
NIPUNA: A Novel Optimizer Activation Function for Deep Neural Networks

 , , ,
, , , 
Abstract
:1. Introduction
- This paper introduces a new activation function named NIPUNA, i.e., for deep neural networks.
- Solves the dying ReLU problem to estimate the optimal slope of the negative portion of the input data, as it has a small positive slope in the negative area of the input.
- Combines the benefits of the ReLU and Swish activations in order to accelerate gradient descent convergence towards global minima and optimize time-intensive computing for deeper layers with huge parameter dimensions.
- The proposed activation function is tested on benchmark datasets using a tailored convolution neural network architecture.
- This study also compares performance on two benchmark datasets using cutting-edge activation functions with various types of deep neural networks.
2. Related Works
3. Problem Definition
3.1. Proposed Activation Function
3.2. Customized Convolution Neural Network (CCNN)
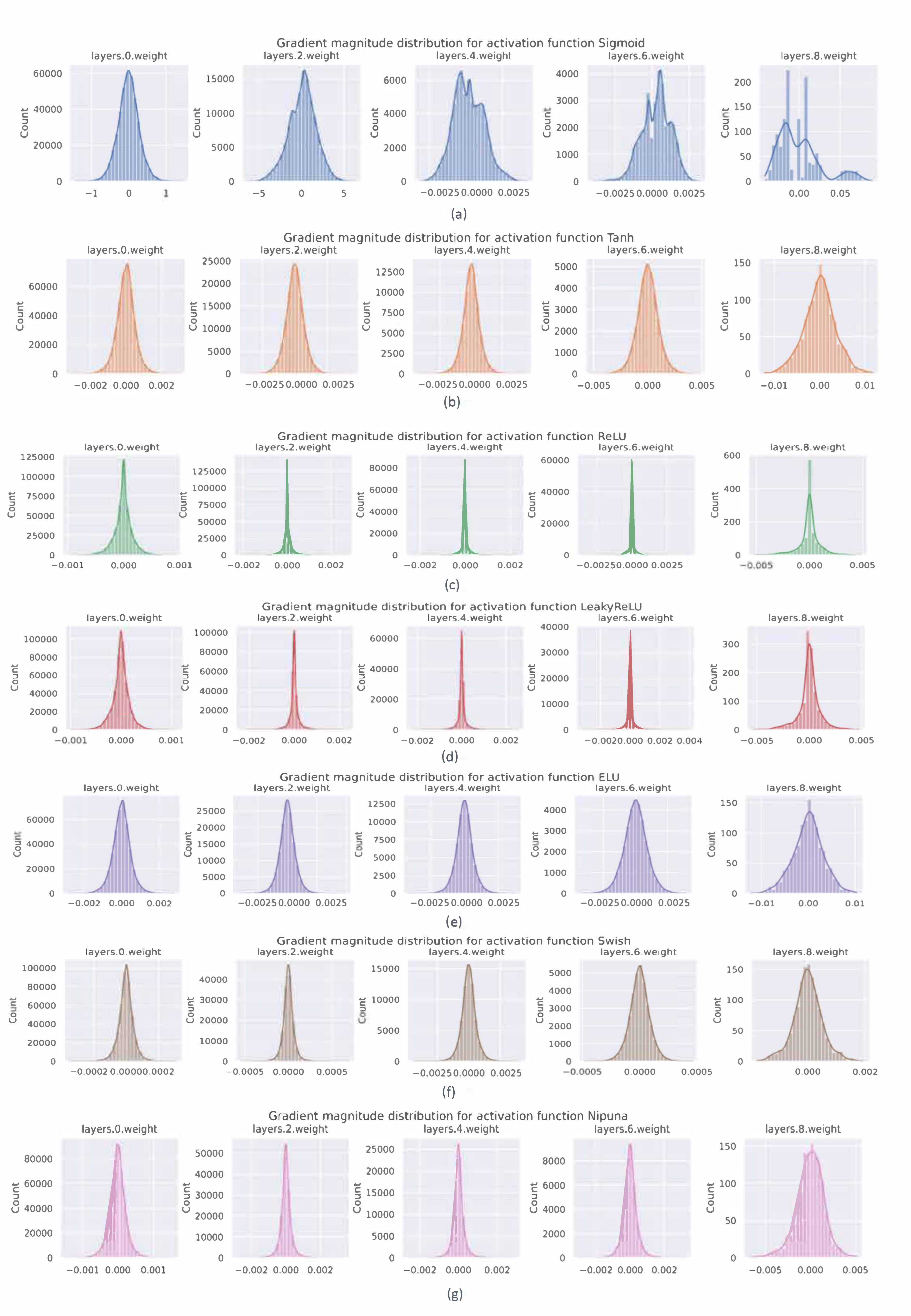
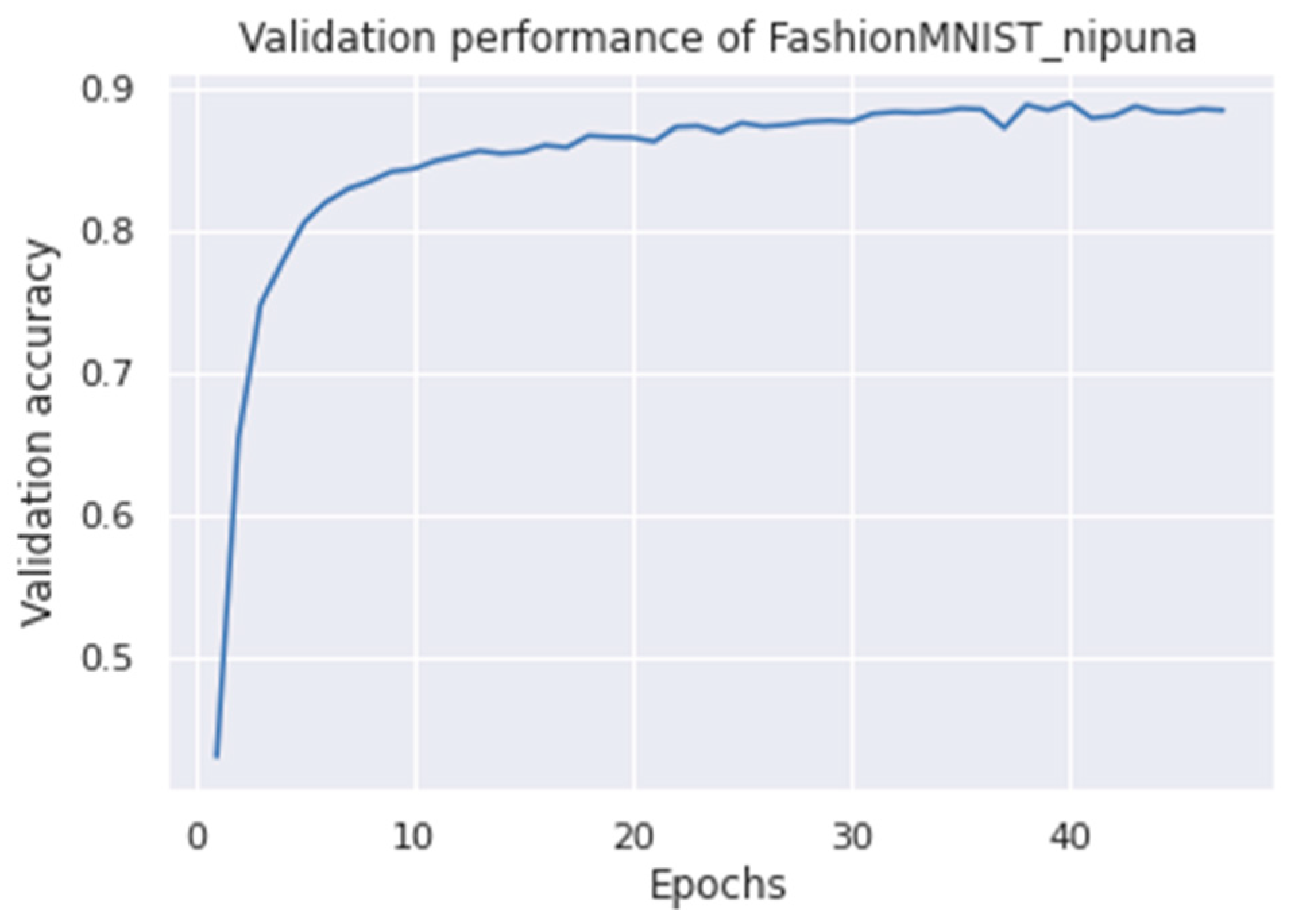
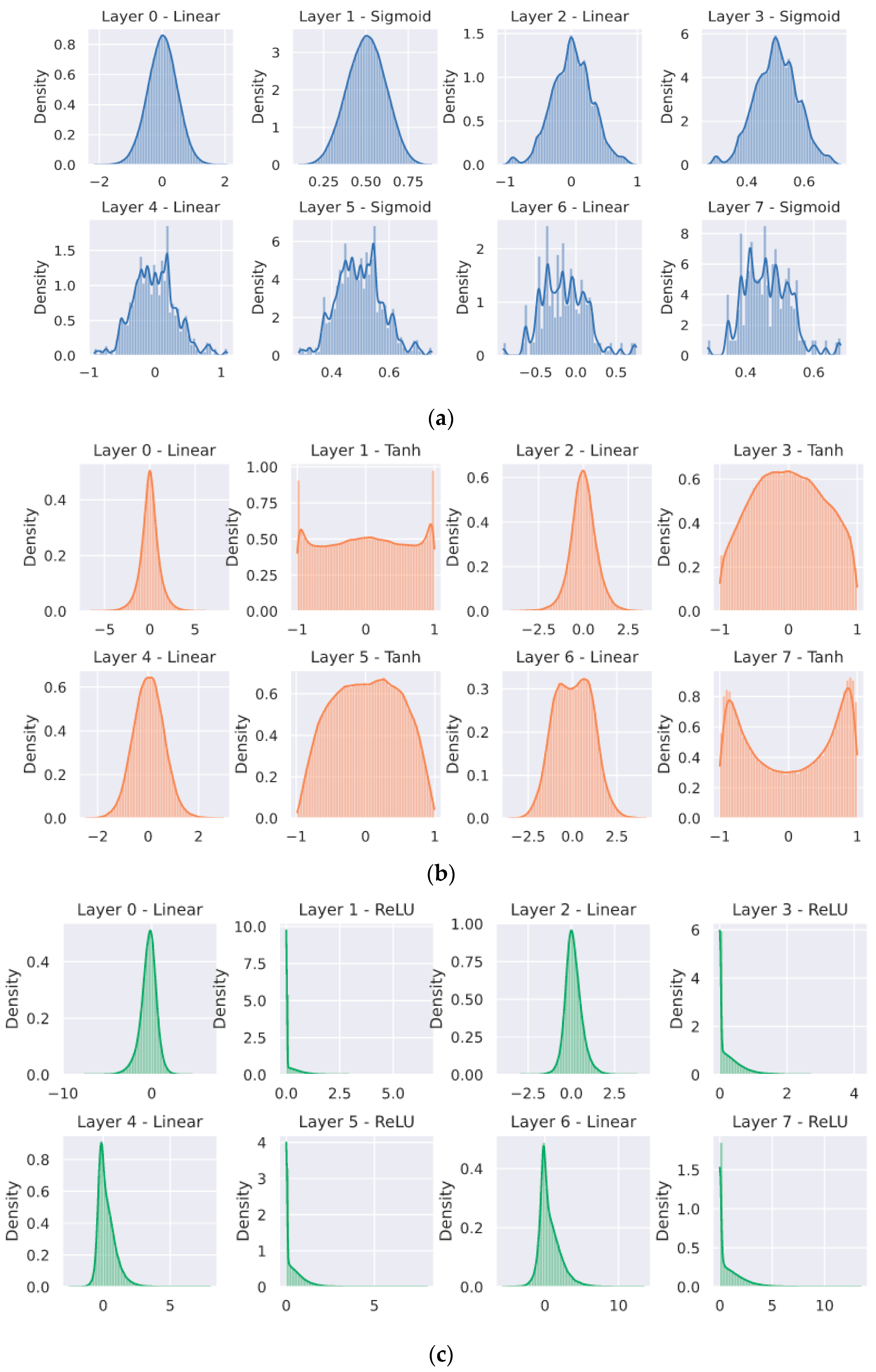
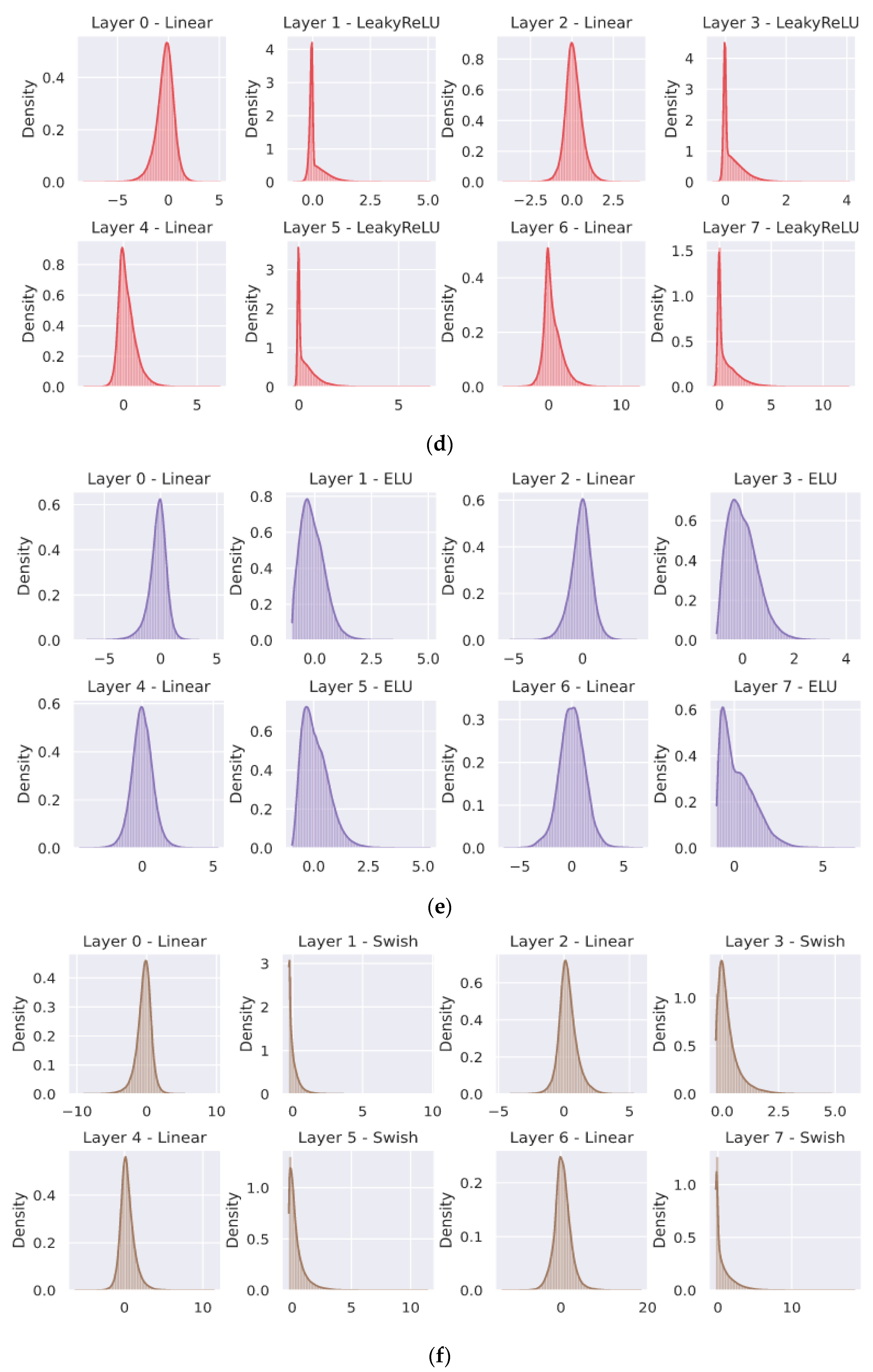
4. Experiments and Their Outcomes
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, UK, 2016. [Google Scholar]
- Yamada, T.; Yabuta, T. Neural network controller using autotuning method for nonlinear functions. IEEE Trans. Neural Netw. 1992, 3, 595–601. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.T.; Chang, W.D. A feedforward neural network with function shape autotuning. Neural Netw. 1996, 9, 627–641. [Google Scholar] [CrossRef]
- Hahnloser, R.H.; Sarpeshkar, R.; Mahowald, M.A.; Douglas, R.J.; Seung, H.S. Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit. Nature 2000, 405, 947–951. [Google Scholar] [CrossRef] [PubMed]
- Jarrett, K.; Kavukcuoglu, K.; Ranzato, A.; Le Cun, Y. What is the best multi-stage architecture for object recognition? In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2146–2153. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Richard, H.R.; Hahnloser, H.; Seung, S. Permitted and forbidden sets in symmetric threshold-linear networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, UK, 2001; pp. 217–223. [Google Scholar]
- Hinton, G.; Salakhutdinov, R. An efficient learning procedure for deep Boltzmann machines. Neural Comput. 2012, 24, 1967–2006. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; Volume 30, p. 3. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Günter, K.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-normalizing neural networks. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 972–981. [Google Scholar]
- Prajit, R.; Zoph, B.; Le, Q.V. Swish: A self-gated activation function. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Singh, B.V.; Kumar, V. Linearized sigmoidal activation: A novel activation function with tractable non-linear characteristics to boost representation capability. Expert Syst. Appl. 2019, 120, 346–356. [Google Scholar]
- Lohani, H.K.; Dhanalakshmi, S.; Hemalatha, V. Performance Analysis of Extreme Learning Machine Variants with Varying Intermediate Nodes and Different Activation Functions. In Cognitive Informatics and Soft Computing; Springer: Berlin/Heidelberg, Germany, 2019; pp. 613–623. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, Nevada, 3–6 December 2012; Volume 1, pp. 1097–1105. [Google Scholar]
- Njikam, S.; Nasser, A.; Zhao, H. A novel activation function for multilayer feed-forward neural networks. Appl. Intell. 2016, 45, 75–82. [Google Scholar] [CrossRef]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical evaluation of rectified activations in convolutional network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Trottier, L.; Giguere, P.; Chaib-Draa, B. Parametric exponential linear unit for deep convolutional neural networks. In Proceedings of the 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 207–214. [Google Scholar]
- Faruk, E.Ö. A novel type of activation function in artificial neural networks: Trained activation function. Neural Netw. 2018, 99, 148–157. [Google Scholar]
- Diganta, M. Mish: A self-regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Liu, X.; Di, X. TanhExp: A smooth activation function with high convergence speed for lightweight neural networks. IET Computer Vision 2021, 15, 136–150. [Google Scholar] [CrossRef]
- Sayan, N.; Bhattacharyya, M.; Mukherjee, A.; Kundu, R. SERF: Towards better training of deep neural networks using log-Softplus ERror activation Function. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 5324–5333. [Google Scholar]
- Wang, X.; Ren, H.; Wang, A. Smish: A Novel Activation Function for Deep Learning Methods. Electronics 2022, 11, 540. [Google Scholar] [CrossRef]
- Shen, S.L.; Zhang, N.; Zhou, A.; Yin, Z.Y. Enhancement of neural networks with an alternative activation function tanhLU. Expert Syst. Appl. 2022, 199, 117181. [Google Scholar] [CrossRef]
- Vallés-Pérez, I.; Soria-Olivas, E.; Martínez-Sober, M.; Serrano-López, A.J.; Vila-Francés, J.; Gómez-Sanchís, J. Empirical study of the modulus as activation function in computer vision applications. Eng. Appl. Artif. Intell. 2023, 120, 105863. [Google Scholar] [CrossRef]
- Deng, L. The MNIST database of handwritten digit images for machine learning research. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Han, X.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
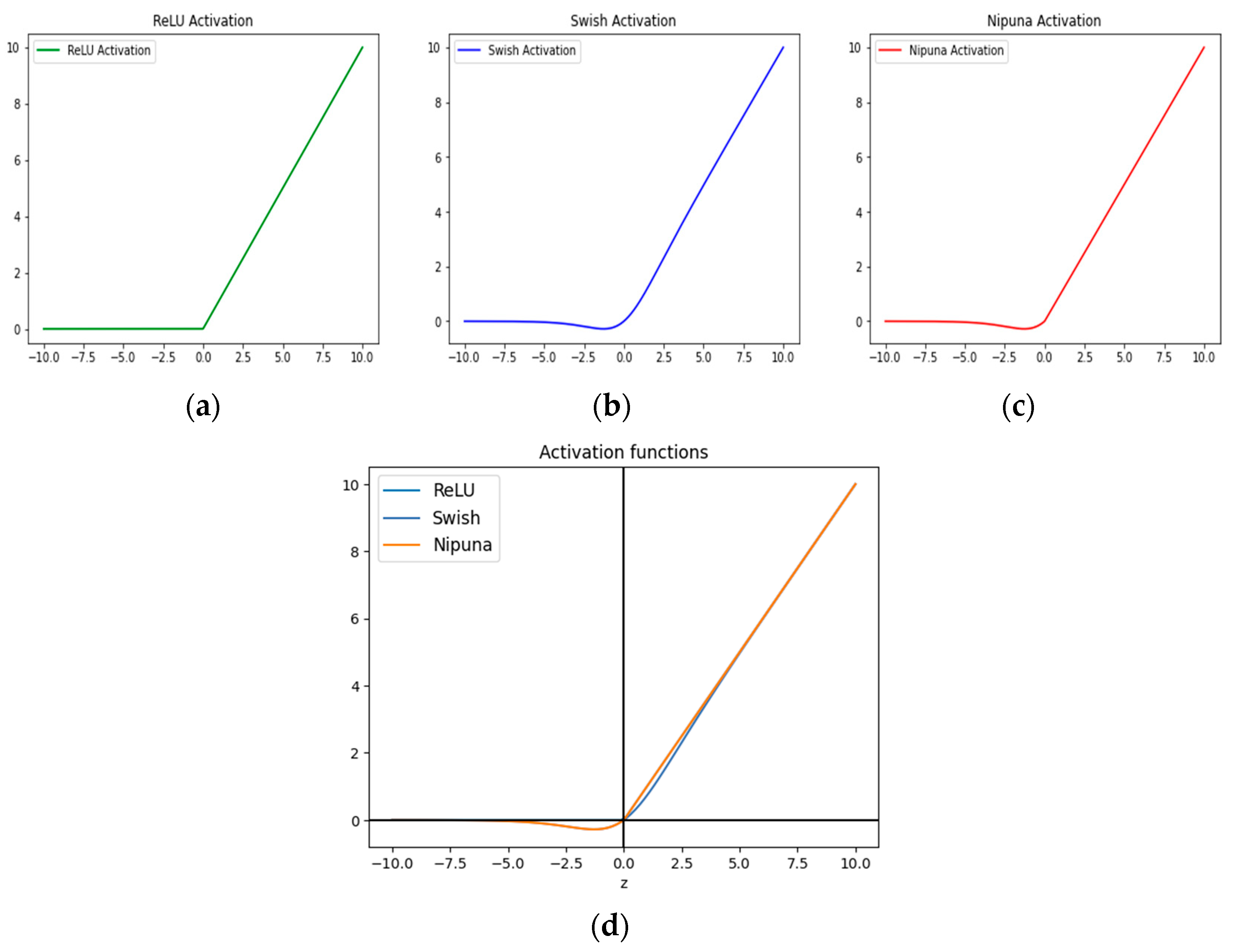








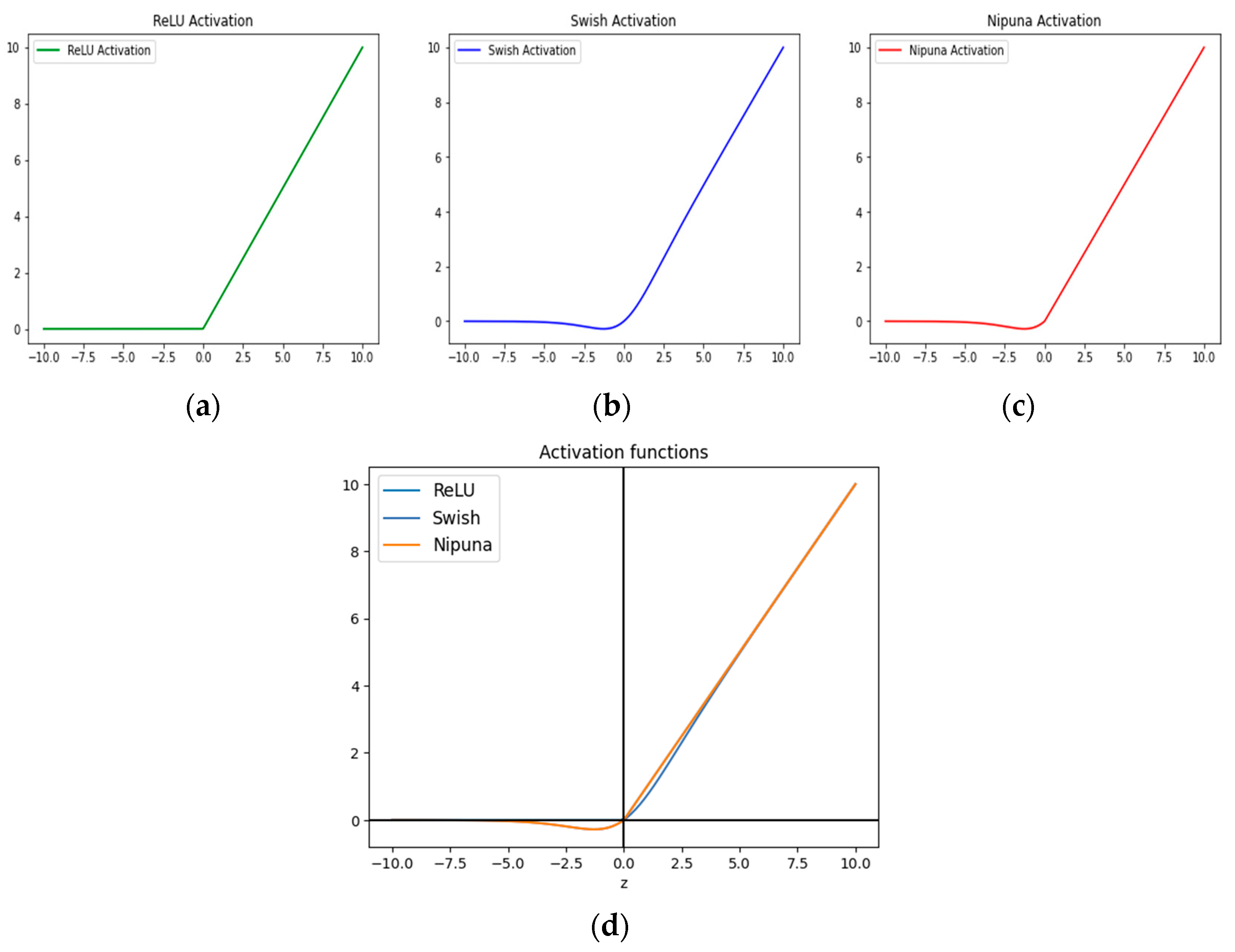{kind=link}
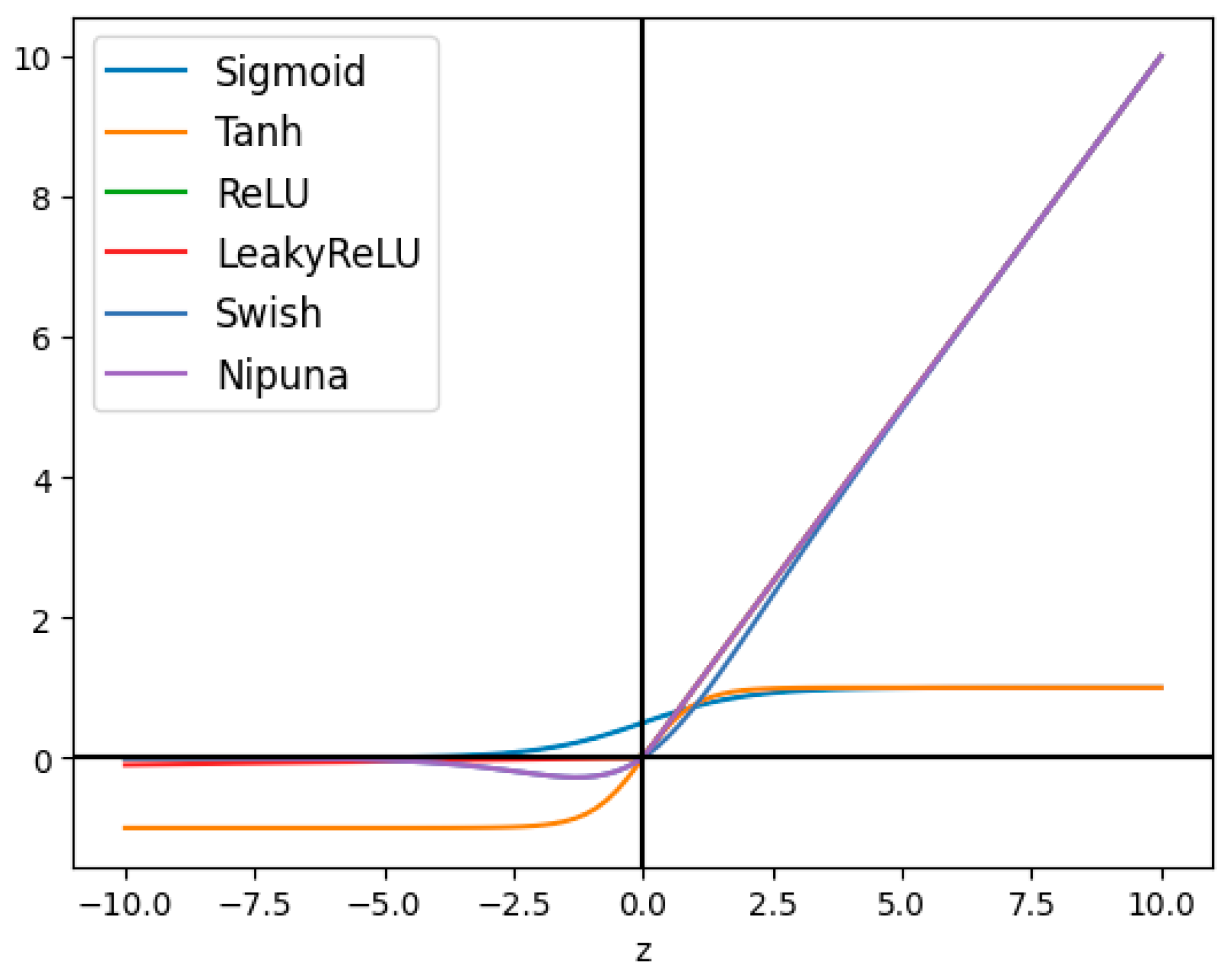{kind=link}
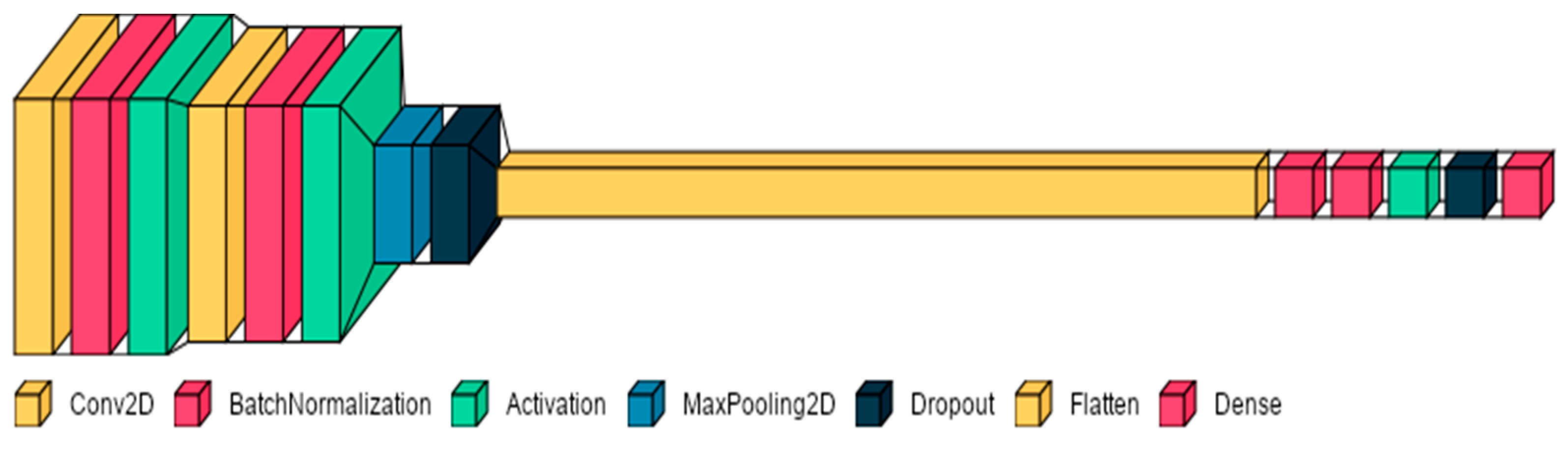{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
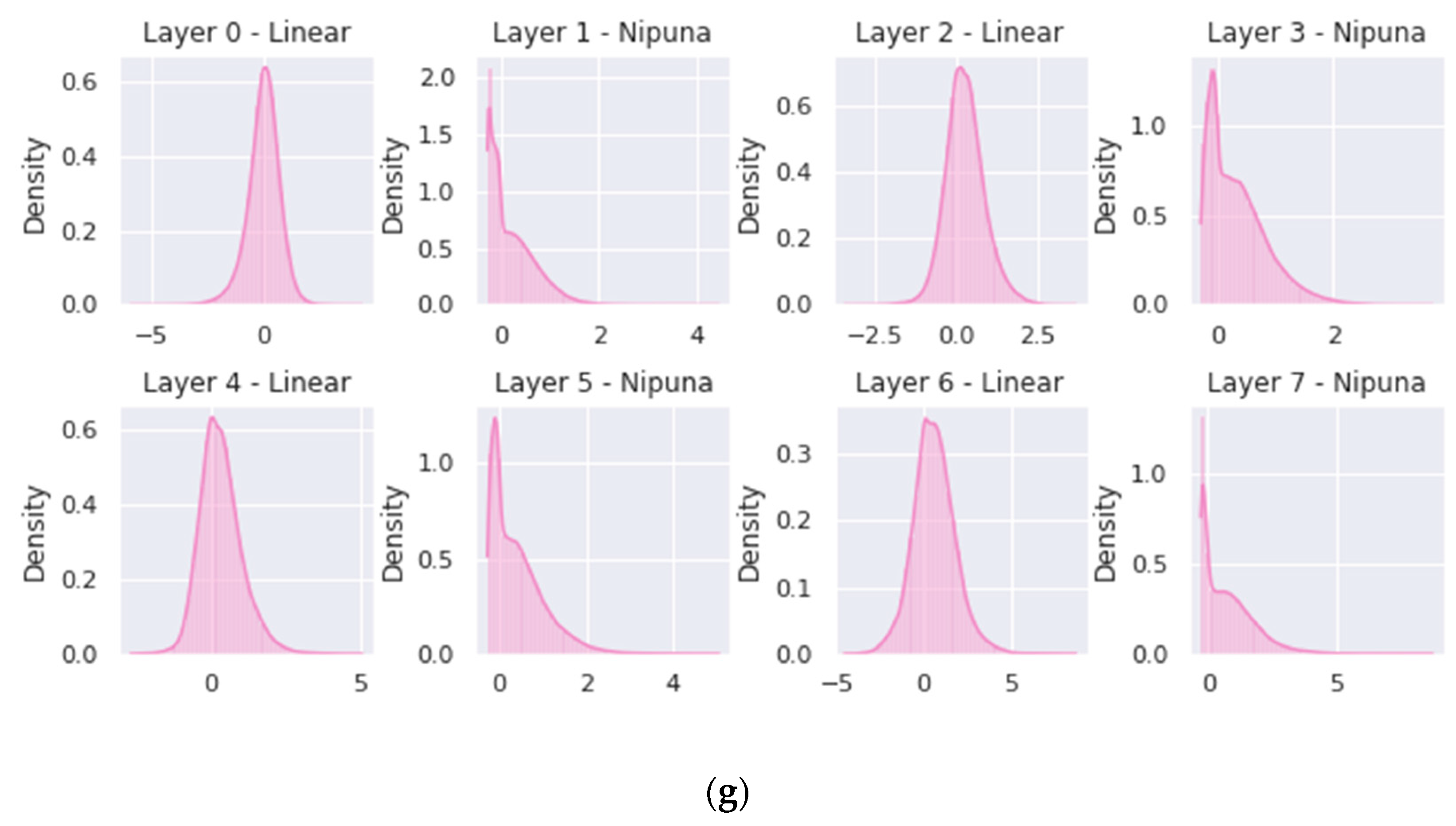{kind=link}
| Dataset: MNIST (50 Epochs), Optimizer = Adam, Kernel_Initializer = HeNormal | |||||
|---|---|---|---|---|---|
| Customized CNN | Activation Type | Accuracy | Loss | ||
| Test | Train | Test | Train | ||
| Sigmoid | 0.9372 | 0.9691 | 0.2404 | 0.1243 | |
| Tanh | 0.9250 | 0.9790 | 0.2930 | 0.0809 | |
| ReLU | 0.9366 | 0.9839 | 0.2684 | 0.0859 | |
| SELU | 0.9247 | 0.9612 | 0.2590 | 0.1321 | |
| Swish | 0.9311 | 0.9850 | 0.2960 | 0.0739 | |
| NIPUNA (Proposed) | 0.9341 | 0.9874 | 0.2652 | 0.0723 | |
| Dataset: MNIST (100 Epochs), Optimizer = SGD, Kernel_Initializer = HeNormal | |||||
|---|---|---|---|---|---|
| Customized CNN | Activation Type | Accuracy | Loss | ||
| Test | Train | Test | Train | ||
| Sigmoid | 0.9242 | 0.9511 | 0.3257 | 0.1579 | |
| Tanh | 0.9150 | 0.9620 | 0.3930 | 0.1274 | |
| ReLU | 0.9266 | 0.9349 | 0.2114 | 0.1810 | |
| SELU | 0.9307 | 0.9723 | 0.3104 | 0.1620 | |
| Swish | 0.9236 | 0.9514 | 0.2216 | 0.1356 | |
| NIPUNA (Proposed) | 0.9337 | 0.9969 | 0.3601 | 0.0212 | |
| Activation Function | Parameters Setting/Initialization | Learned Parameters |
|---|---|---|
| Sigmoid | -- | -- |
| Tanh | -- | -- |
| ReLU | -- | -- |
| SELU | λ ≈ 1.0507, α ≈ 1.6732 | |
| Swish | , | , |
| NIPUNA |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Madhu, G.; Kautish, S.; Alnowibet, K.A.; Zawbaa, H.M.; Mohamed, A.W. NIPUNA: A Novel Optimizer Activation Function for Deep Neural Networks. Axioms 2023, 12, 246. https://doi.org/10.3390/axioms12030246
Madhu G, Kautish S, Alnowibet KA, Zawbaa HM, Mohamed AW. NIPUNA: A Novel Optimizer Activation Function for Deep Neural Networks. Axioms. 2023; 12(3):246. https://doi.org/10.3390/axioms12030246
Chicago/Turabian StyleMadhu, Golla, Sandeep Kautish, Khalid Abdulaziz Alnowibet, Hossam M. Zawbaa, and Ali Wagdy Mohamed. 2023. "NIPUNA: A Novel Optimizer Activation Function for Deep Neural Networks" Axioms 12, no. 3: 246. https://doi.org/10.3390/axioms12030246
APA StyleMadhu, G., Kautish, S., Alnowibet, K. A., Zawbaa, H. M., & Mohamed, A. W. (2023). NIPUNA: A Novel Optimizer Activation Function for Deep Neural Networks. Axioms, 12(3), 246. https://doi.org/10.3390/axioms12030246