Abstract
With the increasing diversification of ore types and the complexity of processing techniques in the mining industry, traditional decision-making methods for mineral processing flowsheets can no longer meet the high efficiency and intelligence requirements. This paper proposes a knowledge graph-based framework for constructing a mineral-processing design knowledge base and knowledge reasoning, aiming at providing intelligent and efficient decision support for mining engineers. This framework integrates Chinese NLP models for text vectorization, optimizes prompt generation through Retrieval Augmented Generation (RAG) technology, realizes knowledge graph construction, and implements knowledge reasoning for nonferrous metal mineral-processing design using large reasoning models. By analyzing the genetic characteristics of ores and the requirements of processing techniques, the framework outputs reasonable flowsheet designs, which could help engineers save research time and labor in optimizing processes, selecting suitable reagents, and adjusting process parameters. Through decision analysis of the mineral-processing flowsheets for three typical copper mines, the framework demonstrates its advantages in improving process flowsheet design, and shows good potential for further application in complex mineral-processing environments.
1. Introduction
With the depletion of global mining resources and the continuous development of mineral-processing technologies, the mining industry is facing unprecedented challenges [1]. The diversity of ores and minerals, along with their complex characteristics, introduces various uncertainties in beneficiation processes and decision making. Factors such as ore types, composition, and mineral structure make the design and optimization of beneficiation processes highly complex. Nonferrous metal mineral processing generally includes crushing, grinding, classification, flotation, gravity separation, and magnetic separation. Each stage’s design and optimization rely on experience and experimental data, and a fixed process model has been largely established, which includes (1) mineralogical research; (2) systematic beneficiation testing (including small-scale tests, expanded continuous tests, semi-industrial or industrial tests); (3) recommending process-flow schemes; (4) beneficiation plant design; and (5) trial production. However, this mode presents serval major drawbacks: (1) long development cycles and high costs; (2) heavy resource consumption and low efficiency; (3) extensive repetitive testing across different ore types; (4) limited inheritance of advanced technologies. While significant achievements have been made during the nearly 100 years of development, it has become increasingly difficult to meet the modern demands for efficiency and precision in mineral processing. Therefore, the exploration of more efficient and intelligent mineral-processing technologies and research models has become an urgent need in the mineral-processing process [2,3,4].
The genetic characteristics of minerals (“three ore genes”: deposit genes, ore genes and mineral genes)—referring to the intrinsic features of ore deposits, ores, and minerals in terms of composition, structure, and properties—play a critical role in the mineral-processing process. These genetic traits not only affect the difficulty of ore separation but also directly determine the choice and design of beneficiation processes. A comprehensive understanding of the genetic traits of ores and minerals, and utilizing this information to develop the optimal processing plan, has become a critical challenge that the mining industry need to address. With the dramatic increase in mining data, traditional manual processing methods are no longer applicable; thus, there is an urgent need to develop new methods to achieve more efficient and precise decision support [5].
Traditional decision support systems are based on expert experience, rule-based knowledge, and simple database queries [6]. They primarily assist decision makers by analyzing basic data and optimizing models. These systems emphasize quantitative support for decision making and use computer technology to process complex data, but they have limited intelligence and adaptability when faced with uncertainty and complexity. Expert systems simulate the decision-making process of experts through rule-based reasoning and knowledge-base management, solving the issue of a lack of intelligence in traditional decision support systems. They can perform qualitative reasoning in complex decision situations and provide decision guidance [7]. However, expert systems typically rely on static rule bases and expert knowledge, making them less effective in dynamically changing environments. With breakthroughs in technologies such as big data, artificial intelligence, knowledge graphs, deep learning, and computational power, intelligent decision-making systems in the mining sector are gradually being applied. These systems are integrating more intelligent and automated decision-making mechanisms, enabling them to handle more complex problems such as multi-objective optimization, real-time data analysis, and data mining. Intelligent decision systems not only rely on expert knowledge but also predict and optimize based on historical and real-time data, allowing for dynamic adjustments and real-time responses. They provide new solutions for the extraction, management, and reasoning of mining knowledge. For instance, natural language processing (NLP) [8] can be used to automatically process and analyze large amounts of mining literature, reports, and data, helping to extract key information; machine learning models can identify patterns and make predictions based on historical data to optimize beneficiation processes; knowledge graphs can visualize the complex knowledge in the mining field, supporting intelligent reasoning and decision making. However, despite these technologies driving the intelligent transformation of mining decision making to some extent, current intelligent decision systems still face challenges, especially in accurately capturing and reasoning the complex relationships between ore characteristics and processing techniques.
To address these challenges, this study proposes a knowledge graph-based framework for constructing a mining beneficiation report knowledge base and knowledge reasoning. The framework integrates advanced natural language processing models like Llama2-Chinese [9], the knowledge graph construction and visualization tool Neo4j, and the reasoning engine Qwen2 [10]. Its goal is to efficiently extract key information from mining reports, build a dynamically updated knowledge network, and perform intelligent reasoning and decision support based on this network. By combining the genetic characteristics of minerals with processing requirements, this framework can provide customized decision support for the beneficiation process, helping mining engineers make more precise choices in complex ore-processing scenarios.
2. Methods
2.1. Intelligent Decision Making for Genetic Mineral Processing Based on Knowledge Reasoning
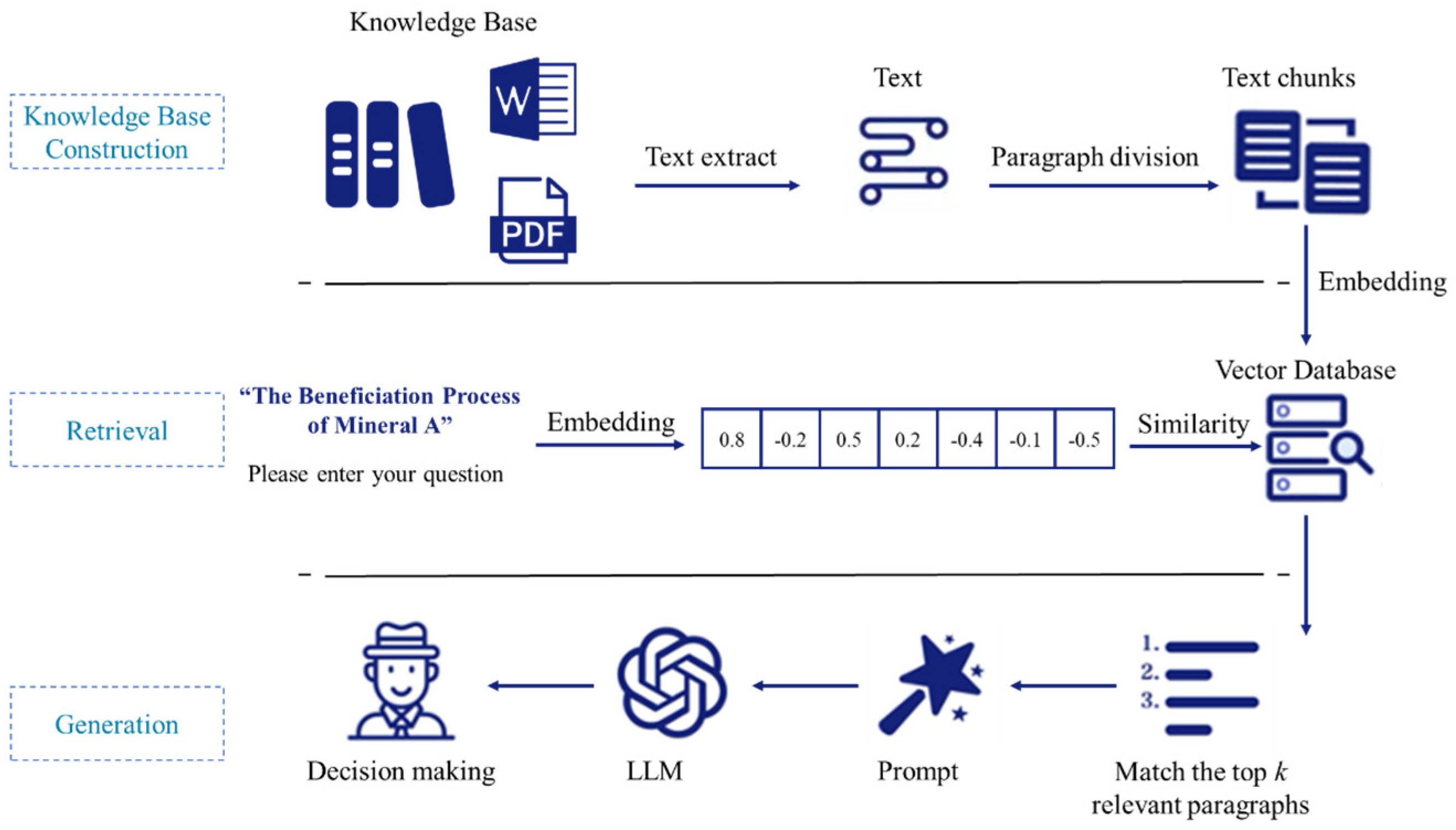
In a foundation-model-based mineral-processing decision-making system, problem modeling involves identifying the processing objectives, constraints, and process requirements of the minerals. The core of the reasoning mechanism is based on process mineralogy reports, beneficiation reports, and mechanism research content, to construct an intelligent decision-making system based on large models. By processing the input ore characteristics and actual demands, the system automatically generates effective decision recommendations. The overall architecture is shown in Figure 1.
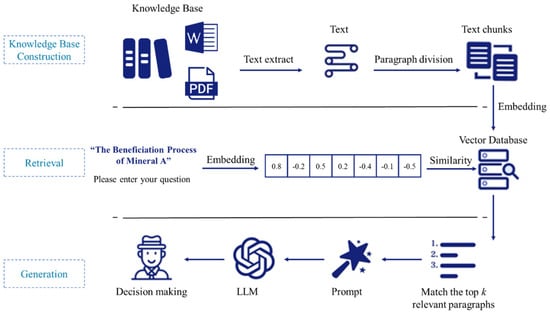
Figure 1.
Overall framework of knowledge-inference-based intelligent decision-making system for genetic mineral processing.
2.2. Knowledge-Base Construction and Vectorization
In the genetic mineral-processing decision-making system, constructing a comprehensive knowledge base is one of the key steps to achieving efficient decision-making. The data sources include process mineralogy reports, beneficiation reports, mechanism research content, etc., covering various aspects such as ore composition, mineral structure, and processing performance, providing the system with necessary raw data and knowledge support.
- (1)
- Process mineralogy: Includes the mineralogical characteristics, physicochemical properties, and processing traits of ores, such as mineral composition, particle-size distribution, elemental occurrence, and performance data for processing methods like flotation, gravity separation, and magnetic separation.
- (2)
- Beneficiation reports: The primary data source covering performance and process parameters during beneficiation, such as recovery rates, concentrate grades, and the relationship between ore properties and processing outcomes.
- (3)
- Mechanism research: Focuses on the physicochemical mechanisms, the kinetics of beneficiation, and mineral–reagent interactions, providing theoretical foundations for process optimization, reagent design, and recovery improvement.
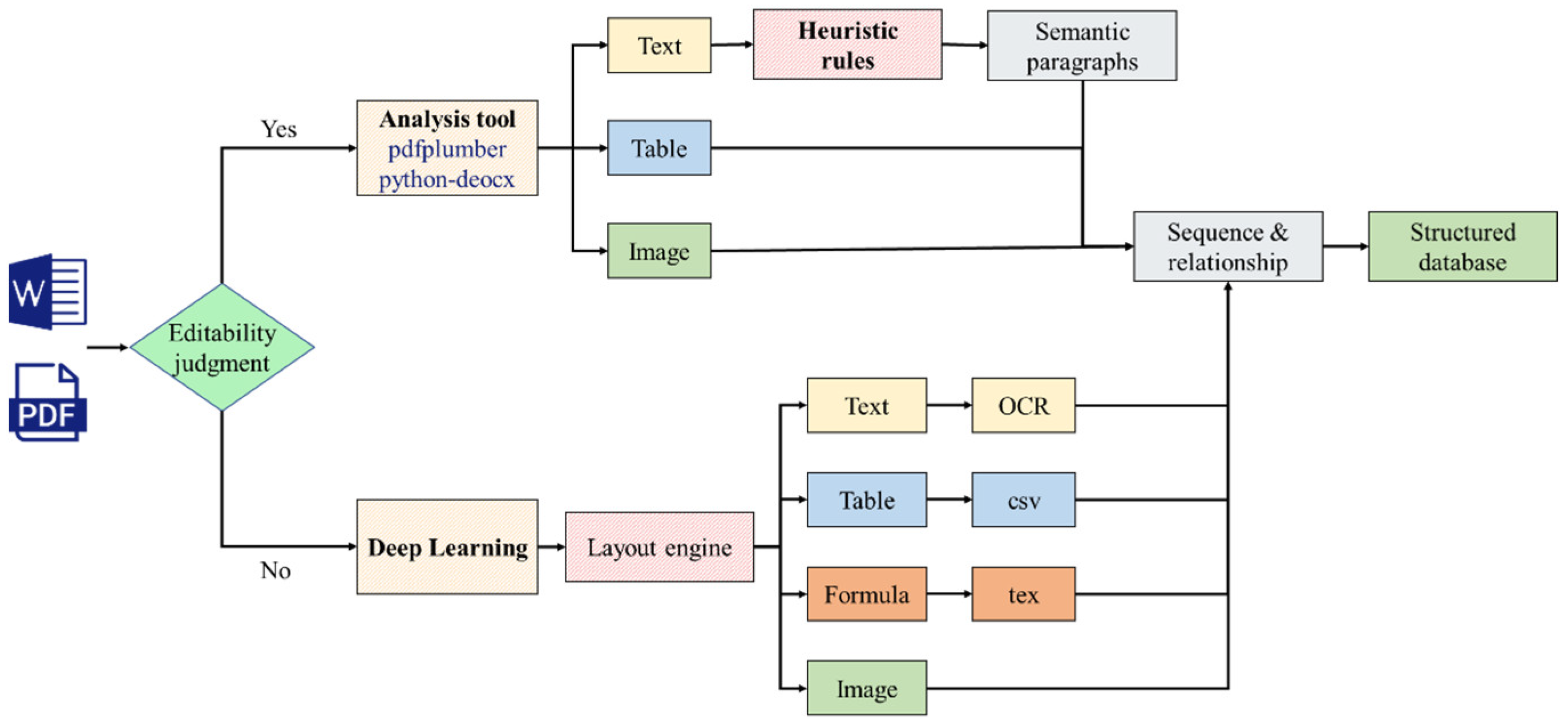
With the accumulation of a large amount of knowledge in the field of mineral processing, including beneficiation theory, process flows, ore characteristics, and historical experimental data, there are a total of 58 sources, including unstructured data formats such as PDF and Word. The system first performs editability checks on the files to determine if the content can be directly parsed. If the file is non-editable (e.g., image-based PDFs), deep learning methods (unstructured) are used for document parsing. If the file is editable (e.g., doc, docx), tools such as pdfplumber for parsing PDF content and python-docx for parsing Word documents are employed to extract text, tables, and images. The complete process is shown in Figure 2. After parsing, the data undergoes relational analysis to identify the sequence and associations between the content, and is finally stored as a structured knowledge base.
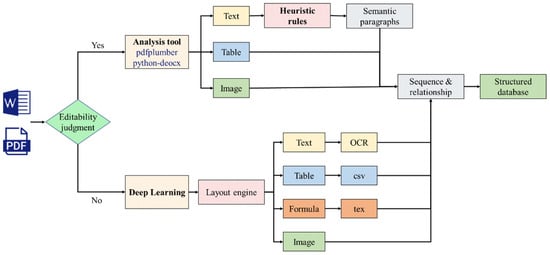
Figure 2.
Knowledge-base construction process.
Knowledge-base vectorization transforms textual data into high-dimensional vector representations, enabling computers to efficiently process and analyze non-numeric data. The Llama2-Chinese-13B model, based on the Transformer architecture, uses text embedding techniques to convert words, sentences, or documents into vectors, where each dimension represents the performance of the text on specific features, thereby capturing semantics and relationships [11]. The vectorization process consists of the following steps:
- (1)
- Tokenization: A Chinese tokenizer is trained using SentencePiece [12] on a Chinese corpus with a vocabulary size of 20,000. The original Llama tokenizer is then combined with this Chinese tokenizer, merging their vocabularies to create a new combined tokenizer called the Chinese Llama tokenizer, with a vocabulary size of 49,953. To accommodate the new tokenizer, the word embeddings and language model head are adjusted from V × H to V′ × H, where V = 32,000 represents the original vocabulary size and V′ = 49,953 is the size of the Chinese Llama tokenizer. New rows are appended to the end of the original embedding matrix, ensuring that the embeddings of the original vocabulary tokens remain unaffected.
- (2)
- Embedding: The model includes an embedding layer, multiple transformer blocks, and a language model head layer. It also incorporates several improvements such as pre-normalization, SwiGLU [13] activation, and a rotary positional encoding (RoPE) [14]. For each position in the token sequence, RoPE vector is added to distinguish the positions of tokens and provide the model with contextual relationship information.
- (3)
- Autoregressive Generation: Given an input token sequence, the model is trained in an autoregressive manner to predict the next token, aiming to minimize the negative log-likelihood as follows:
After obtaining the pre-trained Chinese Llama model, the method used in Alpaca is applied for instruction fine-tuning to continue training the model. Each training sample consists of an instruction and an output.
2.3. Knowledge Graph Construction and Optimization
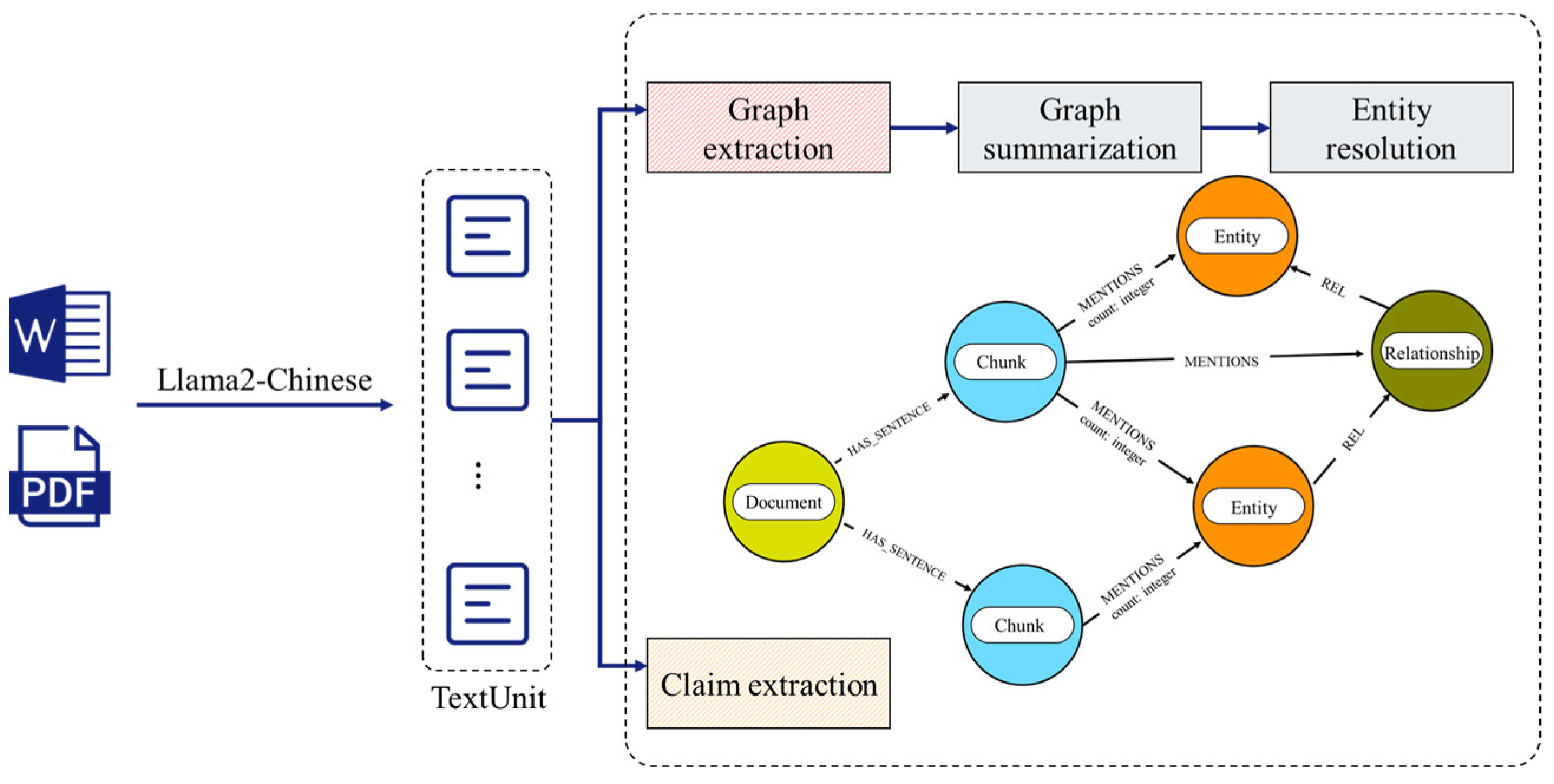
As a core component of artificial intelligence and semantic web technologies, knowledge graphs enable the systematic and structured representation of domain knowledge, promoting deep understanding and intelligent processing of information. In the field of mineral processing, the construction and optimization of knowledge graphs not only enhance decision support capabilities but also provide more accurate and comprehensive information for intelligent systems [15]. By combining large language models (such as Llama2-Chinese) with graph databases (Neo4j), the understanding and reasoning abilities of generative models can be enhanced within the structured representation of the graph, further improving the effectiveness of the knowledge graph. The process of constructing the knowledge graph is shown in Figure 3.
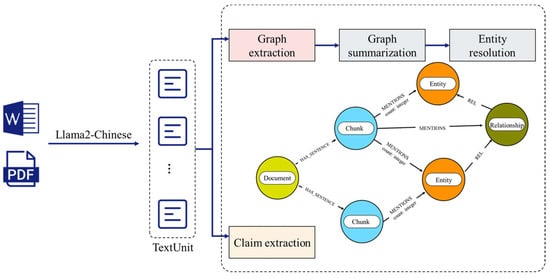
Figure 3.
Knowledge graph construction process.
The process of knowledge graph construction and optimization is as follows:
- (1)
- Graph Extraction: For unstructured or semi-structured documents, text is split into chunks based on a defined strategy. Leveraging the few-shot capability of large language models, latent information is extracted from each chunk, identifying entities (nodes), relationships (edges), and claims (structured data). Contextual and semantic analysis helps recognize associations between entities, forming an initial graph structure with interconnected entities and relationships.
- (2)
- Claim Extraction: Claims are domain-relevant statements or inferences that provide contextual support or Supplementary Information for entity relationships in the knowledge graph. This step focuses on extracting key information valuable for reasoning tasks within the graph.
- (3)
- Community Extraction: Entities are grouped into communities based on their relevance, with each community containing entities highly correlated with each other, often organized into high-level and low-level themes. Communities represent clusters of related concepts, aiding in the hierarchical management of the knowledge graph and highlighting key topics in the domain.
- (4)
- Graph Summarization: A concise summary is generated within each community, summarizing its main content to form a layered overview of the data. This step aims to merge redundant or overlapping nodes and relationships, eliminating irrelevant information to simplify the graph structure. For complex subgraphs, summarization and consolidation make the graph more compact and efficient, improving storage and query performance.
- (5)
- Entity Resolution: After graph summarization, entity resolution addresses ambiguities and redundancies, such as standardizing synonyms or aliases into consistent representations. This step ensures the accuracy and completeness of the knowledge graph, which is crucial for reliable inference.
The refined and optimized knowledge graph, represented clearly and succinctly, is stored using graph database technologies like Neo4j. This enhances query efficiency and reasoning capabilities, providing real-time query and update support for intelligent reasoning and decision making.
2.4. Knowledge Reasoning and Intelligent Decision Making
By structuring domain knowledge through a graph representation, knowledge graphs provide a clear framework for intelligent systems. Building upon this, large models are used for knowledge reasoning, offering intelligent inference support in real-world mineral-processing scenarios based on the constructed knowledge graph. The model can understand various relationships within the graph, and, by combining the “genetic” characteristics of ores and processing requirements, deduce the optimal processing plan.
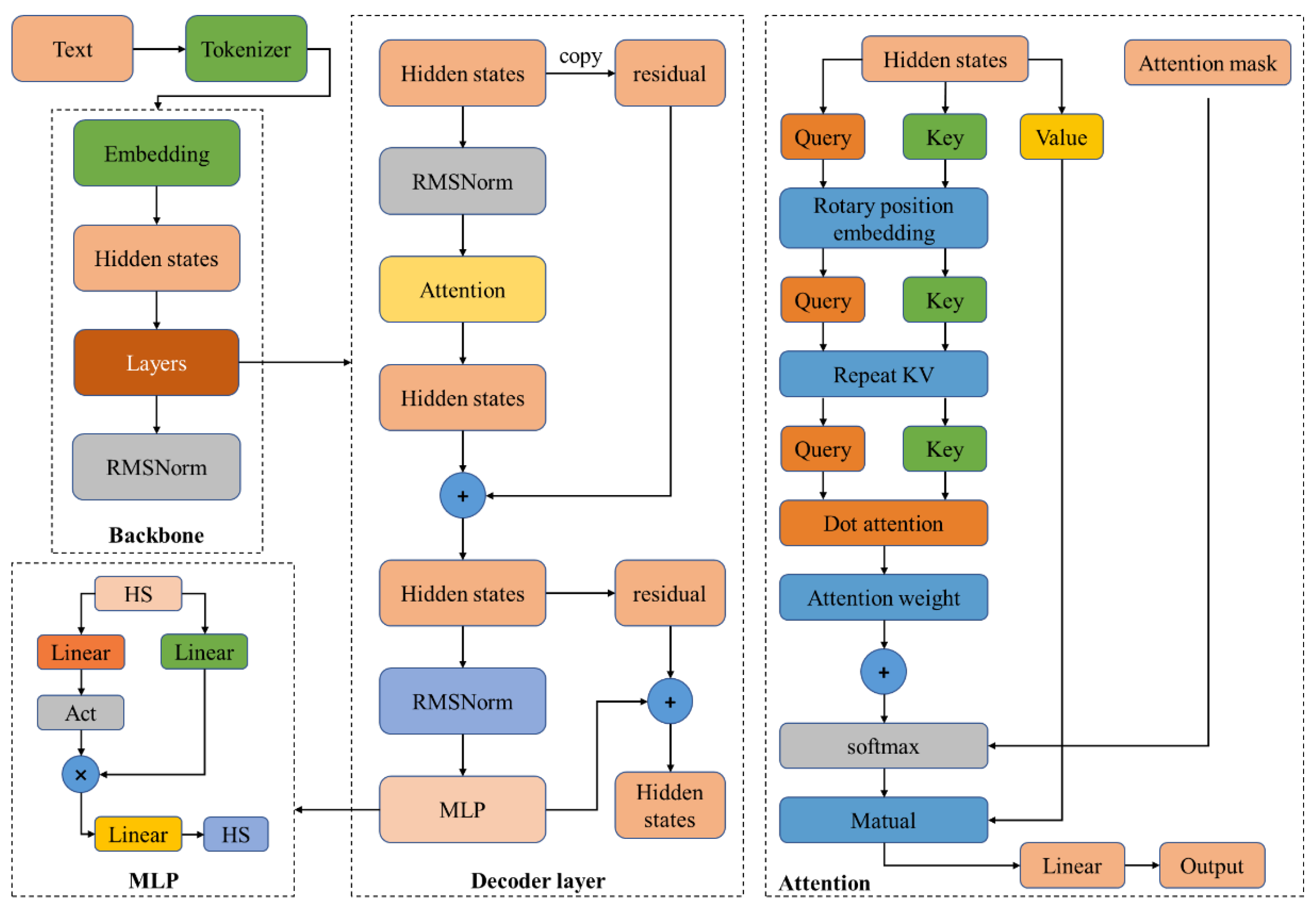
The system uses a Byte-Pair Encoding (BPE) [16] tokenizer with 151,643 regular tokens and 3 control tokens (<|endoftext|>, <im_start>, <im_ned>). The large model, based on the Transformer architecture, adopts Grouped-Query Attention (GQA) [17] to replace traditional Multi-Head Attention (MHA) [18]. GQA optimizes the KV cache [19] during inference, significantly improving throughput. To expand the model’s context window, Dual Chunk Attention with YARN (Yet Another Rescaling method) [20] is employed to split long sequences into manageable chunks. YARN is used to rescale attention weights for better handling of sequences of varying lengths. Additionally, SwiGLU is used as the activation function, RoPE for positional encoding, QKV bias to improve the attention mechanism, and RMSNorm [21] and pre-normalization techniques to enhance training stability. The overall model architecture is shown in Figure 4.
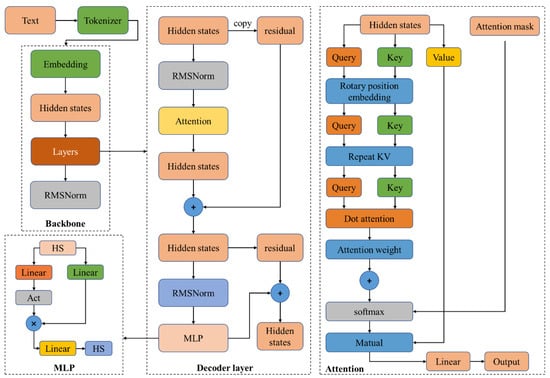
Figure 4.
Overall architecture of foundation model.
By combining large models with knowledge graphs in the field of mineral processing, semantic relationships within the graph can be analyzed to infer potential associations from existing nodes and edges. The process of knowledge reasoning and intelligent decision making is as follows:
- (1)
- Problem Input: The user or system inputs a problem into the intelligent system based on actual production needs (e.g., processing a specific type of ore). For example, “How can iron-rich ores be processed to improve recovery rates?”
- (2)
- Reasoning Process: The large model analyzes the problem and queries relevant entities and relationships within the knowledge graph, such as ore type, physical properties, etc. Based on existing knowledge in the graph and specific domain rules (e.g., the relationship between ore chemical composition and the flotation process), the model infers a recommended processing plan.
- (3)
- Decision Output: The system generates the best processing scheme based on the reasoning results, including the required equipment types, processing parameters, and possible environmental impacts. For complex multi-objective optimization problems, the system can provide multiple options for decision makers to choose from, evaluating the pros and cons of each option.
3. Dataset
The 58-beneficiation key technology research reports we have collected were obtained through significant investments in materials, labor, and financial resources. These reports provide detailed genetic data for three types of ores, including physical and chemical property analysis and their relationship with selectivity. They cover various aspects of mineral processing, such as processes, equipment selection, optimization technologies, and theoretical studies, with a focus on beneficiation processes, extraction efficiencies, and process optimization methods for different ores. In addition to experimental research and technical implementation, these reports also discuss the economic benefits of new technologies, improvements in process flows, and enhancements in production efficiency, thus providing a rich data source for building the knowledge graph. These reports offer a solid data foundation for the intelligent decision-making system based on knowledge reasoning proposed in this paper, and a detailed description of the knowledge base can be found in the Supplementary SII.
These documents provide a systematic analysis of beneficiation process design based on the “three ore genes”: deposit genes, ore genes, and mineral genes. To overcome the challenges in traditional process-flow decision making, we have systematically collected physicochemical data from various ore types and integrated it with beneficiation test data, as shown in Table 1 and Table 2 (Only a portion of the findings is presented here). The knowledge was employed to establish the relationship between ore characteristics and the final process-flow design. By leveraging a data-driven methodology, an intelligent causal inference framework has developed to link ore properties with beneficiation process decision, enhancing the accuracy and reliability of process-flow design.

Table 1.
Matching relationship between mineral dissemination characteristic and beneficiation process flow.
Table 2.
Matching relationship between copper mineral types and beneficiation process flow.
The process mineralogy reports primarily document the physical and chemical properties of ores, ore types, mineralogical characteristics, and changes in composition after processing. These reports provide the necessary foundational data for understanding how ores change during processing, supporting the construction of relationships between ores and processing methods. A high-frequency word statistical analysis was conducted on the dataset, as shown in Table 3.
Table 3.
High-frequency word statistical analysis of knowledge base.
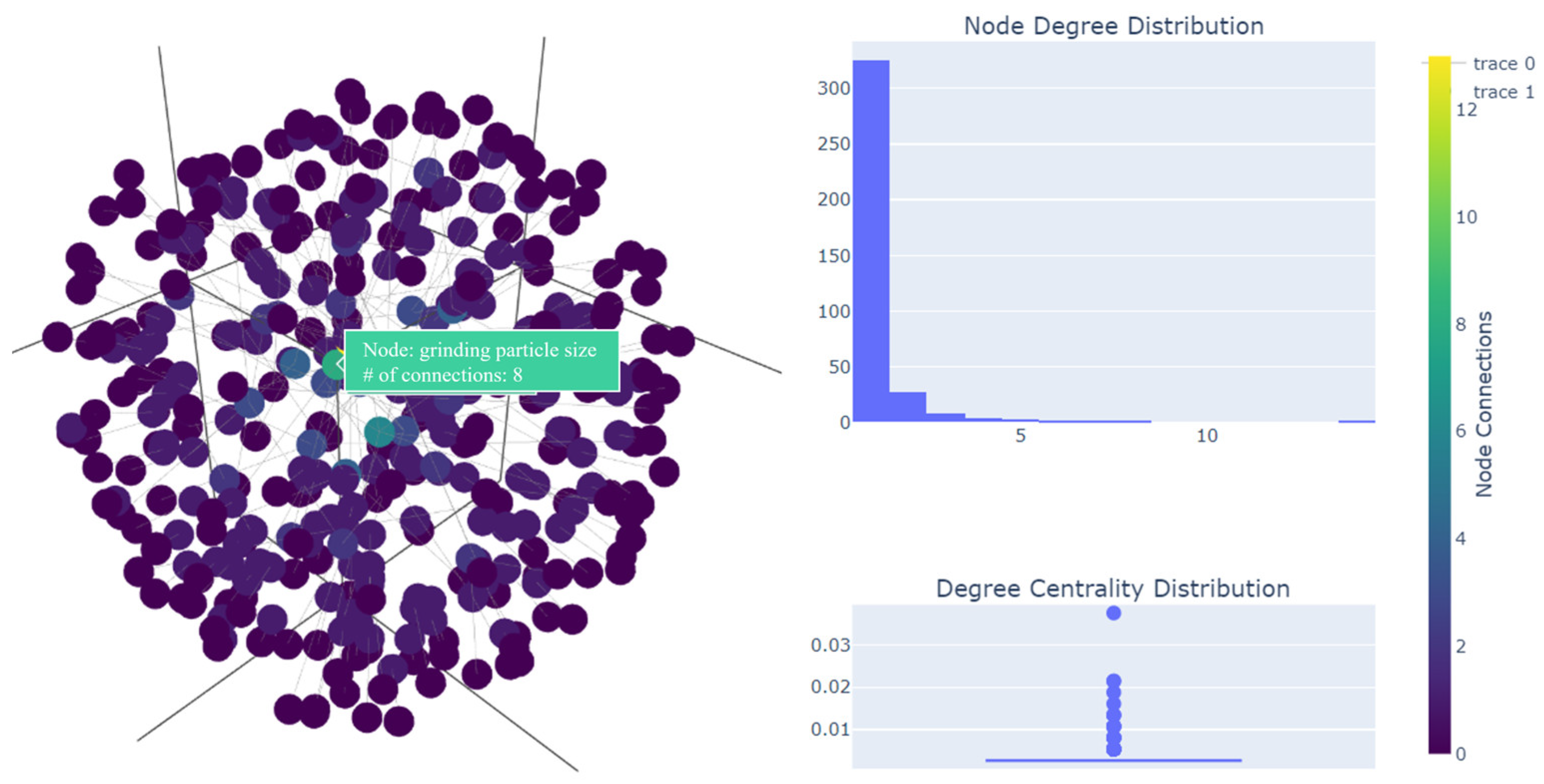
The input corpus is segmented into a series of TextUnits, which act as analyzable units for subsequent processes, and fine-grained references are provided in the outputs. After data cleaning and the standardization of the collected domain knowledge base, prompt optimization is carried out, as shown in Figure 5. The LLM is used to extract all entities, relationships, and key claims from the TextUnits, and a 3D graph is generated to display their communities and member compositions, as shown in Figure 6, to provide a more comprehensive understanding of the dataset.

Figure 5.
Example of prompt optimization.
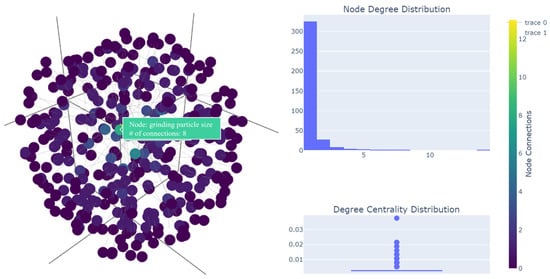
Figure 6.
Visualization of 3D knowledge graph.
4. Results and Discussion
4.1. Knowledge Graph Visualization
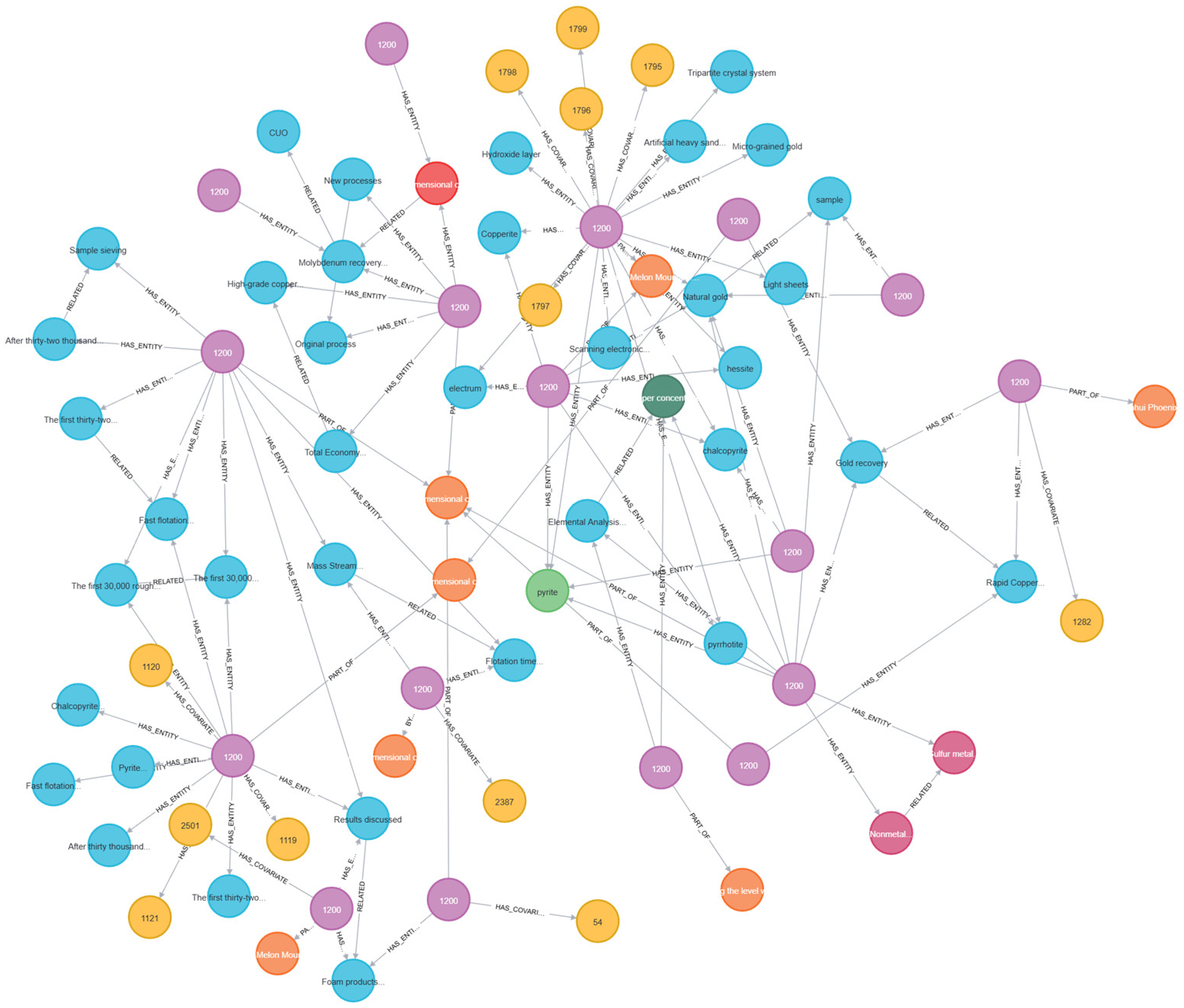
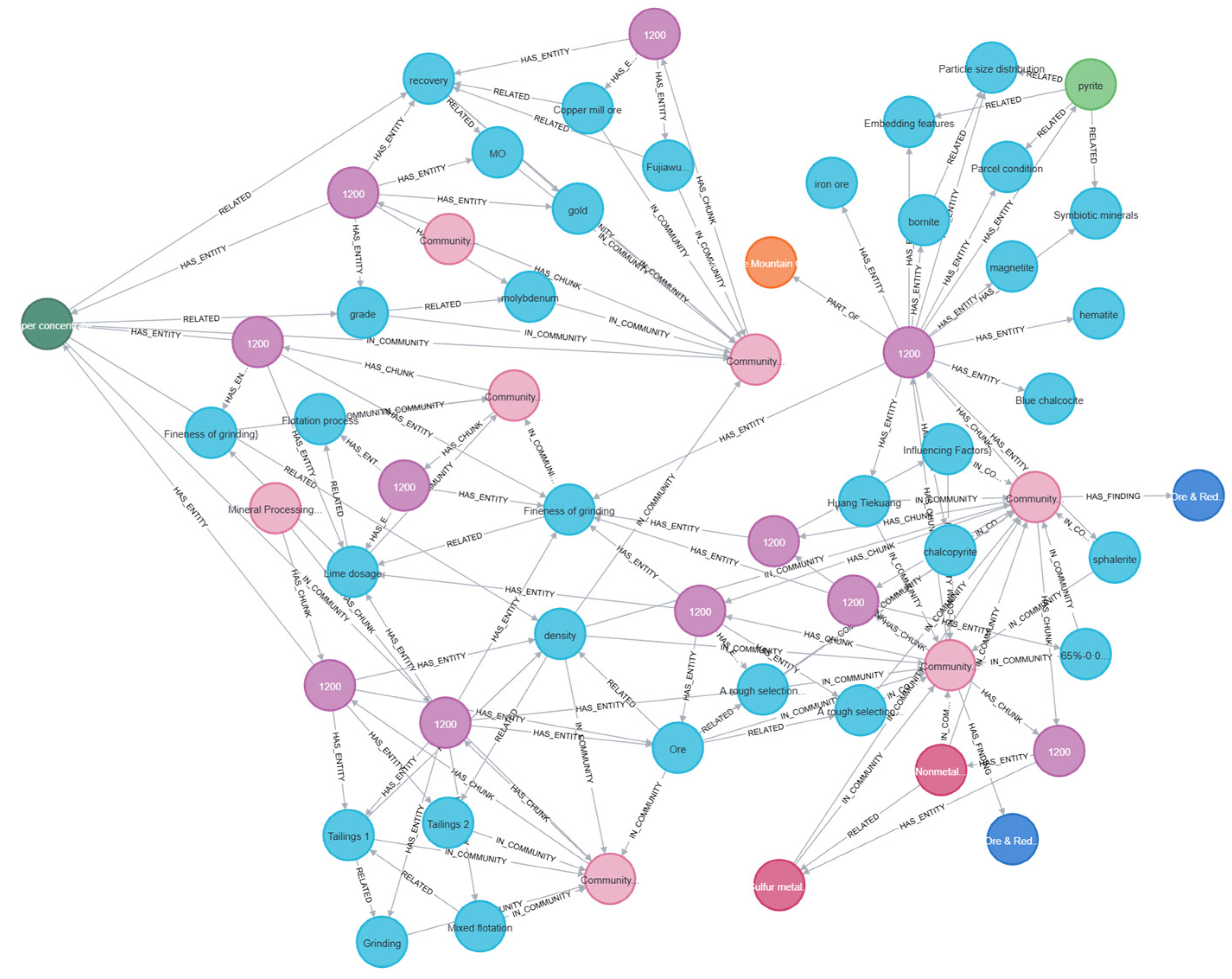
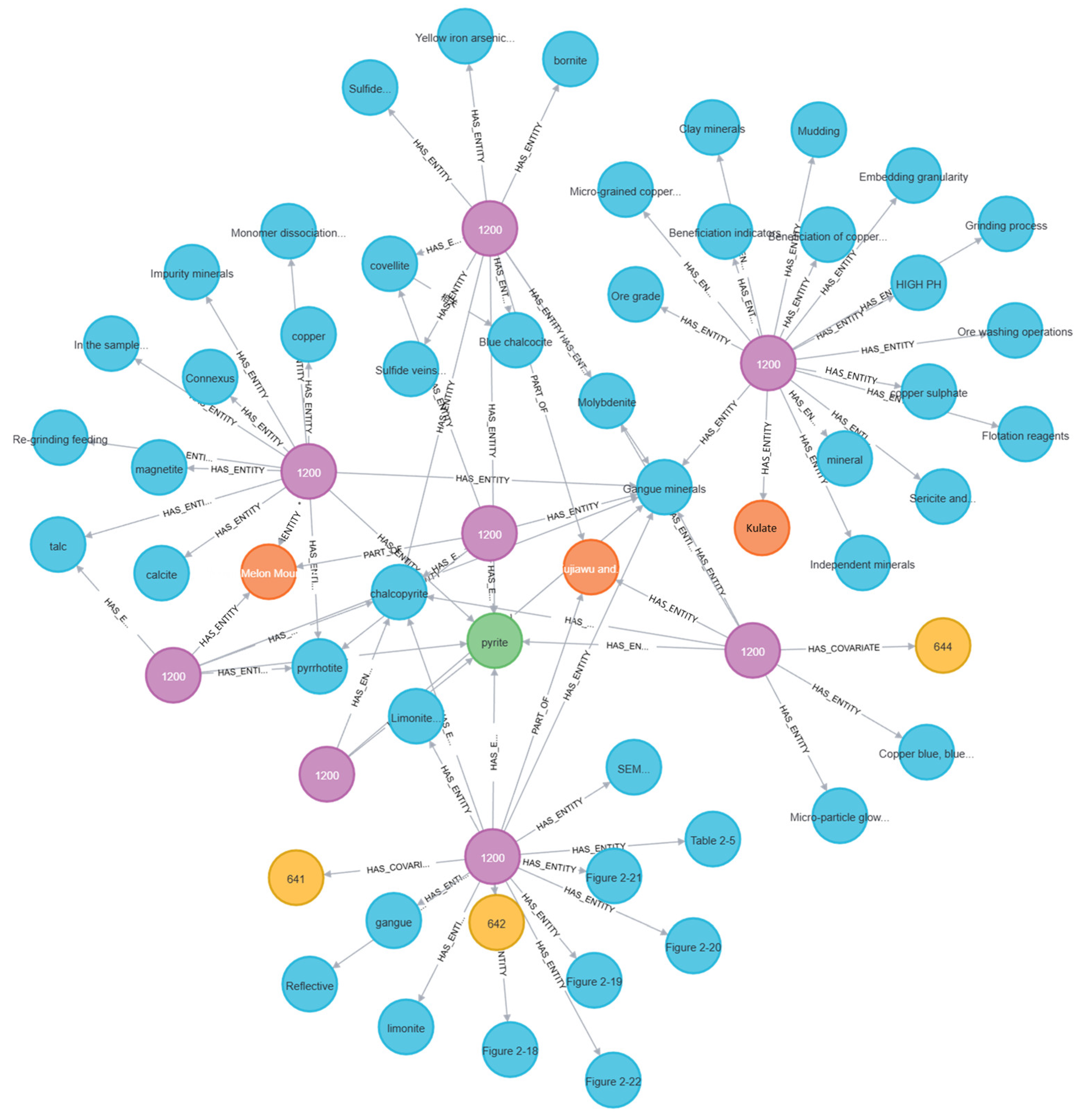
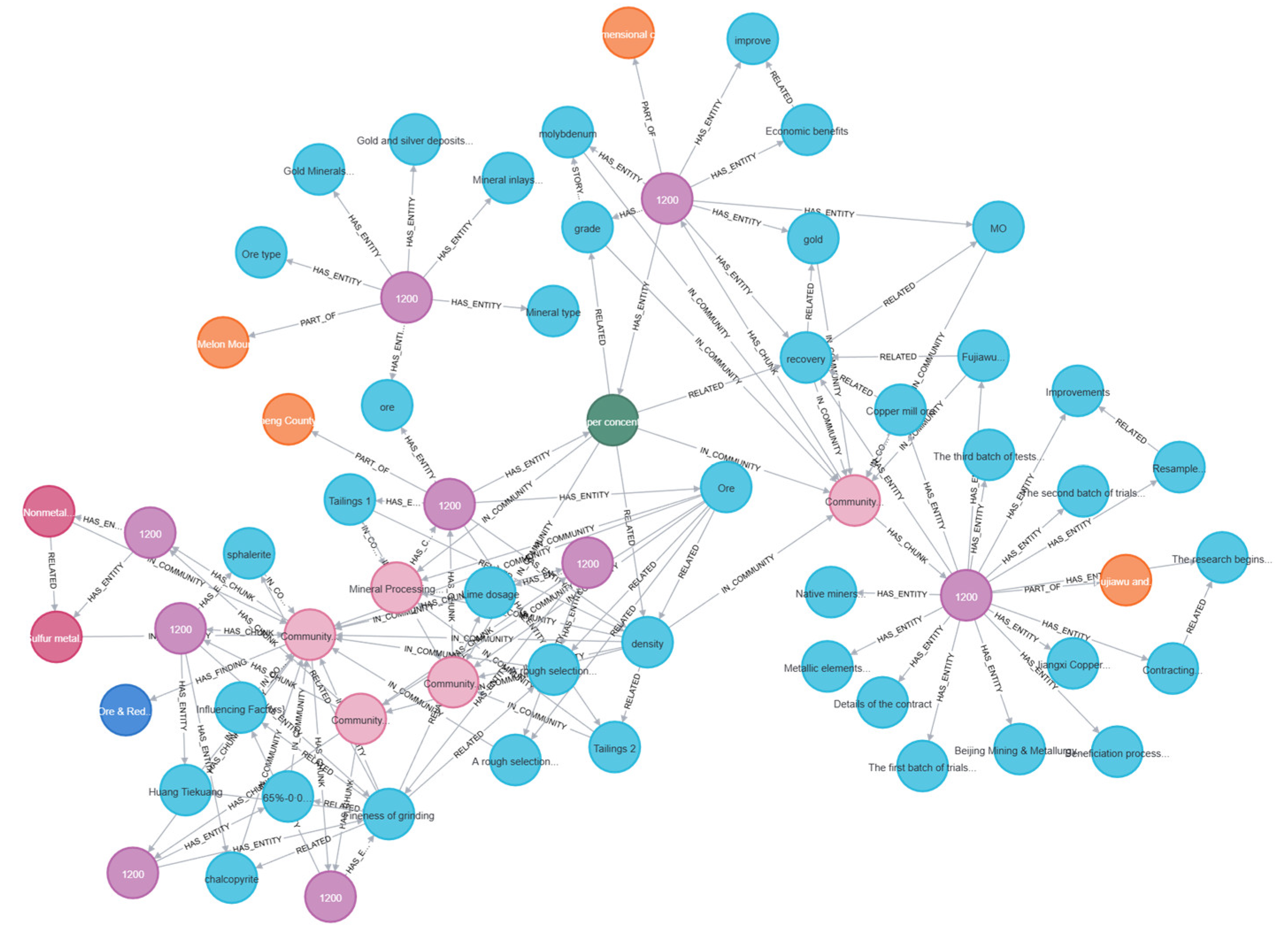
To gain a deeper understanding of the knowledge structure and its inherent relationships in the field of mineral processing, the extracted relationships, after prompt optimization and index construction, are stored in Parquet format files and loaded into the Neo4j graph database for visualization and analysis. This mainly includes the construction and presentation of entity graphs, community graphs, major type graphs, and major mineral graphs, as shown in Figure 7, Figure 8, Figure 9 and Figure 10. By comparing and analyzing these graphs, the distribution characteristics, core topics, key paths, and potential optimization directions of the domain knowledge can be revealed.
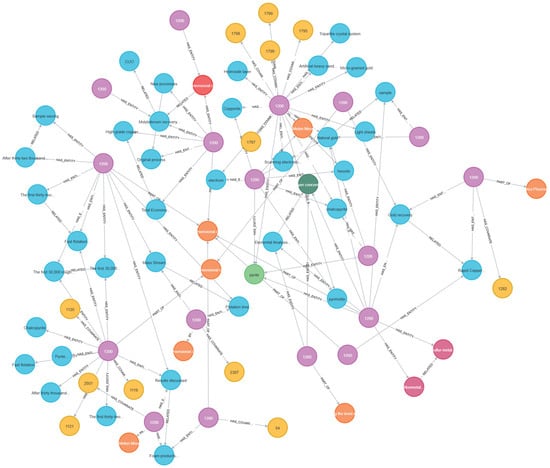
Figure 7.
Entity relationship visualization.
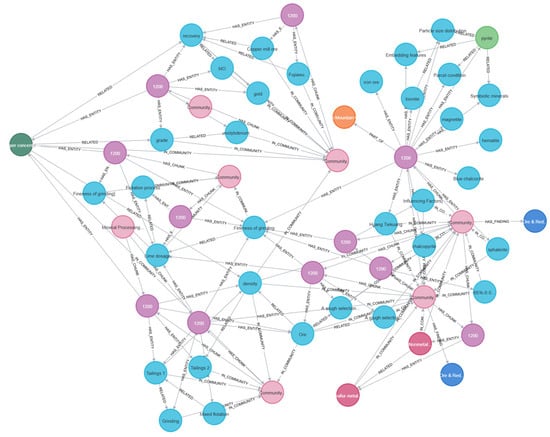
Figure 8.
Community relationship visualization.
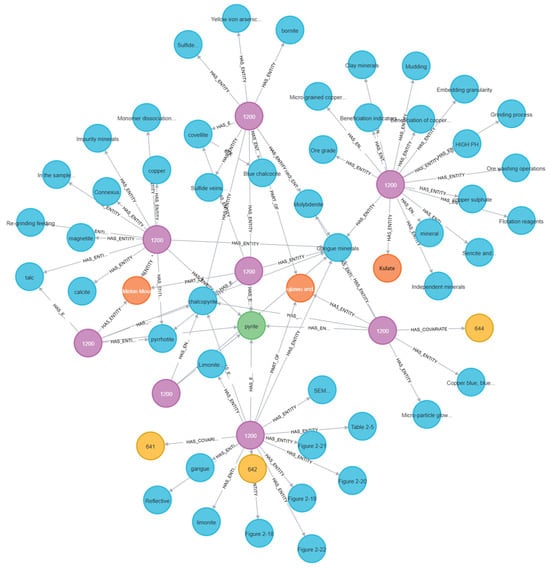
Figure 9.
A visualization of the graph of main types (gangue minerals).
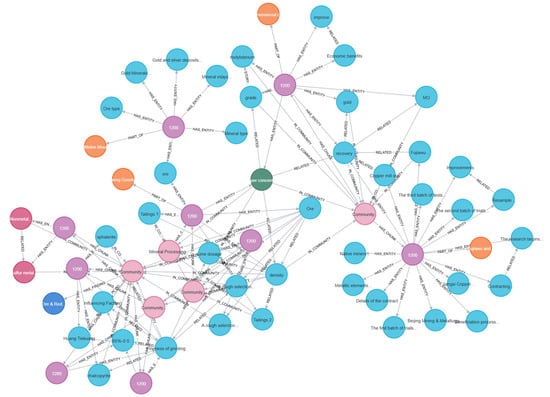
Figure 10.
Main mineral graph visualization.
From the entity graph, it is clear that core nodes such as “mineral properties”, “processing technology”, and “economic benefits” have the highest degree centrality, establishing numerous direct relationships with other entities. This indicates that these concepts play a key connecting role in the knowledge graph and serve as the core foundation for domain knowledge reasoning. A large number of nodes cluster around these core concepts, reflecting the focus and concentration of knowledge points in the mineral processing field.
At the same time, the graph reveals many cross-topic associations, such as the direct link between “ore composition” and “flotation process parameters”, suggesting that process optimization directly depends on the physical and chemical properties of ores. Some nodes have weaker connections with the main graph, such as certain specific experimental conditions or process parameters, which may represent knowledge points within specific research contexts and need to be evaluated in conjunction with domain knowledge to determine their significance.
The community graph, through the clustering structure of knowledge points, displays the thematic division of domain knowledge. The graph is divided into multiple communities, each representing a knowledge subset related to a specific theme. The results of community division reveal the distribution patterns of different topics within the knowledge graph. For example, some communities focus on “ore physical properties” and “mineral types”, while others are centered on “beneficiation process parameter optimization” or “economic feasibility analysis.” There are also significant cross-theme connections between some communities, such as the multiple links between the “economic feasibility analysis” community and the “process optimization” community, indicating that technological decisions directly impact economic viability. Meanwhile, the strong correlation between the “ore properties” community and the “processing techniques” community highlights the decisive role of ore characteristics in process design.
The main types (gangue minerals) and primary mineral graphs categorize and visualize the data based on entity types within the knowledge graph, providing an intuitive representation of the distribution characteristics of different types of knowledge points. From the visualization results, the “mineral types” node occupies a significant proportion, indicating that mineral characteristics are the foundation of mineral processing research. Notably, major mineral types such as “copper ore”, “iron ore”, and “zinc ore” exhibit strong associations with process nodes like “flotation” and “gravity separation”, showing that the physicochemical properties of minerals directly determine the choice of processing techniques. Various process flows also show close connections with “experimental conditions”, such as the reagent dosage and pH in flotation experiments, which directly affect the experimental results. This highlights the importance of optimizing experimental parameters for process improvement.
Through the multi-dimensional analysis of the knowledge graph visualization results, the knowledge structure and intrinsic relationships in the field of mineral processing are clearly presented. This analysis reveals the relationship chain of ore type → processing technology → economic benefits, providing higher-level causal relationships and logical reasoning capabilities. It establishes a solid foundation for the next steps in knowledge reasoning and intelligent decision making.
4.2. Knowledge-Inference-Based Intelligent Decision Making
This section utilizes genetic mineral data from five typical copper mines (Cheng-menshan Copper Mine, Jiangxi Yongping Copper Mine, Dongguashan Copper Mine, etc.; a more detailed description can be found in Supplementary Material SIII) as shown in Table 4. Using large models and intelligent decision-making systems, the beneficiation process flows were designed and optimized. Through a comprehensive analysis of the main elements, mineral composition, particle-size distribution, degree of liberation, and mineral characteristics of the ores, beneficiation process schemes for each mine were derived, followed by multi-dimensional evaluation and analysis.
Table 4.
Genetic mineral data of typical copper mines.
Based on the genetic characteristics of the Chengmenshan Copper Mine, the following beneficiation process is designed, considering the mineral composition, structural characteristics, particle-size distribution, and liberation degree of the ore. The particle-size distribution (44% of particles are below 0.043 mm, and 29% are below 0.020 mm) indicates that fine grinding is required to achieve a higher degree of liberation. The designed grinding process (coarse crushing → medium crushing → fine grinding) effectively meets this requirement, ensuring that the liberation degree of chalcopyrite reaches above 85%, which creates favorable conditions for subsequent flotation.
The addition of a regrinding step further optimizes the processing of middling ores and improves the copper recovery rate. In the flotation stage, given the high content of secondary copper sulfide (50%) and primary copper sulfide (42%), a combination of xanthate collectors and lime depressants is used. This effectively separates copper minerals from pyrite, aligning with the flotation characteristics of skarn-type copper ores. The multi-stage flotation design, including rougher flotation, scavenger flotation, and cleaner flotation, ensures efficient copper recovery while preventing over-grinding and the formation of mineral slimes.
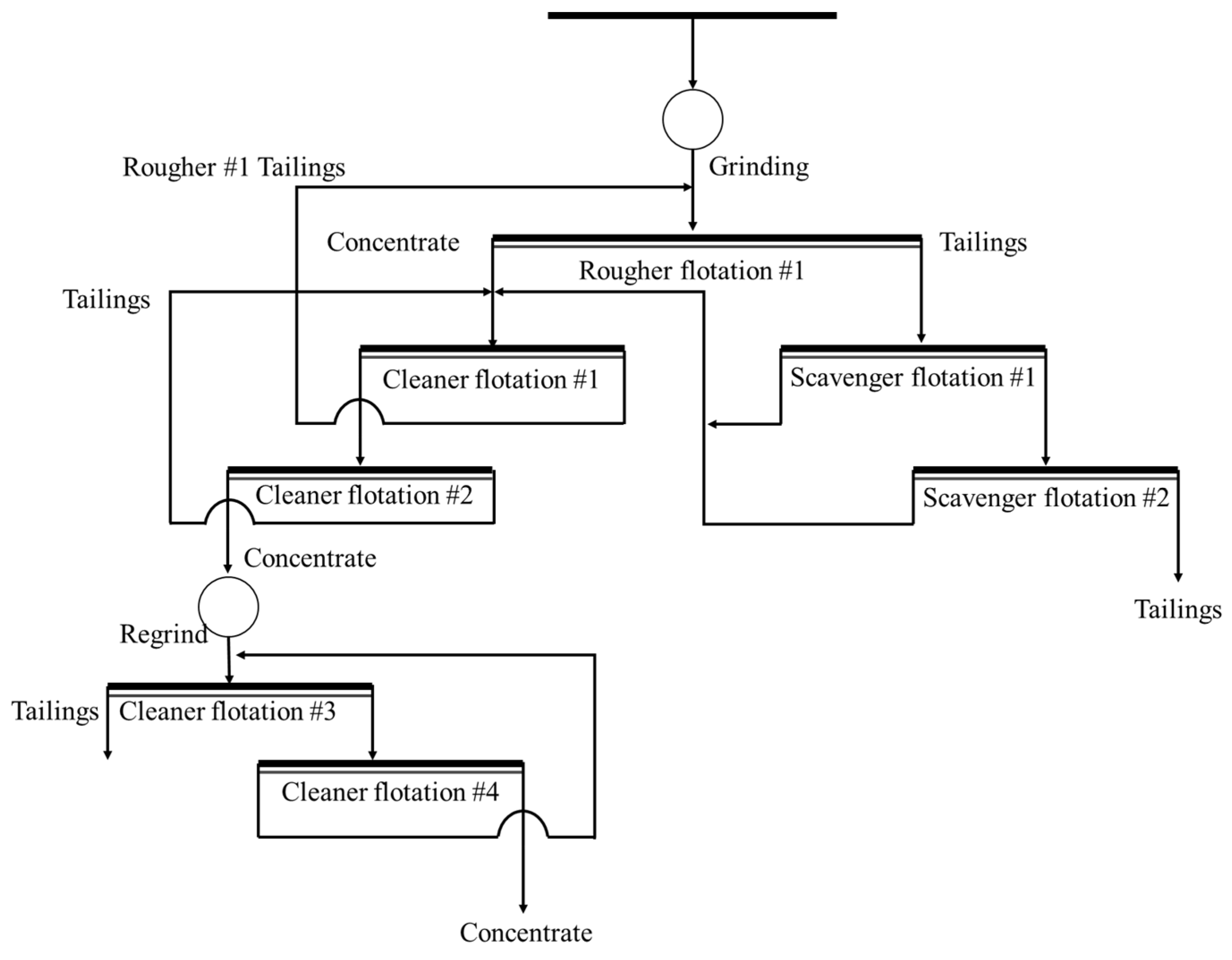
The beneficiation process design output by the knowledge reasoning-based intelligent decision-making system is as follows and is shown in Figure 11.
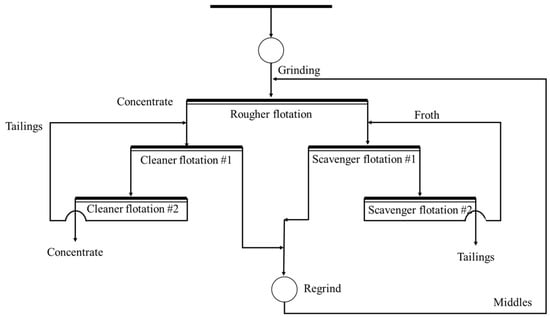
Figure 11.
Predicted process flow for Chengmenshan copper mine.
- (1)
- Crushing Process
Coarse Crushing: Reduce the ore size to facilitate further processing.
Medium Crushing: Break down the ore into an optimal size for fine grinding.
- (2)
- Grinding Process
Fine Grinding: Ensure that particle size distribution is optimized, particularly targeting the liberation of chalcopyrite at 85% or higher.
- (3)
- Flotation Process:
Conditioning and Reagent Addition: Use a combination of xanthate for copper mineral flotation and lime for pyrite depression.
Rougher flotation: First stage to recover a significant amount of copper minerals.
Scavenger flotation: Recover any remaining copper minerals from the tailings.
Cleaner flotation: Ensure high-quality copper concentrate by separating any impurities.
- (4)
- Regrinding: Further optimize the middling ore to improve copper recovery and reduce over-grinding issues.
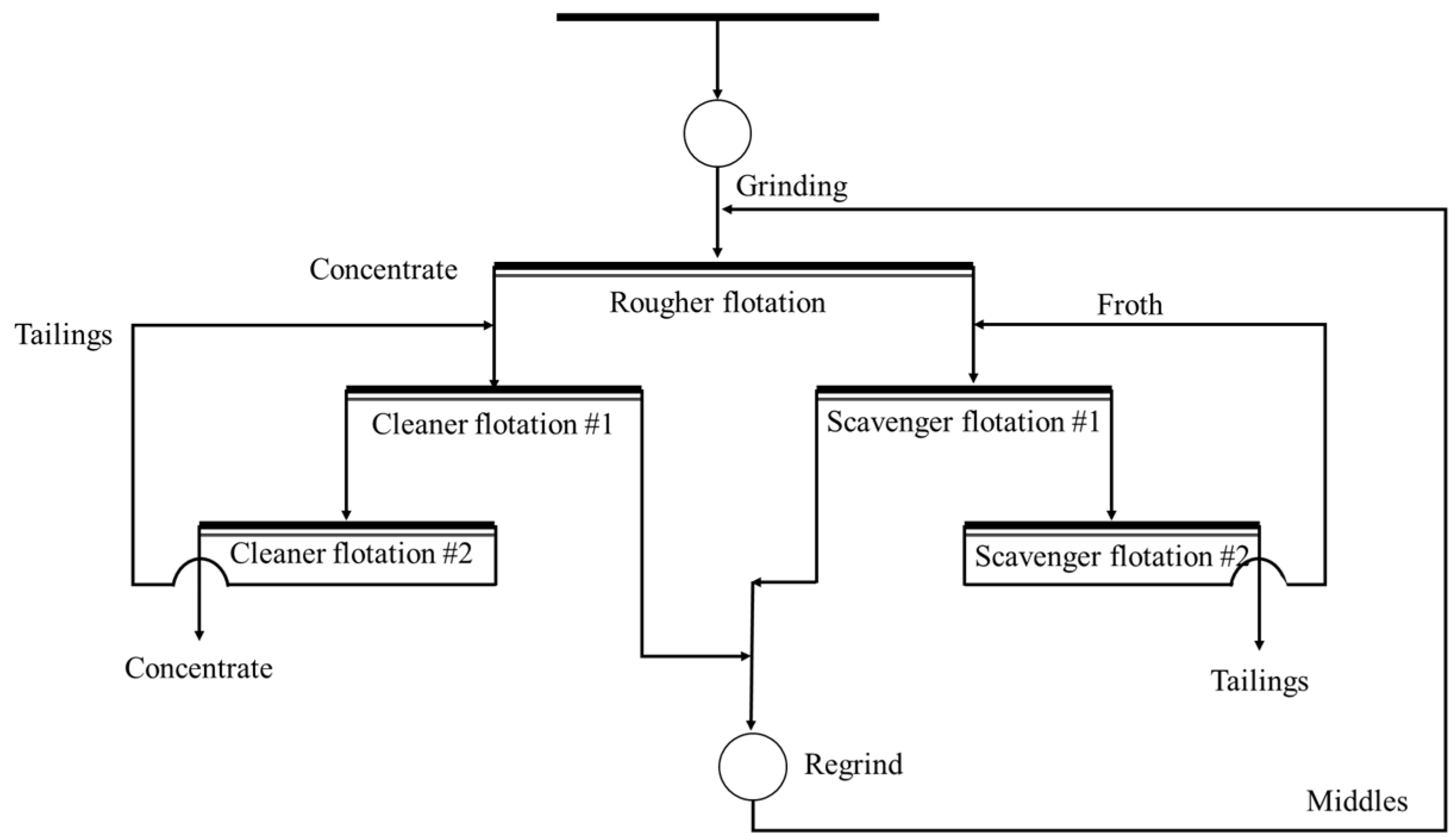
The process flow is designed (as shown in Figure 12) to optimize copper recovery based on the specific genetic characteristics of the Yongping copper ore, including its mineral composition, particle-size distribution, and the high proportion of secondary and primary copper sulfides in the ore:
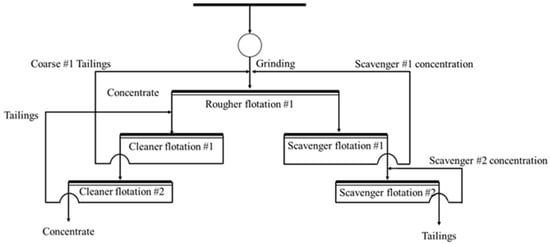
Figure 12.
Predicted process flow for Yongping copper mine.
- (1)
- Primary Crushing, Grinding, and Screening:
The ore is first subjected to primary crushing and grinding to reduce the particle size to a manageable level.
Screening is performed to separate the ore into three size fractions: +0.074 mm, 0.074–0.020 mm, and −0.020 mm. This step ensures that different size fractions can be processed separately, optimizing the subsequent flotation stages.
- (2)
- Flotation Process:
The rougher flotation stage focuses on maximizing the recovery of rougher chalcopyrite by using appropriate flotation reagents, such as xanthates as collectors and lime as a pH regulator.
The purpose of scavenger flotation stage is to further recover any remaining chalcopyrite and improve the overall recovery rate of copper minerals.
The fraction which consists of fine chalcopyrite is treated in the cleaner flotation stage.
- (3)
- Regrinding
Regrind the middling concentrate after selection to ensure that the dissociation degree of chalcopyrite reaches above 85%, and then proceed with flotation recovery.
In this stage, fine chalcopyrite is selectively separated from gangue minerals (such as pyrite and other impurities) to maximize copper recovery and improve concentrate quality. Special care is taken to prevent over-grinding and to avoid the formation of slimes, which could affect flotation efficiency.
The main challenges in processing the Jiangxi Yongping copper ore are the interference from fine slimes (12.37% of the −0.020mm fraction) and the low recovery of oxide copper (1.90%). To mitigate fine slime interference, optimizing the classification process and adding dispersants can reduce slime agglomeration and improve flotation efficiency. For the low-oxide copper recovery, introducing a leaching process, such as sulfuric-acid leaching followed by solvent extraction and electrowinning (SX-EW), can effectively recover copper oxide. Alternatively, flotation optimization with tailored reagents could also enhance copper oxide recovery, though leaching remains the more effective solution. These strategies will improve overall flotation performance and copper recovery.
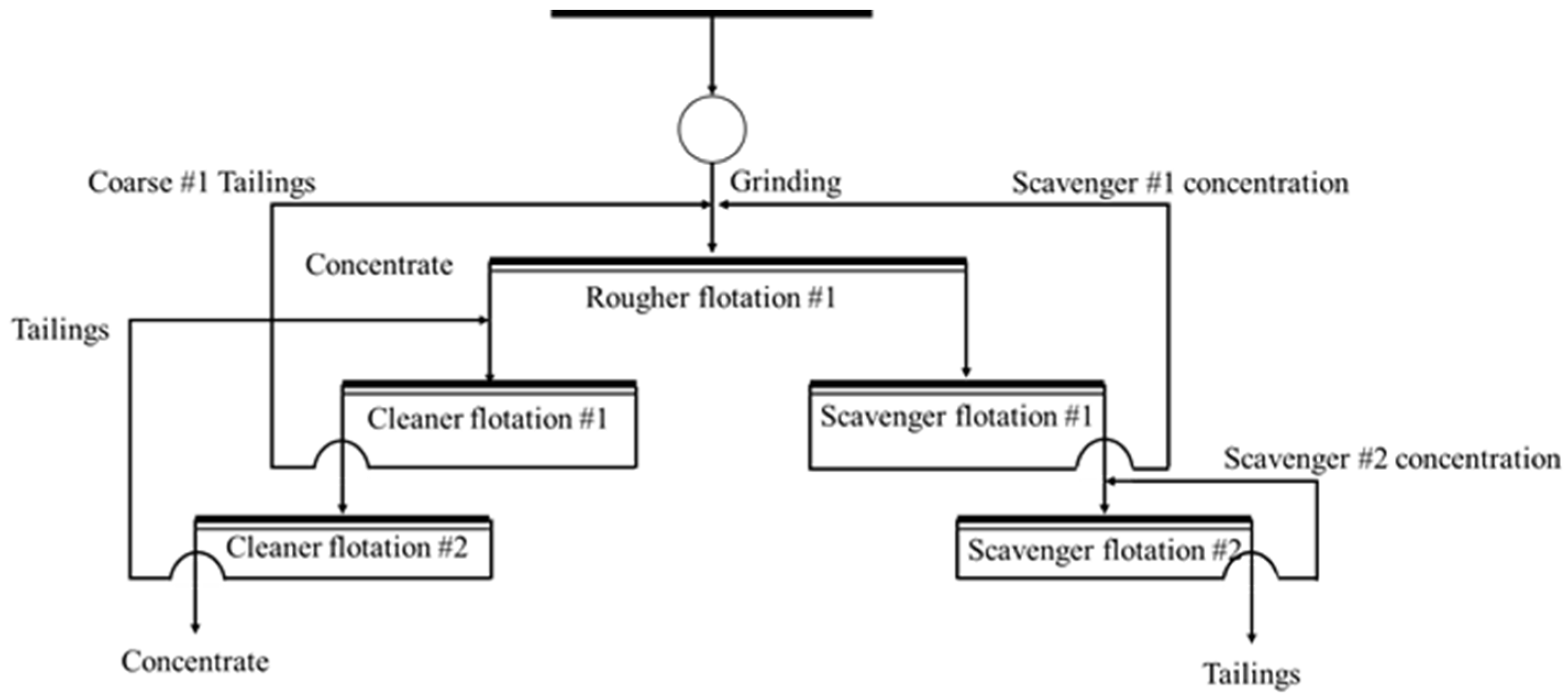
Based on the genetic characteristics of Dongguashan copper ore, the designed beneficiation process is as follows, shown in Figure 13.
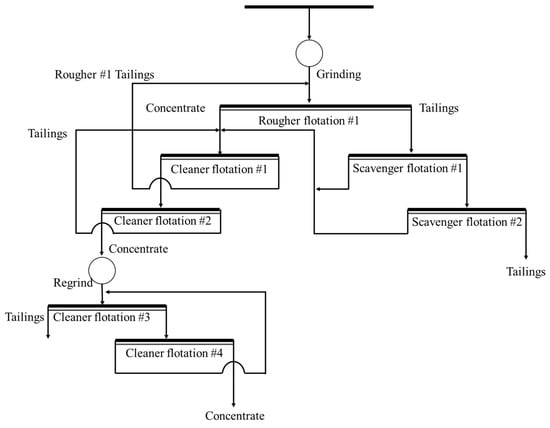
Figure 13.
Predicted process flow for Dongguashan copper mine.
- (1)
- Rougher flotation: Use xanthate collectors (e.g., ethyl xanthate) and frothers (e.g., MIBC) for rougher flotation, prioritizing the flotation of chalcopyrite and secondary copper sulfide. The rougher flotation tailings are then sent to scavenger flotation.
- (2)
- Scavenger flotation: The rougher flotation tailings undergo scavenger flotation to recover uncollected chalcopyrite and secondary copper sulfide.
- (3)
- Cleaner flotation: The concentrates from the rougher and scavenger flotation are subjected to multiple cleaner flotation stages to increase the grade of copper concentrates. During this process, lime is added to adjust the pH to 9–10, suppressing the flotation of pyrite and magnetite.
- (4)
- Regrinding: The cleaner concentrate is regirded to ensure that the chalcopyrite liberation degree reaches above 85%, and then undergoes further flotation for recovery.
This beneficiation process focuses on improving the recovery rate of chalcopyrite through flotation and classification at different stages, especially ensuring efficient recovery of rougher chalcopyrite during the rougher flotation stage. In the scavenger and cleaner flotation stages, precise reagent control and optimization of flotation conditions contribute to improving the recovery of fine-grained minerals. Additionally, the tailings treatment phase is a key aspect of the process design. By employing secondary flotation and tailings resource utilization technologies, it is possible to further recover residual copper minerals while minimizing the environmental impact.
To verify the performance of the intelligent decision-making system based on knowledge reasoning proposed in this paper, the Chengmenshan Copper Mine was selected for the experiment (due to the significant labor and time costs involved in the experiment, only one mine was chosen for verification. A more systematic validation will continue in further research). A detailed beneficiation test was conducted in the laboratory on ore samples from Chengmenshan copper mine, Jiangxi, China. The tests mainly included experiments on the type and dosage of rougher collectors, lime dosage, grinding fineness, and flotation time for roughing and scavenging. Additionally, tests were carried out on the type of selective depressants, selective lime dosage, and regrinding fineness for cleaning. Based on all the condition tests, a closed-circuit test was conducted in the laboratory, as shown in Table 5.
Table 5.
Closed-circuit test results of the traditional process for Chengmenshan copper mine.
The on-site production process follows a copper asynchronous flotation-enhanced flotation rough-concentrate regrinding and separation process. The obtained production indicators include a copper concentrate grade of 22.56% and a copper recovery rate of 80.7%. The results of the actual on-site closed-circuit test are presented in Table 6.
Table 6.
The closed-circuit test results of the mixed ore from Chengmenshan copper mine.
The implementation of the knowledge-based intelligent decision-making system significantly optimized the copper-ore beneficiation process. The system guided the selection of an efficient copper preferential flotation and regrinding strategy, resulting in a predicted copper recovery rate of 82.19%, slightly surpassing the 80.7% achieved through the traditional process. Both methods produced similar process structures and beneficiation indicators, with the key difference being an additional cleaning–scavenging operation in on-site production to reduce middlings circulation, generating an extra tailings stream. In contrast, the decision-making system adopted a sequential copper–sulfur preferential flotation followed by regrinding of the rough copper concentrate. These results demonstrate the system’s potential to enhance beneficiation efficiency and provide a reliable foundation for future process optimization.
5. Conclusions
This study focused on developing an intelligent decision-making framework for nonferrous metal mineral-processing flowsheet design. The primary objective was to overcome the challenges associated with traditional decision-making methods by integrating advanced technologies such as knowledge graphs, LLMs, and NLP. By collecting extensive ore-processing data and constructing a knowledge base using a text vectorization (based on the Llama2-Chinese model), an intelligent inference system based on a Qwen2 reasoning engine was established to translate multi-scale mineral data into actionable process insights.
The results demonstrated that the framework significantly improves process flowsheet design, as evidenced by case studies on Chengmenshan copper mine, Jiangxi, China. The main achievements include the innovative integration of semantic reasoning with domain-specific data and the practical applicability of the framework in complex processing environments. However, the current system relies on a relatively small knowledge base, which may not fully represent rare ore types or emerging technologies, and its generalization capability for non-sulfide ores or polymetallic deposits needs further validation.
This paper extends related studies in process mineralogy and intelligent decision making, addressing gaps in data integration and semantic reasoning. We recognize the need to further refine our approach by expanding the knowledge base and incorporating additional data inputs. Future research will focus on multi-source heterogeneous data to enhance the comprehensiveness and accuracy of the knowledge graph. Exploring hybrid architectures that combine LLMs with reinforcement learning could further improve the system’s dynamic decision-making capabilities. Finally, industrial-scale validation will be essential to assess the framework’s scalability and practical feasibility, thereby solidifying its role in advancing sustainable, data-driven mineral-processing systems.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/min15040374/s1, SI: Beneficiation process-flow decision making based on “three mineral genes”; SII: Complex reactions and interactions between minerals in ore; SIII: An overview of the selected three mine beneficiation process. Refs. [22,23,24,25,26,27,28,29,30] are cited.
Author Contributions
Conceptualization, C.S. and J.Z.; methodology, J.Y. and K.Z.; software, J.Y. and K.Z.; validation, J.Y., K.Z. and T.S.; formal analysis, J.Y. and K.Z.; investigation, J.Y. and Q.W.; resources, J.Y. and Q.W.; data curation, J.Y. and Q.W.; writing—original draft preparation, J.Y., K.Z. and T.S.; writing—review and editing, J.Y., K.Z. and T.S.; visualization, J.Y. and K.Z.; supervision, J.Y., K.Z. and T.S.; project administration, J.Y., K.Z. and T.S.; funding acquisition, J.Y., K.Z. and T.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key R&D Program of China (2021YFC2902704) and pilot project of BGRIMM Technology Group under Grant 02-2419.
Data Availability Statement
The data for this study are restricted to internal use or subject to institutional access policies and cannot be shared publicly. For specific requests, please contact the corresponding author.
Conflicts of Interest
Jiawei Yang, Chuanyao Sun, Qingkai Wang, Kanghui Zhang, and Tao Song are employees of BGRIMM Technology Group. The paper reflects the views of the scientists and not the company.
References
- Wang, K.; Ouyang, L.; Wang, Y. Study of Energy Transition Paths and the Impact of Carbon Emissions under the Dual Carbon Target. Sustainability 2023, 15, 1967. [Google Scholar] [CrossRef]
- Luo, X.; He, K.; Zhang, Y.; He, P.; Zhang, Y. A review of intelligent ore sorting technology and equipment development. Int. J. Miner. Metall. Mater. 2022, 29, 1647–1655. [Google Scholar] [CrossRef]
- Hasidi, O.; Abdelwahed, E.H.; Qazdar, A.; Boulaamail, A.; Krafi, M.; Benzakour, I.; Bourzeix, F.; Baïna, S.; Baïna, K.; Cherkaoui, M. Digital twins-based smart monitoring and optimisation of mineral processing industry. In Proceedings of the International Conference on Smart Applications and Data Analysis, Tangier, Morocco, 18–20 April 2022; pp. 411–424. [Google Scholar]
- Zhironkina, O.; Zhironkin, S. Technological and intellectual transition to mining 4.0: A review. Energies 2023, 16, 1427. [Google Scholar] [CrossRef]
- Vujanovic, V. The basic mineralogic, paragenetic and genetic characteristics of the sulphide deposits exposed in the eastern Black-Sea coastal region (Turkey). Bull. Miner. Res. Explor. 2023, 1974, 2. [Google Scholar]
- Sharma, R.; Kaushik, M.; Peious, S.A.; Bazin, A.; Shah, S.A.; Fister, I.; Yahia, S.B.; Draheim, D. A novel framework for unification of association rule mining, online analytical processing and statistical reasoning. IEEE Access 2022, 10, 12792–12813. [Google Scholar] [CrossRef]
- Bisschoff, R.; Grobbelaar, S. Evaluation of data-driven decision-making implementation in the mining industry. S. Afr. J. Ind. Eng. 2022, 33, 218–232. [Google Scholar] [CrossRef]
- Patwardhan, N.; Marrone, S.; Sansone, C. Transformers in the real world: A survey on nlp applications. Information 2023, 14, 242. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Bai, J.; Bai, S.; Yang, S.; Wang, S.; Tan, S.; Wang, P.; Lin, J.; Zhou, C.; Zhou, J. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv 2023, arXiv:2308.12966. [Google Scholar]
- Cui, Y.; Yang, Z.; Yao, X. Efficient and effective text encoding for chinese llama and alpaca. arXiv 2023, arXiv:2304.08177. [Google Scholar]
- Kudo, T. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. arXiv 2018, arXiv:1808.06226. [Google Scholar]
- Shazeer, N. Glu variants improve transformer. arXiv 2020, arXiv:2002.05202. [Google Scholar]
- Su, J.; Ahmed, M.; Lu, Y.; Pan, S.; Bo, W.; Liu, Y. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing 2024, 568, 127063. [Google Scholar]
- Edge, D.; Trinh, H.; Cheng, N.; Bradley, J.; Chao, A.; Mody, A.; Truitt, S.; Larson, J. From local to global: A graph rag approach to query-focused summarization. arXiv 2024, arXiv:2404.16130. [Google Scholar]
- Sennrich, R. Neural machine translation of rare words with subword units. arXiv 2015, arXiv:1508.07909. [Google Scholar]
- Ainslie, J.; Lee-Thorp, J.; de Jong, M.; Zemlyanskiy, Y.; Lebrón, F.; Sanghai, S. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv 2023, arXiv:2305.13245. [Google Scholar]
- Vaswani, A. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Wu, H.; Tu, K. Layer-Condensed KV Cache for Efficient Inference of Large Language Models. arXiv 2024, arXiv:2405.10637. [Google Scholar]
- Peng, B.; Quesnelle, J.; Fan, H.; Shippole, E. Yarn: Efficient context window extension of large language models. arXiv 2023, arXiv:2309.00071. [Google Scholar]
- Zhang, B.; Sennrich, R. Root mean square layer normalization. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Yu, G. Low-alkalinity copper-sulfur separation technology at Chengmenshan Copper Mine. Nonferrous Metall. Des. Res. 2013, 34, 7–10. (In Chinese) [Google Scholar]
- Peng, J. Experimental study on low-alkalinity copper-sulfur separation at Chengmenshan Copper Mine. Nonferrous Met. (Miner. Process. Sect.) 2011, 1, 19–23. (In Chinese) [Google Scholar]
- Zhang, D. Technical transformation and discussion on the beneficiation process of Dongguashan Copper Mine. Nonferrous Met. (Miner. Process. Sect.) 2009, 61, 22–25+4. (In Chinese) [Google Scholar]
- Xiao, Q.; Kang, H.; Zhao, H.; Wang, Z. Application research on improving grinding quality, efficiency, and reducing consumption at Dongguashan Copper Mine. Min. Metall. 2016, 25, 17–20. (In Chinese) [Google Scholar]
- Li, P.; Yang, L.; Wu, H.; Yan, J.; Kang, H.; Gao, D. Experimental study on the beneficiation of copper-bearing pyrrhotite ores from Dongguashan Copper Mine. Mod. Min. 2021, 37, 124–126+129. (In Chinese) [Google Scholar]
- Wu, X.; Li, C.; Luo, L.; Wu, P. Discussion on beneficiation principle schemes for the development of Dongguashan Copper Mine resources. Nonferrous Met. (Miner. Process. Sect.) 2003, 5, 1–6. (In Chinese) [Google Scholar]
- Peng, G. Analysis of the flotation process at Yongping Copper Mine. Metall. Mine Des. Constr. 2000, 4, 8–10+16. (In Chinese) [Google Scholar]
- Li, C. New Flotation Process and High-Quality Sulfur Concentrate Technology to Improve Beneficiation Indicators at Yongping Copper Mine; Beijing General Research Institute of Mining & Metallurgy: Beijing, China, 2012. (In Chinese) [Google Scholar]
- Yuan, Y.; Peng, H. Experimental study on improving copper recovery at Yongping Copper Mine. Met. Mines 2011, 8, 86–88+93. (In Chinese) [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).