

Predicting Online Behavioural Responses to Transcranial Direct Current Stimulation in Stroke Patients with Anomia
 , and
, and
Abstract
:1. Introduction
2. Methods
2.1. The Neurostimulation Experiment
2.1.1. Participants
2.1.2. Experimental Design
2.1.3. Behavioural Tasks
2.1.4. Neurostimulation with Concurrent fMRI
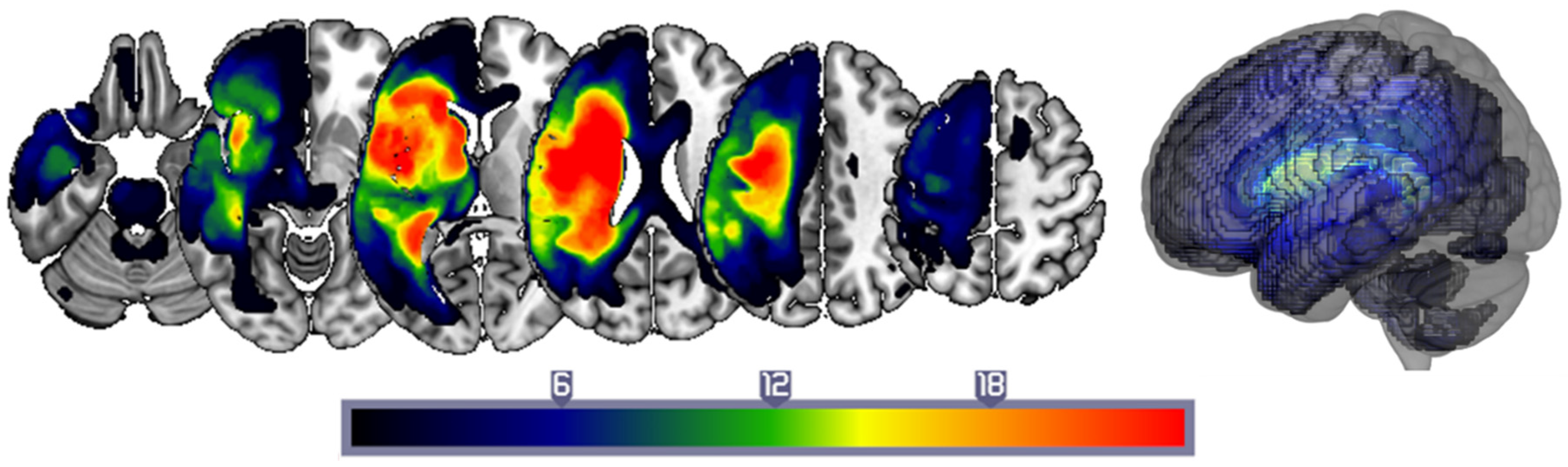
2.1.5. Structural MRI Acquisition and Analysis
2.2. Data Analysis
2.2.1. Data
2.2.2. Associating Predictors to Responses with Partial Least Squares Regression
2.2.3. Model Assessment and Model Comparison
2.2.4. Model Interpretation
3. Results
3.1. Patient Characteristics
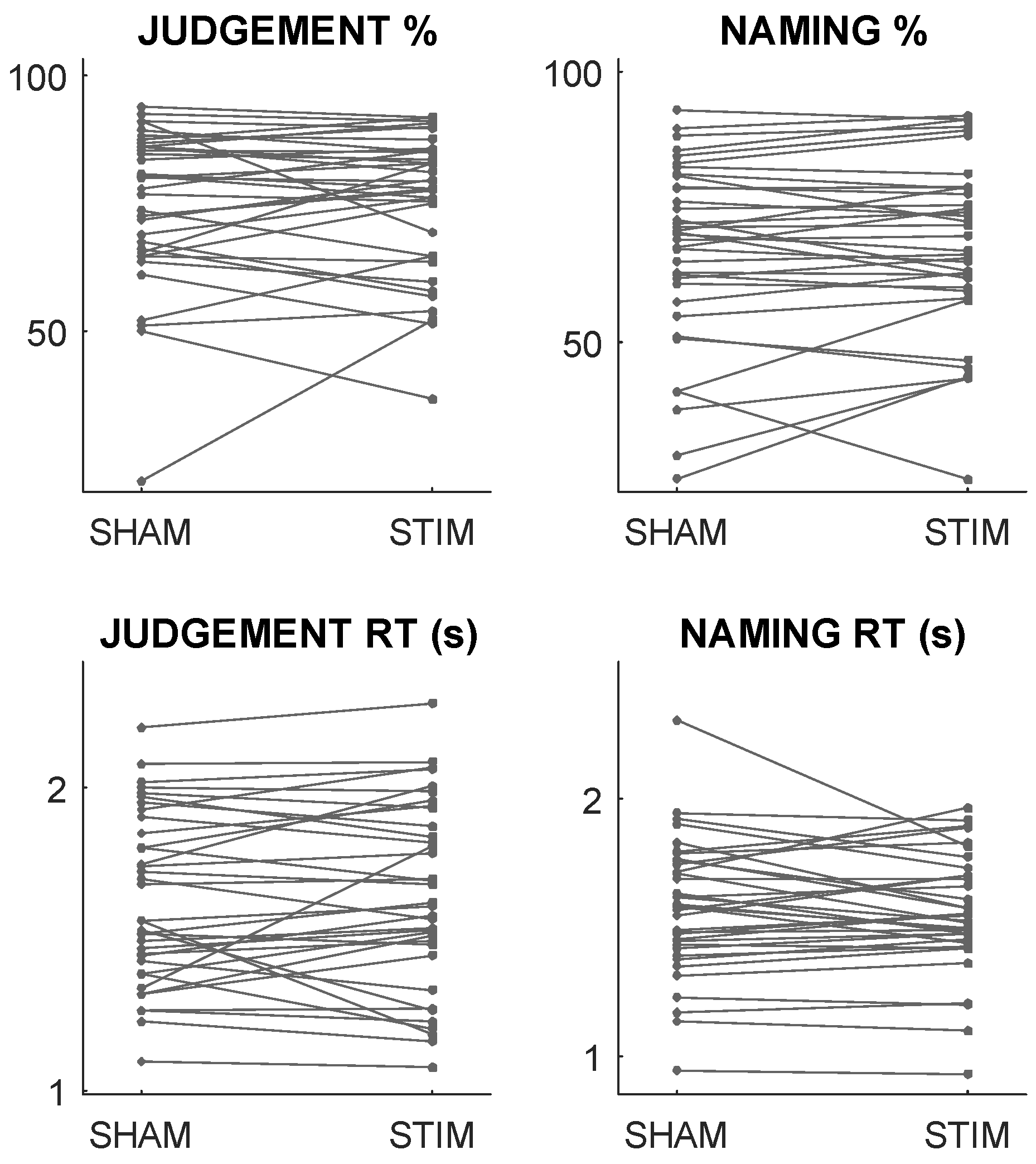
3.2. In-Scanner Behaviour and Stimulation Responses
3.3. Predictive Performance
3.4. Examining the Role of Stimulation Site
3.5. Interpreting the Best Models
4. Discussion
4.1. Inter-Individual Variance in Neurostimulation Responses Is Predictable
4.2. The BRR Model Is Supported
4.3. Model Weights Are (Often) Plausible in the Context of Prior Research
4.4. Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Correction Statement
References
- Laine, M.; Martin, N. Anomia: Theoretical and Clinical Aspects; Psychology Press: London, UK, 2013. [Google Scholar]
- Brady, M.C.; Kelly, H.; Godwin, J.; Enderby, P.; Campbell, P. Speech and language therapy for aphasia following stroke. In Cochrane Database of Systematic Reviews; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2016. [Google Scholar]
- Bakheit, A.M. Drug treatment of poststroke aphasia. Expert Rev. Neurother. 2004, 4, 211–217. [Google Scholar] [CrossRef]
- de Aguiar, V.; Paolazzi, C.L.; Miceli, G. tDCS in post-stroke aphasia: The role of stimulation parameters, behavioral treatment and patient characteristics. Cortex 2015, 63, 296–316. [Google Scholar] [CrossRef] [PubMed]
- Nitsche, M.A.; Cohen, L.G.; Wassermann, E.M.; Priori, A.; Lang, N.; Antal, A.; Paulus, W.; Hummel, F.; Boggio, P.S.; Fregni, F. Transcranial direct current stimulation: State of the art 2008. Brain Stimul. 2008, 1, 206–223. [Google Scholar] [CrossRef] [PubMed]
- Alharbi, M.F.; Armijo-Olivo, S.; Kim, E.S. Transcranial direct current stimulation (tDCS) to improve naming ability in post-stroke aphasia: A critical review. Behav. Brain Res. 2017, 332, 7–15. [Google Scholar] [CrossRef] [PubMed]
- Giordano, J.; Bikson, M.; Kappenman, E.S.; Clark, V.P.; Coslett, H.B.; Hamblin, M.R.; Hamilton, R.; Jankord, R.; Kozumbo, W.J.; McKinley, R.A.; et al. Mechanisms and Effects of Transcranial Direct Current Stimulation. Dose-Response 2017, 15, 1559325816685467. [Google Scholar] [CrossRef] [PubMed]
- Nitsche, M.A.; Paulus, W. Excitability changes induced in the human motor cortex by weak transcranial direct current stimulation. J. Physiol. 2000, 527 Pt 3, 633–639. [Google Scholar] [CrossRef] [PubMed]
- Ulanov, M.A.; Shtyrov, Y.Y.; Stroganova, T.A. Transcranial Direct Current Stimulation as a Tool to Induce Language Recovery in Patients with Post-Stroke Aphasia. Neurosci. Behav. Physiol. 2019, 49, 1169–1180. [Google Scholar] [CrossRef]
- Meinzer, M.; Jähnigen, S.; Copland, D.A.; Darkow, R.; Grittner, U.; Avirame, K.; Rodriguez, A.D.; Lindenberg, R.; Flöel, A. Transcranial direct current stimulation over multiple days improves learning and maintenance of a novel vocabulary. Cortex 2014, 50, 137–147. [Google Scholar] [CrossRef] [PubMed]
- Holland, R.; Leff, A.P.; Josephs, O.; Galea, J.M.; Desikan, M.; Price, C.J.; Rothwell, J.C.; Crinion, J. Speech facilitation by left inferior frontal cortex stimulation. Curr. Biol. 2011, 21, 1403–1407. [Google Scholar] [CrossRef]
- Biou, E.; Cassoudesalle, H.; Cogné, M.; Sibon, I.; De Gabory, I.; Dehail, P.; Aupy, J.; Glize, B. Transcranial direct current stimulation in post-stroke aphasia rehabilitation: A systematic review. Ann. Phys. Rehabil. Med. 2019, 62, 104–121. [Google Scholar] [CrossRef]
- Broca, P. Remarques sur le siége de la faculté du langage articulé, suivies d’une observation d’aphémie (perte de la parole). Bull. Société Anat. 1861, 6, 330–357. [Google Scholar]
- Crinion, J.T.; Leff, A.P. Recovery and treatment of aphasia after stroke: Functional imaging studies. Curr. Opin. Neurol. 2007, 20, 667–673. [Google Scholar] [CrossRef]
- Crosson, B.; McGregor, K.; Gopinath, K.S.; Conway, T.W.; Benjamin, M.; Chang, Y.L.; Moore, A.B.; Raymer, A.M.; Briggs, R.W.; Sherod, M.G.; et al. Functional MRI of language in aphasia: A review of the literature and the methodological challenges. Neuropsychol. Rev. 2007, 17, 157–177. [Google Scholar] [CrossRef]
- Postman-Caucheteux, W.A.; Birn, R.M.; Pursley, R.H.; Butman, J.A.; Solomon, J.M.; Picchioni, D.; McArdle, J.; Braun, A.R. Single-trial fMRI shows contralesional activity linked to overt naming errors in chronic aphasic patients. J. Cogn. Neurosci. 2010, 22, 1299–1318. [Google Scholar] [CrossRef] [PubMed]
- Fridriksson, J.; Bonilha, L.; Baker, J.M.; Moser, D.; Rorden, C. Activity in preserved left hemisphere regions predicts anomia severity in aphasia. Cereb. Cortex 2010, 20, 1013–1019. [Google Scholar] [CrossRef]
- Baker Julie, M.; Rorden, C.; Fridriksson, J. Using Transcranial Direct-Current Stimulation to Treat Stroke Patients with Aphasia. Stroke 2010, 41, 1229–1236. [Google Scholar] [CrossRef]
- Monti, A.; Cogiamanian, F.; Marceglia, S.; Ferrucci, R.; Mameli, F.; Mrakic-Sposta, S.; Vergari, M.; Zago, S.; Priori, A. Improved naming after transcranial direct current stimulation in aphasia. J. Neurol. Neurosurg. Psychiatry 2008, 79, 451–453. [Google Scholar] [CrossRef]
- Klaus, J.; Hartwigsen, G. Failure to Improve Verbal Fluency with Transcranial Direct Current Stimulation. Neuroscience 2020, 449, 123–133. [Google Scholar] [CrossRef]
- Aguilar, O.M.; Kerry, S.J.; Ong, Y.-H.; Callaghan, M.F.; Crinion, J.; Woodhead, Z.V.J.; Price, C.J.; Leff, A.P.; Hope, T.M.H. Lesion-site-dependent responses to therapy after aphasic stroke. J. Neurol. Neurosurg. Psychiatry 2018, 89, 1352–1354. [Google Scholar] [CrossRef]
- Nardo, D.; Pappa, K.; Duncan, J.; Zeidman, P.; Callaghan, M.F.; Leff, A.; Crinion, J. Modulating the left inferior frontal cortex by task domain, cognitive challenge and tDCS. bioRxiv 2021. biorxiv:2021.02.05.429968. [Google Scholar] [CrossRef]
- Rosen, H.; Petersen, S.; Linenweber, M.; Snyder, A.; White, D.; Chapman, L.; Dromerick, A.; Fiez, J.; Corbetta, M. Neural correlates of recovery from aphasia after damage to left inferior frontal cortex. Neurology 2000, 55, 1883–1894. [Google Scholar] [CrossRef] [PubMed]
- Di Pino, G.; Pellegrino, G.; Assenza, G.; Capone, F.; Ferreri, F.; Formica, D.; Ranieri, F.; Tombini, M.; Ziemann, U.; Rothwell, J.C. Modulation of brain plasticity in stroke: A novel model for neurorehabilitation. Nat. Rev. Neurol. 2014, 10, 597. [Google Scholar] [CrossRef]
- Duque, J.; Murase, N.; Celnik, P.; Hummel, F.; Harris-Love, M.; Mazzocchio, R.; Olivier, E.; Cohen, L.G. Intermanual differences in movement-related interhemispheric inhibition. J. Cogn. Neurosci. 2007, 19, 204–213. [Google Scholar] [CrossRef] [PubMed]
- Harris-Love, M.L.; Harrington, R.M. Non-Invasive Brain Stimulation to Enhance Upper Limb Motor Practice Poststroke: A Model for Selection of Cortical Site. Front. Neurol. 2017, 8, 224. [Google Scholar] [CrossRef] [PubMed]
- Pundik, S.; McCabe, J.P.; Hrovat, K.; Fredrickson, A.E.; Tatsuoka, C.; Feng, I.J.; Daly, J.J. Recovery of post stroke proximal arm function, driven by complex neuroplastic bilateral brain activation patterns and predicted by baseline motor dysfunction severity. Front. Hum. Neurosci. 2015, 9, 394. [Google Scholar] [CrossRef]
- Swinburn, K.; Porter, G.; Howard, D. Comprehensive Aphasia Test; Psychology Press: London, UK, 2004. [Google Scholar]
- Kay, J.; Lesser, R.; Coltheart, M. Psycholinguistic Assessments of Language Processing in Aphasia (PALPA); Laurence Erlbaum Associates: Hove, UK, 1992. [Google Scholar]
- Dabul. Apraxia Battery for Adults, 2nd ed.; Pro-Ed.: Austin, TX, USA, 2000. [Google Scholar]
- Szekely, A.; Jacobsen, T.; D’Amico, S.; Devescovi, A.; Andonova, E.; Herron, D.; Lu, C.C.; Pechmann, T.; Pléh, C.; Wicha, N.; et al. A new on-line resource for psycholinguistic studies. J. Mem. Lang. 2004, 51, 247–250. [Google Scholar] [CrossRef]
- Wilson, M. MRC psycholinguistic database: Machine-usable dictionary, version 2.00. Behav. Res. Methods Instrum. Comput. 1988, 20, 6–10. [Google Scholar] [CrossRef]
- Buhrmester, M.D.; Talaifar, S.; Gosling, S.D. An evaluation of Amazon’s Mechanical Turk, its rapid rise, and its effective use. Perspect. Psychol. Sci. 2018, 13, 149–154. [Google Scholar] [CrossRef]
- Nardo, D.; Creasey, M.; Negus, C.; Pappa, K.; Aghaeifar, A.; Reid, A.; Josephs, O.; Callaghan, M.F.; Crinion, J.T. Transcranial direct current stimulation with functional magnetic resonance imaging: A detailed validation and operational guide. Wellcome Open Res. 2023, 6, 143. [Google Scholar] [CrossRef]
- Seghier, M.L.; Ramlackhansingh, A.; Crinion, J.; Leff, A.P.; Price, C.J. Lesion identification using unified segmentation-normalisation models and fuzzy clustering. Neuroimage 2008, 41, 1253–1266. [Google Scholar] [CrossRef]
- Hope, T.M.H.; Nardo, D.; Holland, R.; Ondobaka, S.; Akkad, H.; Price, C.J.; Leff, A.P.; Crinion, J. Lesion site and therapy time predict responses to a therapy for anomia after stroke: A prognostic model development study. Sci. Rep. 2021, 11, 18572. [Google Scholar] [CrossRef] [PubMed]
- Kaplan, E.; Goodglass, H.; Weintraub, S. Boston Naming Test; PRO-Ed: Austin, TX, USA, 2001. [Google Scholar]
- Howard, D.; Patterson, K.E. The Pyramids and Palm Trees Test: A Test of Semantic Access from Words and Pictures; Thames Valley Test Company: London, UK, 1992. [Google Scholar]
- Cattell, R.B.; Cattell, A. Cattell Culture Fair Intelligence Test: A Measure of “g”; Bobbs-Merrill: New York, NY, USA, 1960. [Google Scholar]
- Osterrieth, P.A. Le test de copie d’une figure complexe; contribution a l’etude de la perception et de la memoire. Arch. Psychol. 1944, 30, 206–356. [Google Scholar]
- Wechsler, D. Wechsler Adult Intelligence Scale–Fourth Edition (WAIS–IV); Psychological Corporation: San Antonio, TX, USA, 2014. [Google Scholar]
- Delis, D.C.; Kaplan, E.; Kramer, J.H. Delis-Kaplan Executive Function System; Psychological Corporation: San Antonio, TX, USA, 2001. [Google Scholar]
- Brandt, J.; Benedict, R.H. Hopkins Verbal Learning Test--Revised: Professional Manual; Psychological Assessment Resources: Odessa, FL, USA, 2001. [Google Scholar]
- Robertson, I.H.; Manly, T.; Andrade, J.; Baddeley, B.T.; Yiend, J. Oops!’: Performance correlates of everyday attentional failures in traumatic brain injured and normal subjects. Neuropsychologia 1997, 35, 747–758. [Google Scholar] [CrossRef]
- Hua, K.; Zhang, J.; Wakana, S.; Jiang, H.; Li, X.; Reich, D.S.; Calabresi, P.A.; Pekar, J.J.; van Zijl, P.C.; Mori, S. Tract probability maps in stereotaxic spaces: Analyses of white matter anatomy and tract-specific quantification. Neuroimage 2008, 39, 336–347. [Google Scholar] [CrossRef] [PubMed]
- Eickhoff, S.B.; Stephan, K.E.; Mohlberg, H.; Grefkes, C.; Fink, G.R.; Amunts, K.; Zilles, K. A new SPM toolbox for combining probabilistic cytoarchitectonic maps and functional imaging data. Neuroimage 2005, 25, 1325–1335. [Google Scholar] [CrossRef]
- Tzourio-Mazoyer, N.; Landeau, B.; Papathanassiou, D.; Crivello, F.; Etard, O.; Delcroix, N.; Mazoyer, B.; Joliot, M. Automated anatomical labeling of activations in SPM using a macroscopic anatomical parcellation of the MNI MRI single-subject brain. Neuroimage 2002, 15, 273–289. [Google Scholar] [CrossRef]
- Mori, S.; Wakana, S.; Van Zijl, P.C.; Nagae-Poetscher, L.M. MRI Atlas of Human White Matter; Elsevier: Amsterdam, The Netherlands, 2011; Volume 2. [Google Scholar]
- Wetzels, R.; Grasman, R.P.P.P.; Wagenmakers, E.-J. A Default Bayesian Hypothesis Test for ANOVA Designs. Am. Stat. 2012, 66, 104–111. [Google Scholar] [CrossRef]
- Hope, T.M.H.; Leff, A.P.; Prejawa, S.; Bruce, R.; Haigh, Z.; Lim, L.; Ramsden, S.; Oberhuber, M.; Ludersdorfer, P.; Crinion, J.; et al. Right hemisphere structural adaptation and changing language skills years after left hemisphere stroke. Brain 2017, 140, 1718–1728. [Google Scholar] [CrossRef]
- Holland, R.; Crinion, J. Can tDCS enhance treatment of aphasia after stroke? Aphasiology 2012, 26, 1169–1191. [Google Scholar] [CrossRef] [PubMed]
- Jeffreys, H. Theory of Probability; Oxford University Press: Oxford, UK, 1961. [Google Scholar]
- Cichy, R.M.; Khosla, A.; Pantazis, D.; Torralba, A.; Oliva, A. Comparison of deep neural networks to spatio-temporal cortical dynamics of human visual object recognition reveals hierarchical correspondence. Sci. Rep. 2016, 6, 27755. [Google Scholar] [CrossRef]
- DiCarlo, J.J.; Zoccolan, D.; Rust, N.C. How Does the Brain Solve Visual Object Recognition? Neuron 2012, 73, 415–434. [Google Scholar] [CrossRef] [PubMed]
- Viñas-Guasch, N.; Wu, Y.J. The role of the putamen in language: A meta-analytic connectivity modeling study. Brain Struct. Funct. 2017, 222, 3991–4004. [Google Scholar] [CrossRef] [PubMed]
- Dick, A.S.; Tremblay, P. Beyond the arcuate fasciculus: Consensus and controversy in the connectional anatomy of language. Brain 2012, 135, 3529–3550. [Google Scholar] [CrossRef] [PubMed]
- Ramsey, L.E.; Siegel, J.S.; Lang, C.E.; Strube, M.; Shulman, G.L.; Corbetta, M. Behavioural clusters and predictors of performance during recovery from stroke. Nat. Hum. Behav. 2017, 1, 38. [Google Scholar] [CrossRef]
- Smith, S.R.; Zahka, N.E. Relationship between accuracy and organizational approach on the Rey-Osterrieth Complex Figure and the Differential Ability Scales: A pilot investigation. Child. Neuropsychol. 2006, 12, 383–390. [Google Scholar] [CrossRef]
- Yourganov, G.; Fridriksson, J.; Rorden, C. Estimating the statistical significance of spatial maps for multivariate lesion-symptom analysis. Cortex 2018, 108, 276–278. [Google Scholar] [CrossRef]
- Chun, H.; Keleş, S. Sparse partial least squares regression for simultaneous dimension reduction and variable selection. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2010, 72, 3–25. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
| ALL | BP | BD | ||
|---|---|---|---|---|
| SHAM | Judgement % | 74.9 (±15.2) | 78.2 (±13.7) | 71.6 (±16.4) |
| Judgement RT (s) | 1.63 (±0.28) | 1.54 (±0.31) | 1.72 (±0.24) | |
| Naming % | 66.8 (±16.9) | 72.2 (±16.6) | 61.3 (±15.9) | |
| Naming RT (s) | 1.57 (±0.26) | 1.57 (±0.23) | 1.57 (±0.29) | |
| ANODAL | Judgement % | 75.5 (±13.8) | 77.0 (±13.3) | 73.9 (±14.6) |
| Judgement RT (s) | 1.64 (±0.31) | 1.59 (±0.34) | 1.70 (±0.27) | |
| Naming % | 67.8 (±16.0) | 74.7 (±14.2) | 60.8 (±14.8) | |
| Naming RT (s) | 1.55 (±0.23) | 1.58 (±0.24) | 1.52 (±0.22) |
| DATA | JUDGEMENT % | NAMING % | JUDGEMENT RT | NAMING RT |
|---|---|---|---|---|
| NULL | 1.034/0.033 | 1.028/0.027 | 1.033/0.033 | 1.032/0.030 |
| DEM | 1.213/0.075 | 0.984/0.057 | 1.315/0.090 | 1.379/0.115 |
| BEH | 1.146/0.081 | 0.838/0.091 | 0.861/0.128 | 0.980/0.093 |
| LES | 0.846/0.120 | 0.780/0.095 | 0.828/0.073 | 0.916/0.080 |
| DEM + BEH | 1.153/0.078 | 0.775/0.09 | 0.723/0.118 | 1.020/0.040 |
| DEM + LES | 0.848/0.121 | 0.779/0.094 | 0.830/0.073 | 0.917/0.08 |
| BEH + LES | 0.842/0.107 | 0.749/0.087 | 0.819/0.067 | 0.919/0.08 |
| DEM + BEH + LES | 0.845/0.107 | 0.748/0.087 | 0.821/0.070 | 0.933/0.066 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hope, T.M.H.; Ondobaka, S.; Akkad, H.; Nardo, D.; Pappa, K.; Price, C.J.; Leff, A.P.; Crinion, J.T. Predicting Online Behavioural Responses to Transcranial Direct Current Stimulation in Stroke Patients with Anomia. Life 2024, 14, 331. https://doi.org/10.3390/life14030331
Hope TMH, Ondobaka S, Akkad H, Nardo D, Pappa K, Price CJ, Leff AP, Crinion JT. Predicting Online Behavioural Responses to Transcranial Direct Current Stimulation in Stroke Patients with Anomia. Life. 2024; 14(3):331. https://doi.org/10.3390/life14030331
Chicago/Turabian StyleHope, Thomas M. H., Sasha Ondobaka, Haya Akkad, Davide Nardo, Katerina Pappa, Cathy J. Price, Alexander P. Leff, and Jennifer T. Crinion. 2024. "Predicting Online Behavioural Responses to Transcranial Direct Current Stimulation in Stroke Patients with Anomia" Life 14, no. 3: 331. https://doi.org/10.3390/life14030331
APA StyleHope, T. M. H., Ondobaka, S., Akkad, H., Nardo, D., Pappa, K., Price, C. J., Leff, A. P., & Crinion, J. T. (2024). Predicting Online Behavioural Responses to Transcranial Direct Current Stimulation in Stroke Patients with Anomia. Life, 14(3), 331. https://doi.org/10.3390/life14030331