
Efficient Parallel Design for Self-Play in Two-Player Zero-Sum Games

 , and
, and
Abstract
:1. Introduction
- A formal analysis and empirical validation of the inefficiencies in current parallelized best response oracle systems.
- The MHO framework, improving training efficiency and strategic performance in complex games through optimized parallelization.
- MiniStar, a purpose-built benchmark environment for self-play research in tactical combat scenarios.
2. Related Works
2.1. Self-Play Methods
2.2. Self-Play Simulation Environment
3. Preliminaries
3.1. Two-Player Normal-Form Games
3.2. Meta-Strategy
4. Methodology
| Algorithm 1 Mixed Hierarchical Oracle (MHO) |
|
4.1. Parallelized Oracle
4.2. Model Soups
4.3. Hierarchical Exploration
5. Experiments
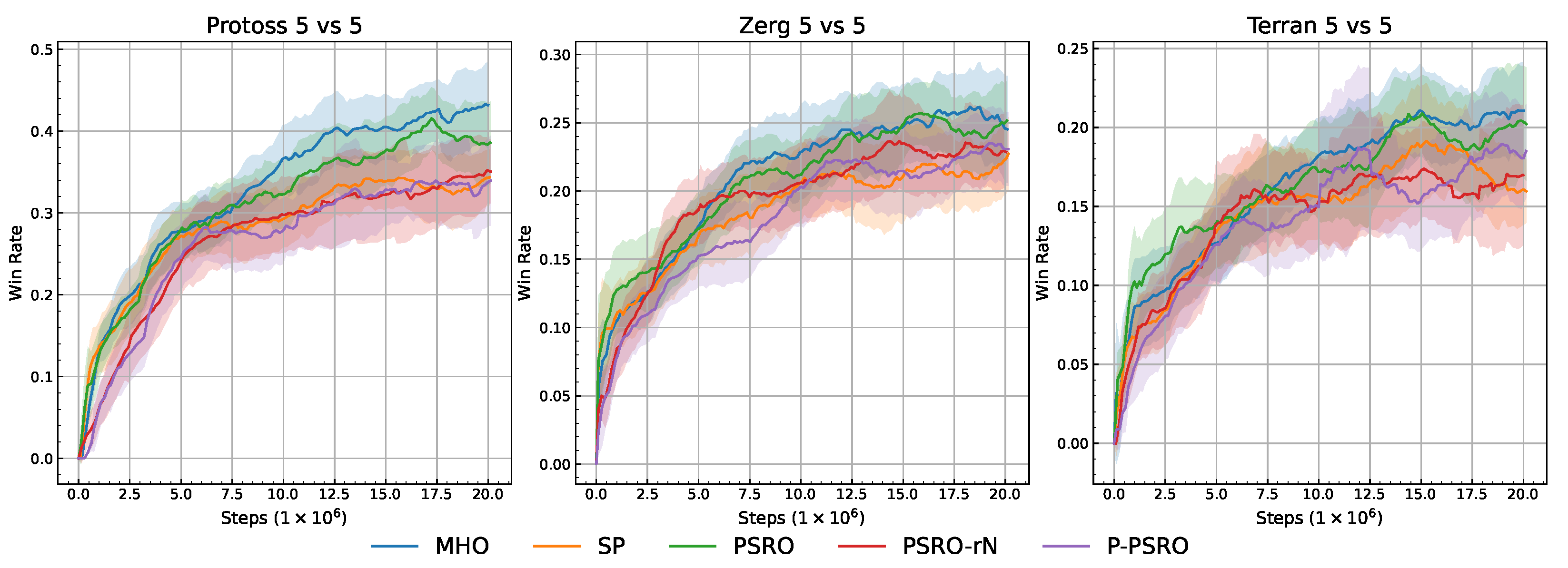
5.1. Experimental Setup
5.2. Experimental Environment
5.2.1. Martix Game
5.2.2. Simulation Scenario
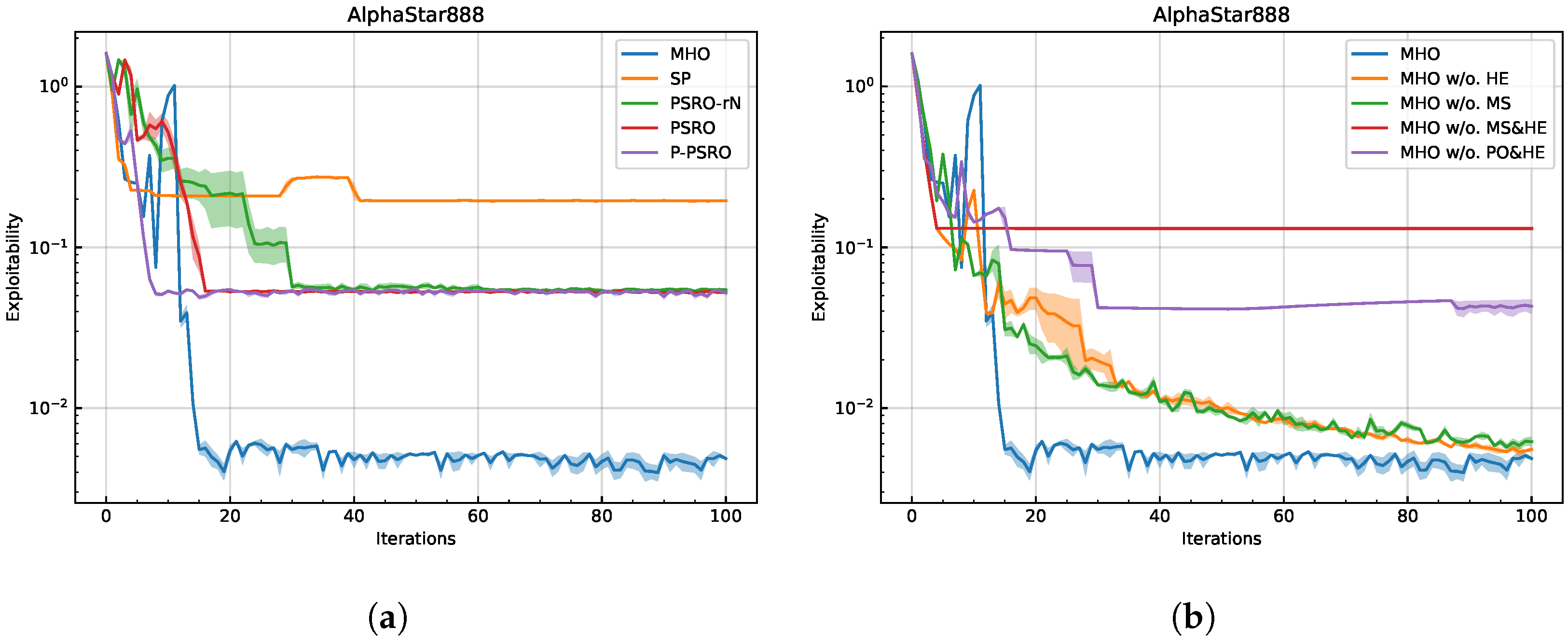
5.3. Results and Analysis
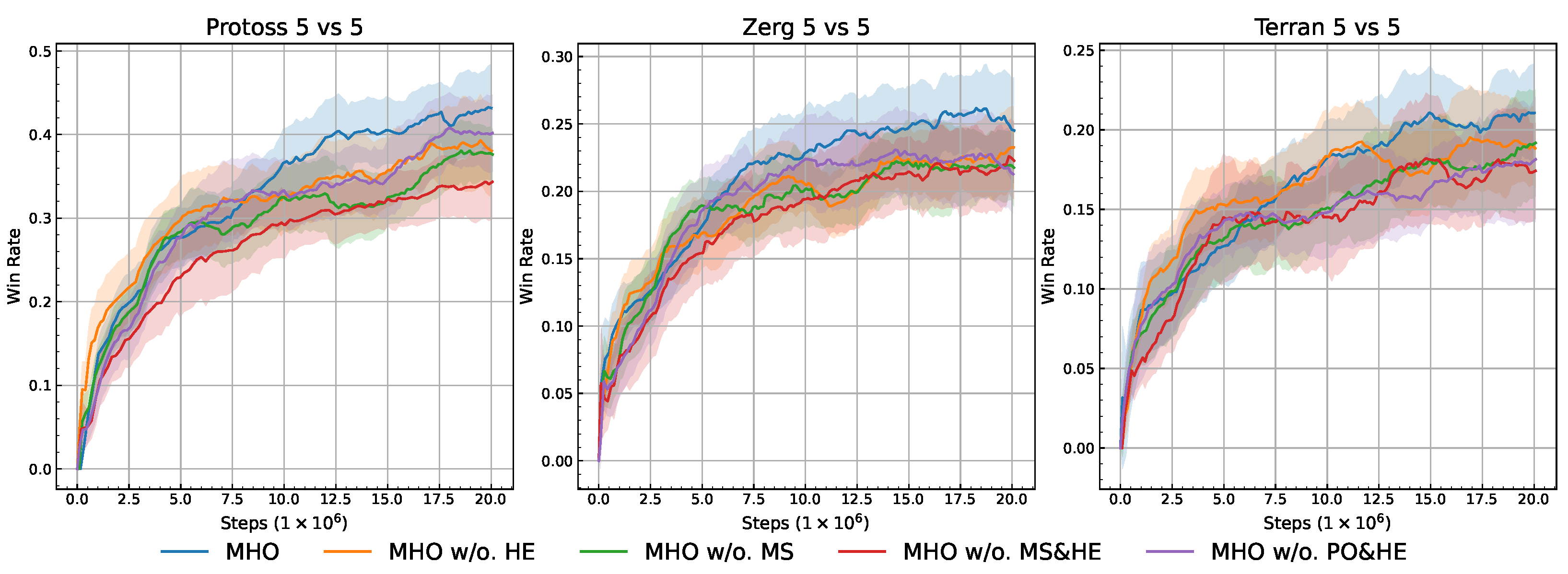
5.4. Ablation Studies
- MHO (Full):PO + MS + HE.
- MHO w/o. HE: Remove HE.
- MHO w/o. MS: Remove MS.
- MHO w/o. MS&HE: Remove both MS and HE.
- MHO w/o. PO&HE: Remove both PO and HE.
5.4.1. Parallelized Oracle
5.4.2. Model Soups
5.4.3. Hierarchical Exploration
5.4.4. Ablation Studies Summary
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Setting | Value | Description |
|---|---|---|
| Oracle Function | Best Response | Function for obtaining oracles. |
| Learning Rate | 0.5 | Learning rate for agents. |
| Improvement Threshold | 0.03 | Convergence criterion. |
| PSRO Meta-Strategy | Nash Equilibrium | Solves the NE-Strategy. |
| MHO Meta-Strategy | Fictitious Self-play | Solves the NE-Strategy. |
| Threads in Pipeline | 3 | Number of parallel learners. |
| Iterations | 100 | Training iterations. |
| Random Seeds | 5 | Number of random seeds. |
| [0.1, 0.15, 0.2] | Weighting factor for entropy. |
| Setting | Value | Description |
|---|---|---|
| Oracle | MAPPO | The reinforcement learning algorithm used for Oracle. |
| Training Steps | 20M | Total number of environment steps for training. |
| Self-Play Mode | 5v5 | Each match features two teams of 5 units each. |
| Unit Composition | [0.45, 0.45, 0.1] | Ratio of 3 unit types (e.g., Zealot/Stalker/Colossus). |
| Spawn Scheme | Surround & Reflect | Randomized initial positions for both factions. |
| PSRO Meta-Strategy | Nash Equilibrium | Meta-Strategy Solver. |
| MHO Meta-Strategy | Fictitious Self-play | Meta-Strategy Solver. |
| Discount Factor () | 0.99 | Discounting for future rewards. |
| Learning Rate | Adam optimizer step size. | |
| PPO Clip Parameter | 0.2 | Clipping range for ratio. |
| Entropy Coefficient | 0.01 | Encourages exploration in MAPPO. |
| Threads in Pipeline | 2 | Number of parallel learners |
| [0.008, 0.012] | Weighting factor for entropy in MAPPO. | |
| Number of Actors | 16 | Number of enviroment in distributed RL. |
| Batch Size | 2048 | Number of sampled transitions per update. |
| Number of Mini-Batches | 1 | Number of mini-batches per epoch in MAPPO. |
| PPO Epochs | 5 | Number of times each sample is reused. |
| GAE Lambda | 0.95 | Exponential decay factor for GAE advantage. |
| Value Loss Weighting | 1.0 | Trade-off coefficient for value function loss. |
| Random Seed | 5 | Number of random seeds used. |
References
- Albrecht, S.V.; Christianos, F.; Schäfer, L. Multi-Agent Reinforcement Learning: Foundations and Modern Approaches; MIT Press: Cambridge, MA, USA, 2024. [Google Scholar]
- Mahajan, A.; Rashid, T.; Samvelyan, M.; Whiteson, S. Maven: Multi-agent variational exploration. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Rashid, T.; Samvelyan, M.; De Witt, C.S.; Farquhar, G.; Foerster, J.; Whiteson, S. Monotonic value function factorisation for deep multi-agent reinforcement learning. J. Mach. Learn. Res. 2020, 21, 1–51. [Google Scholar]
- Samuel, A.L. Some studies in machine learning using the game of checkers. IBM J. Res. Dev. 1959, 3, 210–229. [Google Scholar] [CrossRef]
- Bansal, T.; Pachocki, J.; Sidor, S.; Sutskever, I.; Mordatch, I. Emergent complexity via multi-agent competition. arXiv 2017, arXiv:1710.03748. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. Mastering chess and shogi by self-play with a general reinforcement learning algorithm. arXiv 2017, arXiv:1712.01815. [Google Scholar]
- Schrittwieser, J.; Antonoglou, I.; Hubert, T.; Simonyan, K.; Sifre, L.; Schmitt, S.; Guez, A.; Lockhart, E.; Hassabis, D.; Graepel, T.; et al. Mastering atari, go, chess and shogi by planning with a learned model. Nature 2020, 588, 604–609. [Google Scholar] [CrossRef]
- Moravčík, M.; Schmid, M.; Burch, N.; Lisỳ, V.; Morrill, D.; Bard, N.; Davis, T.; Waugh, K.; Johanson, M.; Bowling, M. Deepstack: Expert-level artificial intelligence in heads-up no-limit poker. Science 2017, 356, 508–513. [Google Scholar] [CrossRef] [PubMed]
- Heinrich, J.; Lanctot, M.; Silver, D. Fictitious self-play in extensive-form games. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 805–813. [Google Scholar]
- Berner, C.; Brockman, G.; Chan, B.; Cheung, V.; Debiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; Hesse, C.; et al. Dota 2 with large scale deep reinforcement learning. arXiv 2019, arXiv:1912.06680. [Google Scholar]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef]
- McMahan, H.B.; Gordon, G.J.; Blum, A. Planning in the presence of cost functions controlled by an adversary. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 536–543. [Google Scholar]
- Heinrich, J.; Silver, D. Deep reinforcement learning from self-play in imperfect-information games. arXiv 2016, arXiv:1603.01121. [Google Scholar]
- Hernandez, D.; Denamganaï, K.; Gao, Y.; York, P.; Devlin, S.; Samothrakis, S.; Walker, J.A. A generalized framework for self-play training. In Proceedings of the 2019 IEEE Conference on Games (CoG), London, UK, 20–23 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Yang, Y.; Luo, J.; Wen, Y.; Slumbers, O.; Graves, D.; Ammar, H.B.; Wang, J.; Taylor, M.E. Diverse auto-curriculum is critical for successful real-world multiagent learning systems. arXiv 2021, arXiv:2102.07659. [Google Scholar]
- Lanctot, M.; Zambaldi, V.; Gruslys, A.; Lazaridou, A.; Tuyls, K.; Pérolat, J.; Silver, D.; Graepel, T. A unified game-theoretic approach to multiagent reinforcement learning. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Sutton, R.S. Reinforcement learning: An introduction. In A Bradford Book; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Wellman, M.P. Methods for empirical game-theoretic analysis. In Proceedings of the AAAI, Boston, MA, USA, 16–20 July 2006; Volume 980, pp. 1552–1556. [Google Scholar]
- Wellman, M.P.; Tuyls, K.; Greenwald, A. Empirical game-theoretic analysis: A survey. arXiv 2024, arXiv:2403.04018. [Google Scholar]
- Bighashdel, A.; Wang, Y.; McAleer, S.; Savani, R.; Oliehoek, F.A. Policy Space Response Oracles: A Survey. arXiv 2024, arXiv:2403.02227. [Google Scholar]
- McAleer, S.; Lanier, J.B.; Fox, R.; Baldi, P. Pipeline psro: A scalable approach for finding approximate nash equilibria in large games. Adv. Neural Inf. Process. Syst. 2020, 33, 20238–20248. [Google Scholar]
- Balduzzi, D.; Garnelo, M.; Bachrach, Y.; Czarnecki, W.; Perolat, J.; Jaderberg, M.; Graepel, T. Open-ended learning in symmetric zero-sum games. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 434–443. [Google Scholar]
- Ellis, B.; Cook, J.; Moalla, S.; Samvelyan, M.; Sun, M.; Mahajan, A.; Foerster, J.; Whiteson, S. Smacv2: An improved benchmark for cooperative multi-agent reinforcement learning. In Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2023) Track on Datasets and Benchmarks, New Orleans, LA, USA, 10–16 December 2023; Volume 36. [Google Scholar]
- Beck, J.; Vuorio, R.; Liu, E.Z.; Xiong, Z.; Zintgraf, L.; Finn, C.; Whiteson, S. A survey of meta-reinforcement learning. arXiv 2023, arXiv:2301.08028. [Google Scholar]
- Rutherford, A.; Ellis, B.; Gallici, M.; Cook, J.; Lupu, A.; Ingvarsson, G.; Willi, T.; Khan, A.; de Witt, C.S.; Souly, A.; et al. Jaxmarl: Multi-agent rl environments in jax. arXiv 2023, arXiv:2311.10090. [Google Scholar]
- Zhong, Y.; Kuba, J.G.; Feng, X.; Hu, S.; Ji, J.; Yang, Y. Heterogeneous-agent reinforcement learning. J. Mach. Learn. Res. 2024, 25, 1–67. [Google Scholar]
- Espeholt, L.; Soyer, H.; Munos, R.; Simonyan, K.; Mnih, V.; Ward, T.; Doron, Y.; Firoiu, V.; Harley, T.; Dunning, I.; et al. Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1407–1416. [Google Scholar]
- Horgan, D.; Quan, J.; Budden, D.; Barth-Maron, G.; Hessel, M.; Van Hasselt, H.; Silver, D. Distributed prioritized experience replay. arXiv 2018, arXiv:1803.00933. [Google Scholar]
- Zhou, M.; Wan, Z.; Wang, H.; Wen, M.; Wu, R.; Wen, Y.; Yang, Y.; Yu, Y.; Wang, J.; Zhang, W. MALib: A parallel framework for population-based multi-agent reinforcement learning. J. Mach. Learn. Res. 2023, 24, 1–12. [Google Scholar]
- Vinyals, O.; Ewalds, T.; Bartunov, S.; Georgiev, P.; Vezhnevets, A.S.; Yeo, M.; Makhzani, A.; Küttler, H.; Agapiou, J.; Schrittwieser, J.; et al. Starcraft ii: A new challenge for reinforcement learning. arXiv 2017, arXiv:1708.04782. [Google Scholar]
- Kurach, K.; Raichuk, A.; Stańczyk, P.; Zajac, M.; Bachem, O.; Espeholt, L.; Riquelme, C.; Vincent, D.; Michalski, M.; Bousquet, O.; et al. Google research football: A novel reinforcement learning environment. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 4501–4510. [Google Scholar]
- Ye, D.; Chen, G.; Zhang, W.; Chen, S.; Yuan, B.; Liu, B.; Chen, J.; Liu, Z.; Qiu, F.; Yu, H.; et al. Towards playing full moba games with deep reinforcement learning. Adv. Neural Inf. Process. Syst. 2020, 33, 621–632. [Google Scholar]
- Ye, D.; Chen, G.; Zhao, P.; Qiu, F.; Yuan, B.; Zhang, W.; Chen, S.; Sun, M.; Li, X.; Li, S.; et al. Supervised learning achieves human-level performance in moba games: A case study of honor of kings. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 908–918. [Google Scholar] [CrossRef]
- Wei, H.; Chen, J.; Ji, X.; Qin, H.; Deng, M.; Li, S.; Wang, L.; Zhang, W.; Yu, Y.; Linc, L.; et al. Honor of kings arena: An environment for generalization in competitive reinforcement learning. Adv. Neural Inf. Process. Syst. 2022, 35, 11881–11892. [Google Scholar]
- Hussein, A.; Gaber, M.M.; Elyan, E.; Jayne, C. Imitation learning: A survey of learning methods. ACM Comput. Surv. (CSUR) 2017, 50, 21. [Google Scholar] [CrossRef]
- Lin, F.; Huang, S.; Pearce, T.; Chen, W.; Tu, W.W. Tizero: Mastering multi-agent football with curriculum learning and self-play. arXiv 2023, arXiv:2302.07515. [Google Scholar]
- Huang, S.; Chen, W.; Zhang, L.; Li, Z.; Zhu, F.; Ye, D.; Chen, T.; Zhu, J. TiKick: Towards Playing Multi-agent Football Full Games from Single-agent Demonstrations. arXiv 2021, arXiv:2110.04507. [Google Scholar]
- Samvelyan, M.; Rashid, T.; De Witt, C.S.; Farquhar, G.; Nardelli, N.; Rudner, T.G.; Hung, C.M.; Torr, P.H.; Foerster, J.; Whiteson, S. The starcraft multi-agent challenge. arXiv 2019, arXiv:1902.04043. [Google Scholar]
- Fudenberg, D.; Tirole, J. Game Theory; MIT Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Brown, G.W. Iterative solution of games by fictitious play. Act. Anal. Prod Alloc. 1951, 13, 374. [Google Scholar]
- Czarnecki, W.M.; Gidel, G.; Tracey, B.; Tuyls, K.; Omidshafiei, S.; Balduzzi, D.; Jaderberg, M. Real world games look like spinning tops. Adv. Neural Inf. Process. Syst. 2020, 33, 17443–17454. [Google Scholar]
- Yu, C.; Velu, A.; Vinitsky, E.; Wang, Y.; Bayen, A.; Wu, Y. The surprising effectiveness of ppo in cooperative, multi-agent games. arXiv 2021, arXiv:2103.01955. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, H.; Chen, B.; Liu, Y.; Han, K.; Liu, J.; Qu, Z. Efficient Parallel Design for Self-Play in Two-Player Zero-Sum Games. Symmetry 2025, 17, 250. https://doi.org/10.3390/sym17020250
Tang H, Chen B, Liu Y, Han K, Liu J, Qu Z. Efficient Parallel Design for Self-Play in Two-Player Zero-Sum Games. Symmetry. 2025; 17(2):250. https://doi.org/10.3390/sym17020250
Chicago/Turabian StyleTang, Hongsong, Bo Chen, Yingzhuo Liu, Kuoye Han, Jingqian Liu, and Zhaowei Qu. 2025. "Efficient Parallel Design for Self-Play in Two-Player Zero-Sum Games" Symmetry 17, no. 2: 250. https://doi.org/10.3390/sym17020250
APA StyleTang, H., Chen, B., Liu, Y., Han, K., Liu, J., & Qu, Z. (2025). Efficient Parallel Design for Self-Play in Two-Player Zero-Sum Games. Symmetry, 17(2), 250. https://doi.org/10.3390/sym17020250