Abstract
Gaussian Splatting (GS) methods, including 3DGS and 2DGS, have demonstrated significant effectiveness in real-time novel view synthesis (NVS), establishing themselves as a key technology in the field of computer graphics. However, GS-based methods still face challenges in rendering high-quality image details. Even when utilizing advanced frameworks, their outputs may display significant rendering artifacts when relying solely on a few input views, such as noise and blurriness. A reasonable approach is to conduct post-processing in order to restore clear details. Therefore, we propose GaussianEnhancer, a general GS-agnostic post-processor that employs a degradation-driven view blending method to improve the rendering quality of GS models. Specifically, we design a degradation modeling method tailored to the GS style and construct a large-scale training dataset to effectively simulate the native rendering artifacts of GS, enabling efficient training. In addition, we present a spatial information fusion framework that includes view fusion and depth modulation modules. This framework successfully integrates related images and leverages depth information from the target image to enhance rendering details. Through our GaussianEnhancer, we effectively eliminate the rendering artifacts of GS models and generate highly realistic image details. Based on GaussianEnhancer, we introduce GaussianEnhancer++, which features an enhanced GS-style degradation simulator, leading to improved enhancement quality. Furthermore, GaussianEnhancer++ can generate ultra-high-resolution outputs from noisy low resolution GS rendered images by leveraging the symmetry between high-resolution and low resolution images. Extensive experiments demonstrate the excellent restoration ability of GaussianEnhancer++ on various novel view synthesis benchmarks.
1. Introduction
Novel view synthesis (NVS) is a fundamental problem in the fields of computer vision and computer graphics, with wide-ranging applications across various domains [1,2,3,4]. While Neural Radiance Fields (NeRF) [5] has revolutionized NVS, leading to significant advancements in this area [6,7,8,9,10], its rendering speed limits real-time deployment. To achieve real-time novel view synthesis, 3D Gaussian Splatting (3DGS) [11] adopts a more efficient rasterization rendering technique, departing from the ray tracing approach of NeRF. The efficiency of this method has attracted increasing research attention and explorations in applications [12,13,14,15,16,17,18,19,20,21,22,23,24]. Despite progress, even state-of-the-art GS models produce artifacts (e.g., noise, blur) under sparse input views, degrading visual quality.
Towards high-quality novel view synthesis, we propose GaussianEnhancer [25], a general GS-agnostic post-processor that employs a degradation-driven view blending method to improve the rendering quality of GS models. The network comprises two primary modules: (1) a degradation simulator for typical GS-style artifacts and (2) a degradation-driven spatial information fusion framework consisting of view fusion and depth modulation components. Building on NeRFLiX [26], GaussianEnhancer systematically analyzes typical GS rendering artifacts and proposes a GS-style degradation simulator that combines traditional and GS-style degradation, such as needle-like artifacts, visible banding artifacts, cloudy artifacts, and floater artifacts. To accommodate variability across scenes and models, we introduce an adaptive gating mechanism that dynamically selects degradation types during simulation. Leveraging this synthetic data, we further develop a spatial information fusion framework integrating multi-view features and depth modulation, enabling effective artifact suppression and detail recovery.
While GaussianEnhancer achieves significant improvements, two critical limitations persist: (1) Incomplete Artifact Coverage. Manually designed degradation models fail to capture the full spectrum of GS rendering artifacts, particularly subtle distortions arising from complex geometric interactions. (2) Resolution Constraints. The framework lacks mechanisms to synthesize high-resolution outputs from low-quality, low-resolution GS renderings, limiting its applicability to high-fidelity scenarios. To overcome these constraints, we propose GaussianEnhancer++, which introduces two pivotal innovations:
(1) Two-stage Degradation Simulator (TSDS). Inspired by NeRFLiX++ [27], our TSDS combines manual and deep generation modeling. The first stage expands the original GaussianEnhancer’s manual simulator with additional GS-specific distortion types (e.g., color distortion). To address residual discrepancies between simulated and real artifacts, the second stage employs a deep generative degradation simulator based on DiffIR [28]. This module learns latent degradation factors from paired real and simulated GS outputs, refining initial artifacts to better match empirical distributions.
(2) Super Spatial Information Fusion (SSIF). Existing GS models struggle with high-resolution rendering due to memory constraints. Drawing from RefSR-NeRF [29], we redesign the spatial fusion module to exploit multi-scale symmetry between high-resolution and low-resolution features. Our SSIF hierarchically fuses details from adjacent views and depth-guided structural priors, enabling both same-resolution enhancement and super-resolution from 1K to 4K outputs.
In summary, our contributions are threefold:
- We present GaussianEnhancer++, a GS-agnostic post-processor designed to eliminate the artifacts produced by GS models and enhance the resolution of rendered images.
- We propose a two-stage degradation simulator that mimics real GS rendering artifacts. Through this simulator, we demonstrate the effectiveness of GaussianEnhancer and GaussianEnhancer++ in improving rendering quality using simulated samples.
- We develop an effective method for spatial information fusion, enhancing the quality of GS-rendered images.
2. Related Work
2.1. Novel View Synthesis
New view synthesis is the process of generating images of a scene or object from new, unseen angles, using a set of existing images or viewpoints. Recently, research on Neural Radiance Fields (NeRF) [5] and related methods have achieved impressive results in new view synthesis and advanced tasks. NeRF uses neural networks to approximate radiance fields and employs volume rendering techniques to achieve high-quality new view synthesis, without requiring explicit modeling of 3D scenes and lighting. This breakthrough has not only opened up new possibilities for novel view synthesis but has also sparked the development of numerous methods and techniques in the field. The rise of NeRF has also led to numerous advancements that address its limitations and deficiencies. Researchers have explored various avenues to overcome challenges such as deformation [30,31], self-calibration [32,33], surface reconstruction [34], and training acceleration [7,8,9].
However, NeRF methods typically use implicit functions, such as MLPs, feature grid representations, or feature point-based representations, to fit the radiance fields, and use rendering formulas for rendering. The requirement to process each sample point along the ray through an MLP to obtain its density and color can hinder real-time rendering performance and limit NeRF’s application potential. Although some NeRF variants have adopted effective sampling strategies or use higher-capacity explicit or hybrid representations, they still face difficult sampling problems and challenges in real-time rendering due to the inherent ray-marching strategy in volume rendering.
By addressing the mentioned constraints, 3DGS [11] overcomes these limitations by employing a rasterization approach that avoids complex ray-marching sampling strategies, enabling real-time rendering with impressive outcomes.Due to its real-time rendering capabilities and impressive rendering performance, 3DGS has attracted increasing attention, and subsequent work has further researched issues such as rendering effects [35], compact representation [36], dynamic modeling [12,14], localization [37], autonomous driving [38], and 3D assets [13]. It has been widely applied to human/avatar modeling [16], surface reconstruction [39,40], inverse rendering [41], and other advanced tasks. However, the 3DGS method faces limitations in capturing complex geometric shapes due to the volumetric Gaussian conflicting with the surface’s thin properties.
In an attempt to address 3DGS reconstruction concerns, 2DGS unfolds the 3D volume into planar Gaussian disks, ensuring a consistent geometric shape for modeling surfaces. However, 2DGS entails a compromise between rendering quality and reconstruction, sacrificing 3DGS’s rendering performance for better 3D reconstruction. Although 2DGS significantly enhances 3D reconstruction, rendering quality falls behind that of 3DGS.
2.2. Degradation Model and High-Resolution Synthesis
Degradation models and image super-resolution (SR) have been a long-standing research topic in the image processing field. The most common and simplest degradation model is bicubic downsampling, which is widely used in numerous non-blind SR methods, including simple downsampling and Gaussian-blur-based downsampling.
Since the introduction of convolutional neural networks (CNNs) into the SR field [42], numerous follow-up works have achieved impressive reconstruction performance on LR images created through bicubic downsampling. Although these methods have made significant progress, the model is too simple, and the performance of non-blind methods may significantly decline when applied to images with varying degradation levels.
Many existing SR methods based on deep neural networks rely on bicubic downsampling and traditional degradation models or their simple variants. Some blind SR methods have also been proposed for unknown degradation cases. Ji et al. [43] model the degradation process as a learned blur kernel and noise pool from the test image, which is then used to synthesize training samples for the SR model. To simulate random factors during degradation, they connect a random vector to the high-resolution image before it is degraded and input to the neural network. In KMSR [44], a generative adversarial network is used to build a kernel pool from real-world photographs, which is then employed to synthesize more realistic training data.
While advancements have been made in blind SR methods, most of them are trained using pre-collected kernel pools, making them not truly blind and challenging to generalize to real-world images. To improve the SR network’s generalization in real-world scenarios, several works have been proposed, which involve constructing a blind degradation model based on multiple degradation factors, such as Gaussian blur, noise, and JPEG compression. Significant progress has been made through various methods, including using a single SR network with multiple degradation levels, kernel estimation, and representation learning.
BSRGAN [45] and Real ESRGAN [46] extend the degradation modeling space by combining comprehensive degradation types and randomly sampled degradation parameters, enhancing variability. Gu et al. [47] proposed an iterative correction-based kernel estimation method, introducing DAN and DASR to further improve blind SR results. Other classical blind SR works include zero-shot learning [48], meta-learning [49], real datasets [50], and unsupervised methods [51]. Zhang et al. [52] introduced a more practical degradation model, including multiple blur types, such as occlusion blur, downsampling, camera sensor noise, and JPEG compression, and incorporating random shuffling strategies.
However, there is no dedicated work focusing on 2DGS degradation. In this research, we propose a 2DGS-style degradation simulator and construct a large-scale training dataset for modeling 2DGS rendering degradation, such as needle-like artifact.
3. GaussianEnhancer
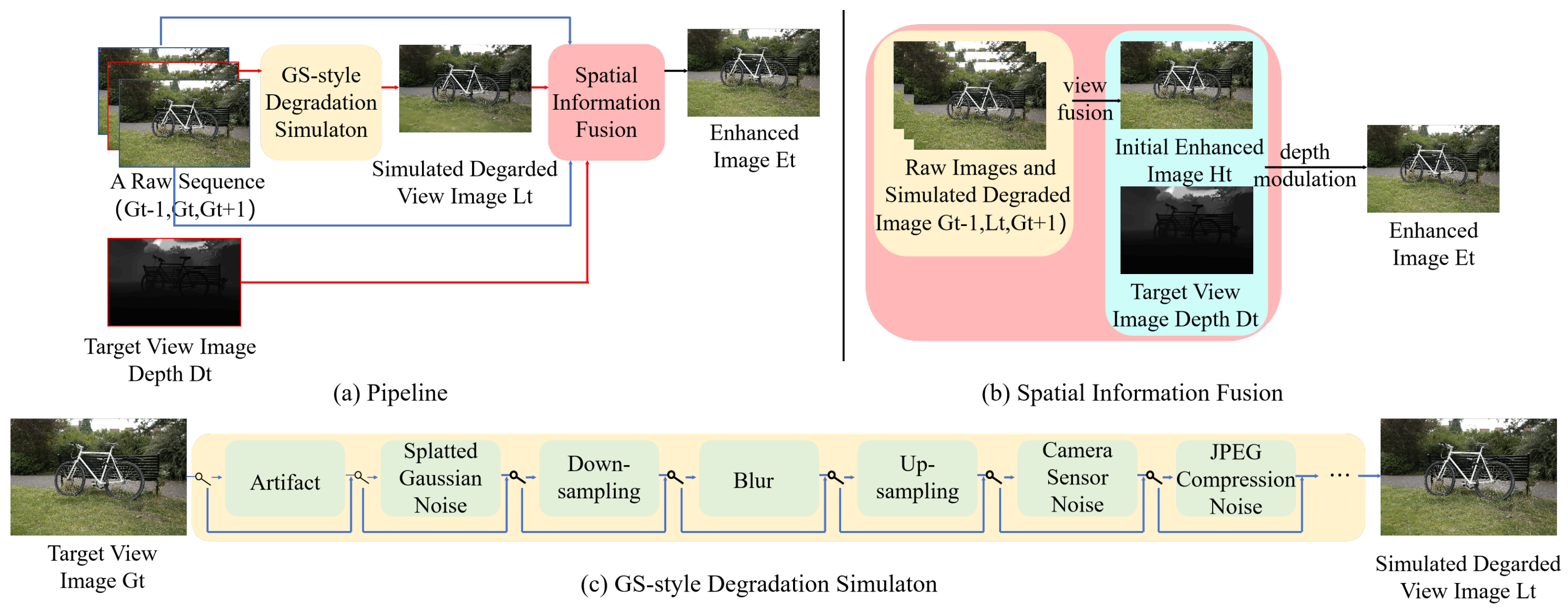
In this work, we present GaussianEnhancer, a general GS-agnostic image restoration post-processor, as shown in Figure 1, which improves the rendering results of GS through view fusion and depth modulation. During the training process, as shown in Figure 1a, for a set of original image sequences, we use our GS-style degradation simulator to simulate the degradation of the target frame. Then, we input the simulated degraded image of the target frame, the original images of adjacent frames, and the depth information of the target frame into the Spatial Information Fusion (SIF) module. Finally, we output the enhanced image of the target frame and use the original target frame image to supervise the output enhanced image of the target frame.
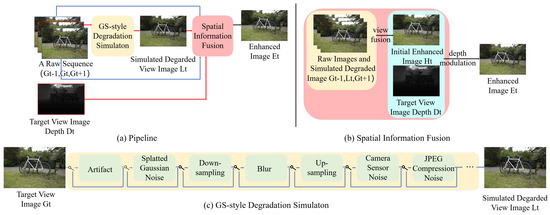
Figure 1.
Illustration of our proposed GaussianEnhancer. (a) Our pipeline. (b) Overview of Spatial Information Fusion (SIF) network. (c) Overview of GS-style degradation Simulator model. The gate controller can generate various degradation scenarios to simulate the different rendering effects of GS on different datasets.
3.1. Preliminaries
We first review the 3D Gaussian Splatting (3DGS) [11] and 2D Gaussian Splatting (2DGS) [40]. 3DGS uses explicit 3D Gaussian points as its main rendering entity. A 3D Gaussian point, with mean vector and covariance matrix , is mathematically defined as:
where x is an arbitrary position within the 3D scene and the covariance matrix of the 3D Gaussian is factorized into a scaling matrix S and a rotation matrix R.
2DGS adopt flat 2D Gaussians embedded in 3D space for scene representation, which is different from 3DGS. Each 2D Gaussian primitive has opacity and view-dependent appearance c with spherical harmonics. For volume rendering, Gaussians sort the projected 2D Gaussians by their depth and compute the color at each pixel by front-to-back alpha blending:
where represents a homogeneous ray emitted from the camera and passing through uv space, while is 2D Gaussian value of the point = in uv space.
3.2. GS-Style Degradation Simulator
We use NeRFLiX [26] as the baseline and incorporate the types of degradation found in the GS model, including needle-like artifacts, visible banding artifacts, cloudy artifacts, and floater artifacts. As shown in Figure 1c, we unify traditional image degradation factors (blur, noise, downsampling) [45,52] with GS-unique distortions through an adaptive gating mechanism that dynamically adjusts degradation combinations across scenes.
Extended Traditional Degradations: (1) Blur is a common image degradation, and it is also present in GS rendering results. To simulate the blur of the GS model, we apply isotropic and anisotropic Gaussian kernels to simulate the blur of the target frame. (2) Noise is omnipresent in real images, as it can be caused by various sources. Given the significant storage costs of 3DGS, many methods apply compression techniques, which inevitably result in JPEG image compression noise. Additionally, we simulate splatted Gaussian noise, another essential factor in GS degradation, as well as camera sensor noise obtained by processing raw sensor data through an image signal processing (ISP) pipeline. (3) Different downsampling methods can significantly impact 3DGS performance [35,53]. To simulate resolution-dependent artifacts, we apply stochastic downsampling (bicubic, bilinear, nearest) followed by upsampling with random stride alignments.
GS-Specific Artifact: Compared to NeRF and other popular super-resolution models, 2DGS and 3DGS exhibits distinct needle-like artifacts [54,55] in certain datasets, such as in the Train scene. In addition, the rendered images of 2DGS, especially in unbounded scenes, display visible banded artifacts. To address the artifacts unique to GS models, we implement relevant degradation designs. Besides those artifacts, other typical artifacts [56,57], such as cloudy artifacts, floater artifacts, also exist.
Adaptive Gating Mechanism: Based on our observations, the degradation levels in GS models vary across different datasets. A naive approach applying all base degradation types simultaneously fails to capture real GS artifact distributions due to over-parameterization and scene-specific bias. Thus, our propose GS-style degradation simulator incorporates a gating mechanism, which randomly selects the basic degradation types included in the degradation process. For example, one training iteration may apply “blur + needle artifacts”, while another activates “noise + floater artifacts”, enhancing stylistic diversity.
3.3. Spatial Information Fusion (SIF)
Our SIF consists of two main components: view fusion and depth modulation, as illustrated in Figure 1b. By integrating these modules, we are able to complete the details of the target frame, thereby improving the overall visual quality. We first select two original frames (, ) closest to the target image (). This maximizes spatially consistent information from neighboring frames. Next, the view fusion branch extracts features from , , and . These features are aligned using deformable convolution to address cross-view parallax. Finally, the aligned features are fused to reconstruct the enhanced target view ().
where represents the degraded target frame image obtained through the GS-style degradation simulator, corresponding to the ground truth . and denote the ground truth of the two neighboring views with respect to the target frame, while is the enhanced view of the target frame produced by the view fusion process. The function D is used to simulate the degradation of the ground truth values, while the function V is responsible for fusing multiple frames.
By integrating deformable convolution into the sampling function, we are able to effectively delve into the complex local temporal context. This functionality enables our view fusion module to gracefully accommodate substantial movements between multiple frames. Additionally, in conjunction with deformable convolution, we learn offsets as sampling parameters, implicitly capturing the forward and backward motion information. These offsets facilitate precise alignment, ensuring temporal coherence and smooth transitions. Through these techniques, we are able to generate high-quality enhanced views of the target frames.
Beyond view fusion, we further introduce depth modulation to refine target frame details. Taking inspiration from the excellent geometric structure of 2DGS [40], we believe that the depth information of the GS model can be fully utilized to enhance the rendering results.
where is the final enhanced result by SIF, and is the depth information corresponding to the target frame.The function S performs depth modulation on the fused image, guided by the depth information, to complete the image details.
4. GaussianEnhancer++
Based on GaussianEnhancer, we propose GaussianEnhancer++ with a stronger GS-style degradation simulator and an effective spatial information fusion method.
4.1. Two-Stage Degradation Simulator (TSDS)
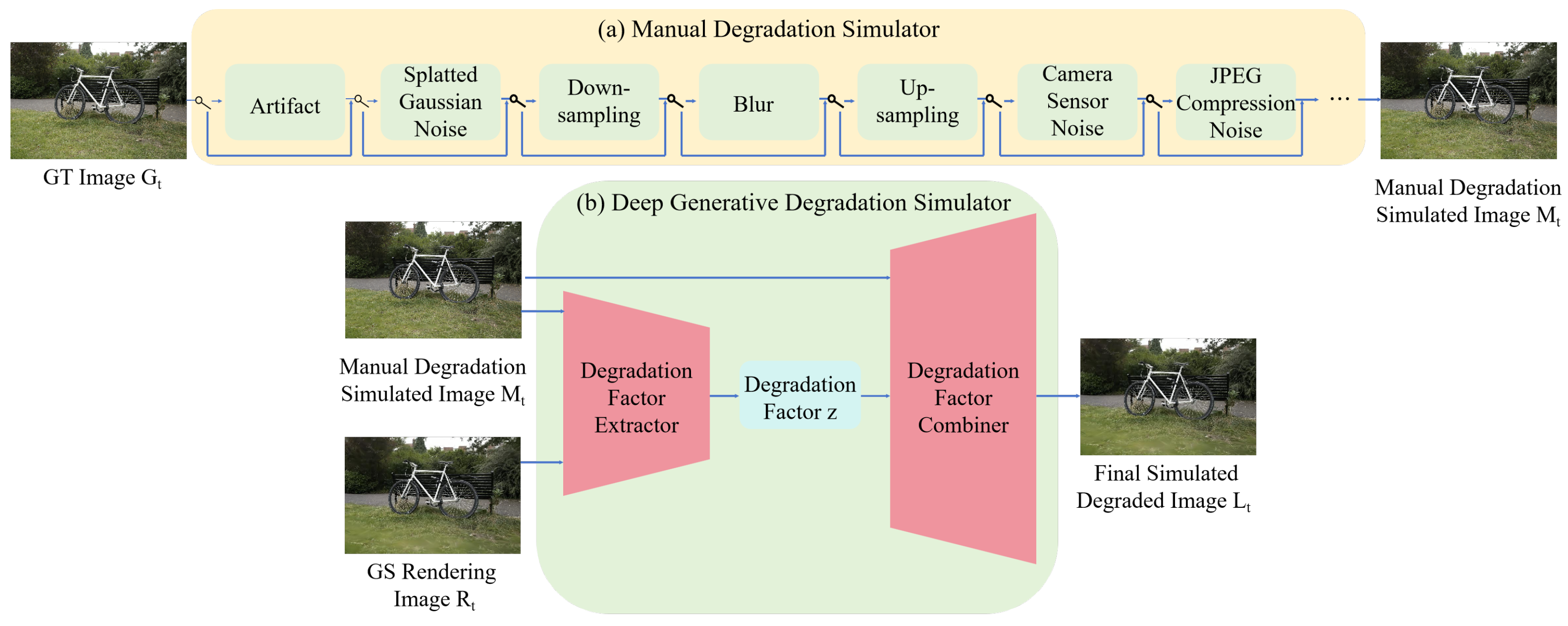
Inspired by NeRFLiX++ [27], the proposed two-stage degradation simulator (TSDS) comprises a manually designed degradation simulator and a deep generative degradation simulator, as shown in Algorithm 1 and Figure 2.
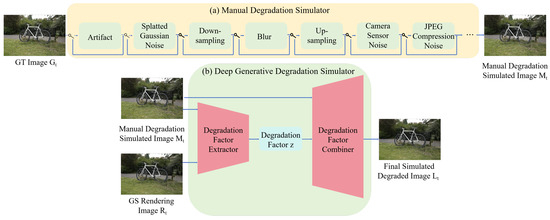
Figure 2.
The pipeline of our two-stage degradation simulator consisted of two sequentially stacked simulators: (a) a manual degradation simulator and (b) a deep generative degradation simulator.
In the first stage, as shown in Figure 2a, we use the same artificial design degradation method as GaussianEnhancer and further included color space degradation. Based on our observations, the GS model may encounter color distortion issues in certain regions when saving images, especially when using PIL for saving. This is because PIL might internally convert the image to a different color space before saving it, leading to potential loss or alteration of certain color information.
| Algorithm 1 Two-stage Degradation Simulator (TSDS) |
|
To overcome the limitations of manually designed degradation, we introduce a deep generative degradation simulator in the second stage, inspired by DiffIR [28]. This module refines the initial degradation results from the first stage , generating artifacts that better align with real GS outputs . As shown in Figure 2b, the deep generative degradation simulator first extracts latent degradation factors z from both the simulated degraded image and the real GS-rendered image via Degradation Factor Extractor. These learned factors z are then combined with through Degradation Factor Combiner to synthesize the final degraded image :
where the function and represent the Degradation Factor Extractor and Degradation Factor Combiner, respectively. and respectively represent the degradation simulation image and the real GS rendered image, and z represents the degradation factor extracted from and using the Degradation Factor Extractor.
4.2. Super Spatial Information Fusion (SSIF)
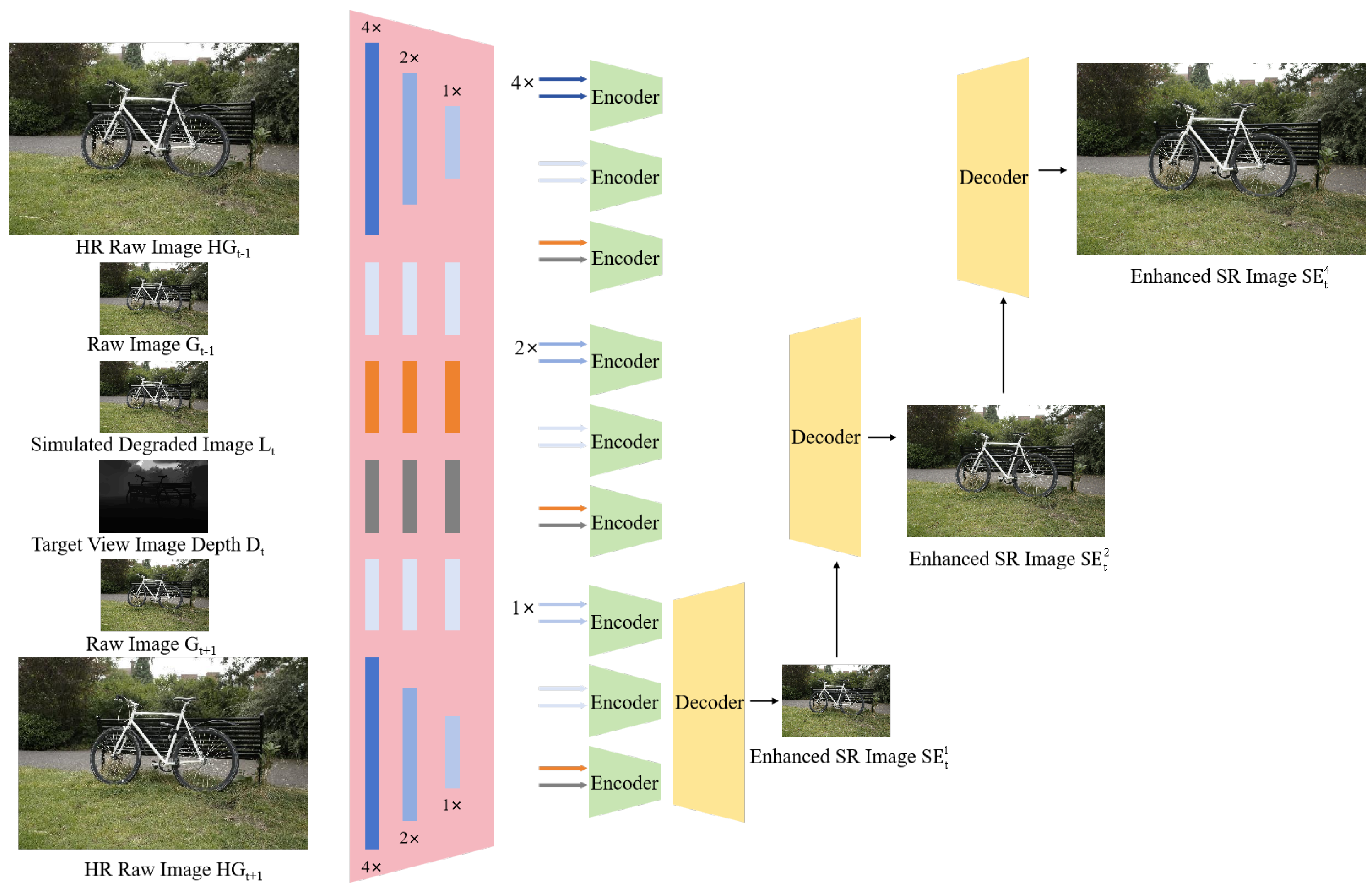
When the resolution of the input original image is too high, the rendering process of the GS model may encounter the problem of excessive memory usage. Therefore, high-resolution images are often downsampled before rendering during the training process. To address the high-resolution rendering limitations of GS models, we enhance GaussianEnhancer’s Spatial Information Fusion (SIF) module. As detailed in Algorithm 2 and Figure 3, our solution draws inspiration from RefSR-NeRF [29]. Super Spatial Information Fusion (SSIF), the upgraded SIF, exploits intrinsic symmetry between high-resolution and low-resolution features, enabling artifact-free super-resolution:
| Algorithm 2 Super Spatial Information Fusion for SR (SSIF-SR) |
|
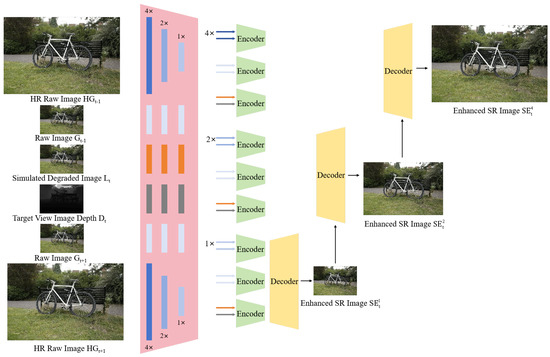
Figure 3.
The framework of our Super Spatial Information Fusion (SSIF) for SR images.
We propose Super Spatial Information Fusion (SSIF), which involves multi-scale feature extraction on all images (simulated degraded images, depth image of target view, and raw images of adjacent views). Subsequently, through a hierarchical process from coarse to fine, we conduct feature matching and information fusion to achieve multi-scale reconstruction results. This method enables the generation of high-quality, high-resolution images from low-quality, low-resolution GS rendered images:
where the functions S, D, and E represent the Super Spatial Information Fusion, Decoder, and Encoder parts, respectively. , , G, L, and D respectively represent the reconstructed enhanced super-resolution image, high-resolution (4K) raw images, low resolution (1K) raw images, the degraded simulated image of the target view, and depth image corresponding to the degraded simulated image. The subscripts t, , and represent the view of the target image and its adjacent views. The superscripts 1, 2, and 4 represent the scale relationship with L. 1 indicates that the scale of is downsampled to same-resolution as L, while 4 indicates that the scale of remains unchanged and is four times the size of L.
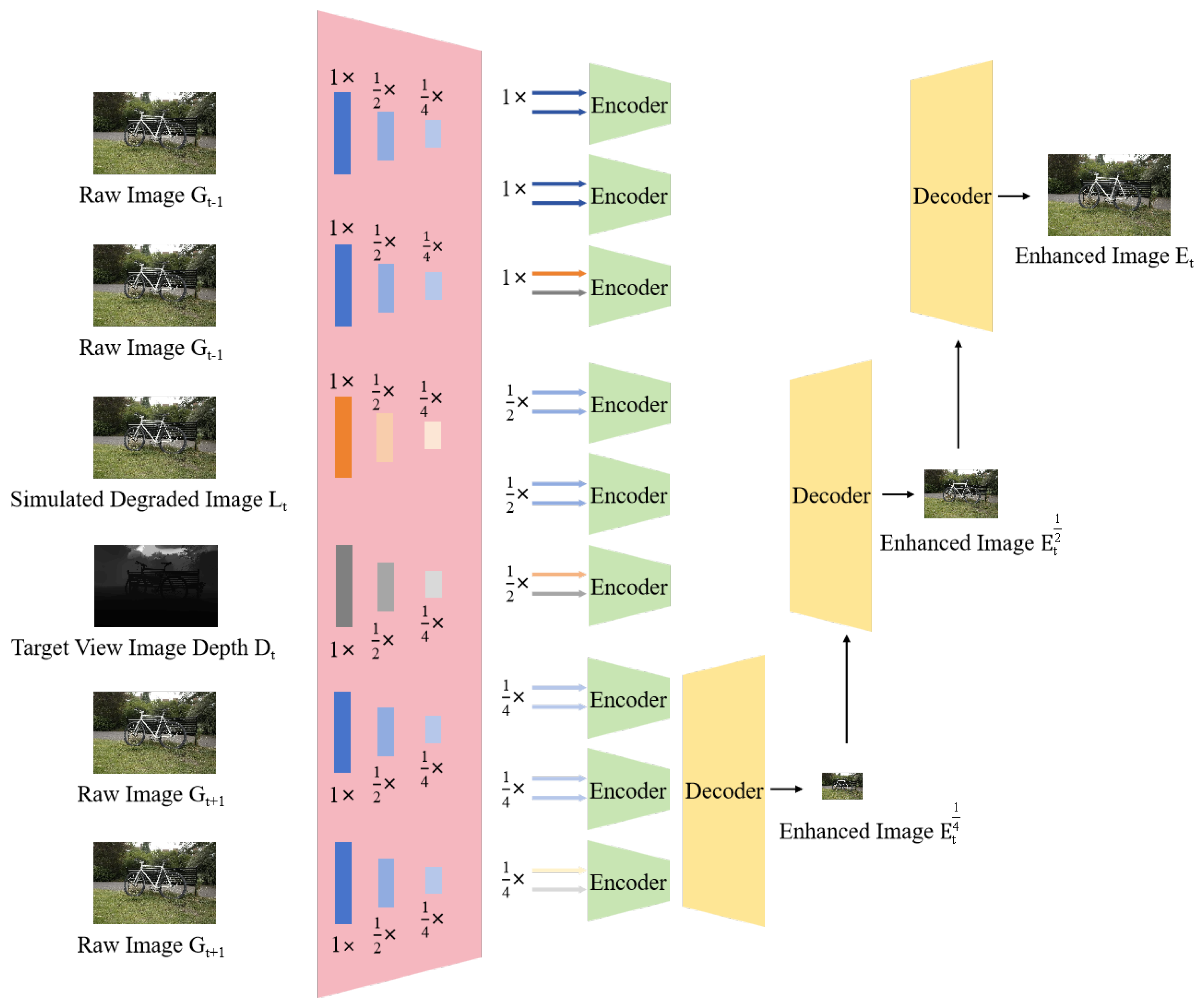
Similarly, as shown in Algorithm 3 and Figure 4, the method of multi-scale reconstruction is still applicable for image enhancement without changing the resolution, and the processing steps are similar to Super Spatial Information Fusion for SR.
| Algorithm 3 Super Spatial Information Fusion for LR (SSIF-LR) |
|
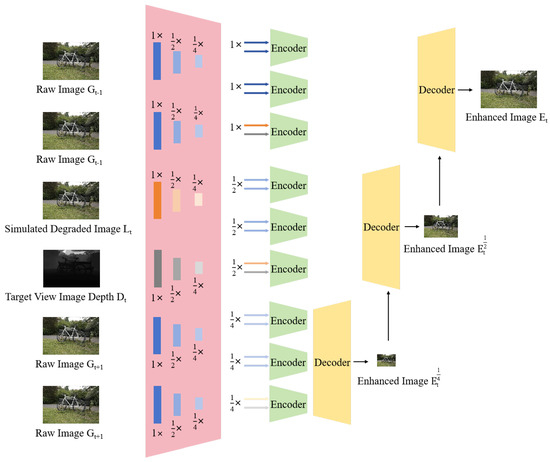
Figure 4.
The framework of our Super Spatial Information Fusion (SSIF) for LR images.
5. Experiments
5.1. Datasets and Evaluation Metric
Datasets: We conduct the experiments on four widely used datasets, including Tanks & Temples [58], Deep Blending [59], Mip-NeRF360 [60] and NeRF-Synthetic [5]. Among them, Tanks & Temples and Deep Blending only used a portion of the dataset provided by 3DGS.
Evaluation Metrics: We adopt the mean of Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM) [61], and the Learned Perceptual Image Patch Similarity (LPIPS) [62] as evaluation metrics in experiments.
5.2. Implementation Details
Firstly, we generate our GS-style degraded image with our two-stage degradation simulator. The first stage, the manual degradation simulator, adopts the same manual design degradation method as the GaussianEnhancer, augmented with color space degradation. In the second stage, the deep generative degradation simulator follows DiffIR [28]. We utilize the results of manual degradation and the real rendered images of the GS model to train a degradation factor generator. This factor refines the initial degradation simulation, producing artifacts closer to real GS outputs. Then, the simulated GS-style degraded images are utilized to train SSIF for better image enhancement of same-resolution and super-resolution. For SSIF (LR) of same-resolution, we downsample all input images to 1/2 and 1/4, respectively, and then reconstruct them from low resolution. For SSIF (SR) of super-resolution, we downsample HR GT to 1/2 and 1/4 to achieve layer-by-layer super-resolution of the input image. The experiments were conducted on a single NVIDIA GeForce RTX 3090 GPU.
5.3. Main Results
5.3.1. Quantitative Comparison
To comprehensively evaluate our method, we conduct super-resolution enhancement and same-resolution enhancement experiments. We compare the rendering results of baseline models with the results after applying our GaussianEnhancer++ and GaussianEnhancer on multiple datasets. As shown in Table 1 and Table 2, we prioritize Mip-NeRF360 [60] dataset for its unique capability to provide multi-resolution ground truth (GT). This is a critical advantage over other GS datasets, which typically offer only single-resolution GT.

Table 1.
Quantitative results of 1K-to-4K Super-Resolution on Mip-NeRF360 [60] dataset (Best, Second Best).
Table 2.
Quantitative results on Mip-NeRF360 [60] (Best, Second Best).
Following experiments on Mip-NeRF360 dataset, we quantify the model complexity and inference time of both GaussianEnhancer++ and GaussianEnhancer across output resolutions, with detailed metrics summarized in Table 3.
Table 3.
Comparison of model complexity and inference time between GaussianEnhancer++ and GaussianEnhancer.
We further validate same-resolution enhancement on Tanks & Temples, Deep Blending, and NeRF-Synthetic datasets. The quantitative results are presented in Table 4, Table 5 and Table 6.
Table 4.
Quantitative results on Tanks & Temples [58] (Best, Second Best).
Table 5.
Quantitative results on Deep Blending [59] (Best, Second Best).
Table 6.
Quantitative results on NeRF-Synthetic [5] (Best, Second Best).
To rigorously validate reliability, we perform repeated experiments and analyze the results statistically, as shown in Table 7, Table 8 and Table 9.
Table 7.
Statistical analysis of GaussianEnhancer++ for enhancing 2DGS [40] across multiple datasets.
Table 8.
Statistical analysis of GaussianEnhancer++ for enhancing 3DGS [11] across multiple datasets.
Table 9.
Statistical analysis of GaussianEnhancer++ for enhancing Mip-Splatting [35] across multiple datasets.
5.3.2. Qualitative Comparison
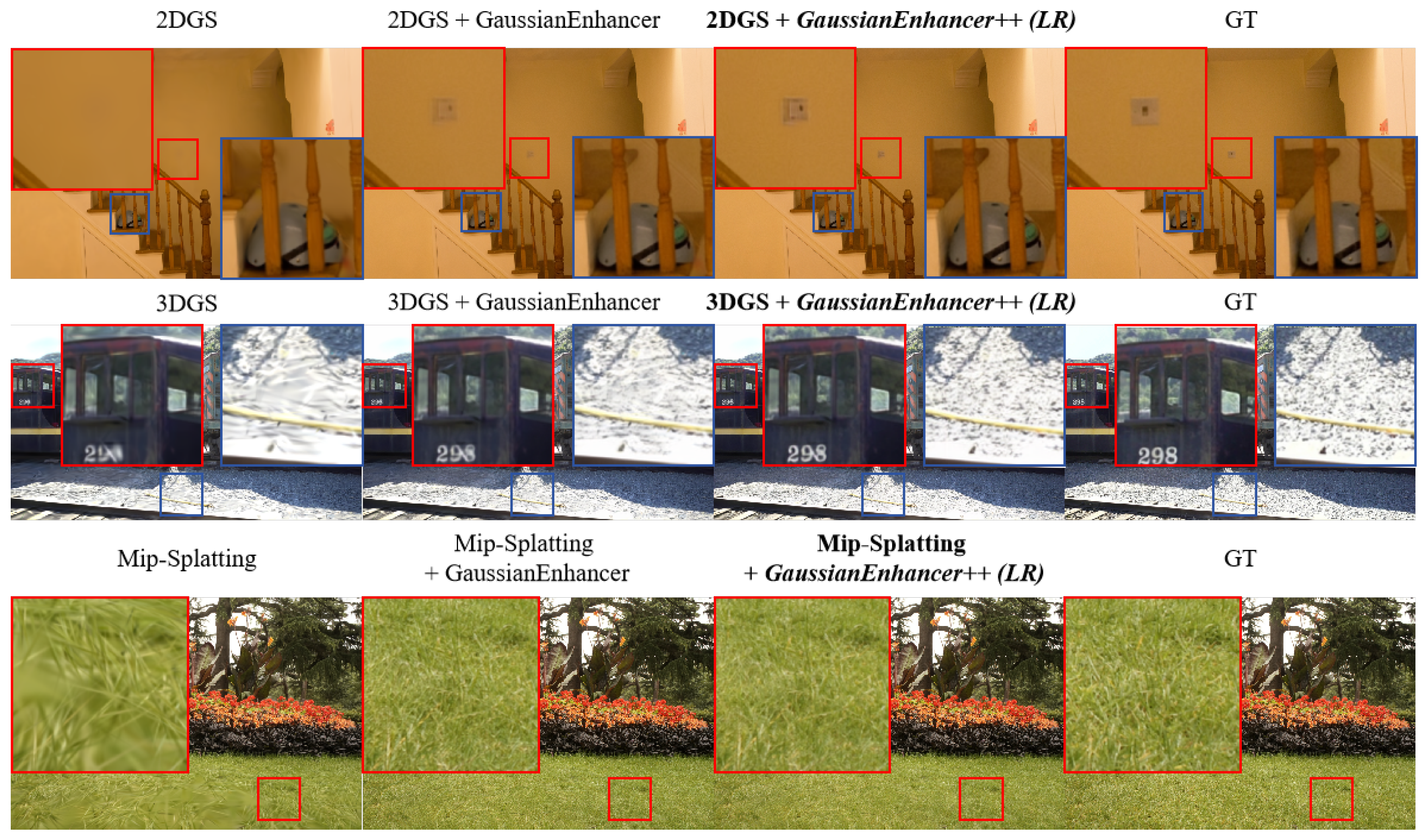
We show the visualization effects of 2DGS, 3DGS, and Mip-Splatting on different datasets with GaussianEnhancer and GaussianEnhancer++. In addition to the enhancement with unchanged resolution, we also demonstrate our enhancement effect on super-resolution. The qualitative results are shown in Figure 5 and Figure 6. It can be observed that our GaussianEnhancer++ network can effectively improve the rendering results of various GS models.

Figure 5.
Qualitative evaluation of the improvement over 2DGS [40], 3DGS [11], and Mip-Splatting [35] on Deep Blending [59], Tanks & Temples [58], and Mip-NeRF360 [60] datasets.

Figure 6.
Qualitative evaluation of the results of super-resolution enhancement of Mip-Splatting 1K resolution rendered images on Mip-NeRF360 dataset to 4K resolution.
To comprehensively validate GaussianEnhancer++’s capability in remediating GS-specific artifacts, we showcase a representative Train scene example in Figure 7. This figure contrasts raw GS-rendered images with inherent degradation issues against their enhanced versions processed by our method, demonstrating significant artifact suppression.

Figure 7.
Comparison of GS-specific artifacts and GaussianEnhancer++ restoration.
5.4. Ablation Study
We use 2DGS as the baseline to conduct ablation studies on GaussianEnhancer++ on Mip-NeRF360 [60] dataset. The experimental results (Table 10) show that both modules (TSDS and SSIF) of our GaussianEnhancer++ can effectively improve the evaluation indicators. When using GaussianEnhancer++ (all), it can better improve the evaluation indicators.
Table 10.
Ablation Study of 2DGS [40] on Mip-NeRF360 [60] dataset (Best, Second Best).
6. Discussion
This study focuses on enhancing the rendering outputs of GS networks through a post-processing framework. Building upon the foundational GaussianEnhancer, we propose GaussianEnhancer++, an advanced method that achieves superior enhancement quality while enabling super-resolution capabilities. To validate its effectiveness, we conduct extensive experiments across multiple datasets, as detailed in Section 5.
6.1. Super-Resolution on Mip-NeRF360 Dataset
We first evaluate our method on the Mip-NeRF360 dataset, uniquely suited for super-resolution analysis due to its inclusion of multi-resolution GT images (1K, 2K, and 4K). Table 1 compares four super-resolution strategies applied to 4K GS outputs (2DGS, 3DGS, and Mip-Splatting): (1) direct bicubic upsampling, (2) bicubic upsampling after GaussianEnhancer enhancement, (3) bicubic upsampling after GaussianEnhancer++(LR) enhancement, and (4) direct super-resolution via GaussianEnhancer++(SR). The results demonstrate that GaussianEnhancer++(SR) achieves the highest visual fidelity, outperforming other methods across all metrics (PSNR, SSIM, LPIPS). For instance, GaussianEnhancer++(SR) improves the PSNR of 2DGS by 2.13 dB compared to naive bicubic upsampling—a sevenfold enhancement over GaussianEnhancer and twofold over GaussianEnhancer++(LR). Visual comparisons in Figure 6 further confirm these quantitative advantages.
6.2. Same-Resolution Enhancement
Our experiments validate GaussianEnhancer++’s efficacy in enhancing 1K-resolution outputs across diverse datasets. On the Mip-NeRF360 dataset (Table 2), GaussianEnhancer++(LR) achieves a 0.69 dB PSNR improvement for 2DGS—double the gain of GaussianEnhancer (0.33 dB)—with similar trends observed for 3DGS and Mip-Splatting.
Table 4, Table 5 and Table 6 validate GaussianEnhancer++’s performance on Tanks & Temples, Deep Blending, and NeRF-Synthetic datasets. GaussianEnhancer++ consistently outperforms baseline GS models and GaussianEnhancer in most scenes. For instance, on Tanks & Temples datasets, it improves 2DGS PSNR by 0.95 dB (vs. 0.67 dB for GaussianEnhancer), while on Deep Blending datasets, 3DGS gains 0.88 dB (vs. 0.40 dB). The sole exception is NeRF-Synthetic datasets, where GaussianEnhancer++ marginally underperforms GaussianEnhancer. We attribute this to the synthetic dataset’s limited geometric complexity, which reduces the demand for advanced enhancement. Nonetheless, GaussianEnhancer++ still surpasses raw GS outputs, confirming its broad applicability. Visual comparisons in Figure 5 further illustrate the qualitative improvements across datasets.
6.3. Computational Resources
Table 3 compares inference resources between GaussianEnhancer and GaussianEnhancer++. While GaussianEnhancer++(LR) exhibits marginally higher latency and memory usage at 1K/2K resolutions, its visual quality improvements justify the trade-off. Notably, GaussianEnhancer++(SR) achieves 4K outputs with latency comparable to GaussianEnhancer’s 1K processing (412 ms vs. 377 ms) and consumes 16.1 GB GPU memory—3.2 GB less than GaussianEnhancer at 2K resolution.
6.4. Statistical Reliability
Table 7, Table 8 and Table 9 present statistical metrics (max, min, mean, standard deviation) from repeated experiments. The stable improvements (PSNR std. dev. ≤ 0.15 dB, SSIM std. dev. ≤ 0.005, LPIPS std. dev. ≤ 0.004) confirm the method’s robustness. All metrics in Table 2, Table 4, Table 5 and Table 6 reflect initial experiment results, not statistical extremes.
6.5. Artifacts Remediation
To explicitly demonstrate the remediation of GS-specific artifacts (e.g., needle-like artifacts, visible banding artifacts), Figure 7 presents a comparison using degraded images from the Train scene. The selected examples highlight raw GS-rendered outputs with pronounced artifacts alongside their enhanced counterparts processed by GaussianEnhancer++. Our method effectively suppresses structural distortions and recovers fine details.
6.6. Ablation Study
Table 10 dissects the contributions of our two-stage degradation simulator (TSDS) and super spatial information fusion (SSIF). While SSIF dominates PSNR improvements, both modules synergistically enhance SSIM and LPIPS. The combined approach achieves a 0.69 dB PSNR gain for 2DGS, though the total improvement (0.65 dB + 0.47 dB) suggests partial redundancy between modules.
6.7. Limitations and Future Work
Despite its advancements, GaussianEnhancer++ has limitations: (1) The deep generative degradation simulator requires extensive real GS data for training, potentially limiting generalization on datasets like NeRF-Synthetic. (2) The current framework lacks real-time capability (Table 3). Future work should prioritize algorithmic optimization for real-time performance and reduce reliance on large training datasets.
7. Conclusions
In this paper, we present GaussianEnhancer++, a general GS-agnostic image restoration post-processor. To address two critical limitations of existing GS models, rendering artifacts and resolution constraints, we introduce Two-Stage Degradation Simulator (TSDS) and Super Spatial Information Fusion (SSIF) module. Specifically, the TSDS combines manual artifact modeling with deep generative refinement, effectively simulating GS-specific distortions including needle-like artifacts, banding effects, and color inconsistencies. This hybrid approach overcomes the coverage limitations of purely handcrafted degradation models while maintaining interpretability. The SSIF framework leverages multi-view geometric priors and hierarchical feature fusion to achieve both artifact suppression and resolution enhancement. By exploiting symmetry between low- and high-resolution features, our method enables direct 4K reconstruction from 1K GS outputs. Extensive experiments across four benchmark datasets (Tanks & Temples, Deep Blending, Mip-NeRF360, and NeRF-Synthetic) demonstrate significant improvements over baseline GS models. For instance, GaussianEnhancer++(SR) improves the PSNR of Mip-Splatting by 1.93 dB compared to naive bicubic upsampling—A twofold enhancement over GaussianEnhancer. However, it is important to acknowledge certain limitations of our approach. The deep generative degradation simulator requires paired real and simulated data for training, which may constrain its adaptability to synthetic datasets with simplified geometries. The SSIF module lacks real-time capability.
Author Contributions
Conceptualization, C.Z.; methodology, C.Z.; software, C.Z. and Q.M.; validation, C.Z. and J.W.; formal analysis, S.Z. and Z.Q.; data curation, C.Z.; writing—original draft preparation, C.Z.; writing—review and editing, M.L., J.W. and Z.H.; visualization, C.Z. and J.W.; supervision, M.L. and Z.H.; project administration, Z.H.; funding acquisition, Z.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work is financially supported by National Natural Science Foundation of China 62176025, 62301066 and U21B2045.
Data Availability Statement
The Tanks & Temples, Deep Blending, Mip-NeRF360 and NeRF-Synthetic datasets used in this study are publicly available at https://github.com/graphdeco-inria/gaussian-splatting (accessed on 27 January 2025), https://jonbarron.info/mipnerf360/ (accessed on 27 January 2025) and https://www.matthewtancik.com/nerf (accessed on 27 January 2025).
Conflicts of Interest
The authors declare no conflict of interest. On behalf of my co-authors, I declare that the work described is original research that has not been published previously and is not under consideration for publication elsewhere, in whole or in part. All listed authors have approved the manuscript.
References
- Zhou, T.; Tulsiani, S.; Sun, W.; Malik, J.; Efros, A.A. View synthesis by appearance flow. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part IV 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 286–301. [Google Scholar]
- Zhou, T.; Tucker, R.; Flynn, J.; Fyffe, G.; Snavely, N. Stereo magnification: Learning view synthesis using multiplane images. arXiv 2018, arXiv:1805.09817. [Google Scholar] [CrossRef]
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. Mvsnet: Depth inference for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 767–783. [Google Scholar]
- Riegler, G.; Koltun, V. Free view synthesis. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIX 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 623–640. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Wei, X.; Zhang, R.; Wu, J.; Liu, J.; Lu, M.; Guo, Y.; Zhang, S. Noc: High-quality neural object cloning with 3d lifting of segment anything. arXiv 2023, arXiv:2309.12790. [Google Scholar]
- Reiser, C.; Peng, S.; Liao, Y.; Geiger, A. Kilonerf: Speeding up neural radiance fields with thousands of tiny mlps. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 14335–14345. [Google Scholar]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph. (TOG) 2022, 41, 1–15. [Google Scholar] [CrossRef]
- Sun, C.; Sun, M.; Chen, H. Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 5459–5469. [Google Scholar]
- Qin, Y.; Li, X.; Zu, L.; Jin, M.L. Novel view synthesis with depth priors using neural radiance fields and cyclegan with attention transformer. Symmetry 2025, 17, 59. [Google Scholar] [CrossRef]
- Kerbl, B.; Kopanas, G.; Leimkühler, T.; Drettakis, G. 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph. 2023, 42, 139:1–139:14. [Google Scholar] [CrossRef]
- Wu, G.; Yi, T.; Fang, J.; Xie, L.; Zhang, X.; Wei, W.; Liu, W.; Tian, Q.; Wang, X. 4d gaussian splatting for real-time dynamic scene rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 20310–20320. [Google Scholar]
- Chen, Z.; Wang, F.; Wang, Y.; Liu, H. Text-to-3d using gaussian splatting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 21401–21412. [Google Scholar]
- Yang, Z.; Gao, X.; Zhou, W.; Jiao, S.; Zhang, Y.; Jin, X. Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 20331–20341. [Google Scholar]
- Szymanowicz, S.; Rupprecht, C.; Vedaldi, A. Splatter image: Ultra-fast single-view 3d reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 10208–10217. [Google Scholar]
- Hu, L.; Zhang, H.; Zhang, Y.; Zhou, B.; Liu, B.; Zhang, S.; Nie, L. Gaussianavatar: Towards realistic human avatar modeling from a single video via animatable 3d gaussians. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 634–644. [Google Scholar]
- Yi, T.; Fang, J.; Wang, J.; Wu, G.; Xie, L.; Zhang, X.; Liu, W.; Tian, Q.; Wang, X. Gaussiandreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 6796–6807. [Google Scholar]
- Tang, J.; Ren, J.; Zhou, H.; Liu, Z.; Zeng, G. Dreamgaussian: Generative gaussian splatting for efficient 3d content creation. arXiv 2023, arXiv:2309.16653. [Google Scholar]
- Chen, Y.; Chen, Z.; Zhang, C.; Wang, F.; Yang, X.; Wang, Y.; Cai, Z.; Yang, L.; Liu, H.; Lin, G. Gaussianeditor: Swift and controllable 3d editing with gaussian splatting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 21476–21485. [Google Scholar]
- Charatan, D.; Li, S.L.; Tagliasacchi, A.; Sitzmann, V. Pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 19457–19467. [Google Scholar]
- Radl, L.; Steiner, M.; Parger, M.; Weinrauch, A.; Kerbl, B.; Steinberger, M. Stopthepop: Sorted gaussian splatting for viewconsistent real-time rendering. ACM Trans. Graph. (TOG) 2024, 43, 1–17. [Google Scholar] [CrossRef]
- Xiong, H.; Muttukuru, S.; Upadhyay, R.; Chari, P.; Kadambi, A. Sparsegs: Real-time 360 sparse view synthesis using gaussian splatting. arXiv 2023, arXiv:2312.00206. [Google Scholar]
- Zhang, D.; Wang, C.; Wang, W.; Li, P.; Qin, M.; Wang, H. Gaussian in the wild: 3d gaussian splatting for unconstrained image collections. arXiv 2024, arXiv:2403.15704. [Google Scholar]
- Du, Y.; Zhang, Z.; Zhang, P.; Sun, F.; Lv, X. Udr-gs: Enhancing underwater dynamic scene reconstruction with depth regularization. Symmetry 2024, 16, 1010. [Google Scholar] [CrossRef]
- Zou, C.; Ma, Q.; Wang, J.; Lu, M.; Zhang, S.; He, Z. GaussianEnhancer: A General Rendering Enhancer for Gaussian Splatting. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025. [Google Scholar]
- Zhou, K.; Li, W.; Wang, Y.; Hu, T.; Jiang, N.; Han, X.; Lu, J. Nerflix: High-quality neural view synthesis by learning a degradation-driven inter-viewpoint mixer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 12363–12374. [Google Scholar]
- Zhou, K.; Li, W.; Jiang, N.; Han, X.; Lu, J. From nerflix to nerflix++: A general nerf-agnostic restorer paradigm. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 3422–3437. [Google Scholar] [CrossRef] [PubMed]
- Xia, B.; Zhang, Y.; Wang, S.; Wang, Y.; Wu, X.; Tian, Y.; Yang, W.; Gool, L.V. Diffir: Efficient diffusion model for image restoration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 13095–13105. [Google Scholar]
- Huang, X.; Li, W.; Hu, J.; Chen, H.; Wang, Y. Refsr-nerf: Towards high fidelity and super resolution view synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 8244–8253. [Google Scholar]
- Jiang, Y.; Hedman, P.; Mildenhall, B.; Xu, D.; Barron, J.T.; Wang, Z.; Xue, T. Alignerf: High-fidelity neural radiance fields via alignment-aware training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 46–55. [Google Scholar]
- Yu, H.; Julin, J.; Milacski, Z.A.; Niinuma, K.; Jeni, L.A. Dylin: Making light field networks dynamic. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 12397–12406. [Google Scholar]
- Yen-Chen, L.; Florence, P.; Barron, J.T.; Rodriguez, A.; Isola, P.; Lin, T. Inerf: Inverting neural radiance fields for pose estimation. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 1323–1330. [Google Scholar]
- Lin, C.; Ma, W.; Torralba, A.; Lucey, S. Barf: Bundle-adjusting neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 5741–5751. [Google Scholar]
- Wang, P.; Liu, L.; Liu, Y.; Theobalt, C.; Komura, T.; Wang, W. Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. arXiv 2021, arXiv:2106.10689. [Google Scholar]
- Yu, Z.; Chen, A.; Huang, B.; Sattler, T.; Geiger, A. Mip-splatting: Alias-free 3d gaussian splatting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 19447–19456. [Google Scholar]
- Lu, T.; Yu, M.; Xu, L.; Xiangli, Y.; Wang, L.; Lin, D.; Dai, B. Scaffold-gs: Structured 3d gaussians for view-daptive rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 20654–20664. [Google Scholar]
- Matsuki, H.; Murai, R.; Kelly, P.H.; Davison, A.J. Gaussian splatting slam. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 18039–18048. [Google Scholar]
- Yan, Y.; Lin, H.; Zhou, C.; Wang, W.; Sun, H.; Zhan, K.; Lang, X.; Zhou, X.; Peng, S. Street gaussians for modeling dynamic urban scenes. arXiv 2023, arXiv:2401.01339. [Google Scholar]
- Guédon, A.; Lepetit, V. Sugar: Surface-aligned gaussian splatting for efficient 3d mesh reconstruction and high-quality mesh rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 5354–5363. [Google Scholar]
- Huang, B.; Yu, Z.; Chen, A.; Geiger, A.; Gao, S. 2d gaussian splatting for geometrically accurate radiance fields. In SIGGRAPH 2024 Conference Papers; Association for Computing Machinery: New York, NY, USA, 2024. [Google Scholar]
- Gao, J.; Gu, C.; Lin, Y.; Li, Z.; Zhu, H.; Cao, X.; Zhang, L.; Yao, Y. Relightable 3d gaussians: Realistic point cloud relighting with brdf decomposition and ray tracing. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2025; pp. 73–89. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 184–199. [Google Scholar]
- Ji, X.; Cao, Y.; Tai, Y.; Wang, C.; Li, J.; Huang, F. Real-world super-resolution via kernel estimation and noise injection. In Proceedings of the CVPR Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 466–467. [Google Scholar]
- Zhou, R.; Susstrunk, S. Kernel modeling super-resolution on real low-resolution images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2433–2443. [Google Scholar]
- Zhang, K.; Liang, J.; Gool, L.V.; Timofte, R. Designing a practical degradation model for deep blind image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 4791–4800. [Google Scholar]
- Wang, X.; Xie, L.; Dong, C.; Shan, Y. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 1905–1914. [Google Scholar]
- Gu, J.; Lu, H.; Zuo, W.; Dong, C. Blind super-resolution with iterative kernel correction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1604–1613. [Google Scholar]
- Shocher, A.; Cohen, N.; Irani, M. “Zero-shot” super-resolution using deep internal learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3118–3126. [Google Scholar]
- Park, S.; Yoo, J.; Cho, D.; Kim, J.; Kim, T.H. Fast adaptation to super-resolution networks via meta-learning. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXVII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 754–769. [Google Scholar]
- Cai, J.; Zeng, H.; Yong, H.; Cao, Z.; Zhang, L. Toward real-world single image super-resolution: A new benchmark and a new model. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3086–3095. [Google Scholar]
- Lugmayr, A.; Danelljan, M.; Timofte, R. Unsupervised learning for real-world super-resolution. In Proceedings of the Compute 2019 IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Zhang, W.; Shi, G.; Liu, Y.; Dong, C.; Wu, X. A closer look at blind super-resolution: Degradation models, baselines, and performance upper bounds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 527–536. [Google Scholar]
- Liang, Z.; Zhang, Q.; Hu, W.; Feng, Y.; Zhu, L.; Jia, K. Analytic-splatting: Anti-aliased 3d gaussian splatting via analytic integration. arXiv 2024, arXiv:2403.11056. [Google Scholar]
- Zhang, Z.; Hu, W.; Lao, Y.; He, T.; Zhao, H. Pixel-gs: Density control with pixel-aware gradient for 3d gaussian splatting. arXiv 2024, arXiv:2403.15530. [Google Scholar]
- Cheng, K.; Long, X.; Yang, K.; Yao, Y.; Yin, W.; Ma, Y.; Wang, W.; Chen, X. Gaussianpro: 3d gaussian splatting with progressive propagation. In Proceedings of the Forty-first International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Franke, L.; Rückert, D.; Fink, L.; Stamminger, M. Trips: Trilinear point splatting for real-time radiance field rendering. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2024; p. e15012. [Google Scholar]
- Zhang, J.; Zhan, F.; Xu, M.; Lu, S.; Xing, E. Fregs: 3d gaussian splatting with progressive frequency regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 21424–21433. [Google Scholar]
- Knapitsch, A.; Park, J.; Zhou, Q.; Koltun, V. Tanks and temples: Benchmarking large-scale scene reconstruction. ACM Trans. Graph. (TOG) 2017, 36, 1–13. [Google Scholar] [CrossRef]
- Hedman, P.; Philip, J.; Price, T.; Frahm, J.; Drettakis, G.; Brostow, G. Deep blending for free-viewpoint image-based rendering. ACM Trans. Graph. (TOG) 2018, 37, 1–15. [Google Scholar] [CrossRef]
- Jonathan, T.; Barron, J.T.; Mildenhall, B.; Verbin, D.; Pratul, P.; Srinivasan, P.P.; Hedman, P. Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 5470–5479. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, Q. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Munich, Germany, 8–14 September 2018; pp. 767–783. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).