiv 2024, arXiv:2407.19696. [Google Scholar]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered object detection in aerial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8311–8320. [Google Scholar]
- Li, C.; Yang, T.; Zhu, S.; Chen, C.; Guan, S. Density map guided object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 190–191. [Google Scholar]
- Huang, Y.; Chen, J.; Huang, D. UFPMP-Det: Toward accurate and efficient object detection on drone imagery. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 28 February–1 March 2022; Volume 36, pp. 1026–1033. [Google Scholar]
- Du, B.; Huang, Y.; Chen, J.; Huang, D. Adaptive sparse convolutional networks with global context enhancement for faster object detection on drone images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 13435–13444. [Google Scholar]
- Chen, L.; Liu, C.; Li, W.; Xu, Q.; Deng, H. DTSSNet: Dynamic Training Sample Selection Network for UAV Object Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5902516. [Google Scholar] [CrossRef]
- Zhang, Z. Drone-YOLO: An efficient neural network method for target detection in drone images. Drones 2023, 7, 526. [Google Scholar] [CrossRef]
- Liu, K.; Fu, Z.; Jin, S.; Chen, Z.; Zhou, F.; Jiang, R.; Chen, Y.; Ye, J. ESOD: Efficient Small Object Detection on High-Resolution Images. arXiv 2024, arXiv:2407.16424. [Google Scholar] [CrossRef]
- Zhang, Y.; Ye, M.; Zhu, G.; Liu, Y.; Guo, P.; Yan, J. FFCA-YOLO for small object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5611215. [Google Scholar] [CrossRef]
- Khalili, B.; Smyth, A.W. SOD-YOLOv8—Enhancing YOLOv8 for Small Object Detection in Aerial Imagery and Traffic Scenes. Sensors 2024, 24, 6209. [Google Scholar] [CrossRef]
- Liu, C.; Gao, G.; Huang, Z.; Hu, Z.; Liu, Q.; Wang, Y. YOLC: You Only Look Clusters for Tiny Object Detection in Aerial Images. IEEE Trans. Intell. Transp. Syst. 2024, 25, 13863–13875. [Google Scholar] [CrossRef]
- Liu, S.; Huang, S.; Li, F.; Zhang, H.; Liang, Y.; Su, H.; Zhu, J.; Zhang, L. DQ-DETR: Dual query detection transformer for phrase extraction and grounding. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 1728–1736. [Google Scholar]
- Liu, J.; Jing, D.; Zhang, H.; Dong, C. SRFAD-Net: Scale-Robust Feature Aggregation and Diffusion Network for Object Detection in Remote Sensing Images. Electronics 2024, 13, 2358. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Chen, L.; Fu, Y.; Gu, L.; Yan, C.; Harada, T.; Huang, G. Frequency-aware feature fusion for dense image prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 10763–10780. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Jin, W.; Qiu, S.; He, Y. Multiscale Spatial-Frequency Domain Dynamic Pansharpening of Remote Sensing Images Integrated with Wavelet Transform. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5408915. [Google Scholar] [CrossRef]
- Shaker, A.; Maaz, M.; Rasheed, H.; Khan, S.; Yang, M.H.; Khan, F.S. Swiftformer: Efficient additive attention for transformer-based real-time mobile vision applications. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 17425–17436. [Google Scholar]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Yu, X.; Gong, Y.; Jiang, N.; Ye, Q.; Han, Z. Scale match for tiny person detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1257–1265. [Google Scholar]
- Liu, J.; Jing, D.; Cao, Y.; Wang, Y.; Guo, C.; Shi, P.; Zhang, H. Lightweight Progressive Fusion Calibration Network for Rotated Object Detection in Remote Sensing Images. Electronics 2024, 13, 3172. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef] [PubMed]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3490–3499. [Google Scholar]
- Biffi, L.J.; Mitishita, E.; Liesenberg, V.; Santos, A.A.d.; Gonçalves, D.N.; Estrabis, N.V.; Silva, J.d.A.; Osco, L.P.; Ramos, A.P.M.; Centeno, J.A.S.; et al. ATSS deep learning-based approach to detect apple fruits. Remote Sens. 2020, 13, 54. [Google Scholar] [CrossRef]
- Lin, T. Focal Loss for Dense Object Detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. Rtmdet: An empirical study of designing real-time object detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment | Parameter |
|---|---|
| Operating System | Red Hat 4.8.5-28 |
| Programming Language | Python 3.11 |
| Framework | Pytorch 2.1 |
| CUDA | CUDA 12.1 |
| GPU | NVIDIA A800 |
| CPU | Intel_6338N_Xeon |
| VRAM | 80 G |
| Parameter | Value | Description |
|---|---|---|
| optimizer | AdamW | Combines Adam with weight decay to prevent overfitting. |
| base_learning_rate | 0.0001 | Initial step size for the optimizer. |
| weight_decay | 0.0001 | Regularization parameter to prevent overfitting by penalizing large weights. |
| global_gradient_clip_norm | 0.1 | Limits gradient norm to ensure stable training and prevent exploding gradients. |
| linear_warmup_steps | 2000 | Defines the maximum norm for gradient clipping during training. |
| minimum learning rate | 0.00001 | Defines the lower bound for the learning rate during training. |
| input image size | 640 × 640 | Specifies the height and width of input images. |
| epochs | 300 | The total passes through the entire training dataset. |
| batch size | 4 | The count of samples is handled in a single forward and backward pass. |
| SFIB | DABF-FPN | EA-AIFI | Params | GFLOPs | Precision | Recall | mAP_50 | mAP_50:95 |
|---|---|---|---|---|---|---|---|---|
| × | × | × | 38.61 | 58.3 | 62.1 | 47.1 | 48.2 | 29.4 |
| ✓ | × | × | 39.81 | 62 | 62.8 | 47.7 | 49.2 | 30.5 |
| ✓ | ✓ | × | 42.39 | 106.9 | 62.9 | 50.0 | 51.9 | 32.7 |
| ✓ | ✓ | ✓ | 42.12 | 106.8 | 65 | 50.8 | 52.3 | 33.2 |
| SFIB | DABF-FPN | EA-AIFI | Params | GFLOPs | Precision | Recall | mAP_50 | mAP_50:95 |
|---|---|---|---|---|---|---|---|---|
| × | × | × | 38.6 | 56.9 | 46.1 | 33.9 | 28.6 | 8.96 |
| ✓ | × | × | 39.8 | 60.6 | 48.5 | 34.6 | 29.7 | 9.04 |
| ✓ | ✓ | × | 42.1 | 103.5 | 46.4 | 35.9 | 30.4 | 9.5 |
| ✓ | ✓ | ✓ | 42.1 | 107.4 | 48.8 | 36.8 | 31.2 | 9.79 |
| Method | BackBone | AP | AP50 | AP75 | APs | APm | APl | Params (M) | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|---|---|
| Two-stage models: | ||||||||||
| Faster-RCNN [54] | ResNet-50 | 20.5 | 34.2 | 21.9 | 10.0 | 29.5 | 43.3 | 41.39 | 208 | 46.8 |
| Cascade-RCNN [55] | ResNet-50 | 20.8 | 33.7 | 22.4 | 10.1 | 29.9 | 45.2 | 69.29 | 236 | 24.6 |
| One-stage models: | ||||||||||
| TOOD [56] | ResNet-50 | 21.4 | 34.6 | 23.0 | 10.4 | 30.3 | 41.6 | 32.04 | 199 | 25.7 |
| ATSS [57] | ResNet-50 | 21.6 | 34.6 | 23.1 | 10.2 | 30.8 | 45.8 | 38.91 | 110 | 35.4 |
| RetinaNet [58] | ResNet-50 | 17.8 | 29.4 | 18.9 | 6.7 | 26.5 | 43.0 | 36.517 | 210 | 54.4 |
| RTMDet [59] | CSPNeXt-tiny | 18.4 | 31.2 | 21.3 | 7.7 | 28.8 | 44.5 | 4.876 | 8.033 | 52.1 |
| YOLOX [60] | Darknet53 | 15.6 | 28.3 | 15.5 | 7.8 | 21.3 | 28.8 | 5.035 | 7.578 | 88.0 |
| YOLOv8m | Darknet53 | 16.2 | 30.7 | 15.2 | 10.7 | 31.9 | 39.1 | 99.0 | 78.7 | 165.2 |
| YOLOv11m | Darknet53 | 16.5 | 30.8 | 15.1 | 10.6 | 32.1 | 39.3 | 87.0 | 68.5 | 156.6 |
| RT-DETR [14] | ResNet-18 | 19.83 | 31.3 | 7.1 | 10.4 | 30.2 | 39.0 | 38.61 | 57.0 | 147.9 |
| USF-DETR | SFIB | 22.10 | 34.7 | 8.9 | 12.3 | 34.1 | 38.1 | 42.12 | 103.6 | 80.4 |
| Method | BackBone | AP | AP50 | AP75 | APs | APm | Params (M) | FPS |
|---|---|---|---|---|---|---|---|---|
| Two-stage models: | ||||||||
| Faster-RCNN [54] | ResNet-50 | 4.1 | 12.2 | 1.8 | 3.7 | 36.9 | 41.39 | 59.7 |
| Cascade-RCNN [55] | ResNet-50 | 4.5 | 12.7 | 2.1 | 3.9 | 37.5 | 69.29 | 39.6 |
| One-stage models: | ||||||||
| ATSS [57] | ResNet-50 | 4.0 | 13.9 | 1.2 | 3.8 | 21.8 | 38.91 | 46.6 |
| RetinaNet [58] | ResNet-50 | 1.6 | 5.7 | 0.5 | 1.4 | 16.6 | 36.517 | 46.3 |
| YOLOX [60] | ResNet-50 | 5.6 | 21.4 | 1.6 | 6.0 | 12.6 | 5.035 | 99.1 |
| YOLOv8m | Darknet53 | 6.0 | 18.6 | 2.2 | 5.7 | 35.3 | 49.6 | 154.9 |
| YOLOv11m | Darknet53 | 6.1 | 18.8 | 2.1 | 5.7 | 38.4 | 48.3 | 153.7 |
| RT-DETR [14] | ResNet-18 | 6.9 | 21.8 | 3.0 | 6.6 | 37.4 | 38.6 | 133.8 |
| USF-DETR | SFIB | 8.3 | 25.4 | 3.2 | 8.1 | 37.9 | 42.1 | 72.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Wang, Y.; Cao, Y.; Guo, C.; Shi, P.; Li, P. Unified Spatial-Frequency Modeling and Alignment for Multi-Scale Small Object Detection. Symmetry 2025, 17, 242. https://doi.org/10.3390/sym17020242
Liu J, Wang Y, Cao Y, Guo C, Shi P, Li P. Unified Spatial-Frequency Modeling and Alignment for Multi-Scale Small Object Detection. Symmetry. 2025; 17(2):242. https://doi.org/10.3390/sym17020242
Chicago/Turabian StyleLiu, Jing, Ying Wang, Yanyan Cao, Chaoping Guo, Peijun Shi, and Pan Li. 2025. "Unified Spatial-Frequency Modeling and Alignment for Multi-Scale Small Object Detection" Symmetry 17, no. 2: 242. https://doi.org/10.3390/sym17020242
APA StyleLiu, J., Wang, Y., Cao, Y., Guo, C., Shi, P., & Li, P. (2025). Unified Spatial-Frequency Modeling and Alignment for Multi-Scale Small Object Detection. Symmetry, 17(2), 242. https://doi.org/10.3390/sym17020242