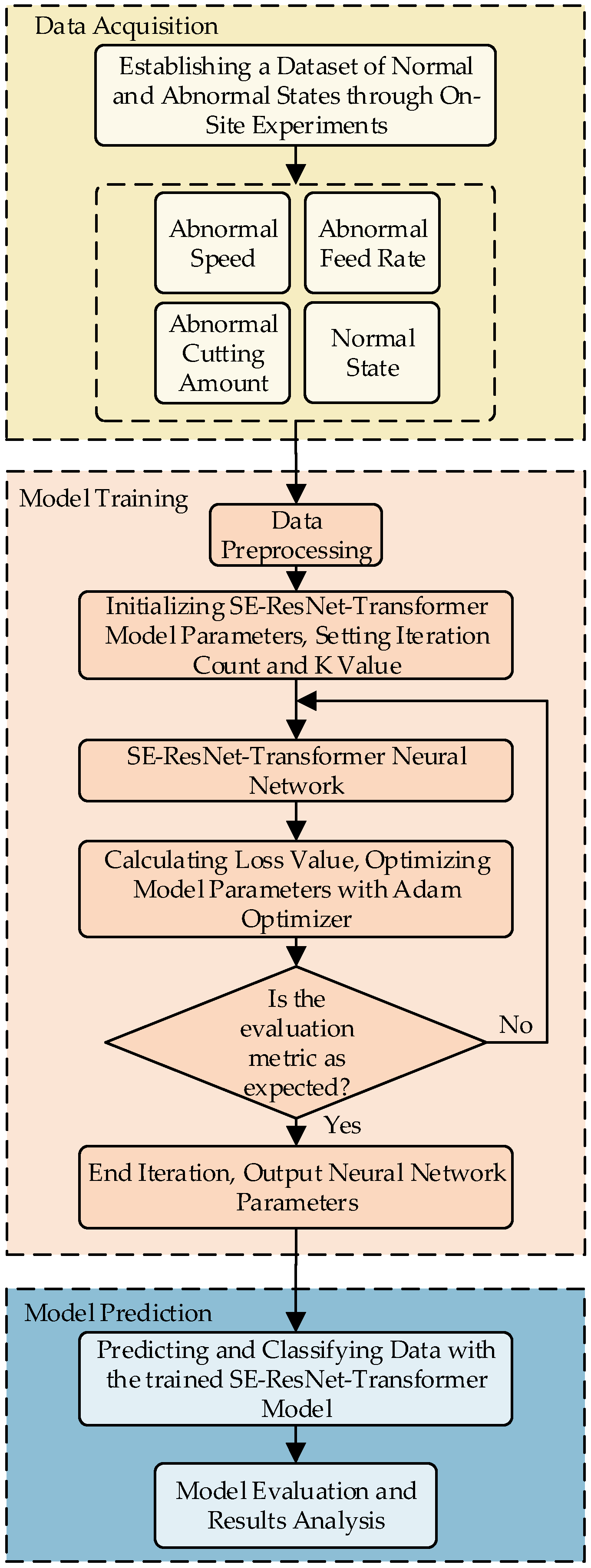
3.1. Data Acquisition
The comprehensive data on multiple sources of parameters, including current, operating temperature, and bearing vibration, comprehensively represent the operational status of CNC machine tools [
29]. The SE-ResNet-Transformer model is trained using parameters derived from the CNC machine tool operating process. The model can predict typical operating states of the feed and spindle systems of the CNC machine tools, including the normal state, spindle speed abnormality, feed axis depth of cut abnormality, and feed volume abnormality.
Figure 10 shows the input multi-source data and the output prediction states.
Data are collected on a CKA6150 CNC lathe (Dalian Machine Tool Group). The lathe is capable of simulating both normal and abnormal machining states. The temperatures of the lathe are collected using PT100-type temperature sensors, and the signals are transmitted through transmitters and preamplifiers to the data acquisition software. The currents are acquired using non-intrusive current sensors, and the signals are transmitted to the acquisition software via transmitters. Vibration data are obtained using acceleration sensors and transformed with a bespoke acquisition card. The data collections are synchronized through an Ethernet interface connected to the acquisition software.
Figure 11 illustrates the sensor placement and sensor type.
Four CNC machine tool states are acquired, including normal state, abnormal spindle speed, abnormal depth of cut, and abnormal feed. The different states of the CNC machine are set by adjusting the cutting parameters of the CNC machine. Cutting parameters reflect temperature and current. Reportedly, the impact of tool wear on vibration and cutting parameters is small in the early and normal wear stages, but it is large in the severe wear stage [
30]. The data used here are collected at the early wear and normal wear stages.
The data generated by the simulation for each state are presented in
Table 2, and 60-mm diameter cast iron cylinders are used as simulation workpieces for machining. The parameters typically employed in the field of machining are established through the accumulation of relevant experience. Normal machining parameters are set based on machining experience. Abnormal spindle speed conditions encompass both excessively high and excessively low speeds, which impact surface quality and machining accuracy. During simulation of an abnormal state with increased depth of cut, the cutting force surges, and the spindle speed and feed remain unchanged. This situation leads to an increase in the vibration amplitude of the machined workpiece, thereby reducing the quality of the machined surface. However, surface quality is usually not affected when the depth of cut is reduced, so the only abnormal depth of cut occurs when the depth of cut is deepened. In the abnormal feed simulation, the feed rate is twice the normal feed rate, and the cutting force in this state is large, which is abnormal in the state of cutting a 60 mm cast iron cylinder. The surface quality is not degraded when the feed is reduced [
31].
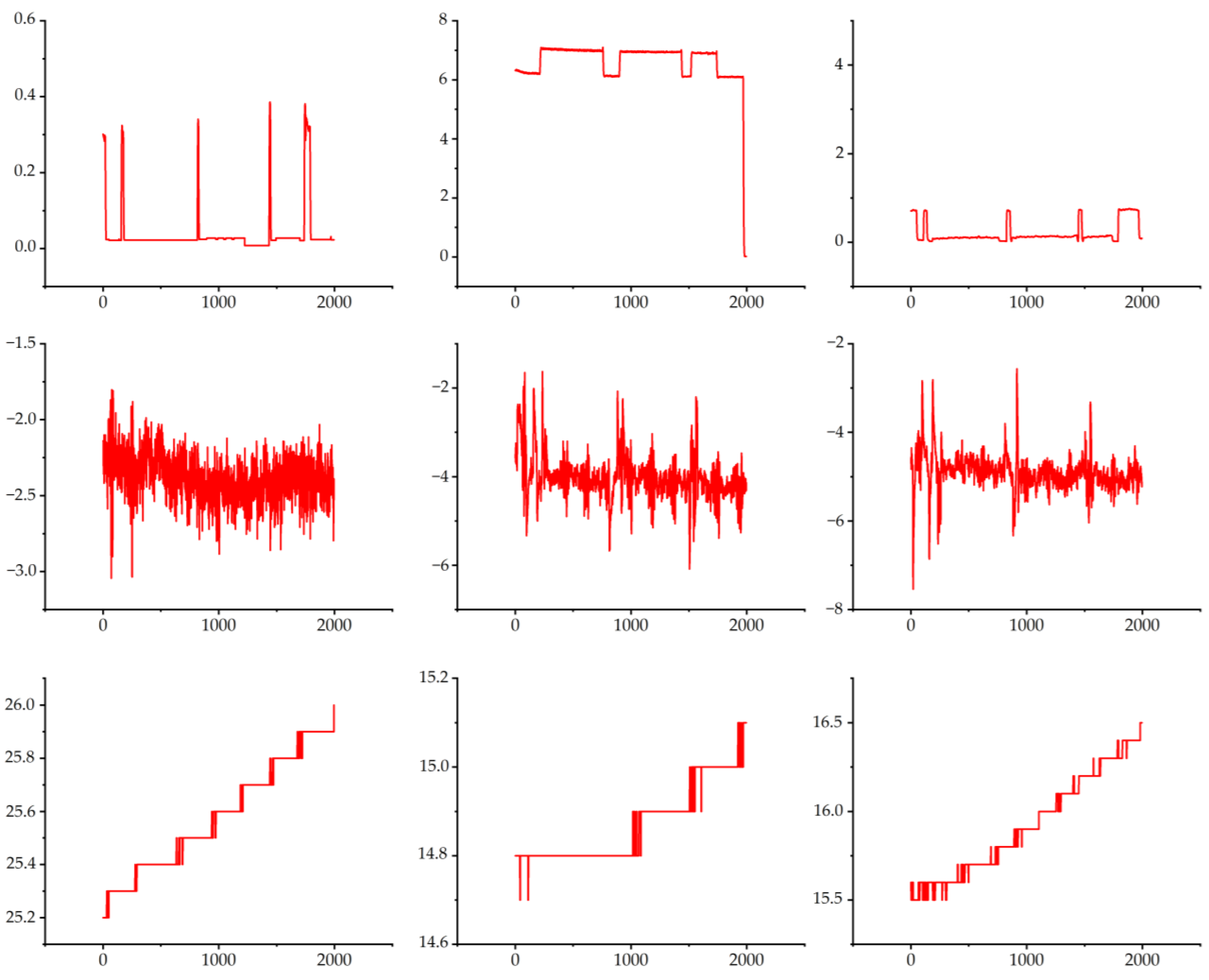
Figure 12 shows the 9 channels of data in the normal state after the data are processed to align the different channels with each other. In the machining process, the normal state is divided into three cycles, and a layer of cast iron is cut in each cycle. As the processing time is prolonged, the temperature slowly increases. The current data change periodically. During machining, the current data change accordingly when the machining process is switched. The vibration data show a high level of vibration during the process changeover. However, the vibration amplitude changes smoothly during machining.
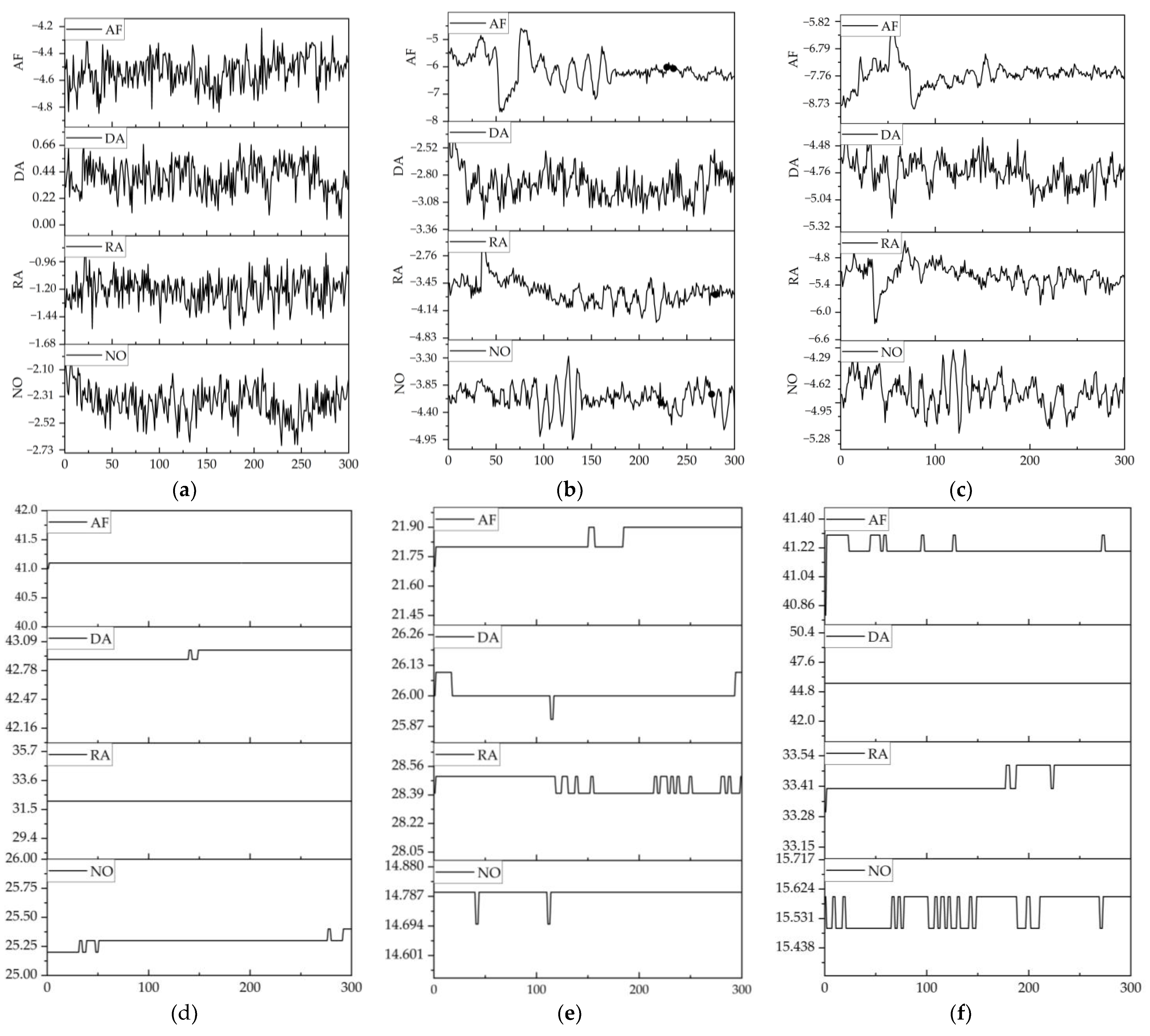
Figure 13 presents the time series of vibration and temperature under various states. Here, an analytical approach in the time domain is employed. Time series are collected, and the features embedded between the before and after time series are extracted. The extracted features are employed to investigate the information pertaining to the future time. The vibration data of a machine tool are used to illustrate the dynamic characteristics of the machine [
32]. The amplitude of vibrations in different states exhibit a varying temporal profile (
Figure 13). As reported, the vibration of CNC machine tools differs with different cutting parameters [
29]. The vibration data are classified on the basis of the fact that different cutting parameters will demonstrate different trends when cutting. For the spindle vibration data, the range of amplitude in vibration differs among different states (cutting parameters) (
Figure 13a). For example, the amplitude fluctuates around −2.3 in the normal state, but it fluctuates around −1.20, 0.4, and −4.6 in the RA, DA, and AF abnormal states, respectively (
Figure 13a). The trends demonstrated in
Figure 13b,c are different depending on the cutting parameters.
Characteristics of the different states are also embedded in the temperature data.
Figure 13d–f shows the trends of the temperature data in different states. Clearly, the temperature of the same part differs among different states. In the case with an approximation of the temperature at the same part, the information of other parts can be used to make a judgement. When the temperature information is not enough, the state can be judged using diagnostic information and current information. Different states can be better judged through data fusion.
3.3. Experimental Results and Discussion
The model is trained, and the test set evaluation metrics are presented in
Table 4.
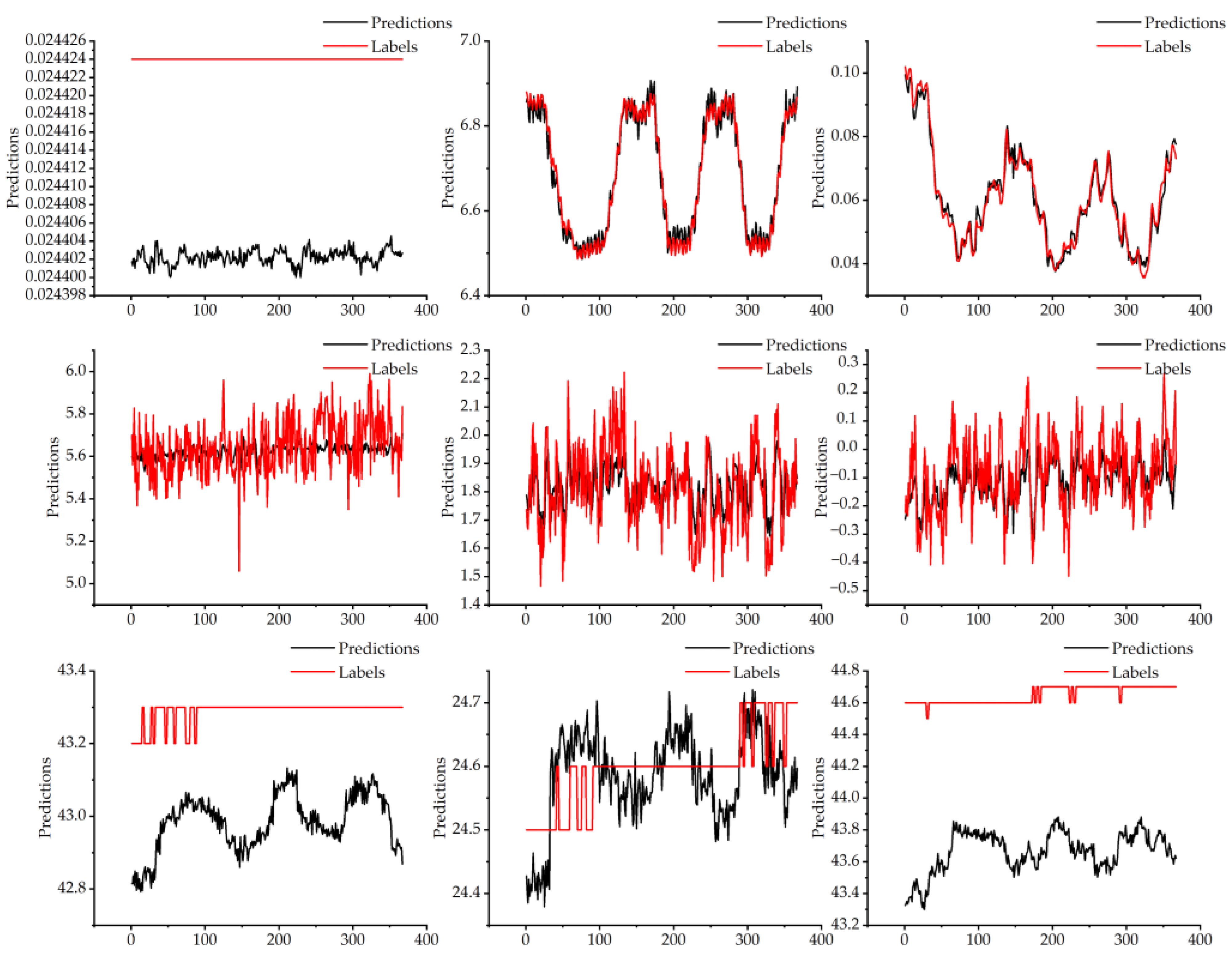
Figure 14 presents the results of the test set predictions.
Table 4 and
Figure 14 demonstrate a high degree of correlations among the spindle current, longitudinal feed axis, and vibration data. In other data, the value of R
2 is not particularly high, but other indicators perform better. Among the data with a low value of R
2, the detected value of the transverse incoming shaft current is 0.024424 A, and the predicted data vary around 0.024402. The three-axis temperature data change in a smooth trend. The range of variation in the given data is relatively limited, as the values vary by only 0.1°, 0.2°, and 0.2° over a total of 400 data points. R
2 is calculated in a way that focuses only on the relationship between the mean and the predicted value. The data predicted by the model will increase errors and cause R
2 to be inaccurate. However, when each datum is analyzed separately, the magnitude of change in the error range is not large and is within acceptable limits. The reason for this phenomenon is the inconsistency between the graduation value and accuracy of the input and output data. The data show that when the precision of the output data is higher than that of the real value, the evaluation effect is worse. In summary, the model is less sensitive to data with small magnitudes of change, insignificant trends, or small differences in input and output precision. Some of the data in the model are poorly evaluated, but with small errors, and thus can be used for feature recognition.
New evaluation metrics are incorporated to better describe the predictive performance of this model. The percentage of error between the predicted and true values can be expressed mathematically as follows:
where
is the error,
is the true value, and
is the predicted value,
The performance of the R
2 underperformance data is evaluated (
Table 5). Errors of the underperformance data are analyzed. The error between the true and predicted current in the transverse feed axis is within 0.000024. The difference between the two curves of predicted and actual data is large (
Figure 12), but the error is small in actual usage. In prediction of temperature, the difference between each prediction and the true value is within 1, 0.3, and 1.4. In practice, the error is small and classification results are acceptable.
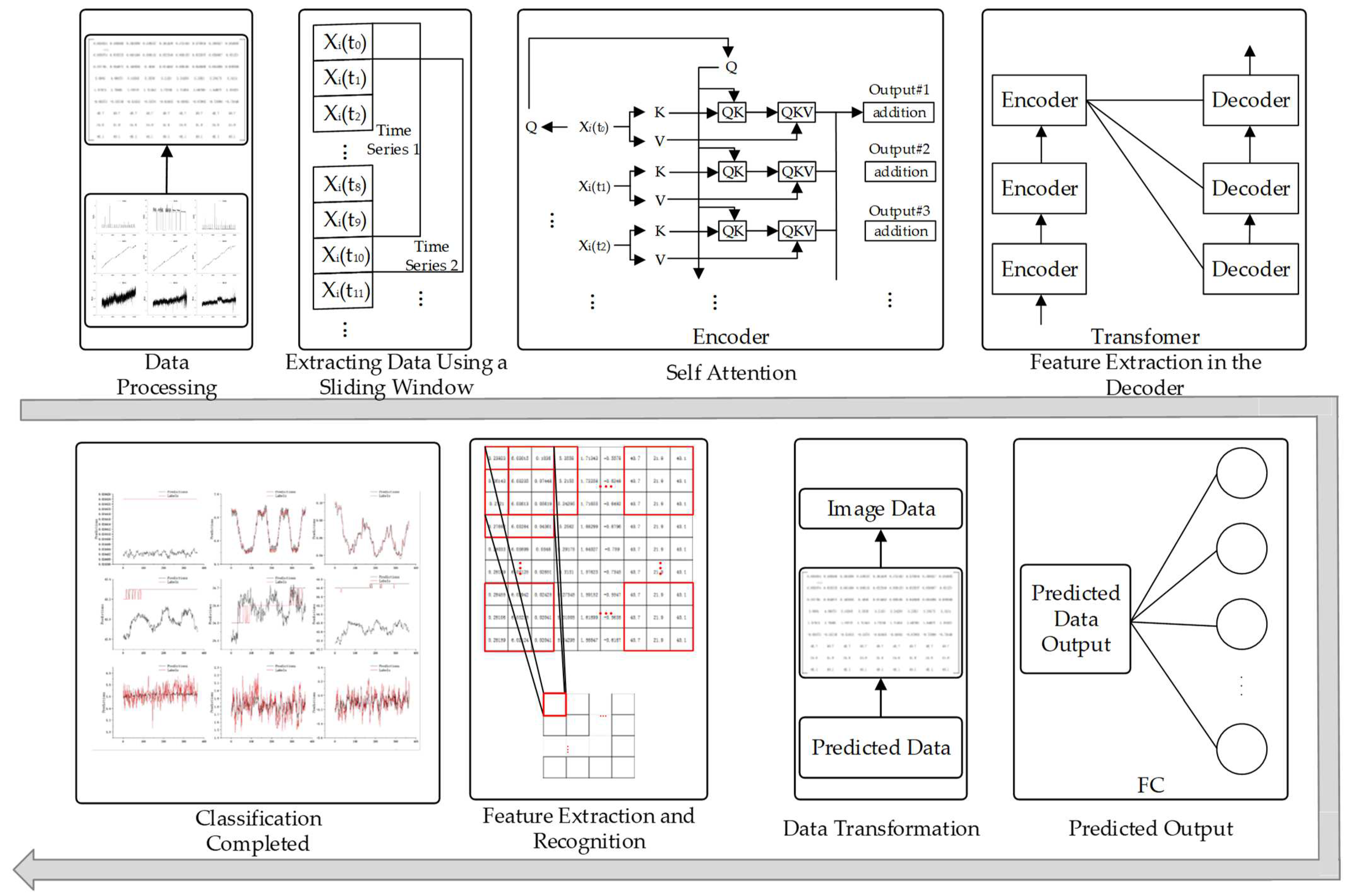
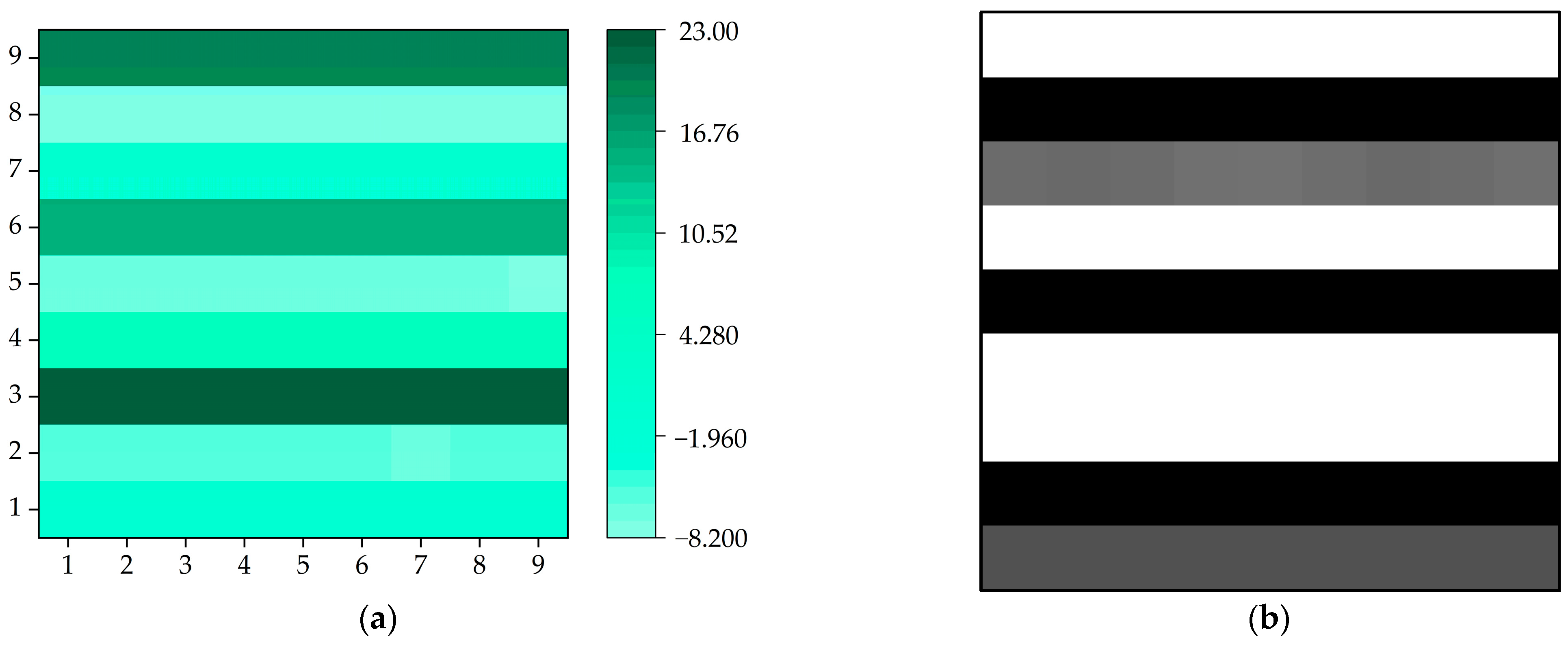
Once the prediction is completed, the predicted data are converted for image reconstruction, and the reconstructed image contains feature information. During the training, a sliding window is used to convert the data into a graph. The data from different channels differ in size among different states, and different data are shown in different colors in
Figure 15. In
Figure 15, there are two types of images, containing a visualization schematic and a real transformation image. Color images are transformed schematic images. Black-and-white images are real data images. This step successfully transforms the data classification situation into an image classification situation.
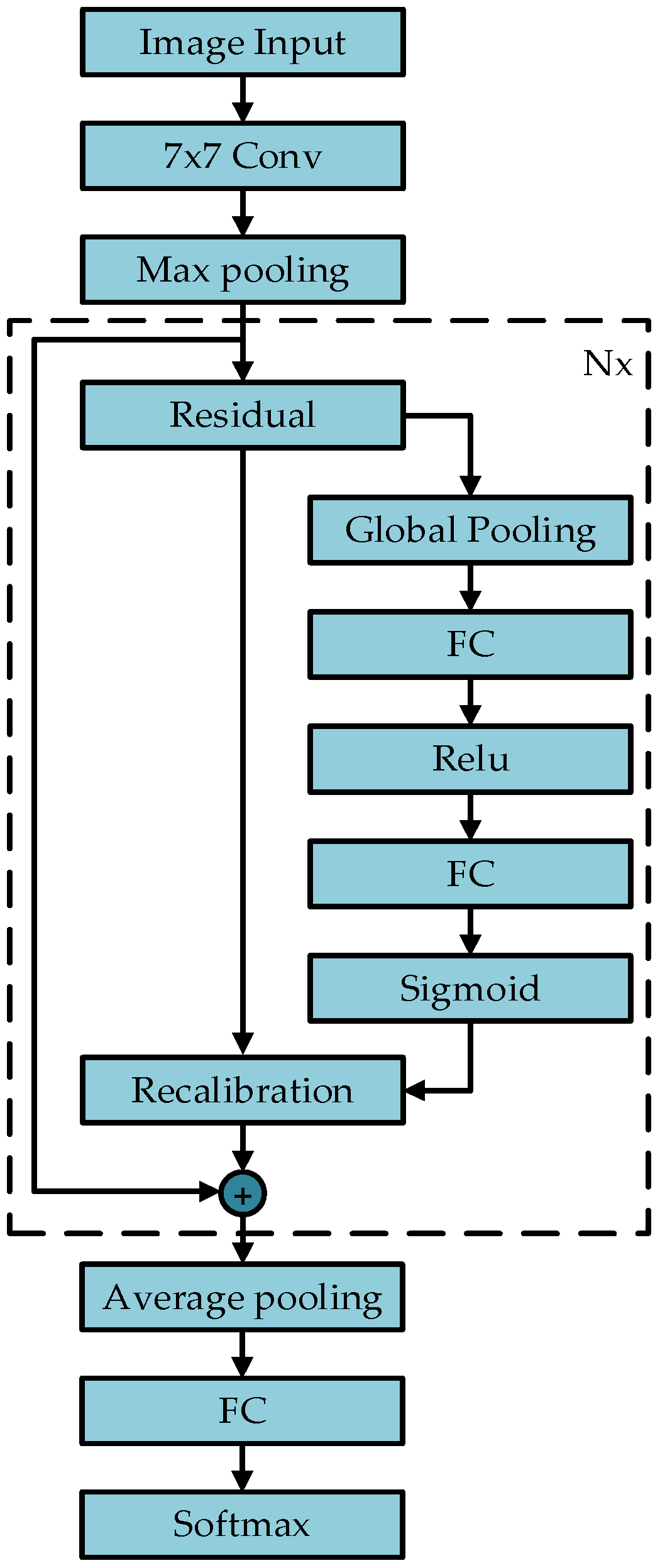
The input image in the SE-Resnet model is 9 × 9 in size, which is first converted to 32 × 32. The number of training data, number of classifications, batch size, learning rate, and weight decay coefficient are 50,000, 4, 128, 0.001, and 0.0005, respectively. The Adam optimization algorithm is used for updating. The evaluation metrics are accuracy and loss.
Figure 16 shows the loss curve and accuracy curve with epochs. In the first three rounds of training, the loss rate on the training set sharply decreases, and the loss decreases severely, but still tends to be 0 on the validation set. This result indicates the model is converging and approaching 0. After 2 epochs, the accuracy on the test set is 100%, and the accuracy on the training set is 99.96% after an iteration to 10. After 5 epochs, the loss rates of the training and test sets are close to overlapping, and there is no excessive variation or overfitting in the curves. These results indicate the model is converging and approaching 0. The model can be trained only with 10 epochs. This is because an image in the format of 9 × 9 only contains 81 pieces of data. Moreover, this model achieves excellent results in 10 epochs of training, thanks to the better performance of the SE-Resnet model.
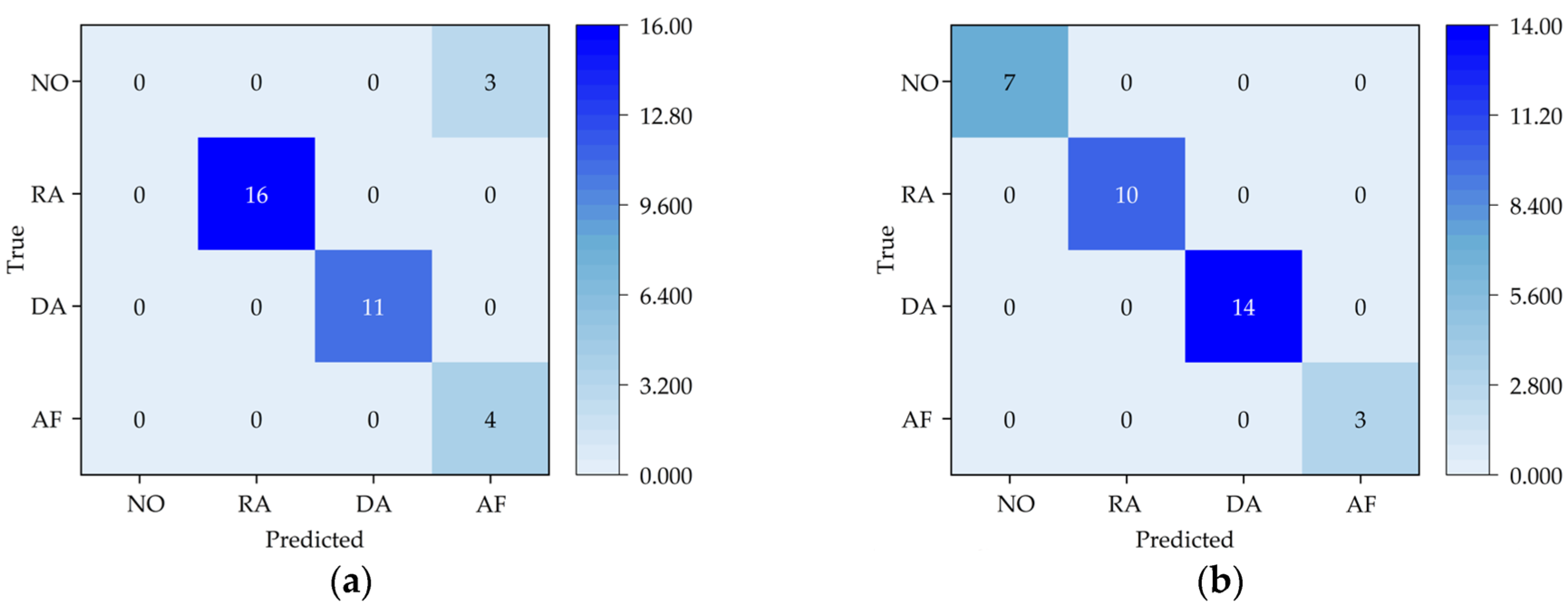
To better demonstrate the classification effect of the SE-Resnet model, a confusion matrix is used to show the classification on different epochs of the test set. NO, RA, DA, and AF in
Figure 17 indicate normal state, abnormal speed, abnormal depth of cut, and abnormal feed, respectively. The confusion matrix consists of two axes representing the true labels and the classified labels, respectively. It discriminates the classification performance according to whether the data cluster is on the diagonal. When true and categorical labels match, they cluster on the diagonal. In cases of classification anomalies, the conditions under which the classification is made can be observed. In the first epoch, classification is evident on the validation set, but there are still cases of misclassification. Three sample points in the normal state are classified as feed anomalies, and the other three classification cases are accurate. In the second epoch of the accuracy surge, the classification on the validation set is excellent, and the four states can be perfectly classified to the states to which they belong.
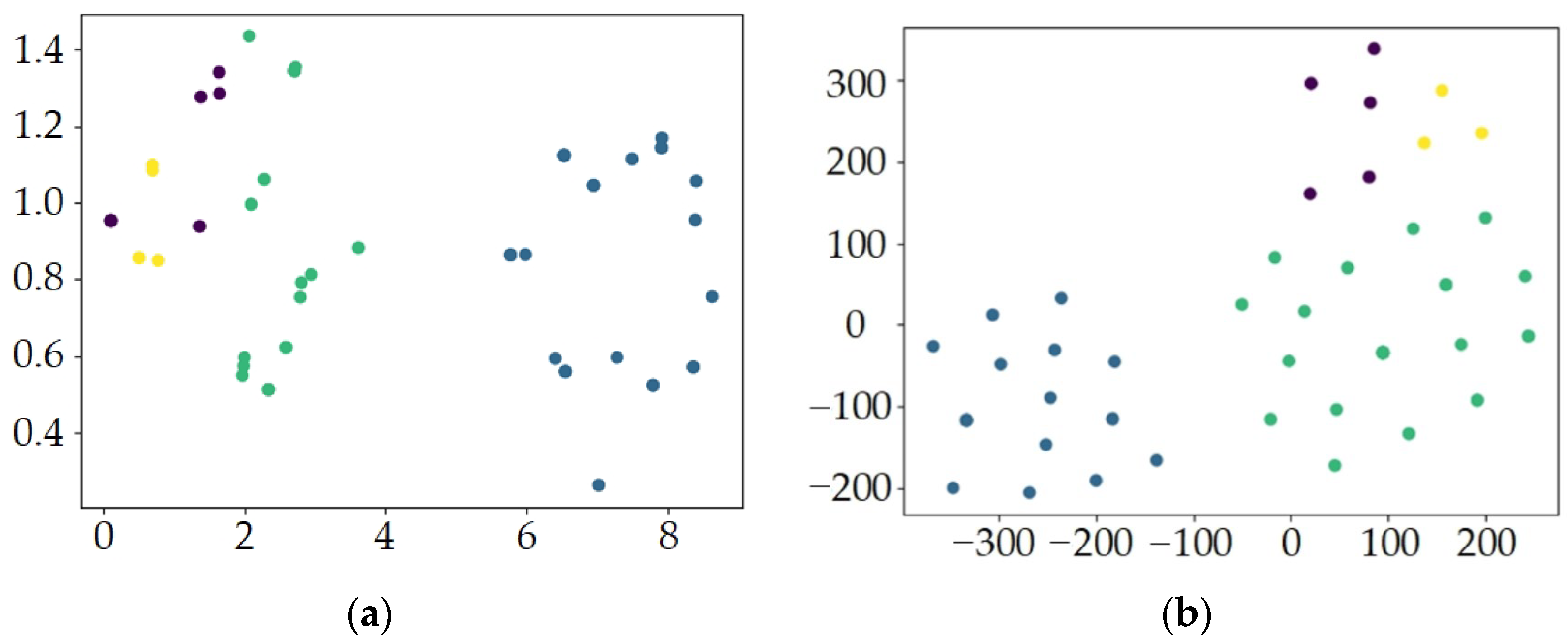
A non-linear dimensionality reduction method is used to validate the performance of the SE-Resnet network. A two-dimensional image is generated to represent the distribution of different categories within different epochs. The results shown in
Figure 18 are from the two epochs, with a large difference in correctness between successive epochs, and the data are downscaled to a 2D plane. Poor clustering is shown in
Figure 18, including high degrees of state mixing and state dispersion. In the case of high accuracy, the state separation is not obvious with fewer feature points, the other three state separation boundaries are clear, and clustering is effective. Although the clustering effect is different across different correctness conditions, it is not significant due to the difference in correctness at 3%.
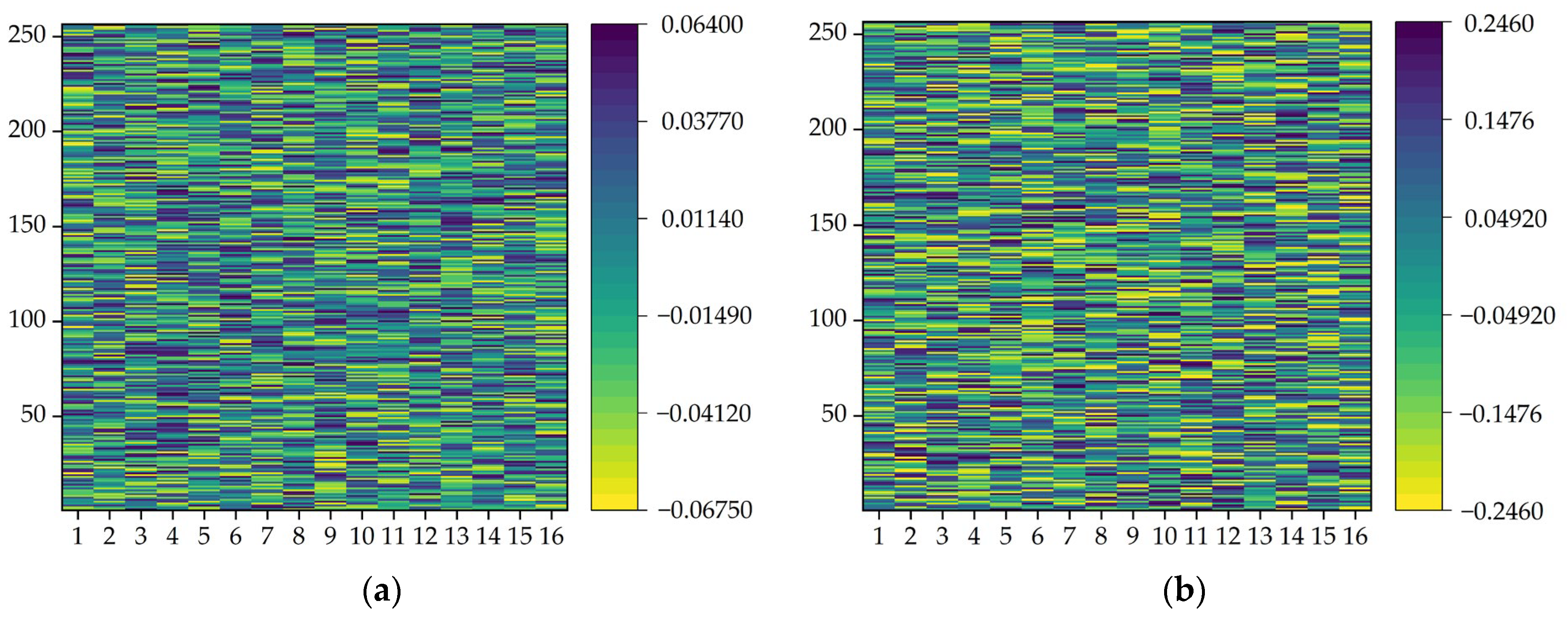
To further investigate the performance of the SE module in the SE-Resnet model, the attention matrices for different channels of the SE module are visualized after each round of training. Data from two channels of SE module attention are extracted from a single network and visualized in different state rounds according to the importance of non-canal data.
Figure 19 shows the results after different visualizations of attention for the two modules in the same training session. The highest weight parameter in the second module is about 0.2 larger than that in the first module (0.06). This result indicates a significant channel in the second module. This significant channel has a weight parameter of 0.2 in the final result determination. The data in this channel are important and can be used in the prediction model to focus on increasing the prediction weights and better update the model performance.
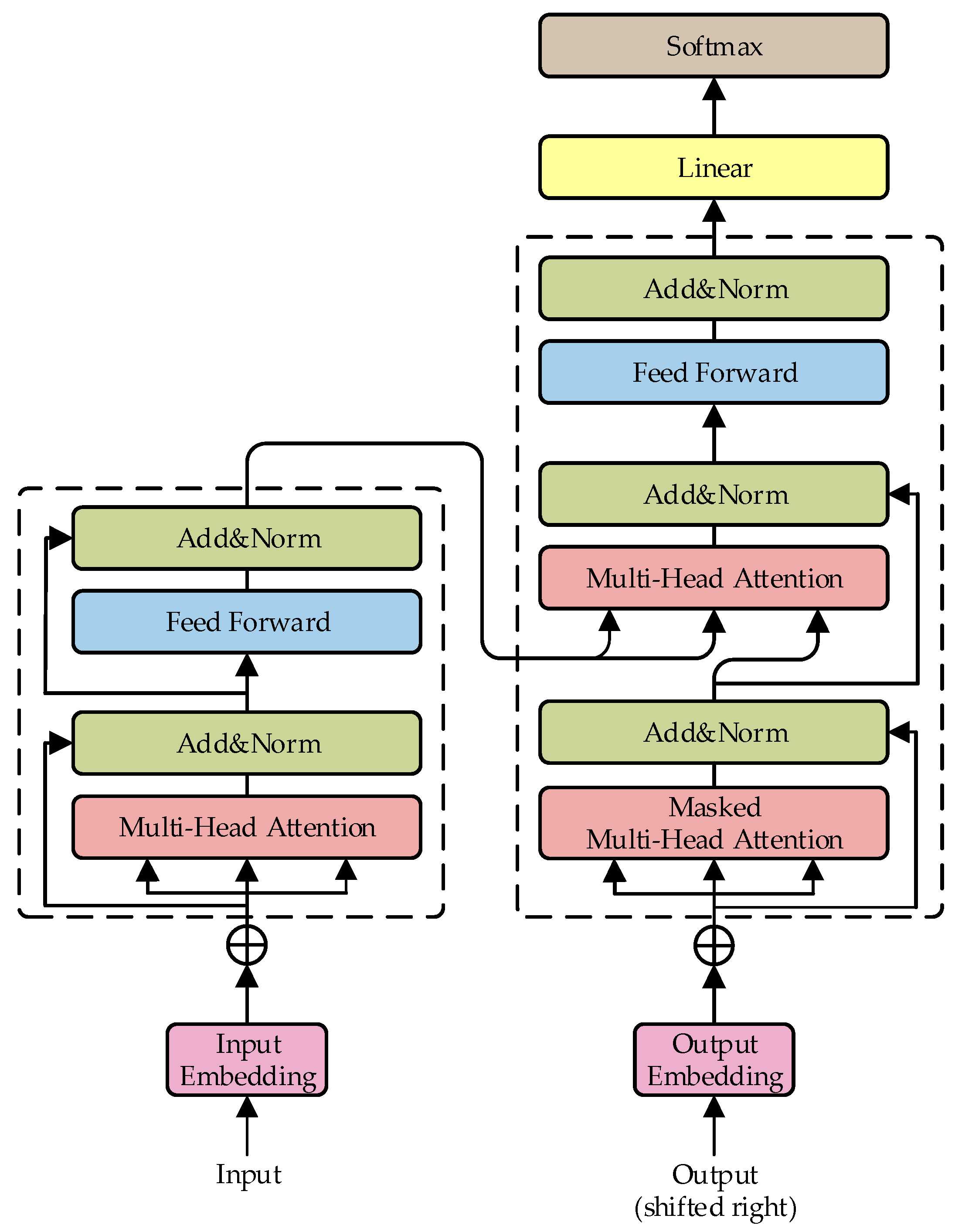
Experimental analysis is performed using the best model after training. The correctness of the method is verified against the predicted data labels. A known state is used as the input, and the current state is the label for the prediction. First, each of the four states is entered into the Transformer model, and thus four types of labeled predicted data are obtained. The four types of data are processed into 2D data, which are fed into the SE-Resnet model for classification. The accuracy of the classification is judged according to the classification results.
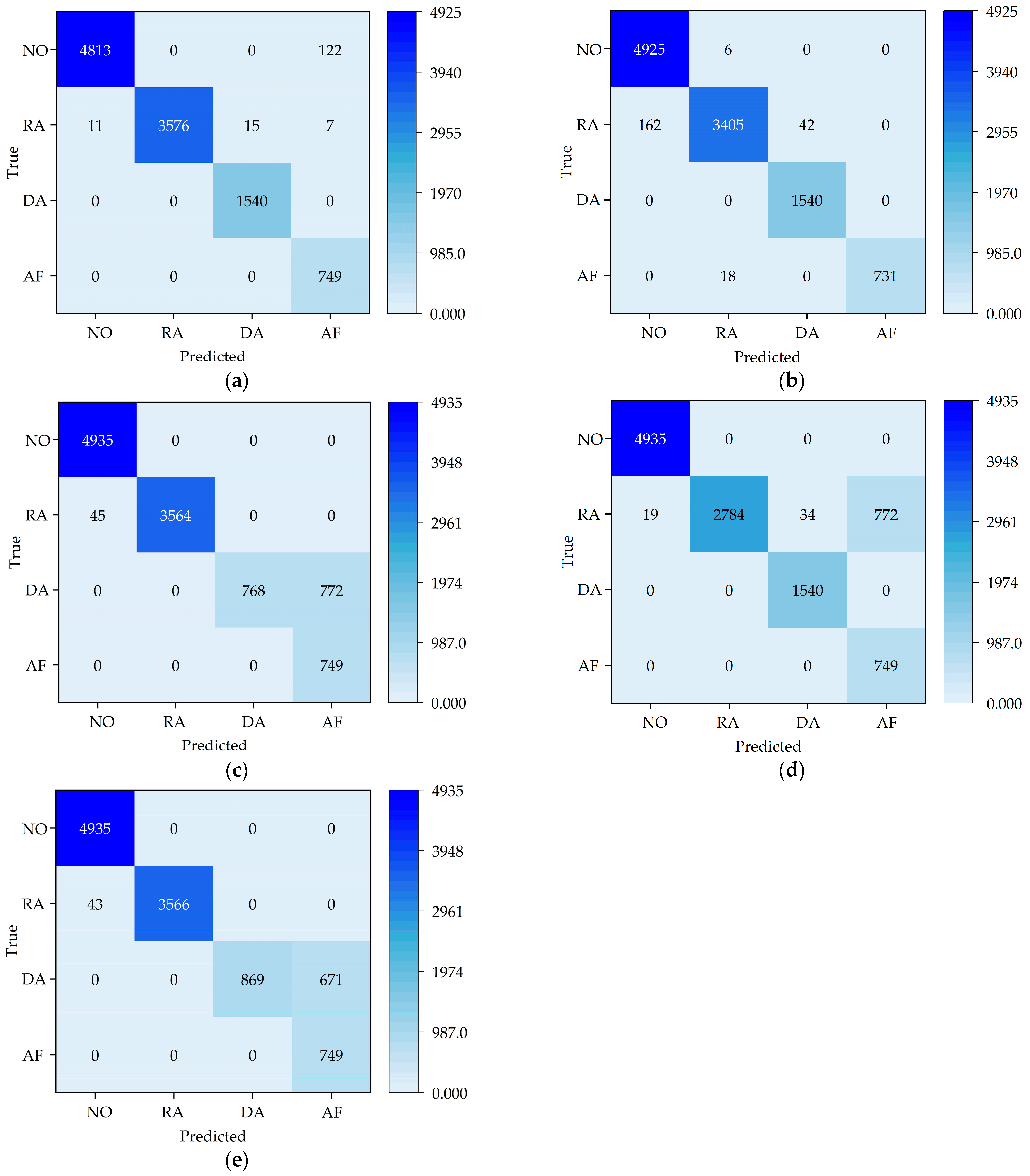
Figure 20 shows the confusion matrix plot of the predicted data displayed after classification. In
Figure 20a, most of the normal state data are classified as normal, but 122 pieces of normal data are classified as abnormal. About 99% of the data in the RPM abnormal state are classified as normal, and 1% of the data are classified into the other three states. The feed rate is abnormal, and the depth-of-cut abnormal state is classified without error. The accuracy of this model is 98.56% (
Table 6).
In the ResNet50 model, the correct rate is 0.67% lower compared to the network including the SE model. It is shown that the SE module improves the classification accuracy. The ResNet34 model has only 92.21% correct classification due to too few layers. The negative effects of too many layers can be eliminated by both the GooLeNet network and the ResNet model. Thus, the difference between the accuracy of the GoogLeNet network and the ResNet34 model is tiny: the accuracy of the GoogLeNet network is 92.45%; the accuracy of the AlexNet network is 93.41%.
The confusion matrix shows the classification error messages. The ResNet50 network is weak in resolving main spindle speed anomalies. The ResNet34 network is not able to distinguish the state of the depth-of-cut anomaly from the state of the feed anomaly. The AlexNet and ResNet34 networks are unable to distinguish the state of the depth-of-cut anomaly from the state of the feed anomaly. It is difficult to distinguish between main spindle speed anomalies and feed anomalies in the GoogLeNet network.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}