
A Novel Grasp Detection Algorithm with Multi-Target Semantic Segmentation for a Robot to Manipulate Cluttered Objects



Abstract
1. Introduction
- A high-performance grasp schema SS-GD is proposed by combining a semantic segmentation module with a grasp detection module to effectively reduce prediction redundancy in multi-target grasp pose detection and improve the probability of robots performing robust grasping operations.
- A grasp detection network is proposed based on Mask-D multi-channel synthetic data, aiming to enhance the perception of shape information for candidate objects. The SE attention mechanism is introduced to further strengthen the network’s feature extraction capability.
- By leveraging various advanced visual algorithms, we explore the optimal segmentation-grasping cascade combination in diverse cluttered grasping scenarios.
- Experimental results in real-world environments demonstrate that our cascade SS-GD algorithm exhibits superior performance in cluttered scenarios, particularly in environments characterized by severe stacking and background interference.
2. Related Works
2.1. Grasp Detection
2.2. Semantic Segmentation in Robots’ Grasp
3. Grasp Representation
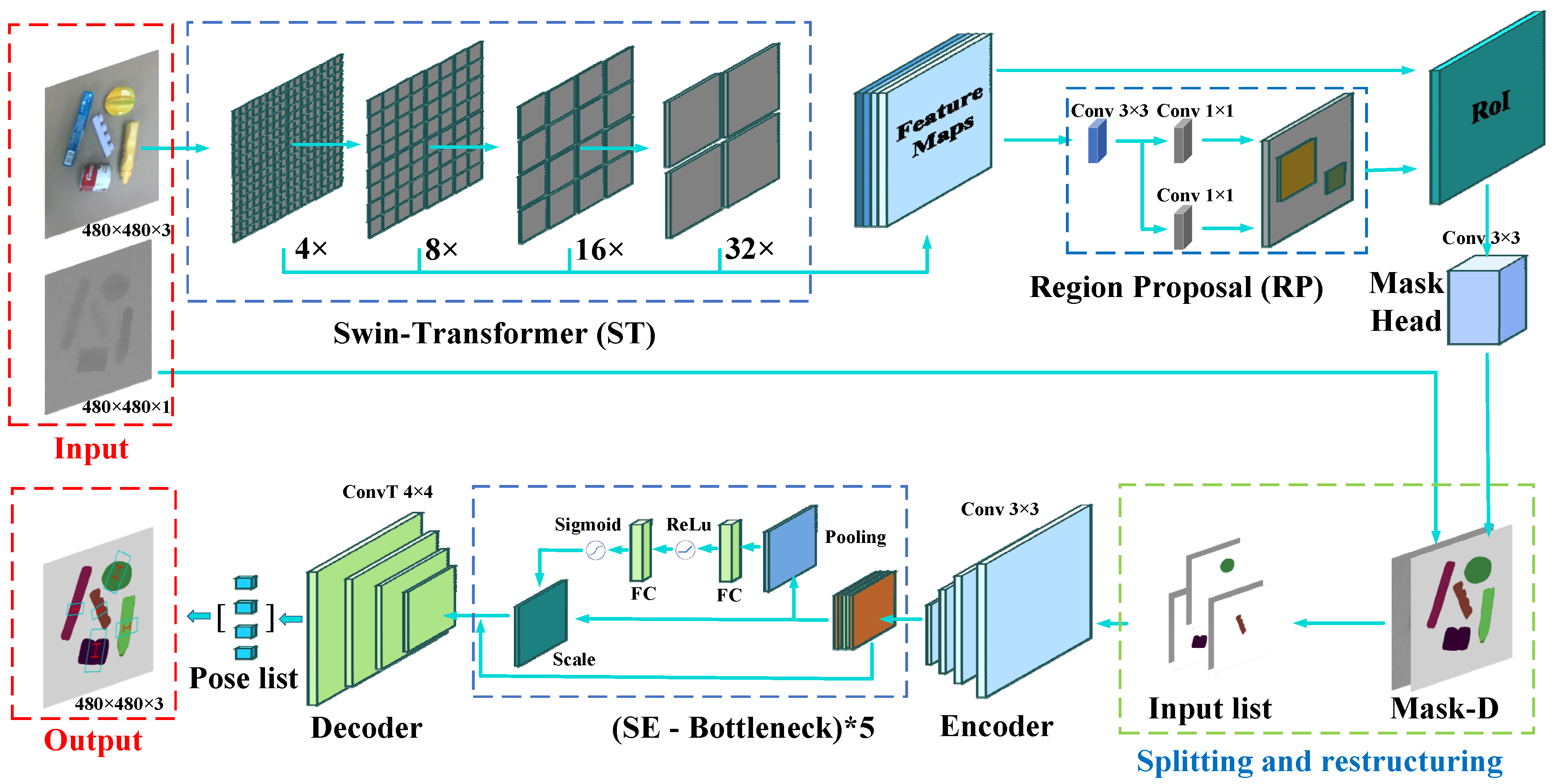
4. Principle and Method
4.1. Semantic Segmentation Module
- (1)
- Training strategy
- (2)
- Evaluation metric
4.2. Grasp Detection Module
- (1)
- Training strategy
- (2)
- Evaluation metric
5. Results and Analysis
5.1. Evaluation on Cornell and Jacquard Datasets
5.2. Ablation Experiments
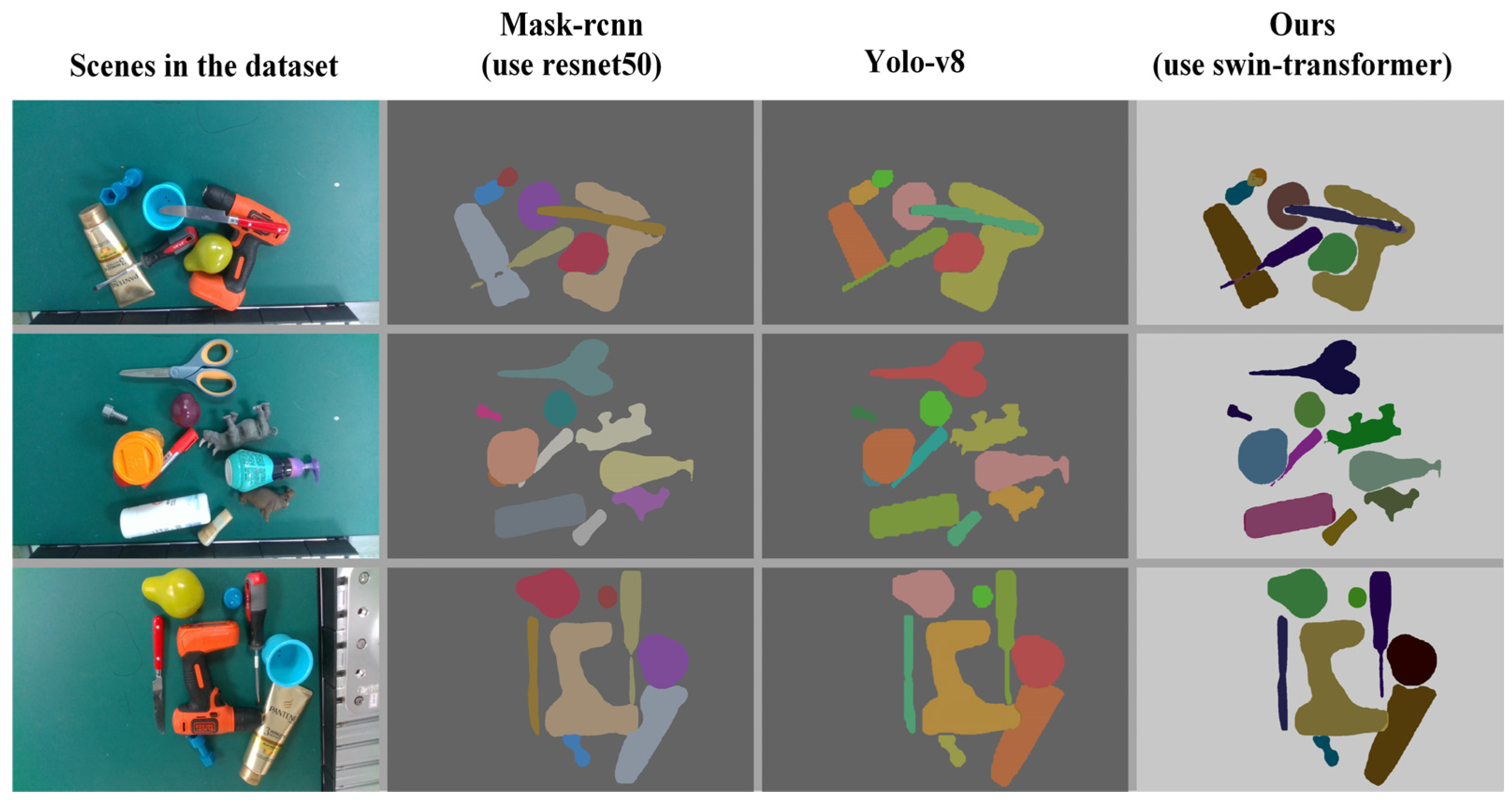
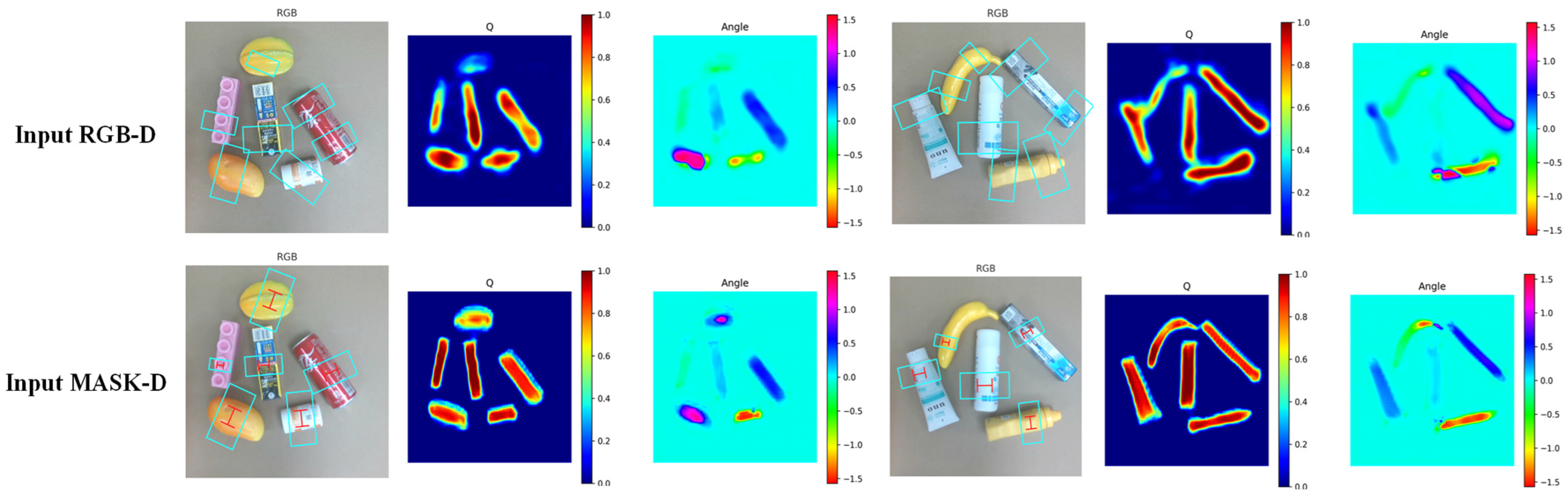
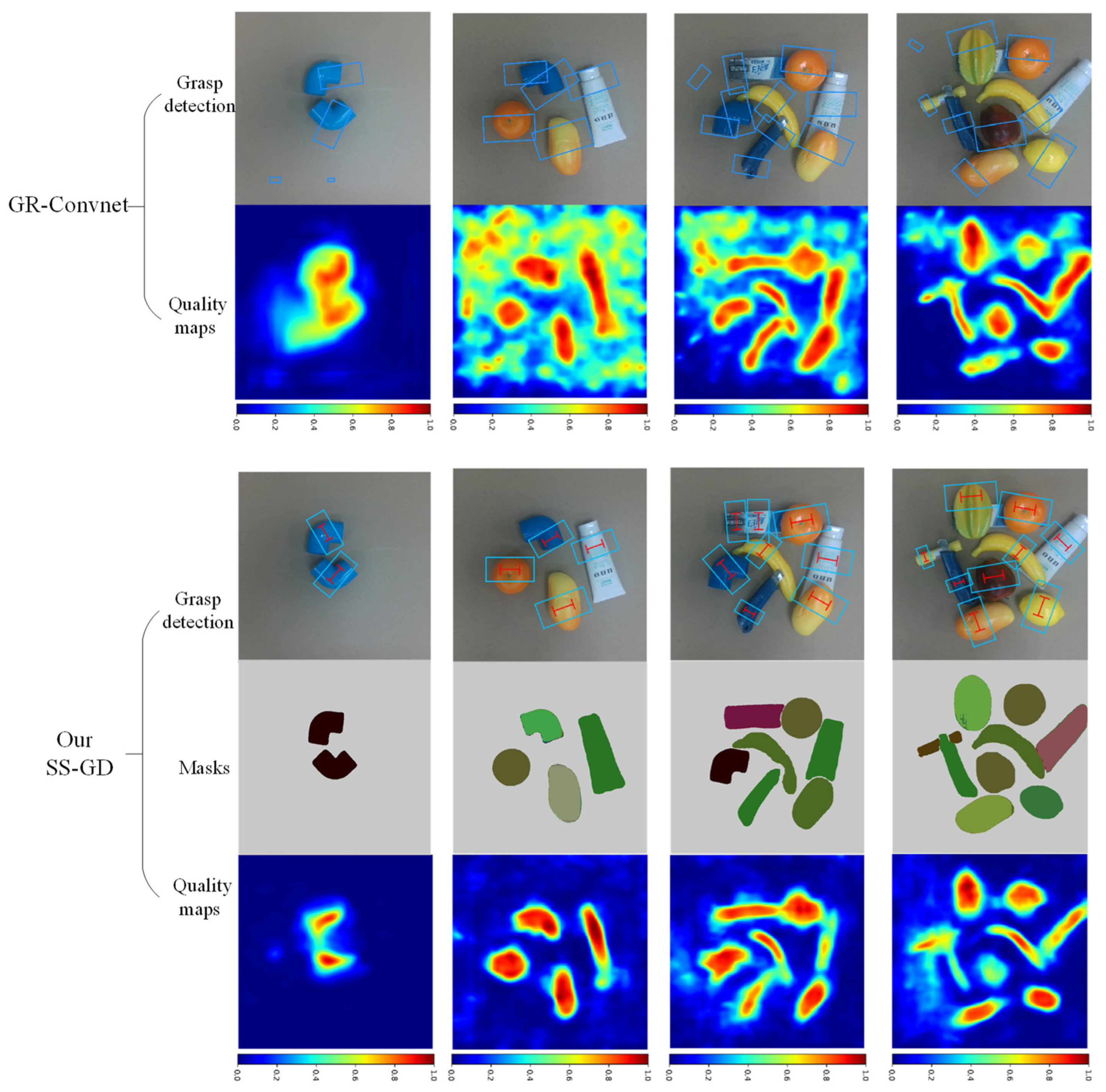
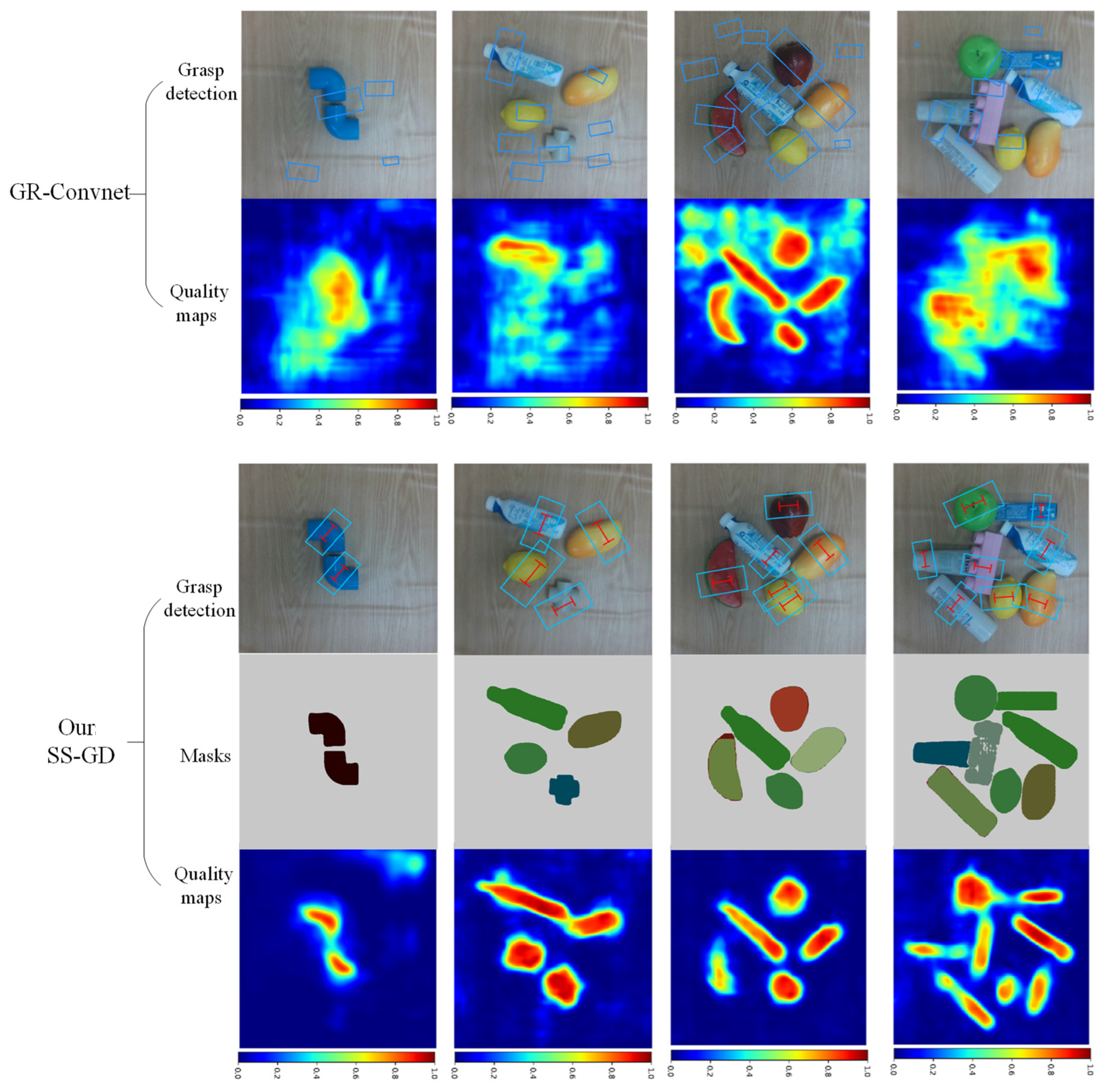
5.3. Comparison Study on Real-World Tasks
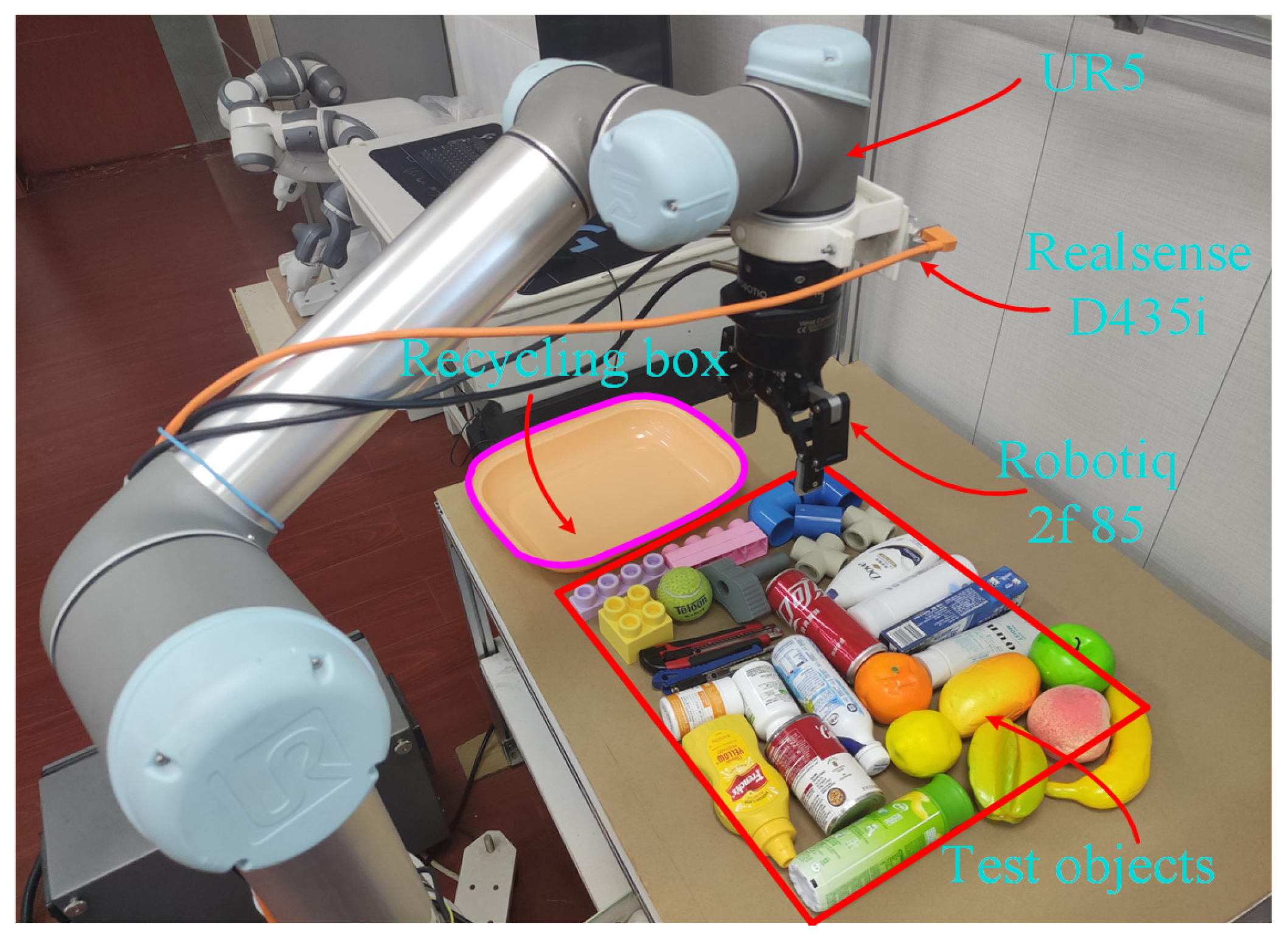
5.4. Grasping Test on Robotic Manipulator
6. Conclusions
- (1)
- Incorporation of Swin Transformer: This component significantly improves object detection in scenarios with occlusion or stacking. By enabling the robot to disregard protrusions formed by stacked objects, Swin Transformer helps avoid unstable grasps that might otherwise occur from focusing on convex shapes created by the stacking of items.
- (2)
- Introduction of the SE Attention Mechanism: This mechanism enhances the grasp detection network by predicting precise grasp poses for each object. It achieves this by combining object masks and depth maps, which helps prevent the generation of multiple detection boxes for a single object.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, J.; Lin, X.; Yu, H. Poat-net: Parallel offset-attention assisted transformer for 3D object detection for autonomous driving. IEEE Access 2021, 9, 151110–151117. [Google Scholar] [CrossRef]
- Pan, X.; Xia, Z.; Song, S.; Li, L.E.; Huang, G. 3D object detection with Point former. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Kuala Lumpur, Malaysia, 19–25 June 2021; pp. 7463–7472. [Google Scholar]
- Wang, C.; Li, C.; Han, Q.; Wu, F.; Zou, X. A Performance Analysis of a Litchi Picking Robot System for Actively Removing Obstructions, Using an Artificial Intelligence Algorithm. Agronomy 2023, 13, 2795. [Google Scholar] [CrossRef]
- Ye, L.; Wu, F.; Zou, X.; Li, J. Path planning for mobile robots in unstructured orchard environments: An improved kinematically constrained bi-directional RRT approach. Comput. Electron. Agric. 2023, 215, 108453. [Google Scholar] [CrossRef]
- Wu, Z.; Tang, Y.; Hong, B.; Liang, B.; Liu, Y. Enhanced precision in dam crack width measurement: Leveraging advanced lightweight network identification for pixel-level accuracy. Int. J. Intell. Syst. 2023, 2023, 9940881. [Google Scholar] [CrossRef]
- Bohg, J.; Morales, A.; Asfour, T.; Kragic, D. Data-driven grasp synthesis—A survey. IEEE Trans. Robot 2014, 30, 289–309. [Google Scholar] [CrossRef]
- He, Z.; Wu, C.; Zhang, S.; Zhao, X. Moment-based 2.5-D visual servoing for textureless planar part grasping. IEEE Trans. Ind. Electron. 2018, 66, 7821–7830. [Google Scholar] [CrossRef]
- Yu, S.; Zhai, D.H.; Xia, Y. CGNet: Robotic Grasp Detection in Heavily Cluttered Scenes. IEEE/ASME Trans. Mech. 2023, 28, 884–894. [Google Scholar] [CrossRef]
- Mahler, J.; Liang, J.; Niyaz, S.; Laskey, M.; Doan, R.; Liu, X.; Ojea, J.A.; Goldberg, K. Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics. arXiv 2017, arXiv:1703.09312. [Google Scholar]
- Li, Y.; Kong, T.; Chu, R.; Li, Y.; Wang, P.; Li, L. Simultaneous semantic and collision learning for 6-DOF grasp pose estimation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 3571–3578. [Google Scholar]
- Jiang, Y.; Moseson, S.; Saxena, A. Efficient grasping from RGB-D images: Learning using a new rectangle representation. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3304–3311. [Google Scholar]
- Depierre, A.; Dellandréa, E.; Chen, L. Jacquard: A large-scale dataset for robotic grasp detection. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 3511–3516. [Google Scholar]
- Morrison, D.; Corke, P.; Leitner, J. Closing the loop for robotic grasping: A real-time, generative grasp synthesis approach. Robotics: Science and Systems (RSS), May 2018. Available online: https://arxiv.org/abs/1804.05172 (accessed on 15 May 2018).
- Kumra, S.; Joshi, S.; Sahin, F. Antipodal robotic grasping using generative residual convolutional neural network. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2021; pp. 9626–9633. [Google Scholar]
- Yu, S.; Zhai, D.-H.; Xia, Y.; Wu, H.; Liao, J. SE-ResUNet: A novel robotic grasp detection method. IEEE Robot. Automat. Lett. 2022, 7, 5238–5245. [Google Scholar] [CrossRef]
- Wang, S.; Zhou, Z.; Kan, Z. When transformer meets robotic grasping: Exploits context for efficient grasp detection. IEEE Robot. Autom. 2022, 7, 8170. [Google Scholar] [CrossRef]
- Asif, U.; Tang, J.; Harrer, S. GraspNet: An Efficient Convolutional Neural Network for Real-time Grasp Detection for Low-powered Devices. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Stockholmsmässan, Sweden, 13–19 July 2018; pp. 4875–4882. [Google Scholar]
- Araki, R.; Onishi, T.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. MT-DSSD: Deconvolutional single shot detector using multi-task learning for object detection, segmentation, and grasping detection. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 10487–10493. [Google Scholar]
- Xu, R.; Chu, F.J.; Tang, C.; Liu, W.; Vela, P.A. An affordance keypoint detection network for robot manipulation. IEEE Robot. Autom. 2021, 6, 2870–2877. [Google Scholar] [CrossRef]
- Xie, C.; Xiang, Y.; Mousavian, A.; Fox, D. Unseen object instance segmentation for robotic environments. IEEE Trans. Robot. 2021, 37, 1343–1359. [Google Scholar] [CrossRef]
- Ainetter, S.; Böhm, C.; Dhakate, R.; Weiss, S.; Fraundorfer, F. Depth-aware object segmentation and grasp detection for robotic picking tasks. arXiv 2021, arXiv:2111.11114. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Kuala Kuala Lumpur, Malaysia, 19–25 June 2021; pp. 10012–10022. [Google Scholar]
- Morrison, D.; Corke, P.; Leitner, J. Learning robust, real-time, reactive robotic grasping. Int. J. Robot. Res. 2022, 39, 183–201. [Google Scholar] [CrossRef]
- Fang, H.S.; Wang, C.; Gou, M.; Lu, C. Graspnet-1billion: A large-scale benchmark for general object grasping. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11444–11453. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Depierre, A.; Dellandréa, E.; Chen, L. Scoring grasp ability based on grasp regression for better grasp prediction. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 4370–4376. [Google Scholar]
- Song, Y.; Gao, L.; Li, X.; Shen, W. A novel robotic grasp detection method based on region proposal networks. Robot. Comput. Integr. Manuf. 2020, 65, 101963. [Google Scholar] [CrossRef]
- Liu, D.; Tao, X.; Yuan, L.; Du, Y.; Cong, M. Robotic objects detection and grasping in clutter based on cascaded deep convolutional neural network. IEEE Trans. Instrum. Meas. 2022, 71, 1–10. [Google Scholar] [CrossRef]
- Zhang, H.; Lan, X.; Bai, S.; Zhou, X.; Tian, Z.; Zheng, N. Roi-based robotic grasp detection for object overlapping scenes. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4768–4775. [Google Scholar]
- Zhang, H.; Lan, X.; Bai, S.; Wan, L.; Yang, C.; Zheng, N. A multi-task convolutional neural network for autonomous robotic grasping in object stacking scenes. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 6435–6442. [Google Scholar]
- Park, D.; Seo, Y.; Shin, D.; Choi, J.; Chun, S.Y. A single multi-task deep neural network with post-processing for object detection with reasoning and robotic grasp detection. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 7300–7306. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Methods | Cornell | Jaquard |
|---|---|---|---|
| Morrison [24] | GGCNN2 | 65.0% | 84.0% |
| Depierre [28] | Grasping Regression | 95.2% | 85.7% |
| Wang [16] | TF-Grasp | 96.7% | 94.6% |
| Kumra [14] | GR-ConvNet | 96.6% | 94.6% |
| Song [29] | RPN | 95.6% | 91.5% |
| Liu [30] | Q-Net | 95.2% | 92.1% |
| Ours | baseline | 94.3% | 93.6% |
| Ours | SS-GD | 97.8% | 94.9% |
| Backbone | Grasp Detection Accuracy (IoU%) | Segmentation Accuracy (IoU%) |
|---|---|---|
| Resnet101 | 89.8 | 74.2 |
| Swin-transformer | 92.6 | 78.6 |
| Method | Grasp Detection Accuracy (IoU%) |
|---|---|
| Baseline | 86.5 |
| SS-GD | 89.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, X.; Chen, Y.; Luo, J.; Shi, C.; Hu, H. A Novel Grasp Detection Algorithm with Multi-Target Semantic Segmentation for a Robot to Manipulate Cluttered Objects. Machines 2024, 12, 506. https://doi.org/10.3390/machines12080506
Zhong X, Chen Y, Luo J, Shi C, Hu H. A Novel Grasp Detection Algorithm with Multi-Target Semantic Segmentation for a Robot to Manipulate Cluttered Objects. Machines. 2024; 12(8):506. https://doi.org/10.3390/machines12080506
Chicago/Turabian StyleZhong, Xungao, Yijun Chen, Jiaguo Luo, Chaoquan Shi, and Huosheng Hu. 2024. "A Novel Grasp Detection Algorithm with Multi-Target Semantic Segmentation for a Robot to Manipulate Cluttered Objects" Machines 12, no. 8: 506. https://doi.org/10.3390/machines12080506
APA StyleZhong, X., Chen, Y., Luo, J., Shi, C., & Hu, H. (2024). A Novel Grasp Detection Algorithm with Multi-Target Semantic Segmentation for a Robot to Manipulate Cluttered Objects. Machines, 12(8), 506. https://doi.org/10.3390/machines12080506