


Classification of Wall Following Robot Movements Using Genetic Programming Symbolic Classifier





Abstract
:1. Introduction
- Is it possible to utilize the GPSC algorithm for the detection of the robot movement using data from ultrasound sensors with high classification accuracy?
- Does the dataset balancing methods have any influence on the classification accuracy of the obtained symbolic expressions using the GPSC algorithm?
- Is it possible to achieve the detection of the robot movement class with high classification accuracy using symbolic expressions that were obtained with the GPSC algorithm improved with the random hyperparameter search method and 5-fold cross-validation?
- Is it possible to achieve a similar classification accuracy of the best symbolic expression that was obtained using a balanced dataset on the original dataset?
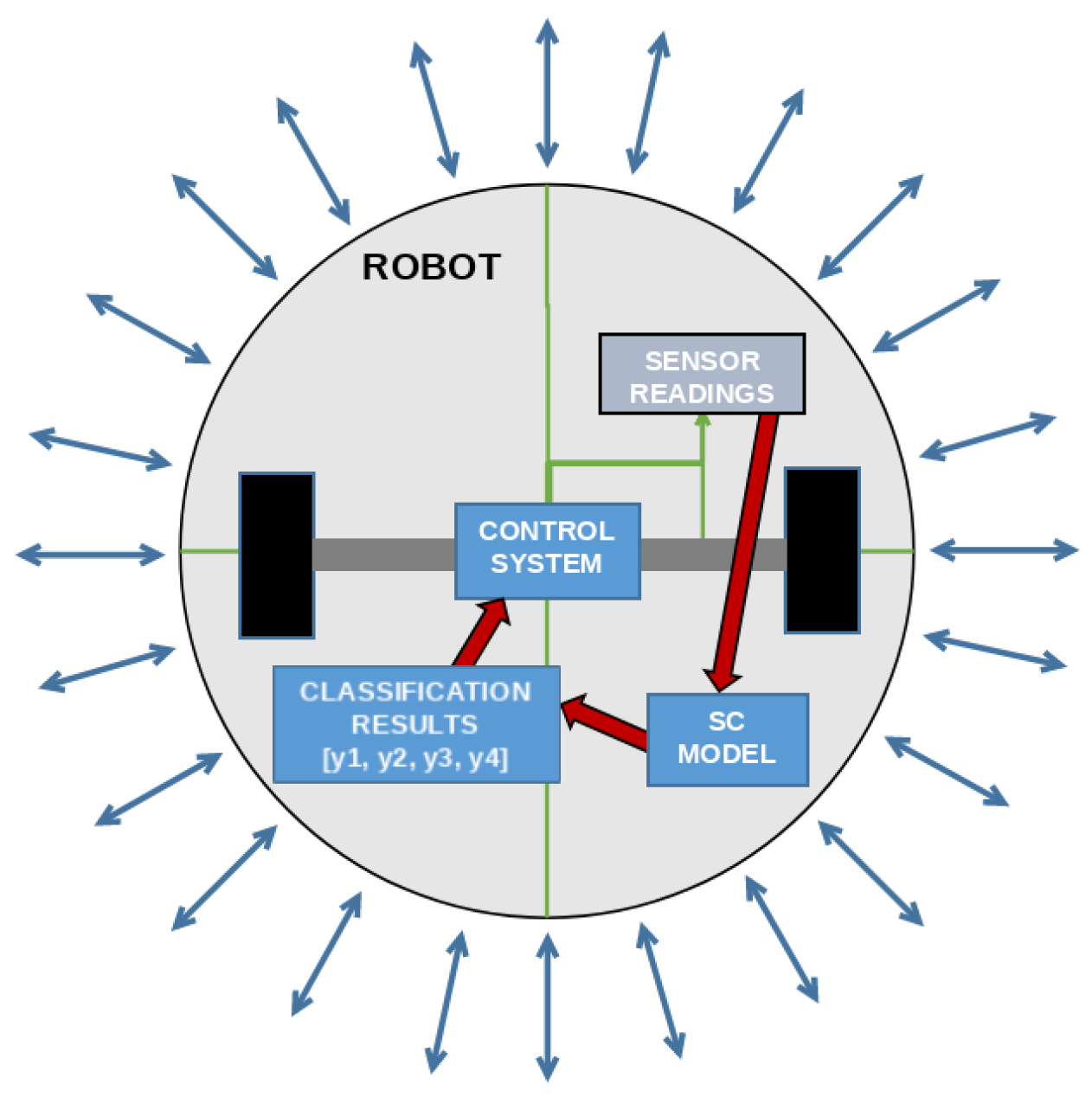
- Investigate the possibility of implementing the GPSC algorithm on data collected from 24 ultrasound sensor data to detect the movement of the wall following robot;
- Investigate if the dataset balancing methods have any influence on the classification accuracy of the obtained symbolic expression using the GPSC algorithm;
- Investigate if the GPSC algorithm in combination with random hyperparameter search and 5-fold cross-validation can generate symbolic expressions with a high classification accuracy of robot movement detection, and;
- Investigate if the set of best symbolic expressions obtained on a balanced dataset variation can produce similar classification accuracy in robot movement detection when applied to the original dataset.
2. Materials and Methods
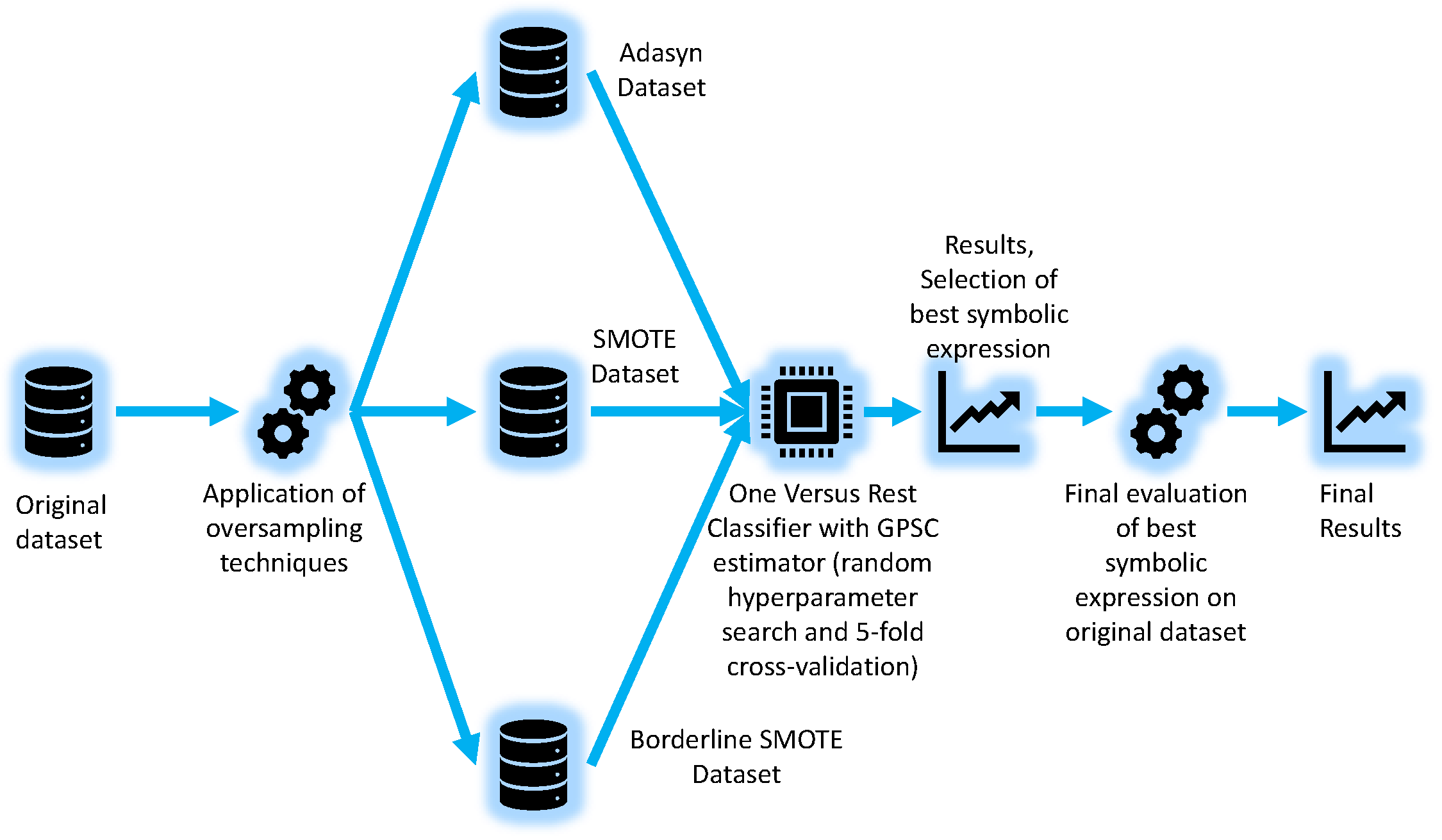
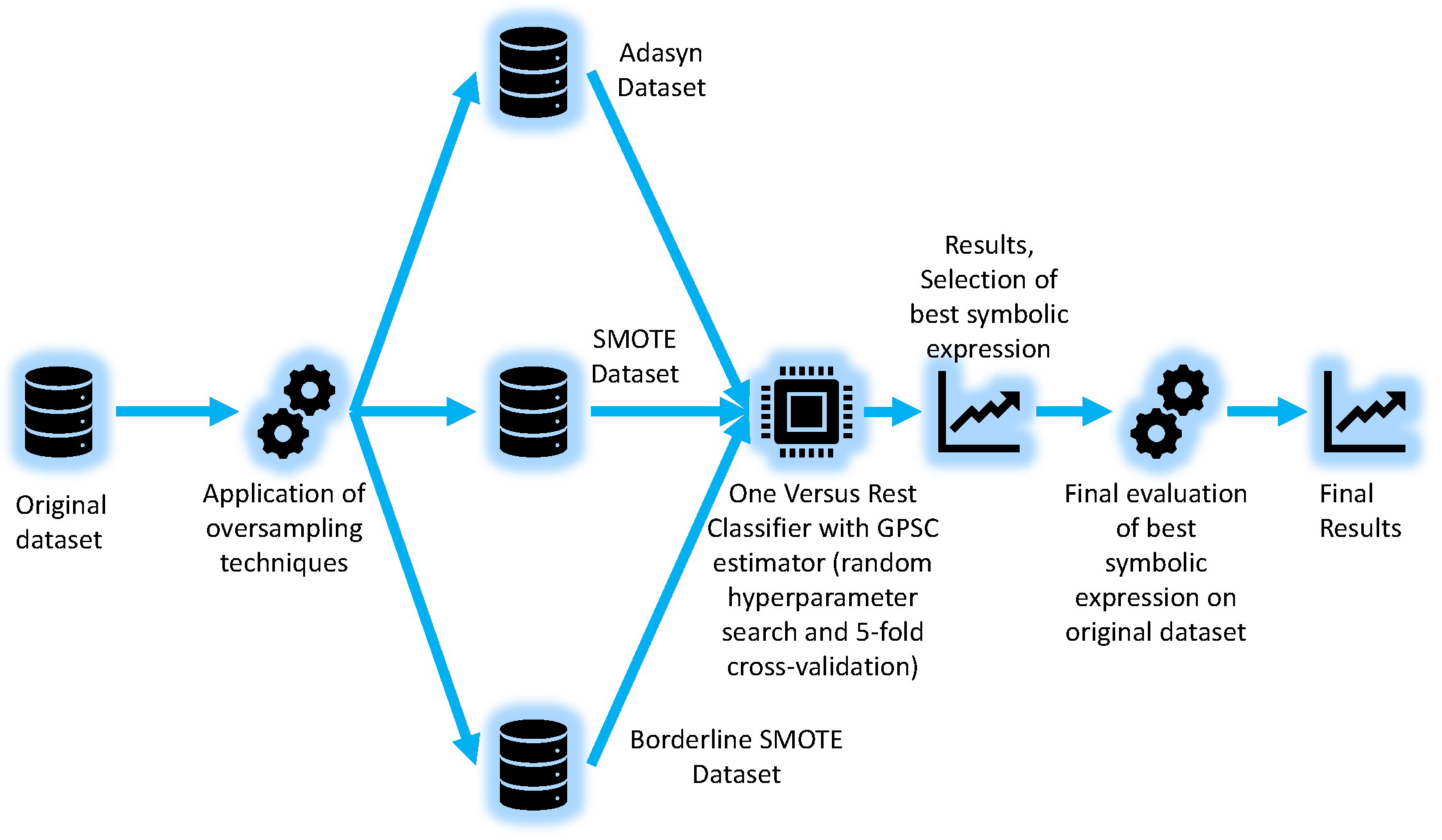
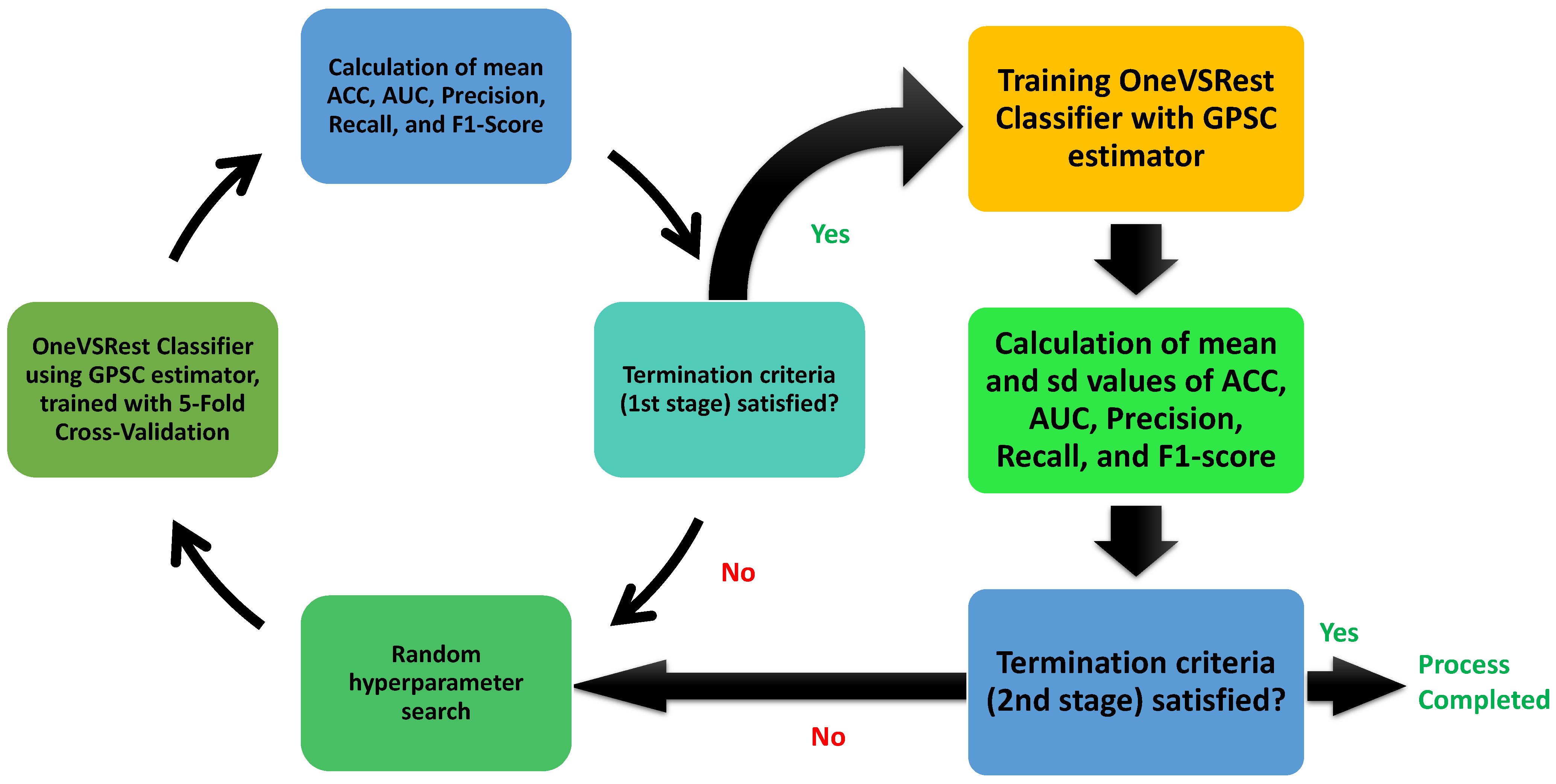
2.1. Research Methodology
- Adaptive Synthetic (ADASYN);
- Synthetic Minority Oversampling (SMOTE);
- Borderline Synthetic Minority Oversampling (Borderline SMOTE) method.
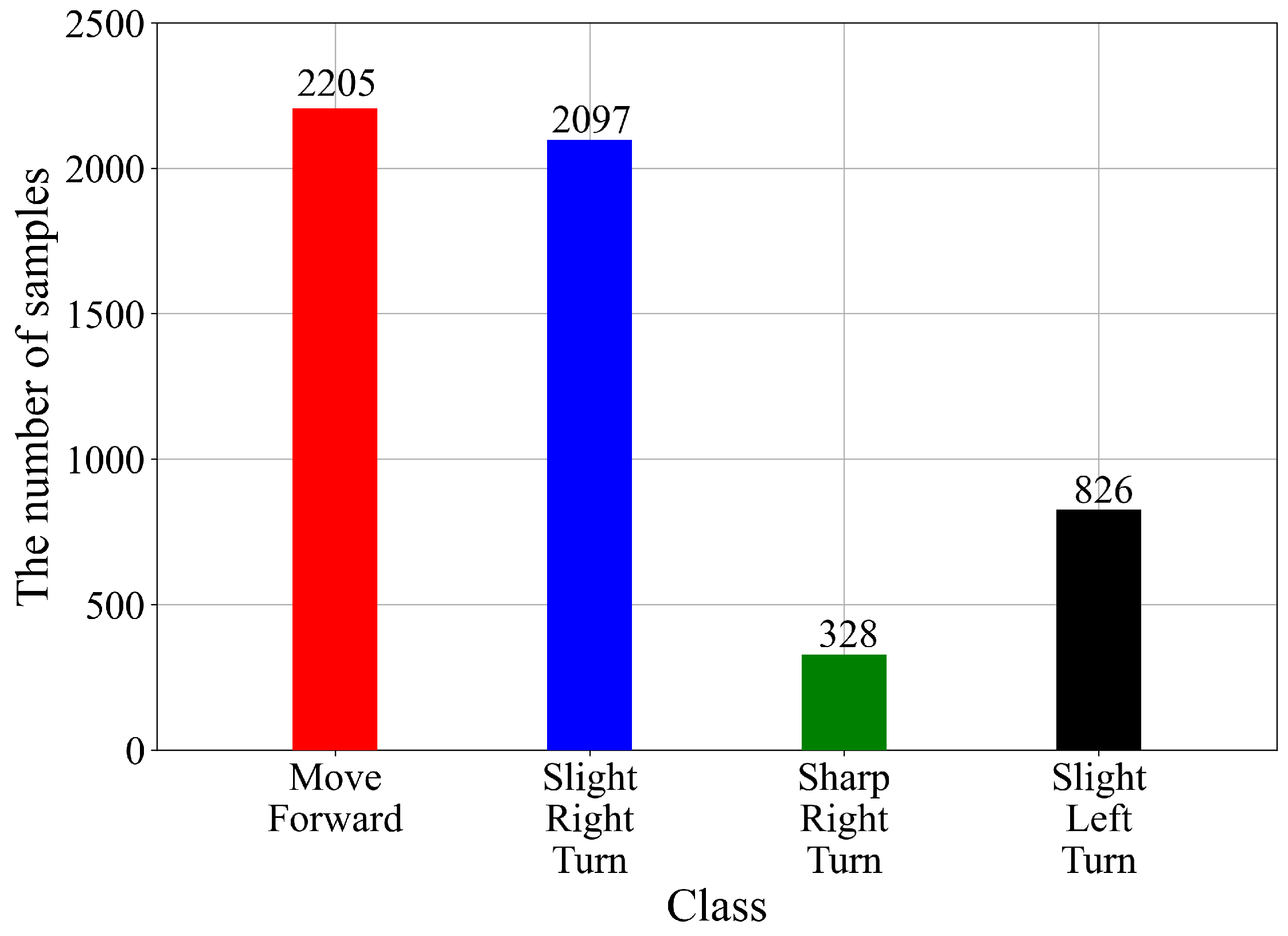
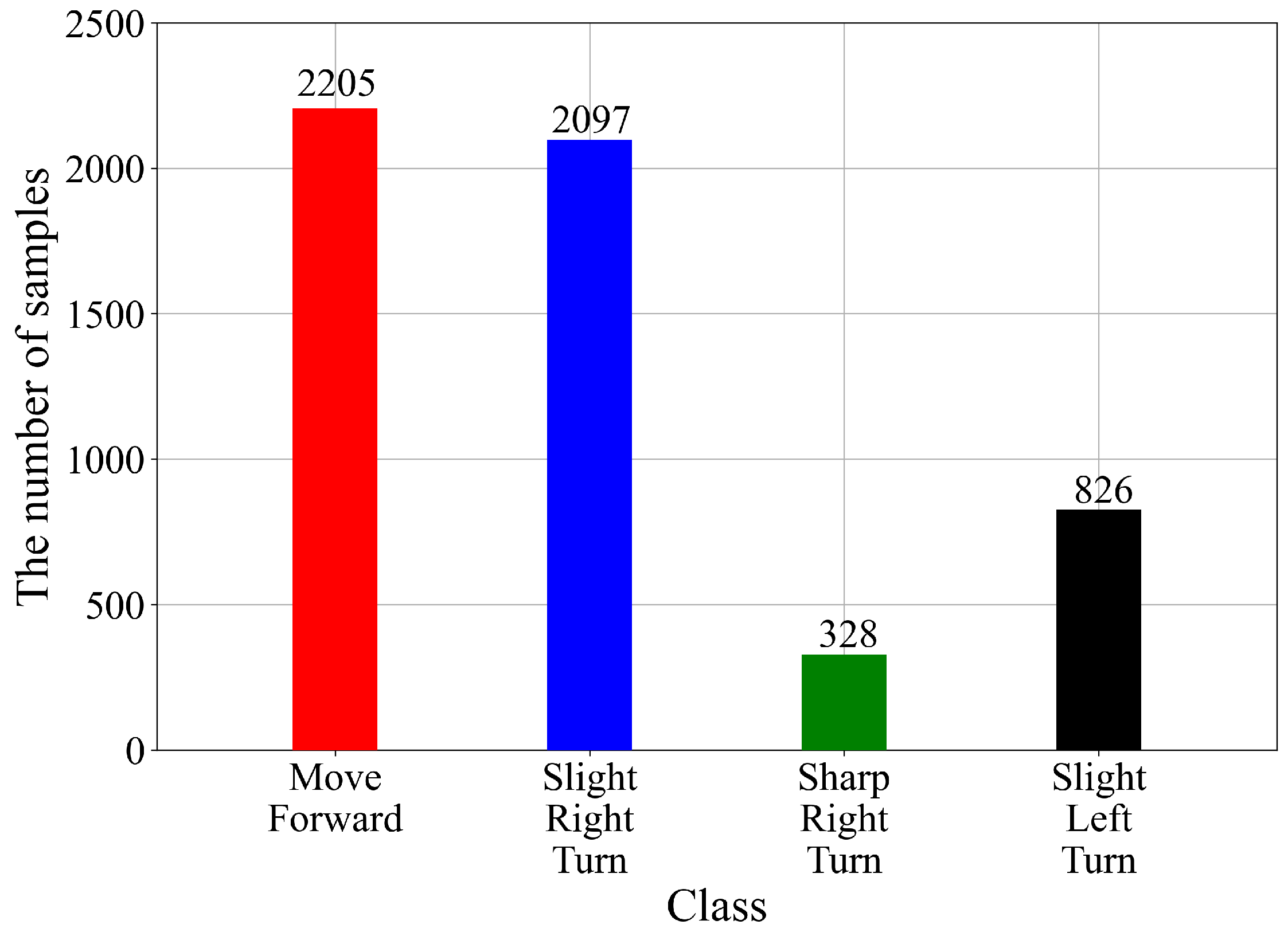
2.2. Dataset Description
- “Move-Forward”;
- “Slight-Right-Turn”;
- “Sharp-Right-Turn”;
- “Slight-Left-Turn”.
2.3. Dataset Balancing Methods
2.3.1. ADASYN
- Random selection of minority data sample from the KNN for data
- Generate the synthetic data sample using the following expression:where , and represent difference vectors in n-dimensional spaces and a random number in the 0 to 1 range, respectively.
2.3.2. Smote
- Calculate the difference between the sample and its nearest neighbor;
- Multiply the difference by a random number between 0 and 1 and add to the sample under consideration.
2.3.3. Borderline SMOTE
- K’ = K all the K nearest neighbors are majority samples;
- the number of majority neighbors is larger than the number of its minority ones. is considered to be easily misclassified and put into a DANGER set;
- the is excluded from further steps.
2.4. One Versus Rest Classifier
- First Binary Classification Dataset: “Move Forward” vs. (“Slight-Right-Turn”, “Sharp-Right-Turn”, and “Slight-Left-Turn”);
- Second Binary Classification Dataset: “Slight-Right-Turn” vs. (“Move Forward”, “Sharp-Right-Turn”, and “Slight-Left-Turn”);
- Third Binary Classification Dataset: “Sharp-Right-Turn” vs. (“Move Forward”, “Slight-Right-Turn”, and “Slight-Left-Turn”);
- Fourth Binary Classification Dataset: “Slight-Left-Turn vs. (“Move Forward”, “Slight-Right-Turn”, and “Sharp-Right-Turn”).
2.5. Genetic Programming-Symbolic Classifier
2.6. Random Hyperparameter Search with 5-Fold Cross-Validation
2.7. Evaluation Metrics and Methodology
2.8. Computational Resources
3. Results
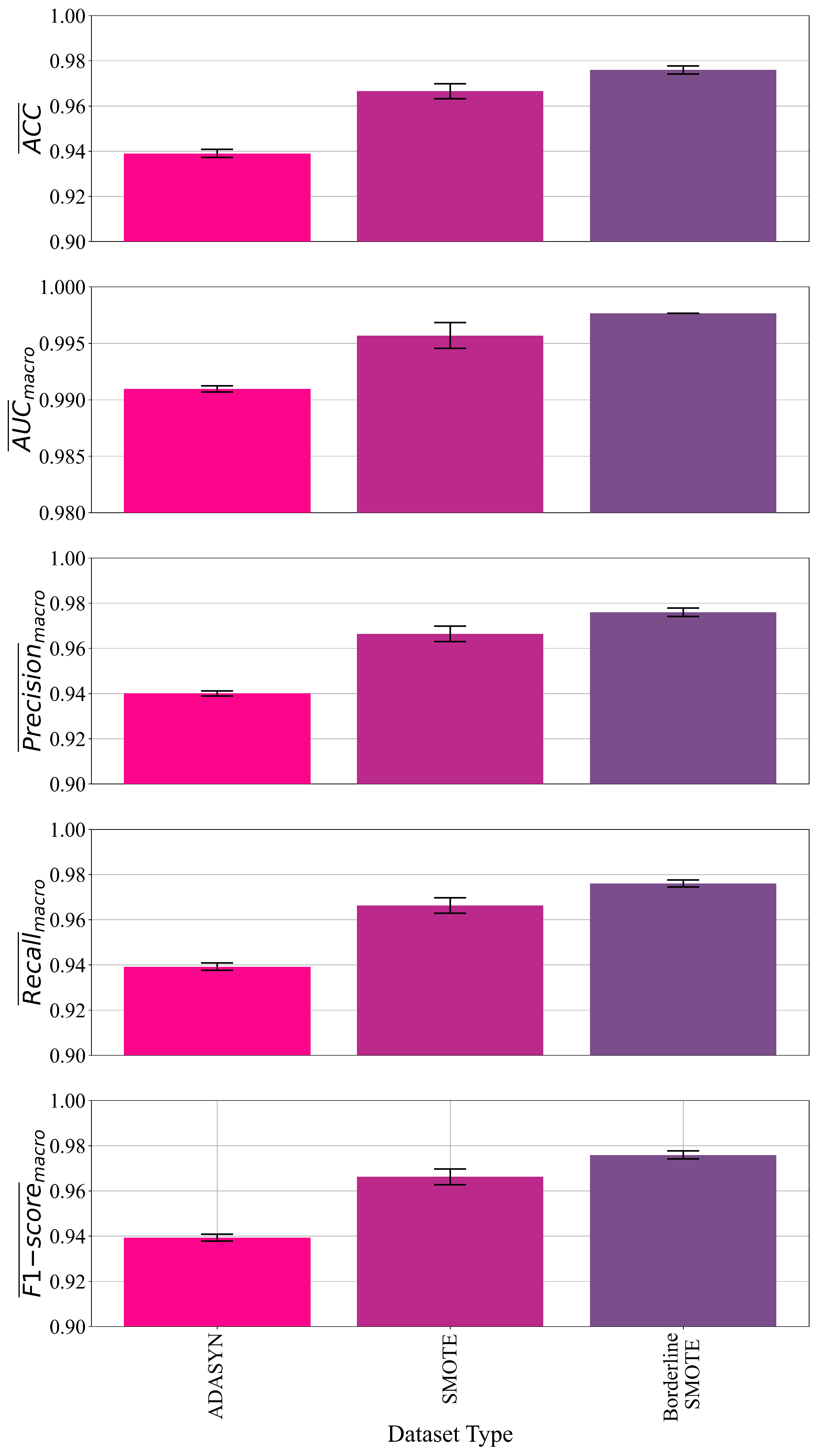
3.1. The Classification Performance of Symbolic Expressions Obtained for Each Dataset Variation
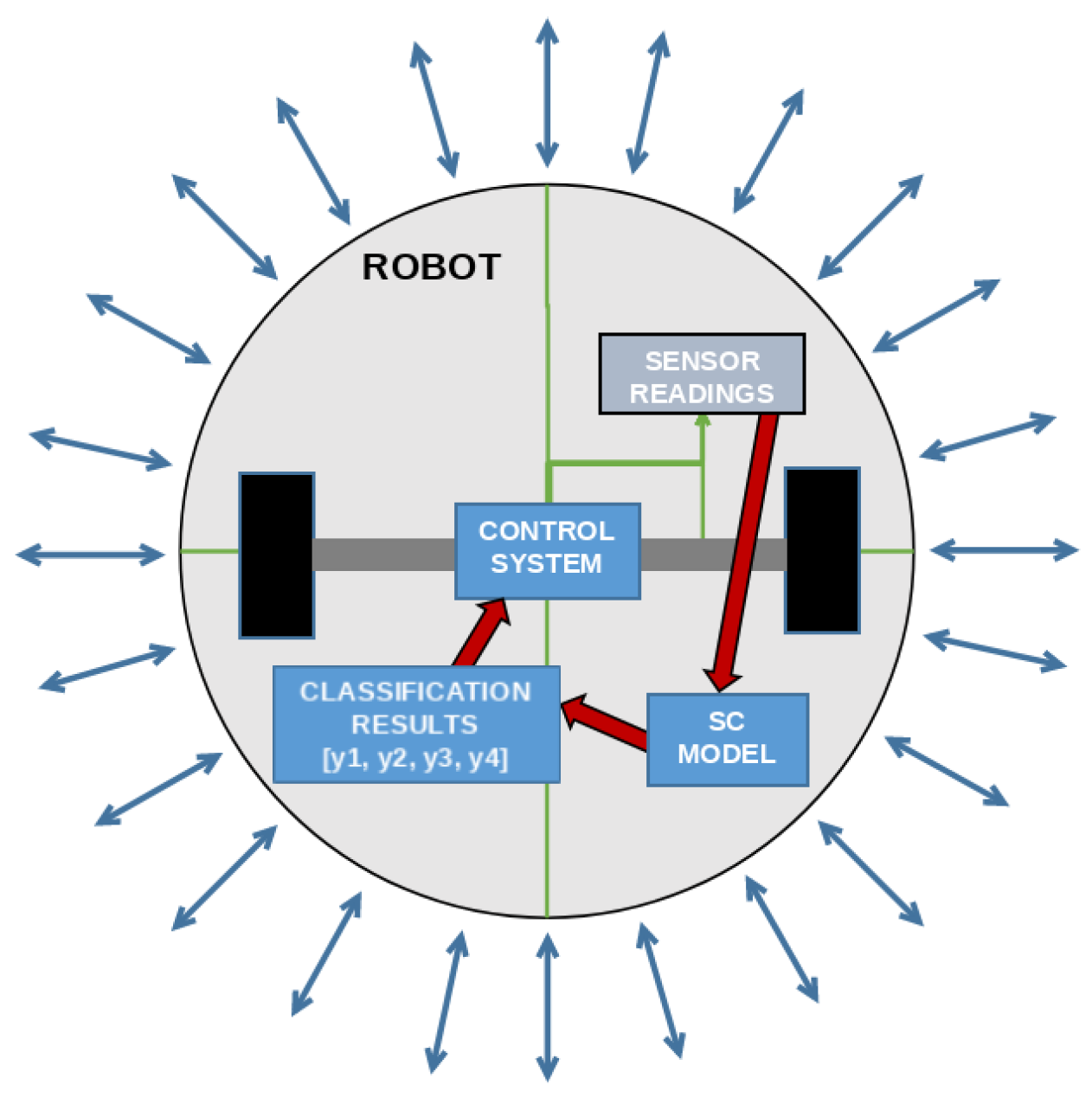
3.2. The Best Set of Symbolic Expressions and Final Evaluation
- Calculate the output of each symbolic expression using original dataset values;
- Use this output in the Sigmoid function to generate the output;
- Transform the obtained output into integer form for each symbolic expression, and;
- Compare the obtained results with the original output and calculate the evaluation metric values.
4. Discussion
5. Conclusions
- The GPSC algorithm successfully generated the symbolic expressions, which can be used for the detection/classification of the robot movement with high classification accuracy;
- The dataset balancing method (ADASY, SMOTE, and BorderlineSMOTE) balanced the original dataset and provided a good starting point for the training of the GPSC algorithm, which resulted in symbolic expressions with high classification accuracy. So the investigation showed that dataset balancing methods have a great influence on the classification accuracy of the obtained symbolic expressions;
- The GPSC algorithm with the random hyperparameter search method and 5-fold cross-validation proved to be a powerful tool in obtaining robust and highly accurate symbolic expressions;
- The investigation showed that the best set of symbolic expressions obtained on a dataset balanced with the oversampling method can be applied to the original dataset and achieve high classification accuracy. This shows the validity of the proposed method;
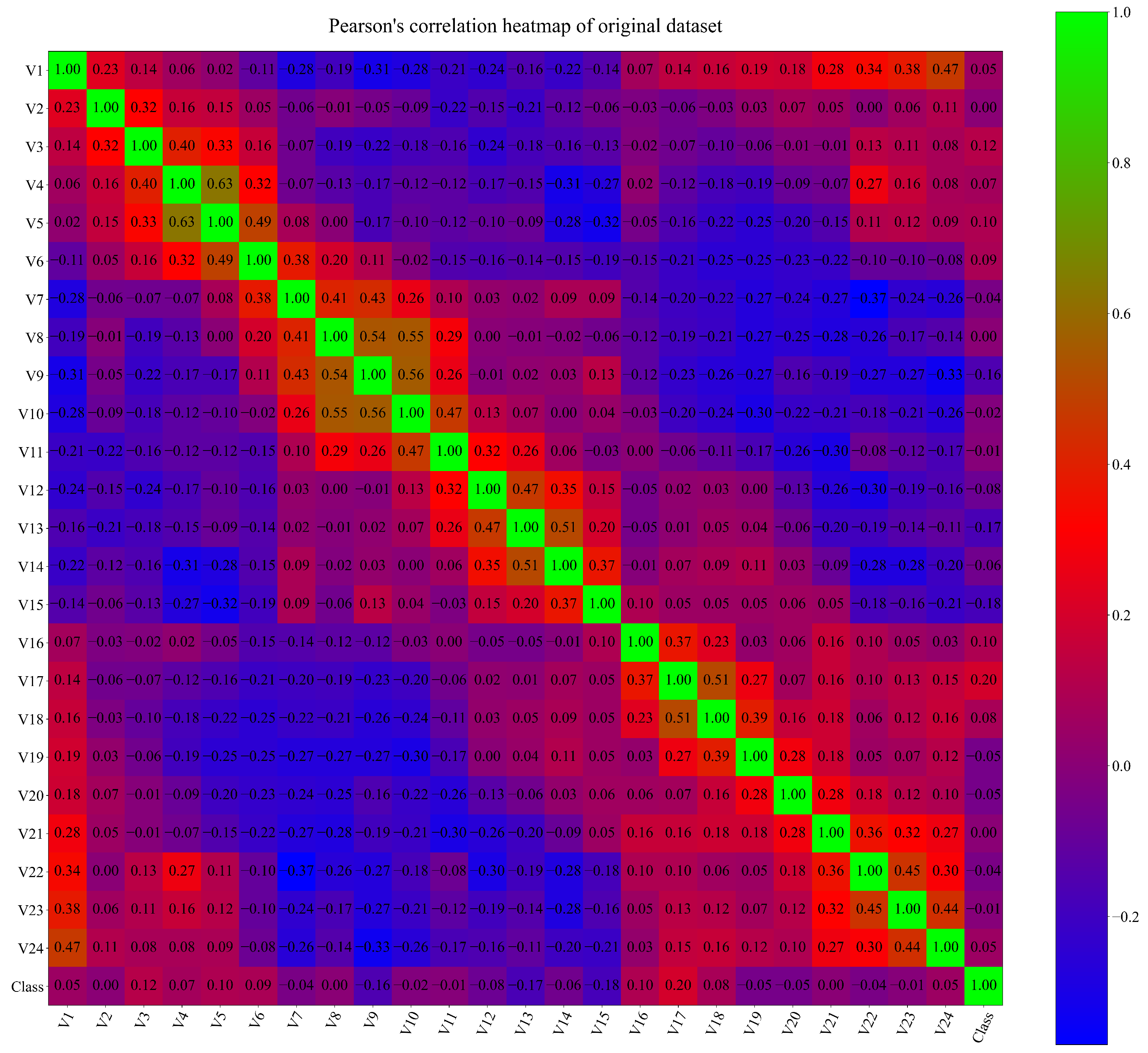
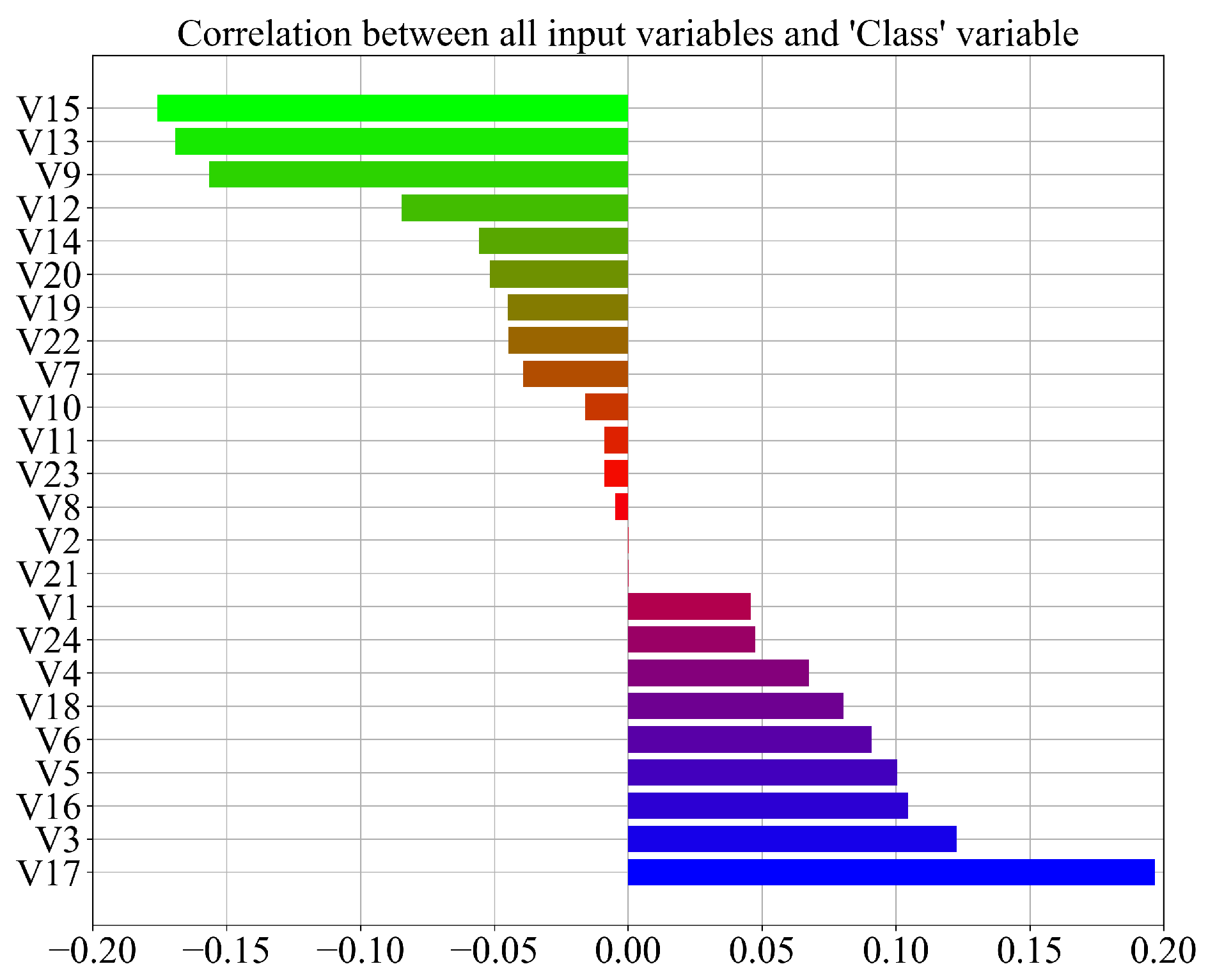
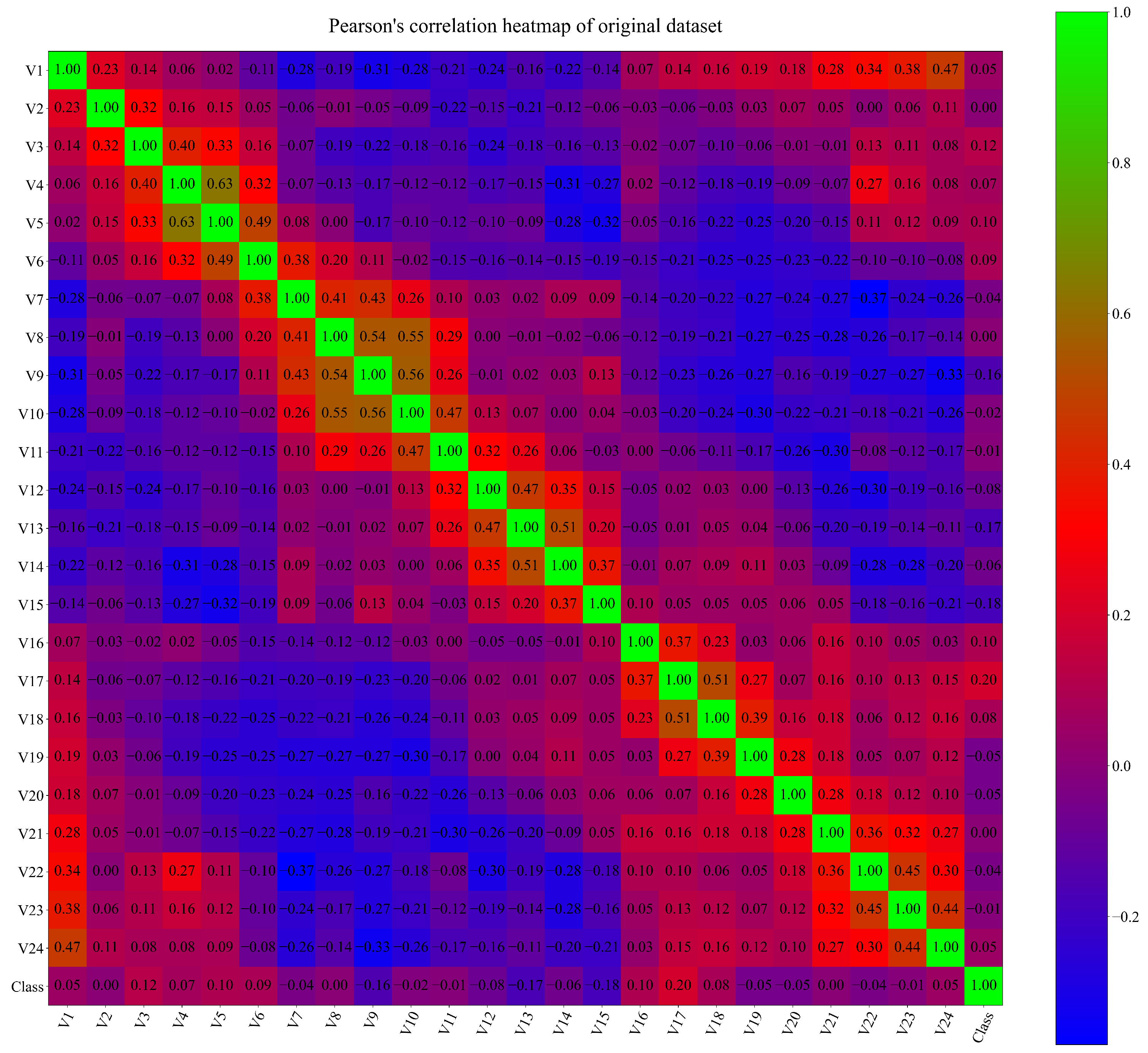
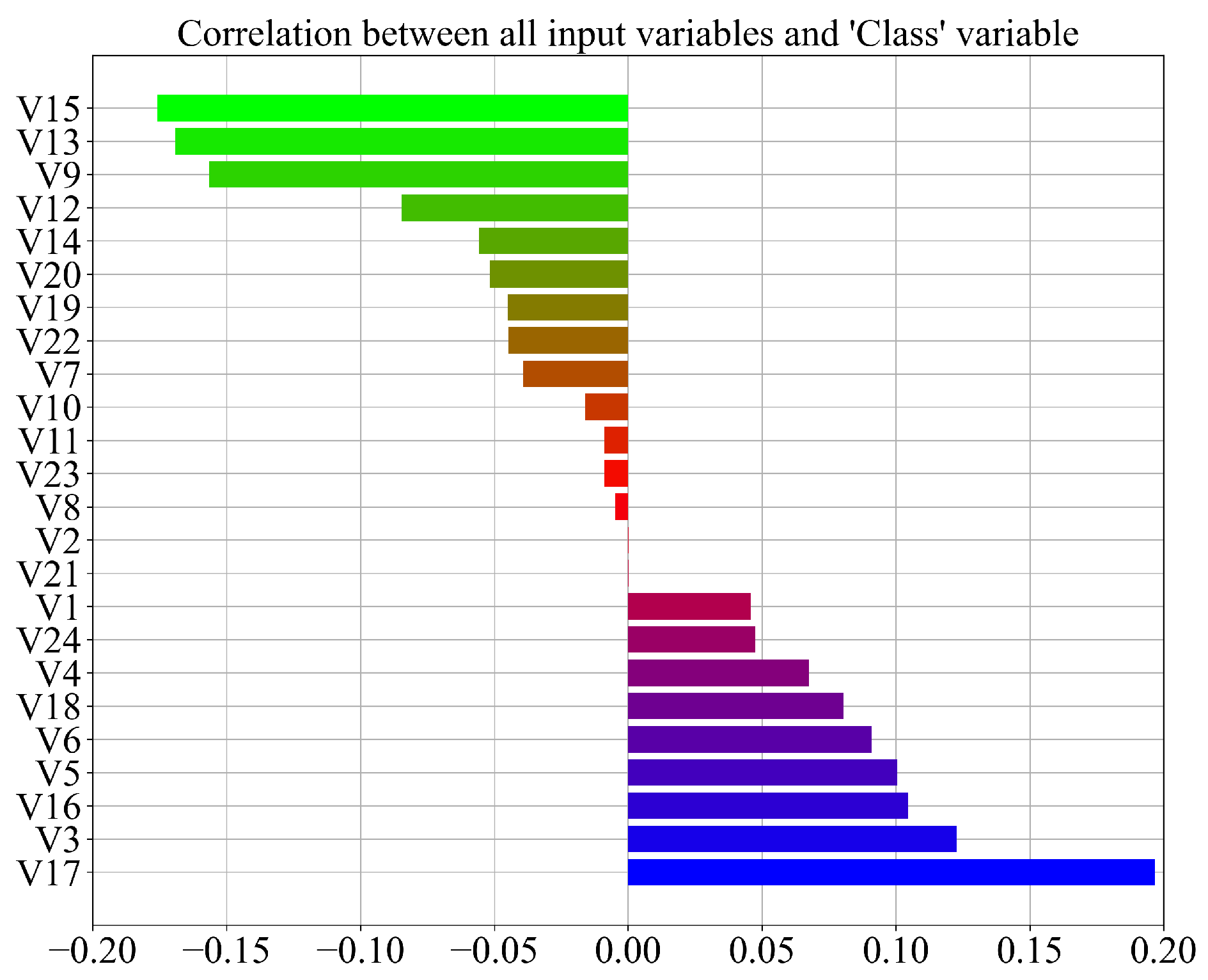
- The procedure showed that a dataset with a low correlation between variables can be used to obtain symbolic expressions with GPSC and that these symbolic expressions do not require all the input variables to classify the movement of the robot.
- Using the proposed method, symbolic expressions are obtained, which are easier to use and understand in comparison to ML models, and require less computational resources for storage and processing than other ML-trained models;
- The oversampling methods can balance the dataset and, by using these datasets, the classification accuracy can be improved;
- Random hyperparameter search and 5-fold cross-validation are useful tools for obtaining robust solutions with high classification accuracy,
- The initial hyperparameter range definition is a painstaking process as the range of each hyperparameter has to be tested. Special attention must be paid to the parsimony coefficient value since this parameter is the most sensitive. Small values can result in a bloat phenomenon, while large values can result in obtaining symbolic expressions with low classification accuracy;
- Regardless of the computational resources used, the execution of GPSC can be a time-consuming process especially if the correlation between input variables is low. If the correlation values between variables are low, GPSC will try to minimize the fitness function value by enlarging the population member’s size, which can in some cases result in the bloat phenomenon.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B
| Algorithm A1 An algorithm with caption | |
▹ Define the vector for sensor readings of length 24 | |
▹ Define the vector for results of length 4 | |
| , , , | ▹ Define the equations, per Appendix A |
▹ Robot control unit | |
| F, , , | ▹ Define possible robot movements |
while True do | |
← | ▹ Get current vector readings |
← | ▹ Calculate and store the predicted class for “Move Forward” |
← | ▹ Calculate and store the predicted class for “Slight Right Turn” |
← | ▹ Calculate and store the predicted class for “Sharp Right Turn” |
← | ▹ Calculate and store the predicted class for “Slight Left Turn” |
if 1 then | |
F | ▹ Instruct robot to move forward |
else if 1 then | |
▹ Instruct robot to do a slight right turn | |
else if 1 then | |
▹ Instruct robot to do a sharp right turn | |
else if 1 then | |
▹ Instruct robot to do a slight left turn | |
end if | |
end while | |
References
- Sánchez-Ibáñez, J.R.; Pérez-del Pulgar, C.J.; García-Cerezo, A. Path Planning for Autonomous Mobile Robots: A Review. Sensors 2021, 21, 7898. [Google Scholar] [CrossRef] [PubMed]
- Mamchenko, M.; Ananyev, P.; Kontsevoy, A.; Plotnikova, A.; Gromov, Y. The concept of robotics complex for transporting special equipment to emergency zones and evacuating wounded people. In Proceedings of the 15th International Conference on Electromechanics and Robotics“ Zavalishin’s Readings”, Online, 2 September 2020; pp. 211–223. [Google Scholar]
- Bravo-Arrabal, J.; Zambrana, P.; Fernandez-Lozano, J.; Gomez-Ruiz, J.A.; Barba, J.S.; García-Cerezo, A. Realistic deployment of hybrid wireless sensor networks based on ZigBee and LoRa for search and Rescue applications. IEEE Access 2022, 10, 64618–64637. [Google Scholar] [CrossRef]
- Al-Obaidi, A.S.M.; Al-Qassar, A.; Nasser, A.R.; Alkhayyat, A.; Humaidi, A.J.; Ibraheem, I.K. Embedded design and implementation of mobile robot for surveillance applications. Indones. J. Sci. Technol. 2021, 6, 427–440. [Google Scholar] [CrossRef]
- Skoczeń, M.; Ochman, M.; Spyra, K.; Nikodem, M.; Krata, D.; Panek, M.; Pawłowski, A. Obstacle detection system for agricultural mobile robot application using RGB-D cameras. Sensors 2021, 21, 5292. [Google Scholar] [CrossRef] [PubMed]
- Pandey, P.; Parasuraman, R. Empirical Analysis of Bi-directional Wi-Fi Network Performance on Mobile Robots in Indoor Environments. In Proceedings of the 2022 IEEE 95th Vehicular Technology Conference: (VTC2022-Spring), Helsinki, Finland, 19–22 June 2022; pp. 1–7. [Google Scholar]
- Choi, H.; Kim, H.; Zhu, Q. Toward practical weakly hard real-time systems: A job-class-level scheduling approach. IEEE Internet Things J. 2021, 8, 6692–6708. [Google Scholar] [CrossRef]
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine learning and deep learning. Electron. Mark. 2021, 31, 685–695. [Google Scholar] [CrossRef]
- Hart, G.L.; Mueller, T.; Toher, C.; Curtarolo, S. Machine learning for alloys. Nat. Rev. Mater. 2021, 6, 730–755. [Google Scholar] [CrossRef]
- Li, J.; Wang, J.; Wang, S.; Yang, C. Human–robot skill transmission for mobile robot via learning by demonstration. Neural Comput. Appl. 2021, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Sevastopoulos, C.; Konstantopoulos, S. A survey of traversability estimation for mobile robots. IEEE Access 2022, 10, 96331–96347. [Google Scholar] [CrossRef]
- Eder, M.; Reip, M.; Steinbauer, G. Creating a robot localization monitor using particle filter and machine learning approaches. Appl. Intell. 2022, 52, 6955–6969. [Google Scholar] [CrossRef]
- Samadi Gharajeh, M.; Jond, H.B. Speed control for leader-follower robot formation using fuzzy system and supervised machine learning. Sensors 2021, 21, 3433. [Google Scholar] [CrossRef] [PubMed]
- Freire, A.L.; Barreto, G.A.; Veloso, M.; Varela, A.T. Short-term memory mechanisms in neural network learning of robot navigation tasks: A case study. In Proceedings of the 2009 6th Latin American Robotics Symposium (LARS 2009), Valparaiso, Chile, 29–30 October 2009; pp. 1–6. [Google Scholar]
- Learning, U.M. Sensor Readings from a Wall-Following Robot. 2017. Available online: https://www.kaggle.com/datasets/uciml/wall-following-robot (accessed on 23 December 2022).
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In International Conference on Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- Duan, K.B.; Rajapakse, J.C.; Nguyen, M.N. One-Versus-One and One-Versus-All Multiclass SVM-RFE for Gene Selection in Cancer Classification. In Evolutionary Computation, Machine Learning and Data Mining in Bioinformatics; Marchiori, E., Moore, J.H., Rajapakse, J.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 47–56. [Google Scholar]
- Poli, R.; Langdon, W.; Mcphee, N. A Field Guide to Genetic Programming. 2008. Available online: https://www.researchgate.net/publication/216301261_A_Field_Guide_to_Genetic_Programming (accessed on 23 December 2022).
- Sturm, B.L. Classification accuracy is not enough. J. Intell. Inf. Syst. 2013, 41, 371–406. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Ling, C.X. Using AUC and accuracy in evaluating learning algorithms. IEEE Trans. Knowl. Data Eng. 2005, 17, 299–310. [Google Scholar] [CrossRef] [Green Version]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Bucolo, M.; Buscarino, A.; Fortuna, L.; Gagliano, S. Force feedback assistance in remote ultrasound scan procedures. Energies 2020, 13, 3376. [Google Scholar] [CrossRef]
- Barba, P.; Stramiello, J.; Funk, E.K.; Richter, F.; Yip, M.C.; Orosco, R.K. Remote telesurgery in humans: A systematic review. Surg. Endosc. 2022, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Lematta, G.J.; Corral, C.C.; Buchanan, V.; Johnson, C.J.; Mudigonda, A.; Scholcover, F.; Wong, M.E.; Ezenyilimba, A.; Baeriswyl, M.; Kim, J.; et al. Remote research methods for Human–AI–Robot teaming. Hum. Factors Ergon. Manuf. Serv. Ind. 2022, 32, 133–150. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Q.; Chi, C.; Wang, C.; Gao, Q.; Zhang, H.; Li, Z.; Mu, Z.; Xu, R.; Sun, Z.; et al. A collaborative robot for COVID-19 oropharyngeal swabbing. Robot. Auton. Syst. 2022, 148, 103917. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 180° | −165° | −150° | −135° | −120° | −105° | |
|---|---|---|---|---|---|---|
| UNIQUE | 1978 | 2035 | 1786 | 1760 | 1825 | 1828 |
| MIN | 0.400 | 0.437 | 0.470 | 0.833 | 1.120 | 1.114 |
| MAX | 1977.000 | 2034.000 | 1786.000 | 1767.000 | 1822.000 | 1828.000 |
| AVG | 1.837 | 2.701 | 2.814 | 3.118 | 3.288 | 3.228 |
| STD | 26.774 | 27.559 | 24.193 | 23.936 | 24.679 | 24.758 |
| −90° | −75° | −60° | −45° | −30° | −15° | |
| UNIQUE | 1532 | 2068 | 1871 | 2005 | 1877 | 1800 |
| MIN | 1.122 | 0.859 | 0.836 | 0.810 | 0.783 | 0.778 |
| MAX | 1530.000 | 2068.000 | 1870.000 | 2003.000 | 1873.000 | 1797.000 |
| AVG | 3.628 | 2.920 | 3.471 | 3.201 | 2.896 | 2.410 |
| STD | 20.730 | 28.003 | 25.327 | 27.128 | 25.377 | 24.348 |
| 0° | 15° | 30° | 45° | 60° | 75° | |
| UNIQUE | 1574 | 1490 | 1468 | 1299 | 1087 | 975 |
| MIN | 0.770 | 0.756 | 0.495 | 0.424 | 0.373 | 0.354 |
| MAX | 1570.000 | 1487.000 | 1465.000 | 1295.000 | 1083.000 | 971.000 |
| AVG | 2.417 | 2.467 | 2.479 | 1.444 | 1.193 | 1.093 |
| STD | 21.287 | 20.177 | 19.891 | 17.563 | 14.690 | 13.174 |
| 90° | 105° | 120° | 135° | 150° | 165° | |
| UNIQUE | 1046 | 1140 | 1359 | 1739 | 1759 | 1858 |
| MIN | 0.340 | 0.355 | 0.380 | 0.370 | 0.367 | 0.377 |
| MAX | 1042.000 | 1136.000 | 1355.000 | 1736.000 | 1758.000 | 1856.000 |
| AVG | 1.254 | 1.290 | 1.270 | 2.103 | 1.884 | 1.926 |
| STD | 14.150 | 15.419 | 18.366 | 23.547 | 23.831 | 25.150 |
| Variable Name | Variable Description | GPSC Variable Representation |
|---|---|---|
| V1 | ultrasound sensor at the front of the robot (180 °) | |
| V2 | ultrasound reading (−165°) | |
| V3 | ultrasound reading (−150°) | |
| V4 | ultrasound reading (−135°) | |
| V5 | ultrasound reading (−120°) | |
| V6 | ultrasound reading (−105°) | |
| V7 | ultrasound reading (−90°) | |
| V8 | ultrasound reading (−75°) | |
| V9 | ultrasound reading (−60°) | |
| V10 | ultrasound reading (−45°) | |
| V11 | ultrasound reading (−30°) | |
| V12 | ultrasound reading (−15°) | |
| V13 | reading of ultrasound sensor situated at the back of the robot (0°) | |
| V14 | ultrasound reading (15°) | |
| V15 | ultrasound reading (30°) | |
| V16 | ultrasound reading (45°) | |
| V17 | ultrasound reading (60°) | |
| V18 | ultrasound reading (75°) | |
| V19 | ultrasound reading (90°) | |
| V20 | ultrasound reading (105°) | |
| V21 | ultrasound reading (120°) | |
| V22 | ultrasound reading (135°) | |
| V23 | ultrasound reading (150°) | |
| V24 | ultrasound reading (165°) | |
| Class | Move-Forward, Slight-Right-Turn, Sharp-Right-Turn, Slight-Left-Turn | y |
| Variable Name | Lower Bound | Upper Bound |
|---|---|---|
| population size | 1000 | 2000 |
| number of generations | 200 | 300 |
| init depth | 3 | 12 |
| tournament size | 100 | 500 |
| crossover | 0.95 | 1 |
| subtree mutation | 0.001 | 1 |
| hoist mutation | 0.001 | 1 |
| point mutation | 0.001 | 1 |
| stopping criteria | ||
| maximum samples | 0.99 | 1 |
| constant range | −100,000 | 100,000 |
| parsimony coefficient |
| Dataset Type | Average CPU Time per Simulation [min] | Length of Symbolic Expressions | |||||
|---|---|---|---|---|---|---|---|
| ADASYN | 0.938 | 0.9909 | 0.94 | 0.939 | 0.939 | 2400 | 1046/594/402/302 |
| SMOTE | 0.966 | 0.9956 | 0.9663 | 0.9662 | 0.9661 | 944/556/544/466 | |
| Borderline SMOTE | 0.975 | 0.997 | 0.975 | 0.976 | 0.9758 | 1183/1657/850/1450 |
| Dataset Type | GPSC Hyperparameters Population_size, Number_of_generations, Tournament_size, Initial ial_depth, Crossover, Subtree_mutation, Hoist_mutation, Point_mutation, Stopping_criteria, Max_samples, Constant_range, Parsimony_coefficient |
|---|---|
| ADASYN | 1590, 102, 115, (4, 7), 0.95, 0.033, 0.0073, 0.0019, , 0.995, (−57,908, 56,911), |
| SMOTE | 1557, 233, 272, (7, 11), 0.965, 0.0022, 0.0079, 0.023, , 0.997, (−34,176, 89,128), |
| Borderline SMOTE | 1421,279,139, (6, 7), 0.95, 0.011, 0.0067, 0.027, , 0.99, (−91,766, 19,819), |
| Evaluation Metric | Mean Value | SD Value |
|---|---|---|
| 0.956 | 0.05 | |
| 0.9536 | 0.057 | |
| 0.9507 | 0.0275 | |
| 0.9809 | 0.01 | |
| 0.9698 | 0.00725 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anđelić, N.; Baressi Šegota, S.; Glučina, M.; Lorencin, I. Classification of Wall Following Robot Movements Using Genetic Programming Symbolic Classifier. Machines 2023, 11, 105. https://doi.org/10.3390/machines11010105
Anđelić N, Baressi Šegota S, Glučina M, Lorencin I. Classification of Wall Following Robot Movements Using Genetic Programming Symbolic Classifier. Machines. 2023; 11(1):105. https://doi.org/10.3390/machines11010105
Chicago/Turabian StyleAnđelić, Nikola, Sandi Baressi Šegota, Matko Glučina, and Ivan Lorencin. 2023. "Classification of Wall Following Robot Movements Using Genetic Programming Symbolic Classifier" Machines 11, no. 1: 105. https://doi.org/10.3390/machines11010105
APA StyleAnđelić, N., Baressi Šegota, S., Glučina, M., & Lorencin, I. (2023). Classification of Wall Following Robot Movements Using Genetic Programming Symbolic Classifier. Machines, 11(1), 105. https://doi.org/10.3390/machines11010105