Abstract
The problem of inverting dynamic complex matrices remains a central and intricate challenge that has garnered significant attention in scientific and mathematical research. The zeroing neural network (ZNN) has been a notable approach, utilizing time derivatives for real-time solutions in noiseless settings. However, real-world disturbances pose a significant challenge to a ZNN’s convergence. We design an accelerated dual-integral structure zeroing neural network (ADISZNN), which can enhance convergence and restrict linear noise, particularly in complex domains. Based on the Lyapunov principle, theoretical analysis proves the convergence and robustness of ADISZNN. We have selectively integrated the SBPAF activation function, and through theoretical dissection and comparative experimental validation we have affirmed the efficacy and accuracy of our activation function selection strategy. After conducting numerous experiments, we discovered oscillations and improved the model accordingly, resulting in the ADISZNN-Stable model. This advanced model surpasses current models in both linear noisy and noise-free environments, delivering a more rapid and stable convergence, marking a significant leap forward in the field.
Keywords:
dynamic complex matrix inversion; zeroing neural network; linear noise; activation function; residual fluctuations MSC:
34A55
1. Introduction
Matrix inversion is a fundamental and crucial problem encountered in various domains [1,2,3,4,5], including mathematics and engineering, chaotic systems [1,2,3], and robotic dynamics [5]. Numerous methods exist for solving this problem, primarily categorized into two approaches. The first is numerical computation methods, such as Newton’s iterative method [6,7], which, though fundamentally serial in nature, suffer from slow computation speed and high resource consumption, rendering them ineffective for efficiently computing the inverse of high-dimensional matrices. Another approach is neural-network-based methods, inherently parallel in computation, such as gradient neural networks (GNNs) [8,9,10,11], renowned for their high computational accuracy and exponential convergence. However, GNNs have their own set of challenges and limitations, particularly when it comes to handling dynamic or time-varying data.
Introduced 20 years ago, the ZNN model proposed by Zhang et al. [12] is a specialized neural network architecture that is more adaptive and efficient for solving real-time matrix inversion problems. However, ZNNs are only applicable in ideal noise-free environments. In reality, various types of noise exist, impairing ZNNs’ convergence to theoretical values. Dynamic matrix inversion encompasses two domains: dynamic real matrix inversion and dynamic complex matrix inversion. According to PID control theory [13], the Integration-Enhanced Zhang Neural Network model (IEZNN) [14], proposed by Jin et al., restricts noise interference and is employed to address dynamic real matrix inversion problems, demonstrating commendable noise restriction capabilities and convergence performance through theoretical analysis and experimental validation.
The applications of dynamic matrix inversion in the complex domain span various scientific and engineering disciplines [15,16,17,18,19]. Mathematical models in the complex domain are crucial for describing phenomena such as control systems [16], signal processing [17], and optical systems [18]. Therefore, this paper focuses on the problem of dynamic complex matrix inversion.
Expanding upon previous research on zeroing neural network (ZNN) models, Zhang et al. proposed a complex-valued ZNN (CVZNN) to address DCMI problems [20]. Xiao et al. introduced a complex-valued noise-tolerant ZNN (CVNTZNN) model [21] aimed at restricting real-world noise interference, inspired by the noise reduction principle of integral-based zeroing neural networks. However, the CVNTZNN model struggles to effectively restrict linear noise. Recently, Hua et al. introduced the dual-integral structure zeroing neural network (DISZNN) model [22]. Leveraging its inherent dual-integral structure, the DISZNN model demonstrates superior performance in restricting linear noise for DCMI problems, as evidenced by theoretical analysis based on Laplace transforms. Moreover, numerous studies suggest that integrating activation functions (AFs) into ZNN models enhances noise tolerance and convergence performance [23,24,25,26,27,28,29,30,31]. Therefore, this paper proposes an accelerated dual-integral structure zeroing neural network (ADISZNN) by combining AFs with the DISZNN model to enhance its noise restriction capabilities against linear noise and accelerate convergence. It is noteworthy that the DISZNN model is restructured in this study, and the convergence and robustness of the ADISZNN model are theoretically analyzed and demonstrated in a different manner.
This article delineates the following scholarly contributions: The integration of DISZNN with a novel activation function has culminated in the development of an accelerated dual-integral structure zeroing neural network (ADISZNN). This model utilizes a dual-integral structure and activation function, demonstrating improved convergence speed. This means that the model’s computed results can more quickly approach the theoretical inverse of the target matrix. Oscillatory fluctuations observed in the steady-state residual error of ADISZNN, particularly with the SBPAF activation function, have been identified and mitigated through targeted enhancements. Theoretical analyses, supported by results from three comparative numerical experiments, confirm the outstanding convergence and robustness of the enhanced stable ADISZNN model. To our knowledge, no prior work has introduced an accelerated dual-integral structure zeroing neural network capable of linear noise cancellation in the context of dynamic complex matrix inversion.
The article is structured into five methodical sections. Section 2 delves into the DCMI problem, presenting the design formulation and procedural details of the ADISZNN model. Section 3 offers a theoretical exposition and validation of ADISZNN’s convergence and robustness, utilizing Lyapunov’s theorem and supported by graphical analyses, with the SBPAF function selected for the model’s activation. In Section 4, we conducted three sets of numerical comparison experiments. The article concludes with a summary of the findings in Section 5.
2. Problem Formulation, Design Formula, and ADISZNN Model
2.1. Consideration of the DCMI Problem
The dynamic complex matrix inverse problem can be described as follows:
where is a nonsingular and smooth dynamic complex coefficient matrix with rank n, and represents the real-time solution of Equation (1), obtained through the ADISZNN model, where denotes the identity matrix. Our aim is to compute such that Equation (1) holds true at any given time . Hence, we have .
As complex numbers consist of real and imaginary parts, Equation (1) can be rewritten as
where is the expansion of the complex matrix , and and are, respectively, the real and imaginary parts of the given matrix . Similarly, and are, respectively, the real and imaginary parts of the state solution , where the imaginary unit is denoted as .
2.2. Design Formula
To compute the dynamic complex matrix inversion, a function is devised to measure the real-time error in Equation (1), as follows:
Its derivative with respect to time t is given by
The design formula of the integration-enhanced zeroing neural network model is as follows [14]:
where design parameters and are adjusted for the rate. By combining Equations (4) and (5), we can derive the following formula:
In actuality, a wide array of noise phenomena are consistently present across numerous practical applications. Examples include the superfluous movements observed in robotic arm operations, as discussed in [32], and the chaotic dynamics within permanent magnet synchronous motor (PMSM) systems, as explored in [33], among others. To more accurately reflect real-world conditions, we introduce noise into Equation (6), thereby obtaining the following equation:
2.3. Dual-Integral Structure ZNN Model Design
The DISZNN model proposed by Hua et al. [22] has demonstrated significant efficacy in the restriction of noise, particularly linear noise. The model for DISZNN is as follows:
in which is the design parameter, the single-integral term restricts noise, while the double-integral term not only restricts noise but also accelerates convergence speed.
2.4. ADISZNN Model Design
It has been mentioned in many papers [23,24,25,26,27,28,29,30,31] that adding an activation function to some ZNN-like models can accelerate the convergence of the error function and enhance the model’s ability to restrict noise. Therefore, we modified the ZNN model by adjusting its design formula to
in which, (·): is an activation function.
To provide a more intuitive description of the model’s evolution, we set
Letting
where .
Thus, we obtain the ADISZNN model,
Therefore, the ADISZNN model form with noise can be reformulated as
Furthermore, since we already know that and , we can further derive the ADISZNN model incorporating noise:
3. Theoretical Analyses
In previous research on DISZNN [22], theoretical analysis of convergence and robustness was demonstrated using Laplace transform methods. However, in this paper, we employ a different approach, based on the Lyapunov principle, for proof. In this section, we primarily discuss and demonstrate the convergence and robustness of the ADISZNN model based on the Lyapunov principle, and analyze and apply lemmas to select the activation function. To better represent the Frobenius norm of , we introduce .
3.1. Convergence
The convergence of the ADISZNN model in the absence of noise is proven in this subsection.
Theorem 1.
(Convergence) In the absence of noise, using the ADISZNN model (16) to solve the DCMI problem, as t tends to infinity, the Frobenius norm of the error approaches zero; that is,
The proof of Theorem 1 is as follows.
Proof of Theorem 1.
We rewrite Equation (18) in the absence of noise interference as
To provide a clearer proof, let , , , , and , respectively, represent the xyth subelements of , , , , and .
Firstly, considering that the equation
under the condition of no noise interference for the ADISZNN model can be transformed into the following form:
the element-wise item of (21) is
its derivative is
Assuming a Lyapunov function , its derivative form is as follows:
Since is positive definite, its derivative is negative definite, thus is asymptotically stable. Therefore, we obtain the equation
and we have
thus,
it is easy to obtain that
Taking the derivative of the above equation, we obtain
in which is the small error in the derivative of .
Let us assume another Lyapunov function:
According to the Lyapunov principle, , , we can obtain
Because of ,
is obtained, thus, .
Clearly, we obtain
Therefore, its matrix form is as follows:
Thus, Theorem 1 is proven. □
3.2. Robustness
In the presence of linear noise in matrix form, the ADISZNN model can still asymptotically approach the theoretical solution. Its effectiveness and convergence in handling DCMI problems will be analyzed and demonstrated.
Theorem 2.
(Robustness)In the presence of linear noise, using the ADISZNN model (17) to solve the DCMI problem, as t tends to infinity, the Frobenius norm of the error approaches zero; that is,
Proof of Theorem 2.
The linear noise is expressed as
where and are constant matrices, and their elements can be written as
According to Theorem 1, and Equations (20) and (21), the ADISZNN model in the presence of linear noise can be transformed into the following form:
with elements as in
Differentiating twice, we can obtain
Taking the first and second derivatives of the noise separately, we obtain and . Then,
Assuming the Lyapunov equation to be
therefore,
Since is positive definite and its derivative is negative definite, is globally asymptotically stable, and we obtain
Substituting into it, we obtain
thus, concluding that
then, we obtain
So, we can derive that as ,
Let
then, we have
therefore, we can deduce that
then, we draw
Clearly, , and and have opposite signs, thus
Furthermore,
which means that we can obtain
so,
According to the Lyapunov theorem, we can obtain
The corresponding matrix form is as follows:
Thus, Theorem 2 is proven. □
3.3. Selection of Activation Function
For the ADISZNN model, different activation functions will result in different degrees of convergence in the model solution. To maintain generality in our discussion, we consider the three most common types of activation functions: linear-like activation functions [26], sigmoid-like activation functions [27], and sign-like activation functions [34,35,36]. Here, we take the linear activation function (LAF), smooth bi-polar sigmoid activation function (SBPSAF), and signal bi-power activation function (SBPAF) as examples. They are defined as follows:
- LAF:
- SBPSAF:where
- SBPAF:where is a symbolic function and the design parameters are , and .
However, determining whether an activation function is suitable is a challenging task. Ref. [35] elucidates a concept within the Lyapunov stability framework, suggesting that the rate of convergence of a system is positively correlated with the magnitude of its derivative near the origin. Specifically, the larger the derivative, the faster the system converges. To illustrate this, Figure 1 in the paper depicts the derivative curves for three activation functions: LAF, SBPSAF, and SBPAF. It is observed that near the origin, the derivative of SBPAF exceeds that of LAF, and similarly, the derivative of LAF surpasses that of SBPSAF. Based on this observation, it can be inferred that the ADISZNN model employing the SBPAF activation function may converge in a shorter time compared to the model using the LAF activation function. Likewise, the model with the LAF activation function is likely to converge faster than the one with the SBPSAF activation function.
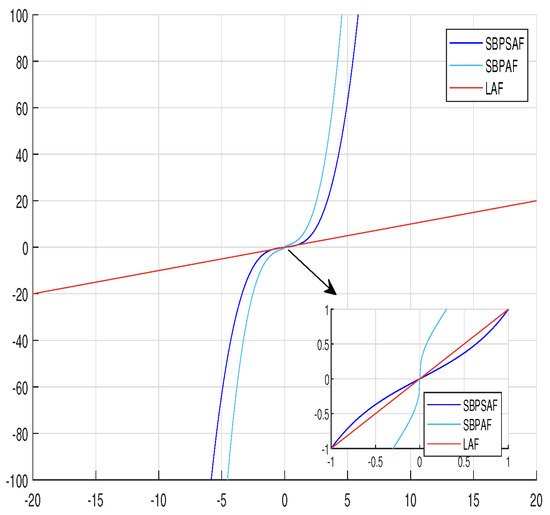
Figure 1.
Three sorts of activation functions presented: linear activation function (LAF) (x) (red solid line), smooth bi-polar sigmoid activation function (SBPSAF) (x) (sky blue solid line), and signal bi-power activation function (SBPAF) (x) (blue solid line).
Therefore, in this article, we will use SBPAF as the activation function adopted by ADISZNN.
4. Simulation and Comparative Numerical Experiments
4.1. Comparison Experiments of Activation Functions
In this section, to further validate the correctness of our activation function selection, we compare the ADISZNN models using three different activation functions.
In this example, a two-dimensional dynamic complex matrix is presented as follows:
For convenience, this matrix only contains the imaginary part. To verify the correctness of the ADISZNN model, the theoretical inverse of the above dynamic complex matrix is obtained through mathematical calculation:
Figure 2 delineates the computational and convergence trajectories of the ADISZNN model across various activation functions, all in the absence of noise. A discernible observation from this figure is that models utilizing the LAF and SBPSAF activation functions achieve near-simultaneous steady-state error close to zero at approximately 2.3 s. In stark contrast, the ADISZNN model equipped with the SBPAF activation function demonstrates a markedly swifter convergence, reaching near-zero error within a mere 0.6 s—a rate that is roughly threefold faster than its counterparts.
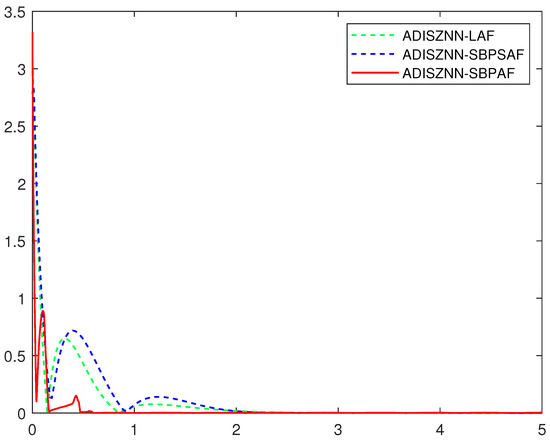
Figure 2.
Comparative graph of the computation and convergence processes of ADISZNN with three different activation functions without noise interference; the design parameters are and : ADISZNN-LAF (green dashed line), ADISZNN-SBPSAF (blue dashed line), ADISZNN-SBPAF (red solid line).
Figure 3, on the other hand, captures the ADISZNN model’s performance under the influence of linear noise, with each subplot showcasing the model’s behavior when driven by the LAF, SBPSAF, and SBPAF activation functions, respectively. For the readers’ ease, a comparative analysis of these models is tabulated in Table 1. The table underscores a significant finding: the proximity of the activation function’s derivative to the origin is positively correlated with the model’s convergence efficiency. Notably, the ADISZNN model harnessing SBPAF exhibits the most rapid convergence. Nonetheless, it is important to note that models incorporating SBPSAF and SBPAF show a relatively diminished robustness when compared to the LAF-equipped model.
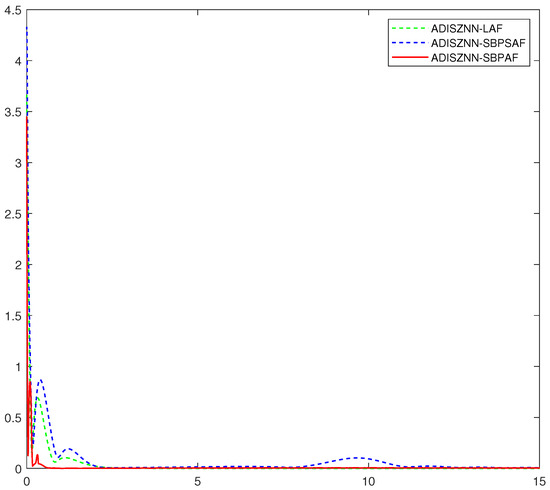
Figure 3.
Comparative graph of the computation and convergence processes of ADISZNN with three different activation functions under linear noise ; the design parameters are and : ADISZNN-LAF (green dashed line), ADISZNN-SBPSAF (blue dashed line), ADISZNN-SBPAF (red solid line).

Table 1.
Comparison of ADISZNN model adopting LAF, SBPSAF, and SBPAF.
These experiments not only confirm the enhanced convergence speed of the ADISZNN model employing the SBPAF activation function proposed in this paper but also validate the appropriateness of the chosen activation function.
Next, we will compare and analyze the convergence performance of the ADISZNN model using the signal bi-power activation function with the DISZNN model without using any activation function under the condition of linear matrix noise interference.
4.2. Comparison Experiments between DISZNN and ADISZNN
The DISZNN model is rewritten as follows:
where is a design parameter.
The error results of the DISZNN model and the ADISZNN model using SBPAF are shown in Figure 4. Under the condition without noise interference, for any initial value of the dynamic complex matrix the error of the DISZNN model converges almost completely to 0 around 2.8 s. When the SBPAF activation function is introduced, the error of the ADISZNN model converges almost completely to 0 within 0.6 s. Therefore, the convergence speed of the ADISZNN model is significantly faster than that of DISZNN.
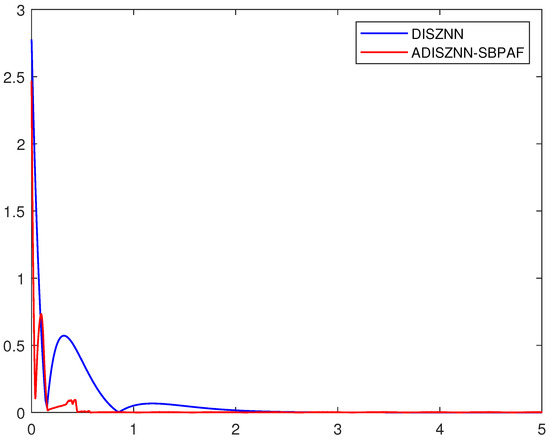
Figure 4.
Convergence comparison of ADISZNN and DISZNN without noise interference; the design parameters are and : ADISZNN-SBPAF (red solid line) and DISZNN (blue solid line).
To compare the tolerance of ADISZNN and DISZNN to noise, a common linear noise is introduced. Their numerical experimental comparison is shown in Figure 5, where the design parameters are set as , , and . Under the interference of linear noise, both DISZNN and ADISZNN can still make the residual close to 0 within approximately 2.8 s and 0.6 s, respectively, which is nearly the same as the case without noise interference. This demonstrates that ADISZNN and DISZNN possess inherent tolerance to linear noise.
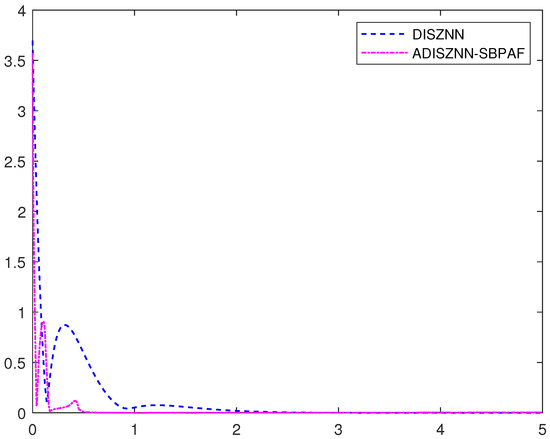
Figure 5.
Convergence comparison of ADISZNN and DISZNN, under linear noise : ADISZNN-SBPAF (pink dotted line) and DISZNN (blue dashed line).
However, during the experimental process, we observed that the residual plot of the ADISZNN model with the signal bi-power activation function exhibits oscillatory fluctuations after reaching the magnitude of at 0.6 s. This indicates a decrease in the precision of the model’s computations, as it fails to maintain stable convergence at the magnitude level. This implies a reduction in the robustness of the ADISZNN model. The residual plots of the ADISZNN model with noise interference and the comparison of residuals between the DISZNN and ADISZNN models without noise interference are shown in Figure 6 and Figure 7, respectively. In the next subsection, we will discuss the stable version (high-precision version) of the ADISZNN model.
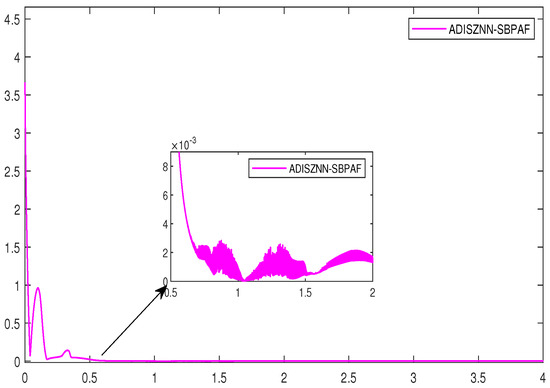
Figure 6.
The amplified residual errors of ADISZNN under linear noise , with design parameters , and .
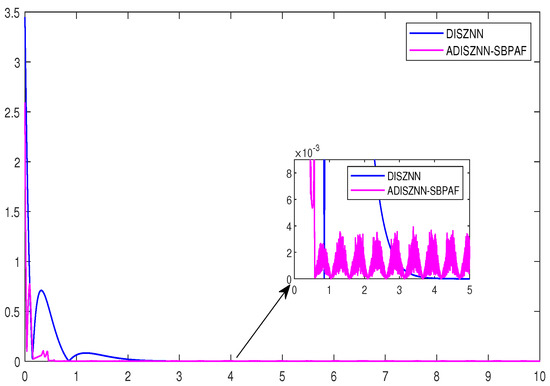
Figure 7.
The amplified residual errors of DISZNN and ADISZNN under no noise, with design parameters , and .
4.3. The Stable ADISZNN Model
In this subsection, we propose an improved version of the ADISZNN-SBPAF model to address the oscillation phenomenon (or precision degradation phenomenon). According to the table in experiment 1, we observe that not only can ADISZNN with the signal bi-power activation function accelerate the convergence compared to the DISZNN model, but also the ADISZNN model with the linear activation function (LAF) can similarly accelerate convergence and exhibit stronger robustness.
Based on this observation, we innovatively propose a stable version of the ADISZNN model: When the error of the ADISZNN model using SBPAF approaches zero (i.e., reaches the order of ), we transition the model to use LAF. This transition alters the calculation and convergence of , transforming the ADISZNN-SBPAF model into the ADISZNN-LAF model. The convergence performance of this approach is illustrated in the Figure 8, Figure 9 and Figure 10.
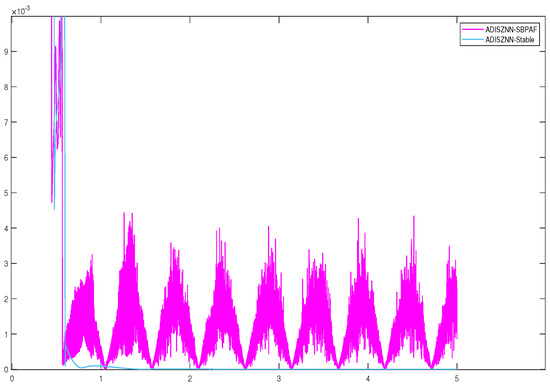
Figure 8.
Comparison of the amplified residual errors of stable ADISZNN and unstable ADISZNN under no noise, with design parameters , and .
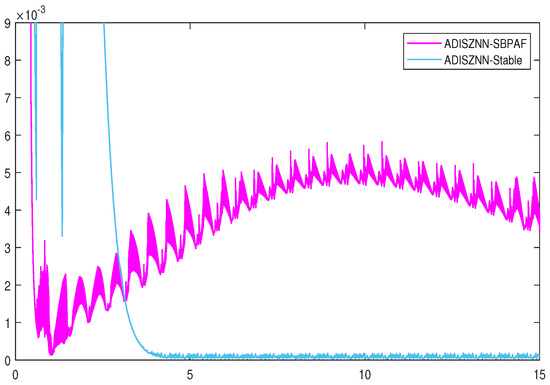
Figure 9.
The detailed residual errors of ADISZNN-Stable and ADISZNN-SBPAF, with noise of .
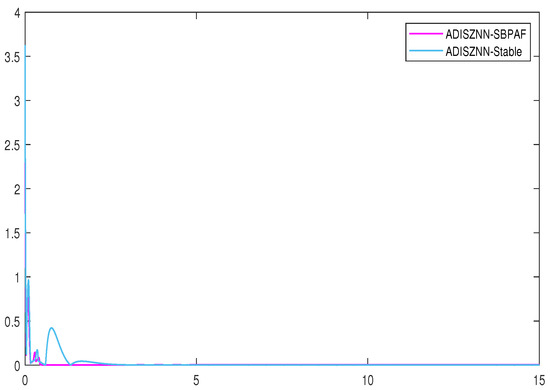
Figure 10.
Residual errors of ADISZNN-Stable and ADISZNN-SBPAF with noise of .
The residual plots in Figure 9 and Figure 10, respectively, depict the effects of our improvement on the stable version of the ADISZNN model compared to the unstable version (For the reader’s enhanced comprehension, Figure 8 illustrates the comparison of amplified residual errors between the stable and unstable variants of ADISZNN in the absence of noise). While this enhancement results in a slight increase in the convergence time, it strengthens the model’s resistance to noise and improves its robustness. Additionally, the computational accuracy is elevated from the order of to , thereby enhancing the convergence performance of the model.
In Figure 11, a comparison between the stable version of the ADISZNN model and the original DISZNN model is presented. Compared to the original DISZNN model, the stable version of the ADISZNN model exhibits significant improvements. When the computed solution of the model converges to a theoretical state approximation , the convergence time of the stable ADISZNN model is reduced from 2.8 s to 1.9 s. Moreover, the convergence curve of the stable ADISZNN model appears smoother and more refined. Both models achieve a computational accuracy of when fully converged. These results indicate that the improved stable version of the ADISZNN model not only enhances the convergence speed but also maintains robustness comparable to that of the DISZNN model.
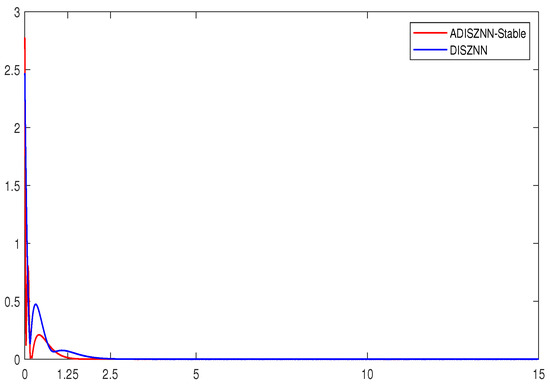
Figure 11.
The comparison of the residual errors of stable ADISZNN and DISZNN under linear noise of , with design parameters , and .
To underscore the merits of the ADISZNN-Stable model, Figure 12 and Figure 13 depict comparative trajectory plots of the DISZNN alongside the ADISZNN-Stable model under conditions of linear noise. Additionally, Figure 14 presents an analysis of residual errors, contrasting the performance of the DISZNN with that of the ADISZNN-Stable model in an environment devoid of noise.
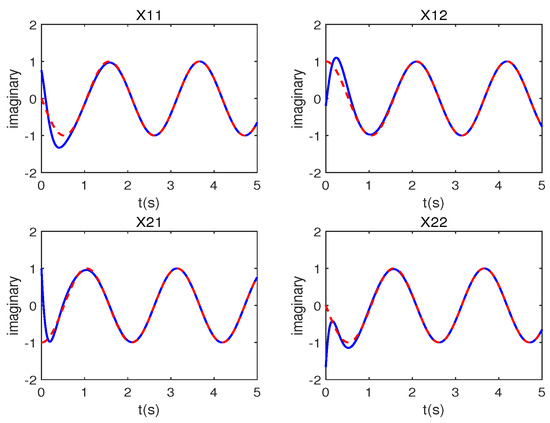
Figure 12.
Trajectory analysis for problem (41) under linear noise of ; the red line points represent the theoretical solution, while the blue line points show the DISZNN model’s solutions.
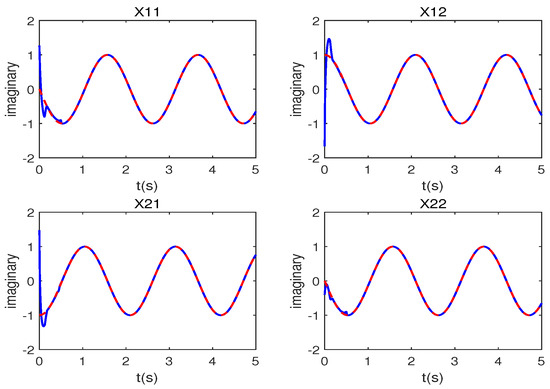
Figure 13.
Trajectory analysis for problem (41) under linear noise of ; the red line points represent the theoretical solution, while the blue line points show the ADISZNN-Stable model’s solutions.
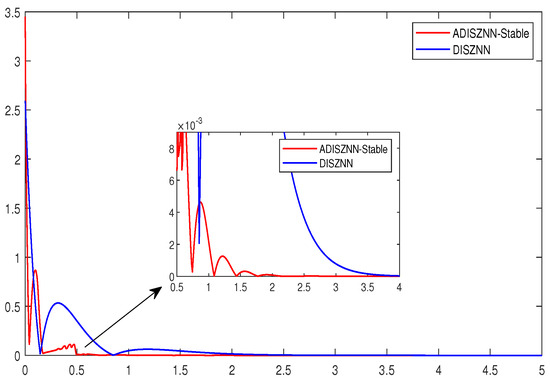
Figure 14.
Comparison of the amplified residual errors of stable ADISZNN and DISZNN under no noise, with design parameters , and .
5. Conclusions
This article introduces a novel enhancement to the DISZNN model through the integration of an activation function, culminating in an accelerated dual-integral structure ZNN model. This model exhibits enhanced resilience against linear noise interference, particularly pertinent for dynamic complex matrix inversion challenges. The paper unfolds with the following key contributions: initially, the design formula for a single-integral structure and the DISZNN model are presented and analyzed; subsequently, the architecture of the ADISZNN model is designed, with a theoretical examination of its convergence and robustness; thirdly, both experimental and theoretical analyses are employed to assess the influence of various activation functions on the ADISZNN’s convergence efficacy, thereby substantiating the efficacy of our selected activation function; fourthly, comparative tests under linear noise conditions between the ADISZNN and DISZNN models underscore the ADISZNN’s superior convergence capabilities, albeit with the caveat that the ADISZNN model utilizing the SBPAF activation function exhibits oscillatory behavior, potentially compromising its robustness. In light of these findings, we propose refinements to the ADISZNN-SBPAF model, yielding a more stable iteration of the ADISZNN. Comparative experimentation facilitates the identification of the optimal ZNN configuration. Future inquiries are suggested to investigate the potential applications of the ADISZNN model within the engineering sector. This paper presents the ADISZNN model, which has certain limitations, specifically detailed in Appendix A.
Author Contributions
Conceptualization, Y.H. and F.Y.; methodology, T.W. and Y.H.; software, F.Y. and Y.H.; validation, F.Y. and Y.H.; formal analysis, F.Y.; investigation, T.W.; resources, Y.H.; data curation, F.Y.; writing—original draft preparation, F.Y.; writing—review and editing, Y.H.; visualization, F.Y.; supervision, Y.H.; project administration, F.Y.; funding acquisition, Y.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the National Natural Science Foundation of China under Grant No. 62062036, Grant No. 62066015 and Grant No. 62006095, and the College Students’ Innovation Training Center Project at Jishou University under Grant No. JDCX20231012.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this article:
| ZNN | Zeroing neural network |
| GNN | Gradient neural network |
| DNSZNN | Dual noise-suppressed ZNN |
| DISZNN | Dual-integral structure zeroing neural network |
| CVZNN | Complex-valued ZNN |
| IEZNN | Integral-enhanced ZNN |
| CVNTZNN | Complex-valued noise-tolerant ZNN |
| ADISZNN | Accelerated dual-integral structure zeroing neural network |
| DRMI | Dynamic real matrix inversion |
| DCMI | Dynamic complex matrix inversion |
| AF | Activation function |
| LAF | Linear activation function |
| SBPAF | Signal bi-power activation function |
| SBPSAF | Smooth bi-polar sigmoid activation function |
Appendix A. Limitation
- The ADISZNN model and the ADISZNN-Stable model proposed in this paper currently do not handle discontinuous noise.
- This paper restricts the inversion of matrices to be non-singular, smooth, dynamic, and complex. The problem of inverting singular or non-smooth matrices is not addressed in this paper.
References
- Jin, J.; Chen, W.; Ouyang, A.; Yu, F.; Liu, H. A time-varying fuzzy parameter zeroing neural network for the synchronization of chaotic systems. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 8, 364–376. [Google Scholar] [CrossRef]
- Zhang, R.; Xi, X.; Tian, H.; Wang, Z. Dynamical analysis and finite-time synchronization for a chaotic system with hidden attractor and surface equilibrium. Axioms 2022, 11, 579. [Google Scholar] [CrossRef]
- Rasouli, M.; Zare, A.; Hallaji, M.; Alizadehsani, R. The synchronization of a class of time-delayed chaotic systems using sliding mode control based on a fractional-order nonlinear PID sliding surface and its application in secure communication. Axioms 2022, 11, 738. [Google Scholar] [CrossRef]
- Gao, R. Inverse kinematics solution of Robotics based on neural network algorithms. J. Ambient Intell. Humaniz. Comput. 2020, 11, 6199–6209. [Google Scholar] [CrossRef]
- Hu, Z.; Xiao, L.; Li, K.; Li, K.; Li, J. Performance analysis of nonlinear activated zeroing neural networks for time-varying matrix pseudoinversion with application. Appl. Soft Comput. 2021, 98, 106735. [Google Scholar] [CrossRef]
- Ramos, H.; Monteiro, M.T.T. A new approach based on the Newton’s method to solve systems of nonlinear equations. J. Comput. Appl. Math. 2017, 318, 3–13. [Google Scholar] [CrossRef]
- Andreani, R.; Haeser, G.; Ramos, A.; Silva, P.J. A second-order sequential optimality condition associated to the convergence of optimization algorithms. IMA J. Numer. Anal. 2017, 37, 1902–1929. [Google Scholar]
- Zhang, Y. Revisit the analog computer and gradient-based neural system for matrix inversion. In Proceedings of the 2005 IEEE International Symposium on, Mediterrean Conference on Control and Automation Intelligent Control, Limassol, Cyprus, 27–29 June 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 1411–1416. [Google Scholar]
- Zhang, Y.; Chen, K.; Tan, H.Z. Performance analysis of gradient neural network exploited for online time-varying matrix inversion. IEEE Trans. Autom. Control 2009, 54, 1940–1945. [Google Scholar] [CrossRef]
- Zhang, Y.; Shi, Y.; Chen, K.; Wang, C. Global exponential convergence and stability of gradient-based neural network for online matrix inversion. Appl. Math. Comput. 2009, 215, 1301–1306. [Google Scholar] [CrossRef]
- Xiao, L.; Li, K.; Tan, Z.; Zhang, Z.; Liao, B.; Chen, K.; Jin, L.; Li, S. Nonlinear gradient neural network for solving system of linear equations. Inf. Process. Lett. 2019, 142, 35–40. [Google Scholar] [CrossRef]
- Zhang, Y.; Ge, S. A general recurrent neural network model for time-varying matrix inversion. In Proceedings of the 42nd IEEE International Conference on Decision and Control (IEEE Cat. No. 03CH37475), Maui, HI, USA, 9–12 December 2003; IEEE: Piscataway, NJ, USA, 2003; Volume 6, pp. 6169–6174. [Google Scholar]
- Johnson, M.A.; Moradi, M.H. PID Control; Springer: Heidelberg, Germany, 2005. [Google Scholar]
- Jin, L.; Zhang, Y.; Li, S. Integration-enhanced Zhang neural network for real-time-varying matrix inversion in the presence of various kinds of noises. IEEE Trans. Neural Networks Learn. Syst. 2015, 27, 2615–2627. [Google Scholar] [CrossRef]
- Golub, G.H.; Van Loan, C.F. Matrix Computations; JHU Press: Baltimore, MD, USA, 2013. [Google Scholar]
- Ogata, K. Control systems analysis in state space. In Modern Control Engineering; Pearson Education, Inc.: Hoboken, NJ, USA, 2010; pp. 648–721. [Google Scholar]
- Smith, S. Digital Signal Processing: A Practical Guide for Engineers and Scientists; Newnes: Boston, UK, 2003. [Google Scholar]
- Saleh, B.E.; Teich, M.C. Fundamentals of Photonics; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- Trefethen, L.N.; Bau, D. Numerical Linear Algebra; Siam: Philadelphia, PA, USA, 2022; Volume 181. [Google Scholar]
- Zhang, Y.; Li, Z.; Li, K. Complex-valued Zhang neural network for online complex-valued time-varying matrix inversion. Appl. Math. Comput. 2011, 217, 10066–10073. [Google Scholar] [CrossRef]
- Xiao, L.; Zhang, Y.; Zuo, Q.; Dai, J.; Li, J.; Tang, W. A noise-tolerant zeroing neural network for time-dependent complex matrix inversion under various kinds of noises. IEEE Trans. Ind. Inform. 2019, 16, 3757–3766. [Google Scholar] [CrossRef]
- Hua, C.; Cao, X.; Xu, Q.; Liao, B.; Li, S. Dynamic Neural Network Models for Time-Varying Problem Solving: A Survey on Model Structures. IEEE Access 2023, 11, 65991–66008. [Google Scholar] [CrossRef]
- Dai, J.; Jia, L.; Xiao, L. Design and analysis of two prescribed-time and robust ZNN models with application to time-variant Stein matrix equation. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 1668–1677. [Google Scholar] [CrossRef]
- Li, S.; Chen, S.; Liu, B. Accelerating a recurrent neural network to finite-time convergence for solving time-varying Sylvester equation by using a sign-bi-power activation function. Neural Process. Lett. 2013, 37, 189–205. [Google Scholar] [CrossRef]
- Lan, X.; Jin, J.; Liu, H. Towards non-linearly activated ZNN model for constrained manipulator trajectory tracking. Front. Phys. 2023, 11, 1159212. [Google Scholar] [CrossRef]
- Liao, B.; Zhang, Y. From different ZFs to different ZNN models accelerated via Li activation functions to finite-time convergence for time-varying matrix pseudoinversion. Neurocomputing 2014, 133, 512–522. [Google Scholar] [CrossRef]
- Xiao, L. A nonlinearly activated neural dynamics and its finite-time solution to time-varying nonlinear equation. Neurocomputing 2016, 173, 1983–1988. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, Y. Superior robustness of power-sum activation functions in Zhang neural networks for time-varying quadratic programs perturbed with large implementation errors. Neural Comput. Appl. 2013, 22, 175–185. [Google Scholar] [CrossRef]
- Liao, B.; Zhang, Y. Different complex ZFs leading to different complex ZNN models for time-varying complex generalized inverse matrices. IEEE Trans. Neural Netw. Learn. Syst. 2013, 25, 1621–1631. [Google Scholar] [CrossRef]
- Xiao, L.; Tan, H.; Jia, L.; Dai, J.; Zhang, Y. New error function designs for finite-time ZNN models with application to dynamic matrix inversion. Neurocomputing 2020, 402, 395–408. [Google Scholar] [CrossRef]
- Lv, X.; Xiao, L.; Tan, Z.; Yang, Z. Wsbp function activated Zhang dynamic with finite-time convergence applied to Lyapunov equation. Neurocomputing 2018, 314, 310–315. [Google Scholar] [CrossRef]
- Li, Z.; Liao, B.; Xu, F.; Guo, D. A New Repetitive Motion Planning Scheme With Noise Suppression Capability for Redundant Robot Manipulators. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 5244–5254. [Google Scholar] [CrossRef]
- Liao, B.; Han, L.; Cao, X.; Li, S.; Li, J. Double integral-enhanced Zeroing neural network with linear noise rejection for time-varying matrix inverse. CAAI Trans. Intell. Technol. 2023, 9, 197–210. [Google Scholar] [CrossRef]
- Zhang, M. A varying-gain ZNN model with fixed-time convergence and noise-tolerant performance for time-varying linear equation and inequality systems. Authorea Prepr. 2023. Available online: https://www.techrxiv.org/doi/full/10.36227/techrxiv.16988404.v1 (accessed on 4 April 2024).
- Zhang, Z.; Deng, X.; Qu, X.; Liao, B.; Kong, L.D.; Li, L. A varying-gain recurrent neural network and its application to solving online time-varying matrix equation. IEEE Access 2018, 6, 77940–77952. [Google Scholar] [CrossRef]
- Han, L.; Liao, B.; He, Y.; Xiao, X. Dual noise-suppressed ZNN with predefined-time convergence and its application in matrix inversion. In Proceedings of the 2021 11th International Conference on Intelligent Control and Information Processing (ICICIP), Dali, China, 3–7 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 410–415. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).