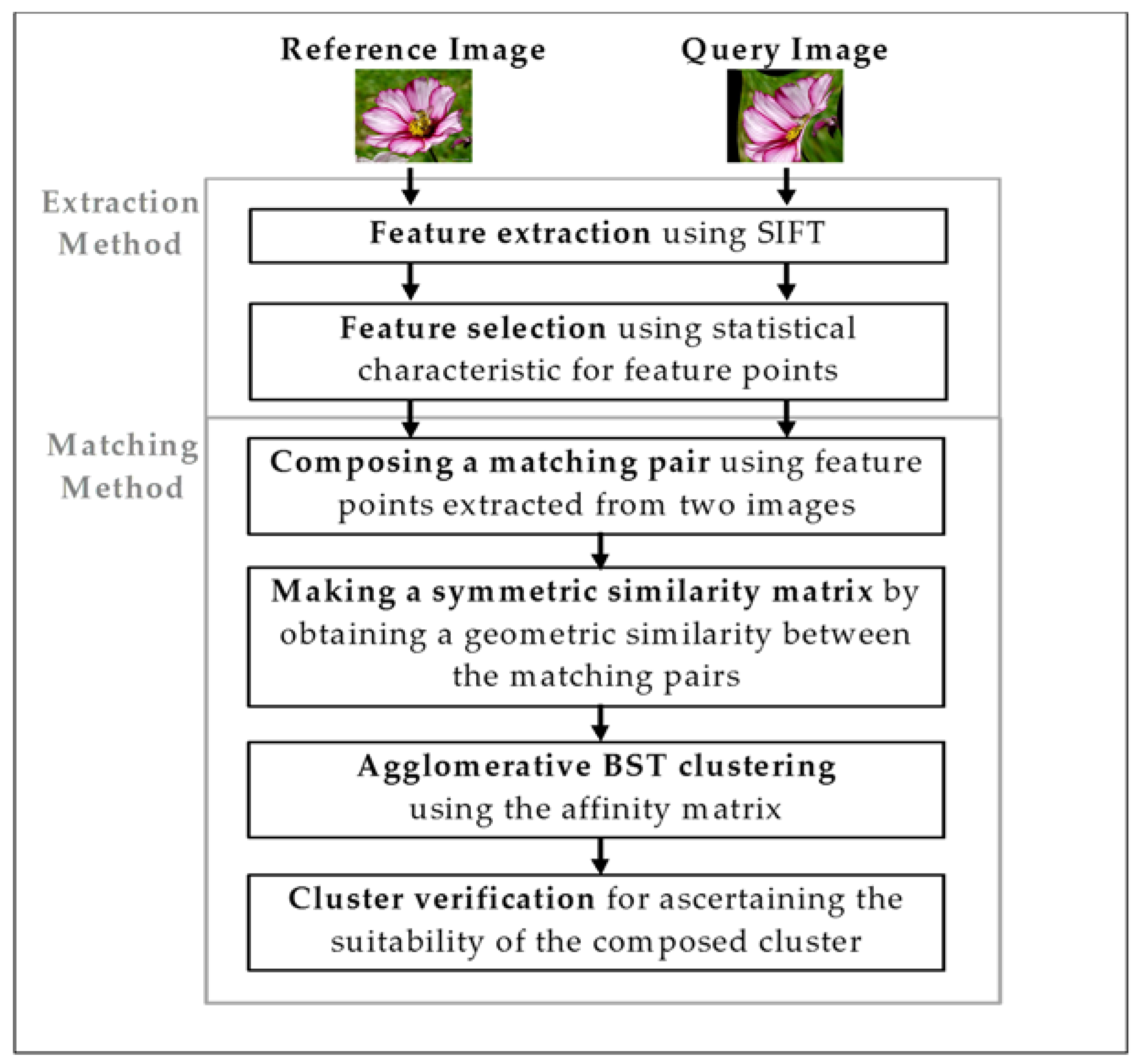
3.2.1. Composing a Matching Pair
To compose a matching pair, the feature points extracted from two images are compared [
26]. The formula used here is the Euclidean distance, as expressed in Equation (2).
Equation (2) is an equation for finding the Euclidean distance of , which is the th feature vector of the reference image, and , which is the th feature vector of the query image. If (·) is smaller than an arbitrary threshold, the feature points and are composed as a matching pair. One feature point can compose up to the maximum of k matching pairs using the knn method. NM matching pairs composed in this manner undergo the overlap checking process expressed as Equation (3).
A matching pair (
is composed with two feature points matched in two images. In other words,
consists of the respective feature points from the reference and query images. In Equation (3),
represents the respective positions of two feature points. Here,
, where
is the position of the feature point extracted from the reference image, and
is the position of the feature point extracted from the query image. When the
th matching pair
and
th matching pair
are compared, if
matches
, or
matches
, they are determined to be overlapped, and the number one is assigned to
. With this equation, one or zero is assigned to every
, and finally, an overlap matrix of size
NM ×
NM with
for all
as its elements is generated. In
Figure 3, the circles mean the feature points and lines mean the matching pairs. In addition, dotted lines are overlapped matching pairs and the solid-lines are non-overlapped matching pairs. The generated overlap matrix is used in the clustering process.
3.2.2. Making a Symmetric Similarity Matrix
With a deformable object, various deformations may occur because its shape can change. Therefore, it is difficult to evaluate image matching with deformable objects using conventional geometric verification. From the matching pairs composed of the typical conventional geometric verification RANSAC [
5], a transform matrix is generated and inliers and outliers are distinguished. On the other hand, a deformable object cannot be defined with a single transform matrix.
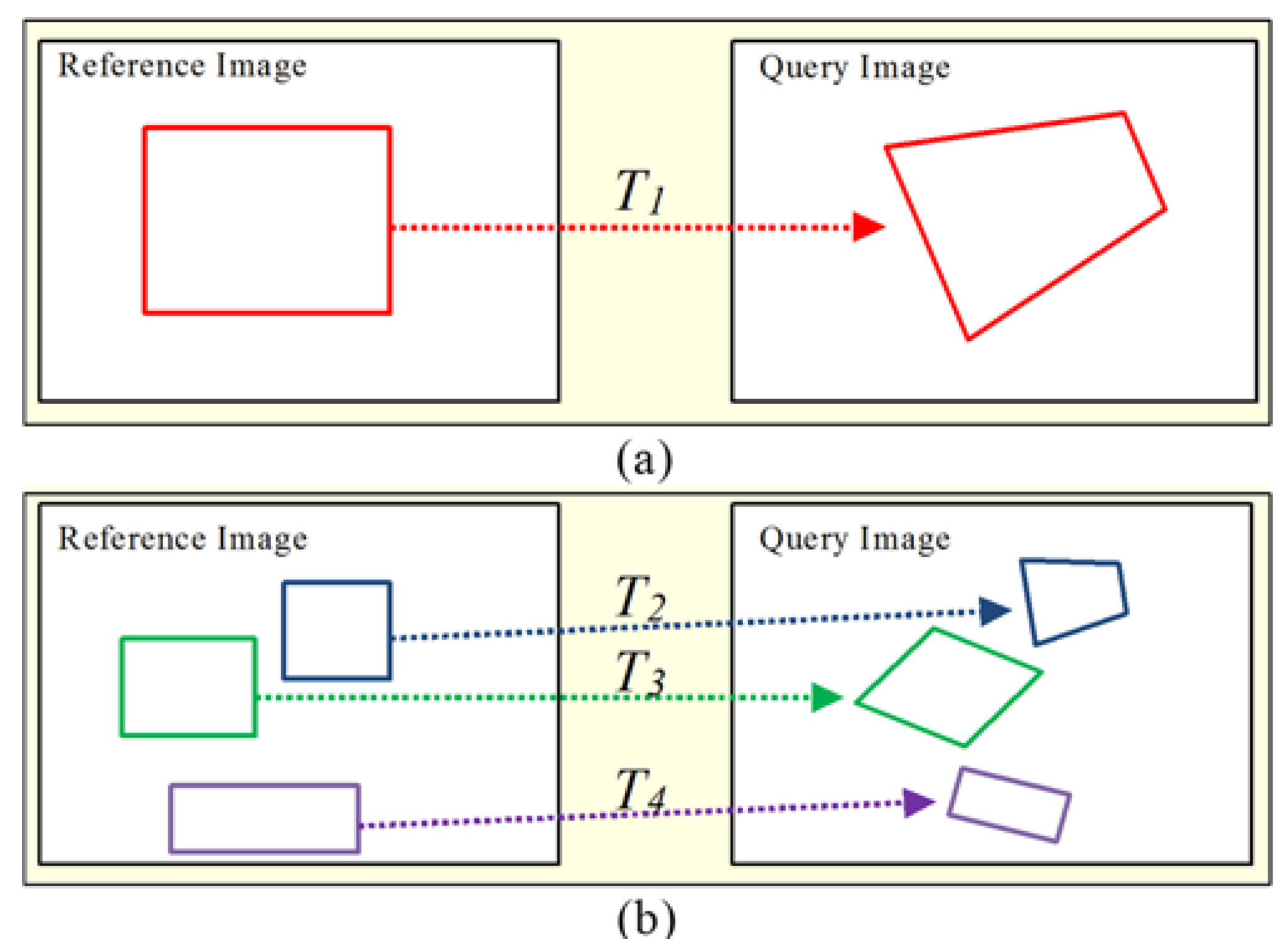
Figure 4a presents two images with rigid objects, one of which has one transform matrix (
T1). The reference image’s rigid object is transformed geometrically to
T1 in the query image. On the other hand,
Figure 4b shows two images with deformable objects, and has many transform matrices (
T2,
T3, and
T4). In this case, a deformable object of the reference image is transformed geometrically to
T2,
T3, and
T4, in the query image. Therefore, because a deformable object cannot be defined with one transform matrix, a new method is required for the approach by generating many transform matrices in a small region. One method used here is to make a symmetric similarity matrix. The symmetric similarity matrix consists of the similarity between transform matrices composed in a point unit. In other words, a symmetric similarity matrix is composed of geometric similarity between all matching pairs.
To find the geometric similarity between a matching pair, first, a transform matrix is obtained between a matching pair. The transform matrix used here is a homography matrix [
27]. Because a homography matrix uses the projective transform method among various transform matrices, it is suitable for obtaining geometric similarity. To compose a homography matrix, the position (
pi), scale (
si), and orientation (
oi) of a feature point are used, and the matrix is composed using the WGC (Weak Geometric Consistency) [
28] method. Using the homography matrix (
) composed this way, the geometric similarity (
) between a matching pair is found using the Pairwise-WGC [
29] method, as expressed in (4).
The two matching pairs to be compared are given as
) and
).
denotes the Euclidean distance, and
is small if
and
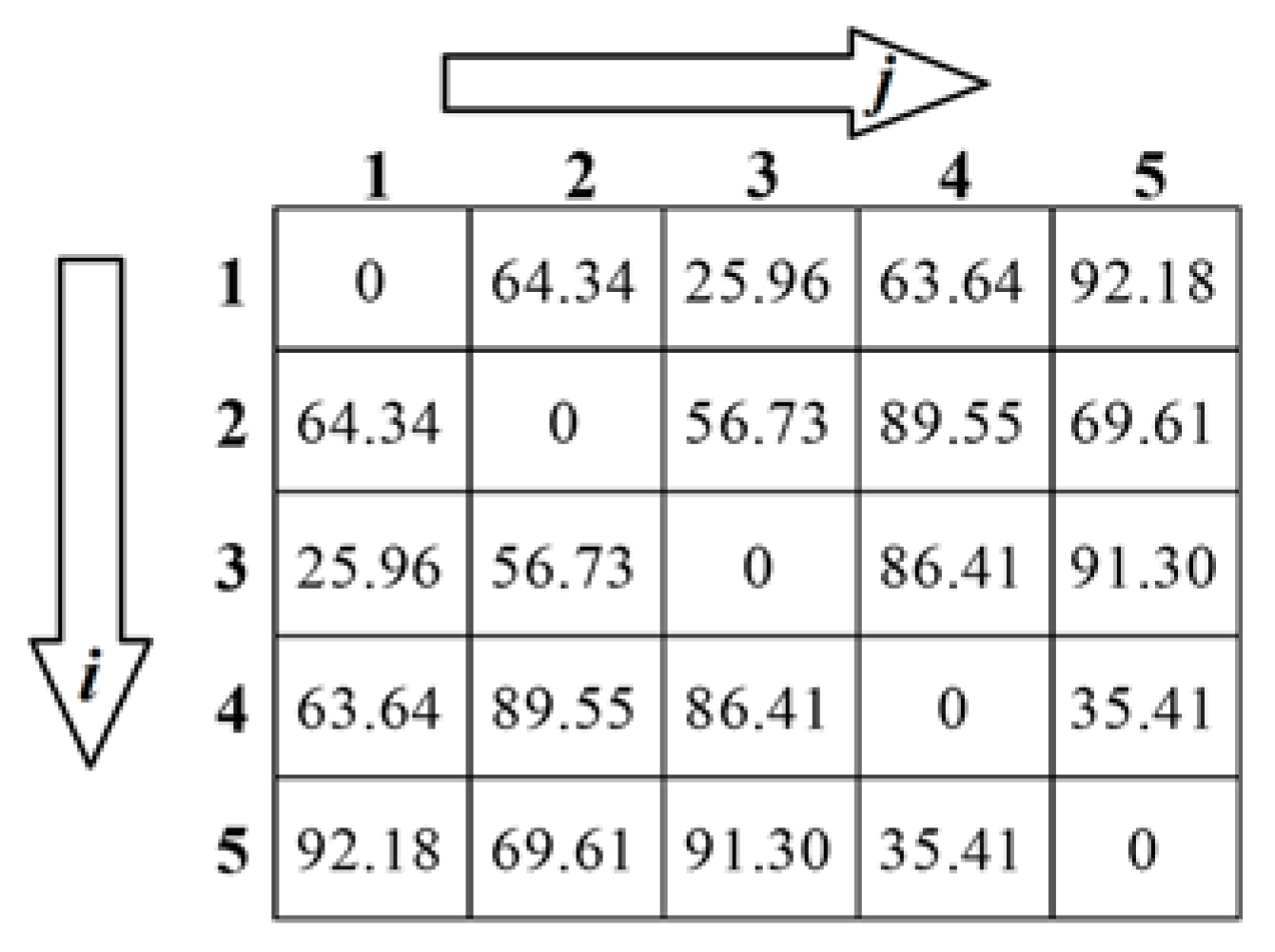
are similar. If geometric similarity is obtained between every matching pair, a symmetric similarity matrix of size
NM ×
NM with
as the element is composed, as shown in
Figure 5. The symmetric similarity matrix has zero diagonal elements.
As written in Equation (5), each element of a symmetric similarity matrix represents geometric similarity ( between a matching pair and , and means the similarity () between and . Here, the and indices become the minimum units for clustering.
Simply composing a symmetric similarity matrix does not mean a new geometric verification. The new geometric verification intended here refers to everything, from using the composed symmetric similarity matrix, to finally performing the cluster verification after undergoing the clustering process.
3.2.3. Agglomerative BST (Binary Search Tree) Clustering
For clustering, agglomerating clusters by identifying the similarities between the cluster hierarchically is common. The methods for identifying the similarity between clusters include AGNES using the single-link, complete-link, and average-link methods [
30]. In the ACC and IACC algorithm [
21,
22], clustering is performed adaptively using the adaptive partial link method. These clustering methods, however, have a large limitation in that the speed decreases with increasing number of clusters. In general, when the number of initial clusters is
n, the hierarchical clustering method has a complexity of
O(
n3) because the similarity between clusters needs to be calculated and updated. Here, updating means obtaining a new similarity between an agglomerated cluster and the remaining clusters. The complexity of the similarity calculation between clusters can be reduced using the symmetric similarity matrix obtained earlier, but an additional calculation is essential in the case of an update. In this paper, an algorithm is proposed to reduce the complexity by simplifying the conventional agglomerative hierarchical clustering. The update process that comprises a large proportion of the complexity is omitted, and clustering is performed by constructing a BST (Binary Search Tree) [
31] with the basic clusters obtained from symmetric similarity matrix.
The pseudocode presented earlier shows the BST clustering process in detail. In the initialization part, Ntree is the number of binary trees (BTt) generated, and BTt represents the tth binary tree. The BST clustering process that appears hereon is performed the maximum of Nbc times. Nbc is the number of in the upper triangular part, excluding the diagonal elements in the symmetric similarity matrix, and . When the BST clustering process is examined, first, and with minimum similarity are found in the symmetric similarity matrix (because the symmetric similarity matrix is a symmetrical matrix, they are found only when ). Here, BST clustering is terminated if the similarity is larger than the given threshold (similarity threshold). Next, an element of the overlap matrix with and as the index is confirmed. If the value for is one, clustering is not formed because the feature point with an overlap between positions cannot be considered as a robust feature.
Agglomerative BST Clustering
Ntree = 0, k = 0, BTt = {ø}, sumS = 0 // Initialization
/* BST clustering */
repeat
k = k + 1
// Find i,j
if sim(i,j) > δs then {break}
// overlap check
if ovlp[i,j] then {sim(i,j) = ∞, continue}
// Using BST, Searching & Inserting
chk = 0, t = 0
repeat
if {i,j} ∈ BTt then {chk = 1, break}
else if i ∈ BTt then {Insert j into BTt , chk = 1, break}
else if j ∈ BTt then {Insert i into BTt , chk = 1, break}
else {t = t + 1}
until t = = Ntree
// make new BTt
if chk = = 0 and sim(i,j) < thres(δs,sumS) then {
Make BTt and Insert i,j into BTt
Ntree = Ntree + 1
sumS += sim(i,j) }
sim(i,j) = ∞
until k = = Nbc
if any one of the nodes in BTt (0 ≤ t ≤ Ntree) is the same, merges them.
The rest of BTt is cluster Ct (0 ≤ t ≤ Ncluster)
In the next part, searching and inserting
and
is performed using BST. This process is performed the maximum of
Ntree times, and if a node is searched at least once in BT
t, it is terminated. In total, there are three cases of nodes searched from BT
t. The first is the case where both
and
are searched. Here, because all pertinent nodes exist, the process is terminated without insertion. Next is a case where only
is searched. Here,
is inserted as a new leaf node in BT
t, and the process is terminated. Finally, in the case where only
is searched,
is inserted as a new leaf node, and the process is terminated.
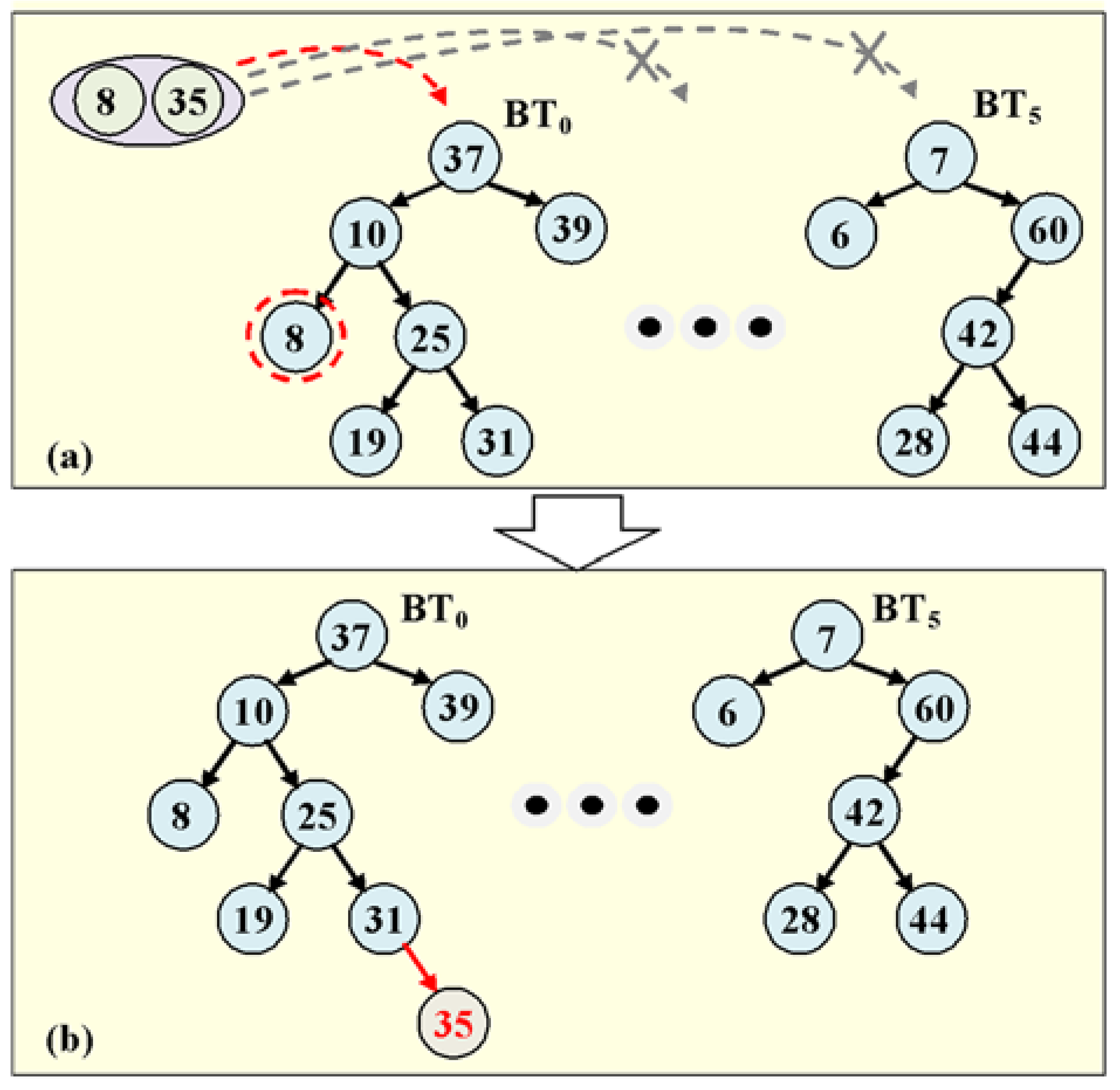
Figure 6 gives an example of the searching and inserting process of BT
t. For example, when the
= 8 and
= 35,
Figure 6a shows that the node 8 of BT
0 is searched. This is the case where
is searched. As shown in
Figure 6b,
= 35 is inserted as a new leaf node in BT
0 because
is not searched in BT
0.
A new BT
t is generated when
t = 0 or searching is not done. To generate a new BT
t, an additional threshold is required. The root node (first node) is important for generating binary trees. If the root node is incorrect, binary tree generated from the root node can generate large errors. The additional threshold makes the root node more robust. As written in Equation (6), it is an adaptive threshold. Because
increases as BT
t is generated, threshold must also increase. The adaptive threshold is the value that divides similarity threshold (
) by the mean of the sum of root node’s similarities. In the BT
t generated here,
and
are inserted as new nodes. Next, it finds new
with the minimum similarity value again by providing
and clustering is repeated the maximum of
Nbc times. Finally, it checks whether to merge between the generated binary trees. If any one of the nodes in the generated binary trees is the same, they are merged. To merge or not, all the rest of BT
t generated this way become cluster
with the basic clusters. For example, in BT
5 of
Figure 6, because all nodes form a basic cluster,
= {7,6,60,42,28,44}. The clusters
generated this way finally undergo cluster verification.
3.2.4. Cluster Verification
Finally, in the matching method, the cluster verification step determines the suitability of the clusters
obtained as described earlier. This step is required because even if a cluster is agglomerated by the geometric similarity between the basic clusters, there is still the possibility of error. In particular, this must be considered when the cluster area is too small when the possibility of error is high.
Figure 7 gives examples of mismatching results without using cluster verification, where the cluster area is too small compared to the entire image area.
Cluster Verification
cluster Ct, t = 0
areaimg1 = entire reference image(=img1) area
areaimg2 = entire query image(=img2) area
repeat
{cvimg1, cvimg2} = find each convex-hull in Ct
ratioimg1 = (calculate area of cvimg1)/areaimg1
ratioimg2 = (calculate area of cvimg2)/areaimg2
qmin = min(ratioimg1, ratioimg2)
qratio = qmin/max(ratioimg1, ratioimg2)
qsize = the number of elements in Ct
if qmin > τmin and qratio > τratio
and qsize > τsize then {Ct is TRUE}
t = t + 1
until t = = Ncluster
The previous pseudocode shows the proposed cluster verification step. Cluster verification obtains the determination criteria based on the ratio between the entire image area and the cluster area. The cluster area is calculated by obtaining a convex hull from the positions of the feature points. Here, the feature points can be obtained from the indices that correspond to each element of cluster . Using the ratio that can be obtained from both the reference and query images, the minimum value and ratio of the minimum and maximum values are obtained. As another criterion, , the number of elements of , is obtained. These three determination criteria and respective thresholds, , , and , are compared, and when they are all larger than the respective thresholds, the pertinent cluster is determined to be suitable. If at least one is determined to be suitable from the clusters, , two images are finally determined to be matching.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}