1. Introduction
About 1.3 million people die annually worldwide due to traffic accidents, with 93% of these fatalities occurring in low- and middle-income countries such as China and India [
1], despite these countries having only around 60% of the world’s vehicles. Automated vehicles are considered to be effective in reducing traffic accidents. In the past decade, some High-level Automated Vehicles (HAVs) have been designed by high-tech companies, such as Waymo, Tesla, and Baidu [
2,
3,
4]. HAVs need to be thoroughly tested to prove they are safe enough before being accepted by the public, which is pretty challenging. For example, a self-driving vehicle made by Tesla, a leading American automotive company, crashed into a truck due to a flaw in its perception system that relied on deep-learning technologies [
5,
6]. Factors from two perspectives contribute to the difficulty of testing HAVs. First, integrating artificial-intelligence technologies into HAVs, such as deep-learning technologies, may introduce uncertainties and risks due to their poor interpretability [
7]. Moreover, there are theoretically infinite scenarios in natural traffic, including those that are never observed. A study indicates that millions of miles of road testing are required to prove that a self-driving vehicle is safe enough, which is impractical and unaffordable [
8].
Scenario-Based Testing (SBT) is a promising method for HAV testing, which validates and evaluates an HAV safety based on its performance in specific scenarios. A scenario is a temporal sequence of scenes, which includes static objects, dynamic objects, and interrelationships between them [
9]. Based on the level of abstraction, there are three types of scenarios: function, logical, and concrete [
10]. Function scenarios have the highest-level abstraction, in which natural language is exploited to describe scenarios. In logical scenarios, parameter ranges and distributions are used to define scenarios. A concrete value combination of scenario parameters can define a concrete scenario. To describe highway scenarios better, a five-layer model is proposed in [
11], which includes road networks, traffic participants, weather, et al. Furthermore, the authors in [
12] present a modified six-layer model for urban scenario description.
For convenience, “scenario” refers to a concrete scenario in this study if no specific notation is assigned. There are numerous natural traffic scenarios; most are boring and meaningless for AV testing [
13]. For example, working on a well-maintained road with no other vehicles or bad weather conditions poses no challenge to the VUT. Rather, the critical and challenging scenarios are significant for scenario-based testing. In a critical scenario, the Vehicle Under Test (VUT) is responsible for at least one collision or near crash [
14]. It is a hot research topic to generate critical scenarios for AV testing.
In [
15,
16], performance boundaries refer to the ones around which VUT performance varies greatly in two adjacent scenarios. Boundary scenarios are those located near performance boundaries. In this study, the performance boundary in an Operational Designed Domain (ODD) [
17] is between the sets of critical and non-critical scenarios, and boundary scenarios are near the performance boundary. It is essential to test Highly Automated Vehicles (HAVs) in boundary scenarios to investigate why even minor changes in scenario parameters may lead to a collision. For example, given a new HAV, it is reasonable and expected that many critical scenarios can be found in its ODD. However, it will consume many resources to execute all critical scenarios in the physical or simulation world. To enhance testing efficiency, it is a good option for developers to investigate the HAV performance in boundary scenarios. Furthermore, based on boundary scenarios, the performance boundary can be fitted, which can assist in generating critical scenarios [
16,
18]. However, it is challenging to identify a large number of diverse boundary scenarios with limited resources because of their rarity. Theoretically, a scenario should not be identified as a boundary one before being proved near the performance boundary, which often requires the execution of many scenarios. In this study, we aim to efficiently generate numerous and diverse scenarios likely to be boundary scenarios, known as candidate scenarios.
The main contributions of this study are as follows:
- (1)
A novel approach is proposed to obtain a High-Performance Classifier (HPC) for efficiently classifying critical and non-critical scenarios without consuming significant resources. This approach combines the Gaussian Process Classification (GPC) and Support Vector Machine (SVM) algorithms, which mutually detect uncertain scenarios and improve each other’s performance iteratively.
- (2)
A distance-based method is presented for identifying candidate scenarios using the HPC without executing scenarios. This approach enables the efficient identification of potential boundary scenarios.
- (3)
This study also uses local sampling iteratively to generate diverse candidate scenarios based on a small set of them. This approach can be applied to generate high-dimensional candidate scenarios efficiently.
The rest of this paper is organized as follows. In
Section 2, we review related works.
Section 3 presents the methodology proposed by this study to efficiently generate diverse boundary scenarios without consuming significant computing resources. In
Section 4, we describe the detailed settings of the simulation experiments. We provide all numerical results of the simulation experiments and our discussions in
Section 5. Finally, we conclude this study in
Section 6.
2. Related Works
There are two main methodologies for scenario generation: coverage-oriented and criticality-oriented. Coverage-oriented methods generate diverse scenarios that comprehensively fill the ODD to test AVs. Random sampling [
13], mutation testing [
19], and combinatorial testing [
20] can all be exploited to generate diverse scenarios. However, most scenarios generated by coverage-based methods are not challenging for the VUT, and many scenario executions are required, which demands extensive computing resources. On the other hand, criticality-oriented methods aim to find diverse or the most critical scenarios for HAV testing, reducing unnecessary scenario executions. There are many strategies for critical scenario generation, such as Accelerated Evaluation (AE) [
21,
22,
23,
24], search-algorithm-based methods [
14,
25,
26,
27,
28,
29], and Reinforcement Learning-based critical scenario generation [
30,
31,
32,
33,
34].
AE is first proposed by [
21] for HAV testing. First, a large amount of NDD is collected, and the original parameter distribution is fitted. Second, the original distribution is skewed by importance sampling, resulting in an accelerated distribution. Finally, Monte Carlo is used to sample the accelerated distribution, generating scenarios for AV testing. AE can generate more critical scenarios than random sampling and naturalistic scenarios, in which VUT performance can be skewed back to that in natural traffic. Simulation experiments show that AE can generate 200~20,000 times more challenging scenarios than road testing. AE is further improved by reducing the gap between the real parameter distribution and the fitted one, finding the optimal hyperparameters for IS by searching algorithms [
21] or the cross-entropy method [
24]. However, AE still generates many non-critical scenarios and sometimes requires knowledge about the VUT.
Search algorithms have been applied to solve optimization problems, such as structure optimization [
35] and vehicle routing [
36]. Guided by a fitness function, search algorithms can iteratively search for the most critical scenarios. Many search algorithms are used to search for critical scenarios, such as Particle Swarm Optimization (PSO) algorithm [
26], Genetic Algorithm (GA) [
25], and Rapidly exploring Random Tree (RRT) [
29]. There are three keys to achieving good results based on search algorithms: designing an appropriate fitness function, balancing exploration and exploitation, and reducing the search space. Different fitness functions usually derive scenarios with varying characteristics [
37]. Some criticality metrics are sometimes used as the fitness function, such as Time-To-Collision (TTC) [
38] and its variants [
39,
40,
41,
42,
43]. However, to our knowledge, no signal metric can measure the criticality of all scenarios. It seems an excellent option to combine several scenarios to consider various aspects of the scenario. In [
44], a weighted sum of several metrics is used to measure the criticality of a scenario. Although the fitness function design is still open, several templates are provided in [
45]. A search algorithm must avoid local optima and find the best global solution to the original problem. In [
25], a local fuzzed is applied for exploitation, and GA is exploited for exploration. Simulation experiments show that GA-Fuzzer can find three times more critical cut-in scenarios and consumes fewer computing resources than Reinforce Learning-base Adaptive Stress Testing (RLAST) [
33]. However, search algorithm-based methods rely on fitness functions designed by experts. Moreover, a conclusion that the VUT is safe enough cannot be made if no critical scenario is detected because they are all falsification methods.
Reinforcement Learning (RL) is a powerful machine-learning technique and has been used in many fields, such as robot control [
46] and graph generation [
47]. Like search algorithm-based methods, guided by a pre-defined reward function, challenging scenarios are adaptively generated by RL. In [
31], RL identifies critical cut-in scenarios guided by a reward function involving distance headway, TTC, and the required lateral acceleration for collision avoidance. The results of simulation experiments indicate that RLAST can adaptively generate adversarial maneuvers for reference vehicles to disturb the VUT, leading to a 37% increase in the proportion of detected critical scenarios compared to random sampling [
33]. Simulation results in [
33] show that RLAST is more likely to generate a critical cut-in scenario that makes the VUT fail than Monte Carlo. However, RL-based methods heavily rely on the quality of the pre-defined reward function. Furthermore, similar to search algorithm-based methods, no conclusion about the safety of the VUT can be made if no critical scenario is found. It may take numerous iterations to identify critical scenarios using RL, requiring extensive high-fidelity scenario simulations.
Given the performance boundary which divides the ODD into a critical subspace and a non-critical subspace, all criticality-oriented methods mentioned above can be applied to generate critical scenarios in the critical subspace. A decision tree classifier is used to find the performance boundary in [
48], which results in a critical and non-critical subspace. After that, A multi-objective population-based search algorithm is adopted to find critical scenarios in the critical space. Experimental results demonstrate that within 24 h, 731 distinct critical scenarios are generated to evaluate the performance of an Autonomous Emergency Braking (AEB) system.
Performance boundary detection can be broadly categorized into two types of methods: regressor-based and classifier-based. Regressor-based methods leverage high-performance regression models to estimate the performance of the SUT in all scenarios within the ODD, without actually executing each scenario. These methods generally begin by modeling the logical scenario and then use searching techniques, such as adaptive sampling and swarm-based searching, to identify boundary scenarios. Once a diverse set of boundary scenarios is identified, the performance boundary can be derived through fitting or clustering techniques. In [
15], a novel approach is presented for detecting performance boundaries between distinct modes. The methodology leverages Gaussian Process Regression (GPR) to construct a Surrogate Model (SM) using a set of random scenarios. Then, adaptive sampling is used to find new and uncertain scenarios based on the variance of the GPR model to improve the GPR-based SM iteratively. With the enhancement of the GPR-based SM, new scenarios tend to be boundary scenarios. Finally, boundaries between different performance modes are identified by density-based clustering. Experiment results demonstrate that the proposed approach successfully identified the boundaries between three performance modes of an uncrewed underwater vehicle. However, it required an extensive computation of 850 thousand scenario executions.
The authors in [
49] present a coverage-oriented adaptive sampling strategy to find and execute diverse scenarios involving the VUT. Based on scenario parameters and VUT performance in these executed scenarios, a set of training data is collected and used to train a Multi-Layer Perception (MLP) -based SM. Then, the Descent Searching Approach (DSA) is exploited to search for boundary scenarios based on the MLP-based SM. The results of the simulation experiments show that this methodology is effective in obtaining a high-performance SM and finding boundary scenarios. However, a significant limitation of this methodology is that it still requires many scenario executions to train the high-performance SM. Additionally, the methodology may face challenges in finding boundary scenarios in a high-dimensional Operational Design Domain (ODD).
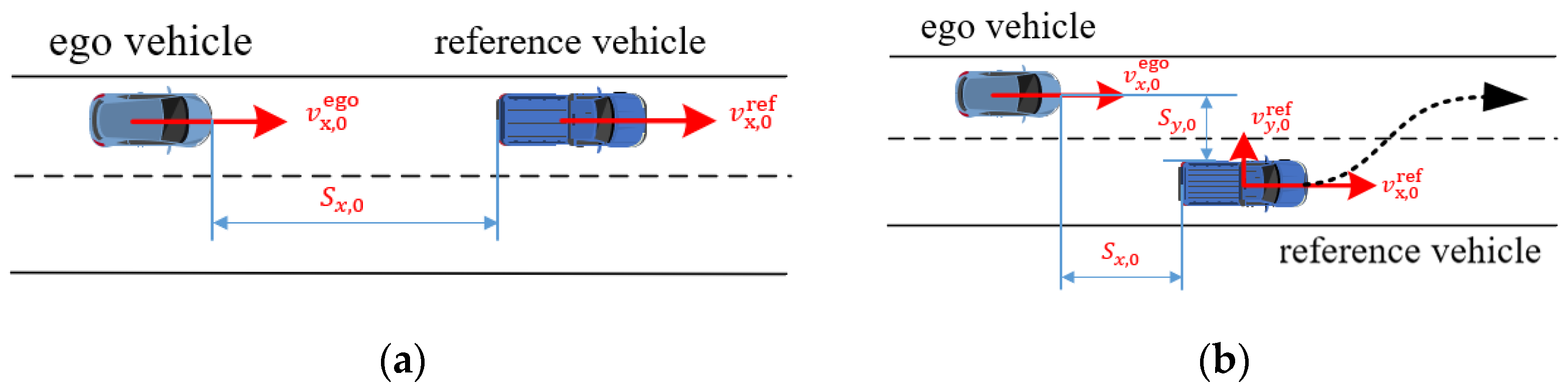
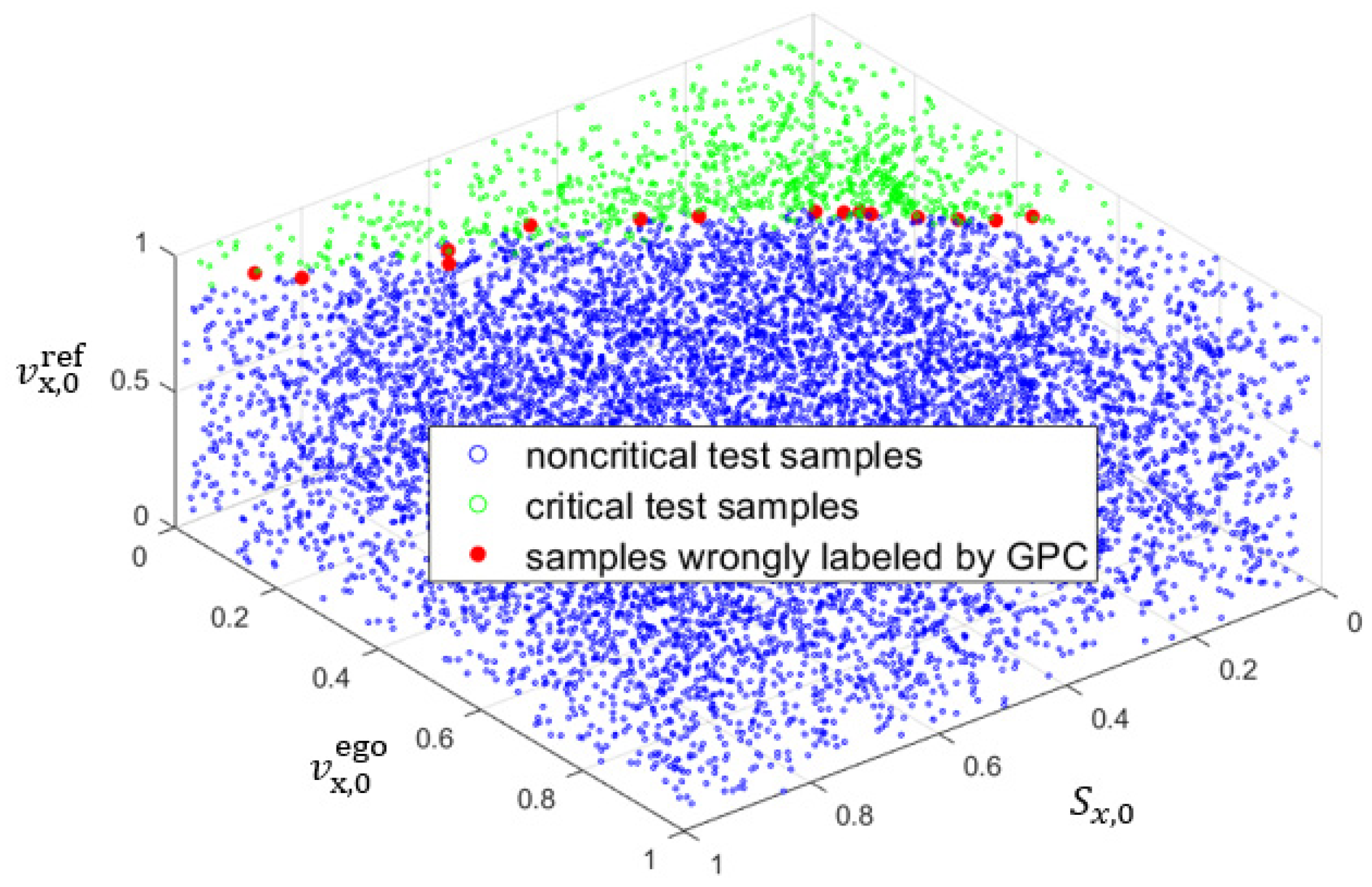
Classifier-based methods find the performance boundary based on an HPC, which classifies all scenarios in the ODD without scenario executions. In [
18], Gaussian Process Classification (GPC) is used to find the performance boundary. A GPC model is trained and used to label scenarios in the ODD based on a set of executed scenarios generated by random sampling. The performance boundary is finally estimated, separating the sets of critical and non-critical scenarios. The front-collision-avoidance scenario is described for simulation experiments, involving two vehicles driving on a curved road, the low-speed one (the reference vehicle) and the approaching one (the ego). Three parameters are exploited to describe the scenario: the ego speed, the speed of the reference vehicle, and the aperture angle of the radar sensor of the ego. Numerical results show that less than 1000 random scenarios are sufficient to find the performance boundary. However, this methodology is not compared with other approaches. In addition, As pointed out by the authors of [
18], many random scenarios might be needed to train a high-performance GPC model to classify critical and non-critical high-dimensional scenarios, which are resource intensive.
In [
50], Gaussian Processes are exploited to distinguish critical and non-critical scenarios. First, a small set of random scenarios is executed to train a GPC model for classifying critical and non-critical scenarios and a GPR model for predicting scenario criticality and uncertainty. Then, a heuristic is adopted to search for critical and uncertain scenarios in the critical space estimated by the GPC model based on the GPR model. After that, the new scenarios are executed and added to the training dataset for GPC and GPR. Simulation experiments involving the scenario described in [
18] are carried out to evaluate this methodology. Experiment results show that 56% of the scenarios found by the heuristic algorithm end with a collision. In this methodology, the quality of the new scenarios found by the heuristic algorithm relies on the performance of the GP models. Since the new scenarios tend to be critical and uncertain, the GP model only performs well in a specific critical subspace of the ODD. Therefore, if the initial scenarios for model training are not diverse enough, it is challenging to quickly enhance the performance of the GP models in the whole ODD.
Based on the analysis of the studies mentioned above, it is evident that HPCs or regressors are essential for detecting boundary scenarios. However, it is challenging to obtain these classifiers with limited computing resources. Inspired by [
18,
49,
50], this study presents a methodology to obtain an HPC. GPC and Support Vector Machines (SVM) are employed in this study to classify critical and non-critical scenarios. In contrast to [
18,
50], these two classifiers guide each other to find uncertain scenarios and improve their performance iteratively. Then the HPC is used to search for candidate scenarios without executing scenarios. Finally, local sampling is exploited to derive more boundary scenarios based on a small number of them.
3. Methodology
3.1. A Distance-Based Approach
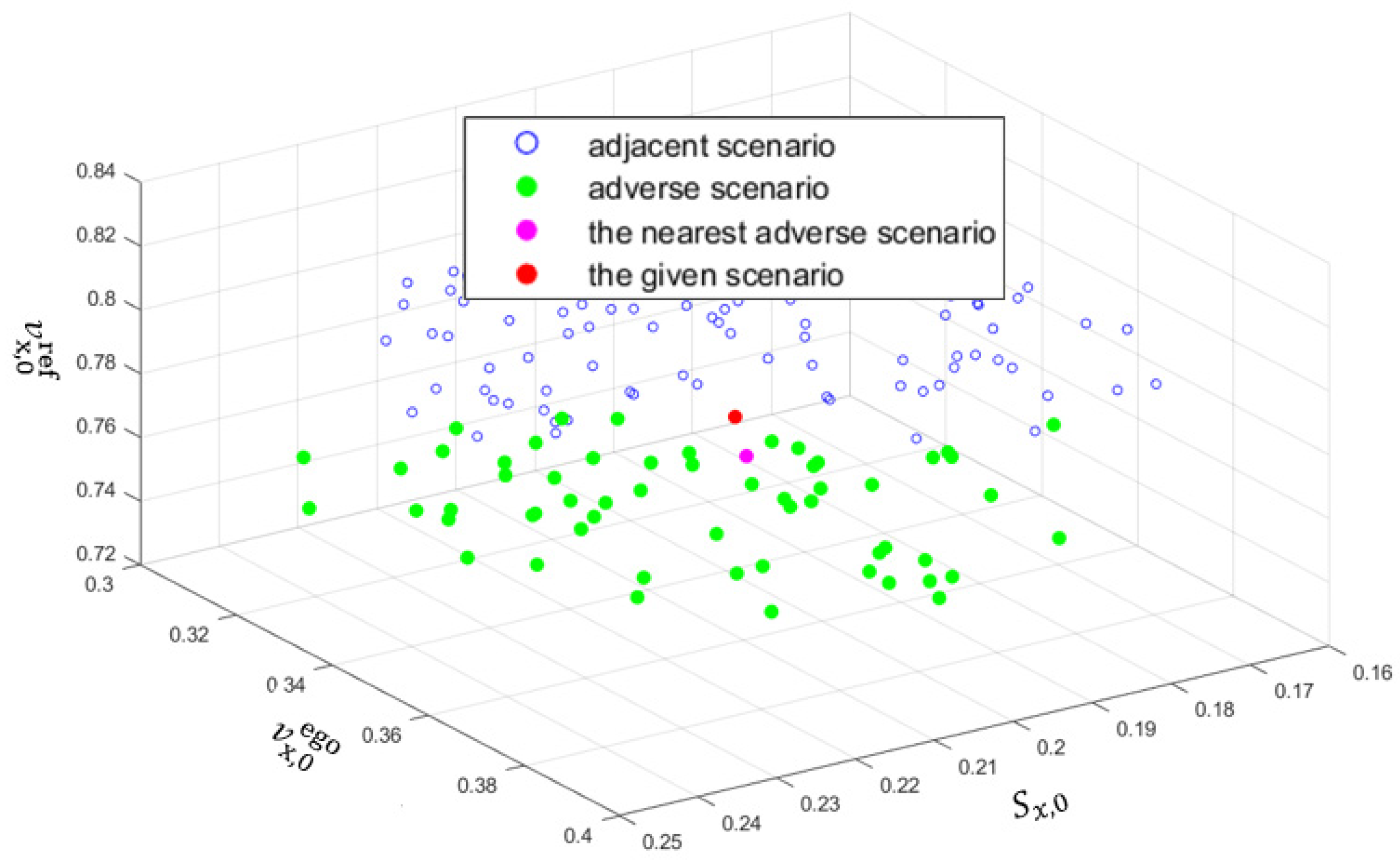
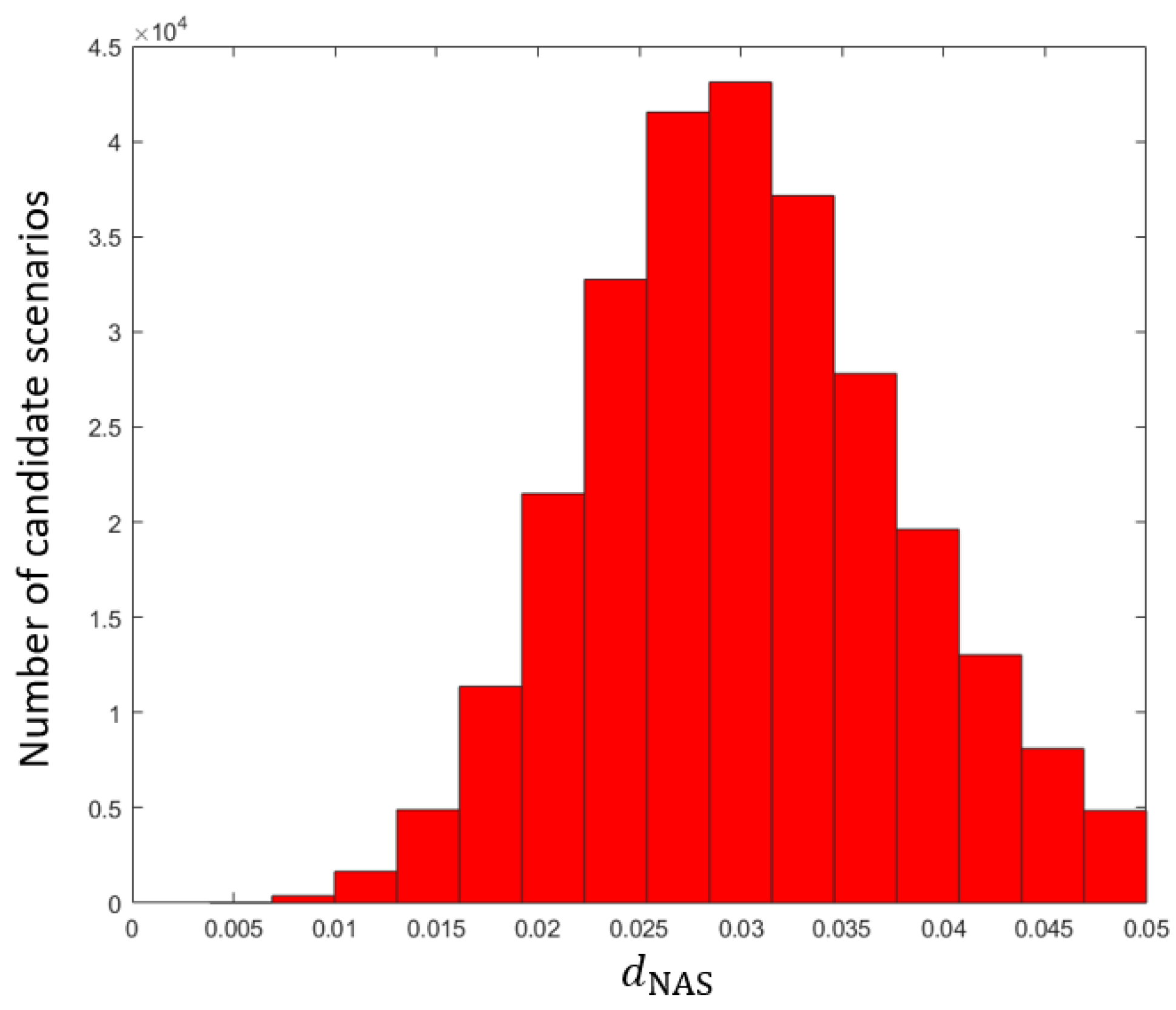
Before presenting the overall framework in the following section of the methodology, it is necessary to introduce some important terms and a distance-based approach for determining whether a scenario is near the performance boundary. First, several adjacent scenarios near the given scenario are generated by random sampling and executed one by one to determine their class labels based on the VUT performance. A scenario is critical if the VUT is responsible for a collision. Adverse scenarios are the adjacent scenarios that belong to the class different from the given scenario .
For a given scenario
from class 1, if at least one adverse scenario
belonging to class 2 is found, the scenario
is regarded as a boundary scenario, as shown in
Figure 1. It is worth noting that the question of how close the given scenario needs to be to its adverse scenarios to be considered a boundary scenario is still an open question in this field. The threshold for distance may depend on various factors, such as the specific ODD, the performance requirements for the VUT, and the available resources to execute and evaluate scenarios. Therefore, more research is needed to determine a suitable threshold for different situations. In this study, the distance between the nearest adverse scenario
and the given scenario
is expressed as
. It is apparent that the smaller the
is, the closer the given scenario
is to the performance boundary. It should be emphasized that the adverse scenarios of the given scenario are also boundary ones.
3.2. Overall Framework
This study aims to find diverse candidate scenarios consuming as few resources as possible. Three missions must be completed to achieve it. First, acquire an HPC that can accurately classify critical and non-critical scenarios in the ODD. Second, find a set of diverse candidate scenarios based on the HPC. Since high-dimensional candidate scenarios are rare in the ODD, the third mission is to obtain more diverse candidate scenarios based on a few.
The map between VUT performance and scenario parameters can be highly nonlinear and uncertain due to the complexity of HAV systems and natural traffic. Gaussian Process (GP) and Support Vector Machine (SVM) are widely used for classification and regression [
51,
52]. Compared with Artificial Neural Networks (ANN), SVM and GP can derive good results based on much less training data [
53,
54]. Furthermore, SVM is robust to outliers, and GP is good at capturing uncertainty and modeling nonlinear relationships. Therefore, SVM and GPC are both suitable for scenario classification. These two classifiers dig for information in the training data from different perspectives. SVM works on the structure information of the training data, while GPC minds information based on the probability theory. In this study, SVM and GPC guide each other in finding uncertain scenarios, improving the performance of both iteratively. If two classifiers generate two different class labels for one scenario, the scenario is considered uncertain. If two classifiers produce different class labels for a given scenario, that scenario can be considered to be an uncertain scenario. It is necessary to execute all uncertain scenarios to identify informative scenarios for both classifiers. By doing so, we can potentially obtain at least one HPC.
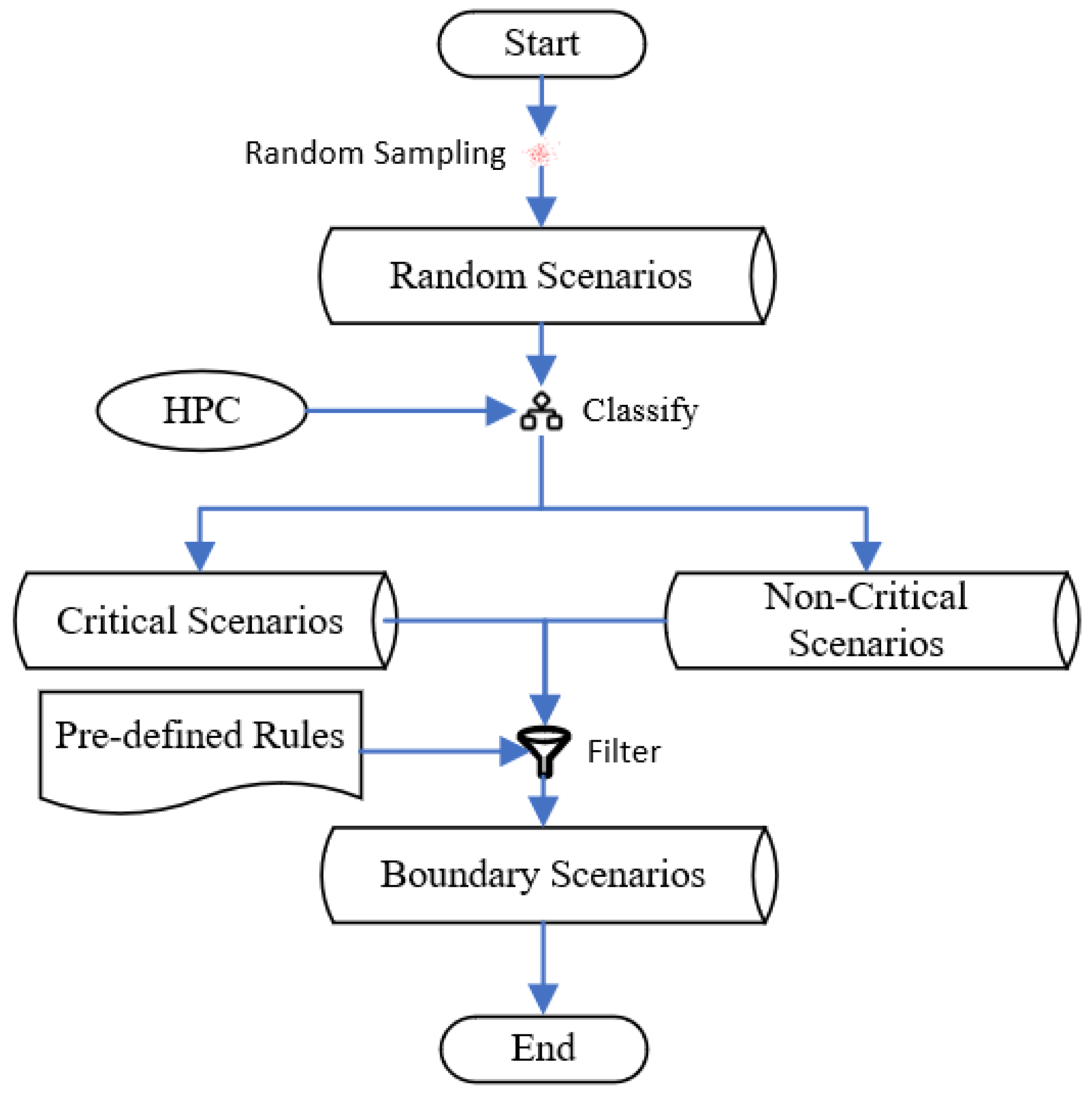
To identify candidate scenarios based on one HPC, several scenarios are generated by random sampling. Then, the HPC is used to classify all of these random scenarios. Finally, all candidate scenarios are identified using the distance-based method mentioned above.
Finally, the third mission is completed by local sampling, which can iteratively search for more candidate scenarios based on a small initial set of them.
3.3. Gaussian Processes
GP is a non-parametric machine-learning technique for pattern identification, regression, and classification [
51]. For more details about GP, see [
55,
56]. “Non-parametric” does not mean that no parameters are needed, but because the relevant parameters are automatically optimized and do not need to be set by the user. A GP model is a set of random variables. The joint distributions of more than one of these random variables are joint Gaussian distributions [
57]. A GP
can be represented by Equation (1):
where
is a mean function often assumed to be 0 for convenience,
is a covariance function.
A covariance function can be any function involving two inputs. Although many covariance functions exist, the most widely used one is the square exponential covariance function, as shown in Equation (2). According to the square exponential covariance function, if the distance between two samples increases, their correlation will decrease exponentially.
where
and
are hyperparameters.
Given a training dataset
, where
is the size of the training dataset,
is a vector of inputs in
,
is the observed outputs corresponding to
, as shown in Equation (3).
where
is the real output,
is an independent Gaussian noise with variance
.
Based on the definition of GP, the distributions of the observed outputs
and the predicted outputs
can be described by Equation (4).
where the mean function is assumed to be 0,
,
,
,
,
is a matrix of inputs in the training data
.
is the dimension of the input space
.
is the matrix of test input.
Based on Bayesian theory,
can be derived by Equation (5):
Therefore, given a test input
, the output of a GP model is the Gaussian distribution of
, involving a mean and a variance, as shown in Equation (6). The mean is considered the predicted output for regression problems, and the variance indicates the confidence of the prediction.
For classification, the training data can be represented as
, where
is the class label of
. The GP tackles classification problems by predicting the class probability
, which is the input of a logical function, deriving the predicted class. GPC mainly includes two steps. First, the distribution of the latent variable
is predicted. The class probability
is obtained as shown in Equation (7).
3.4. Support Vector Machines
SVM is a supervised learning technique proposed by Vapnik and has been used for pattern recognition, classification, and regression [
52,
58,
59,
60]. Unlike Artificial Neural Networks (ANN), SVM is built on solid theoretical foundations. For a detailed introduction to SVM, see [
61,
62]. In this study, SVM is used for classification. Rather than trying to find the classes for all training data as in other classification techniques, SVM aims to find maximum-margin hyperplanes that divide the feather space into several sub-spaces that belong to different classes. In other words, rather than aiming at minimizing empirical risk, SVM aims to minimize structural risk, making SVM robust to outliers and with a good generalization ability [
63]. In a linear separable case, a training dataset is given as
where
,
is the size of the training dataset,
is the dimension of
.
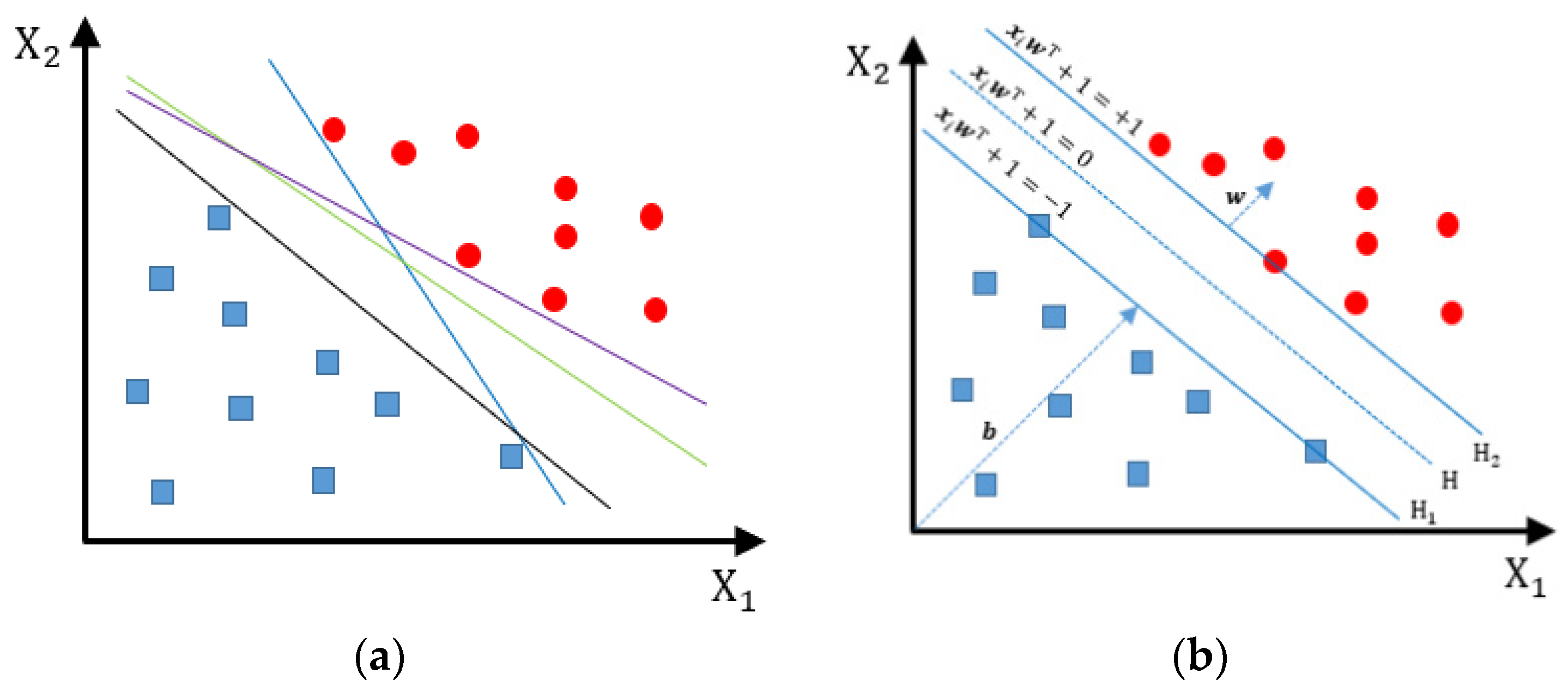
can be 1 for one class or −1 for the other class. Therefore, the hyperplane that separates the training data can be described by
in Equation (8) and
Figure 2. The distance between the hyperplane and the nearest points is called the margin. It is obvious that there may be numerous hyperplanes. The purpose of SVM is to find the optimal hyperplane between two parallel hyperplanes,
and
[
52]. There are no training data between
and
. When the distance between
and
is maximized, the training points on them are called support vectors.
where
is normal to the hyperplane
,
is the Euclidean norm of
,
and
are scalable.
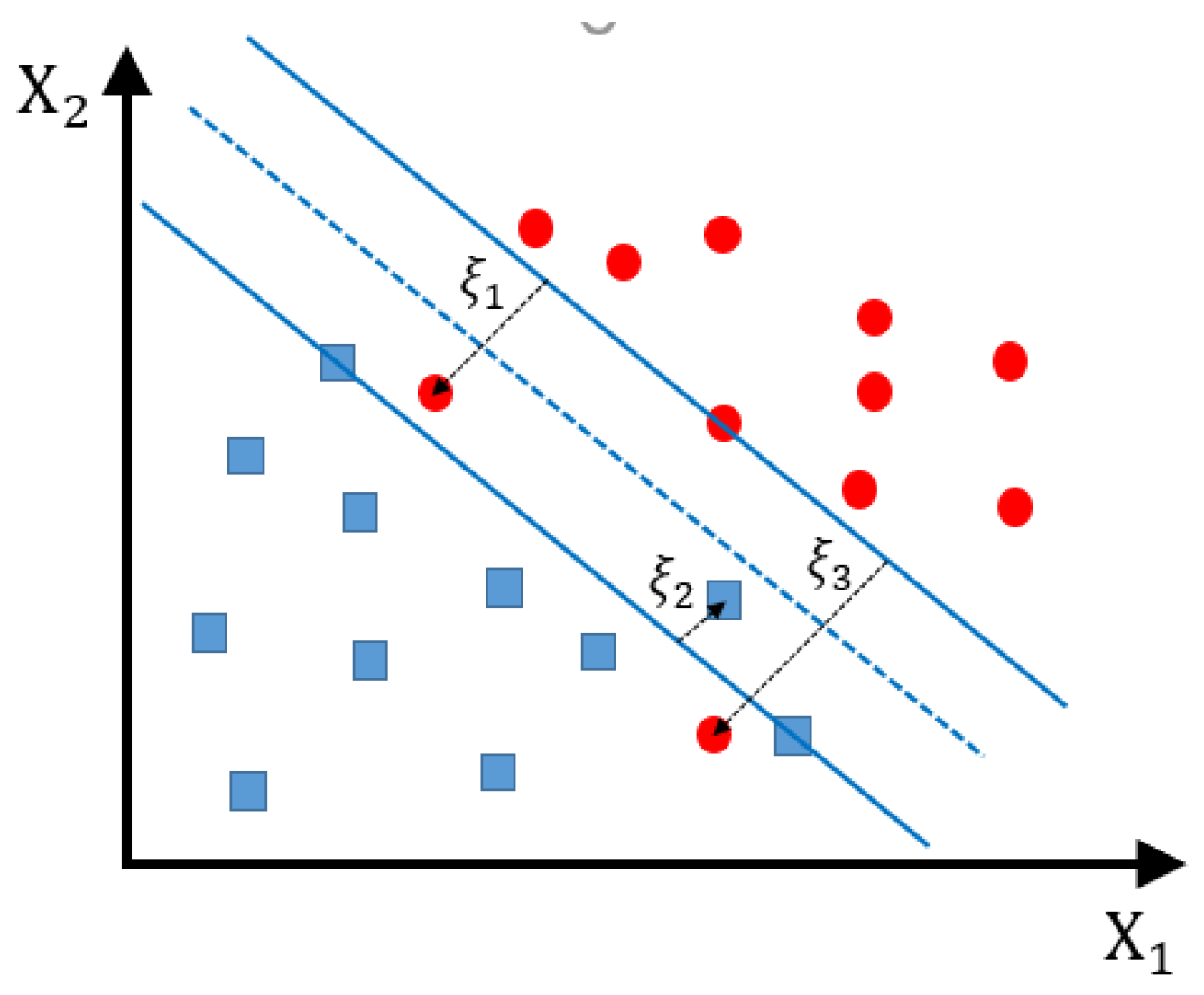
If the training is not linearly separable, no hyperplanes can separate the training data, which usually happens in practical cases. There are two solutions to tackle this problem. First, slack variables
are introduced, as shown in
Figure 3. Then, the problem of finding the optimal hyperplane is equivalent to the minimization of
, where
is the penalty parameter that controls the width of the soft margin, as shown in Equation (9). The Lagrangian for maximizing the soft margin is shown in Equation (10).
If a linear SVM cannot yield good results even though the margin between two classes has been maximized, a nonlinear SVM is needed to tackle the problem. The nonlinear SVM works based on the assumption that the training data that are not linearly separable in the original space
tend to be linear separable after being mapped by a function
to a high-dimensional feather space
. Therefore, the most significant difference between linear SVM and nonlinear SVM is that the hyperplanes exist in the feather space
rather than the original space
. It is not easy to find the best mapping function
. However, based on the Lagrangian shown by Equation (10), the kernel function
(Equation (11)) can achieve our purpose indirectly.
There are many popular kernel functions, as shown in
Table 1. This study uses the Gaussian kernel function for classification based on SVM.
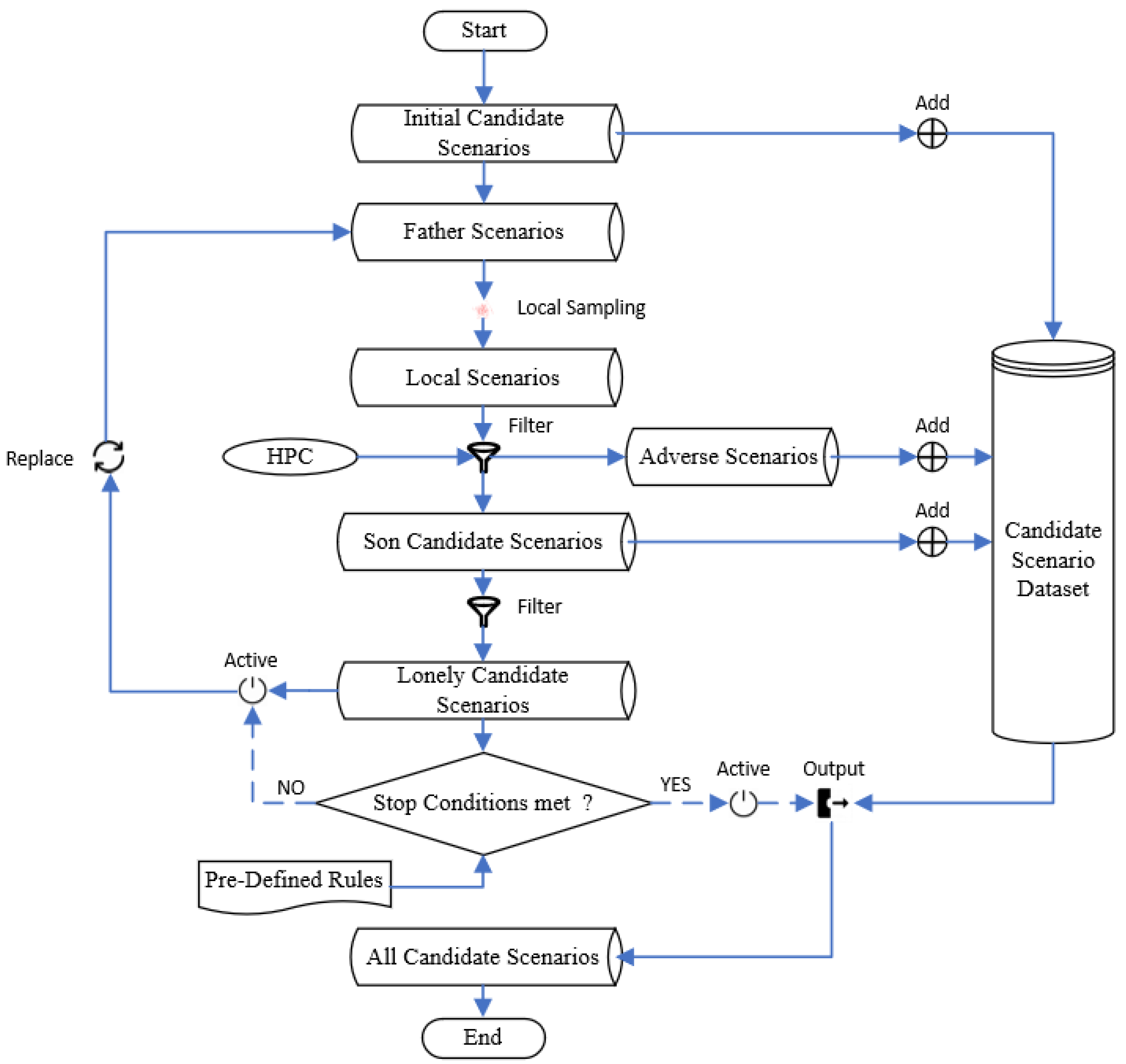
3.5. Obtaining High-Performance Classifiers
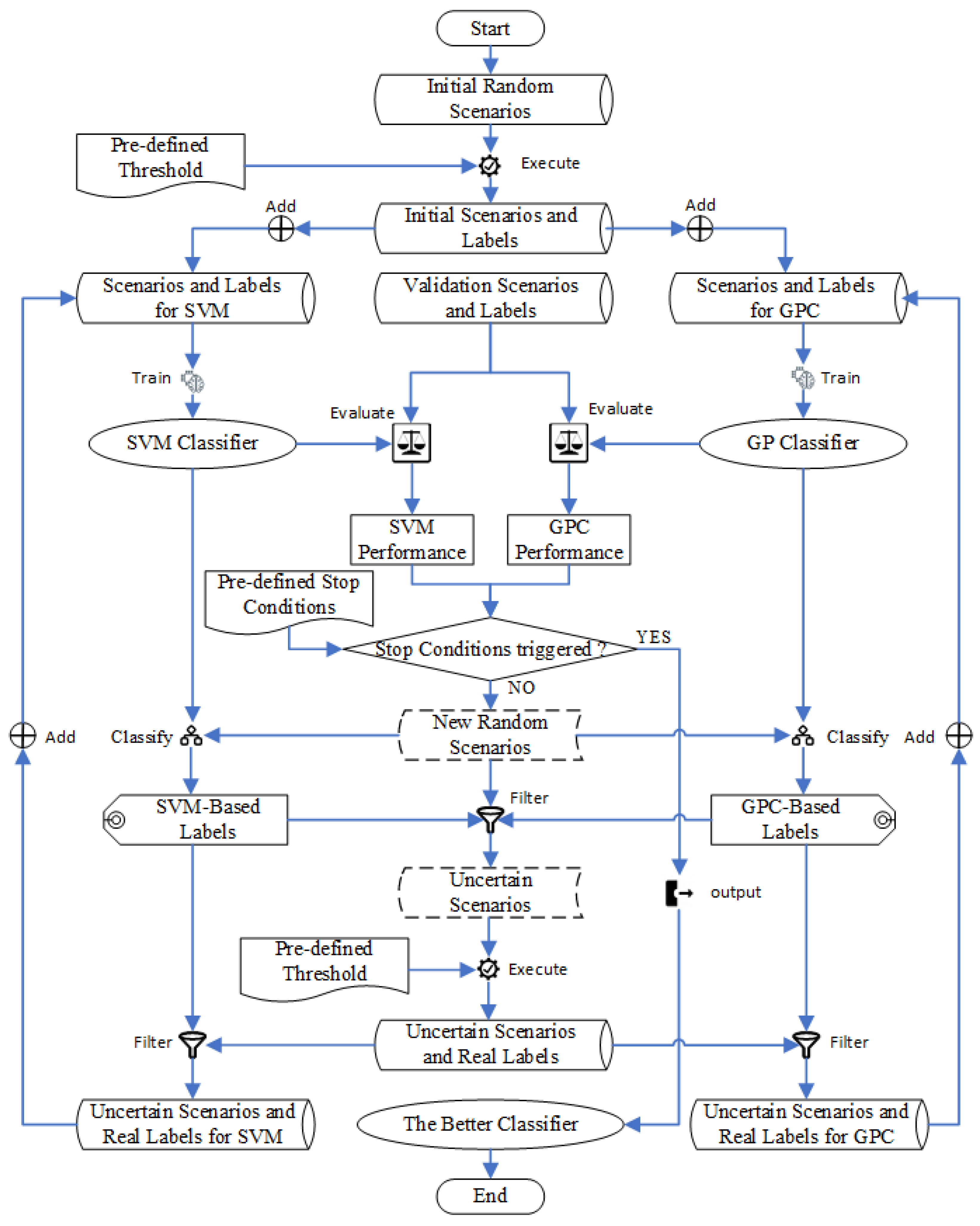
This study proposes a strategy for obtaining an HPC, as illustrated in
Figure 4. In this strategy, SVM and GPC classifiers guide each other to iteratively identify uncertain scenarios that improve their respective performances. A scenario is considered uncertain if it is classified differently by the SVM and GPC classifiers. This strategy can be divided into five steps:
Step 1: the initial scenarios are randomly generated and executed. Their class labels are generated based on a pre-defined criticality metric and a threshold. For example, “1” is the label for critical scenarios, and “0” is for non-critical scenarios. The initial scenario dataset with labels will be used as a training dataset for SVM and GPC in Step 2.
Step 2: The SVM and GPC classifiers are trained based on their respective training datasets.
Step 3: A test dataset is used to evaluate the performance of the SVM and GPC classifiers. If pre-defined conditions are met, the iteration stops. If not, the next step is executed.
Step 4: Generate random scenarios again. The classifiers obtained in Step 2 are used to label them. Therefore, all uncertain scenarios can be identified.
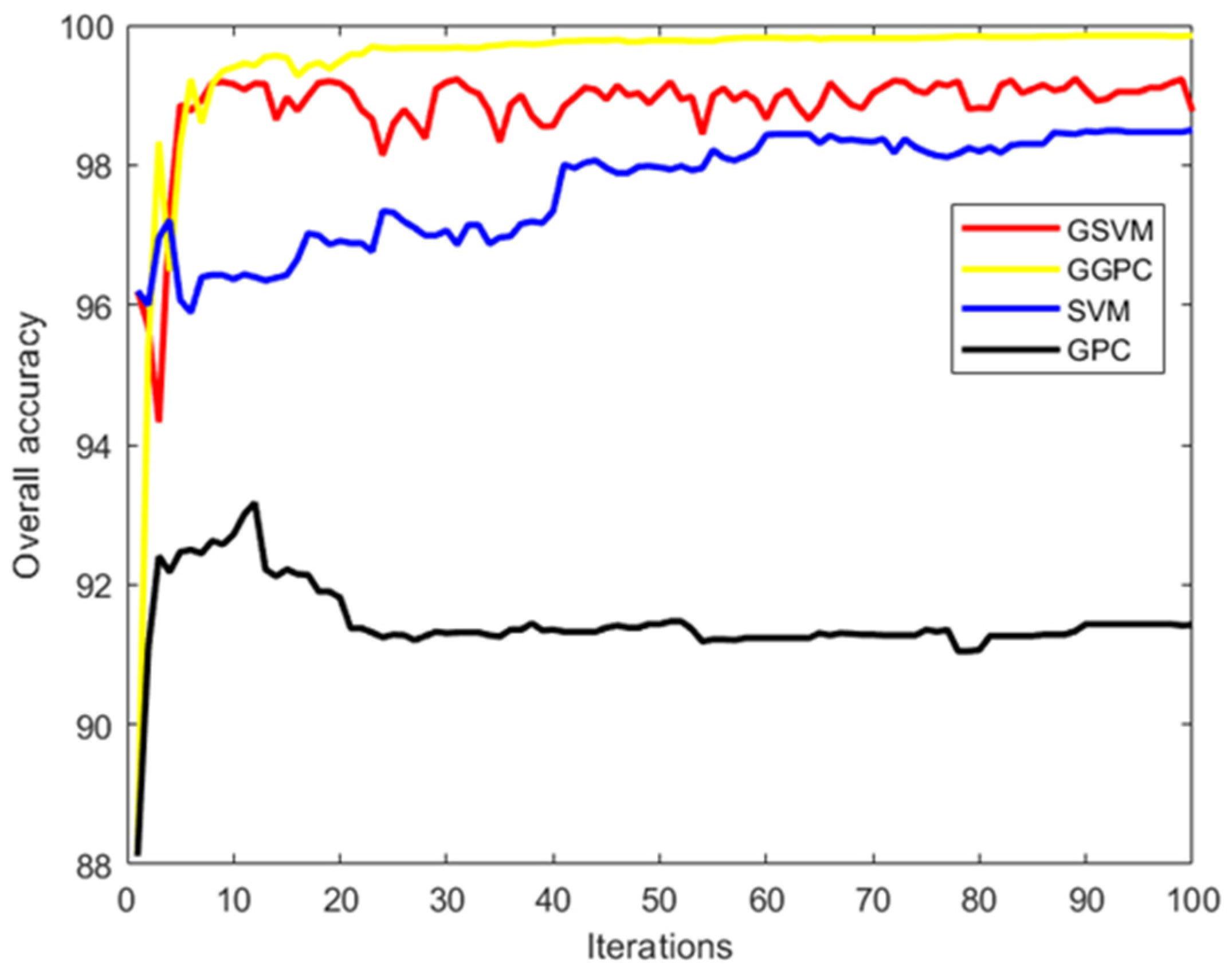
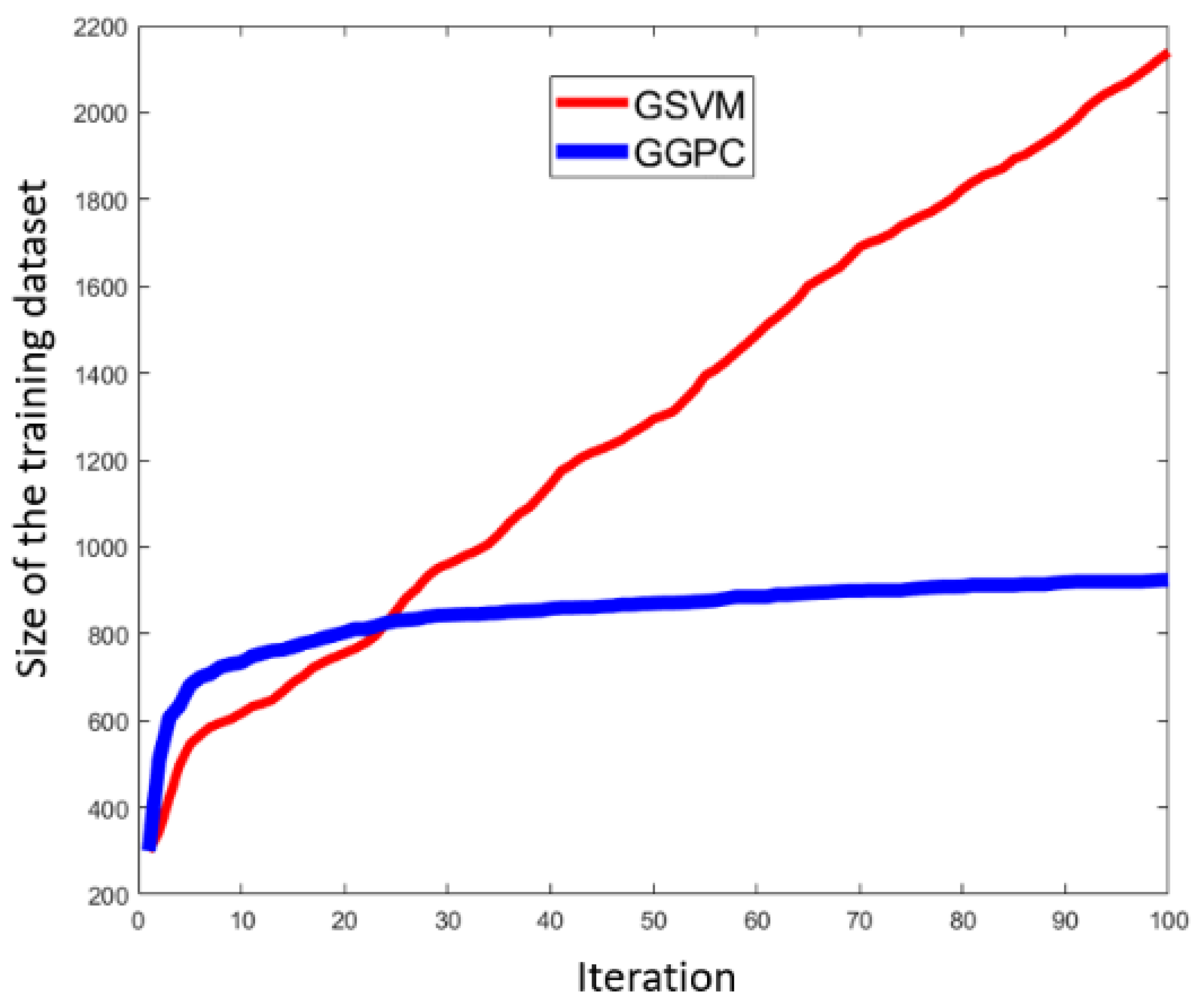
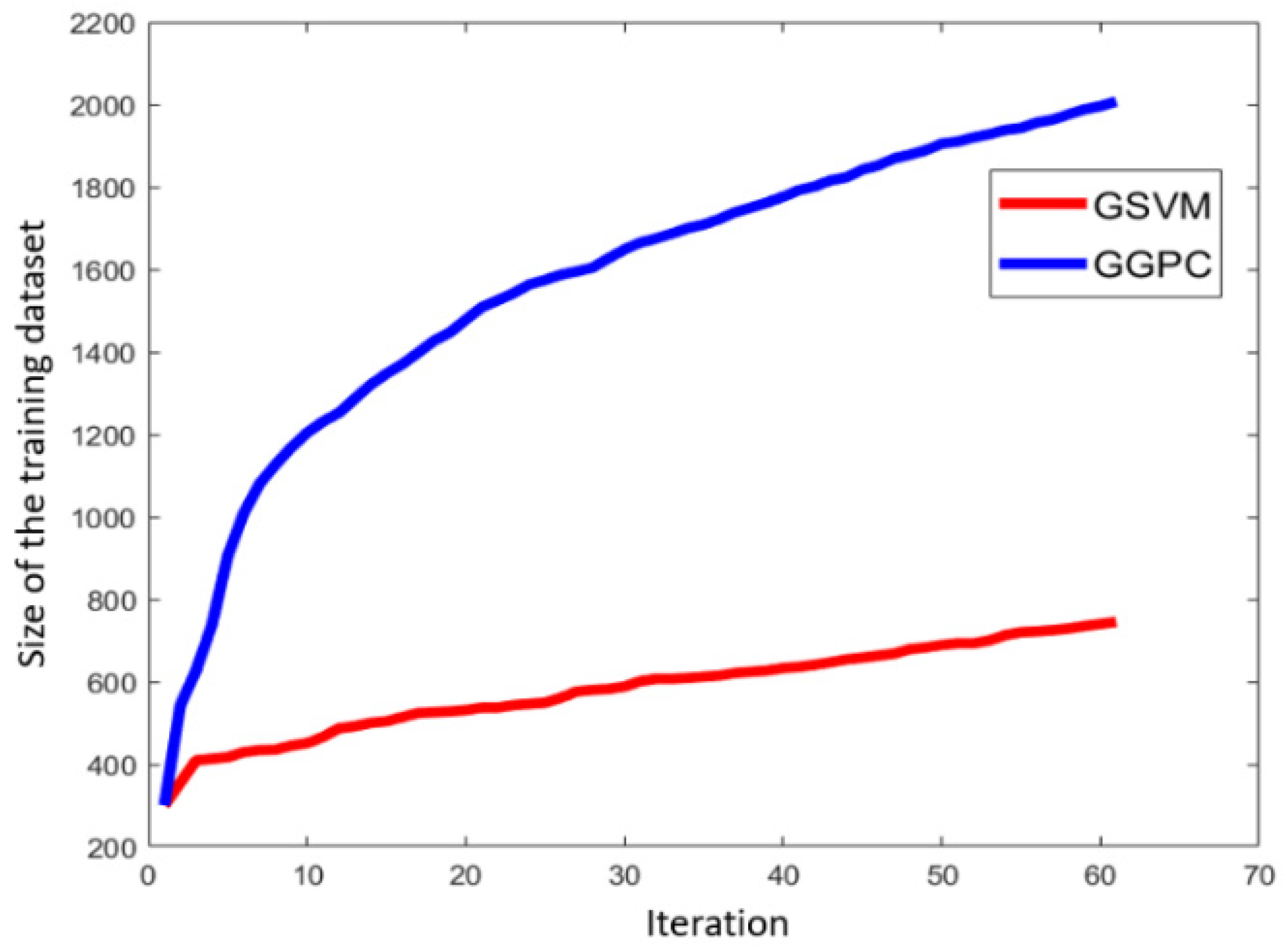
Step 5: All uncertain scenarios identified in Step 4 are executed, and their real labels are acquired based on the pre-defined criticality threshold. The uncertain scenarios that the SVM or GPC did not classify correctly are added to the training dataset for SVM or GPC, updating the training dataset. The iteration goes back to Step 2 until at least one of the stop conditions is met. Finally, the better of the two classifiers is selected as the HPC for scenario classification. For convenience, the SVM and GPC classifiers obtained using this method are called the Guided SVM (GSVM) model and the Guided GPC (GGPC) model, respectively.
3.6. Searching for Candidate Scenarios Based on an HPC
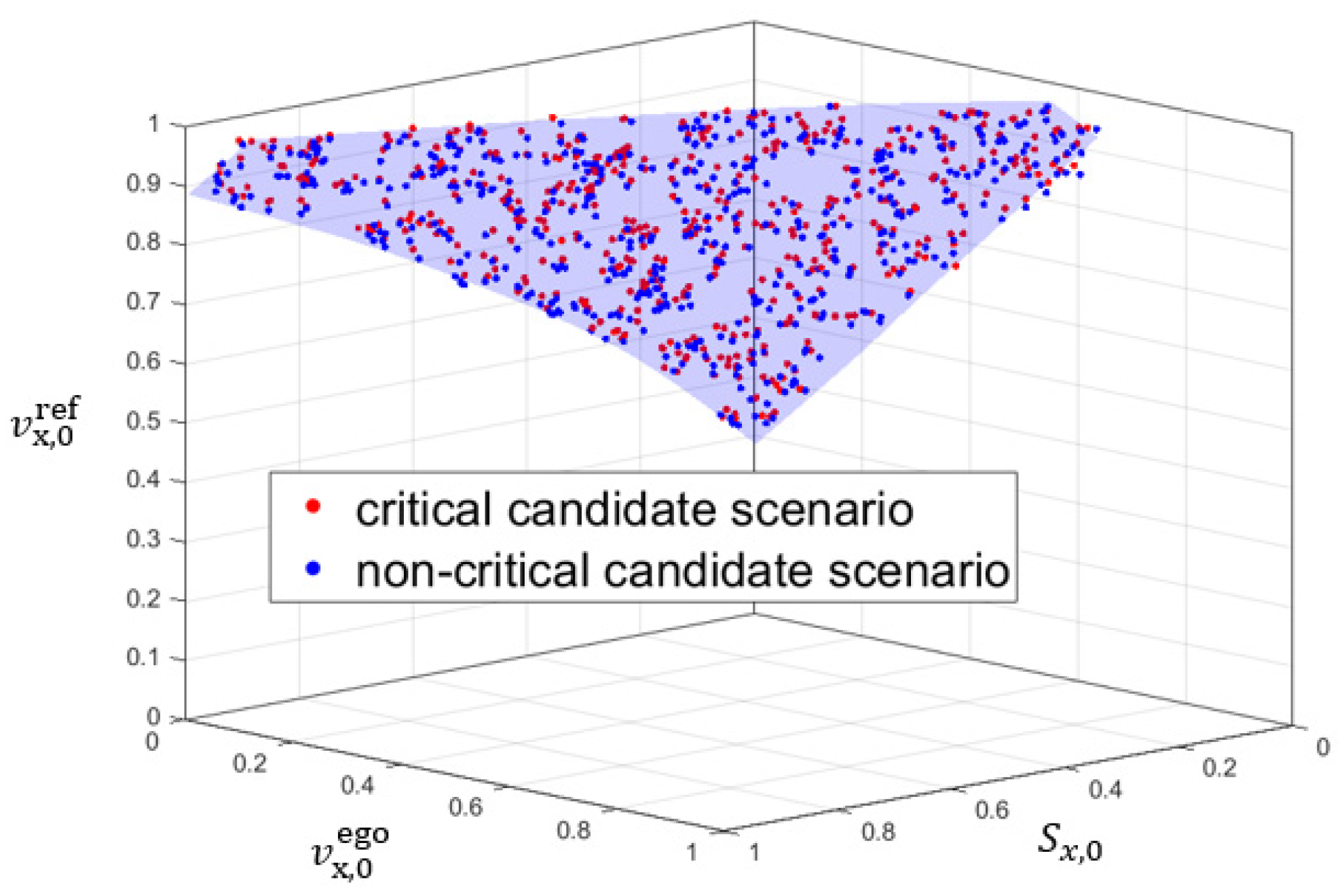
To identify candidate scenarios based on one HPC, the method shown in
Figure 5 can be used, which involves two iterative steps.
Step 1: Several scenarios are generated by random sampling, and their labels are derived based on the HPC.
Step 2: All candidate scenarios in the random scenario dataset are identified based on the distance-based method described in
Section 3.1. It is worth noting that the labels of the random scenarios are all derived based on the HPC rather than scenario execution.
Using this method, candidate scenarios can be efficiently identified, and further scenario execution can be focused on informative scenarios that can improve the classifier performance. This approach can help reduce the consumption of computing resources and make the process more efficient.
3.7. Generating Diverse Candidate Scenarios by Local Sampling
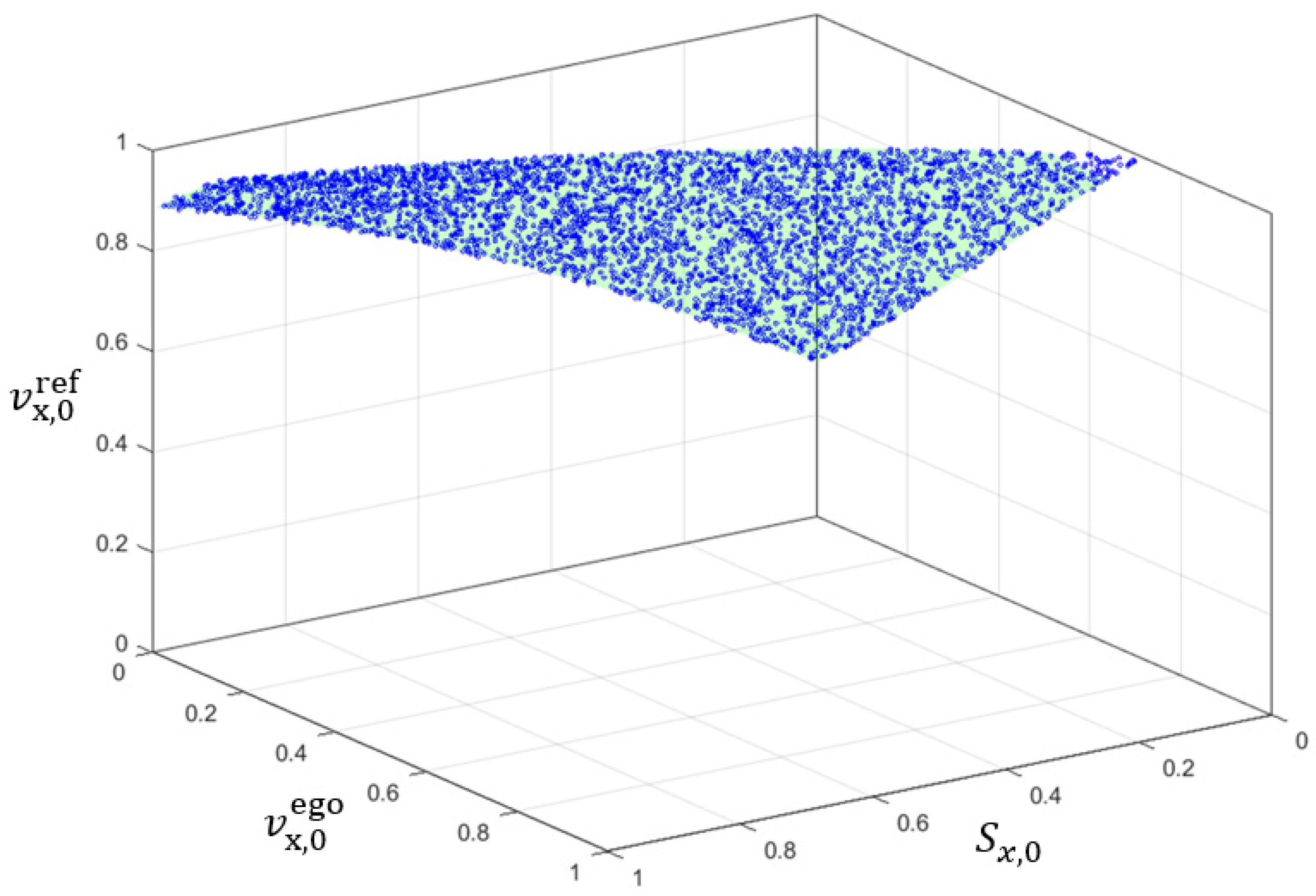
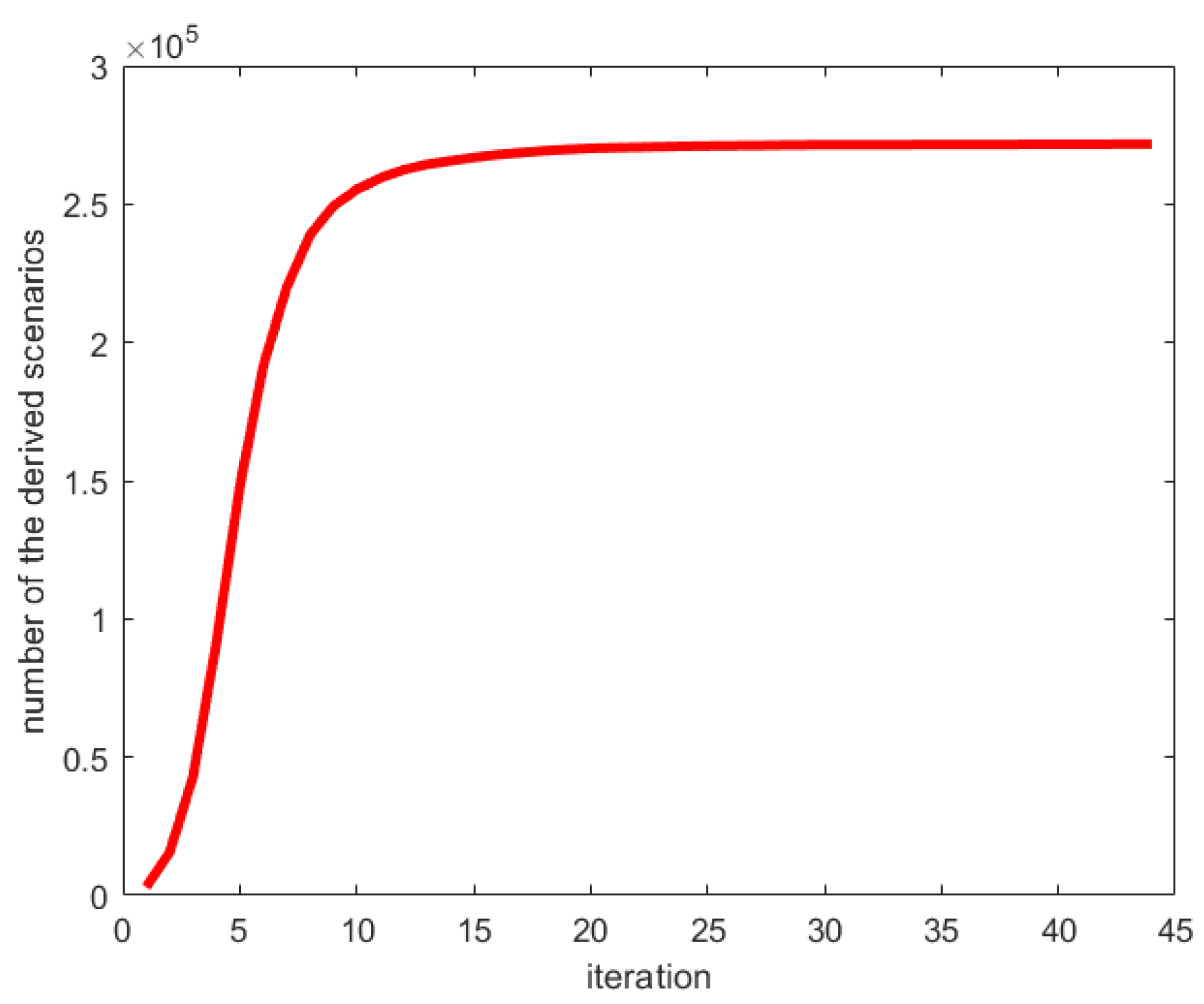
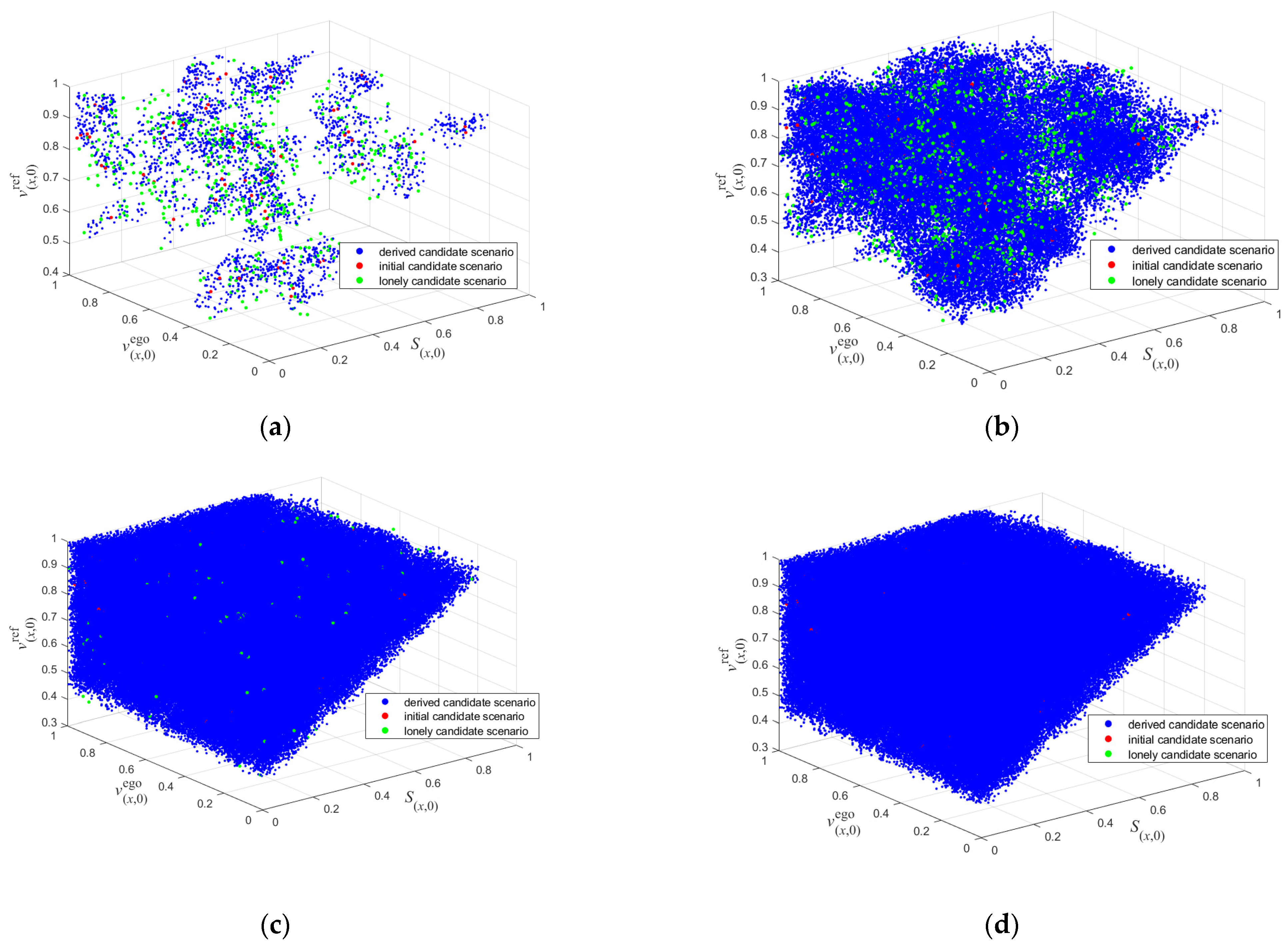
Theoretically, it is possible to generate numerous candidate scenarios based on one HPC by classifying many random scenarios. However, high-dimensional boundary scenarios in a random scenario set are rare, which means that a significant number of random scenarios would be required to identify the candidate ones based on the HPC. This process can consume many computing resources, even though no scenario execution is involved.
This study proposes a method to efficiently identify diverse candidate scenarios by deriving many boundary scenarios based on a small set of them. The method consists of five steps, as shown in
Figure 6.
Step 1: Local sampling. Generate adjacent scenarios around each father candidate scenario . For convenience, the candidate scenarios in the given candidate scenario dataset are called father candidate scenarios, and the candidate scenarios generated by local sampling are called son candidate scenarios.
Step 2: Find son candidate scenarios. Identify son candidate scenarios in the scenarios generated in Step 1 based on the distance-based method described in
Section 3.1.
Step 3: Identify lonely candidate scenarios. The lonely candidate scenarios do not have enough adjacent scenarios around. All lonely candidate scenarios can be identified by checking the distance between scenarios. Then, the lonely scenarios are considered father scenarios. Iterate Steps 1 to 3 until pre-defined conditions are met, which can be iterating enough times, or the number of lonely candidate scenarios is less than a threshold et al.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}