Abstract
Consider a class of coupled Stein equations arising from jump control systems. An operator Smith algorithm is proposed for calculating the solution of the system. Convergence of the algorithm is established under certain conditions. For large-scale systems, the operator Smith algorithm is extended to a low-rank structured format, and the error of the algorithm is analyzed. Numerical experiments demonstrate that the operator Smith iteration outperforms existing linearly convergent iterative methods in terms of computation time and accuracy. The low-rank structured iterative format is highly effective in approximating the solutions of large-scale structured problems.
Keywords:
coupled Stein equations; operator Smith algorithm; jump control system; low rank; large-scale problems MSC:
65F45; 65F10
1. Introduction
Consider the discrete-time jump control systems given by
where , , and with . Here, N represents the scale of the jump control system. Efficient control in the analysis and design of jump systems involves associating the observability Gramian and controllability Gramian [1], which are solutions of the corresponding coupled discrete-time Stein equations (CDSEs):
Here, for , is the input matrix, is symmetric and positive semi-definite, and with probability values satisfying . Numerous methods, ranging from classical to state-of-the-art, have been developed over the past decades to address the single Stein equation (i.e., in (1)), particularly for special matrix structures. For example, Betser et al. investigated solutions tailored to cases where coefficient matrices are in companion forms [2]. Hueso et al. devised a systolic algorithm for the triangular Stein equation [3]. Li et al. introduced an iterative method for handling large-scale (the term “large-scale” refers to the scale N of the corresponding equations being large) Stein and Lyapunov equations with low-ranked structures [4]. Fan et al. discussed generalized Lyapunov and Stein equations, deriving connections from rational Riccati equations [5]. Yu et al. scrutinized large-scale Stein equations featuring high-ranked structures [6].
For CDSEs (1), the parallel iteration [7], essentially a stationary iteration for linear systems, is a commonly used method to compute the desired solution. This approach has been extended to an implicit sequential format [8], leveraging the latest information from obtained solutions to accelerate the iteration of the left part. The gradient-based iterative algorithm, introduced for solving CDSEs, explicitly determines the optimal step size to achieve the maximum convergence rate [9]. By utilizing positive operator theory, two iterative algorithms were established for solving CDSEs [10], later extended to Itô stochastic systems. The continuous-time Lyapunov equations can be transformed into CDSEs via the Cayley transformation [11], although determining the optimal Cayley parameter remains a challenge. For other related iterative methods of continuous-time Lyapunov equations, consult [12,13,14,15,16] and the corresponding references.
CDSEs also arise from solving sub-problems of coupled discrete-time Riccati equations from optimized control systems. The difference method [17] and CM method [18] were proposed to tackle the sub-problems of CDSEs. Ivanov [19] developed two Stein iterations that also exploit the latest information of previously derived solutions for acceleration. Notably, the iteration schemes provided in [8] are almost identical to these two Stein iterations [19], essentially corresponding to the Gauss–Jacobi and the Gauss–Seidel iterations applied to coupled matrix equations. Successive over-relaxation (SOR) iterations and their variants for CDSEs were explored in [20,21], though determining the optimal SOR parameter remains challenging. One limitation of the aforementioned methods is that they are linearly convergent, and the potential structures (such as the low rank and sparseness) of the matrices are not fully exploited. To enhance the convergence rate of iterative methods, the Smith method was employed to solve the single Stein equation [22] and extended to structured large-scale problems [4,11]. This method offers the advantage of being parameter-free and converging quadratically to the desired symmetric solution. A similar idea was extended to address some stochastic matrix equations in [5]. In this paper, we adapt the Smith method to an operator version to compute the solution of CDSEs and subsequently construct the corresponding low-ranked format for large-scale problems. The main contributions encompass the following significant aspects:
- We introduce the operator defined asThis operator formulation enables us to adapt the Smith iteration [4,11,22] to an operator version, denoted as the operator Smith algorithm (OSA). By doing so, the iteration maintains quadratic convergence for computing the symmetric solution of CDSEs (1). Our numerical experiments demonstrate that the OSA outperforms existing linearly convergent iterations in terms of both the CPU time and accuracy.
- To address large-scale problems, we structure the OSA in a low-ranked format with twice truncation and compression (TC). One TC applies to the factor in the constructed operator (2), while the other TC applies to the factor in the approximated solution. This approach effectively reduces the column dimensions of the low-rank factors in symmetric solutions.
- We redesign the residual computation to suit large-scale computations. We incorporate practical examples from industries [23] to validate the feasibility and effectiveness of the presented low-ranked OSA. This not only demonstrates its practical utility but also lays the groundwork for exploring various large-scale structured problems.
This paper is structured as follows. Section 2 outlines the iterative scheme of the OSA for CDSEs (1), along with a convergence analysis. Comparative results on small-scale problems highlight the superior performance of the OSA compared to other linearly convergent iterations. Section 3 delves into the development of the low-ranked OSA, providing details on truncation and compression techniques, residual computations, as well as complexity and error analysis. In Section 4, we present numerical experiments from industrial applications to illustrate the effectiveness of the introduced low-ranked OSA in real-world scenarios.
Throughout this paper, (or simply I) is the identity matrix. For a matrix , is the spectral radius of A. Unless stated otherwise, the norm is the ∞-norm of a matrix. For matrices A and , the direct sum means the block diagonal matrix . For symmetric matrices A and , we say () if is a positive definite (semi-definite) matrix.
2. Operator Smith Iteration for CDSEs
2.1. Iteration Scheme
The operator Smith algorithm (OSA) represents a generalization of the Smith iteration applied to a single matrix equation [4].
With the initial , the OSA for CDSEs (1) is given by
where represents the k-th iteration satisfying .
Remark 1.
By the definition of the operator , it is not difficult to see that doubles the former operator for . Specifically, the operator acting on a matrix is equivalent to applying the former operator twice on that matrix. To illustrate, let us consider as an example. For , the operator on Q (i.e., in (3)) is
Thus, the effect of is equivalent to , demonstrating that effectively doubles . This doubling property extends the concept of Smith iteration for a single equation [4,11]. In this sense, (4) is referred to as the OSA.
The following proposition indicates the concrete form of in the OSA (4):
Proposition 1.
Proof.
To obtain the convergence of the OSA, we further assume that all for are d-stable, i.e.,
The following theorem concludes the convergence of the OSA:
Theorem 1.
Let and such that . Then, the sequence generated by (4) is convergent to the solution
of the CDSEs when is d-stable. Moreover, one has
where for .
Proof.
Remark 2.
It is evident from Theorem 1 that the OSA admits the quadratic convergence rate when . This highlights its superiority over the prevailing linearly convergent iterations [8,19,21,24] both on accuracy and CPU time, as elaborated in the next subsection.
2.2. Examples
In this subsection, we present several examples that highlight the superior performance of the OSA compared to linearly convergent iterations [8,19,21,24]. Notably, the iteration method outlined in [8] is identical to the one in [19]. Additionally, other linearly convergent iterations exhibit similar numerical behaviors. Therefore, for accuracy and CPU time comparisons, we select the iteration method from [8,19], referred to as “FIX” in this subsection. It is important to note that the discrete-time Lyapunov equation in “FIX” was solved using the built-in function “dlyap” in Matlab 2019a [25].
Example 1.
This example is from a slight modification of the all-pass SISO system [26], where the controllability and observability Gramians are quasi-inverse to each other, i.e., for some . This property indicates that the system has a single Hankel singular value of multiplicity equal to the system’s order. The derived system matrices are as follows:
where and are matrices with zero elements except for the last row of and , respectively (both and are random row vectors with elements from the interval (0, 1)); and are both tri-diagonal matrix but with and , respectively; ; and . We consider and select the probability matrix .
We evaluate the OSA and FIX for dimensions and and present their numerical behaviors in Table 1. Here, and record the CPU time of the current iteration and accumulated iterations, respectively. The Rel_Res column exhibits the relative residual of CDSEs in each iteration. From Table 1, it is evident that the OSA achieves equation residuals of within five iterations for different dimensions. The CPU time required for the OSA is significantly less than that required for FIX. Conversely, FIX maintains equation residuals at the level of even after 11 iterations. The symbol “∗” in the table indicates that, despite resuming the iteration, it can not further reduce the equation residuals to terminate the FIX.

Table 1.
History of CPU time and residual for OSA and FIX in Example 1.
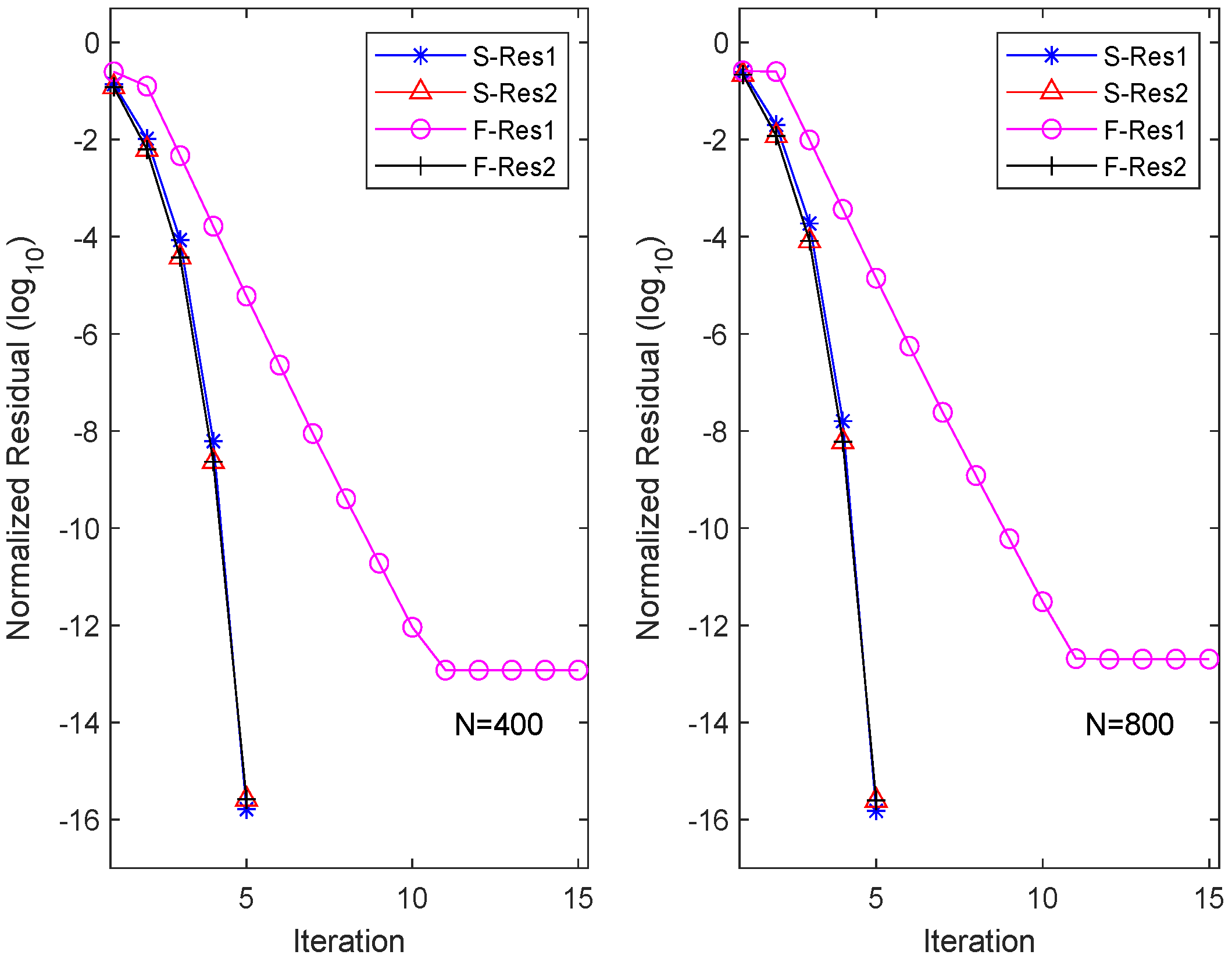
To visualize the residuals of each equation (here, ) for different iteration methods, we plot the history of the equation residuals in Figure 1. Here, “S-Resi” and “F-Resi” () represent the residuals of equations obtained by the OSA and FIX, respectively. The figure illustrates that the OSA has quadratic convergence. Interestingly, although FIX converges rapidly for solving the second equation, it maintains linear convergence for solving the first equation, resulting in an overall linear convergence for FIX.
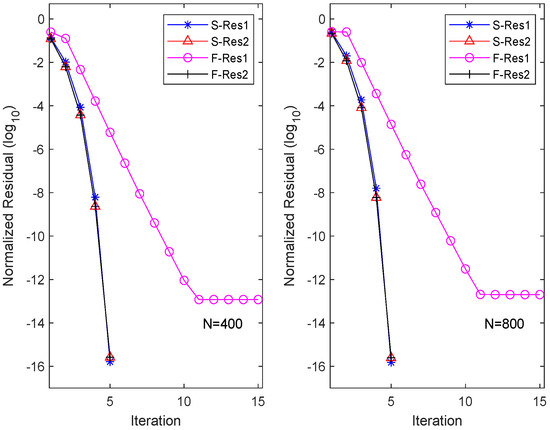
Figure 1.
Residual history in each equation for OSA and FIX.
We further consider modified system matrices
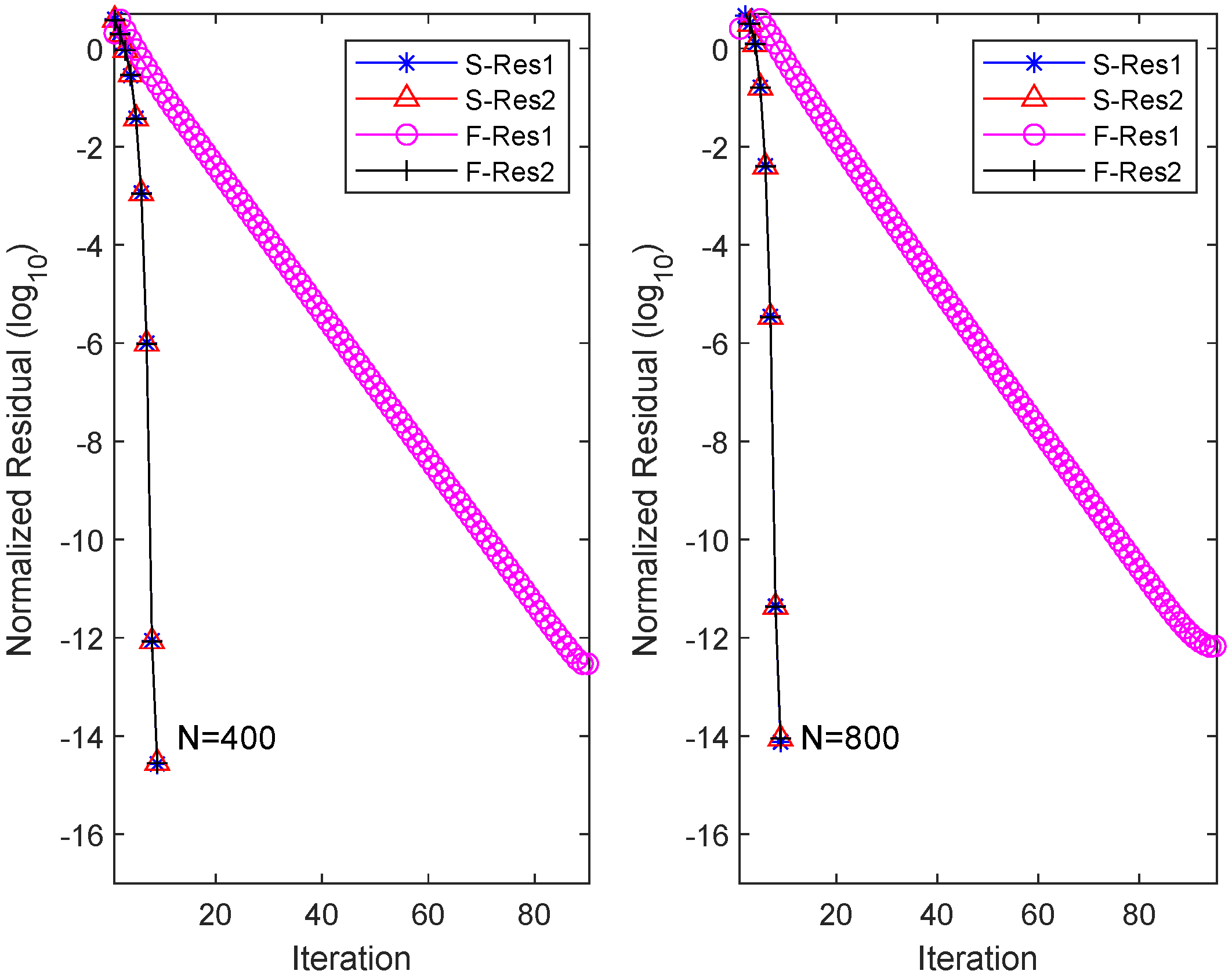
where and are matrices with zero elements except for the last row of and , respectively. In this case, the spectral radii of matrices and are 0.96 and 0.95, respectively. We rerun the OSA and FIX algorithm, and the obtained results are recorded in Figure 2. From the plot, it can be observed that for , the OSA requires nine iterations to achieve equation residuals at the level, with a total time of 10.17 s. Conversely, FIX, after consuming 51.31 s over 90 iterations, only achieves equation residuals at the scale of . Further numerical experiments demonstrate that even by increasing the number of iterations, FIX fails to further reduce the residual level. Similar numerical results are obtained for the scale of .
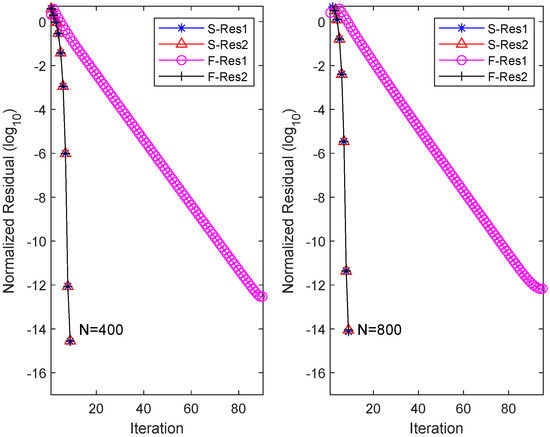
Figure 2.
Residual history in each equation for OSA and FIX when and .
Example 2.
Consider a slight modification of a chemical reaction by a convection reaction partial differential equation on the unit square [27], given by
where x is a function of time (t), vertical position (v), and horizontal position (z). The boundaries of interest in this problem lie on a square with opposite corners at (0, 0) and (1, 1). The function is zero on these boundaries. This PDE is discretized using centered difference approximations on a grid of points. The dimension N of A is the product of the state space dimension , resulting in a sparsity pattern of A as
Here we take
where
The parameter and the probability matrix .
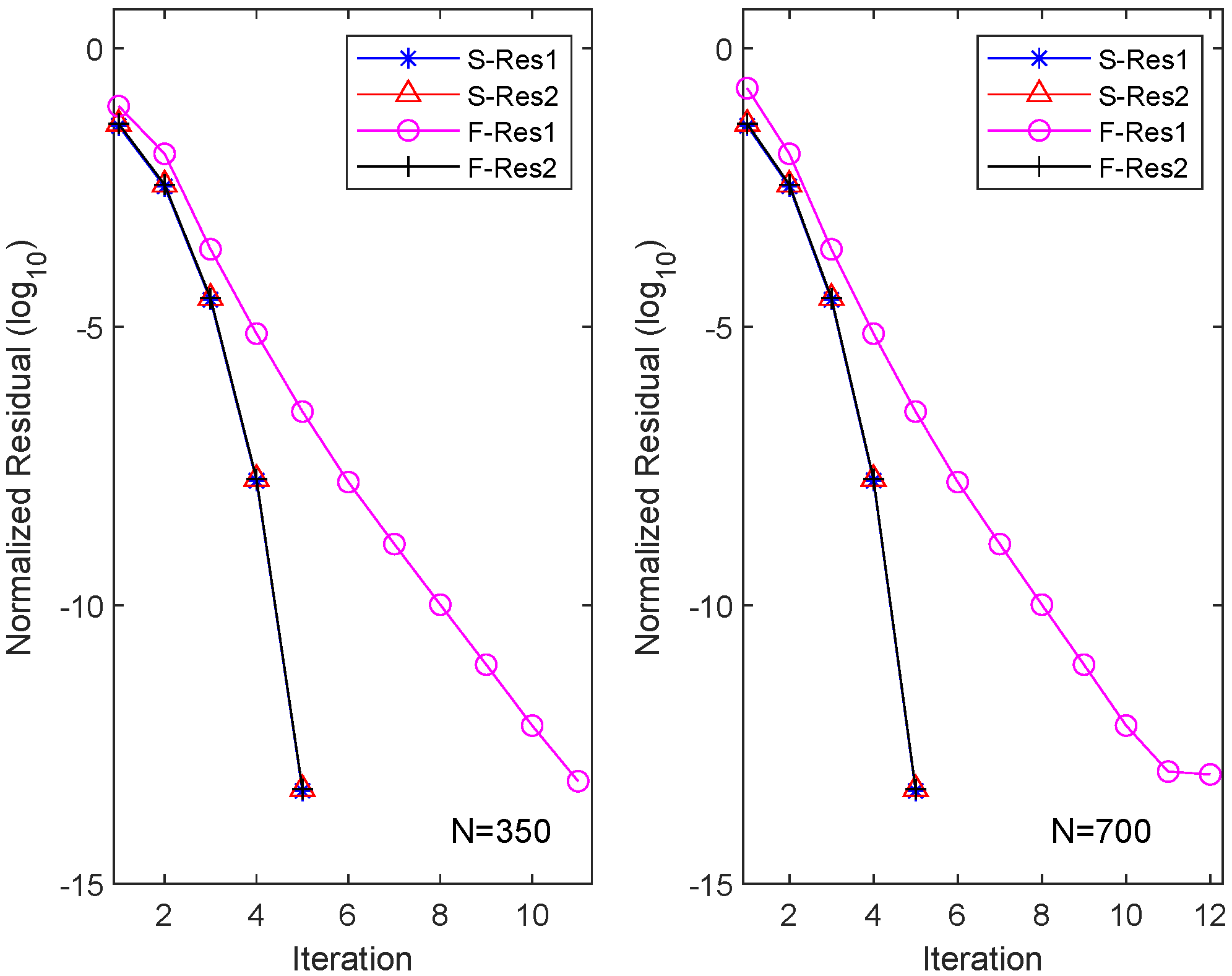
Similarly, we applied the OSA and FIX iterations to CDSEs with dimensions and , and the results are presented in Table 2. It is evident that the OSA can achieve equation residuals of within five iterations, with the required CPU time approximately one-ninth of that needed for the FIX iterations. However, FIX only attains equation residuals of after 10 iterations. We also depict the residuals of the two different iteration methods for their respective m equations (here ) in Figure 3. The figure illustrates that the OSA exhibits quadratic convergence, while FIX demonstrates only linear convergence.
Table 2.
History of CPU time and residual for OSA and FIX in Example 2.
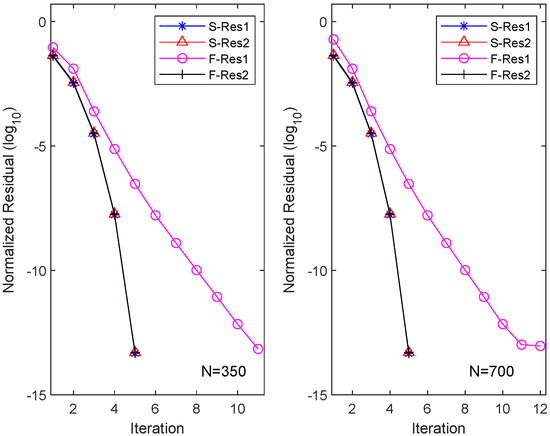
Figure 3.
Residual history in each equation for OSA and FIX in Example 2.
3. Structured Algorithm for Large-Scale Problems
In numerous practical scenarios [23], matrix is often sparse, and is typically of a low-ranked structure. Therefore, in this section, we adapt the OSA to a low-ranked format, well-suited for large-scale computations.
3.1. Structured Iteration Scheme
Given the initial matrices for , we show that the iteration (4) can be organized as the following format:
where , , , and are of forms in the following proposition.
Proposition 2.
3.2. Truncation and Compression
It is evident that the columns of at the k-th iteration will scale approximately as , where is the initial column number of the factor . Consequently, we implement the truncation and compression (TC) to reduce the column number of low-rank factors [11,28]. Notably, our algorithm employs the TC technique twice within one iteration: once for and once for .
For simplicity in notation, we omit the subscript i for low-rank factors. Recalling (8) and (9), we perform TC on and using QR decompositions with column pivoting. Then, one has
where and are permutation matrices ensuring that the diagonal elements of the decomposed block triangular matrices decrease in absolute value. Additionally, and represent constants, and is some small tolerance controlling TC. Let and denote the respective column numbers of and , bounded above by a given . Then, their ranks satisfy
with . The truncated factors are still denoted as
respectively. The compressed kernels are denoted as
where and represent the abbreviated kernels in (8) and (9) without subscript i, respectively.
3.3. Computation of Residuals
Given the initial matrix , for the initial residual of the CDSEs is
where , .
When the k-th iteration is available, the residual of CDSEs has the decomposition
with
Similarly, we also impose the truncation and compression on , i.e, implementing the QR decomposition with pivoting:
where is a pivoting matrix and is some constant. Let . The corresponding kernel of residual is also denoted as
and the terminating condition of the whole algorithm is chosen to be
with being the tolerance.
3.4. Large-Scale Algorithm and Complexity
The OSA with a low-rank structure equipped with TC is summarized in the following OSA_lr Algorithm 1.
To show the computational complexity of the algorithm OSA_lr, we assume that all matrices for are sufficiently sparse. This allows us to consider the cost of both the product and solving the equation , which are both within the range of floating-point operations (flops), where B is an matrix with and c is a constant. Additionally, the number of truncated columns of and for all are denoted as and , respectively. The flops and memory of the k-th iteration are summarized in Table 3 below.
| Algorithm 1: Algorithm OSA_lr. Solve large-scale CDSEs with low-ranked |
Inputs: Sparse matrices , low-rank factors for , probability matrix , truncation tolerance , upper bound and the iteration tolerance . Outputs: Low-ranked matrix and the kernel matrix with the solution . 1. Set and for . 2. For until convergence, do 3. Compute and as in (8). 4. Truncate and compress as in (10) with accuracy . 6. Compute and as in (9). 7. Truncate and compress as in (10) with accuracy . 9. Evaluate the relative residual Rel_Res in (19). 11. If Rel_Res , break, End. 12. ; 14. End (For) 18. Output , . |
Table 3.
Complexity and memory at k-th iteration in algorithm OSA_lr.
3.5. Error Analysis
In this subsection, we will conduct the error analysis of OSA_lr. For , let
be the errors yielded by roundoff or iteration. Here, and are true matrices, while and are the practical iteration matrices. The following lemma indicates the error propagation of the operator.
Lemma 1.
Proof.
By merely retaining one order error of and , it follows from the definition of in (3) that the practical operator is
We have the following error bound at the -th iteration.
Theorem 2.
Given errors and as in (20), the error at the -th iteration has the bound
where m, p, α, and are defined in Lemma 1 and τ is the error of TC described in Section 3.2.
4. Numerical Examples
In this section, we illustrate the effectiveness of OSA_lr in computing symmetric solutions to large-scale CDSEs (1) through practical examples [23,26,27,30,31,32,33]. The algorithm OSA_lr was coded by MATLAB 2019a on a 64-bit PC running Windows 10. The computer is equipped with a 3.0 GHz Intel Core i5 processor with six cores and six threads, 32 GB RAM, and a machine unit roundoff value of eps = . The maximum allowed column number of the low-ranked factors in OSA_lr is bounded by = 1000, and the tolerance for the TC of columns is set to . In our experiments, we also attempted using eps as the TC tolerance for but found it had no impact on the computation accuracy. The residuals of the equations are calculated in (19) with a termination tolerance of . It is noteworthy that we no longer compare with the linearly convergent iterative methods in Section 2, as the computational complexity of those algorithms per iteration is .
Example 3.
We still employ the modification of the all-pass SISO system [26] in Section 2, but here we take N = 12,000. We list the calculated results of OSA_lr in Table 4, where the columns and record the CPU time for each iteration and for cumulative iterations, respectively. The Resi and Rel_Resi () columns provide the absolute residual and relative residual computed by OSA_lr at each iteration, respectively. The () columns indicate the column number of the low-ranked factor .
Table 4.
CPU time and residual in Example 3.
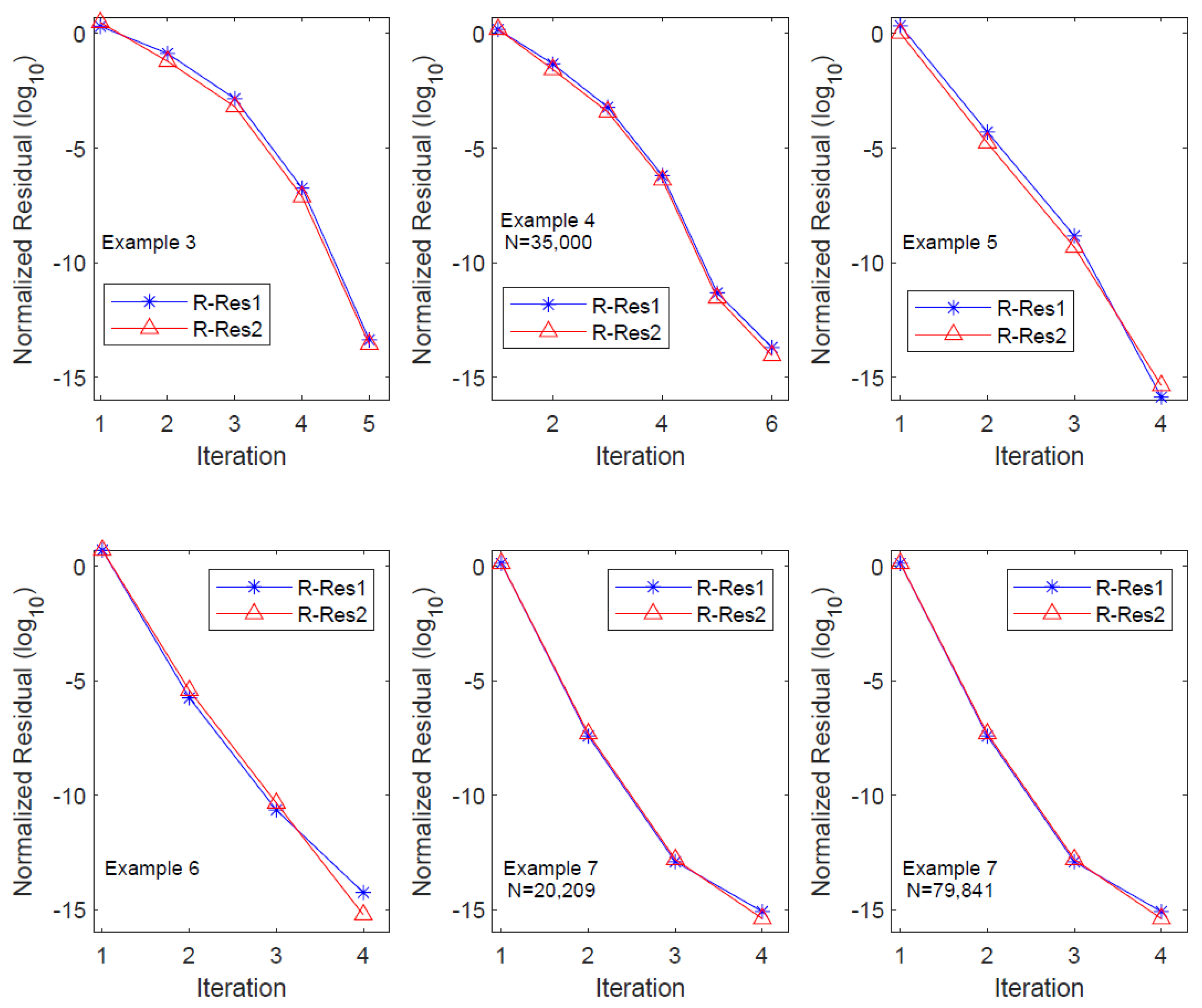
From the table, it is evident that OSA_lr achieves the prescribed equation residual level within five iterations, and the residual history demonstrates the quadratic convergence of the algorithm. The column count for the low-ranked factor expands at a rate greater than twice with each iteration, resulting in an exponential increase in the CPU time. Particularly, significant growth in the CPU time occurs during the third and fourth iterations. In numerical experiments, we observed that this substantial increase in the CPU time primarily lies in the residual computation step, specifically in Step 9 of OSA_lr. Hence, further investigation on the efficient evaluation of the equation residual is a crucial consideration for large-scale computations. We also plot the residual history of OSA_lr in Figure 7 to show its performance, where R-Res_i () denotes the relative residual of the i-th equation.
Example 4.
We continue to examine CDSEs from Example 2 [27,30], but with larger scales N = 21,000, 28,000, and 35,000. The derived results of OSA_lr are presented in Table 5.
Table 5.
CPU time and residual in Example 4.
The symbols , , Resi, Rel_Resi, and () are defined similarly to those in Example 3. In all experiments, the equation residuals (in ) reached the predetermined residual level by the sixth iteration. For equations of different dimensions, the Resi columns indicate that the algorithm OSA_lr is of nearly quadratic convergence, except for the final two iterations. The column reveals that, in the fifth and sixth iterations, the column number of the factor increased by nearly five times and six times, respectively. This resulted in a substantial increase in the CPU time during the last two iterations. A further detailed analysis indicated that this increased time primarily came from the computation of equation residuals in the final two steps. The performance of OSA_lr on the residual history with N = 35,000 is plotted in Figure 7, where R-Res_i () denotes the relative residual of the i-th equation.
Example 5.
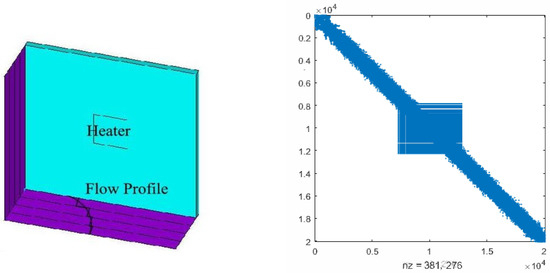
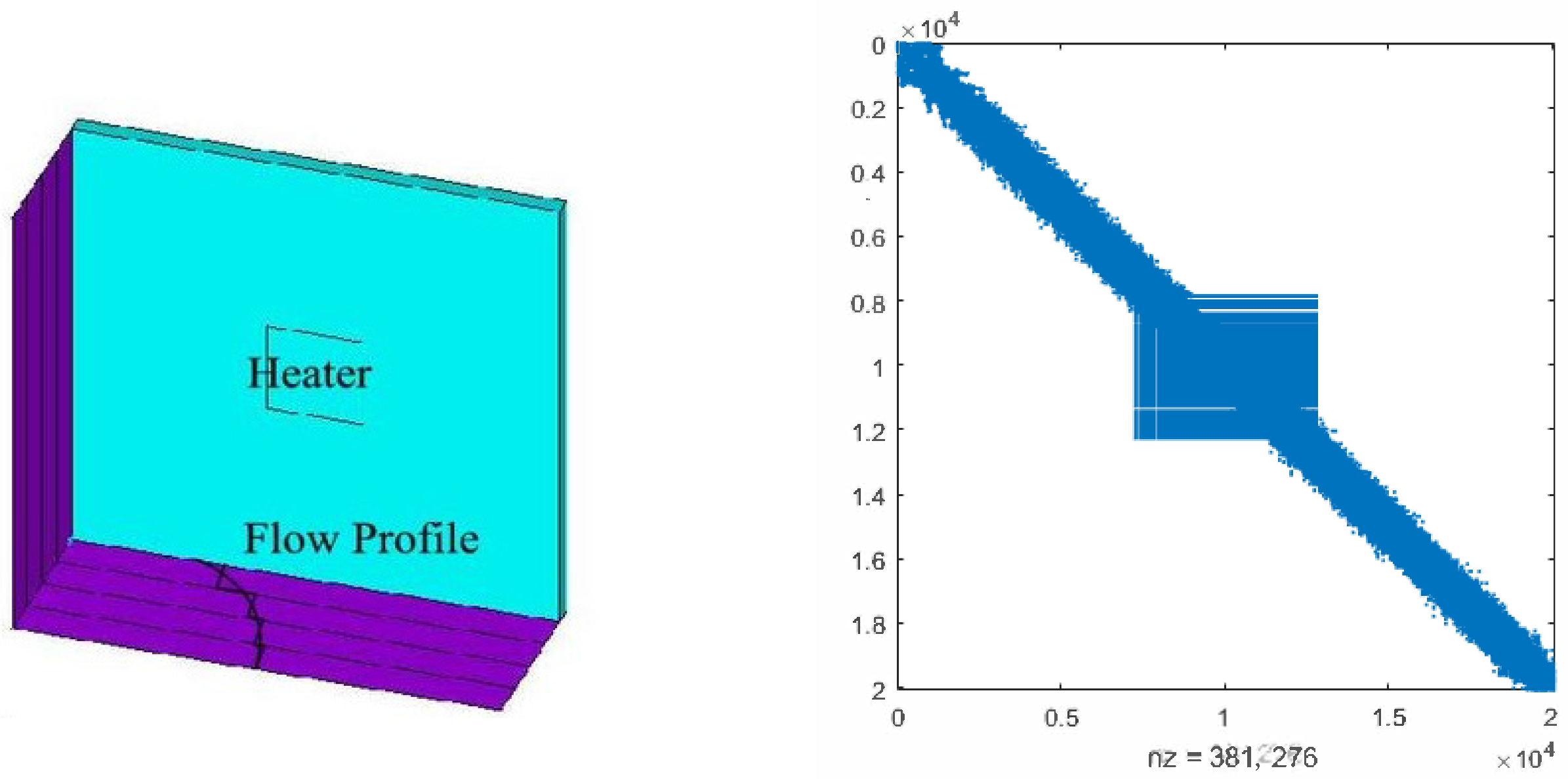
Consider the thermal convective flow control systems in [23,30,31]. These problems involve a flow region with a prescribed velocity profile, incorporating convective transport. Achieving solution accuracy with upwind finite element schemes typically requires a considerable number of elements for a physically meaningful simulation. In the illustrated scenario (see the left side of Figure 4), a 3D model of a chip is subjected to forced convection, utilizing tetrahedral element type SOLID70 as described by [34]. Both the Dirichlet boundary conditions and initial conditions are set to 0.
Figure 4.
The 3D model of the chip and the discretized matrix .
We consider the case that the fluid speed is zero and the discretization matrices are symmetric. The system matrices are
where and are random numbers from (0, 1) and matrices , , and (N = 20,082) can be found at [23]. Since and have almost the same sparse structure, we only plot in the right of Figure 4, where the non-zero elements attain the scale of 381,276. In the numerical experiments, we set and use the probability matrix . We ran OSA_lr for 10 different and and recorded the averaged CPU time, residual of CDSEs, and column dimension of the low-ranked factor in Table 6.
Table 6.
CPU time and residual in Example 5.
The computational results in Table 6 reveal that OSA_lr requires only four iterations to achieve the predetermined equation residual accuracy. Moreover, the Resi and Rel_Resi columns indicate that OSA_lr exhibits quadratic convergence. The column demonstrates that the column count of the low-rank factor approximately doubles in the first three iterations but experiences a close to three-fold increase in the final iteration. In terms of the CPU time for each iteration, the time required for the final iteration is significantly greater than the sum of the preceding three. A detailed analysis indicates that the primary reason for this phenomenon is similar to the previous examples, wherein the computation of equation residuals in the algorithm accounts for the majority of the time. The performance of OSA_lr on the residual history is plotted in Figure 7, where R-Res_i () denotes the relative residual of the i-th equation.
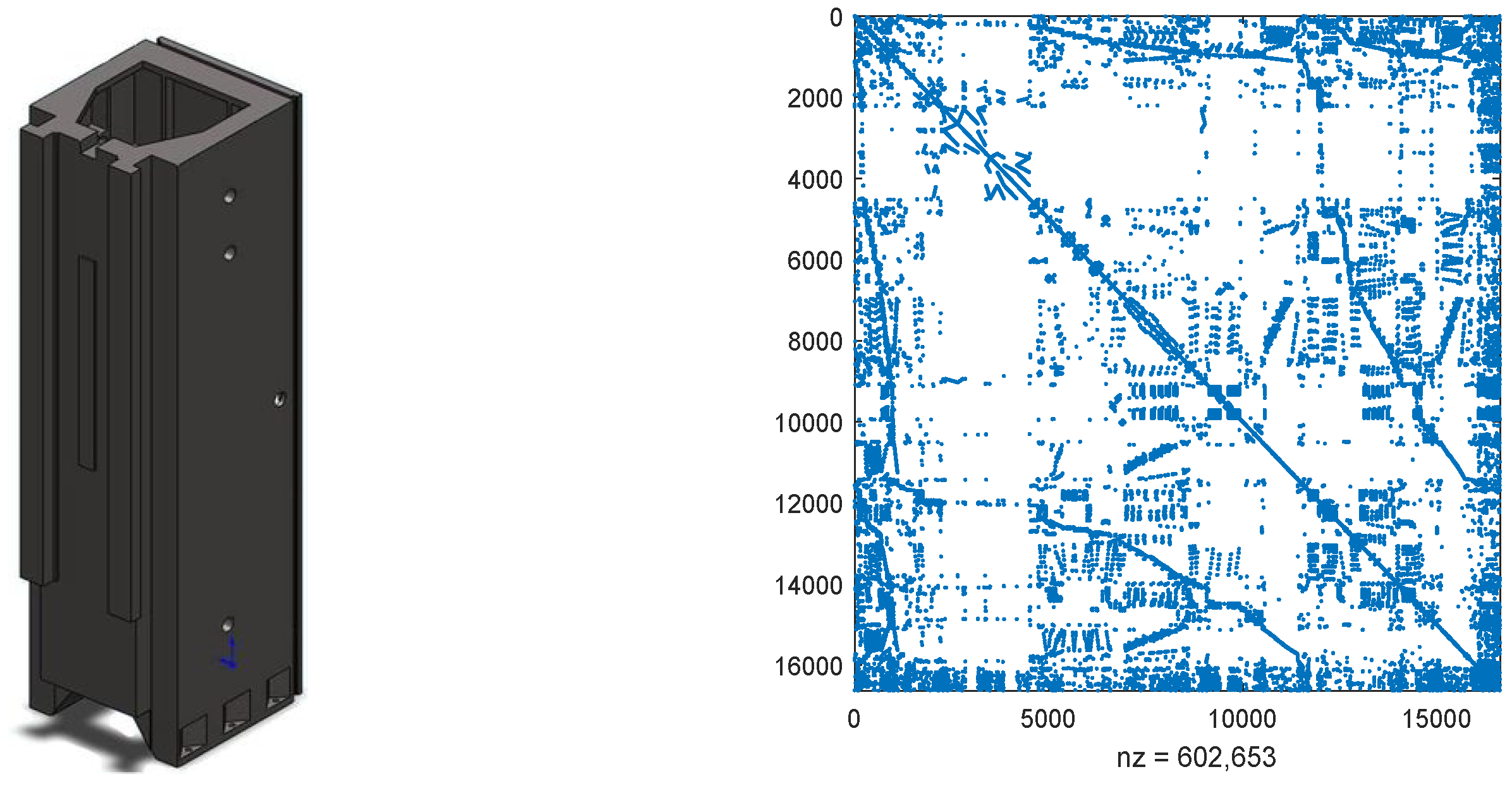
Example 6.
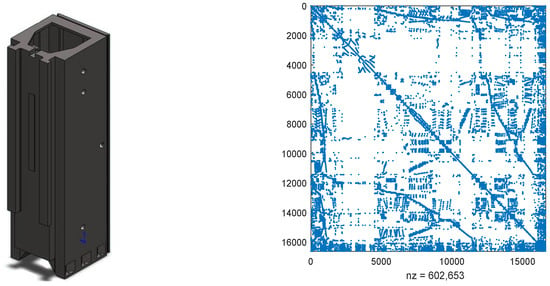
Consider the structurally vertical stand model from machinery control systems, depicted on the left side of Figure 5, representing a segment of a machine tool [30]. In this structural component, a set of guide rails is situated on one of its surfaces. Throughout the machining process, a tool slide traverses various positions along these rails [32]. The model was created and meshed using ANSYS. For spatial discretization, the finite element method with linear Lagrange elements was employed and implemented in FEniCS.
Figure 5.
The vertical stand model and the discretized matrix .
The derived system matrices are
where and are random numbers from (0, 1) and and are vectors with all elements being zeros except fives ones located in rows (3341, 6743, 8932, 11,324, and 16,563) and rows (1046, 2436, 6467, 8423, and 12,574), respectively. As the sparse structures of and are analogous, the right of Figure 5 only exhibits the structure of , which contains 602,653 non-zero elements. Matrices and can be found at [23]. In this example, we set and use the probability matrix as .
We utilized OSA_lr to solve the CDSEs, and the computed results are presented in Table 7. It can be observed from the table that OSA_lr terminates after four iterations, achieving a high-precision solution, where the equation residuals reach a level of to . The iteration history in the Resi and Rel_Resi columns illustrates the quadratic convergence of OSA_lr. The column indicates that in the second, third, and fourth iterations, the column count of the low-rank factor approximately doubles, triples, and quadruples, respectively. This demonstrates that the truncation and compression techniques have a limited impact on reducing the column count of in this scenario. Similarly, reveals that the CPU time for the final iteration is significantly greater than the sum of the preceding three, primarily due to the algorithm spending substantial time computing equation residuals in the last iteration.
Table 7.
CPU time and residual in Example 6.
Example 7.
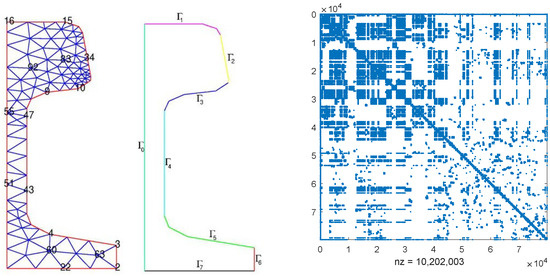
Consider a semi-discretized heat transfer problem aimed at optimizing the cooling of steel profiles in control systems, as discussed in works by [23,30]. The order of the models varies due to the application of different refinements to the computational mesh. For the discretization process, the ALBERTA-1.2 fem-toolbox [33] and the linear Lagrange elements are utilized. The initial mesh (depicted on the left in Figure 6) is generated using MATLAB’s pdetool.
Figure 6.
The initial mesh for cooling of steel and the discretized matrix and .
We slightly modify the model matrices as follows:
where and for N = 20,209 and and for N = 79,841. In this experiment, we take and , with , being a random number in (0, 1). Matrices , , and can be found at [23]. The sparse structures of matrices and are nearly identical, and for illustration purposes, we only display the structure of with N = 79,841 on the right side of Figure 6. The probability matrix is defined as
We employed OSA_lr to solve CDSEs under two different dimensions, and the computed results are presented in Table 8. It is evident from the table that OSA_lr terminates after achieving the predetermined equation residual levels for various dimensions. The Rel_Resi column indicates a significant decrease in the relative equation residuals to the level of by the second iteration, enabling the algorithm to obtain a high-precision solution in only four iterations. The two columns of demonstrate that, for different dimensions, the column count of the low-rank factor increases by a factor of two, indicating that truncation and compression techniques effectively constrain the growth of the column count of in this scenario. Similarly, the column reveals that in the final iteration, due to the computation of equation residuals, OSA_lr consumes considerably more CPU time than the sum of the preceding three iterations. The performances of OSA_lr on the residual history with N = 20,209, 799,841 are plotted in Figure 7, where R-Res_i () denotes the relative residual of the i-th equation.
Table 8.
CPU time and residual in Example 7.
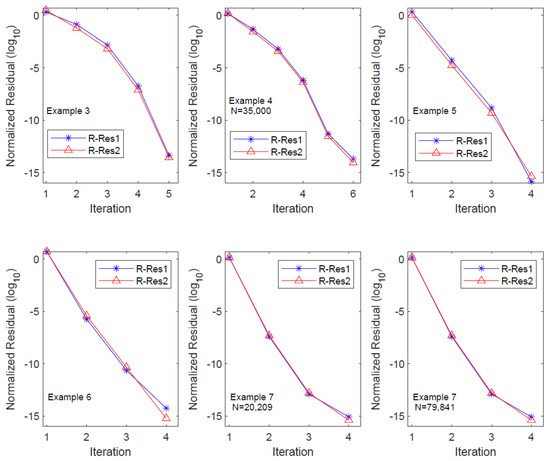
Figure 7.
Relative residual histories for OSA_lr in Examples 3–7.
Figure 7.
Relative residual histories for OSA_lr in Examples 3–7.
5. Conclusions
This paper introduces an OSA method for coupled Stein equations in a class of jump systems. The convergence of the algorithm is established. For large-structured problems, the OSA method is extended to a low-rank structured iterative format, and an error propagation analysis of the algorithm is conducted. Numerical experiments, drawn from practical problems [23], indicate that in small-scale computations, the OSA outperforms existing linearly convergent iterative methods in terms of both the CPU time and accuracy. In large-scale computations, OSA_lr efficiently computes high-precision solutions for CDSEs. Nevertheless, the experiments reveal that the time spent on residual computation in the final iteration is relatively high. Therefore, improving the efficiency of the algorithm’s termination criteria is a direction for further research in future work, and it is currently under consideration.
Author Contributions
Conceptualization, B.Y.; methodology, B.Y.; software, B.H.; validation, N.D.; formal analysis, N.D. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the NSF of China (11801163), the NSF of Hunan Province (2021JJ50032, 2023JJ50165, 2024JJ7162), and the Degree & Postgraduate Education Reform Project of Hunan University of Technology and Hunan Province (JGYB23009, 2024JGYB210).
Data Availability Statement
All examples and data can be found in [30].
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chen, C.-T. Linear System Theory and Design, 3rd ed.; Oxford University Press: New York, NY, USA, 1999. [Google Scholar]
- Betser, A.; Cohen, N.; Zeheb, E. On solving the Lyapunov and Stein equations for a companion matrix. Syst. Control Lett. 1995, 25, 211–218. [Google Scholar] [CrossRef]
- Hueso, J.L.; Martínez, G.; Hernández, V. A systolic algorithm for the triangular Stein equation. J. VLSI Signal Process. Syst. Signal Image Video Technol. 1993, 5, 49–55. [Google Scholar] [CrossRef]
- Li, T.-X.; Weng, P.C.-Y.; Chu, E.K.-W.; Lin, W.-W. Large-scale Stein and Lyapunov Equations, Smith Method, and Applications. Numer. Algorithms 2013, 63, 727–752. [Google Scholar] [CrossRef]
- Fan, H.-Y.; Weng, P.C.-Y.; Chu, K.-W. Numerical solution to generalized Lyapunov/Stein and rational Riccati equations in stochastic control. Numer. Algorithms 2016, 71, 245–272. [Google Scholar] [CrossRef]
- Yu, B.; Dong, N.; Tang, Q. Factorized squared Smith method for large-scale Stein equations with high-rank terms. Automatica 2023, 154, 111057. [Google Scholar] [CrossRef]
- Borno, I.; Gajic, Z. Parallel algorithm for solving coupled algebraic Lyapunov equations of discrete-time jump linear systems. Comput. Math. Appl. 1995, 30, 1–4. [Google Scholar] [CrossRef]
- Wu, A.-G.; Duan, G.-R. New Iterative algorithms for solving coupled Markovian jump Lyapunov equations. IEEE Trans. Auto. Control 2015, 60, 289–294. [Google Scholar]
- Zhou, B.; Duan, G.-R.; Li, Z.-Y. Gradient based iterative algorithm for solving coupled matrix equations. Syst. Control. Lett. 2009, 58, 327–333. [Google Scholar] [CrossRef]
- Li, Z.-Y.; Zhou, B.; Lam, J.; Wang, Y. Positive operator based iterative algorithms for solving Lyapunov equations for Itô stochastic systems with Markovian jumps. Appl. Math. Comput. 2011, 217, 8179–8195. [Google Scholar] [CrossRef]
- Yu, B.; Fan, H.-Y.; Chu, E.K.-W. Smith method for projected Lyapunov and Stein equations. UPB Sci. Bull. Ser. A 2018, 80, 191–204. [Google Scholar]
- Sun, H.-J.; Zhang, Y.; Fu, Y.-M. Accelerated smith iterative algorithms for coupled Lyapunov matrix equations. J. Frankl. Inst. 2017, 354, 6877–6893. [Google Scholar] [CrossRef]
- Li, T.-Y.; Gajic, Z. Lyapunov iterations for solving coupled algebraic Riccati equations of Nash differential games and algebraic Riccati equations of zero-sum games. In New Trends in Dynamic Games and Applications; Olsder, G.J., Ed.; Annals of the International Society of Dynamic Games; Birkhäuser: Boston, MA, USA, 1995; Volume 3. [Google Scholar]
- Wicks, M.; De Carlo, R. Solution of Coupled Lyapunov Equations for the Stabilization of Multimodal Linear Systems. In Proceedings of the 1997 American Control Conference (Cat. No.97CH36041), Albuquerque, NM, USA, 4–6 June 1997; Volume 3, pp. 1709–1713. [Google Scholar]
- Ivanov, I.G. An Improved method for solving a system of discrete-time generalized Riccati equations. J. Numer. Math. Stoch. 2011, 3, 57–70. [Google Scholar]
- Qian, Y.-Y.; Pang, W.-J. An implicit sequential algorithm for solving coupled Lyapunov equations of continuous-time Markovian jump systems. Automatica 2015, 60, 245–250. [Google Scholar] [CrossRef]
- Costa, O.L.V.; Aya, J.C.C. Temporal difference methods for the maximal solution of discrete-time coupled algebraic Riccati equations. J. Optim. Theory Appl. 2001, 109, 289–309. [Google Scholar] [CrossRef]
- Costa, O.L.V.; Marques, R.P. Maximal and stabilizing Hermitian solutions for discrete-time coupled algebraic Riccati equations. Math. Control Signals Syst. 1999, 12, 167–195. [Google Scholar] [CrossRef]
- Ivanov, I.G. Stein iterations for the coupled discrete-time Riccati equations. Nonlinear Anal. Theory Methods Appl. 2009, 71, 6244–6253. [Google Scholar] [CrossRef]
- Bai, L.; Zhang, S.; Wang, S.; Wang, K. Improved SOR iterative method for coupled Lyapunov matrix equations. Afr. Math. 2021, 32, 1457–1463. [Google Scholar] [CrossRef]
- Tian, Z.-L.; Xu, T.-Y. An SOR-type algorithm based on IO iteration for solving coupled discrete Markovian jump Lyapunov equations. Filomat 2021, 35, 3781–3799. [Google Scholar] [CrossRef]
- Penzl, T. A cyclic low-rank Smith method for large sparse Lyapunov equations. SIAM J. Sci. Comput. 1999, 21, 1401–1408. [Google Scholar] [CrossRef]
- Korvink, G.; Rudnyi, B. Oberwolfach Benchmark Collection. In Dimension Reduction of Large-Scale Systems; Benner, P., Sorensen, D.C., Mehrmann, V., Eds.; Lecture Notes in Computational Science and Engineering; Springer: Berlin/Heidelberg, Germany, 2005; Volume 45. [Google Scholar]
- Wang, Q.; Lam, J.; Wei, Y.; Chen, T. Iterative solutions of coupled discrete Markovian jump Lyapunov equations. Comput. Math. Appl. 2008, 55, 843–850. [Google Scholar] [CrossRef]
- Mathworks. MATLAB User’s Guide; Mathworks: Natick, MA, USA, 2020; Available online: https://www.mathworks.com/help/pdf_doc/matlab/index.html (accessed on 15 March 2024).
- Ober, R.J. Asymptotically Stable All-Pass Transfer Functions: Canonical Form, Parametrization and Realization. IFAC Proc. Vol. 1987, 20, 181–185. [Google Scholar] [CrossRef]
- Chahlaoui, Y.; Van Dooren, P. Benchmark examples for model reduction of linear time-invariant dynamical systems. In Dimension Reduction of Large-Scale Systems; Springer: Berlin/Heidelberg, Germany, 2005; Volume 45, pp. 379–392. [Google Scholar]
- Chu, E.K.-W.; Weng, P.C.-Y. Large-scale discrete-time algebraic Riccati equations—Doubling algorithm and error analysis. J. Comput. Appl. Math. 2015, 277, 115–126. [Google Scholar] [CrossRef]
- Higham, N.J. Functions of Matrices: Theory and Computation; SIAM: Philadelphia, PA, USA, 2008. [Google Scholar]
- Chahlaoui, Y.; Van Dooren, P. A collection of benchmark examples for model reduction of linear time invariant dynamical systems. Work. Note 2002. Available online: https://eprints.maths.manchester.ac.uk/1040/1/ChahlaouiV02a.pdf (accessed on 15 March 2024).
- Moosmann, C.; Greiner, A. Convective thermal flow problems. In Dimension Reduction of Large-Scale Systems; Lecture Notes in Computational Science and Engineering; Springer: Berlin/Heidelberg, Germany, 2005; Volume 45, pp. 341–343. [Google Scholar]
- Lang, N. Numerical Methods for Large-Scale Linear Time-Varying Control Systems and Related Differential Matrix Equations; Logos-Verlag: Berlin, Germany, 2018. [Google Scholar]
- Schmidt, A.; Siebert, K. Design of Adaptive Finite Element Software—The Finite Element Toolbox ALBERTA; Lecture Notes in Computational Science and Engineering; Springer: Berlin/Heidelberg, Germany, 2005; Volume 42. [Google Scholar]
- Harper, C.A. Electronic Packaging and Interconnection Handbook; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).