
A Recommendation Model for Selling Rules in the Telecom Retail Industry

 , and
, and
Abstract
:1. Introduction
2. Related Work
2.1. Data Mining in the Telecommunications Industry
2.2. K-Means Clustering
2.3. C5.0 Decision Tree Classification
3. Methodology
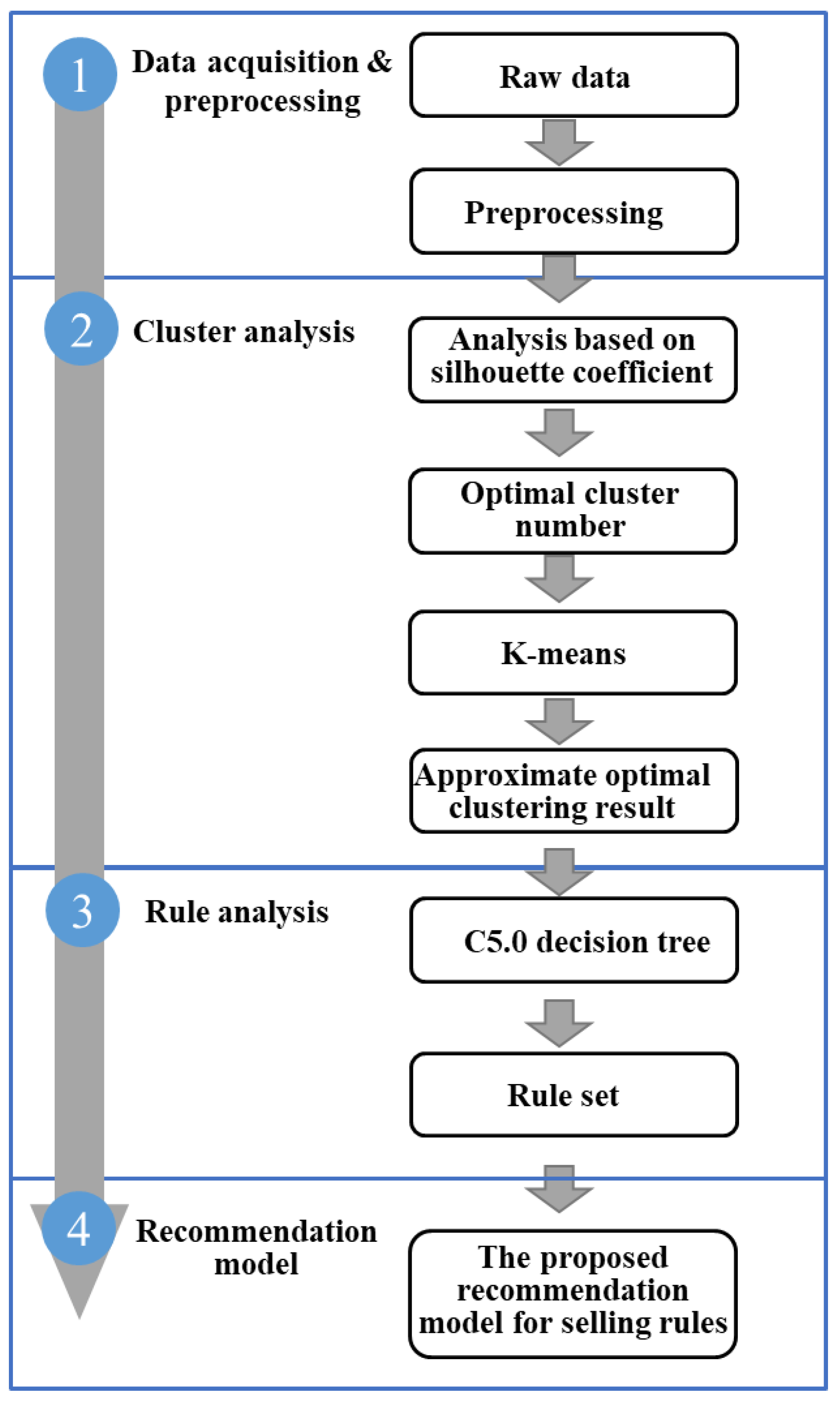
3.1. Research Framework
3.2. Data Acquisition and Preprocessing
3.3. Cluster Analysis
- Step 1. The number of clusters is set at K;
- Step 2. K data points are selected as the cluster centers;
- Step 3. The distance between each data point and each cluster center is calculated so as to classify the data point into its closest cluster;
- Step 4. In each cluster, a new center is calculated using all data points belonging in the respective cluster;
- Step 5. Step 3 and Step 4 are repeated until clustering results no longer change or the maximum number of iterations is reached.
3.4. Rule Analysis
4. Experimental Results and Discussion
4.1. Case Company and Data Preparation
4.2. Dataset and Preprocessing
4.3. Experimental Results
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shirazi, F.; Mohammadi, M. A big data analytics model for customer churn prediction in the retiree segment. Int. J. Inf. Manag. 2019, 48, 238–253. [Google Scholar] [CrossRef]
- Su, T.; Xu, H.; Zhou, X. Particle swarm optimization-based association rule mining in big data environment. IEEE Access 2019, 7, 161008–161016. [Google Scholar] [CrossRef]
- Wang, J.; Yang, Y.; Wang, T.; Sherratt, R.S.; Zhang, J. Big data service architecture: A survey. J. Internet Technol. 2020, 21, 393–405. [Google Scholar]
- Castelo-Branco, F.; Reis, J.L.; Vieira, J.C.; Cayolla, R. Business Intelligence and Data Mining to Support Sales in Retail. In Marketing and Smart Technologies; Springer: Singapore, 2020; pp. 406–4191. [Google Scholar]
- Krivosheya, E. The role of financial innovations in consumer behavior in the Russian retail payments market. Technol. Forecast. Soc. Chang. 2020, 161, 120304. [Google Scholar] [CrossRef]
- Hawthorne, R.; Grzybowski, L. Distribution of the benefits of regulation vs. competition: The case of mobile telephony in South Africa. Int. J. Ind. Organ. 2021, 74, 102673. [Google Scholar] [CrossRef]
- Gupta, M.K.; Chandra, P. A comprehensive survey of data mining. Int. J. Inf. Technol. 2020, 12, 1243–1257. [Google Scholar] [CrossRef]
- Gupta, V.K.; Ting, Q.U.; Tiwari, M.K. Multi-period price optimization problem for omnichannel retailers accounting for customer heterogeneity. Int. J. Prod. Econ. 2019, 212, 155–167. [Google Scholar] [CrossRef]
- Wang, C.N.; Nguyen, N.A.T.; Fu, H.P.; Hsu, H.P.; Dang, T.T. Efficiency assessment of seaport terminal operators using DEA Malmquist and epsilon-based measure models. Axioms 2021, 10, 48. [Google Scholar] [CrossRef]
- Espadinha-Cruz, P.; Fernandes, A.; Grilo, A. Lead management optimization using data mining: A case in the telecommunications sector. Comput. Ind. Eng. 2021, 154, 107122. [Google Scholar] [CrossRef]
- Chen, Y.; Cheung, C.M.; Tan, C.W. Omnichannel business research: Opportunities and challenges. Decis. Support Syst. 2018, 109, 1–4. [Google Scholar] [CrossRef]
- Keramati, A.; Marandi, R.J. Addressing churn prediction problem with Meta-heuristic, Machine learning, Neural Network and data mining techniques: A case study of a telecommunication company. Int. J. Future Comput. Commun. 2015, 4, 350. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Hou, B.; Wu, Y.; Zhao, D.; Xie, A.; Zou, P. Giant fight: Customer churn prediction in traditional broadcast industry. J. Bus. Res. 2021, 131, 630–639. [Google Scholar] [CrossRef]
- Cavalinhos, S.; Marques, S.H.; de Fátima Salgueiro, M. The use of mobile devices in-store and the effect on shopping experience: A systematic literature review and research agenda. Int. J. Consum. Stud. 2021, 45, 1198–1216. [Google Scholar] [CrossRef]
- Sinaga, K.P.; Yang, M.S. Unsupervised K-means clustering algorithm. IEEE Access 2020, 8, 80716–80727. [Google Scholar] [CrossRef]
- Lingxian, Y.; Jiaqing, K.; Shihuai, W. Online Retail Sales Prediction with Integrated Framework of K-mean and Neural Network. In Proceedings of the 2019 10th International Conference on E-business, Management and Economics, Beijing, China, 15–17 July 2019; pp. 115–118. [Google Scholar]
- Chowdhury, K.; Chaudhuri, D.; Pal, A.K.; Samal, A. Seed selection algorithm through K-means on optimal number of clusters. Multimed. Tools Appl. 2019, 78, 18617–18651. [Google Scholar] [CrossRef]
- Ou, T.Y.; Chen, Y.J.; Tsai, W.L. Sales Forecasting of Perishable Foods with Multiple Stores and Communities- An Empirical Study of Convenience Stores in Taiwan. Int. J. Intell. Technol. Appl. Stat. 2020, 13, 385–409. [Google Scholar]
- Priyanka; Kumar, D. Decision tree classifier: A detailed survey. Int. J. Inf. Decis. Sci. 2020, 12, 246–269. [Google Scholar]
- Sato, N.; Kuruma, H.; Nakagawa, Y.; Ogawa, H. Formal Verification of a Decision-Tree Ensemble Model and Detection of Its Violation Ranges. IEICE Trans. Inf. Syst. 2020, 103, 363–378. [Google Scholar] [CrossRef] [Green Version]
- Lu, C.L.; Chen, C.T. A study of applying data mining approach to the information disclosure for Taiwan’s stock market investors. Expert Syst. Appl. 2009, 36, 3536–3542. [Google Scholar] [CrossRef]
- Wang, G.; Wu, N. A Comparative Study on Contract Recommendation Model: Using Macao Mobile Phone Datasets. IEEE Access 2020, 8, 39747–39757. [Google Scholar] [CrossRef]
- Wang, S.T. Integrating KPSO and C5. 0 to analyze the omnichannel solutions for optimizing telecommunication retail. Decis. Support Syst. 2018, 109, 39–49. [Google Scholar] [CrossRef]
- Chiang, W.Y. Using a data-driven marketing strategy on customer relationship management: An empirical case of urban coffee shops in Taiwan. Br. Food J. 2020, 123, 1610–1625. [Google Scholar] [CrossRef]
- Acquila-Natale, E.; Iglesias-Pradas, S. A matter of value? Predicting channel preference and multichannel behaviors in retail. Technol. Forecast. Soc. Chang. 2021, 162, 120401. [Google Scholar] [CrossRef]
- Berne, M.; Vialle, P.; Whalley, J. An analysis of the disruptive impact of the entry of Free Mobile into the French mobile telecommunications market. Telecommun. Policy 2019, 43, 262–277. [Google Scholar] [CrossRef]
- Ghodous, M.; Alesheikh, A.A.; Saeidian, B. Analyzing public participant data to evaluate citizen satisfaction and to prioritize their needs via K-means. FCM ICA 2016, 55, 70–81. [Google Scholar] [CrossRef]


{kind=link}
| Telecom Carrier F | Telecom Carrier W | Telecom Carrier T | Total | |
|---|---|---|---|---|
| Number of data | 6900 | 1869 | 1547 | 10,316 |
| Ratio of data | 66.89% | 18.12% | 14.99% | 100% |
| Cluster | Number of Rule | Number of Data | Ratio of Data |
|---|---|---|---|
| Cluster 1 | 3 | 3146 | 30.5% |
| Cluster 2 | 5 | 1691 | 16.39% |
| Cluster 3 | 1 | 2493 | 24.17% |
| Cluster 4 | 8 | 1977 | 19.16% |
| Cluster 5 | 3 | 1009 | 9.78% |
| Number | Rules for the Category of Selling Recommendation | Accuracy |
|---|---|---|
| Rule 1.1 | IF commodity cost < TWD 5001, and gross profit < TWD 5001, THEN selling recommendation is Cluster 1 | 100% |
| Rule 1.2 | IF commodity cost between TWD 5001 and TWD 10,000, and gross profit < TWD 5001, THEN selling recommendation is Cluster 1 | 99% |
| Rule 1.3 | IF commodity cost < TWD 5001, and project commission between TWD 3001 and TWD 6000, THEN selling recommendation is Cluster 1 | 97% |
| Rule 2.1 | IF commodity cost between TWD 10,001 and TWD 15,001, and gross profit < TWD 5001, THEN selling recommendation is Cluster 2 | 100% |
| Rule 2.2 | IF commodity cost between TWD 10,001 and TWD 15,001, and commodity project price between TWD 4001 and TWD 8000, THEN selling recommendation is Cluster 2 | 100% |
| Rule 2.3 | IF commodity cost between TWD 10,001 and TWD 15,001, and commodity project price between TWD 8001 and TWD 12,000, THEN selling recommendation is Cluster 2 | 100% |
| Rule 2.4 | IF commodity cost between TWD 10,001 and TWD 15,001, and commodity project price > TWD 12,000, THEN selling recommendation is Cluster 2 | 100% |
| Rule 2.5 | IF commodity cost between TWD 10,001 and TWD 15,001, and gross profit between TWD 10,001 and TWD 15,001, THEN selling recommendation is Cluster 2 | 100% |
| Rule 3.1 | IF commodity cost > TWD 15,001, and commodity project price > TWD 12,001, THEN selling recommendation is Cluster 3 | 100% |
| Rule 4.1 | IF gross profit between TWD 5001 and TWD 10,000, and commodity project price < TWD 4001, THEN selling recommendation is Cluster 4 | 100% |
| Rule 4.2 | IF commodity cost between TWD 5001 and TWD 10,000, and gross profit between TWD 5001 and TWD 10,000, THEN selling recommendation is Cluster 4 | 100% |
| Rule 4.3 | IF commodity cost < TWD 5001, and gross profit between TWD 10,001 and TWD 15,000, THEN selling recommendation is Cluster 4 | 99% |
| Rule 4.4 | IF commodity cost < TWD 5001, and gross profit between TWD 5001 and TWD 10,000, THEN selling recommendation is Cluster 4 | 96% |
| Rule 4.5 | IF commodity cost between TWD 5001 and TWD 10,000, and gross profit between TWD 10,001 and TWD 15,000, THEN selling recommendation is Cluster 4 | 97% |
| Rule 4.6 | IF project tariffs between TWD 401 and TWD 600, and gross profit between TWD 5001 and TWD 10,000, and commodity project price between TWD 4001 and TWD 8000, THEN selling recommendation is Cluster 4 | 100% |
| Rule 4.7 | IF commodity cost < TWD 5001, and gross profit > TWD 15,000, THEN selling recommendation is Cluster 4 | 89% |
| Rule 4.8 | IF commodity cost between TWD 5001 and TWD 10,000, and gross profit > TWD 15,000, THEN selling recommendation is Cluster 4 | 100% |
| Rule 5.1 | IF commodity cost > TWD 15,001, and commodity project price between TWD 8001 and TWD 12,000, THEN selling recommendation is Cluster 5 | 100% |
| Rule 5.2 | IF commodity cost > TWD 15,001, and commodity project price between TWD 4001 and TWD 8000, THEN selling recommendation is Cluster 5 | 100% |
| Rule 5.3 | IF commodity cost > TWD 15,001, and commodity project price < TWD 4001, THEN selling recommendation is Cluster 5 | 100% |
| Item | Cluster 1 | Cluster 2 | Cluster 3 | Cluster 4 | Cluster 5 |
|---|---|---|---|---|---|
| Commodity cost | Medium-low | Medium-high | High | Medium-low | High |
| Commodity project price | Low | Medium-low | High | Low | Medium-high |
| Gross profit | Low | Low | Low | Low | Low |
| Project tariffs | Medium-low | Medium-high | High | Medium-high | High |
| Project commission | Low | Medium-low | Medium | Medium | Medium |
| Advance payments | Low | Low | Low | Low | Low |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ou, T.-Y.; Tsai, W.-L.; Lee, Y.-C.; Chang, T.-H.; Lee, S.-H.; Huang, F.-F. A Recommendation Model for Selling Rules in the Telecom Retail Industry. Axioms 2022, 11, 265. https://doi.org/10.3390/axioms11060265
Ou T-Y, Tsai W-L, Lee Y-C, Chang T-H, Lee S-H, Huang F-F. A Recommendation Model for Selling Rules in the Telecom Retail Industry. Axioms. 2022; 11(6):265. https://doi.org/10.3390/axioms11060265
Chicago/Turabian StyleOu, Tsung-Ying, Wen-Lung Tsai, Yi-Chen Lee, Tien-Hsiang Chang, Shih-Hsiung Lee, and Fen-Fen Huang. 2022. "A Recommendation Model for Selling Rules in the Telecom Retail Industry" Axioms 11, no. 6: 265. https://doi.org/10.3390/axioms11060265
APA StyleOu, T.-Y., Tsai, W.-L., Lee, Y.-C., Chang, T.-H., Lee, S.-H., & Huang, F.-F. (2022). A Recommendation Model for Selling Rules in the Telecom Retail Industry. Axioms, 11(6), 265. https://doi.org/10.3390/axioms11060265