

Feature Symmetry Fusion Remote Sensing Detection Network Based on Spatial Adaptive Selection

Abstract
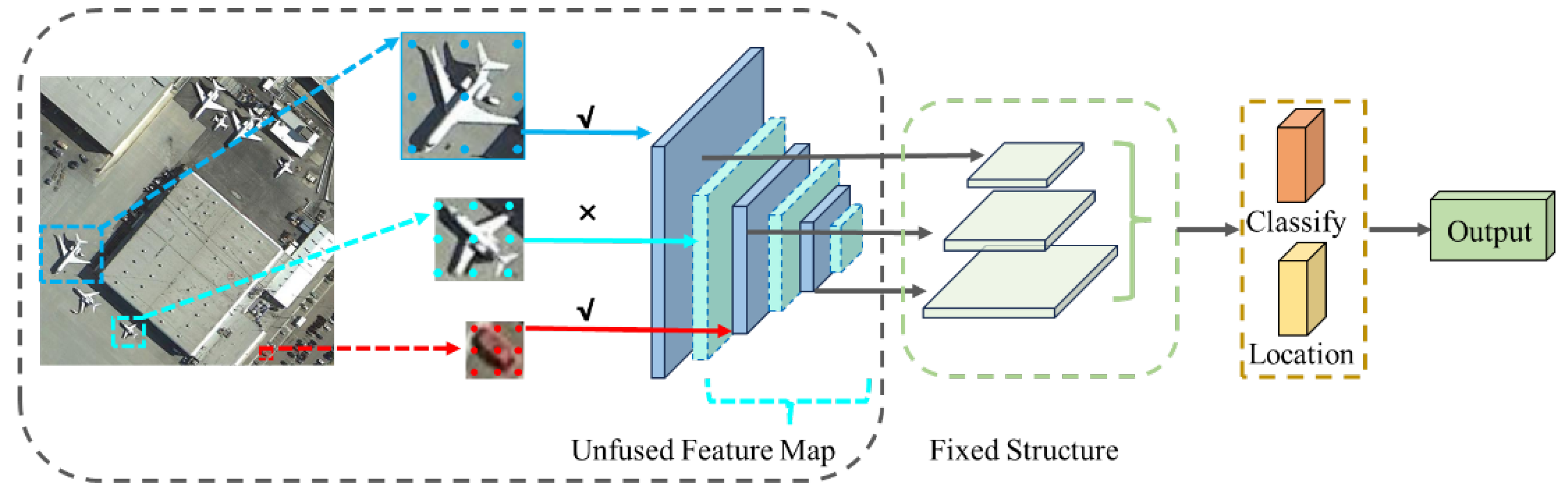
:1. Introduction
2. Related Works
2.1. Rotation Feature Extraction
2.2. Feature Fusion
3. Methodology
3.1. Basic Architecture
3.2. Convolutional Sequence
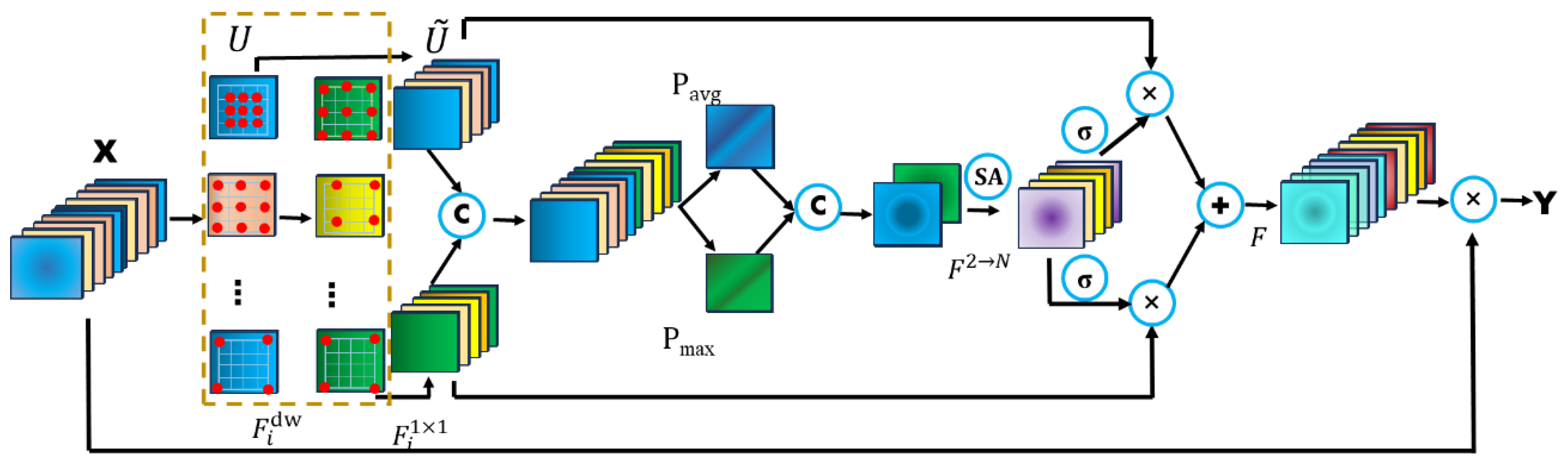
3.3. Spatial Selection Mechanism
3.4. Loss Function
4. Experiments
4.1. Experimental Dataset
4.2. Comparative Experiments
4.2.1. Comparative Experiment Results on DOTA
4.2.2. Comparative Experiment Results on UCAS-AOD
4.2.3. Comparative Experimental Results on HRSC2016
4.3. Ablation Studies
4.3.1. Analysis Experiment of Different Components
4.3.2. Convolutional Sequence Experiment
4.3.3. Analysis of Parameters Related to Spatial Dynamic Selection Mechanism
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yi, X.; Gu, S.; Wu, X.; Jing, D. AFEDet: A Symmetry-Aware Deep Learning Model for Multi-Scale Object Detection in Aerial Images. Symmetry 2025, 17, 488. [Google Scholar] [CrossRef]
- Deng, C.; Jing, D.; Han, Y.; Wang, S.; Wang, H. FAR-Net: Fast Anchor Refining for Arbitrary-Oriented Object Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6505805. [Google Scholar] [CrossRef]
- Zhu, H.; Jing, D. Optimizing Slender Target Detection in Remote Sensing with Adaptive Boundary Perception. Remote Sens. 2024, 16, 2643. [Google Scholar] [CrossRef]
- Chen, P.; Li, Q.; Li, Q.; Wu, Z. Remote Sensing Image Object Detection Method with Feature Denoising Fusion Module. In Proceedings of the 2024 IEEE 7th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 15–17 March 2024. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhong, W.; Guo, F.; Xiang, S. Ship Target Detection Model for Remote Sensing Images of Rotating Rectangular Regions. J. Comput. Aided Des. Graph. 2019, 31, 11. [Google Scholar]
- Chen, H.B.; Jiang, S.; He, G.; Zhang, B.; Yu, H. TEANS: A Target Enhancement and Attenuated Nonmaximum Suppression Object Detector for Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 632–636. [Google Scholar] [CrossRef]
- Qu, J.S.; Su, C.; Zhang, Z.; Razi, A. Dilated Convolution and Feature Fusion SSD Network for Small Object Detection in Remote Sensing Images. IEEE Access 2020, 8, 82832–82843. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision—ECCV 2016; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905 LNCS. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, H.; Zhou, K.; Han, T. SSD ship target detection based on CReLU and FPN improvement. J. Instrum. 2020, 41, 183–190. [Google Scholar]
- Singh, B.; Davis, L.S. An Analysis of Scale Invariance in Object Detection—SNIP. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Lu, Y.; Javidi, T.; Lazebnik, S. Adaptive Object Detection Using Adjacency and Zoom Prediction. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2351–2359. [Google Scholar] [CrossRef]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006. [Google Scholar]
- Yang, X.; Yan, J. Arbitrary-Oriented Object Detection with Circular Smooth Label. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Zhao, T.; Liu, N.; Celik, T.; Li, H.C. An Arbitrary-Oriented Object Detector Based on Variant Gaussian Label in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8013605. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Xue, N.; Xia, G.S. ReDet: A Rotation-equivariant Detector for Aerial Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Zhu, Y.; Du, J.; Wu, X. Adaptive Period Embedding for Representing Oriented Objects in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7247–7257. [Google Scholar] [CrossRef]
- Yang, X.; Liu, Q.; Yan, J.; Li, A.; Zhang, Z.; Yu, G. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Huang, Z.; Li, W.; Xia, X.G.; Wu, X.; Tao, R. A Novel Nonlocal-Aware Pyramid and Multiscale Multitask Refinement Detector for Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5601920. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Xian, S.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects; Shanghai Jiao Tong University: Shanghai, China; Institute of Electrics, Chinese Academy of Sciences: Beijing, China, 2019. [Google Scholar]
- Xu, C.; Ma, C.; Yuan, H.; Sheng, K.; Dong, W.; Guo, X.; Pan, X.; Ren, Y. Dynamic Refinement Network for Oriented and Densely Packed Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets V2: More Deformable, Better Results. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Liu, Z. Dynamic Convolution: Attention Over Convolution Kernels. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Liu, Z.; Yuan, L.W.L.; Yang, Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. In Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods, Porto, Portugal, 24–26 February 2017. [Google Scholar]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015. [Google Scholar] [CrossRef]
- Hou, L.; Lu, K.; Xue, J.; Li, Y. Shape-adaptive selection and measurement for oriented object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G.S. Align Deep Features for Oriented Object Detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5602511. [Google Scholar] [CrossRef]
- Cheng, G.; Yao, Y.; Li, S.; Li, K.; Xie, X.; Wang, J.; Yao, X.; Han, J. Dual-Aligned Oriented Detector. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5618111. [Google Scholar] [CrossRef]
- Cheng, G.; Wang, J.; Li, K.; Xie, X.; Lang, C.; Yao, Y.; Han, J. Anchor-free Oriented Proposal Generator for Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5625411. [Google Scholar] [CrossRef]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Yang, X.; Zhou, Y.; Zhang, G.; Yang, J.; Wang, W.; Yan, J.; Zhang, X.; Tian, Q. The KFIoU Loss for Rotated Object Detection. arXiv 2022, arXiv:2201.12558. [Google Scholar]
- Di, W.; Zhang, Q.; Xu, Y.; Zhang, J.; Du, B.; Tao, D.; Zhang, L. Advancing Plain Vision Transformer Towards Remote Sensing Foundation Model. IEEE Trans. Geosci. Remote Sens. 2022, 61, 5607315. [Google Scholar]
- Ming, Q.; Miao, L.; Zhou, Z.; Song, J.; Yang, X. Sparse Label Assignment for Oriented Object Detection in Aerial Images. Remote Sens. 2021, 13, 2664. [Google Scholar] [CrossRef]
- Ming, Q.; Miao, L.; Zhou, Z.; Dong, Y. CFC-Net: A Critical Feature Capturing Network for Arbitrary-Oriented Object Detection in Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5605814. [Google Scholar] [CrossRef]
- Ming, Q.; Miao, L.; Zhou, Z.; Song, J.; Dong, Y.; Yang, X. Task interleaving and orientation estimation for high-precision oriented object detection in aerial images. ISPRS J. Photogramm. Remote Sens. 2023, 196, 241–255. [Google Scholar] [CrossRef]
- Ming, Q.; Miao, L.; Zhou, Z.; Yang, X.; Dong, Y. Optimization for Arbitrary-Oriented Object Detection via Representation Invariance Loss. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8021505. [Google Scholar] [CrossRef]
- Ming, Q.; Zhou, Z.; Miao, L.; Zhang, H.; Li, L. Dynamic Anchor Learning for Arbitrary-Oriented Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Qian, W.; Yang, X.; Peng, S.; Yan, J.; Guo, Y. Learning Modulated Loss for Rotated Object Detection. In Proceedings of the National Conference on Artificial Intelligence, Virtual, 19–21 May 2021. [Google Scholar]
- Yi, J.; Wu, P.; Liu, B.; Huang, Q.; Qu, H.; Metaxas, D. Oriented Object Detection in Aerial Images with Box Boundary-Aware Vectors. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | SASM [31] | s²ANet [32] | R3Det [22] | SCRDet [24] | Rol-Trans [6] | ReDet [20] | DODet [33] | AOPG [34] | ORCNN [35] | KFloU [36] | RVSA [37] | Ours |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PL | 89.54 | 88.89 | 89.80 | 89.98 | 88.65 | 88.81 | 89.96 | 89.88 | 89.84 | 89.44 | 88.97 | 92.38 |
| BD | 85.94 | 83.60 | 83.77 | 80.65 | 82.60 | 82.48 | 85.52 | 85.57 | 85.43 | 84.41 | 85.76 | 86.74 |
| BR | 57.73 | 57.74 | 48.11 | 52.09 | 52.53 | 60.83 | 58.01 | 60.90 | 61.09 | 62.22 | 61.46 | 67.24 |
| GTF | 78.41 | 81.95 | 66.77 | 68.36 | 70.87 | 80.82 | 81.22 | 81.51 | 79.82 | 82.51 | 81.27 | 84.68 |
| SV | 79.78 | 79.94 | 78.76 | 68.36 | 77.93 | 78.34 | 78.71 | 78.70 | 79.71 | 80.10 | 79.98 | 71.02 |
| LV | 84.19 | 83.19 | 83.27 | 60.32 | 76.67 | 86.06 | 85.46 | 85.29 | 85.35 | 86.07 | 85.31 | 80.47 |
| SH | 89.25 | 89.11 | 87.84 | 72.41 | 86.87 | 88.31 | 88.59 | 88.85 | 88.82 | 88.68 | 88.30 | 88.01 |
| TC | 90.87 | 90.78 | 90.82 | 90.85 | 90.71 | 90.87 | 90.89 | 90.89 | 90.88 | 90.90 | 90.84 | 89.86 |
| BC | 58.80 | 84.87 | 85.38 | 87.94 | 83.83 | 88.77 | 87.12 | 87.60 | 86.68 | 87.32 | 85.06 | 90.36 |
| ST | 87.27 | 87.81 | 85.51 | 86.86 | 82.51 | 87.03 | 87.80 | 87.65 | 87.73 | 88.38 | 87.50 | 79.84 |
| SBF | 63.82 | 70.30 | 65.57 | 65.02 | 53.95 | 68.65 | 70.50 | 71.66 | 72.21 | 72.80 | 66.77 | 70.32 |
| RA | 67.81 | 68.25 | 62.68 | 66.68 | 67.61 | 66.90 | 71.54 | 68.69 | 70.80 | 71.95 | 73.11 | 84.37 |
| HA | 78.67 | 78.30 | 67.53 | 66.25 | 74.67 | 79.26 | 82.06 | 82.31 | 82.42 | 78.96 | 84.75 | 79.51 |
| SP | 79.35 | 77.01 | 78.56 | 68.24 | 68.75 | 79.71 | 77.43 | 77.32 | 78.18 | 74.95 | 81.88 | 68.63 |
| HC | 69.37 | 69.58 | 72.62 | 65.2 | 61.03 | 74.67 | 74.47 | 73.10 | 74.11 | 75.27 | 77.58 | 69.41 |
| mAP | 79.17 | 79.42 | 76.47 | 72.61 | 74.61 | 80.10 | 80.62 | 80.66 | 80.87 | 80.93 | 81.24 | 81.64 |
| Model | Backbone | Input_SIZE | Car | Airplane | mAP |
|---|---|---|---|---|---|
| Faster RCNN [5] | ResNet50 | 800 × 800 | 86.87 | 89.86 | 88.36 |
| RoI Transformer [6] | ResNet50 | 800 × 800 | 88.02 | 90.02 | 89.02 |
| SLA [38] | ResNet50 | 800 × 800 | 88.57 | 90.30 | 89.44 |
| CFC-Net [39] | ResNet50 | 800 × 800 | 89.29 | 88.69 | 89.49 |
| TIOE-Det [40] | ResNet50 | 800 × 800 | 88.83 | 90.15 | 89.49 |
| RIDet-O [41] | ResNet50 | 800 × 800 | 88.88 | 90.35 | 89.62 |
| DAL [42] | ResNet50 | 800 × 800 | 89.25 | 90.49 | 89.87 |
| S2ANet [32] | ResNet50 | 800 × 800 | 89.56 | 90.42 | 89.99 |
| Ours | ResNet50 | 800 × 800 | 90.28 | 92.19 | 91.34 |
| Model | Backbone | mAP (07) |
|---|---|---|
| RoI-Transformer [6] | ResNet101 | 86.20 |
| RSDet [43] | ResNet50 | 86.50 |
| BBAVectors [44] | ResNet101 | 88.60 |
| R3Det [22] | ResNet101 | 89.26 |
| S2ANet [32] | ResNet101 | 90.17 |
| ReDet [20] | ResNet101 | 90.46 |
| Oriented R-CNN [35] | ResNet101 | 90.50 |
| Ours | LargeKernel | 91.20 |
| Ordinary Convolution | Convolutional Kernel Sequence | Spatial Selection Mechanism | Accuracy mAP (%) |
|---|---|---|---|
| ✓ | ✗ | ✗ | 82.95 |
| ✓ | ✗ | ✓ | 87.53 |
| ✗ | ✓ | ✗ | 88.76 |
| ✗ | ✓ | ✓ | 91.20 |
| Convolutional Kernel Sequence (k, d) | Experience Wild RF | Quantity | Parameter Quantity # P | Accuracy mAP (%) |
|---|---|---|---|---|
| (23, 1) | 23 | 1 | 40.4 K | 82.95 |
| (5, 1) → (7, 3) | 23 | 2 | 11.3 K | 91.20 |
| (29, 1) | 29 | 1 | 60.4 K | 83.94 |
| (5, 1) → (7, 4) | 29 | 2 | 11.3 K | 89.68 |
| (3, 1) → (5, 2) → (7, 3) | 29 | 3 | 11.3 K | 89.37 |
| Convolutional Kernel Sequence (k, d) | Experience Wild RF | Spatial Selection SS | Speed FPS | Accuracy mAP (%) |
|---|---|---|---|---|
| (3, 1) → (5, 2) | 11 | - | 22.1 | 88.21 |
| (5, 1) → (7, 3) | 23 | - | 21.3 | 88.93 |
| (5, 1) → (7, 4) | 29 | - | 21.7 | 89.68 |
| (5, 1) → (7, 3) | 23 | ✓ | 20.7 | 91.20 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, H.; Jing, D.; Zhao, F.; Zha, S. Feature Symmetry Fusion Remote Sensing Detection Network Based on Spatial Adaptive Selection. Symmetry 2025, 17, 602. https://doi.org/10.3390/sym17040602
Xiao H, Jing D, Zhao F, Zha S. Feature Symmetry Fusion Remote Sensing Detection Network Based on Spatial Adaptive Selection. Symmetry. 2025; 17(4):602. https://doi.org/10.3390/sym17040602
Chicago/Turabian StyleXiao, Heng, Donglin Jing, Fujun Zhao, and Shaokang Zha. 2025. "Feature Symmetry Fusion Remote Sensing Detection Network Based on Spatial Adaptive Selection" Symmetry 17, no. 4: 602. https://doi.org/10.3390/sym17040602
APA StyleXiao, H., Jing, D., Zhao, F., & Zha, S. (2025). Feature Symmetry Fusion Remote Sensing Detection Network Based on Spatial Adaptive Selection. Symmetry, 17(4), 602. https://doi.org/10.3390/sym17040602