


A Neural Network Weights Initialization Approach for Diagnosing Real Aircraft Engine Inter-Shaft Bearing Faults





Abstract
:1. Introduction
1.1. Related Work Analysis and Research Gaps
- None of the discussed works consider realistic datasets except for reference [8]. Instead, a test-bench is always used to generate these data. In terms of conclusions, the results cannot be projected in real-world circumstances at this moment.
- Outlier removals received no attention in this case. In fact, this ignores real operating conditions that always result in massive data distortions, leading to increasing prediction uncertainties.
- Other data complexity reduction issues related to feature extraction, noise removal, and class imbalance, receive less reasonable attention, but there is undoubtedly a need to consider such constraints since driven sequential data are always exposed to such uncertainty under real-world operational conditions.
1.2. Contributions
- In an attempt to reach more realistic conclusions and generalize obtained results via investigating new unseen samples, a realistic dataset of inter-shaft bearing faults is used in this case [8]. This enables obtained further reliable conclusions compared to ones obtained from non-realistic test-benches experiments in the state of the art by exploring a further challenging feature space emulating real condition.
- Real systems are usually subject to change either in physical properties (i.e., degradation) or in operating conditions. In this context, our work considers using adaptive learning features of LSTM strengthened by root-mean-square propagation to improve its adaptability and allow better generalization on upcoming data.
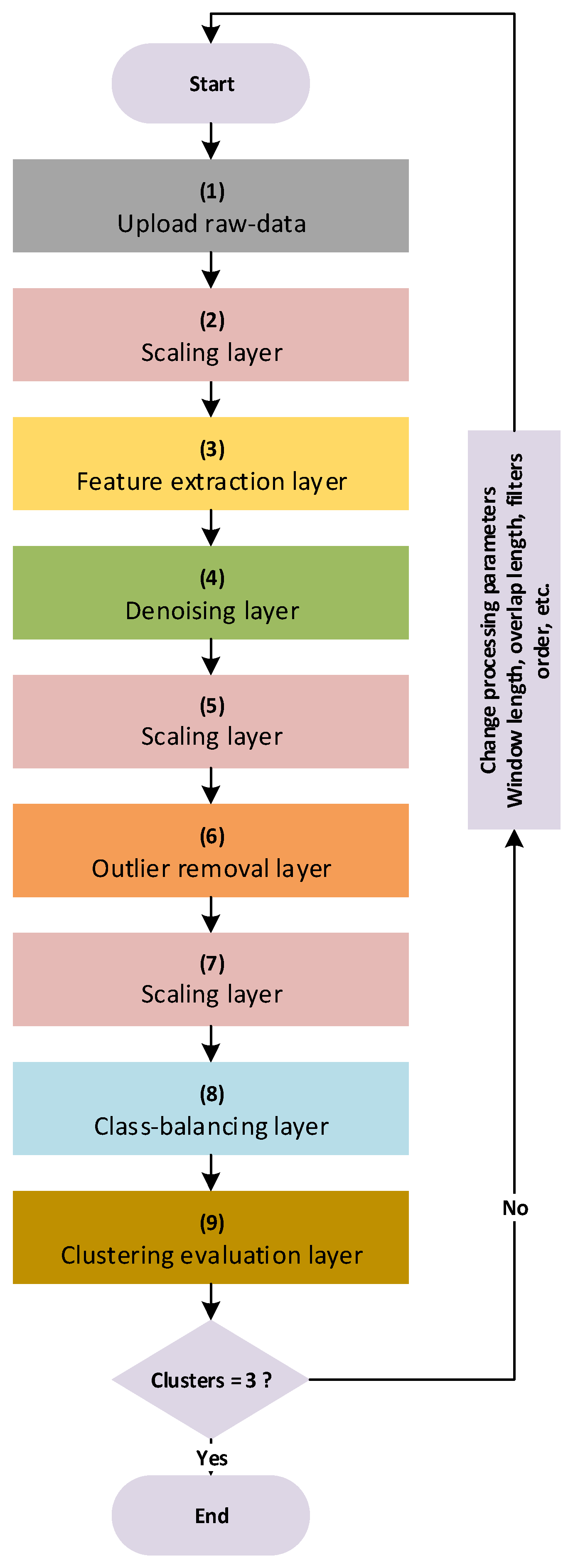
- With the aim of improving data quality, a set of data preprocessing layers are well constructed for this purpose. These layers integrate algorithms for future extraction, outlier removal, denoising, scaling and class balancing with different types to analyze and explore different data features and further improving its scatters representational quality.
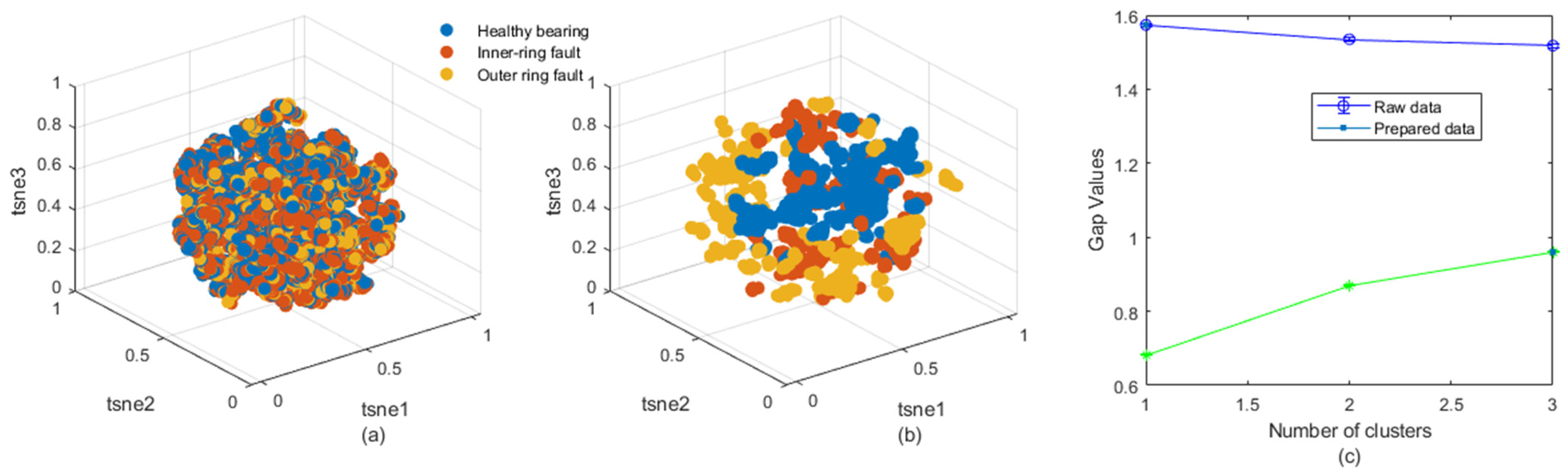
- The results of data preprocessing layers are made subject to final data quality assessment layer. Such investigation is rendered available by involving Gap analysis under k-means clustering to identify the optimal number of clusters required to group similar data points effectively. Gap analysis helps to assess clustering quality results by comparing the within-cluster dispersion to that of data. The analysis provides insights into determining the appropriate number of clusters, which aids to see whether prepared data patterns could be distinguished or not by the supervised learning algorithm since labels are already existing.
- A further process of learning parameters initialization is given to the LSTM network in a sort of collaborative learning from a series of best LSTM approximators recursively in multiple rounds via RWI. This is expected to help in reaching better understanding of data drift and allowing the LSTM network to capture better performances rather than random parameter initialization.
1.3. Outlines
2. Materials
2.1. Data Description
2.2. Preprocessing Methodology
2.2.1. Data Uploading Layer
2.2.2. Scaling Layer
2.2.3. Feature Extraction Layer
2.2.4. Denoising Layer
2.2.5. Outlier Removal Layer
2.2.6. Class-Balancing Layer
2.2.7. Clustering Evaluation Layer
2.3. Some Illustrative Examples
3. Methods and Findings
3.1. Methods
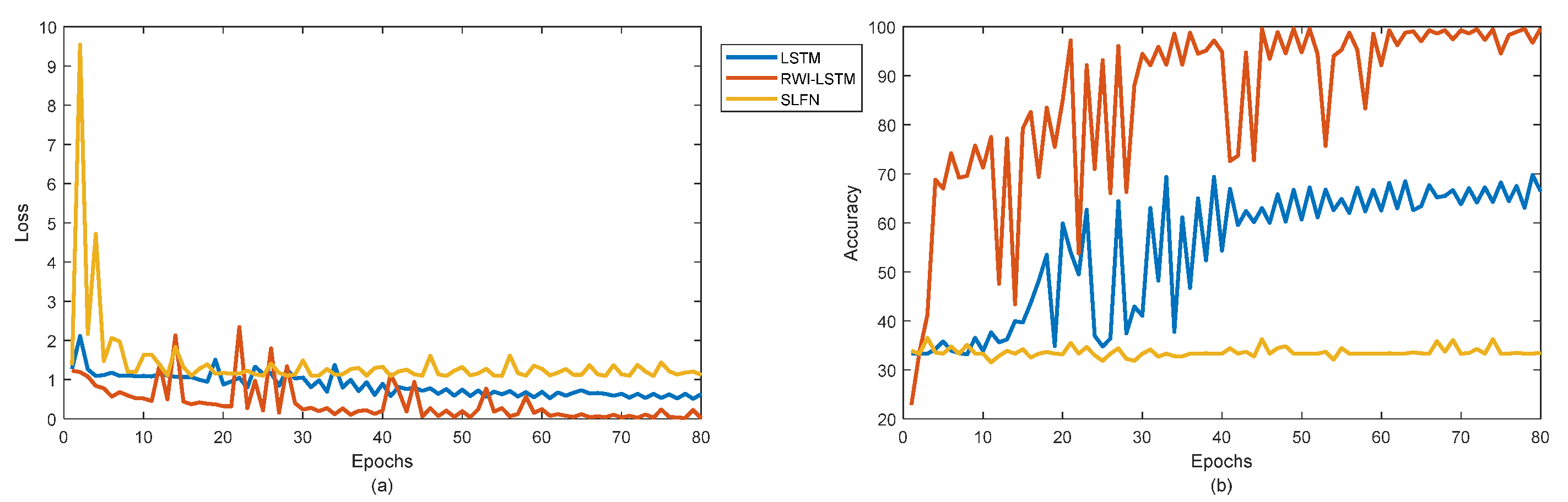
3.2. Application, Results and Discussion
3.3. Comparison Statement
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Berghout, T.; Benbouzid, M. A Systematic Guide for Predicting Remaining Useful Life with Machine Learning. Electronics 2022, 11, 1125. [Google Scholar] [CrossRef]
- Khan, S.; Yairi, T. A Review on the Application of Deep Learning in System Health Management. Mech. Syst. Signal Process. 2018, 107, 241–265. [Google Scholar] [CrossRef]
- Ma, Y.; Yang, J.; Li, L. Meta Bi-Classifier Gradient Discrepancy for Noisy and Universal Domain Adaptation in Intelligent Fault Diagnosis. Knowl.-Based Syst. 2023, 276, 110735. [Google Scholar] [CrossRef]
- Daga, A.P.; Fasana, A.; Marchesiello, S.; Garibaldi, L. The Politecnico Di Torino Rolling Bearing Test Rig: Description and Analysis of Open Access Data. Mech. Syst. Signal Process. 2019, 120, 252–273. [Google Scholar] [CrossRef]
- Jia, L.; Chow, T.W.S.; Yuan, Y. GTFE-Net: A Gramian Time Frequency Enhancement CNN for Bearing Fault Diagnosis. Eng. Appl. Artif. Intell. 2023, 119, 105794. [Google Scholar] [CrossRef]
- Tan, H.; Xie, S.; Ma, W.; Yang, C.; Zheng, S. Correlation Feature Distribution Matching for Fault Diagnosis of Machines. Reliab. Eng. Syst. Saf. 2023, 231, 108981. [Google Scholar] [CrossRef]
- Thelaidjia, T.; Chetih, N.; Moussaoui, A.; Chenikher, S. Successive Variational Mode Decomposition and Blind Source Separation Based on Salp Swarm Optimization for Bearing Fault Diagnosis. Int. J. Adv. Manuf. Technol. 2023, 125, 5541–5556. [Google Scholar] [CrossRef]
- Hou, L.; Yi, H.; Jin, Y.; Gui, M.; Sui, L.; Zhang, J.; Chen, Y. Inter-Shaft Bearing Fault Diagnosis Based on Aero-Engine System: A Benchmarking Dataset Study. J. Dyn. Monit. Diagn. 2023. [Google Scholar] [CrossRef]
- Ohki, M.; Zervakis, M.E.; Venetsanopoulos, A.N. 3-D Digital Filters. In Control and Dynamic Systems; Academic Press: Cambridge, MA, USA, 1995; pp. 49–88. [Google Scholar]
- Smith, S.W. Moving average filters. In Digital Signal Processing; Elsevier: Amsterdam, The Netherlands, 2003; pp. 277–284. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data preprocessing. In Data Mining; Elsevier: Amsterdam, The Netherlands, 2012; pp. 83–124. [Google Scholar]
- Qiu, G.; Gu, Y.; Chen, J. Selective Health Indicator for Bearings Ensemble Remaining Useful Life Prediction with Genetic Algorithm and Weibull Proportional Hazards Model. Meas. J. Int. Meas. Confed. 2020, 150, 107097. [Google Scholar] [CrossRef]
- Bhuiyan, M.I.H.; Ahmad, M.O.; Swamy, M.N.S. Spatially Adaptive Wavelet-Based Method Using the Cauchy Prior for Denoising the SAR Images. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 500–507. [Google Scholar] [CrossRef]
- Smiti, A. A Critical Overview of Outlier Detection Methods. Comput. Sci. Rev. 2020, 38, 100306. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. Ecol. Appl. 2011, 30, e02043. [Google Scholar] [CrossRef]
- Tibshirani, R.; Walther, G.; Hastie, T. Estimating the Number of Clusters in a Data Set Via the Gap Statistic. J. R. Stat. Soc. Ser. B Stat. Methodol. 2001, 63, 411–423. [Google Scholar] [CrossRef]
- van der Maaten, L.; Hinton, G.E. Visualizing Data Using T-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Tharwat, A. Classification Assessment Methods. Appl. Comput. Inform. 2021, 17, 168–192. [Google Scholar] [CrossRef]
- Berghout, T.; Benbouzid, M. Diagnosis and Prognosis of Faults in High-Speed Aeronautical Bearings with a Collaborative Selection Incremental Deep Transfer Learning Approach. Appl. Sci. 2023, 13, 10916. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Refs. | Data Complexity | Data Drift | Realistic Test Bed? | |||
|---|---|---|---|---|---|---|
| Feature Extraction | Denoising | Outliers Removing | Class Balancing | |||
| [3] | ✓ | ✓ | 🗴 | ✓ | 🗴 | 🗴 |
| [5] | 🗴 | ✓ | 🗴 | 🗴 | 🗴 | 🗴 |
| [6] | 🗴 | 🗴 | 🗴 | ✓ | ✓ | 🗴 |
| [7] | ✓ | 🗴 | 🗴 | 🗴 | 🗴 | 🗴 |
| [8] | 🗴 | 🗴 | 🗴 | 🗴 | ✓ | ✓ |
| This paper | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Layers | Options |
|---|---|
| Upload raw-data |
|
| Scaling layer |
|
| Feature extraction layer |
|
| Denoising layer |
|
| Outlier detection layer |
|
| Class-balancing layer |
|
| Clustering evaluation layer |
|
| Method | Accuracy | F1 − Score | Precision | Recall | Standard Deviation | Evaluation Method |
|---|---|---|---|---|---|---|
| SLFN * | 0.3438 | 0.3438 | 0.3438 | 0.3438 | 10−8 | Cross validation |
| LSTM * | 0.596 | 0.590 | 0.596 | 0.596 | 1.77 × 10−5 | Cross validation |
| LSTM [8] | 0.854 | - | - | - | - | Random 70–30% splitting |
| RWI-LSTM * | 0.920 | 0.920 | 0.929 | 0.938 | 8.4901 × 10−4 | Cross validation |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Berghout, T.; Bentrcia, T.; Lim, W.H.; Benbouzid, M. A Neural Network Weights Initialization Approach for Diagnosing Real Aircraft Engine Inter-Shaft Bearing Faults. Machines 2023, 11, 1089. https://doi.org/10.3390/machines11121089
Berghout T, Bentrcia T, Lim WH, Benbouzid M. A Neural Network Weights Initialization Approach for Diagnosing Real Aircraft Engine Inter-Shaft Bearing Faults. Machines. 2023; 11(12):1089. https://doi.org/10.3390/machines11121089
Chicago/Turabian StyleBerghout, Tarek, Toufik Bentrcia, Wei Hong Lim, and Mohamed Benbouzid. 2023. "A Neural Network Weights Initialization Approach for Diagnosing Real Aircraft Engine Inter-Shaft Bearing Faults" Machines 11, no. 12: 1089. https://doi.org/10.3390/machines11121089
APA StyleBerghout, T., Bentrcia, T., Lim, W. H., & Benbouzid, M. (2023). A Neural Network Weights Initialization Approach for Diagnosing Real Aircraft Engine Inter-Shaft Bearing Faults. Machines, 11(12), 1089. https://doi.org/10.3390/machines11121089