

Intelligent Scheduling in Open-Pit Mining: A Multi-Agent System with Reinforcement Learning


Abstract
:1. Introduction
2. Related Works
2.1. Scheduling in Open-Pit Mining
2.2. Reinforcement Learning in Mining
3. Methodology
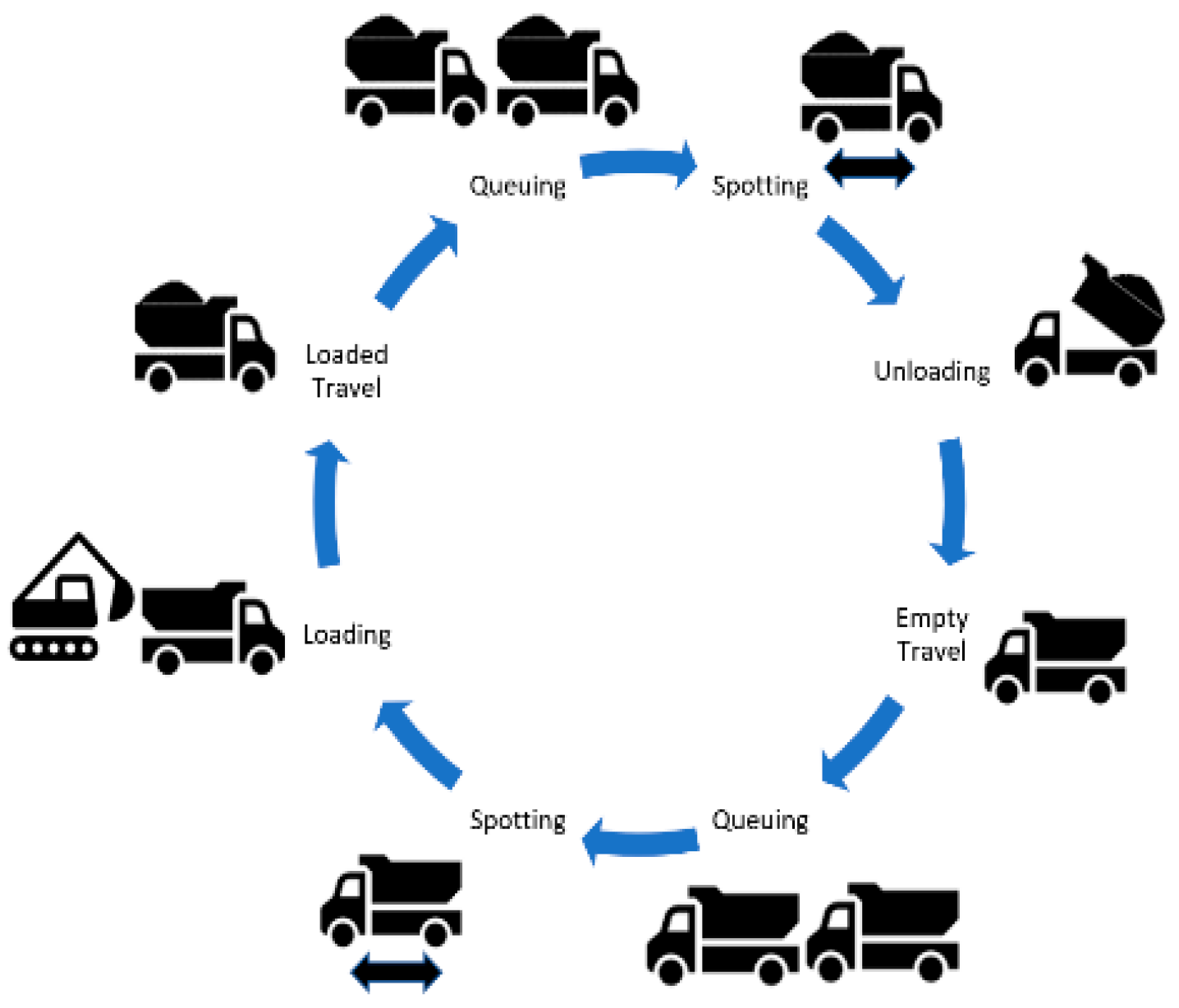
3.1. Problem Statement
3.2. The MAS-TDRL
3.2.1. Agents
3.2.2. Coordination Mechanism
3.2.3. Agent Decision-Making
3.2.4. Reinforcement Learning
- α = 0.01 is the learning rate which controls how much the new experience influences the existing knowledge;
- γ = 0.98 is the discount factor, which prioritizes long-term rewards over immediate gains;
- r is the reward received from the environment;
- maxa′Q(s′,a′) is the highest expected future reward for the next possible action.
3.2.5. MAS-TDLR Implementation
3.3. Simulation and Evaluation Metrics
4. Results and Discussion
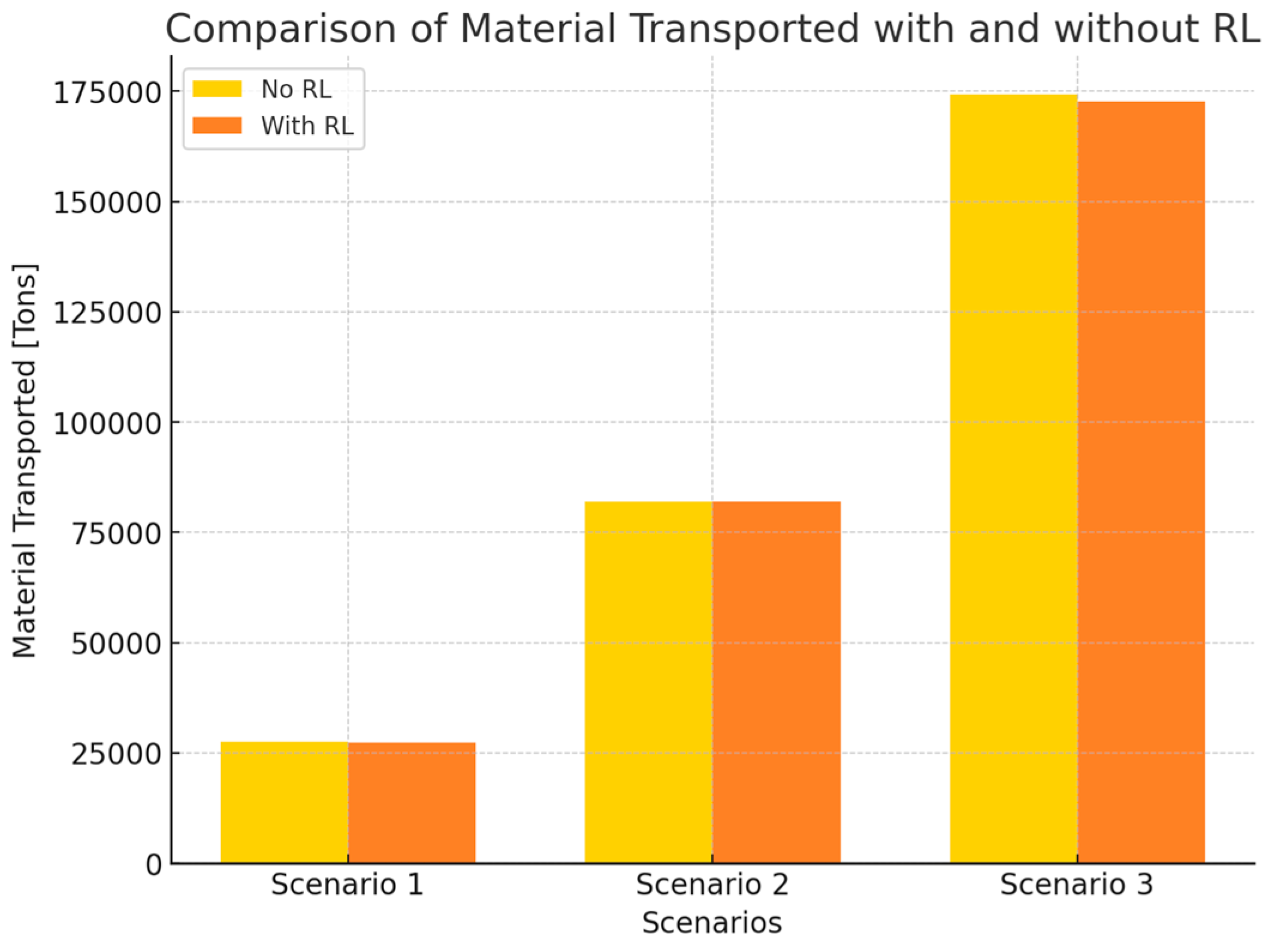
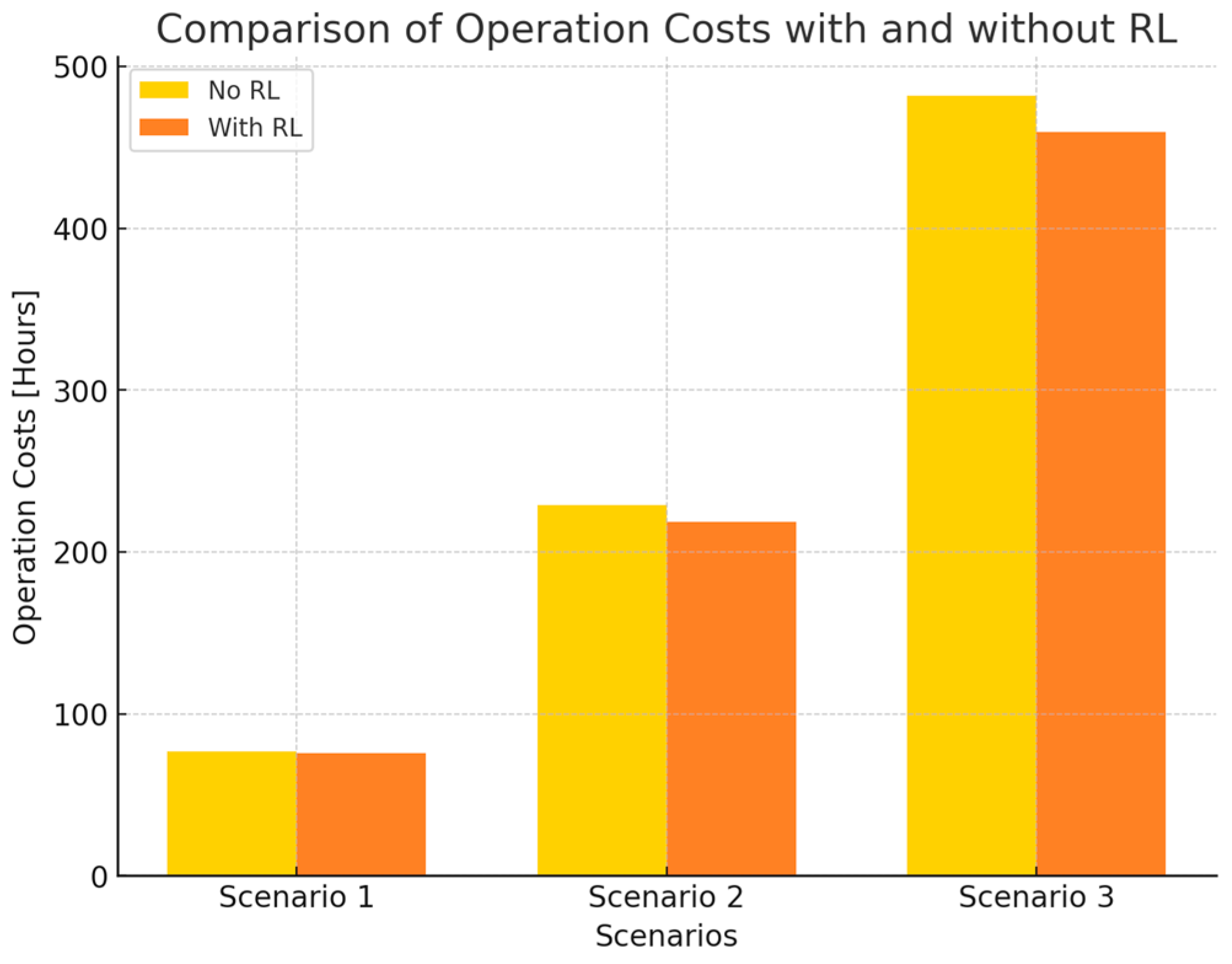
4.1. Analysis from the Perspective of Production and Scheduling
4.2. Analysis of the Negotiation Process and Computation Time
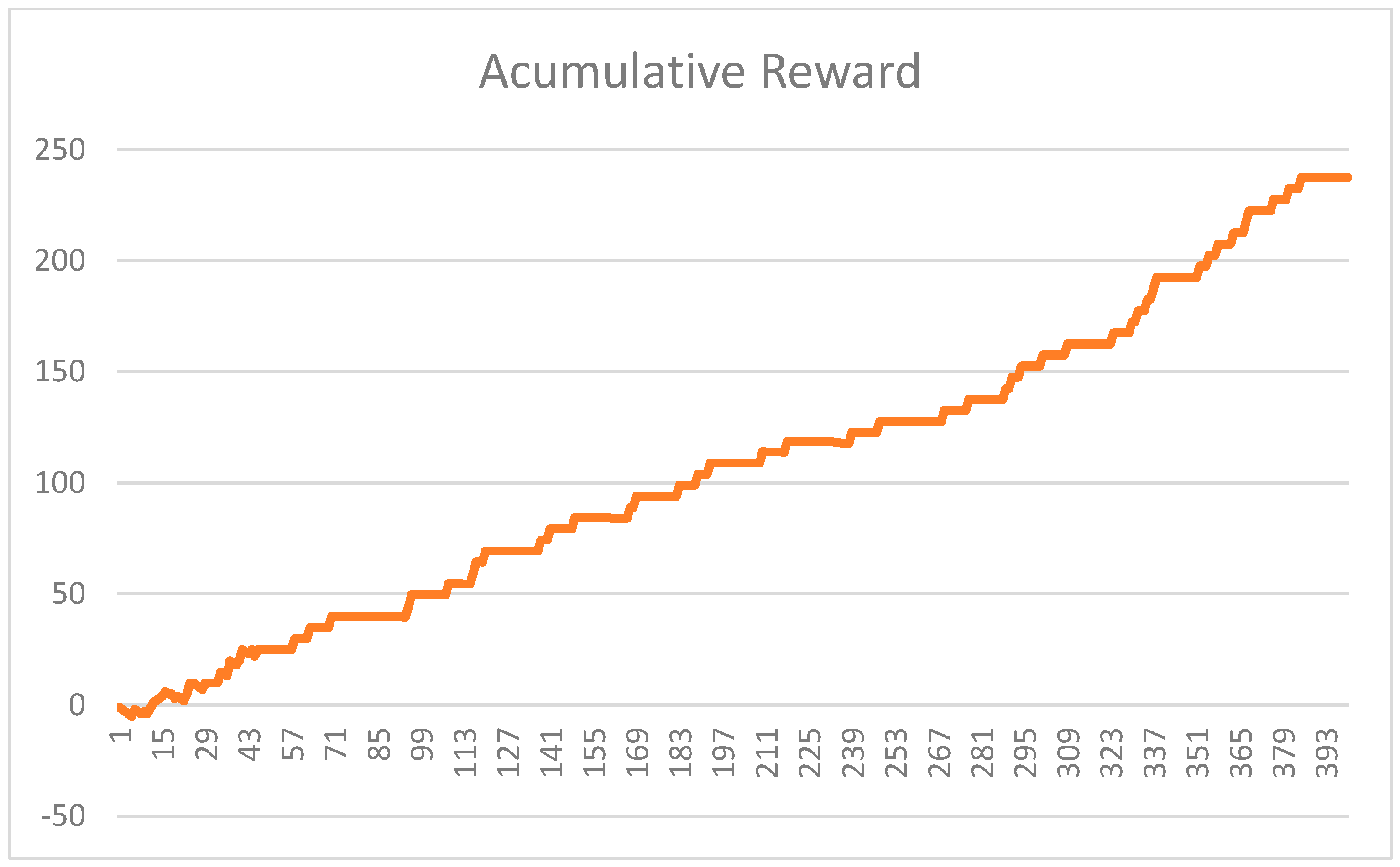
4.3. Analysis of the Learning Process
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MAS | Multi-Agent System |
| MAS-TD | Multi-Agent System for Truck Dispatching |
| RL | Reinforcement Learning |
| MAS-TDLR | Multi-Agent System for Truck Dispatching with Reinforcement Learning |
| CNP | Contract Net Protocol |
References
- Alarie, S.; Gamache, M. Overview of Solution Strategies Used in Truck Dispatching Systems for Open Pit Mines. Int. J. Surf. Min. Reclam. Environ. 2002, 16, 59–76. [Google Scholar] [CrossRef]
- Icarte, G.; Rivero, E.; Herzog, O. An Agent-based System for Truck Dispatching in Open-pit Mines. In Proceedings of the 12th International Conference on Agents and Artificial Intelligence—Volume 1: ICAART; Rocha, A., Steels, L., van den Herik, J., Eds.; SciTePress: Valleta, Malta, 2020; pp. 73–81. [Google Scholar]
- Adams, K.K.; Bansah, K.K. Review of Operational Delays in Shovel-Truck System of Surface Mining Operations. In Proceedings of the 4th UMaT Biennial International Mining and Mineral Conference, Tarkwa, Ghana, 3–6 August 2016; pp. 60–65. [Google Scholar]
- Icarte, G.; Herzog, O. A multi-agent system for truck dispatching in an open-pit mine. In Abstracts of the Second International Conference Mines of the Future 13 & 14 June 2019, Institute of Mineral Resources Engineering, RWTH Aachen University; Lottermoser, B., Ed.; Verlag Mainz: Aachen, Germany, 2019. [Google Scholar]
- Patterson, S.R.; Kozan, E.; Hyland, P. Energy efficient scheduling of open-pit coal mine trucks. Eur. J. Oper. Res. 2017, 262, 759–770. [Google Scholar] [CrossRef]
- Newman, A.M.; Rubio, E.; Caro, R.; Weintraub, A.; Eurek, K. A review of operations research in mine planning. Interfaces 2010, 40, 222–245. [Google Scholar] [CrossRef]
- Chang, Y.; Ren, H.; Wang, S. Modelling and optimizing an open-pit truck scheduling problem. Discret. Dyn. Nat. Soc. 2015, 2015, 745378. [Google Scholar] [CrossRef]
- Da Costa, F.P.; Souza, M.J.F.; Pinto, L.R. Um modelo de programação matemática para alocação estática de caminhões visando ao atendimento de metas de produção e qualidade. Rem Rev. Esc. De Minas 2005, 58, 77–81. [Google Scholar] [CrossRef]
- Krzyzanowska, J. The impact of mixed fleet hauling on mining operations at Venetia mine. J. South. Afr. Inst. Min. Metall. 2007, 107, 215–224. [Google Scholar]
- Zhang, X.; Guo, A.; Ai, Y.; Tian, B.; Chen, L. Real-Time Scheduling of Autonomous Mining Trucks via Flow Allocation-Accelerated Tabu Search. IEEE Trans. Intell. Veh. 2022, 7, 466–479. [Google Scholar] [CrossRef]
- Huo, D.; Sari, Y.A.; Kealey, R.; Zhang, Q. Reinforcement Learning-Based Fleet Dispatching for Greenhouse Gas Emission Reduction in Open-Pit Mining Operations. Resour. Conserv. Recycl. 2023, 188, 106664. [Google Scholar] [CrossRef]
- Yaakoubi, Y.; Dimitrakopoulos, R. Learning to schedule heuristics for the simultaneous stochastic optimization of mining complexes. Comput. Oper. Res. 2023, 159, 106349. [Google Scholar] [CrossRef]
- Zhang, C.; Odonkor, P.; Zheng, S.; Khorasgani, H.; Serita, S.; Gupta, C. Dynamic Dispatching for Large-Scale Heterogeneous Fleet via Multi-agent Deep Reinforcement Learning. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 1436–1441. [Google Scholar] [CrossRef]
- Noriega, R.; Pourrahimian, Y. Shovel Allocation and Short-Term Production Planning in Open-Pit Mines Using Deep Reinforcement Learning. Int. J. Min. Reclam. Environ. 2024, 38, 442–459. [Google Scholar] [CrossRef]
- de Carvalho, J.P.; Dimitrakopoulos, R. Integrating short-term stochastic production planning updating with mining fleet management in industrial mining complexes: An actor-critic reinforcement learning approach. Appl. Intell. 2023, 53, 23179–23202. [Google Scholar] [CrossRef]
- Feng, Z.; Liu, G.; Wang, L.; Gu, Q.; Chen, L. Research on the Multiobjective and Efficient Ore-Blending Scheduling of Open-Pit Mines Based on Multiagent Deep Reinforcement Learning. Sustainability 2023, 15, 5279. [Google Scholar] [CrossRef]
- Smith, R.G. The Contract Net Protocol: High-level communication and control in a distributed problem solver. IEEE Trans. Comput. 1980, C-29, 1104–1113. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Bellifemine, F.; Caire, G.; Greenwood, D. Developing Multi-Agent Systems with JADE; John Wiley & Sons: Chichester, UK, 2007. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Set | Index | Description |
|---|---|---|
| S | s | Shovels |
| R | r | Trucks |
| Ls | l | Slot time of the shovel s |
| J | j | Destinations |
| Parameters | ||
| Cs | Loading time of shovel s | |
| Cj | Unloading time at the destination j | |
| Travel time from shovel s to the destination j | ||
| Travel time of truck r to shovel s (only at the beginning of the shift) | ||
| Travel time from the destination j to next shovel s’ | ||
| Ar | Truck capacity | |
| The target of extracted material by shovel s | ||
| M | Sufficiently large positive number | |
| Decision Variables | ||
| Xr,s,l | 1 if the truck r loads at shovel s in the time slot l, otherwise 0 | |
| Loading start time of shovel s in time slot l | ||
| Unloading start time of material extracted by shovel s in time slot l | ||
| 1 if truck r was loaded by shovel s in time slot l before being loaded in shovel s’ and slot time l’. Otherwise 0. | ||
| Assignment | Destination | Start Time of the Trip | Arrival Time | Start Time of Loading/Unloading | End Time of the Assignment |
|---|---|---|---|---|---|
| 0 | Shovel.10 | 05:57:01 | 06:10:23 | 06:10:36 | 06:15:12 |
| 1 | WasteDump.07 | 06:15:12 | 06:32:33 | 06: 38:23 | 06:40:23 |
| 2 | Shovel.01 | 06:45:25 | 06:58:47 | 07:00:10 | 07:05:35 |
| 3 | WasteDump.05 | 07:05:35 | 07:22:24 | 07:26:38 | 07:27:12 |
| 4 | Shovel.03 | 07:37:44 | 07:41:25 | 07:43:18 | 07:48:32 |
| Scenario ID | Number of Trucks | Number of Shovels |
|---|---|---|
| 1 | 15 | 5 |
| 2 | 50 | 10 |
| 3 | 100 | 25 |
| Equipment | Property | Unit | Min Value | Max Value |
|---|---|---|---|---|
| Trucks | Velocity loaded | [km/hr] | 20 | 25 |
| Velocity empty | [km/hr] | 40 | 55 | |
| Capacity | [tons] | 300 | 370 | |
| Spotting time | [sec] | 20 | 80 | |
| Current load | [tons] | 0 | 370 | |
| Shovel | Capacity | [tons] | 35 | 80 |
| Load time | [sec] | 8 | 30 | |
| Dig time | [sec] | 8 | 20 | |
| Destination | Location at mine (crusher, stockpile, or waste dump) | |||
| Crusher | Equipment discharging | [number of trucks] | 1 | 1 |
| Stockpile | Equipment discharging | [number of trucks] | 1 | 20 |
| Waste Dump | Equipment discharging | [number of trucks] | 1 | 20 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Icarte-Ahumada, G.; Herzog, O. Intelligent Scheduling in Open-Pit Mining: A Multi-Agent System with Reinforcement Learning. Machines 2025, 13, 350. https://doi.org/10.3390/machines13050350
Icarte-Ahumada G, Herzog O. Intelligent Scheduling in Open-Pit Mining: A Multi-Agent System with Reinforcement Learning. Machines. 2025; 13(5):350. https://doi.org/10.3390/machines13050350
Chicago/Turabian StyleIcarte-Ahumada, Gabriel, and Otthein Herzog. 2025. "Intelligent Scheduling in Open-Pit Mining: A Multi-Agent System with Reinforcement Learning" Machines 13, no. 5: 350. https://doi.org/10.3390/machines13050350
APA StyleIcarte-Ahumada, G., & Herzog, O. (2025). Intelligent Scheduling in Open-Pit Mining: A Multi-Agent System with Reinforcement Learning. Machines, 13(5), 350. https://doi.org/10.3390/machines13050350