
Text2shape Deep Retrieval Model: Generating Initial Cases for Mechanical Part Redesign under the Context of Case-Based Reasoning




Abstract
1. Introduction
2. Related Work
2.1. Text Data Representation and Analysis
2.2. 3D Shape Data Representation and Analysis
2.3. Retrieval from Text Descriptions to 3D Shapes
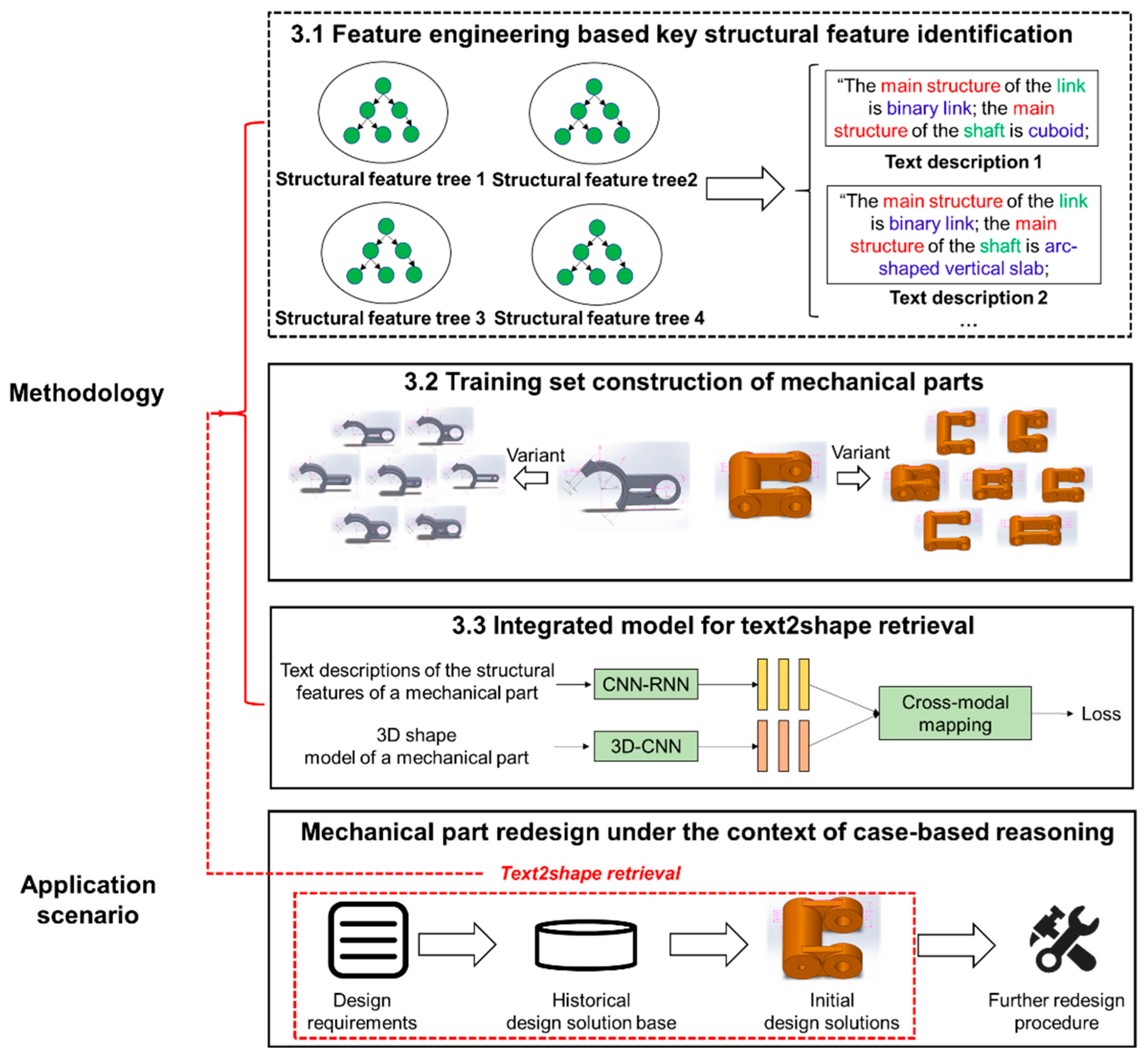
3. The Text2shape Deep Retrieval Model
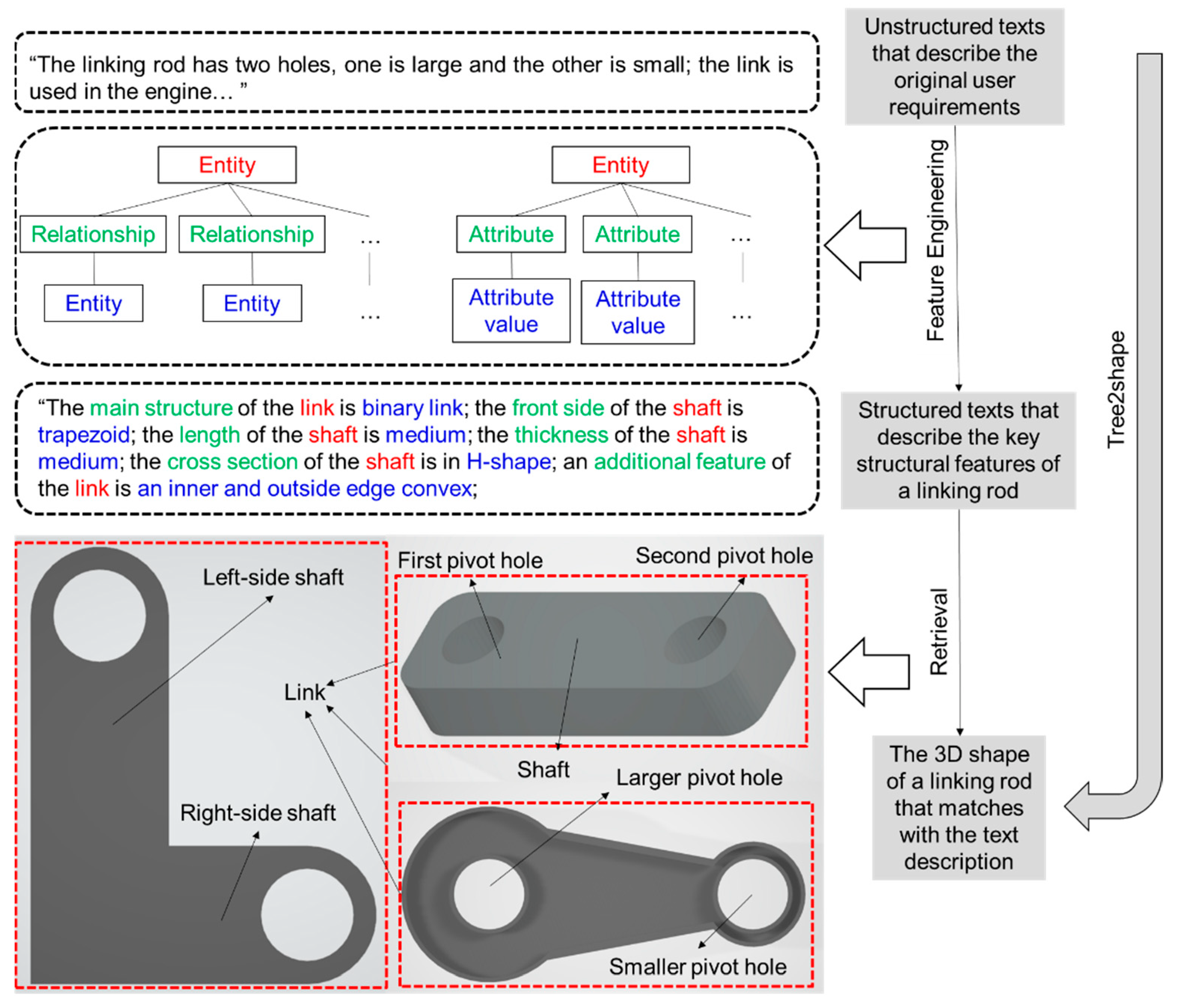
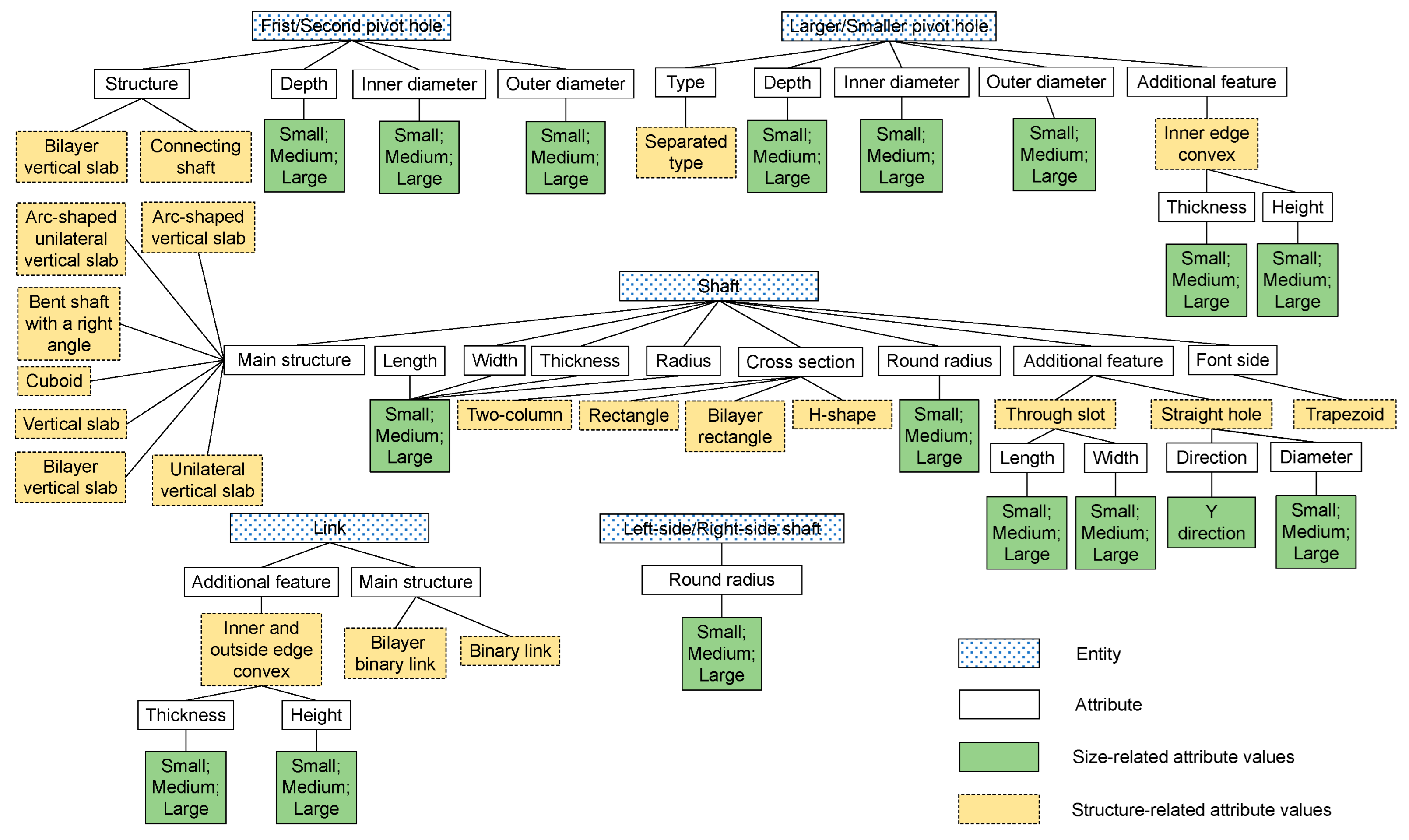
3.1. Feature Engineering Based Identification for Key Structural Features
3.2. Training Set Construction
3.2.1. Constructing the 3D Shape Models
3.2.2. Preparing the Text Descriptions for the 3D Models
3.2.3. Setting up a Guidance for Building the Training Set by Multiple Participators
- (a)
- Consistent terminology: Using different terms to express the same features in the text descriptions would increase the number of training samples required for the training. Therefore, all the participators should use the same terminology to express the features.
- (b)
- Using the same layout directions for the 3D models: When providing the text descriptions, the 3D models of the linking rods should be located in the same coordinate system with the same layout directions. For example, in order to accurately describe the direction of a hole structure in the shaft (i.e., X, Y, or Z direction), the pivot holes of all the linking rods should be facing to the same direction.
- (c)
- Unified distinction of pivot holes: For the linking rods of which the pivot holes have the same inner diameter, Left-side/Right-side pivot holes were used as the unified terms to further describe the other structural features of the two pivot holes. For the linking rods of which the pivot holes have different inner diameters (these types of linking rods are usually used on internal combustion engines), Larger/Smaller pivot holes were used as the unified terms.
- (d)
- Unified standards for size-related attribute values: As mentioned before, in order to reduce the difficulty of training the deep retrieval model, the size-related attribute values were simplified as Small/Medium/Large, and the values were given using the average values of the samples as benchmarks.
- (e)
- Unified final check: After the training set has been constructed, the 3D models and their corresponding text descriptions provided by multiple participators should be checked by one designer.
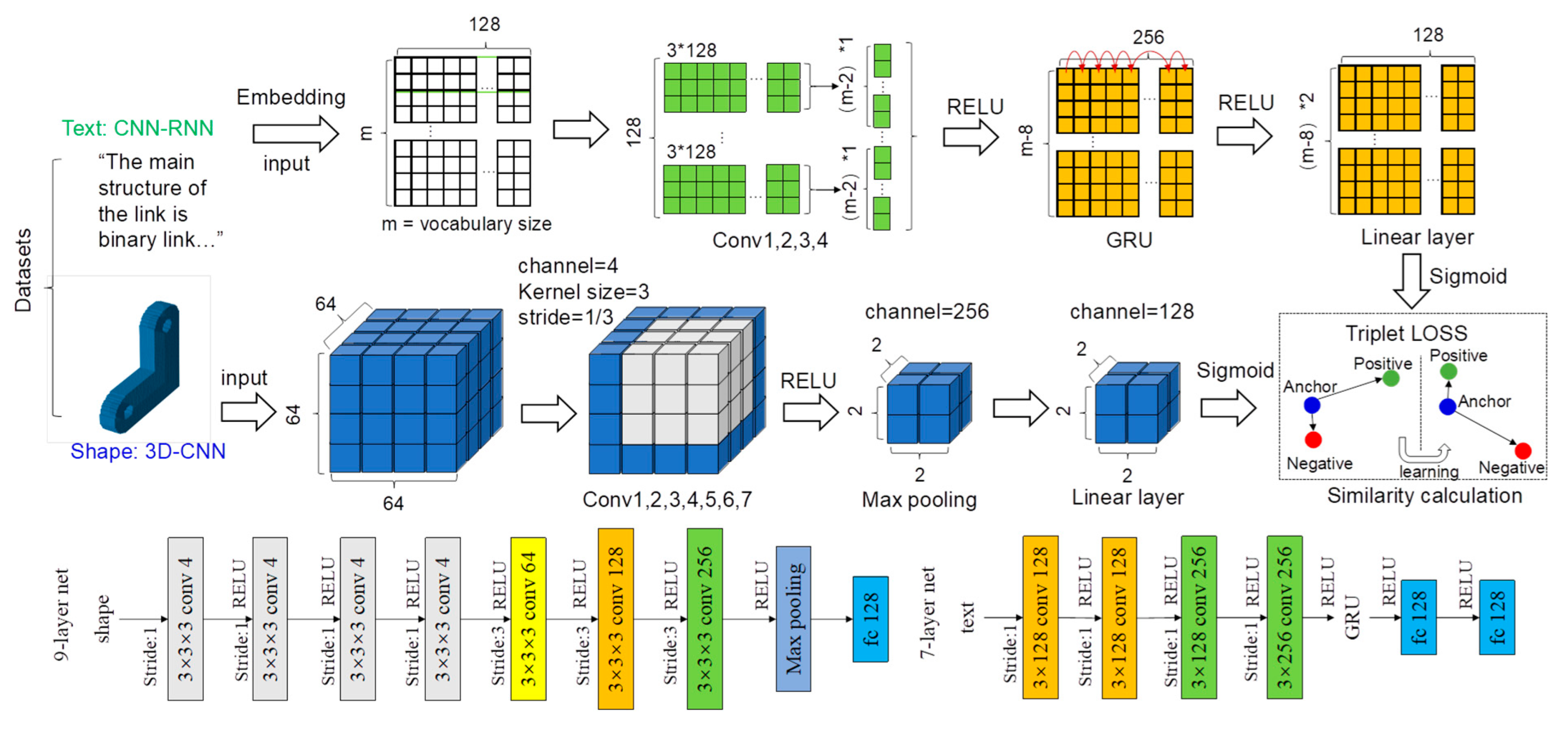
3.3. An Integrated Model of CNN and RNN for Text2shape Retrieval
3.3.1. Representing the Data Features of the Text Descriptions with an Integrated Model of CNN and RNN
3.3.2. Representing the Data Features of the 3D Voxel Models with a CNN Based Model
3.3.3. Calculating the Similarity between Text Descriptions and 3D Voxel Models with a Triplet Loss Based Method
4. Case Study
4.1. Operating Environment
4.2. Training Set Preparation
4.3. Training Details
4.3.1. Tuning the Deep Retrieval Model with an Orthogonal Experiment-Based Method
4.3.2. Verifying the Experiment Results with Range Analysis and Variance Analysis
4.4. Retrieval Case Study
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Das, R.; Godbole, A.; Naik, A.; Tower, E.; Jia, R.; Zaheer, M.; Hajishirzi, H.; McCallum, A. Knowledge base question answering by case-based reasoning over subgraphs. arXiv 2022, arXiv:2202.10610. [Google Scholar]
- Li, S.; Chen, L. Pattern-based reasoning for rapid redesign: A proactive approach. Res. Eng. Des. 2010, 21, 25–42. [Google Scholar] [CrossRef]
- Brooks, B. The pulley model: A descriptive model of risky decision-making. Saf. Sci. Monit. 2007, 11, 1–14. [Google Scholar]
- Wang, Z.; Long, C.; Cong, G.; Ju, C. Effective and efficient sports play retrieval with deep representation learning. In Proceedings of the KDD ‘19: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Malkiel, I.; Nagler, A.; Mrejen, M.; Arieli, U.; Wolf, L.; Suchowski, H. Deep learning for design and retrieval of nano-photonic structures. arXiv 2017, arXiv:1702.07949. [Google Scholar]
- Tangelder, J.W.H.; Veltkamp, R.C. A survey of content based 3D shape retrieval methods. Multide. Tools Appl. 2008, 39, 441–471. [Google Scholar] [CrossRef]
- Yang, Y.B.; Lin, H.; Zhu, Q. Content based 3D model retrieval: A survey. Chin. J. Comput. 2004, 27, 1297–1310. [Google Scholar]
- Yuan, J.F.; Hameed, A.R.; Li, B.; Lu, Y.; Schreck, T.; Bai, S.; Bai, X.; Bui, N.-M.; Do, M.N.; Do, T.-L.; et al. A comparison of methods for 3D scene shape retrieval. Comput. Vis. Image Underst. 2020, 201, 103070. [Google Scholar] [CrossRef]
- Chen, K.; Choy, C.B.; Savva, M.; Chang, A.X.; Funkhouser, T.; Savarese, S. Text2Shape: Generating shapes from natural language by learning joint embeddings. In Proceedings of the Computer Vision-ACCV 2018, Perth, Australia, 2–6 December 2018. [Google Scholar]
- Hu, N.; Zhou, H.; Liu, A.A.; Huang, X.; Zhang, S.; Jin, G.; Guo, J.; Li, X. Collaborative distribution alignment for 2D image-based 3D shape retrieval. J. Vis. Commun. Image R. 2022, 83, 103426. [Google Scholar] [CrossRef]
- Angrish, A.; Bharadwaj, A.; Starly, B. MVCNN++: Computer-aided design model shape classification and retrieval using multi-view convolutional neural networks. J. Comput. Inf. Sci. Eng. 2021, 21, 011001. [Google Scholar] [CrossRef]
- Kim, E.Y.; Shin, S.Y.; Lee, S.; Lee, K.J.; Lee, K.H.; Lee, K.M. Triplanar convolution with shared 2D kernels for 3D classification and shape retrieval. Comput. Vis. Image Underst. 2020, 193, 102901. [Google Scholar] [CrossRef]
- Song, D.; Li, T.B.; Li, W.H.; Nie, W.Z.; Liu, W.; Liu, A.A. Universal cross-domain 3D model retrieval. IEEE Multimed. 2021, 23, 2721–2731. [Google Scholar] [CrossRef]
- Qiao, H.; Wu, Q.Y.; Yu, S.L.; Du, J.; Xiang, Y. A 3D assembly model retrieval method based on assembly information. Assem. Autom. 2019, 39, 556–565. [Google Scholar] [CrossRef]
- Sun, X.Y.; Wu, J.J.; Zhang, X.M.; Zhang, X.M.; Zhang, Z.T.; Zhang, C.K.; Xue, T.F.; Tenenbaum, J.B.; Freeman, W.T. Pix3D: Dataset and methods for single-image 3D shape modeling. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Qin, F.W.; Qiu, S.; Gao, S.M.; Bai, J. 3D CAD model retrieval based on sketch and unsupervised variational autoencoder. Adv. Eng. Inform. 2022, 51, 101427. [Google Scholar] [CrossRef]
- Manda, B.; Dhayarkar, S.; Mitheran, S.; Viekash, V.K.; Muthuganapathy, R. ‘CADSketchNet’-An annotated sketch dataset for 3D CAD model retrieval with deep neural networks. Comput. Graph. 2021, 99, 100–113. [Google Scholar] [CrossRef]
- Kuo, W.; Angelova, A.; Lin, T.Y.; Dai, A. Mask2CAD: 3D shape prediction by learning to segment and retrieve. In Proceedings of the Computer Vision-ECCV, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Li, Z.; Xu, J.Y.; Zhao, Y.; Li, W.H.; Nie, W.Z. MPAN: Multi-part attention network for point cloud based 3D shape retrieval. IEEE Access 2020, 8, 157322–157332. [Google Scholar] [CrossRef]
- Kim, H.; Yeo, C.; Lee, I.D.; Mun, D. Deep-learning-based retrieval of piping component catalogs for plant 3D CAD model reconstruction. Comput. Ind. 2020, 123, 103320. [Google Scholar] [CrossRef]
- Wang, Z.; Lin, H. 3D shape retrieval based on Laplace operator and joint Bayesian model. Vis. Inform. 2020, 4, 69–76. [Google Scholar] [CrossRef]
- Son, H.; Lee, S.H. Three-dimensional model retrieval in single category geometry using local ontology created by object part segmentation through deep neural network. J. Mech. Sci. Technol. 2021, 35, 5071–5079. [Google Scholar] [CrossRef]
- Udaiyar, P. Cross-Modal Data Retrieval and Generation Using Deep Neural Networks. Master’s Thesis, RIT Scholar Works, Rochester Institute of Technology, New York, NY, USA, 2020. [Google Scholar]
- Huang, L. Space of preattentive shape features. J. Vis. 2020, 20, 10. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, H.; Shi, G.; Liu, Z.; Zhou, Q. A model of text-enhanced knowledge graph representation learning with mutual attention. IEEE Access 2020, 8, 52895–52905. [Google Scholar] [CrossRef]
- Jiang, Z.; Gao, S.; Chen, L. Study on text representation method based on deep learning and topic information. Computing 2020, 102, 623–642. [Google Scholar] [CrossRef]
- Yan, R.; Peng, L.; Xiao, S.; Yao, G. Primitive representation learning for scene text recognition. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Luo, L.X. Network text sentiment analysis method combining LDA text representation and GRU-CNN. Pers. Ubiquit. Comput. 2019, 23, 405–412. [Google Scholar] [CrossRef]
- Sinoara, R.A.; Jose, C.C.; Rossi, R.G.; Navigli, R.; Rezende, S.O. Knowledge-enhanced document embeddings for text classification. Knowl. Based Syst. 2019, 163, 955–971. [Google Scholar] [CrossRef]
- Song, R.; Gao, S.; Yu, Z.; Zhang, Y.; Zhou, G. Case2vec: Joint variational autoencoder for case text embedding representation. Int. J. Mach. Learn. Cyb. 2021, 12, 2517–2528. [Google Scholar] [CrossRef]
- Guo, S.; Yao, N. Polyseme-aware vector representation for text classification. IEEE Access 2020, 8, 135686–135699. [Google Scholar] [CrossRef]
- Hou, W.; Liu, Q.; Cao, L. Cognitive aspects-based short text representation with named entity, Concept and Knowledge. Appl. Sci. 2020, 10, 4893. [Google Scholar] [CrossRef]
- Feng, Y.; Feng, Y.; You, H.; Zhao, X.; Gao, Y. MeshNet: Mesh neural network for 3D shape representation. In Proceedings of the AAAI’19: AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Gao, Z.; Yan, J.; Zhai, G.; Zhang, J.; Yang, Y.; Yang, X. Learning local neighboring structure for robust 3D shape representation. In Proceedings of the AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 22 February–1 March 2022. [Google Scholar]
- Gal, R.; Bermano, A.; Zhang, H.; Daniel, C.O. MRGAN: Multi-rooted 3D shape representation learning with unsupervised part disentanglement. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW 2021), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Jiang, C.; Sud, A.; Makadia, A.; Huang, J.; Nießner, M.; Funkhouser, T. Local implicit grid representations for 3D scenes. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zheng, Z.; Yu, T.; Dai, Q.; Liu, Y. Deep implicit templates for 3D shape representation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Chen, Z.; Zhang, Y.; Genova, K.; Fanello, S.; Bouaziz, S.; Häne, C.; Du, R.; Keskin, C.; Funkhouser, T.; Tang, D. Multiresolution deep implicit functions for 3D shape representation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV 2021), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Tristan, A.A.; Stavros, T.; Sven, D.; Allan, J. Representing 3D shapes with probabilistic directed distance fields. arXiv 2021, arXiv:2112.05300. [Google Scholar]
- Wei, X.; Gong, Y.; Wang, F.; Sun, X.; Sun, J. Learning canonical view representation for 3D shape recognition with arbitrary views. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV 2021), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Tretschk, E.; Tewari, A.; Golynanik, V.; Zollhöfer, M.; Stoll, C.; Theobalt, C. PatchNets: Patch-based generalizable deep implicit 3D shape representations. In Proceedings of the Computer Vision-ECCV 2020, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Hao, L.; Wang, H. Geometric feature statistics histogram for both real-valued and binary feature representations of 3D local shape. Image Vis. Comput. 2022, 117, 104339. [Google Scholar] [CrossRef]
- Han, Z.; Shang, M.; Wang, X.; Liu, Y.; Zwicker, M. Y2Seq2Seq: Cross-modal representation learning for 3D shape and text by joint reconstruction and prediction of view and word sequences. In Proceedings of the AAAI Conference on Artificial Intelligence 2019, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Ruan, Y.; Lee, H.; Zhang, K.; Chang, A.X. TriCoLo: Trimodal contrastive loss for fine-grained text to shape retrieval. arXiv 2022, arXiv:2201.07366. [Google Scholar]
- Wu, Y.; Wang, S.; Huang, Q. Multi-modal semantic autoencoder for cross-modal retrieval. Neurocomputing 2019, 331, 165–175. [Google Scholar] [CrossRef]
- Tang, C.; Yang, X.; Wu, B.; Han, Z.; Chang, Y. Part2Word: Learning joint embedding of point clouds and text by matching parts to words. arXiv 2021, arXiv:2107.01872. [Google Scholar]
- Li, D.; Wang, Y.; Zhang, Y.; Mu, X. Fast retrieving approach for 3D models based on semantic tree. In Proceedings of the 2018 International Conference on Virtual Reality and Intelligent Systems (ICVRIS), Changsha, China, 10–11 August 2018. [Google Scholar]
- França, T.; Braga, A.M.B.; Ayala, H.V.H. Feature engineering to cope with noisy data in sparse identification. Expert Syst. Appl. 2022, 188, 115995. [Google Scholar] [CrossRef]
- Kanjilal, R.; Uysal, I. The future of human activity recognition: Deep learning or feature engineering? Neural Process. Lett. 2021, 53, 561–579. [Google Scholar] [CrossRef]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Maxim0815 Text2shape [Source Code]. 2020. Available online: https://github.com/maxim0815/text2shape (accessed on 17 March 2022).
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wang, C.; Wang, C.; Pan, H.; Yue, Y. Effect of structure parameters on low nitrogen performance of burner based on orthogonal experiment method. Case Stud. Therm. Eng. 2022, 39, 102404. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Project | Project Content |
|---|---|
| Operating system | Microsoft Windows 10 |
| Python environment | Python 3.9 |
| Virtual environment | Anaconda3-5.2.0 |
| Programming software | PyCharm 2022.1.3 |
| Number | Batch Size (A) | Learning Rate (B) | Epoch (C) | Convolution Layer Number (D) | Accuracy (E) /% |
|---|---|---|---|---|---|
| 1 | 16 | 0.001 | 50 | 3 | 3.77 |
| 2 | 16 | 0.0001 | 200 | 4 | 64.77 |
| 3 | 16 | 0.00001 | 100 | 5 | 46.45 |
| 4 | 32 | 0.001 | 200 | 5 | 30.00 |
| 5 | 32 | 0.0001 | 100 | 3 | 55.62 |
| 6 | 32 | 0.00001 | 50 | 4 | 69.38 |
| 7 | 64 | 0.001 | 100 | 4 | 48.44 |
| 8 | 64 | 0.0001 | 50 | 5 | 71.09 |
| 9 | 64 | 0.00001 | 200 | 3 | 57.81 |
| T1j | 114.99 | 82.21 | 144.24 | 117.2 | 447.33 |
| T2j | 155 | 191.48 | 150.51 | 182.59 | |
| T3j | 177.34 | 173.64 | 152.58 | 147.54 | |
| Rj | 62.35 | 109.27 | 8.34 | 65.39 | |
| Order | B > D > A > C | ||||
| Best level | A3 | B2 | C3 | D2 | |
| Best combination | A3B2C3D2 | ||||
| Number | Learning Rate (A) | Batch Size (B) | Convolution Layer Number (C) | Epoch (D) | Accuracy (E) /% |
|---|---|---|---|---|---|
| 1 | 0.001 | 4 | 4 | 50 | 64.44 |
| 2 | 0.001 | 16 | 5 | 100 | 48.86 |
| 3 | 0.001 | 32 | 6 | 200 | 61.25 |
| 4 | 0.001 | 64 | 7 | 500 | 42.19 |
| 5 | 0.0001 | 4 | 5 | 142 | 53.89 |
| 6 | 0.0001 | 16 | 4 | 500 | 42.61 |
| 7 | 0.0001 | 32 | 7 | 50 | 48.12 |
| 8 | 0.0001 | 64 | 6 | 100 | 58.59 |
| 9 | 0.00001 | 4 | 6 | 142 | 90.00 |
| 10 | 0.00001 | 16 | 7 | 200 | 58.52 |
| 11 | 0.00001 | 32 | 4 | 100 | 82.50 |
| 12 | 0.00001 | 64 | 5 | 50 | 60.16 |
| 13 | 0.000001 | 4 | 7 | 100 | 95.00 |
| 14 | 0.000001 | 16 | 6 | 50 | 85.23 |
| 15 | 0.000001 | 32 | 5 | 500 | 74.37 |
| 16 | 0.000001 | 64 | 4 | 200 | 69.53 |
| T1j | 216.74 | 303.33 | 259.08 | 257.95 | 1035.26 |
| T2j | 203.21 | 235.22 | 237.28 | 284.95 | |
| T3j | 291.18 | 266.24 | 295.07 | 243.19 | |
| T4j | 324.13 | 230.47 | 243.83 | 249.17 | |
| Rj | 120.92 | 72.86 | 57.79 | 41.76 | |
| Order | A > B > C > D | ||||
| Best level | A4 | B1 | C3 | D2 | |
| Best combination | A4B1C3D2 | ||||
| Number | Learning Rate (A) | Batch Size (B) | Convolution Layer Number (C) | Accuracy (D) /% |
|---|---|---|---|---|
| 1 | 0.00001 | 4 | 6 | 91.67 |
| 2 | 0.00001 | 4 | 7 | 77.78 |
| 3 | 0.00001 | 16 | 6 | 98.30 |
| 4 | 0.00001 | 16 | 7 | 59.66 |
| 5 | 0.000001 | 4 | 6 | 96.67 |
| 6 | 0.000001 | 4 | 7 | 97.78 |
| 7 | 0.000001 | 16 | 6 | 94.89 |
| 8 | 0.000001 | 16 | 7 | 86.93 |
| T1j | 327.41 | 363.9 | 381.53 | 703.68 |
| T2j | 376.27 | 339.78 | 322.15 | |
| Rj | 48.86 | 24.12 | 59.38 | |
| Order | C > A > B | |||
| Best level | A2 | B1 | C1 | |
| Best combination | A2B1C1 | |||
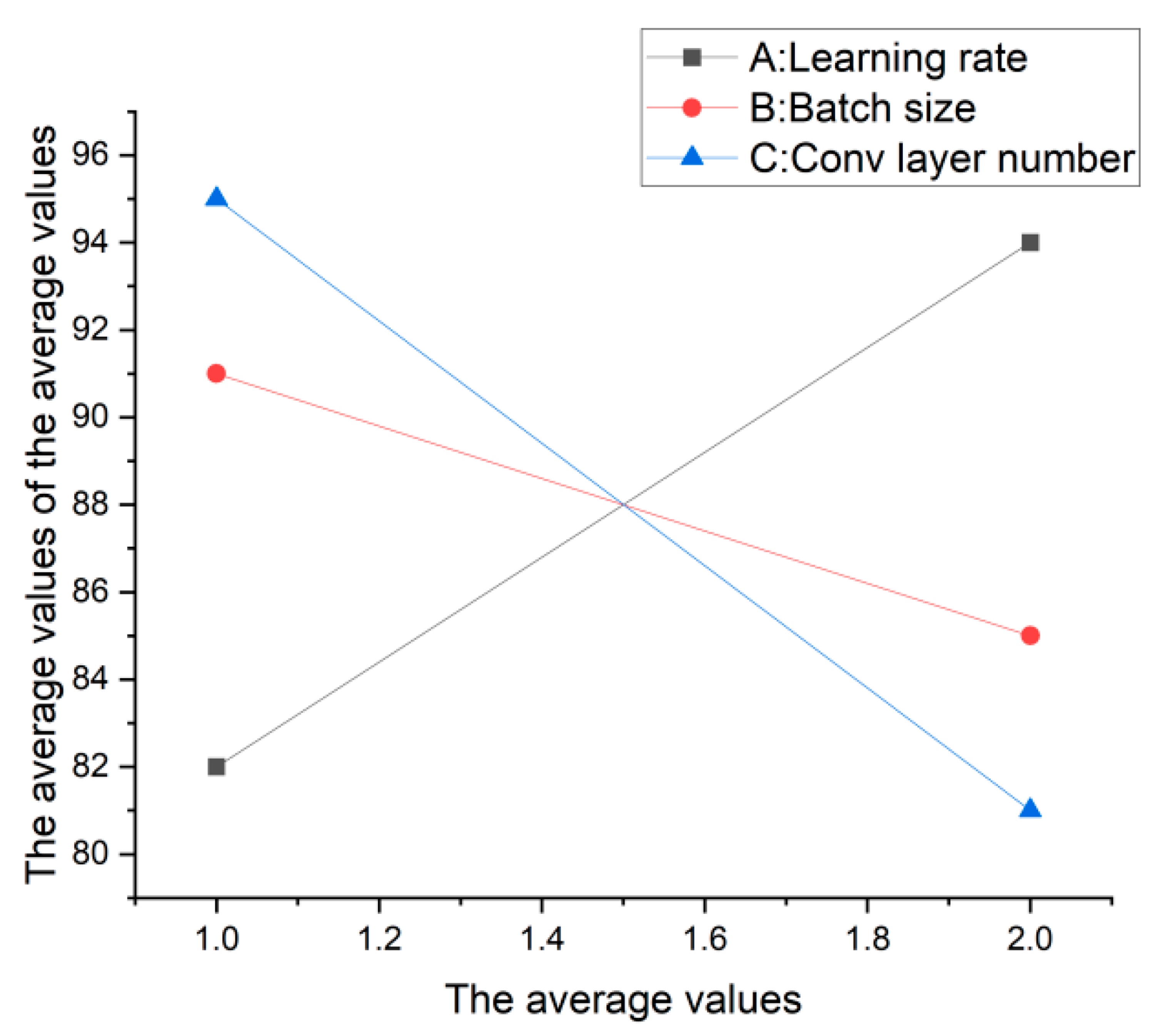
| Level | Learning Rate (A) | Batch Size (B) | Convolution Layer Number (C) |
|---|---|---|---|
| 1 | 81.85 | 90.97 | 95.38 |
| 2 | 94.07 | 84.94 | 80.54 |
| Delta | 12.22 | 6.03 | 14.84 |
| Order | 2 | 3 | 1 |
| Factor | Freedom | Adj SS | Adj MS | F Value | p Value |
|---|---|---|---|---|---|
| A | 1 | 298.41 | 298.41 | 2.75 | 0.173 |
| B | 1 | 72.72 | 72.72 | 0.67 | 0.459 |
| C | 1 | 440.75 | 440.75 | 4.06 | 0.114 |
| Error | 4 | 434.70 | 108.68 | ||
| Total | 7 | 1246.58 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zang, T.; Yang, M.; Yong, W.; Jiang, P. Text2shape Deep Retrieval Model: Generating Initial Cases for Mechanical Part Redesign under the Context of Case-Based Reasoning. Machines 2022, 10, 967. https://doi.org/10.3390/machines10110967
Zang T, Yang M, Yong W, Jiang P. Text2shape Deep Retrieval Model: Generating Initial Cases for Mechanical Part Redesign under the Context of Case-Based Reasoning. Machines. 2022; 10(11):967. https://doi.org/10.3390/machines10110967
Chicago/Turabian StyleZang, Tianshuo, Maolin Yang, Wentao Yong, and Pingyu Jiang. 2022. "Text2shape Deep Retrieval Model: Generating Initial Cases for Mechanical Part Redesign under the Context of Case-Based Reasoning" Machines 10, no. 11: 967. https://doi.org/10.3390/machines10110967
APA StyleZang, T., Yang, M., Yong, W., & Jiang, P. (2022). Text2shape Deep Retrieval Model: Generating Initial Cases for Mechanical Part Redesign under the Context of Case-Based Reasoning. Machines, 10(11), 967. https://doi.org/10.3390/machines10110967