1. Introduction
As an important part of modern decision-making science, multi-attribute group decision-making (MAGDM) has been applied with enormous success to various fields such as strategic planning, portfolio selection, medical diagnosis, and military system evaluation [
1,
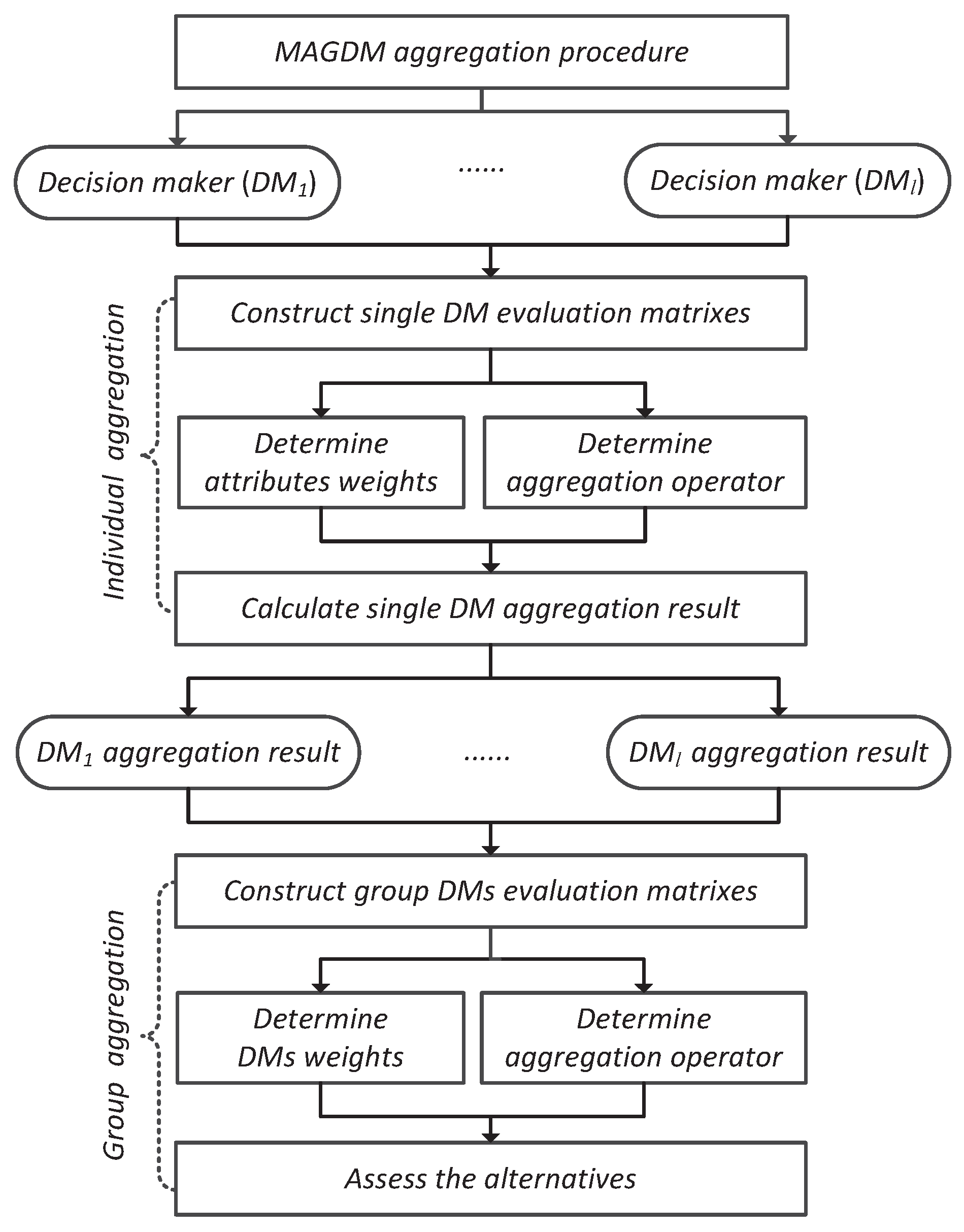
2]. To better understand the procedure for solving MAGDM problems, we develop a general framework for the MAGDM aggregation procedure (see
Figure 1) which contains two stages: (1) individual aggregation, which is a multi-attribute decision-making process for each decision maker (DM) composed by multiple attributes and multiple alternatives; and (2) group aggregation, which is a decision-making process composed of multiple experts and multiple alternatives. In both stages, developing efficient aggregation methods and determining the optimal weights for aggregation operators are two key steps.
Methods developed for aggregating information can be classified into three types. The first is the weighted-average method, which aggregates the information by using different importance degrees of the arguments [
3,
4]. The second is the probabilistic aggregation method, which unifies the ordered weighted averaging (OWA) operator and the corresponding probabilities by incorporating the importance degree of each case in the aggregation process [
5,
6]. The third is the deviation aggregation method, which minimizes the deviation between the aggregation result and evaluation information characterized by distance metrics or penalty functions [
7,
8].
Reference-dependent utility function to characterize psychological factors. There is a consensus that the psychological factors of the DM, such as reference wealth [
9], cognitive elements [
10] and the behavior towards risk [
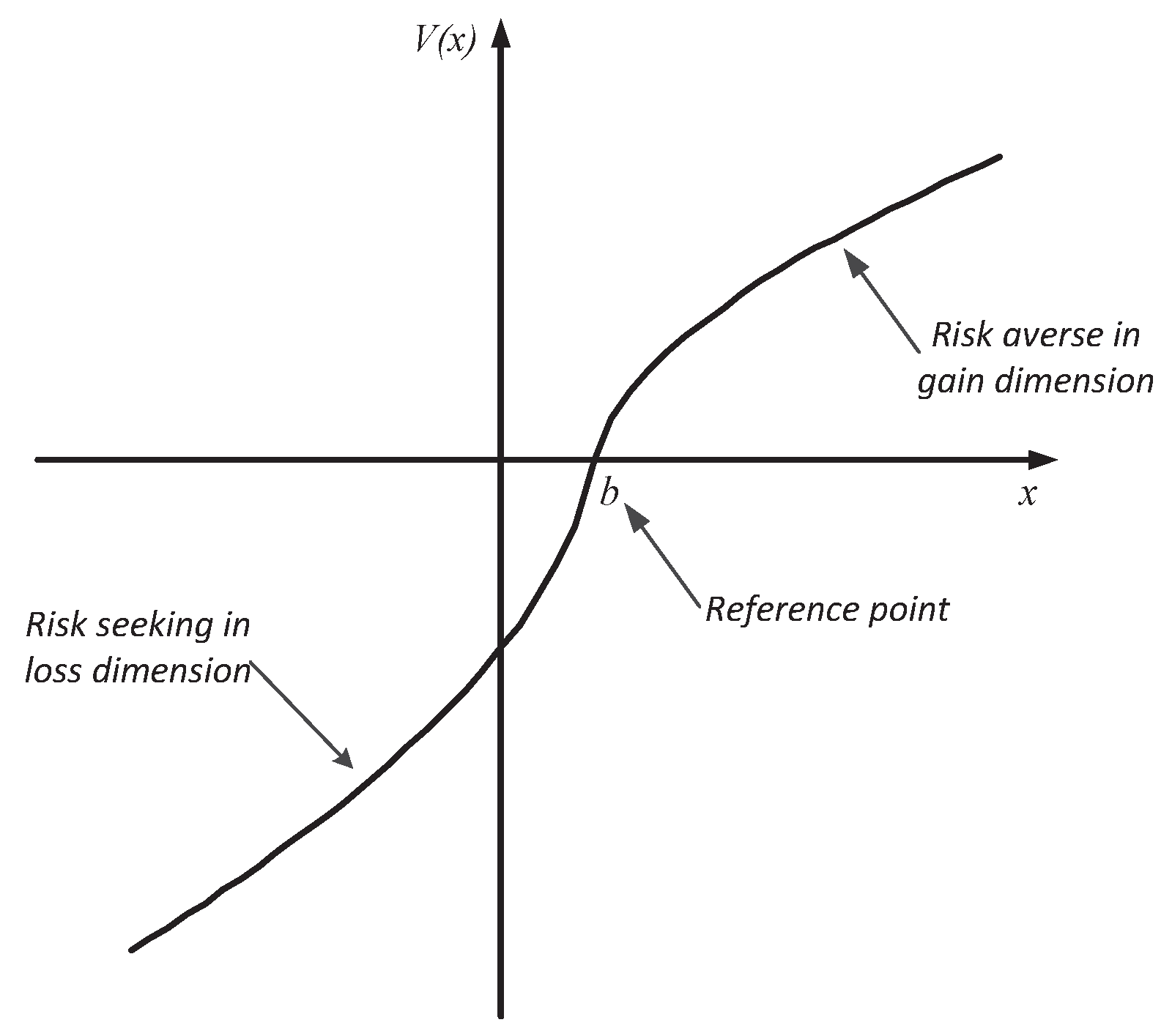
11], play important roles in decision analysis. Nevertheless, the aforementioned aggregation methods fail to capture the psychological character of DMs in the aggregation process. In this paper, we attempt to partially fill this gap by modeling psychological factors via reference-dependent utility functions (RUs). The most famous RU is the value function of Prospect theory [
12,
13], which involves a basic utility function, loss aversion coefficient and a reference outcome. This is the fundamental framework of RUs.
We build the multi-attribute aggregation operators upon two types of RUs: an
S-shaped RU [
9,
14] and a non-
S-shaped RU [
11,
15]. The
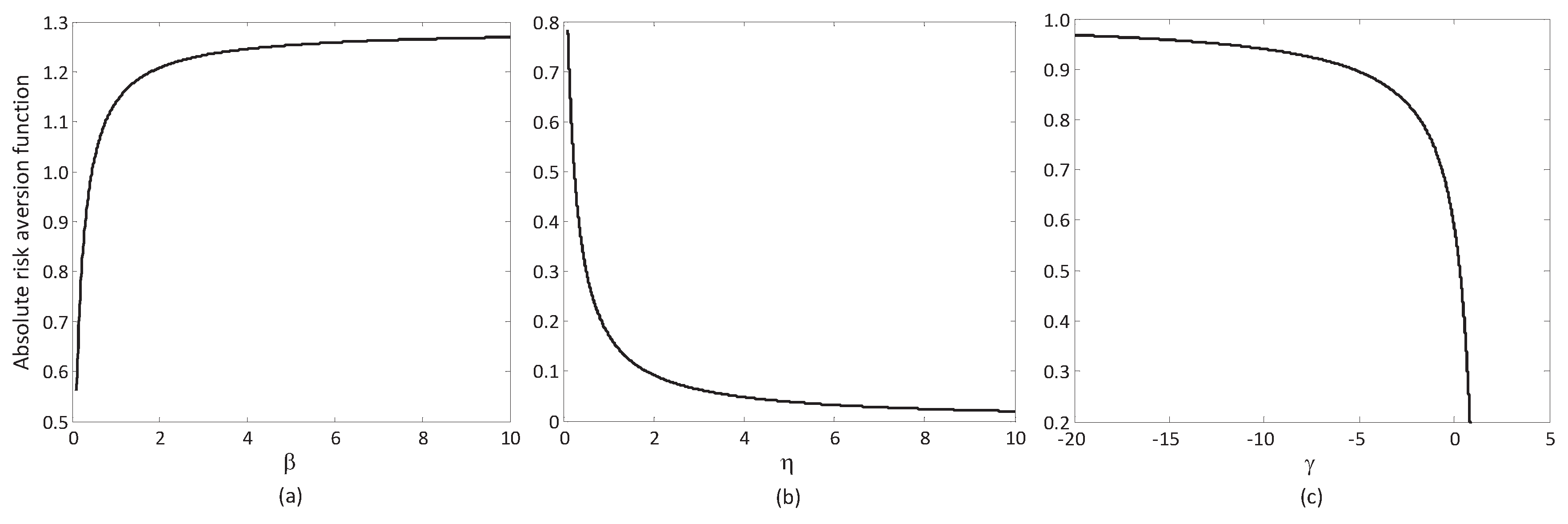
S-shaped RU describes the risk attitude of a DM who is risk-averse for relative gains (with a concave function above the reference point) and risk-seeking for relative losses (with a convex function below the reference point), as can be seen in
Figure 2. On the other hand, the non-
S-shaped RU maintains concavity regardless of the value of outcomes (either above or below the reference point), indicating risk-aversion for both gains and losses (see
Figure 3). How to choose an RU depends on the DM’s psychological standpoint: if the DM views relative losses as distorted positive (negative) outcomes, then his/her attitude tends to be risk-averse (risk-seeking) [
16]. Although RUs have been widely applied to behavioral models of decision-making in economics and finance [
17,
18], to the best of our knowledge, there is little research of RU-based MAGDM aggregation methods.
Weight models of attributes and decision makers. Another crucial step in the application of aggregation operators to MAGDM is to determine the associated weights for both attributes and DMs (see,
Figure 1). Relevant methods include the minimum variance method [
19], minimum dispersion method [
20], minimum chi-square method [
21], minimum disparity method [
22], and maximum Bayesian entropy method [
23]. An unresolved issue in the aforementioned methods is how to factor the influence of input arguments in the process of determining weights. In practice, an attribute with similar attribute values across most alternatives is deemed less important, so it should be assigned a smaller weight; on the other hand, an attribute with values fluctuating across alternatives is considered more important, it then should be assigned a larger weight.
The weights of DMs also play an important role in the aggregation process. Many researchers directly apply attribute weight models to compute the weights of DMs, such as the minimum variance method [
19], minimum chi-square method [
21], minimizing distances from the extreme points (MDP) method [
24], voting method [
25] and improved minimax disparity method [
26]. However, the common disadvantage of the above approaches is that the high subjectivity of DMs may cause inaccuracy, sometimes leading to biased decision results.
We aim to resolve the above issues by developing two new optimization weight models. On the one hand, our model considers the impact of the attribute variation across the alternatives on choosing the optimal alternative; we will assign a relatively larger (smaller) weight to an attribute having a larger (smaller) variation across the alternatives. On the other hand, we try to achieve a fairly small deviation among the weights to maintain fairness.
Our contributions. We summarize our contributions in three directions.
- (1)
To investigate the impact of DMs psychological factors on the decision-making result, we propose for the first time two new operators based on RUs: the
S-shaped and non-
S-shaped operators. The DM can choose different RU operators to get the result according to his/her attitude toward the relative losses. To be specific, if the attitude of the DM is risk-seeking for relative losses, he/she can use the
S-shaped operators (see Equation (
11)) to select the optimal alternative. If the attitude of the DM is risk-averse for relative losses, he/she can apply the non-
S-shaped operators (see, Equation (
16)) in the decision-making process. If the attitude of a DM is risk-neutral, he/she can make decisions via the generalized ordered weighted multiple averaging (GOWMA) operator (see, Equation (
18)) which is degenerated by the non-
S-shaped operator. The main advantage of the RU operators is that they not only reflect the psychological character of the DM while the aforementioned aggregation methods fail to capture in the aggregation process, but also generate a family of aggregation operators by taking different parameters. Specifically, the RU operators can degenerate to the existing aggregation operators (see
Table A1,
Table A2 and
Table A3 in
Appendix A.3), which can be seen as the particular case of the RU operators.
- (2)
To determine the associated weights for the multiple attributes and DMs, we propose an attribute- deviation weight model and a DMs-deviation weight model (see, models (
19) and (
20)). Going beyond the framework of existing weight models which ignored the dependence on the attribute variation (deviation), our new weight models consider the variations impacts of the attribute values on the determination of the weight in aggregation process. In addition, the attributes weights and the DMs weights are calculated by using attribute-deviation and DM-deviation models respectively, while the most research uses the same model to determine the associated weights for both attributes and DMs, sometimes leading to biased decision results.
- (3)
We develop a new approach for MAGDM based on the RU operators and the weight models. In addition, the numerical examples are given to illustrate the application of the approach. Two novel findings emerge from the numerical analysis in
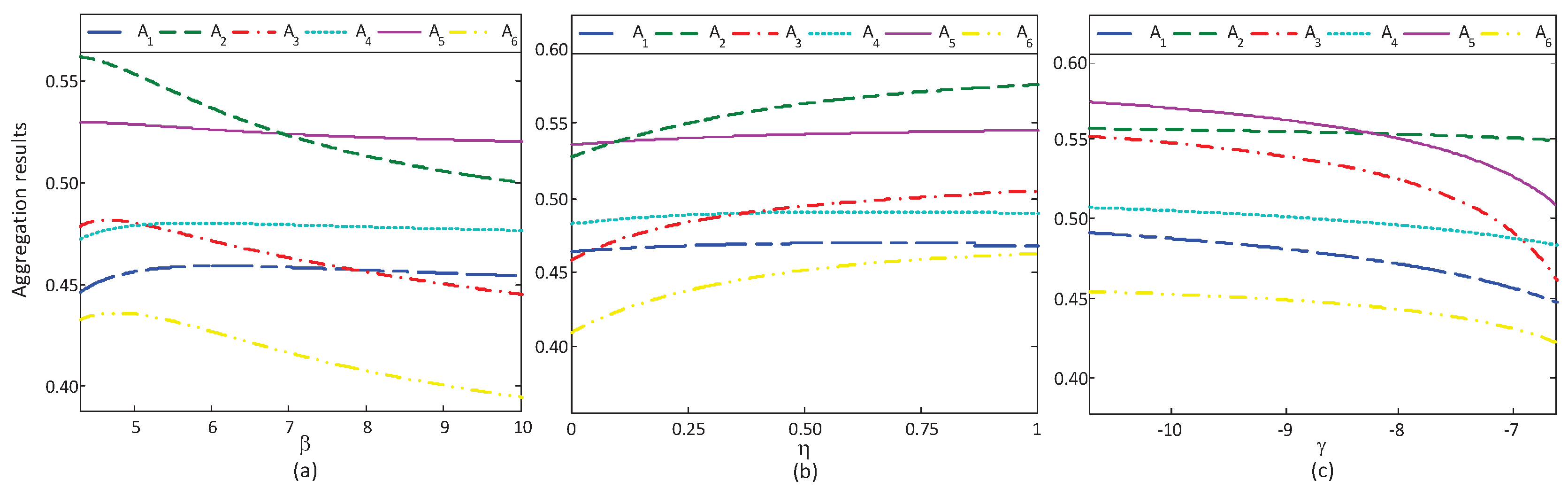
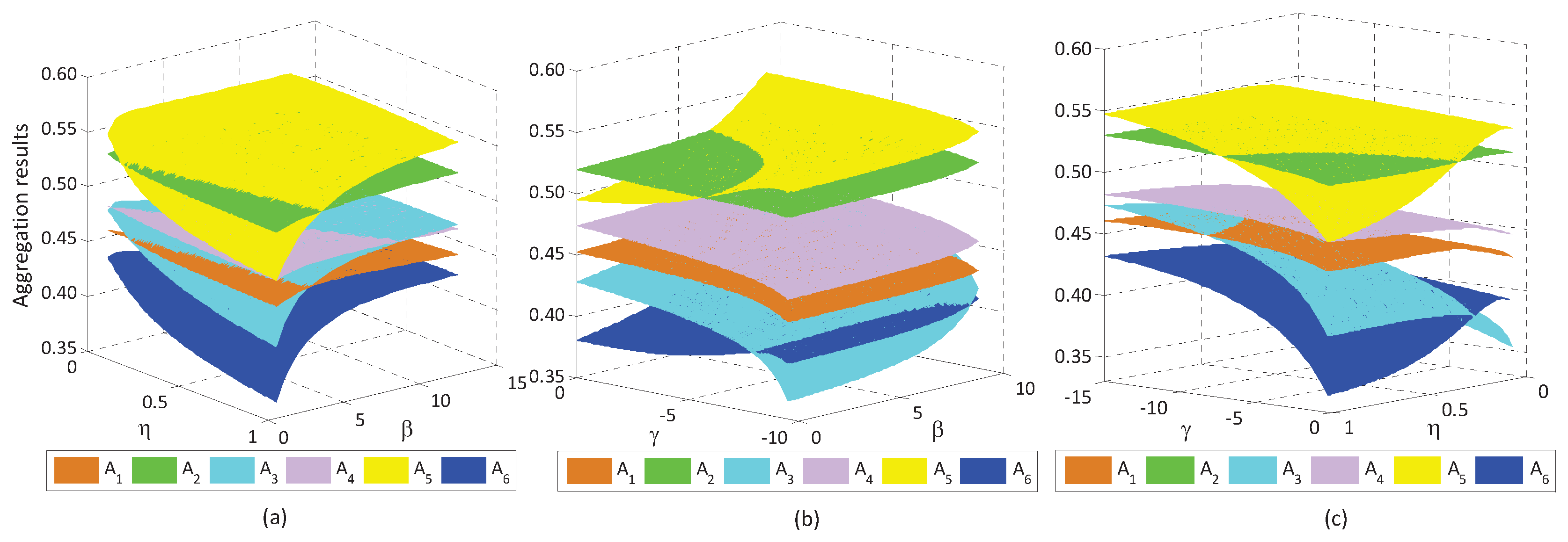
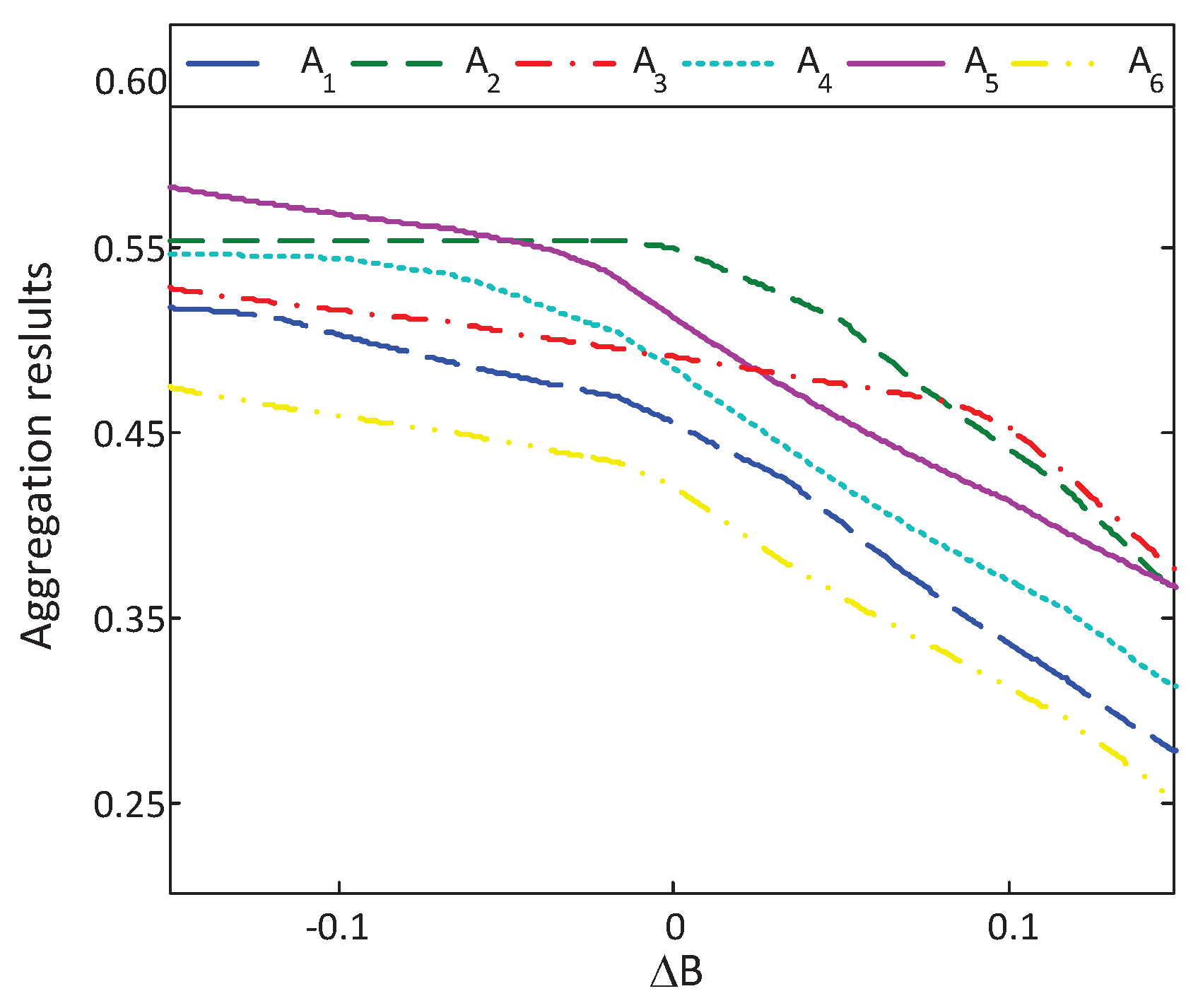
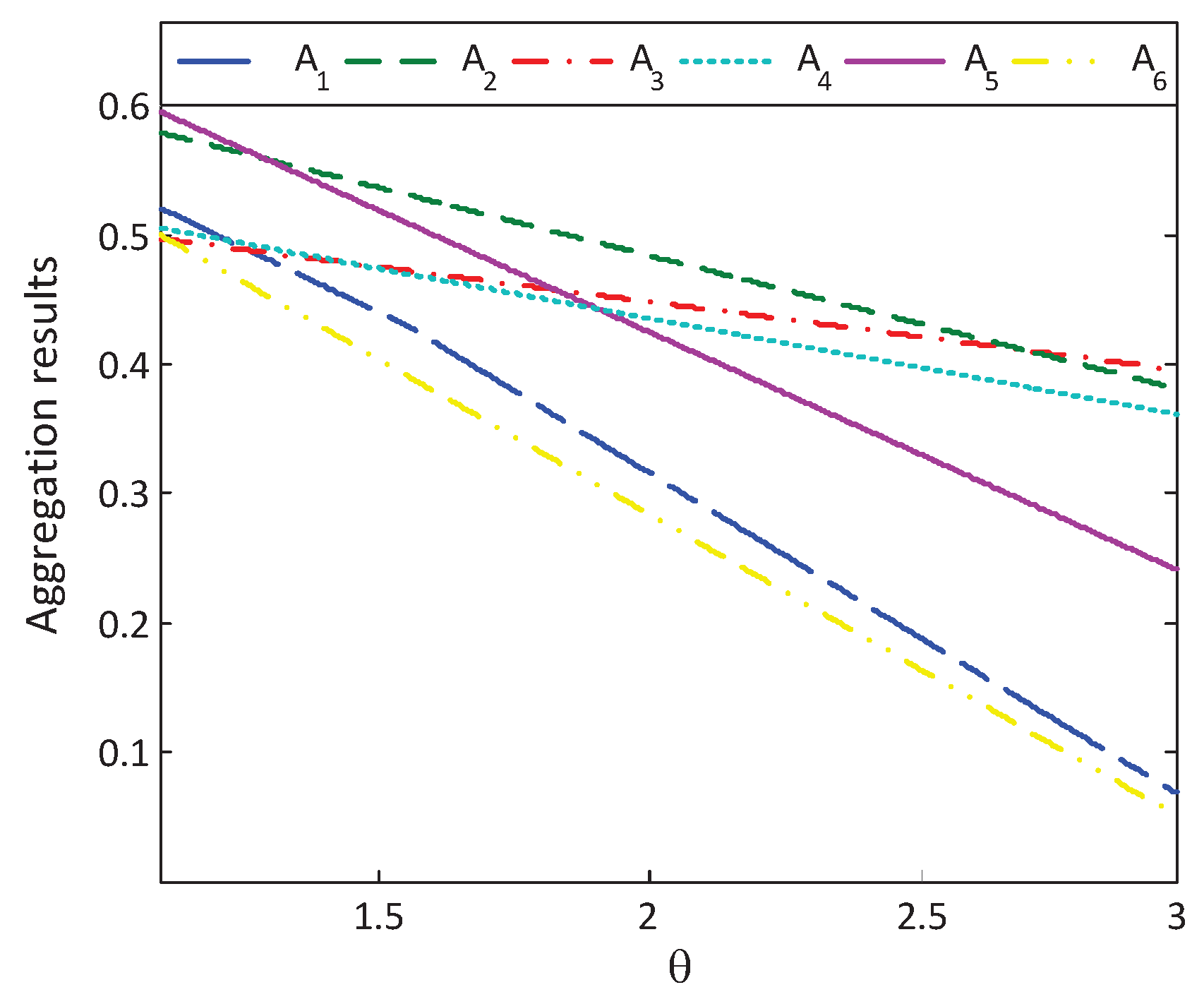
Section 6. First, the optimal alternative will change to a relatively prudent alternative with the absolute risk aversion coefficient increasing. Second, the optimal alternative changes to a relatively risky one with the reference point (or, loss aversion coefficient) increasing.
The rest of the paper is organized as follows. Under the general frameworks of
S-shaped RU,
Section 2 derives the
S-shaped operators for the DM whose attitude is risk-seeking for relative losses. As for the specific
S-shaped RU, we focus on prospect value function and
S-shaped hyperbolic absolute risk aversion function respectively and develop their corresponding aggregation operators. Under the general frameworks of non-
S-shaped RU,
Section 3 proposes the non-
S-shaped operators for the DM whose attitude is risk-averse for relative losses. As for the specific non-
S-shaped RU, we focus on non-
S-shaped hyperbolic absolute risk aversion function and develop its corresponding aggregation operators. In
Section 4, we construct two new nonlinear optimization weight models by applying the deviation measure method. The approach is summarized through six steps in
Section 5 and its superiority is tested via numerical examples in
Section 6. In the end, the conclusions are drawn in
Section 7, and all proofs are given in the E-companion.
4. New Weight Models for Reference-Dependent Aggregation Operators
Because MAGDM problems have multiple alternatives, multiple attributes and multiple DMs, it becomes a crucial step to appropriately determine the weights of the attributes and the DMs. In this section, we propose new models to compute weights; our models capture realistic features in the decision-making process by taking into account the variations of the attribute values. In practice, if the values of an attribute have a small (large) variation across all alternatives, such an attribute should play a less (more) important role in choosing the optimal alternative, thus it deserves a smaller (larger) weight. We first compute weights for the attributes (
Section 4.1) and next compute weights for the DMs (
Section 4.2).
4.1. Weight Model for Attributes
We briefly review related weight methods in the literature. One popular idea is to obtain the desired OWA operator according to a given orness level (an attitudinal character of the DM; see [
33] for details of orness) which is formulated as a constrained optimization problem. The objectives of the optimization problems include the minimum variance method [
19], minimum dispersion method [
20], minimum chi-square method [
21], minimum disparity method [
22], and maximum Bayesian entropy method [
23], etc.
The methods mentioned above, however, fail to consider the influence of the input argument information on weighting the attribute. In other words, these methods assume that the determination of the weights for the attribute is independent of the distributions of the attribute values, which is evidently unreasonable [
34].
It is a consensus in decision science that the larger variation the outcomes of an attribute have across the alternatives, the more important this attribute becomes (indicating a larger weight should be assigned) [
34]. For instance, we consider the following two decision matrices
and
; here
is derived from
(with the two columns in
swapped):
In the matrix , attribute should play a less significant role than in the decision-making process because outcomes of have similar values across all alternatives (thus a very small variation occurs) while the outcomes of have a much larger variation across and . If outcomes of an attribute (such as ) are nearly identical, then such an attribute can perhaps be removed from the decision-making process (that is, a zero weight can be assigned to this attribute).
Nevertheless, the weight models reviewed above fail to take into account the impact of the attribute variation. In addition, these weight models will yield the same weights for the two decision matrices and (with the two columns in swapped), which is unrealistic. To the best of our knowledge, there is little research considering the impact of the attributes variations on the determination of operators weights. To resolve this issue, we propose a new weight model for the attributes. In our model, a relatively larger (smaller) weight will be assigned to an attribute having a larger (smaller) variation across the alternatives. We name our model as the attribute-deviation weight model.
Generalizing the weight model in Wang & Parkan [
20], we propose a new optimization model to determine the weights of the attributes. Here,
denotes the attribute weight vector for the
kth DM.
We now explain the objective function of our new model. To maintain fairness, all attributes should be considered equally important, thus suggesting equal weights. On the other hand, the impact of the attribute variations should also be considered in the determination of the weights. That is, an attribute with a larger variation should be assigned a larger weight. In our model, the first term in the objective function of model (
19) accounts for the attribute deviation:
denotes the deviation of
and
, and
represents the deviation of all alternatives for the attribute
under the
. Next, the second term aims to minimize the total variation of the weights. The two factors
and
stand for the relative importance of the two terms, here,
= 1. The set
H represents incomplete information regarding the weights (e.g., due to the lack of data and limited knowledge about the problem domain) [
35,
36]. The set
H usually satisfies one or several of the following forms:
A weak ranking: ;
A strict ranking: ;
A ranking with multiples: ;
An interval form: ;
A ranking of differences: , for , , 0.
Remark 2 (Generality of the attribute-weight model (19))
. We advocate that model (19) not only captures the evaluation information of DM, but also maintains certain fairness. If , the objective function of model (19) focuses on maximizing the total deviation for the attributes across all alternatives. On the other hand, if , model (19) degenerates to several existing models, including the minimum chi-square model [21], minimum disparity model [22], etc. Similar to model (
4), various forms for the deviation measure
d can be used in model (
19). Without loss of generality, this paper considers
.
4.2. Weight Model for Decision Makers
Once the individual aggregation is completed, there will exist a new matrix composed of multiple DMs and multiple alternatives. Due to the participation of multiple DMs, the final decision should be made collectively; it should reflect opinions of all DMs. A remaining question in the decision-making process is how weights of DMs should be determined.
Attribute weight models have been applied to compute the weights of DMs, such as the minimum variance method [
19], minimum chi-square method [
21], minimizing distances from the extreme points (MDP) method [
24], voting method [
25] and improved minimax disparity method [
26]. However, the common disadvantage of the above approaches is that the high subjectivity of DMs may cause decision inaccuracy, sometimes leading to biased decision results.
In order to resolve this issue, we propose a new method. The idea of this method is to allocate larger weights to DMs that have smaller individual aggregation deviation. Specifically, if the kth DM’s opinions are more agreeable to the optimal aggregation result, that is, the kth individual result is closer to the optimal aggregation result , a larger weight will be assigned to the kth DM.
We illustrate our idea by considering three DM matrices
,
and
, and their ideal matrix
(average of the three matrices). There are three alternatives and two attributes.
It is easy to see that
is closest to
while
is farthest from
. Consequently, the weights should satisfy
. Therefore, we propose the following new optimization model to compute the optimal weights for DMs.
where
represents the weight vector for the DMs,
denotes the deviation
and
, and
denotes the deviation of
and
.
Similar to the model (
19), the second term of the objective function in (
20) aims to maintain fairness for all DMs.
is a weighting set and has the similar condition in model (
19). We call model (
20) as the DM-deviation weight model.
We remark that the nonlinear optimization problems (
19) and (
20) (along with their corresponding optimal weight vectors
and
) can be quickly solved by numerical solvers, such as MATLAB and Lingo software. We conduct detailed numerical experiments in
Section 6, where we use Lingo to solve models (
19) and (
20).
7. Conclusions
This paper introduced new reference-dependent utility functions in the aggregation process. To better model the psychological factors in MAGDM, we proposed S-shaped RU and non-S-shaped RU aggregation operators to characterize two attitudes of DMs for relative losses: risk-seeking and risk-averse. The S-shaped operator represented one type of aggregation functions where the attitude of the DM is risk-seeking for relative losses, and the non-S-shaped operator indicated another type of aggregation functions where the attitude of the DM is risk-averse for relative losses. In addition, the non-S-shaped operator can degenerate into the GOWMA operator, which implied the attitude of the DM is risk-neutral. Specifically, we developed an SOMR aggregation operator and an NOMR aggregation operator under S-shaped HARA and non-S-shaped HARA utility framework; we found that they are commutative, monotonic, bounded and idempotent.
In addition, we proposed an attribute-deviation weight model and a DMs-deviation weight model to determine the weights of attributes and DMs, which overcame the shortcomings of the existing aggregation operator weight models. We summarized the new MAGDM approach based on the RU operators and the weight models. In the end, we tested its effectiveness and demonstrated how to choose the optimal alternatives via numerical examples. The approach can be used in many fields such as strategic planning, portfolio selection, medical diagnosis, and military system evaluation. We believe that our proposed approach leaves space for further study of many interesting questions regarding (1) how to obtain accurate information about psychological preference from the DM; and (2) how to choose the utilities that will most efficiently guide the optimization problem to an optimal decision-making.



{kind=link}
{kind=link}
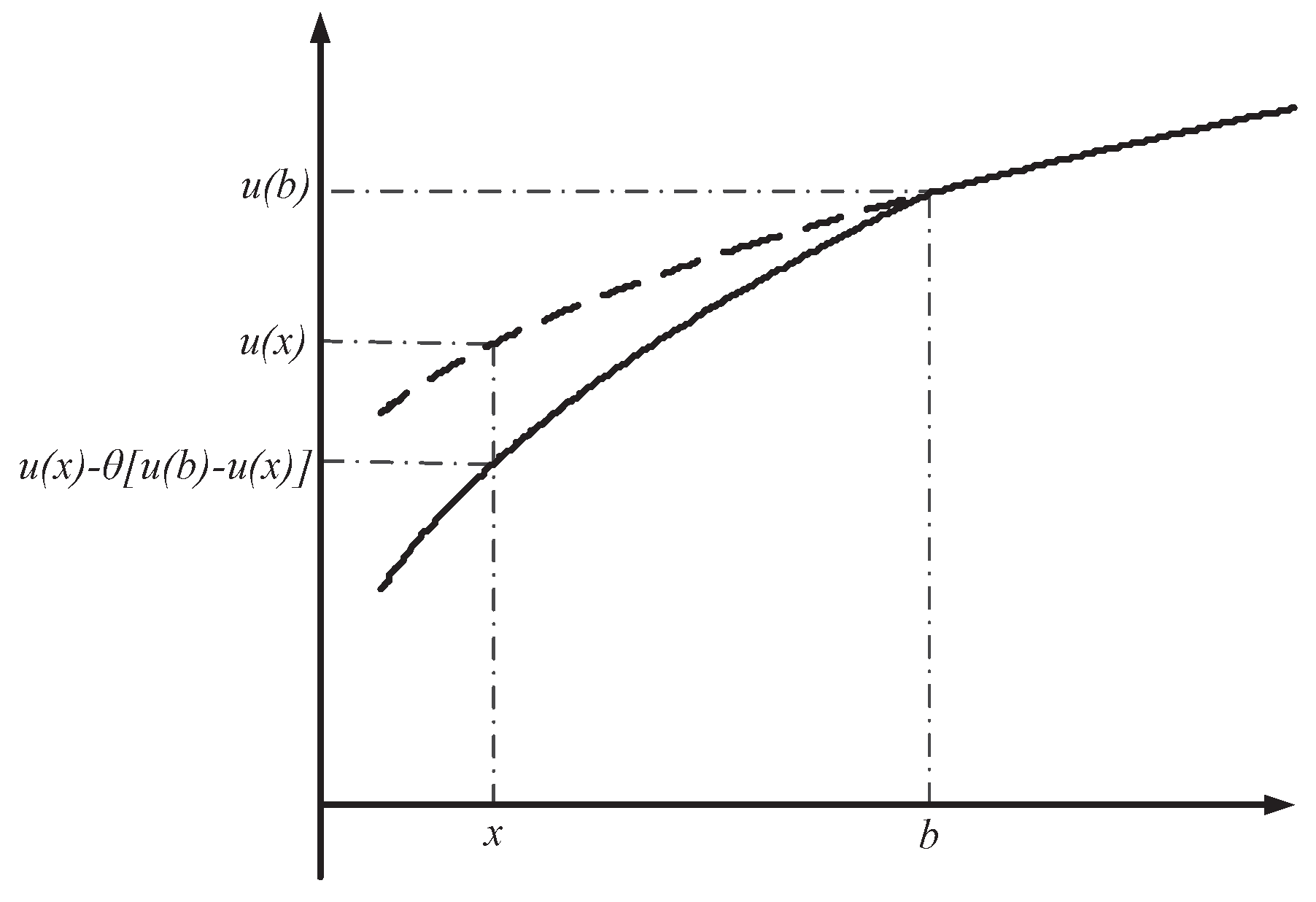{kind=link}
{kind=link}
{kind=link}
{kind=link}
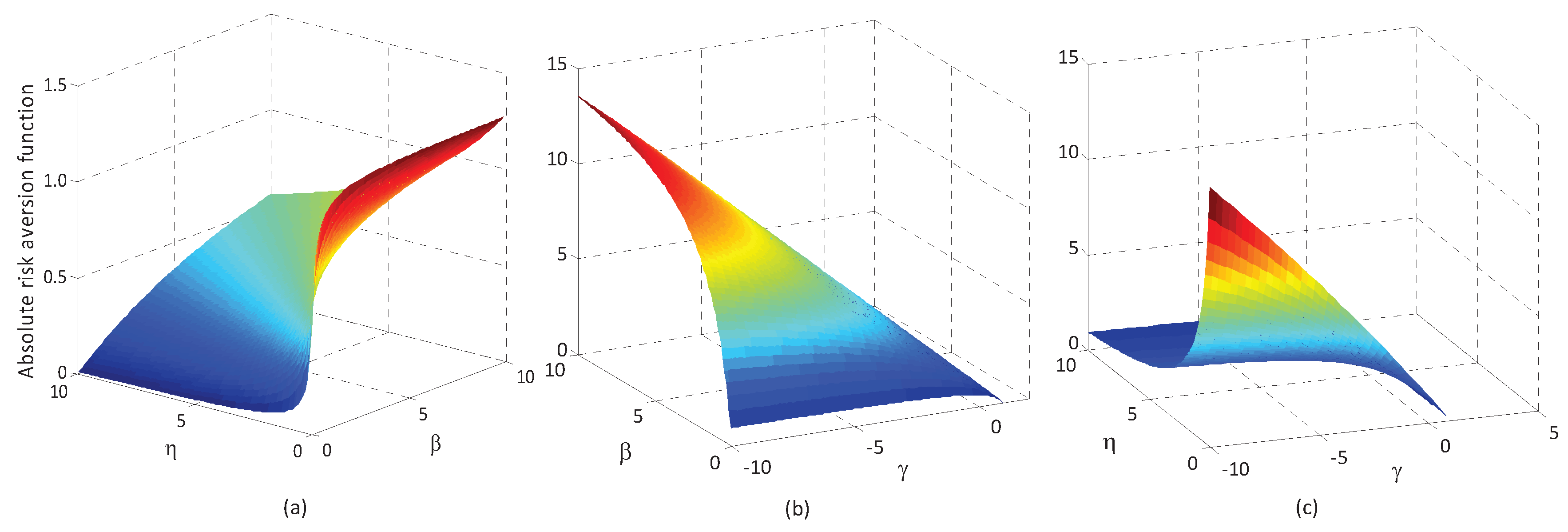{kind=link}
{kind=link}
{kind=link}








